Post Syndicated from Joel Spolsky original https://www.joelonsoftware.com/2022/12/19/progress-on-the-block-protocol/
Since the 1990s, the web has been a publishing place for human-readable documents.
Documents published on the web are in HTML. HTML has a little bit of structure, for example, “here is a paragraph” or “emphasize this word.”
Then you stir in some CSS, which adds some pretty decorations to the structure, saying things like: make those paragraphs have tiny gray sans-serif text! And then people think you are hip. Unless they are older, and they can’t read your tiny gray words, so they give up on you.
That’s “structure,” as far as it goes, on the web.
Imagine, for example, that you mention a book on the web.
Goodnight Moon
by Margaret Wise Brown
Illustrated by Clement Hurd
Harper & Brothers, 1947
ISBN 0-06-443017-0
There’s not much structure there. A naive computer program reading this web page might not realize I was even mentioning a book. All I did was make the title bold.
So, also since the 1990s, people have realized that we can make the web a much more useful place to publish information if we applied a bit more structure. As early as 1999, Tim Berners-Lee was writing about the Semantic Web:
“I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers. A ‘Semantic Web’, which makes this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The ‘intelligent agents’ people have touted for ages will finally materialize.”
Tim Berners-Lee, Weaving The Web, 1999 HarperSanFrancisco (Chapter 12)
Using the Semantic Web you might publish a book title with a lot more detail that makes it computer-readable. To do this, you would probably start by going to schema.org and looking up their idea of a book. Then you could use one of a number of formats, like RDF or JSON-LD, to add additional markup to your HTML saying “hey! here’s a book!”
Ok, well, doing that is kinda hard to figure out, and, to be honest, it’s homework. Once your beautiful blog post is published and human-readable, it’s hard to gather the mental energy to figure out how to add the additional fancy markups that will make your web page computer-readable, and, unless there is already a computer reading your web pages, at this point, you usually give up. So, yeah. That was 1999, and not much progress has been made and there is very little of this semantic markup in the wild.
Well.
We would like to fix this, because human progress depends on getting more and more information in formats that are readily accessible, both by regular humans, their dumb A.I. li’l sibs, and your more traditional computer programs.

Here is something I believe: people will only add semantic markup to their web pages if doing so is easier than not.
In other words, the cost of adding semantic markup has to be zero or negative, or this whole project is not going anywhere.
Now imagine this world for a second:
- I want to insert a book into my blog post
- I type /book
- A search box appears where I start typing in the title of my book and choose from an autocomplete list.
- Once I find the book, a block gets inserted in my blog post showing details of the book in a format I like, with nice semantic markup behind the scenes.
In this world I did less work to insert a book (because I was assisted by a UI that looked up the details for me).
You can imagine the same scenario applying to literally any other kind of structured data.
- I want to insert an address into my blog post
- I type /address
- A search box appears where I start to type a location, which autocompletes in the way you have seen Instagram and Google Maps and a million other apps do it
- Once I choose the address, a block gets inserted showing the details of the address complete with semantic markup behind the scenes.
My “address block” might have any visual appearance. Visitors to my web page might see the address, or a little map, or a little map in Japanese, etc. etc. The semantic content is there behind the scenes. So, for example, my web browser might know “gosh this is an address! Maybe you want to do address-y things with it, like go there,” and then my browser might offer me options to summon a self-driving car and even call an ambulance when the self-driving car self-drives into a snowbank.
My two simplistic examples of “book” and “address” are interesting right now because (a) you can probably think of 1,000,000 more data types like this, and (b) none of these things work right now, because even though almost every web editing environment has a concept of “blocks,” none of them are extensible. WordPress has (oh gosh) hundreds of block types, but they don’t have thousands or millions, they don’t have “book” or “address” or “Burning Man Theme Camp” yet, and there’s no ecosystem by which developers and users can contribute new block types.
So I guess I gotta wait around for someone at WordPress to develop all the blocks I want to use. And then someone at Notion, and then someone at Trello, and then someone at Mailchimp, and someone at every other vendor that provides a text editor.
I have a better plan.
The web was built with open protocols. Suppose we all agree on a protocol for blocks.
Any developer that wants to create a new block can conform to this protocol.
Any kind of web-text-editing application can also conform to this protocol.
Then if anyone goes to the trouble of creating a cool “book” or “address” block, we’ll all be able to use it, anywhere.
And we shall dub this protocol, oh I don’t know, the Block Protocol.
And it should be, I think, 100% free, open, and public, so that there is no impediment to anyone on earth using it. And in fact if you want to make blocks that are open source or public, good for you, but if for some reason you would like to make private or commercial blocks, that’s fine too.
Where we’re up to
It’s been about a year since we started talking about the Block Protocol, and we’ve made a lot of progress figuring out how it has to work to do all the things it will need to do, in a clean and straightforward way.
But this is all going nowhere if it requires 93,000,000 humans to cooperate with my crazy scheme just to get it off the ground.
So what we did is build a WordPress Plugin that allows you to embed Block Protocol blocks into posts on your WordPress sites just as easily as you insert any other block.
Since WordPress powers 43% of the web, that means if you build a block for the Block Protocol, it’ll be widely usable right away.
Here’s a video demo:
The WordPress Plugin will be free, and it will be widely available in February, when we’ll also publish version 0.3 of the Block Protocol specification. You can get early access now.

In fact, if you were thinking of writing a plugin for WordPress for your own kind of custom block, you’ll find that using our plugin as your starting point is a lot easier, because you don’t have to know anything about WordPress Plugins or write any PHP code. So even if you don’t care for any of my crazy theories and just want to add a block to WordPress, this is the way to go.
Ultimately, though, we just want to make it easier to add useful semantic, structured information to the web, and this is the first step.
PS We just set up a Discord server for the Block Protocol where you can participate, ask questions, and meet the team.
PPS You can follow me on Mastodon, where I am @[email protected]. I don’t post that much, but I’m enjoying hanging out there in a human-to-human environment where there isn’t an algorithm stirring up righteous indignation about the latest fake-outrage of the day.





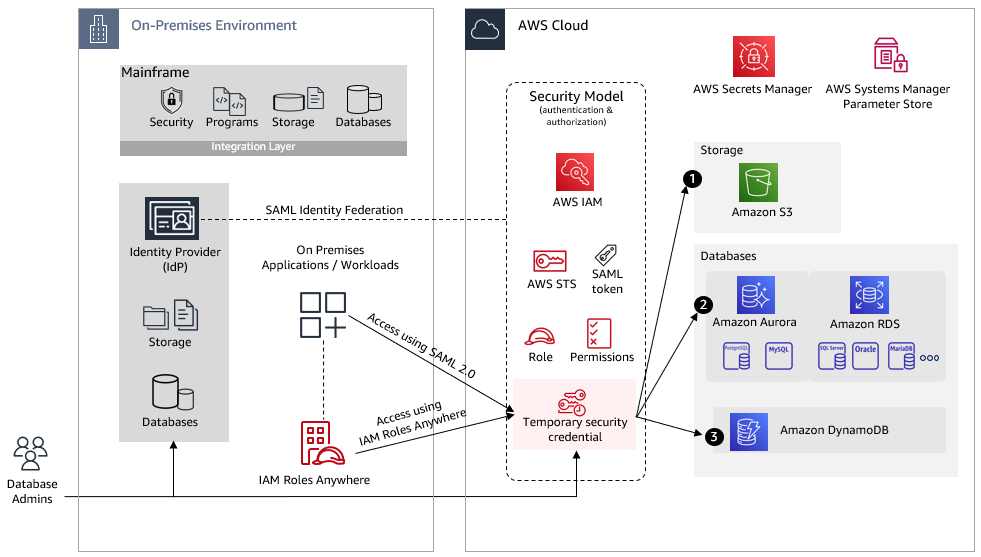













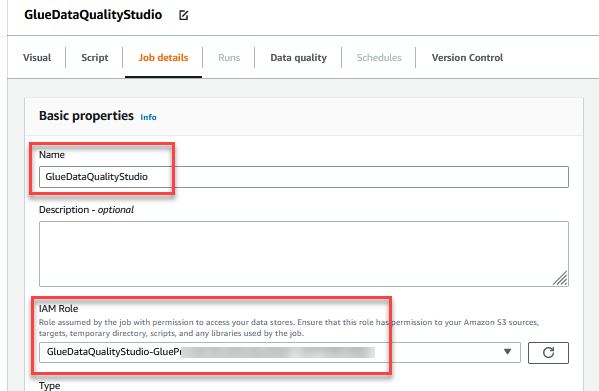

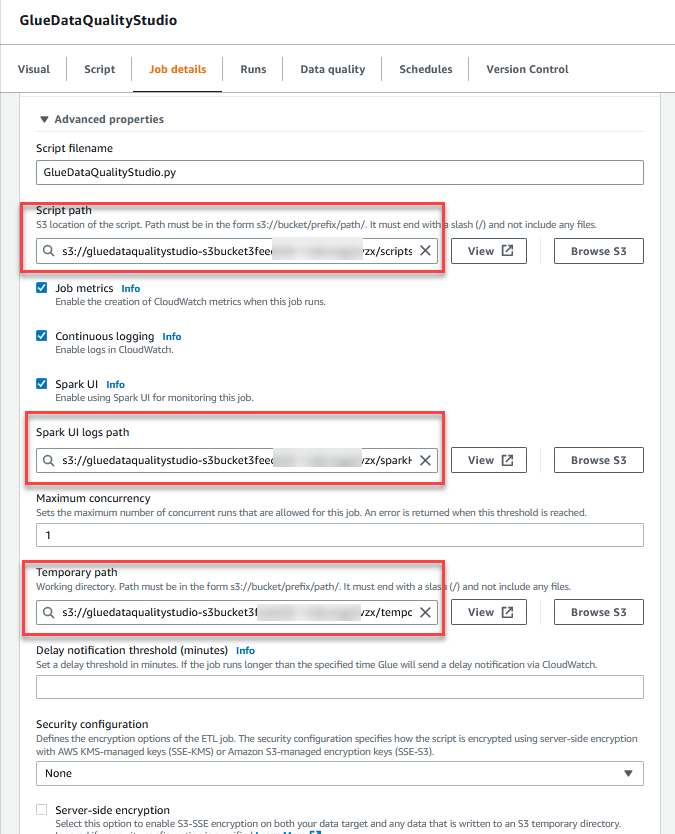





































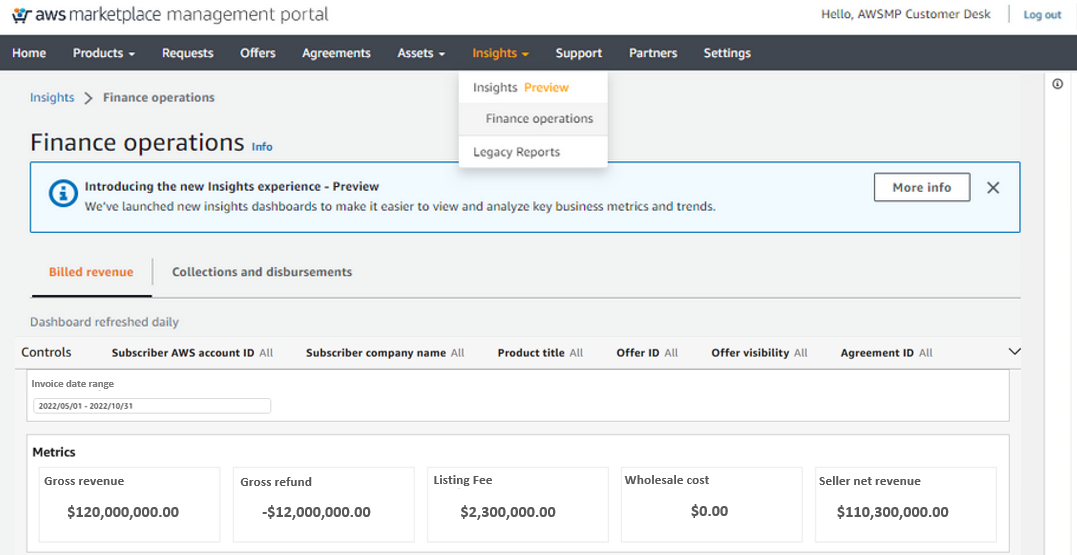
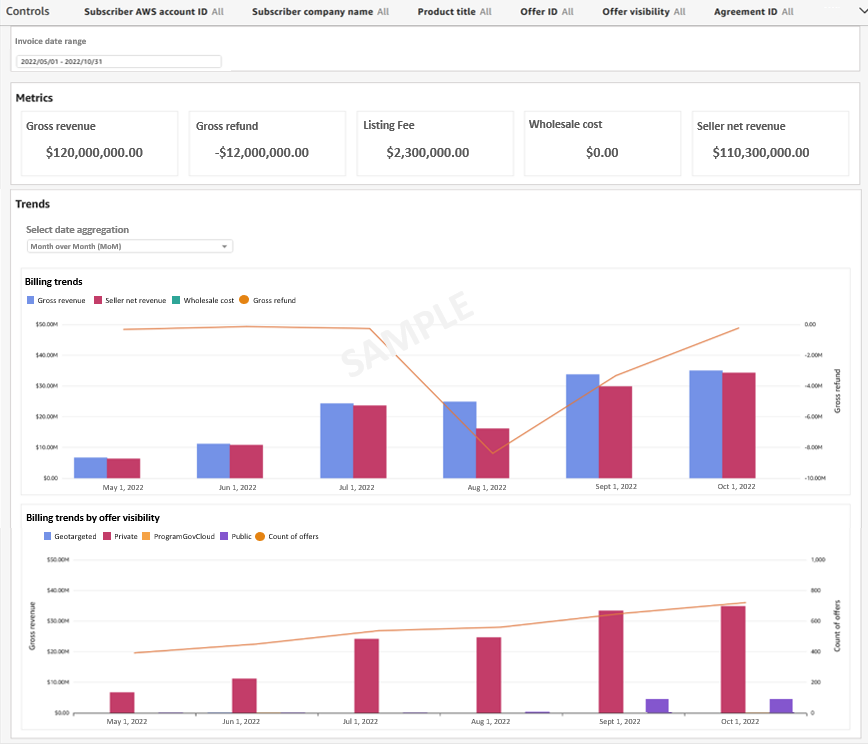
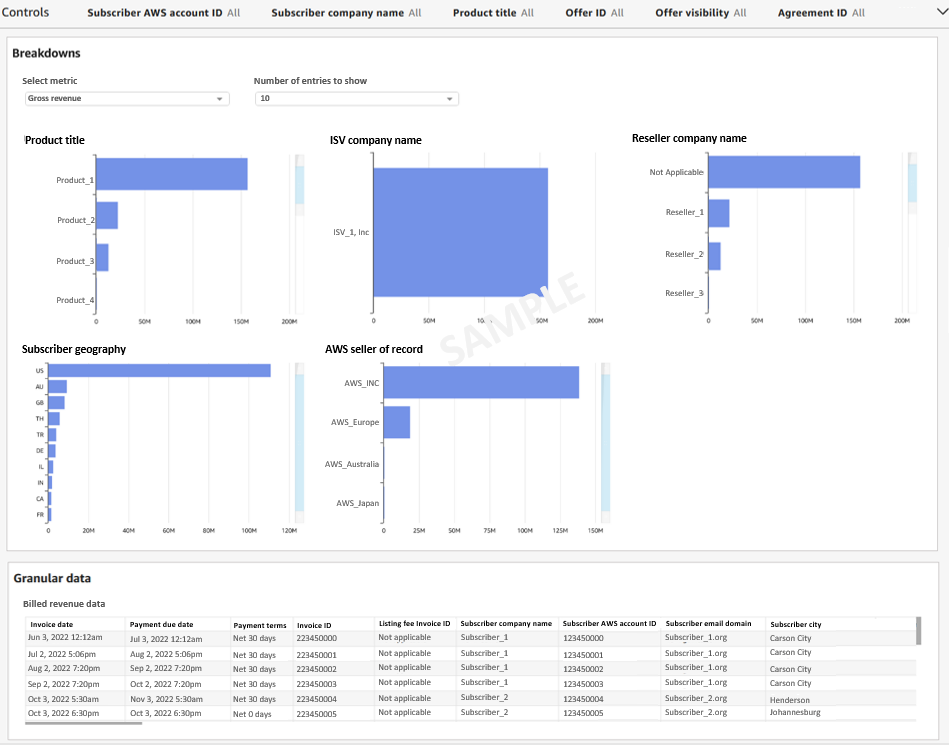
 Snigdha Sahi is a Senior Product Manager (Technical) with Amazon Web Services (AWS) Marketplace. She has diverse work experience across product management, product development and management consulting. A technology enthusiast, she loves brainstorming and building products that are intuitive and easy to use. In her spare time, she enjoys hiking, solving Sudoku and listening to music.
Snigdha Sahi is a Senior Product Manager (Technical) with Amazon Web Services (AWS) Marketplace. She has diverse work experience across product management, product development and management consulting. A technology enthusiast, she loves brainstorming and building products that are intuitive and easy to use. In her spare time, she enjoys hiking, solving Sudoku and listening to music. Vincent Larchet is a Principal Software Development Engineer on the AWS Marketplace team based in Vancouver, BC. Outside of work, he is a passionate wood worker and DIYer.
Vincent Larchet is a Principal Software Development Engineer on the AWS Marketplace team based in Vancouver, BC. Outside of work, he is a passionate wood worker and DIYer.
