I’ve been ridiculously burned out for a while now but I’m taking the month off to recover and that’s giving me an opportunity to catch up on a lot of stuff. This has included me actually writing some code to work with the Pluton in my Thinkpad Z13. I’ve learned some more stuff in the process, but based on everything I know I’d still say that in its current form Pluton isn’t a threat to free software.
So, first up: by default on the Z13, Pluton is disabled. It’s not obviously exposed to the OS at all, which also means there’s no obvious mechanism for Microsoft to push out a firmware update to it via Windows Update. The Windows drivers that bind to Pluton don’t load in this configuration. It’s theoretically possible that there’s some hidden mechanism to re-enable it at runtime, but that code doesn’t seem to be in Windows at the moment. I’m reasonably confident that “Disabled” is pretty genuinely disabled.
Second, when enabled, Pluton exposes two separate devices. The first of these has an MSFT0101 identifier in ACPI, which is the ID used for a TPM 2 device. The Pluton TPM implementation doesn’t work out of the box with existing TPM 2 drivers, though, because it uses a custom start method. TPM 2 devices commonly use something called a “Command Response Buffer” architecture, where a command is written into a buffer, the TPM is told to do a thing, and the response to the command ends up in another buffer. The mechanism to tell the TPM to do a thing varies, and an ACPI table exposed to the OS defines which of those various things should be used for a given TPM. Pluton systems have a mechanism that isn’t defined in the existing version of the spec (1.3 rev 8 at the time of writing), so I had to spend a while staring hard at the Windows drivers to figure out how to implement it. The good news is that I now have a patch that successfully gets the existing Linux TPM driver code work correctly with the Pluton implementation.
The second device has an MSFT0200 identifier, and is entirely not a TPM. The Windows driver appears to be a relatively thin layer that simply takes commands from userland and passes them on to the chip – I haven’t found any userland applications that make use of this, so it’s tough to figure out what functionality is actually available. But what does seem pretty clear from the code I’ve looked at is that it’s a component that only responds when it’s asked – if the OS never sends it any commands, it’s not able to do anything.
One key point from this recently published Microsoft doc is that the whole “Microsoft can update Pluton firmware” thing does just seem to be the ability for the OS to push new code to the chip at runtime. That means Microsoft can’t arbitrarily push new firmware to the chip – the OS needs to be involved. This is unsurprising, but it’s nice to see some stronger confirmation of that.
Anyway. tl;dr – Pluton can (now) be used as a regular TPM. Pluton also exposes some additional functionality which is not yet clear, but there’s no obvious mechanism for it to compromise user privacy or restrict what users can run on a Free operating system. The Pluton firmware update mechanism appears to be OS mediated, so users who control their OS can simply choose not to opt in to that.
Based on a screenshot from Apple, these categories are covered when you flip on Advanced Data Protection: device backups, messages backups, iCloud Drive, Notes, Photos, Reminders, Safari bookmarks, Siri Shortcuts, Voice Memos, and Wallet Passes. Apple says the only “major” categories not covered by Advanced Data Protection are iCloud Mail, Contacts, and Calendar because “of the need to interoperate with the global email, contacts, and calendar systems,” according to its press release.
You can see the full list of data categories and what is protected under standard data protection, which is the default for your account, and Advanced Data Protection on Apple’s website.
With standard data protection, Apple holds the encryption keys for things that aren’t end-to-end encrypted, which means the company can help you recover that data if needed. Data that’s end-to-end encrypted can only be encrypted on “your trusted devices where you’re signed in with your Apple ID,” according to Apple, meaning that the company—or law enforcement or hackers—cannot access your data from Apple’s databases.
Note that this system doesn’t have the backdoor that was in Apple’s previous proposal, the one put there under the guise of detecting CSAM.
Apple says that it will roll out worldwide by the end of next year. I wonder how China will react to this.
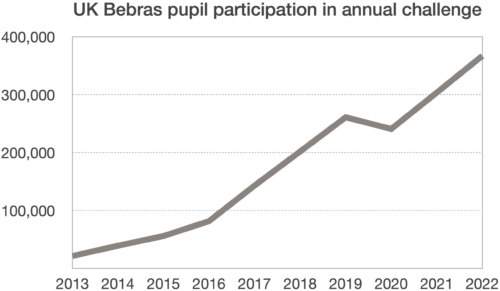
This November, teachers across the UK helped 367,023 learners participate in the annual free UK Bebras Challenge of computational thinking.
‘Bebras’ is Lithuanian and means ‘beaver’.
We support this challenge in the UK, together with Oxford University, and Bebras Challenges run across the world, with more than 3 million learners from schools in 54 countries taking part in 2021. Bebras encourages a love of computational thinking, computer science, and problem solving, especially among learners who haven’t yet realised they have these skills.
More and more schools are taking part in the UK Bebras Challenge
Nearly every year since 2013, more UK schools have been participating in Bebras. We think this is because for teachers, registering and entering learners is easy, the online system does all the marking automatically, and teachers receive comprehensive results that can be helpful for assessment.
The computational thinking problems within Bebras are tailored for different age groups, use clear language, and are accessible to colour-blind learners. There is also a challenge for learners with visual impairments. Teachers who run Bebras in their schools seem to love it and regularly tell colleagues about it.
“Our pupils really enjoy [Bebras] and I find it so helpful to teach computational thinking with real-life strategies. We also find the data and information about our pupils’ performance extremely helpful.” — Teacher in London
Age-appropriate computational thinking problems
In the UK Bebras Challenge, the younger learners aged 6 to 10 usually take part in teams and have plenty of time to discuss how to solve the computational thinking problems they are presented with.
Older learners, aged 10 to 18, try to solve as many problems as they can in 40 minutes. The problems they are presented with start off easy and get increasingly difficult. The 10% of participants who solve the most problems are then invited to take part in the Oxford University Computing Challenge (OUCC), an annual programming challenge.
Year-round free resources for teachers
Although the OUCC is only open to some Bebras participants, all of the OUCC problems are archived and teachers registered with Bebras can use them to make auto-marking quizzes for all of their learners at any time of the year. Part of the goal of UK Bebras is to support teachers with free resources, and the UK Bebras online quizzes facility now has computational thinking tasks from the Bebras archive, plus auto-marking Blockly programming problems and text-based programming problems, which can be solved using commonly taught programming languages.
The organizations served by Projects Galileo and Athenian face the same security challenges as some of the world’s largest companies, but lack the budget to protect themselves. Sophisticated phishing campaigns attempt to compromise user credentials. Bad actors find ways to disrupt connectivity to critical resources. However, the tools to defend against these threats have historically only been available to the largest enterprises.
We’re excited to help fix that. Starting today, we are making the Cloudflare One Zero Trust suite available to teams that qualify for Project Galileo or Athenian at no cost. Cloudflare One includes the same Zero Trust security and connectivity solutions used by over 10,000 customers today to connect their users and safeguard their data.
Same problem, different missions
Athenian Project candidates work to safeguard elections in the United States. Project Galileo applicants launched their causes to support journalists, encourage artistic expression, or protect persecuted groups. They each set out to fix difficult and painful problems. None of the applications to our programs wrote their mission statement to deal with phishing attacks or internal data loss.
However, security problems plague these teams. Instead of being able to focus on their unique mission, these groups spend money, time, and energy attempting to defend from attacks. The headaches range from expensive distractions to outright breaches. Even the mundane work to connect employees to important tools continues to be a headache. Every chore or incident takes away from the ability of these organizations to advance their cause.
We built Cloudflare One to solve the common security problems that can derail any team. Our mission is to help build a better Internet and, in doing so, we create tools that allow the groups served by the Athenian Project and Project Galileo spend as much of their day solving their own unique challenges.
The products we are making available today provide security against a broad, and growing, range of attacks that target how a team works together on the Internet. Project Galileo and Athenian candidates can choose to start in any place depending on their existing security challenges. If you need a guide on where to get started, we’ve broken down three common first steps that we recommend.
1) Stop phishing attacks
Many phishing attacks start with a malicious link buried in a single email from a sender that seems trustworthy. A user in your organization clicks on that link, believing it to be from a teammate or manager, and lands on a website that looks almost identical to your identity provider or one of the web applications they use every day. They input their username and password, sending their credentials directly to the attacker.
Cloudflare One’s email security, our Area 1 product, is our first line of phishing defense. Area 1 scans the emails headed to your organization for the presence of potential phishing campaigns and other types of security attacks. Malicious messages never arrive without interrupting the emails that your team should receive. You can deploy Area 1 in minutes with a few changes to your DNS records to safeguard your Microsoft 365, Gmail, or nearly any other email deployment.
As part of today’s announcement, we are making Area 1 available to Project Galileo and Athenian organizations at no cost. The same level of protection trusted by large corporations from Werner Enterprises to Fortune 500 consumer packaged goods firms is now available to your team.
In some cases, an email evades detection or the phishing link reaches your users through other channels. Cloudflare One can still help. When your team members navigate the Internet, they rely on DNS queries made by their device in order to translate the hostname of a website to the IP address of the server. Their device sends those queries to a DNS resolver.
Cloudflare runs the world’s fastest DNS resolver, 1.1.1.1, and we offer a security version that also filters DNS queries made to destinations that are known to be malicious. If a user accidentally clicks on a link from a text message or in a website, their device first sends that DNS query to Cloudflare. If dangerous, we stop the query before the malicious destination can load. If benign, we’ll respond with the destination faster than other resolvers.
Cloudflare’s DNS filtering keeps the US Federal Government safe, but can be deployed by teams of any size. You can secure entire office networks with the change of one router setting or deploy our roaming agent to keep your users safe wherever they work. Together with email protection, your team can filter out phishing attacks in a defense-in-depth approach.
2) Connect employees and partners
Many teams that qualify for Project Galileo had to find ways to work across geographies long before the pandemic sent employees home from other companies. These teams typically deployed a legacy virtual private network (VPN) to allow team members from across the world to reach the tools they needed to collect data, file stories, or submit research. At best, those VPN deployments slowed down user connectivity and introduced maintenance headaches. At worst, they gave anyone on the network overly broad access to nearly any resource.
With Cloudflare One, your team can operate in any location and still reach your internal tools while controlling exactly who can access which application or service. Organizations that need to operate a traditional private network can run one on Cloudflare by deploying our device client (WARP) on user endpoints and establishing outbound connections to our global network via Cloudflare Tunnel. Users enjoy the performance and availability of Cloudflare’s network while administrators can build granular permissions without the need for additional application development.
We also know that many Galileo and Athenian organizations work alongside hundreds or thousands of partners and volunteers. Those users need to also reach internal resources but are not willing or able to install software on their personal devices.
To solve that challenge, Cloudflare One can be deployed in a fully clientless mode that can use multiple identity providers including consumer options like Google, Facebook, and LinkedIn. Users authenticate with the single-sign on option they already use from any mobile or desktop device. Administrators control which users can reach specific applications while logging every attempt.
3) Secure your team’s path to the Internet
Beyond phishing attacks, bad actors target organizations with other types of threats like malware hidden in downloads. Researchers and journalists exploring a topic with untrusted sources can bring ransomware back into the entire organization. Team members connecting to the Internet from a hotel Wi-Fi network can have unencrypted DNS queries monitored and reported.
Cloudflare One provides every member of your team with an encrypted, secured on-ramp to the entire Internet. Powered by the same Cloudflare WARP agent that helps millions of users enjoy a more private Internet connection, Cloudflare’s Secure Web Gateway filters all Internet-bound for hidden threats.
When users inadvertently connect to a malicious destination, Cloudflare One will block the attempt and present them with a page explaining what just happened. In the other direction, Cloudflare’s network scans downloads for malware and blocks the download before the user can open it.
The same filtering can be extended to keep sensitive data from leaving your organization. You can build rules that flag file uploads that contain personal information or patterns that are unique to your team or focus area. With just a few clicks, you can create policies that prevent the accidental or malicious loss of data while also restricting uploads to approved destinations.
All without the need for an enterprise IT department
Today’s announcement makes the security technology deployed by the world’s largest enterprises available to organizations of any size. And, despite the broad impact of Athenian and Galileo organizations, that size tends to be smaller.
The teams supported by Project Galileo focus limited resources on advancing journalism, artistic expression, human rights, and other causes. The state and local governments who qualify for the Athenian Project spend their days protecting democracy in the United States. Both groups tend to lack the resources of a Fortune 500 to staff and operate a large IT department.
We built Cloudflare One as a service that a team could configure and deploy in a matter of hours and still benefit from comprehensive Zero Trust security. We’ve published a Zero Trust Roadmap that your team can use to determine how to get started with guidelines for the time required at each step.
How to get started
We’re excited to extend Projects Galileo and Athenian to include Cloudflare One. Are you an existing qualified organization or interested in applying? Follow the link here and here to get started.
If you are not part of Project Galileo or Athenian, but still want to begin deploying Cloudflare One, we make the service available at no cost to teams of up to 50 users. Click here to sign up.
One of the largest and most noticeable changes to OpenShot 3.0 is
our improved video preview, resulting in smoother video preview and
fewer freezes and pauses during previewing. But to understand why
things are so much smoother, we need to look deeper into our
decoding engine. We have rearchitected our decoder to be much more
resilient to missing packets, missing timestamps, and better
understanding when we are missing video or audio data, so we can
move on without pausing.
Linus has released the 6.1 kernel; he is preparing for a tricky holiday merge window:
So here we are, a week late, but last week was nice and slow, and I’m
much happier about the state of 6.1 than I was a couple of weeks ago
when things didn’t seem to be slowing down.
Of course, that means that now we have the merge window from hell,
just before the holidays, with me having some pre-holiday travel
coming up too. So while delaying things for a week was the right thing
to do, it does make the timing for the 6.2 merge window awkward.
In the early days of Cloudflare, we made it a policy that every new hire had to interview with either me or my co-founder Michelle. It’s still the case today, though we now have more than 3,000 employees, continue to hire great people as we find them, and, because there are only so many hours in the day, have had to enlist a few more senior executives to help with these final calls.
At first, these calls were about helping screen for new members of our small team. But, as our team grew, the purpose of these calls changed. Today, by the time I do the final call with someone we’ve made the decision to hire them, so it’s rarely about screening. Instead, the primary purpose is to make sure everyone joining has had a positive conversation with a senior member of our team, so if in the future they ever see something going wrong they’ll hopefully feel a bit more comfortable letting one of us know. I think because of that these calls are some of the most important work I do.
But, for me, there’s another purpose. I get to hear first-hand why people chose to apply. That’s a barometer for what we’re doing right, evaluated by someone with a perspective outside the organization. And, nearly every day, I hear some version of the same thing: the most consistent reason new employees want to join Cloudflare is because of our mission and the breadth of our impact.
Our team wants the work they do to have a real, positive impact for the millions of users of our services and the billions of Internet users our decisions affect downstream. It makes me smile every time someone we’re about to extend an offer to says something along the lines of “when Cloudflare pushes a new feature or product, you’re changing the entire Internet for the better. And I want to be part of that.” That’s why I continue to be excited about my job too.
It may seem like our mission to “help build a better Internet” has been around forever, but it wasn’t something we had at the beginning. It developed as the natural outgrowth of the team we assembled and the products we built. Today, it’s integral to Cloudflare’s DNA. Our team has always been optimistic about the Internet and its potential to do good, especially if it is founded on respect for certain values like security, privacy, interoperability, and wide availability.
That’s why the focus on privacy over the past few years was always easy for us. We never sold customer data to marketers — that just didn’t seem like what would be a part of a better Internet — so when it came time to comply with new privacy laws, we didn’t have to pull back operations or cut off lines of revenue. Instead, we rolled out the use of Universal SSL to expand encryption broadly for the Internet, and we created our first consumer-facing product, a privacy-first DNS resolver.
As we kick off this year’s Impact Week, we certainly see a number of challenges for the Internet, though we think the opportunities for the Internet continue to far outweigh those challenges. Around the world, we see a number of countries rejecting the opportunity to maximize the potential of the Internet, and instead, passing new laws and regulations seeking to assert narrow control of the Internet for their own self-interested purposes, including in some cases for things like commercial advantage, censorship, or surveillance.
For example, around the Russian invasion of Ukraine, we’ve seen the Russian government launch cyberattacks and use targeted Internet outages to further torment the people in Ukraine, while at the same time pressing citizens in Russia to only use Internet tools and view information controlled by the Russian government.
Yet for all those challenges, we saw a disparate group of people and companies, including Cloudflare, come together to defend Ukraine from these attacks and do everything in their power to get the Internet back online as soon as possible. Nearly a year into the war, and despite the relentless efforts of a very powerful nation, the Internet remains a positive force for good in Ukraine, a way for them to get the message out about the horrific actions of the Russian government, and a tool for dissidents inside Russia to escape the attempted grip of censorship. When Russia personally sanctioned me earlier this year I took it as a badge of honor we were doing something right.
At the same time, the promise of the Internet continues to bring increased opportunity, especially in still developing parts of the world. Increased access to reliable and secure Internet in those countries will enable education, healthcare, and commerce in ways humanity has been struggling to advance for decades.
And we’ve seen recently in Iran that the Internet remains the leading tool for liberation for oppressed voices who seek to shake the control of authoritarian governments. This led to the somewhat unusual step by the US government of relaxing some of the sanctions against Iran in order to permit companies like Cloudflare greater freedom to ensure that the general population in Iran can have access to the Internet to support their cause.
Although issues like war, oppression, and misinformation are as old as humanity itself, the Internet is novel in its ability to bring together marginalized people who previously were unable to find and engage with each other based on distance, repression, or resources. To make sure the Internet fulfills that part of its promise, Project Galileo celebrated its 8th anniversary this year, and continues to support groups that unite underprivileged girls in India, the LGBTQIA+ community in the Nile River Valley, refugees needing health care services in a private environment. In total, through Project Galileo we provide Cloudflare’s services for free to more than 2,100 organizations in over 100 countries. That’s some of the work I’m the most proud of.
Over the course of this Impact Week, we will tell other stories about the way that the Internet, and Cloudflare specifically, provide an optimistic opportunity to improve our world. And that includes the entire world, especially as the Internet is poised to further close the gaps that have existed in Internet services to the developing world since its founding.
We will describe the way Cloudflare is focused on our own impact through emissions and the lessons we are applying to our products and operations to make sure that we are being responsible stewards of the Earth’s resources. We will review the ways that we are working to ensure that the necessary resources needed to benefit from the Internet aren’t limited to large companies with big budgets and the resources to buy the best tools.
From individuals and small businesses, to nonprofits and other community organizations, we want to make sure that the costs of cybersecurity and reliability don’t exclude those poised to benefit the most from the Internet. Specifically this year, we’re focused on making sure that sensitive groups — including local governments and critical infrastructure — are benefiting from new Zero Trust tools that are increasingly necessary for all organizations.
At the end of the week, we’ll release our annual Impact Report that provides a comprehensive review of our approach to these issues, especially when it comes to sustainability and ensuring that the Internet remains a widely-available and principled place.
We take pride in the principles that lie at the core of what we do as a company. Although many of us wake up every day scanning the Internet for the latest cyberattacks that we have to address or the latest congestion on the Internet to relieve, we are energized by the Internet’s ongoing promise to make life better for billions of people. This Impact Week we get to wake up and focus on those stories and share with you why all of us are here. We hope you are as excited as we are.
WebAuthn improves login security a lot by making it significantly harder for a user’s credentials to be misused – a WebAuthn token will only respond to a challenge if it’s issued by the site a secret was issued to, and in general will only do so if the user provides proof of physical presence[1]. But giving people tokens is tedious and also I have a new laptop which only has USB-C but does have a working fingerprint reader and I hate the aesthetics of the Yubikey 5C Nano, so I’ve been thinking about what WebAuthn looks like done without extra hardware.
Let’s talk about the broad set of problems first. For this to work you want to be able to generate a key in hardware (so it can’t just be copied elsewhere if the machine is compromised), prove to a remote site that it’s generated in hardware (so the remote site isn’t confused about what security assertions you’re making), and tie use of that key to the user being physically present (which may range from “I touched this object” to “I presented biometric evidence of identity”). What’s important here is that a compromised OS shouldn’t be able to just fake a response. For that to be possible, the chain between proof of physical presence to the secret needs to be outside the control of the OS.
For a physical security token like a Yubikey, this is pretty easy. The communication protocol involves the OS passing a challenge and the source of the challenge to the token. The token then waits for a physical touch, verifies that the source of the challenge corresponds to the secret it’s being asked to respond to the challenge with, and provides a response. At the point where keys are being enrolled, the token can generate a signed attestation that it generated the key, and a remote site can then conclude that this key is legitimately sequestered away from the OS. This all takes place outside the control of the OS, meeting all the goals described above.
How about Macs? The easiest approach here is to make use of the secure enclave and TouchID. The secure enclave is a separate piece of hardware built into either a support chip (for x86-based Macs) or directly on the SoC (for ARM-based Macs). It’s capable of generating keys and also capable of producing attestations that said key was generated on an Apple secure enclave (“Apple Anonymous Attestation”, which has the interesting property of attesting that it was generated on Apple hardware, but not which Apple hardware, avoiding a lot of privacy concerns). These keys can have an associated policy that says they’re only usable if the user provides a legitimate touch on the fingerprint sensor, which means it can not only assert physical presence of a user, it can assert physical presence of an authorised user. Communication between the fingerprint sensor and the secure enclave is a private channel that the OS can’t meaningfully interfere with, which means even a compromised OS can’t fake physical presence responses (eg, the OS can’t record a legitimate fingerprint press and then send that to the secure enclave again in order to mimic the user being present – the secure enclave requires that each response from the fingerprint sensor be unique). This achieves our goals.
The PC space is more complicated. In the Mac case, communication between the biometric sensors (be that TouchID or FaceID) occurs in a controlled communication channel where all the hardware involved knows how to talk to the other hardware. In the PC case, the typical location where we’d store secrets is in the TPM, but TPMs conform to a standardised spec that has no understanding of this sort of communication, and biometric components on PCs have no way to communicate with the TPM other than via the OS. We can generate keys in the TPM, and the TPM can attest to those keys being TPM-generated, which means an attacker can’t exfiltrate those secrets and mimic the user’s token on another machine. But in the absence of any explicit binding between the TPM and the physical presence indicator, the association needs to be up to code running on the CPU. If that’s in the OS, an attacker who compromises the OS can simply ask the TPM to respond to an challenge it wants, skipping the biometric validation entirely.
Windows solves this problem in an interesting way. The Windows Hello Enhanced Signin doesn’t add new hardware, but relies on the use of virtualisation. The agent that handles WebAuthn responses isn’t running in the OS, it’s running in another VM that’s entirely isolated from the OS. Hardware that supports this model has a mechanism for proving its identity to the local code (eg, fingerprint readers that support this can sign their responses with a key that has a certificate that chains back to Microsoft). Additionally, the secrets that are associated with the TPM can be held in this VM rather than in the OS, meaning that the OS can’t use them directly. This means we have a flow where a browser asks for a WebAuthn response, that’s passed to the VM, the VM asks the biometric device for proof of user presence (including some sort of random value to prevent the OS just replaying that), receives it, and then asks the TPM to generate a response to the challenge. Compromising the OS doesn’t give you the ability to forge the responses between the biometric device and the VM, and doesn’t give you access to the secrets in the TPM, so again we meet all our goals.
On Linux (and other free OSes), things are less good. Projects like tpm-fido generate keys on the TPM, but there’s no secure channel between that code and whatever’s providing proof of physical presence. An attacker who compromises the OS may not be able to copy the keys to their own system, but while they’re on the compromised system they can respond to as many challenges as they like. That’s not the same security assertion we have in the other cases.
Overall, Apple’s approach is the simplest – having binding between the various hardware components involved means you can just ignore the OS entirely. Windows doesn’t have the luxury of having as much control over what the hardware landscape looks like, so has to rely on virtualisation to provide a security barrier against a compromised OS. And in Linux land, we’re fucked. Who do I have to pay to write a lightweight hypervisor that runs on commodity hardware and provides an environment where we can run this sort of code?
[1] As I discussed recently there are scenarios where these assertions are less strong, but even so
Jan Rude added a new module that gives users the ability to brute-force login for Linux Syncovery. This expands Framework’s capability to scan logins to Syncovery, a popular web GUI for backups.
WordPress extension SQL injection module
Cydave, destr4ct, and jheysel-r7 contributed a new module that takes advantage of a vulnerable WordPress extension. This allows Framework users to take advantage of CVE-2022-0739, leveraging a UNION-based SQL injection to gather hashed passwords of WordPress users. For vulnerable versions, anyone who can access the BookingPress plugin page will also have access to all the credentials in the database, yikes! There are currently 3,000 active installs of the plugin, which isn’t a huge number by WordPress standards—but the ease of remote exploitation makes it a fun addition to the framework.
VMware vCenter "vScalation" Privilege Escalation by Yuval Lazar and h00die, which exploits CVE-2021-22015 – This PR adds a privilege escalation for users in the cis group to escalate to root on certain versions of vCenter. A service file /usr/lib/vmware-vmon/java-wrapper-vmon has improper permissions allowing cis group members to write to it. Upon host reboot or vmware-vmon service restart, a root shell is obtained.
Enhancements and features (2)
#17214 from h00die – This PR improves upon the data gathered on a vCenter server originally implemented in #16871, including library integration, optimization, and de-duplication.
#17332 from bcoles – Updates windows/gather/enum_proxy to support non-Meterpreter sessions (shell, PowerShell).
Bugs fixed (5)
#17183 from rbowes-r7 – This adds some small changes, cleanups, and fixes to the linux/http/zimbra_unrar_cve_2022_30333 and linux/http/zimbra_cpio_cve_2022_41352 Zimbra exploit modules, along with linux/local/zimbra_slapper_priv_esc documentation. Particularly, this fixes an issue that prevented the exploit modules from working properly when the handler was prematurely shut down.
#17305 from cgranleese-r7 – Updates Metasploit’s RPC to automatically choose an appropriate payload if module.execute is invoked without a payload set. This mimics the functionality of msfconsole.
#17323 from h00die – Fixes a bug when attempting to detect enlightenment_sys in exploits/linux/local/ubuntu_enlightenment_mount_priv_esc.
#17330 from zeroSteiner – This fixes an issue in the ProxyShell module, which limited the email enumeration to 100 entries. Now, it correctly enumerates all the emails before finding one that is suitable for exploitation.
#17342 from gwillcox-r7 – This adds the necessary control to the search queries used to find vulnerable certificate templates in an AD CS environment. Prior to this, non-privileged users would not be able to read the security descriptor field.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate and you can get more details on the changes since the last blog post from GitHub:
To install fresh without using git, you can use the open-source-only Nightly Installers or the binary installers (which also include the commercial edition).
We continue to expand the scope of our assurance programs at Amazon Web Services (AWS), and we are pleased to announce that our Regions and AWS Edge locations in Europe are now certified by the Portuguese GNS/NSO (National Security Office) at the National Restricted level. This certification demonstrates our ongoing commitment to adhere to the heightened expectations for cloud service providers to process, transmit, and store classified data.
The GNS certification is based on NIST SP800-53 R4 and CSA CCM v4 frameworks, with the goal of protecting the processing and transmission of classified information.
As of this writing, 26 services offered in Europe are in scope of this certification. For up-to-date information, including when additional services are added, see the AWS Services in Scope by Compliance Program and select GNS.
AWS strives to continuously bring services into the scope of its compliance programs to help you meet your architectural and regulatory needs. If you have questions or feedback about GNS Portugal compliance, reach out to your AWS account team.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
This article talks about public land in the US that is completely surrounded by private land, which in some cases makes it inaccessible to the public. But there’s a hack:
Some hunters have long believed, however, that the publicly owned parcels on Elk Mountain can be legally reached using a practice called corner-crossing.
Corner-crossing can be visualized in terms of a checkerboard. Ever since the Westward Expansion, much of the Western United States has been divided into alternating squares of public and private land. Corner-crossers, like checker pieces, literally step from one public square to another in diagonal fashion, avoiding trespassing charges. The practice is neither legal nor illegal. Most states discourage it, but none ban it.
It’s an interesting ambiguity in the law: does checker trespass on white squares when it moves diagonally over black squares? But, of course, the legal battle isn’t really about that. It’s about the rights of property owners vs the rights of those who wish to walk on this otherwise-inaccessible public land.
This particular hack will be adjudicated in court. State court, I think, which means the answer might be different in different states. It’s not an example I discuss in my new book, but it’s similar to many I do discuss. It’s the act of adjudicating hacks that allows systems to evolve.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.