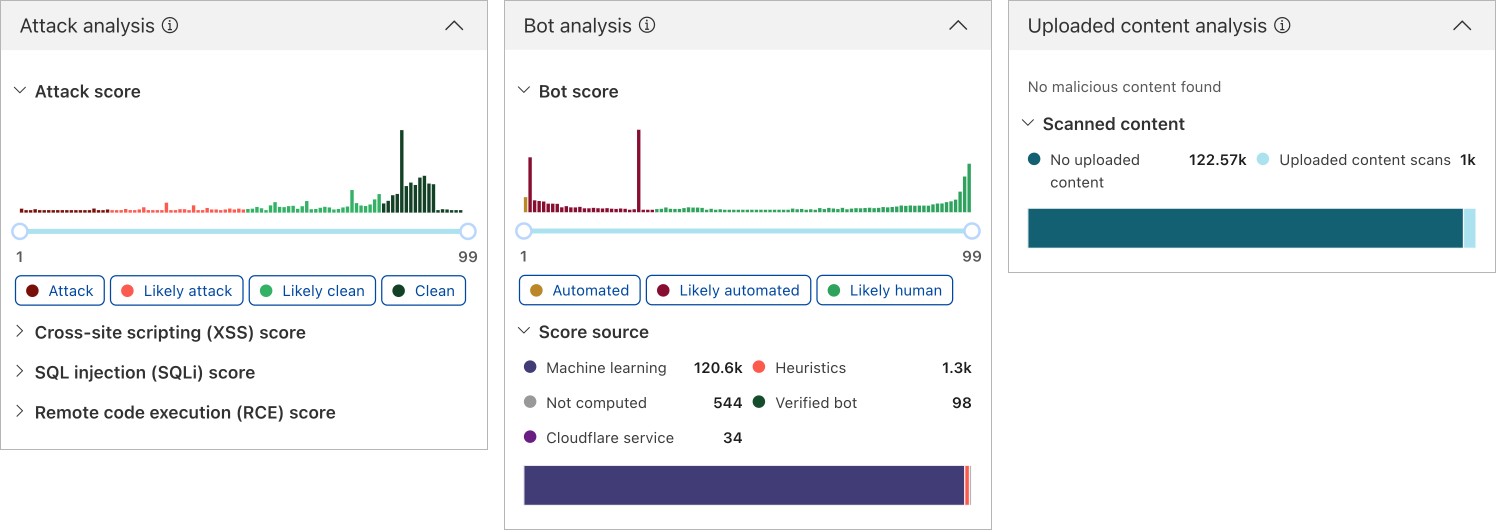
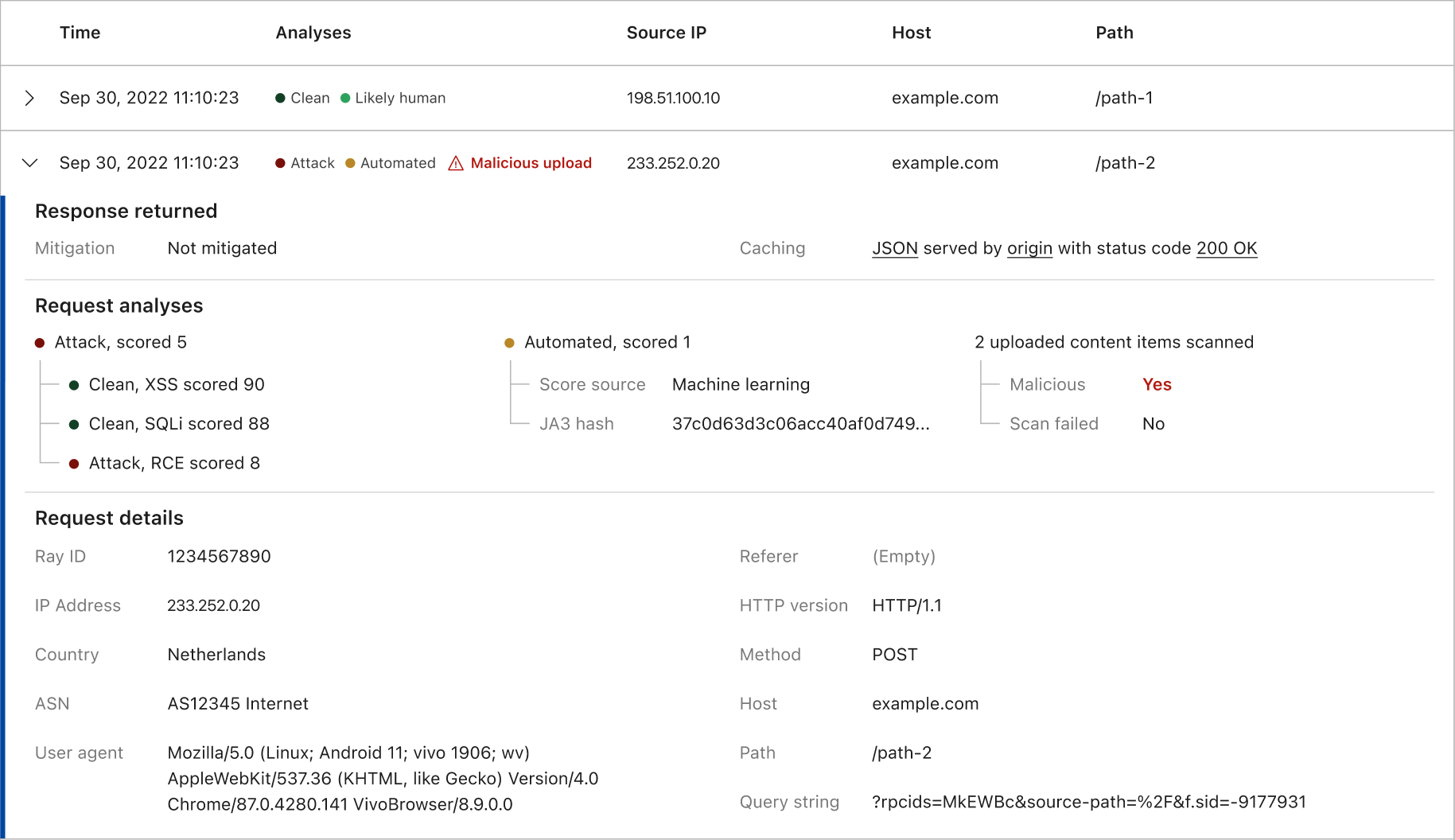
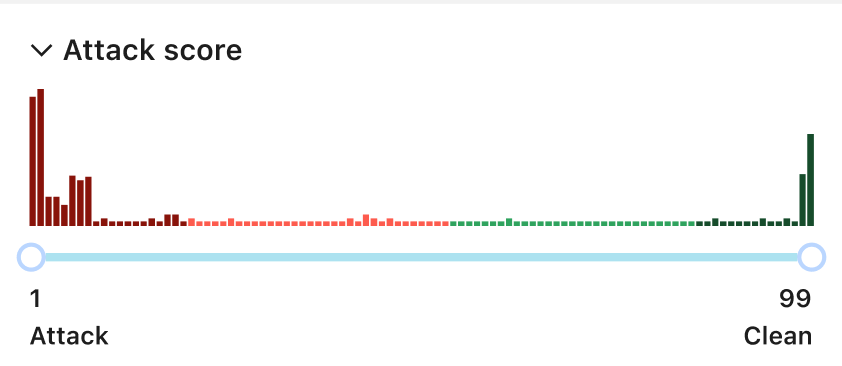
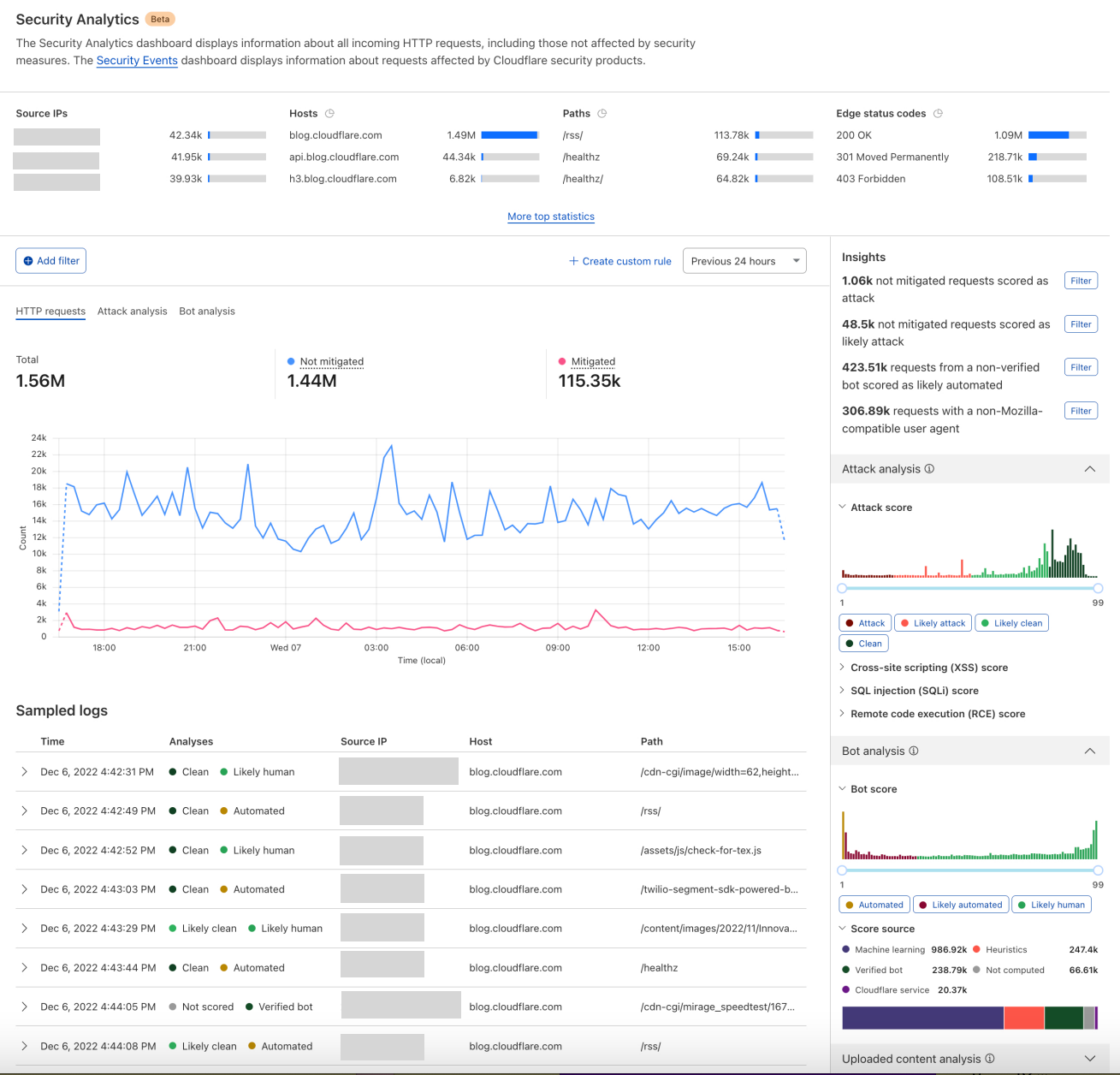
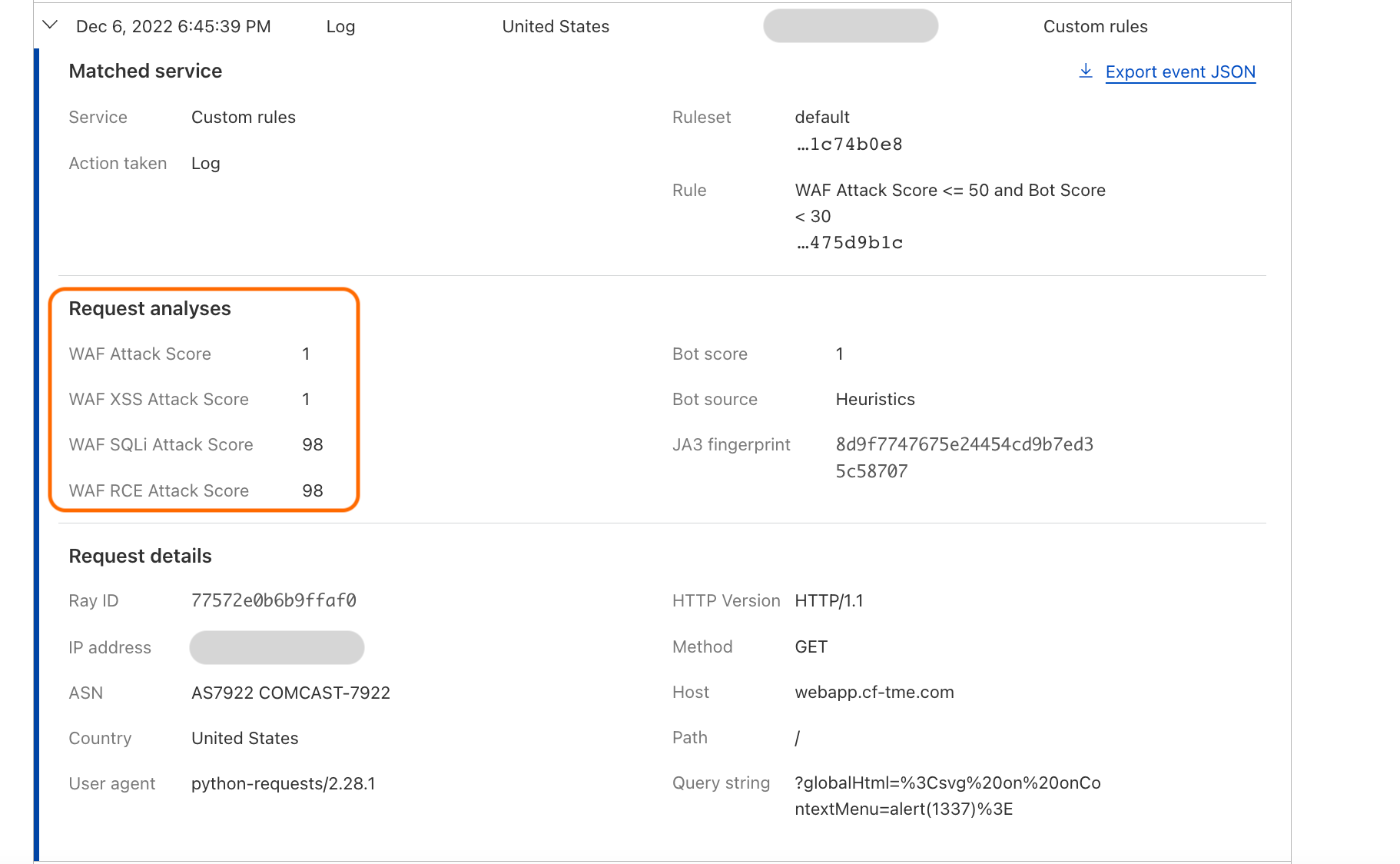
Post Syndicated from Ranjan Burman original https://aws.amazon.com/blogs/big-data/enable-multi-az-deployments-for-your-amazon-redshift-data-warehouse/
November 2023: This post was reviewed and updated with the general availability of Multi-AZ deployments for provisioned RA3 clusters.
Originally published on December 9th, 2022.
Amazon Redshift is a fully managed, petabyte scale cloud data warehouse that enables you to analyze large datasets using standard SQL. Data warehouse workloads are increasingly being used with mission-critical analytics applications that require the highest levels of resilience and availability. Amazon Redshift is a cloud-based data warehouse that supports many recovery capabilities to address unforeseen outages and minimize downtime. Amazon Redshift RA3 instance types store their data in Redshift Managed Storage (RMS), which is backed by Amazon Simple Storage Service (Amazon S3) making it highly available and durable by default. Amazon Redshift also supports automatic backups that can recover a data warehouse, automatically remediate failures and relocates clusters to different AZs without changes to applications. Although many customers benefit from these features, enterprise data warehouse customers require a low Recovery Time Objective (RTO) and higher availability to support their business continuity with minimal impact to applications.
Amazon Redshift just announced the general availability of Multi-AZ deployments for provisioned RA3 clusters that support running your data warehouse in two Availability Zones simultaneously and can continue operating in unforeseen failure scenarios. A Multi-AZ deployment is intended for customers with mission-critical analytics applications that require the highest levels of resilience and availability.
A Redshift Multi-AZ deployment leverages compute resources in two AZs to scale data warehouse workload processing. In situations where there is a high level or concurrency Redshift will automatically leverage the resources in both AZs to scale the workload for both read and write requests.
Our pre-launch tests found that Amazon Redshift Multi-AZ deployments reduce recovery time to under 60 seconds or less in the unlikely case of an AZ failure.
Single-AZ vs. Multi-AZ deployment
Amazon Redshift requires a cluster subnet group to create a cluster in your VPC. The cluster subnet group includes information about the VPC ID and a list of subnets in your VPC. When you launch a cluster, Amazon Redshift either creates a default cluster subnet group automatically or you choose a cluster subnet group of your choice so that Amazon Redshift can provision your cluster in one of the subnets in the VPC. You can configure your cluster subnet group to add subnets from different Availability Zones that you want Amazon Redshift to use for cluster deployment.
All Amazon Redshift clusters today are created and situated in a particular Availability Zone within an AWS Region and thus called Single-AZ deployments. For a Single-AZ deployment, Amazon Redshift selects the subnet from one of the Availability Zones within a Region and deploys the cluster there. You can choose an Availability Zone for deployment, and Amazon Redshift will deploy your cluster in the chosen Availability Zone based on the subnets provided.
On the other hand, a multi-AZ deployment is provisioned in two Availability Zones simultaneously. For a Multi-AZ deployment, Amazon Redshift automatically selects two subnets from two different Availability Zones and deploys an equal number of compute nodes in each Availability Zone. All these compute nodes are utilized via a single endpoint as compute nodes from both Availability Zones are used for workload processing.
As shown in the following diagrams, Amazon Redshift deploys a cluster in a single Availability Zone for Single-AZ deployment, and two Availability Zones for Multi-AZ deployment.
Auto recovery of multi-AZ deployment
In the unlikely event of an Availability Zone failure, Amazon Redshift Multi-AZ deployments continue to serve your workloads by automatically using resources in the other Availability Zone. You are not required to make any application changes to maintain business continuity during unforeseen outages since a multi-AZ deployment is accessed as a single data warehouse with one endpoint. Amazon Redshift Multi-AZ deployments are designed to ensure there is no data loss, and you can query all data committed up until the point of failure.
As shown in the below diagram, if there is an unlikely event that causes compute nodes in AZ1 to fail, then a multi-AZ deployment automatically recovers to use compute resources in AZ2. Amazon Redshift will also automatically provision identical compute nodes in another availability zone (AZ3) to continue operating simultaneously in two Availability zones (AZ2 and AZ3).
Amazon Redshift Multi-AZ deployment is not only used for protection against the possibility of Availability Zone failures, but it can also maximize your data warehouse performance by automatically distributing workload processing across two Availability Zones. A Multi-AZ deployment will always process an individual query using compute resources only from one Availability Zone, but it can automatically distribute processing of multiple simultaneous queries to both Availability Zones to increase overall performance for high concurrency workloads.
It’s a good practice to set up automatic retries in your extract, transform, and load (ETL) processes and dashboards so that they can be reissued and served by the cluster in the secondary Availability Zone when an unlikely failure happens in the primary Availability Zone. If a connection is dropped, it can then be retried or reestablished immediately. In addition, queries and loads that were running in the failed Availability Zone will be aborted. New queries issued at or after a failure occurs may experience run delays while the multi-AZ data warehouse is being recovered to a two AZ setup.
Overview of solution
In this post, we provide a walkthrough of how to create and manage a Multi-AZ deployment for Amazon Redshift using the AWS Management Console. We also test the fault tolerance of an Amazon Redshift Multi-AZ data warehouse and monitor queries in your Multi-AZ deployment.
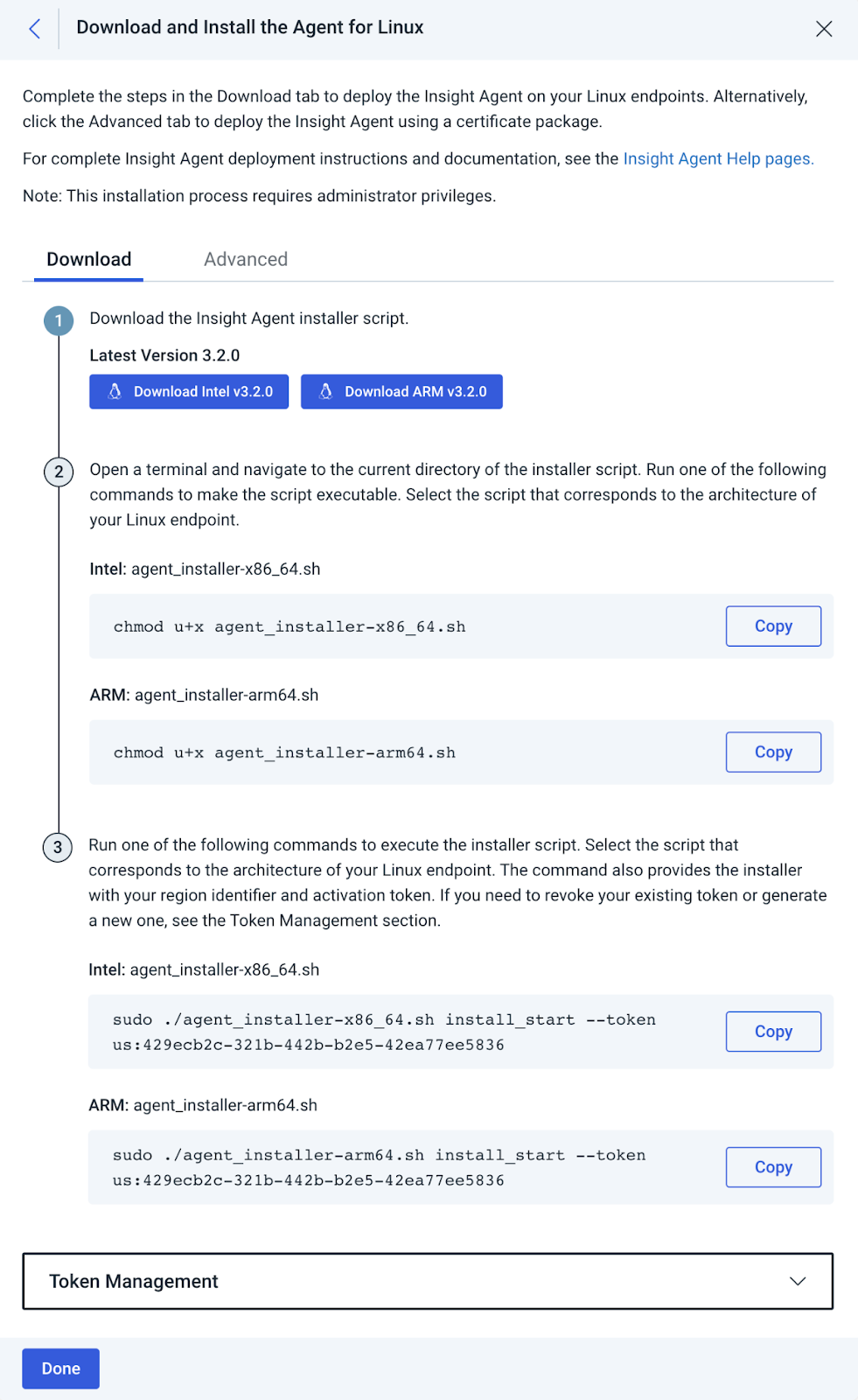
Create a new Multi-AZ deployment from the console
You can easily create a new multi-AZ deployments through Amazon Redshift console. Amazon Redshift will deploy the same number of nodes in each of the two Availability Zones for a Multi-AZ deployment. All nodes of a multi-AZ deployment can perform read and write workload processing during normal operation. A Multi-AZ deployment is supported only for provisioned RA3 clusters.
Follow these steps to create an Amazon Redshift provisioned cluster in two Availability Zones:
- On the Amazon Redshift console, in the navigation pane, choose Clusters.
- Click on Create cluster.
For general information about creating clusters, see Creating a cluster.
- Choose one of the RA3 node types on the Node type drop-down menu. The Multi-AZ deployment option only becomes available when you choose an RA3 node type.
- For Multi-AZ deployment, select Multi-AZ option.
- For Number of nodes per AZ, enter the number of nodes that you need for your cluster.


- Under the Database configurations, choose Admin user name and Admin user password.
- Turn Use defaults on next to Additional configurations to modify the default settings.
- Under Network and security, specify the following:
- For Virtual private cloud (VPC), choose the VPC you want to deploy the cluster in.
- For VPC security groups, either leave as default or add the security groups of your choice.
- For Cluster subnet group, either leave as default or add a cluster subnet group of your choice. For a Multi-AZ deployment, a cluster subnet group must include one subnet each from at least three or more different Availability Zones.
For general information about managing cluster subnet groups, see Cluster subnet groups

- Under Database configuration, for Database port, you either use the default value 5439 or choose a value from the range of 5431–5455 and 8191–8215.
- Under Database configuration, in the Database encryption section, to use a custom AWS Key Management Service (AWS KMS) key other than the default KMS key, choose Customize encryption settings. This option is deselected by default.
- Under Choose an AWS KMS key, you can either choose an existing KMS key, or choose Create an AWS KMS key to create a new KMS key.
For more information to create key using KMS, refer to Creating keys.

- Choose Create cluster.
When the cluster creation succeeds, you can view the details on the cluster details page.
Under General information, you can see Multi-AZ as Yes.

On the Properties tab, under Network and security settings, you can find the details on the primary and secondary Availability Zone.

Create a new Multi-AZ deployment from the CLI
The following create-cluster AWS CLI command shows how to create a Multi-AZ cluster
aws redshift create-cluster
--port 5439
--master-username master
--master-user-password ######
--node-type ra3.4xlarge
--number-of-nodes 2
--profile maz-test
--endpoint-url https://redshift.us-east-1.amazonaws.com
--region eu-west-1
--cluster-identifier redshift-cluster-1
--multi-az
--maintenance-track-name CURRENT
--encrypted
Convert a Single-AZ deployment to Multi-AZ deployment
To convert an existing Single-AZ deployment to a Multi-AZ deployment, you can go to the Redshift console and select your Redshift cluster that currently is Single-AZ setup and navigate to Actions and select Activate Multi-AZ. Your Single-AZ cluster must be encrypted for a successful conversion to Multi-AZ. During conversion to Multi-AZ, Redshift will double the total number of nodes distributing them equally in each AZ. Redshift will not allow you to split existing number of nodes while converting to Multi-AZ to maintain consistent query performance.
Complete the following steps to create a Multi-AZ deployment restored from a snapshot:
- On the Amazon Redshift console, in the navigation pane, choose Clusters.
- Select your cluster and navigate to the cluster details page.
- On the Actions menu, choose Activate Multi-AZ.

- Review the modification summary and confirm by choosing Activate Multi-AZ.

Using the below AWS CLI command you can convert a single AZ Redshift data warehouse to Multi-AZ.
aws redshift modify-cluster
--profile maz-test
--endpoint-url https://redshift.eu-west-1.amazonaws.com
--region eu-west-1
--cluster-identifier redshift-cluster-1
--multi-az
Convert a Multi-AZ deployment to Single-AZ deployment
Redshift also supports conversion of a Multi-AZ deployment into Single-AZ. This option provides customers with the flexibility to switch between different deployments with few easy steps as follows:
- On the Amazon Redshift console, in the navigation pane, choose Clusters.
- Select your cluster and navigate to the cluster details page.
- On the Actions menu, choose Deactivate Multi-AZ.

- Review the modification summary and confirm by choosing Deactivate Multi-AZ.

Creating a Multi-AZ data warehouse restored from a snapshot
Existing customers can also create a Multi-AZ deployment by restoring a snapshot from an existing Single-AZ deployment. See the required steps as below.
- On the Amazon Redshift console, in the navigation pane, choose Clusters.
- Select the cluster and navigate to the cluster details page.
- Choose the Maintenance
- Select a snapshot and choose Restore snapshot, Restore to provisioned cluster.

- Review the Cluster configuration and Cluster details values of the new cluster to be created using the snapshot information.
- Select Multi-AZ option and update the properties of the new cluster, then choose Restore cluster from snapshot at the bottom of the page.

Resizing a Multi-AZ data warehouse
Redshift Multi-AZ feature also supports resizing Multi-AZ Redshift cluster deployments to change the cluster configuration based on scaling needs. You can change both number and type of nodes as per needs.
- On the Amazon Redshift console, in the navigation pane, choose Clusters.
- Select your cluster and navigate to the cluster details page.
- On the Actions menu, choose
- Once selected it will bring into another screen to show cluster resize screen where you can choose type and number of nodes and click on Resize cluster.


Failing over Multi-AZ deployment
In addition to the automatic recovery process, you can also trigger this process manually for your data warehouse using the Failover primary compute option. This approach can be used to manage operational maintenance and other planned operational procedures as per the needs of the respective environment. When the cluster successfully recovers, Multi-AZ deployment becomes available. Your Multi-AZ deployment also automatically provisions new compute nodes in another Availability Zone as soon as it is available.
Let’s manually trigger the Failover of your Redshift Multi-AZ deployment.
- On the Amazon Redshift console, choose Clusters in the navigation pane.
- Navigate to the cluster detail page
- From Actions, choose Failover primary compute.
- When prompted, choose Confirm.


After the cluster is back to Available status, you can observe that the primary and secondary Availability Zones have changed.
The following screenshot shows the status before injecting failure.

The following screenshot shows the status after injecting failure.

Restore a table from snapshot
You can restore a single table from a snapshot from your Multi-AZ cluster. When you restore a single table from a snapshot, you specify the source snapshot, database, schema, and table name, and the target database, schema, and a new table name for the restored table.
To restore a table from a snapshot:
- On the Amazon Redshift console, in the navigation pane, choose Clusters.
- Select your cluster and navigate to the cluster details page.
- On the Actions menu, choose Restore table.
- Enter the information about which snapshot, source table, and target table to use, and then choose Restore table.

Enable public connections for your Multi-AZ data warehouse
- From the navigation menu, choose CLUSTERS.
- Choose the Multi-AZ cluster that you want to modify.
- Choose Actions.
- Choose Turn on Publicly accessible.
- Choose Elastic IP address, if you do not choose one, an address will be randomly assigned to you.
- Choose Save changes.


Monitor queries for Multi-AZ deployments
A Multi-AZ deployment uses compute resources that are deployed in both Availability Zones and can continue operating in the event that the resources in a given Availability Zone are not available. All the compute resources are used at all times, which allows full operation across two Availability Zones in both read and write operations.
You can query SYS_views in the pg_catalog schema to monitor Multi-AZ query runs. The SYS_views cover query run activities and stats from primary and secondary clusters.
The following are the system tables in the SYS_view list:
Follow these steps to monitor the query run on Multi-AZ deployment from the Amazon Redshift Console:
- On the Amazon Redshift console, connect to the database in your Multi-AZ deployment and run queries through the query editor.
- Run any sample query on the Multi-AZ Redshift deployment.
- For a Multi-AZ deployment, you can identify a query and the Availability Zone where it is being run (running on the primary or secondary availability zone) by using the
compute_type column in the SYS_QUERY_HISTORY table. The valid values for the compute type column are as follows:
- primary – When run on primary availability zone in the Multi-AZ deployment.
- secondary – When run on secondary availability zone in the Multi-AZ deployment.
The following is a sample query using the compute_type column to monitor a query:
dev=# select (compute_type) as compute_type, left(query_text, 50) query_text from sys_query_history order by start_time desc;
compute_type | query_text
--------------+----------------------------------------------------
secondary | select count(*) from t1;
primary select count(*) from t2;
You can also access the query history from the console to analyze your query diagnostics.
- On the Query monitoring tab, choose Connect to database.

- For Connection, choose Create a new connection
- For Authentication, choose Temporary credentials
- For Database name, enter the database name (for example,
dev).
- For Database user, enter the database user name (for example,
awsuser).
- Choose Connect.

After you’re connected, under Query Monitoring, on the Query history tab, you can view all the queries and loads, as shown in the following screenshot.

Under Metric filters, you can use the various filters in the Additional filtering options section to view query history based on Time interval, Users, Databases, or SQL commands.

There are a few limitations when working with Amazon Redshift Multi-AZ in preview mode, refer here for the limitations.
Customer feedback
 |
Janssen Pharmaceuticals, a subsidiary of Johnson & Johnson, researches and manufactures medicines with a focus on the changing needs of patients and the healthcare industry.
“Janssen Pharmaceutical uses Amazon Redshift to enable critical insights that drive important business decisions for our data scientists, data stewards, business users, and external stakeholders. With Amazon Redshift Multi-AZ, we can be confident that our data warehouse will always be available without any disruptions that might delay impact our ability to make critical business decisions.”
– Shyam Mohapatra, Director of Information Technology – Janssen Pharmaceutical Companies of Johnson & Johnson
|
 |
Stripe is a technology company that builds economic infrastructure for the internet. Stripe’s products power payments for online and in-person retailers, subscriptions businesses, software platforms and marketplaces, and everything in between.
“Millions of companies use Stripe’s software and APIs to accept payments, send payouts, and manage their businesses online. Access to their Stripe data via leading data warehouses like Amazon Redshift has been a top request from our customers. Our customers needed highly available, secure, fast, and integrated analytics at scale without building complex data pipelines or moving and copying data around. With Stripe Data Pipeline for Amazon Redshift, we’re helping our customers set up a direct and reliable data pipeline in a few clicks.
Stripe Data Pipeline enables our customers to automatically share their complete, up-to-date Stripe data with their Amazon Redshift data warehouse, and take their business analytics and reporting to the next level.”
– Brian Brunner, Senior Manager, Engineering at Stripe
|
Conclusion
This post demonstrated how to configure an Amazon Redshift Multi-AZ deployment in two Availability Zones and test the fault tolerance of your workloads during an unlikely failure of an Availability Zone. Amazon Redshift Multi-AZ deployment also helps improve overall performance of your data warehouse because compute nodes in both Availability Zones are used for read and write operations. Amazon Redshift Multi-AZ data warehouse helps meet the demands of customers with mission critical analytics applications that require the highest levels of availability and resiliency. For more details, refer Configuring Multi-AZ deployment.
About the Authors
 Ranjan Burman is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 16 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with cloud solutions.
Ranjan Burman is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 16 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with cloud solutions.
 Saurav Das is part of the Amazon Redshift Product Management team. He has more than 16 years of experience in working with relational databases technologies and data protection. He has a deep interest in solving customer challenges centered around high availability and disaster recovery.
Saurav Das is part of the Amazon Redshift Product Management team. He has more than 16 years of experience in working with relational databases technologies and data protection. He has a deep interest in solving customer challenges centered around high availability and disaster recovery.
 Anusha Challa is a Senior Analytics Specialist Solutions Architect focused on Amazon Redshift. She has helped many customers build large-scale data warehouse solutions in the cloud and on premises. She is passionate about data analytics and data science.
Anusha Challa is a Senior Analytics Specialist Solutions Architect focused on Amazon Redshift. She has helped many customers build large-scale data warehouse solutions in the cloud and on premises. She is passionate about data analytics and data science.
Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
 Suresh Patnam is a Principal BDM – GTM AI/ML Leader at AWS. He works with customers to build IT strategy, making digital transformation through the cloud more accessible by using data and AI/ML. In his spare time, Suresh enjoys playing tennis and spending time with his family.
Suresh Patnam is a Principal BDM – GTM AI/ML Leader at AWS. He works with customers to build IT strategy, making digital transformation through the cloud more accessible by using data and AI/ML. In his spare time, Suresh enjoys playing tennis and spending time with his family.
































 Ranjan Burman is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 16 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with cloud solutions.
Ranjan Burman is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 16 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with cloud solutions. Saurav Das is part of the Amazon Redshift Product Management team. He has more than 16 years of experience in working with relational databases technologies and data protection. He has a deep interest in solving customer challenges centered around high availability and disaster recovery.
Saurav Das is part of the Amazon Redshift Product Management team. He has more than 16 years of experience in working with relational databases technologies and data protection. He has a deep interest in solving customer challenges centered around high availability and disaster recovery.