Post Syndicated from George Conti original https://aws.amazon.com/blogs/security/how-to-add-authentication-single-page-web-application-with-amazon-cognito-oauth2-implementation/
In this post, I’ll be showing you how to configure Amazon Cognito as an OpenID provider (OP) with a single-page web application.
This use case describes using Amazon Cognito to integrate with an existing authorization system following the OpenID Connect (OIDC) specification. OIDC is an identity layer on top of the OAuth 2.0 protocol to enable clients to verify the identity of users. Amazon Cognito lets you add user sign-up, sign-in, and access control to your web and mobile apps quickly and easily. Some key reasons customers select Amazon Cognito include:
- Simplicity of implementation: The console is very intuitive; it takes a short time to understand how to configure and use Amazon Cognito. Amazon Cognito also has key out-of-the-box functionality, including social sign-in, multi-factor authentication (MFA), forgotten password support, and infrastructure as code (AWS CloudFormation) support.
- Ability to customize workflows: Amazon Cognito offers the option of a hosted UI where users can sign-in directly to Amazon Cognito or sign-in via social identity providers such as Amazon, Google, Apple, and Facebook. The Amazon Cognito hosted UI and workflows help save your team significant time and effort.
- OIDC support: Amazon Cognito can securely pass user profile information to an existing authorization system following the ODIC authorization code flow. The authorization system uses the user profile information to secure access to the app.
Amazon Cognito overview
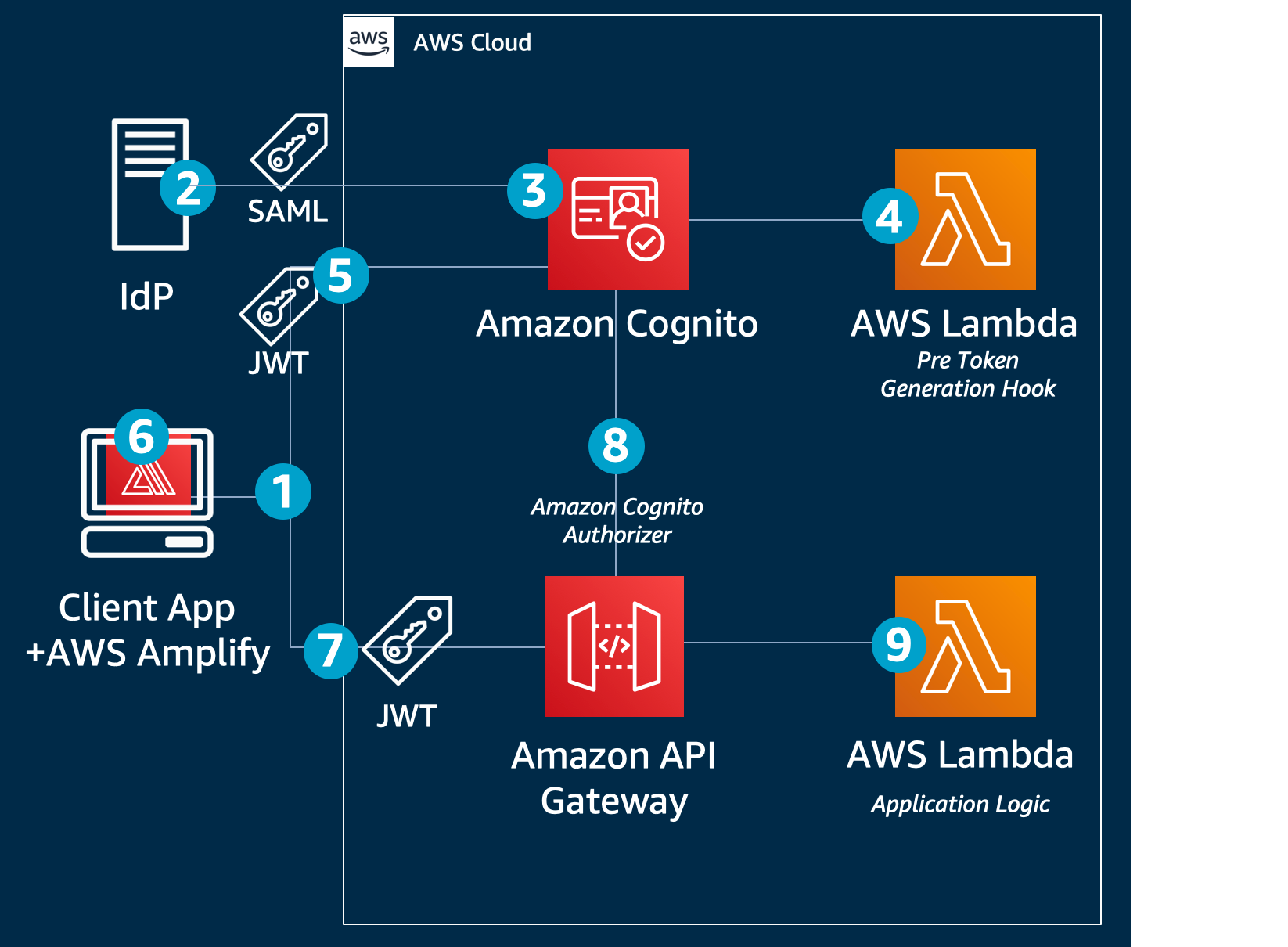
Amazon Cognito follows the OIDC specification to authenticate users of web and mobile apps. Users can sign in directly through the Amazon Cognito hosted UI or through a federated identity provider, such as Amazon, Facebook, Apple, or Google. The hosted UI workflows include sign-in and sign-up, password reset, and MFA. Since not all customer workflows are the same, you can customize Amazon Cognito workflows at key points with AWS Lambda functions, allowing you to run code without provisioning or managing servers. After a user authenticates, Amazon Cognito returns standard OIDC tokens. You can use the user profile information in the ID token to grant your users access to your own resources or you can use the tokens to grant access to APIs hosted by Amazon API Gateway. You can also exchange the tokens for temporary AWS credentials to access other AWS services.

Figure 1: Amazon Cognito sign-in flow
OAuth 2.0 and OIDC
OAuth 2.0 is an open standard that allows a user to delegate access to their information to other websites or applications without handing over credentials. OIDC is an identity layer on top of OAuth 2.0 that uses OAuth 2.0 flows. OAuth 2.0 defines a number of flows to manage the interaction between the application, user, and authorization server. The right flow to use depends on the type of application.
The client credentials flow is used in machine-to-machine communications. You can use the client credentials flow to request an access token to access your own resources, which means you can use this flow when your app is requesting the token on its own behalf, not on behalf of a user. The authorization code grant flow is used to return an authorization code that is then exchanged for user pool tokens. Because the tokens are never exposed directly to the user, they are less likely to be shared broadly or accessed by an unauthorized party. However, a custom application is required on the back end to exchange the authorization code for user pool tokens. For security reasons, we recommend the Authorization Code Flow with Proof Key Code Exchange (PKCE) for public clients, such as single-page apps or native mobile apps.
The following table shows recommended flows per application type.
| Application |
CFlow |
Description |
| Machine |
Client credentials |
Use this flow when your application is requesting the token on its own behalf, not on behalf of the user |
| Web app on a server |
Authorization code grant |
A regular web app on a web server |
| Single-page app |
Authorization code grant PKCE |
An app running in the browser, such as JavaScript |
| Mobile app |
Authorization code grant PKCE |
iOS or Android app |
Securing the authorization code flow
Amazon Cognito can help you achieve compliance with regulatory frameworks and certifications, but it’s your responsibility to use the service in a way that remains compliant and secure. You need to determine the sensitivity of the user profile data in Amazon Cognito; adhere to your company’s security requirements, applicable laws and regulations; and configure your application and corresponding Amazon Cognito settings appropriately for your use case.
Note: You can learn more about regulatory frameworks and certifications at AWS Services in Scope by Compliance Program. You can download compliance reports from AWS Artifact.
We recommend that you use the authorization code flow with PKCE for single-page apps. Applications that use PKCE generate a random code verifier that’s created for every authorization request. Proof Key for Code Exchange by OAuth Public Clients has more information on use of a code verifier. In the following sections, I will show you how to set up the Amazon Cognito authorization endpoint for your app to support a code verifier.
The authorization code flow
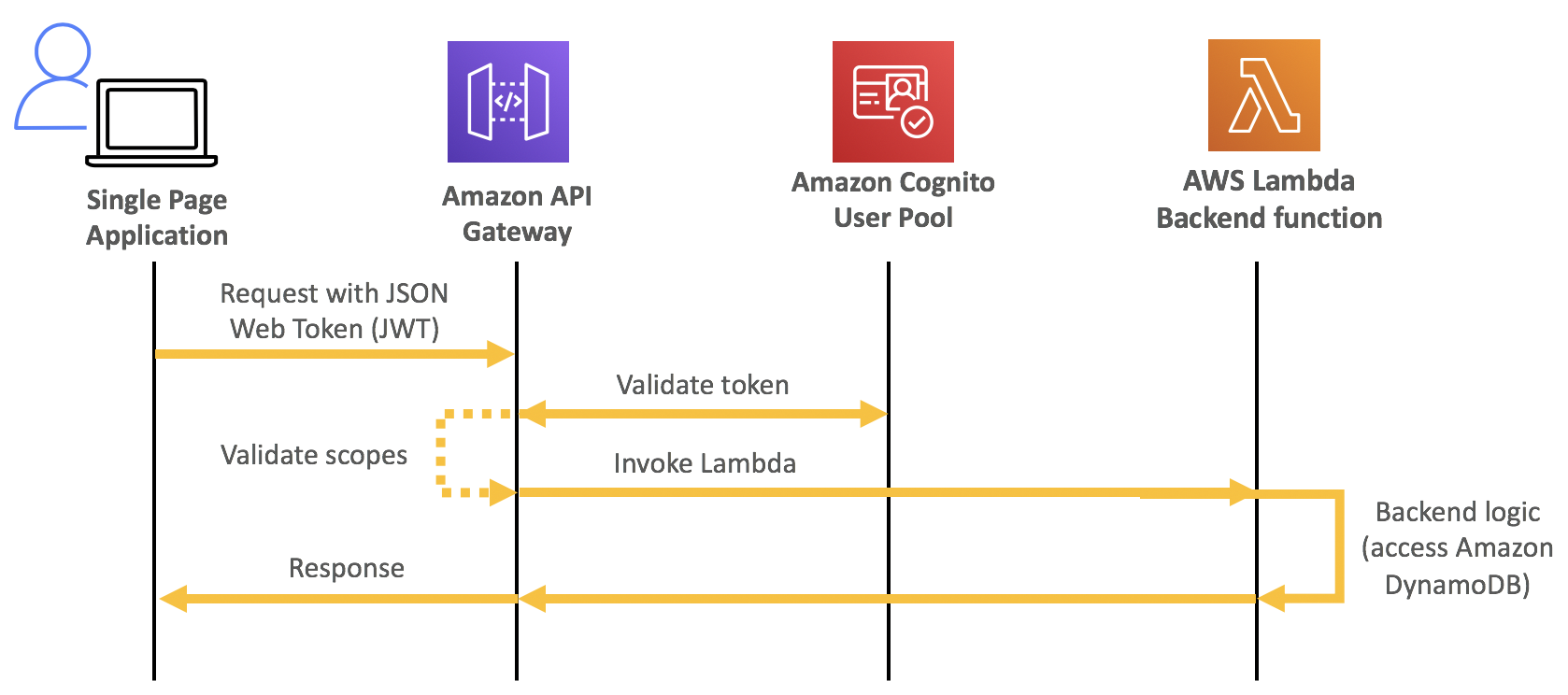
In OpenID terms, the app is the relying party (RP) and Amazon Cognito is the OP. The flow for the authorization code flow with PKCE is as follows:
- The user enters the app home page URL in the browser and the browser fetches the app.
- The app generates the PKCE code challenge and redirects the request to the Amazon Cognito OAuth2 authorization endpoint (/oauth2/authorize).
- Amazon Cognito responds back to the user’s browser with the Amazon Cognito hosted sign-in page.
- The user signs in with their user name and password, signs up as a new user, or signs in with a federated sign-in. After a successful sign-in, Amazon Cognito returns the authorization code to the browser, which redirects the authorization code back to the app.
- The app sends a request to the Amazon Cognito OAuth2 token endpoint (/oauth2/token) with the authorization code, its client credentials, and the PKCE verifier.
- Amazon Cognito authenticates the app with the supplied credentials, validates the authorization code, validates the request with the code verifier, and returns the OpenID tokens, access token, ID token, and refresh token.
- The app validates the OpenID ID token and then uses the user profile information (claims) in the ID token to provide access to resources.(Optional) The app can use the access token to retrieve the user profile information from the Amazon Cognito user information endpoint (/userInfo).
- Amazon Cognito returns the user profile information (claims) about the authenticated user to the app. The app then uses the claims to provide access to resources.
The following diagram shows the authorization code flow with PKCE.

Figure 2: Authorization code flow
Implementing an app with Amazon Cognito authentication
Now that you’ve learned about Amazon Cognito OAuth implementation, let’s create a working example app that uses Amazon Cognito OAuth implementation. You’ll create an Amazon Cognito user pool along with an app client, the app, an Amazon Simple Storage Service (Amazon S3) bucket, and an Amazon CloudFront distribution for the app, and you’ll configure the app client.
Step 1. Create a user pool
Start by creating your user pool with the default configuration.
Create a user pool:
- Go to the Amazon Cognito console and select Manage User Pools. This takes you to the User Pools Directory.
- Select Create a user pool in the upper corner.
- Enter a Pool name, select Review defaults, and select Create pool.
- Copy the Pool ID, which will be used later to create your single-page app. It will be something like region_xxxxx. You will use it to replace the variable YOUR_USERPOOL_ID in a later step.(Optional) You can add additional features to the user pool, but this demonstration uses the default configuration. For more information see, the Amazon Cognito documentation.
The following figure shows you entering the user pool name.

Figure 3: Enter a name for the user pool
The following figure shows the resulting user pool configuration.

Figure 4: Completed user pool configuration
Step 2. Create a domain name
The Amazon Cognito hosted UI lets you use your own domain name or you can add a prefix to the Amazon Cognito domain. This example uses an Amazon Cognito domain with a prefix.
Create a domain name:
- Sign in to the Amazon Cognito console, select Manage User Pools, and select your user pool.
- Under App integration, select Domain name.
- In the Amazon Cognito domain section, add your Domain prefix (for example, myblog).
- Select Check availability. If your domain isn’t available, change the domain prefix and try again.
- When your domain is confirmed as available, copy the Domain prefix to use when you create your single-page app. You will use it to replace the variable YOUR_COGNITO_DOMAIN_PREFIX in a later step.
- Choose Save changes.
The following figure shows creating an Amazon Cognito hosted domain.

Figure 5: Creating an Amazon Cognito hosted UI domain
Step 3. Create an app client
Now create the app client user pool. An app client is where you register your app with the user pool. Generally, you create an app client for each app platform. For example, you might create an app client for a single-page app and another app client for a mobile app. Each app client has its own ID, authentication flows, and permissions to access user attributes.
Create an app client:
- Sign in to the Amazon Cognito console, select Manage User Pools, and select your user pool.
- Under General settings, select App clients.
- Choose Add an app client.
- Enter a name for the app client in the App client name field.
- Uncheck Generate client secret and accept the remaining default configurations.
Note: The client secret is used to authenticate the app client to the user pool. Generate client secret is unchecked because you don’t want to send the client secret on the URL using client-side JavaScript. The client secret is used by applications that have a server-side component that can secure the client secret.
- Choose Create app client as shown in the following figure.
Figure 6: Create and configure an app client
- Copy the App client ID. You will use it to replace the variable YOUR_APPCLIENT_ID in a later step.
The following figure shows the App client ID which is automatically generated when the app client is created.
Figure 7: App client configuration
Step 4. Create an Amazon S3 website bucket
Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. We use Amazon S3 here to host a static website.
- Sign in to the AWS Management Console and open the Amazon S3 console.
- Choose Create bucket to start the Create bucket wizard.
- In Bucket name, enter a DNS-compliant name for your bucket. You will use this in a later step to replace the YOURS3BUCKETNAME variable.
- In Region, choose the AWS Region where you want the bucket to reside.
Note: It’s recommended to create the Amazon S3 bucket in the same AWS Region as Amazon Cognito.
- Look up the region code from the region table (for example, US-East [N. Virginia] has a region code of us-east-1). You will use the region code to replace the variable YOUR_REGION in a later step.
- Choose Next.
- Select the Versioning checkbox.
- Choose Next.
- Choose Next.
- Choose Create bucket.
- Select the bucket you just created from the Amazon S3 bucket list.
- Select the Properties tab.
- Choose Static website hosting.
- Choose Use this bucket to host a website.
- For the index document, enter index.html and then choose Save.
Step 5. Create a CloudFront distribution
Amazon CloudFront is a fast content delivery network service that helps securely deliver data, videos, applications, and APIs to customers globally with low latency and high transfer speeds—all within a developer-friendly environment. In this step, we use CloudFront to set up an HTTPS-enabled domain for the static website hosted on Amazon S3.
Create a CloudFront distribution (web distribution) with the following modified default settings:
- Sign into the AWS Management Console and open the CloudFront console.
- Choose Create Distribution.
- On the first page of the Create Distribution Wizard, in the Web section, choose Get Started.
- Choose the Origin Domain Name from the dropdown list. It will be YOURS3BUCKETNAME.s3.amazonaws.com.
- For Restrict Bucket Access, select Yes.
- For Origin Access Identity, select Create a New Identity.
- For Grant Read Permission on Bucket, select Yes, Update Bucket Policy.
- For the Viewer Protocol Policy, select Redirect HTTP to HTTPS.
- For Cache Policy, select Managed-Caching Disabled.
- Set the Default Root Object to index.html.(Optional) Add a comment. Comments are a good place to describe the purpose of your distribution, for example, “Amazon Cognito SPA.”
- Select Create Distribution. The distribution will take a few minutes to create and update.
- Copy the Domain Name. This is the CloudFront distribution domain name, which you will use in a later step as the DOMAINNAME value in the YOUR_REDIRECT_URI variable.
Step 6. Create the app
Now that you’ve created the Amazon S3 bucket for static website hosting and the CloudFront distribution for the site, you’re ready to use the code that follows to create a sample app.
Use the following information from the previous steps:
- YOUR_COGNITO_DOMAIN_PREFIX is from Step 2.
- YOUR_REGION is the AWS region you used in Step 4 when you created your Amazon S3 bucket.
- YOUR_APPCLIENT_ID is the App client ID from Step 3.
- YOUR_USERPOOL_ID is the Pool ID from Step 1.
- YOUR_REDIRECT_URI, which is https://DOMAINNAME/index.html, where DOMAINNAME is your domain name from Step 5.
Create userprofile.js
Use the following text to create the userprofile.js file. Substitute the preceding pre-existing values for the variables in the text.
var myHeaders = new Headers();
myHeaders.set('Cache-Control', 'no-store');
var urlParams = new URLSearchParams(window.location.search);
var tokens;
var domain = "YOUR_COGNITO_DOMAIN_PREFIX";
var region = "YOUR_REGION";
var appClientId = "YOUR_APPCLIENT_ID";
var userPoolId = "YOUR_USERPOOL_ID";
var redirectURI = "YOUR_REDIRECT_URI";
//Convert Payload from Base64-URL to JSON
const decodePayload = payload => {
const cleanedPayload = payload.replace(/-/g, '+').replace(/_/g, '/');
const decodedPayload = atob(cleanedPayload)
const uriEncodedPayload = Array.from(decodedPayload).reduce((acc, char) => {
const uriEncodedChar = ('00' + char.charCodeAt(0).toString(16)).slice(-2)
return `${acc}%${uriEncodedChar}`
}, '')
const jsonPayload = decodeURIComponent(uriEncodedPayload);
return JSON.parse(jsonPayload)
}
//Parse JWT Payload
const parseJWTPayload = token => {
const [header, payload, signature] = token.split('.');
const jsonPayload = decodePayload(payload)
return jsonPayload
};
//Parse JWT Header
const parseJWTHeader = token => {
const [header, payload, signature] = token.split('.');
const jsonHeader = decodePayload(header)
return jsonHeader
};
//Generate a Random String
const getRandomString = () => {
const randomItems = new Uint32Array(28);
crypto.getRandomValues(randomItems);
const binaryStringItems = randomItems.map(dec => `0${dec.toString(16).substr(-2)}`)
return binaryStringItems.reduce((acc, item) => `${acc}${item}`, '');
}
//Encrypt a String with SHA256
const encryptStringWithSHA256 = async str => {
const PROTOCOL = 'SHA-256'
const textEncoder = new TextEncoder();
const encodedData = textEncoder.encode(str);
return crypto.subtle.digest(PROTOCOL, encodedData);
}
//Convert Hash to Base64-URL
const hashToBase64url = arrayBuffer => {
const items = new Uint8Array(arrayBuffer)
const stringifiedArrayHash = items.reduce((acc, i) => `${acc}${String.fromCharCode(i)}`, '')
const decodedHash = btoa(stringifiedArrayHash)
const base64URL = decodedHash.replace(/\+/g, '-').replace(/\//g, '_').replace(/=+$/, '');
return base64URL
}
// Main Function
async function main() {
var code = urlParams.get('code');
//If code not present then request code else request tokens
if (code == null){
// Create random "state"
var state = getRandomString();
sessionStorage.setItem("pkce_state", state);
// Create PKCE code verifier
var code_verifier = getRandomString();
sessionStorage.setItem("code_verifier", code_verifier);
// Create code challenge
var arrayHash = await encryptStringWithSHA256(code_verifier);
var code_challenge = hashToBase64url(arrayHash);
sessionStorage.setItem("code_challenge", code_challenge)
// Redirtect user-agent to /authorize endpoint
location.href = "https://"+domain+".auth."+region+".amazoncognito.com/oauth2/authorize?response_type=code&state="+state+"&client_id="+appClientId+"&redirect_uri="+redirectURI+"&scope=openid&code_challenge_method=S256&code_challenge="+code_challenge;
} else {
// Verify state matches
state = urlParams.get('state');
if(sessionStorage.getItem("pkce_state") != state) {
alert("Invalid state");
} else {
// Fetch OAuth2 tokens from Cognito
code_verifier = sessionStorage.getItem('code_verifier');
await fetch("https://"+domain+".auth."+region+".amazoncognito.com/oauth2/token?grant_type=authorization_code&client_id="+appClientId+"&code_verifier="+code_verifier+"&redirect_uri="+redirectURI+"&code="+ code,{
method: 'post',
headers: {
'Content-Type': 'application/x-www-form-urlencoded'
}})
.then((response) => {
return response.json();
})
.then((data) => {
// Verify id_token
tokens=data;
var idVerified = verifyToken (tokens.id_token);
Promise.resolve(idVerified).then(function(value) {
if (value.localeCompare("verified")){
alert("Invalid ID Token - "+ value);
return;
}
});
// Display tokens
document.getElementById("id_token").innerHTML = JSON.stringify(parseJWTPayload(tokens.id_token),null,'\t');
document.getElementById("access_token").innerHTML = JSON.stringify(parseJWTPayload(tokens.access_token),null,'\t');
});
// Fetch from /user_info
await fetch("https://"+domain+".auth."+region+".amazoncognito.com/oauth2/userInfo",{
method: 'post',
headers: {
'authorization': 'Bearer ' + tokens.access_token
}})
.then((response) => {
return response.json();
})
.then((data) => {
// Display user information
document.getElementById("userInfo").innerHTML = JSON.stringify(data, null,'\t');
});
}}}
main();
Create the verifier.js file
Use the following text to create the verifier.js file.
var key_id;
var keys;
var key_index;
//verify token
async function verifyToken (token) {
//get Cognito keys
keys_url = 'https://cognito-idp.'+ region +'.amazonaws.com/' + userPoolId + '/.well-known/jwks.json';
await fetch(keys_url)
.then((response) => {
return response.json();
})
.then((data) => {
keys = data['keys'];
});
//Get the kid (key id)
var tokenHeader = parseJWTHeader(token);
key_id = tokenHeader.kid;
//search for the kid key id in the Cognito Keys
const key = keys.find(key =>key.kid===key_id)
if (key === undefined){
return "Public key not found in Cognito jwks.json";
}
//verify JWT Signature
var keyObj = KEYUTIL.getKey(key);
var isValid = KJUR.jws.JWS.verifyJWT(token, keyObj, {alg: ["RS256"]});
if (isValid){
} else {
return("Signature verification failed");
}
//verify token has not expired
var tokenPayload = parseJWTPayload(token);
if (Date.now() >= tokenPayload.exp * 1000) {
return("Token expired");
}
//verify app_client_id
var n = tokenPayload.aud.localeCompare(appClientId)
if (n != 0){
return("Token was not issued for this audience");
}
return("verified");
};
Create an index.html file
Use the following text to create the index.html file.
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>MyApp</title>
<meta name="description" content="My Application">
<meta name="author" content="Your Name">
</head>
<body>
<h2>Cognito User</h2>
<p style="white-space:pre-line;" id="token_status"></p>
<p>Id Token</p>
<p style="white-space:pre-line;" id="id_token"></p>
<p>Access Token</p>
<p style="white-space:pre-line;" id="access_token"></p>
<p>User Profile</p>
<p style="white-space:pre-line;" id="userInfo"></p>
<script language="JavaScript" type="text/javascript"
src="https://kjur.github.io/jsrsasign/jsrsasign-latest-all-min.js">
</script>
<script src="js/verifier.js"></script>
<script src="js/userprofile.js"></script>
</body>
</html>
Upload the files into the Amazon S3 Bucket you created earlier
Upload the files you just created to the Amazon S3 bucket that you created in Step 4. If you’re using Chrome or Firefox browsers, you can choose the folders and files to upload and then drag and drop them into the destination bucket. Dragging and dropping is the only way that you can upload folders.
- Sign in to the AWS Management Console and open the Amazon S3 console.
- In the Bucket name list, choose the name of the bucket that you created earlier in Step 4.
- In a window other than the console window, select the index.html file to upload. Then drag and drop the file into the console window that lists the destination bucket.
- In the Upload dialog box, choose Upload.
- Choose Create Folder.
- Enter the name js and choose Save.
- Choose the js folder.
- In a window other than the console window, select the userprofile.js and verifier.js files to upload. Then drag and drop the files into the console window js folder.
Note: The Amazon S3 bucket root will contain the index.html file and a js folder. The js folder will contain the userprofile.js and verifier.js files.
Step 7. Configure the app client settings
Use the Amazon Cognito console to configure the app client settings, including identity providers, OAuth flows, and OAuth scopes.
Configure the app client settings:
- Go to the Amazon Cognito console.
- Choose Manage your User Pools.
- Select your user pool.
- Select App integration, and then select App client settings.
- Under Enabled Identity Providers, select Cognito User Pool.(Optional) You can add federated identity providers. Adding User Pool Sign-in Through a Third-Party has more information about how to add federation providers.
- Enter the Callback URL(s) where the user is to be redirected after successfully signing in. The callback URL is the URL of your web app that will receive the authorization code. In our example, this will be the Domain Name for the CloudFront distribution you created earlier. It will look something like https://DOMAINNAME/index.html where DOMAINNAME is xxxxxxx.cloudfront.net.
Note: HTTPS is required for the Callback URLs. For this example, I used CloudFront as a HTTPS endpoint for the app in Amazon S3.
- Next, select Authorization code grant from the Allowed OAuth Flows and OpenID from Allowed OAuth Scopes. The OpenID scope will return the ID token and grant access to all user attributes that are readable by the client.
- Choose Save changes.
Step 8. Show the app home page
Now that the Amazon Cognito user pool is configured and the sample app is built, you can test using Amazon Cognito as an OP from the sample JavaScript app you created in Step 6.
View the app’s home page:
- Open a web browser and enter the app’s home page URL using the CloudFront distribution to serve your index.html page created in Step 6 (https://DOMAINNAME/index.html) and the app will redirect the browser to the Amazon Cognito /authorize endpoint.
- The /authorize endpoint redirects the browser to the Amazon Cognito hosted UI, where the user can sign in or sign up. The following figure shows the user sign-in page.

Figure 8: User sign-in page
Step 9. Create a user
You can use the Amazon Cognito user pool to manage your users or you can use a federated identity provider. Users can sign in or sign up from the Amazon Cognito hosted UI or from a federated identity provider. If you configured a federated identity provider, users will see a list of federated providers that they can choose from. When a user chooses a federated identity provider, they are redirected to the federated identity provider sign-in page. After signing in, the browser is directed back to Amazon Cognito. For this post, Amazon Cognito is the only identity provider, so you will use the Amazon Cognito hosted UI to create an Amazon Cognito user.
Create a new user using Amazon Cognito hosted UI:
- Create a new user by selecting Sign up and entering a username, password, and email address. Then select the Sign up button. The following figure shows the sign up screen.

Figure 9: Sign up with a new account
- The Amazon Cognito sign up workflow will verify the email address by sending a verification code to that address. The following figure shows the prompt to enter the verification code.

Figure 10: Enter the verification code
- Enter the code from the verification email in the Verification Code text box.
- Select Confirm Account.
Step 10. Viewing the Amazon Cognito tokens and profile information
After authentication, the app displays the tokens and user information. The following figure shows the OAuth2 access token and OIDC ID token that are returned from the /token endpoint and the user profile returned from the /userInfo endpoint. Now that the user has been authenticated, the application can use the user’s email address to look up the user’s account information in an application data store. Based on the user’s account information, the application can grant/restrict access to paid content or show account information like order history.

Figure 11: Token and user profile information
Note: Many browsers will cache redirects. If your browser is repeatedly redirecting to the index.html page, clear the browser cache.
Summary
In this post, we’ve shown you how easy it is to add user authentication to your web and mobile apps with Amazon Cognito.
We created a Cognito User Pool as our user directory, assigned a domain name to the Amazon Cognito hosted UI, and created an application client for our application. Then we created an Amazon S3 bucket to host our website. Next, we created a CloudFront distribution for our Amazon S3 bucket. Then we created our application and uploaded it to our Amazon S3 website bucket. From there, we configured the client app settings with our identity provider, OAuth flows, and scopes. Then we accessed our application and used the Amazon Cognito sign-in flow to create a username and password. Finally, we logged into our application to see the OAuth and OIDC tokens.
Amazon Cognito saves you time and effort when implementing authentication with an intuitive UI, OAuth2 and OIDC support, and customizable workflows. You can now focus on building features that are important to your core business.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the Amazon Cognito forum or contact AWS Support.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.