Post Syndicated from Mitch Beaumont original https://aws.amazon.com/blogs/security/introducing-iam-access-analyzer-custom-policy-checks/
AWS Identity and Access Management (IAM) Access Analyzer was launched in late 2019. Access Analyzer guides customers toward least-privilege permissions across Amazon Web Services (AWS) by using analysis techniques, such as automated reasoning, to make it simpler for customers to set, verify, and refine IAM permissions. Today, we are excited to announce the general availability of IAM Access Analyzer custom policy checks, a new IAM Access Analyzer feature that helps customers accurately and proactively check IAM policies for critical permissions and increases in policy permissiveness.
In this post, we’ll show how you can integrate custom policy checks into builder workflows to automate the identification of overly permissive IAM policies and IAM policies that contain permissions that you decide are sensitive or critical.
What is the problem?
Although security teams are responsible for the overall security posture of the organization, developers are the ones creating the applications that require permissions. To enable developers to move fast while maintaining high levels of security, organizations look for ways to safely delegate the ability of developers to author IAM policies. Many AWS customers implement manual IAM policy reviews before deploying developer-authored policies to production environments. Customers follow this practice to try to prevent excessive or unwanted permissions finding their way into production. Depending on the volume and complexity of the policies that need to be reviewed; these reviews can be intensive and take time. The result is a slowdown in development and potential delay in deployment of applications and services. Some customers write custom tooling to remove the manual burden of policy reviews, but this can be costly to build and maintain.
How do custom policy checks solve that problem?
Custom policy checks are a new IAM Access Analyzer capability that helps security teams accurately and proactively identify critical permissions in their policies. Custom policy checks can also tell you if a new version of a policy is more permissive than the previous version. Custom policy checks use automated reasoning, a form of static analysis, to provide a higher level of security assurance in the cloud. For more information, see Formal Reasoning About the Security of Amazon Web Services.
Custom policy checks can be embedded in a continuous integration and continuous delivery (CI/CD) pipeline so that checks can be run against policies without having to deploy the policies. In addition, developers can run custom policy checks from their local development environments and get fast feedback about whether or not the policies they are authoring are in line with your organization’s security standards.
How to analyze IAM policies with custom policy checks
In this section, we provide step-by-step instructions for using custom policy checks to analyze IAM policies.
Prerequisites
To complete the examples in our walkthrough, you will need the following:
- An AWS account, and an identity that has permissions to use the AWS services, and create the resources, used in the following examples. For more information, see the full sample code used in this blog post on GitHub.
- An installed and configured AWS CLI. For more information, see Configure the AWS CLI.
- The AWS Cloud Development Kit (AWS CDK). For installation instructions, refer to Install the AWS CDK.
Example 1: Use custom policy checks to compare two IAM policies and check that one does not grant more access than the other
In this example, you will create two IAM identity policy documents, NewPolicyDocument and ExistingPolicyDocument. You will use the new CheckNoNewAccess API to compare these two policies and check that NewPolicyDocument does not grant more access than ExistingPolicyDocument.
Step 1: Create two IAM identity policy documents
- Use the following command to create ExistingPolicyDocument.
- Use the following command to create NewPolicyDocument.
Notice that ExistingPolicyDocument grants access to the ec2:StartInstances and ec2:StopInstances actions if the condition key aws:ResourceTag/Owner resolves to true. In other words, the value of the tag matches the policy variable aws:username. NewPolicyDocument grants access to the same actions, but does not include a condition key.
Step 2: Check the policies by using the AWS CLI
- Use the following command to call the CheckNoNewAccess API to check whether NewPolicyDocument grants more access than ExistingPolicyDocument.
After a moment, you will see a response from Access Analyzer. The response will look similar to the following.
In this example, the validation returned a result of FAIL. This is because NewPolicyDocument is missing the condition key, potentially granting any principal with this identity policy attached more access than intended or needed.
Example 2: Use custom policy checks to check that an IAM policy does not contain sensitive permissions
In this example, you will create an IAM identity-based policy that contains a set of permissions. You will use the CheckAccessNotGranted API to check that the new policy does not give permissions to disable AWS CloudTrail or delete any associated trails.
Step 1: Create a new IAM identity policy document
- Use the following command to create IamPolicyDocument.
Step 2: Check the policy by using the AWS CLI
- Use the following command to call the CheckAccessNotGranted API to check if the new policy grants permission to the set of sensitive actions. In this example, you are asking Access Analyzer to check that IamPolicyDocument does not contain the actions cloudtrail:StopLogging or cloudtrail:DeleteTrail (passed as a list to the access parameter).
Because the policy that you created contains both cloudtrail:StopLogging and cloudtrail:DeleteTrail actions, Access Analyzer returns a FAIL.
Example 3: Integrate custom policy checks into the developer workflow
Building on the previous two examples, in this example, you will automate the analysis of the IAM policies defined in an AWS CloudFormation template. Figure 1 shows the workflow that will be used. The workflow will initiate each time a pull request is created against the main branch of an AWS CodeCommit repository called my-iam-policy (the commit stage in Figure 1). The first check uses the CheckNoNewAccess API to determine if the updated policy is more permissive than a reference IAM policy. The second check uses the CheckAccessNotGranted API to automatically check for critical permissions within the policy (the validation stage in Figure 1). In both cases, if the updated policy is more permissive, or contains critical permissions, a comment with the results of the validation is posted to the pull request. This information can then be used to decide whether the pull request is merged into the main branch for deployment (the deploy stage is shown in Figure 1).
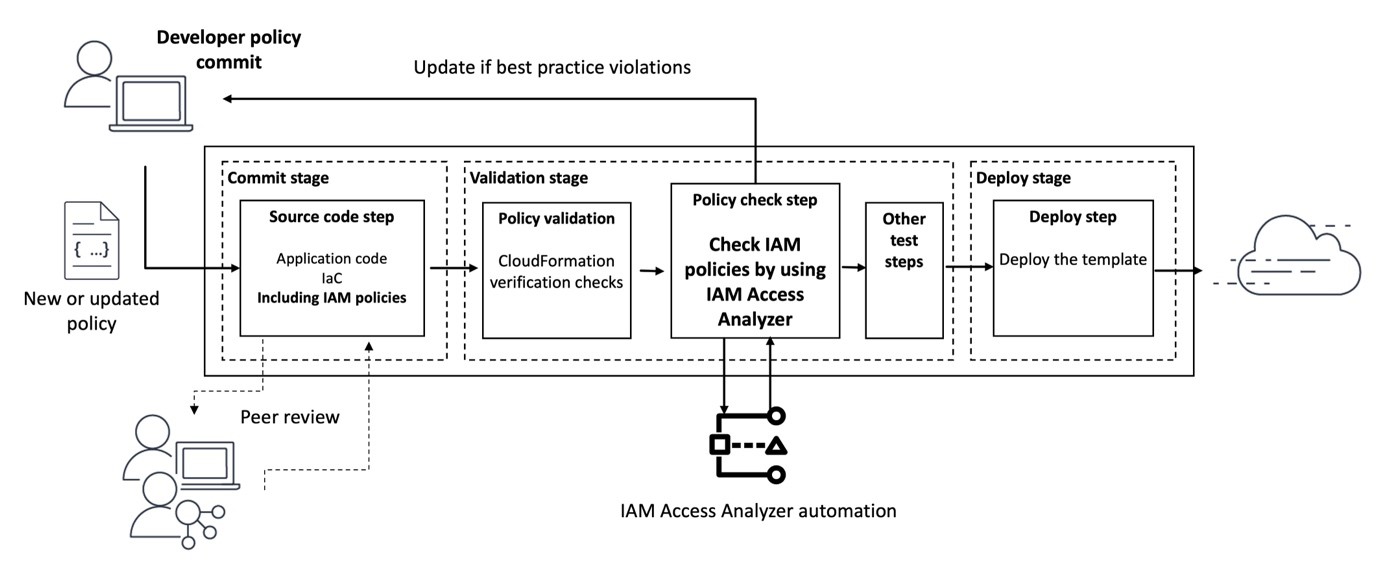
Figure 1: Diagram of the pipeline that will check policies
Step 1: Deploy the infrastructure and set up the pipeline
- Use the following command to download and unzip the Cloud Development Kit (CDK) project associated with this blog post.
- Create a virtual Python environment to contain the project dependencies by using the following command.
- Activate the virtual environment with the following command.
- Install the project requirements by using the following command.
- Use the following command to update the CDK CLI to the latest major version.
- Before you can deploy the CDK project, use the following command to bootstrap your AWS environment. Bootstrapping is the process of creating resources needed for deploying CDK projects. These resources include an Amazon Simple Storage Service (Amazon S3) bucket for storing files and IAM roles that grant permissions needed to perform deployments.
- Finally, use the following command to deploy the pipeline infrastructure.
The deployment will take a few minutes to complete. Feel free to grab a coffee and check back shortly.
When the deployment completes, there will be two stack outputs listed: one with a name that contains CodeCommitRepo and another with a name that contains ConfigBucket. Make a note of the values of these outputs, because you will need them later.
The deployed pipeline is displayed in the AWS CodePipeline console and should look similar to the pipeline shown in Figure 2.

Figure 2: AWS CodePipeline and CodeBuild Management Console view
In addition to initiating when a pull request is created, the newly deployed pipeline can also be initiated when changes to the main branch of the AWS CodeCommit repository are detected. The pipeline has three stages, CheckoutSources, IAMPolicyAnalysis, and deploy. The CheckoutSource stage checks out the contents of the my-iam-policy repository when the pipeline is triggered due to a change in the main branch.
The IAMPolicyAnalysis stage, which runs after the CheckoutSource stage or when a pull request has been created against the main branch, has two actions. The first action, Check no new access, verifies that changes to the IAM policies in the CloudFormation template do not grant more access than a pre-defined reference policy. The second action, Check access not granted, verifies that those same updates do not grant access to API actions that are deemed sensitive or critical. Finally, the Deploy stage will deploy the resources defined in the CloudFormation template, if the actions in the IAMPolicyAnalysis stage are successful.
To analyze the IAM policies, the Check no new access and Check access not granted actions depend on a reference policy and a predefined list of API actions, respectively.
- Use the following command to create the reference policy.
This reference policy sets out the maximum permissions for policies that you plan to validate with custom policy checks. The iam:PassRole permission is a permission that allows an IAM principal to pass an IAM role to an AWS service, like Amazon Elastic Compute Cloud (Amazon EC2) or AWS Lambda. The reference policy says that the only way that a policy is more permissive is if it allows iam:PassRole on this group of sensitive resources: arn:aws:iam::*:role/my-sensitive-roles/*”.
Why might a reference policy be useful? A reference policy helps ensure that a particular combination of actions, resources, and conditions is not allowed in your environment. Reference policies typically allow actions and resources in one statement, then deny the problematic permissions in a second statement. This means that a policy that is more permissive than the reference policy allows access to a permission that the reference policy has denied.
In this example, a developer who is authorized to create IAM roles could, intentionally or unintentionally, create an IAM role for an AWS service (like EC2 for AWS Lambda) that has permission to pass a privileged role to another service or principal, leading to an escalation of privilege.
- Use the following command to create a list of sensitive actions. This list will be parsed during the build pipeline and passed to the CheckAccessNotGranted API. If the policy grants access to one or more of the sensitive actions in this list, a result of FAIL will be returned. To keep this example simple, add a single API action, as follows.
- So that the CodeBuild projects can access the dependencies, use the following command to copy the cnna-reference-policy.file and sensitive-actions.file to an S3 bucket. Refer to the stack outputs you noted earlier and replace <ConfigBucket> with the name of the S3 bucket created in your environment.

Step 2: Create a new CloudFormation template that defines an IAM policy
With the pipeline deployed, the next step is to clone the repository that was created and populate it with a CloudFormation template that defines an IAM policy.
- Install git-remote-codecommit by using the following command.
For more information on installing and configuring git-remote-codecommit, see the AWS CodeCommit User Guide.
- With git-remote-codecommit installed, use the following command to clone the my-iam-policy repository from AWS CodeCommit.
If you’ve configured a named profile for use with the AWS CLI, use the following command, replacing <profile> with the name of your named profile.
- Use the following command to create the CloudFormation template in the local clone of the repository.
The actions in the IAMPolicyValidation stage are run by a CodeBuild project. CodeBuild environments run arbitrary commands that are passed to the project using a buildspec file. Each project has already been configured to use an inline buildspec file.
You can inspect the buildspec file for each project by opening the project’s Build details page as shown in Figure 3.
Figure 3: AWS CodeBuild console and build details
Step 3: Run analysis on the IAM policy
The next step involves checking in the first version of the CloudFormation template to the repository and checking two things. First, that the policy does not grant more access than the reference policy. Second, that the policy does not contain any of the sensitive actions defined in the sensitive-actions.file.
- To begin tracking the CloudFormation template created earlier, use the following command.
- Commit the changes you have made to the repository.
- Finally, push these changes to the remote repository.
- Pushing these changes will initiate the pipeline. After a few minutes the pipeline should complete successfully. To view the status of the pipeline, do the following:
- Navigate to https://<region>.console.aws.amazon.com/codesuite/codepipeline/pipelines (replacing <region> with your AWS Region).
- Choose the pipeline called accessanalyzer-pipeline.
- Scroll down to the IAMPolicyValidation stage of the pipeline.
- For both the check no new access and check access not granted actions, choose View Logs to inspect the log output.
- If you inspect the build logs for both the check no new access and check access not granted actions within the pipeline, you should see that there were no blocking or non-blocking findings, similar to what is shown in Figure 4. This indicates that the policy was validated successfully. In other words, the policy was not more permissive than the reference policy, and it did not include any of the critical permissions.

Figure 4: CodeBuild log entry confirming that the IAM policy was successfully validated

Step 4: Create a pull request to merge a new update to the CloudFormation template
In this step, you will make a change to the IAM policy in the CloudFormation template. The change deliberately makes the policy grant more access than the reference policy. The change also includes a critical permission.
- Use the following command to create a new branch called add-new-permissions in the local clone of the repository.
- Next, edit the IAM policy in ec2-instance-role.yaml to include an additional API action, dynamodb:Delete* and update the resource property of the inline policy to use an IAM role in the /my-sensitive-roles/*” path. You can copy the following example, if you’re unsure of how to do this.
- Commit the policy change and push the updated policy document to the repo by using the following commands.
- The add-new-permissions branch is currently a local branch. Use the following command to push the branch to the remote repository. This action will not initiate the pipeline, because the pipeline only runs when changes are made to the repository’s main branch.
- With the new branch and changes pushed to the repository, follow these steps to create a pull request:
- Navigate to https://console.aws.amazon.com/codesuite/codecommit/repositories (don’t forget to the switch to the correct Region).
- Choose the repository called my-iam-policy.
- Choose the branch add-new-permissions from the drop-down list at the top of the repository screen.

Figure 5: my-iam-policy repository with new branch available
- Choose Create pull request.
- Enter a title and description for the pull request.
- (Optional) Scroll down to see the differences between the current version and new version of the CloudFormation template highlighted.
- Choose Create pull request.
- The creation of the pull request will Initiate the pipeline to fetch the CloudFormation template from the repository and run the check no new access and check access not granted analysis actions.
- After a few minutes, choose the Activity tab for the pull request. You should see a comment from the pipeline that contains the results of the failed validation.
Figure 6: Results from the failed validation posted as a comment to the pull request


Why did the validations fail?
The updated IAM role and inline policy failed validation for two reasons. First, the reference policy said that no one should have more permissions than the reference policy does. The reference policy in this example included a deny statement for the iam:PassRole permission with a resource of /my-sensitive-role/*. The new created inline policy included an allow statement for the iam:PassRole permission with a resource of arn:aws:iam::*:role/my-sensitive-roles/my-custom-admin-role. In other words, the new policy had more permissions than the reference policy.
Second, the list of critical permissions included the dynamodb:DeleteTable permission. The inline policy included a statement that would allow the EC2 instance to perform the dynamodb:DeleteTable action.
Cleanup
Use the following command to delete the infrastructure that was provisioned as part of the examples in this blog post.
Conclusion
In this post, I introduced you to two new IAM Access Analyzer APIs: CheckNoNewAccess and CheckAccessNotGranted. The main example in the post demonstrated one way in which you can use these APIs to automate security testing throughout the development lifecycle. The example did this by integrating both APIs into the developer workflow and validating the developer-authored IAM policy when the developer created a pull request to merge changes into the repository’s main branch. The automation helped the developer to get feedback about the problems with the IAM policy quickly, allowing the developer to take action in a timely way. This is often referred to as shifting security left — identifying misconfigurations early and automatically supporting an iterative, fail-fast model of continuous development and testing. Ultimately, this enables teams to make security an inherent part of a system’s design and architecture and can speed up product development workflow.
You can find the full sample code used in this blog post on GitHub.
To learn more about IAM Access Analyzer and the new custom policy checks feature, see the IAM Access Analyzer documentation.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.