Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/introducing-bidirectional-event-integrations-with-salesforce-and-amazon-eventbridge/
This post is written by Alseny Diallo, Prototype Solutions Architect and Rohan Mehta, Associate Cloud Application Architect.
AWS now supports Salesforce as a partner event source for Amazon EventBridge, allowing you to send Salesforce events to AWS. You can also configure Salesforce with EventBridge API Destinations and send EventBridge events to Salesforce. These integrations enable you to act on changes to your Salesforce data in real-time and build custom applications with EventBridge and over 100 built-in sources and targets.
In this blog post, you learn how to set up a bidirectional integration between Salesforce and EventBridge and use cases for working with Salesforce events. You see an example application for interacting with Salesforce support case events with automated workflows for detecting sentiment with AWS AI/ML services and enriching support cases with customer order data.
Integration overview
Salesforce is a customer relationship management (CRM) platform that gives companies a single, shared view of customers across their marketing, sales, commerce, and service departments. Salesforce Event Relays for AWS enable bidirectional event flows between Salesforce and AWS through EventBridge.
Amazon EventBridge is a serverless event bus that makes it easier to build event-driven applications at scale using events generated from your applications, integrated software as a service (SaaS) applications, and AWS services. EventBridge partner event source integrations enable customers to receive events from over 30 SaaS applications and ingest them into their AWS applications.
Salesforce as a partner event source for EventBridge makes it easier to build event-driven applications that span customers’ data in Salesforce and applications running on AWS. Customers can send events from Salesforce to EventBridge and vice versa without having to write custom code or manage an integration.
EventBridge joins Amazon AppFlow as a way to integrate Salesforce with AWS. The Salesforce Amazon AppFlow integration is well suited for use cases that require ingesting large volumes of data, like a daily scheduled data transfer sending Salesforce records into an Amazon Redshift data warehouse or an Amazon S3 data lake. The Salesforce EventBridge integration is a good fit for real-time processing of changes to individual Salesforce records.
Use cases
Customers can act on new or modified Salesforce records through integrations with a variety of EventBridge targets, including AWS Lambda, AWS Step Functions, and API Gateway. The integration can enable use cases across industries that must act on customer events in real time.
- Retailers can automatically unify their Salesforce data with AWS data sources. When a new customer support case is created in Salesforce, enrich the support case with recent order data from that customer retrieved from an orders database running on AWS.
- Media and entertainment providers can augment their omnichannel experiences with AWS AI/ML services to increase customer engagement. When a new customer account is created in Salesforce, use Amazon Personalize and Amazon Simple Email Service to send a welcome email with personalized media recommendations.
- Insurers can automate form processing workflows. When a new insurance claim form PDF is uploaded to Salesforce, extract the submitted information with Amazon Textract and orchestrate processing the claim information with AWS Step Functions.
Solution overview
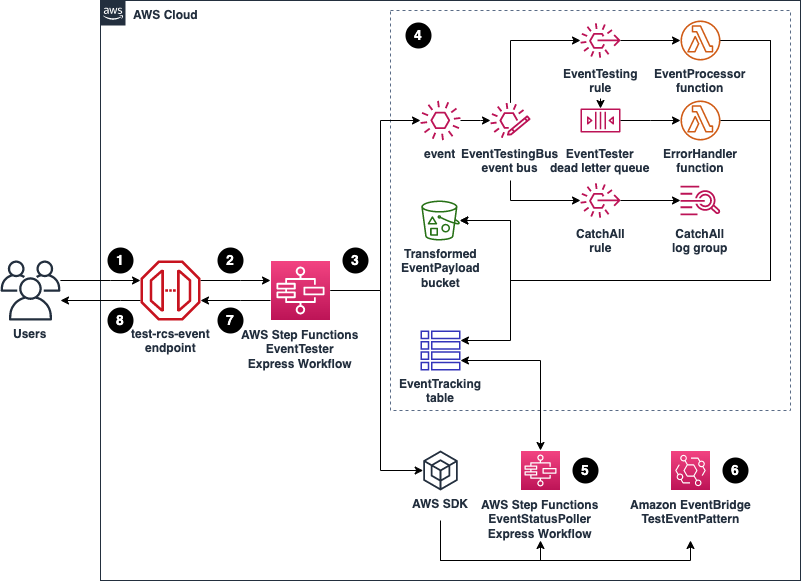
The example application shows how the integration can enhance customer support experiences by unifying support tickets with customer order data, detecting customer sentiment, and automating support case workflows.

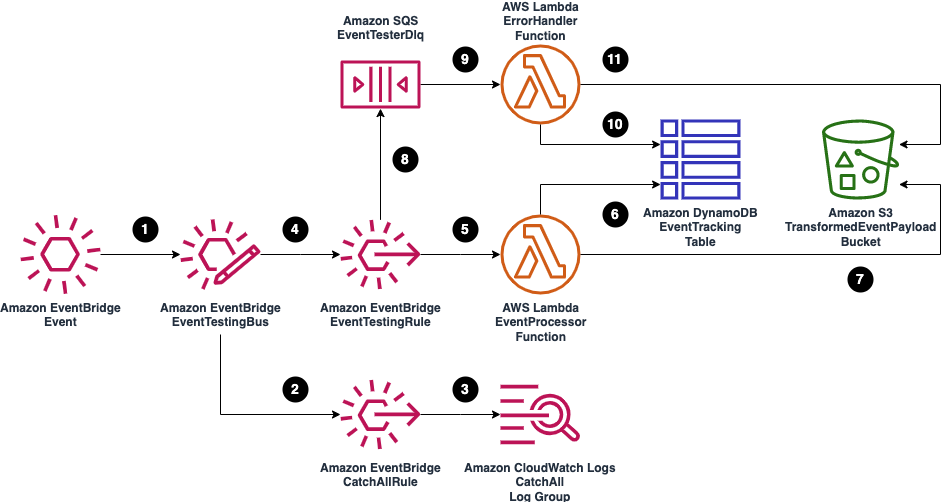
- A new case is created in Salesforce and an event is sent to an EventBridge partner event bus.
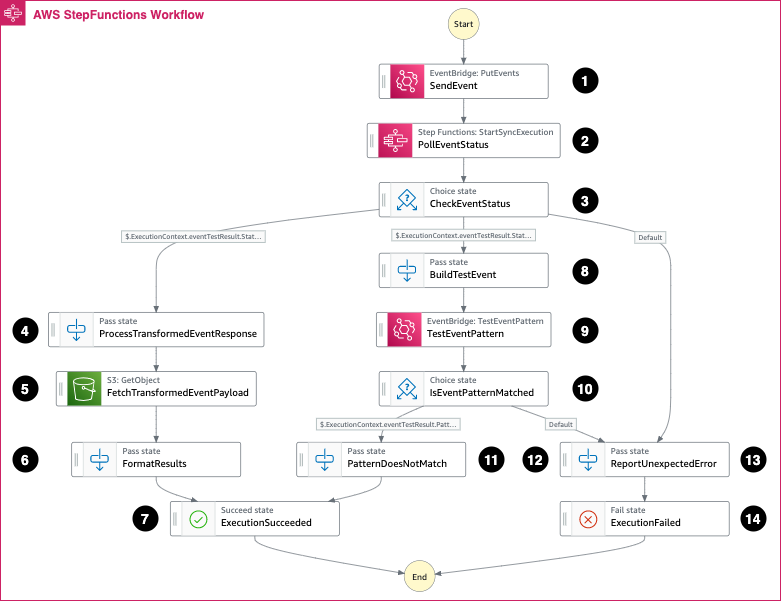
- If the event matches the EventBridge rule, the rule sends the event to both the Enrich Case and Case Processor Workflows in parallel.
- The Enrich Case Workflow uses the Customer ID in the event payload to query the Orders table for the customer’s recent order. If this step fails, the event is sent to an Amazon SQS dead letter queue.
- The Enrich Case Workflow publishes a new event with the customer’s recent order to an EventBridge custom event bus.
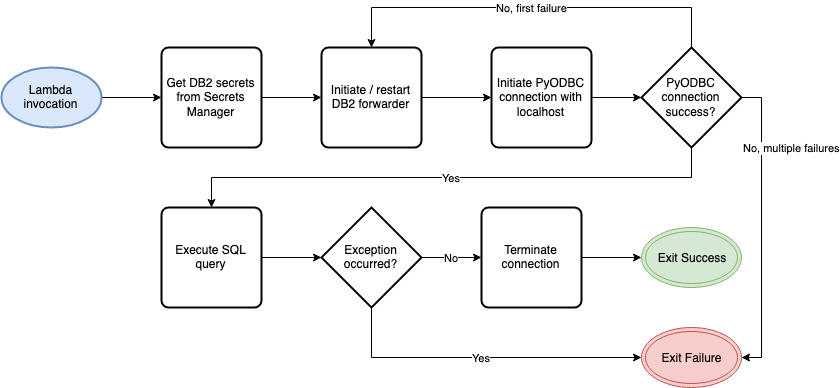
- The Case Processor Workflow performs sentiment analysis on the support case content and sends a customized text message to the customer. See the diagram below for details on the workflow.
- The Case Processor Workflow publishes a new event with the sentiment analysis results to the custom event bus.
- EventBridge rules match the events published to the associated rules: CaseProcessorEventRule and EnrichCaseAppEventRule.
- These rules send the events to EventBridge API Destinations. API Destinations sends the events to Salesforce HTTP endpoints to create two Salesforce Platform Events.
- Salesforce data is updated with the two Platform Events:
- The support case record is updated with the customer’s recent order details and the support case sentiment.
- If the support case sentiment is negative, a task is created for an agent to follow up with the customer.
The Case Processor workflow uses Step Functions to process the Salesforce events.
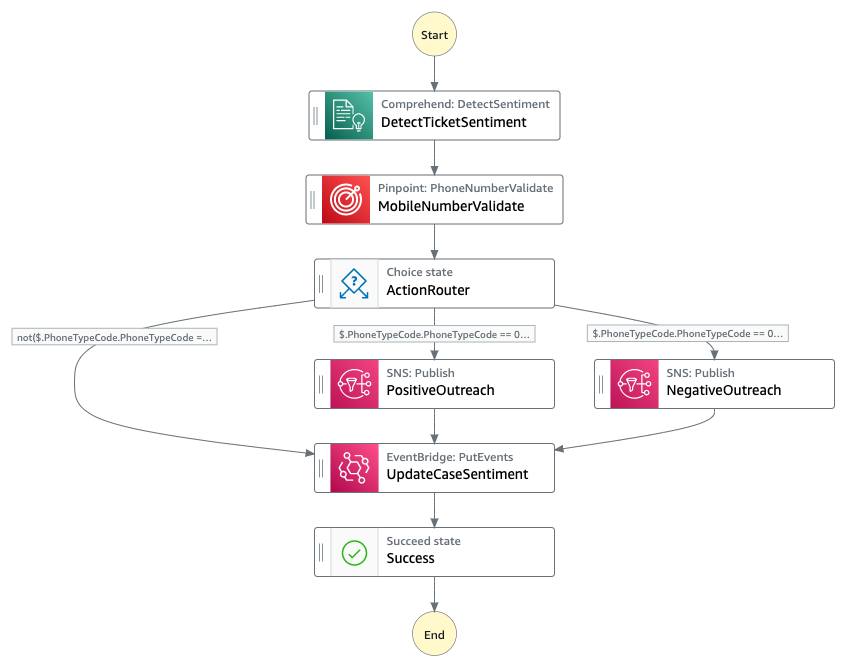
- Detect the sentiment of the customer feedback using Amazon Comprehend. This is positive, negative, or neutral.
- Check if the customer phone number is a mobile number and can receive SMS using Amazon Pinpoint’s mobile number validation endpoint.
- If the customer did not provide a mobile number, bypass the SMS steps and put an event with the detected sentiment onto the custom event bus.
- If the customer provided a mobile number, send them an SMS with the appropriate message based on the sentiment of their case.
- If sentiment is positive or neutral, the message is thanking the customer for their feedback.
- If the sentiment is negative, the message offers additional support.
- The state machine then puts an event with the sentiment analysis results onto the custom event bus.
Prerequisites
- An AWS account and an AWS user with AdministratorAccess (see the instructions on the AWS Identity and Access Management (IAM) console).
- Access to the following AWS services: AWS Step Functions, Amazon EventBridge, Amazon Comprehend, Amazon Pinpoint, Amazon Simple Notification Service.
- AWS SAM CLI using the instructions here.
Environment setup
- Follow the instructions here to set up your Salesforce Event Relay. Once you have an event bus created with the partner event source, proceed to step 2.
- Copy the ARN of the event bus.
- Create a Salesforce Connected App. This is used for the API Destinations configuration to send updates back into Salesforce.
- You can create a new user within Salesforce with appropriate API permissions to update records. The user name and password is used by the API Destinations configuration.
- The example provided by Salesforce uses a Platform Event called “Carbon Comparison”. For this sample app, you create three custom platform events with the following configurations:
- Customer Support Case (Salesforce to AWS):

- Processed Support Case (AWS to Salesforce):

- Enrich Case (AWS to Salesforce):

- Customer Support Case (Salesforce to AWS):
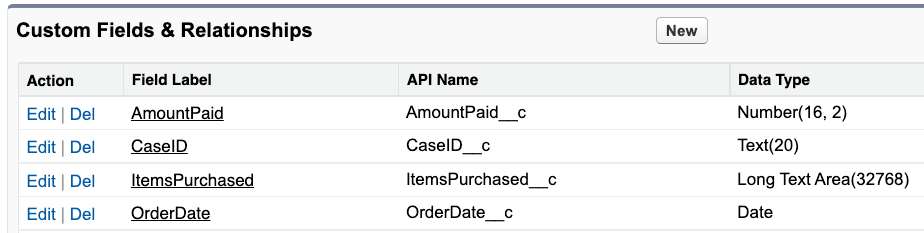
- This example application assumes that a custom Sentiment field is added to the Salesforce Case record type. See this link for how to create custom fields in Salesforce.
- The example application uses Salesforce Flows to trigger outbound platform events and handle inbound platform events. See this link for how to use Salesforce Flows to build event driven applications on Salesforce.
- Clone the AWS SAM template here.
sam build sam deploy —guidedFor the parameter prompts, enter:


- SalesforceOauthClientId and SalesforceOauthClientSecret: Use the values created with the Connected App in step 3.
- SalesforceUsername and SalesforcePassword: Use the values created for the new user in step 4.
- SalesforceOauthUrl: Salesforce URL for OAuth authentication
- SalesforceCaseProcessorEndpointUrl: Salesforce URL for creating a new Processed Support Case Platform Event object, in this case: https://MyDomainName.my.salesforce.com/services/data/v54.0/sobjects/Processed_Support_Case__e
- SFEnrichCaseEndpointUrl: Salesforce URL for creating a new Enrich Case Platform Event object, in this case: https://MyDomainName.my.salesforce.com/services/data/v54.0/sobjects/Enrich_Case__e
- SalesforcePartnerEventBusArn: Use the value from step 2.
- SalesforcePartnerEventPattern: The detail-type value should be the API name of the custom platform event, in thiscase: {“detail-type”: [“Customer_Support_Case__e”]}
Conclusion
This blog shows how to act on changes to your Salesforce data in real-time using the new Salesforce partner event source integration with EventBridge. The example demonstrated how your Salesforce data can be processed and enriched with custom AWS applications and updates sent back to Salesforce using EventBridge API Destinations.
To learn more about EventBridge partner event sources and API Destinations, see the EventBridge Developer Guide. For more serverless resources, visit Serverless Land.