Post Syndicated from Dina Kozlov original https://blog.cloudflare.com/mcp-demo-day/
Today, we’re excited to collaborate with Anthropic, Asana, Atlassian, Block, Intercom, Linear, PayPal, Sentry, Stripe, and Webflow to bring a whole new set of remote MCP servers, all built on Cloudflare, to enable Claude users to manage projects, generate invoices, query databases, and even deploy full stack applications — without ever leaving the chat interface.
Since Anthropic’s introduction of the Model Context Protocol (MCP) in November, there’s been more and more excitement about it, and it seems like a new MCP server is being released nearly every day. And for good reason! MCP has been the missing piece to make AI agents a reality, and helped define how AI agents interact with tools to take actions and get additional context.
But to date, end-users have had to install MCP servers on their local machine to use them. Today, with Anthropic’s announcement of Integrations, you can access an MCP server the same way you would a website: type a URL and go.

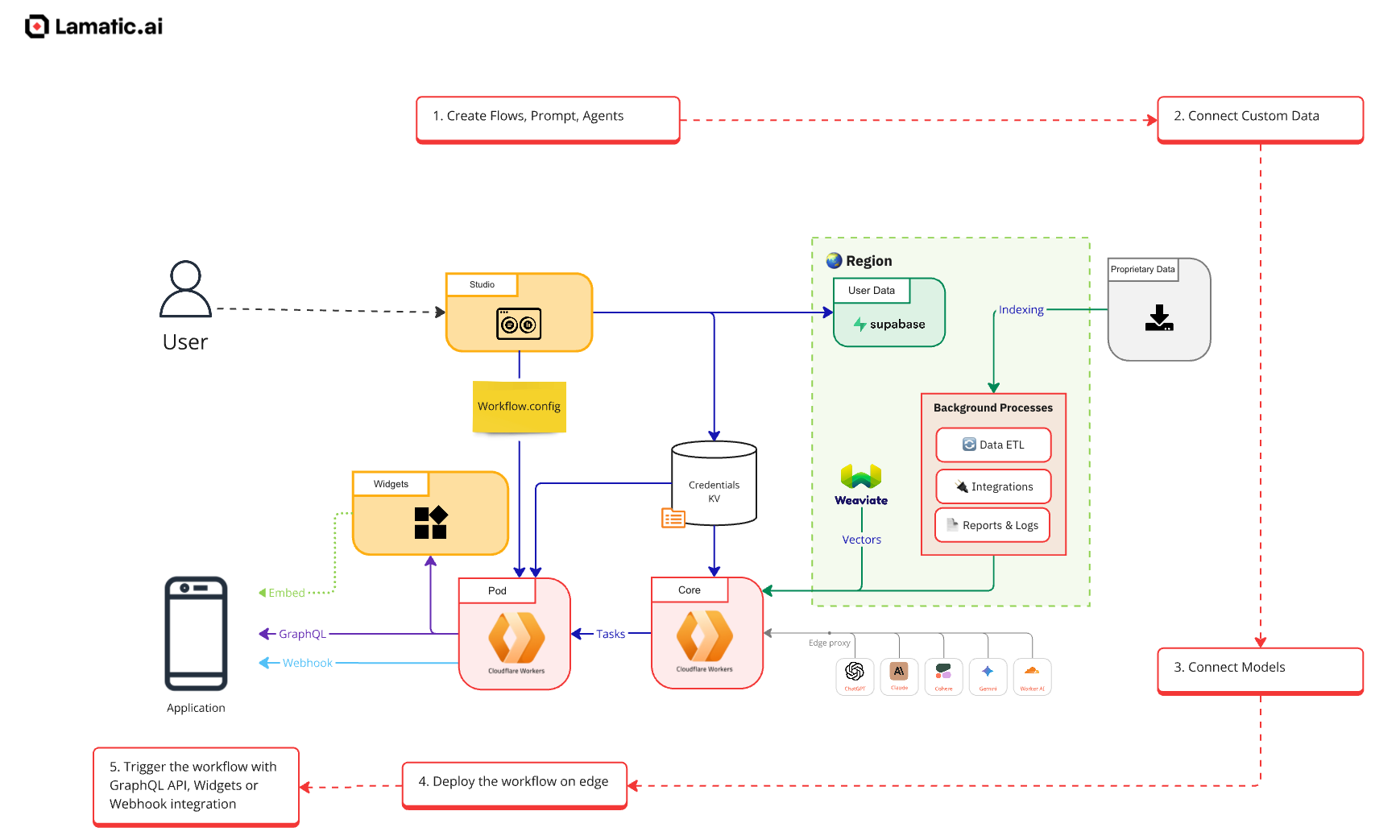
At Cloudflare, we’ve been focused on building out the tooling that simplifies the development of remote MCP servers, so that our customers’ engineering teams can focus their time on building out the MCP tools for their application, rather than managing the complexities of the protocol. And if you’re wondering just how easy is it to deploy a remote MCP server on Cloudflare, we’re happy to tell you that it only takes one click to get an MCP server — pre-built with support for the latest MCP standards — deployed.
But you don’t have to take our word for it, see it for yourself! Industry leaders are taking advantage of the ease of use to deliver new AI-powered experiences to their users by building their MCP servers on Cloudflare and now, you can do the same — just click “Deploy to Cloudflare” to get started.

Keep reading to learn more about the new capabilities that these companies are unlocking for their users and how they were able to deliver them. Or, see it in action by joining us for Demo Day on May 1 (today) at 10:00 AM PST.
We’re also making Cloudflare’s remote MCP servers available to customers today and sharing what we learned from building them out.
It wasn’t always the expectation that every service, whether a store, real estate agent, or service would have a website. But as more people gained access to an Internet connection, that quickly became the case.
We’re in the midst of a similar transition now to every web user having access to AI tools, turning to them for many tasks. If you’re a developer, it’s likely the case that the first place you turn when you go to write code now is to a tool like Claude. It seems reasonable then, that if Claude helped you write the code, it would also help you deploy it.
Or if you’re not a developer, if Claude helped you come up with a recipe, that it would also help you order the required groceries.
With remote MCP, all of these scenarios are now possible. And just like the first businesses built on the web had a first mover advantage, the first businesses to be built in an MCP-forward way are likely to reap the benefits.
The faster a user can experience the value of your product, the more likely they will be to succeed, upgrade, and continue to use your product. By connecting services to agents through MCP, users can simply ask for what they need and the agent will handle the rest, getting them to that “aha” moment faster.
Businesses that adopt MCP will quickly see the impact:
Not every user has the time to learn your dashboard or read through documentation to understand your product. With MCP, they don’t need to. They just describe what they want, and the agent figures out the rest.
MCP can keep track of a user’s requests and interactions, so future tool calls can be adapted to their usage patterns and preferences. This makes it easy to deliver more personalized, relevant experiences based on how each person actually uses your product.
Rather than relying on feature comparison tables, the AI agent can explain how a higher-tier plan helps a specific user accomplish their goals.
You don’t need to build every integration or experience in-house. By exposing your tools via MCP, you let users connect your product to the rest of their stack. Agents can combine tools across providers, enabling integrations without requiring you to support every third-party service directly.
Since the launch of MCP, we’ve shared how we’re making it easy for developers to build and deploy remote MCP servers — from abstracting away protocol complexity to handling auth and transport, to supporting fully stateful MCP servers (by default) that “sleep” when they’re not used to minimize idle costs.

We’re continuing to ship updates regularly — adding support for the latest changes to the MCP standard and making it even easier to get your server to production:
-
Supporting the new Streamable HTTP transport: Your MCP servers can now use the latest Streamable HTTP transport alongside SSE, ensuring compatibility with the latest standards. We’ve updated the AI Playground and mcp-remote proxy as well, giving you a remote MCP client to easily test the new transport.
-
Python support for MCP servers: You can now build MCP servers on Cloudflare using Python, not just JavaScript/TypeScript.
-
Improved docs, starter templates, and deploy flows: We’ve added new quickstart templates, expanded our documentation to cover the new transport method, and shared best practices for building MCP servers based on our learnings.
But rather than telling you, we thought it would be better to show you what our customers have built and why they chose Cloudflare for their MCP deployment.
Today, work lives across many different apps and services. By investing in MCP, Asana can meet users where they are, enabling agent-driven interoperability across tools and workflows. Users can interact with the Asana Work Graph using natural language to get project updates, search for tasks, manage projects, send comments, and update deadlines from an MCP client.
Users will be able to orchestrate and integrate different pieces of work seamlessly — for example, turning a project plan or meeting notes from another app into a fully assigned set of tasks in Asana, or pulling Asana tasks directly into an MCP-enabled IDE for implementation. This flexibility makes managing work across systems easier, faster, and more natural than ever before.
To accelerate the launch of our first-party MCP server, Asana built on Cloudflare’s tooling, taking advantage of the foundational infrastructure to move quickly and reliably in this fast-evolving space.
“At Asana, we’ve always focused on helping teams coordinate work effortlessly. MCP connects our Work Graph directly to AI tools like Claude.ai, enabling AI to become a true teammate in work management. Our integration transforms natural language into structured work – creating projects from meeting notes or pulling updates into AI. Building on Cloudflare’s infrastructure allowed us to deploy quickly, handling authentication and scaling while we focused on creating the best experience for our users.” – Prashant Pandey, Chief Technology Officer, Asana
Learn more about Asana’s MCP server here.
Jira and Confluence Cloud customers can now securely interact with their data directly from Anthropic’s Claude app via the Atlassian Remote MCP Server in beta. Hosted on Cloudflare infrastructure, users can summarize work, create issues or pages, and perform multi-step actions, all while keeping data secure and within permissioned boundaries.
Users can access information from Jira and Confluence wherever they use Claude to:
-
Summarize Jira work items or Confluence pages
-
Create Jira work items or Confluence pages directly from Claude
-
Get the model to take multiple actions in one go, like creating issues or pages in bulk
-
Enrich Jira work items with context from many different sources to which Claude has access
-
And so much more!
“AI is not one-size-fits-all and we believe that it needs to be embedded within a team’s jobs to be done. That’s why we’re so excited to invest in MCP and meet teams in more places where they already work. Hosting on Cloudflare infrastructure means we can bring this powerful integration to our customers faster and empower them to do more than ever with Jira and Confluence, all while keeping their enterprise data secure. Cloudflare provided everything from OAuth to out-of-the-box remote MCP support so we could quickly build, secure, and scale a fully operational setup.” — Taroon Mandhana, Head of Product Engineering, Atlassian
Learn more about Atlassian’s MCP server here.
At Intercom, the transformative power of AI is becoming increasingly clear. Fin, Intercom’s AI Agent, is now autonomously resolving over 50% of customer support conversations for leading companies such as Anthropic. With MCP, connecting AI to internal tools and systems is easier than ever, enabling greater business value.
Customer conversations, for instance, offer valuable insights into how products are being used and the experiences customers are having. However, this data is often locked within the support platform. The Intercom MCP server unlocks this rich source of customer data, making it accessible to anyone in the organization using AI tools. Engineers, for example, can leverage conversation history and user data from Intercom in tools like Cursor or Claude Code to diagnose and resolve issues more efficiently.
“The momentum behind MCP is exciting. It’s making it easier and easier to connect assistants like Claude.ai and agents like Fin to your systems and get real work done. Cloudflare’s toolkit is accelerating that movement even faster. Their clear documentation, purpose-built tools, and developer-first platform helped Intercom go from concept to production in under a day, making the Intercom MCP server launch effortless. We’ll be encouraging our customers to leverage Cloudflare to build and deploy their own MCP servers to securely and reliably connect their internal systems to Fin and other clients.” — Jordan Neill, SVP Engineering, Intercom
The Linear MCP server allows users to bring the context of their issues and product development process directly into AI assistants when it’s needed. Whether that is refining a product spec in Claude, collaborating on fixing a bug with Cursor, or creating issues on the fly from an email.
“We’re building on Cloudflare to take advantage of their frameworks in this fast-moving space and flexible, fast, compute at the edge. With MCP, we’re bringing Linear’s issue tracking and product development workflows directly into their AI tools of choice, eliminating context switching for teams. Our goal is simple: let developers and product teams access their work where they already are—whether refining specs in Claude, debugging in Cursor, or creating issues from conversations. This seamless integration helps our customers stay in flow and focused on building great products” — Tom Moor, Head of US Engineering, Linear
Learn more about Linear’s MCP server here.
“MCPs represent a new paradigm for software development. With PayPal’s remote MCP server on Cloudflare, now developers can delegate to an agent with natural language to seamlessly integrate with PayPal’s portfolio of commerce capabilities. Whether it’s managing inventory, processing payments, tracking shipping, handling refunds, AI agents via MCP can tap into these capabilities to autonomously execute and optimize commerce workflows. This is a revolutionary development for commerce, and the best part is, developers can begin integrating with our MCP server on Cloudflare today.” – Prakhar Mehrotra, SVP of Artificial Intelligence, PayPal
Learn more about PayPal’s MCP server here.
With the Sentry MCP server, developers are able to query Sentry’s context right from their IDE, or an assistant like Claude, to get errors and issue information across projects or even for individual files.
Developers can also use the MCP to create projects, capture setup information, and query project and organization information – and use the information to set up their applications for Sentry. As we continue to build out the MCP further, we’ll allow teams to bring in root cause analysis and solution information from Seer, our Agent, and also look at simplifying instrumentation for sentry functionality like traces, and exception handling.
Hosting this on Cloudflare and using Remote MCP, we were able to sidestep a number of the complications of trying to run locally, like scaling or authentication. Remote MCP lets us leverage Sentry’s own OAuth configuration directly. Durable Object support also lets us maintain state within the MCP, which is important when you’re not running locally.
“Sentry’s commitment has always been to the developer, and making it easier to keep production software running stable, and that’s going to be even more true in the AI era. Developers are utilizing tools like MCP to integrate their stack with AI models and data sources. We chose to build our MCP on Cloudflare because we share a vision of making it easier for developers to ship software, and are both invested in ensuring teams can build and safely run the next generation of AI agents. Debugging the complex interactions arising from these integrations is increasingly vital, and Sentry provides the essential visibility needed to rapidly diagnose and resolve issues. MCP integrates this crucial Sentry context directly into the developer workflow, empowering teams to consistently build and deploy reliable applications.” — David Cramer, CPO and Co-Founder, Sentry
Learn more about Sentry’s MCP server here.
Square’s APIs are a comprehensive set of tools that help sellers take payments, create and track orders, manage inventory, organize customers, and more. Now, with a dedicated Square MCP server, sellers can enlist the help of an AI agent to build their business on Square’s entire suite of API resources and endpoints. By integrating with AI agents like Claude and codename goose, sellers can craft sophisticated, customized use cases that fully utilize Square’s capabilities, at a lower technical barrier.
Learn more about Block’s MCP server here.
“MCP is emerging as a new AI interface. In the near-future, MCP may become the default way, or in some cases the only way, people, businesses, and code discover and interact with services. With Stripe’s agent toolkit and Cloudflare’s Agent SDK, developers can now monetize their MCPs with just a few lines of code.” — Jeff Weinstein, Product Lead at Stripe
The Webflow MCP server supports CMS management, auditing and improving SEO, content localization, site publishing, and more. This enables users to manage and improve their site directly from their AI agent.
“We see MCP as a new way to interact with Webflow that aligns well with our mission of bringing development superpowers to everyone. MCP is not just a different surface over our APIs, instead we’re thinking of it in terms of the actions it supports: publish a website, create a CMS collection, update content, and more. MCP lets us expose those actions in a way that’s discoverable, secure, and deeply contextual. It opens the door to new workflows where AI and humans can work side-by-side, without needing to cobble together solutions or handle low-level API details. Cloudflare supports this aim by offering the reliability, performance, and developer tooling we need to build modern web infrastructure. Their support for remote MCP servers is mature and well-integrated, and their approach to authentication and durability aligns with how we think about the scale and security of these offerings.” — Utkarsh Sengar, VP of Engineering, Webflow
Learn more about Webflow’s MCP server here.
If you’re looking to build a remote MCP server for your service, get started with our documentation, watch the tutorial below, or use the button below to get a starter remote MCP server deployed to production. Once the remote MCP server is deployed, it can be used from Claude, Cloudflare’s AI playground, or any remote MCP client.
In addition, we launched a new YouTube video walking you through building MCP servers, using two of our MCP templates.
If you have any questions or feedback for us, you can reach us via email at [email protected].

































{kind=link}