Post Syndicated from alexk original https://blog.zabbix.com/supercharge-zabbix-with-powerful-insights/12841/
A new set of trigger functions for long-term analysis of trend data will allow Zabbix to analyze historical data and generate alerts on detected anomalies.
Contents
I. Types of monitoring (0:39)
II. Zabbix 5.2 new functions (5:34)
III. In a nutshell (13:28)
IV. Questions & Answers (14:17)
Types of monitoring
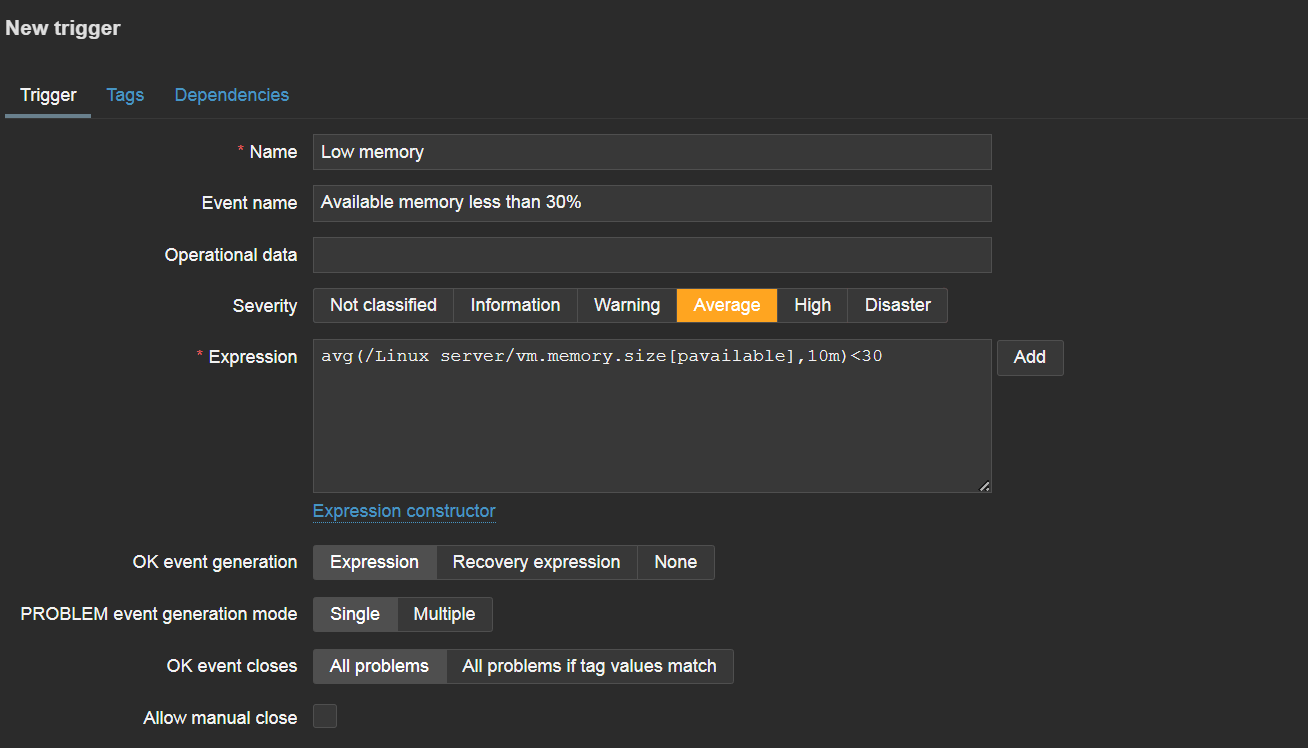
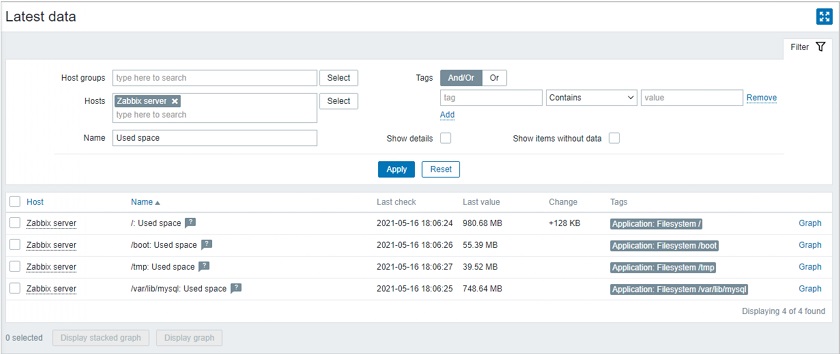
Let’s start with a philosophical observation. In many cases, configuring monitoring entities is a pretty straightforward exercise. For instance, we know that computers should have some free disk space as applications won’t work otherwise; that CPU should not run at 100oC; that user-facing application should respond in less than a couple of seconds, otherwise, users will notice and complain. To be alerted when any of these expectations fail, we need to use triggers. A trigger can be as simple as {Host:cpu.temp.avg(5m)} > 100.
However, in some situations, it is difficult to decide right from wrong. Some cases can’t be evaluated without a proper context. For instance, is it OK if RAM is 70% full? The answer is our favorite ‘it depends’. If RAM was just 20% full a week ago, chances are big that some application is leaking and your memory usage will continue growing. But if your RAM usage stays at 70% for three years in a row, there are even better chances that it stays so for another three years.
Another it-depends example is web traffic monitoring. Intuitively, we know that it’s perfectly normal to have uneven traffic distribution across days of week or months. But every website has its usage patterns, so even when we figure out what is normal and what’s not for one specific website, it’s difficult to scale this knowledge to other websites.

Web traffic monitoring
So, in the grand scheme of things, it all boils down to finding a good baseline for parameters we want to monitor. And baselines are usually defined by previous knowledge.
So, in such cases, instead of figuring out a fixed threshold (some fixed value or percentage), we need to figure out data points in the past that we want to compare to our current data points.
- Compare values to known thresholds.
{Host:cpu.temp.avg(5m)} > 100
- Baseline — compare to unknown thresholds.

Finding the right points in the past (or rather, finding a good interval to look back to) is still something that the user must supply manually, even though we are also working on automating this in the future. But Zabbix 5.2 gives you some tools to make comparisons to baseline way easier.
Web traffic monitoring example
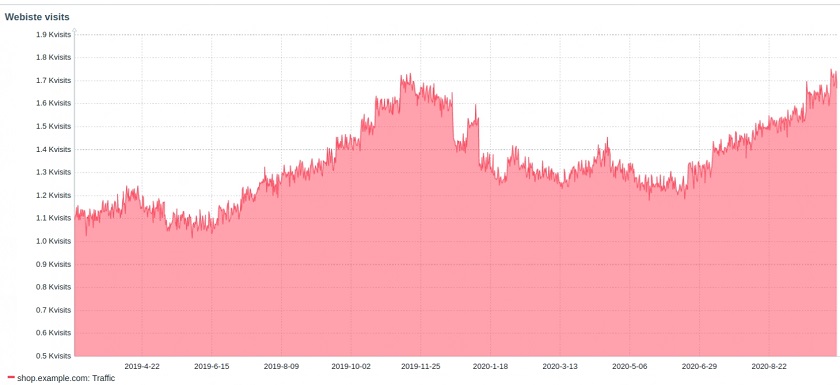
Let’s consider a history of website visits for an imaginary commerce site — shop.example.com.

Commercial site web traffic monitoring
The numbers are different at any given point in time, yet all these are normal in a certain context. Overall, we see a growing trend in 2020 as compared to 2019. But there are seasonal traffic spikes. The biggest ones are around Christmas.
Site administrators like to be informed of any traffic anomalies (such as fraud traffic, for example), but hate false positives caused by seasonal spikes.
If we want to detect anomalies here, we can get an average for some period and compare it to an average for the same period a year before.
If we know that our organic year-to-year growth is not likely to exceed, for instance, 15 %, then it’s seemingly easy to do this in virtually any version of Zabbix: we take the average traffic over 30 days and check if it exceeds the same period a year ago by more than 15 %.

However, there are a few problems with this trigger expression.
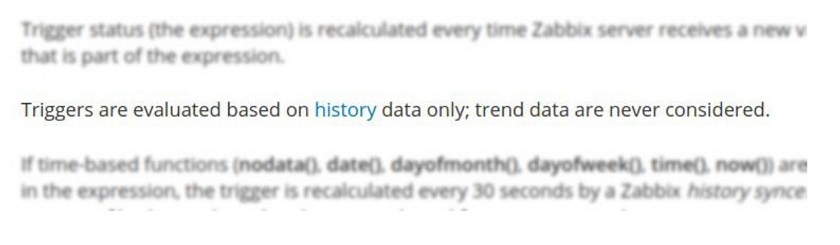
1. First, we look 1 year back in history. But if we look into Zabbix 5.0 documentation about triggers, we see this:
 This means that we need to keep a full and detailed history for at least 1 year (13 months, in this specific case). It is a passable solution if we ingest the traffic data daily. But what if we do it every minute? What if we do it every minute for a thousand websites?
This means that we need to keep a full and detailed history for at least 1 year (13 months, in this specific case). It is a passable solution if we ingest the traffic data daily. But what if we do it every minute? What if we do it every minute for a thousand websites?
2. In Zabbix, we specify time as 30d and 365d. As you may know, in Zabbix, this is just a fancy way to specify 187,200 and 68,328,000 seconds. Zabbix 5.0 doesn’t have the time suffix for a month and a year just because this cannot be simply translated to the number of seconds. Even though 30d is very close to 28d and 31d, it’s still not the same.
3. The result of avg() function with or without the second time shift parameter always depends on the specific time of the calculation. This is because Zabbix calculates time shifts by subtracting the interval from the current time. This makes it impossible to calculate aggregates between, for instance, the first and the last day of a week, a month, or a year.
Zabbix 5.2 new functions
That is why we introduce new trigger functions, which address all the specified issues. We also added few other trigger features, which improve event presentation. These functions are similar to the non-trend counterparts but are optimized for baseline monitoring use cases.
trendavg(period, period_shift)
trendcount(period, period_shift)
trenddelta(period, period_shift)
trendmax(period, period_shift)
trendmin(period, period_shift)
trendmin(period, period_shift)
- The new functions use trends tables instead of history (do not forget to set proper trend storage period):

- period and period_shift parameters use the Gregorian calendar instead of the number of seconds.
— h (hour), d (day), w (week), M (month), and y (year).
- These functions are easy on system resources because they do calculations only when a period ends.
In addition to the new trigger functions, we also added the ability to set customized event name.
The customized event name lets you fine-tune how the event looks in the Zabbix UI (in screens like problems and problem widget) and include trigger expression calculation results.
This field is optional, you can continue using the trigger Name field instead.
There is also a new macro {? … }. It can be used for expressions inside the event name.
Triggers
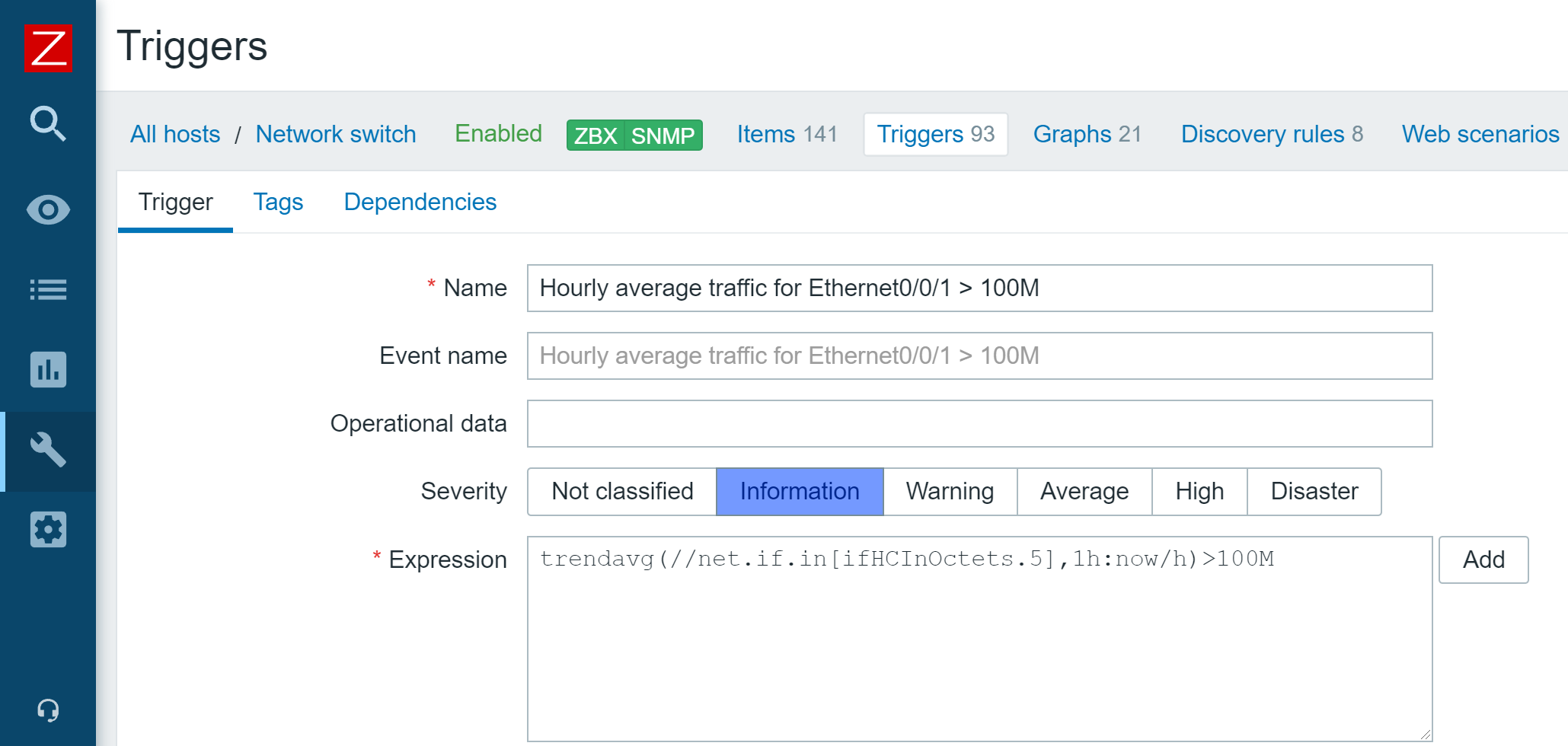
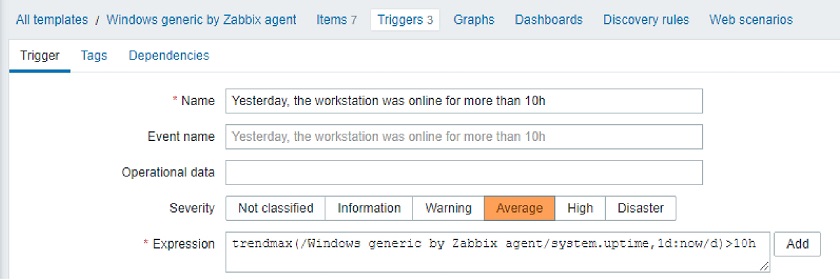
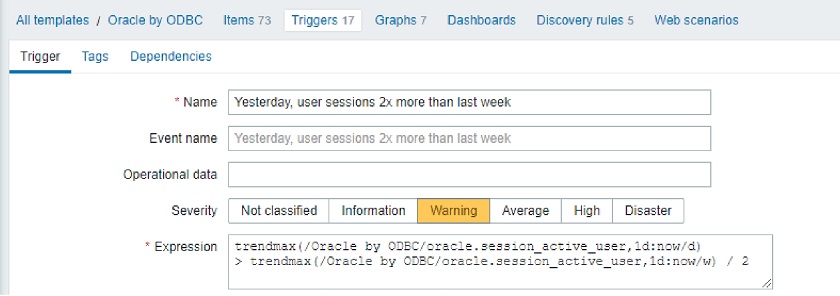
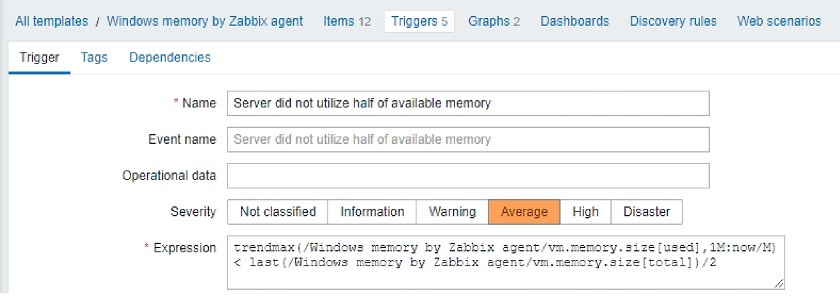
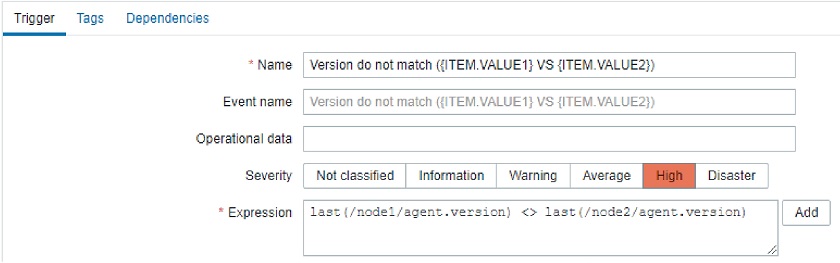
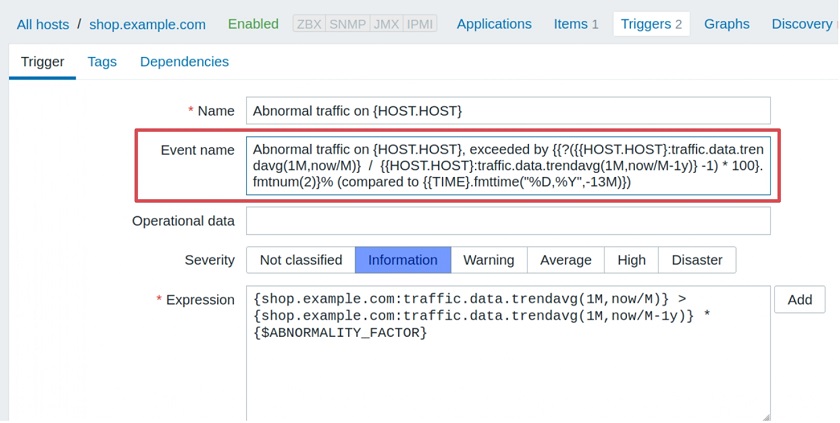
Let’s reconfigure our trigger in the Zabbix 5.2 style.

Zabbix 5.2-style triggers
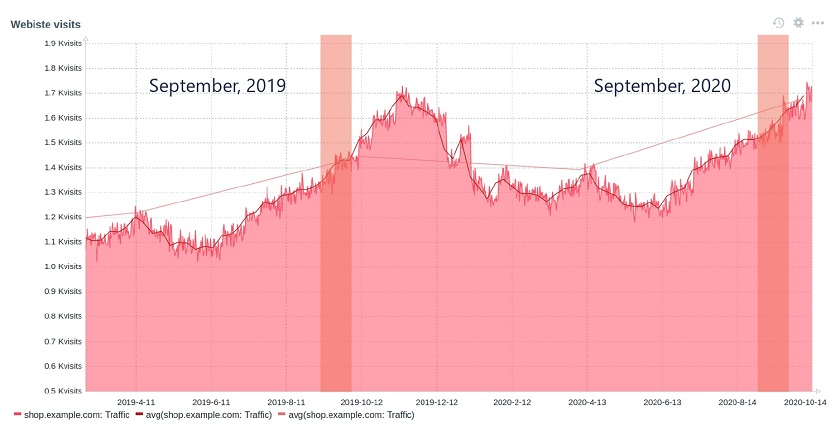
Let’s see what are the arguments for trendavg() function: 1M and now/M.
- The first argument means that we use calendar month as an aggregation period. So, depending on the month’s trendavg() will be doing calculations for, it will pick up the first and the last date of the month. The same goes for other possible interval suffixes — h for hour, d for day, w for week, and y for year.
- The second parameter, as in regular aggregate functions, means a time shift. But to distinguish between old and new types of shifts, we call them period shifts. The period shift denotes the last point in the timeline for our aggregation.
For instance, for October 13, 2020, trendavg(1M) will calculate the value for the period from September 1, 2020, to September 30, 2020, and trendavg(1M, 1M-1y) will calculate the value for the period from September 1, 2019, to September 30, 2019.
Event name field
In Zabbix 5.2, you can continue using the Name field with the content copied to the Event name field. But if you specify the Event name, it will be used for all corresponding events instead.
The Event name supports the new macro {?…}, so you can put another trigger expression inside this macro to show some related calculations. We call it the expression macro. For instance, the Event name will be displayed on the Problem screen as follows:

This trigger generates problems like this:

It’s already very useful, but this percentage will look better if we could round it up. It wouldn’t hurt to show what month we compare our traffic against. To do that, we have added two formatting functions:
— applicable to ITEM.VALUE, ITEM.LASTVALUE, and expression macros.
— fmtnum(2) gives 14.85 instead of 14.8512345.
- fmttime(format, time_shift)
— applicable to {TIME}.
— uses strftime format codes.
— formats time, for instance, {TIME}.fmttime(“%B,%Y”) gives October,2020.
Let’s see how we can improve our Event name with new formatting functions:

It looks somewhat scary on the trigger configuration screen, but Zabbix will reward us by generating events like this:

But the new functions are not limited to a single use case of comparing some data from a recent period to some past period.
Cloud budget monitoring example
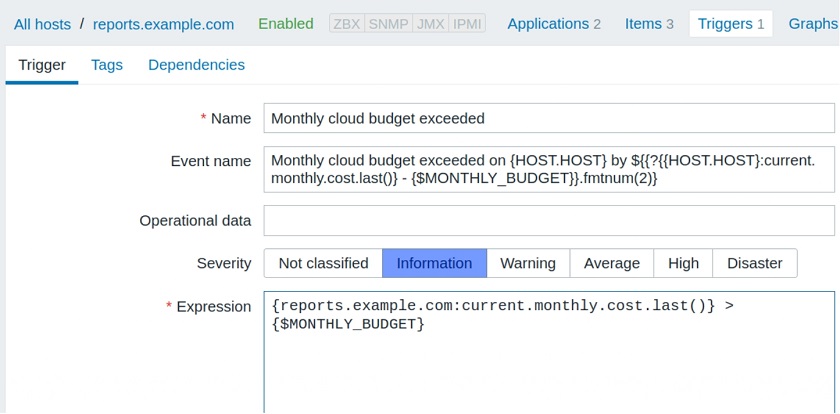
Let’s consider another real-world example. Imagine that your IT department runs some very important services in the Cloud. And, of course, your finance department sends a monthly budget you don’t want to overrun. You receive cloud usage records from one or more cloud providers and ingest this data periodically into monitoring.
You could set up a trigger with a trendsum() by one month to check whether you exceeded your fixed budget in the previous months or not. But you want to know about the budget overrun ASAP. If you exceed your monthly budget in the middle of a month, your quick reaction might save the company money.

In the chart, we see the even distribution of cloud usage costs up to the last dates of September. Then the usage starts going up. When should you start worrying?
Again, the new trend functions come to the rescue.
The solution is to use the period_shift parameter, just not in the past, but rather in the future. For instance, if today’s date is October 22, this expression will calculate the sum() from October 1 to October 31.
There is one problem, though. To save precious computing resources, Zabbix evaluates these functions in triggers only when the period is over. However, these functions are also available in calculated items, and we can use arbitrary calculation intervals there.
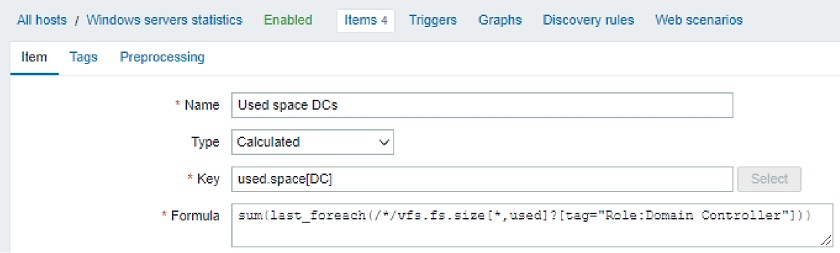
So, the solution is to set up a calculated item, use trendsum() in the formula, and specify some reasonable update interval (for instance, one hour or one day).

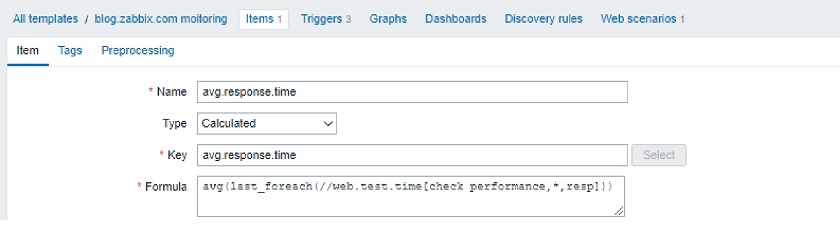
Here, on the right-hand side of the chart, we see the current period, which is not over yet. Let’s take a look at the item definition.
This is the formula to calculate the current calendar period. Then, we can add a simple trigger referencing this calculated item:

Formula to calculate the current calendar period
You can also use the new expression macro in this trigger. You don’t need to have trend functions anywhere in the formula for this.

Once the trigger fires, you will see the following problem on the Problem screen — a nice and clean message containing all the information we need.

Use cases
There are many more possible applications for the new functions besides the examples above. Generally, these trend functions can be applied not only to IT metrics but also to many other real-world KPIs, for example:
— Business performance (to calculate annual revenue, profitability, etc.).
— Sales and marketing (for instance, monthly average, customer acquisition costs, sales target rate).
— Warehousing (such as weekly shipments, return rates, etc.).
— Human resources (for instance, annual training costs, overtime hours, etc.).
— Customer support (such as average response time or the number of issues per month).
We expect these functions to pave the way for Zabbix to new territories, which have been previously occupied by CRMs and other business analytics systems.
In a nutshell
- Zabbix trend functions — a new way to analyze history without storing historical data.
- Zabbix trend functions support calendar hours, days, weeks, months, and years.
- New trigger field Event name – lets us display events with context.
- New formatting functions let us present numbers and dates in a flexible manner.
- Long-term data analysis just got easier and better with the new Zabbix 5.2.
Questions & Answers
Question. What’s the maximum time period for these new trigger functions? For how long can we analyze the data?
Answer. The maximum time period is not limited by any hardcoded values. The only limit you should keep in mind is just the size of your trend data history. But there are no limitations in the code whatsoever that would limit this use. You also should keep in mind that the longer is the period the bigger the database load is. That’s also a factor to consider.
Question. Is this trend data that we’re analyzing also going to be stored in the value cache or some other place?
Answer. it’s not stored in the value cache at the moment. These trigger functions recalculate their values only after the period is over. So it’s not of much use for value cache. But if this is required by some demanding applications, we’ll add this in the later versions.