Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=5PmclgVQ0LI
Yearly Archives: 2024
[$] Debating ifupdown replacements for Debian trixie
Post Syndicated from jzb original https://lwn.net/Articles/989055/
Debian does not have an official way to configure
networking. Instead, it has four
recommended ways to configure networking, one of which is the
venerable ifupdown, which
has been part of Debian since the turn of the century and is showing its
age. A conversation about its maintainability and possible replacement with ifupdown‑ng has
led to discussions about the default network-management tools for
Debian “trixie”
(Debian 13, which is expected in 2025) and beyond. No route to consensus
has been found, yet.
Microsoft Is Adding New Cryptography Algorithms
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/09/microsoft-is-adding-new-cryptography-algorithms.html
Microsoft is updating SymCrypt, its core cryptographic library, with new quantum-secure algorithms. Microsoft’s details are here. From a news article:
The first new algorithm Microsoft added to SymCrypt is called ML-KEM. Previously known as CRYSTALS-Kyber, ML-KEM is one of three post-quantum standards formalized last month by the National Institute of Standards and Technology (NIST). The KEM in the new name is short for key encapsulation. KEMs can be used by two parties to negotiate a shared secret over a public channel. Shared secrets generated by a KEM can then be used with symmetric-key cryptographic operations, which aren’t vulnerable to Shor’s algorithm when the keys are of a sufficient size.
The ML in the ML-KEM name refers to Module Learning with Errors, a problem that can’t be cracked with Shor’s algorithm. As explained here, this problem is based on a “core computational assumption of lattice-based cryptography which offers an interesting trade-off between guaranteed security and concrete efficiency.”
ML-KEM, which is formally known as FIPS 203, specifies three parameter sets of varying security strength denoted as ML-KEM-512, ML-KEM-768, and ML-KEM-1024. The stronger the parameter, the more computational resources are required.
The other algorithm added to SymCrypt is the NIST-recommended XMSS. Short for eXtended Merkle Signature Scheme, it’s based on “stateful hash-based signature schemes.” These algorithms are useful in very specific contexts such as firmware signing, but are not suitable for more general uses.
Ransomware Groups Demystified: Lynx Ransomware
Post Syndicated from Rapid7 Labs original https://blog.rapid7.com/2024/09/12/ransomware-groups-demystified-lynx-ransomware/

As part of our research and tracking of threats, Rapid7 Labs is actively monitoring new and upcoming threat groups and the ransomware domain is known for having a large number of them. In the Ransomware Radar Report, Rapid7 Labs shared the observation that in the first half of 2024, 21 new or rebranded ransomware groups surfaced. Many of those are not immediately coming into the spotlight as abusing some fancy new or recently discovered vulnerability, or — as we measure activity — posting a large number of data leaks.
Rapid7 Labs has an ongoing commitment to help organizations understand and mitigate the complex world of ransomware, and this includes highlighting these newer groups. In this post we’re going to focus on the recently-emerged Lynx ransomware group.
Intro to the Lynx group
The Lynx ransomware group was identified in July 2024, and has claimed more than 20 victims in various industry sectors to date. The group is using both single and double extortion techniques against their victims; however, they claim to be “ethical” with regards to choosing victims, according to their press release on July 24th:
“Lynx Ransomware core motivation is grounded in financial incentives, with a clear intention to avoid undue harm to organizations. We recognize the importance of ethical considerations in the pursuit of financial gain and maintain a strict policy against targeting governmental institutions, hospitals, or non-profit organizations, as these sectors play vital roles in society.”
When a victim has been hit, the infamous readme.txt surfaces on desktops and contains the link to the Tor site of Lynx and the ID needed to enter the portal:
Along with the portal for victims to log in, the group is hosting a public blog and also a leaks page where victims are showcased in an attempt to enforce payment.
Analyzing Lynx ransomware
In order to conduct our analysis, we took a sample that had been observed being used in August 2024.

Underground rumors claim that the Lynx group has purchased the source code from another group Rapid7 tracks: INC ransomware. When conducting a binary diff on the samples of Lynx and INC ransomware, the overall results show a 48 percent similarity score, where the functions have a score of 70.8 percent:
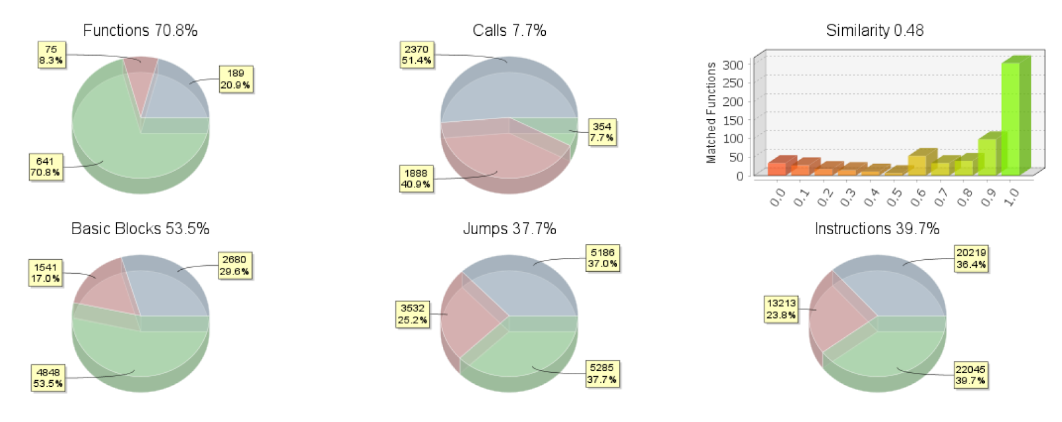
Based on the diff and some other comparisons we conducted, there are overlaps in functions and arguments, but in our opinion not enough to prove fully that Lynx was derived from INC ransomware’s source code.
An initial look at the Lynx ransomware sample finds that in the code, three URLs stand out as already pointing to suspicious sites:
hxxp://lynxblog[.]net/
hxxp://lynxch2k5xi35j7hlbmwl7d6u2oz4vp2wqp6qkwol624cod3d6iqiyqd[.]onion/login
hxxp://lynxbllrfr5262yvbgtqoyq76s7mpztcqkv6tjjxgpilpma7nyoeohyd[.]onion/disclosures
In addition, the ransomware has several command line options to run:
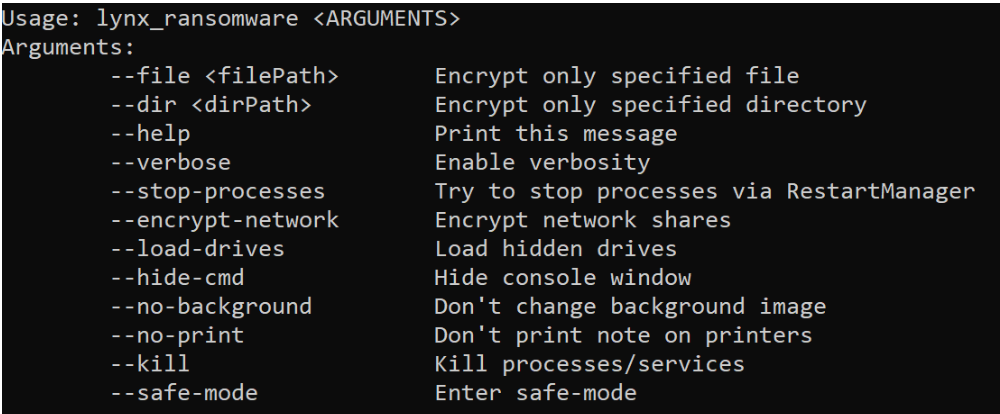
Inside the ransomware, the readme.txt — aka the ransomware notification — is hidden using Base64 to decode the message. The ID to log into the portal will be generated, but overall the note is similar to other ransomware notes:
Your data is stolen and encrypted.
Download TOR Browser to contact with us.
ID
~ %id%
Chat site:
~ TOR Network: http://lynxchatly4zludmhmi75jrwhycnoqvkxb4prohxmyzf4euf5gjxroad.onion/login
~ TOR Mirror #1: http://lynxchatfw4rgsclp4567i4llkqjr2kltaumwwobxdik3qa2oorrknad.onion/login
~ TOR Mirror #2: http://lynxchatohmppv6au67lloc2vs6chy7nya7dsu2hhs55mcjxp2joglad.onion/login ~ TOR Mirror #3: http://lynxchatbykq2vycvyrtjqb3yuj4ze2wvdubzr2u6b632trwvdbsgmyd.onion/login
Key ransomware functionalities:
1.Process and Service Management:
- The ransomware attempts to kill various system processes and services using methods like the RestartManager. It specifically targets services that might hinder the encryption process, such as backup-related services.
- It enumerates and stops dependent services and processes, utilizing system APIs such as EnumDependentServicesW and ControlService.
2.Shadow Copy Deletion:
- A major target of this ransomware is deleting volume shadow copies, which are often used to restore data. The string “Successfully delete shadow copies from %c:” suggests the use of vssadmin or other similar commands to ensure backup files are removed.
3.File Encryption:
- It encrypts files across the system, including network shares and drives (Encrypt network shares, Load hidden drives). The use of terms like “Encrypting file: %s” and “Encrypt only specified directory” indicates the ransomware can focus on specific folders or file types, increasing its precision.
- There is also the ability to encrypt only selected files, directories, or network shares based on configuration (–file, –dir <dirPath>, –encrypt-network).
Lynx: Ones to watch
While the Lynx ransomware group says it takes an “ethical” stance, there is no scenario where attacking and extorting victims can be viewed in that way. Lynx’s aggressive targeting and dual extortion tactics make them a threat to watch. With overlaps in functionality between Lynx and INC ransomware, the potential for source code sharing and evolution among ransomware groups remains a critical concern for defenders.
As organizations navigate these threats, it’s crucial to stay vigilant, invest in robust security measures, and be prepared to respond quickly to ransomware incidents. Rapid7 Labs will continue to monitor and analyze the activities of groups like Lynx to provide timely insights and actionable intelligence for the community.
New stable kernels released
Security updates for Thursday
Post Syndicated from jake original https://lwn.net/Articles/990040/
Security updates have been issued by Debian (chromium and redis), Fedora (nextcloud, python3.10, python3.13, python3.6, vim, and wolfssl), Mageia (expat, libpcap, and microcode), Oracle (dovecot, kernel, and kernel-container), Red Hat (kernel and krb5), SUSE (389-ds, colord, containerd, curl, expat, glib2, go1.22, go1.23, kernel, libpcap, postgresql16, and runc), and Ubuntu (expat, libxmltok, linux, linux-aws, linux-azure, linux-bluefield, linux-gcp, linux-gkeop, linux-ibm, linux-kvm, linux-oracle, linux, linux-aws, linux-gcp, linux-gke, linux-ibm, linux-lowlatency, linux-oem-6.8, linux-oracle, linux-aws-5.4, linux-azure-5.4, linux-gcp-5.4, linux-hwe-5.4, linux-ibm-5.4, linux-oracle-5.4, linux-raspi-5.4, linux-azure, linux-iot, linux-nvidia, linux-nvidia-lowlatency, python-setuptools, setuptools, tiff, and unbound).
Manage Unifi with HACS Unifi Hotspot Manager
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=tZzd7Uq8mpE
2024 Ultimate Portable Projector Comparison
Post Syndicated from The Hook Up original https://www.youtube.com/watch?v=jmmGQOSAReI
Backblaze Open Sources Boardwalk Workflow Engine for Ansible
Post Syndicated from Pat Patterson original https://www.backblaze.com/blog/backblaze-open-sources-boardwalk-workflow-engine-for-ansible/

If you maintain cloud infrastructure as part of your job, as our Cloud Operations team here at Backblaze does, you’ll recognize the wisdom in the mantra, “Automate early, automate often”. When you’re working with tens, hundreds, or even thousands of production servers, manually applying changes gets old very quickly!
Today, Backblaze is releasing a new open source project: Boardwalk, hosted on GitHub at https://github.com/Backblaze/boardwalk, to help automate rolling maintenance jobs like kernel and operating system (OS) upgrades. Boardwalk is a linear Ansible workflow engine, written in Python, that our infrastructure systems engineers built to help automate complex operations tasks for large numbers of production hosts.
Why did Backblaze create Boardwalk?
Back in 2021, the Backblaze Storage Cloud platform comprised about 1,800 servers, the majority of which were Storage Pods. Upgrading those machines to a new OS version was an arduous task. The job took over a year and required well over 1,000 hours of hands-on toil by our data center staff. It was clear that we would need to automate the next OS upgrade, especially since it would involve even more machines.
While there are a range of tools available for this kind of work, we couldn’t just feed a list of server addresses into one of them and set it loose. Each Storage Pod is a server fitted with between 26 and 60 hard drives containing customer data, plus a boot drive holding the server’s OS. Twenty pods make up a Backblaze Vault.
Normal storage operations are as follows: Incoming customer data is assigned to a Vault for storage, then split into 20 shards, each of which is stored in a separate Pod. (I’m skipping some of the details here; for the full story, see How Backblaze Scales Our Storage Cloud). If you’ve followed our Drive Stats blog posts over the years, you’ll know that, at our scale, drives fail every day, so any one of those Pods can be taken temporarily offline for a drive replacement at any time.
This architecture means that we have to be quite intentional when we take Pods offline for upgrade.
Remotely upgrading the OS on a Storage Pod takes about 40 minutes. When the pod goes offline for upgrade, we put its Vault into read-only mode so that the upgraded server doesn’t have to catch up with writes that occurred when it was offline; the remaining 19 Pods in the Vault can still serve read requests. While one Storage Pod is being upgraded, we absolutely do not want a second Storage Pod in the same Vault upgrading.
Doing so would reduce read performance for the Vault, since fewer Storage Pods would be available to handle incoming requests, as well as increasing the risk that random drive failures in the other Pods might take the entire Vault offline. Once the upgrade is complete and the Pod comes back online, the Vault is returned to read-write mode.
The challenge of automation at scale
Backblaze has a long history of using Ansible to configure and deploy changes to its fleets of servers. However, while Ansible is a very capable agentless, modular, remote execution and configuration management engine, it isn’t well suited to complex, multi-stage operations tasks at Backblaze’s scale. Ansible playbooks have always helped us automate most of the process of managing so many servers, but eventually we hit challenges trying to reduce human toil even further.
Ansible is connection-oriented and most operations are performed on remote hosts, rather than on the administrative machine. From the administrative machine, Ansible connects to a remote host, copies code over, and executes it. There’s no practical way to run pre-checks about a host before connecting to it. This makes long-running background jobs difficult to work with using Ansible alone.
For example, if a playbook is running for days or weeks and fails, Ansible doesn’t retain any knowledge of where it left off, and can’t make any offline decisions about which hosts it needs to finish up with. When the playbook is re-run, Ansible will attempt to connect to all of the hosts it had previously connected to, potentially resulting in a long recovery time for a failed job. Considering Backblaze runs thousands of Storage Pods, this takes a long time!
The reality was that we needed something more, but also wanted to leverage all of our history with Ansible, including the playbooks that we had built, and the skills we already had. So we decided to build a workflow engine around Ansible, and we called it Boardwalk.
What does Boardwalk do?
We created Boardwalk to manage these kinds of long-running Ansible workflows, codifying our vast experience operating storage systems at scale. Boardwalk makes it easy to define workflows composed of a series of jobs to perform tasks on hosts using Ansible. It connects to hosts one-at-a-time, running jobs in a defined order, and maintaining local state as it goes; this makes stopping and resuming long-running Ansible workflows easy and efficient. It’s designed and built to be easy for DevOps and systems engineers to introduce, and frontline operators to use, while leveraging existing playbooks.
One of Boardwalk’s features is its ability to connect to a host and determine whether it should run a job on that host now, or leave it until later. When we use Boardwalk to perform rolling OS upgrades, it connects to a Pod and requests that the Pod temporarily remove itself from its Vault. The Pod checks that the other 19 Pods in the Vault are online and healthy; if so, then that Pod proceeds. Then Boardwalk can run the Ansible playbook to upgrade it. If, on the other hand, one or more of the other Pods are offline for some reason, that Pod sends a failure response to Boardwalk, causing the upgrade to be postponed until the Vault is in its correct state.
When Boardwalk is working on a host, it acquires a virtual “lock,” and saves its progress as it walks through the steps. The lock prevents multiple instances of Boardwalk from conflicting with each other, and the progress state allows Boardwalk to pick up where it left off in case of failure. If something does go wrong, an alert brings a human into the loop. Once a Pod has been successfully upgraded, Boardwalk updates its local state accordingly.
In practice, for OS upgrades, we run a single Boardwalk workflow per data center, which keeps things simple. It has a list of all of the servers it needs to upgrade, and quietly works down the list, with little or no manual intervention.
In this way, in our most recent OS upgrade, we were able to upgrade 6,000 servers over the course of nine months, with zero impact on availability and minimal intervention from data center staff. Customers were able to read files regardless of whether a Pod was being upgraded in one of the Vaults holding their data; file uploads were automatically sent to Pods in read-write mode.
What can I do with Boardwalk?
Today, we are releasing Boardwalk under the MIT License, a permissive open source license with very few restrictions on reuse. You are free to download Boardwalk, run it yourself, modify it, build it into a product, even sell it, as long as you observe the terms of the license.
We anticipate that most Boardwalk users will be able to use it as-is to automate long-running jobs across large numbers of hosts, but we welcome contributions from the community, whether they be documentation, examples, fixes, or enhancements.
We do not require contributors to sign a Contributor License Agreement (CLA) or Developer’s Certificate of Origin (DCO); instead, we simply accept contributions subject to the GitHub Terms of Service, specifically section D.6, which states, helpfully, in both legalese and plain English:
Whenever you add Content to a repository containing notice of a license, you license that Content under the same terms, and you agree that you have the right to license that Content under those terms. If you have a separate agreement to license that Content under different terms, such as a contributor license agreement, that agreement will supersede.
Isn’t this just how it works already? Yep. This is widely accepted as the norm in the open-source community; it’s commonly referred to by the shorthand “inbound=outbound”. We’re just making it explicit.
The CONTRIBUTING file explains how to build and test Boardwalk, and how to submit your contribution via a pull request. After you submit your pull request, a project maintainer will review it and respond within two weeks, likely much less unless we are flooded with contributions!
How Do I Get Started?
The README file at https://github.com/Backblaze/boardwalk is the best place to start—it contains much more detail on Boardwalk’s architecture, design, installation, and usage. Feel free to ask questions at the Boardwalk project discussions page, or file an issue if you encounter a bug or see an opportunity to enhance Boardwalk. We hope you find Boardwalk useful, and look forward to hearing how you’re using it!
We’d like to express our gratitude to Mat Hornbeek for not only writing the initial version of Boardwalk, but also kindly contributing to this article some time after he moved on from Backblaze to a new opportunity. Thanks, Mat!
The post Backblaze Open Sources Boardwalk Workflow Engine for Ansible appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
Protecting APIs from abuse using sequence learning and variable order Markov chains
Post Syndicated from Peter Foster original https://blog.cloudflare.com/protecting-apis-from-abuse-using-sequence-learning-and-variable-order-markov
Consider the case of a malicious actor attempting to inject, scrape, harvest, or exfiltrate data via an API. Such malicious activities are often characterized by the particular order in which the actor initiates requests to API endpoints. Moreover, the malicious activity is often not readily detectable using volumetric techniques alone, because the actor may intentionally execute API requests slowly, in an attempt to thwart volumetric abuse protection. To reliably prevent such malicious activity, we therefore need to consider the sequential order of API requests. We use the term sequential abuse to refer to malicious API request behavior. Our fundamental goal thus involves distinguishing malicious from benign API request sequences.
In this blog post, you’ll learn about how we address the challenge of helping customers protect their APIs against sequential abuse. To this end, we’ll unmask the statistical machine learning (ML) techniques currently underpinning our Sequence Analytics product. We’ll build on the high-level introduction to Sequence Analytics provided in a previous blog post.
API sessions
Introduced in the previous blog post, let’s consider the idea of a time-ordered series of HTTP API requests initiated by a specific user. These occur as the user interacts with a service, such as while browsing a website or using a mobile app. We refer to the user’s time-ordered series of API requests as a session. Choosing a familiar example, the session for a customer interacting with a banking service might look like:
| Time Order | Method | Path | Description |
|---|---|---|---|
| 1 | POST | /api/v1/auth | Authenticates a user |
| 2 | GET | /api/v1/accounts/{account_id} | Displays account balance, where account_id is an account belonging to the user |
| 3 | POST | /api/v1/transferFunds | Containing a request body detailing an account to transfer funds from, an account to transfer funds to, and an amount of money to transfer |
One of our aims is to enable our customers to secure their APIs by automatically suggesting rules applicable to our Sequence Mitigation product for enforcing desired sequential behavior. If we enforce the expected behavior, we can prevent unwanted sequential behavior. In our example, desired sequential behavior might entail that /api/v1/auth must always precede /api/v1/accounts/{account_id}.
One important challenge we had to address is that the number of possible sessions grows rapidly as the session length increases. To see why, we can consider the alternative ways in which a user might interact with the example banking service: The user may, for example, execute multiple transfers, and/or check the balance of multiple accounts, in any order. Assuming that there are 3 possible endpoints, the following graph illustrates possible sessions when the user interacts with the banking service:
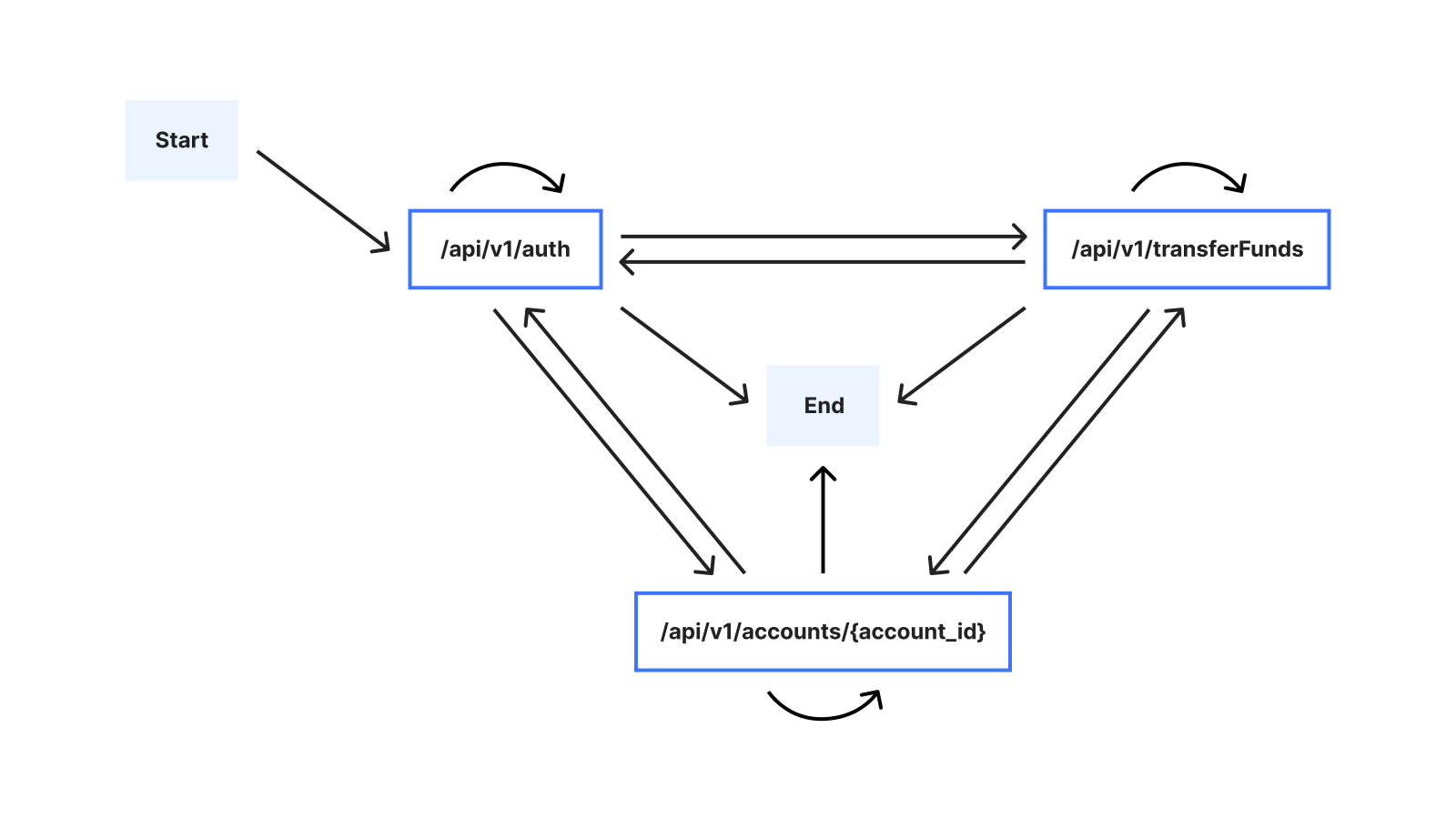
Because of this large number of possible sessions, suggesting mitigation rules requires that we address the challenge of summarizing sequential behavior from past session data as an intermediate step. We’ll refer to a series of consecutive endpoints in a session (for example /api/v1/accounts/{account_id} → /api/v1/transferFunds) in our example as a sequence. Specifically, a challenge we needed to address is that the sequential behavior relevant for creating rules isn’t necessarily apparent from volume alone: Consider for example that /api/transferFunds might nearly always be preceded by /api/v1/accounts/{account_id}, but also that the sequence /api/v1/transferFunds → /api/v1/accounts/{account_id} might occur relatively rarely, compared to the sequence /api/v1/auth → /api/v1/accounts/{account_id}. It is therefore conceivable that if we were to summarize based on volume alone, we might potentially deem the sequence /api/v1/accounts/{account_id} → /api/v1/transferFunds as unimportant, when in fact we ought to surface it as a potential rule.
Learning important sequences from API sessions
A widely-applied modeling approach applicable to sequential data is the Markov chain, in which the probability of each endpoint in our session data depends only on a fixed number of preceding endpoints. First, we’ll show how standard Markov chains can be applied to our session data, while pointing out some of their limitations. Second, we’ll show how we use a less well-known, but powerful, type of Markov chain to determine important sequences.
For illustrative purposes, let’s assume that there are 3 possible endpoints in our session data. We’ll represent these endpoints using the letters a, b and c:
-
a: /api/v1/auth
-
b: /api/v1/accounts/{account_id}
-
c: /api/v1/transferFunds
In its simplest form, a Markov chain is nothing more than a table which tells us the probability of the next letter, given knowledge of the immediately preceding letter. If we were to model past session data using the simplest kind of Markov chain, we might end up with a table like this one:
| Known preceding endpoint in the session | Estimated probability of next endpoint in the session | ||
| a | b | c | |
| a | 0.10 (1555) | 0.89 (13718) | 0.01 (169) |
| b | 0.03 (9618) | 0.63 (205084) | 0.35 (113382) |
| c | 0.02 (3340) | 0.67 (109896) | 0.31 (51553) |
Table 1
Table 1 lists the parameters of the Markov chain, namely the estimated probabilities of observing a, b or c as the next endpoint in a session, given knowledge of the immediately preceding endpoint in the session. For example, the 3rd row cell with value 0.67 means that given knowledge of immediately preceding endpoint c, the estimated probability of observing b as the next endpoint in a session is 67%, regardless of whether c was preceded by any endpoints. Thus, each entry in the table corresponds to a sequence of two endpoints. The values in brackets are the number of times we saw each two-endpoint sequence in past session data and are used to compute the probabilities in the table. For example, the value 0.01 is the result of evaluating the fraction 169 / (1555+13718+169). This method of estimating probabilities is known as maximum likelihood estimation.
To determine important sequences, we rely on credible intervals for estimating probabilities instead of maximum likelihood estimation. Instead of producing a single point estimate (as described above), credible intervals represent a plausible range of probabilities. This range reflects the amount of data available, i.e. the total number of sequence occurrences in each row. More data produces narrower credible intervals (reflecting a greater degree of certainty) and conversely less data produces wider credible intervals (reflecting a lesser degree of certainty). Based on the values in brackets in the table above, we thus might obtain the following credible intervals (entries in boldface will be explained further on):
| Known preceding endpoint in the session | Estimated probability of next endpoint in the session | ||
| a | b | c | |
| a | 0.09-0.11 (1555) | 0.88-0.89 (13718) | 0.01-0.01 (169) |
| b | 0.03-0.03 (9618) | 0.62-0.63 (205084) | 0.34-0.35 (113382) |
| c | 0.02-0.02 (3340) | 0.66-0.67 (109896) | 0.31-0.32 (51553) |
Table 2
For brevity, we won’t demonstrate here how to work out the credible intervals by hand (they involve evaluating the quantile function of a beta distribution). Notwithstanding, the revised table indicates how more data causes credible intervals to shrink: note the first row with a total of 15442 occurrences in comparison to the second row with a total of 328084 occurrences.
To determine important sequences, we use slightly more complex Markov chains than those described above. As an intermediate step, let’s first consider the case where each table entry corresponds to a sequence of 3 endpoints (instead of 2 as above), exemplified by the following table:
| Known preceding endpoints in the session | Estimated probability of next endpoint in the session | ||
| a | b | c | |
| aa | 0.09-0.13 (173) | 0.86-0.90 (1367) | 0.00-0.02 (13) |
| ba | 0.09-0.11 (940) | 0.88-0.90 (8552) | 0.01-0.01 (109) |
| ca | 0.09-0.12 (357) | 0.87-0.90 (2945) | 0.01-0.02 (35) |
| ab | 0.02-0.02 (272) | 0.56-0.58 (7823) | 0.40-0.42 (5604) |
| bb | 0.03-0.03 (6067) | 0.60-0.60 (122796) | 0.37-0.37 (75801) |
| cb | 0.03-0.03 (3279) | 0.68-0.68 (74449) | 0.29-0.29 (31960) |
| ac | 0.01-0.09 (6) | 0.77-0.91 (144) | 0.06-0.19 (19) |
| bc | 0.02-0.02 (2326) | 0.77-0.77 (87215) | 0.21-0.21 (23612) |
| cc | 0.02-0.02 (1008) | 0.43-0.44 (22527) | 0.54-0.55 (27919) |
Table 3
Table 3 again lists the estimated probabilities of observing a, b or c as the next endpoint in a session, but given knowledge of 2 immediately preceding endpoints in the session (instead of 1 immediately preceding endpoint as before). That is, the 3rd row cell with interval 0.09-0.13 means that given knowledge of immediately preceding endpoints ca, the probability of observing a as the next endpoint has a credible interval spanning 9% and 13%, regardless of whether ca was preceded by any endpoints. In parlance, we say that the above table represents a Markov chain of order 2. This is because the entries in the table represent probabilities of observing the next endpoint, given knowledge of 2 immediately preceding endpoints as context.
As a special case, the Markov chain of order 0 simply represents the distribution over endpoints in a session. We can tabulate the probabilities as follows, in relation to a single row corresponding to an ‘empty context’:
| Known preceding endpoints in the session | Estimated probability of next endpoint in the session | ||
| a | b | c | |
| 0.03-0.03 (15466) | 0.64-0.65 (328732) | 0.32-0.33 (165117) |
Table 4
Note that the probabilities in Table 4 do not solely represent the case where there were no preceding endpoints in the session. Rather, the probabilities are for the occurrence of endpoints in the session, for the general case where we have no knowledge of the preceding endpoints and regardless of how many endpoints previously occurred.
Returning to our task of identifying important sequences, one possible approach might be to simply use a Markov chain of some fixed order N. For example, if we were to apply a threshold of 0.85 to the lower bounds of credible intervals in Table 3, we’d retain 3 sequences in total. On the other hand, this approach comes with two noteworthy limitations:
-
We need a way to select a suitable value for the model order N.
-
Since the model order remains fixed, identified sequences all have the same length N+1.
Variable order Markov chains
Variable order Markov chains (VOMCs) are a more powerful extension of the described fixed-order Markov chains which address the preceding limitations. VOMCs make use of the fact that for some chosen value of the Markov chain of fixed order N, the probability table might include statistically redundant information: Let’s compare Tables 3 and 2 above and consider in Table 3 the rows in boldface corresponding to contexts aa, ba, ca (these 3 contexts all share a as their suffix).
For all the 3 possible next endpoints a, b, c, these rows specify credible intervals which overlap with their respective estimates in Table 2 corresponding to context a (also indicated in boldface). We can interpret these overlapping intervals as representing no discernible difference between probability estimates, given knowledge of a as the preceding endpoint. With no discernible effect of what preceded a on the probability of the next endpoint, we can consider these 3 rows in Table 3 redundant: We may ‘collapse’ them by replacing them with the row in Table 2 corresponding to context a.
The result of revising Table 3 as described looks as follows (with the new row indicated in boldface):
| Known preceding endpoints in the session | Estimated probability of next endpoint in the session | ||
| a | b | c | |
| a | 0.09-0.11 (1555) | 0.88-0.89 (13718) | 0.01-0.01 (169) |
| ab | 0.02-0.02 (272) | 0.56-0.58 (7823) | 0.40-0.42 (5604) |
| ac | 0.03-0.03 (6067) | 0.60-0.60 (122796) | 0.37-0.37 (75801) |
| bb | 0.03-0.03 (3279) | 0.68-0.68 (74449) | 0.29-0.29 (31960) |
| bc | 0.01-0.09 (6) | 0.77-0.91 (144) | 0.06-0.19 (19) |
| cb | 0.02-0.02 (2326) | 0.77-0.77 (87215) | 0.21-0.21 (23612) |
| cc | 0.02-0.02 (1008) | 0.43-0.44 (22527) | 0.54-0.55 (27919) |
Table 5
Table 5 represents a VOMC, because the context length varies: In the example, we have context lengths 1 and 2. It follows that entries in the table represent sequences of length varying between 2 and 3 endpoints, depending on context length. Generalizing the described approach of collapsing contexts leads to the following algorithm sketch for learning a VOMC in an offline setting:
(1) Define the table T containing the estimated probability of the next endpoint in a session, given alternatively 0, 1, 2, …, N_max preceding endpoints in the session. That is, form a single table by concatenating the rows corresponding to Markov chains of fixed orders 0, 1, 2, …, N_max.
(2) is_modified := true
(3) DO WHILE is_modified
(4) D := all contexts in T which are not suffixes of at least 1 other context in T
(5) is_modified = false
(6) FOR ctx IN C
(7) IF length(ctx) > 0
(8) parent_ctx := the context obtained by deleting the leftmost endpoint in ctx
(9) IF is_collapsible(ctx, parent_ctx)
(10) Modify T by discarding ctx
(11) is_modified = true
In the pseudo-code, length(ctx) is the length of context ctx. On line 9, is_collapsible() involves comparing credible intervals for the contexts ctx and parent_ctx in the manner described for generating Table 5: is_collapsible() evaluates to true, if and only if we observe that all credible intervals overlap, when comparing contexts ctx and parent_ctx separately for each of the possible next endpoints. The maximum sequence length is N_max+1, where N_max is some constant. On line 4, we say that context q is a suffix of another context p if we can form p by prepending zero or more endpoints to q. (According to this definition, the ‘empty context’ mentioned above for the order 0 model is a suffix of all contexts in T.) The above algorithm sketch is a variant of the ideas first introduced by Rissanen [1], Ron et al. [2].
Finally, we take the entries in the resulting table T as our important sequences. Thus, the result of applying VOMCs is a set of sequences that we deem important. For Sequence Analytics however, we believe that it is additionally useful to rank sequences. We do this by computing a ‘precedence score’ between 0.0 and 1.0, which is the number of occurrences of the sequence divided by the number of occurrences of the last endpoint in the sequence. Thus, precedence scores close to 1.0 indicate that a given endpoint is nearly always preceded by the remaining endpoints in the sequence. In this way, manual inspection of the highest-scoring sequences is a semi-automated heuristic for creating precedence rules in our Sequence Mitigation product.
Learning sequences at scale
The preceding represents a very high-level overview of the statistical ML techniques that we use in Sequence Analytics. In practice, we have devised an efficient algorithm which does not require an upfront training step, but rather updates the model continuously as the data arrive and generates a frequently-updating summary of important sequences. This approach allows us to overcome additional challenges around memory cost not touched on in this blog post. Most significantly, a straightforward implementation of the algorithm sketch above would still result in the number of table rows (contexts) exploding with increasing maximum sequence length. A further challenge we had to address is how to ensure that our system is able to deal with high-volume APIs, without adversely impacting CPU load. We use a horizontally scalable adaptive sampling strategy upfront, such that more aggressive sampling is applied to high-volume APIs. Our algorithm then consumes the sampled streams of API requests. After a customer onboards, sequences are assembled and learned over time, so that the current summary of important sequences represents a sliding window with a look-back interval of approximately 24 hours. Sequence Analytics further stores sequences in Clickhouse and exposes them via a GraphQL API and via the Cloudflare dashboard. Customers who would like to enforce sequence rules can do so using Sequence Mitigation. Sequence Mitigation is what is responsible for ensuring that rules are shared and matched in distributed fashion on Cloudflare’s global network — another exciting topic for a future blog post!
What’s next
Now that you have a better understanding of how we surface important API request sequences, stay tuned for a future blog post in this series, where we’ll describe how we find the anomalous API request sequences that customers may want to stop. For now, API Gateway customers can get started in two ways: with Sequence Analytics to explore important API request sequences and with Sequence Mitigation to enforce sequences of API requests. Enterprise customers that haven’t purchased API Gateway can get started by enabling the API Gateway trial inside the Cloudflare Dashboard or contacting their account manager.
School Lunch: Last Week Tonight with John Oliver (HBO)
Post Syndicated from LastWeekTonight original https://www.youtube.com/watch?v=-YypArYDcjA
Zabbix for MSPs with Andre Morton
Post Syndicated from Michael Kammer original https://blog.zabbix.com/zabbix-for-msps-with-andre-morton/28748/
To help make sure that everyone’s up to speed with Zabbix Summit 2024 speakers and their topics, we’re continuing our series of interviews with Andre Morton of AGM Network Consultancy LTD. Keep reading to learn how he feels Zabbix can alleviate the typical pain points of managed service providers (MSPs), see how he uses Zabbix to maintain control of his network, and find out what he appreciates most about Zabbix.
Please tell us a bit about yourself and the journey that led you to AGM Network Consultancy LTD.
I started out studying Network Engineering at the University of Greenwich, and then went on to undertake a Masters of Networks and Security at the University of Kent. During my Masters, I was the a one-man IT Team for a Child Care agency spanning the UK. I then went on to work at three small IT companies/MSPs, being the only Network Engineer at each company and managing networks with 80 – 200 customers.
How long have you been using Zabbix? How has it impacted your everyday tasks?
I have been using Zabbix for about 10 years now. At first, I just used it to get insights via SNMP. Then I began using it to create visual troubleshooting aids for myself and non-networking team members. Finally, I began using Zabbix as my main inventory gathering tool for networking and infrastructure devices. When it comes to that, Zabbix has enabled me to control how I want to monitor the network, avoiding vendor limitations and allowing me to build my own scripts to run tests and actions that I would not otherwise be able to do.
Can you give us a few clues about what we can expect to hear during your Zabbix Summit presentation?
I may have to condense some things, as I don’t want to be too technical or take too long! I’ll definitely talk about what drew me to Zabbix, how I used Zabbix to turn problems that require a large amount of attention and time into scripts that can identify the problems and capture the problem states, and how Zabbix dashboards help me to get a clear overview of customer and site problems/general status. I’ll also speak about scripts that we now use to troubleshoot and undertake remote actions, give examples of what the value of the monitoring data is to MSPs before and after the problem, and let everyone in on my upcoming plans for Zabbix, which include webhooks from the map, scripts; Zabbix’s place in our bespoke systems, and network automation.
What, in your opinion, are the biggest pain points MSPs have, and how can Zabbix help alleviate them?
I’d say that there are two big pain points that Zabbix is of assistance with – providing troubleshooting time for big problems, and making sure that historical data is ready for troubleshooting.
What do you appreciate the most about Zabbix in your role?
Zabbix allows me to drastically reduce the amount of administration and troubleshooting that I have to undertake and provides a live inventory of devices (software/firmware details). Thanks to Zabbix, I don’t have to use multiple tools or log into multiple devices to get software and firmware version details.
The post Zabbix for MSPs with Andre Morton appeared first on Zabbix Blog.
Comic for 2024.09.12 – Til Death
Post Syndicated from Explosm.net original https://explosm.net/comics/til-death
New Cyanide and Happiness Comic
На север: Острови от вълна сред вълните на Атлантика (втора част)
Post Syndicated from Светла Стоянова original https://www.toest.bg/na-sever-ostrovi-ot-vulna-sred-vulnitie-na-atlantika-vtora-chast/

Освен с овцете, вълната и пуловерите, през последните години Фарьорските острови стават известни и със своите иновативни идеи: някои от тях инфраструктурни, предвид особеното им географско местоположение, други – творчески, забавни и едновременно полезни.
Фарьорските острови са самоуправляваща се област в рамките на Кралство Дания, но отдалечени на около 1100 км северозападно от него. Парламентът им е един от най-старите в света, водещ началото си от заселването на островите през IX век. Нарича се Льогтинг, в буквален превод Събрание за закони, и в днешно време има 33 членове. С територия от едва 1400 км² и население от 54 320 души (към 2023 г.) Фарьорските острови постигат скоростно развитие през последните няколко десетилетия – от бедна страна с множество малки селца се превръща в модерно и напредничаво общество.


Сградите на Парламента; типична фарьорска църква © Светла Стоянова
Заради стратегическото им географско разположение във водите между Европа и Северна Америка, Фарьорските острови са военна база на британските и американските войници през Втората световна война. Макар и да звучи парадоксално, войната дава възможност за развитие, тъй като новозаселилите се войници строят летища, пътища и инфраструктура. Днес стандартът на живот е висок, а страната притежава международна фериботна линия, свързваща островите с Дания и Исландия, самостоятелна авиолиния с полети до осем страни и дори ресторант, получил две звезди „Мишлен“.
В миналото придвижването ставало предимно пеша или по вода, като почти всяко семейство разполагало с лодка. С построяването на все повече пътища автомобилите постепенно изместват водния транспорт и от риболовна нация, която разчита на улова за прехраната си, фарьорците се превръщат във все по-модерно и глобализирано общество. Някои хора днес казват, че с изоставянето на лодките си отива и цяло едно знание за плаването, риболова и всички традиции, предавани от поколение на поколение.
Младите днес често не умеят да пускат плавателен съд по вода, да се справят в бурно море или да разпознават рибите.
С развитието на пътищата през ХХ век са построени и много еднолентови тунели, за да се съкрати обиколният морски път от единия край на острова до другия. Днес тунелите наброяват повече от самите острови, на някои места има дори по два тунела един до друг – стария, тесен и мрачен, и новия, просторен и яркоосветен. Пътищата са модерни и поддържани, а тунелите минават през фиорди и през планини, за да свържат отдалечените острови и по-труднодостъпните им селища.


Малко село на брега на морето © Светла Стоянова
През 2020 г. е отворен първият в света едновременно планински и подводен тунел с три различни отсечки, които са свързани в кръгово движение под водата.
Дълъг 11 км, тунелът преминава неусетно от планински в подводен, достигайки дълбочина до 187 м под морското равнище. Тъй като според фарьорците всяко място може да бъде подходящо за изкуство, центърът на кръговото е осветен в различни цветове и е опасан от художествена творба – скулптурна група от човешки силуети, хванати за ръце, напомнящи обединеността на народа.
Все пак част от градския транспорт още се осъществява и по море с редовни фериботи, но в случай че вълнението на океана не го позволява, се пътува и по въздух – с хеликоптери като междуостровен транспорт. Всеки хеликоптер може да поеме до 12 пътници и пътуването е кратко, но с живописна гледка към зелените планини отвисоко. Цените са достъпни, защото пътуването по въздух не се въприема като луксозно удоволствие, а като обикновено средство за придвижване, когато се налага.



Фарьорски къщи © Светла Стоянова
Устойчиви както на суровото време, така и на чуждите влияния, фарьорците са задружни и едновременно с това се обръщат с топлина и любопитство към другите.
Вероятно малкият им брой е предпоставка за повече изява, което, от своя страна, ги кара да чувстват отговорност към обществото и да вярват, че могат да повлияят за промяна към по-добро. Въпреки честата миграция към Дания, много млади хора предпочитат да останат, защото осъзнават, че гласът им ще бъде чут и ще могат да допринесат с нещо за развитието на родното си място.
Освен това
фарьорците се превръщат в един от най-бързо увеличаващите се народи в Европа – близо три пъти за последните сто години.
Много силна е вярата им, че именно те са най-ценният ресурс на страната, защото дори и природните дадености да се изчерпят, хората са онези, които ще намерят и друг начин за оцеляване. Чрез сътрудничеството помежду им се гради по-доброто бъдеще – съединението прави силата, ама по фарьорски.
Освен обединени, фарьорците неведнъж се доказват и като изобретателни и стават известни със забележителните си идеи за развитието на туризма. Пример за това е едно необичайно събитие – ежегодно островите „затварят“ за туристи и „отварят“ за доброволци, които подобряват туристическата инфраструктура. Събитието е национален проект, наречен Closed for Maintenance, Open for Voluntourism („Затворено поради ремонт, отворено за доброволчество“).
Кандидатите от цял свят са избирани на случаен принцип в началото на всяка година. За няколко дни те извършват разнообразни дейности навън: обозначават и облагородяват туристически пътеки на труднодостъпни места, изграждат площадки за красиви гледки и закачат вериги към скалите на потенциално хлъзгави терени. В замяна на работата си те получават подслон в различни селища, както и топла храна по време на престоя си. Участниците работят с ентусиазъм и създават по-добри условия за туризма на островите, но също приятелства и мили спомени.
Започнала като експеримент през 2019 г., инициативата се приема отлично и става традиция. Един от участниците сподели, че проектът наистина има смисъл – доброволците са доволни да поработят навън в прекрасната природа и същевременно с това да свършат нещо наистина полезно.
Trump, Triggered
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=2DQDEjQYwx4
[$] LWN.net Weekly Edition for September 12, 2024
Post Syndicated from corbet original https://lwn.net/Articles/988984/
The LWN.net Weekly Edition for September 12, 2024 is available.
Hurricane Francine Live Stream Rolled into Home Automation & Tech Mix
Post Syndicated from digiblur DIY original https://www.youtube.com/watch?v=L4FdVKWi4BA
Crash at Crush, 1896
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=hP-ATM0VerA
2024.9 Release Highlights #homeassistant #homeautomation #smarthome
Post Syndicated from Home Assistant original https://www.youtube.com/watch?v=WwJTxijPsec
Hands Across the Pacific
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=Kh83DqO1vMc