Post Syndicated from Debu Panda original https://aws.amazon.com/blogs/big-data/integrate-tableau-and-microsoft-entra-id-with-amazon-redshift-using-aws-iam-identity-center/
This post is co-written with Sid Wray, Jade Koskela, and Ravi Bhattiprolu from SalesForce.
Amazon Redshift and Tableau empower data analysis. Amazon Redshift is a cloud data warehouse that processes complex queries at scale and with speed. Its advanced query optimization serves results to Tableau. Tableau’s extensive capabilities and enterprise connectivity help analysts efficiently prepare, explore, and share data insights company-wide.
Customers can integrate Amazon Redshift with Tableau using single sign-on (SSO) capabilities enabled by AWS IAM Identity Center integration with trusted identity propagation. You can use this to seamlessly implement authentication with third-party identity providers (IdP) and authorization with Redshift. It positions Amazon Redshift as an AWS managed application, allowing you to take full advantage of the trusted identity propagation feature.
Amazon Web Services (AWS) collaborated with Tableau to enable SSO support for accessing Amazon Redshift from Tableau. Both Tableau Desktop 2023.3.9 and Tableau Server 2023.3.9 releases support trusted identity propagation with IAM Identity Center. This SSO integration is available for Tableau Desktop, Tableau Server, and Tableau Prep.
This blog post provides a step-by-step guide to integrating IAM Identity Center with Microsoft Entra ID as the IdP and configuring Amazon Redshift as an AWS managed application. Additionally, you’ll learn how to set up the Amazon Redshift driver in Tableau, enabling SSO directly within Tableau Desktop.
Solution overview
The following diagram illustrates the architecture of the Tableau SSO integration with Amazon Redshift, IAM Identity Center, and Microsoft Entra ID.
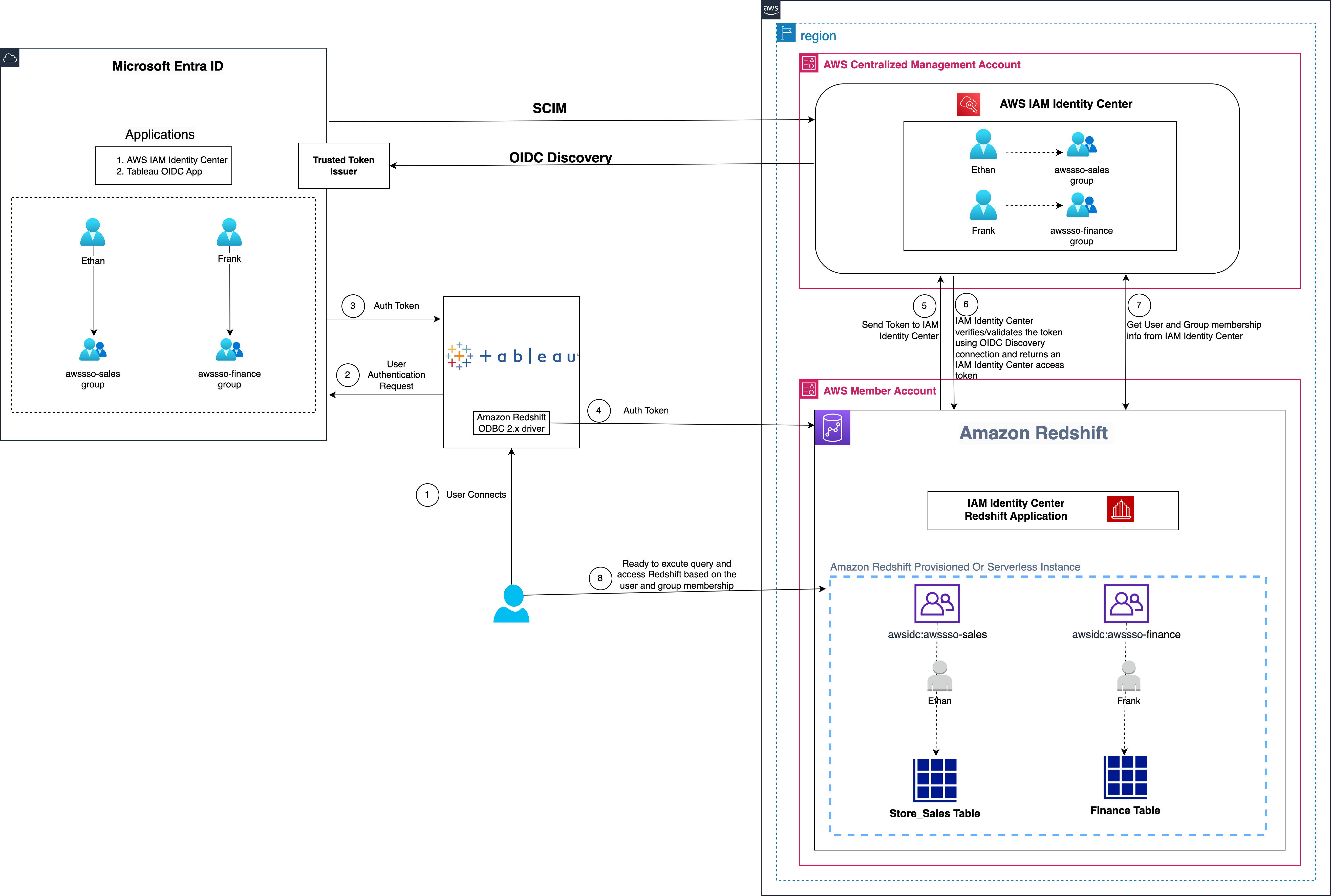
Figure 1: Solution overview for Tableau integration with Amazon Redshift using IAM Identity Center and Microsoft Entra ID
The solution depicted in Figure 1 includes the following steps:
- The user configures Tableau to access Amazon Redshift using IAM Identity Center.
- On a user sign-in attempt, Tableau initiates a browser-based OAuth flow and redirects the user to the Microsoft Entra ID sign-in page to enter the sign-in credentials.
- After successful authentication, Microsoft Entra ID issues authentication tokens (ID and access token) to Tableau.
- The Amazon Redshift driver then makes a call to the Amazon Redshift-enabled Identity Center application and forwards the access token.
- Amazon Redshift passes the token to IAM Identity Center for validation.
- IAM Identity Center first validates the token using the OpenID Connect (OIDC) discovery connection to the trusted token issuer (TTI) and returns an IAM Identity Center generated access token for the same user. In Figure 1, the TTI is the Microsoft Entra ID server.
- Amazon Redshift then uses the access token to obtain the user and group membership information from Identity Center.
- The Tableau user will be able to connect with Amazon Redshift and access data based on the user and group membership returned from IAM Identity Center.
Prerequisites
Before you begin implementing the solution, you must have the following in place:
- Set up IAM Identity Center and Amazon Redshift integration by following the steps in Integrate Identity Provider (IdP) with Amazon Redshift Query Editor V2 using AWS IAM Identity Center for seamless Single Sign-On.
- Download and install the latest ODBC 2.X Driver.
- Install Tableau Desktop 2023.3.9 or above version.
- Install Tableau Server 2023.3.9 or above version. For Tableau Server installation, see Install and Configure Tableau Server.
- Use an Entra ID account that has an active subscription. You need an admin role to set up the application on Entra ID. If you don’t have an Entra ID account, you can create an account for free.
Walkthrough
In this walkthrough, you will use the following steps to build the solution:
- Set up the Microsoft Entra ID OIDC application
- Collect Microsoft Entra ID information
- Set up a trusted token issuer in IAM Identity Center
- Set up client connections and trusted token issuers
- Set up the Tableau OAuth config files for Microsoft Entra ID
- Install the Tableau OAuth config file for Tableau Desktop
- Set up the Tableau OAuth config file for Tableau Server or Tableau Cloud
- Federate to Amazon Redshift from Tableau Desktop
- Federate to Amazon Redshift from Tableau Server
Set up the Microsoft Entra ID OIDC application
To create your Microsoft Entra application and service principal, follow these steps:
- Sign in to the Microsoft Entra admin center as Cloud Application Administrator (at the least).
- Browse to App registrations under Manage, and choose New registration.
- Enter a name for the application. For example,
Tableau-OIDC-App. - Select a supported account type, which determines who can use the application. For this example, select the first option in the list.
- Under Redirect URI, select Web for the type of application you want to create. Enter the URI where the access token is sent to. In this example, you’re using localhost, so enter http://localhost:55556/Callback and http://localhost/auth/add_oauth_token.
- Choose Register.
- In the navigation pane, choose Certificates & secrets.
- Choose New client secret.
- Enter a Description and select an expiration for the secret or specify a custom lifetime. For this example, keep the Microsoft recommended default expiration value of 6 months. Choose Add.
- Copy the secret value.
Note: It will only be presented one time; after that you cannot read it. - In the navigation pane, under Manage, choose Expose an API.
- If you’re setting up for the first time, you can see Set to the right of Application ID URI.
- Choose Set, and then choose Save.
- After the application ID URI is set up, choose Add a scope.
- For Scope name, enter a name. For example,
redshift_login. - For Admin consent display name, enter a display name. For example,
redshift_login. - For Admin consent description, enter a description of the scope.
- Choose Add scope.
For more information about setting up the Microsoft Entra app, see Register a Microsoft Entra app and create a service principal.
Collect Microsoft Entra ID information
To configure your IdP with IAM Identity Center and Amazon Redshift, collect the following parameters from Microsoft Entra ID. If you don’t have these parameters, contact your Microsoft Entra ID admin.
- Tenant ID,Client ID and Audience value: To get these values:
- Sign in to the Azure portal with your Microsoft account.
- Under Manage, choose App registrations.
- Choose the application that you created in previous sections.
- On the left panel, choose Overview, a new page will appear containing the Essentials section. You can find the Tenant ID,Client ID and Audience value (Application ID URI) as shown in the following figure:

Figure 2: Overview section of OIDC application

- Scope: To find your scope value:
- In the navigation pane of the OIDC application, under Manage, choose Expose an API.
- You will find the value under Scopes as shown in the following figure:

Figure 3: Application scope

Set up a trusted token issuer in IAM Identity Center
At this point, you have finished configurations in the Entra ID console; now you’re ready to add Entra ID as a TTI. You will start by adding a TTI so you can exchange tokens. In this step, you will create a TTI in the centralized management account. To create a TTI, follow these steps:
- Open the AWS Management Console and navigate to IAM Identity Center, and then to the Settings
- Select the Authentication tab and under Trusted token issuers, choose Create trusted token issuer.
- On the Set up an external IdP to issue trusted tokens page, under Trusted token issuer details, do the following:
- For Issuer URL, enter the OIDC discovery URL of the external IdP that will issue tokens for trusted identity propagation. The URL would be:
https://sts.windows.net/<tenantid>/. To find your Microsoft Entra tenant ID, see Collect Microsoft Entra ID information. - For Trusted token issuer name, enter a name to identify this TTI in IAM Identity Center and in the application console.
- Under Map attributes, do the following:
- For Identity provider attribute, select an attribute from the list to map to an attribute in the Identity Center identity store. You can choose Email, Object Identifier, Subject, and Other. This example uses Other where we’re specifying the upn (user principal name) as the Identity provider attribute to map with Email from the IAM identity Center attribute.
- For IAM Identity Center attribute, select the corresponding attribute for the attribute mapping.
- Under Tags (optional), choose Add new tag, specify a value for Key, and optionally for Value. For information about tags, see Tagging AWS IAM Identity Center resources.
- For Issuer URL, enter the OIDC discovery URL of the external IdP that will issue tokens for trusted identity propagation. The URL would be:
Figure 4 that follows shows the set up for TTI.

Figure 4: Create a trusted token issuer
- Choose Create trusted token issuer.
Set up client connections and trusted token issuers
A third-party application (such as Tableau) that isn’t managed by AWS exchanges the external token (JSON Web Token (JWT) for an IAM Identity Center token before calling AWS services.
The JWT must contain a subject (sub) claim, an audience (aud) claim, an issuer (iss), a user attribute claim, and a JWT ID (JTI) claim. The audience is a value that represents the AWS service that the application will use, and the audience claim value must match the value that’s configured in the Redshift application that exchanges the token.
In this section, you will specify the audience claim in the Redshift application, which you will get from Microsoft Entra ID. You will configure the Redshift application in the member account where the Redshift cluster or serverless instance is.
- Select IAM Identity Center connection from Amazon Redshift console menu.

Figure 5: Redshift IAM Identity Center connection
- Select the Amazon Redshift application that you created as part of the prerequisites.
- Select the Client connections tab and choose Edit.
- Choose Yes under Configure client connections that use third-party IdPs.
- Select the checkbox for Trusted token issuer that you created in the previous section.
- Enter the aud claim value under Configure selected trusted token issuers. For example,
api://1230a234-b456-7890-99c9-a12345bcc123. To get the audience value, see Collect Microsoft Entra ID information. - Choose Save.

Figure 6: Adding an audience claim for the TTI
Your IAM Identity Center, Amazon Redshift, and Microsoft Entra ID configuration is complete. Next, you need to configure Tableau.
Set up the Tableau OAuth config files for Microsoft Entra ID
To integrate Tableau with Amazon Redshift using IAM Identity Center, you need to use a custom XML. In this step, you use the following XML and replace the values starting with the $ sign and highlighted in bold. The rest of the values can be kept as they are, or you can modify them based on your use case. For detailed information on each of the elements in the XML file, see the Tableau documentation on GitHub.
Note: The XML file will be used for all the Tableau products including Tableau Desktop, Server, and Cloud. You can use the following XML or you can refer to Tableau’s github.
The following is an example XML file:
Install the Tableau OAuth config file for Tableau Desktop
After the configuration XML file is created, it must be copied to a location to be used by Amazon Redshift Connector from Tableau Desktop. Save the file from the previous step as .xml and save it under Documents\My Tableau Repository\OAuthConfigs.
Note: Currently, this integration isn’t supported in macOS because the Redshift ODBC 2.X driver isn’t supported yet for MAC. It will be supported soon.
Set up the Tableau OAuth config file for Tableau Server or Tableau Cloud
To integrate with Amazon Redshift using IAM Identity Center authentication, you must install the Tableau OAuth config file in Tableau Server or Tableau Cloud.
- Sign in to the Tableau Server or Tableau Cloud using admin credentials.
- Navigate to Settings.
- Go to OAuth Clients Registry and select Add OAuth Client
- Choose following settings:
- Connection Type: Amazon Redshift
- OAuth Provider: Custom_IdP
- Client Id: Enter your IdP client ID value
- Client Secret: Enter your client secret value
- Redirect URL: Enter
http://localhost/auth/add_oauth_token. This example uses localhost for testing in a local environment. You should use the full hostname with https. - Choose OAuth Config File. Select the XML file that you configured in the previous section.
- Select Add OAuth Client and choose Save.

Figure 7: Create an OAuth connection in Tableau Server or Cloud
Federate to Amazon Redshift from Tableau Desktop
Now you’re ready to connect to Amazon Redshift from Tableau as an Entra ID federated user. In this step, you create a Tableau Desktop report and publish it to Tableau Server.
- Open Tableau Desktop.
- Select Amazon Redshift Connector and enter the following values:
- Server: Enter the name of the server that hosts the database and the name of the database you want to connect to.
- Port: Enter 5439.
- Database: Enter your database name. This example uses dev.
- Authentication: Select OAuth.
- Federation Type: Select Identity Center.
- Identity Center Namespace: You can leave this value blank.
- OAuth Provider: This value should automatically be pulled from your configured XML. It will be the value from the element
oauthConfigId. - Select Require SSL.
- Choose Sign in.

Figure 8: Tableau Desktop OAuth connection

- Enter your IdP credentials in the browser pop-up window.

Figure 9: Microsoft Entra sign in page
- When authentication is successful, you will see the message shown in Figure 10 that follows.

Figure 10: Successful authentication using Tableau


Congratulations! You’re signed in using the IAM Identity Center integration with Amazon Redshift. Now you’re ready to explore and analyze your data using Tableau Desktop.

Figure 11: Successful connection using Tableau Desktop
After signing in, you can create your own Tableau Report on the desktop version and publish it to your Tableau Server. For this example, we created and published a report named SalesReport.
Federate to Amazon Redshift from Tableau Server
After you have published the report from Tableau Desktop to Tableau Server, sign in as a non-admin user and view the published report (SalesReport in this example) using IAM Identity Center authentication.
- Sign in to the Tableau Server site as a non-admin user.
- Navigate to Explore and go to the folder where your published report is stored.
- Select the report and choose Sign In.

Figure 12: User audit in sys_query_history
- To authenticate, enter your non-admin Microsoft Entra ID (Azure) credentials in the browser pop-up.
Figure 13: Tableau Server sign In
- After your authentication is successful, you can access the report.

Figure 14: Tableau report


Verify user identity from Amazon Redshift
As an optional step, you can audit the federated IAM Identity Center user from Amazon Redshift.
Figure 15 is a screenshot from the Amazon Redshift system table (sys_query_history) showing that user Ethan from Microsoft Entra ID is accessing the sales report.

Figure 15: User audit in sys_query_history
Clean up
Complete the following steps to clean up your resources:
- Delete the IdP applications that you created to integrate with IAM Identity Center.
- Delete the IAM Identity Center configuration.
- Delete the Amazon Redshift application and the Amazon Redshift provisioned cluster or serverless instance that you created for testing.
- Delete the AWS Identity and Access Management (IAM) role and IAM policy that you created as part of the prerequisites for IAM Identity Center and Amazon Redshift integration.
- Delete the permission set from IAM Identity Center that you created for Amazon Redshift Query Editor V2 in the management account.
Conclusion
This post explored a streamlined approach to access management for data analytics by using Tableau’s support for OIDC for SSO. The solution facilitates federated user authentication, where user identities from an external IdP are trusted and propagated to Amazon Redshift. You learned how to configure Tableau Desktop and Tableau Server to seamlessly integrate with Amazon Redshift using IAM Identity Center for SSO. By harnessing this integration between a third-party IdP and IAM Identity Center, users can securely access Amazon Redshift data sources within Tableau without managing separate database credentials.
The following are key resources to learn more about Amazon Redshift integration with IAM Identity Center:
- Connect Redshift with IAM Identity Center
- Integrate Identity Provider (IdP) with Amazon Redshift Query Editor V2 and SQL Client using AWS IAM Identity Center for seamless Single Sign-On
- Integrate Tableau and Okta with Amazon Redshift using AWS IAM Identity Center
- Simplify access management with Amazon Redshift and AWS Lake Formation
- Set up cross-account AWS Glue Data Catalog access using AWS Lake Formation and AWS IAM Identity Center with Amazon Redshift and Amazon QuickSight
About the Authors
 Debu Panda is a Senior Manager, Product Management at AWS. He is an industry leader in analytics, application platform, and database technologies, and has more than 25 years of experience in the IT world.
Debu Panda is a Senior Manager, Product Management at AWS. He is an industry leader in analytics, application platform, and database technologies, and has more than 25 years of experience in the IT world.
 Sid Wray is a Senior Product Manager at Salesforce based in the Pacific Northwest with nearly 20 years of experience in Digital Advertising, Data Analytics, Connectivity Integration and Identity and Access Management. He currently focuses on supporting ISV partners for Salesforce Data Cloud.
Sid Wray is a Senior Product Manager at Salesforce based in the Pacific Northwest with nearly 20 years of experience in Digital Advertising, Data Analytics, Connectivity Integration and Identity and Access Management. He currently focuses on supporting ISV partners for Salesforce Data Cloud.
 Adiascar Cisneros is a Tableau Senior Product Manager based in Atlanta, GA. He focuses on the integration of the Tableau Platform with AWS services to amplify the value users get from our products and accelerate their journey to valuable, actionable insights. His background includes analytics, infrastructure, network security, and migrations.
Adiascar Cisneros is a Tableau Senior Product Manager based in Atlanta, GA. He focuses on the integration of the Tableau Platform with AWS services to amplify the value users get from our products and accelerate their journey to valuable, actionable insights. His background includes analytics, infrastructure, network security, and migrations.
 Jade Koskela is a Principal Software Engineer at Salesforce. He has over a decade of experience building Tableau with a focus on areas including data connectivity, authentication, and identity federation.
Jade Koskela is a Principal Software Engineer at Salesforce. He has over a decade of experience building Tableau with a focus on areas including data connectivity, authentication, and identity federation.
 Harshida Patel is a Principal Solutions Architect, Analytics with AWS.
Harshida Patel is a Principal Solutions Architect, Analytics with AWS.
 Maneesh Sharma is a Senior Database Engineer at AWS with more than a decade of experience designing and implementing large-scale data warehouse and analytics solutions. He collaborates with various Amazon Redshift Partners and customers to drive better integration.
Maneesh Sharma is a Senior Database Engineer at AWS with more than a decade of experience designing and implementing large-scale data warehouse and analytics solutions. He collaborates with various Amazon Redshift Partners and customers to drive better integration.
 Ravi Bhattiprolu is a Senior Partner Solutions Architect at AWS. He collaborates with strategic independent software vendor (ISV) partners like Salesforce and Tableau to design and deliver innovative, well-architected cloud products, integrations, and solutions to help joint AWS customers achieve their business goals.
Ravi Bhattiprolu is a Senior Partner Solutions Architect at AWS. He collaborates with strategic independent software vendor (ISV) partners like Salesforce and Tableau to design and deliver innovative, well-architected cloud products, integrations, and solutions to help joint AWS customers achieve their business goals.



 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike. Gyan Radhakrishnan is a Software Development Engineer on the AWS Glue team. He is working on designing and building end-to-end solutions for data intensive applications.
Gyan Radhakrishnan is a Software Development Engineer on the AWS Glue team. He is working on designing and building end-to-end solutions for data intensive applications. Simon Kern is a Software Development Engineer on the AWS Glue team. He is enthusiastic about serverless technologies, data engineering and building great services.
Simon Kern is a Software Development Engineer on the AWS Glue team. He is enthusiastic about serverless technologies, data engineering and building great services. Dana Adylova is a Software Development Engineer on the AWS Glue team. She is working on building software for supporting data intensive applications. In her spare time, she enjoys knitting and reading sci-fi.
Dana Adylova is a Software Development Engineer on the AWS Glue team. She is working on building software for supporting data intensive applications. In her spare time, she enjoys knitting and reading sci-fi. Matt Su is a Senior Product Manager on the AWS Glue team. He enjoys helping customers uncover insights and make better decisions using their data with AWS Analytic services. In his spare time, he enjoys skiing and gardening.
Matt Su is a Senior Product Manager on the AWS Glue team. He enjoys helping customers uncover insights and make better decisions using their data with AWS Analytic services. In his spare time, he enjoys skiing and gardening.