Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=4PhOyp4LdzU
Yearly Archives: 2024
Naughty Or Nice with Steph Pham – New Art Photography Course 😈 👸🏻
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=34A4IGD7JW4
Detecting Pegasus Infections
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/12/detecting-pegasus-infections.html
This tool seems to do a pretty good job.
The company’s Mobile Threat Hunting feature uses a combination of malware signature-based detection, heuristics, and machine learning to look for anomalies in iOS and Android device activity or telltale signs of spyware infection. For paying iVerify customers, the tool regularly checks devices for potential compromise. But the company also offers a free version of the feature for anyone who downloads the iVerify Basics app for $1. These users can walk through steps to generate and send a special diagnostic utility file to iVerify and receive analysis within hours. Free users can use the tool once a month. iVerify’s infrastructure is built to be privacy-preserving, but to run the Mobile Threat Hunting feature, users must enter an email address so the company has a way to contact them if a scan turns up spyware—as it did in the seven recent Pegasus discoveries.
В битката за власт спечелиха овцете
Post Syndicated from Емилия Милчева original https://www.toest.bg/v-bitkata-za-vlast-specheliha-ovtsete/

Единствените печеливши от политическата криза, разнебитила държавата, са малко над 1700 овце във Велинградско, които трябваше да бъдат принудително умъртвени заради положителни проби за чума по дребните преживни животни. Сега ще си мрат под карантина. Или пък няма да мрат и ще продължат да раждат агнета, а институциите ще продължат да се разпадат под тежестта на политическата нестабилност.
Докато партиите се боричкат за власт и всички са вторачени в поредния епизод от сагата „Кой ще е следващият премиер“, овцете във Велинградско живеят необезпокоявани – сякаш са получили специален имунитет от бюрокрацията.
Иронията при овцете е, че не толкова силата на местните фермери или аргументите им срещу лабораторните резултати спасиха кожите на тия дребни преживни животни, а простият факт, че системата на държавността е толкова парализирана, че няма кой да изпълни заповедта.
Всъщност не смее.
Под страх от вдигане на градуса на напрежение служебният министър на МВР Атанас Илков и на земеделието и храните Георги Тахов предпочетоха да избегнат сблъсъци и избраха половинчато решение. Овцете останаха живи, а фермата – под карантина. Решението им бе резултат не от консенсус, а от страха от ескалация и пълния разпад на доверието в институциите.
МВР се страхува от сигурни сблъсъци
Повече от две седмици Министерството на земеделието и храните (МЗХ) и Българската агенция за безопасност на храните (БАБХ) се опитват да убедят фермерите на стадата, за които има вече две положителни проби, че животните трябва да се евтаназират, за да не се допусне разпространение на заразата, а те ще бъдат компенсирани. За 1760 овце бяха обещани над 700 000 лв. „Наддаването“ приближи 1 млн. лв., но стопаните не се съгласиха. На помощ им се притекоха хора от различни краища на България, които образуваха жива верига около животновъдното стопанство и не допуснаха държавни ветеринари и какъвто и да било представител на държавата.
Тя отстъпи пред напора на гражданския протест, макар да е действала със сила при други в центъра на София, но при управлението на редовно правителство.
Няма да се умъртвяват животни от фермата във Велинград, за които имаше информация, че са болни от чума, съобщиха съвместно от МЗХ и МВР. Стопанството остава под карантина, въвеждат се временни мерки за ограничаване на движението на дребни преживни животни от и към област Пазарджик.
Ако МВР се беше опитало да влезе, охранявайки екипите на БАБХ с мобилни инсинератори, сблъсъкът и окървавяването на протеста бяха неизбежни. Протестиращите срещу евтаназията на стадото, сред които има и животновъди, и енергетици от „Марица-изток“, в действителност осъществиха гражданско неподчинение.
Протестът им е символ на недоверието към институциите и тяхната неспособност да действат прозрачно и компетентно. Нито БАБХ, нито МВР се ползват с особено обществено доверие – не само заради частната лаборатория, която владееше контрола на ГКПП Капитан Андреево, тоест входа и изхода на ЕС към Азия, не само заради опорочените избори, но и заради куп други афери.
„Величие“ – при овцете, също и „Единение“
А на снежния разкалян терен в Родопите пред фермите се появиха с мегафони и телефони в ръце активисти на „Величие“ – партията, на която не достигнаха по-малко от 30 гласа, за да прескочи бариерата за влизане в парламента. Сега очаква Конституционният съд да я „пусне“ след жалбите за частично касиране на изборите.
Най-гласовитият сред тези „хора от народа“ е Йордан Мицкулев, самият той от Велинград, който излъчва непрекъснато в социалните мрежи. Сред последните му призиви във Facebook е, че свири сбор за непримиримите:
Всички са добре дошли на първия общонационален събор на НЕПРИМИРИМИТЕ, който ще се провежда всяка година на 07.12 на поляните пред фермата на бай Рибан.
Носете със себе си гайди, тъпани, доброто си настроение и най-вече БЪЛГАРСКИЯ ДУХ.
Нека да покажем на целия свят, че в България има достатъчно борбени хора, които няма да приведат глава, пред мародерствата на новите ни поробители!*
Идеологът на „Величие“ Ивелин Михайлов се произнесе за Велинград, но не отиде на поляните с аргумента „да не се спекулира, че е протест на „Величие“. И направи рейд в Брюксел, където заяви, че мафията и корупцията са се сраснали, а лицата им са Пеевски и Борисов.
Три дни при протестиращите бе и бившият заместник-министър на земеделието Иван Христанов, регистрирал партия „Единение“. Според него министърът на земеделието Георги Тахов отишъл при протестиращите, за да им каже: „.. или вземате един милион и убиваме овцете, или ще пратим жандармерията и ще бъде отнето разрешението на животновъдните обекти.“ Запитан за слухове за контрабанден внос от собствениците на фермата във Велинградско на животни от Гърция (където допреди месец и половина върлуваше такава чума по дребните преживни животни), Христанов заяви в студиото на „Актуално“, че това означава, че БАБХ не си върши работата.
Всяка глава добитък трябва да има документ за произход, а през българските граници може да влезе всичко.
Може, щом на вратите им са правилните „пазачи“. Частната лаборатория, „уредена“ за ъндърграунд босове от същата тази БАБХ на ГКПП Капитан Андреево, потвърждава думите му. Самият Христанов като зам.-министър положи много усилия да бъде премахната оттам.
Политика на гърба на недоволството
Докато фермерите губят поминъка си, политици печелят – симпатии, подкрепа и ефирно време. Хората се борят за справедливост, политиците се борят за по-добра позиция в следващите избори. И когато всичко приключи, кой остава с празни ръце?
Пак хората.
Случаят със стадото във Велинград, което собствениците му и насъбралите се не позволиха да бъде умъртвено, напомня онзи в Попово, където хората блокираха месеци наред пътища и протестираха заради начина, по който МВР работи по случая със смъртта на 24-годишния мотоциклетист Момчил Георгиев.
Държавата отслабва, гражданските протести зачестяват, а вълните на недоволство радикализират хората. Всеки следващ случай, в който институциите се опитват да наложат решения с насилие или без ясна обосновка, само увеличава разривите в обществото и подкопава доверието към властта.
Когато институциите отказват да обяснят, да действат прозрачно и да уважават правата на гражданите, те губят моралното право да изискват доверие и напускат полето на диалога. А на терена излизат кресльовци с мегафони.
* Оригиналният правопис и пунктуация са запазени.
NetBox as Home CMDB and Integrated with Zabbix
Post Syndicated from Janne Pikkarainen original https://blog.zabbix.com/netbox-as-home-cmdb-and-integrated-with-zabbix/29324/
Welcome to another episode of What’s up, home? weirdness! Who wouldn’t have their own NetBox at home – and who wouldn’t think of it as a home CMDB? I’ve just started experimenting with it. For those who do not know, a Configuration Management Database (CMDB) is the source of truth for your inventory of stuff. In data centers, it keeps track of your servers, their cables, and everything else, telling you in which data center and which rack they are.
For me… well, take a look at for yourself. One picture says more than a thousand words of my storytelling.
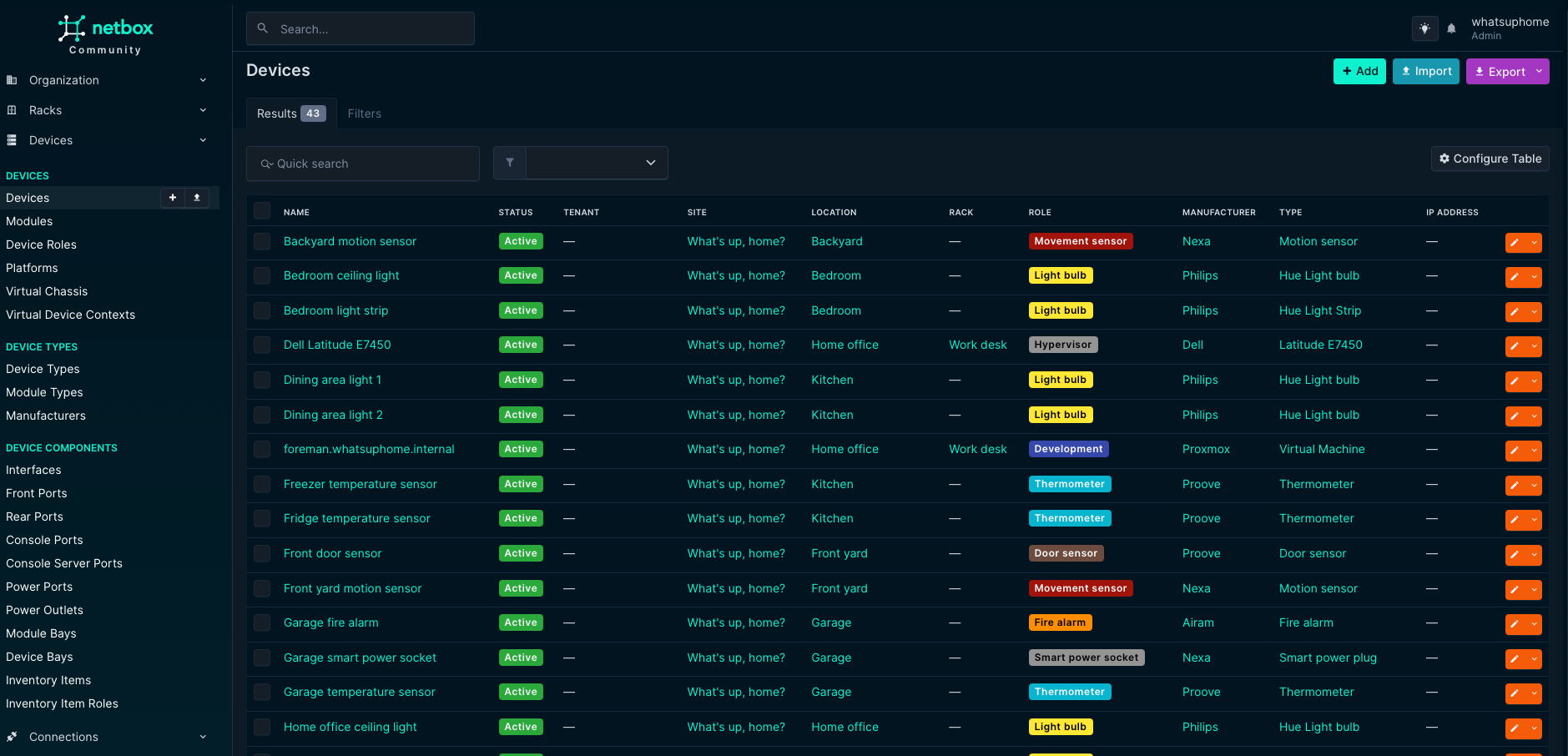
What is it good for?
Well… in the real business world, it’s good for many things – from knowing about your assets, their serial numbers, purchase dates, hardware configuration, and so much else. I could go as deep as that, but there’s a limit how far even I want to go with these little experiments. Today’s case is merely to demonstrate the flexibility of Zabbix, yet again.
How did I do this?
I quickly threw the data in to NetBox by hand — it looks by a lot of work to do, but in fact, it wasn’t too bad – took me about 45 minutes to do the following:
- Create a Site called “”What’s up, home?”
- Create the rooms by adding new locations and making the previously created site as their parent
- Add some manufacturers
- Add some device roles
- Add some device types
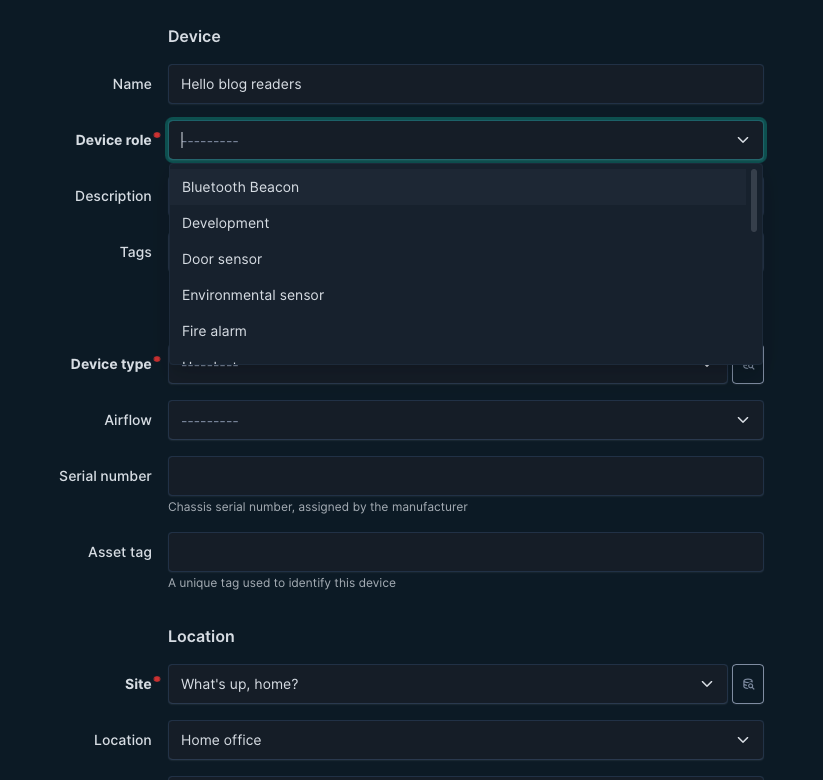
After that, adding the devices themselves is a breeze. If you have not used NetBox, this is what adding a new device looks like. Yes yes, in the real business world there would have been many more items for me to fill in, but for this case I only added the mandatory items and even those I could do just by choosing from the drop-down menus. Not a big deal.
…and the Zabbix integration?
Actually, this is something I created many years ago for other purposes, but still seems to work with today’s versions of NetBox. My little template queries NetBox over its API and asks if it has anything that matches with the host name that’s in Zabbix. If it has, then it gets the rack location and other stuff.

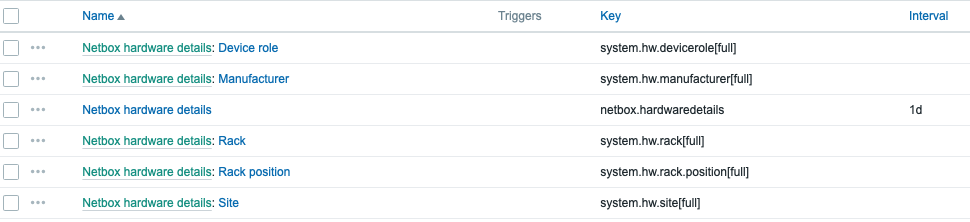
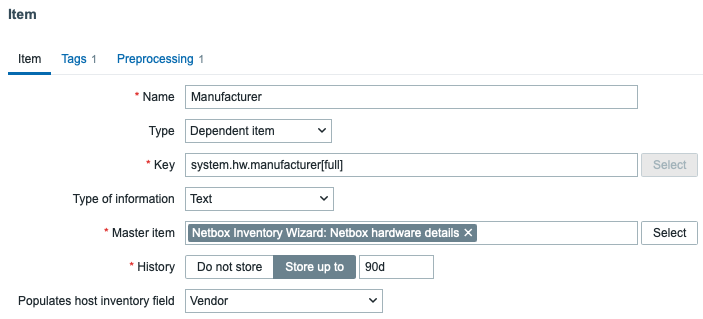
How this then works is pretty standard stuff. Retrieve a master item…
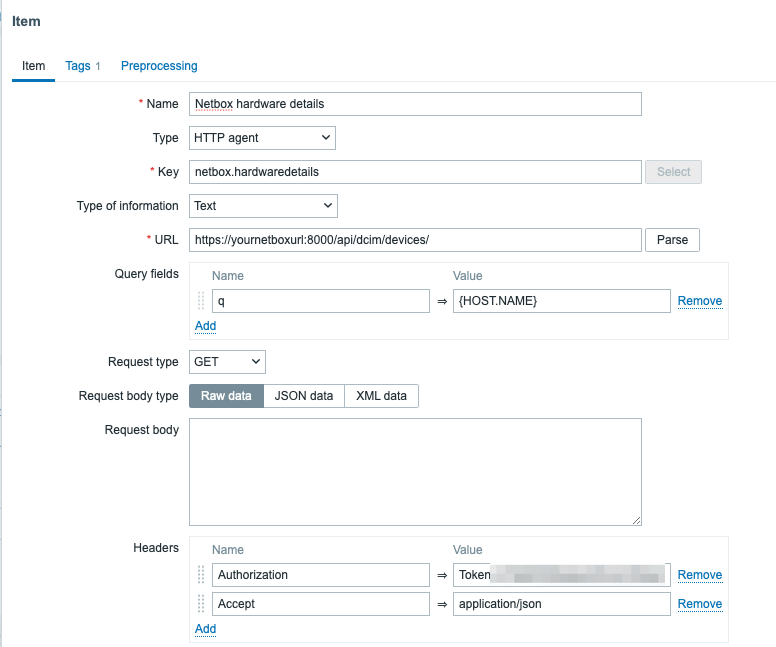
…and the dependent items then gather the data, parse some JSONPaths with Zabbix item preprocessing, and at least some of the items also populate bits and pieces in the Zabbix inventory. This is handy in real world, as your alerts can then contain the exact rack location and so forth about your failing devices. Add them as tags or add them as part of the alert text, your imagination is your limit.
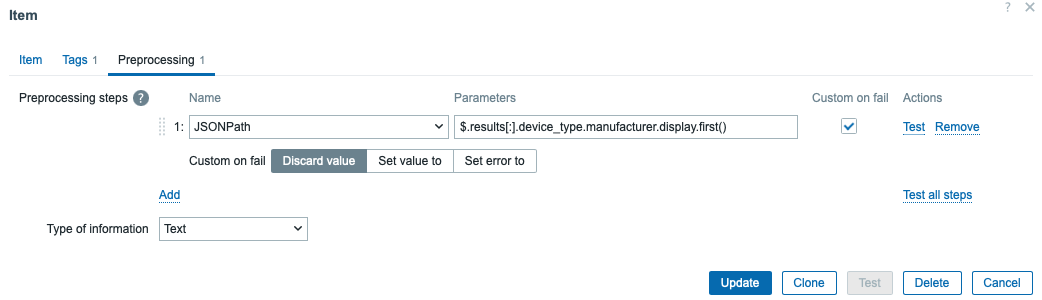
Does it work?
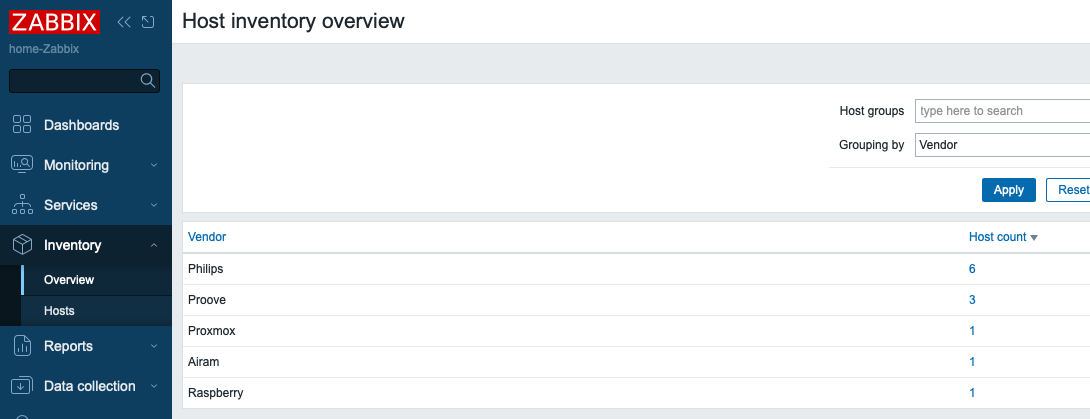
Of course it does! Here’s the inventory grouped by manufacturer:
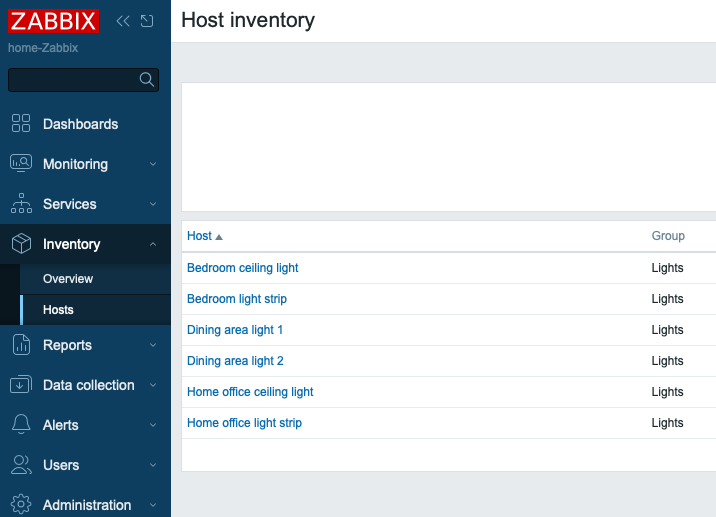
If I click on any of them, I get this:
Of course I can also browse the data through the latest data, for example…
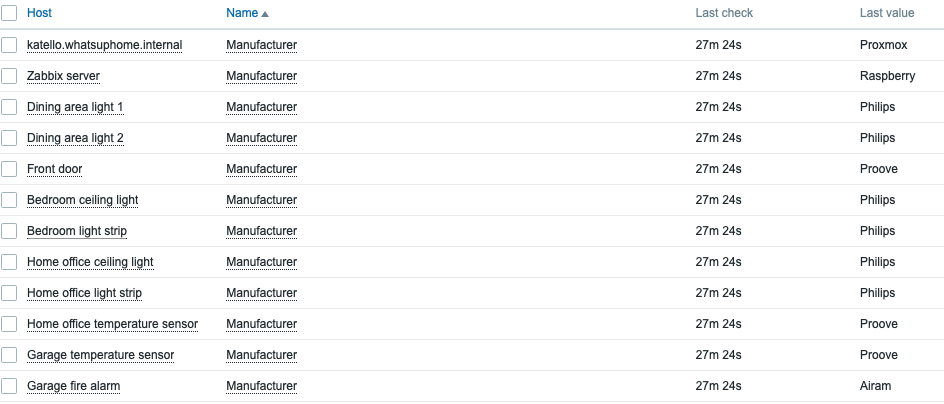
…or I could just create some dashboards for visualizing all this. I have not done that yet, as this is what I did tonight so far and now I’m going to bed. To be continued – maybe! For now, the template only pulls data from NetBox, but I’d like to push data towards it as well, to also tell if a light bulb is powered on or not, for example. Stay tuned!
The post NetBox as Home CMDB and Integrated with Zabbix appeared first on Zabbix Blog.
На второ четене: „Матео остана без работа“
Post Syndicated from Стефан Иванов original https://www.toest.bg/na-vtoro-chetene-mateo-ostana-bez-rabota/
„Матео остана без работа“ от Гонсало М. Тавареш

превод от португалски Даринка Кирчева, София: изд. „Ерго“, 2021
Тавареш има много награди и номинации. Наричан е португалският Кафка и наследник на Сарамаго. Според португалската критика има поне 160 превода на негови книги в 35 държави. Но не заради това избрах за втори път да пиша за него.
Когато видях името на Тавареш в каталога на „Ерго“, се сетих за удоволствието от „Дневник на чумата“ преди година. Заглавието на настоящата му книга ми беше смътно познато. Стана ми ясно защо едва след като я прочетох, преписах си на компютър бележките и проверих дали някой е писал за нея на български.
Помнех, че Марин Бодаков ми е говорил за тази книга. Но бях забравил, че е говорил за нея и във видео. Отне ми два часа да се насиля да го пусна. Беше ми трудно. Прозорецът стоеше отворен, но просто не го пусках. Не знаех как ще реагирам, когато отново го чуя и видя, а няма как това да се случи отново в живота ми, в плът и кръв. Едно от тези неща, съвпадения, синхроничности, които те изваждат от релси и те нокаутират.
Не мога да не цитирам и преразкажа част от това, което Марин говори. И да му отговоря. Искам отново да вляза в разговор с него. И съм благодарен за тази възможност.
След биобиблиографското си въведение за Тавареш и как е чел (а с него и аз, защото ми ги пращаше) откъсите от „Дневник на чумата“, публикувани в „Либерален преглед“, как ги следи и колко харесва тези вкопчени във всекидневието фрагменти, Марин ахва пред „Матео остана без работа“.
Не точно заради сложната повествователна конструкция, чиято композиция е истории, вързани с верижка една за друга.
Историите вървят по азбучния ред на имената на героите в тях. И така, докато се стигне до М и Матео.
Тази конструкция има своите клопки, двойни дъна и уловки. Това са еврейски имена. Те идват от надгробни плочи на евреи, депортирани в концентрационни лагери. Имена на жертви и мъченици. На корицата и между отделните части има фотографии на чудовищно красиви и зловещи манекени.
Марин не говори за връзка с Кафка, а по-скоро за близост с Борхес. С неговите филигранни конструкции, симетрии и иронично осъзнато безсилие на литературата да бъде както изчерпателна, така и същностно полезна в лечебните и човеколюбиви амбиции на изкуството. Не е случайно също, че редактор на превода е Анна Златкова, преводачка и на Борхес.
Третата част на книгата, след 24 текста за отделните персонажи и след по-дългия текст за самия Матео, е съставен от микроесета и философски парчета. Те се явяват авторовият ключ за книгата. Така, казва Марин, може да се прецени доколко той съвпада с читателския.

Тази книга с лекота поставя редица проблеми. Въпреки огромната ерудиция на автора, това не е учена книга – Тавареш не спекулира с ерудиция. Това не е и надменна книга. Писането на португалеца тук се състои в деликатната работа на тънката граница между реда и хаоса и доколко формата може да подреди съдържанието. С традиционни хватки и класически трикове писателят сглобява историите една с друга. Монтира ги заедно в един пъзел. Същностното му занимание обаче е друго. И то е ювелирно и ненатрапчиво проведено.
Тавареш пита как можем, като разказваме, да подредим света, ползвайки класически прийоми. Като имаме начало, завръзка, кулминация, развръзка и финал.
Как може разказването на истории с кристално ясна и прозрачна структура да поеме всичко причудливо, болезнено, неустановено и да го опитоми.
Да го направи поносимо, да го подчини на реда, за да не довежда до късо съединение в съзнанието. Да обезсили немислимото. Можем ли, пита се и Марин, с думите си, чрез литературата, да вложим порядък, има ли нужда от това усилие и какво в крайна сметка ни дава то. Какво се случва, когато очовечаваме чудовищното, когато даваме човешка мярка на немислимото и на неопределеното.
Марин не би нарекъл тази книга постмодерна, а старомодна. Аз бих добавил: и човешка. Писателска и човешка. Авторът вади на показ занаята и инструментите си. Демонстрира ги. Тази овладяна, но пищна словесна показност е провокирана от болезнен и честен интерес. Тавареш се интересува от способността да мислим и от възможностите на литературата да се опитва да съшие парчетата на един изначално разпокъсан и проблематичен свят, в дъното на който има нещо, което не подлежи на лечение. Има рана и безсмислие. В историите го има и обсценното говорене, фигурира и сквернословието, но не с такъв тон се усеща разбирането, с което са пропити текстовете – разбиране, че нито една разказана история няма да подреди хаоса на света веднъж и завинаги.
Тавареш не вие срещу смъртта на светлината в литературата, напротив, радва се на ценността на проблясъците, на самоценността на извлечената от словото светлина. Това е силата и това е слабостта на литературата. Тя свети, но гасне. Гасне, но свети. Този безмилостен и лишен от илюзии поглед не обезкуражава. Той успокоява и дава коректна представа за състоянието за силата на думите. И на човека.
Бих искал да кажа на Марин кое ме е разсмяло и кое ме е трогнало. Къде съм видял смъртта да се промъква между редовете. Къде съм усетил неназовимото и къде според мен е тайният център на книгата.
Как съм усетил определена близост както с „Некролози“ на Сароян и със „Спун Ривър“ на Мастърс, така и със Сесар Айра, с Гомбрович, с Жорж Перек, с Едуардо Галеано и с „Българският модел“ на Стратиев. И колко всъщност тази прозаична щафета, в която абсурдът триумфира и реалността е дала накъсо, ми изглежда като почти документална хроника на едно наистина възможно всекидневие. Фактът, че (както пише в бележка под линия Даринка Кирчева)
в португалския език няма въпросителна частица, подобна на българската „ли“, нито инверсия за изразяване на въпрос и само въпросителният знак отличава въпросителното от съобщителното изречение,
прави още по-възможна метаморфозата на фантастичното в реалистично в света на Тавареш.
Героите му тичат в посока обратна на движението на кръговото, мият боклук и го връщат отново в магазина, задават въпроси за анкети с възможни отговори само „да“ или „не“, имат тикове, синдром на Турет и изкуствено сърце, татуират си Менделеевата таблица на брайлова азбука, събират хлебарки, воюват гротескно помежду си и така нататък, и така нататък.
При Тавареш, бих казал на Марин,
колебанието тържествува.
В компанията на непрекъснато преобръщане и поставяне под въпрос. Непоколебим е отказът да се вземе реалността наготово. Светът и животът ни са за Тавареш кървава задача, дългосрочна спекулация и болезнен ребус. И всяка възможна концепция и хипотеза за разгадаването им са добре дошли. Толкова са нужни опорна точка и минимално количество сигурност, за да може да се понесе това, което реалността неспирно поднася с перверзна и постоянна усмивка. Нужно е петно светлина преди черната точка.
Активните дарители на „Тоест“ получават постоянна отстъпка в размер нa 20% от коричната цена на всички заглавия от каталога на издателство „Ерго“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Антония Апостолова, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.
Не сме безгрешни, но сме коледни
Post Syndicated from original https://www.toest.bg/ne-sme-bezgreshni-no-sme-koledni/

Сложихте ли вече коледната украса? Планирахте ли къде ще пътувате и изобщо какво ще правите през ваканцията? Добре, а подготвени ли сте езиково да посрещнете предстоящите коледно-новогодишни празници? Моля, не реагирайте с учудване, защото е възможно да сбъркате правописа на най-различни думи и пожелания, които стават актуални точно в този календарен период.
Никулден, имените дни и рибата
Да започнем по-отдалече, а именно от Никулден, още повече че свети Николай Чудотворец се смята за първообраз на Дядо Коледа, който е наричан Санта Клаус в западните страни (от нидерландското съкратено име Sinterklaas < Sint Nicolaas). На този ден празнуват Николовци и Николаевци, Нини и Николини – всички те са именици, въпреки че аутокоректът го подчертава. За разлика от тях, именниците представляват текстове или списъци с имена, най-известен от които е може би Именникът на българските ханове.
Ако досега не сте знаели за това важно разграничение1, запомнете го, защото ще ви потрябва и на Игнажден, Рождество Христово, Стефановден, Васильовден, Йордановден, Ивановден… С две думи, ще ви трябва и по-нататък през годината, когато ще поискате да напишете на някой именик „Честит имен ден!“. Да, само първата буква е главна, понеже именият ден, а също и рожденият ден са, така да се каже, индивидуални празници за конкретния човек и не са дорасли до главната буква.
В духа на специфичното трапезно разбиране на християнството от немалко българи ще обърнем внимание на традиционните рибни ястия, с които се свързва Никулден. Названието на шарана няма как да го сгрешите, но ако споделяте рецепта за пъстърва или толстолоб, не пишете пастърва или толостолоб. Девесилът пък е подходящ за рибена чорба, а названието на тази подправка съм го срещала поне в четири варианта, в които е-тата се заменят произволно с и-та в най-различни комбинации. Аз бих написала лющян, както си го знам от малка, но казват, че не било книжовно…
Предколедни вълнения
След Никулден времето рязко се свива и не стига нито за купуването на подаръци, нито за цялата работа на света, която трябва да се свърши до 23 декември на всяка цена, нито за украсяването на дома, затова е добре да сложим елхата, лампичките, имитациите на борови клонки (екологията преди всичко!) и гирляндите по-рано. Обикновено всички тези неща с изключение на елхата, разбира се, са повечко на брой, и надали ще употребите названията в единствено число, но имайте предвид, че гирляндата е от женски род, а не от мъжки. Заели сме думата от италианския език (ghirlanda ‘венец’) заедно с рода ѝ, макар да сме променили нейното значение. Впрочем скоро разбрах, че е модерно играчките за елхата вече да се наричат орнаменти.
С въпросните играчки/орнаменти и с най-различни нещица, носещи коледния дух, може да се сдобиете от празничните базари и тук е моментът да поставим и изясним няколко проблема. Първо, всички коледни работи се пишат поначало с малка буква. Празникът е Коледа – с главна буква, обаче прилагателното коледен, образувано от въпросното съществително собствено име, е с малка: коледни празници, коледни песни, коледни сладки, коледна ваканция, коледен романтичен филм, коледно парти… Изключение се прави, ако прилагателното е първа дума в съставно собствено име (състоящо се от две или повече думи), например Коледният базар във Варна2.
Второ, да ми простят онези, които посещават базарите основно заради греяното вино, че поставям толкова съществен проблем на второ място, но така се получи. Апелирам към колегите от Института за български език да включат в БЕРОН особеното прилагателно име греян, защото, ето, пие си човек ароматното вино на базара, стопля си тялото и душицата и в приповдигнато настроение иска да сподели това значимо събитие в социалните мрежи. В един момент обаче се замисля как аджеба се пише тая дума, търси я в БЕРОН и не я намира! Не е редно ентусиазмът да секва точно в този момент, колеги, а освен това греяното вино и греяната ракия имат по-широко приложение – народната медицина например ги препоръчва при настинка и ред заболявания и неразположения на горния дихателен тракт. Чудеса правели тези напитки!
Трето, преди да е настъпил Бъдни вечер, трябва да купим и надпишем коледните картички – в случай че искаме да уважим тази традиция. Напоследък предпочитаме да отправяме пожеланията си виртуално, но все едно дали ще изберем хартията, чата, или някоя от социалните мрежи, ще придадем писмен вид на своите поздравления. Как да честитим правилно? Ето така например:
Весела Коледа и честита Нова година!
Честито Рождество Христово!
Логиката и съответно правилата в българския правопис се различават от логиката и правилата в английския, затова ви моля: не пишете Весела Коледа и Честита Нова Година! С главна буква се пише само първата дума в съставно собствено име и ако то съдържа и друго име, което поначало се пише с главна буква, тя се запазва, естествено. Рождество Христово се пише с начална главна буква, тъй като е название на християнски празник, а Христов (от Христос) се пише с главна буква и извън това собствено име, защото е притежателно прилагателно както Иванов (от Иван), да речем. При Нова година и Бъдни вечер положението е различно, тъй като думите година и вечер се пишат поначало с малка буква – те не са собствени имена сами по себе си.
И за да е още по-сложно, Нова година се пише с начална главна буква само когато имаме предвид празника, тоест деня 1 януари, в който честваме началото на годината. Ако става въпрос за всички предстоящи 365 дни, тогава началната буква е малка (но и първата дума обикновено е членувана и това помага да се ориентираме):
Нека новата година ти донесе много радост и незабравими мигове!
Трапезата на Бъдни вечер
Отново стигнахме до кулинарните традиции, а те повеляват на този ден да се сервират само постни ястия, понеже 24 декември е последният ден от постите за Рождество Христово. Тук има вероятност да напишете посни вместо постни, тъй като при по-небрежен изговор съгласната т не се произнася в групата -стн-. При колебание може да направите бърза проверка и без речник. Как? Като търсите форма на думата или друга дума със същия корен, в която след съмнителната съгласна (има ли тук т, или няма?) стои гласна – постен, пости: аха, има т, значи и постни се пише с т.
Въпреки че ястията не бива да съдържат животински продукти, разнообразието е голямо: зелеви или лозови сарми, печен боб, пълнени чушки, варено жито, ошав, питка, тиквеник; на масата се слагат също туршия, плодове, ядки… Грешки ви дебнат най-вече при сармите, ошава и туршията, все думи, които сме заели от турския език или с негово посредничество.
Думите сарма и сърма бяха дублети в кулинарията, но през 2002 г. сърма отпадна – вероятно за да се избегне омонимията със сърма. Макар да минаха вече 22 години, публикацията за тези думи в „Как се пише?“ се радва на голям интерес преди Бъдни вечер, което означава, че някои дублети са твърде жилави и устояват на кодификаторските решения.
За ошава, колкото и да мисля, не мога да намеря разумна причина да се пише с в. Хем на турски е hoşaf, хем като го произнасяме, крайната съгласна, дори и да е в, се обеззвучава. Погледнах обаче в Речника на българския език (1895–1904) от Найден Геров и там си е ошавъ, та даже има и ошавець. В по-късни правописни речници продължавам да откривам само ошав, което ме навежда на мисълта, че никой не е намерил достатъчно основания да ревизира това отдавнашно решение.
За туршията Геров е разколебан и дава и варианта трушия, който, мисля, е широко разпространен в Източна България, включително и в моя роден говор. Така или иначе, сега е правилна само формата туршия, която следва турската дума turşu.
Един от обредите (а не обрядите) на Бъдни вечер е коледуването – младежи, водени от по-възрастен женен мъж, обикалят къщите и пеят песни, с които пожелават здраве и берекет (а не берекед) на стопаните. Ако описвате този обичай, внимавайте и при колачетата, дарявани на коледарите. Думата е производна от колак ‘кравай’, а тя пък – от забравената вече коло, вместо която днес употребяваме колело. Да, колачетата са кравайчета и имат формата на колело, затова и се пишат с о, а не с у, а кулачетата (кулаче < кулак) вече ще ни отведат по други етимологични пътеки, които е по-добре да оставим на Екатерина Петрова.
От Коледа до Василица
Сигурно сте били послушни и през нощта след Бъдни вечер Дядо Коледа ще ви остави подарък под елхата, който с удоволствие ще разопаковате сутринта още по пижама. Обидно би било да напомням, че името на добрия старец се пише с две главни букви, но ще посоча правилото, на което се подчинява неговият правопис, а също така и на Баба Марта, Кума Лиса, та дори и на Братя Грим, Майка Тереза и Патриарх Евтимий. Първата дума, макар да е съществително нарицателно, е станала неразделна част от собственото име на тези персонажи и личности и затова се пише с главна буква.
На Рождество Христово се слага край на постите, но след като започнах това изречение, се чудя как да го продължа, защото дори много от хората, които се смятат за православни, постят само на Бъдни вечер. Неслучайно се говори за ВиК християни – мнозина се сещат за съществуването на Бога само на двата най-големи църковни празника. На Коледа вече е напълно разрешено да се блажи и влизаме в така наречения от мен сезон на пържолите. Също както те могат да се приготвят по най-различни начини, и думата може да приеме различни облици: правилния пържола, но и пръжола, пражола и паржола. Въпреки че вероятно има чужд произход, в крайна сметка ние сме я осмислили като резултат от пържене, а не от пражене (диалектна дума), което обяснява буквата ъ3.
Ваканцията бързо се изнизва и идва Нова година със звън на кристални чаши, бенгалски огън, пиратки и фойерверки. Проблемната дума е заета от немски и в общи линии следва транскрипцията на оригиналната Feuerwerk. Предпоставките за грешки са много, затова и тук трябва да внимавате правописно и не само – действайте умно и предпазливо с „огнените изделия“.
Още в новогодишната нощ може да ви сурвакат близки деца – обичай, който вече е ограничен в рамките семейството и познатите, но все пак виждам по столичните улици да се продават сурвакници, така че да преговорим правописа и на тези думи. Макар най-вероятно прилагателното сурва (Сурва, сурва година…) да е диалектен вариант на сурова, точно той стои в основата и на сурвакам, и на сурвакница, затова не пишете суровакам, суровакница.
Вече стигнахме до финала – Васильовден, който всъщност съвпада календарно с Нова година. Празникът е наричан също Василица или Васильовица и е известен сред ромската общност като Банго Васил, но се отбелязва по-късно – на 14 януари. Тук трябва просто да не залитате към Василевица и Василевден.
Празничното ни правописно пътешествие може да продължи с Богоявление (Йордановден) и Ивановден, когато имен ден празнува кажи-речи половината от българския народ, но е време да сложим точка, понеже време всъщност нямаме. Вече е 6 декември, Никулден, навлизаме в друго измерение и трябва да свършим всичката работа във Вселената. О, и да изнамерим най-хубавите подаръци за хората, които обичаме – не непременно материални.
1 Разграничението беше направено през 2012 г. Дотогава именник (човек) и именник (текст/списък) бяха омоними.
2 За употребата на главна и малка буква при коледен базар вижте повече обяснения и примери.
3 По отношение на пържола/пръжола първият вариант е правилен, защото в многосрични думи се пише и изговаря -ър-, а не -ръ-, ако след тази група има една съгласна (ж).
Езикът може да е вкусен и извън блюдото – онзи, българският език, на който говорим от малки и на който около 24 май се кълнем в обич. А той в същността си е средство за общуване и за да ни служи добре, непрекъснато се променя. Да го погледнем в неговата динамика и да се опитаме да разберем какво става и защо, кои са движещите механизми и как те са свързани с обществените процеси. И тъй като задачата не е лека, ще го правим постепенно – на порции.
Why is NYC called "Gotham?"
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=aGtuSDY4EAU
Seismologists
Post Syndicated from xkcd.com original https://xkcd.com/3021/

Apertis v2024 released
Post Syndicated from corbet original https://lwn.net/Articles/1001013/
Apertis is a Collabora-developed
Debian derivative distribution designed to be incorporated into electronic
devices; the v2024
release is now available. It is now based on the Bookworm release, and
includes support for Podman, ONNX
Runtime, OP-TEE, and more.
Apertis relies on the Debian Free Software Guidelines to ensure all
software shipped is open source or, in limited cases, at least
freely distributable. However, for some customers this is not
enough to be able to adopt OSS solutions as in their evaluations
some provisions in common licenses like the GPL-3 are at odds with
regulatory constraints they are subject to. Apertis does not set to
solve this decades-long debate, and instead its goal is to increase
the adoption of modern, maintained OSS solutions in markets where
this has historically been a challenge. To enable this, Apertis
supports avoiding the use of any software under some licenses (like
the [GPL v3.0 license family) on target images, while still making
them fully available for development and for customers that do not
share those licensing concerns. To avoid these licenses, Apertis
uses more modern alternatives instead of relying on outdated and
unmaintained pre-GPL-3 versions. For instance, coreutils and
findutils (GPL-3+) are replaced in Apertis by rust-coreutils and
rust-findutils.
Why is Chicago called "The Second City?"
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=lNT809gEscw
Let’s Encrypt sets date for ending OCSP support
Post Syndicated from jzb original https://lwn.net/Articles/1000941/
In July, Let’s Encrypt announced it was ending
support “as soon as possible
” for the Online
Certificate Status Protocol (OCSP) in favor of Certificate
Revocation Lists (CRLs) due to privacy concerns. The organization
has now announced
that it has set a timeline, and will be turning off its OCSP
responders on August 6, 2025. There is additional action required
for Let’s Encrypt users who use the OCSP Must Staple Extension:
As of January 30, 2025, issuance requests that include the OCSP
Must Staple extension will fail, unless the requesting account has
previously issued a certificate containing the OCSP Must Staple
extension.As of May 7, all issuance requests that include the OCSP Must
Staple extension will fail, including renewals. Please change your
ACME client configuration to not request the extension.
How REA Group approaches Amazon MSK cluster capacity planning
Post Syndicated from Eunice Aguilar original https://aws.amazon.com/blogs/big-data/how-rea-group-approaches-amazon-msk-cluster-capacity-planning/
This post was written by Eunice Aguilar and Francisco Rodera from REA Group.
Enterprises that need to share and access large amounts of data across multiple domains and services need to build a cloud infrastructure that scales as need changes. REA Group, a digital business that specializes in real estate property, solved this problem using Amazon Managed Streaming for Apache Kafka (Amazon MSK) and a data streaming platform called Hydro.
REA Group’s team of more than 3,000 people is guided by our purpose: to change the way the world experiences property. We help people with all aspects of their property experience—not just buying, selling, and renting—through the richest content, data and insights, valuation estimates, and home financing solutions. We deliver unparalleled value to our customers, Australia’s real estate agents, by providing access to the largest and most engaged audience of property seekers.
To achieve this, the different technical products within the company regularly need to move data across domains and services efficiently and reliably.
Within the Data Platform team, we have built a data streaming platform called Hydro to provide this capability across the whole organization. Hydro is powered by Amazon MSK and other tools with which teams can move, transform, and publish data at low latency using event-driven architectures. This type of structure is foundational at REA for building microservices and timely data processing for real-time and batch use cases like time-sensitive outbound messaging, personalization, and machine learning (ML).
In this post, we share our approach to MSK cluster capacity planning.
The problem
Hydro manages a large-scale Amazon MSK infrastructure by providing configuration abstractions, allowing users to focus on delivering value to REA without the cognitive overhead of infrastructure management. As the use of Hydro grows within REA, it’s crucial to perform capacity planning to meet user demands while maintaining optimal performance and cost-efficiency.
Hydro uses provisioned MSK clusters in development and production environments. In each environment, Hydro manages a single MSK cluster that hosts multiple tenants with differing workload requirements. Proper capacity planning makes sure the clusters can handle high traffic and provide all users with the desired level of service.
Real-time streaming is a relatively new technology at REA. Many users aren’t yet familiar with Apache Kafka, and accurately assessing their workload requirements can be challenging. As the custodians of the Hydro platform, it’s our responsibility to find a way to perform capacity planning to proactively assess the impact of the user workloads on our clusters.
Goals
Capacity planning involves determining the appropriate size and configuration of the cluster based on current and projected workloads, as well as considering factors such as data replication, network bandwidth, and storage capacity.
Without proper capacity planning, Hydro clusters can become overwhelmed by high traffic and fail to provide users with the desired level of service. Therefore, it’s very important to us to invest time and resources into capacity planning to make sure Hydro clusters can deliver the performance and availability that modern applications require.
The capacity planning approach we follow for Hydro covers three main areas:
- The models used for the calculation of current and estimated future capacity needs, including the attributes used as variables in them
- The models used to assess the approximate expected capacity required for a new Hydro workload joining the platform
- The tooling available to operators and custodians to assess the historical and current capacity consumption of the platform and, based on them, the available headroom
The following diagram shows the interaction of capacity usage and the precalculated maximum usage.

Although we don’t have this capability yet, the goal is to take this approach one step further in the future and predict the approximate resource depletion time, as shown in the following diagram.

To make sure our digital operations are resilient and efficient, we must maintain a comprehensive observability of our current capacity usage. This detailed oversight allows us not only to understand the performance limits of our existing infrastructure, but also to identify potential bottlenecks before they impact our services and users.
By proactively setting and monitoring well-understood thresholds, we can receive timely alerts and take necessary scaling actions. This approach makes sure our infrastructure can meet demand spikes without compromising on performance, ultimately supporting a seamless user experience and maintaining the integrity of our system.
Solution overview
The MSK clusters in Hydro are configured with a PER_TOPIC_PER_BROKER level of monitoring, which provides metrics at the broker and topic levels. These metrics help us determine the attributes of the cluster usage effectively.
However, it wouldn’t be wise to display an excessive number of metrics on our monitoring dashboards because that could lead to less clarity and slower insights on the cluster. It’s more valuable to choose the most relevant metrics for capacity planning rather than displaying numerous metrics.
Cluster usage attributes
Based on the Amazon MSK best practices guidelines, we have identified several key attributes to assess the health of the MSK cluster. These attributes include the following:
- In/out throughput
- CPU usage
- Disk space usage
- Memory usage
- Producer and consumer latency
- Producer and consumer throttling
For more information on right-sizing your clusters, see Best practices for right-sizing your Apache Kafka clusters to optimize performance and cost, Best practices for Standard brokers, Monitor CPU usage, Monitor disk space, and Monitor Apache Kafka memory.
The following table contains the detailed list of all the attributes we use for MSK cluster capacity planning in Hydro.
| Attribute Name | Attribute Type | Units | Comments |
|---|---|---|---|
| Bytes in | Throughput | Bytes per second | Relies on the aggregate Amazon EC2 network, Amazon EBS network, and Amazon EBS storage throughput |
| Bytes out | Throughput | Bytes per second | Relies on the aggregate Amazon EC2 network, Amazon EBS network, and Amazon EBS storage throughput |
| Consumer latency | Latency | Milliseconds | High or unacceptable latency values usually indicate user experience degradation before reaching actual resource (for example, CPU and memory) depletion |
| CPU usage | Capacity limits | % CPU user + CPU system | Should stay under 60% |
| Disk space usage | Persistent storage | Bytes | Should stay under 85% |
| Memory usage | Capacity limits | % Memory in use | Should stay under 60% |
| Producer latency | Latency | Milliseconds | High or unacceptable sustained latency values usually indicate user experience degradation before reaching actual capacity limits or actual resource (for example, CPU or memory) depletion |
| Throttling | Capacity limits | Milliseconds, bytes, or messages | High or unacceptable sustained throttling values indicate capacity limits are being reached before actual resource (for example, CPU or memory) depletion |
By monitoring these attributes, we can quickly evaluate the performance of the clusters as we add more workloads to the platform. We then match these attributes to the relevant MSK metrics available.
Cluster capacity limits
During the initial capacity planning, our MSK clusters weren’t receiving enough traffic to provide us with a clear idea of their capacity limits. To address this, we used the AWS performance testing framework for Apache Kafka to evaluate the theoretical performance limits. We conducted performance and capacity tests on the test MSK clusters that had the same cluster configurations as our development and production clusters. We obtained a more comprehensive understanding of the cluster’s performance by conducting these various test scenarios. The following figure shows an example of a test cluster’s performance metrics.

To perform the tests within a specific time frame and budget, we focused on the test scenarios that could efficiently measure the cluster’s capacity. For instance, we conducted tests that involved sending high-throughput traffic to the cluster and creating topics with many partitions.
After every test, we collected the metrics of the test cluster and extracted the maximum values of the key cluster usage attributes. We then consolidated the results and determined the most appropriate limits of each attribute. The following screenshot shows an example of the exported test cluster’s performance metrics.
 |
Capacity monitoring dashboards
As part of our platform management process, we conduct monthly operational reviews to maintain optimal performance. This involves analyzing an automated operational report that covers all the systems on the platform. During the review, we evaluate the service level objectives (SLOs) based on select service level indicators (SLIs) and assess the monitoring alerts triggered from the previous month. By doing so, we can identify any issues and take corrective actions.
To assist us in conducting the operational reviews and to provide us with an overview of the cluster’s usage, we developed a capacity monitoring dashboard, as shown in the following screenshot, for each environment. We built the dashboard as infrastructure as code (IaC) using the AWS Cloud Development Kit (AWS CDK). The dashboard is generated and managed automatically as a component of the platform infrastructure, along with the MSK cluster.

By defining the maximum capacity limits of the MSK cluster in a configuration file, the limits are automatically loaded into the capacity dashboard as annotations in the Amazon CloudWatch graph widgets. The capacity limits annotations are clearly visible and provide us with a view of the cluster’s capacity headroom based on usage.
We determined the capacity limits for throughput, latency, and throttling through the performance testing. Capacity limits of the other metrics, such as CPU, disk space, and memory, are based on the Amazon MSK best practices guidelines.
During the operational reviews, we proactively assess the capacity monitoring dashboards to determine if more capacity needs to be added to the cluster. This approach allows us to identify and address potential performance issues before they have a significant impact on user workloads. It’s a preventative measure rather than a reactive response to a performance degradation.
Preemptive CloudWatch alarms
We have implemented preemptive CloudWatch alarms in addition to the capacity monitoring dashboards. These alarms are configured to alert us before a specific capacity metric reaches its threshold, notifying us when the sustained value reaches 80% of the capacity limit. This method of monitoring enables us to take immediate action instead of waiting for our monthly review cadence.
Value added by our capacity planning approach
As operators of the Hydro platform, our approach to capacity planning has provided a consistent way to assess how far we are from the theoretical capacity limits of all our clusters, regardless of their configuration. Our capacity monitoring dashboards are a key observability instrument that we review on a regular basis; they’re also useful while troubleshooting performance issues. They help us quickly tell if capacity constraints could be a potential root cause of any ongoing issues. This means that we can use our current capacity planning approach and tooling both proactively or reactively, depending on the situation and need.
Another benefit of this approach is that we calculate the theoretical maximum usage values that a given cluster with a specific configuration can withstand from a separate cluster without impacting any actual users of the platform. We spin up short-lived MSK clusters through our AWS CDK based automation and perform capacity tests on them. We do this quite often to assess the impact, if any, that changes made to the cluster’s configurations have on the known capacity limits. According to our current feedback loop, if these newly calculated limits change from the previously known ones, they are used to automatically update our capacity dashboards and alarms in CloudWatch.
Future evolution
Hydro is a platform that is constantly improving with the introduction of new features. One of these features includes the ability to conveniently create Kafka client applications. To meet the increasing demand, it’s essential to stay ahead of capacity planning. Although the approach discussed here has served us well so far, it’s by no means the final stage , and there are capabilities that we need to extend and areas we need to improve on.
Multi-cluster architecture
To support critical workloads, we’re considering using a multi-cluster architecture using Amazon MSK, which would also affect our capacity planning. In the future, we plan to profile workloads based on metadata, cross-check them with capacity metrics, and place them in the appropriate MSK cluster. In addition to the existing provisioned MSK clusters, we will evaluate how the Amazon MSK Serverless cluster type can complement our platform architecture.
Usage trends
We have added CloudWatch anomaly detection graphs to our capacity monitoring dashboards to track any unusual trends. However, because the CloudWatch anomaly detection algorithm only evaluates up to 2 weeks of metric data, we will reassess its usefulness as we onboard more workloads. Aside from identifying usage trends, we will explore options to implement an algorithm with predictive capabilities to detect when MSK cluster resources degrade and deplete.
Conclusion
Initial capacity planning lays a solid foundation for future improvements and provides a safe onboarding process for workloads. To achieve optimal performance of our platform, we must make sure that our capacity planning strategy evolves in line with the platform’s growth. As a result, we maintain a close collaboration with AWS to continually develop additional features that meet our business needs and are in sync with the Amazon MSK roadmap. This makes sure we stay ahead of the curve and can deliver the best possible experience to our users.
We recommend all Amazon MSK users not miss out on maximizing their cluster’s potential and to start planning their capacity. Implementing the strategies listed in this post is a great first step and will lead to smoother operations and significant savings in the long run.
About the Authors
 Eunice Aguilar is a Staff Data Engineer at REA. She has worked in software engineering in various industries throughout the years and recently for property data. She’s also an advocate for women interested in transitioning into tech, along with the well-versed who she takes inspiration from.
Eunice Aguilar is a Staff Data Engineer at REA. She has worked in software engineering in various industries throughout the years and recently for property data. She’s also an advocate for women interested in transitioning into tech, along with the well-versed who she takes inspiration from.
 Francisco Rodera is a Staff Systems Engineer at REA. He has extensive experience building and operating large-scale distributed systems. His interests are automation, observability, and applying SRE practices to business-critical services and platforms.
Francisco Rodera is a Staff Systems Engineer at REA. He has extensive experience building and operating large-scale distributed systems. His interests are automation, observability, and applying SRE practices to business-critical services and platforms.
![]() Khizer Naeem is a Technical Account Manager at AWS. He specializes in Efficient Compute and has a deep passion for Linux and open-source technologies, which he leverages to help enterprise customers modernize and optimize their cloud workloads.
Khizer Naeem is a Technical Account Manager at AWS. He specializes in Efficient Compute and has a deep passion for Linux and open-source technologies, which he leverages to help enterprise customers modernize and optimize their cloud workloads.
Seamless Data Migration with Custom Upload Timestamps
Post Syndicated from Bala Krishna Gangisetty original https://www.backblaze.com/blog/seamless-data-migration-with-custom-upload-timestamps/
Migrating data to the cloud? Ensuring that original timestamps remain intact through a cloud migration can be a critical factor for successful data management at scale. Losing these timestamps can lead to operational challenges that hinder your ability to track data effectively, set proper lifecycle rules, create custom events, and more.
Backblaze B2 Cloud Storage now offers the Custom Upload Timestamps feature to help you manage your data. Today, I’m sharing details on the new feature, benefits, and how to enable it.
What are Custom Upload Timestamps?
The Custom Upload Timestamps feature is designed specifically to retain the original timestamps of your files during a migration. It is especially beneficial for users who rely on lifecycle rules to dictate file deletion or archiving based on age for compliance, to track file age manually, or maintain historical context of file.
Imagine this scenario: You have a critical file on another cloud storage provider, governed by a lifecycle rule that deletes it after 1,000 days. If you move the file to Backblaze B2 on day 999, the timestamp would be overwritten and you’d have to restart that lifecycle from day one. However, with this new feature, the original timestamp remains intact, and the file will still get deleted on day 1,000, just as planned. This capability not only simplifies the migration process, but also ensures continuity in your data retention policies, keeping your storage costs in line with expectations.
Benefits of Custom Upload Timestamps
Lifecycle rules play a crucial role in managing data retention, particularly when migrating large datasets. Losing the original timestamps means you’d have to manually reconfigure your rules or wait much longer for lifecycle events to take effect. The benefits of retaining original timestamps extend beyond just lifecycle rules.
Here is why this feature is essential:
- Operational efficiency: Knowing the original timestamp of files allows for better organization and tracking. This is vital for businesses that rely on historical data to inform decisions or manage projects. When timestamps reset, it can lead to confusion and disarray in managing files. You may find yourself dealing with files that should have been deleted or archived but aren’t because of the reset timeline.
- Compliance: For organizations that must adhere to regulatory standards for data retention, preserving timestamps can help meet legal requirements. It provides a clear audit trail and evidence of when files were created or modified.
- Decreased workload: Manually tracking and reconfiguring lifecycle rules consumes valuable time and resources. By retaining the original timestamps, you eliminate unnecessary workloads.
- File age tracking: Whether you’re managing backups, archival processes, or simple organizational tasks, knowing the age of a file can inform your decisions regarding when to review or delete files.
- Historical context: For projects that span long periods, retaining timestamps helps maintain the context of data. This can be critical for collaborative efforts or projects that require consistent documentation.
Ultimately, the custom upload timestamps feature supports greater data portability, making it easier to move and manage large datasets. It ensures that migration to B2 Cloud Storage is as seamless as possible—without the need to reset or alter your data management policies.
Ready to get started?
The Custom Upload Timestamps feature is enabled by default for all B2 Cloud Storage customers. To utilize this feature, you need to include the X-Bz-Custom-Upload-Timestamp parameter when calling the b2_upload_file API. This simple addition allows you to retain the original timestamp of your file, thereby preserving its lifecycle state without interruptions and ensuring that your data remains organized and easy to track.
By retaining the original timestamps, Backblaze B2 helps increase the ease and granularity with which you can manage your data, especially for organizations migrating large volumes of data. You can transition your data while maintaining control over important metadata like the original timestamp, streamlining your operations, improving overall efficiency, and avoiding the stress of potential compliance issues.
What next?
To make the most of the Custom Upload Timestamp feature, consider the following actionable steps:
- Review your migration workflow. Before starting the migration, ensure that your processes include the
X-Bz-Custom-Upload-Timestampparameter in your upload scripts or APIs. This will help prevent any disruption in tracking important metadata. - Test the feature. Conduct a pilot migration with a small number of files. This will allow you to confirm that the timestamps are retained correctly. Monitor the behavior of your data tracking after this test migration to ensure everything operates as expected.
- Verify lifecycle rules. Once you complete the migration, take the time to check that your lifecycle policies continue to function as intended on B2 Cloud Storage. This verification step is crucial to avoid unexpected data retention issues.
- Engage with Support. If you have any questions or encounter challenges, don’t hesitate to reach out to our Support team. We’re here to help you make the most of B2 Cloud Storage.
For more details, visit our API documentation to ensure you’re ready for a smooth migration. By leveraging the Custom Upload Timestamps feature, you can simplify your data management processes.
The post Seamless Data Migration with Custom Upload Timestamps appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
AWS post-quantum cryptography migration plan
Post Syndicated from Matthew Campagna original https://aws.amazon.com/blogs/security/aws-post-quantum-cryptography-migration-plan/
Amazon Web Services (AWS) is migrating to post-quantum cryptography (PQC). Like other security and compliance features in AWS, we will deliver PQC as part of our shared responsibility model. This means that some PQC features will be transparently enabled for all customers while others will be options that customers can choose to implement to help meet their requirements. This transition will happen in phases, starting with systems that communicate over untrusted networks such as the internet.
The threat of a large-scale quantum computer, sometimes referred to as a cryptographically relevant quantum computer, is its potential to break the public-key cryptographic algorithms in use today. These algorithms are used in most communication protocols and digital signature schemes. For the past eight years, AWS—along with other industry leaders, government agencies, and academia—has been advocating, researching, and proposing new public-key cryptographic algorithms that are resistant to quantum computing. Because customers rely on cryptography performed by AWS to secure their data, we engaged in this work early on to minimize the effort and the impact of the eventual migration to PQC. While there is no evidence that a quantum computer powerful enough to break the public key cryptography in use throughout AWS exists today, we are not waiting. We would rather put protections in place now to protect the security of our customers’ data into the future.
This post summarizes where AWS is today in the journey of migrating to PQC and outlines our path forward.
For the past five years we’ve deployed early versions of PQC algorithms under evaluation by the U.S. National Institute of Standards and Technology (NIST) in both our open-source libraries and security-critical services to allow customers to test the performance impact of moving to PQC. For example, our open-source library for algorithm implementations (AWS-LC), our implementation of TLS (s2n) and core security services like AWS Key Management Service (AWS KMS), AWS Secrets Manager and AWS Certificate Manager (ACM) have had implementations of NIST PQC proposed algorithms for key encapsulation as far back as 2019.
On August 13, 2024, the NIST announced three new post-quantum cryptographic (PQC) algorithms as Federal Information Processing Standards (FIPS). This was the result of NIST’s PQC Standardization Process started in 2016. AWS employees are contributors to many of the proposed schemes including the three new FIPS standards.
- FIPS 203, Module-Lattice-Based Key-Encapsulation Mechanism Standard (ML-KEM), a module lattice-based KEM originally submitted under the name CRYSTALS-Kyber
- FIPS 204, Module-Lattice-Based Digital Signature Standard (ML-DSA), a module lattice-based digital signature algorithm initially submitted as CRYSTALS-Dilithium
- FIPS 205, Stateless Hash-Based Digital Signature Standard (SLH-DSA), a stateless hash-based signature scheme that began as SPHINCS+
Many of our customers have been tracking the standardization process, including the U.S. Government’s Commercial National Security Algorithms (CNSA) Suite 2.0 requirements around PQC adoption and the European Commission’s Recommendation on a Coordinated Implementation Roadmap for the transition to Post-Quantum Cryptography.
Now that the first round of PQC algorithms has been standardized, we can start to implement them for long-term support. Here’s our approach to implementing PQC to provide a seamless transition for our customers who rely on our services and open-source tools to handle cryptographic operations on their behalf.
AWS will take a multi-layered approach to migrating to PQC over the coming years. We define the simultaneous workstreams as:
- Workstream 1: Inventory of existing systems, identification and development of new standards, testing, and migration planning. While the first set of algorithm standards has been published, there are additional standards to come that will define how PQC should be integrated in specific applications and protocols to ensure interoperability.
- Workstream 2: Integration of PQC algorithms on public AWS endpoints to provide long-lived confidentiality of customer data transmitted to AWS.
- Workstream 3: Integration of PQC signing algorithms into AWS cryptographic services to enable customers to deploy new post-quantum long-lived roots of trust to be used for functions such as software, firmware, and document signing.
- Workstream 4: Integration of PQC signing algorithms into AWS services to enable the use of post-quantum signatures for session-based authentication such as server and client certificate validation.
Workstream 1
We view the work here as an ongoing aspect of our migration plan. It has already informed our overall strategy and prioritized our migration based on our customers’ needs.
Similar to our customers, we had to look across all of the places where we use cryptography to determine which implementations needed migration and at which priority. One of the important decisions we made was to focus more on encryption in transit and less on encryption at rest. Public key (asymmetric) cryptography is the foundation of encryption in transit because it enables two parties to negotiate a shared secret across an untrusted network—it’s today’s traditional public key algorithms that are at risk of being compromised by a cryptographically relevant quantum computer. Based on the current consensus across the industry, the risk of a cryptographically relevant quantum computer to the 256-bit symmetric key cryptography isn’t something that needs to be mitigated. Because data at rest in AWS is encrypted using 256-bit symmetric cryptography, we believe that we don’t need to re-encrypt existing customer data or change the symmetric algorithms and keys that we use to encrypt future data.
While the security of symmetric encryption keys and algorithms isn’t impacted by a cryptographically relevant quantum computer, there are cases where public key algorithms are used to negotiate a shared symmetric key, thereby creating risk that the symmetric key could be compromised. The first use of public key cryptography in AWS that we will migrate to PQC is exactly this case—where we negotiate a shared symmetric key between our customers and the public endpoints of AWS services. The networks that customers use to communicate with AWS services are often outside the control of either AWS or the customer, and therefore susceptible to a bad actor capturing data now and then brute-force decrypting it in the future using a cryptographically relevant quantum computer. Workstream 2 discusses this plan in more detail.
The next use of public key cryptography in AWS that we will migrate to PQC is where we offer the ability to create a key pair that acts as a long-term root of trust, typically used to apply a digital signature to software, firmware, or documents. These types of key pairs might need to be valid for digital signing years into the future because they can’t easily be updated. Think of the firmware on satellites, gaming consoles, and other IoT devices where replacing the public key pairs and the signing algorithm code might not be possible over the life of the device. Workstream 3 describes this plan in more detail.
The final area of public key cryptography in AWS that we will migrate to PQC is where we offer the ability to create a key pair that acts as a shorter-term root of trust, typically used to apply a digital signature to a single transaction, a web session, or some other ephemeral message. The most common example of this use case is the way that digital certificates are used to authenticate the server or client in a TLS session. You might assume that workstreams 2 and 3 handle the risks to session key negotiation and digital signatures in a TLS session, so what’s left to protect? It turns out that the way that public key cryptography is used to mutually authenticate two parties using digital certificates to exchange a message is heavily dependent on standards and interoperability across a large set of internet infrastructure. Getting the industry to agree on those standards and testing interoperability will take time before this workstream is finished. Workstream 4 describes this plan in more detail.
We’ve talked about how AWS has done its cryptographic inventory and our plan to migrate to PQC. If you don’t delegate all your cryptographic operations to AWS, what should you be doing to prepare? While no single approach will be right for all applications and industries, here are some resources with more context on recommendations that we contributed to or used as part of our work:
- CISA Quantum-Readiness: Migration to Post-Quantum Cryptography
- CISA Strategy for Migrating to Automated Post-Quantum Cryptography Discovery and Inventory Tools
- ETSI TR 103 619 Migration strategies and recommendations to Quantum Safe schemes
While doing an inventory of cryptography across your organization to prioritize PQC migration might be a multi-year effort for you, we have a couple of tactical recommendations to consider in the short-term. First, work to make sure that you have agility in your abilities to distribute updated versions of software. This is a critical capability for any organization in the context of vulnerability management and software lifecycle maintenance. This ability will be required to adopt new PQ versions of the AWS Command Line Interface (AWS CLI) and AWS SDKs when we publish them. You might also need to update third-party software components that use TLS or other cryptographic implementations used to communicate with AWS services to make sure that you can take advantage of the PQC we offer.
Second, we strongly encourage you to begin a comprehensive program to adopt TLS 1.3 across your entire organization. This and later versions of TLS not only offer security and performance improvements using classical public key cryptography, but they are strictly mandated to be able to use PQC at all. Even if you recently updated to TLS 1.2 in your clients and servers, you still have work to do to prepare your systems for a PQC future.
Workstream 2
Customers communicate with cloud services using protocols based on public key cryptography. These protocols (such as TLS) help ensure that customers’ communications are confidential and cannot be altered in transit. To protect our customers’ long-term need for confidentiality, we pioneered a mechanism known as hybrid post-quantum key agreement. Hybrid post-quantum key agreement combines Elliptic-Curve Diffie-Hellman (ECDH), a classic key exchange algorithm, with a post-quantum key encapsulation method, such as the newly standardized ML-KEM algorithm. The resulting two keys are combined to establish session communication keys that encrypt the network traffic. An adversary would need to break both of these public-key primitives (ECDH and ML-KEM) to break the confidentiality property provided by the hybrid key agreement.
AWS has taken the first step in deploying PQC by implementing ML-KEM within AWS-LC, our open-source FIPS-140-3-validated cryptographic library. AWS-LC is the core cryptographic library used throughout AWS. Relevant to this workstream, it’s used in s2n-tls, our open-source TLS implementation used across AWS services with HTTPS-based endpoints.
The Internet Engineering Task Force (IETF) is currently finalizing the TLS protocol standard incorporating post-quantum cryptography. Upon completion of this standard, AWS will update s2n-tls to align with these new specifications. After we have the ML-KEM implementation from AWS-LC integrated with a version of s2n based on IETF standards, we will begin deployment of this s2n version across all AWS public endpoints that offer HTTPS-based interfaces. This represents most AWS services, typically accessed through the AWS SDK or AWS CLI. AWS services that offer public endpoints with other interfaces such as SFTP, IPsec, or SSH will get ML-KEM support as standards bodies such as the IETF publish implementation guidance for those protocols.
As a part of migrating AWS managed service endpoints to PQC over TLS, we’ll also be enabling services that provide server-side TLS termination for your workloads, including Elastic Load Balancing (ELB), Amazon API Gateway, and Amazon CloudFront. This will allow you to use the same digital certificates that you’ve been using with these services and let them negotiate the server-side TLS session using ML-KEM on your behalf. This will provide the long-term confidentiality of your TLS sessions without you having to upgrade the underlying certificates themselves to some as-yet-undefined PQC standard.
To further strengthen this transition to ML-KEM, AWS is collaborating with key industry initiatives, including the National Cybersecurity Center of Excellence (NCCoE) Migration to Post-Quantum Cryptography, the Linux Foundation’s Post Quantum Cryptography Alliance, and the Rust TLS Project. These partnerships are crucial in helping to ensure seamless interoperability between different implementations of PQC solutions across the technology landscape.
Workstream 3
Many of our customers manufacture systems with firmware, operating systems, and pre-installed third-party applications. These components are cryptographically signed using a public-key-based root of trust to maintain the security and authenticity of systems as they deliver services to end users. Some of these systems, such as smart TVs connected to set-top boxes, might operate without internet connectivity for a decade or longer until they’re installed.
Additionally, certain customers must embed long-lived roots of trust directly into their hardware during manufacturing—a process that cannot be reversed or updated. For devices designed to operate for 10+ years, the security of these initial roots of trust must remain robust even when cryptographically relevant quantum computers become available.
To address this need for long-lived roots of trust for code and document signing, AWS will adopt ML-DSA, a new digital signature algorithm that is believed to be secure against adversaries in possession of a cryptographically relevant quantum computer. We will first offer ML-DSA as a feature within AWS Key Management Service (AWS KMS), enabling customers to generate and use PQC keys as roots of trust for signing operations within the FIPS-140-3 Level 3 validated hardware security modules (HSMs) used in AWS KMS. This integration represents a crucial milestone in our PQC roadmap, providing customers with the capability to establish secure, quantum-resistant roots of trust and authentication for their long-term security needs.
This long-term perspective underscores the importance of implementing PQC early, helping to ensure that systems will remain secure throughout their entire operational lifetime, even if they are disconnected for a prolonged period. While Amazon will use this capability from AWS KMS to protect our own roots of trust, we encourage you to consider ways in which this capability might help you do the same.
Workstream 4
In workstream 2 we discussed how PQC can be deployed to protect against risks to the confidentiality of data shared across a communication channel. To complete the story, there still needs to be a way to protect the authenticity of server and client identities over a communication channel in a post-quantum world.
Digital signatures are used today for end-entity authentication in networking protocols such as TLS and SSH. Customers use certificates from a trusted certificate authority (CA) that binds a public key to an identity using a digital signature to authenticate service and client endpoints. While some of the PQC standards available today (e.g. ML-DSA) could be implemented with certificates to address the post-quantum risk, the work cannot begin without further standardization and interoperability testing between certificate authorities and the systems that use digital certificates. The primary reason for this delay has to do with how publicly trusted certificates are validated today by recipients of a signed message. In the TLS protocol, for example, the client connecting to a server that presents a chain of digital certificates would need to validate all PQC signatures embedded in each certificate to determine if the server is authentic. The format of those signatures and the processes by which the certificates are issued and managed is governed by the Certificate Authority (CA) Browser Forum. The internet browser manufacturers and certificate issuer members of the CA Browser Forum need to determine how PQC will work for certificate issuance and validation before anyone can safely use them for publicly trusted certificates in TLS sessions. Amazon Trust Services is a certificate issuer and member of the CA Browser Forum; we are engaged to help drive these standards to expedite interoperability testing.
While the PQC story is being finalized for publicly trusted certificates, the AWS Private CA service isn’t necessarily blocked for the same reasons from issuing privately trusted certificates using PQC algorithms like ML-DSA. We would be able to do this because privately trusted certificates aren’t strictly beholden to the rules published by the CA Browser Forum. Customers using privately trusted certificates have the freedom to implement both the client and server portions of a PQC authentication scheme when they control the software on both ends. When workstream 3 is finished and ML-DSA is available for use from AWS KMS for signing operations, AWS Private CA will consider offering PQC as a part of certificate issuance for those customers who are ready to adopt it for their private networking channels. Our open-source AWS-LC and s2n solutions will be available for our customers to implement the PQC certificate validation functions on their clients and servers if need be.
Conclusion
In this post, we covered how AWS will migrate to PQC as part of our shared responsibility model. We also provided guidance to you on how to start your PQC migration strategy, and what part of that strategy you can expect AWS to provide. The road ahead will present new challenges and new opportunities as the industry performs the migration to new cryptographic algorithms. For additional information, blog posts, and periodic updates on our PQC migration, keep watching the AWS Post-Quantum Cryptography page.
If you want to learn more about post-quantum cryptography with AWS, contact the post-quantum cryptography team.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Security, Identity, & Compliance re:Post or contact AWS Support.
Broadcom 3.5D XDSiP with Face-To-Face 3.5D For 2026 XPUs and Beyond
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/broadcom-3-5d-xdsip-with-face-to-face-3-5d-for-2026-xpus-and-beyond/
Broadcom 3.5D XDSiP with Face-to-Face 3.5D packaging already has a number of design wins for big custom 2026 XPUs
The post Broadcom 3.5D XDSiP with Face-To-Face 3.5D For 2026 XPUs and Beyond appeared first on ServeTheHome.
‘Tis the Season for COSMIC Alpha 4! (System76 Blog)
Post Syndicated from jzb original https://lwn.net/Articles/1000927/
System76 has announced the
fourth alpha release of its Rust-based COSMIC desktop. New features
in this version include the ability to set default applications,
region and language settings, a new Accessibility applet, as well as
support for
variable refresh rate (VRR) in the cosmic-comp compositor and the
display settings tool. See the blog post for a full list of fixes and
performance improvements. LWN covered the first alpha
release in August.
[$] Debian opens a can of username worms
Post Syndicated from jzb original https://lwn.net/Articles/1000485/
It has long been said that naming things
is one of the hard things to do in computer science. That may be
so, but it pales in comparison to the challenge of handling
usernames properly in applications. This is especially true when multiple
applications are involved, and they are all supposed to agree on what
characters are, and are not, allowed. The Debian project is facing
that problem right now, as two user-creation utilities disagreed about
which names are allowable. A plan is in place to sort this out
before the release of Debian 13 (“trixie”) sometime next year.
Peter Attia | Outlive: The Science & Art of Longevity | Talks at Google
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=H8eBCOWQoio
The ULTIMATE Peplink Configuration Guide!
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=BZgtoFaCbj0