Post Syndicated from Nideesh K T original https://aws.amazon.com/blogs/security/how-to-use-whatsapp-to-send-amazon-cognito-notification-messages/
While traditional channels like email and SMS remain important, businesses are increasingly exploring alternative messaging services to reach their customers more effectively. In recent years, WhatsApp has emerged as a simple and effective way to engage with users. According to statista, as of 2024, WhatsApp is the most popular mobile messenger app worldwide and has reached over two billion monthly active users in January 2024.
Amazon Cognito lets you add user sign-up and authentication to your mobile and web applications. Among many other features, Cognito provides a custom SMS sender AWS Lambda trigger for using third-party providers to send notifications. In this post, we’ll be using WhatsApp as the third-party provider to send verification codes or multi-factor authentication (MFA) codes instead of SMS during Cognito user pool sign up.
Note: WhatsApp is a third-party service subject to additional terms and charges. Amazon Web Services (AWS) isn’t responsible for third-party services that you use to send messages with a custom SMS sender in Amazon Cognito.
Overview
By default, Amazon Cognito uses Amazon Simple Notification Service (Amazon SNS) for delivery of SMS text messages. Cognito also supports custom triggers that will allow you to invoke an AWS Lambda function to support additional providers such as WhatsApp.
The architecture shown in Figure 1 depicts how to use a custom SMS sender trigger and WhatsApp to send notifications. The steps are as follows:
- A user signs up to an Amazon Cognito user pool.
- Cognito invokes the custom SMS sender Lambda function and sends the user’s attributes, including the phone number and a one-time code to the Lambda function. This one-time code is encrypted using a custom symmetric encryption AWS Key Management Service (AWS KMS) key that you create.
- The Lambda function decrypts the one-time code using a Decrypt API call to your AWS KMS key.
- The Lambda function then obtains the WhatsApp access token from AWS Secrets Manager. The WhatsApp access token needs to be generated through Meta Business Settings (which are covered in the next section) and added to Secrets Manager. Lambda also parses the phone number, user attributes, and encrypted secrets.
- Lambda sends a POST API call to the WhatsApp API and WhatsApp delivers the verification code to the user as a message. The user can then use the verification code to verify their contact information and confirm the sign-up.
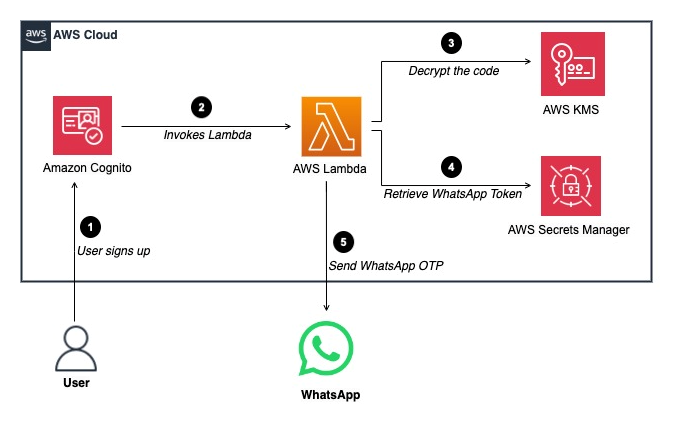
Figure 1: Custom SMS sender trigger flow
Prerequisites
- Create an AWS account if you don’t already have one and sign in. The AWS Identity and Access Management (IAM) role that you use must have sufficient permissions to make the necessary AWS service calls and manage AWS resources such as creating and updating Lambda functions, Amazon Cognito user pools, Secrets Manager, AWS KMS keys, and IAM roles.
- A Meta (Facebook) developer account. For more details go to the Meta for Developers console.
- Git installed.
- AWS Cloud Development Kit (AWS CDK) Toolkit installed and configured.
- Node.js with NPM installed.
- Docker installed and running.
Implementation
In the next steps, we look at how to create a Meta app, create a new system user, get the WhatsApp access token and create the template to send the WhatsApp token.
Create and configure an app for WhatsApp communication
To get started, create a Meta app with WhatsApp added to it, along with the customer phone number that will be used to test.
To create and configure an app
- Open the Meta for Developers console, choose My Apps and then choose Create App (or choose an existing Business type app and skip to step 4).
- Select Other choose Next and then select Business as the app type and choose Next.
- Enter an App name, App contact email, choose whether or not to attach a Business portfolio and choose Create app.
- Open the app Dashboard and in the Add product to your app section, under WhatsApp, choose Set up.
- Create or select an existing Meta business portfolio and choose Continue.
- In the left navigation pane, under WhatsApp, choose API Setup.
- Under Send and receive messages, take a note of the Phone number ID, which will be needed in the AWS CDK template later.
- Under To, add the customer phone number you want to use for testing. Follow the instructions to add and verify the phone number.
Note: You must have WhatsApp registered with the number and the WhatsApp client installed on your mobile device.
Create a user for accessing WhatsApp
Create a system user in Meta’s Business Manager and assign it to the app created in the previous step. The access tokens generated for this user will be used to make the WhatsApp API calls.
To create a user
- Open Meta’s Business Manager and select the business you created or associated your application with earlier from the dropdown menu under Business settings.
- Under Users, select System users and then choose Add to create a new system user.
- Enter a name for the System Username and set their role as Admin and choose Create system user.
- Choose Assign assets.
- From the Select asset type list, select Apps. Under Select assets, select your WhatsApp application’s name. Under Partial access, turn on the Test app option for the user. Choose Save Changes and then choose Done.
- Choose Generate New Token, select the WhatsApp application created earlier, and leave the default 60 days as the token expiration. Under Permissions select WhatsApp_business_messaging and WhatsApp_business_management and choose Generate Token at the bottom.
- Copy and save your access token. You will need this for the AWS CDK template later. Choose OK. For more details on creating the access token, see WhatsApp’s Business Management API Get Started guide.
Create a template in WhatsApp
Create a template for the verification messages that will be sent by WhatsApp.
To create a template
- Open Meta’s WhatsApp Manager.
- On the left icon pane, under Account tools, choose Message template and then choose Create Template.
- Select Authentication as the category.
- For the Name, enter otp_message.
- For Languages, enter English.
- Choose Continue.
- In the next screen, select Copy code and choose Submit.
Note: It’s possible that Meta might change the process or the UI. See the Meta documentation for specific details.
For more information on WhatsApp templates, see Create and Manage Templates.
Create a Secrets Manager secret
Use the Secrets Manager console to create a Secrets Manager secret and set the secret to the WhatsApp access token.
To create a secret
- Open the AWS Management Console and go to Secrets Manager.

Figure 2: Open the Secrets Manager console
- Choose Store a new secret.
Figure 3: Store a new secret
- Under Choose a secret type, choose Other type of secret and under Key/value pairs, select the Plaintext tab and enter Bearer followed by the WhatsApp access token (Bearer <WhatsApp access token>).
Figure 4: Add the secret
- For the encryption key, you can use either the AWS KMS key that Secrets Manager creates or a customer managed AWS KMS key that you create and then choose Next.
- Provide the secret name as the WhatsAppAccessToken, choose Next, and then choose Store to create the secret.
- Note the secret Amazon Resource Name (ARN) to use in later steps.



Deploy the solution
In this section, you clone the GitHub repository and deploy the stack to create the resources in your account.
To clone the repository
- Create a new directory, navigate to that directory in a terminal and use the following command to clone the GitHub repository that has the Lambda and AWS CDK code:
- Change directory to the pattern directory:
To deploy the stack
- Configure the phone number ID obtained from WhatsApp, the secret name, secret ARN, and the Amazon Cognito user pool self-service sign-up option in the constants.ts file.
Open the lib/constants.ts file and edit the fields. The SELF_SIGNUP value must be set to true for the purpose of this proof of concept. The SELF_SIGNUP value represents the Boolean value for the Amazon Cognito user pool sign-up option, which when set to true allows public users to sign up.
Warning: If you activate user sign-up (enable self-registration) in your user pool, anyone on the internet can sign up for an account and sign in to your applications.
- Install the AWS CDK required dependencies by running the following command:
- This project uses typescript as the client language for AWS CDK. Run the following command to compile typescript to JavaScript:
- From the command line, configure AWS CDK (if you have not already done so):
- Install and run Docker. We’re using the aws-lambda-python-alpha package in the AWS CDK code to build the Lambda deployment package. The deployment package installs the required modules in a Lambda compatible Docker container.
- Deploy the stack:
Test the solution
Now that you’ve completed implementation, it’s time to test the solution by signing up a user on Amazon Cognito and confirming that the Lambda function is invoked and sends the verification code.
To test the solution
- Open AWS CloudFormation console.
- Select the WhatsappOtpStack that was deployed through AWS CDK.
- On the Outputs tab, copy the value of cognitocustomotpsenderclientappid.
- Run the following AWS Command Line Interface (AWS CLI) command, replacing the client ID with the output of cognitocustomotpsenderclientappid, username, password, email address, name, phone number, and AWS Region to sign up a new Amazon Cognito user.
Example:
Note: Password requirements are a minimum length of eight characters with at least one number, one lowercase letter, and one special character.
The new user should receive a message on WhatsApp with a verification code that they can use to complete their sign-up.
Cleanup
- Run the following command to delete the resources that were created. It might take a few minutes for the CloudFormation stack to be deleted.
- Delete the secret WhatsAppAccessToken that was created from the Secrets Manager console.
Conclusion
In this post, we showed you how to use an alternative messaging platform such as WhatsApp to send notification messages from Amazon Cognito. This functionality is enabled through the Amazon Cognito custom SMS sender trigger, which invokes a Lambda function that has the custom code to send messages through the WhatsApp API. You can use the same method to use other third-party providers to send messages.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the Amazon Cognito re:Post or contact AWS Support.
Want more AWS Security news? Follow us on X.



