IPFS, the distributed file system and content addressing protocol, has been around since 2015, and Cloudflare has been a user and operator since 2018, when we began operating a public IPFS gateway. Today, we are announcing our plan to transition this gateway traffic to the Interplanetary Shipyard (“Shipyard”) team and discussing what it means for users and the future of IPFS gateways.
As announced in April 2024, many of the IPFS core developers and maintainers now work within a newly created, independent entity called Interplanetary Shipyard (“Shipyard”). For IPFS to continue exemplifying the open-source ethos, its core developers will work for Shipyard, rather than Protocol Labs, where IPFS was invented and incubated. By operating as a collective, ongoing maintenance and support of important protocols like IPFS are now even more community-owned and managed. We fully support this “exit to community” and are excited to see Shipyard build more great infrastructure for the open web.
On May 14th, 2024, we will begin to transition traffic that comes to Cloudflare’s public IPFS gateway to Shipyard’s IPFS gateway at ipfs.io or dweb.link. Cloudflare’s public IPFS gateway is just one of many – part of a distributed ecosystem that also includes Pinata, eth.limo, and many more. Visit the IPFS Public Gateway Checker to see the other publicly available IPFS gateways.
Cloudflare believes in helping build a better Internet for all and an accessible and private Internet, principles that Protocol Labs, IPFS, and Shipyard all share. We believe the IPFS gateway transition to Shipyard will boost ecosystem collaboration, increase protocol resiliency, and ensure healthy stewardship and governance. Cloudflare is proud to be a partner of Shipyard in this transition and will continue to help sponsor their work as gateway stewards.
What happens next
All traffic using the cloudflare-ipfs.com or cf-ipfs.com hostname(s) will continue to work without interruption and be redirected to ipfs.io or dweb.link until August 14th, 2024, at which time the Cloudflare hostnames will no longer connect to IPFS and all users must switch the hostname they use to ipfs.io or dweb.link to ensure no service interruption takes place. If you are using either of the Cloudflare hostnames, please be sure to switch to one of the new ones as soon as possible ahead of the transition date to avoid any service interruptions!
It is important to both Cloudflare and Shipyard that this transition is completed seamlessly and with as little impact to users as possible. With that in mind, there is no change to the amount or type of end user information that is visible to either Cloudflare or Shipyard before or after the completion of this transition.
We’re excited to see further development and projects from the IPFS community and play our part in helping those applications be secure, performant, and reliable!
—
About Shipyard
Interplanetary Shipyard is an engineering collective that delivers user agency through technical advancements in IPFS and libp2p. As the core maintainers of open source projects in the Interplanetary Stack (including IPFS and libp2p implementations such as Kubo, Rainbow, Boxo, Helia, and go/js-libp2p/js-libp2p), and supporting performance measurement tooling (Probelab), they are committed to open source innovation and building bridges between traditional web frameworks and the decentralized ecosystem. To achieve this, their engineers work alongside technical teams in web2 and web3 to promote adoption and drive practical applications.
Golang 1.20 introduced support for Profile Guided Optimization (PGO) to the go compiler. This allows guiding the compiler to introduce optimizations based on the real world behaviour of your system. In the Observability Team at Cloudflare, we maintain a few Go-based services that use thousands of cores worldwide, so even the 2-7% savings advertised would drastically reduce our CPU footprint, effectively for free. This would reduce the CPU usage for our internal services, freeing up those resources to serve customer requests, providing measurable improvements to our customer experience. In this post, I will cover the process we created for experimenting with PGO – collecting representative profiles across our production infrastructure and then deploying new PGO binaries and measuring the CPU savings.
How does PGO work?
PGO itself is not a Go-specific tool, although it is relatively new. PGO allows you to take CPU profiles from a program running in production and use that to optimise the generated assembly for that program. This includes a bunch of different optimisations such as inlining heavily used functions more aggressively, reworking branch prediction to favour the more common branches, and rearranging the generated code to lump hot paths together to save on CPU cache swapping.
The general flow for using PGO is to compile a non-PGO binary and deploy it to production, collect CPU profiles from the binary in production, and then compile a second binary using that CPU profile. CPU Profiles contain samples of what the CPU was spending the most time on when executing a program, which provides valuable context to the compiler when it’s making decisions about optimising a program. For example, the compiler may choose to inline a function that is called many times to reduce the function call overhead, or it might choose to unroll a particularly jump-heavy loop. Crucially, using a profile from production can guide the compiler much more efficiently than any upfront heuristics.
A practical example
In the Observability team, we operate a system we call “wshim”. Wshim is a service that runs on every one of our edge servers, providing a push gateway for telemetry sourced from our internal Cloudflare Workers. Because this service runs on every server, and is called every time an internal worker is called, wshim requires a lot of CPU time to run. In order to track exactly how much, we put wshim into its own cgroup, and use cadvisor to expose Prometheus metrics pertaining to the resources that it uses.
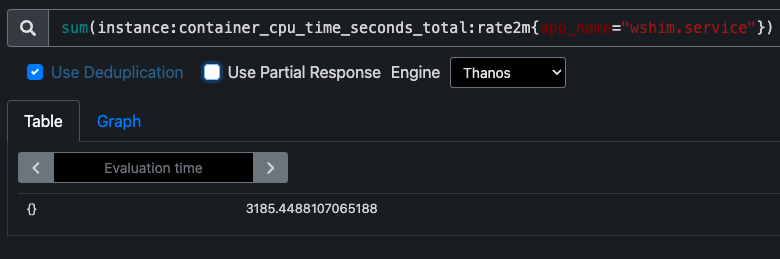
Before deploying PGO, wshim was using over 3000 cores globally:
container_cpu_time_seconds is our internal metric that tracks the amount of time a CPU has spent running wshim across the world. Even a 2% saving would return 60 cores to our customers, making the Cloudflare network even more efficient.
The first step in deploying PGO was to collect representative profiles from our servers worldwide. The first problem we run into is that we run thousands of servers, each with different usage patterns at given points in time – a datacenter serving lots of requests during daytime hours will have a different usage pattern than a different data center that locally is in the middle of the night. As such, selecting exactly which servers to profile is paramount to collecting good profiles for PGO to use.
In the end, we decided that the best samples would be from those datacenters experiencing heavy load – those are the ones where the slowest parts of wshim would be most obvious. Even further, we will only collect profiles from our Tier 1 data centers. These are data centers that serve our most heavily populated regions, are generally our largest, and are generally under very heavy loads during peak hours.
Concretely, we can get a list of high CPU servers by querying our Thanos infrastructure:
num_profiles="1000"
# Fetch the top n CPU users for wshim across the edge using Thanos.
cloudflared access curl "https://thanos/api/v1/query?query=topk%28${num_profiles}%2Cinstance%3Acontainer_cpu_time_seconds_total%3Arate2m%7Bapp_name%3D%22wshim.service%22%7D%29&dedup=true&partial_response=true" --compressed | jq '.data.result[].metric.instance' -r > "${instances_file}"
Go makes actually fetching CPU profiles trivial with pprof. In order for our engineers to debug their systems in production, we provide a method to easily retrieve production profiles that we can use here. Wshim provides a pprof interface that we can use to retrieve profiles, and we can collect these again with bash:
# For every instance, attempt to pull a CPU profile. Note that due to the transient nature of some data centers
# a certain percentage of these will fail, which is fine, as long as we get enough nodes to form a representative sample.
while read instance; do fetch-pprof $instance –port 8976 –seconds 30' > "${working_dir}/${instance}.pprof" & done < "${instances_file}"
wait $(jobs -p)
And then merge all the gathered profiles into one, with go tool:
# Merge the fetched profiles into one.
go tool pprof -proto "${working_dir}/"*.pprof > profile.pprof
It’s this merged profile that we will use to compile our pprof binary. As such, we commit it to our repo so that it lives alongside all the other deployment components of wshim:
And update our Makefile to pass in the -pgo flag to the go build command:
build:
go build -pgo ./pgo/profile.pprof -o /tmp/wshim ./cmd/wshim
After that, we can build and deploy our new PGO optimized version of wshim, like any other version.
Results
Once our new version is deployed, we can review our CPU metrics to see if we have any meaningful savings. Resource usages are notoriously hard to compare. Because wshim’s CPU usage scales with the amount of traffic that any given server is receiving, it has a lot of potentially confounding variables, including the time of day, day of the year, and whether there are any active attacks affecting the datacenter. That being said, we can take a couple of numbers that might give us a good indication of any potential savings.
Firstly, we can look at the CPU usage of wshim immediately before and after the deployment. This may be confounded by the time difference between the sets, but it shows a decent improvement. Because our release takes just under two hours to roll to every tier 1 datacenter, we can use PromQLs `offset` operator to measure the difference:
This indicates that following the release, we’re using ~97 cores fewer than before the release, a ~3.5% reduction. This seems to be inline with the upstream documentation that gives numbers between 2% and 14%.
The second number we can look at is the usage at the same time of day on different days of the week. The average usage for the 7 days prior to the release was 3067.83 cores, whereas the 7 days after the release were 2996.78, a savings of 71 CPUs. Not quite as good as our 97 CPU savings, but still pretty substantial!
This seems to prove the benefits of PGO – without changing the code at all, we managed to save ourselves several servers worth of CPU time.
Future work
Looking at these initial results certainly seems to prove the case for PGO – saving multiple servers worth of CPU without any code changes is a big win for freeing up resources to better serve customer requests. However, there is definitely more work to be done here. In particular:
On Thursday, Google said an anonymous source notified it of the vulnerability. The vulnerability carries a severity rating of 8.8 out of 10. In response, Google said, it would be releasing versions 124.0.6367.201/.202 for macOS and Windows and 124.0.6367.201 for Linux in subsequent days.
“Google is aware that an exploit for CVE-2024-4671 exists in the wild,” the company said.
Google didn’t provide any other details about the exploit, such as what platforms were targeted, who was behind the exploit, or what they were using it for.
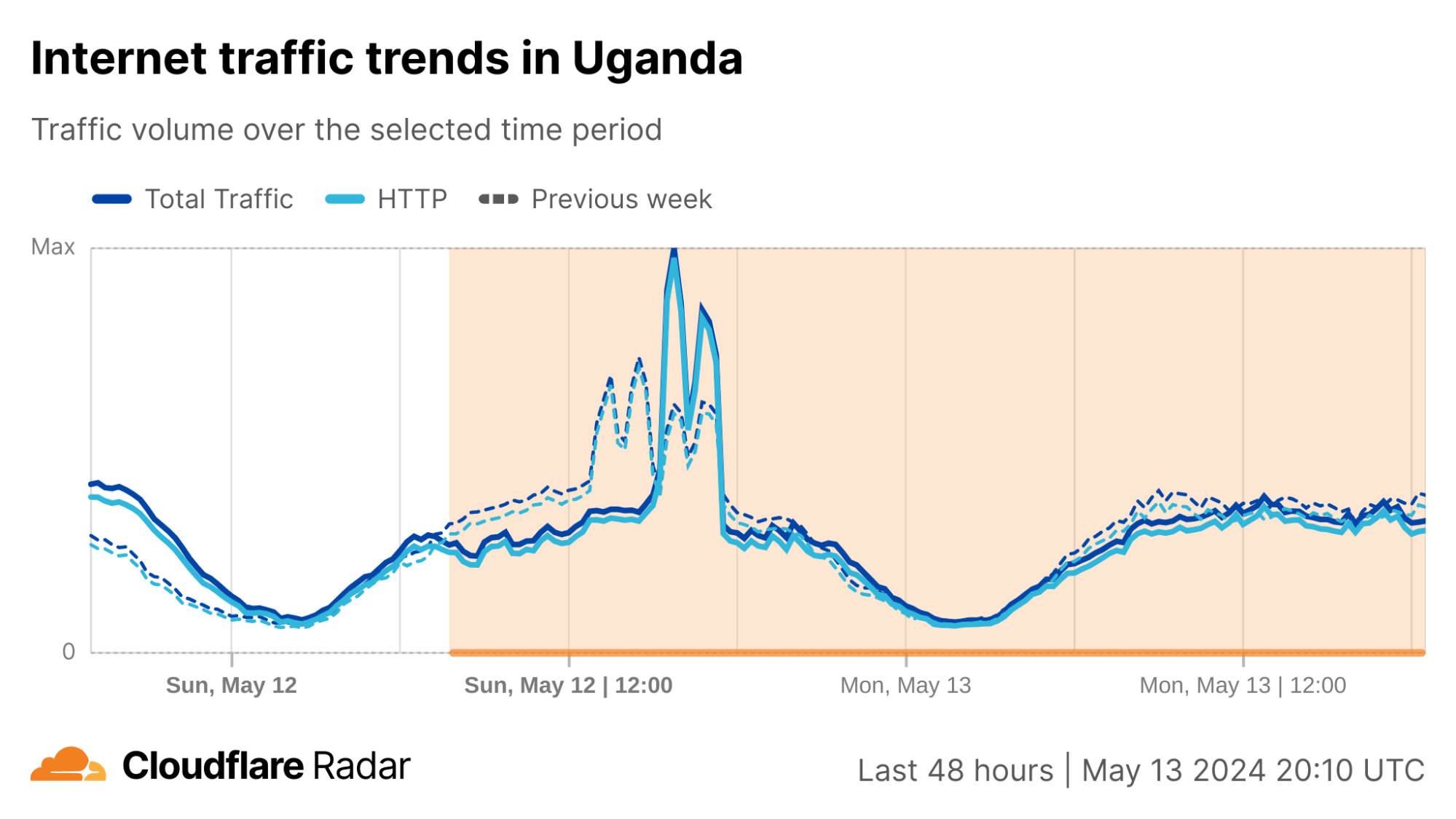
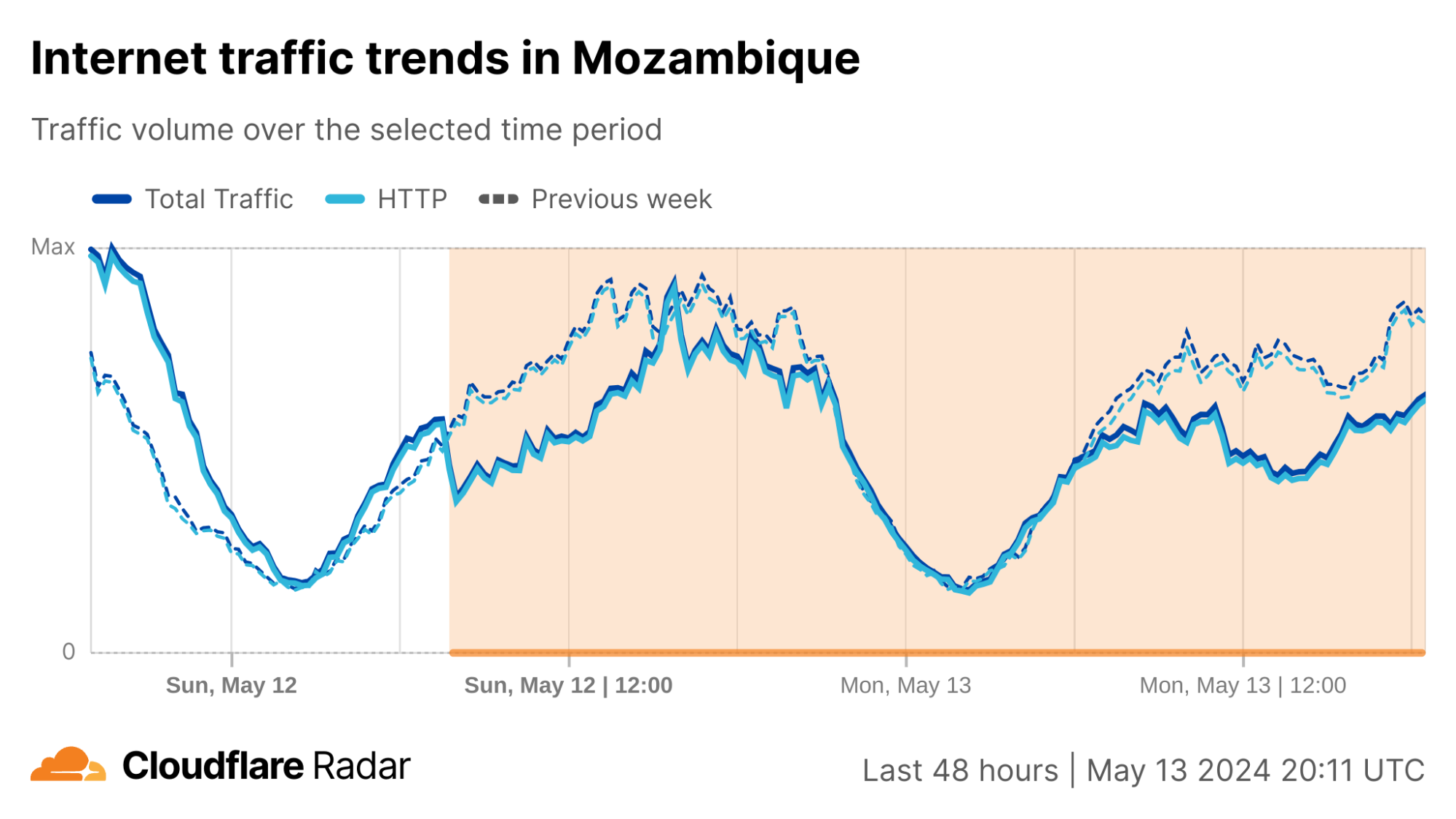
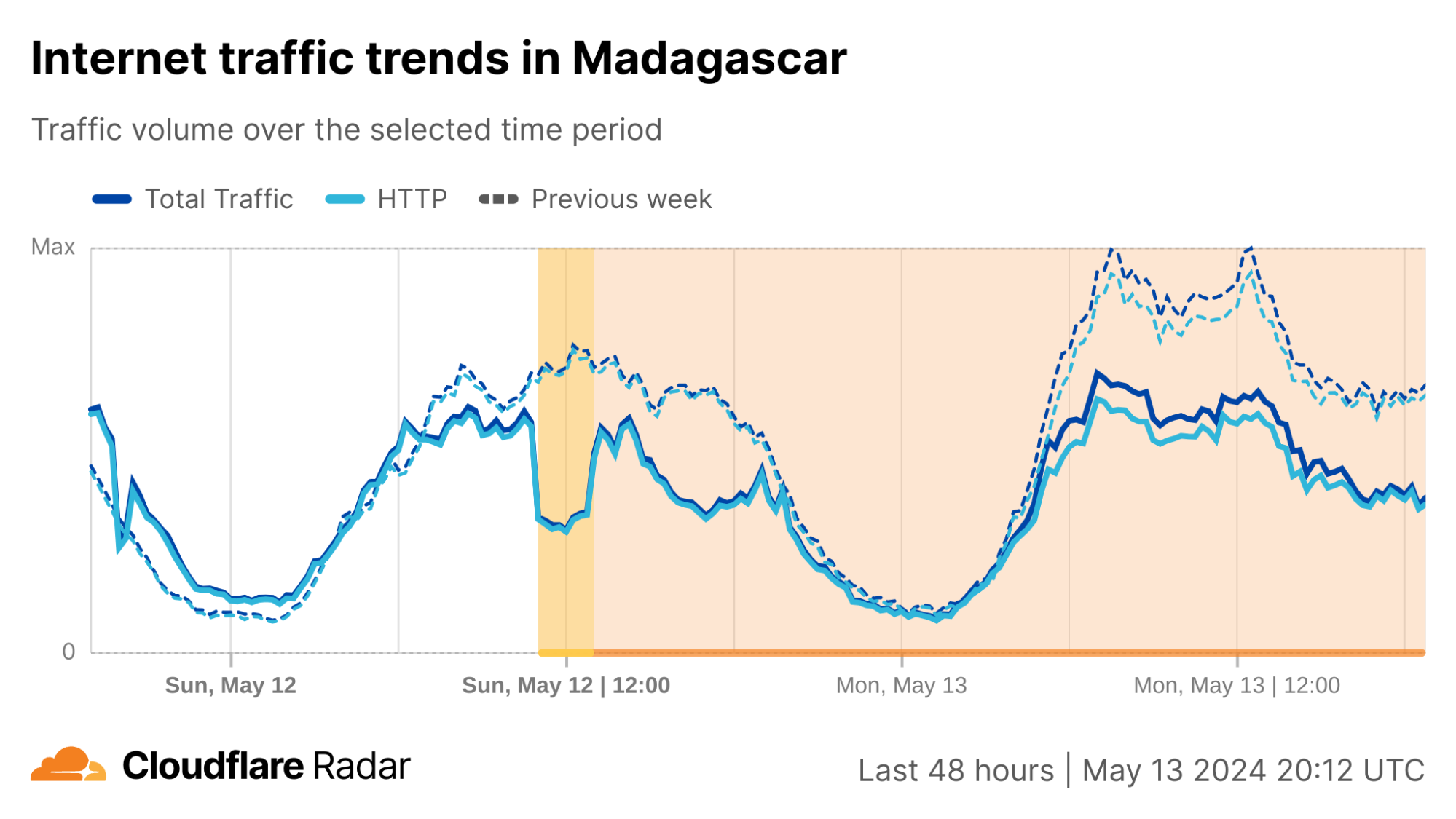
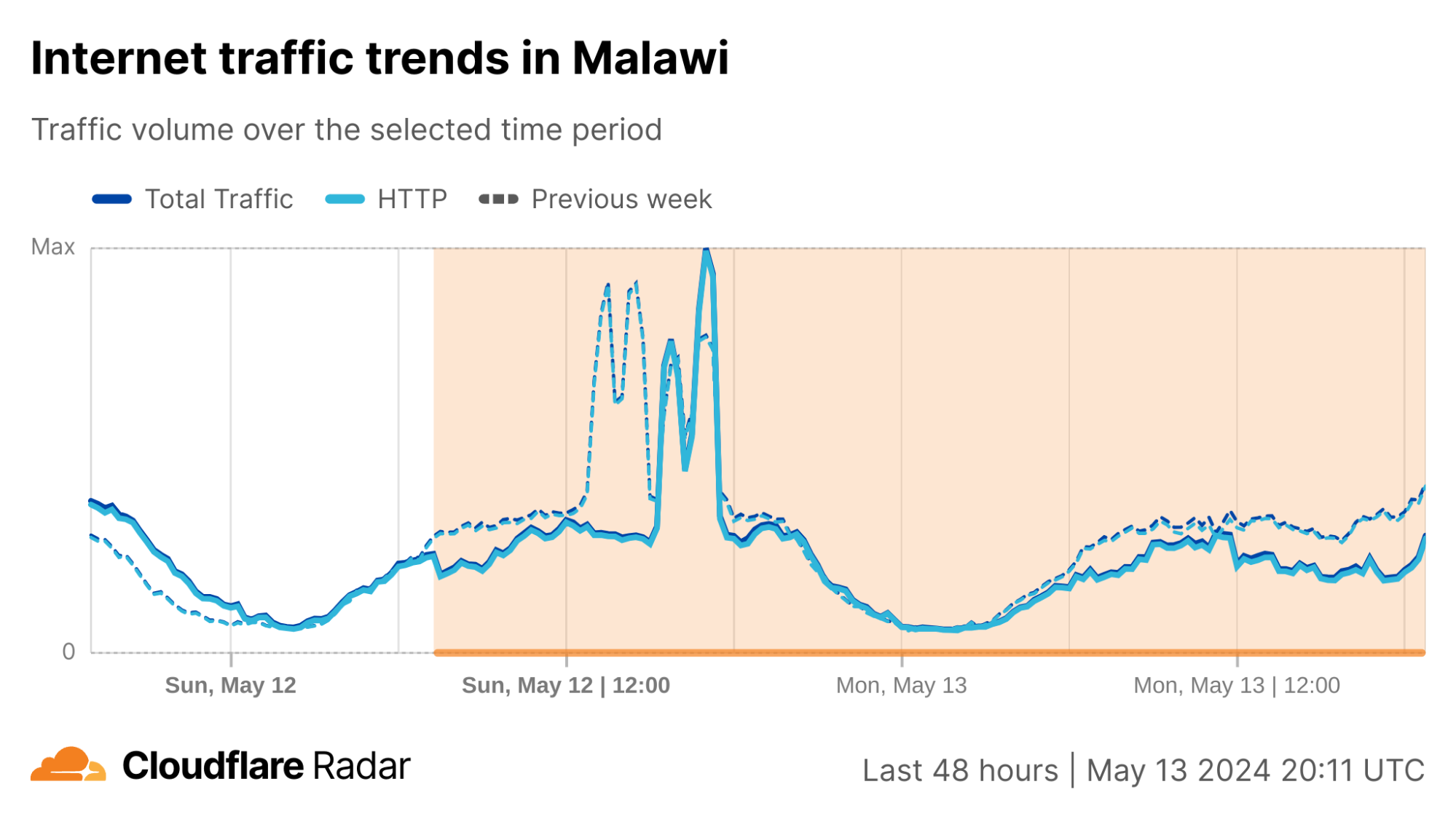
On Sunday, May 12, issues with the ESSAy and Seacom submarine cables again disrupted connectivity to East Africa, impacting a number of countries previously affected by a set of cable cuts that occurred nearly three months earlier.
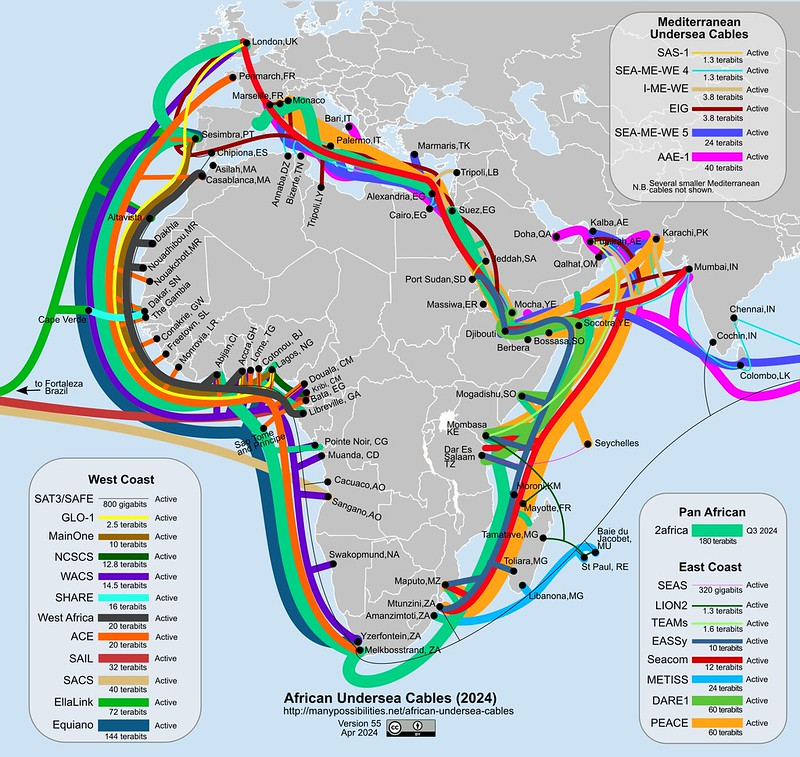
Already suffering from reduced capacity due to the February cable cuts, these countries were impacted by a second set of cable cuts that occurred on Sunday, May 12. According to a social media post from Ben Roberts, Group CTIO at Liquid Intelligent Technologies in Kenya, faults on the EASSy and Seacom cables again disrupted connectivity to East Africa, as he noted “All sub sea capacity between East Africa and South Africa is down.” A BBC article citing Roberts stated that the EASSy cable had been cut approximately 45km (28 miles) north of the South African port city of Durban. A subsequent press release issued by the Communications Authority of Kenya stated that the cut had occurred at the Mtunzini teleport station (in South Africa). As seen in the map below, both the EASSy and Seacom cables land in Mtunzini.
Map of African undersea cables, April 2024. Source: https://manypossibilities.net/african-undersea-cables/
Impacts to country-level Internet traffic
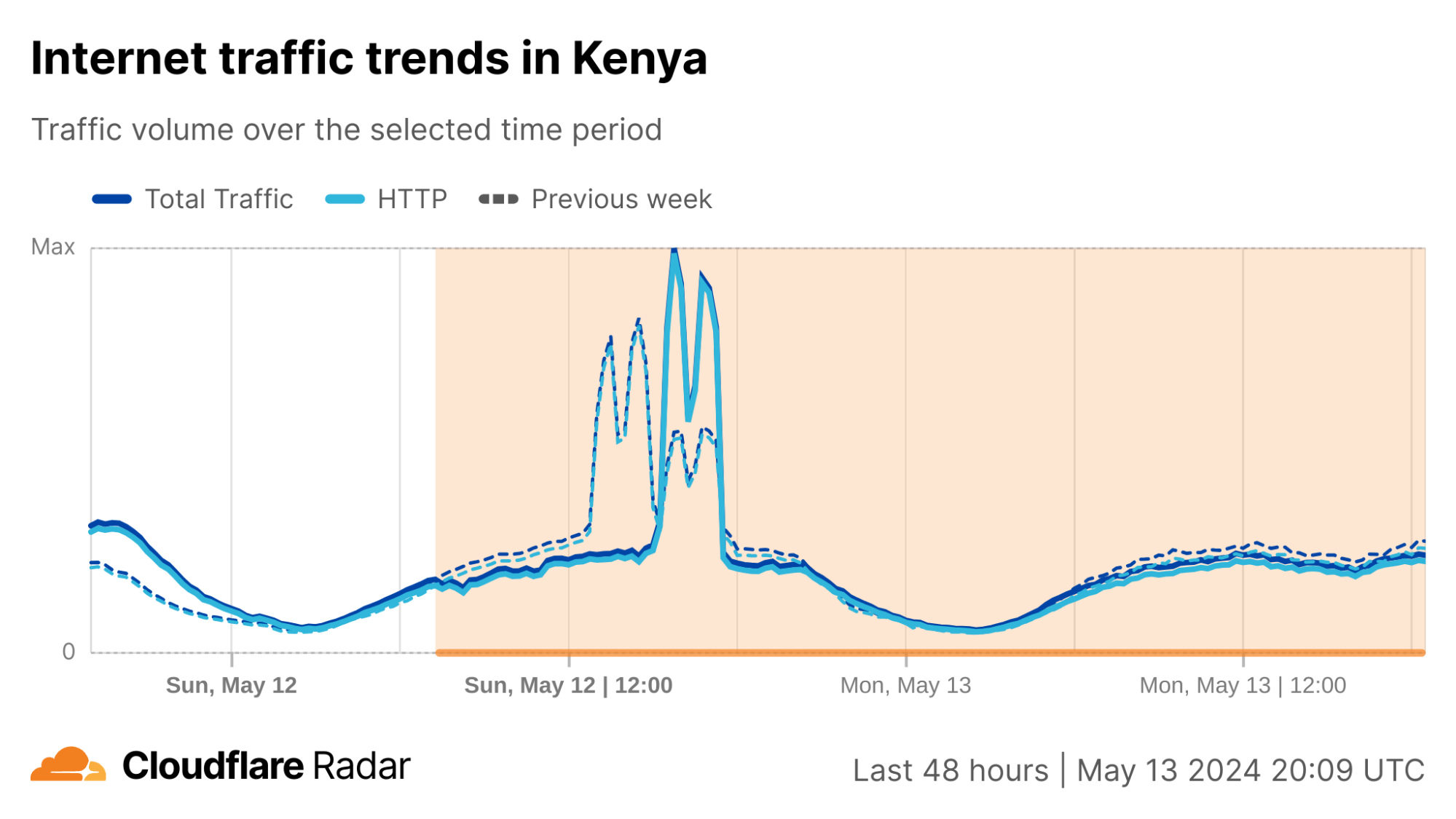
Cloudflare Radar saw traffic levels across a number of the impacted countries drop just before 11:00 local time (08:00 UTC). As seen in the graphs below, the magnitude of impact varied by country, with traffic initially dropping by 10-25% in Kenya, Uganda, Madagascar, and Mozambique, while traffic in Rwanda, Malawi, and Tanzania dropped by one-third or more as compared to the previous week.
In Kenya and Uganda, the overall impact appeared to be low, with traffic generally remaining just below expected levels in the day and a half following the cable faults. In the other countries, the overnight trough of the diurnal traffic patterns remained consistent with the previous week’s traffic levels, but otherwise traffic remains significantly lower than expected.
The importance of redundancy
In Kenya, the impact may have been nominal due to steps taken by providers like Safaricom and Airtel Kenya. In a May 12 social media post, Safaricom noted “…We have since activated redundancy measures to minimise service interruption and keep you connected as we await the full restoration of the cable.” In a subsequent social media post on May 13, Safaricom noted “Thanks to our redundancy plans and capacity investment across multiple undersea cables our services continue to be available, however some customers may experience slow connectivity and speeds.” Similarly, a social media post from Airtel Kenya noted “Following yesterday’s undersea fiber cut that has impacted internet connectivity, we would like to update you that we have taken measures to improve your browsing experience through additional capacity enhancement.”
Similarly, the previously referenced press release from the Communications Authority of Kenya talked about actions being taken, stating “Meanwhile, the Authority has directed service providers to take proactive steps to secure alternative routes for their traffic and is monitoring the situation closely to ensure that incoming and outbound internet connectivity is available. The East Africa Marine System (TEAMS) cable, which has not been affected by the cut, is currently being utilised for local traffic flow while redundancy on the South Africa route has been activated to minimize the impact.”
What’s next?
Once the necessary permits are secured and the cable faults are located, repairs can often be completed in several days. However, because cable repair ships are something of a scarce resource, there is often a delay to both engage a vessel and for it to travel to the area where the cable damage occurred, whether from its baseport or the location of a previous repair. However, in this case that delay may be comparatively short, as submarine cable industry observer @philBE2 predicts “Expecting the usual suspect, CS Leon Thevenin, now moored in Cape Town, to be swiftly mobilized for an expeditious repair mission…”
AWS IAM Identity Center is the preferred way to provide workforce access to Amazon Web Services (AWS) accounts, and enables you to provide workforce access to many AWS managed applications, such as Amazon Q Developer (Formerly known as Code Whisperer).
As we continue to release more AWS managed applications, customers have told us they want to onboard to IAM Identity Center to use AWS managed applications, but some aren’t ready to migrate their existing IAM federation for AWS account management to Identity Center.
In this blog post, I’ll show you how you can enable Identity Center and use AWS managed applications—such as Amazon Q Developer—without migrating existing IAM federation flows to Identity Center.
A recap on AWS managed applications and trusted identity propagation
Just before re:Invent 2023, AWS launched trusted identity propagation, a technology that allows you to use a user’s identity and groups when accessing AWS services. This allows you to assign permissions directly to users or groups, rather than model entitlements in AWS Identity and Access Management (IAM). This makes permissions management simpler for users. For example, with trusted identity propagation, you can grant users and groups access to specific Amazon Redshift clusters without modeling all possible unique combinations of permissions in IAM. Trusted identity propagation is available today for Redshift and Amazon Simple Storage Service (Amazon S3), with more services and features coming over time.
In 2023, we released Amazon Q Developer, which is integrated with IAM Identity Center, generally available as an AWS managed application. When you’re using Amazon Q Developer outside of AWS in integrated development environments (IDEs) such as Microsoft Visual Studio Code, Identity Center is used to sign in to Amazon Q Developer.
Amazon Q Developer is one of many AWS managed applications that are integrated with the OAuth 2.0 functionality of IAM Identity Center, and it doesn’t use IAM credentials to access the Q Developer service from within your IDEs. AWS managed applications and trusted identity propagation don’t require you to use the permission sets feature of Identity Center and instead use OpenID Connect to grant your workforce access to AWS applications and features.
IAM Identity Center for AWS application access only
In the following section, we use IAM Identity Center to sign in to Amazon Q Developer as an example of an AWS managed application.
Prerequisites
The steps in this post require that you have administrative level access to an organization in AWS Organizations.
Step 1: Enable an organization instance of IAM Identity Center
To begin, you must enable an organization instance of IAM Identity Center. While it’s possible to use IAM Identity Center without an AWS Organizations organization, we generally recommend that customers operate with such an organization.
The IAM Identity Center documentation provides the steps to enable an organizational instance of IAM Identity Center, as well as prerequisites and considerations. One consideration I would emphasize here is the identity source. We recommend, wherever possible, that you integrate with an external identity provider (IdP), because this provides the most flexibility and allows you to take advantage of the advanced security features of modern identity platforms.
IAM Identity Center is available at no additional cost.
Note: In late 2023, AWS launched account instances for IAM Identity Center. Account instances allow you to create additional Identity Center instances within member accounts of your organization. Wherever possible, we recommend that customers use an organization instance of IAM Identity Center to give them a centralized place to manage their identities and permissions. AWS recommends account instances when you want to perform a proof of concept using Identity Center, when there isn’t a central IdP or directory that contains all the identities you want to use on AWS and you want to use AWS managed applications with distinct directories, or when your AWS account is a member of an organization in AWS Organizations that is managed by another party and you don’t have access to set up an organization instance.
Step 2: Set up your IdP and synchronize identities and groups
After you’ve enabled your IAM Identity Center instance, you need to set up your instance to work with your chosen IdP and synchronize your identities and groups. The IAM Identity Center documentation includes examples of how to do this with many popular IdPs.
After your identity source is connected, IAM Identity Center can act as the single source of identity and authentication for AWS managed applications, bridging your external identity source and AWS managed applications. You don’t have to create a bespoke relationship between each AWS application and your IdP, and you have a single place to manage user permissions.
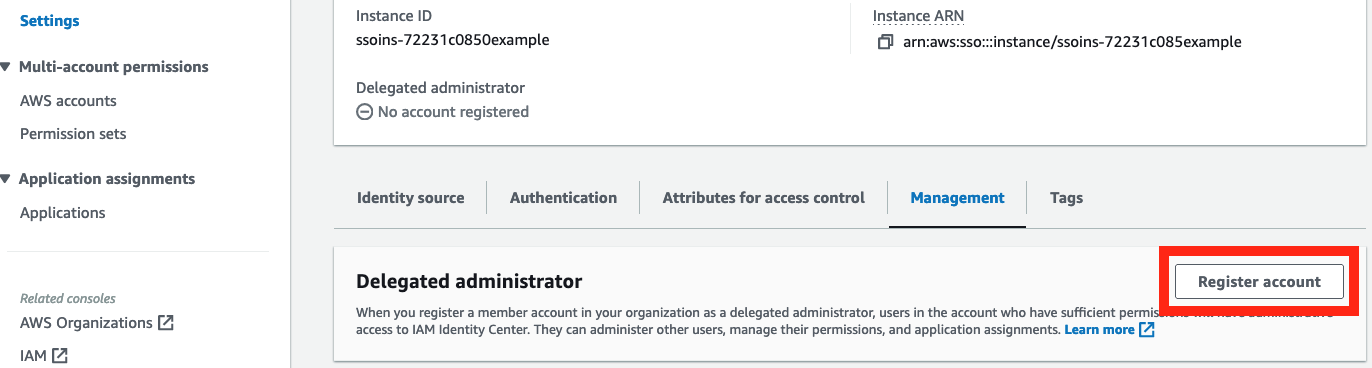
Step 3: Set up delegated administration for IAM Identity Center
As a best practice, we recommend that you only access the management account of your AWS Organizations organization when absolutely necessary. IAM Identity Center supports delegated administration, which allows you to manage Identity Center from a member account of your organization.
To set up delegated administration
Go to the AWS Management Console and navigate to IAM Identity Center.
In the left navigation pane, select Settings. Then select the Management tab and choose Register account.
From the menu that follows, select the AWS account that will be used for delegated administration for IAM Identity Center. Ideally, this member account is dedicated solely to the purpose of administrating IAM Identity Center and is only accessible to users who are responsible for maintaining IAM Identity Center.
Figure 1: Set up delegated administration
Step 4: Configure Amazon Q Developer
You now have IAM Identity Center set up with the users and groups from your directory, and you’re ready to configure AWS managed applications with IAM Identity Center. From a member account within your organization, you can now enable Amazon Q Developer. This can be any member account in your organization and should not be the one where you set up delegated administration of IAM Identity Center, or the management account.
Note: If you’re doing this step immediately after configuring IAM Identity Center with an external IdP with SCIM synchronization, be aware that the users and groups from your external IdP might not yet be synchronized to Identity Center by your external IdP. Identity Center updates user information and group membership as soon as the data is received from your external IdP. How long it takes to finish synchronizing after the data is received depends on the number of users and groups being synchronized to Identity Center.
To enable Amazon Q Developer
Open the Amazon Q Developer console. This will take you to the setup for Amazon Q Developer.
Figure 2: Open the Amazon Q Developer console
Choose Subscribe to Amazon Q.
Figure 3: The Amazon Q developer console
You’ll be taken to the Amazon Q console. Choose Subscribe to subscribe to Amazon Q Developer Pro.
Figure 4: Subscribe to Amazon Q Developer Pro
After choosing Subscribe, you will be prompted to select users and groups you want to enroll for Amazon Q Developer. Select the users and groups you want and then choose Assign.
Figure 5: Assign user and group access to Amazon Q Developer
After you perform these steps, the setup of Amazon Q Developer as an AWS managed application is complete, and you can now use Amazon Q Developer. No additional configuration is required within your external IdP or on-premises Microsoft Active Directory, and no additional user profiles have to be created or synchronized to Amazon Q Developer.
Note: There are charges associated with using the Amazon Q Developer service.
In their IDE, a user can sign in to Amazon Q Developer by entering the start URL and AWS Region and choosing Sign in. Figure 6 shows what this looks like in Visual Studio Code. The Amazon Q extension for Visual Studio Code is available to download within Visual Studio Code.
Figure 6: Signing in to the Amazon Q Developer extension in Visual Studio Code
After choosing Use with Pro license, and entering their Identity Center’s start URL and Region, the user will be directed to authenticate with IAM Identity Center and grant the Amazon Q Developer application access to use the Amazon Q Developer service.
When this is successful, the user will have the Amazon Q Developer functionality available in their IDE. This was achieved without migrating existing federation or AWS account access patterns to IAM Identity Center.
Clean up
If you don’t wish to continue using IAM Identity Center or Amazon Q Developer, you can delete the Amazon Q Developer Profile and Identity Center instance within their respective consoles, within the AWS account they are deployed into. Deleting your Identity Center instance won’t make changes to existing federation or AWS account access that is not done through IAM Identity Center.
Conclusion
In this post, we talked about some recent significant launches of AWS managed applications and features that integrate with IAM Identity Center and discussed how you can use these features without migrating your AWS account management to permission sets. We also showed how you can set up Amazon Q Developer with IAM Identity Center. While the example in this post uses Amazon Q Developer, the same approach and guidance applies to Amazon Q Business and other AWS managed applications integrated with Identity Center.
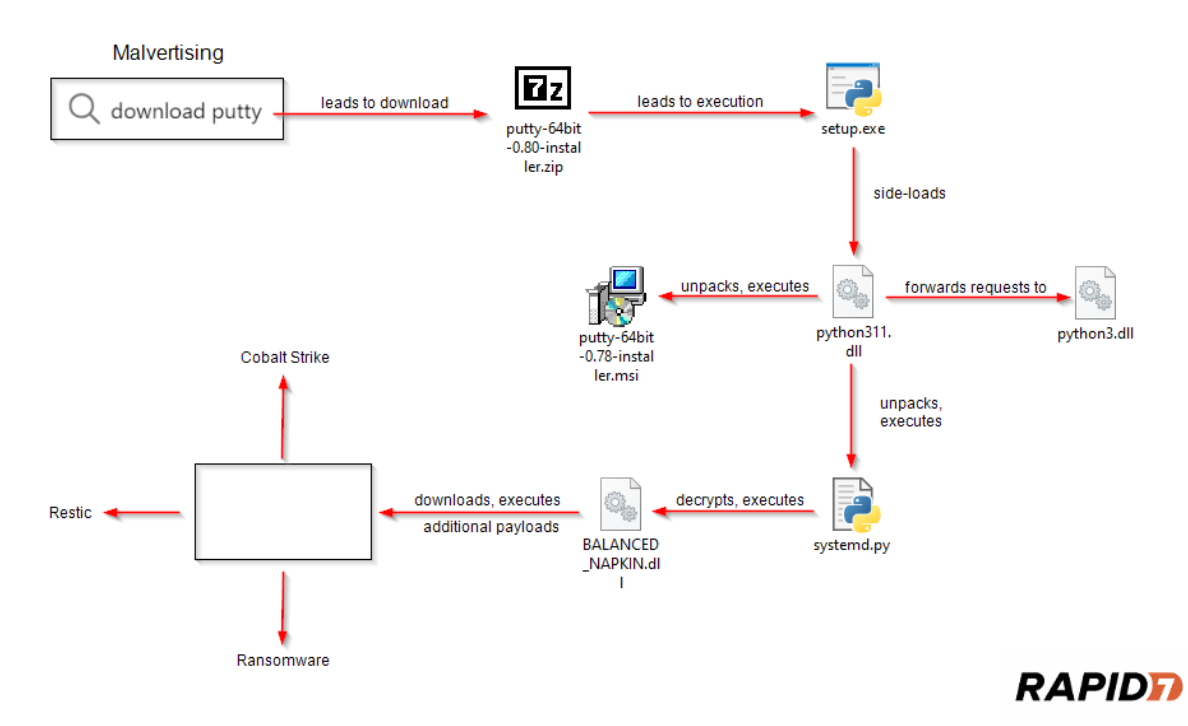
Rapid7 has observed an ongoing campaign to distribute trojanized installers for WinSCP and PuTTY via malicious ads on commonly used search engines, where clicking on the ad leads to typo squatted domains. In at least one observed case, the infection has led to the attempted deployment of ransomware. The analysis conducted by Rapid7 features updates to past research, including a variety of new indicators of compromise, a YARA rule to help identify malicious DLLs, and some observed changes to the malware’s functionality. Rapid7 has observed the campaign disproportionately affects members of IT teams, who are most likely to download the trojanized files while looking for legitimate versions. Successful execution of the malware then provides the threat actor with an elevated foothold and impedes analysis by blurring the intentions of subsequent administrative actions.
Figure 1. Simplified overview of the attack flow.
Overview
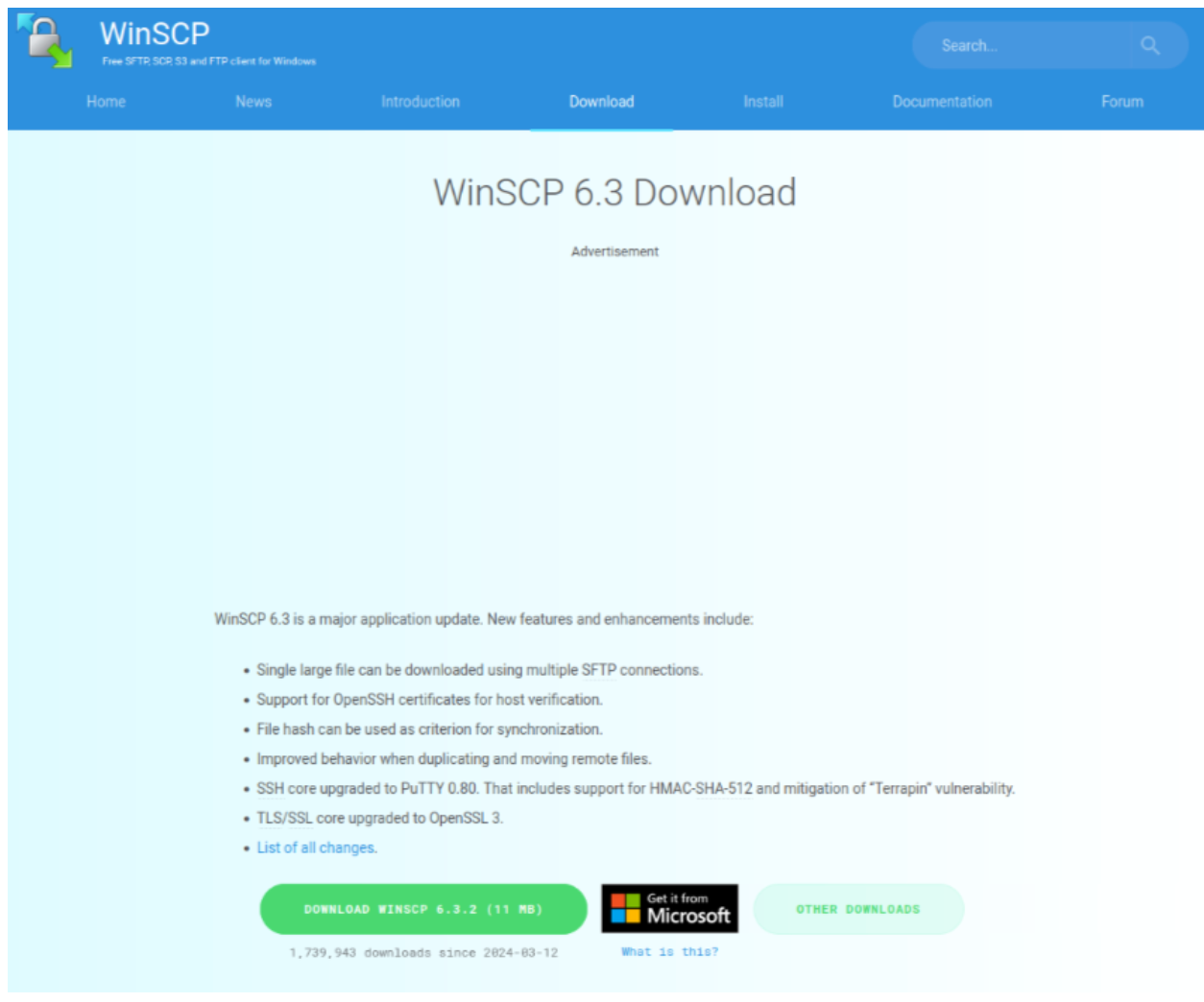
Beginning in early March 2024, Rapid7 observed the distribution of trojanized installers for the open source utilities WinSCP and PuTTy. WinSCP is a file transfer client, PuTTY a secure shell (SSH) client. The infection chain typically begins after a user searches for a phrase such as download winscp or download putty, on a search engine like Microsoft’s Bing. The search results include an ad for the software the user clicks on, which ultimately redirects them to either a clone of the legitimate website, in the case of WinSCP, or a simple download page in the case of PuTTY. In both cases, a link to download a zip archive containing the trojan from a secondary domain was embedded on the web page.
Figure 2. Appearance of the cloned WinSCP website.
The infection begins after the user has downloaded and extracted the contents of the zip archive and executed setup.exe, which is a renamed copy of pythonw.exe, the legitimate Python hidden console window executable.
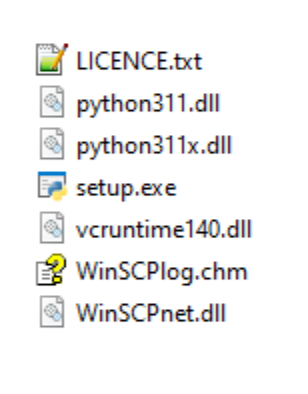
Figure 3. Files contained within an archive targeting WinSCP.
Upon execution, setup.exe loads the malicious DLL python311.dll. As seen in Figure 2, the copy of the legitimate python311 DLL which setup.exe is intended to load has actually been renamed to python311x.dll. This technique is known as DLL side-loading, where a malicious DLL can be loaded into a legitimate, signed, executable by mimicking partial functionality and the name of the original library. The process of side-loading the DLL is also facilitated by hijacking the DLL search order, where attempts are made to load DLLs contained within the same directory first, before checking other directories on the system where a legitimate copy might be present. Rapid7 has also observed the Python 3.11 library being targeted in prior malware campaigns, such as the novel IDAT loader, discovered by Rapid7 during August of 2023.
The primary payload contained within python311.dll is a compressed archive encrypted and included within the DLL’s resource section. During execution, this archive is unpacked to execute two child processes.
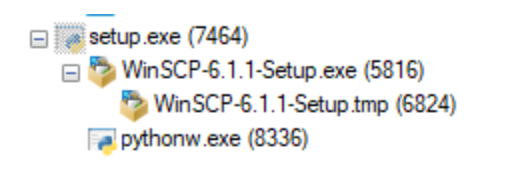
Figure 4. The process tree spawned by the malware.
First, the malware executes the unpacked copy of the legitimate WinSCP installer, seen in Figure 3 as WinSCP-6.1.1-Setup.exe. Then, the malicious Python script systemd.py is executed via pythonw.exe after being unpacked into the staging directory %LOCALAPPDATA%\Oracle\ along with numerous Python dependencies. Following the successful execution of both processes, setup.exe then terminates.
The script systemd.py, executed via pythonw.exe, decrypts and executes a second Python script then performs decryption and reflective DLL injection of a Sliver beacon. Reflective DLL injection is the process of loading a library into a process directly from memory instead of from disk. In several cases, Rapid7 observed the threat actor take quick action upon successful contact with the Sliver beacon, downloading additional payloads, including Cobalt Strike beacons. The access is then used to establish persistence via scheduled tasks and newly created services after pivoting via SMB. In a recent incident, Rapid7 observed the threat actor attempt to exfiltrate data using the backup utility Restic, and then deploy ransomware, an attempt which was ultimately blocked during execution.
To take a more in depth look at the malware delivery and functionality, we analyzed a malware sample recently observed being delivered to users looking for a PuTTY installer.
Initial Access
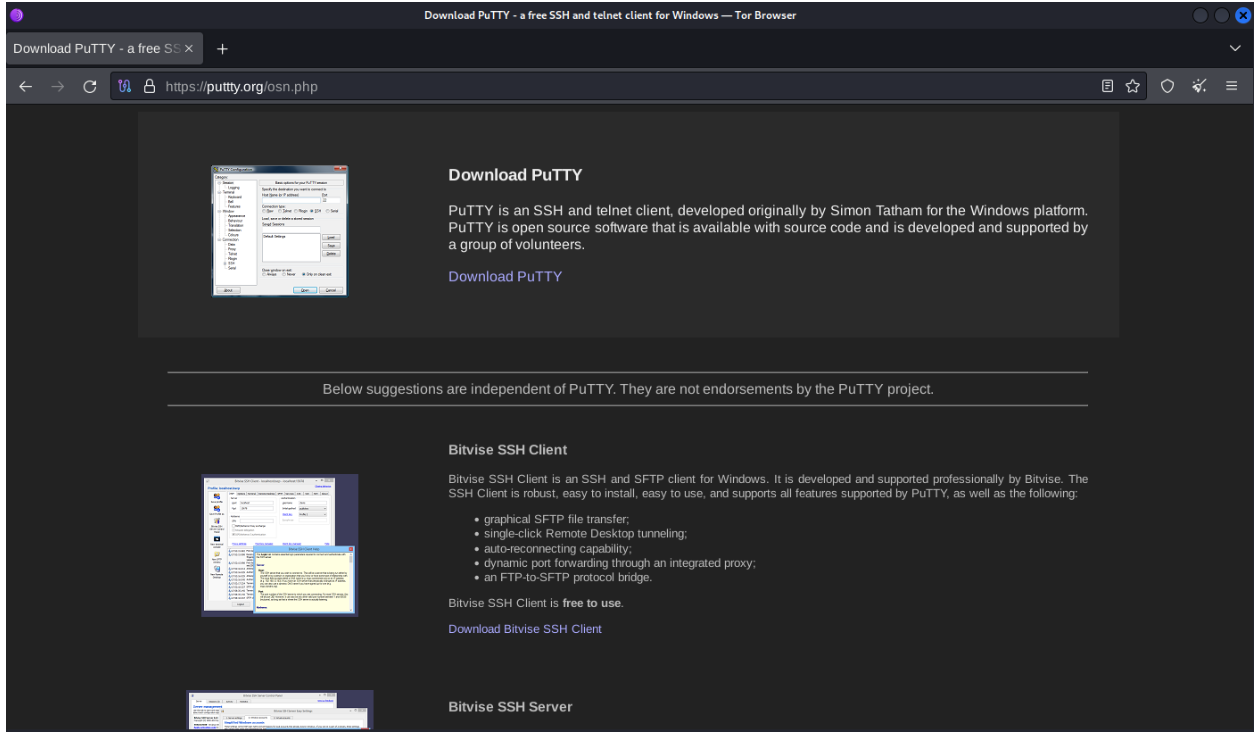
The source of the infection was a malicious ad served to the user after their search for download putty. When the user clicked on the ad, which are typically pushed to the top of the search results for visibility, they were redirected to a typo-squatted domain at the URL hxxps://puttty[.]org/osn.php. The landing page includes a download button for PuTTY, as well as two legitimate links to download a Bitvise SSH server/client. However, when the download link is clicked by the user it calls the embedded function loadlink(), which redirects the user to hxxps://puttty[.]org/dwnl.php, which then finally redirects the user to the most recent host of the malicious zip archive to serve the download. At the time of writing, puttty[.]org and the relevant URLs were still active, serving the zip archive putty-0.80-installer.zip from the likely compromised WordPress domain areauni[.]com.
Figure 5. Landing page for the malicious ad.
Rapid7 observed the base domain, puttty[.]org was also serving a cloned version of a PuTTY help article available at BlueHost, where the download link provided is actually for the official distributor of the software. This relatively benign page is most likely conditionally served as a way to reduce suspicion as noted by Malwarebytes.
In comparison, the typo-squatted WinSCP domains conditionally redirected visits to Rick Astley’s Never Gonna Give You Up. Classic.
Execution
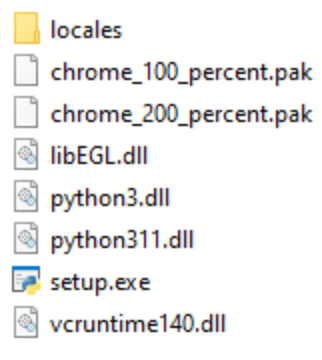
Upon extracting the zip archive putty-0.80-installer.zip, the user is once again presented with setup.exe, a renamed copy of pythonw.exe, to entice the user to initiate the infection by launching the executable.
Figure 7. The extracted contents of putty-0.80-installer.zip.
Once executed, setup.exe will side-load the malicious DLL python311.dll. The DLL python311.dll then loads a renamed copy of the legitimate DLL, python3.dll, from the same directory after dynamically resolving the necessary functions from kernel32.dll by string match. Future requests for exported functions made by setup.exe can then be forwarded to python3.dll by python311.dll. This technique is commonly used when side-loading malware, so legitimate requests are proxied, which avoids unexpected behavior and improves stability of the payload delivery.
Figure 8. Dynamic resolution of GetProcAddress.
Following the successful sideloading procedure, the malware then performs pre-unpacking setup by dynamically resolving additional functions from ntdll.dll. The malware still uses functionality similar to the publicly available AntiHook and KrakenMask libraries to facilitate setup and execution, as previously noted by eSentire, which provides additional evasion capabilities. AntiHook contains functionality to enumerate the loaded modules of a process, searching each one for hooks, and remaps a clean, unhooked version of the module’s text section, if hooks are found. KrakenMask contains functionality to spoof the return address of function calls, to evade stack traces, and functionality to encrypt the processes virtual memory at rest to evade memory scanners.
Figure 9. ASM stub containing the return address spoofing logic, as seen in KrakenMask.Figure 10. Snippet of the function that performs byte comparisons to check for hooks, as seen in AntiHook.
The library ntdll.dll contains functions which make up the Windows Native API (NTAPI), which is generally the closest a process executed in user mode can get to utilizing functionality from the operating system’s kernel. By resolving NTAPI functions for use, malware can bypass detection applied to more commonly used user mode functions (WINAPI) and access lower level functionality that is otherwise unavailable. Several of the NTAPI function pointers resolved by the malware can be used for evasion techniques such as Event Tracing for Windows (ETW) tampering and bypass of the Anti-Malware Scan Interface (AMSI) as has been observed in prior Nitrogen campaign samples. Some of the functions are dynamically resolved from ntdll.dll are found using concatenation of stack strings to form the full name of the target API just before resolution is attempted, likely to help evade detection.
Resolved ntdll.dll functions
EtwEventWrite
EtwEventWriteFull
EtwNotificationRegister
EtwEventRegister
Table 1. Functions the malware dynamically resolves from ntdll.dll.
Other observed function strings
WldpQueryDynamicCodeTrust (wldp.dll)
AmsiScanBuffer (amsi.dll)
Table 2. Other evasion related WINAPI function strings observed in the malware
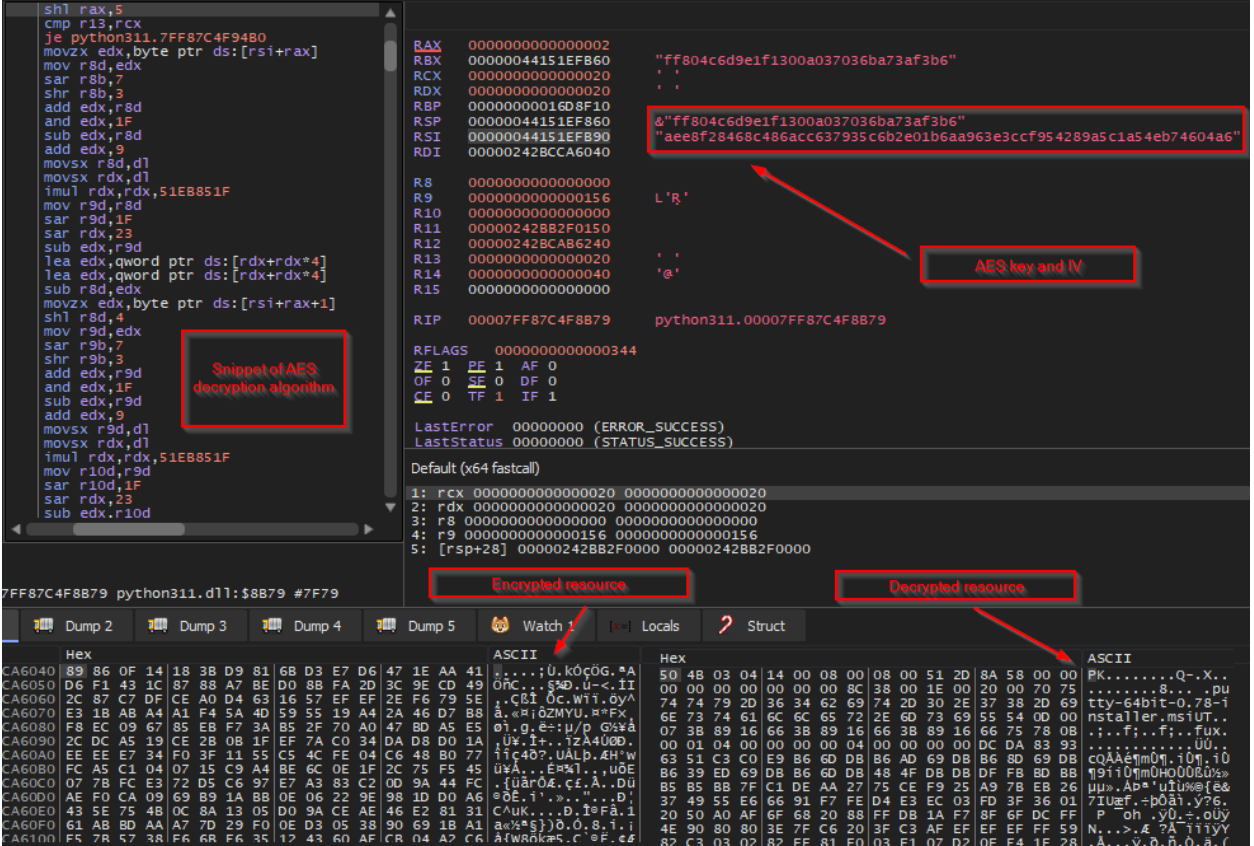
With setup complete, an encrypted resource stored within the resource section of python311.dll is retrieved using common resource WINAPI calls, including FindResourceA, LoadResource, SizeOfResource, and FreeResource.
Figure 11. The encrypted resource is loaded into memory and decrypted using AES-256.
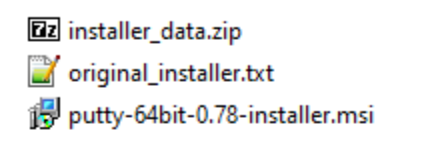
The resource is then decrypted in memory using an AES-256 hex key and initialization vector (IV) that are stored in the data section in plain text. The resulting file is a zip archive which contains three compressed files, including a legitimate MSI installation package for PuTTY and another compressed archive named installer_data.zip.
Figure 12. Decrypted and decompressed contents of the resource.
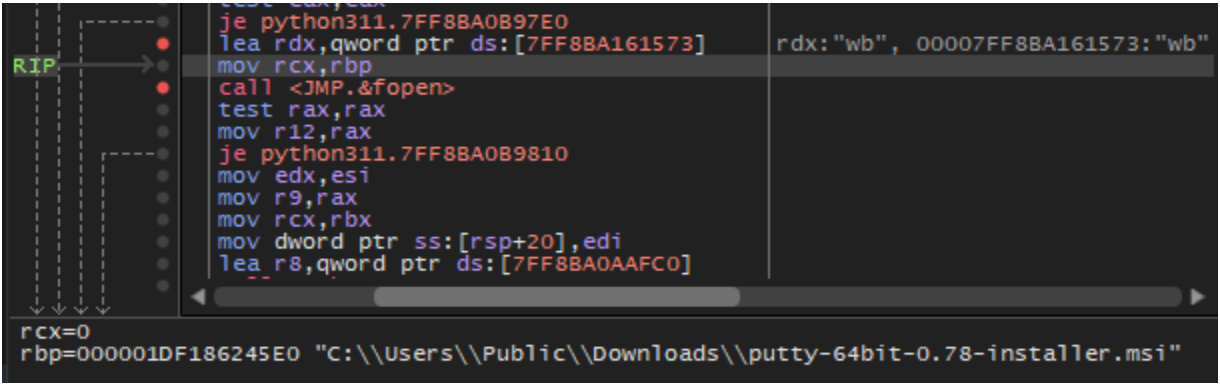
To execute the PuTTY installer, the malware first creates a copy of the MSI file in the hard-coded directory C:\Users\Public\Downloads\ via a call to fopen and then decompresses and writes the retrieved MSI package content with multiple successive calls to fwrite and other CRT library file io functions, followed by fclose. The full output path is assembled by concatenating the target directory with the desired file name, which is retrieved from original_installer.txt. The contents of original_installer.txt are identical to the name of the MSI package observed in the resource, for this sample: putty-64bit-0.78-installer.msi.
Figure 13. The malware creates the PuTTY MSI package within the public downloads directory.
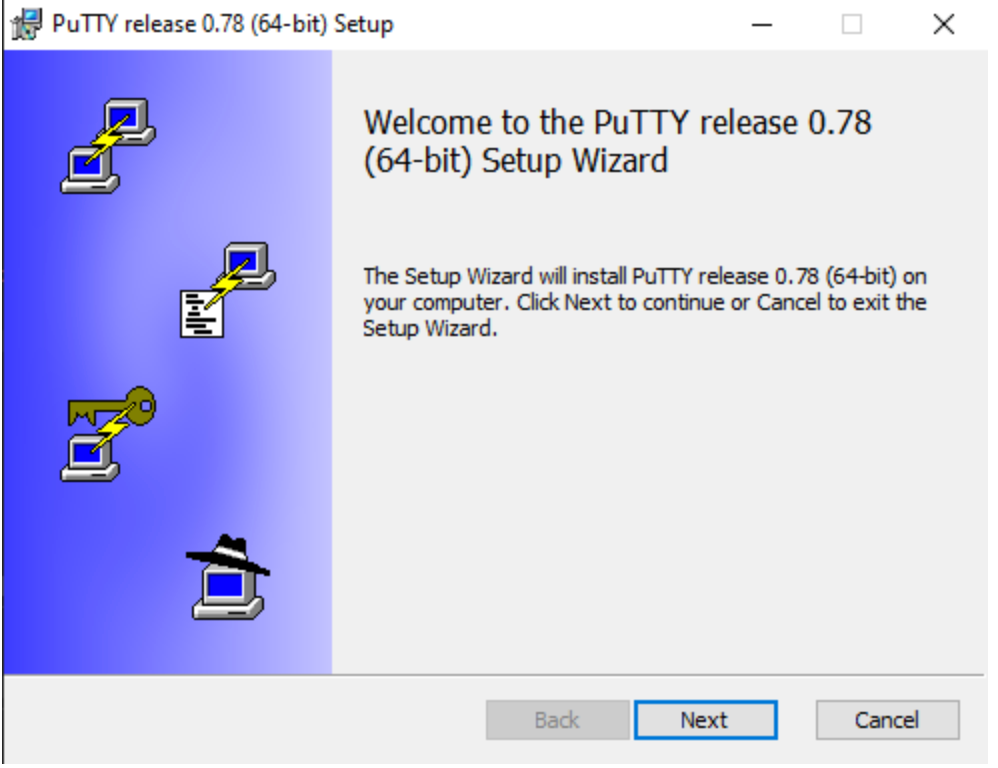
The MSI package is then executed by a call to CreateProcessW with the command line msiexec.exe ALLUSERS=1 /i C:\Users\Public\Downloads\putty-64bit-0.78-installer.msi. So, before the execution of the next malware payload the user is provided with the software they were originally looking for. This functionality is commonly seen with trojans to avoid suspicion by the end user, as the user only sees the legitimate installation window pop up after initial execution. However, the version numbers between the executed MSI package, putty-64bit-0.78-installer.msi, and the initially downloaded zip archive, putty-64bit-0.80-installer.zip, don’t match — a potential indicator.
Figure 14. The user only sees the installation window after executing setup.exe.
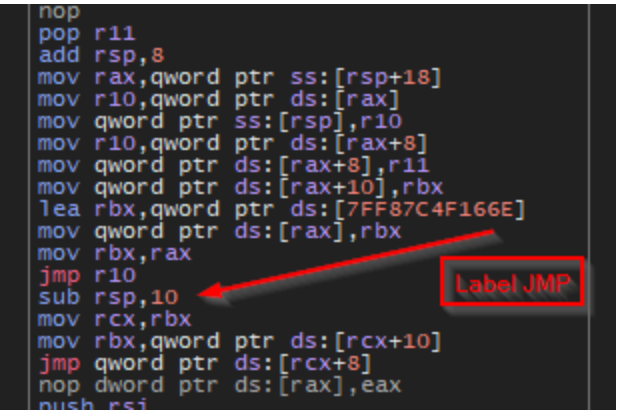
The same procedure is then repeated to copy the decompressed contents of the folder Oracle contained within the zip archive installer_data.zip to the staging directory created at %LOCALAPPDATA%\Oracle\. After the unpacking process is complete, another call by the malware to CreateProcessW executes the next payload with the command line %LOCALAPPDATA%\Oracle\pythonw.exe %LOCALAPPDATA%\Oracle\systemd.py. With its purpose completed, the loader then clears memory and passes back control to setup.exe, which promptly terminates, leaving the pythonw.exe process running in the background.
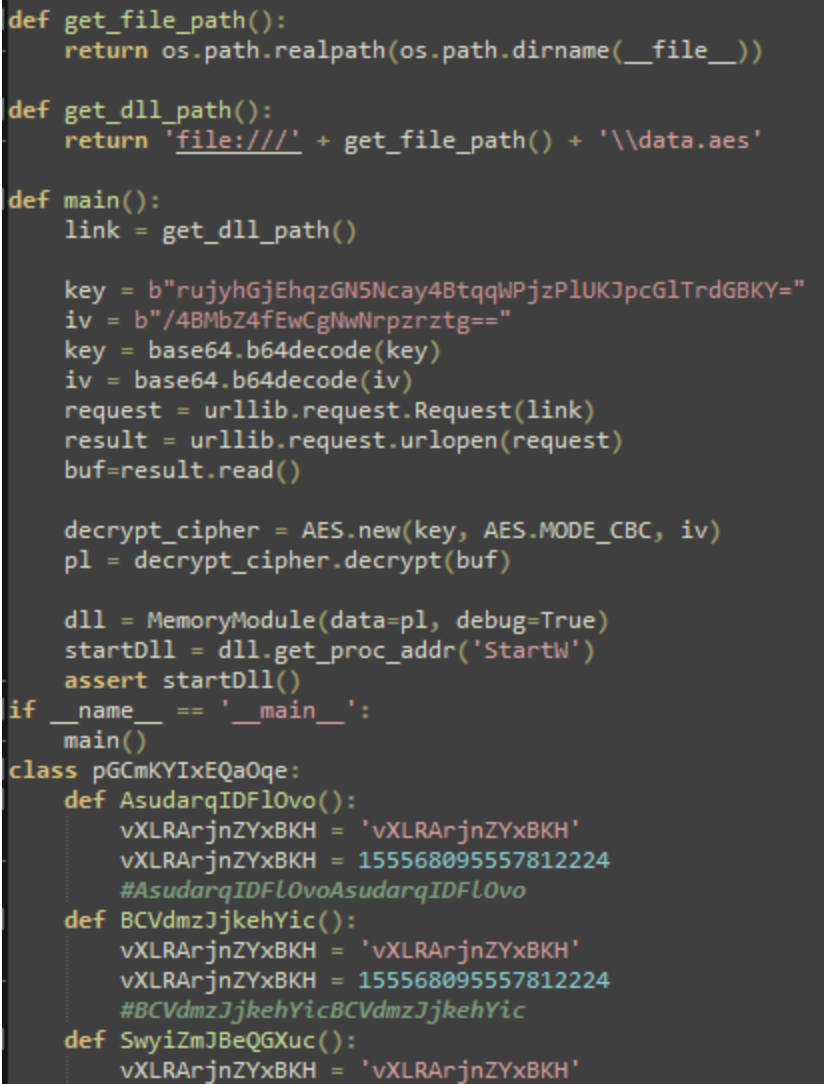
Figure 15. Core functionality of systemd.py.
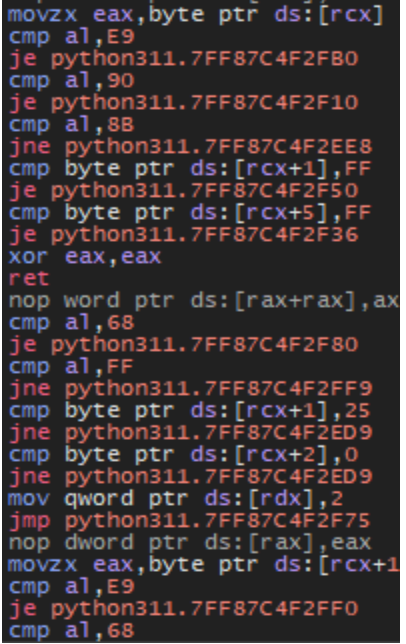
The Python script systemd.py contains multiple junk classes, which in turn contain numerous junk function definitions to pad out the core script. Ultimately, the script decrypts the file %LOCALAPPDATA%\Oracle\data.aes, which is a Sliver beacon DLL (original name: BALANCED_NAPKIN.dll), performs local injection of the Sliver DLL, and then calls the export StartW. The contents of main and other included functionality within the script appears to have been mostly copied from the publicly available Github repo for PythonMemoryModule.
Figure 16. Strings within the DLL: The beacon was clearly generated by the Sliver framework.
Rapid7 recommends verifying the download source of freely available software. Check that the hash of the downloaded file(s) match those provided by the official distributor and that they contain a valid and relevant signature. The DLLs that are side-loaded by malware are often unsigned, and are often present in the same location as the legitimately signed and renamed original, to which requests are forwarded. Bookmark the official distribution domains for the download of future updates.
DNS requests for permutations of known domains can also be proactively blocked or the requests can be redirected to a DNS sinkhole. For example, by using the publicly available tool DNSTwist we can identify several additional suspicious domains that match the observed ASNs and country codes observed for many of the C2 IPv4 addresses observed to be contacted by the malware as well as known malware hosts/facilitators.
Domain
IPv4
ASN
wnscp[.]net
91.92.253[.]80
AS394711:LIMENET
puttyy[.]org
82.221.136[.]24
AS50613:Advania Island ehf
puutty[.]org
82.221.129[.]39
AS50613:Advania Island ehf
putyy[.]org
82.221.136[.]1
AS50613:Advania Island ehf
Table 3. More suspicious domains found via DNSTwist.
Rapid7 observed impacted users are disproportionately members of information technology (IT) teams who are more likely to download installers for utilities like PuTTY and WinSCP for updates or setup. When the account of an IT member is compromised, the threat actor gains a foothold with elevated privileges which impedes analysis by blending in their actions with that of the administrator(s), stressing the importance of verifying the source of files before download, and their contents before execution.
The user clicks on a malicious ad populated from a typical search engine query for a software utility and is ultimately redirected to a page hosting malware.
The user downloads and executes setup.exe (renamed pythonw.exe), which side-loads and executes the malicious DLL python311.dll.
Execution
T1059.006: Command and Scripting Interpreter: Python
The malware executes a python script to load and execute a Sliver beacon.
Persistence
T1543.003: Create or Modify System Process: Windows Service
The threat actor creates a service to execute a C2 beacon. The threat actor loads a vulnerable driver to facilitate disabling antivirus software and other defenses present.
The threat actor attempts the deployment of ransomware after exfiltrating data.
Rapid7 Detections
For Rapid7 MDR and InsightIDR customers, the following detection rules are currently deployed and alerting against malware campaigns like the one described in this blog:
Detections
Suspicious Process – Sliver C2 Interactive Shell Execution via PowerShell
Suspicious Process – Python Start Processes in Staging Directories
Attacker Technique – Renamed PythonW.exe Executed From Non-Standard Folder
Suspicious Service: Service Installed With Command Line using Python
Agents for Amazon Bedrock now supports Provisioned Throughput pricing model – As agentic applications scale, they require higher input and output model throughput compared to on-demand limits. The Provisioned Throughput pricing model makes it possible to purchase model units for the specific base model.
Amazon EC2 Inf2 instances are now available in new regions – These instances are optimized for generative AI workloads and are generally available in the Asia Pacific (Sydney), Europe (London), Europe (Paris), Europe (Stockholm), and South America (Sao Paulo) Regions.
AWS Amplify Gen 2 is now generally available – AWS Amplify offers a code-first developer experience for building full-stack apps using TypeScript and enables developers to express app requirements like the data models, business logic, and authorization rules in TypeScript. AWS Amplify Gen 2 has added a number of features since the preview, including a new Amplify console with features such as custom domains, data management, and pull request (PR) previews.
Amazon Elastic Container Registry (ECR) adds pull through cache support for GitLab Container Registry – ECR customers can create a pull through cache rule that maps an upstream registry to a namespace in their private ECR registry. Once rule is configured, images can be pulled through ECR from GitLab Container Registry. ECR automatically creates new repositories for cached images and keeps them in-sync with the upstream registry.
Getting started with Amazon Q in VS Code – Check out this excellent step-by-step guide by Rohini Gaonkar that covers installing the extension for features like code completion chat, and productivity-boosting capabilities powered by generative AI.
AWS open source news and updates – My colleague Ricardo writes about open source projects, tools, and events from the AWS Community. Check out Ricardo’s page for the latest updates.
Upcoming AWS events Check your calendars and sign up for upcoming AWS events:
AWS Summits – Join free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. Register in your nearest city: Bengaluru (May 15–16), Seoul (May 16–17), Hong Kong (May 22), Milan (May 23), Stockholm (June 4), and Madrid (June 5).
AWS re:Inforce – Explore 2.5 days of immersive cloud security learning in the age of generative AI at AWS re:Inforce, June 10–12 in Pennsylvania.
AWS Community Days – Join community-led conferences that feature technical discussions, workshops, and hands-on labs led by expert AWS users and industry leaders from around the world: Turkey (May 18), Midwest | Columbus (June 13), Sri Lanka (June 27), Cameroon (July 13), Nigeria (August 24), and New York (August 28).
The 6.9 kernel was released
on May 12 after a typical nine-week development cycle. Once again,
this is a major release containing a lot of changes and new features. Our
merge-window summaries (part 1, part 2) covered those changes; now that
the development cycle is complete, the time has come to look at where all
that work came from — and to introduce a new and experimental LWN feature
for readers interested in this kind of information.
Maintainers of open-source projects sometimes have disagreements with
contributors over how contributions are reviewed, modified, merged, and
credited. A written policy describing how contributions are handled can
help maintainers set reasonable expectations for potential contributors.
In turn, that can make the maintainer’s job easier because it can help
reduce a source of friction in the project. A guide to help create this
kind of policy for a project has recently been developed.
Явно въпросът „защо отиваме на избори“ продължава да стои и затова направих едно сравнение между документите, които се разменяха публично преди опита за ротация: меморандума на ППДБ и споразумението на ГЕРБ. Сложил съм цитати от документите по темите, по които имаше разминаване, за да стане ясно каква е причината да отидем на избори. Документът е тук.
А ето обобщение:
По съдебната реформа ППДБ предлага конкретика за Закона за съдебната власт и свързани закони, а ГЕРБ предлага декларативно очертаване на това колко е важна съдебната реформа
ППДБ настоява кандидатите за органи на съдебната власт да бъдат оценявани единствено по техните качества, а ГЕРБ предлага да се избират само такива, предлагани от партии с „евроатлантическа ориентация“ (да се чете: гарантирано участие на ДПС)
ППДБ предлага да няма плаващи мнозинства (т.е. ГЕРБ да не приемат неща с Възраждане и ИТН, както се случваше нерядко и както показа анализа на Стража от вчера), а ГЕРБ предлага да си запази това право като „способ за законодателна целесъобразност“
ППДБ предлага срокове и етапи на реформата в службите, а ГЕРБ предлагат „разговор за службите да бъде проведен“ (иначе казано: „тати ще ми купи колело, ама друг път“)
Относно регулаторите, ППДБ предлага ясни срокове за техния избор и премахване на свръховластяването на председателите (напр. на КЗК), докато ГЕРБ предлага обратното – липса на срокове и допълнително овластяване на председателите, като само те да могат да предлагат заместници.
Всички други твърдения, свързани с министерски постове, кой бил обиден и т.н. нямат общо с реалната причина да сме за 6-ти път на избори в рамките на 3 години.
Command Your Attack Surface with a next-gen SIEM built for the Cloud First Era
Rapid7 is excited to share that we are named a Challenger for InsightIDR in the 2024 Gartner Magic Quadrant for SIEM. In a crowded and constantly changing space, this is our sixth time to be recognized in the report. While the Magic Quadrant offers a great snapshot of the current marketplace, we are always looking ahead to what teams will need to be successful in the next era of cybersecurity.
We believe that the future of SIEM will be defined by the ability to:
Connect and synthesize expansive security telemetry as efficiently as possible
Pinpoint the most critical and actionable insights with the scale and speed of AI
Deliver the contextualized data, expert guidance, and automation to confidently take action against threats – wherever they start
We are proud to bring these elevated security outcomes to the thousands of customers across the globe who trust Rapid7 at the center of their SOC.
Actionable Visibility You Can Trust – From Endpoint to Cloud
As organizations’ attack surfaces continue to expand and security systems become more fragmented, teams are challenged to get reliable visibility and context to effectively monitor their environment, end-to-end. As your organization embraces digital transformation, adopts SaaS solutions, and/or fosters agile business development, you need security solutions that can grow with your business without the burden of infrastructure management or lagging scale.
InsightIDR is a cloud-native SIEM – purpose-built to support an organization’s scale with the speed of the cloud-first era. With flexible data ingestion – including our own lightweight, native endpoint agent, sensor, and collector as well as the ability to collect and parse diverse data from your wider ecosystem – customers are able to quickly synthesize their most critical telemetry, without the heavy management burdens of traditional SIEM technologies.
Many traditional SIEM approaches leave it all on the customer to figure out how to action their data once in their platform. This leaves resource-constrained teams on their heels and sorting through mounds of data without being able to pinpoint the insights that matter. InsightIDR’s flexible search modes boost both power-users’ and beginners’ ability to quickly turn data into actionable insights and leverage pre-built queries and dashboards as a jumping-off point for action. And with 13-months of readily searchable data logs by default, your data is always ready for you, whenever you need it.
AI-Driven Behavioral Detections to Pinpoint Today’s Advanced Threats
The current threat climate requires a high degree of vigilance and detections content curation to be able to keep pace with adversaries’ ever-growing arsenal of tactics, techniques, and procedures (TTPs). This is one of the most challenging domains for security teams to master and carve out time for – and unfortunately most SIEMs have led with a logging-centric approach, putting the work of threat-intelligence gathering and detections engineering on the customer to parse.
From the beginning, InsightIDR pioneered the detections-centric SIEM, focused on pinpointing and eliminating real threats as quickly as possible. Our library contains over 8,000 detections, giving customers complete coverage across all stages of the MITRE ATT&CK. Our detections engineering experts are constantly curating threat intelligence – including unique raw intelligence from our renowned Rapid7 Open Source Community (including Metasploit, the #1 pentesting tool in the world, Velociraptor digital forensics and incident response framework, and AttackKB vulnerability database) – to ensure customers have coverage against emergent threats (and because our platform is SaaS-delivered, customers immediately receive new detections content ).
Rapid7 holds 56 patents across proprietary analytics frameworks and AI, which contribute to our layered detections strategy. AI-powered attacker and user behavioral analytics detect stealthy attacker behavior and unknown threats that can often go undetected, and complement known indicators of compromise (IOCs) for total coverage. This is the same detections library that our Rapid7 MDR team leverages, so our SIEM customers have high efficacy, low-noise detections they can trust out of the gate.
Response Built for Cloud and Distributed Environments
In the critical moments of an attack, the last thing a security analyst wants to be doing is hopping tabs between different solutions to get the full picture. But security solution sprawl has forced too many SOCs to be tied up being systems integrators vs. being able to focus on actual security work.
InsightIDR’s investigation views eliminate tab-hopping and disparate alert trails. When an alert is fired, customers see a consolidated timeline view of an attack, lateral movement, impacted users and assets, and related CVEs in a single view. Detailed evidence and intelligence, ATT&CK mapping, and vetted recommendations provide all relevant detail at the customer’s fingertips – so even your most junior analyst can respond like an expert, every time. Customers can also pivot from these investigation views into the Velociraptor DFIR framework to more broadly query distributed endpoint fleets to understand the full scope of an attack and avoid repeat occurrences.
One of the biggest challenges of today’s landscape is navigating response to complex cloud environments. Our simplified cloud threat alert view ensures SOC teams can confidently triage cloud provider alerts – like those from GuardDuty – with a purpose-built alert framework that parses out critical alert summaries, impacted resources, queries, and recommends responses to prioritize and act as quickly as possible on threats across cloud workloads. Regardless of where threats begin, with InsightIDR your team is covered and always knows what to do next.
Let Rapid7 Help You Take Command of Your Attack Surface
The complexities of today’s modern attack surface can be daunting, and are too often compounded by disparate solutions or legacy approaches that can make things worse. Rapid7’s integrated platform approach synthesizes your security data ecosystem to deliver unified exposure management and detection and response that maximizes efficiency and security outcomes. Thank you to our customers and partners who trust Rapid7 as their security consolidation partner of choice, and have contributed to recognitions like this Gartner Magic Quadrant for SIEM.
Please register for our cybersecurity event on May 21st to learn how Rapid7 can help you build cyber resilience and take command of your attack surface.
Gartner does not endorse any vendor, product or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER is a registered trademark and service mark of Gartner and Magic Quadrant and Peer Insights are a registered trademark, of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.
Gartner Peer Insights content consists of the opinions of individual end users based on their own experiences with the vendors listed on the platform, should not be construed as statements of fact, nor do they represent the views of Gartner or its affiliates. Gartner does not endorse any vendor, product or service depicted in this content nor makes any warranties, expressed or implied, with respect to this content, about its accuracy or completeness, including any warranties of merchantability or fitness for a particular purpose.
Gartner Peer Insights reviews constitute the subjective opinions of individual end users based on their own experiences and do not represent the views of Gartner or its affiliates.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.