Post Syndicated from Geographics original https://www.youtube.com/watch?v=qAU33U57a4Y
Yearly Archives: 2024
Deprecation of Lake Formation’s Governed Tables Feature
Post Syndicated from Mert Hocanin original https://aws.amazon.com/blogs/big-data/deprecation-of-lake-formations-governed-tables-feature/
After careful consideration, we have made the decision to end support for Governed Tables, effective December 31, 2024, to focus on open source transactional table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. This decision stems from customer preference for these open source solutions, which offer ACID-compliant transactions, compaction, time travel, and other features previously provided by Governed Tables. Amazon Web Services (AWS) has enhanced our support for these formats across various analytics services, including Amazon Athena, Amazon EMR (Elastic MapReduce), AWS Glue, and Amazon Redshift, with features that include automatic compaction support for Apache Iceberg, retention and snapshot expiration and orphan file deletion for Apache Iceberg, enhancements to AWS Glue Data Catalog CreateTable API to create Apache Iceberg tables, and AWS Glue Crawlers schema detection support across Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. Customers can now use these open source formats to achieve ACID-compliant transactions with Amazon Simple Storage Service (Amazon S3) backed data, benefiting from their rich features and wide compatibility.
After December 31, 2024, customers will no longer be able to create Governed Tables transactions (lakeformation:StartTransaction), write to Governed Tables (lakeformation:UpdateTableObjects), or query your Governed Tables using Amazon Athena. Customers will still be able to access their table state information by calling the lakeformation:GetTableObjects and transaction information by calling lakeformation:ListTransactions until February 17, 2025. After February 17, 2025, all Governed Table APIs will start to fail. Governed Tables metadata will continue to exist within the AWS Glue Data Catalog, and the Governed Tables data will remain in your S3 buckets. No other table types will be affected by this change, including Hive (Apache Parquet, CSV, ORC, and so on), Iceberg, Hudi, and Delta Lake tables.
Migrating your Governed Tables
Customers can migrate their tables from Governed Tables to one of the open source formats by copying their governed table data directly to Apache Iceberg using Amazon Athena. To migrate data to Iceberg, you can use the Amazon Athena CREATE TABLE AS (CTAS) statement, as shown in the following code example.
You can specify additional table-level properties, which are listed in the Amazon Athena User Guide. If you specify partitions or buckets as part of the Apache Iceberg table definition, then you may run into the 100 partition per bucket limitation. In this case, refer to Use CTAS and INSERT INTO to work around the 100 partition limit.
If you require any assistance migrating your tables, or have any questions, reach out to us at [email protected].
About the author
 Mert Hocanin is a Principal Big Data Architect with AWS Lake Formation.
Mert Hocanin is a Principal Big Data Architect with AWS Lake Formation.
Lingerie Boudoir Shoot with the Nikon Zf
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=kjCPcM3pBCQ
The Cloud Storage Playbook: 4 Best Practices for Sports Teams
Post Syndicated from Laquie Campbell original https://www.backblaze.com/blog/the-cloud-storage-playbook-4-best-practices-for-sports-teams/

Video and data are the lifeblood of sports teams and leagues, fueling everything from fan engagement to game analysis.
To keep operations running smoothly, sports teams need to ensure that assets are stored securely, managed cost effectively, and kept ready for quick access. Cloud storage is increasingly part of sports teams’ data management playbooks, integrating with existing workflows and media tools so that teams can stay sharp and keep fans engaged.
Let’s break down what’s driving data growth in the sports market, use cases for cloud storage, and four best practices you can use to adopt cloud storage in a hybrid approach.
What’s driving data growth for sports teams?
During a given game, teams typically capture multiple camera angles, including sideline and aerial views, along with player-specific footage. Inside the stadium, teams use video and data to create an immersive fan experience, with big-screen displays and other screens showing player profiles, replays, real-time stats, and more. The action doesn’t stop there. Live feeds and exclusive content delivered on mobile devices add interactivity, bringing the game closer to the audience.
Sports teams generate a massive amount of video and image data during a game. As an example, a given professional sports game may involve around 10–12 cameras, and each can generate several terabytes of high-definition (high-def) footage over the course of the game.
High-def video files can range from 1–3GB per minute of footage, meaning a two to three hour game with multiple cameras might produce dozens of terabytes. On top of that, teams use high speed cameras for slow motion analysis, which further increases the data volume. When considering still images from different angles and high-resolution (hi-res) formats, the overall image and video data generated per game can easily reach 10–20TB or more, depending on the resolution and frame rates used.
How sports organizations take advantage of cloud storage: Key use cases
Given the massive data growth in sports organizations, many teams rely on cloud storage to help them store, manage, and use that data effectively. Here’s how they do it.
Replacing aging on-premises systems
Professional sports teams have long relied on on-premises storage like LTO tape systems or servers to keep their game footage, player performance data, and other critical content safe. But as time goes on, these systems become harder to maintain, prone to breakdowns, and outmatched by the growing volume of data. As media and data continue to pile up, teams need storage that can scale fast without requiring a major investment in new infrastructure.
By using cloud storage—typically through a hybrid infrastructure that utilizes both cloud and on-premises systems—sports organizations can off-load some of the hassle of maintaining and upgrading aging physical systems. Cloud storage eliminates the need for constant hardware replacements, freeing up IT teams to focus on more strategic plays.
Eagles retire LTO, drafting up an active cloud archive
With multiple championships behind them, the Philadelphia Eagles had decades of incredible content to mine and protect, but they needed to draft and train up some new technical assets to stay in contention. They retired their LTO-6 system and shifted hundreds of terabytes off of their storage area network (SAN) to a true cloud archive in Backblaze B2 Cloud Storage. Check out their game plan for protecting data and improving media workflows in the cloud.
Enhancing video management and distribution
By implementing cloud storage for hot archives, a league or team can store all video content in a centralized repository that offers instant access from anywhere, especially when paired with cloud-friendly media asset management (MAM) tools.
Cloud storage simplifies the process of sharing large video files with players, broadcasters, and media outlets, boosting an organization’s ability to monetize its content.
Backblaze B2 Live Read changes the game
Advanced services like Live Read give teams the ability to access, edit, and transform media as it’s uploaded. This speeds up content retrieval for analysis, editing, and distribution, making it especially useful on game days, when quick access to video and analytics can influence real-time decisions and help create up-to-the-minute content.
Business continuity and disaster recovery
Keeping sensitive data and high value media safe is nonnegotiable for sports organizations. A natural disaster, cyberattack, data breach, or other threat to stored data and media can cause days or weeks of downtime, making critical assets inaccessible and leading to significant operational disruptions.
Teams are using cloud storage to create geographic redundancy that ensures that data stays secure and recoverable even in the event of a local disaster. Tools like Object Lock add an extra layer of protection, making sure that data can’t be tampered with or deleted.
Integrating AI capabilities
AI is employed by sports teams to automate video analysis and content tagging, create highlight reels almost instantly, and scale personalization efforts.
Using the cloud to implement AI for sports media makes sense thanks to its scalability, processing power, and accessibility. Cloud platforms can handle vast amounts of video data and provide the computational resources necessary for AI-driven tasks like real-time analysis, high-speed editing, and video rendering. The cloud also enables collaboration across multiple locations, allowing teams, coaches, and analysts to access and process data seamlessly. Cloud-based AI is cost efficient, as teams only pay for the resources they use, avoiding the high costs of maintaining dedicated on-premises AI infrastructure.
Leverage video understanding with Twelve Labs
Twelve Labs’ video understanding platform allows you to build AI functionality into your workflows, giving you the ability to automate metadata tagging and search video archives with natural language. Check out how it integrates with cloud storage in Backblaze B2.
Optimizing costs
As traditional storage systems scale up, they can become prohibitively expensive—not only in direct costs, but also in ongoing maintenance and management. Cloud storage is inherently scalable, capable of handling growing volumes of content and data without breaking the bank.
Cloud storage helps sports teams optimize data storage costs by offering scalable, flexible pricing models that align with their data needs. Depending on their needs, teams can choose to pay for the exact amount of storage they use or to leverage capacity-based storage plans, but in either case, they’ll avoid the need for expensive on-premises hardware that often requires over-provisioning.
With cloud storage, teams can dynamically scale storage up or down based on their requirements—like during the season when video data surges—though it’s essential to consider things like egress fees in cost calculations. Backblaze, for example, includes 3x free egress, which can reduce costs significantly.
Hybrid cloud storage for sports teams
Many organizations take a phased approach in embracing cloud storage, or choose to continue leveraging on-premises storage infrastructure along with new cloud storage resources in a hybrid model. As with any deployment of new technology, this process is best undertaken with a thoughtful game plan.
Four best practices for adopting hybrid cloud storage
1. Assess your current infrastructure
Begin by auditing the on-premises storage systems you currently rely on to maintain team footage and data. Knowing where your storage infrastructure falls short, you can set clear objectives for a hybrid solution, such as increased accessibility or more cost-effective scaling options, and then map out your shift to the cloud. Evaluate capacity, performance, and scalability limits to help identify pain points (e.g., slow access to media files, high costs) and inform prioritization of the data or content that should move to the cloud.
2. Prioritize media for migration
Depending on your goals, you’ll prioritize different media for a cloud migration. For example, if your goal is to modernize your archive and make it more accessible for monetization, it makes sense to move archives off LTO to an active cloud archive. On the other hand, if your goal is streamlining remote workflows, your production data is likely first up for a cloud migration while you can maintain on-premises solutions for your archives as long as they’re serving your needs.
3. Leverage hybrid storage as a transition stage
With a cloud storage platform that integrates smoothly with existing on-prem storage and applications, you are well positioned to implement a hybrid cloud solution. A hybrid storage model allows you to shift operations to the cloud gradually, without the need for an abrupt overhaul. As you navigate this transition, your team can begin to take advantage of cloud scalability and flexibility without abandoning familiar workflows or compromising performance.
4. Establish clear data management policies
Structured data management helps prevent inefficiencies, such as duplicated or misplaced files, and ensures that storage solutions align with operational needs. Create clear policies for where media and data are stored (on-prem or cloud), when and how each should be moved, and which users have access (and at what level).
Preparing for the future
As sports organizations continue to generate and rely on massive amounts of video and data, cloud storage is increasingly becoming a strategic necessity. By embracing cloud storage, teams and leagues can increase their efficiency, improve fan engagement, enhance performance analysis, and ensure operational continuity—all while optimizing costs and future-proofing their infrastructure. The result? More streamlined, secure, and scalable storage that supports long-term success on and off the field.
The post The Cloud Storage Playbook: 4 Best Practices for Sports Teams appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
Enhancing data privacy with layered authorization for Amazon Bedrock Agents
Post Syndicated from Jeremy Ware original https://aws.amazon.com/blogs/security/enhancing-data-privacy-with-layered-authorization-for-amazon-bedrock-agents/
Customers are finding several advantages to using generative AI within their applications. However, using generative AI adds new considerations when reviewing the threat model of an application, whether you’re using it to improve the customer experience for operational efficiency, to generate more tailored or specific results, or for other reasons.
Generative AI models are inherently non-deterministic, meaning that even when given the same input, the output they generate can vary because of the probabilistic nature of the models. When using managed services such as Amazon Bedrock in your workloads, there are additional security considerations to help ensure protection of data that’s accessed by Amazon Bedrock.
In this blog post, we discuss the current challenges that you may face regarding data controls when using generative AI services and how to overcome them using native solutions within Amazon Bedrock and layered authorization.
Definitions
Before we get started, let’s review some definitions.
Amazon Bedrock Agents: You can use Amazon Bedrock Agents to autonomously complete multistep tasks across company systems and data sources. Agents can be used to enrich entry data to provide more accurate results or to automate repetitive tasks. Generative AI agents can make decisions based on input and the environmental data they have access to.
Layered authorization: Layered authorization is the practice of implementing multiple authorization checks between the application components beyond the initial point of ingress. This includes service-to-service authorization, carrying the true end-user identity through application components, and adding end-user authorization for each operation in addition to the service authorization.
Trusted identity propagation: Trusted identity propagation provides more simply defined, granted, and logged user access to AWS resources. Trusted identity propagation is built on the OAuth 2.0 authorization framework, which allows applications to access and share user data securely without the need to share passwords.
Amazon Verified Permissions: Amazon Verified Permissions is a fully managed authorization service that uses the provably correct Cedar policy language, so you can build more secure applications.
Challenge
As you build on AWS, there are several services and features that you can use to help ensure your data or your customers’ data is secure. This might include encryption at-rest with Amazon Simple Storage Service (Amazon S3) default encryption or AWS Key Management Service (AWS KMS) keys, or the use of prefixes in Amazon S3 or partition keys in Amazon DynamoDB to separate tenants’ data. These mechanisms are great for dealing with data at-rest and separation of data partitions, but after a generative AI powered application enables customers to access a variety of data (different sensitivity types of data, multiple tenants’ data, and so on) based on user input, the risk of disclosure of sensitive data increases (see the data privacy FAQ for more information about data privacy at AWS). This is because access to data is now being passed to an untrusted identity (the model) within the workload operating on behalf of the calling principal.
Many customers are using Amazon Bedrock Agents in their architecture to augment user input with additional information to improve responses. Agents might also be used to automate repetitive tasks and streamline workflows. For example, chatbots can be useful tools for improving user experiences, such as summarizing patient test results for healthcare providers. However, it’s important to understand the potential security risks and mitigation strategies when implementing chatbot solutions.
A common architecture involves invoking a chatbot agent through an Amazon API Gateway. The API gateway validates the API call using an Amazon Cognito or AWS Lambda authorizer and then passes the request to the chatbot agent to perform its function.
A potential risk arises when users can provide input prompts to the chatbot agent. This input could lead to prompt injection (OWASP LLM:01) or sensitive data disclosure (OWASP LLM:06) vulnerabilities. The root cause is that the chatbot agent often requires broad access permissions through an AWS Identity and Access Management (IAM) service role with access to various data stores (such as S3 buckets or databases), to fulfill its function. Without proper security controls, a threat actor from one tenant could potentially access or manipulate data belonging to another tenant.
Solution
While there is no single solution that can mitigate all risks, having a proper threat model of your consumer application to identify risks (such unauthorized access to data) is critical. AWS offers several generative AI security strategies to assist you in generating appropriate threat models. In this post, we focus on layered authorization throughout the application, focusing on a solution to support a consumer application.
Note: This can also be accomplished using Trusted identity propagation (TIP) and Amazon S3 Access Grants for a workforce application.
By using a strong authentication process such as an OpenID Connect (OIDC) identity provider (IdP) for your consumers enhanced with multi-factor authentication (MFA), you can govern access to invoke the agents at the API gateway. We recommend that you also pass custom parameters to the agent—as shown in Figure 1, using the JWT token from the header of the request. With such a configuration, the agent will evaluate an isAuthorized request with Amazon Verified Permissions to confirm that the calling user has access to the data requested prior to the agent running its described function. This architecture is shown in Figure 1:

Figure 1: Authorization architecture
The steps of the architecture are as follows:
- The client connects to the application frontend.
- The client is redirected to the Amazon Cognito user pool UI for authentication.
- The client receives a JWT token from Amazon Cognito.
- The application frontend uses the JWT token presented by the client to authorize a request to the Amazon Bedrock agent. The application frontend adds the JWT token to the
InvokeAgent APIcall. - The agent reviews the request, calls the knowledge base if required, and calls the Lambda function. The agent includes the JWT token provided by the application frontend into the Lambda invocation context.
- The Lambda function uses the JWT token details to authorize subsequent calls to DynamoDB tables using Verified Permissions (6a), and calls the DynamoDB table only if the call is authorized (6b).
Deep dive
When you design an application behind an API gateway that triggers Amazon Bedrock agents, you must create an IAM service role for your agent with a trust policy that grants AssumeRole access to Amazon Bedrock. This role should allow Amazon Bedrock to get the OpenAPI schema for your agent Action Group Lambda function from the S3 bucket and allow for the bedrock:InvokeModel action to the specified model. If you did not select the default KMS key to encrypt your agent session data, you must grant access in the IAM service role to access the customer managed KMS key. Example policies and trust relationship are shown in the following examples.
The following policy grants permission to invoke an Amazon Bedrock model. This will be granted to the agent. In the resource, we are specifically targeting an approved foundational model (FM).
Next, we add a policy statement that allows the Amazon Bedrock agent access to S3:GetObject and targets a specific S3 bucket with a condition that the account number matches one within our organization.
Finally, we add a trust policy that grants Amazon Bedrock permissions to assume the defined role. We have also added conditional statements to make sure that the service is calling on behalf of our account to help prevent the confused deputy problem.
Amazon Bedrock agents use a service role and don’t propagate the consumer’s identity natively. This is where the underlying problem of protecting tenants’ data might exist. If the agent is accessing unclassified data, then there’s no need to add layered authorization because there’s no additional segregation of access needed based on the authorization caller. But if the application has access to sensitive data, you must carry authorization into processing the agent’s function.
You can do this by adding an additional layer to the Lambda function triggered by invoking the agent. First, initialize the agent to make an isAuthorized call to Verified Permissions. Only upon an Allow response will the agent perform the rest of its function. If the response from Verified Permissions is Deny, then the agent should return a status 403 or a friendly error message to the user.
Verified Permissions must have pre-built policies to dictate how authorization should occur when data is being accessed. For example, you might have a policy like the following to grant access to patient records if the calling principal is a doctor.
In this example, the authorization logic to handle this decision is within the agent Lambda. To do so, the Lambda function first builds the entities structure by decoding the JWT passed as a custom parameter to the Amazon Bedrock agent to assess the calling principal’s access. The requested data should also be included in the isAuthorized call. After this data is passed to Verified Permissions, it will assess the access decision based on the context provided and the policies within the policy store. As a policy decision point (PDP), it’s important to note that the allow or deny decision must be enforced at the application level. Based on this decision, access to the data will be allowed or denied. The resources being accessed should be categorized to help the application evaluate access control. For example, if the data is stored in DynamoDB, then patients might be separated by partition keys that are defined in the Verified Permissions schema and referenced in a hierarchal sense.
Conclusion
In this post, you learned how you can improve data protection by using AWS native services to enforce layered authorization throughout a consumer application that uses Amazon Bedrock Agents. This post has shown you the steps to improve enforcement of access controls through identity processes. This can help you build applications using Amazon Bedrock Agents and maintain strong isolation of data to mitigate unintended sensitive data disclosure.
We recommend the Secure Generative AI Solutions using OWASP Framework workshop to learn more about using Verified Permissions and Amazon Bedrock Agents to enforce layered authorization throughout an application.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
[$] BTF, Rust, and the kernel toolchain
Post Syndicated from daroc original https://lwn.net/Articles/991719/
BPF Type Format (BTF),
BPF’s debugging information format, has undergone rapid evolution to match
the evolving needs of BPF programs. José Marchesi spoke at Kangrejos about some
of that work — and how it could impact Rust, specifically. He discussed debug
information, kernel-specific relocations, and the planned changes to kernel
stack unwinding. Each of these will require some amount of work to fully
support in Rust, but preliminary signs look promising.
Manjaro 24.1 released
Post Syndicated from jzb original https://lwn.net/Articles/992660/
Version
24.1 of the Arch-based Manjaro
distribution is now available with the 6.10 Linux kernel,
GNOME 46.5, KDE Plasma 6.1 and KDE Gear 24.08:
Plasma 6.1 on Wayland now has a feature that “remembers” what you were
doing in your last session like it did under X11. Although this is
still work in progress, If you log off and shut down your computer
with a dozen open windows, Plasma will now open them for you the next
time you power up your desktop, making it faster and easier to get
back to what you were doing. At Manjaro we are still defaulting to
X11, however switching to Wayland can be done easily by selecting the
wanted session in your display manager.
The project also offers minimal install images with the 6.6 LTS and
6.1 LTS kernels to support older hardware as needed.
Security updates for Wednesday
Post Syndicated from jzb original https://lwn.net/Articles/992650/
Security updates have been issued by AlmaLinux (grafana), Fedora (cjson and php), Oracle (389-ds-base, freeradius, grafana, kernel, and krb5), Slackware (cryfs, cups, and mozilla), SUSE (OpenIPMI, openssl-3, openvpn, thunderbird, and tomcat), and Ubuntu (cups, cups-filters, knot-resolver, linux-raspi, linux-raspi-5.4, orc, php7.4, php8.1, php8.3, python-asyncssh, ruby-devise-two-factor, and vim).
Patent troll Sable pays up, dedicates all its patents to the public!
Post Syndicated from Emily Terrell original https://blog.cloudflare.com/patent-troll-sable-pays-up
Back in February, we celebrated our victory at trial in the U.S. District Court for the Western District of Texas against patent trolls Sable IP and Sable Networks. This was the culmination of nearly three years of litigation against Sable, but it wasn’t the end of the story.
Today we’re pleased to announce that the litigation against Sable has finally concluded on terms that we believe send a strong message to patent trolls everywhere — if you bring meritless patent claims against Cloudflare, we will fight back and we will win.
We’re also pleased to announce additional prizes in Project Jengo, and to make a final call for submissions before we determine the winners of the Final Awards. As a reminder, Project Jengo is Cloudflare’s effort to fight back against patent trolls by flipping the incentive structure that has encouraged the growth of patent trolls who extract settlements out of companies using frivolous lawsuits. We do this by asking the public to help identify prior art that can invalidate any of the patents that a troll holds, not just the ones that are asserted against Cloudflare. We’ve already given out over $125,000 to individuals since the launch of Project Jengo in 2017, and we’re looking forward to celebrating the successful end of the Sable iteration of Project Jengo with our Final Awards!
To learn more about how things concluded with Sable and next steps in Project Jengo, read on.
Background
For anyone just joining us on this odyssey, here is a little background on how we got here:
Sable sued Cloudflare back in March 2021. Sable is a patent troll. It doesn’t make, develop, innovate, or sell anything. Sable IP is merely a shell entity formed to monetize (make money from) an ancient patent portfolio acquired by Sable Networks from Caspian Networks in 2006. Caspian Networks was a router company that went out of business nearly 20 years ago. Using Caspian’s old patents, Sable sued Cloudflare and many other companies, including Cisco, Fortinet, Check Point, SonicWall, and Juniper Networks, alleging patent infringement. While these other companies resolved their disputes with Sable out of court, Cloudflare fought back.
Sable initially asserted around 100 claims from four different patents against Cloudflare, accusing multiple Cloudflare products and features of infringement. Sable’s patents — the old Caspian Networks patents — related to hardware-based router technologies common over 20 years ago. Sable’s infringement arguments stretched these patent claims to their limits (and beyond) as Sable tried to apply Caspian’s hardware-based technologies to Cloudflare’s modern software-defined services delivered on the cloud.
Cloudflare fought back against Sable by launching a new round of Project Jengo, Cloudflare’s prior art contest, seeking prior art to invalidate all of Sable’s patents.
After years of Cloudflare aggressively litigating against Sable’s patents before the U.S. Patent and Trademark Office and the district court, Sable was left with only one claim from one patent to assert against Cloudflare at trial. If you’d like to know more, we described those battles, in which Cloudflare successfully eliminated around 99% of Sable’s claims, in more detail in a prior blog post.
Sable and Cloudflare came together in a five-day jury trial in Waco, Texas in February 2024. At trial, Sable did its best to try to map its decades-old router technology onto Cloudflare’s modern software-based architecture. But Sable’s case was riddled with technical issues and its efforts backed only by the desire for a payout.
The jury agrees: Cloudflare does not infringe
To defeat Sable’s claim of infringement we needed to explain to the jury — in clear and understandable terms — why what Cloudflare does is different from what was covered by claim 25 of Sable’s remaining patent, U.S. Patent No. 7,012,919 (the ’919 patent). To do this, we enlisted the help of one of our talented Cloudflare engineers, Eric Reeves, as well as Dr. Paul Min, Senior Professor of Electrical & Systems Engineering at Washington University, an expert in the field of computer networking. Eric and Dr. Min helped us explain to the jury the multiple reasons we didn’t infringe.

From slide deck presented by Cloudflare to the jury during the trial
First, we explained that the accused Cloudflare products (Magic Transit and Argo for Packets) do not route “flows” or “micro-flows” as required by claim 25. Instead, they handle packets individually, on a packet-by-packet basis. Indeed, processing each packet individually is important to the functioning of these products and Cloudflare’s DDoS and security services as a whole.
Eric also helped to tell our invention story to the jury. He explained how the Cloudflare team saw problems that needed to be solved, and built unique and innovative new products to solve them. He described the work that went into developing Magic Transit and Argo for Packets, and how these products are part of Cloudflare’s modern software-based approach, which is fundamentally different from the hardware-based technology of the ’919 patent. Together, Eric and Dr. Min explained how the benefits of Magic Transit and Argo for Packets enjoyed by Cloudflare’s customers are not attributable to any technology claimed by the ’919 patent.
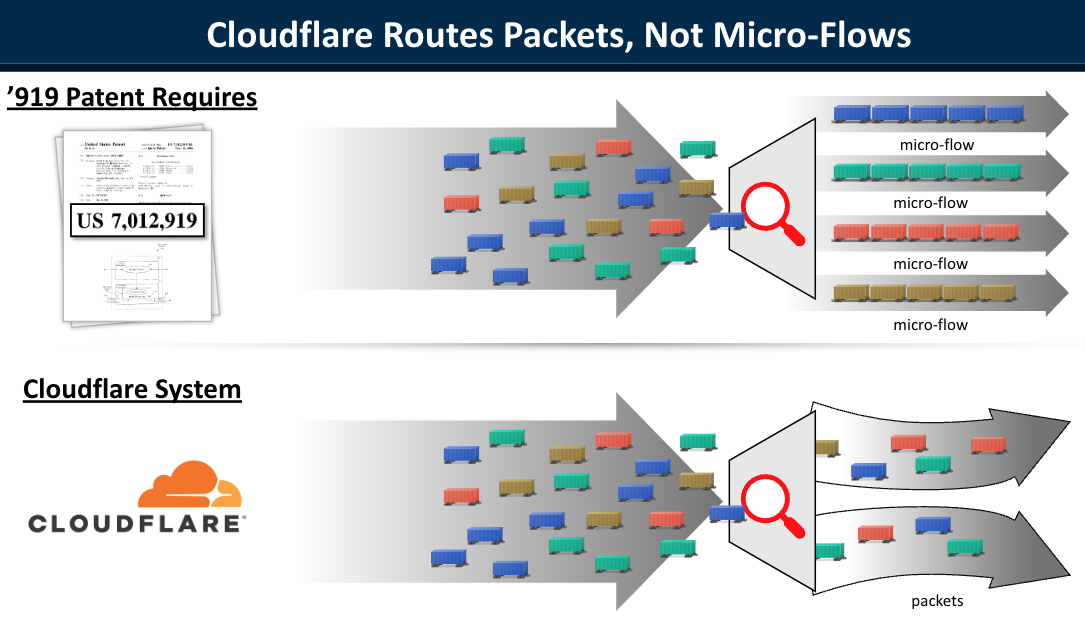
From slide deck presented by Cloudflare to the jury during the trial
Second, we explained that Cloudflare doesn’t infringe because claim 25 of the ’919 patent requires certain processes to occur “at” ingress and egress line cards, and Cloudflare’s accused servers do not include line cards.

From slide deck presented by Cloudflare to the jury during the trial
As Dr. Min explained, “line cards” are a specific type of hardware — a physical hardware “card” — that are commonly used in routers. Sable’s witnesses could not deny that the technology of the ’919 patent was tied to old router technology. After all, Caspian Networks Inc. (where the ’919 patent inventors worked) was a router company. Caspian’s core products were routers, and we showed the jury documents describing Caspian’s routers, which used “flow-based” technology on physical hardware line cards.

Trial exhibit, image of sample line card
While Sable’s technical expert tried his hardest to convince the jury that various software and hardware components of Cloudflare’s servers constitute “line cards,” his explanations defied credibility. The simple fact is that Cloudflare’s servers do not have line cards.
Ultimately, the jury understood, returning a verdict that Cloudflare does not infringe claim 25 of the ‘919 patent.

Excerpt from Verdict Form completed by the jury
The jury agrees: Sable’s patent claim is invalid
In addition to proving that we do not infringe, we also took on the challenge of proving to the jury that claim 25 of the ’919 patent is invalid and never should have been issued.
Proving invalidity to a jury is hard. The burden on the defendant is high: Cloudflare needed to prove by clear and convincing evidence that claim 25 is invalid. And, proving it by describing how the claim is obvious in light of the prior art is complicated.
To do this, we again relied on our technical expert, Dr. Min, to explain how two prior art references, U.S. Patent No. 6,584,071 (Kodialam) and U.S. Patent No. 6,680,933 (Cheeseman) together render claim 25 of the ’919 patent obvious. Kodialam and Cheeseman are patents from Nortel Networks and Lucent relating to router technology developed in the late 1990s. Both are prior art to the ’919 patent (i.e., they pre-date the priority date of the ’919 patent), and when considered together by a person skilled in the area of computer engineering and computer networking technology, they rendered obvious the so-called invention of claim 25.

Excerpt from Verdict Form completed by the jury
Sable does not get its payday …
Sable’s real motivation for suing Cloudflare — its desire for a payout — was made clear by Sable’s trial witnesses, who were unified only by their desire to present a wildly inflated view of the alleged “value” of the Sable patent and the damages allegedly owed by Cloudflare.
Sable’s attorneys tried their best to present their clients as reasonable businessmen, just trying to get what they’re owed for Cloudflare’s purported use of Sable’s patent. But Sable couldn’t hide its true colors from the jury. When Sable presented testimony from Brooks Borchers, the founder of Sable IP, Mr. Borchers was forced to admit that Sable IP is in the “business” of filing lawsuits.

Excerpt from Borchers trial testimony
In fact, Mr. Borchers was forced to admit that Sable’s approach is to sue first and ask questions later. Even among patent trolls, this is hardly a noble business practice.

Excerpts from Borchers trial testimony
What’s more, Mr. Borchers and his lawyers have teamed up on cases like this before, following the same sue-first-and-ask-questions-later playbook in hopes of a payout. Sable’s true motivations for suing Cloudflare were on full display after this testimony, making Sable’s damages demand all the more galling.
Sable’s damages expert, Stephen Dell, told the jury that Sable was owed somewhere between $25 million and $94.2 million in damages. But, Mr. Dell was forced to admit to multiple flaws in his damages calculation, and Cloudflare’s damages expert Chris Bakewell explained to the jury how bad inputs and faulty assumptions led Mr. Dell to a wildly inflated damages figure. Indeed, after hearing Sable’s expert’s testimony, Judge Albright said he was “very skeptical” of Mr. Dell’s opinions, explaining that he was “very concerned that there’s not support for his methodology.”
In the end, Mr. Dell’s outsized damages demand didn’t matter because the jury found that Cloudflare did not infringe and that the asserted patent claim is invalid. But, it was revealing of Sable’s motivation (greed) and the lengths that it would go to try to get a payout.
When all was said and done, after all the testimony and argument, we were thrilled when the jury returned its verdict — after less than two hours of deliberations — finding across the board for Cloudflare. The jury’s verdict is truly a validation of our strong belief in the importance of standing up to patent trolls like Sable, and we are grateful for the jury’s time, attention and consideration!
Sable admits defeat, and agrees to pay Cloudflare!
A jury verdict is not the end of the road in a patent case … there are post-trial motions, appeals, and other procedural hurdles to jump through before a case is truly over. Tired from the fight, and smarting from its loss, Sable decided it wanted to throw in the towel and end the fight once and for all.
In the end, Sable agreed to pay Cloudflare $225,000, grant Cloudflare a royalty-free license to its entire patent portfolio, and to dedicate its patents to the public, ensuring that Sable can never again assert them against another company.
Let’s repeat that first part, just to make sure everyone understands:
Sable, the patent troll that sued Cloudflare back in March 2021 asserting around 100 claims across four patents, in the end wound up paying Cloudflare. While this $225,000 can’t fully compensate us for the time, energy and frustration of having to deal with this litigation for nearly three years, it does help to even the score a bit. And we hope that it sends an important message to patent trolls everywhere to beware before taking on Cloudflare.

Excerpt from the Dedication to the Public and Royalty Free License Agreement between Sable and Cloudflare
And, let’s talk a bit more about that final part:
Sable has agreed to dedicate its entire patent portfolio to the public. This means that Sable will tell the U.S. Patent and Trademark Office that it gives up all of its legal rights to its patent portfolio. Sable can never again use these patents to sue for infringement; they can never again use these patents to try to make a quick buck.

Excerpt from the Dedication to the Public and Royalty Free License Agreement between Sable and Cloudflare
To sum it up …
Cloudflare fought back against the patent troll and we won. We not only defeated Sable’s claims in court, we forced Sable to pay Cloudflare for the trouble, and we got Sable’s patents dedicated to the public, ensuring that it can never assert these patents against any other company ever again. It was admittedly a lot of work for Cloudflare, but totally worth it.
Project Jengo for Sable: Conclusion of the Case
A crucial part of our efforts to secure this across-the-board win are our Project Jengo participants.
Since the launch of the Project Jengo for the Sable case, we’ve received hundreds of prior art references from dedicated Project Jengo participants. So far we have awarded $70,000 in prizes to the winners of Chapters 1 through 8. And we still have $30,000 in prizes to award in the Final Awards.
This blog post marks the official “Conclusion of the Case” under the Project Jengo Sable Rules. We will continue to accept submissions during the 30-day Grace Period, which lasts until November 2, 2024, and then will move on to selecting winners of the Final Awards.
We are thrilled to announce the winners of Chapters 7 and 8
We publicly celebrated the Chapter 1, Chapter 2, Chapter 3 and Chapters 4-6 winners in previous blog posts. However, as the trial approached in the Sable case, we chose not to make public announcements for the Chapter 7 and 8 winners out of respect for the judicial process. Now that the case is over, we are delighted to give a big public shout out to the winners of Project Jengo Chapters 7 and 8!
We selected four total winners in Chapters 7 and 8, each receiving prizes of $5,000, for a grand total of $20,000. Our Chapter 7 winners, George W. and Madhu, each provided helpful and detailed charts containing element-by-element comparisons of the prior art to the relevant Sable patents. George W. is an electrical engineer and lawyer, who is active in the intellectual property community. He learned about Project Jengo in an article posted online, and thought it was a clever idea. The Chapter 8 winners, Jatin and Ketan, also provided thoughtful and detailed submissions. Jatin submitted two pieces of prior art that were particularly good references for Sable’s U.S. Patent No. 7,012,919, which contains the one claim that remained asserted against Cloudflare at trial.
We also want to again thank our prior chapter winners and everyone who participated in Project Jengo! We look forward to selecting the Final Awards winners — it will be fun to take a walk down memory lane re-reviewing the fantastic prior art submitted by our prior winners, and we can’t wait to check out the new submissions, too! Please use the “Submit Prior Art” link on this page for your final entries. Once we’ve announced our Final Awards, we will also update the Sable patents prior art listing on our website, to share all the prior art submitted by our Project Jengo participants.
How Cloudflare auto-mitigated world record 3.8 Tbps DDoS attack
Post Syndicated from Manish Arora original https://blog.cloudflare.com/how-cloudflare-auto-mitigated-world-record-3-8-tbps-ddos-attack
Since early September, Cloudflare’s DDoS protection systems have been combating a month-long campaign of hyper-volumetric L3/4 DDoS attacks. Cloudflare’s defenses mitigated over one hundred hyper-volumetric L3/4 DDoS attacks throughout the month, with many exceeding 2 billion packets per second (Bpps) and 3 terabits per second (Tbps). The largest attack peaked 3.8 Tbps — the largest ever disclosed publicly by any organization. Detection and mitigation was fully autonomous. The graphs below represent two separate attack events that targeted the same Cloudflare customer and were mitigated autonomously.
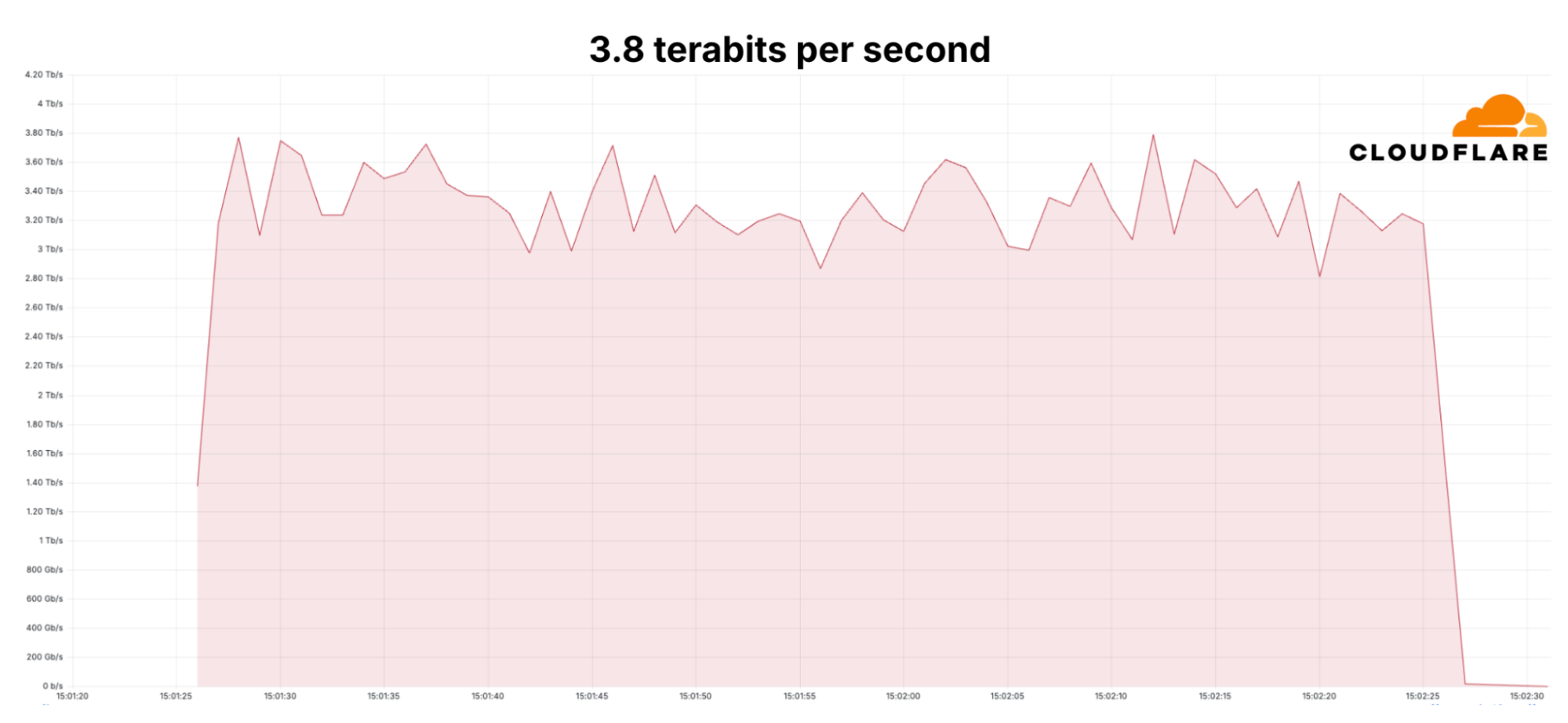
A mitigated 3.8 Terabits per second DDoS attack that lasted 65 seconds
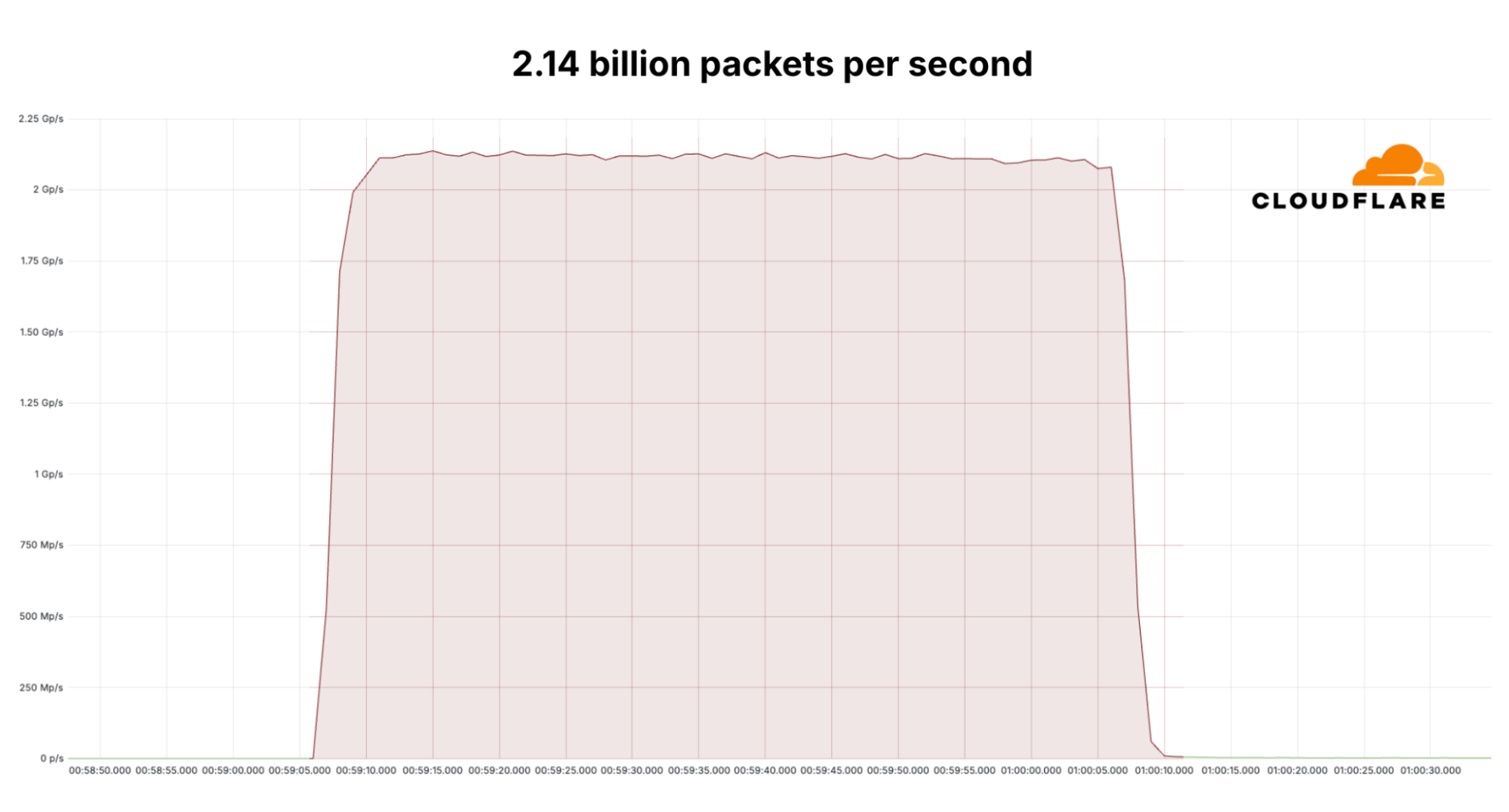
A mitigated 2.14 billion packet per second DDoS attack that lasted 60 seconds
Cloudflare customers are protected
Cloudflare customers using Cloudflare’s HTTP reverse proxy services (e.g. Cloudflare WAF and Cloudflare CDN) are automatically protected.
Cloudflare customers using Spectrum and Magic Transit are also automatically protected. Magic Transit customers can further optimize their protection by deploying Magic Firewall rules to enforce a strict positive and negative security model at the packet layer.
Other Internet properties may not be safe
The scale and frequency of these attacks are unprecedented. Due to their sheer size and bits/packets per second rates, these attacks have the ability to take down unprotected Internet properties, as well as Internet properties that are protected by on-premise equipment or by cloud providers that just don’t have sufficient network capacity or global coverage to be able to handle these volumes alongside legitimate traffic without impacting performance.
Cloudflare, however, does have the network capacity, global coverage, and intelligent systems needed to absorb and automatically mitigate these monstrous attacks.
In this blog post, we will review the attack campaign and why its attacks are so severe. We will describe the anatomy of a Layer 3/4 DDoS attack, its objectives, and how attacks are generated. We will then proceed to detail how Cloudflare’s systems were able to autonomously detect and mitigate these monstrous attacks without impacting performance for our customers. We will describe the key aspects of our defenses, starting with how our systems generate real-time (dynamic) signatures to match the attack traffic all the way to how we leverage kernel features to drop packets at wire-speed.
Campaign analysis
We have observed this attack campaign targeting multiple customers in the financial services, Internet, and telecommunication industries, among others. This attack campaign targets bandwidth saturation as well as resource exhaustion of in-line applications and devices.
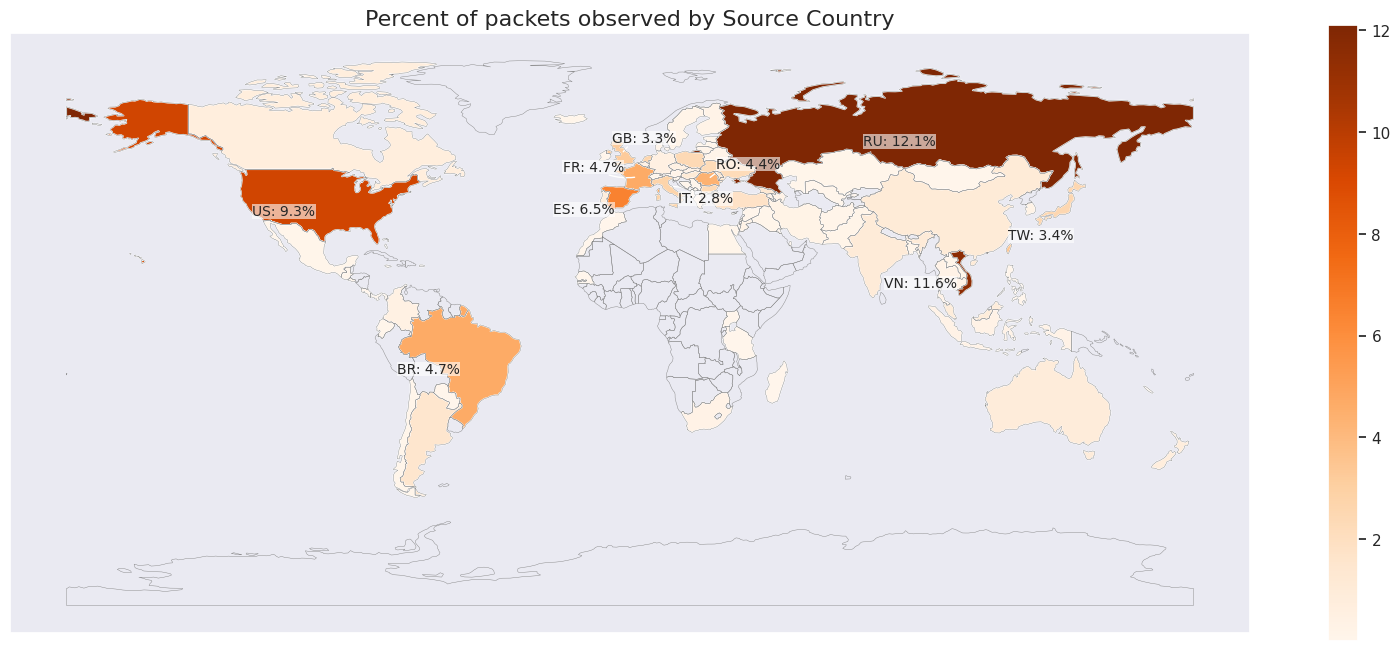
The attacks predominantly leverage UDP on a fixed port, and originated from across the globe with larger shares coming from Vietnam, Russia, Brazil, Spain, and the US.
The high packet rate attacks appear to originate from multiple types of compromised devices, including MikroTik devices, DVRs, and Web servers, orchestrated to work in tandem and flood the target with exceptionally large volumes of traffic. The high bitrate attacks appear to originate from a large number of compromised ASUS home routers, likely exploited using a CVE 9.8 (Critical) vulnerability that was recently discovered by Censys.
Anatomy of DDoS attacks
Before we discuss how Cloudflare automatically detected and mitigated the largest DDoS attacks ever seen, it‘s important to understand the basics of DDoS attacks.
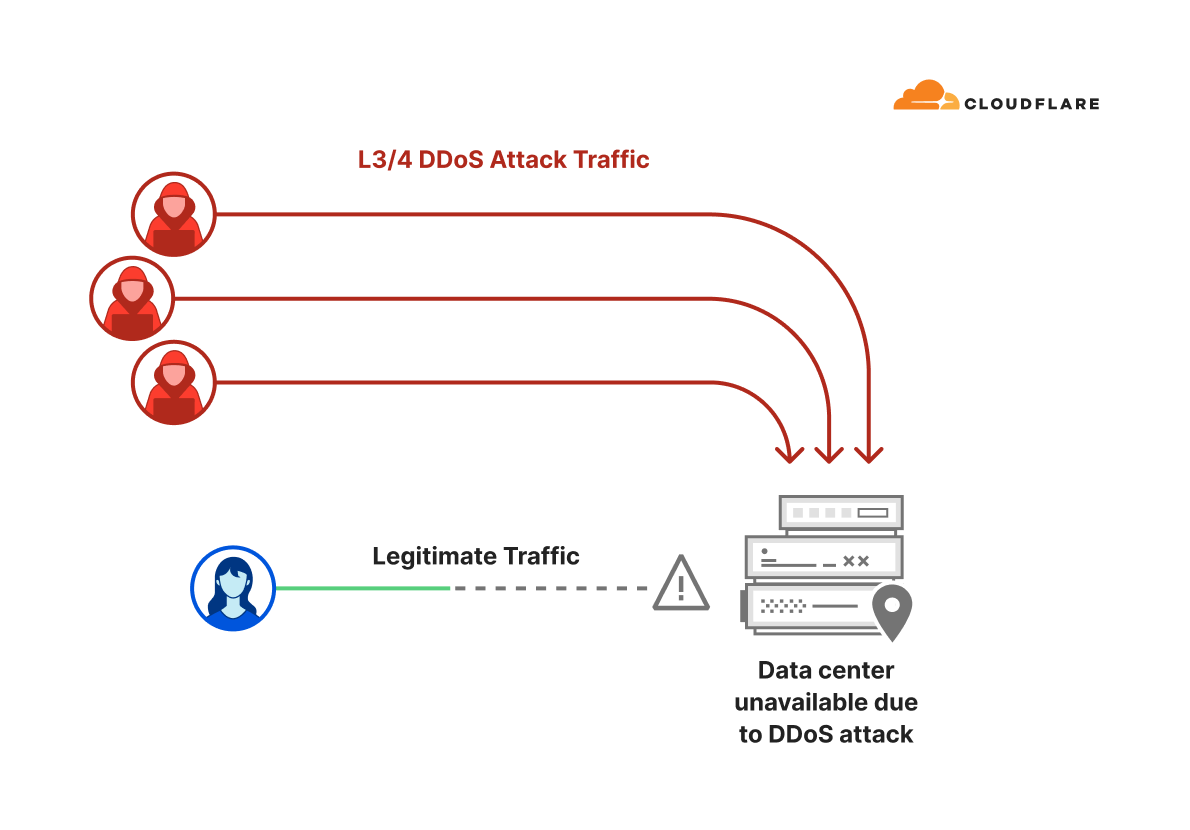
Simplified diagram of a DDoS attack
The goal of a Distributed Denial of Service (DDoS) attack is to deny legitimate users access to a service. This is usually done by exhausting resources needed to provide the service. In the context of these recent Layer 3/4 DDoS attacks, that resource is CPU cycles and network bandwidth.
Exhausting CPU cycles
Processing a packet consumes CPU cycles. In the case of regular (non-attack) traffic, a legitimate packet received by a service will cause that service to perform some action, and different actions require different amounts of CPU processing. However, before a packet is even delivered to a service there is per-packet work that needs to be done. Layer 3 packet headers need to be parsed and processed to deliver the packet to the correct machine and interface. Layer 4 packet headers need to be processed and routed to the correct socket (if any). There may be multiple additional processing steps that inspect every packet. Therefore, if an attacker sends at a high enough packet rate, then they can potentially saturate the available CPU resources, denying service to legitimate users.
To defend against high packet rate attacks, you need to be able to inspect and discard the bad packets using as few CPU cycles as possible, leaving enough CPU to process the good packets. You can additionally acquire more, or faster, CPUs to perform the processing — but that can be a very lengthy process that bears high costs.
Exhausting network bandwidth
Network bandwidth is the total amount of data per time that can be delivered to a server. You can think of bandwidth like a pipe to transport water. The amount of water we can deliver through a drinking straw is less than what we could deliver through a garden hose. If an attacker is able to push more garbage data into the pipe than it can deliver, then both the bad data and the good data will be discarded upstream, at the entrance to the pipe, and the DDoS is therefore successful.

Defending against attacks that can saturate network bandwidth can be difficult because there is very little that can be done if you are on the downstream side of the saturated pipe. There are really only a few choices: you can get a bigger pipe, you can potentially find a way to move the good traffic to a new pipe that isn’t saturated, or you can hopefully ask the upstream side of the pipe to stop sending some or all of the data into the pipe.
Generating DDoS attacks
If we think about what this means from the attackers point of view you realize there are similar constraints. Just as it takes CPU cycles to receive a packet, it also takes CPU cycles to create a packet. If, for example, the cost to send and receive a packet were equal, then the attacker would need an equal amount of CPU power to generate the attack as we would need to defend against it. In most cases this is not true — there is a cost asymmetry, as the attacker is able to generate packets using fewer CPU cycles than it takes to receive those packets. However, it is worth noting that generating attacks is not free and can require a large amount of CPU power.
Saturating network bandwidth can be even more difficult for an attacker. Here the attacker needs to be able to output more bandwidth than the target service has allocated. They actually need to be able to exceed the capacity of the receiving service. This is so difficult that the most common way to achieve a network bandwidth attack is to use a reflection/amplification attack method, for example a DNS Amplification attack. These attacks allow the attacker to send a small packet to an intermediate service, and the intermediate service will send a large packet to the victim.
In both scenarios, the attacker needs to acquire or gain access to many devices to generate the attack. These devices can be acquired in a number of different ways. They may be server class machines from cloud providers or hosting services, or they can be compromised devices like DVRs, routers, and webcams that have been infected with the attacker’s malware. These machines together form the botnet.
How Cloudflare defends against large attacks
Now that we understand the fundamentals of how DDoS attacks work, we can explain how Cloudflare can defend against these attacks.
Spreading the attack surface using global anycast
The first not-so-secret ingredient is that Cloudflare’s network is built on anycast. In brief, anycast allows a single IP address to be advertised by multiple machines around the world. A packet sent to that IP address will be served by the closest machine. This means when an attacker uses their distributed botnet to launch an attack, the attack will be received in a distributed manner across the Cloudflare network. An infected DVR in Dallas, Texas will send packets to a Cloudflare server in Dallas. An infected webcam in London will send packets to a Cloudflare server in London.
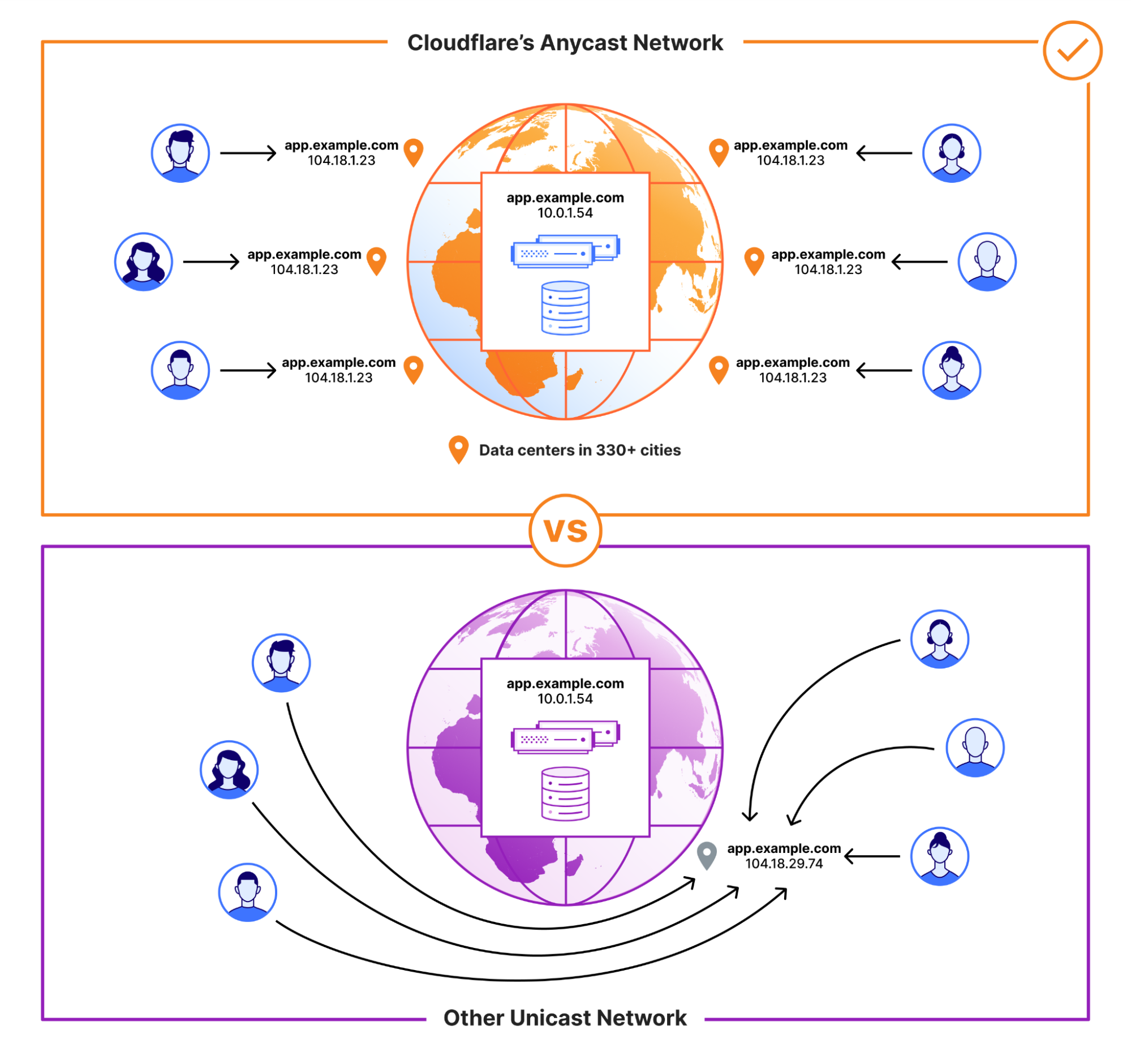
Anycast vs. Unicast networks
Our anycast network additionally allows Cloudflare to allocate compute and bandwidth resources closest to the regions that need them the most. Densely populated regions will generate larger amounts of legitimate traffic, and the data centers placed in those regions will have more bandwidth and CPU resources to meet those needs. Sparsely populated regions will naturally generate less legitimate traffic, so Cloudflare data centers in those regions can be sized appropriately. Since attack traffic is mainly coming from compromised devices, those devices will tend to be distributed in a manner that matches normal traffic flows sending the attack traffic proportionally to datacenters that can handle it. And similarly, within the datacenter, traffic is distributed across multiple machines.
Additionally, for high bandwidth attacks, Cloudflare’s network has another advantage. A large proportion of traffic on the Cloudflare network does not consume bandwidth in a symmetrical manner. For example, an HTTP request to get a webpage from a site behind Cloudflare will be a relatively small incoming packet, but produce a larger amount of outgoing traffic back to the client. This means that the Cloudflare network tends to egress far more legitimate traffic than we receive. However, the network links and bandwidth allocated are symmetrical, meaning there is an abundance of ingress bandwidth available to receive volumetric attack traffic.
Generating real-time signatures
By the time you’ve reached an individual server inside a datacenter, the bandwidth of the attack has been distributed enough that none of the upstream links are saturated. That doesn’t mean the attack has been fully stopped yet, since we haven’t dropped the bad packets. To do that, we need to sample traffic, qualify an attack, and create rules to block the bad packets.
Sampling traffic and dropping bad packets is the job of our l4drop component, which uses XDP (eXpress Data Path) and leverages an extended version of the Berkeley Packet Filter known as eBPF (extended BPF). This enables us to execute custom code in kernel space and process (drop, forward, or modify) each packet directly at the network interface card (NIC) level. This component helps the system drop packets efficiently without consuming excessive CPU resources on the machine.
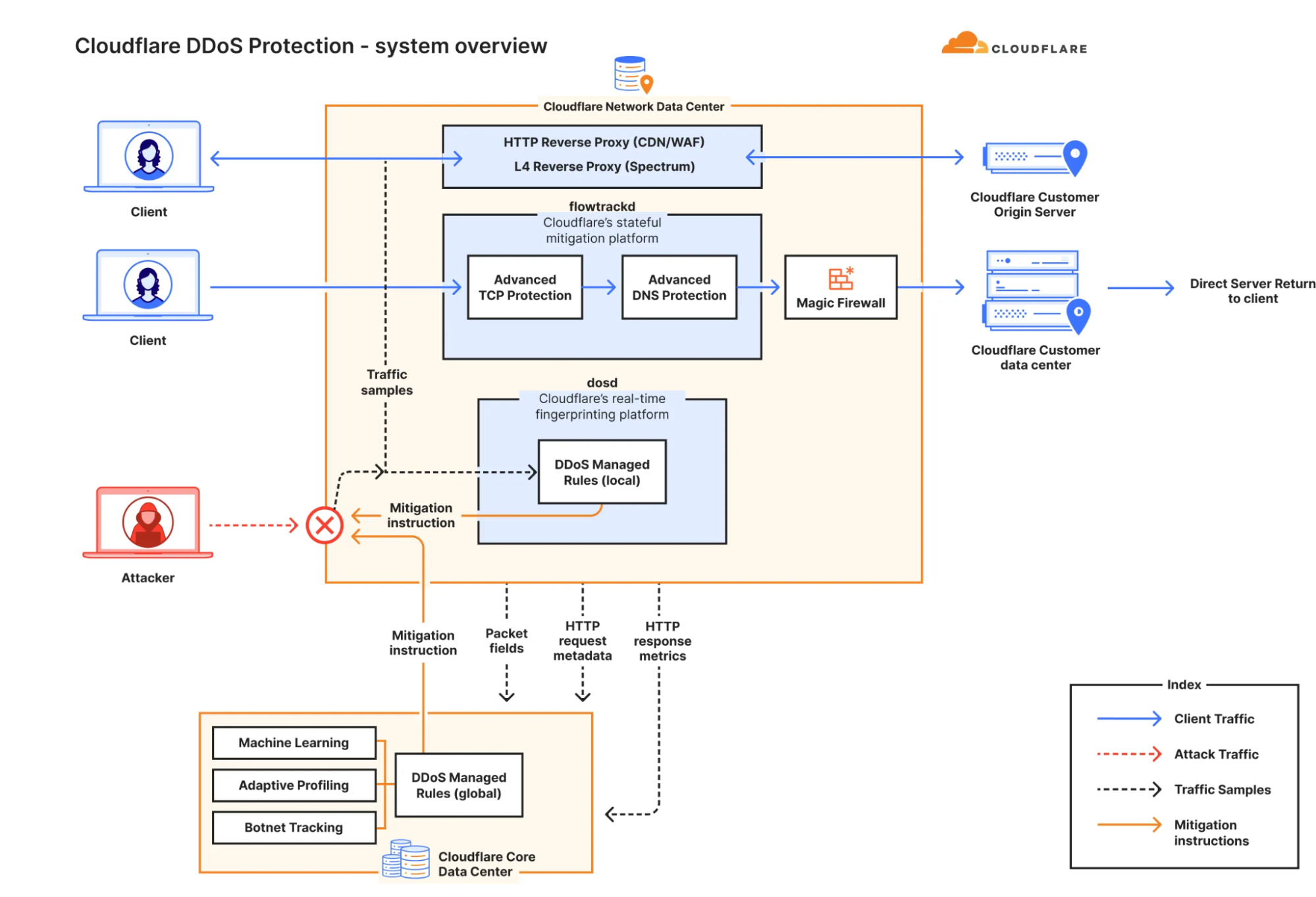
Cloudflare DDoS protection system overview
We use XDP to sample packets to look for suspicious attributes that indicate an attack. The samples include fields such as the source IP, source port, destination IP, destination port, protocol, TCP flags, sequence number, options, packet rate and more. This analysis is conducted by the denial of service daemon (dosd). Dosd holds our secret sauce. It has many filters which instruct it, based on our curated heuristics, when to initiate mitigation. To our customers, these filters are logically grouped by attack vectors and exposed as the DDoS Managed Rules. Our customers can customize their behavior to some extent, as needed.
As it receives samples from XDP, dosd will generate multiple permutations of fingerprints for suspicious traffic patterns. Then, using a data streaming algorithm, dosd will identify the most optimal fingerprints to mitigate the attack. Once attack is qualified, dosd will push a mitigation rule inline as an eBPF program to surgically drop the attack traffic.
The detection and mitigation of attacks by dosd is done at the server level, at the data center level and at the global level — and it’s all software defined. This makes our network extremely resilient and leads to almost instant mitigation. There are no out-of-path “scrubbing centers” or “scrubbing devices”. Instead, each server runs the full stack of the Cloudflare product suite including the DDoS detection and mitigation component. And it is all done autonomously. Each server also gossips (multicasts) mitigation instructions within a data center between servers, and globally between data centers. This ensures that whether an attack is localized or globally distributed, dosd will have already installed mitigation rules inline to ensure a robust mitigation.
Strong defenses against strong attacks
Our software-defined, autonomous DDoS detection and mitigation systems run across our entire network. In this post we focused mainly on our dynamic fingerprinting capabilities, but our arsenal of defense systems is much larger. The Advanced TCP Protection system and Advanced DNS Protection system work alongside our dynamic fingerprinting to identify sophisticated and highly randomized TCP-based DDoS attacks and also leverages statistical analysis to thwart complex DNS-based DDoS attacks. Our defenses also incorporate real-time threat intelligence, traffic profiling, and machine learning classification as part of our Adaptive DDoS Protection to mitigate traffic anomalies.
Together, these systems, alongside the full breadth of the Cloudflare Security portfolio, are built atop of the Cloudflare network — one of the largest networks in the world — to ensure our customers are protected from the largest attacks in the world.
Comic for 2024.10.02 – Chicken
Post Syndicated from Explosm.net original https://explosm.net/comics/chicken
New Cyanide and Happiness Comic
Myths, Monsters and the Mummy
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=JhXZcIhrsrA
California AI Safety Bill Vetoed
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/10/california-ai-safety-bill-vetoed.html
Governor Newsom has vetoed the state’s AI safety bill.
I have mixed feelings about the bill. There’s a lot to like about it, and I want governments to regulate in this space. But, for now, it’s all EU.
(Related, the Council of Europe treaty on AI is ready for signature. It’ll be legally binding when signed, and it’s a big deal.)
Thank You for Calling, President Trump
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=tjudot9ox9g
Служебен адрес. Как парламентът върна гражданските права на десетки хиляди души
Post Syndicated from Светла Енчева original https://www.toest.bg/slujeben-adres/

В последната седмица от съществуването си парламентът почти без дебати върна гражданските права на голяма група хора. Това стана с подкрепата на ГЕРБ и ПП–ДБ и въпреки всички останали парламентарни групи (плюс независимите депутати). Инициативата е на трима депутати – Деница Сачева (ГЕРБ), Божидар Божанов (ПП–ДБ, „Да, България“) и Александър Ненков (ГЕРБ).
Става въпрос за промените в Закона за гражданската регистрация (ЗГР), с които се въвежда т.нар. служебен адрес. На такъв могат да бъдат регистрирани хората, които по една или друга причина не са в състояние да докажат редовен постоянен адрес в България. А без това не могат да им се издадат документи за самоличност.
Какво не можем без лични документи?
Замисляли ли сте се за колко много неща, които смятаме за даденост, ни трябват документи за самоличност? Без лична карта или паспорт не можем не само да гласуваме или да сключим брак. Нямаме право и да се осигуряваме, да имаме законен дом, все едно дали собствен, или под наем, банкова сметка. Не можем да пътуваме в чужбина, да сключваме договори, не можем дори да имаме телефон на свое име.
Строго погледнато, дори на улицата не можем да излезем, защото, ако служител на реда поиска да се легитимираме, сме длъжни да представим личен документ. Нито можем да заведем съдебно дело, че са нарушени правата ни.
Ромският активист Огнян Исаев дава още примери какво означава да нямаш лична карта:
Парче пластика, а всъщност свобода или робство… да не можеш да припознаеш новороденото си дете, да не можеш да запишеш детето си на градина или училище, да не можеш да работиш и да имаш доходи, да не можеш да се разболяваш, защото няма как да се лекуваш… да не можеш дори да напуснеш този ад, в който си се озовал.
Изглежда абсурдно, но ако нямате лични документи, могат да откажат дори да ви погребат. На това основание през 2009 г. българските власти в продължение на две седмици са отказвали погребение на нигерийския протестантски пастор Джонсън Ибитуй, разказва синът му. Ибитуй е преподавал в български университет, имал е езикова школа, но когато не успял да поднови документите си, държавата го сметнала за недостоен и за вечен покой.
Колко и какви са хората без български документи за самоличност?
Оценките за броя на българските граждани и чужденците в България, които не могат да се регистрират по постоянен адрес в страната и поради това остават без документи за самоличност, варират в много широки граници. Според „Продължаваме промяната“ българските граждани с този проблем са над 50 000.
В годишния доклад на Българския хелзинкски комитет (БХК) за 2022 г. обаче се посочва, че към юли 2022 г. 187 883 български граждани нямат лична карта, като 109 233 от тях живеят в България и имат настоящ адрес (но за издаване на документи за самоличност е нужен постоянен адрес). От БХК са получили данните от МВР по реда на Закона за достъп до обществена информация, но от Вътрешното министерство са отказали да предоставят сведения колко точно са хората с „невалиден“ адрес.
При всички случаи мнозинството неможещи да се регистрират адресно в България са български граждани. Те се делят на две основни групи. В първата влизат предимно хора от ромски махали. Някои от тях например живеят в къщи, които никога не са били узаконявани, и затова нямат валиден адрес. Обитателите на много от тези къщи нямат и договори с дружествата, предоставящи комунални услуги. Други са имали адресна регистрация, но са принудително изведени от домовете си, за да бъдат жилищата им съборени. После адресът е заличен и хората не могат да се регистрират отново.
Втората голяма група са българите в чужбина, които не притежават имот в България. За да се регистрира адресно, човек трябва да представи нотариален акт, договор за наем (с писмено съгласие от наемодателя) или доказателство за платени битови сметки. При липса на такива не се издават лични документи. Затова много от тези хора, макар формално да не са лишени от българското си гражданство, на практика губят своите граждански права в родината си. А ако нямат двойно гражданство, липсата на български документи създава проблем за статута им и в страните, в които пребивават.
В България има, макар и далеч по-малко, чужденци, които не могат да си извадят документи за самоличност. Сред тях са чужденците без легален статут, но не само те. Някои от хората, получили статут на бежанци, хуманитарен статут или убежище в България, научавайки добрата новина, че страната е решила да ги спаси, изпадат в омагьосан кръг. Те са живели в някое от общежитията на Държавната агенция за бежанците и след получаването на статута са длъжни да устроят живота си сами. Трябва бързо да си извадят лични документи, но за тази цел се налага да имат адресна регистрация. Няма как обаче да се сдобият с договор за наем, ако нямат лични документи.
Как се стигна до омагьосания кръг с адресните регистрации и документите за самоличност?
През 2011 г. на власт е първото правителство на Бойко Борисов. От ГЕРБ внасят подписан лично от Борисов законопроект за промяна на ЗГР. С него се предлага за адресна регистрация да се представя документ за собственост или за право на ползване, както и съгласие от собственика – или лично, или нотариално заверено. Предвижда се и хората, променили настоящия си адрес между 01.09.2010 г. и 31.01.2011 г., да се регистрират отново.
Краят на януари 2011 г. е избран във връзка с промените в Изборния кодекс, с които се въвежда т.нар. уседналост при гласуването – задължението едно лице да е било регистрирано по постоянен или настоящ адрес определен брой месеци преди изборите.
В проекта за промяна на ЗГР се посочва като мотив защитата на интересите на собствениците срещу случаи на злоупотреби – на адреса на имота им се регистрират хора, които не живеят на него. По-важната цел обаче е борбата с т.нар. изборен туризъм – практиката избиратели да се регистрират в определена община само за да гласуват в нея.
Законопроектът е приет на второ четене в парламента почти без дебати, като се изключи точката за пререгистрирането на променилите адреса си между 01.09.2010 г. и 31.01.2011 г. Възразяват от БСП, а особено активна е Мая Манолова, която смята предложението за противоконституционно. Според нея „минимум 50 000 български граждани ще бъдат наказани“ в резултат на това изискване, защото ще трябва да повторят едно административно действие, представяйки документи, които не са им били нужни преди.
Въпреки че в началото на парламентарното заседание се регистрират 124 депутати, по-малко от 80 участват в гласуването на промените в ЗГР, като повечето са от ГЕРБ, а народните представители от останалите групи масово не се включват. Единствено по точката, срещу която възразява Манолова, 9 депутати от БСП гласуват против.
В дебатите не се засяга темата, че промените ще доведат до лишаването на десетки хиляди български граждани от граждански права, тъй като ще ги оставят без документи за самоличност.
През декември 2011 г. обаче Мая Манолова и съпартийката ѝ Милена Христова внасят законопроект за облекчаване на правилата за адресната регистрация. „Без лична карта един човек е анонимен и напълно безпомощен“, аргументира се Манолова. Според нея в резултат на затягането на правилата за адресна регистрация около 10 000 души остават без лични документи, „но процесът е лавинообразен и ще засяга все повече хора“.
В резултат правилата леко се облекчават, като се добавят и други документи, с които човек да доказва, че живее на определен адрес – например битови сметки. Но това не решава проблема на голямата част от хората, които остават без български документи за самоличност – въпреки всички анализи и доклади (ето например един от първите) за огромните измерения на проблема.
Освен ромите и българите в чужбина, потърпевши от промените в ЗГР през 2011 г., макар и в по-малка степен, са и част от хората, които живеят под наем в България. Причината е, че доста хазяи отказват да съдействат за адресната регистрация на наемателите, за да не им се наложи да плащат данъци върху наемите. Това затруднява наемателите да гласуват, ако трябва да пътуват с часове до постоянния си адрес. Също не могат да имат личен лекар в населеното място, в което живеят, нито децата им имат шанс в класациите за детска градина и основно училище.
Как се стигна до въвеждането на служебни адреси?
Седмица преди приемането на последните промени в ЗГР, с които се въведоха служебните адреси, от ПП се похвалиха, че идеята е тяхна и на коалиционните им партньори от „Демократична България“ (ДБ). И подчертаха, че инициативата е още от времето на кабинета на Кирил Петков, когато е създадена работна група към Министерството на регионалното развитие и благоустройството (МРРБ) по темата. А законопроектът е довършен по времето на правителството на Николай Денков.
Вярно е, че през януари 2024 г., когато премиер беше Денков, МРРБ анонсира въвеждането на служебен адрес за гражданите без редовен адрес. ПП обаче не са сред вносителите на последните предложения, които бяха приети на 25 септември 2024 г. и които са внесени от Деница Сачева и Александър Ненков от ГЕРБ и Божидар Божанов от „Да, България“, част от ДБ.
Освен това нито ПП, нито ДБ, нито впрочем и ГЕРБ са внесли законопроект за промяна на ЗГР. Сачева, Божанов и Ненков всъщност внасят в Комисията по регионална политика доклад с предложение за допълване на законопроект на „Възраждане“.
От партията на Костадин Костадинов предлагат ЗГР да стане още по-рестриктивен за хората с проблеми с адресната регистрация. Те искат да има проверки по домовете, за да се установи дали регистриралите се на един адрес действително живеят там, а също така да се увеличат санкциите за нарушителите. А това би засегнало онези, които са помогнали на хора, неможещи да докажат редовен адрес, като са им предоставили своя. Особено засегнати са и гражданите, които няма да могат вече да разчитат на такава помощ и има вероятност да останат без документи за самоличност заради това.
Предложенията, внесени от Сачева, Божанов и Ненков, представляват решение на проблема с невъзможните адресни регистрации на ромите, попаднали в омагьосания кръг на отнетите граждански права, на българите в чужбина, които не разполагат с имот в родината си, както и на бежанците, получили легален статут.
Гласуването протича с доста рехаво участие от страна на част от парламентарните групи. Най-стабилно присъствие имат от ГЕРБ, ПП–ДБ, „Възраждане“ и ИТН. От ДПС се включват максимум 10 депутати, от БСП – 4, от независимите – 7. Самото гласуване е разделено на 16 части, защото предложените текстове са много. В повечето случаи ГЕРБ и ПП–ДБ гласуват заедно, а срещу тях са „Възраждане“, ИТН и депутатите от останалите групи. Тоест от ДПС гласуват срещу правата на част от традиционните си избиратели, а БСП вече не се и опитва да е социална както през 2011 г., а е последователно националпопулистка.
Дебати почти няма. Срещу въвеждането на служебни адреси възразява депутатката от „Възраждане“ Маргарита Махаева. „За вечни времена ли ще бъде тази регистрация?“, пита тя. Според нея служебните адреси трябва да се предоставят „само в изключителни случаи“ и за кратък период. „След това да намерят къде да се регистрират, вече е тяхна си работа“, смята Махаева. Контрапредложенията ѝ не се приемат.
Служебните адреси помагат за възстановяването на правата на хората в гетата и на емигрантите, но нямат отношение към проблемите на наемателите, чиито хазяи отказват да ги регистрират, защото укриват данъци.
„Глътка въздух“ – позицията на ромския активист
Огнян Исаев разглежда промените в ЗГР в контекста на правата на ромите. В коментар за „Тоест“ той припомня, че „още от създаването на Третата българска държава българските власти някъде частично, някъде изцяло ограничават гражданските права на ромите“. Например през 1901 г. Народното събрание отнема избирателните им права. Според Исаев промените в ЗГР от 2011 г. на практика отнемат гражданството на голям брой роми.
Много български политици си мислят, че ромските избиратели се печелят само с купуване и натиск, а не „с нормални и човешки разговори“, смята Исаев. Той определя последните промени в ЗГР като „глътка въздух“. Но подчертава, че „истинското освобождение ще настъпи, когато се промени и Законът за устройство на територията така, че всички неформални ромски махали станат формално част от общините, а не бели петна на картите им“.
„Ромските тегоби са експериментални“, казва Огнян Исаев и пояснява: ако експериментите с ограничаването на правата на ромите са успешни, те ще се приложат под една или друга форма върху цялото население.
Същото твърдение се отнася и за ЛГБТИ (лесбийки, гей мъже, бисексуални, транс и интерсекс) хората, както и за всяка друга група, обявена за „обществен враг“. Когато се приеха поправките по руски образец против ЛГБТИ „пропагандата“ в училище в Закона за училищното и предучилищното образование, вносителите от „Възраждане“ веднага пробваха да прокарат и регистрацията на т.нар. чуждестранни агенти – отново в унисон с путинското законодателство. Предложението не мина най-вече защото от ГЕРБ бяха против. Както впрочем и промените в ЗГР през 2011 и през 2024 г., и забраната на „пропагандата“ в училище минаха, защото ГЕРБ беше за.
Обратите в отнемането и предоставянето на права показват как в българската политика базови ценности се превръщат в залог на ситуативни интереси и моментни конфигурации. Така човек не знае дали утре ще го превърнат в поредната опитна мишка с отнети права, или ще го прехвърлят от групата на мишките при човешките същества. Днес поне за ромите има „глътка въздух“. До следващата изненада.
Намаляване на бюрокрацията във връзка с превенцията на пране на пари
Post Syndicated from Bozho original https://blog.bozho.net/blog/4383
„8. Намаляване на бюрокрацията във връзка превенцията на прането на пари – повече служебни справки и по-малко излишни документи, които финансовите институции и други организации събират от клиентите си.“
Почти всеки клиент на банка е бил викан да си даде актуални данни. Искат се всякакви документи – и фирмени, и лични. И всичко това, за да се изпълнят криворазбраните изисквания за превенция на пране на пари. Защо криворазбрани – защото при цялата бюрокрация, България има сериозен проблем с прането на пари, влезе в сивия списък на рискови държави, а напр.
Божков изтегли необезпокояван 67 милиона в кеш.
Междувременно, Европейският съюз прие шестия пакет мерки срещу изпирането на пари, което значи още промени в близко бъдеще. България спазва „буквата“ на закона, но често ѝ убягва духа, което значи прекомерна тежест без нужния ефект.
В 49-ото Народно събрание свърших две неща по темата: 1) събрах (с помощта на бранша) конкретни справки в публични регистри, които, ако бъдат приложени, могат да спестят разнасяне на документи, свързани с изпирането на пари, и 2) прокарах облекчения в Закона за мерките срещу изпирането на пари, така че да не отпадне задължението за представяне на документи, които могат да бъдат свалени от Търговския регистър. С моя редакция беше уредено и съхранението и достъпа до електронен архив (когато оригиналните документи са електронни).
В следващия парламент ще опитам да придвижа отпадането на максимално голямо количество излишни документи, които могат да бъдат заменени със справки; което пък ще спести фразата „обикалям за едни документи“ и периодичното разхождане до клон на финансови институции.
Смятам също така, че финансовото разузнаване, което е основен орган за превенцията на пране на пари, трябва да бъде в структурата на Министерство на финансите, защото в ДАНС няма добра среда за съвременни методи за превенция.
С по-малко бюрокрация и повече ефективност и дигитализация можем едновременно да облекчим финансовите институции, гражданите и бизнеса, и да постигнем по-добри резултати в борбата с прането на пари.
Материалът Намаляване на бюрокрацията във връзка с превенцията на пране на пари е публикуван за пръв път на БЛОГодаря.
The Distant Early Warning Line
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=fW5r728_Xso
Ingredients
Post Syndicated from xkcd.com original https://xkcd.com/2993/

Don’t Believe the HYPE!! FujiFilm X100VI 6 Months Later
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=FOFRkQhtl5w
THG Podcast: Hurricanes that Made History
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=ETTJoHzmixs