Post Syndicated from Anton Aleksandrov original https://aws.amazon.com/blogs/compute/more-room-to-build-serverless-services-now-support-payloads-up-to-1-mb/
To support cloud applications that increasingly depend on rich contextual data, AWS has raised the maximum payload size from 256 KB to 1 MB for asynchronous AWS Lambda function invocations, Amazon Simple Queue Service (Amazon SQS), and Amazon EventBridge. Developers can use this enhancement to build and maintain context-rich event-driven systems and reduce the need for complex workarounds such as data chunking or external large object storage.
Overview
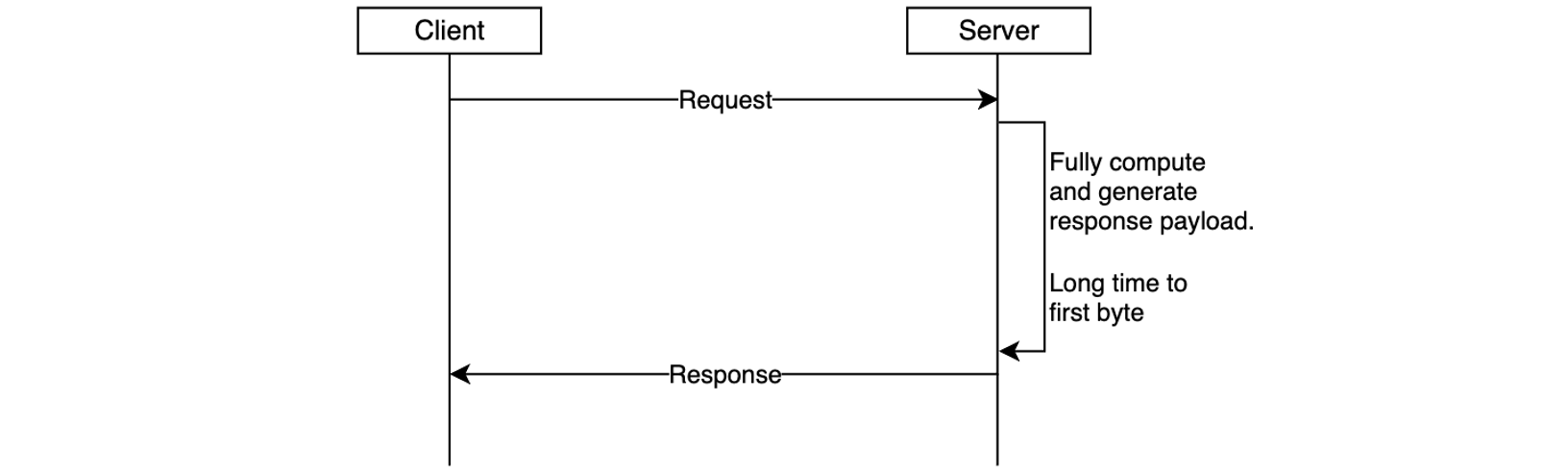
Modern cloud applications rely on context-rich, structured data to drive intelligent behavior. Large language model (LLM) prompts, telemetry signals, personalization data, machine learning (ML) outputs, and user interaction logs are no longer simple strings. Instead, they’re typically complex, nested JSON or YAML objects carrying meaningful context. Previously, developers working with serverless services such as Amazon SQS, Lambda (asynchronous invocations and Amazon SQS event-source mapping), or EventBridge had to carefully manage their data to fit within the 256 KB payload size limit. This commonly meant chunking larger payloads, externalizing payloads to object stores such as Amazon S3, or using data compression. These workarounds added complexity and latency, creating edge cases that were difficult to monitor and debug.
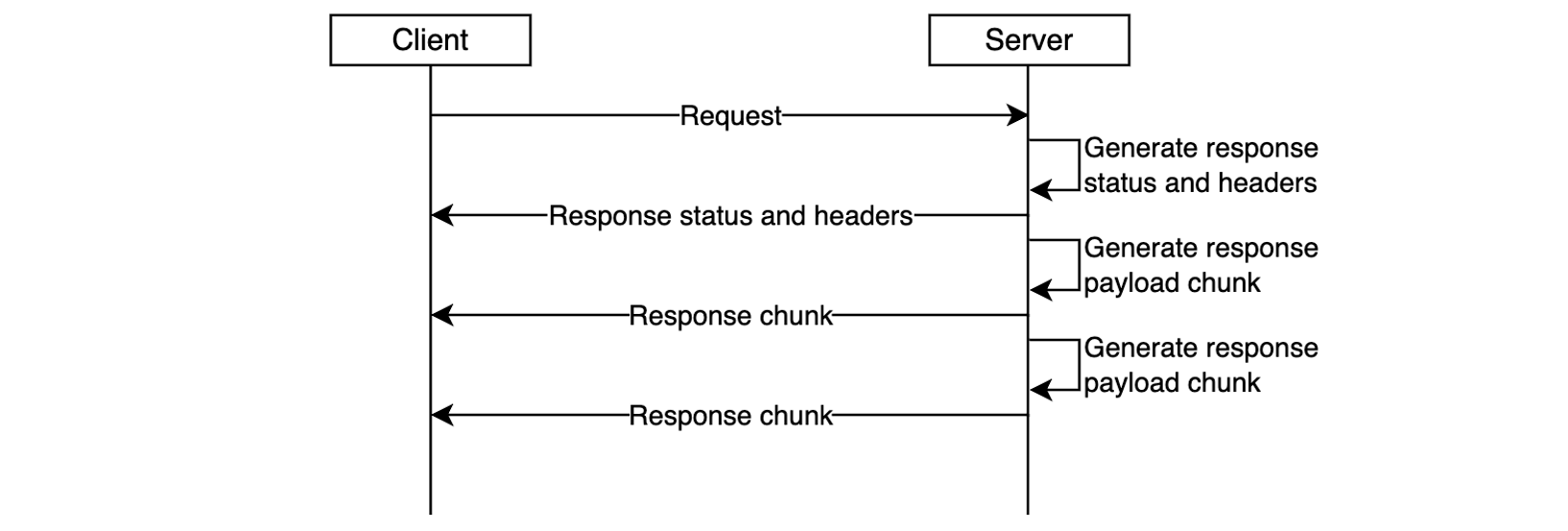
With the recent launches, you can now transmit payloads up to 1 MB, significantly reducing the need for complex data chunking and architectural workarounds. This increased capacity streamlines design patterns, reduces operational overhead, and makes event-driven systems more intuitive to build and maintain. Developers can now include richer data in single payloads—from detailed LLM prompts and full system states to comprehensive context and complete transaction histories.
The new 1 MB payload size limit applies to asynchronous Lambda function invocations, whether you trigger them using either SQS event-source mapping, AWS Command Line Interface (AWS CLI), AWS SDKs, Lambda Invoke API, or AWS services such as EventBridge. The increased limit also extends to all messages and events flowing through Amazon SQS queues and EventBridge Event Buses.
Getting started
There’s nothing you need to do to get started. This enhancement is automatically applied to all new and existing Lambda functions, SQS queues, and EventBridge Event Buses.
If you were previously chunking data at 256KB (or lower) threshold, then you might need to make changes to your service configurations or business logic code to start using the new limit. For example, if you’ve explicitly set Amazon SQS MaximumMessageSize attribute, then you might need to adjust it to a new desired value. Larger payloads might also result in higher costs, as described in the following section.
Real-world example: rich event context in agentic event-driven architectures
Event-driven architectures allow services to operate independently without centralized coordination. In these systems, comprehensive event context is essential. With the increased 1 MB payload limit, events can now carry more comprehensive data—from user profiles and order details to historical interactions. This enables services such as inventory, shipping, and notifications to act autonomously.
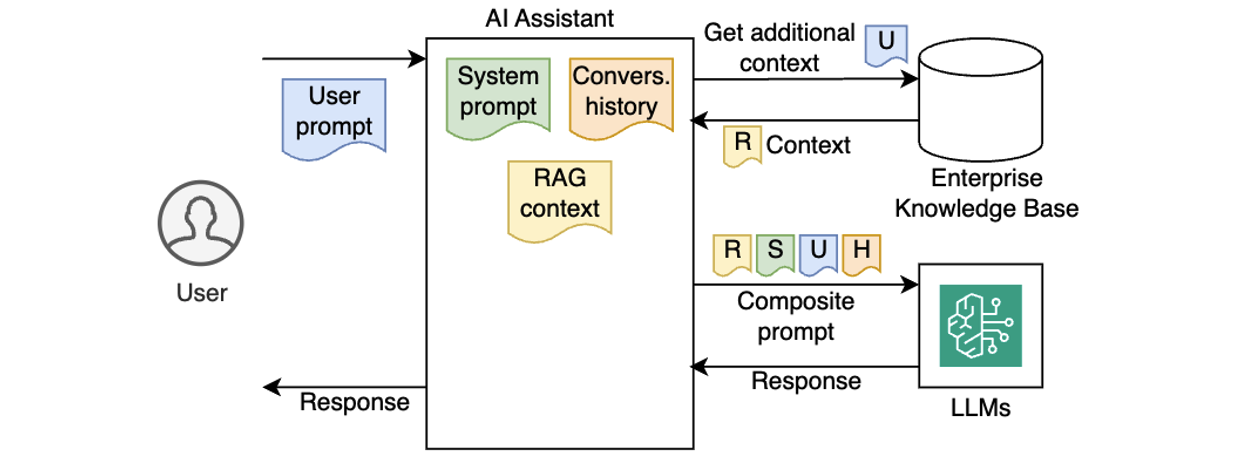
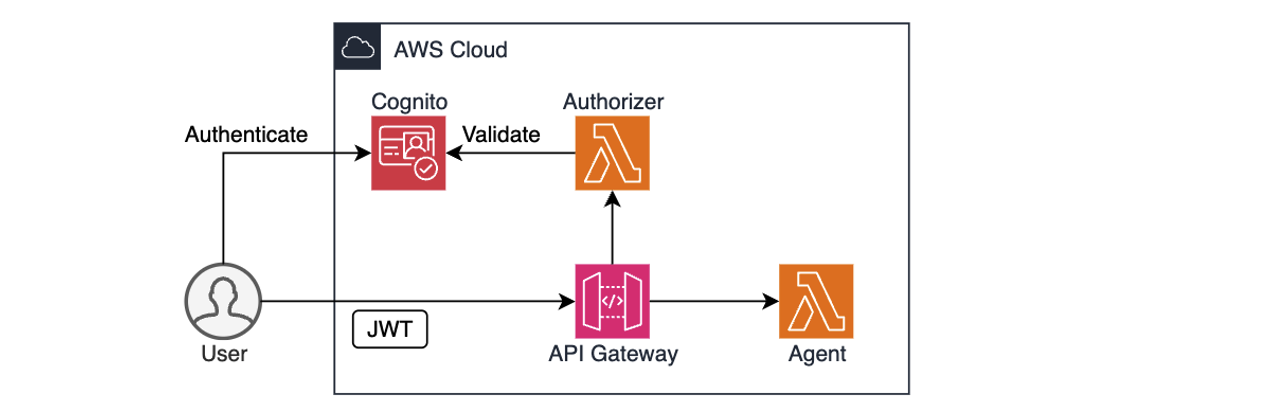
Consider the following example. In hospitality and quick-service industries, customer satisfaction depends on timely, thoughtful service recovery. When a guest submits negative feedback through a survey, review, or complaint form, service teams must gather context, interpret the issue, and craft a response. Traditionally, this meant manually piecing together visit logs, loyalty data, and prior complaints. Now, this can be fully automated using an AI agent powered by AWS serverless services and Amazon Bedrock, as shown in the following figure.
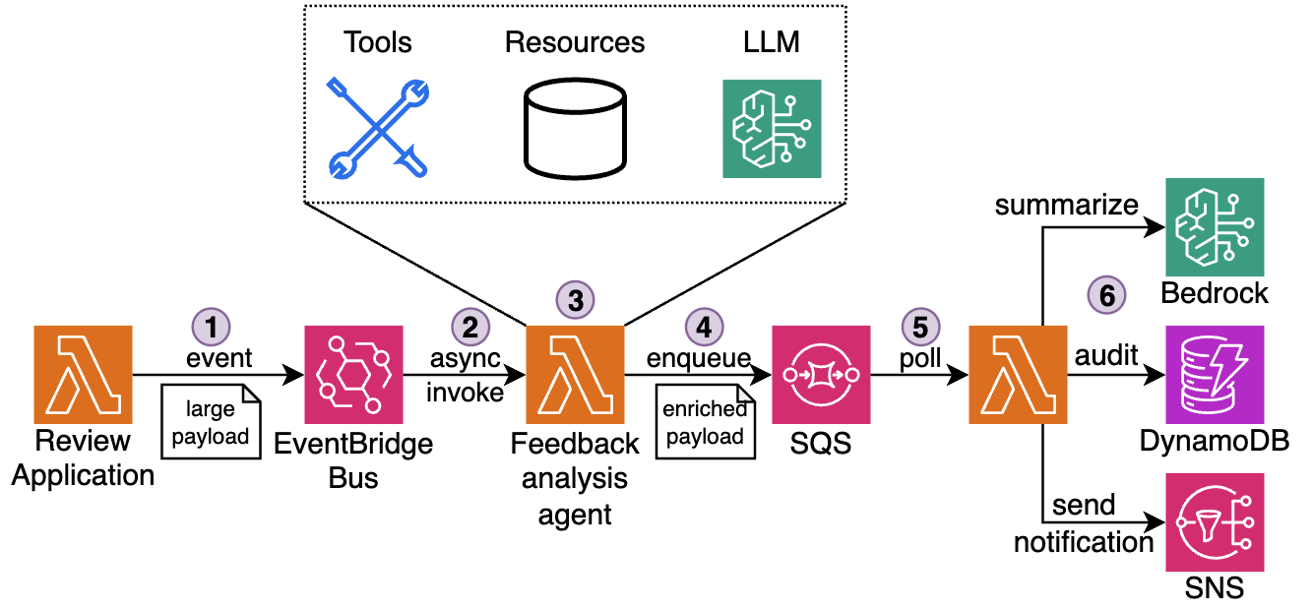 Figure 1: Customer feedback processing pipeline
Figure 1: Customer feedback processing pipeline
The workflow:
- Receive: A new review is submitted through the Review application and emitted as an event to EventBridge Event Bus.
- Detect: Event Bus delivers the event to downstream Feedback analysis agent. The agent running in a Lambda function recognizes the review as low-rating or complaint.
- Enrich: The agent collects the guest’s visit metadata, booking details, loyalty activity, and complaint history using attached MCP tools into a single structured JSON payload (up to 1 MB).
- Queue: The payload is sent to an SQS queue for further asynchronous processing by downstream components.
- Generate: A separate Lambda function polls messages from Amazon SQS and invokes an Amazon Bedrock model to analyze the full complaint context, draft a personalized response, suggest a gesture (such as a refund or credit), and classify issue severity.
- Deliver: The message is logged and sent to the customer, and to the service team for further analysis.
This use case demonstrates the importance of having a rich context: current and previous visits details, loyalty tier, prior interactions, and feedback history. Previously, teams had to offload pieces of context to Amazon S3 and reference them externally, adding latency and architectural complexity. The new 1 MB payload size means that all this information can be transported together, improving the serverless agentic workflow efficiency and streamlining maintenance.
Best practices when using large payloads
The following sections outline best practices that you should apply when using larger payloads.
Performance considerations
Monitor Lambda function memory usage carefully when working with larger payloads, because parsing and processing complex JSON objects can increase memory usage and execution duration. Test your systems thoroughly under load, especially for high-throughput applications, by benchmarking with realistic payload sizes and traffic patterns. Although the payload limit has increased to 1 MB, the Lambda 15-minute timeout and memory limits remain unchanged. When applicable, you can use compression to process even larger datasets efficiently, but remember to account for the added CPU overhead of compression and decompression in your performance calculations. Read the Monitoring best practices for event delivery with Amazon EventBridge post for more best practices to tune your event-driven architectures performances.
Operational guidelines
Configure dead-letter-queues (DLQ) to make sure that failed messages are retained for inspection and troubleshooting. This becomes especially important with larger payloads, because debugging complex data structures necessitates access to the complete message context. Implement robust error handling and retries to manage transient failures, particularly when processing rich payload content that may contain nested structures or complex relationships.
To further optimize throughput, you can batch similar smaller events together into a single payload. However, avoid mixing unrelated events and maintain clear boundaries between different business domains and processes.
Always make sure that your downstream dependencies are capable of handling larger payloads.
When to use external storage
Even with the increased 1 MB payload limit, there are scenarios where patterns such as claim check remain a sound architectural choice. These patterns involve storing a full payload in an external system, such as Amazon S3, and passing a lightweight reference through your event stream. This approach continues to provide value when payloads exceed the new limit, when data needs to be reused by multiple consumers, or when strict governance, traceability, and security requirements are involved. For example, audit logs, image metadata, or large ML inference inputs may still surpass the 1 MB boundary, even when compressed. Instead of risking truncation or fragmentation, a claim check enables consistent, scalable access to the complete data set.
You can use open source libraries such as the Kafka sink connector for EventBridge and Amazon SQS Extended Client Library (available for Python and Java) that abstract complexities of storing large objects in external storage.
Cost management
Although larger payloads enable richer context in your applications, logging full payloads can increase storage and processing costs. Services such as CloudWatch Logs charge based on data volume, thus implementing selective logging, payload truncation, or sampling becomes crucial for high-volume events. Consider logging only essential fields or implementing smart sampling strategies based on business importance.
For full payload archival and retention, evaluate cost-effective storage solutions such as Amazon S3 with appropriate lifecycle policies. This can include moving older logs to cheaper storage tiers or implementing automated cleanup procedures for non-critical data. Balance your retention needs with cost optimization by defining clear policies for what data needs to be kept and for how long.
Review the pricing pages for AWS Lambda, Amazon EventBridge, and Amazon SQS to learn about the costs of delivering and processing events and messages.
Conclusion
The increase in maximum payload size from 256 KB to 1 MB enables developers to build more efficient distributed architectures. You can use this enhancement to transport richer context in event and message payloads, reducing the need for complex workarounds that previously added architectural complexity and operational overhead. This added room to transmit rich context means that you can streamline your workflows, improve observability, and reduce architectural complexity whether using choreography or orchestration patterns.
Go to the developer guides for AWS Lambda, Amazon EventBridge, and Amazon SQS, to learn more about how to take advantage of this update.
To learn more about serverless architectures, visit Serverless Land.
 Figure 1. A multitude of telemetry sources in Kubernetes clusters
Figure 1. A multitude of telemetry sources in Kubernetes clusters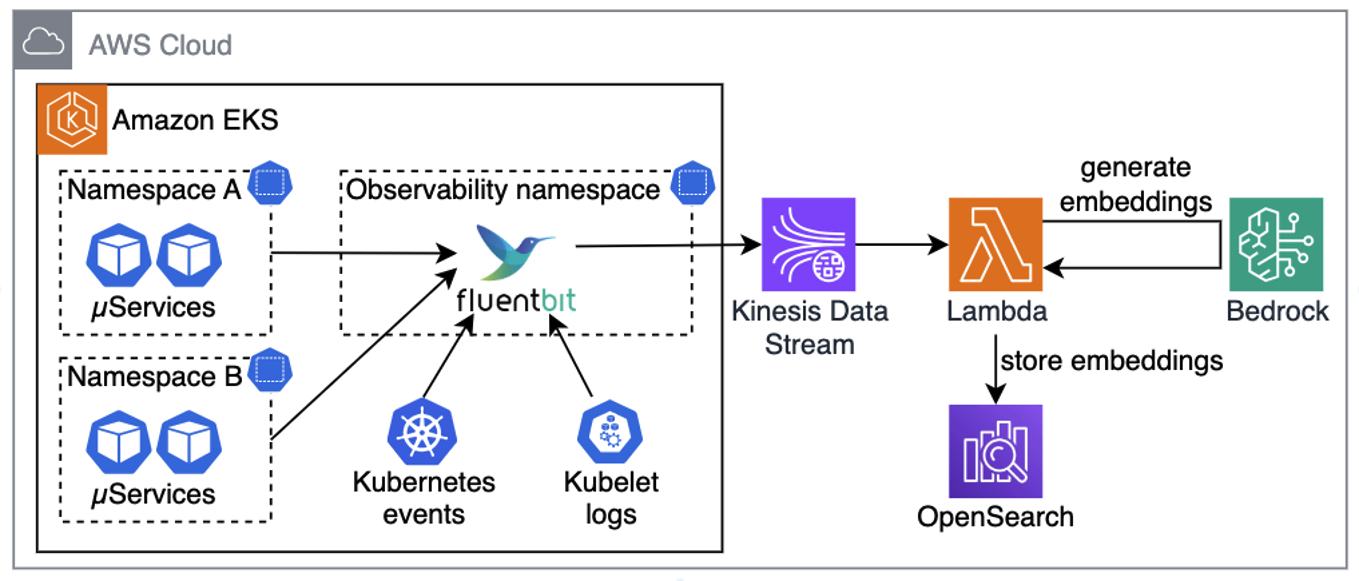 Figure 2. Collecting telemetry from sources, generating embeddings, and saving in OpenSearch
Figure 2. Collecting telemetry from sources, generating embeddings, and saving in OpenSearch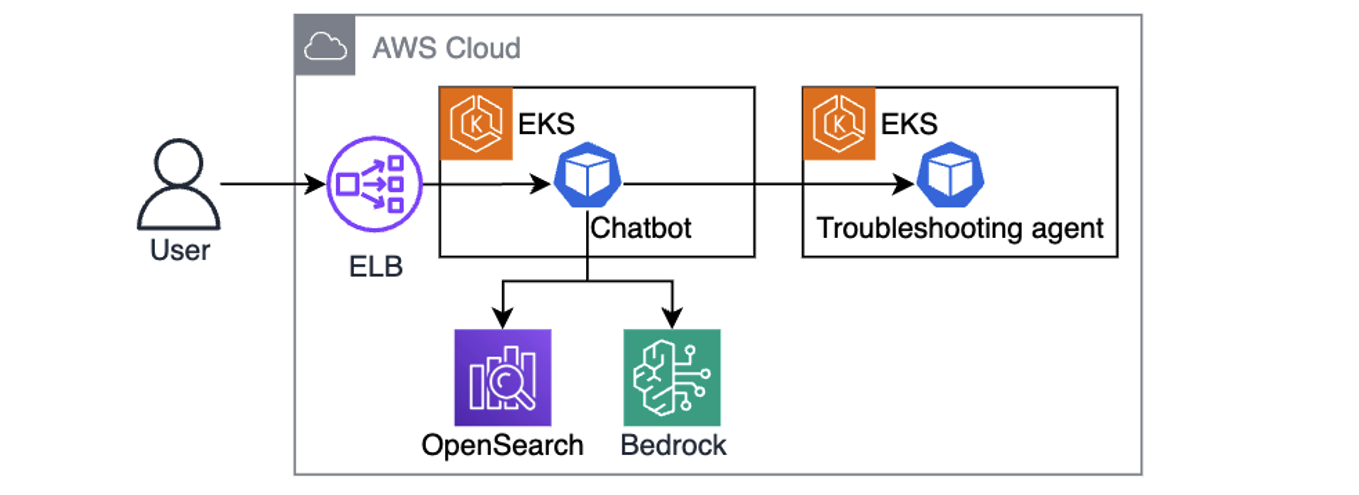 Figure 3. Chatbot is using user queries augmented with telemetry context to send kubectl commands to the troubleshooting assistant.
Figure 3. Chatbot is using user queries augmented with telemetry context to send kubectl commands to the troubleshooting assistant. 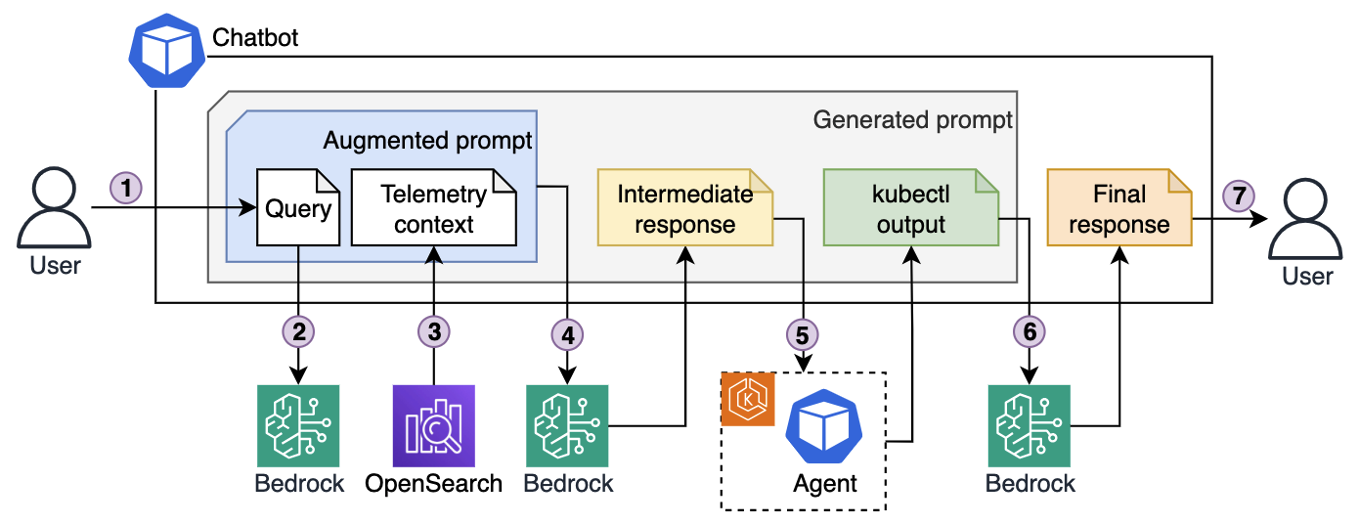 Figure 4. Iterative troubleshooting process.
Figure 4. Iterative troubleshooting process.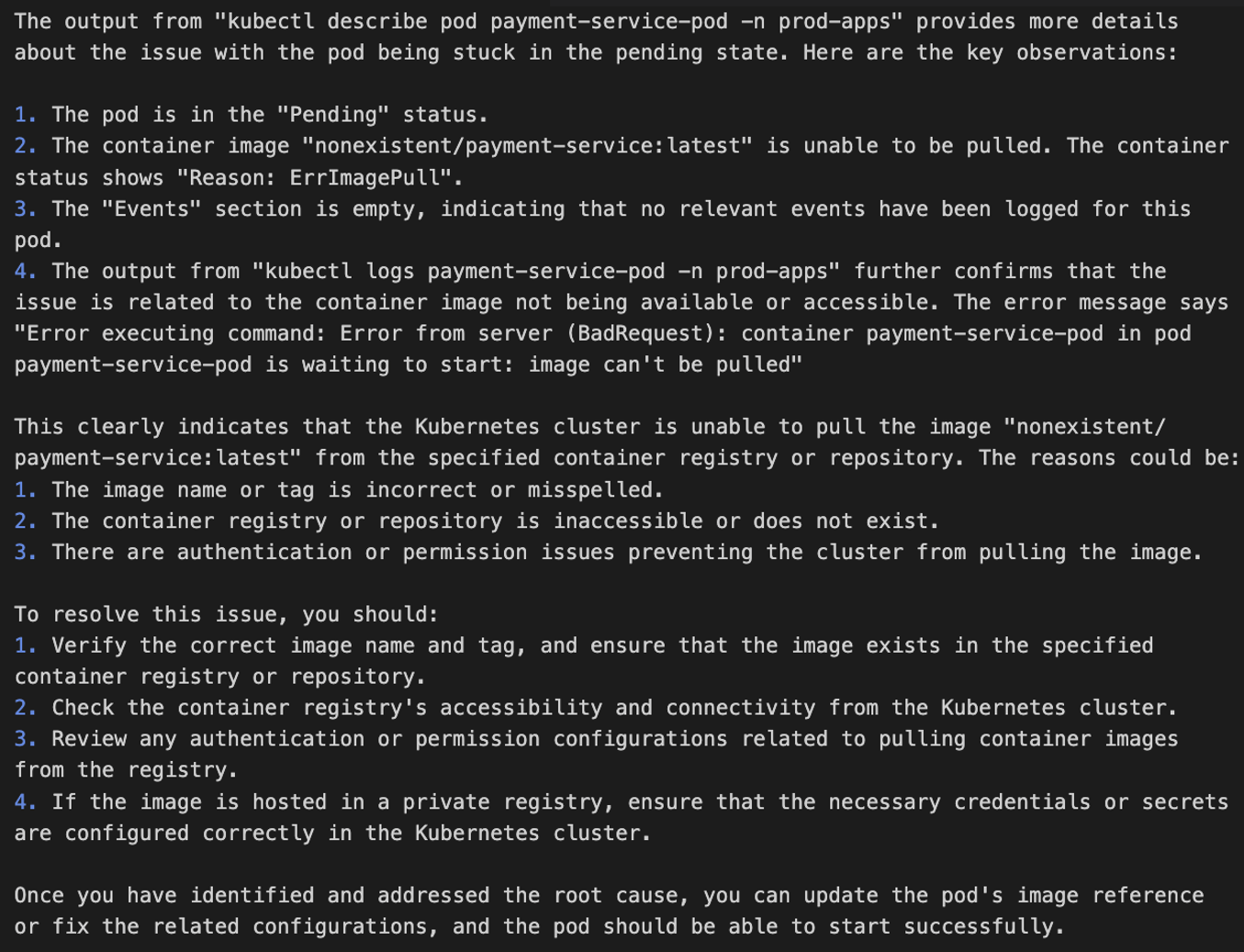 Figure 5. EKS cluster troubleshooting, example output
Figure 5. EKS cluster troubleshooting, example output