Post Syndicated from James Le original https://aws.amazon.com/blogs/big-data/optimize-multimodal-search-using-the-twelvelabs-embed-api-and-amazon-opensearch-service/
This blog is co-authored by James Le, Head of Developer Experience – TwelveLabs
The exponential growth of video content has created both opportunities and challenges. Content creators, marketers, and researchers are now faced with the daunting task of efficiently searching, analyzing, and extracting valuable insights from vast video libraries. Traditional search methods such as keyword-based text search often fall short when dealing with video content to analyze the visual content, spoken words, or contextual elements within the video itself, leaving organizations struggling to effectively search through and unlock the full potential of their multimedia assets.
With the integration of TwelveLabs’ Embed API and Amazon OpenSearch Service, we can interact with and derive value from video content. By using TwelveLabs‘ advanced AI-powered video understanding technology and OpenSearch Service’s search and analytics capabilities, we can now perform advanced video discovery and gain deeper insights.
In this blog post, we show you the process of integrating TwelveLabs Embed API with OpenSearch Service to create a multimodal search solution. You’ll learn how to generate rich, contextual embeddings from video content and use OpenSearch Service’s vector database capabilities to enable search functionalities. By the end of this post, you’ll be equipped with the knowledge to implement a system that can transform the way your organization handles and extracts value from video content.
TwelveLabs’ multimodal embeddings process visual, audio, and text signals together to create unified representations, capturing the direct relationships between these modalities. This unified approach delivers precise, context-aware video search that matches human understanding of video content. Whether you’re a developer looking to enhance your applications with advanced video search capabilities, or a business leader seeking to optimize your content management strategies, this post will provide you with the tools and steps to implement multimodal search for your organizational data.
About TwelveLabs
TwelveLabs is an Advanced AWS Partner and AWS Marketplace Seller that offers video understanding solutions. Embed API is designed to revolutionize how you interact with and extract value from video content.
At its core, the Embed API transforms raw video content into meaningful, searchable data by using state-of-the-art machine learning models. These models extract and represent complex video information in the form of dense vector embeddings, each a standard 1024-dimensional vector that captures the essence of the video content across multiple modalities (image, text, and audio).

Key features of TwelveLabs Embed API
Below are the key features of TwelveLabs Embed API:
- Multimodal understanding: The API generates embeddings that encapsulate various aspects of the video, including visual expressions, body language, spoken words, and overall context.
- Temporal coherence: Unlike static image-based models, TwelveLabs’ embeddings capture the interrelations between different modalities over time, providing a more accurate representation of video content.
- Flexibility: The API supports native processing of all modalities present in videos, eliminating the need for separate text-only or image-only models.
- High performance: By using a video-native approach, the Embed API provides more accurate and temporally coherent interpretation of video content compared to traditional CLIP-like models.
Benefits and use cases
The Embed API offers numerous advantages for developers and businesses working with video content:
- Enhanced Search Capabilities: Enable powerful multimodal search across video libraries, allowing users to find relevant content based on visual, audio, or textual queries.
- Content Recommendation: Improve content recommendation systems by understanding the deep contextual similarities between videos.
- Scene Detection and Segmentation: Automatically detect and segment different scenes within videos for easier navigation and analysis.
- Content Moderation: Efficiently identify and flag inappropriate content across large video datasets.
Use cases include:
- Anomaly detection
- Diversity sorting
- Sentiment analysis
- Recommendations
Architecture overview
The architecture for using TwelveLabs Embed API and OpenSearch Service for advanced video search consists of the following components:
- TwelveLabs Embed API: This API generates 1024-dimensional vector embeddings from video content, capturing visual, audio, and textual elements.
- OpenSearch Vector Database: Stores and indexes the video embeddings generated by TwelveLabs.
- Secrets Manager to store secrets such as API access keys, and the Amazon OpenSearch Service username and password.
- Integration of TwelveLabs SDK and the OpenSearch Service client to process videos, generate embeddings, and index them in OpenSearch Service.
The following diagram illustrates:
- A video file is stored in Amazon Simple Storage Service (Amazon S3). Embeddings of the video file are created using TwelveLabs Embed API.
- Embeddings generated from the TwelveLabs Embed API are now ingested to Amazon OpenSearch Service.
- Users can search the video embeddings using text, audio, or image. The user uses TwelveLabs Embed API to create the corresponding embeddings.
- The user searches video embeddings in Amazon OpenSearch Service and retrieves the corresponding vector.

The use case
For the demo, you will work on these videos: Robin bird forest Video by Federico Maderno from Pixabay and Island Video by Bellergy RC from Pixabay.
However, the use case can be expanded to various other segments. For example, the news organization struggles with:
- Needle-in-haystack searches through thousands of hours of archival footage
- Manual metadata tagging that misses nuanced visual and audio context
- Cross-modal queries such as querying a video collection using text or audio descriptions
- Rapid content retrieval for breaking news tie-ins
By integrating TwelveLabs Embed API with OpenSearch Service, you can:
- Generate 1024-dimensional embeddings capturing each video’s visual concepts. The embeddings are also capable of extracting spoken narration, on-screen text, and audio cues.
- Enable multimodal search capabilities allowing users to:
- Find specific demonstrations using text-based queries.
- Locate activities through image-based queries.
- Identify segments using audio pattern matching.
- Reduce search time from hours to seconds for complex queries.
Solution walkthrough
GitHub repository contains a notebook with detailed walkthrough instructions for implementing advanced video search capabilities by combining TwelveLabs’ Embed API with Amazon OpenSearch Service.
Prerequisites
Before you proceed further, verify that the following prerequisites are met:
- Confirm that you have an AWS account. Sign in to the AWS account.
- Create a TwelveLabs account because it will be required to get the API Key. TwelveLabs offer free tier pricing but you can upgrade if necessary to meet your requirement.
- Have an Amazon OpenSearch Service domain. If you don’t have an existing domain, you can create one using the steps outlined in our public documentation for Creating and Managing Amazon OpenSearch Service Domain. Make sure that the OpenSearch Service domain is accessible from your Python environment. You can also use Amazon OpenSearch Serverless for this use case and update the interactions to OpenSearch Serverless using AWS SDKs.
Step 1: Set up the TwelveLabs SDK
Start by setting up the TwelveLabs SDK in your Python environment:
- Obtain your API key from TwelveLabs Dashboard.
- Follow steps here to create a secret in AWS Secrets Manager. For example, name the secret as
TL_API_Key.Note down the ARN or name of the secret (TL_API_Key) to retrieve. To retrieve a secret from another account, you must use an ARN.For an ARN, we recommend that you specify a complete ARN rather than a partial ARN. See Finding a secret from a partial ARN.Use this value for the SecretId in the code block below.
import boto3
import json
secrets_manager_client=boto3.client("secretsmanager")
API_secret=secrets_manager_client.get_secret_value(
SecretId="TL_API_KEY"
)
TL_API_KEY=json.loads(API_secret["SecretString"])["TL_API_Key"]
Step 2: Generate video embeddings
Use the Embed API to create multimodal embeddings that are contextual vector representations for your videos and texts. TwelveLabs video embeddings capture all the subtle cues and interactions between different modalities, including the visual expressions, body language, spoken words, and the overall context of the video, encapsulating the essence of all these modalities and their interrelations over time.
To create video embeddings, you must first upload your videos, and the platform must finish processing them. Uploading and processing videos require some time. Consequently, creating embeddings is an asynchronous process comprised of three steps:
- Upload and process a video: When you start uploading a video, the platform creates a video embedding task and returns its unique task identifier.
- Monitor the status of your video embedding task: Use the unique identifier of your task to check its status periodically until it’s completed.
- Retrieve the embeddings: After the video embedding task is completed, retrieve the video embeddings by providing the task identifier. Learn more in the docs.
Video processing implementation
This demo depends upon some video data. To use this, you will download two mp4 files and upload it to an Amazon S3 bucket.
- Click on the links containing the Robin bird forest Video by Federico Maderno from Pixabay and Island Video by Bellergy RC from Pixabay videos.
- Download the
21723-320725678_small.mp4 and 2946-164933125_small.mp4 files.
- Create an S3 bucket if you don’t have one already. Follow the steps in the Creating a bucket doc. Note down the name of the bucket and replace it the code block below (Eg.,
MYS3BUCKET).
- Upload the
21723-320725678_small.mp4 and 2946-164933125_small.mp4 video files to the S3 bucket created in the step above by following the steps in the Uploading objects doc. Note down the name of the objects and replace it the code block below (Eg., 21723-320725678_small.mp4 and 2946-164933125_small.mp4)
s3_client=boto3.client("s3")
bird_video_data=s3_client.download_file(Bucket='MYS3BUCKET', Key='21723-320725678_small.mp4', Filename='robin-bird.mp4')
island_video_data=s3_client.download_file(Bucket='MYS3BUCKET', Key='2946-164933125_small.mp4', Filename='island.mp4')
def print_segments(segments: List[SegmentEmbedding], max_elements: int = 1024):
for segment in segments:
print(
f" embedding_scope={segment.embedding_scope} start_offset_sec={segment.start_offset_sec} end_offset_sec={segment.end_offset_sec}"
)
print(f" embeddings: {segment.embeddings_float[:max_elements]}")
# Initialize client with API key
twelvelabs_client = TwelveLabs(api_key=TL_API_KEY)
video_files=["robin-bird.mp4", "island.mp4"]
tasks=[]
Embedding generation process
With the SDK configured, generate embeddings for your video and monitor task completion with real-time updates. Here you use the Marengo 2.7 model to generate the embeddings:
for video in video_files:
# Create embedding task
task = twelvelabs_client.embed.task.create(
model_name="Marengo-retrieval-2.7",
video_file=video
)
print(
f"Created task: id={task.id} engine_name={task.model_name} status={task.status}"
)
def on_task_update(task: EmbeddingsTask):
print(f" Status={task.status}")
status = task.wait_for_done(
sleep_interval=2,
callback=on_task_update
)
print(f"Embedding done: {status}")
# Retrieve and inspect results
task = task.retrieve()
if task.video_embedding is not None and task.video_embedding.segments is not None:
print_segments(task.video_embedding.segments)
tasks.append(task)
Key features demonstrated include:
- Multimodal capture: 1024-dimensional vectors encoding visual, audio, and textual features
- Model specificity: Using Marengo-retrieval-2.7 optimized for scientific content
- Progress tracking: Real-time status updates during embedding generation
Expected output
Created task: id=67ca93a989d8a564e80dc3ba engine_name=Marengo-retrieval-2.7 status=processing
Status=processing
Status=processing
Status=processing
Status=processing
Status=processing
Status=processing
Status=processing
Status=processing
Status=processing
Status=ready
Embedding done: ready
embedding_scope=clip start_offset_sec=0.0 end_offset_sec=6.0
embeddings: [0.022429451, 0.00040668788, -0.01825908, -0.005862708, -0.03371106,
-6.357456e-05, -0.015320076, -0.042556215, -0.02782445, -0.00019097517, 0.03258314,
-0.0061399476, -0.00049206393, 0.035632476, 0.028209884, 0.02875258, -0.035486065,
-0.11288028, -0.040782217, -0.0359422, 0.015908664, -0.021092793, 0.016303983,
0.06351931,…………………
Step 3: Set up OpenSearch
To enable vector search capabilities, you first need to set up an OpenSearch client and test the connection. Follow these steps:
Install the required libraries
Install the necessary Python packages for working with OpenSearch:
!pip install opensearch-py
!pip install botocore
!pip install requests-aws4auth
Configure the OpenSearch client
Set up the OpenSearch client with your host details and authentication credentials:
from opensearchpy import OpenSearch, RequestsHttpConnection, helpers
from requests_aws4auth import AWS4Auth
from requests.auth import HTTPBasicAuth
# OpenSearch connection configuration
# host = 'your-host.aos.us-east-1.on.aws'
host = 'search-new-domain-mbgs7wth6r5w6hwmjofntiqcge.aos.us-east-1.on.aws'
port = 443 # Default HTTPS port
# Get OpenSearch username secret from Secrets Manager
opensearch_username=secrets_manager_client.get_secret_value(
SecretId="AOS_username"
)
opensearch_username_string=json.loads(opensearch_username["SecretString"])["AOS_username"]
# Get OpenSearch password secret from Secrets Manager
opensearch_password = secrets_manager_client.get_secret_value(
SecretId="AOS_password"
)
opensearch_password_string=json.loads(opensearch_password["SecretString"])["AOS_password"]
auth=(opensearch_username_string, opensearch_password_string)
# Create the client configuration
client_aos = OpenSearch(
hosts=[{'host': host, 'port': port}],
http_auth=auth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection
)
# Test the connection
try:
# Get cluster information
cluster_info = client_aos.info()
print("Successfully connected to OpenSearch")
print(f"Cluster info: {cluster_info}")
except Exception as e:
print(f"Connection failed: {str(e)}")
Expected output
If the connection is successful, you should see a message like the following:
Successfully connected to OpenSearch
Cluster info: {'name': 'bb36e8d98ee7bd517891ecd714bfb9d7', ...}
This confirms that your OpenSearch client is properly configured and ready for use.
Step 4: Create an index in OpenSearch Service
Next, you create an index optimized for vector search to store the embeddings generated by the TwelveLabs Embed API.
Define the index configuration
The index is configured to support k-nearest neighbor (kNN) search with a 1024-dimensional vector field. You will these values for this demo but follow these best practices to find appropriate values for your application. Here’s the code:
# Define the enhanced index configuration
index_name = 'twelvelabs_index'
new_vector_index_definition = {
"settings": {
"index": {
"knn": "true",
"number_of_shards": 1,
"number_of_replicas": 0
}
},
"mappings": {
"properties": {
"embedding_field": {
"type": "knn_vector",
"dimension": 1024
},
"video_title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"segment_start": {
"type": "date"
},
"segment_end": {
"type": "date"
},
"segment_id": {
"type": "text"
}
}
}
}
Create the Index
Use the following code to create the index in OpenSearch Service:
# Create the index in OpenSearch
response = client_aos.indices.create(index=index_name, body=new_vector_index_definition, ignore=400)
# Retrieve and display index details to confirm creation
index_info = client_aos.indices.get(index=index_name)
print(index_info)
Expected output
After running this code, you should see details of the newly created index. For example:
{'twelvelabs_index': {'aliases': {}, 'mappings': {'properties': {'embedding_field': {'type': 'knn_vector', 'dimension': 1024}}}, 'settings': {...}}}
The following screenshot confirms that an index named twelvelabs_index has been successfully created with a knn_vector field of dimension 1024 and other specified settings. With these steps completed, you now have an operational OpenSearch Service domain configured for vector search. This index will serve as the repository for storing embeddings generated from video content, enabling advanced multimodal search capabilities.

Step 5: Ingest embeddings to the created index in OpenSearch Service
With the TwelveLabs Embed API successfully generating video embeddings and the OpenSearch Service index configured, the next step is to ingest these embeddings into the index. This process helps ensure that the embeddings are stored in OpenSearch Service and made searchable for multimodal queries.
Embedding ingestion process
The following code demonstrates how to process and index the embeddings into OpenSearch Service:
from opensearchpy.helpers import bulk
def generate_actions(tasks, video_files):
count = 0
for task in tasks:
# Check if video embeddings are available
if task.video_embedding is not None and task.video_embedding.segments is not None:
embeddings_doc = task.video_embedding.segments
# Generate actions for bulk indexing
for doc_id, elt in enumerate(embeddings_doc):
yield {
'_index': index_name,
'_id': doc_id,
'_source': {
'embedding_field': elt.embeddings_float,
'video_title': video_files[count],
'segment_start': elt.start_offset_sec,
'segment_end': elt.end_offset_sec,
'segment_id': doc_id
}
}
print(f"Prepared bulk indexing data for task {count}")
count += 1
# Perform bulk indexing
try:
success, failed = bulk(client_aos, generate_actions(tasks, video_files))
print(f"Successfully indexed {success} documents")
if failed:
print(f"Failed to index {len(failed)} documents")
except Exception as e:
print(f"Error during bulk indexing: {e}")
Explanation of the code
- Embedding extraction: The
video_embedding.segments object contains a list of segment embeddings generated by the TwelveLabs Embed API. Each segment represents a specific portion of the video.
- Document creation: For each segment, a document is created with a key (
embedding_field) that stores its 1024-dimensional vector, video_title with the title of the video, segment_start and segment_end indicating the timestamp of the video segment, and a segment_id.
- Indexing in OpenSearch: The
index() method uploads each document to the twelvelabs_index created earlier. Each document is assigned a unique ID (doc_id) based on its position in the list.
Expected output
After the script runs successfully, you will see:
- A printed list of embeddings being indexed.
- A confirmation message:
Prepared bulk indexing data for task 0
Prepared bulk indexing data for task 1
Successfully indexed 6 documents
Result
At this stage, all video segment embeddings are now stored in OpenSearch and ready for advanced multimodal search operations, such as text-to-video or image-to-video queries. This sets up the foundation for performing efficient and scalable searches across your video content.
Step 6: Perform vector search in OpenSearch Service
After embeddings are generated, you use it as a query vector to perform a kNN search in the OpenSearch Service index. Below are the functions to perform vector search and format the search results:
# Function to perform vector search
def search_similar_segments(query_vector, k=5):
query = {
"size": k,
"_source": ["video_title", "segment_start", "segment_end", "segment_id"],
"query": {
"knn": {
"embedding_field": {
"vector": query_vector,
"k": k
}
}
}
}
response = client_aos.search(
index=index_name,
body=query
)
results = []
for hit in response['hits']['hits']:
result = {
'score': hit['_score'],
'title': hit['_source']['video_title'],
'start_time': hit['_source']['segment_start'],
'end_time': hit['_source']['segment_end'],
'segment_id': hit['_source']['segment_id']
}
results.append(result)
return (results)
# Function to format search results
def print_search_results(results):
print("\nSearch Results:")
print("-" * 50)
for i, result in enumerate(results, 1):
print(f"\nResult {i}:")
print(f"Video: {result['title']}")
print(f"Time Range: {result['start_time']} - {result['end_time']}")
print(f"Similarity Score: {result['score']:.4f}")
Key points:
- The
_source field contains the video title, segment start, segment end, and segment id corresponding to the video embeddings.
- The
embedding_field in the query corresponds to the field where video embeddings are stored.
- The k parameter specifies how many top results to retrieve based on similarity.
Step 7:Performing text-to-video search
You can use text-to-video search to retrieve video segments that are most relevant to a given textual query. In this solution, you will do this by using TwelveLabs’ text embedding capabilities and OpenSearch’s vector search functionality. Here’s how you can implement this step:
Generate text embeddings
To perform a search, you first need to convert the text query into a vector representation using the TwelveLabs Embed API:
from typing import List
from twelvelabs.models.embed import SegmentEmbedding
def print_segments(segments: List[SegmentEmbedding], max_elements: int = 1024):
for segment in segments:
print(
f" embedding_scope={segment.embedding_scope} start_offset_sec={segment.start_offset_sec} end_offset_sec={segment.end_offset_sec}"
)
print(f" embeddings: {segment.embeddings_float[:max_elements]}")
# Create text embeddings for the query
text_res = twelvelabs_client.embed.create(
model_name="Marengo-retrieval-2.7",
text="Bird eating food", # Replace with your desired query
)
print("Created a text embedding")
print(f" Model: {text_res.model_name}")
# Extract and inspect the generated text embeddings
if text_res.text_embedding is not None and text_res.text_embedding.segments is not None:
print_segments(text_res.text_embedding.segments)
vector_search = text_res.text_embedding.segments[0].embeddings_float
print("Generated Text Embedding Vector:", vector_search)
Key points:
- The Marengo-retrieval-2.7 model is used to generate a dense vector embedding for the query.
- The embedding captures the semantic meaning of the input text, enabling effective matching with video embeddings.
Perform vector search in OpenSearch Service
After the text embedding is generated, you use it as a query vector to perform a kNN search in the OpenSearch index:
# Define the vector search query
query_vector = vector_search
text_to_video_search = search_similar_segments(query_vector)
# print(text_video_search)
print_search_results(text_to_video_search)
Expected output
The following illustrates similar results retrieved from OpenSearch.
Search Results:
--------------------------------------------------
Result 1:
Video: robin-bird.mp4
Time Range: 18.0 - 21.087732
Similarity Score: 0.4409
Result 2:
Video: robin-bird.mp4
Time Range: 12.0 - 18.0
Similarity Score: 0.4300
Result 3:
Video: island.mp4
Time Range: 0.0 - 6.0
Similarity Score: 0.3624
Insights from results
- Each result includes a similarity score indicating how closely it matches the query, a time range indicating the start and end offset in seconds, and the video title.
- Observe that the top 2 results correspond to the robin bird video segments matching the Bird eating food query.
This process demonstrates how textual queries such as Bird eating food can effectively retrieve relevant video segments from an indexed library using TwelveLabs’ multimodal embeddings and OpenSearch’s powerful vector search capabilities.
Step 8: Perform audio-to-video search
You can use audio-to-video search to retrieve video segments that are most relevant to a given audio input. By using TwelveLabs’ audio embedding capabilities and OpenSearch’s vector search functionality, you can match audio features with video embeddings in the index. Here’s how to implement this step:
Generate audio embeddings
To perform the search, you first convert the audio input into a vector representation using the TwelveLabs Embed API:
# Create audio embeddings for the input audio file
audio_res = twelvelabs_client.embed.create(
model_name="Marengo-retrieval-2.7",
audio_file="audio-data.mp3", # Replace with your desired audio file
)
# Print details of the generated embedding
print(f"Created audio embedding: model_name={audio_res.model_name}")
print(f" Model: {audio_res.model_name}")
# Extract and inspect the generated audio embeddings
if audio_res.audio_embedding is not None and audio_res.audio_embedding.segments is not None:
print_segments(audio_res.audio_embedding.segments)
# Store the embedding vector for search
vector_search = audio_res.audio_embedding.segments[0].embeddings_float
print("Generated Audio Embedding Vector:", vector_search)
Key points:
- The Marengo-retrieval-2.7 model is used to generate a dense vector embedding for the input audio.
- The embedding captures the semantic features of the audio, such as rhythm, tone, and patterns, enabling effective matching with video embeddings
Perform vector search in OpenSearch Service
After the audio embedding is generated, you use it as a query vector to perform a k-nearest neighbor (kNN) search in OpenSearch:
# Perform vector search
query_vector = vector_search
audio_to_video_search = search_similar_segments(query_vector)
# print(text_video_search)
print_search_results(audio_to_video_search)
Expected output
The following shows video segments retrieved from OpenSearch Service based on their similarity to the input audio.
Search Results:
--------------------------------------------------
Result 1:
Video: island.mp4
Time Range: 6.0 - 12.0
Similarity Score: 0.2855
Result 2:
Video: robin-bird.mp4
Time Range: 18.0 - 21.087732
Similarity Score: 0.2841
Result 3:
Video: robin-bird.mp4
Time Range: 12.0 - 18.0
Similarity Score: 0.2837
Result 4:
Video: island.mp4
Time Range: 0.0 - 6.0
Similarity Score: 0.2835
Here notice that segments from both videos are returned with a low similarity score.
Step 9: Performing images-to-video search
You can use image-to-video search to retrieve video segments that are visually similar to a given image. By using TwelveLabs’ image embedding capabilities and OpenSearch Service’s vector search functionality, you can match visual features from an image with video embeddings in the index. Here’s how to implement this step:
Generate Image Embeddings
To perform the search, you first convert the input image into a vector representation using the TwelveLabs Embed API:
# Create image embeddings for the input image file
image_res = twelvelabs_client.embed.create(
model_name="Marengo-retrieval-2.7",
image_file="image-data.jpg", # Replace with your desired image file
)
# Print details of the generated embedding
print(f"Created image embedding: model_name={image_res.model_name}")
print(f" Model: {image_res.model_name}")
# Extract and inspect the generated image embeddings
if image_res.image_embedding is not None and image_res.image_embedding.segments is not None:
print_segments(image_res.image_embedding.segments)
# Store the embedding vector for search
vector_search = image_res.image_embedding.segments[0].embeddings_float
print("Generated Image Embedding Vector:", vector_search)
Key points:
- The Marengo-retrieval-2.7 model is used to generate a dense vector embedding for the input image.
- The embedding captures visual features such as shapes, colors, and patterns, enabling effective matching with video embeddings
Perform vector search in OpenSearch
After the image embedding is generated, you use it as a query vector to perform a k-nearest neighbor (kNN) search in OpenSearch:
# Perform vector search
query_vector = vector_search
image_to_video_search = search_similar_segments(query_vector)
# print(text_video_search)
print_search_results(image_to_video_search)
Expected output
The following shows video segments retrieved from OpenSearch based on their similarity to the input image.
Search Results:
--------------------------------------------------
Result 1:
Video: island.mp4
Time Range: 6.0 - 12.0
Similarity Score: 0.5616
Result 2:
Video: island.mp4
Time Range: 0.0 - 6.0
Similarity Score: 0.5576
Result 3:
Video: robin-bird.mp4
Time Range: 12.0 - 18.0
Similarity Score: 0.4592
Result 4:
Video: robin-bird.mp4
Time Range: 18.0 - 21.087732
Similarity Score: 0.4540
Observe that image of an ocean was used to search the videos. Video clips from the island video are retrieved with a higher similarity score in the first 2 results.
Clean up
To avoid charges, delete resources created while following this post. For Amazon OpenSearch Service domains, navigate to the AWS Management Console for Amazon OpenSearch Service dashboard and delete the domain.
Conclusion
The integration of TwelveLabs Embed API with OpenSearch Service provides a cutting-edge solution for advanced video search and analysis, unlocking new possibilities for content discovery and insights. By using TwelveLabs’ multimodal embeddings, which capture the intricate interplay of visual, audio, and textual elements in videos, and combining them with OpenSearch Service’s robust vector search capabilities, this solution enables highly nuanced and contextually relevant video search.
As industries increasingly rely on video content for communication, education, marketing, and research, this advanced search solution becomes indispensable. It empowers businesses to extract hidden insights from their video content, enhance user experiences in video-centric applications and make data-driven decisions based on comprehensive video analysis
This integration not only addresses current challenges in managing video content but also lays the foundation for future innovations in how we interact with and derive value from video data.
Get started
Ready to explore the power of TwelveLabs Embed API? Start your free trial today by visiting TwelveLabs Playground to sign up and receive your API key.
For developers looking to implement this solution, follow our detailed step-by-step guide on GitHub to integrate TwelveLabs Embed API with OpenSearch Service and build your own advanced video search application.
Unlock the full potential of your video content today!
About the Authors
 James Le runs the Developer Experience function at TwelveLabs. He works with partners, developers, and researchers to bring state-of-the-art video foundation models to various multimodal video understanding use cases.
James Le runs the Developer Experience function at TwelveLabs. He works with partners, developers, and researchers to bring state-of-the-art video foundation models to various multimodal video understanding use cases.
 Gitika is an Senior WW Data & AI Partner Solutions Architect at Amazon Web Services (AWS). She works with partners on technical projects, providing architectural guidance and enablement to build their analytics practice.
Gitika is an Senior WW Data & AI Partner Solutions Architect at Amazon Web Services (AWS). She works with partners on technical projects, providing architectural guidance and enablement to build their analytics practice.
Kruthi is a Senior Partner Solutions Architect specializing in AI and ML. She provides technical guidance to AWS Partners in following best practices to build secure, resilient, and highly available solutions in the AWS Cloud.
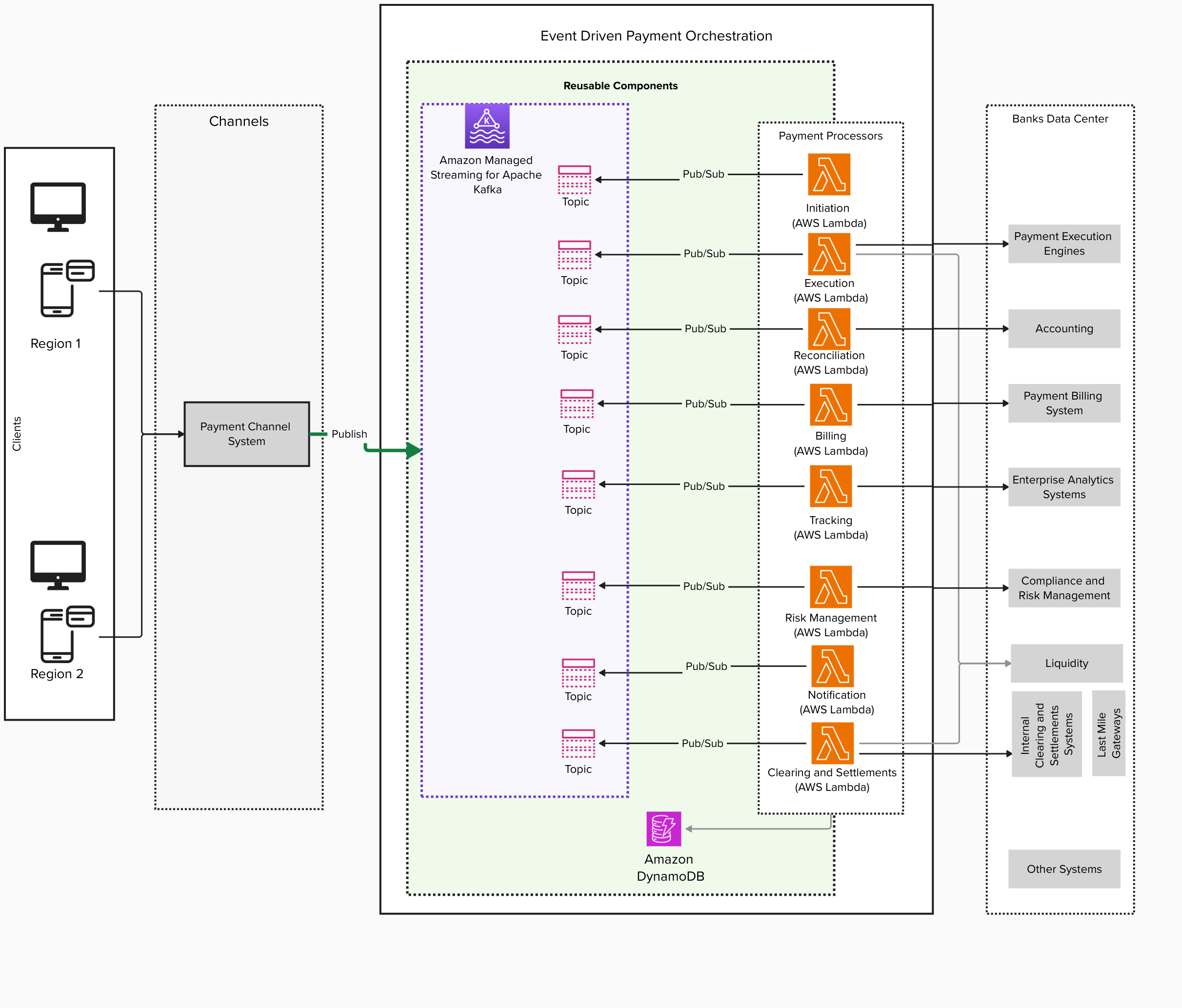











 Neeraj Kaushik is an Open Group Certified Distinguish Architect at IBM with two decades of experience in client-facing delivery roles. His experience spans several industries, including travel and transportation, banking, retail, education, healthcare, and anti-human trafficking. As a trusted advisor, he works directly with the client executive and architects on business strategy to define a technology roadmap. As a hands-on Chief Architect AWS Professional Certified Solution Architect, AWS Certified Machine Learning Specialist and Natural Language Processing Expert, he has led multiple complex cloud modernization programs and AI initiatives.
Neeraj Kaushik is an Open Group Certified Distinguish Architect at IBM with two decades of experience in client-facing delivery roles. His experience spans several industries, including travel and transportation, banking, retail, education, healthcare, and anti-human trafficking. As a trusted advisor, he works directly with the client executive and architects on business strategy to define a technology roadmap. As a hands-on Chief Architect AWS Professional Certified Solution Architect, AWS Certified Machine Learning Specialist and Natural Language Processing Expert, he has led multiple complex cloud modernization programs and AI initiatives. Jay Pandya is a Senior Partner Solutions Architect in the Global Systems Integrator (GSI) team at Amazon Web Services (AWS). He has over 30 years of IT experience and is helping and providing guidance to AWS GSI partners to build, design, and architect agile, scalable, highly available, and secure solutions on AWS. Outside of the office, Jay enjoys spending time with his family and traveling, and he is an aviation enthusiast and avid sports and Formula 1 fan.
Jay Pandya is a Senior Partner Solutions Architect in the Global Systems Integrator (GSI) team at Amazon Web Services (AWS). He has over 30 years of IT experience and is helping and providing guidance to AWS GSI partners to build, design, and architect agile, scalable, highly available, and secure solutions on AWS. Outside of the office, Jay enjoys spending time with his family and traveling, and he is an aviation enthusiast and avid sports and Formula 1 fan. Vijay Gokarn is a Senior Solution Architect at IBM with extensive experience across industries including financial services, healthcare, industrial, retail, and travel and hospitality. He leads complex AWS transformation initiatives, drawing on his hands-on expertise as an AWS Certified Solutions Architect Associate. Vijay specializes in serverless architectures, event-driven systems, and enterprise modernization. As a skilled architect and team leader, he has delivered impactful solutions in cloud modernization, digital banking, and intelligent automation. His passion lies in bridging business strategy with technical execution to drive scalable digital transformation.
Vijay Gokarn is a Senior Solution Architect at IBM with extensive experience across industries including financial services, healthcare, industrial, retail, and travel and hospitality. He leads complex AWS transformation initiatives, drawing on his hands-on expertise as an AWS Certified Solutions Architect Associate. Vijay specializes in serverless architectures, event-driven systems, and enterprise modernization. As a skilled architect and team leader, he has delivered impactful solutions in cloud modernization, digital banking, and intelligent automation. His passion lies in bridging business strategy with technical execution to drive scalable digital transformation. Subhash Sharma is Sr. Partner Solutions Architect at AWS. He has more than 25 years of experience in delivering distributed, scalable, highly available, and secured software products using Microservices, AI/ML, the Internet of Things (IoT), and Blockchain using a DevSecOps approach. In his spare time, Subhash likes to spend time with family and friends, hike, walk on beach, and watch TV.
Subhash Sharma is Sr. Partner Solutions Architect at AWS. He has more than 25 years of experience in delivering distributed, scalable, highly available, and secured software products using Microservices, AI/ML, the Internet of Things (IoT), and Blockchain using a DevSecOps approach. In his spare time, Subhash likes to spend time with family and friends, hike, walk on beach, and watch TV.

































 Yogesh Dhimate is a Sr. Partner Solutions Architect at AWS, leading technology partnership with Salesforce. Prior to joining AWS, Yogesh worked with leading companies including Salesforce driving their industry solution initiatives. With over 20 years of experience in product management and solutions architecture Yogesh brings unique perspective in cloud computing and artificial intelligence.
Yogesh Dhimate is a Sr. Partner Solutions Architect at AWS, leading technology partnership with Salesforce. Prior to joining AWS, Yogesh worked with leading companies including Salesforce driving their industry solution initiatives. With over 20 years of experience in product management and solutions architecture Yogesh brings unique perspective in cloud computing and artificial intelligence. Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open source solutions. Outside of his work, Avijit likes to travel, hike, watch sports, and listen to music.
Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open source solutions. Outside of his work, Avijit likes to travel, hike, watch sports, and listen to music. Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field.
Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field. Mike Patterson is a Senior Customer Solutions Manager in the Strategic ISV segment at AWS. He has partnered with Salesforce Data Cloud to align business objectives with innovative AWS solutions to achieve impactful customer experiences. In his spare time, he enjoys spending time with his family, sports, and outdoor activities.
Mike Patterson is a Senior Customer Solutions Manager in the Strategic ISV segment at AWS. He has partnered with Salesforce Data Cloud to align business objectives with innovative AWS solutions to achieve impactful customer experiences. In his spare time, he enjoys spending time with his family, sports, and outdoor activities. Drew Loika is a Director of Product Management at Salesforce and has spent over 15 years delivering customer value via data platforms and services. When not diving deep with customers on what would help them be more successful, he enjoys the acts of making, growing, and exploring the great outdoors.
Drew Loika is a Director of Product Management at Salesforce and has spent over 15 years delivering customer value via data platforms and services. When not diving deep with customers on what would help them be more successful, he enjoys the acts of making, growing, and exploring the great outdoors.









 Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate. Francisco Morillo is a Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink.
Francisco Morillo is a Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink. Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. Ismail focuses on architecting solutions for organizations across their end-to-end data analytics estate, including batch and real-time streaming, big data, data warehousing, and data lake workloads. He primarily partners with airlines, manufacturers, and retail organizations to support them to achieve their business objectives with well-architected data platforms.
Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. Ismail focuses on architecting solutions for organizations across their end-to-end data analytics estate, including batch and real-time streaming, big data, data warehousing, and data lake workloads. He primarily partners with airlines, manufacturers, and retail organizations to support them to achieve their business objectives with well-architected data platforms.







 Kenny Rajan is a Principal Enterprise Architect at AWS specializing in integrating generative AI with enterprise systems like SAP and Adobe. He helps organizations modernize their digital experience platforms and supply chain and back-end systems through data and AI-powered cloud solutions. Outside of work, he contributes to technology education and charitable initiatives.
Kenny Rajan is a Principal Enterprise Architect at AWS specializing in integrating generative AI with enterprise systems like SAP and Adobe. He helps organizations modernize their digital experience platforms and supply chain and back-end systems through data and AI-powered cloud solutions. Outside of work, he contributes to technology education and charitable initiatives. Rafał Pawłaszek is a Senior Cloud Application Architect at AWS. Rafał supports customer transformation to the cloud and customer enablement in the cloud. Outside of work, he is interested in astronomy, astrophysics, and psychology, and loves spending time with family.
Rafał Pawłaszek is a Senior Cloud Application Architect at AWS. Rafał supports customer transformation to the cloud and customer enablement in the cloud. Outside of work, he is interested in astronomy, astrophysics, and psychology, and loves spending time with family. Basheer Sheriff is a Senior Solutions Architect at AWS. He loves to help customers solve interesting problems using new technology. He is based in Melbourne, Australia, and likes to play sports such as football and cricket.
Basheer Sheriff is a Senior Solutions Architect at AWS. He loves to help customers solve interesting problems using new technology. He is based in Melbourne, Australia, and likes to play sports such as football and cricket. Kamen Sharlandjiev is a Sr. Big Data Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news!
Kamen Sharlandjiev is a Sr. Big Data Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news!





 Deependra Shekhawat is a Senior Energy and Utilities Industry Specialist Solutions Architect based in Sydney, Australia. In his role, Deependra helps Energy companies across APJ region use cloud technologies to drive sustainability and operational efficiency. He specializes in creating robust data foundations and advanced workflows that enable organizations to harness the power of big data, analytics, and machine learning for solving critical industry challenges.
Deependra Shekhawat is a Senior Energy and Utilities Industry Specialist Solutions Architect based in Sydney, Australia. In his role, Deependra helps Energy companies across APJ region use cloud technologies to drive sustainability and operational efficiency. He specializes in creating robust data foundations and advanced workflows that enable organizations to harness the power of big data, analytics, and machine learning for solving critical industry challenges. Senaka Ariyasinghe is a Senior Partner Solutions Architect working with Global Systems Integrators at AWS. In his role, Senaka guides AWS partners in the APJ region to design and scale well-architected solutions, focusing on generative AI, machine learning, cloud migrations, and application modernization initiatives.
Senaka Ariyasinghe is a Senior Partner Solutions Architect working with Global Systems Integrators at AWS. In his role, Senaka guides AWS partners in the APJ region to design and scale well-architected solutions, focusing on generative AI, machine learning, cloud migrations, and application modernization initiatives. Sandeep Kushwaha is a Senior Data Scientist at Wipro and has extensive experience in big data and machine learning. With a strong command of Apache Spark, Sandeep has designed and implemented cutting-edge cloud solutions that optimize data processing and drive efficiency. His expertise in using AWS services and best practices, combined with his deep knowledge of data management and automation, has enabled him to lead successful projects that meet complex technical challenges and deliver high-impact results.
Sandeep Kushwaha is a Senior Data Scientist at Wipro and has extensive experience in big data and machine learning. With a strong command of Apache Spark, Sandeep has designed and implemented cutting-edge cloud solutions that optimize data processing and drive efficiency. His expertise in using AWS services and best practices, combined with his deep knowledge of data management and automation, has enabled him to lead successful projects that meet complex technical challenges and deliver high-impact results.












 Matthias Rudolph is a Solutions Architect at AWS, digitalizing the German manufacturing industry, focusing on analytics and big data. Before that he was a lead developer at the German manufacturer KraussMaffei Technologies, responsible for the development of data platforms.
Matthias Rudolph is a Solutions Architect at AWS, digitalizing the German manufacturing industry, focusing on analytics and big data. Before that he was a lead developer at the German manufacturer KraussMaffei Technologies, responsible for the development of data platforms. Dipankar Mazumdar is a Staff Data Engineer Advocate at Onehouse.ai, focusing on open-source projects like Apache Hudi and XTable to help engineering teams build and scale robust analytics platforms, with prior contributions to critical projects such as Apache Iceberg and Apache Arrow.
Dipankar Mazumdar is a Staff Data Engineer Advocate at Onehouse.ai, focusing on open-source projects like Apache Hudi and XTable to help engineering teams build and scale robust analytics platforms, with prior contributions to critical projects such as Apache Iceberg and Apache Arrow. Stephen Said is a Senior Solutions Architect and works with Retail/CPG customers. His areas of interest are data platforms and cloud-native software engineering.
Stephen Said is a Senior Solutions Architect and works with Retail/CPG customers. His areas of interest are data platforms and cloud-native software engineering.





















 Diego Colombatto is a Senior Partner Solutions Architect at AWS. He brings more than 15 years of experience in designing and delivering Digital Transformation projects for enterprises. At AWS, Diego works with partners and customers advising how to leverage AWS technologies to translate business needs into solutions.
Diego Colombatto is a Senior Partner Solutions Architect at AWS. He brings more than 15 years of experience in designing and delivering Digital Transformation projects for enterprises. At AWS, Diego works with partners and customers advising how to leverage AWS technologies to translate business needs into solutions. Angel Conde Manjon is a Sr. EMEA Data & AI PSA, based in Madrid. He has previously worked on research related to Data Analytics and Artificial Intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on Data and AI.
Angel Conde Manjon is a Sr. EMEA Data & AI PSA, based in Madrid. He has previously worked on research related to Data Analytics and Artificial Intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on Data and AI. Tiziano Curci is a Manager, EMEA Data & AI PDS at AWS. He leads a team that works with AWS Partners (G/SI and ISV), to leverage the most comprehensive set of capabilities spanning databases, analytics and machine learning, to help customers unlock the through power of data through an end-to-end data strategy.
Tiziano Curci is a Manager, EMEA Data & AI PDS at AWS. He leads a team that works with AWS Partners (G/SI and ISV), to leverage the most comprehensive set of capabilities spanning databases, analytics and machine learning, to help customers unlock the through power of data through an end-to-end data strategy.




 Mackenzie Johnson is a Senior Manager at ActionIQ. She is an innovative marketing strategist who’s passionate about the convergence of complementary technologies and amplifying joint value. With extensive experience across digital transformation storytelling, she thrives on educating enterprise businesses about the impact of CX based on a data-driven approach.
Mackenzie Johnson is a Senior Manager at ActionIQ. She is an innovative marketing strategist who’s passionate about the convergence of complementary technologies and amplifying joint value. With extensive experience across digital transformation storytelling, she thrives on educating enterprise businesses about the impact of CX based on a data-driven approach. Phil Catterall is a Senior Product Manager at ActionIQ and leads product development on ActionIQ’s foundational data management, processing, and query federation capabilities. He’s passionate about designing and building scalable data products to empower business users in new ways.
Phil Catterall is a Senior Product Manager at ActionIQ and leads product development on ActionIQ’s foundational data management, processing, and query federation capabilities. He’s passionate about designing and building scalable data products to empower business users in new ways. Sain Das is a Senior Product Manager on the Amazon Redshift team and leads Amazon Redshift GTM for partner programs including the Powered by Amazon Redshift and Redshift Ready programs.
Sain Das is a Senior Product Manager on the Amazon Redshift team and leads Amazon Redshift GTM for partner programs including the Powered by Amazon Redshift and Redshift Ready programs.