Post Syndicated from original https://vasil.ludost.net/blog/?p=3458
Това е подготвения текст за лекцията, доста се разминава с това, което
говорих, но би трябвало поне смисъла да е същия 🙂

Ще ви разкажа за една от основните ми задачи в последните 5 години.
Преди да започна в StorPool, monitoring-ът представляваше нещо, което
периодично се изпълняваше на всяка машина и пращаше mail, който не беше съвсем
лесен за разбиране – нямаше начин да се види едно обща картина. За да мога да
се ориентирам, сглобих нещо, което да ми помогне да виждам какво се случва.
Лекцията разказва за крайния резултат.
Ще го повторя няколко пъти, но няма нищо особено специално, магическо или ново
в цялата лекция. Правя това от няколко години, и честно казано, не мислех, че
има смисъл от подобна лекция, понеже не показва нещо ново – не съм направил откритие
или нещо невероятно.
Имаше учудващо голям интерес към лекцията, за това в крайна сметка реших да я
направя.
Та, как пред ръководството да оправдаем хабенето на ресурси за подобна система
и да обясним, че правим нещо смислено, а не се занимаваме с глупости?
Ако нещо не се следи, не работи. Това е от типа “очевидни истини”, и е малка
вариация на максима от нашия development екип, които казват “ако нещо не е
тествано, значи не работи”. Това го доказваме всеки път, когато се напише нов
вид проверка, и тя изведнъж открие проблем в прилична част от всички
съществуващи deployment-и. (наскоро написахме една, която светна само на 4
места, и известно време проверявахме дали няма някаква грешка в нея)
Monitoring-ът като цяло е от основните инструменти за постигане на situational
awareness.
На кратко, situational awareness е “да знаеш какво се случва”. Това е различно
от стандартното “предполагам, че знам какво се случва”, което много хора правят
и което най-хубаво се вижда в “рестартирай, и ще се оправи”. Ако не знаеш къде
е проблема и действаш на сляпо, дори за малко да изчезне, това на практика нищо
не значи.
Та е много важно да сме наясно какво се случва. И по време на нормална работа,
и докато правим проблеми, т.е. промени – важно е да имаме идея какво става.
Много е полезно да гледаме логовете докато правим промени, но monitoring-а може
да ни даде една много по-пълна и ясна картина.
Да правиш нещо и изведнъж да ти светне alert е супер полезно.
(По темата за situational awareness и колко е важно да знаеш какво се случва и
какви са последствията от действията ти мога да направя отделна лекция…
А всичко, което забързва процеса на откриване на проблем и съответно решаването
му, както и всяко средство, което дава възможност да се изследват събития и
проблеми води до това системите да имат по-нисък downtime. А да си кажа, не
знам някой да обича downtime.
Да започнем с малко базови неща, които трябва да обясня, като говоря за monitoring.
Едното от нещата, които се събират и се използват за наблюдаване на системи са
т.нар. метрики. Това са данни за миналото състояние на системата – може да си
ги представите най-лесно като нещата, които се визуализират с grafana.
Най-честата им употреба е и точно такава, да се разглеждат и да се изследва
проблем, който се е случил в миналото (или пък да се генерират красиви картинки
колко хубаво ви работи системата, което маркетинга много обича).
Друго нещо, за което са много полезни (понякога заедно с малко статистически
софтуер) е да се изследват промени в поведението или как определена промяна е
повлияла. Това до колкото знам му казват да сте “data driven”, т.е. като
правите нещо, да гледате дали данните казват, че сте постигнали това, което
искате.
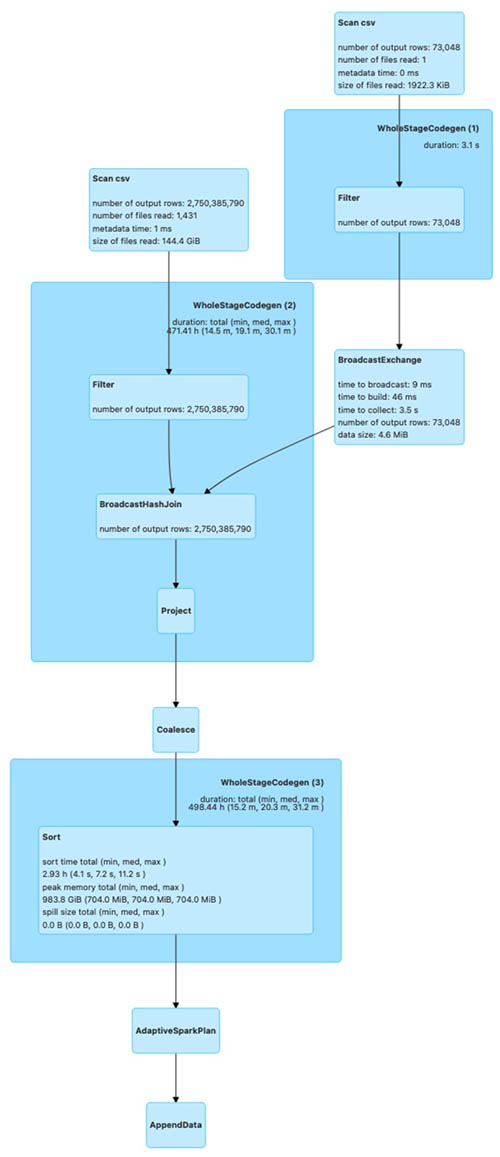
Метриките, които аз събирам са веднъж в секунда, за много различни компоненти
на системата – дискове, процесори, наши процеси, мрежови интерфейси. В момента
са няколко-стотин хиляди точки в секунда, и тук съм показал една примерна –
показва данните за една секунда за един процесор на една машина, заедно с малко
тагове (че например процесорът не се използва от storage системата, та за това
там пише “nosp”) и с timestamp.
Метриките са нещо, което не искаме да се изгуби по пътя или по някаква друга
причина, защото иначе може да се окаже, че не можем да разберем какво се е
случило в даден момент в системата. В някакъв вид те са като “логове”.
Метриките се събират веднъж в секунда, защото всичко друго не е достатъчно ясно
и може да изкриви информацията. Най-простия пример, който имам е как събитие,
което се случва веднъж в минута не може да бъде забелязано като отделно такова
на нищо, което не събира метрики поне веднъж на 10 секунди.
Също така, събития, които траят по секунда-две може да имат сериозно отражение
в/у потребителското усещане за работа на системата, което пак да трябва да е
нещо, което да трябва да се изследва. В 1-секундните метрики събитието може да
е се е “размазало” достатъчно, че да не е видимо и да е в границите на
статистическата грешка.
Имам любим пример, с cron, който работеше на една секунда и питаше един RAID
контролер “работи ли ти батерията?”. Това караше контролера да блокира всички
операции, докато провери и отговори, и на минутните графики имаше повишение на
латентността на операциите (примерно) от 200 на 270 микросекунди, и никой не
можеше да си обясни защо. На секундните си личеше, точно на началото на всяка
минута, един голям пик, който много бързо ни обясни какво става.
(отказвам да коментирам защо проверката на статуса на батерията или каквото и
да е, което питаме контролера отвисява нещата, най-вече защото не знам къде
живеят авторите на firmware)
Та това се налага да го обяснявам от време на време, и да се дразня на системи
като Prometheus, където практически по-добра от 3-секундна резолюция не може да
се постигне.
Също така, не знам дали мога да обясня колко е готино да пускате тестове, да
сте оставили една grafana да refresh-ва веднъж в секунда и почти в реално време
да може да виждате и да показвате на хората как влияят (или не) разлини
действия на системата, от типа на “тук заклахме половината мрежа и почти не се
усети”.
Другото нещо, което се следи е текущото състояние на системата. Това е нещото,
от което се смята статуса на системата в nagios, icinga и други, и от което се
казва “тук това не работи”. Системите, които получават тази информация решават
какви проблеми има, кого и дали да известят и всякакви такива неща.
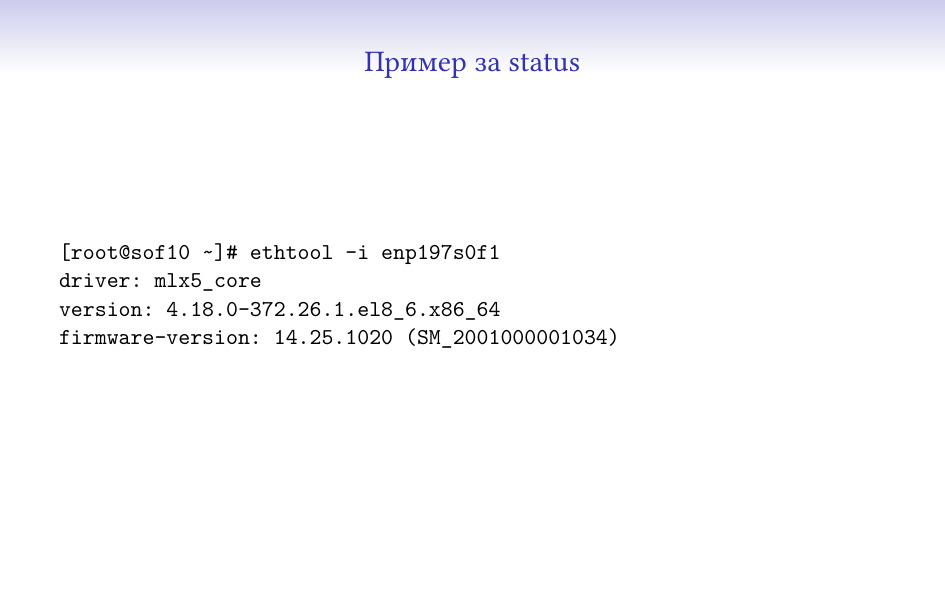
Статусът е нещо по-общо, и май нямам пример, който мога да събера на един слайд
и да може да се разбере нещо. Много често той носи допълнителна информация,
от която може да дойде нещо друго, например “мрежовата карта е с еди-коя-си
версия на firmware”, от което да решим, че там има известен проблем и да
показваме алармата по различен начин.
Метриките са доста по-ясни като формат, вид и употреба – имат измерение във
времето и ясни, числови параметри. Останалите данни рядко са толкова прости и
през повечето време съдържат много повече и различна информация, която не
винаги може да се представи по този начин.
Един пример, който мога да дам и който ми отне някакво време за писане беше
нещо, което разпознава дали дадени интерфейси са свързани на правилните места.
За целта събирах LLDP от всички сървъри, и после проверявах дали всички са
свързани по същия начин към същите switch-ове. Този тип информация сигурно може
да се направи във вид на метрики, но единствено ще стане по-труден за употреба,
вместо да има някаква полза.
А какъв е проблема с цялата тази работа, не е ли отдавна решен, може да се питате…
Като за начало, ако не се постараете, данните ви няма да стигнат до вас. Без
буфериране в изпращащата страна, без използване на резервни пътища и други
такива, ще губите достатъчна част от изпращаните си данни, че да имате дупки в
покритието и неяснота какво се случва/се е случило.
Данните са доста. Написал съм едни приблизителни числа, колкото да си проличи
генералния обем на данните, налагат се някакви трикове, така че да не ви удави,
и определено да имате достатъчно място и bandwidth за тях.
Дори като bandwidth не са малко, и хубавото на това, че имаме контрол в/у двете
страни, e че можем да си ги компресираме, и да смъкнем около 5 пъти трафика.
За това ни помага и че изпращаните данни са текстови, CSV или JSON – и двете
доста се поддават на компресия.
Няма някой друг service при нас, който да ползва сравнимо количество internet
bandwidth, дори някакви mirror-и 🙂
Идващите данни трябва да се съхраняват за някакво време. Добре, че фирмата
се занимава със storage, та ми е по-лесно да си поискам хардуер за целта…
За да можем все пак да съберем всичко, пазим само 2 дни секундни данни и 1
година минутни. InfluxDB се справя прилично добре да ги компресира – мисля, че
в момента пазим общо около двайсетина TB данни само за метрики. За
monitoring данните за debug цели държим пращаните от последните 10 часа, но
това като цяло е лесно разширимо, ако реша да му дам още място, за момента
се събират в около 1.6TiB.
(Това е и една от малкото ми употреби на btrfs, защото изглежда като
единствената достъпна файлова система с компресия… )
Ако погледнем още един път числата обаче, тук няма нищо толкова голямо, че да
не е постижимо в почти “домашни” условия. Гигабит интернет има откъде да си
намерите, терабайтите storage дори на ssd/nvme вече не са толкова
скъпи, и скорошните сървърни процесори на AMD/Intel като цяло могат да вършат
спокойно тая работа. Та това е към обясненията “всъщност, всеки може да си го
направи” 🙂
Системите, които наблюдаваме са дистрибутирани, shared-nothing, съответно
сравнително сложни и проверката дали нещо е проблем често включва “сметка” от
няколко парчета данни. Като сравнително прост пример за някаква базова проверка
– ако липсва даден диск, е проблем, но само ако не сме казали изрично да бъде
изваден (флаг при диска) или ако се използва (т.е. присъства в едни определени
списъци). Подобни неща в нормална monitoring система са сложни за описване и
биха изисквали език за целта.
Имаме и случаи, в които трябва да се прави някаква проверка на база няколко
различни системи, например такива, които регулярно си изпращат данни – дали
това, което едната страна очаква, го има от другата. Понякога отсрещните страни
може да са няколко 🙂
Статусът се изпраща веднъж в минута, и е добре да може да се обработи
достатъчно бързо, че да не се натрупва опашка от статуси на същата система.
Това значи, че monitoring-ът някакси трябва да успява да сдъвче данните
достатъчно бързо и да даде резултат, който да бъде гледан от хора.
Това има значение и за колко бързо успяваме да реагираме на проблеми, защото
все пак да се реагира трябва трябва да има на какво 🙂
И имаме нужда тази система да е една и централизирана, за можем да следим
стотиците системи на едно място. Да гледаш 100 различни места е много трудно и
на практика загубена кауза. Да не говорим колко трудно се оправдава да се сложи
по една система при всеки deployment само за тази цел.
Това има и други предимства, че ако наблюдаваните системи просто изпращат данни
и ние централно ги дъвчем, промяна в логиката и добавяне на нов вид проверка
става много по-лесно. Дори в модерните времена, в които deployment-а на хиляда
машини може да е сравнително бърз, пак трудно може да се сравнява с един локален
update.
И това трябва да работи, защото без него сме слепи и не знаем какво се случва,
не го знаят и клиентите ни, които ползват нашия monitoring. Усещането е като
донякъде да стоиш в тъмна стая и да чакаш да те ударят по главата…
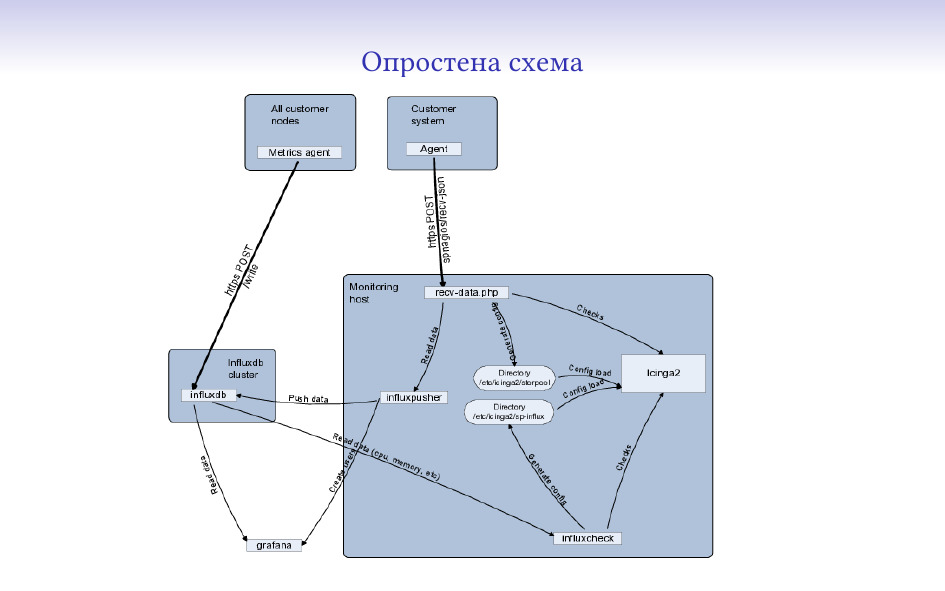
От какво е сглобена текущата ни система?
За база на системата използвам icinga2. В нея се наливат конфигурации, статуси
и тя решава какви аларми да прати и поддържа статус какво е състоянието в
момента.
Беше upgrade-ната от icinga1, която на около 40% от текущото натоварване умря и
се наложи спешна миграция.
InfluxDB, по времето, в което започвах да пиша системата беше най-свястната от
всичките съществуващи time series бази.
Като изключим доста осакатения език за заявки (който се прави на SQL, но е
много далеч и е пълен със странни ограничения), и че не трябва да се приема за
истинска база (много глезотии на mysql/pgsql ги няма), InfluxDB се справя добре
в последните си версии и не може да бъде crash-ната с някоя заявка от
документацията. Основното нещо, което ми се наложи да правя беше да прескоча
вътрешния механизъм за агрегиране на данни и да си напиша мой (който не помня
дали release-нахме), който да може да върши същото нещо паралелно и с още малко
логика, която ми трябваше.
От някакво време има и версия 2, която обаче е променила достатъчно неща, че да
не мога още да планирам миграция до нея.
Както обясних, проверките по принцип са не-елементарни (трудно ми е да кажа
сложни) и логиката за тях е изнесена извън icinga.
В момента има около 10k реда код, понеже се добавиха всякакви глезотии и
интересни функционалности (човек като има много данни, все им намира
приложение), но началната версия за базови неща беше около 600 реда код, с
всичко базово. Не мисля, че отне повече от няколко дни да се сглоби и да се
види, че може да върши работа.
Ако ползвате стандартен метод за активни проверки (нещо да се свързва до
отсрещната страна, да задава въпрос и от това да дава резултат), никога няма да
стигнете хиляди в секунда без сериозно клъстериране и ползване много повече
ресурси.
Дори и да не ползвате стандартните методи, пак по-старите версии на icinga не
се справят с толкова натоварване. При нас преди няколко години надминахме
лимита на icinga1 и изборът беше м/у миграция или клъстериране. Миграцията се
оказа по-лесна (и даде някакви нови хубави функционалност, да не говорим, че се
ползваше вече софтуер от тоя век).
Основният проблем е архитектурен, старата icinga е един процес, който прави
всичко и се бави на всякакви неща, като комуникация с други процеси,
писане/четене от диска, и колкото и бърза да ни е системата, просто не може да
навакса при около 20-30к съществуващи услуги и няколко-стотин статуса в
секунда. А като му дадеш да reload-не конфигурацията, и съвсем клякаше.
Изобщо, технически това един бивш колега го описваше като “десет литра лайна
в пет литра кофа”.
Новата например reload-ва в отделен процес, който не пречи на главния.
Признавам си, не обичам Prometheus. Работи само на pull, т.е. трябва да може да
се свързва до всичките си крайни станции, и като го пуснахме за вътрешни цели с
около 100-200 машини, почна да му става сравнително тежко при проверка на 3
секунди. Също така изобщо няма идеята да се справя с проблеми на internet-а,
като просто интерполира какво се е случило в периода, в който не е имал
свързаност.
Върши работа за някакви неща, но определен е далеч от нашия случай. Според мен
е и далеч от реалността и единствената причина да се ползва толкова е многото
натрупани готови неща под формата на grafana dashboard-и и exporter-и.
Компонентите са в общи лини ясни:
Агентите събират информация и се стараят да ни я пратят;
Получателите я взимат, анализират, записват и т.н.;
Анализаторите дъвчат събраната информация и на база на нея добавят още
проверки.
Тук не измислих как да го покажа, но това е един thread, който събира данни (от
няколко такива), и има един който изпраща данните и се старае да стигнат. Пак е
сравнително малко код и може да бъде сглобен почти от всеки.
За данни, за които повече бързаме да получим и не буферираме, има друг
интересен трик – да имате няколко входни точки (при нас освен нашия си интернет
имаме един “домашен”, който да работи дори да стане някакво бедствие с
останалия), съответно агентът се опитва да се свърже едновременно с няколко
места и което първо отговори, получава данните.
Понеже това е писано на perl по исторически причини, беше малко странно да се
направи (понеже select/poll на perl, non-blocking връзки и подобни неща не са
съвсем стандартни), но сега мога да го похваля, че работи много добре и се
справя вкл. и с IPv6 свързаност.
И всичкия код, който получава/прави анализи си е тип ETL
(extract-transform-load). Взима едни данни, дъвче, качва обратно.
В нашия случай това, което връща са състояния и конфигурации (ще го покажа
по-долу).
И един елементарен пример, почти директно от кода – обикаля данните за набор от
машини, проверява дали в тях има нещо определено (kernel, за който нямаме
качена поддръжка) и го отбелязва.
Има и по-интересни такива неща (анализи на латентности от метриките, например),
но нямаше да са добър пример за тук 🙂
“Липсата на сигнал е сигнал” – можем да знаем, че нещо цялостно или част от
него не ни говори, понеже имаме контрол в/у агентите и кода им, и знаем
кога/как трябва да се държат.
Някой би казал, че това се постига по-добре с активна проверка (“тия хора
пингват ли се?”), но това се оказва много сложно да се прави надеждно, през
интернета и хилядите firewall-и по пътя. Също така, не може да се очаква
интернета на всички да работи добре през цялото време (заради което и всичките
агенти са направени да се борят с това).
Както казах по-рано, Интернета не работи 🙂
Един от най-важните моменти в подобна система е колко работа изисква за
рутинните си операции. Понеже аз съм мързел и не обичам да се занимавам с
описване на всяка промяна, системата автоматично се конфигурира на база на
пристигналите данни, решава какви системи следи, какви услуги, вижда дали нещо
е изчезнало и т.н. и като цяло работи съвсем сама без нужда от пипане.
Има функционалност за специфична конфигурация за клиент, която изисква ръчна
намеса, както и изтриването на цялостни системи от monitoring-а, но това като
цяло са доста редки случаи.
Системата се грижи всичко останало да се случва съвсем само.
Това, което според мен е най-важното за тази и подобни системи – няма нищо
особено сложно в тях, и всеки, който се нуждае от нещо такова може да си го
сглоби. Първоначалната ми версия е била около 600 реда код, и дори в момента в
10-те хиляди реда човек може да се ориентира сравнително лесно и да добави
нещо, ако му се наложи.
Като пример, дори python програмистите при нас, които считат, че php-то трябва
да се забрани със закон, са успявали да си добавят функционалност там
сравнително лесно и със съвсем малко корекции по стила от моя страна.
Самото php се оказва много удобно за подобни цели, основно защото успява да се
справи и с объркани данни (което се случва при разни ситуации) и не убива
всичко, а си се оплаква и свършва повечето работа. Разбира се, това не е
единствения подходящ език, аз лично писах на него, защото ми беше лесен – но
ако искате да сглобите нещо, в наши дни може да го направите почти на каквото и
си искате и да работи. Python и js са някакви основни кандидати (като езици,
дето хората знаят по принцип), само не препоръчвам shell и C 🙂
Така че, ако ви трябва нещо такова – с по-сложна логика, да издържа повече
натоварване, да прави неща, дето ги няма в други системи – не е особено сложно
да го сглобите и да тръгне, нещо минимално се сглабя за няколко дни, а се
изплаща супер бързо 🙂
Monitoring системата се налага да се следи, разбира се. Всичкият софтуер се
чупи, този, който аз съм правил – още повече. По случая други колеги направиха
нещо, което да следи всичките ни вътрешни физически и виртуални машини, и това
между другото следи и големия monitoring 🙂
Изглежда по коренно различен начин – използва Prometheus, Alertmanager и за
база VictoriaMetrics, което в общи линии значи, че двете системи рядко имат
същите видове проблеми. Също така и допълнителния опит с Prometheus ми показа,
че определено е не е бил верния избор за другата система 🙂
Може би най-големият проблем, който съм имал е да обясня какво значи текста на
дадена аларма на други колеги. Тук например съм казал “има малък проблем (за
това е WARNING), в услугата bridge, има един счупен, нула игнорирани (по разни
причини) и 2 общо, и този на машина 4 е down” – и това поне трима различни
човека са ми казвали, че не се разбира. Последното ми решение на проблема е да
карам да ми дадат как очакват да изглежда и да го пренаписвам. От една страна,
съобщенията станаха по-дълги, от друга – не само аз ги разбирам 🙂
Няколко пъти се е случвало системата да изпрати notification на много хора по
различни причини – или грешка в някоя аларма, или просто има проблем на много
места. Като цяло първото може доста да стресне хората, съответно вече (със
съвсем малко принуда) има няколко staging среди, които получават всички
production данни и в които може да се види какво ще светне, преди да е стигнало
до хора, които трябва да му обръщат внимание.
Изобщо, ако човек може да си го позволи, най-доброто тестване е с production
данните.
Основна задача за всяка такава система трябва да е да се намалят алармите до
минимум. Би трябвало фалшивите да са минимален брой (ако може нула), а едно
събитие да генерира малко и информативни такива. Също така, трябва да има лесен
механизъм за “умълчаване” на някаква част от алармите, когато нещо е очаквано.
Това е може би най-сложната задача, понеже да се прецени кога нещо е проблем и
кога не е изисква анализ и познаване на системата, понякога в дълбини, в които
никой не е навлизал.
Решението тук е да се вземат алармите за един ден, и да се види кое от тях е
безсмислено и кое може да се махне за сметка на нещо друго, след което мноооого
внимателно да се провери, че това няма да скрие истински проблем, вероятно с
гледане на всички останали задействания на неприемливото съобщение. Което е
бавна, неблагодарна и тежка работа 🙂
Не исках да слагам този slide в началото, че сигурно нямаше да остане никой да
слуша лекцията. Оставям го да говори сам за себе си:)