Post Syndicated from Steve Roberts original https://aws.amazon.com/blogs/aws/introducing-bobs-used-books-a-new-real-world-net-sample-application/
Today, I’m happy to announce that a new open-source sample application, a fictitious used books eCommerce store we call Bob’s Used Books, is available for .NET developers working with AWS. The .NET advocacy and development teams at AWS talk to customers regularly and, during those conversations, often receive requests for more in-depth samples. Customers tell us that, while small code snippets serve well to illustrate the mechanics of an API, their development teams also need and want to make use of fuller, more real-world samples to understand better how to construct modern applications for the cloud. Today’s sample application release is in response to those requests.
Bob’s Used Books is a sample eCommerce application built using ASP.NET Core version 6 and represents an initial modernization of a typical on-premises custom application. Representing a first stage of modernization, the application uses modern cross-platform .NET, enabling it to run on both Windows and Linux systems in the cloud. It’s typical of what many .NET developers are just now going through, porting their own applications from .NET Framework to .NET using freely available tools from AWS such as the Toolkit for .NET Refactoring and the Porting Assistant for .NET.
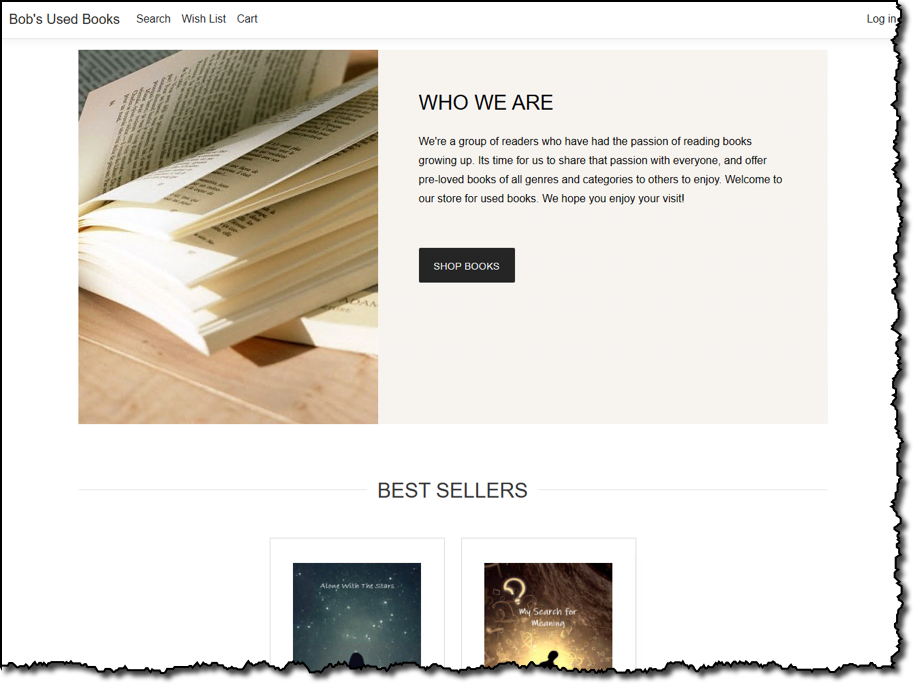
Sample application features
Customers of our fictional bookstore can browse and search on the store for used books and view details on selected books such as price, condition, genre, and more:

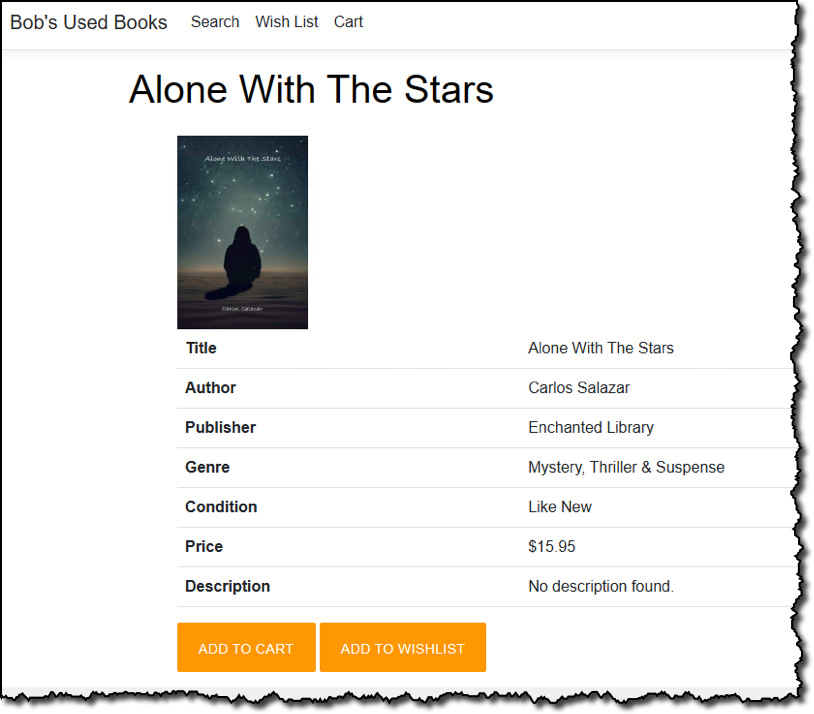
Just like a real e-commerce store, customers can add books to a shopping cart, pending subsequent checkout, or to a personal wish list. When the time comes to purchase, the customer can start the checkout process, which will encourage them to sign in if they are an existing customer or sign up during the process.
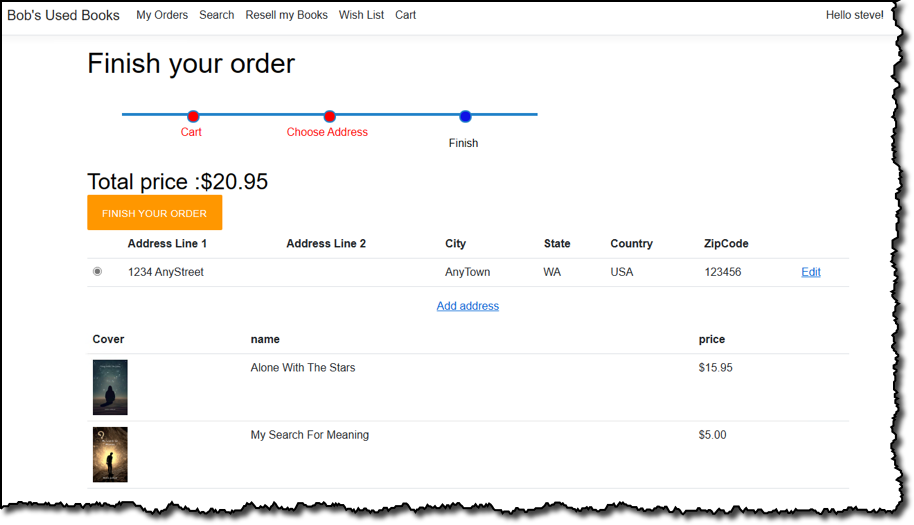
In this sample application, the bookstore’s staff uses the same web application to manage inventory and customer orders. Role-based authentication is used to determine whether it’s a staff member signing in, in which case they can view an administrative portal, or a regular store customer. For staff, having accessed the admin portal, they start with a dashboard view that summarizes pending, in-process, or completed orders and the state of the store’s inventory:

Staff can edit inventory to add new books, complete with cover images, or adjust stock levels. From the same dashboard, staff can also view and process pending orders.

Not shown here, but something I think is pretty cool, is a simulated workflow where customers can re-sell their books through the store. This involves the customer submitting an application, the store admin evaluating and deciding whether to purchase from the customer, the customer “posting” the book to the store if accepted, and finally the admin adding the book into inventory and reimbursing the customer. Remember, this is all fictional, however—no actual financial transactions take place!
Application architecture
The bookstore sample didn’t start as a .NET Framework-based application that needed porting to .NET, but it does use a monolithic MVC (model-view-controller) application design, typical of the .NET Framework development era (and still in use today). It also uses a single Microsoft SQL Server database to contain inventory, shopping cart, user data, and more.
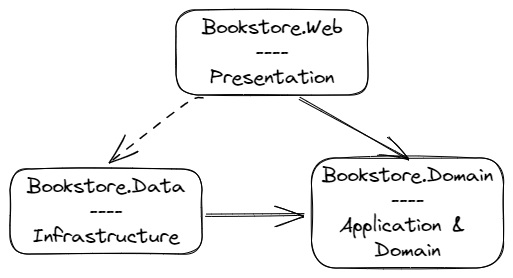
When fully deployed to AWS, the application makes use of several services. These provide resources to host the application, provide configuration to the running application, and also provide useful functionality to the running code, such as image verification:
- Amazon Cognito – used for customer and bookstore staff authentication. The application uses Cognito‘s Hosted UI to provide sign-in and sign-up functionality.
- Amazon Relational Database Service (RDS) – manages a single Microsoft SQL Server Express instance containing inventory, customer, and other typical data for an e-commerce application.
- Amazon Simple Storage Service (Amazon S3) – an S3 bucket is used to store cover images for books.
- AWS Systems Manager Parameter Store – contains runtime configuration data, including the name of the S3 bucket for cover images, and Cognito user pool details.
- AWS Secrets Manager – holds the user and password details for the underlying SQL Server database in RDS.
- Amazon CloudFront – provides a domain for accessing the cover images in the S3 bucket, which means the bucket does not need to be publicly available.
- Amazon Rekognition – used to verify that cover images uploaded for a book do not contain objectionable content.
The application is a starting point to showcase further modernization opportunities in the future, such as adopting purpose-built databases instead of using a single relational database, decomposing the monolith to use microservices (for the latter, AWS provides the Microservice Extractor for .NET), and more. The .NET development, advocacy, and solution architect teams here at AWS are quite excited at the opportunities for new content, using this sample, to illustrate those modernization opportunities in the upcoming months. And, as the sample is open-source, we’re also interested to see where the .NET development community takes it regarding modernization.
Running the application
My colleague Brad Webber, a Solutions Architect at AWS, has written the first in a series of technical blog posts we’ll be publishing about the sample. You’ll find these on the new .NET on AWS blog channel. In his first post, you’ll learn more about how to run or debug the application on your own machine as well as deploy it completely to the AWS cloud.
The application uses SQL Server Express localdb instance for its database needs when running outside the cloud, which means you do currently need to be using a Windows machine to run or debug. Launch profiles, accessible from Visual Studio, Visual Studio Code, or JetBrains Rider (all on Windows), are used to select how the application runs (for example, with no or some cloud resources):
- Local – When you select this launch profile, the application runs completely on your machine, using no cloud resources, and doesn’t need an AWS account. This enables you to investigate and experiment with the code incurring no charges for cloud resources.
- Integrated – When you use this profile, the application still runs locally on your Windows machine and continues to use the localdb database instance, but now also uses some AWS resources, such as an S3 bucket, Rekognition, Cognito, and others. This profile enables you to learn how you can use AWS services within your application code, using the AWS SDK for .NET and various extension libraries that we distribute on NuGet (for a full list of all available libraries you can use when developing your applications, see the .NET on AWS repository on GitHub). To enable you to set up the cloud resources needed by the application when using this profile, an AWS Cloud Development Kit (AWS CDK) project is provided in the sample repository, making it easy to set up and tear down those resources on demand.
Deploying the Sample to AWS
You can also deploy the entire application to the AWS Cloud, in this case, to virtual machines in Amazon Elastic Compute Cloud (Amazon EC2) with a SQL Server Express database instance in Amazon Relational Database Service (RDS). The deployment uses resources compatible with the AWS Free Tier but do note, however, that you may still incur charges if you exceed the Free Tier limits. Unlike running the application on your own machine, which requires Windows because of the localdb dependency, you can deploy the application to AWS from any machine, including those running macOS and Linux. Once again, a CDK project is included in the repository to get you started, and Brad’s blog post goes into more detail on these steps so I won’t repeat them here.
Using virtual machines in the cloud is often a first step in modernizing on-premises applications because of similarity with an on-premises server setup, hence the reason for supporting Amazon EC2 deployments out-of-the-box. In the future, we’ll be adding content showing how to deploy the application to container services on AWS, such as AWS App Runner, Amazon Elastic Container Service (Amazon ECS), and Amazon Elastic Kubernetes Service (EKS).
Next steps
The Bob’s Used Books sample application is available now on GitHub. We encourage you, if you’re a .NET developer working on AWS and looking for a deeper, more real-world sample, to clone the repository and take the application for a spin. We’re also curious about what modernization journeys you would decide to take with the application, which will help us create future content for the sample. Let us know in the issues section of the repository. And if you want to contribute to the sample, we welcome contributions!