Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=RfAxrqm_-i4
A Look Into the War in Ukraine and America’s Security Concerns | The Atlantic Festival 2022
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=DVxamRjFsns
Friday Squid Blogging: Another Giant Squid Washes Up on New Zealand Beach
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/09/friday-squid-blogging-another-giant-squid-washes-up-on-new-zealand-beach.html
This one has chewed-up tentacles.
(Note that this is a different squid than the one that recently washed up on a South African beach.)
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Read my blog posting guidelines here.
Седмицата (19–24 септември)
Post Syndicated from Йовко Ламбрев original https://toest.bg/editorial-19-24-september-2022/
Макар до финала на предизборната кампания да остана само седмица, ако не прекарвате повечко време във Facebook, може съвсем успешно и да я пропуснете. Стойностен политически дебат между опоненти на практика няма. Партийните дейци говорят основно пред своя си електорат. И сякаш всички се държат като заек на магистрала, заслепен от светлините на прииждащите автомобили. Иначе, като споменаваме Facebook, струва си да обърнете внимание на поредицата статии на Йоан Запрянов в „Капитал“, които разследват как ГЕРБ и „Възраждане“ се възползват от социалната мрежа за влияние върху гласоподавателите. В този контекст прави впечатление подходът на „Продължаваме промяната“ с кратките им видеопослания по наболели теми.
Във връзка именно с партиите и използването на дигиталните канали за комуникация по време на предизборната кампания е интервюто на Лора Филева от „Дневник“ с Горан Георгиев, експерт в програма „Сигурност“ на Центъра за изследване на демокрацията. Сред тревожните изводи от последните анализи на ЦИД е, че от осемте партии, за които се прогнозира, че ще влязат в следващия парламент, „Възраждане“ има категорично доминантно присъствие в социалните мрежи – 61% от близо 7 млн. интеракции през последните 12 месеца. Както и че в България има активни агенти на влияние, финансирани от Кремъл, които през последните десет години правят каквото си искат без никаква реакция от държавата.

В този ред на мисли е интересно какво се случва около БСП, от която отново се очаква да бъде евентуална патерица в управлението. Кампания след кампания около Столетницата не само не се ражда нищо ново, но неоплевените бурени на „автентично лявата“ задушават цялото лявоцентристко политическо пространство. Според Емилия Милчева „Позитано“ 20 е толкова далеч от корените и проблемите на електората си, че опортюнизмът е единствената идеология, която ръководството на партията е в състояние да припознае и прегърне. Прочетете коментара ѝ, озаглавен „Лозето на социалистите не ще Станишев, а мотика“.
В Близкия изток никога не е спокойно. През седмицата протестите в Иран се ожесточиха до преки стълкновения със силите на реда. Многохилядните демонстрации започнаха на 16 септември, след като 22-годишната кюрдистанка Махса Амини, задържана от полицията за неправилно носене на хиджаб, почина в ареста. Има десетки загинали, но хората продължават повече от седмица да са по улиците в защита на базовите си права. Особено смели са иранските жени, които протестират срещу религиозните догми, захвърляйки хиджабите си и режейки косите си. Властите в Иран спряха достъпа до интернет в опит да заглушат социалните мрежи, в които протестиращите организират съпротивата си.

Влиянието на Иран в региона е значително и няма как да не присъства и в разговора, посветен на Ирак, между нашия близкоизточен анализатор Мирослав Зафиров и д-р Инна Рудолф, която е старши научен сътрудник в Международния център за изследване на радикализацията (ICSR) и дългогодишен наблюдател на проблемите в Ирак. Да прочетете на български такова експертно интервю е изключително рядка възможност у нас, затова не пропускайте този материал.
Иначе, разбира се, че международната тема номер едно е войната в Украйна.
Това, което е станало в Изюм, не е никаква „втора Буча“. Това е втори сталинизъм или второ Гестапо. Само на тези места са извършвани изтезанията, приложени към украинските цивилни в Изюм в наши дни.
Така започва статията „Сталин и изтезанията. Как Изюм върна историята 70 години назад“ на Татяна Ваксберг, която разказва за мъченията, извършвани от руснаците в окупираните от тях територии от Украйна. Не пропускайте и другата статия на Ваксберг в „Свободна Европа“ – във връзка с обявената от Кремъл „частична“ мобилизация.

На този фон от събития и новини е напълно нормално да имаме потребност от учебник по човещина. Такъв според Стефан Иванов може да бъде романът „Живи“ от китайския писател Ю Хуа, преведен на български от Стефан Русинов. „Отдавна не бях чел такава съвременна проза. Едновременно сурова и брутална, но пропита със съчувствие, красота и любов. И пронизана от изкупление“, пише Стефан Иванов в новата си препоръка от рубриката ни „ На второ четене“, която рецензия сама по себе си е много емоционална, по човешки топла и много докосваща.

Наскоро приключи юбилейното издание на Международния фестивал за уличен и куклен театър „Панаир на куклите“ и Зорница Христова ни предлага кратък обзор на посетените от нея пиеси в рамките на фестивала. Кукленият театър може да използва каквито си иска изразни средства, да се играе в зала или на улицата, с „петрушки“, марионетки, предмети от ежедневието, сенки и дори… без кукли. И в този смисъл е едно от изкуствата с най-висок потенциал да изненадва ума, смята Зорница.
Накрая някак не ми се иска да пропуснете един филм, който – да, разбира се, че е обвързан с предизборната кампания на „Продължаваме промяната“, но всъщност общественият интерес към този скандал би следвало да е с размери далеч извън рамките на която и да е кампания. Затова е задължително да го гледате, независимо на коя политическа партия симпатизирате.
Приятно четене и гледане!
Ирак днес. Разговор с Инна Рудолф
Post Syndicated from Мирослав Зафиров original https://toest.bg/inna-rudolf-interview/
Д-р Инна Рудолф е старши научен сътрудник в Международния център за изследване на радикализацията (ICSR) и постдокторантски научен сътрудник в Центъра за изследване на разделените общества към Кралския колеж в Лондон. В рамките на докторската си дисертация в Катедрата по военни науки към Кралския колеж Рудолф се фокусира върху хибридизацията на управлението на сектора за сигурност, изследвайки иракската паравоенна организация Народни мобилизационни сили (PMF) и стремежа им за легитимност в държавата. С нея разговаря Мирослав Зафиров.
Неотдавна в интервю за „Тоест“ ливанският анализатор Надим Шехади спомена, че страната му е в плен на наложения от Иран модел на „Хизбулла“, държавата се задъхва в прегръдките на движението. Шехади сравни Ливан с Ирак. Вие склонна ли сте да мислите в такива сравнителни категории, или все пак предпочитате да стоите далеч от подобни паралели?
Разбира се, подобни паралели са възможни, ако вземем предвид системната корупция и практиката на политически патронаж и клиентелизъм, упражнявани от политическите партии с религиозна принадлежност. Въпреки това по-скоро бих се въздържала да правя подобни сравнения или да анализирам иракския политически живот с презумпцията за едно неизбежно репликиране на модела на „Хизбулла“, налаган в Ливан.
Основната причина за моята въздържаност е фрагментацията в рамките на шиитския политически елит в Ирак. Споровете в тази затворена общност и между отделните нейни центрове на влияние доведоха наскоро до патова ситуация, в която самият лидер на „Хизбулла“ Хасан Насралла трябваше да се намеси в качеството си на посредник.
Истината е, че в огромното си разнообразие шиитските политически лидери не са в състояние сами да постигнат компромис по принципни въпроси, които касаят съдбата на модела на управление на Ирак, заложен от 2003 г. насам и познат с термина „мухассаса“ – разпределение на властта и нейните привилегии на етнически и религиозен принцип. Поради своята разединеност тези политически играчи не са в състояние да повторят модела на „Хизбулла“, който гарантира на движението неговата сила и доминантна роля в Ливан.
Ако ми позволите нова препратка към Ливан, там се смята, че от съществено значение за националната история на страната са появата и делото на имам Муса ас Садр. Неговата работа сред населението и ролята му за консолидацията на шиитската общност, както и заслугите му за самото ливанско общество са обект на множество анализи. В каква степен дори спекулативно можем да сравним политическото поведение на Муса ас Садр с това на неговия племенник Муктада ас Садр?
Преди всичко и имам Муса ас Садр, и Муктада ас Садр представят себе си като защитници на онеправданите. И двамата демонстрират виртуозната си способност да мобилизират масите, като се стремят към влияние, надхвърлящо рамките на тяхната религиозна общност. Ако трябва да използвам терминологията на Антонио Грамши, и Муктада, и неговият чичо Муса ас Садр претендират за ролята на „органични интелектуалци“, те се стремят към пиедестала на морални ментори, които са в състояние да „модифицират и задават начина на мислене и поведението на масите“.
Но докато днес методите на Муктада ас Садр в политически аспект биват поставяни под съмнение дори от неговите поддръжници, то имам Муса ас Садр е все още окичван с ореол от ливанските шиити. Неговото мистериозно изчезване дори често се сравнява с това на легендарния свещен дванайсети имам Мухаммад ас Махди.
Имам Муса ас Садр изчезва през 1979 г. в Либия по време на официално посещение по покана на Муамар Кадафи, а имам Мухаммад ас Махди – през IХ век в град Самара, днешен Ирак. Според шиитската традиция имам Ас Махди се намира в т.нар. скриване, което ще продължи до Деня на страшния съд – б.р.
За разлика от своя чичо, Муктада ас Садр има доста по-земен образ, част от злободневните събития в Ирак. Той е много по-въвлечен в политическия живот на страната си, което прави всички опити да бъде представен като отявлен лидер на съпротивата все по-трудни. В крайна сметка дори Муктада ас Садр не може да бъде непрекъснато на гребена на вълната. По някакъв начин той ми напомня на героя от поемата на Христо Смирненски за стълбата – с всяко следващо стъпало губиш частица от своя интегритет, като постепенно принасяш в жертва изконните си морални ценности.
Само иранското влияние ли е пречка пред развитието на Ирак? Кои са основните хронологични репери, които според Вас диктуват събитията в страната днес? През 2005 г. референдумът за нова конституция донесе усещане сред масовата публика за начало на нов етап в историята на Ирак, но с модела си на разделение на властите не създаде ли тази конституция и проблемите, чиито последствия наблюдаваме?
Ще преиначим фактите, ако изцяло отдадем вината за сегашното състояние на Ирак на някакво зловредно иранско влияние. Да поясня: аз по никакъв начин не омаловажавам огромното влияние на Иран върху по-голямата част от политическите лидери, които доминират на иракската сцена. Протестното социално движение в Ирак, познато под името „Тишрийн“ (зародило се в Багдад през октомври 2019 г., движението настоява за реформи, които да сложат край на политическата система, базирана на разделението на властта на етнически и религиозен принцип – б.р.), обвинява Иран за това, че подкрепя корупционния модел и управляващата класа от 2003 г. насам.
Проблемът на иракската Конституция, както видяхме отново неотдавна, е в двусмислията, които тя съдържа. Тези двусмислия отварят пътя за интерпретации – и за съжаление, за политизиране, особено в отсъствието на независимо правораздаване. В подобни условия заложените неясноти в текста на основния закон може лесно да послужат като аргумент на хора, които се стараят да интерпретират буквата на закона в своя полза. Не искам да твърдя, че именно Конституцията следва да бъде обвинявана за съществуващата система на разпределение на политически постове и влияние на етнически и религиозен принцип. Виновник за създалата се ситуация е по-скоро манталитетът на политическия елит и начинът, по който се прилага Конституцията – това е, което според мен изкривява духа ѝ преди всичко.
Като че ли новата история на Ирак след 2003 г. е низ от събития, които някой би нарекъл ключови. Доколкото в история има нещо „ключово“, смятате ли, че Ирак премина през етап на отрезвяване след агресията на ИДИЛ – и кои от научените уроци днес са поставени на изпитание? Отново виждаме политическо разединение сред елита в Багдад и Ербил…
Разделението между Багдад и Ербил не е онова, което ме тревожи най-много. В крайна сметка заинтересованите от това да експлоатират системата винаги ще намерят начин да постигнат компромис, който да им позволи да запазят позициите си и да избегнат сценарий, при който ще им бъде търсена отговорност.
Моето основно безпокойство като страничен наблюдател е отсъствието на доверие у хората в държавата и институциите. В много скорошни интервюта иракчаните, независимо от етническата или религиозната си принадлежност, посочваха един и същи проблем – отсъствието на държавата. Непрекъснато чувах, че „няма държава“. Това усещане за отчужденост е много опасно, тъй като от него могат да се възползват зловредни сили, особено там, където държавата със своите институции наистина отсъства. В тези области, където представителите на държавата биват възприемани като корумпирани и незаинтересовани, няма да е никак трудно за членовете на паравоенни формирования, на милиции да представят себе си за алтернатива, поставяйки по този начин хората в положение на подчинение.
По тази причина Багдад следва да е научил урока си от катастрофалните последици от действията на ИДИЛ и пренебрегването на обществените тежнения. Жертвите на ИДИЛ заслужават и очакват правосъдието да възтържествува. Не на последно място – и това е много важно: иракските общности, живеещи на север, не заслужават да бъдат стигматизирани като колаборационисти, тъй като това би засилило тяхнaта маргинализация и търсейки спасение и покровителство другаде, те допълнително биха били тласнати в обятията на центробежните сили. Така както се случи през 2014 г.
Близкият изток преживява значителни по своята сила социални, икономически и политически промени. Започнатото през 2010 г. продължава да отеква не само в Ирак, но и в Сирия, Ливан, Йемен, Либия, Палестина. Като човек с дълбоки професионални и академични знания за региона какво е Вашето мнение за бъдещето на Близкия изток днес, в контекста и на войната в Украйна?
Общественият дебат по отношение на войната в Украйна още веднъж демонстрира травмата и незаздравелите рани в общественото съзнание на хората в Близкия изток, преживели множество недобре планирани чуждестранни намеси. Има такива, разбира се, които категорично осъждат руската агресия срещу Украйна и симпатизират на Украйна, но все пак съществува немалка част от обществото в ислямския свят, която е скептична спрямо всяка форма на намеса от страна на Запада във войната.
За съжаление, не са малко и онези, които гледат на войната в Украйна и през призмата на максимата, че „врагът на моя враг е мой съюзник“. В очите на подобни хора всяко събитие, което поставя на изпитание модела на западната демокрация, заслужава да бъде приветствано, без да се взема под внимание цената, която плаща местното население в зоната на конфликта.
Друг противоречив аспект на общественото възприятие бе степента на гостоприемство, което украинските бежанци получиха в сравнение с тези от Сирия, чието нещастие, за съжаление, вече не е в центъра на вниманието на световната общественост. Подобни интерпретации може лесно да бъдат използвани от популисти и демагози, които търсят способ да вбият клин в обществото, предлагайки „отговори“ чрез конспиративни теории. Тези хора се опитват да убедят обществата в Близкия изток в уж изконната недоброжелателност на Запада спрямо хората в региона.
Източник заглавна снимка: UNDP Iraq, 2019, CC BY-NC 2.0 / Flickr
Общително изкуство. Няколко пиеси от Панаира на куклите
Post Syndicated from Зорница Христова original https://toest.bg/panair-na-kuklite-2022/
Кукленият театър е общително изкуство. Публика от деца и възрастни (като придружители или сами по себе си), в зала или без зала (може пък да ви пресрещне в естеството си на уличен театър), с каквито си ще изразни средства – от класическите „петрушки“, през марионетки, костюми, преобразени предмети от ежедневието или няколко най-прости парчета материал, театър на сенките… та дори, пряко името си, и без кукли може да се играе. В този смисъл – едно от изкуствата с най-висок потенциал да изненадва ума.
Международният фестивал за уличен и куклен театър „Панаир на куклите“ използва този потенциал доста сериозно. В минали издания човек е можел да се порадва например на театър на сенките по Платоновата история за „топчестите хора“ (онези съвършени човеци с две глави, четири ръце и пр., отпреди разрязването ни на „половинки“), на китайски театър и какво ли не още. Панаирът има вярна публика, която чака новото му издание на всеки две години. Има защо.
Тазгодишното издание приключи съвсем скоро, на 18 септември. То беше юбилейно – Панаирът на куклите съществува вече 20 години. Достатъчно време за натрупване на опит и престиж, които да доведат тук разнообразни спектакли от разнообразни страни. В случая имаше 16 чуждестранни трупи от Франция, Канада, Испания, Италия, Гърция, Белгия, Чехия, Словения, Словакия, Германия, примесени с трупи от различни български градове. Но макар да е много интересно да видиш какво правят зад граница, далеч невинаги произходът на спектакъла означаваше нещо за качеството му.


Панаирът беше открит с „Приключенията на Доктор Дулитъл“ на режисьорката Катя Петрова, по сценография на Юлиян Табаков и музика на Христо Йоцов. Тази постановка е обърната към детската публика, като майсторството надгражда условието за разбираемост и забава, вместо да го пропуква. Тоест това е театър, на който спокойно може да отидете с дете и то да се радва, докато вие от своя страна забелязвате как са вплетени елементите на мюзикъл, прожектираните декори, как се преминава от костюми към кукли, а после към друг тип кукли и пр. Щастливото съчетание между висок вкус и способност за забавление е типично за всички замесени, а в костюмите доста личи, че животните са любима тема за рисуване на Юлиян Табаков. Фаворит ми е прасето.
„Ламята от улица Войтешка“ по Карел Чапек беше постановка на Държавен куклен театър – Габрово. Тя беше на границата с игралния театър – всъщност имаше само една кукла и тя доста бледнееше в сравнение с чудесната игра на актьорите. Самите те наподобяваха кукли, илюстрации, анимационни персонажи… Играта им разсмиваше и затрогваше, особено тази на Петър Гайдаров в главната роля на г-н Тротина от Бюрото за изгубени вещи. Може би вярното определение тук би било „драматичен театър за деца“. Вече имам втора причина да тръгна на културен туризъм към Габрово (освен че изложбите в Дома на хумора и сатирата си струва да се следят).


Канадската пиеса „Великото творение“ на La Tortue Noire обаче беше интересна само на хартия. Представиха ни алхимик, който пипа някакви книги и бърка нещо в хаванче, докато над главата му изниква миниатюрна сценография, която би трябвало да показва мислите му. Е, с това изречение може да броите, че сте гледали постановката – нямаше нищо повече, нито история, нито някаква визуална поезия. Поне да бяха отработили като хората трика с актьора в черни дрехи, скрит на заден фон. По-скоро мизансцен, отколкото театър.

В програмата имаше две постановки, тип „микротеатър“ – интересна иновация, не съм виждала нещо такова да се играе у нас. Избрах μSPUTNIK на чехите от Mir Theatre DRAMA LABEL. Всъщност най-вълнуващото беше, че в залата си само ти и актьорите – по един зрител на 15 минути, параван, процеп, кутийка, в която миниатюрните кукли се движат по определени жлебове и създават историйка. Красиво беше, но все още е само форма, черупка, в която тепърва ще се пръква орех. Моделът с театър за един зрител обаче си струва да се използва и в други форми, мисля, че там има много хляб.
Изключително съжалявам, че трябваше да изпусна „Механика на душата“ на испанците Zero en conducta. Единайсетгодишната ми заместничка сподели за разказвач, чието лице е съставено от телата на актьорите, за история между танца и кукловодството, история за съживяване и препредаване на духа.
Аз ви каня да надникнем и в други представления на трупата. И да се надяваме на следващия Панаир на куклите да дойдат пак.
Заглавна снимка: „Механика на душата“ © Zero en conducta
На второ четене: „Живи“ от Ю Хуа
Post Syndicated from Стефан Иванов original https://toest.bg/na-vtoro-chetene-zhivi-yu-hua/
Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Севда Семер, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.
„Живи“ от Ю Хуа
превод от китайски Стефан Русинов, изд. „Жанет 45“, 2020
 Понякога изпитвам изключителни затруднения да говоря или пиша за книга, която наистина ми харесва. В такива случаи съм склонен да я препоръчам категорично и без аргументи, защото тя говори достатъчно добре сама за себе си и ми е доставила неимоверно удоволствие, което просто бих искал да споделя, и нищо повече. Такава е и книгата на Ю Хуа. За добро или за лошо, ще се наложи да съм по-детайлен.
Понякога изпитвам изключителни затруднения да говоря или пиша за книга, която наистина ми харесва. В такива случаи съм склонен да я препоръчам категорично и без аргументи, защото тя говори достатъчно добре сама за себе си и ми е доставила неимоверно удоволствие, което просто бих искал да споделя, и нищо повече. Такава е и книгата на Ю Хуа. За добро или за лошо, ще се наложи да съм по-детайлен.
Но първо искам да изразя благодарността си към преводача Стефан Русинов. Той е методичен, последователен и награждаван за усърдието си контрабандист на съвременна китайска литература. Един от малцината, за съжаление. Негова е отговорността да можем да четем и У Цин, Лиу Цъсин, Ма Дзиен и Мо Йен на български. Той водеше и рубриката „Китай отвътре“ в „Тоест“ за промените в страната през последните четири десетилетия, разказани през погледа на китайски писатели.
Ю Хуа има неочаквано вдъхновение за романа си. То идва, по собствените му думи, от американската фолк песен Old Black Joe. Тя е за трудностите в живота на афроамерикански роб, за смъртта на семейството му, но и за несломимата му воля за живот и светла доброта.
Когато бях с десет години по-млад от сега, се сдобих с една лентяйска професия: да събирам народни песни из селата. Цяло лято изкарах като безцелно врабче, скитайки се сред къщите и нивята, напоени със слънчеви лъчи и цикадно цвъртене.
По забележително лекомислен начин започва този потресаващ роман. Още от началото книгата тече плавно, с хумор и увлича спонтанно да бъде четена и на глас. Така е до самия ѝ край. От първите страници на книгата лъха на младежка свобода и бохемско нехайство, а живият им, земен език напомня на естествено опияняващата и сочна свежест на Радичков и почудата му от разнообразието на природата и хорските дела.
Събирачът на песни скоро се натъква на Фу-Гуей, чиято житейска история изслушва от началото до края. Фу-Гуей разказва за лъкатушенията, които е преживял и понесъл на гърба си. Той израства като наследник на богат земевладелец, докато чудовищните исторически събития, причинени от Китайската революция, променят фундаментално тъканта на обществото. Контрастът между предреволюционния му статус на егоистичен богат безделник, буквално носен на раменете на проститутка, докато армията приближава селото му, и следреволюционния му статус на преследван селянин е рязък. Той постепенно се превръща в добър и предан съпруг и баща, чиято мисия е да запази живи себе си и семейството си. Неслучайно наричат тази творба на Ю Хуа „китайската книга на Йов“.
Романът описва поредица от трагедии на фона на период, определил посоката на развитие на Китай до ден днешен. Това позволява на читателите да видят жестокостта на войната, култа към личността и обожествяването на политическите фигури, мисли и движения. Вижда се и катастрофалният провал на иновативните идеологически, земеделски и промишлени реформи, довели до неописуем масов глад, болка, страдание и смърт. В такива преломни времена, когато властта своеволно проиграва съдбата и живота на населението на една огромна страна, т.нар. обикновени хора като Фу-Гуей са най-големите жертви.
Изумителното в книгата е, че Фу-Гуей не се изживява като жертва – не, по никакъв начин. Той проявява радикален стоицизъм, сила и смирение и въпреки трагичната си съдба продължава пътя си с изумителна воля за живот. Фу-Гуей живее на инат. Въпреки всичко, което му се случва, и всички, които надживява, той е решен да посрещне финала на историята си в мир и спокойствие. С достойнството и хумора на препатилия.
Отдавна не бях чел такава съвременна проза. Едновременно сурова и брутална, но пропита със съчувствие, красота и любов. И пронизана от изкупление. Романът с лекота можеше да бъде едностранна морализаторска история, но без усилие чупи калъпа на предвидимото, на клишето. Писателят е напълно честен, когато споделя: „В момента сякаш съм по-наясно от всякога защо пиша – старая се да доближа истината.“ И го постига в този малък шедьовър, побрал епична история в рамките на само двеста страници.
Ю Хуа също има интересна лична история. Родителите му са лекари, домът им гледа към моргата и той често вижда и чува скърбящи хора. След гимназията учи стоматология и пет години е зъболекар. Установява, че това не му подхожда особено. Както той казва в интервю от 2003 г., „вътрешността на устата е едно от най-грозните зрелища на света“. Решен е да описва други зрелища и да стане писател.
По времето на Културната революция и хунвейбините хората са насърчавани да бъдат доносници и да изобличават онези, за които смятат, че са се отклонили от социалистическия път. Стените по градовете са покрити с лозунги и обвинения. Тъй като почти няма достъп до книги, тези четива са едни от първите допири на Ю Хуа с литература. „Спомням си, че носех чантата си с книги на път за вкъщи от училище и четях всеки плакат, докато вървях – казва той в същото интервю. – Не се интересувах от революционните лозунги. Интересувах се от историите.“
Ю Хуа често се притеснява, че ще види името на баща си в някой публичен донос. Страхът му е бил основателен, защото един ден баща му бил наречен „предрешил се хазяин“ и „капиталистически проводник“. Обвиненията произтичат от родовата история на Ю Хуа. Семейството на дядо му е притежавало много земя. Но дядо му – „мързеливец и гуляйджия“, както го нарича писателят – разпродава имотите малко по малко, за да плати за екстравагантния си начин на живот, докато през 1949 г. пропилява всичко и губи статуса си. За щастие, нищо освен публично посрамване не застига бащата на Ю Хуа и няма други последствия за него или семейството му.
Тази история стои в основата на „Живи“, но е изведена до нивото на притча и мит, в който последните са първи. Разказът, макар и наситен с детайли от китайското всекидневие, история и култура, е универсален. Ю Хуа е писател от категорията на Чехов, Тони Морисън и В. С. Найпол.
Докато четях, на няколко пъти се сещах за дядо ми от Котел и приживе заделените от него пари за погребение. Някак не се изненадах, когато това присъстваше и в „Живи“. Сетих се и за стихотворение на Марин Бодаков:
Кой знае
Наруших неприкосновения запас,
достатъчен за скромно погребение
(а вкъщи сме поне чeтирима),
и наистина не знам какво означава това:
може би знак за триумфираща бедност
или предчувствие за вечен живот…
Ако някой все още се чуди каква му е не само Хекуба, но и Ю Хуа, или защо му е да чете китайски роман, ще го кажа кратко – това е учебник по човещина. Такaва е и филмовата адаптация на Джан И-моу, спечелила „Гран При“ на фестивала в Кан през 1994 г.
Във време, белязано от война, недостиг на хуманност и преизобилие от бруталност и лъжа, такова писане е противоотрова. С такива книги добротата може да си осигури ако не вечен, то поне достатъчно дълъг живот. Не само на хартия.
Заглавно изображение: Колаж от корицата на книгата (худ. Георги Калев, изд. „Жанет 45“) и снимка на Ben Moreland / Unsplash
Активните дарители на „Тоест“ получават постоянна отстъпка в размер на 20% от коричната цена на всички заглавия от каталога на „Жанет 45“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
Metasploit Weekly Wrap-Up
Post Syndicated from Jeffrey Martin original https://blog.rapid7.com/2022/09/23/metasploit-weekly-wrap-up-177/
Have you built out that awesome media room?

If your guilty pleasures include using a mobile device to make your home entertainment system WOW your guests, you might be using Unified Remote. I hope you are extra cautious about what devices you let on that WiFi network. A prolific community member h00die added a module this week that uses a recently published vulnerability from H4RK3NZ0 to leverage an unprotected configuration page exposed on the media service, combined with just a little bit of protocol info the module makes that media server a prime target for pranks and other less friendly activities by guests on the network.
Finding the needles in that Linux memory stack
Brought to you by the combined efforts of many members of the Metasploit Community, Linux meterpeter payloads now offer a new way to hunt down passwords in memory on all those delicious Linux sessions you gather with Metasploit. The new post/linux/gather/mimipenguin module hunts down clear text passwords in Linux memory based on MimiPenguin.
We all love to share code with the public
A new module this week makes sharing public code risky business if you are using a bitbucket server to host that repository. Checkout out the nitty gritty in our blog post from earlier this week.
Metasploit plays well with others
Last week’s update brought with it an awesome way to utilize Metasploit with payload generated by Sliver that even ranked a call out in their latest release notes. Great to see the community promoting these updates for more people to learn about and utilize.
New module content (4)
- VICIdial Multiple Authenticated SQLi by h00die, which exploits CVE-2022-34878 – This PR adds a module which exploits several authenticated sqli in VICIdial (CVE-2022-34876, CVE-2022-34877, CVE-2022-34878).
- Bitbucket Git Command Injection by Jang, Ron Bowes, Shelby Pace, and TheGrandPew, which exploits CVE-2022-36804 – Adds an exploit for CVE-2022-36804 which is an unauthenticated RCE in Bitbucket.
- Unified Remote Auth Bypass to RCE by H4RK3NZ0 and h00die, which exploits CVE-2022-3229 – This adds an exploit module to exploit an authentication bypass to achieve remote code execution in Unified Remote on Windows. Note that the latest version (3.11.0.2483) is vulnerable, which makes it a 0-Day.
- MimiPenguin by Shelby Pace, bcoles, and huntergregal, which exploits CVE-2018-20781 – This adds a port of Mimipenguin to Metasploit. Relying on mem_search() and mem_read(), this searches the memory regions of various processes for needles that are found near passwords in cleartext. Using the locations for all of the needles found, this will search the nearby regions for possible passwords.
Enhancements and features (6)
- #16940 from adfoster-r7 – Rewrites Metasploit’s datastore to fix multiple bugs and edge cases. The
unsetcommand will now consistently unset previously set datastore values, so that default values are used once again. Explicitly clearing a datastore value can be done with theset --clear OptionNamecommand. Modules that require protocol specific option names such as SMBUser/FTPUser/BIND_DN/etc can now be consistently set with just username/password/domain options, i.e.set username Administratorinstead ofset SMBUser Administrator. This rewrite is currently behind a feature flag which can be enabled withfeatures set datastore_fallbacks true. - #17002 from bcoles – The
lib/msf/core/post/windows/accounts.rb,lib/msf/core/post/windows/ldap.rb, andlib/msf/core/post/windows/wmic.rblibraries have been updated to replace calls toload_extapiwith ExtAPI compatibility checks which will check if the session supports ExtAPI, since if the sessions supports ExtAPI, it should already be loaded. - #17003 from bcoles –
enum_patcheshas had its code updated to output the patches enumerated as a table and store the results long term in a CSV file. Additionally, a check has been added to see if the current session supports the required Meterpreter extension compatibility prior to trying to run the module. Finally, the code and documentation have been cleaned up and modernized. - #17015 from jmartin-r7 – Updates
auxiliary/scanner/http/http_loginto report login success when the http status code is in the range200,201,300-308. This functionality is user-configurable withset HttpSuccessCodes 200. - #17049 from bcoles – Adds Notes module meta information and replaces custom
get_membersmethod withget_members_from_groupfrom the Post API. - #17051 from bcoles – Adds module documentation, notes for module meta information, and improves module error handling.
Bugs fixed (3)
- #17023 from zeroSteiner – The
post/windows/manage/rollback_defender_signaturesmodule has been updated to work on WoW64 sessions, and has had its code updated so that the default action is now a valid option. - #17036 from zeroSteiner – Fixes a bug where the
sessionscommand would show the connection as coming from losthost 127.0.0.1, instead of the correct peer host address for reverse_http Meterpreter sessions. - #17052 from adfoster-r7 – Fixes an error in Metasploit-framework when the host machine has OpenSSL 3.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
binary installers (which also include the commercial edition).
Run a data processing job on Amazon EMR Serverless with AWS Step Functions
Post Syndicated from Siva Ramani original https://aws.amazon.com/blogs/big-data/run-a-data-processing-job-on-amazon-emr-serverless-with-aws-step-functions/
There are several infrastructure as code (IaC) frameworks available today, to help you define your infrastructure, such as the AWS Cloud Development Kit (AWS CDK) or Terraform by HashiCorp. Terraform, an AWS Partner Network (APN) Advanced Technology Partner and member of the AWS DevOps Competency, is an IaC tool similar to AWS CloudFormation that allows you to create, update, and version your AWS infrastructure. Terraform provides friendly syntax (similar to AWS CloudFormation) along with other features like planning (visibility to see the changes before they actually happen), graphing, and the ability to create templates to break infrastructure configurations into smaller chunks, which allows better maintenance and reusability. We use the capabilities and features of Terraform to build an API-based ingestion process into AWS. Let’s get started!
In this post, we showcase how to build and orchestrate a Scala Spark application using Amazon EMR Serverless, AWS Step Functions, and Terraform. In this end-to-end solution, we run a Spark job on EMR Serverless that processes sample clickstream data in an Amazon Simple Storage Service (Amazon S3) bucket and stores the aggregation results in Amazon S3.
With EMR Serverless, you don’t have to configure, optimize, secure, or operate clusters to run applications. You will continue to get the benefits of Amazon EMR, such as open source compatibility, concurrency, and optimized runtime performance for popular data frameworks. EMR Serverless is suitable for customers who want ease in operating applications using open-source frameworks. It offers quick job startup, automatic capacity management, and straightforward cost controls.
Solution overview
We provide the Terraform infrastructure definition and the source code for an AWS Lambda function using sample customer user clicks for online website inputs, which are ingested into an Amazon Kinesis Data Firehose delivery stream. The solution uses Kinesis Data Firehose to convert the incoming data into a Parquet file (an open-source file format for Hadoop) before pushing it to Amazon S3 using the AWS Glue Data Catalog. The generated output S3 Parquet file logs are then processed by an EMR Serverless process, which outputs a report detailing aggregate clickstream statistics in an S3 bucket. The EMR Serverless operation is triggered using Step Functions. The sample architecture and code are spun up as shown in the following diagram.

The provided samples have the source code for building the infrastructure using Terraform for running the Amazon EMR application. Setup scripts are provided to create the sample ingestion using Lambda for the incoming application logs. For a similar ingestion pattern sample, refer to Provision AWS infrastructure using Terraform (By HashiCorp): an example of web application logging customer data.
The following are the high-level steps and AWS services used in this solution:
- The provided application code is packaged and built using Apache Maven.
- Terraform commands are used to deploy the infrastructure in AWS.
- The EMR Serverless application provides the option to submit a Spark job.
- The solution uses two Lambda functions:
- Ingestion – This function processes the incoming request and pushes the data into the Kinesis Data Firehose delivery stream.
- EMR Start Job – This function starts the EMR Serverless application. The EMR job process converts the ingested user click logs into output in another S3 bucket.
- Step Functions triggers the EMR Start Job Lambda function, which submits the application to EMR Serverless for processing of the ingested log files.
- The solution uses four S3 buckets:
- Kinesis Data Firehose delivery bucket – Stores the ingested application logs in Parquet file format.
- Loggregator source bucket – Stores the Scala code and JAR for running the EMR job.
- Loggregator output bucket – Stores the EMR processed output.
- EMR Serverless logs bucket – Stores the EMR process application logs.
- Sample invoke commands (run as part of the initial setup process) insert the data using the ingestion Lambda function. The Kinesis Data Firehose delivery stream converts the incoming stream into a Parquet file and stores it in an S3 bucket.
For this solution, we made the following design decisions:
- We use Step Functions and Lambda in this use case to trigger the EMR Serverless application. In a real-world use case, the data processing application could be long running and may exceed Lambda’s timeout limits. In this case, you can use tools like Amazon Managed Workflows for Apache Airflow (Amazon MWAA). Amazon MWAA is a managed orchestration service makes it easier to set up and operate end-to-end data pipelines in the cloud at scale.
- The Lambda code and EMR Serverless log aggregation code are developed using Java and Scala, respectively. You can use any supported languages in these use cases.
- The AWS Command Line Interface (AWS CLI) V2 is required for querying EMR Serverless applications from the command line. You can also view these from the AWS Management Console. We provide a sample AWS CLI command to test the solution later in this post.
Prerequisites
To use this solution, you must complete the following prerequisites:
- Install the AWS CLI. For this post, we used version 2.7.18. This is required in order to query the
aws emr-serverlessAWS CLI commands from your local machine. Optionally, all the AWS services used in this post can be viewed and operated via the console. - Make sure to have Java installed, and JDK/JRE 8 is set in the environment path of your machine. For instructions, see the Java Development Kit.
- Install Apache Maven. The Java Lambda functions are built using mvn packages and are deployed using Terraform into AWS.
- Install the Scala Build Tool. For this post, we used version 1.4.7. Make sure to download and install based on your operating system needs.
- Set up Terraform. For steps, see Terraform downloads. We use version 1.2.5 for this post.
- Have an AWS account.
Configure the solution
To spin up the infrastructure and the application, complete the following steps:
- Clone the following GitHub repository.
The providedexec.shshell script builds the Java application JAR (for the Lambda ingestion function) and the Scala application JAR (for the EMR processing) and deploys the AWS infrastructure that is needed for this use case. - Run the following commands:
To run the commands individually, set the application deployment Region and account number, as shown in the following example:
The following is the Maven build Lambda application JAR and Scala application package:
- Deploy the AWS infrastructure using Terraform:
Test the solution
After you build and deploy the application, you can insert sample data for Amazon EMR processing. We use the following code as an example. The exec.sh script has multiple sample insertions for Lambda. The ingested logs are used by the EMR Serverless application job.
The sample AWS CLI invoke command inserts sample data for the application logs:
To validate the deployments, complete the following steps:
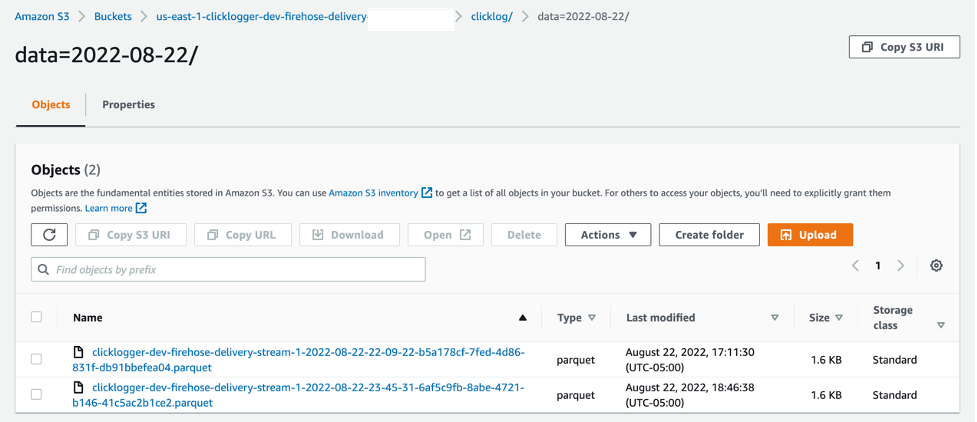
- On the Amazon S3 console, navigate to the bucket created as part of the infrastructure setup.
- Choose the bucket to view the files.
You should see that data from the ingested stream was converted into a Parquet file. - Choose the file to view the data.
The following screenshot shows an example of our bucket contents.
Now you can run Step Functions to validate the EMR Serverless application. - On the Step Functions console, open
clicklogger-dev-state-machine.
The state machine shows the steps to run that trigger the Lambda function and EMR Serverless application, as shown in the following diagram.
- Run the state machine.
- After the state machine runs successfully, navigate to the
clicklogger-dev-output-bucket on the Amazon S3 console to see the output files.

- Use the AWS CLI to check the deployed EMR Serverless application:
- On the Amazon EMR console, choose Serverless in the navigation pane.
- Select
clicklogger-dev-studioand choose Manage applications. - The Application created by the stack will be as shown below
clicklogger-dev-loggregator-emr-<Your-Account-Number>

 Now you can review the EMR Serverless application output.
Now you can review the EMR Serverless application output. - On the Amazon S3 console, open the output bucket (
us-east-1-clicklogger-dev-loggregator-output-).
The EMR Serverless application writes the output based on the date partition, such as2022/07/28/response.md.The following code shows an example of the file output:




Clean up
The provided ./cleanup.sh script has the required steps to delete all the files from the S3 buckets that were created as part of this post. The terraform destroy command cleans up the AWS infrastructure that you created earlier. See the following code:
To do the steps manually, you can also delete the resources via the AWS CLI:
Conclusion
In this post, we built, deployed, and ran a data processing Spark job in EMR Serverless that interacts with various AWS services. We walked through deploying a Lambda function packaged with Java using Maven, and a Scala application code for the EMR Serverless application triggered with Step Functions with infrastructure as code. You can use any combination of applicable programming languages to build your Lambda functions and EMR job application. EMR Serverless can be triggered manually, automated, or orchestrated using AWS services like Step Functions and Amazon MWAA.
We encourage you to test this example and see for yourself how this overall application design works within AWS. Then, it’s just the matter of replacing your individual code base, packaging it, and letting EMR Serverless handle the process efficiently.
If you implement this example and run into any issues, or have any questions or feedback about this post, please leave a comment!
References
- Terraform: Beyond the Basics with AWS
- Amazon EMR Serverless is now generally available
- Amazon EMR Serverless Now Generally Available – Run Big Data Applications without Managing Servers
- Provision AWS infrastructure using Terraform (By HashiCorp): an example of web application logging customer data
About the Authors
 Sivasubramanian Ramani (Siva Ramani) is a Sr Cloud Application Architect at Amazon Web Services. His expertise is in application optimization & modernization, serverless solutions and using Microsoft application workloads with AWS.
Sivasubramanian Ramani (Siva Ramani) is a Sr Cloud Application Architect at Amazon Web Services. His expertise is in application optimization & modernization, serverless solutions and using Microsoft application workloads with AWS.
 Naveen Balaraman is a Sr Cloud Application Architect at Amazon Web Services. He is passionate about Containers, serverless Applications, Architecting Microservices and helping customers leverage the power of AWS cloud.
Naveen Balaraman is a Sr Cloud Application Architect at Amazon Web Services. He is passionate about Containers, serverless Applications, Architecting Microservices and helping customers leverage the power of AWS cloud.
How to Build a Life LIVE (With Arthur Brooks and Daniel Pink) | The Atlantic Festival 2022
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=NEP5d_R3fCc
Kathy Rastle | Learning to Read | Talks at Google
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=U_RUfYozxGY
Ultimate Long Lens Shootout – Nikkor Z 800mm VS 400mm Z + 2X TC
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=89BmtSJp6Ss
Upgrade Amazon EMR Hive Metastore from 5.X to 6.X
Post Syndicated from Jianwei Li original https://aws.amazon.com/blogs/big-data/upgrade-amazon-emr-hive-metastore-from-5-x-to-6-x/
If you are currently running Amazon EMR 5.X clusters, consider moving to Amazon EMR 6.X as it includes new features that helps you improve performance and optimize on cost. For instance, Apache Hive is two times faster with LLAP on Amazon EMR 6.X, and Spark 3 reduces costs by 40%. Additionally, Amazon EMR 6.x releases include Trino, a fast distributed SQL engine and Iceberg, high-performance open data format for petabyte scale tables.
To upgrade Amazon EMR clusters from 5.X to 6.X release, a Hive Metastore upgrade is the first step before applications such as Hive and Spark can be migrated. This post provides guidance on how to upgrade Amazon EMR Hive Metastore from 5.X to 6.X as well as migration of Hive Metastore to the AWS Glue Data Catalog. As Hive 3 Metastore is compatible with Hive 2 applications, you can continue to use Amazon EMR 5.X with the upgraded Hive Metastore.
Solution overview
In the following section, we provide steps to upgrade the Hive Metastore schema using MySQL as the backend.. For any other backends (such as MariaDB, Oracle, or SQL Server), update the commands accordingly.
There are two options to upgrade the Amazon EMR Hive Metastore:
- Upgrade the Hive Metastore schema from 2.X to 3.X by using the Hive Schema Tool
- Migrate the Hive Metastore to the AWS Glue Data Catalog
We walk through the steps for both options.
Pre-upgrade prerequisites
Before upgrading the Hive Metastore, you must complete the following prerequisites steps:
- Verify the Hive Metastore database is running and accessible.
You should be able to run Hive DDL and DML queries successfully. Any errors or issues must be fixed before proceeding with upgrade process. Use the following sample queries to test the database: - To get the Metastore schema version in the current EMR 5.X cluster, run the following command in the primary node:
The following code shows our sample output:
- Stop the Metastore service and restrict access to the Metastore MySQL database.
It’s very important that no one else accesses or modifies the contents of the Metastore database while you’re performing the schema upgrade.To stop the Metastore, use the following commands:For Amazon EMR release 5.30 and 6.0 onwards (Amazon Linux 2 is the operating system for the Amazon EMR 5.30+ and 6.x release series), use the following commands:
You can also note the total number of databases and tables present in the Hive Metastore before the upgrade, and verify the number of databases and tables after the upgrade.
- To get the total number of tables and databases before the upgrade, run the following commands after connecting to the external Metastore database (assuming the Hive Metadata DB name is hive):
- Take a backup or snapshot of the Hive database.
This allows you to revert any changes made during the upgrade process if something goes wrong. If you’re using Amazon Relational Database Service (Amazon RDS), refer to Backing up and restoring an Amazon RDS instance for instructions. - Take note of the Hive table storage location if data is stored in HDFS.
If all the table data is on Amazon Simple Storage Service (Amazon S3), then no action is needed. If HDFS is used as the storage layer for Hive databases and tables, then take a note of them. You will need to copy the files on HDFS to a similar path on the new cluster, and then verify or update the location attribute for databases and tables on the new cluster accordingly.
Upgrade the Amazon EMR Hive Metastore schema with the Hive Schema Tool
In this approach, you use the persistent Hive Metastore on a remote database (Amazon RDS for MySQL or Amazon Aurora MySQL-Compatible Edition). The following diagram shows the upgrade procedure.

To upgrade the Amazon EMR Hive Metastore from 5.X (Hive version 2.X) to 6.X (Hive version 3.X), we can use the Hive Schema Tool. The Hive Schema Tool is an offline tool for Metastore schema manipulation. You can use it to initialize, upgrade, and validate the Metastore schema. Run the following command to show the available options for the Hive Schema Tool:
Be sure to complete the prerequisites mentioned earlier, including taking a backup or snapshot, before proceeding with the next steps.
- Note down the details of the existing Hive external Metastore to be upgraded.
This includes the RDS for MySQL endpoint host name, database name (for this post, hive), user name, and password. You can do this through one of the following options:- Get the Hive Metastore DB information from the Hive configuration file – Log in to the EMR 5.X primary node, open the file
/etc/hive/conf/hive-site.xml, and note the four properties:
- Get the Hive Metastore DB information from the Amazon EMR console – Navigate to the EMR 5.X cluster, choose the Configurations tab, and note down the Metastore DB information.

- Get the Hive Metastore DB information from the Hive configuration file – Log in to the EMR 5.X primary node, open the file

- Create a new EMR 6.X cluster.
To use the Hive Schema Tool, we need to create an EMR 6.X cluster. You can create a new EMR 6.X cluster via the Hive console or the AWS Command Line Interface (AWS CLI), without specifying external hive Metastore details. This lets the EMR 6.X cluster launch successfully using the default Hive Metastore. For more information about EMR cluster management, refer to Plan and configure clusters. - After your new EMR 6.X cluster is launched successfully and is in the waiting state, SSH to the EMR 6.X primary node and take a backup of
/etc/hive/conf/hive-site.xml: - Stop Hive services:
Now you update the Hive configuration and point it to the old hive Metastore database.
- Modify
/etc/hive/conf/hive-site.xmland update the properties with the values you collected earlier: - On the same or new SSH session, run the Hive Schema Tool to check that the Metastore is pointing to the old Metastore database:
The output should look as follows (old-hostname, old-dbname, and old-username are the values you changed):
You can upgrade the Hive Metastore by passing the
-upgradeSchemaoption to the Hive Schema Tool. The tool figures out the SQL scripts required to initialize or upgrade the schema and then runs those scripts against the backend database. - Run the
upgradeSchemacommand with-dryRun, which only lists the SQL scripts needed during the actual run:The output should look like the following code. It shows the Metastore upgrade path from the old version to the new version. You can find the upgrade order on the GitHub repo. In case of failure during the upgrade process, these scripts can be run manually in the same order.
- To upgrade the Hive Metastore schema, run the Hive Schema Tool with
-upgradeSchema:The output should look like the following code:
In case of any issues or failures, you can run the preceding command with verbose. This prints all the queries getting run in order and their output.
If you encounter any failures during this process and you want to upgrade your Hive Metastore by running the SQL yourself, refer to Upgrading Hive Metastore.
If HDFS was used as storage for the Hive warehouse or any Hive DB location, you need to update the
NameNodealias or URI with the new cluster’s HDFS alias. - Use the following commands to update the HDFS
NameNodealias (replace<new-loc> <old-loc>with the HDFS root location of the new and old clusters, respectively):You can run the following command on any EMR cluster node to get the HDFS
NameNodealias:At first you can run with the
dryRunoption, which displays all the changes but aren’t persisted. For example:However, if the new location needs to be changed to a different HDFS or S3 path, then use the following approach.
First connect to the remote Hive Metastore database and run the following query to pull all the tables for a specific database and list the locations. Replace
HiveMetastore_DBwith the database name used for the Hive Metastore in the external database (for this post, hive) and the Hive database name (default):Identify the table for which location needs to be updated. Then run the Alter table command to update the table locations. You can prepare a script or chain of Alter table commands to update the locations for multiple tables.
- Start and check the status of Hive Metastore and HiveServer2:
Post-upgrade validation
Perform the following post-upgrade steps:
- Confirm the Hive Metastore schema is upgraded to the new version:
The output should look like the following code:
- Run the following Hive Schema Tool command to query the Hive schema version and verify that it’s upgraded:
- Run some DML queries against old tables and ensure they are running successfully.
- Verify the table and database counts using the same commands mentioned in the prerequisites section, and compare the counts.
The Hive Metastore schema migration process is complete, and you can start working on your new EMR cluster. If for some reason you want to relaunch the EMR cluster, then you just need to provide the Hive Metastore remote database that we upgraded in the previous steps using the options on the Amazon EMR Configurations tab.
Migrate the Amazon EMR Hive Metastore to the AWS Glue Data Catalog
The AWS Glue Data Catalog is flexible and reliable, and can reduce your operation cost. Moreover, the Data Catalog supports different versions of EMR clusters. Therefore, when you migrate your Amazon EMR 5.X Hive Metastore to the Data Catalog, you can use the same Data Catalog with any new EMR 5.8+ cluster, including Amazon EMR 6.x. There are some factors you should consider when using this approach; refer to Considerations when using AWS Glue Data Catalog for more information. The following diagram shows the upgrade procedure.

To migrate your Hive Metastore to the Data Catalog, you can use the Hive Metastore migration script from GitHub. The following are the major steps for a direct migration.
Make sure all the table data is stored in Amazon S3 and not HDFS. Otherwise, tables migrated to the Data Catalog will have the table location pointing to HDFS, and you can’t query the table. You can check your table data location by connecting to the MySQL database and running the following SQL:
Make sure to complete the prerequisite steps mentioned earlier before proceeding with the migration. Ensure the EMR 5.X cluster is in a waiting state and all the components’ status are in service.
- Note down the details of the existing EMR 5.X cluster Hive Metastore database to be upgraded.
As mentioned before, this includes the endpoint host name, database name, user name, and password. You can do this through one of the following options:- Get the Hive Metastore DB information from the Hive configuration file – Log in to the Amazon EMR 5.X primary node, open the file
/etc/hive/conf/hive-site.xml, and note the four properties:
- Get the Hive Metastore DB information from the Amazon EMR console – Navigate to the Amazon EMR 5.X cluster, choose the Configurations tab, and note down the Metastore DB information.
- Get the Hive Metastore DB information from the Hive configuration file – Log in to the Amazon EMR 5.X primary node, open the file
- On the AWS Glue console, create a connection to the Hive Metastore as a JDBC data source.
Use the connection JDBC URL, user name, and password you gathered in the previous step. Specify the VPC, subnet, and security group associated with your Hive Metastore. You can find these on the Amazon EMR console if the Hive Metastore is on the EMR primary node, or on the Amazon RDS console if the Metastore is an RDS instance. - Download two extract, transform, and load (ETL) job scripts from GitHub and upload them to an S3 bucket:
If you configured AWS Glue to access Amazon S3 from a VPC endpoint, you must upload the script to a bucket in the same AWS Region where your job runs.
Now you must create a job on the AWS Glue console to extract metadata from your Hive Metastore to migrate it to the Data Catalog.
- On the AWS Glue console, choose Jobs in the navigation pane.
- Choose Create job.
- Select Spark script editor.
- For Options¸ select Upload and edit an existing script.
- Choose Choose file and upload the
import_into_datacatalog.pyscript you downloaded earlier. - Choose Create.

- On the Job details tab, enter a job name (for example,
Import-Hive-Metastore-To-Glue). - For IAM Role, choose a role.
- For Type, choose Spark.

- For Glue version¸ choose Glue 3.0.
- For Language, choose Python 3.
- For Worker type, choose G1.X.
- For Requested number of workers, enter 2.

- In the Advanced properties section, for Script filename, enter
import_into_datacatalog.py. - For Script path, enter the S3 path you used earlier (just the parent folder).

- Under Connections, choose the connection you created earlier.

- For Python library path, enter the S3 path you used earlier for the file
hive_metastore_migration.py. - Under Job parameters, enter the following key-pair values:
--mode: from-jdbc--connection-name: EMR-Hive-Metastore--region: us-west-2

- Choose Save to save the job.
- Run the job on demand on the AWS Glue console.






If the job runs successfully, Run status should show as Succeeded. When the job is finished, the metadata from the Hive Metastore is visible on the AWS Glue console. Check the databases and tables listed to verify that they were migrated correctly.
Known issues
In some cases where the Hive Metastore schema version is on a very old release or if some required metadata tables are missing, the upgrade process may fail. In this case, you can use the following steps to identify and fix the issue. Run the schemaTool upgradeSchema command with verbose as follows:
This prints all the queries being run in order and their output:
Note down the query and the error message, then take the required steps to address the issue. For example, depending on the error message, you may have to create the missing table or alter an existing table. Then you can either rerun the schemaTool upgradeSchema command, or you can manually run the remaining queries required for upgrade. You can get the complete script that schemaTool runs from the following path on the primary node /usr/lib/hive/scripts/metastore/upgrade/mysql/ or from GitHub.
Clean up
Running additional EMR clusters to perform the upgrade activity in your AWS account may incur additional charges. When you complete the Hive Metastore upgrade successfully, we recommend deleting the additional EMR clusters to save cost.
Conclusion
To upgrade Amazon EMR from 5.X to 6.X and take advantage of some features from Hive 3.X or Spark SQL 3.X, you have to upgrade the Hive Metastore first. If you’re using the AWS Glue Data Catalog as your Hive Metastore, you don’t need to do anything because the Data Catalog supports both Amazon EMR versions. If you’re using a MySQL database as the external Hive Metastore, you can upgrade by following the steps outlined in this post, or you can migrate your Hive Metastore to the Data Catalog.
There are some functional differences between the different versions of Hive, Spark, and Flink. If you have some applications running on Amazon EMR 5.X, make sure test your applications in Amazon EMR 6.X and validate the function compatibility. We will cover application upgrades for Amazon EMR components in a future post.
About the authors
 Jianwei Li is Senior Analytics Specialist TAM. He provides consultant service for AWS enterprise support customers to design and build modern data platform. He has more than 10 years experience in big data and analytics domain. In his spare time, he like running and hiking.
Jianwei Li is Senior Analytics Specialist TAM. He provides consultant service for AWS enterprise support customers to design and build modern data platform. He has more than 10 years experience in big data and analytics domain. In his spare time, he like running and hiking.
 Narayanan Venkateswaran is an Engineer in the AWS EMR group. He works on developing Hive in EMR. He has over 17 years of work experience in the industry across several companies including Sun Microsystems, Microsoft, Amazon and Oracle. Narayanan also holds a PhD in databases with focus on horizontal scalability in relational stores.
Narayanan Venkateswaran is an Engineer in the AWS EMR group. He works on developing Hive in EMR. He has over 17 years of work experience in the industry across several companies including Sun Microsystems, Microsoft, Amazon and Oracle. Narayanan also holds a PhD in databases with focus on horizontal scalability in relational stores.
 Partha Sarathi is an Analytics Specialist TAM – at AWS based in Sydney, Australia. He brings 15+ years of technology expertise and helps Enterprise customers optimize Analytics workloads. He has extensively worked on both on-premise and cloud Bigdata workloads along with various ETL platform in his previous roles. He also actively works on conducting proactive operational reviews around the Analytics services like Amazon EMR, Redshift, and OpenSearch.
Partha Sarathi is an Analytics Specialist TAM – at AWS based in Sydney, Australia. He brings 15+ years of technology expertise and helps Enterprise customers optimize Analytics workloads. He has extensively worked on both on-premise and cloud Bigdata workloads along with various ETL platform in his previous roles. He also actively works on conducting proactive operational reviews around the Analytics services like Amazon EMR, Redshift, and OpenSearch.
 Krish is an Enterprise Support Manager responsible for leading a team of specialists in EMEA focused on BigData & Analytics, Databases, Networking and Security. He is also an expert in helping enterprise customers modernize their data platforms and inspire them to implement operational best practices. In his spare time, he enjoys spending time with his family, travelling, and video games.
Krish is an Enterprise Support Manager responsible for leading a team of specialists in EMEA focused on BigData & Analytics, Databases, Networking and Security. He is also an expert in helping enterprise customers modernize their data platforms and inspire them to implement operational best practices. In his spare time, he enjoys spending time with his family, travelling, and video games.
Arch Linux drops Python 2
Post Syndicated from original https://lwn.net/Articles/909226/
Arch Linux has announced
that Python 2 is being removed from the distribution’s repositories.
“If you still require the python2 package you can keep it around, but
”
please be aware that there will be no security updates.
[$] BPF as a safer kernel programming environment
Post Syndicated from original https://lwn.net/Articles/909095/
For better or worse, C is the lingua franca in the world of kernel
engineering. The core logic of the Linux kernel is written entirely in
C (with a bit of assembly), as are its drivers and modules. While C is
rightfully celebrated for
its powerful yet simple semantics, it is an older language that lacks
many of the features present in modern languages such as
Rust. The
BPF subsystem, on the other hand,
provides a programming environment that allows engineers to write
programs that can run safely in kernel space. At the 2022 Linux Plumbers
Conference in Dublin, Ireland, Alexei Starovoitov presented an overview
of how BPF has evolved over the years to provide a new model for kernel
programming.
What’s Up, Home? – How Zabbix Can Help You with Rising Electricity Bills
Post Syndicated from Janne Pikkarainen original https://blog.zabbix.com/whats-up-home-how-zabbix-can-help-you-with-rising-electricity-bills/23582/
Can you monitor your upcoming electricity bills with Zabbix? Of course, you can! By day, I am a monitoring technical lead in a global cyber security company. By night, I monitor my home with Zabbix & Grafana Labs and make some weird experiments with them. Welcome to my weekly blog about the project.
With the current world events, energy prices are soaring. But how much do I need to really pay next month for my electricity? Zabbix to the rescue!
(Yes, in Finland I can check that from my electricity company’s page, but where’s the fun in that?)

Fixed vs spot price
There are two kinds of electricity contracts you can subscribe to in Finland. With a fixed price, you can be sure your bill does not fluctuate that much from month to month, as you pay the same price per kilowatt for every hour of the day. In this kind of deal, the electricity company adds some extra to each kilowatt, so you will automatically pay some extra compared to the electricity market price, but at least you don’t get so severely surprised by market price peaks.
Then there’s the spot price, where you pay only the electricity market price. This can and will vary a lot depending on the hour of the day, but at least in theory, this is the cheapest option in the long run. But, if the market price goes WAY up, like it tends to do in the winter, and has now been peaking due to world events, this can add to your bill.
Nordpool, please respond
There’s Nord Pool (“Nord Pool runs the leading power market in Europe, offering day-ahead and intraday markets to our customers”), and there’s a Python library for accessing Nord Pool electricity prices. With it, I could get hour-by-hour prices, but for this experiment, let’s stick with the average kWh price. The example script on the GitHub page shows all kinds of data, and for fun let’s use Zabbix item preprocessing to parse the average price from its output.
I now have the below script on running as a cron task every night, so my results will be updated once per 24 hours.

So, Zabbix then reads the file contents, like in so many of my previous blog posts.

Next, let’s add some preprocessing. The regular expression part gets the Average value from the script output, and the custom multiplier changes the value from “Euros per Megawatt” to “Euros per Kilowatt”, for it to be a familiar value for me from the electricity bills.

And… it’s working! As I know our average consumption, let’s add a new Grafana dashboard.

Four seasons
During summer, we don’t actually use very much electricity compared to our harsh winter; for example, keeping our garage “warm” (about +10C) during winter contributes to our electricity bill quite a lot.
Here’s a dashboard showing some guesstimations of how expensive the different seasons will be for us. Or, hopefully cheap, if the long overdue new Olkiluoto 3 nuclear plant finally could operate at its full capacity here in Finland.

The guesstimate above is missing some taxes and electricity transfer prices, so the reality will be a bit more expensive than this. Maybe I should also add some triggers to Zabbix to make me alert about any really crazy price changes.
Anyway, now I can start gathering nuts for the cold winter as it seems that it will be an expensive one.
I have been working at Forcepoint since 2014 and I’m happy that my laptop does not consume too much electricity. — Janne Pikkarainen
This post was originally published on the author’s LinkedIn account.
The post What’s Up, Home? – How Zabbix Can Help You with Rising Electricity Bills appeared first on Zabbix Blog.
Are the Classics Overrated? Debate ft. Freestyle Love Supreme’s FLS+ | The Atlantic Festival 2022
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=Ece_h8er2B4
Three new stable kernels
Post Syndicated from original https://lwn.net/Articles/909210/
The 5.19.11, 5.15.70, and 5.10.145 stable kernels are now available. As
usual, they contain important fixes throughout the kernel tree.
Security updates for Friday
Post Syndicated from original https://lwn.net/Articles/909208/
Security updates have been issued by Debian (bind9, expat, firefox-esr, mediawiki, and unzip), Fedora (qemu and thunderbird), Oracle (webkit2gtk3), SUSE (ardana-ansible, ardana-cobbler, ardana-tempest, grafana, openstack-heat-templates, openstack-horizon-plugin-gbp-ui, openstack-neutron-gbp, openstack-nova, python-Django1, rabbitmq-server, rubygem-puma, ardana-ansible, ardana-cobbler, grafana, openstack-heat-templates, openstack-murano, python-Django, rabbitmq-server, rubygem-puma, dpdk, freetype2, rubygem-rack, and virtualbox), and Ubuntu (etcd, libjpeg-turbo, linux-gcp, linux-gke, linux-raspi, linux-oem-5.17, linux-raspi-5.4, python-oauthlib, and python3.5).
The FREE ‘Never Obsolete’ PC from 2000! eMachines eTower 566ir
Post Syndicated from LGR original https://www.youtube.com/watch?v=qQo0yOqOb_4