Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/building-dynamic-amazon-sns-subscriptions-for-auto-scaling-container-workloads/
This post is written by Mithun Mallick, Senior Specialist Solutions Architect, App Integration.
Amazon Simple Notification Service (SNS) is a serverless publish subscribe messaging service. It supports a push-based subscriptions model where subscribers must register an endpoint to receive messages. Amazon Simple Queue Service (SQS) is one such endpoint, which is used by applications to receive messages published on an SNS topic.
With containerized applications, the container instances poll the queue and receive the messages. However, containerized applications can scale out for a variety of reasons. The creation of an SQS queue for each new container instance creates maintenance overhead for customers. You must also clean up the SNS-SQS subscription once the instance scales in.
This blog walks through a dynamic subscription solution, which automates the creation, subscription, and deletion of SQS queues for an Auto Scaling group of containers running in Amazon Elastic Container Service (ECS).
Overview
The solution is based on the use of events to achieve the dynamic subscription pattern. ECS uses the concept of tasks to create an instance of a container. You can find more details on ECS tasks in the ECS documentation.
This solution uses the events generated by ECS to manage the complete lifecycle of an SNS-SQS subscription. It uses the task ID as the name of the queue that is used by the ECS instance for pulling messages. More details on the ECS task ID can be found in the task documentation.
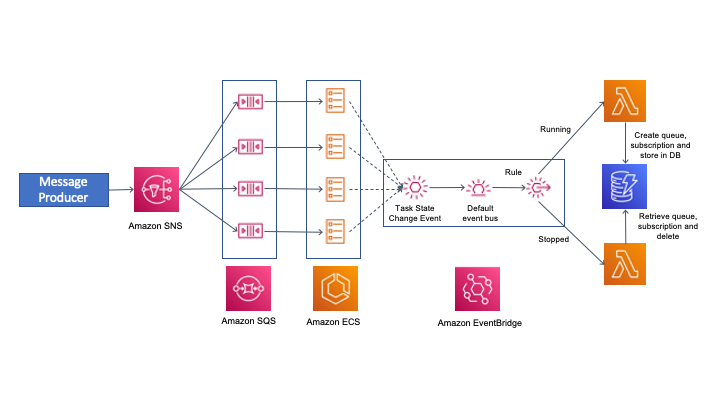
This also uses Amazon EventBridge to apply rules on ECS events and trigger an AWS Lambda function. The first rule detects the running state of an ECS task and triggers a Lambda function, which creates the SQS queue with the task ID as queue name. It also grants permission to the queue and creates the SNS subscription on the topic.
As the container instance starts up, it can send a request to its metadata URL and retrieve the task ID. The task ID is used by the container instance to poll for messages. If the container instance terminates, ECS generates a task stopped event. This event matches a rule in Amazon EventBridge and triggers a Lambda function. The Lambda function retrieves the task ID, deletes the queue, and deletes the subscription from the SNS topic. The solution decouples the container instance from any overhead in maintaining queues, applying permissions, or managing subscriptions. The security permissions for all SNS-SQS management are handled by the Lambda functions.
This diagram shows the solution architecture:

Events from ECS are sent to the default event bus. There are various events that are generated as part of the lifecycle of an ECS task. You can find more on the various ECS task states in ECS task documentation. This solution uses ECS as the container orchestration service but you can also use Amazon Elastic Kubernetes Service.(EKS). For EKS, you must apply the rules for EKS task state events.
Walkthrough of the implementation
The code snippets are shortened for brevity. The full source code of the solution is in the GitHub repository. The solution uses AWS Serverless Application Model (AWS SAM) for deployment.
SNS topic
The SNS topic is used to send notifications to the ECS tasks. The following snippet from the AWS SAM template shows the definition of the SNS topic:
SNSDynamicSubsTopic:
Type: AWS::SNS::Topic
Properties:
TopicName: !Ref DynamicSubTopicName
Container instance
The container instance subscribes to the SNS topic using an SQS queue. The container image is a Java class that reads messages from an SQS queue and prints them in the logs. The following code shows some of the message processor implementation:
AmazonSQS sqs = AmazonSQSClientBuilder.defaultClient();
AmazonSQSResponder responder = AmazonSQSResponderClientBuilder.standard()
.withAmazonSQS(sqs)
.build();
SQSMessageConsumer consumer = SQSMessageConsumerBuilder.standard()
.withAmazonSQS(responder.getAmazonSQS())
.withQueueUrl(queue_url)
.withConsumer(message -> {
System.out.println("The message is " + message.getBody());
sqs.deleteMessage(queue_url,message.getReceiptHandle());
}).build();
consumer.start();
The queue_url highlighted is the task ID of the ECS task. It is retrieved in the constructor of the class:
String metaDataURL = map.get("ECS_CONTAINER_METADATA_URI_V4");
HttpGet request = new HttpGet(metaDataURL);
CloseableHttpResponse response = httpClient.execute(request);
HttpEntity entity = response.getEntity();
if (entity != null) {
String result = EntityUtils.toString(entity);
String taskARN = JsonPath.read(result, "$['Labels']['com.amazonaws.ecs.task-arn']").toString();
String[] arnTokens = taskARN.split("/");
taskId = arnTokens[arnTokens.length-1];
System.out.println("The task arn : "+taskId);
}
queue_url = sqs.getQueueUrl(taskId).getQueueUrl();
The queue URL is constructed from the task ID of the container. Each queue is dedicated to each of the tasks or the instances of the container running in ECS.
EventBridge rules
The following event pattern on the default event bus captures events that match the start of the container instance. The rule triggers a Lambda function:
EventPattern:
source:
- aws.ecs
detail-type:
- "ECS Task State Change"
detail:
desiredStatus:
- "RUNNING"
lastStatus:
- "RUNNING"
The start rule routes events to a Lambda function that creates a queue with the name as the task ID. It creates the subscription to the SNS topic and grants permission on the queue to receive messages from the topic.
This event pattern matches STOPPED events of the container task. It also triggers a Lambda function to delete the queue and the associated subscription:
EventPattern:
source:
- aws.ecs
detail-type:
- "ECS Task State Change"
detail:
desiredStatus:
- "STOPPED"
lastStatus:
- "STOPPED"
Lambda functions
There are two Lambda functions that perform the queue creation, subscription, authorization, and deletion.
The SNS-SQS-Subscription-Service
The following code creates the queue based on the task id, applies policies, and subscribes it to the topic. It also stores the subscription ARN in a Amazon DynamoDB table:
# get the task id from the event
taskArn = event['detail']['taskArn']
taskArnTokens = taskArn.split('/')
taskId = taskArnTokens[len(taskArnTokens)-1]
create_queue_resp = sqs_client.create_queue(QueueName=queue_name)
response = sns.subscribe(TopicArn=topic_arn, Protocol="sqs", Endpoint=queue_arn)
ddbresponse = dynamodb.update_item(
TableName=SQS_CONTAINER_MAPPING_TABLE,
Key={
'id': {
'S' : taskId.strip()
}
},
AttributeUpdates={
'SubscriptionArn':{
'Value': {
'S': subscription_arn
}
}
},
ReturnValues="UPDATED_NEW"
)
The cleanup service
The cleanup function is triggered when the container instance is stopped. It fetches the subscription ARN from the DynamoDB table based on the taskId. It deletes the subscription from the topic and deletes the queue. You can modify this code to include any other cleanup actions or trigger a workflow. The main part of the function code is:
taskId = taskArnTokens[len(taskArnTokens)-1]
ddbresponse = dynamodb.get_item(TableName=SQS_CONTAINER_MAPPING_TABLE,Key={'id': { 'S' : taskId}})
snsresp = sns.unsubscribe(SubscriptionArn=subscription_arn)
queuedelresp = sqs_client.delete_queue(QueueUrl=queue_url)
Conclusion
This blog shows an event driven approach to handling dynamic SNS subscription requirements. It relies on the ECS service events to trigger appropriate Lambda functions. These create the subscription queue, subscribe it to a topic, and delete it once the container instance is terminated.
The approach also allows the container application logic to focus only on consuming and processing the messages from the queue. It does not need any additional permissions to subscribe or unsubscribe from the topic or apply any additional permissions on the queue. Although the solution has been presented using ECS as the container orchestration service, it can be applied for EKS by using its service events.
For more serverless learning resources, visit Serverless Land.