Post Syndicated from David Johnson original https://www.backblaze.com/blog/where-and-why-object-storage-excels-throughout-the-ai-model-lifecycle/

No single technology has changed the way we use data quite like AI. From massive training sets to constant streams of checkpoint and inference data, AI applications are data intensive, to say the least.
Thankfully, there’s an answer. Object storage—with its scalability, flexibility, and cost-effectiveness—is uniquely suited to AI at every stage of the model lifecycle.
In this blog post, we’ll take a quick look at what object storage is, why it’s a perfect fit for AI workloads, and how Backblaze B2 Cloud Storage offers unique advantages for AI teams looking to innovate quickly, easily, and cost-effectively.
What is object storage?
Think of object storage as a giant, organized bucket for all your files. Instead of stuffing things into folders or breaking them into blocks, you just drop each file (an “object”), with a unique tag and some helpful notes (metadata), into your storage solution.
Unlike traditional file or block storage, object storage uses a flat address space. Each object is assigned a unique identifier and can be tagged with rich metadata, making it easy to search, retrieve, and manage at scale.
Because of this unique architecture, object storage is ideal for handling unstructured data—such as images, video, audio, text, and sensor data—which is the meat and potatoes of most modern AI workflows. Also, being cloud-based, object storage is inherently designed for massive scalability and accessibility over the internet (often via S3 API).
Ebook: “Why Object Storage Is Ideal for AI Workflows”
Want to take a deeper dive into the world of object storage? Check out our latest ebook, “Why Object Storage is Ideal for AI Workloads,” and discover the advantages this architecture has to offer across the model lifecycle.

Understanding AI’s data storage needs at each stage of the model lifecycle
Before diving into the benefits of object storage, let’s first define and outline the AI model lifecycle. While some may slice and dice it a little differently, generally speaking, we can break the AI model lifecycle down into the following stages:
- Data ingestion and collection: Massive, often petabyte-scale datasets are gathered from a diversity of sources.
- Data preparation and storage: Raw data is cleaned, labeled, transformed, and stored for future retrieval and processing.
- Model training: Data is fed into AI training algorithms, typically deployed across many nodes in a GPU cluster—usually requiring high throughput, parallel access, and lengthy processing times.
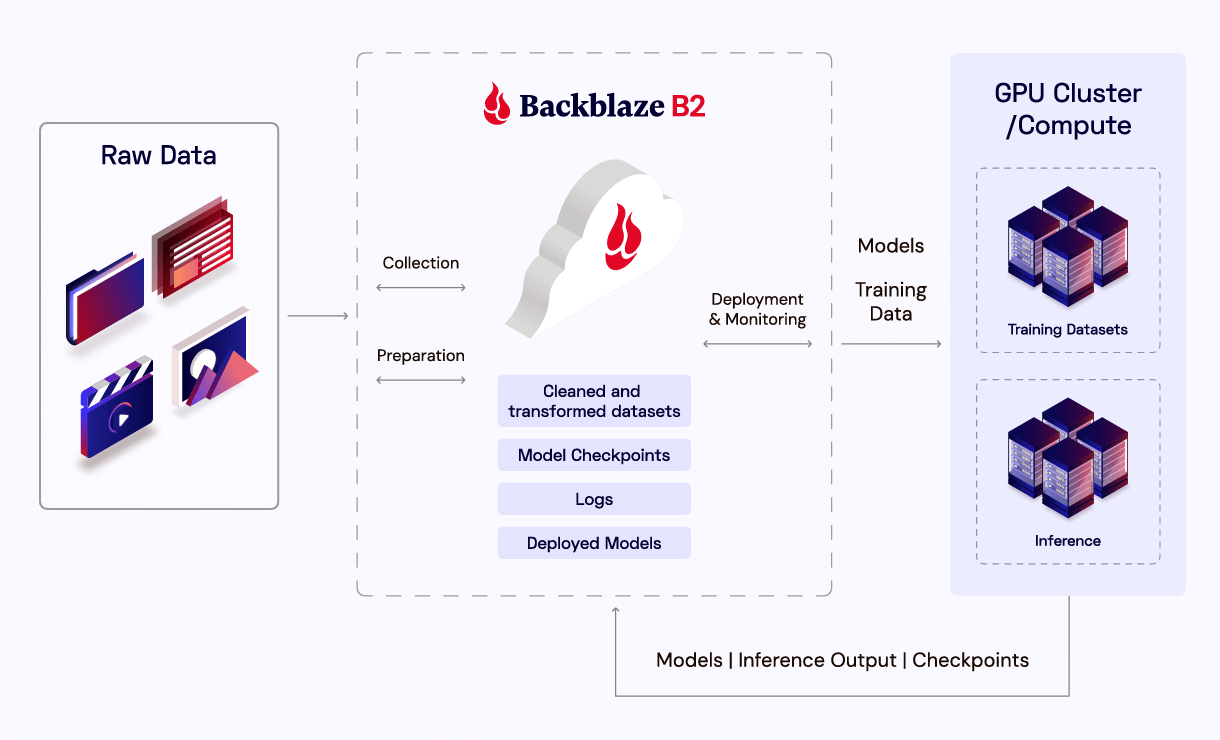
- Deployment and inference: Trained models are deployed into live applications where they take in new data and make inferences based on that data.
- Monitoring and archiving: Continuous monitoring generates substantial amounts of log data and performance metrics that must be versioned, stored, and archived for compliance or retraining purposes.
As you can see, each stage of the model lifecycle presents its own unique set of data demands—with each one requiring plenty of planning, work, and preparation. And at every one of these stages, matters of scale, speed, accessibility, and cost are mission-critical to a project’s success.
Where object storage excels: Scalability for data ingestion and collection
Object storage offers virtually unlimited scalability for large, and ever-expanding datasets, making it an ideal solution for the earliest stages of AI development. With no need to create volumes or file systems, organizations can quickly start uploading data to object storage. In addition to this seamless scalability, object storage also shines in its ability to support a diverse range of structured and unstructured data types without the need for rigid hierarchies. In this way, AI teams can ingest all sorts of data to support whatever their unique application needs; and do it quickly and efficiently.
Flexible data preparation and storage
Cloud-based object storage systems are excellent for maintaining easily-accessible, version-controlled datasets that allow for lightning fast iteration and collaboration. Capabilities like version recovery (which allows teams to easily revert datasets to previous states with simple API calls) and concurrent access (which gives multiple team members the ability to work on the same datasets simultaneously without conflicts) are also key to the data preparation and storage phase of AI development.
Reliable, high-performance data storage for model training
For the model training stage of the AI lifecycle, object storage supports parallel access and high throughput, both of which are absolutely essential for GPU-intensive training workloads. Reliable shuttling of large datasets to GPU clusters, wherever they may be, is key for keeping things efficient. Meanwhile, streamlined storage of model checkpoints from those clusters gives teams peace of mind in knowing that a mid-training failure state will not place them all the way back at square one.
Plus, lifecycle management features allow completed or outdated training datasets to be automatically archived—reducing clutter and optimizing storage costs, all while keeping active training data easily accessible.
Efficient versioning for deployment and inference
AI models are always a work in progress. Once deployed and operational, they have to be routinely evaluated and tuned. To that end, object storage makes it easy to store and retrieve a range of valuable information, including model checkpoints, test results, and inference data.
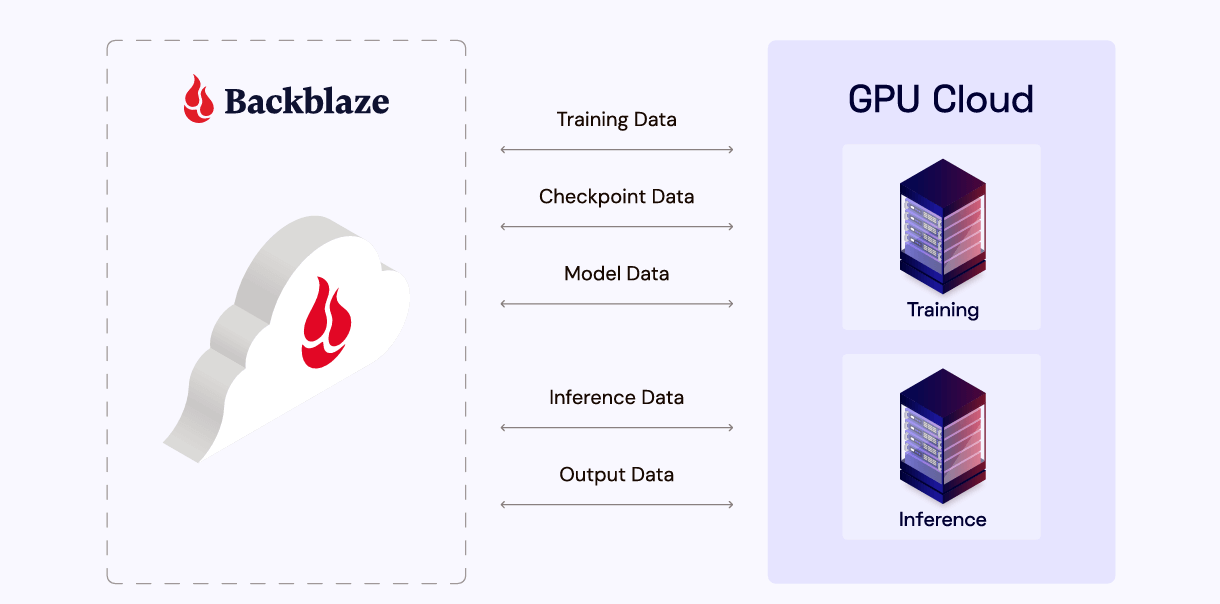
Built-in versioning and object immutability features support reproducibility and audit trails, so you can always trace which data and models produced which results. Together, these capabilities make for robust and effective lifecycle management, significantly boosting reliability and compliance.
Cost-effectiveness and durability for monitoring and archiving
When in the field, continuous monitoring of AI models generates a whole lot of log data and performance metrics. Object storage automates the management of these resources through customizable lifecycle rules, automatically deleting or archiving out-of-date inference logs based on predefined timelines (e.g., after 30–180 days).
This significantly reduces the need for manual oversight, conserves engineering resources, and ensures that relevant performance data remains accessible for compliance and regulatory auditing.
Meanwhile, with the right vendor, object storage solutions can offer competitive pricing models—sometimes including the separation of compute from storage—to ensure cost-effectiveness throughout the late stages of the AI lifecycle. Finally, high durability (of 11 nines or more) and redundancies protect models and datasets which become increasingly valuable over time.
Backblaze B2: Cost-effective, high-performance object storage for your AI workloads
Backblaze B2 Cloud Storage takes all the inherent advantages of cloud-based object storage for AI workloads and amplifies them—through competitive, transparent pricing; reliable, high performance; and seamless integration and support to ensure your project is not only efficient and affordable, but most importantly, successful.
- Competitive, transparent pricing: One-fifth of the cost of most hyperscalers’ solutions, with no hidden costs and three times your total storage volume in free egress included. Plus, fully-transparent, predictable pricing models ensure your organization is fully aware and prepared for the costs associated with your applications.
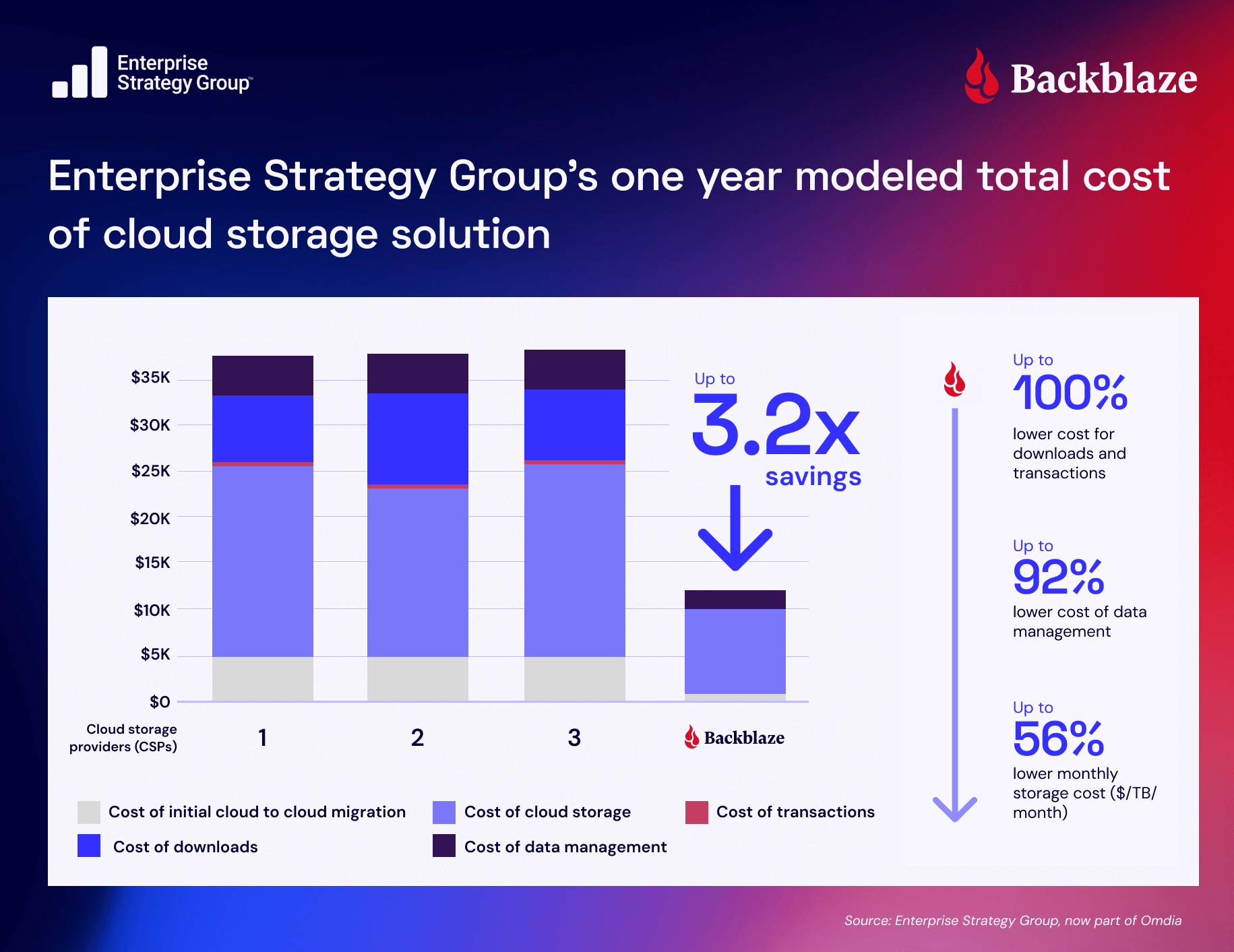
- High performance and reliability: Upload speeds up to 30% faster than AWS S3 for many workloads, plus a 99.9% uptime SLA with 11 nines of durability, ensure always-hot, instantly accessible data for demanding AI workloads.
- Seamless adoption and integration, accompanied by expert support: With features like Universal Data Migration and no hidden delete fees, B2 Cloud Storage uniquely streamlines cost-effective data management for AI. Backblaze B2 also boasts S3 API compatibility for true plug-and-play functionality with leading AI and machine learning ops (MLOps) tools and technologies.
Plus, our truly agnostic solution allows organizations to freely and easily connect to any compute or GPU environment (or environments), free of vendor lock-in and fees. And in case you want some support along the way, our team of dedicated solution engineers are available to tailor and fine-tune your architecture and operations to best suit whatever the unique needs of your AI project may be.
Optimize your AI lifecycle with cloud object storage from Backblaze B2
Data is one of the most important, and most challenging, aspects of AI development. And with their unprecedented data demands, traditional block and file storage systems frequently come up short in supporting modern AI applications. At the same time, legacy cloud storage solutions come with enormous burdens of cost, inflexibility, and the ever-looming threat of lock-in.
Cloud-based object storage offers the perfect solution to all these challenges—with the right mixture of performance, efficiency, and cost-effectiveness that AI projects need.It’s so-well-suited, in fact, that we’ve written an entire white paper on the subject! So, if you’re interested in taking a deeper dive into the topic, check out our ebook, Why Object Storage is Ideal for AI Workloads, today.
The post Where and Why Object Storage Excels Throughout the AI Model Lifecycle appeared first on Backblaze Blog | Cloud Storage & Cloud Backup

























 Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon SageMaker team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on
Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon SageMaker team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on  Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments, building LEGOs and watching anime with his daughters.
Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments, building LEGOs and watching anime with his daughters. Balaji Kumar Gopalakrishnan is a Principal Engineer at Amazon Finance Technology. He has been with Amazon since 2013, solving real-world challenges through technology that directly impact the lives of Amazon customers. Outside of work, Balaji enjoys hiking, painting, and spending time with his family. He is also a movie buff!
Balaji Kumar Gopalakrishnan is a Principal Engineer at Amazon Finance Technology. He has been with Amazon since 2013, solving real-world challenges through technology that directly impact the lives of Amazon customers. Outside of work, Balaji enjoys hiking, painting, and spending time with his family. He is also a movie buff! Mohit Dawar is a Senior Software Engineer at AWS working on DataZone and SageMaker Unified Studio. Over the past three years, he has led efforts around the core metadata catalog, generative AI-powered metadata curation, and lineage visualization. He enjoys working on large-scale distributed systems, experimenting with AI to improve user experience, and building tools that make data governance feel effortless. Connect with him on
Mohit Dawar is a Senior Software Engineer at AWS working on DataZone and SageMaker Unified Studio. Over the past three years, he has led efforts around the core metadata catalog, generative AI-powered metadata curation, and lineage visualization. He enjoys working on large-scale distributed systems, experimenting with AI to improve user experience, and building tools that make data governance feel effortless. Connect with him on  Mark Horta is a Software Development Manager at AWS working on DataZone and SageMaker Unified Studio. He is responsible for leading the engineering efforts for SageMaker Catalog focusing on generative-AI metadata generation and curation and data lineage.
Mark Horta is a Software Development Manager at AWS working on DataZone and SageMaker Unified Studio. He is responsible for leading the engineering efforts for SageMaker Catalog focusing on generative-AI metadata generation and curation and data lineage.