Smatch is a GPL-licensed
static-analysis tool for C that has a lot of specialized checks for the kernel. Smatch
has been used in the kernel for more than 20 years; Dan
Carpenter, its primary author, decided last year that some details of its plugin system
were due for a rewrite. He spoke at Linaro Connect 2025 about his work on
Smatch, the changes to its implementation, and how those changes enabled him to easily
add additional checks for locking bugs in the kernel.
The “Local Mess” GitHub
repository is dedicated to the disclosure of an Android tracking
exploit used by (at least) Meta and Yandex.
While there are subtle differences in the way Meta and Yandex
bridge web and mobile contexts and identifiers, both of them
essentially misuse the unvetted access to localhost sockets. The
Android OS allows any installed app with the INTERNET permission to
open a listening socket on the loopback interface
(127.0.0.1). Browsers running on the same device also access this
interface without user consent or platform mediation. This allows
JavaScript embedded on web pages to communicate with native Android
apps and share identifiers and browsing habits, bridging ephemeral
web identifiers to long-lived mobile app IDs using standard Web
APIs.
This backdoor, the use of which has evidently stopped since its disclosure,
allow tracking of users across sites regardless of cookie policies or use of
incognito browser modes.
We’ve recently added support for the FinalizationRegistry API in Cloudflare Workers. This API allows developers to request a callback when a JavaScript object is garbage-collected, a feature that can be particularly relevant for managing external resources, such as memory allocated by WebAssembly (Wasm). However, despite its availability, our general advice is: avoid using it directly in most scenarios.
Our decision to add FinalizationRegistry — while still cautioning against using it — opens up a bigger conversation: how memory management works when JavaScript and WebAssembly share the same runtime. This is becoming more common in high-performance web apps, and getting it wrong can lead to memory leaks, out-of-memory errors, and performance issues, especially in resource-constrained environments like Cloudflare Workers.
In this post, we’ll look at how JavaScript and Wasm handle memory differently, why that difference matters, and what FinalizationRegistry is actually useful for. We’ll also explain its limitations, particularly around timing and predictability, walk through why we decided to support it, and how we’ve made it safer to use. Finally, we’ll talk about how newer JavaScript language features offer a more reliable and structured approach to solving these problems.
Memory management 101
JavaScript
JavaScript relies on automatic memory management through a process called garbage collection. This means developers do not need to worry about freeing allocated memory, or lifetimes. The garbage collector identifies and reclaims memory occupied by objects that are no longer needed by the program (that is, garbage). This helps prevent memory leaks and simplifies memory management for developers.
function greet() {
let name = "Alice"; // String is allocated in memory
console.log("Hello, " + name);
} // 'name' goes out of scope
greet();
// JavaScript automatically frees allocated memory at some point in future
WebAssembly
WebAssembly (Wasm) is an assembly-like instruction format designed to run high-performance applications on the web. While it initially gained prominence in web browsers, Wasm is also highly effective on the server side. At Cloudflare, we leverage Wasm to enable users to run code written in a variety of programming languages, such as Rust and Python, directly within our V8 isolates, offering both performance and versatility.
Wasm runtimes are designed to be simple stack machines, and lack built-in garbage collectors. This necessitates manual memory management (allocation and deallocation of memory used by Wasm code), making it an ideal compilation target for languages like Rust and C++ that handle their own memory.
Wasm modules operate on linear memory: a resizable block of raw bytes, which JavaScript views as an ArrayBuffer. This memory is organized in 64 KB pages, and its initial size is defined when the module is compiled or loaded. Wasm code interacts with this memory using 32-bit offsets — integer values functioning as direct pointers that specify a byte offset from the start of its linear memory. This direct memory access model is crucial for Wasm’s high performance. The host environment (which in Cloudflare Workers is JavaScript) also shares this ArrayBuffer, reading and writing (often via TypedArrays) to enable vital data exchange between Wasm and JavaScript.
A core Wasm design is its secure sandbox. This confines Wasm code strictly to its own linear memory and explicitly declared imports from the host, preventing unauthorized memory access or system calls. Direct interaction with JavaScript objects is blocked; communication occurs through numeric values, function references, or operations on the shared ArrayBuffer. This strong isolation is vital for security, ensuring Wasm modules don’t interfere with the host or other application components, which is especially important in multi-tenant environments like Cloudflare Workers.
Bridging WebAssembly memory with JavaScript often involves writing low-level “glue” code to convert raw byte arrays from Wasm into usable JavaScript types. Doing this manually for every function or data structure is both tedious and error-prone. Fortunately, tools like wasm-bindgen and Emscripten (Embind) handle this interop automatically, generating the binding code needed to pass data cleanly between the two environments. We use these same tools under the hood — wasm-bindgen for Rust-based workers-rs projects, and Emscripten for Python Workers — to simplify integration and let developers focus on application logic rather than memory translation.
Interoperability
High-performance web apps often use JavaScript for interactive UIs and data fetching, while WebAssembly handles demanding operations like media processing and complex calculations for significant performance gains, allowing developers to maximize efficiency. Given the difference in memory management models, developers need to be careful when using WebAssembly memory in JavaScript.
For this example, we’ll use Rust to compile a WebAssembly module manually. Rust is a popular choice for WebAssembly because it offers precise control over memory and easy Wasm compilation using standard toolchains.
Rust
Here we have two simple functions. make_buffer creates a string and returns a raw pointer back to JavaScript. The function intentionally “forgets” the memory allocated so that it doesn’t get cleaned up after the function returns. free_buffer, on the other hand, expects the initial string reference handed back and frees the memory.
// Allocate a fresh byte buffer and hand the raw pointer + length to JS.
// *We intentionally “forget” the Vec so Rust will not free it right away;
// JS now owns it and must call `free_buffer` later.*
#[no_mangle]
pub extern "C" fn make_buffer(out_len: *mut usize) -> *mut u8 {
let mut data = b"Hello from Rust".to_vec();
let ptr = data.as_mut_ptr();
let len = data.len();
unsafe { *out_len = len };
std::mem::forget(data);
return ptr;
}
/// Counterpart that **must** be called by JS to avoid a leak.
#[no_mangle]
pub unsafe extern "C" fn free_buffer(ptr: *mut u8, len: usize) {
let _ = Vec::from_raw_parts(ptr, len, len);
}
JavaScript
Back in JavaScript land, we’ll call these Wasm functions and output them using console.log. This is a common pattern in Wasm-based applications since WebAssembly doesn’t have direct access to Web APIs, and rely on a JavaScript “glue” to interface with the outer world in order to do anything useful.
const { instance } = await WebAssembly.instantiate(WasmBytes, {});
const { memory, make_buffer, free_buffer } = instance.exports;
// Use the Rust functions
const lenPtr = 0; // scratch word in Wasm memory
const ptr = make_buffer(lenPtr);
const len = new DataView(memory.buffer).getUint32(lenPtr, true);
const data = new Uint8Array(memory.buffer, ptr, len);
console.log(new TextDecoder().decode(data)); // “Hello from Rust”
free_buffer(ptr, len); // free_buffer must be called to prevent memory leaks
You can find all code samples along with setup instructions here.
As you can see, working with Wasm memory from JavaScript requires care, as it introduces the risk of memory leaks if allocated memory isn’t properly released. JavaScript developers are often unfamiliar with manual memory management, and it’s easy to forget returning memory to WebAssembly after use. This can become especially tricky when Wasm-allocated data is passed into JavaScript libraries, making ownership and lifetime harder to track.
While occasional leaks may not cause immediate issues, over time they can lead to increased memory usage and degrade performance, particularly in memory-constrained environments like Cloudflare Workers.
FinalizationRegistry
FinalizationRegistry, introduced as part of the TC-39 WeakRef proposal, is a JavaScript API which lets you run “finalizers” (aka cleanup callbacks) when an object gets garbage-collected. Let’s look at a simple example to demonstrate the API:
const my_registry = new FinalizationRegistry((obj) => { console.log("Cleaned up: " + obj); });
{
let temporary = { key: "value" };
// Register this object in our FinalizationRegistry -- the second argument,
// "temporary", will be passed to our callback as its obj parameter
my_registry.register(temporary, "temporary");
}
// At some point in the future when temporary object gets garbage collected, we'll see "Cleaned up: temporary" in our logs.
Let’s see how we can use this API in our Wasm-based application:
const { instance } = await WebAssembly.instantiate(WasmBytes, {});
const { memory, make_buffer, free_buffer } = instance.exports;
// FinalizationRegistry would be responsible for returning memory back to Wasm
const cleanupFr = new FinalizationRegistry(({ ptr, len }) => {
free_buffer(ptr, len);
});
// Use the Rust functions
const lenPtr = 0; // scratch word in Wasm memory
const ptr = make_buffer(lenPtr);
const len = new DataView(memory.buffer).getUint32(lenPtr, true);
const data = new Uint8Array(memory.buffer, ptr, len);
// Register the data buffer in our FinalizationRegistry so that it gets cleaned up automatically
cleanupFr.register(data, { ptr, len });
console.log(new TextDecoder().decode(data)); // → “Hello from Rust”
// No need to manually call free_buffer, FinalizationRegistry will do this for us
We can use a FinalizationRegistry to manage any object borrowed from WebAssembly by registering it with a finalizer that calls the appropriate free function. This is the same approach used by wasm-bindgen. It shifts the burden of manual cleanup away from the JavaScript developer and delegates it to the JavaScript garbage collector. However, in practice, things aren’t quite that simple.
Inherent issues with FinalizationRegistry
There is a fundamental issue with FinalizationRegistry: garbage collection is non-deterministic, and may clean up your unused memory at some arbitrary point in the future. In some cases, garbage collection might not even run and your “finalizers” will never be triggered.
“A conforming JavaScript implementation, even one that does garbage collection, is not required to call cleanup callbacks. When and whether it does so is entirely down to the implementation of the JavaScript engine. When a registered object is reclaimed, any cleanup callbacks for it may be called then, or some time later, or not at all.”
Even Emscripten mentions this in their documentation: “… finalizers are not guaranteed to be called, and even if they are, there are no guarantees about their timing or order of execution, which makes them unsuitable for general RAII-style resource management.”
Given their non-deterministic nature, developers seldom use finalizers for any essential program logic. Treat them as a last-ditch safety net, not as a primary cleanup mechanism — explicit, deterministic teardown logic is almost always safer, faster, and easier to reason about.
Enabling FinalizationRegistry in Workers
Given its non-deterministic nature and limited early adoption, we initially disabled the FinalizationRegistry API in our runtime. However, as usage of Wasm-based Workers grew — particularly among high-traffic customers — we began to see new demands emerge. One such customer was running an extremely high requests per second (RPS) workload using WebAssembly, and needed tight control over memory to sustain massive traffic spikes without degradation. This highlighted a gap in our memory management capabilities, especially in cases where manual cleanup wasn’t always feasible or reliable. As a result, we re-evaluated our stance and began exploring the challenges and trade-offs of enabling FinalizationRegistry within the Workers environment, despite its known limitations.
Preventing footguns with safe defaults
Because this API could be misused and cause unpredictable results for our customers, we’ve added a few safeguards. Most importantly, cleanup callbacks are run without an active async context, which means they cannot perform any I/O. This includes sending events to a tail Worker, logging metrics, or making fetch requests.
While this might sound limiting, it’s very intentional. Finalization callbacks are meant for cleanup — especially for releasing WebAssembly memory — not for triggering side effects. If we allowed I/O here, developers might (accidentally) rely on finalizers to perform critical logic that depends on when garbage collection happens. That timing is non-deterministic and outside your control, which could lead to flaky, hard-to-debug behavior.
We don’t have full control over when V8’s garbage collector performs cleanup, but V8 does let us nudge the timing of finalizer execution. Like Node and Deno, Workers queue FinalizationRegistry jobs only after the microtask queue has drained, so each cleanup batch slips into the quiet slots between I/O phases of the event loop.
Security concerns
The Cloudflare Workers runtime is specifically engineered to prevent side-channel attacks in a multi-tenant environment. Prior to enabling the FinalizationRegistry API, we did a thorough analysis to assess its impact on our security model and determine the necessity of additional safeguards. The non-deterministic nature of FinalizationRegistry raised concerns about potential information leaks leading to Spectre-like vulnerabilities, particularly regarding the possibility of exploiting the garbage collector (GC) as a confused deputy or using it to create a timer.
GC as confused deputy
One concern was whether the garbage collector (GC) could act as a confused deputy — a security antipattern where a privileged component is tricked into misusing its authority on behalf of untrusted code. In theory, a clever attacker could try to exploit the GC’s ability to access internal object lifetimes and memory behavior in order to infer or manipulate sensitive information across isolation boundaries.
However, our analysis indicated that the V8 GC is effectively contained and not exposed to confused deputy risks within the runtime. This is attributed to our existing threat models and security measures, such as the isolation of user code, where the V8 Isolate serves as the primary security boundary. Furthermore, even though FinalizationRegistry involves some internal GC mechanics, the callbacks themselves execute in the same isolate that registered them — never across isolates — ensuring isolation remains intact.
GC as timer
We also evaluated the possibility of using FinalizationRegistry as a high-resolution timing mechanism — a common vector in side-channel attacks like Spectre. The concern here is that an attacker could schedule object finalization in a way that indirectly leaks information via the timing of callbacks.
In practice, though, the resolution of such a “GC timer” is low and highly variable, offering poor reliability for side-channel attacks. Additionally, we control when finalizer callbacks are scheduled — delaying them until after the microtask queue has drained — giving us an extra layer of control to limit timing precision and reduce risk.
Following a review with our security research team, we determined that our existing security model is sufficient to support this API.
Predictable cleanups?
JavaScript’s Explicit Resource Management proposal introduces a deterministic approach to handle resources needing manual cleanup, such as file handles, network connections, or database sessions. Drawing inspiration from constructs like C#’s using and Python’s with, this proposal introduces the using and await using syntax. This new syntax guarantees that objects adhering to a specific cleanup protocol are automatically disposed of when they are no longer within their scope.
Let’s look at a simple example to understand it a bit better.
class MyResource {
[Symbol.dispose]() {
console.log("Resource cleaned up!");
}
use() {
console.log("Using the resource...");
}
}
{
using res = new MyResource();
res.use();
} // When this block ends, Symbol.dispose is called automatically (and deterministically).
The proposal also includes additional features that offer finer control over when dispose methods are called. But at a high level, it provides a much-needed, deterministic way to manage resource cleanup. Let’s now update our earlier WebAssembly-based example to take advantage of this new mechanism instead of relying on FinalizationRegistry:
const { instance } = await WebAssembly.instantiate(WasmBytes, {});
const { memory, make_buffer, free_buffer } = instance.exports;
class WasmBuffer {
constructor(ptr, len) {
this.ptr = ptr;
this.len = len;
}
[Symbol.dispose]() {
free_buffer(this.ptr, this.len);
}
}
{
const lenPtr = 0;
const ptr = make_buffer(lenPtr);
const len = new DataView(memory.buffer).getUint32(lenPtr, true);
using buf = new WasmBuffer(ptr, len);
const data = new Uint8Array(memory.buffer, ptr, len);
console.log(new TextDecoder().decode(data)); // → “Hello from Rust”
} // Symbol.dispose or free_buffer gets called deterministically here
Explicit Resource Management provides a more dependable way to clean up resources than FinalizationRegistry, as it runs cleanup logic — such as calling free_buffer in WasmBuffer via [Symbol.dispose]() and the using syntax — deterministically, rather than relying on the garbage collector’s unpredictable timing. This makes it a more reliable choice for managing critical resources, especially memory.
Future
Emscripten already makes use of Explicit Resource Management for handling Wasm memory, using FinalizationRegistry as a last resort, while wasm-bindgen supports it in experimental mode. The proposal has seen growing adoption across the ecosystem and was recently conditionally advanced to Stage 4 in the TC39 process, meaning it’ll soon officially be part of the JavaScript language standard. This reflects a broader shift toward more predictable and structured memory cleanup in WebAssembly applications.
We recently added support for this feature in Cloudflare Workers as well, enabling developers to take advantage of deterministic resource cleanup in edge environments. As support for the feature matures, it’s likely to become a standard practice for managing linear memory safely and reliably.
FinalizationRegistry: still not dead yet?
Explicit Resource Management brings much-needed structure and predictability to resource cleanup in WebAssembly and JavaScript interop applications, but it doesn’t make FinalizationRegistry obsolete. There are still important use cases, particularly when a Wasm-allocated object’s lifecycle is out of your hands or when explicit disposal isn’t practical. In scenarios involving third-party libraries, dynamic lifecycles, or integration layers that don’t follow using patterns, FinalizationRegistry remains a valuable fallback to prevent memory leaks.
Looking ahead, a hybrid approach will likely become the standard in Wasm-JavaScript applications. Developers can use ERM for deterministic cleanup of Wasm memory and other resources, while relying on FinalizationRegistry as a safety net when full control isn’t possible. Together, they offer a more reliable and flexible foundation for managing memory across the JavaScript and WebAssembly boundary.
Чавдар Парушев: Да си призная, за себе си и до момента не мога да реша дали Джошуа Стивънсън е искрено каещ се грешник, месеци след като изиграх „Киберпънк“. Той несъмнено може да бъде такъв. Но в същото време поведението му може да бъде осмислено и като една голяма поза, едно голямо премятане на всичко и всички.
Джошуа Стивънсън е осъден на смърт престъпник без право на помилване. Няма контрол над това. Ще бъде екзекутиран със сигурност. Може обаче да промени формата на екзекуцията си от, да кажем, смъртоносна инжекция на разпъване на кръст. Защо? При първата форма би умрял бързо и безболезнено, но и безименно, безследно. А ако изиграе каещия се грешник и го направи добре, ако превърне екзекуцията си в танц на ума, ще постигне въжделената цел на всеки наемник от града (В. включително) – да умре като легенда с гръм и трясък. Ще остави своята следа, ще накара всички да го запомнят, щат – не щат. Потенциално милиони ще съпреживяват живота в последните му мигове. Ще гледат през неговите очи, ще кървят с неговите рани, ще издишат последния му дъх. Убиецът и измамникът ще изиграе всички като за последно, за да го запомнят като светец.
Тъкмо „Грешника“ ме постави като играч в ситуация на лудонаративен дисонанс. Историята започва с приемането на поръчение за убийството на Джошуа Стивънсън. Задача, която се чудех дали ще трябва да изпълня, докато се движех към правилното място в играта. Бях си поставил за цел да играя с несмъртоносни оръжия, които зашеметяват, без да убиват. За разлика от кажи-речи почти всички други заглавия, „Киберпънк“позволява такова пацифистко проиграване в по-голямата си част. От друга страна, в случай че играчът избере да не убие Джошуа, умира поръчителят.
Ако подобно на Миглена също мога да кажа, че изиграх „Киберпънк“ в пълен прехлас, то е заради това, че играта поставя сериозни въпроси, без да бърза да им отговаря. Парадоксално или не, удоволствието от нея е толкова по-голямо, колкото повече тя не се изчерпва единствено с лудическото удоволствие от играенето. Един от водещите такива въпроси според мен е кой и какво е Джони Сребърната ръка.
Кадри от „Киберпънк“
В плана на играта Джони е пълен невронен запис на рокаджия бунтар, подобаващо циничен, нарцистичен, изживял своя смъртоносен и бляскав миг на слава в терористичен жест на съпротива срещу големите корпорации петдесет години по-рано. В игровото настояще Джони е дигитално копие на себе си, записан върху експериментален биочип, имплантиран в главата на В. (персонажа аватар на играча в „Киберпънк“). Джони е „прожектиран“ в главата и мислите на В. Но той е „прожектиран“ и върху тялото и генетиката на В. в процес на бавно превземане или пренаписване на психиката, както го определи Еньо. Един непредвиден полеви тест на бета-версия на технология за безсмъртие, която би позволила на съзнанието да надживява тленността на първородното си тяло и да заживява в нови.
Откъдето и да бъде погледнат, този образ на Джони сблъсква перспективи и явява важни напрежения и размивания на основополагащи граници (като тази между органично и неорганично, между човек и машина). Джони е самият ръб на перпендикулярно засрещане на равнините на човешкото и машинното. Засрещане, в което тези равнини се събират, разделят, проникват, разсичат, разполовяват и залепват една за друга. Двойният образ на Джони-В. е впечатляващо сгъстен и богат на смисли. Ще опитам да очертая някои без претенции за изчерпателност.
Да започнем от живия, органичен Джони отпреди настоящето в играта. Органичен, но не съвсем. Персонажът има механична протеза от сребрист метал вместо лява ръка, откъдето и прякорът му Сребърната ръка. В плана на разказа тази метална ръка изглежда набавена на персонажа, за да го направи лесно открояващ се, лесно запомнящ се. Да бъде основа на неговия „бранд“. Да формира движение от почитатели, които да се идентифицират с него (и идентифицирайки се, да се самооразличават), за да удовлетворяват собствените си идентичностни потребности. Сякаш металните жици на електрическата китара (най-често изработвани от сплав на алуминий, никел и кобалт, също сребристи на цвят) са се издължили в ръка за Джони. Сякаш чрез металната ръка на Джони китарата и музиката се сливат. Една почти кентаврическа фигура на човек-китара, фигура на човек-изкуство-бунт (рок музика все пак).
В същото време тази сребърна ръка за Джони е напълно функционално равностойна на органичната му. Тя е протеза, която позволява на персонажа да свири неподражаемо и виртуозно (а също така да борави без неудобство с пистолети, взривни устройства). Рокът на Джони се ражда колкото изпод органичната, толкова и изпод металната му ръка. Още преди персонажът да бъде превърнат в дигитално копие, заредено в органичен ум, това, което прави Джони Джони, е частично машина, снадена върху органиката му.
Същевременно наративът на играта поставя въпроса, без да отговаря нито еднозначно, нито окончателно дали дигиталният Джони е идентичен на органичния Джони. Продължава ли той да живее в машината под някаква нова сложна форма, или това, което се явява от машината като призрак на миналото, е симулация, ерзац човек, само подобен на действителния.
Да си припомним, че мотивът за човек и човешко съзнание на запис на магнетофонна лента или друг носител далеч не е нов в научната фантастика. Такива ерзац човеци на запис са мъртвите линии в киберпънк романите на Уилям Гибсън от 70-те и 80-те. Мотивът е водещ за „Юбик“ на Филип Дик от 1969-та. Присъства в разкази и произведения на Роджър Зелазни (в „Създания от мрак и светлина“ например победените врагове са превърнати в мислещи вещи – килими бюра, преспапиета – за злорада наслада на победителя си). Същият този мотив продължава да бъде важен и за актуални автори, като Нийл Стивънсън (особено в „Падение, или Додж в ада“, публикувана през 2019 г.). За Стивънсън дигиталните мъртви пазят ценностите и стремежите на органичния си живот, но са новоформиращи се и различни личности. За Гибсън мъртвите линии са по-скоро набор от логаритмично управлявани реакции, снети от съзнанието на някога жив човек, отколкото действително мислещи същества. Полуживотът в „Юбик“, както и в „Киберпънк“ поддържа въпроса отговорен, доколкото той е смислово по-важен именно като въпрос, отколкото като който и да е от възможните си отговори.
Играчът, поемащ контрола над В., е свободен да осмисля Джони, както реши – като мъртва линия, като полуживот, като пълноценно и равностойно на органичното дигитално съществуване. При определен стил на игра Джони търпи развитие, променя се, израства. Нарцистичният циник, пълно говедо с жените в живота си, който се интересува само от собствената си музика бунт (пък всичко останало да го гази валяк), достига до готовност да жертва себе си за В., да бъде заличен, за да може В. да живее. Но дори и при такова проиграване на историята това развитие може да се дължи колкото на втория шанс, получен от Джони, който съжителства в тялото на В. и наблюдава как някой друг постъпва различно и доживява до по-голяма личностна зрялост, толкова и на пряко пренаписване на „софтуера“ Джони от страна на органичния В. (влиянието и психическото пренаписване върви и в двете посоки между Джони и В.).
За да завърши, за да изиграе играта докрай, играчът трябва да вземе решение, да избере какво да прави с Джони – да му позволи ли да живее, жертвайки В., или не. А за да реши, трябва да си отговори на въпросите кой и какво е Джони. Дали това е духът на миналото, искрицата бунт, изразена в музика, която трябва да оживее отново, или не. Дали това е експеримент по машинно безсмъртие, на който трябва да се даде път, или пък да се спре; да му се позволи да бъде успешен или да бъде провален. Дали Джони е само дигитален запис, софтуер, призракът на машината, на машинно движения град и логаритмично подчиненото съществуване, на което не трябва да се позволява да пренаписва органичното. Не трябва да му се позволява да се възпроизвежда отново и отново върху и за сметка на органичното, отнемайки правото на новото и различното, на бъдещето (персонифицирано в лицето на младежа В.) да бъде. В крайна сметка човек или машина е Джони, човек или машина е В.? Кой трябва да остане, кой трябва да си отиде, кой може и трябва да бъде?
Този избор, осмислян или не, е предоставен на всеки играч и на всяко проиграване. Смятам, че това е едно (без да е единственото) от сериозните достижения на „Киберпънк“, които трябва да се признаят на играта. Достижение, заради което тя заслужава по-задълбочено внимание, включително и множество преигравания. Играта кара играча да прави избори в това сложно засрещане на размиващи се граници между човешкото и машинното. И това е разгърнато по далеч по-задълбочен и пълнокръвен начин в сравнение с предходни опити за проиграване на тази дилема в други игри. Помним колко по-повърхностно прави това „Ефектът на масата“ в третата си част например.
Миглена Николчина: Във финала на „Шест лица търсят автор“, пиеса от Луиджи Пирандело, играещите на сцената – наричам ги така, защото част от актьорите играят, че са… актьори, а друга част играят „измислени“ персонажи, които „не играят“, те са „себе си“ и затова претендират, че са по-истински от „актьорите“, – та всички те започват да крещят по повод смъртта на един от персонажите: „Измислица! Действителност!“ (на български има превод като „Преструвка! Действителност!“ А на италиански е Finzione! Realtà! – тоест можем да кажем и „Фикция! Действителност!“). Някои крещят едното, други другото, трети и двете, всичко това щедро поръсено с удивителни и въпросителни. Грешника е в тази ситуация. Колкото и да се преструва, той умира, смъртта му е истинска… в един виртуален свят. Тоест в два виртуални свята – вътрешния на играта, където смъртта му ще се заснеме в „танц“, и външния, нашия, на играчите. Тази смърт е едното, другото и двете заедно. Така този разказ притчово удвоява големия разказ на „Киберпънк“, в чиято рамка се появява и извежда жертвата като сърцевина на смисъла му.
В големия разказ жертвата грешник е Джони, чийто танц нашият аватар (и ние с него) ще трябва да изживее в тази амалгама на илюзия и действителност, която е принципно изкуството. Аватарът е назован с инициала V., което се произнася Ви – може би има други обяснения, но ще отбележа, че на полски така се произнася вие – тоест ние сме вие – за кого? За Джони? За играта и нейните създатели, които впрочем са се вписали в картата като улични продавачи на „танци“? За ние-то на музика и бунт, на ето ни и нас, това сме ние, „Червените китари“, To właśnie my?
И тук ще се върна към темата за дисонанса. Аз играех като жена и трябва да си призная, че първото изскачане от мене на Джони, този демоничен Хийтклиф с външността на Киану Рийвс, направо ме отнесе. Самото двойничество на персонажа ми се струва по-работещо, ако аватарът е жена – психологическата динамика става друга. Еньо вече обрисува аватара като наемник, който се бори да оцелее, но е постоянно „центробежно“ разсейван от съблазните на града. Този наемник се оказва чипиран – обладан, раздвоен – с Джони: музикант, гений, бунтар, циник, развалина, самоубиец – всичко това едновременно. Но дори в ексцесите – или може би тъкмо в тях – на алкохол, секс и прочее опиянения той е несводим до търсенето на оцеляване. И ето го лудонаративния дисонанс, вграден в самия раздвоен герой – оцеляване на всяка цена (сделки, апартаменти, коли, секс и прочее разсейващи сюжети) или битка, терор, взрив, самоубийство (основния сюжет).
И двете страни са страни на един невъзможен бунт – с тази разлика, че в епохата на Джони все още са опитвали да се бунтуват, та било то с музика и дрога. Чипът „Джони“ е вклиняването на тази предишна епоха в деградиралите руини от онова, което се е получило от нея. И все пак внушението е, че невъзможният бунт е и необходим, а това означава, че той може да се случи само като останала напълно незабелязана или медийно тиражирана жертва: фикция, действителност.
(Следва продължение.)
В рубриката „Игромислие“ публикуваме разговори, в които се срещат, съпоставят и противопоставят различни гледни точки към многоизмерния, многожанров феномен на видеоигрите – не толкова като електронен спорт, колкото като нов синтез на изкуствата и като ново поле на общуване и социалност.
We’re thrilled to celebrate yet another incredible year of young people reaching for the stars, as the European Astro Pi Challenge 2024/25 draws to a close. Teams from across Europe and ESA Member States are now receiving their well-deserved certificates and data from the International Space Station (ISS). It’s been a truly inspiring year, showcasing the phenomenal talent and dedication of young coders and scientists.
The European Astro Pi Challenge is an ESA Education project run in collaboration with us here at the Raspberry Pi Foundation. It offers young people the amazing opportunity to conduct scientific investigations in space by writing computer programs that run on Raspberry Pi computers on board the ISS, called Astro Pis.
There‘s a lot to celebrate from this year’s Astro Pi, so let’s take a look at some of the highlights for each of our inspiring Missions: Mission Zero and Mission Space Lab.
Figure 1: A selection of images taken by Mission Space Lab teams
Mission Zero: Inspiring coding, creativity, and inclusion
Mission Zero reached more young people than ever before in 2024/25, with 25,405 young people participating in 17,285 teams. After passing the rigorous testing and moderation processes, an amazing 17,109 teams (25,210 young people) were successful in getting their programs to run on the ISS.
One of the great things about Mission Zero is that we see a good gender balance in participation. This year, 44% of participants identified as “female” and 4% as “prefer to self-describe”, “prefer not to say”, or “other”. This means that Mission Zero has achieved a more balanced gender representation than is typically seen in computing subjects, where the ratio is around 20:80 girls to boys.
Mission Space Lab: More teams have their programs run in space
Mission Space Lab gives young people the opportunity to calculate the speed of the ISS in orbit using sensor and camera data collected from the Astro Pis on board the ISS. This year, 1859 young people in 552 teams participated in Mission Space Lab. Notably, 309 Mission Space Lab teams, or 95% of submissions, ran their programs on the ISS and are now analysing the data they collected. That’s 73 more teams achieving flight status than in 2023/24, and a total of 1084 young people receiving unique data sets from space and certificates.
Running a program in space is very different from testing it on the ground. It’s always interesting to see how well your program has performed and how accurate the final output is. Below, you can see a scatter graph of the team estimates produced by their programs. The actual speed of the ISS is no secret: it’s travelling about 7.67 kilometres per second. How have teams performed with the ISS speed task?
Figure 2: Mission Space Lab teams’ speed estimates graph
Inspiring and impactful
Another highlight from this year has been seeing how impactful participation can be for young people and mentors facilitating the activity. We receive lots of valuable feedback from the Astro Pi community each year, and it’s always heartwarming to hear what your experience has been and how we can improve the challenge. Here are a couple of quotes from the community who took part this year:
Mission Zero mentor: “Having their programs run in space really motivated them to take part because it was an exciting reward and something they wanted to talk about with their friends.”
Parent of a Mission Zero participant: “I was completely inexperienced in Python, but easily managed to help my 7-year-old.”
More Code Clubs participating in 2024/25
It has been great to see lots of Code Clubs taking part in Astro Pi this year, both for Mission Zero and Mission Space Lab. This year, 986 young people from 700 teams did Mission Zero at their Code Club: that’s double the number from 2023/24. Plus, 43 Mission Space Lab teams from Code Clubs took part. That’s 143 young people, or almost double the number compared to the year before.
We ran two code-alongs for the Code Club community this year, and it is encouraging to see increases for both missions. We will continue to support young people from all settings who want to take part in Astro Pi next year, whether it’s at school, Code Club, or other venues.
Conclusion
In summary, it’s been a great year for Astro Pi. We’ve reached lots of young people through the challenge, met many inspiring mentors, and seen some really positive trends. Plus, all the operations on the space station that make Astro Pi possible went smoothly: when you are running programs in space, that isn’t always the case!
None of it would have been possible without the tireless efforts of the teachers, mentors, and educators who help run Astro Pi in your communities. From everyone here at Mission Control, thank you.
If you’d like to tell us how we can provide more support to help you run Astro Pi, please email [email protected].
We’ll be back for more stellar space adventures in coding in September 2025.
The Certificate Transparency ecosystem has been improving transparency for the web PKI since 2013. It helps make clear exactly what certificates each certificate authority has issued and makes sure errors or compromises of certificate authorities are detectable.
Let’s Encrypt participates in CT both as a certificate issuer and as a log operator. For the past year, we’ve also been running an experiment to help validate a next-generation design for Certificate Transparency logs. That experiment is now nearing a successful conclusion. We’ve demonstrated that the new architecture (called the “Static CT API”) works well, providing greater efficiency and making it easier to run huge and reliable CT log services with comparatively modest resources. The Static CT API also makes it easier to download and share data from CT logs.
The Sunlight log implementation, alongside other Static CT API log implementations, is now on a path to production use. Browsers are now officially accepting Static CT API logs into their log programs as a means to help guarantee that the contents of CA-issued certificates are all publicly disclosed and publicly accessible (see Safari’s and Chrome’s recent announcements), although the browsers also require the continued use of a traditional RFC 6962 log alongside the new type.
All of this is good news for everyone who runs, submits certificates to, or monitors a CT log: as the new architecture gets adopted, we can expect to see more organizations running more logs, at lower cost, and with greater overall capacity to keep up with the large volume of publicly-trusted certificates.
Certificate Transparency
Certificate Transparency (CT) was introduced in 2013 in response to concerns about how Internet users could detect misbehavior and compromise of certificate authorities. Prior to CT, it was possible for a CA to issue an inaccurate or malicious certificate that could be used to attack a relatively small number of users, and that might never come to wider attention. A team led by Google responded to this by creating a transparency log mechanism, where certificate authorities (like Let’s Encrypt) must disclose all of the certificates that we issue by submitting them to public log services. Web browsers now generally reject certificates unless the certificates include cryptographic proof (“Signed Certificate Timestamps”, or SCTs) demonstrating that they were submitted to and accepted by such logs.
The CT logs themselves use a cryptographic append-only ledger to prove that they haven’t deleted or modified their records. There are currently over a dozen CT log services, most of them also run by certificate authorities, including Let’s Encrypt’s own Oak log.
The Static CT API
The original 2013 CT log design has been used with relatively few technical changes since it was first introduced, but several other transparency logging systems have been created in other areas, such as sumdb for Golang, which helps ensure that the contents of Golang package updates are publicly recorded. While they were originally inspired by CT, more-recently invented transparency logs have improved on its design.
The current major evolution of CT was led by Filippo Valsorda, a cryptographer with an interest in transparency log mechanisms, with help from others in the CT ecosystem. Portions of the new design are directly based on sumdb. In addition to designing the new architecture, Valsorda also wrote the implementation that we’ve been using, called Sunlight, with support from Let’s Encrypt. We’re excited to see that there are now at least three other compatible implementations: Google’s trillian-tessera, Cloudflare’s Azul, and an independent project called Itko.
The biggest change for the Static CT API is that logs are now represented, and downloaded by verifiers, as simple collections of flat files (called “tiles,” so some implementers have also been referring to these as “tiled logs” or “tlogs”). Anyone who wants to download log data can do so just by downloading these files. This is great for log operators because these simple file downloads can be distributed in various ways, including caching by a CDN, which was less practical and efficient for the classic CT API.
The new design is also simpler and more efficient from the log operator’s perspective, making it cheaper to run logs. As we said last year, this may enable us and other operators to increase reliability and availability by running several separate logs, likely with lower overall resource requirements than a single traditional log.
Our Sunlight experiment
Filippo Valsorda’s Sunlight logo (CC BY-ND 4.0), “based on a real place in the vicinity of Rome”
For the past year, we’ve run three Sunlight logs, called Twig, Willow, and Sycamore. We’ve been logging all of our own issued certificates, which represent a majority of the total volume of all publicly-trusted certificates, into our Sunlight logs. Sunlight logged these certificates quickly and correctly on relatively modest server hardware. Notably, each log’s write side was handled comfortably by just a single server. We also achieved high availability for these log services throughout the course of this experiment. (Because our Sunlight logs are not yet trusted by web browsers, we didn’t include the SCT proofs that they returned to us in the actual certificates we gave out to our subscribers; those proofs wouldn’t have been of use to our subscribers yet and would just have taken up space.)
A potential failure mode of traditional CT logs is that they could be unacceptably slow in incorporating newly-submitted certificates (known as missing the maximum merge delay), which can result in a log becoming distrusted. This isn’t a possibility for our new Sunlight-based logs: they always completely incorporate newly-submitted certificates before returning an SCT to the submitter, so the effective merge delay is zero! Of course, any log can suffer outages for a variety of reasons, but this feature of Sunlight makes it less likely that any outages will be fatal to a log’s continued operation.
We’ve demonstrated that Sunlight and the Static CT API work in practice, and this demonstration has helped to confirm the browser developers’ hope that Static CT API logs can become an officially-supported part of CT. As a result, the major browsers that enforce CT have now permitted Static CT API logs to apply for inclusion in browsers as publicly-trusted logs, and we’re preparing to apply for this status for our Willow and Sycamore logs with the Chrome and Safari CT log programs.
Let’s Encrypt will run at least these two logs, and possibly others over time, for the foreseeable future. Once they’re trusted by browsers, we’ll encourage other CAs to submit to them as well, and we’ll begin including SCTs from these logs in our own certificates (alongside SCTs from traditional CT logs).
How to participate
The new Static CT API and the rollout of tile-based logs will bring various changes and opportunities for community members.
New Certificate Transparency log operators
Companies and non-profit organizations could help support the web PKI by running a CT log and applying for it to be publicly trusted. Implementations like Sunlight will have substantially lower resource requirements than first-generation CT logs, particularly when cached behind a CDN. The biggest resource demands for a log operator will be storage and upstream bandwidth. A publicly-trusted log is also expected to maintain relatively high availability, because CAs need logs to be available in order to continue issuing certificates.
We don’t have statistics to share about the exact resource requirements for such a log yet, but after we have practical experience running a fully publicly-trusted Sunlight log, we should be able to make this more concrete. As noted above, the compute side of the log can be handled by a single server. Sunlight author Filippo Valsorda has recently started running a Sunlight log—also on just a single server—and offered more detailed cost breakdowns for that log’s setup, with an estimated total cost around $10,000 per year. The costs for our production Static CT API logs may be higher than those for Filippo’s log, but still far less than the costs for our traditional RFC 6962 logs.
As with trust decisions about CAs, browser developers are the authorities about which CT logs become publicly trusted. Although any person or organization can run a log, browser developers will generally prefer to trust logs whose continued availability they’re confident of—typically those run by stable organizations with experience running some form of public Internet services. Unlike becoming a certificate authority, running a log does not require a formal audit, as the validation of the log’s availability and correctness can be performed purely by observation.
Certificate authorities
Once the Willow and Sycamore logs are trusted by browsers, our fellow certificate authorities can choose to start logging certificates to them as part of their issuance processes. (Initially, you should still include at least one SCT from a traditional CT log in each certificate.) The details, including the log API endpoints and keys, are available at our CT log page. You can start submitting to these logs right away if you prefer; just bear in mind that the SCTs they return aren’t useful to subscribers yet, and won’t be useful until browsers are updated to trust the new logs.
CT data users
You can monitor CT in order to watch for certificate issuances for your own domain names, or as part of monitoring or security products or services, or for Internet security research purposes. Many of our colleagues have been doing this for some time as a part of various tools they maintain. The Static CT API should make this easier, because you’ll be able to download and share log tiles as sets of ordinary files.
If you already run such monitoring tools, please note that you’ll need to update your data pipeline in order to access Static CT API logs; since the read API is not backwards-compatible, CT API clients will need to be modified to support the new API. Without updated tools, your view of the CT system will become partial!
Also note that getting a complete view of all of CT will still require downloading data from traditional logs, which will probably continue to be true for several years.
Software developers
As logs based on the new API enter production use, it will be important to have tools to interact with and search these logs. We can all benefit from more software that understands how to do this. Since file downloads are such a familiar piece of software functionality, it will probably be easier for developers to develop against the new API compared to the original one.
We’ve also continued to see greater integration of transparency logging tools into other kinds of services, such as software updates. There’s a growing transparency log ecosystem that’s always in need of more tools and integrations. As we mentioned above, transparency logs are increasingly learning from one another, and there are also mechanisms for more direct integration between different kinds of transparency logs (known as “witnessing”). Software developers can help improve different aspects of Internet security by contributing to this active and growing area.
Conclusion
The Certificate Transparency community and larger transparency logging community have experienced a virtuous cycle of innovation, sharing ideas and implementation code between different systems and demonstrating the feasibility of new mechanisms and functionality. With the advent of tile-based logging in CT, the state of the art has moved forward in a way that helps log operators run our logs much more efficiently without compromising security.
We’re proud to have participated in this experiment and the engineering conversation around the evolution of logging architectures. Now that we’ve shown how well the new API really works at scale, we look forward to having publicly-trusted Sunlight logs later this year!
The Certificate Transparency ecosystem has been improving transparency for the web PKI since 2013. It helps make clear exactly what certificates each certificate authority has issued and makes sure errors or compromises of certificate authorities are detectable.
Let’s Encrypt participates in CT both as a certificate issuer and as a log operator. For the past year, we’ve also been running an experiment to help validate a next-generation design for Certificate Transparency logs. That experiment is now nearing a successful conclusion. We’ve demonstrated that the new architecture (called the “Static CT API”) works well, providing greater efficiency and making it easier to run huge and reliable CT log services with comparatively modest resources. The Static CT API also makes it easier to download and share data from CT logs.
The Sunlight log implementation, alongside other Static CT API log implementations, is now on a path to production use. Browsers are now officially accepting Static CT API logs into their log programs as a means to help guarantee that the contents of CA-issued certificates are all publicly disclosed and publicly accessible (see Safari’s and Chrome’s recent announcements), although the browsers also require the continued use of a traditional RFC 6962 log alongside the new type.
All of this is good news for everyone who runs, submits certificates to, or monitors a CT log: as the new architecture gets adopted, we can expect to see more organizations running more logs, at lower cost, and with greater overall capacity to keep up with the large volume of publicly-trusted certificates.
Certificate Transparency
Certificate Transparency (CT) was introduced in 2013 in response to concerns about how Internet users could detect misbehavior and compromise of certificate authorities. Prior to CT, it was possible for a CA to issue an inaccurate or malicious certificate that could be used to attack a relatively small number of users, and that might never come to wider attention. A team led by Google responded to this by creating a transparency log mechanism, where certificate authorities (like Let’s Encrypt) must disclose all of the certificates that we issue by submitting them to public log services. Web browsers now generally reject certificates unless the certificates include cryptographic proof (“Signed Certificate Timestamps”, or SCTs) demonstrating that they were submitted to and accepted by such logs.
The CT logs themselves use a cryptographic append-only ledger to prove that they haven’t deleted or modified their records. There are currently over a dozen CT log services, most of them also run by certificate authorities, including Let’s Encrypt’s own Oak log.
The Static CT API
The original 2013 CT log design has been used with relatively few technical changes since it was first introduced, but several other transparency logging systems have been created in other areas, such as sumdb for Golang, which helps ensure that the contents of Golang package updates are publicly recorded. While they were originally inspired by CT, more-recently invented transparency logs have improved on its design.
The current major evolution of CT was led by Filippo Valsorda, a cryptographer with an interest in transparency log mechanisms, with help from others in the CT ecosystem. Portions of the new design are directly based on sumdb. In addition to designing the new architecture, Valsorda also wrote the implementation that we’ve been using, called Sunlight, with support from Let’s Encrypt. We’re excited to see that there are now at least three other compatible implementations: Google’s trillian-tessera, Cloudflare’s Azul, and an independent project called Itko.
The biggest change for the Static CT API is that logs are now represented, and downloaded by verifiers, as simple collections of flat files (called “tiles,” so some implementers have also been referring to these as “tiled logs” or “tlogs”). Anyone who wants to download log data can do so just by downloading these files. This is great for log operators because these simple file downloads can be distributed in various ways, including caching by a CDN, which was less practical and efficient for the classic CT API.
The new design is also simpler and more efficient from the log operator’s perspective, making it cheaper to run logs. As we said last year, this may enable us and other operators to increase reliability and availability by running several separate logs, likely with lower overall resource requirements than a single traditional log.
Our Sunlight experiment
Filippo Valsorda’s Sunlight logo (CC BY-ND 4.0), “based on a real place in the vicinity of Rome”
For the past year, we’ve run three Sunlight logs, called Twig, Willow, and Sycamore. We’ve been logging all of our own issued certificates, which represent a majority of the total volume of all publicly-trusted certificates, into our Sunlight logs. Sunlight logged these certificates quickly and correctly on relatively modest server hardware. Notably, each log’s write side was handled comfortably by just a single server. We also achieved high availability for these log services throughout the course of this experiment. (Because our Sunlight logs are not yet trusted by web browsers, we didn’t include the SCT proofs that they returned to us in the actual certificates we gave out to our subscribers; those proofs wouldn’t have been of use to our subscribers yet and would just have taken up space.)
A potential failure mode of traditional CT logs is that they could be unacceptably slow in incorporating newly-submitted certificates (known as missing the maximum merge delay), which can result in a log becoming distrusted. This isn’t a possibility for our new Sunlight-based logs: they always completely incorporate newly-submitted certificates before returning an SCT to the submitter, so the effective merge delay is zero! Of course, any log can suffer outages for a variety of reasons, but this feature of Sunlight makes it less likely that any outages will be fatal to a log’s continued operation.
We’ve demonstrated that Sunlight and the Static CT API work in practice, and this demonstration has helped to confirm the browser developers’ hope that Static CT API logs can become an officially-supported part of CT. As a result, the major browsers that enforce CT have now permitted Static CT API logs to apply for inclusion in browsers as publicly-trusted logs, and we’re preparing to apply for this status for our Willow and Sycamore logs with the Chrome and Safari CT log programs.
Let’s Encrypt will run at least these two logs, and possibly others over time, for the foreseeable future. Once they’re trusted by browsers, we’ll encourage other CAs to submit to them as well, and we’ll begin including SCTs from these logs in our own certificates (alongside SCTs from traditional CT logs).
How to participate
The new Static CT API and the rollout of tile-based logs will bring various changes and opportunities for community members.
New Certificate Transparency log operators
Companies and non-profit organizations could help support the web PKI by running a CT log and applying for it to be publicly trusted. Implementations like Sunlight will have substantially lower resource requirements than first-generation CT logs, particularly when cached behind a CDN. The biggest resource demands for a log operator will be storage and upstream bandwidth. A publicly-trusted log is also expected to maintain relatively high availability, because CAs need logs to be available in order to continue issuing certificates.
We don’t have statistics to share about the exact resource requirements for such a log yet, but after we have practical experience running a fully publicly-trusted Sunlight log, we should be able to make this more concrete. As noted above, the compute side of the log can be handled by a single server. Sunlight author Filippo Valsorda has recently started running a Sunlight log—also on just a single server—and offered more detailed cost breakdowns for that log’s setup, with an estimated total cost around $10,000 per year. The costs for our production Static CT API logs may be higher than those for Filippo’s log, but still far less than the costs for our traditional RFC 6962 logs.
As with trust decisions about CAs, browser developers are the authorities about which CT logs become publicly trusted. Although any person or organization can run a log, browser developers will generally prefer to trust logs whose continued availability they’re confident of—typically those run by stable organizations with experience running some form of public Internet services. Unlike becoming a certificate authority, running a log does not require a formal audit, as the validation of the log’s availability and correctness can be performed purely by observation.
Certificate authorities
Once the Willow and Sycamore logs are trusted by browsers, our fellow certificate authorities can choose to start logging certificates to them as part of their issuance processes. (Initially, you should still include at least one SCT from a traditional CT log in each certificate.) The details, including the log API endpoints and keys, are available at our CT log page. You can start submitting to these logs right away if you prefer; just bear in mind that the SCTs they return aren’t useful to subscribers yet, and won’t be useful until browsers are updated to trust the new logs.
CT data users
You can monitor CT in order to watch for certificate issuances for your own domain names, or as part of monitoring or security products or services, or for Internet security research purposes. Many of our colleagues have been doing this for some time as a part of various tools they maintain. The Static CT API should make this easier, because you’ll be able to download and share log tiles as sets of ordinary files.
If you already run such monitoring tools, please note that you’ll need to update your data pipeline in order to access Static CT API logs; since the read API is not backwards-compatible, CT API clients will need to be modified to support the new API. Without updated tools, your view of the CT system will become partial!
Also note that getting a complete view of all of CT will still require downloading data from traditional logs, which will probably continue to be true for several years.
Software developers
As logs based on the new API enter production use, it will be important to have tools to interact with and search these logs. We can all benefit from more software that understands how to do this. Since file downloads are such a familiar piece of software functionality, it will probably be easier for developers to develop against the new API compared to the original one.
We’ve also continued to see greater integration of transparency logging tools into other kinds of services, such as software updates. There’s a growing transparency log ecosystem that’s always in need of more tools and integrations. As we mentioned above, transparency logs are increasingly learning from one another, and there are also mechanisms for more direct integration between different kinds of transparency logs (known as “witnessing”). Software developers can help improve different aspects of Internet security by contributing to this active and growing area.
Conclusion
The Certificate Transparency community and larger transparency logging community have experienced a virtuous cycle of innovation, sharing ideas and implementation code between different systems and demonstrating the feasibility of new mechanisms and functionality. With the advent of tile-based logging in CT, the state of the art has moved forward in a way that helps log operators run our logs much more efficiently without compromising security.
We’re proud to have participated in this experiment and the engineering conversation around the evolution of logging architectures. Now that we’ve shown how well the new API really works at scale, we look forward to having publicly-trusted Sunlight logs later this year!
Join us at AWS re:Inforce 2025 from June 16 to 18 as we dive deep into identity and access management, where we’ll explore how organizations are securing identities at scale. As the traditional security perimeter continues to dissolve in our hybrid and multi-cloud world, this year’s sessions showcase how AWS customers are building comprehensive identity-centric security strategies that span workforce and customer identities. From authenticating and authorizing human and machine identities to implementing least privilege access controls and securing identities that help drive AI adoption, you’ll discover practical approaches to modernizing your identity architecture.
Whether you’re managing enterprise workforce identities across complex organizational structures or building customer-facing applications that require seamless and secure authentication experiences, the Identity and Access Management track offers insights for every security professional. We’ve carefully curated sessions that address today’s most pressing identity challenges, including zero trust implementation patterns, unified workforce identity management across cloud and on-premises environments, and scalable customer identity and access management (CIAM) solutions. Through technical deep-dives, hands-on workshops, and customer case studies, you’ll learn how to use AWS Identity and Access Management (IAM), AWS IAM Identity Center, AWS Directory Services, Amazon Cognito, and other AWS services to build robust identity foundations that support both security and business agility.
In this post, we highlight some of the key sessions. With over 30 sessions dedicated to identity management, we feature valuable learnings for executives and practitioners alike. Let AWS experts and partners share practical challenges and solutions with you. Let’s explore what you can expect at this year’s conference.
Zero trust and principle of least privilege
IAM304 | Breakout session | Empowering developers to implement least-privilege IAM permissions Wolters Kluwer, a global provider of professional information, software solutions, and services and GoTo Technologies (formerly LogMeIn Inc.), a U.S.-based software company that provides cloud-based remote work tools for collaboration and IT management use AWS IAM Access Analyzer to simplify and accelerate their journey to least privilege. Join this session to learn more about their use cases and their journey to empower their builders to refine IAM policies to remove excessive permissions. Gain insights into their strategies, best practices, and lessons learned for continuously monitoring unused permissions across their organization and building processes to streamline remediations.
IAM343 | Code talk | Scale Beyond RBAC: Transform App Access Control using AVP & Cedar This session focuses on transforming an existing application from role-based access control (RBAC) to policy-based access control (PBAC) using Amazon Verified Permissions (AVP) and Cedar policy. The drive for least privilege has led to role explosion in RBAC model and necessitates a shift towards PBAC, augmenting RBAC with attribute-based access control (ABAC). You will learn how to move authorization logic out of application code and implementing a centralized PBAC model. Attendees will also learn to define permissions as policies using Cedar and seamlessly migrate from RBAC to PBAC with minimal application logic changes, enabling more granular and scalable access control.
Securing Identities in the AI era
IAM373 | Workshop | Identity without barriers: user-aware access for AWS analytics services This hands-on workshop explores AWS IAM Identity Center’s Trusted Identity Propagation, teaching participants how to enable secure identity propagation across integrated applications. Through practical exercises, attendees will learn to configure identity propagation and use it with services such as Amazon Redshift, Amazon Athena, Amazon Q Business, and more. Participants will gain experience with cross-account scenarios, audit logging configuration, and troubleshooting common integration challenges. You must bring your laptop to participate.
IAM321 | Lightning talk | Building trust in Agentic AI through authentication and access control AI agents execute tasks for humans, operating independently with or without human presence, while collaborating seamlessly across on-premise and multi-cloud environments. This dynamic setup poses unique challenges in human/agent authentication, identity propagation/delegation, and resource authorization. Leverage Amazon Cognito, Verified Permissions, and Bedrock to master effective Identity and Access Management (IAM) for your AI agents. Through real-world examples using OAuth2-based identity management, machine-to-machine authentication, and policy-based access control, you’ll unlock the ability to scale complex agent interactions securely, empowering you to build robust, scalable Agentic AI solutions.
IAM441 | Code Talk | The Right Way to Secure AI Agents with Code Examples GenAI agents run tasks on behalf of human users with or without users being present, and often interact with each other across on-premise and different cloud providers. This brings new challenges in identity authentication, propagation, delegation, and resource authorization in the overall agentic AI solution. Learn how Amazon Cognito’s OAuth2-based identity management, machine-to-machine authentication, combined with Amazon Verified Permission’s fine-grained authorization can enable secure delegation patterns for AI agents, while preserving human identity and consent, agent machine identity, and other request context throughout the agent chain. We’ll walk through real-world examples with agents built on Amazon Bedrock or other frameworks.
Workforce identity management
IAM302 | Breakout session | Workforce identity for gen AI and analytics Managing secure, consistent workforce access for generative AI and analytics is critical for unlocking innovation while protecting sensitive data. In this demo-filled session, you’ll see how centralized identity management and trusted identity propagation can deliver a user-centric data access experience. You’ll also learn how AWS IAM Identity Center simplifies access to AWS services such as Amazon Redshift, Amazon Athena, and AWS Lake Formation, while enabling fine-grained access to data based on user identity to help meet your security and compliance needs.
IAM341 | Code Talk | Visualizing Workforce Identity: Graph-Based Analysis for Access Rights Discover how to gain deep insights into workforce identity relationships and resource access patterns by visualizing AWS IAM Identity Center data using graph databases. Learn how you can explore complex identity relationships, permission inheritance and resource access across your organization; get practical approaches to ingestion of identity data, creating graph queries for security analysis, and building visualization dashboards to help identify potential resource access risks. We’ll explore real-world scenarios for detecting excessive permissions, analyzing group memberships and resource access, and tracking resource access rights changes over time to strengthen your identity security posture.
Customer and Machine identity management
IAM332 | Chalk Talk | Securing and monitoring machine identities with Amazon Cognito Unlock the power of secure machine-to-machine (M2M) authorization using Amazon Cognito’s OAuth2 client credentials flow. This session dives deep into implementing M2M authorization, featuring real-world optimization strategies for both security and cost. Learn essential security best practices, multi-tenant reference architectures, and monitoring techniques that ensure your M2M usage remains efficient and secure. Whether you’re building microservices, handling API authorization, or scaling your distributed systems, this session will equip you with actionable insights and patterns for successful M2M implementations. Bring your challenges and questions for an interactive discussion on Cognito-powered M2M authorization.
IAM372 | Workshop | Building CIAM Solutions with Amazon Cognito Learn how to use Amazon Cognito for your solutions’ CIAM needs. Use hands on examples to build fully functional solutions and see some of the new features in action like the new Managed Login UI, Passwordless logins now supported natively and more.
AWS identity foundation
IAM305 | Breakout session | Establishing a data perimeter on AWS, featuring Block, Inc. Organizations are storing an unprecedented and increasing amount of data on AWS for a range of use cases including data lakes, analytics, machine learning, and enterprise applications. They want to make sure that sensitive non-public data is protected from unintended access. In this session, dive deep into the controls that you can use to create a data perimeter to help ensure that only your trusted identities are accessing trusted resources from expected networks. Hear from Block, Inc. a leading fintech company about how they use data perimeter controls in their AWS environment to meet their security objectives.
IAM451 | Builders session | Securing GenAI Apps: Fine-Grained Access Control for Amazon Bedrock Agents Want to secure GenAI applications accessing your organizational data? Learn how to implement intelligent access controls for Amazon Bedrock-powered applications accessing your organizational data. In this builder’s session, you’ll build a defense-in-depth approach that combines authentication using Amazon Cognito and fine-grained authorization with Amazon Verified Permissions to secure access for Bedrock AI Agents. Implement layered permissions that protect sensitive data without limiting your GenAI capabilities.
Conclusion
As organizations continue to navigate the complexities of modern identity architecture, implementing a robust IAM framework remains critical for maintaining security posture while enabling seamless access across hybrid environments. The disappearance of the identity perimeter and the shift towards identity-first security demands a more sophisticated approach to authentication and authorization workflows, making continuous validation and adaptive access policies paramount. The community at re:inforce, strives to provide you with solutions, tactics, and strategies that you can use to propel your business forward.
If you have feedback about this post, submit comments in the Comments section below.
Microsoft is addressing 67 vulnerabilities this June 2025 Patch Tuesday. Microsoft has evidence of in-the-wild exploitation for just one of the vulnerabilities published today, and that is reflected in CISA KEV. Separately, Microsoft is aware of existing public disclosure for one other freshly published vulnerability. Microsoft’s luck holds for a ninth consecutive Patch Tuesday, since neither of today’s zero-day vulnerabilities are evaluated as critical severity at time of publication. Today also sees the publication of eight critical remote code execution (RCE) vulnerabilities. Two browser vulnerabilities have already been published separately this month, and are not included in the total.
Windows WebDAV: zero-day RCE
Remember the WebDAV standard? It has been seven years since Microsoft has published a vulnerability in the Windows implementation of WebDAV, and today’s publication of CVE-2025-33053 is the first zero-day vulnerability on record. Originally dreamed up in the 1990s to support interactivity on the web, WebDAV may be familiar to Exchange admins and users of a certain vintage, since older versions of Exchange, up to and including Exchange Server 2010, supported WebDAV as a means for interacting with mailboxes and public folders.
It will surprise no one that Windows still more or less supports WebDAV, and that turns out to be a bit of a problem. Microsoft acknowledges Check Point Research (CPR) on the advisory; CPR in turn attributes exploitation of CVE-2025-33053 to an APT, which they track as Stealth Falcon, an established threat actor with a long-running interest in governments and government-adjacent entities across the Middle East and the surrounding area.
Curiously, the Microsoft advisory does not mention that the Windows implementation of WebDAV is listed as deprecated since November 2023, which in practical terms means that the WebClient service no longer starts by default. The advisory also has attack complexity as low, which means that exploitation does not require preparation of the target environment in any way that is beyond the attacker’s control. Exploitation relies on the user clicking a malicious link. It’s not clear how an asset would be immediately vulnerable if the service isn’t running, but all versions of Windows receive a patch, including those released since the deprecation of WebClient, like Server 2025 and Windows 11 24H2. On Server 2025, for instance, it’s still possible to install the WebDAV Redirector server feature, which then causes the WebClient service to appear.
SMB client: zero-day EoP
Publicly disclosed elevation of privilege (EoP) zero-day vulnerabilities that lead to SYSTEM are always going to be worth a closer look, and CVE-2025-33073 is no exception. The advisory sets out that the easiest path to exploitation simply requires the user to connect to a malicious SMB server controlled by the attacker. It’s not entirely clear from the advisory whether simply connecting is enough to trigger exploitation, or whether successful authentication is required, since there is currently conflicting language in two separate FAQ entries with almost-identical titles: “How could an attacker exploit this/the vulnerability?” It may well be that Microsoft will come back around and clarify this wording, but in the meantime the only safe assumption is that fortune favours the attacker.
Windows KDC Proxy: critical RCE
The Windows KDC Proxy Service (KPSSVC) receives a patch today for CVE-2025-33071, which describes a critical unauthenticated RCE vulnerability where exploitation is via abuse of a cryptographic protocol weakness. The good news is that only Windows Server assets configured as a Kerberos Key Distribution Center Proxy Protocol server — happily, this is not enabled as standard configuration for a domain controller — and exploitation requires that the attacker win a race condition. The bad news is that Microsoft considers exploitation more likely regardless, and since a KDC proxy helps Kerberos requests from untrusted networks more easily access trusted assets without any need for a direct TCP connection from the client to the domain controller, the trade-off here is that the KDC proxy itself is quite likely to be exposed to an untrusted network. Patching this vulnerability should be top of mind for affected defenders this month.
Office preview pane: trio of critical RCEs
Microsoft expects that exploitation of three Office critical RCE vulns patched today is more likely. CVE-2025-47162, CVE-2025-47164, and CVE-2025-47167 share several attributes: each was discovered by prolific researcher 0x140ce, who topped the MSRC 2025 Q1 leaderboard, and each includes the Preview Pane as a vector, which always ups the ante for defenders. Admins responsible for installations of Microsoft 365 Apps for Enterprise — also confusingly referred to as “Microsoft 365 for Office” in the advisory FAQ — will have to hang on, since patches for today’s vulnerabilities aren’t yet available for that particular facet of the Microsoft 365 kaleidoscope.
Microsoft lifecycle update
June is a quiet month for Microsoft product lifecycle changes. The next batch of significant Microsoft product lifecycle status changes are due in July 2025, when the SQL Server 2012 ESU program draws to a close, along with support for Visual Studio 2022 17.8 LTSC.
Jean Baptiste Lallement, a member of Canonical’s desktop team, has announced
that Ubuntu will drop support for GNOME on X11 in the 25.10
(“Questing Quokka”) release set for October. GNOME plans to remove
X11 support in GNOME 49, which is scheduled for September, so
Ubuntu is looking to be proactive:
Ubuntu 25.10 is the last interim release before our next LTS (Ubuntu
26.04). By moving now, we give developers and users a full cycle to
adapt before the next LTS, align with GNOME 49 and reduce
fragmentation while simplifying our support matrix heading into the
LTS.
Fedora decided in
early May to drop X11 support for GNOME in Fedora 43, which
is also due in October.
In my spare time I enjoy building Gundam models, which are model kits to build iconic mechas from the Gundam universe. You might be wondering what this has to do with software engineering. Product engineers can be seen as the engineers who take these kits and build the Gundam itself. They are able to utilize all pieces and build a working product that is fun to collect or even play with!
Platform engineers, on the other hand, supply the tools needed to build these kits (like clippers and files) and maybe even build a cool display so everyone can see the final product. They ensure that whoever is constructing it has all the necessary tools, even if they don’t physically build the Gundam themselves.
About a year ago, my team at GitHub moved to the infrastructure organization, inheriting new roles and Areas of Responsibility (AoRs). Previously, the team had tackled external customer problems, such as building the new deployment views across environments. This involved interacting with users who depend on GitHub to address challenges within their respective industries. Our new customers as a platform engineering team are internal, which makes our responsibilities different from the product-focused engineering work we were doing before.
Going back to my Gundam example, rather than constructing kits, we’re now responsible for building the components of the kits. Adapting to this change meant I had to rethink my approach to code testing and problem solving.
Whether you’re working on product engineering or on the platform side, here are a few best practices to tackle platform problems.
Understanding your domain
One of the most critical steps before tackling problems is understanding the domain. A “domain” is the business and technical subject area in which a team and platform organization operate. This requires gaining an understanding of technical terms and how these systems interact to provide fast and reliable solutions. Here’s how to get up to speed:
Talk to your neighbors: Arrange a handover meeting with a team that has more knowledge and experience with the subject matter. This meeting provides an opportunity to ask questions about terminology and gain a deeper understanding of the problems the team will be addressing.
Investigate old issues: If there is a backlog of issues that are either stale or still persistent, they may give you a better understanding of the system’s current limitations and potential areas for improvement.
Read the docs: Documentation is a goldmine of knowledge that can help you understand how the system works.
Bridging concepts to platform-specific skills
While the preceding advice offers general guidance applicable to both product and platform teams, platform teams — serving as the foundational layer — necessitate a more in-depth understanding.
Networks: Understanding network fundamentals is crucial for all engineers, even those not directly involved in network operations. This includes concepts like TCP, UDP, and L4 load balancing, as well as debugging tools such as dig. A solid grasp of these areas is essential to comprehend how network traffic impacts your platform.
Operating systems and hardware: Selecting appropriate virtual machines (VMs) or physical hardware is vital for both scalability and cost management. Making well-informed choices for particular applications requires a strong grasp of both. This is closely linked to choosing the right operating system for your machines, which is important to avoid systems with vulnerabilities or those nearing end of life.
Infrastructure as Code (IaC): Automation tools like Terraform, Ansible, and Consul are becoming increasingly essential. Proficiency in these tools is becoming a necessity as they significantly decrease human error during infrastructure provisioning and modifications.
Distributed systems: Dealing with platform issues, particularly in distributed systems, necessitates a deep understanding that failures are inevitable. Consequently, employing proactive solutions like failover and recovery mechanisms is crucial for preserving system reliability and preventing adverse user experiences. The optimal approach for this depends entirely on the specific problem and the desired system behavior.
Knowledge sharing
By sharing lessons and ideas, engineers can introduce new perspectives that lead to breakthroughs and innovations. Taking the time to understand why a project or solution did or didn’t work and sharing those findings provides new perspectives that we can use going forward.
Here are three reasons why knowledge sharing is so important:
Teamwork makes the dream work: Collaboration often results in quicker problem resolution and fosters new solution innovation, as engineers have the opportunity to learn from each other and expand upon existing ideas.
Prevent lost knowledge: If we don’t share our lessons learned, we prevent the information from being disseminated across the team or organization. This becomes a problem if an engineer leaves the company or is simply unavailable.
Improve our customer success: As engineers, our solutions should effectively serve our customers. By sharing our knowledge and lessons learned, we can help the team build reliable, scalable, and secure platforms, which will enable us to create better products that meet customer needs and expectations!
But big differences start to appear between product engineering and infrastructure engineering when it comes to the impact radius and the testing process.
Impact radius
With platforms being the fundamental building blocks of a system, any change (small or large) can affect a wide range of products. Our team is responsible for DNS, a foundational service that impacts numerous products. Even a minor alteration to this service can have extensive repercussions, potentially disrupting access to content across our site and affecting products ranging from GitHub Pages to GitHub Copilot.
Understand the radius: Or understand the downstream dependencies. Direct communication with teams that depend on our service provides valuable insights into how proposed changes may affect other services.
Postmortems: By looking at past incidents related to our platform and asking “What is the impact of this incident?”, we can form more context around what change or failure was introduced, how our platform played a role in it, and how it was fixed.
Monitoring and telemetry: Condense important monitoring and logging into a small and quickly digestible medium to give you the general health of the system. This could be a Single Availability Metric (SAM), for example. The ability to quickly glance at a single dashboard allows engineers to rapidly pinpoint the source of an issue and streamlines the debugging and incident mitigation process, as compared to searching through and interpreting detailed monitors or log messages.
Testing changes
Testing changes in a distributed environment can be challenging, especially for services like DNS. A crucial step in solving this issue is utilizing a test site as a “real” machine where you can implement and assess all your changes.
Infrastructure as Code (IaC): When using tools like Terraform or Ansible, it’s crucial to test fundamental operations like provisioning and deprovisioning machines. There are circumstances where a machine will need to be re-provisioned. In these cases, we want to ensure the machine is not accidentally deleted and that we retain the ability to create a new one if needed.
End-to-End (E2E): Begin directing some network traffic to these servers. Then the team can observe host behavior by directly interacting with it, or we can evaluate functionality by diverting a small portion of traffic.
Self-healing: We want to test the platform’s ability to recover from unexpected loads and identify bottlenecks before they impact our users. Early identification of bottlenecks or bugs is crucial for maintaining the health of our platform.
Ideally changes will be implemented on a host-by-host basis once testing is complete. This approach allows for individual machine rollback and prevents changes from being applied to unaffected hosts.
What to remember
Platform engineering can be difficult. The systems GitHub operates with are complex and there are a lot of services and moving parts. However, there’s nothing like seeing everything come together. All the hard work our engineering teams do behind the scenes really pays off when the platform is running smoothly and teams are able to ship faster and more reliably — which allows GitHub to be the home to all developers.
Amazon OpenSearch Serverless is a fully managed search and analytics service that automatically provisions and scales infrastructure to help you run search and analytics workloads without cluster management. With OpenSearch Serverless, you can quickly build search and analytics capabilities into your applications.
As organizations scale their use of OpenSearch Serverless, understanding network architecture and DNS management becomes increasingly important. Building upon the connectivity patterns discussed in our previous post Network connectivity patterns for Amazon OpenSearch Serverless, this post covers advanced deployment scenarios focused on centralized and distributed access patterns—specifically, how enterprises can simplify network connectivity across multiple AWS accounts and extend access to on-premises environments for their OpenSearch Serverless deployments.
We outline two key deployment patterns:
Pattern 1 – A centralized endpoint model where interface virtual private cloud (VPC) endpoints for OpenSearch Serverless are deployed in a shared services VPC, allowing spoke VPCs from other AWS accounts and on premises to access OpenSearch Serverless collections through these consolidated endpoints.
Pattern 2 – A distributed endpoint model where interface VPC endpoints are created in individual spoke VPCs, with multiple consumers (central account, on-premises networks, and other spoke accounts) accessing these endpoints through centralized DNS management. This approach provides direct connectivity within each spoke VPC while maintaining centralized DNS control and management across the organization.
Before diving into advanced deployment patterns, let’s review the DNS behavior of OpenSearch Serverless when accessed through an interface VPC endpoint (AWS PrivateLink). Understanding this foundational aspect can help clarify the connectivity patterns we explore in this post.
OpenSearch Serverless interface VPC endpoint DNS resolution
When creating an OpenSearch Serverless interface VPC endpoint, the service automatically provisions three private hosted zones: one visible private hosted zone us-east-1.aoss.amazonaws.com that handles domain resolution for the OpenSearch Serverless collection and dashboard, another visible private hosted zone us-east-1.opensearch.amazonaws.com that manages resolution for the OpenSearch UI (OpenSearch Dashboards), and one hidden internal private hosted zone that manages the final DNS resolution to private IP addresses.
Our objective in this post is to explore how the two private hosted zones for OpenSearch Serverless work together: the visible private hosted zone us-east-1.aoss.amazonaws.com for collections and dashboards, and the hidden private hosted zone for final DNS resolution to private IP addresses. We examine how these private hosted zones enable scalable DNS resolution in both centralized and distributed architectures. The following workflow diagram shows the DNS resolution flow for the us-east-1 AWS Region. The same pattern applies to other Regions, with the Region identifiers in the DNS records changing accordingly.
The workflow consists of the following steps:
A user requests access to a collection URL (for example, abc.us-east-1.aoss.amazonaws.com).
The DNS request is sent to the Amazon Route 53 Resolver, which checks the visible private hosted zone us-east-1.aoss.amazonaws.com and finds a CNAME record pointing to the endpoint-specific domain.
The Route 53 Resolver uses the hidden internal private hosted zone to resolve this endpoint-specific domain to the VPC endpoint’s private IP address.
Traffic is allowed only if it originates from the interface VPC endpoint approved by OpenSearch Serverless network policies.
Although this DNS Resolution Process provides flexible and secure private access, it becomes complex when you need connectivity from multiple VPCs, different AWS accounts, or on-premises networks. The following patterns address these challenges and outline strategies to simplify network access and DNS management for OpenSearch Serverless in such environments.
Pattern 1: Centralized interface VPC endpoint for OpenSearch Serverless
This pattern uses a centralized approach where a shared services AWS account with a shared services VPC hosts the OpenSearch Serverless interface VPC endpoint and OpenSearch Serverless collection. From there, other AWS accounts with Amazon VPCs (spoke VPCs) need to be able to access OpenSearch Serverless collections through this central endpoint. Organizations commonly implement this setup in hub-and-spoke network designs that connect their VPCs using either AWS Transit Gateway or AWS Cloud WAN. The following diagram illustrates this architecture.
Challenge
When accessing from on-premises networks, both network access and DNS resolution for the OpenSearch Serverless interface VPC endpoint work successfully. However, although the endpoint is network-accessible from spoke VPCs (for example, through Transit Gateway or AWS Cloud WAN), DNS resolution from these VPCs fail.
This happens because OpenSearch Serverless creates and uses a private hosted zone us-east-1.aoss.amazonaws.com that is only associated with the VPC containing the endpoint, in this case, the Shared Services VPC. Simply sharing this private hosted zone with the spoke VPCs doesn’t solve the problem, because the wildcard CNAME record references a DNS name privatelink.c0X.sgw.iad.prod.aoss.searchservices.aws.dev. This DNS name can’t be resolved from other VPCs without additional configuration, because it belongs to a private hosted zone privatelink.c0X.sgw.iad.prod.aoss.searchservices.aws.dev that is only associated with the shared services VPC. This private hosted zone isn’t visible in your account and is controlled by AWS.
Solution: Use Amazon Route 53 Profiles for cross-VPC DNS resolution
To enable centralized DNS resolution, you can use Amazon Route 53 Profiles. With Route 53 Profiles, you can manage and apply DNS-related Amazon Route 53 configurations across multiple VPCs and AWS accounts. The following diagram illustrates the solution architecture.
Create a Route 53 Profile in the shared services account.
Associate the interface VPC endpoint for OpenSearch Serverless with the Route 53 Profile.
The Route 53 Profile automatically associates the hidden private hosted zone with the profile.
Associate the private hosted zone us-east-1.aoss.amazonaws.com that was automatically created by OpenSearch Serverless with the Route 53 Profile.
Share the Route 53 Profile with your other AWS accounts in your organization using AWS Resource Access Manager (AWS RAM).
Associate the spoke VPCs (located in different accounts) with the Route 53 Profile.
If you have an existing Route 53 Profile in your shared services account that is already associated to spoke VPCs, you can simply associate the OpenSearch Serverless interface VPC endpoint and the private hosted zone us-east-1.aoss.amazonaws.com to this profile.
After completing these steps, the DNS resolution for the OpenSearch Serverless collection and dashboard endpoints works seamlessly from spoke VPCs associated with the Route 53 Profile. Clients in spoke VPCs can resolve and access OpenSearch Serverless collections and dashboards through the centralized VPC endpoint.
Pattern 2: Distributed interface VPC endpoint for OpenSearch Serverless
Each spoke VPC, residing in its respective AWS account, hosts its own OpenSearch Serverless collection and interface VPC endpoint. We now want to achieve the following:
Centralize DNS management in a shared services VPC to provide consistent resolution for OpenSearch Serverless collections deployed across multiple spoke accounts
Provide on-premises resources with DNS resolution capability for all OpenSearch Serverless collections across the organization through a Route 53 Resolver inbound endpoint in the shared services VPC
The following diagram illustrates this architecture.
Challenge
Managing DNS resolution for OpenSearch Serverless collections and dashboards becomes complex in this distributed model because each interface VPC endpoint creates its own set of private hosted zones that are only associated with their respective VPCs. This creates a fragmented DNS landscape where the shared services VPC and on-premises networks need a consolidated way to resolve domains of OpenSearch Serverless collections and dashboards across multiple spoke accounts.
Solution: Use a self-managed private hosted zone in the shared services VPC for on-prem DNS resolution
To enable centralized DNS resolution for distributed endpoints, create a self-managed private hosted zone in the shared services account and associate it with the shared services VPC. Within this private hosted zone, you can create CNAME records that map each OpenSearch Serverless collection endpoint to its respective interface VPC endpoint DNS names in the spoke accounts. The following diagram illustrates this architecture.
Implementation consists of the following steps:
Create a self-managed private hosted zone in the shared services account with the domain name us-east-1.aoss.amazonaws.com and associate it with the shared services VPC. For each OpenSearch Serverless collection, create a CNAME record that points to the Regional DNS name of its corresponding interface VPC endpoint.
This configuration enables both on-premises resources and resources in the shared services VPC to resolve OpenSearch Serverless endpoints that are in the spoke accounts.
After you complete these steps, each OpenSearch Serverless interface VPC endpoint remains within its original AWS account, maintaining security boundaries and account-level autonomy. On-premises systems can access OpenSearch Serverless collections and dashboards using original collection DNS names (for example, {collection-name}.us-east-1.aoss.amazonaws.com) through DNS resolution provided by the private hosted zone in the shared services VPC.
Conclusion
As organizations scale their adoption of OpenSearch Serverless, establishing secure and centralized network access becomes increasingly important. In this post, we explored two architectural patterns specifically around DNS management:
Centralized endpoint model – This pattern is ideal when a shared services account manages the OpenSearch Serverless interface VPC endpoints, allowing multiple spoke accounts to access OpenSearch Serverless collections and dashboards through a centralized set of network resources.
Distributed endpoint model with centralized DNS – This pattern is suitable for organizations that require account-level autonomy, where each AWS account manages its own OpenSearch Serverless interface VPC endpoints, while DNS resolution is centralized through a shared self-managed private hosted zone in a shared services account.
By understanding the DNS architecture of OpenSearch Serverless and using services like Route 53 Profiles and AWS RAM, organizations can build secure and robust access patterns that align with their organizational structure and needs.
About the Authors
Ankush Goyal is a Enterprise Support Lead in AWS Enterprise Support who helps customers streamline their cloud operations on AWS. He is a results-driven IT professional with over 20 years of experience.
Anvesh Koganti is a Solutions Architect at AWS specializing in Networking. He focuses on helping customers build networking architectures for highly scalable and resilient AWS environments. Outside of work, Anvesh is passionate about consumer technology and enjoys listening to podcasts on tech and business. When disconnecting from the digital world, Anvesh spends time outdoors hiking and biking.
Salman Ahmed is a Senior Technical Account Manager in AWS Enterprise Support. He specializes in guiding customers through the design, implementation, and support of AWS solutions. Combining his networking expertise with a drive to explore new technologies, he helps organizations successfully navigate their cloud journey. Outside of work, he enjoys photography, traveling, and watching his favorite sports teams.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.













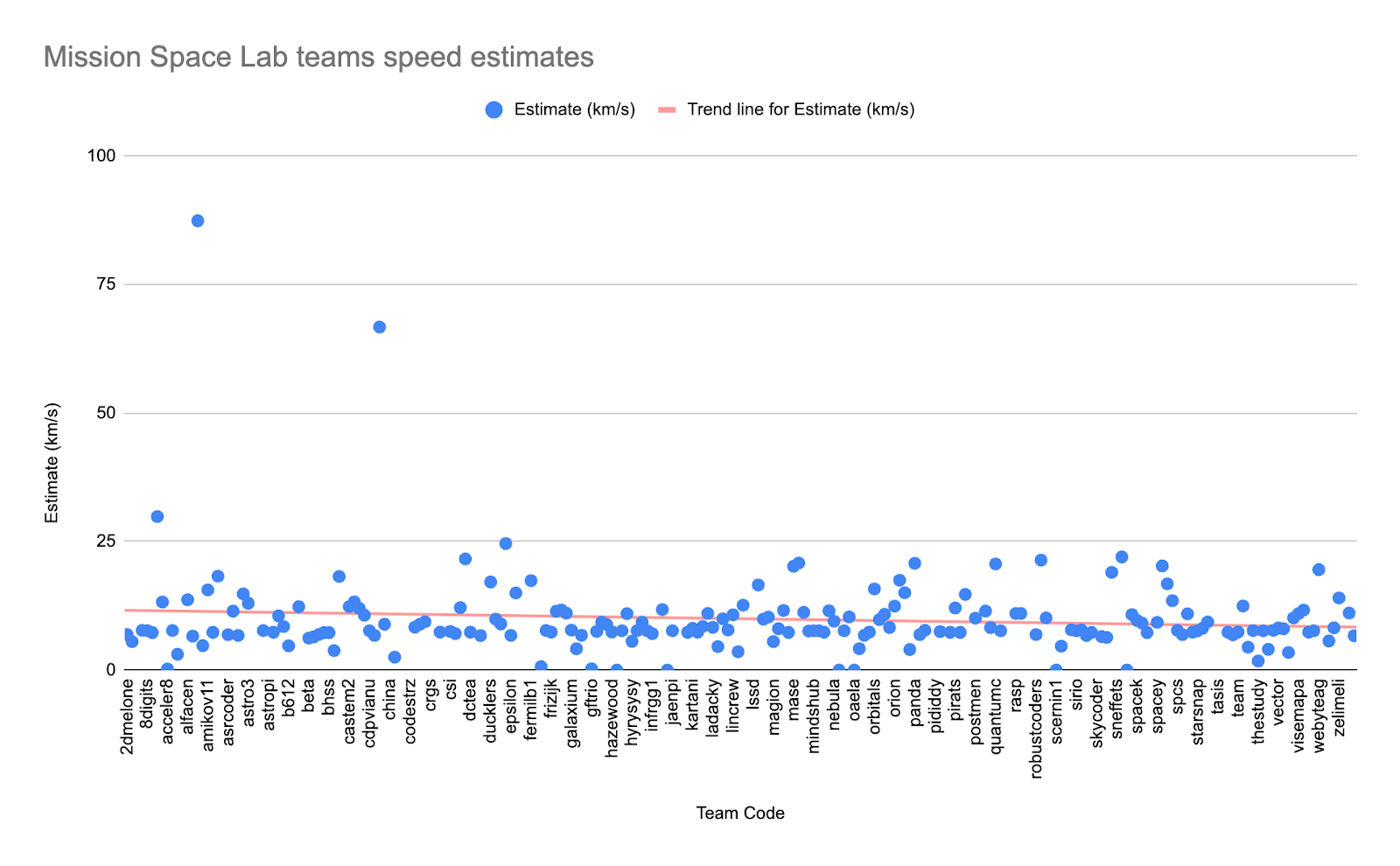













 Ankush Goyal is a Enterprise Support Lead in AWS Enterprise Support who helps customers streamline their cloud operations on AWS. He is a results-driven IT professional with over 20 years of experience.
Ankush Goyal is a Enterprise Support Lead in AWS Enterprise Support who helps customers streamline their cloud operations on AWS. He is a results-driven IT professional with over 20 years of experience. Anvesh Koganti is a Solutions Architect at AWS specializing in Networking. He focuses on helping customers build networking architectures for highly scalable and resilient AWS environments. Outside of work, Anvesh is passionate about consumer technology and enjoys listening to podcasts on tech and business. When disconnecting from the digital world, Anvesh spends time outdoors hiking and biking.
Anvesh Koganti is a Solutions Architect at AWS specializing in Networking. He focuses on helping customers build networking architectures for highly scalable and resilient AWS environments. Outside of work, Anvesh is passionate about consumer technology and enjoys listening to podcasts on tech and business. When disconnecting from the digital world, Anvesh spends time outdoors hiking and biking. Salman Ahmed is a Senior Technical Account Manager in AWS Enterprise Support. He specializes in guiding customers through the design, implementation, and support of AWS solutions. Combining his networking expertise with a drive to explore new technologies, he helps organizations successfully navigate their cloud journey. Outside of work, he enjoys photography, traveling, and watching his favorite sports teams.
Salman Ahmed is a Senior Technical Account Manager in AWS Enterprise Support. He specializes in guiding customers through the design, implementation, and support of AWS solutions. Combining his networking expertise with a drive to explore new technologies, he helps organizations successfully navigate their cloud journey. Outside of work, he enjoys photography, traveling, and watching his favorite sports teams.