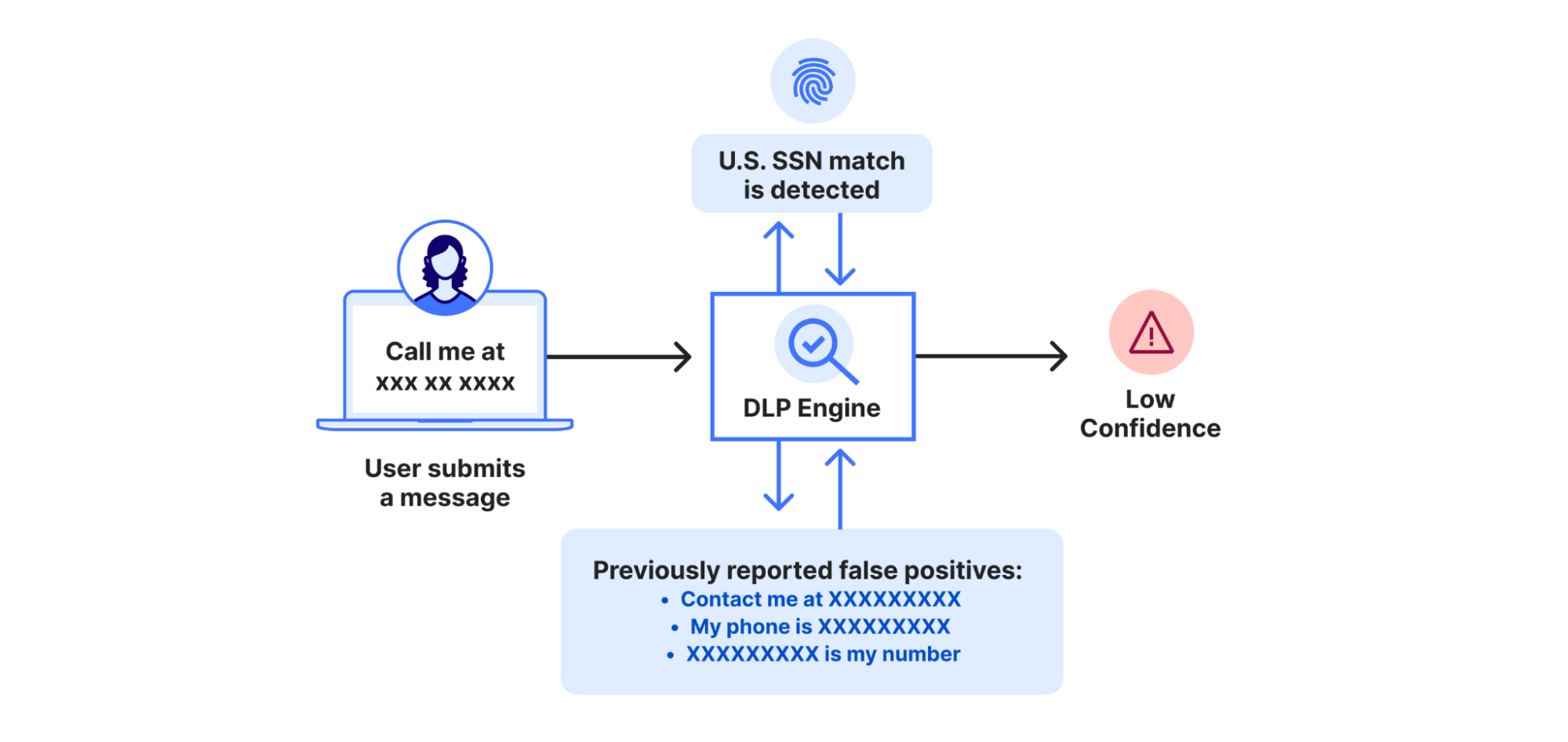
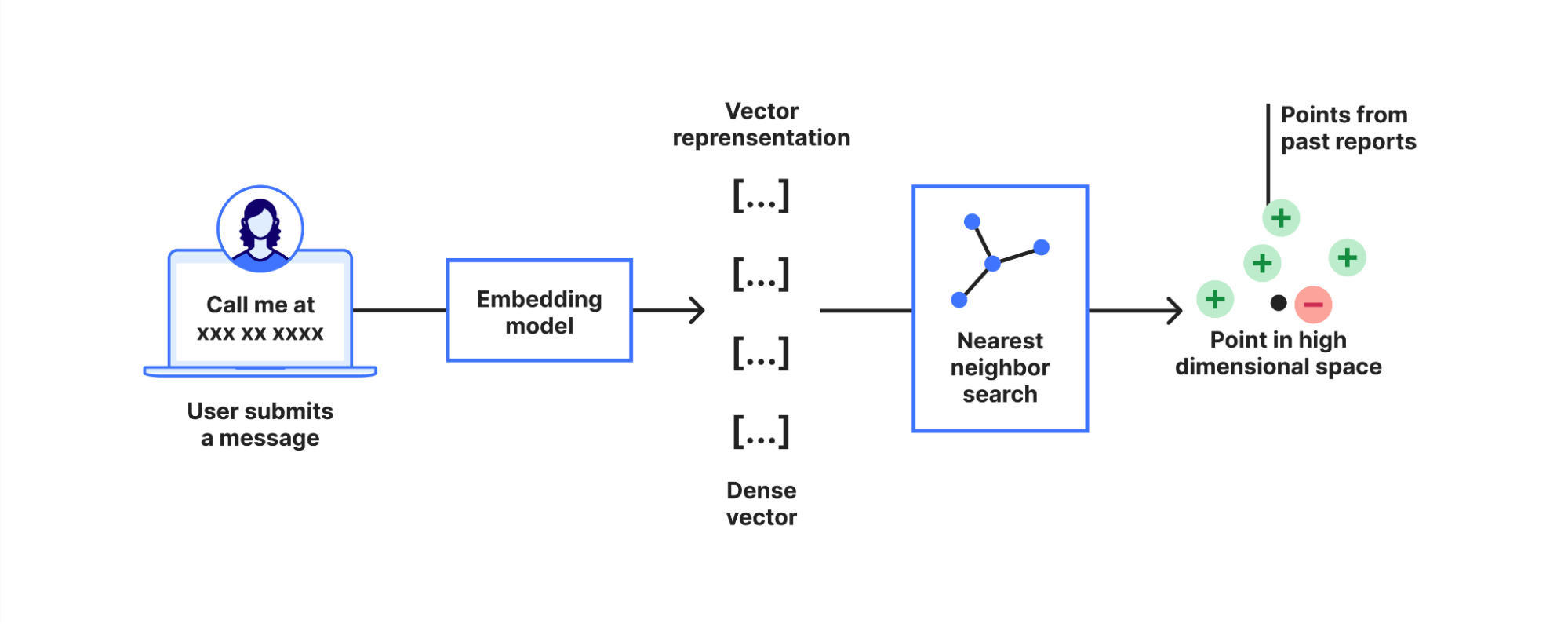
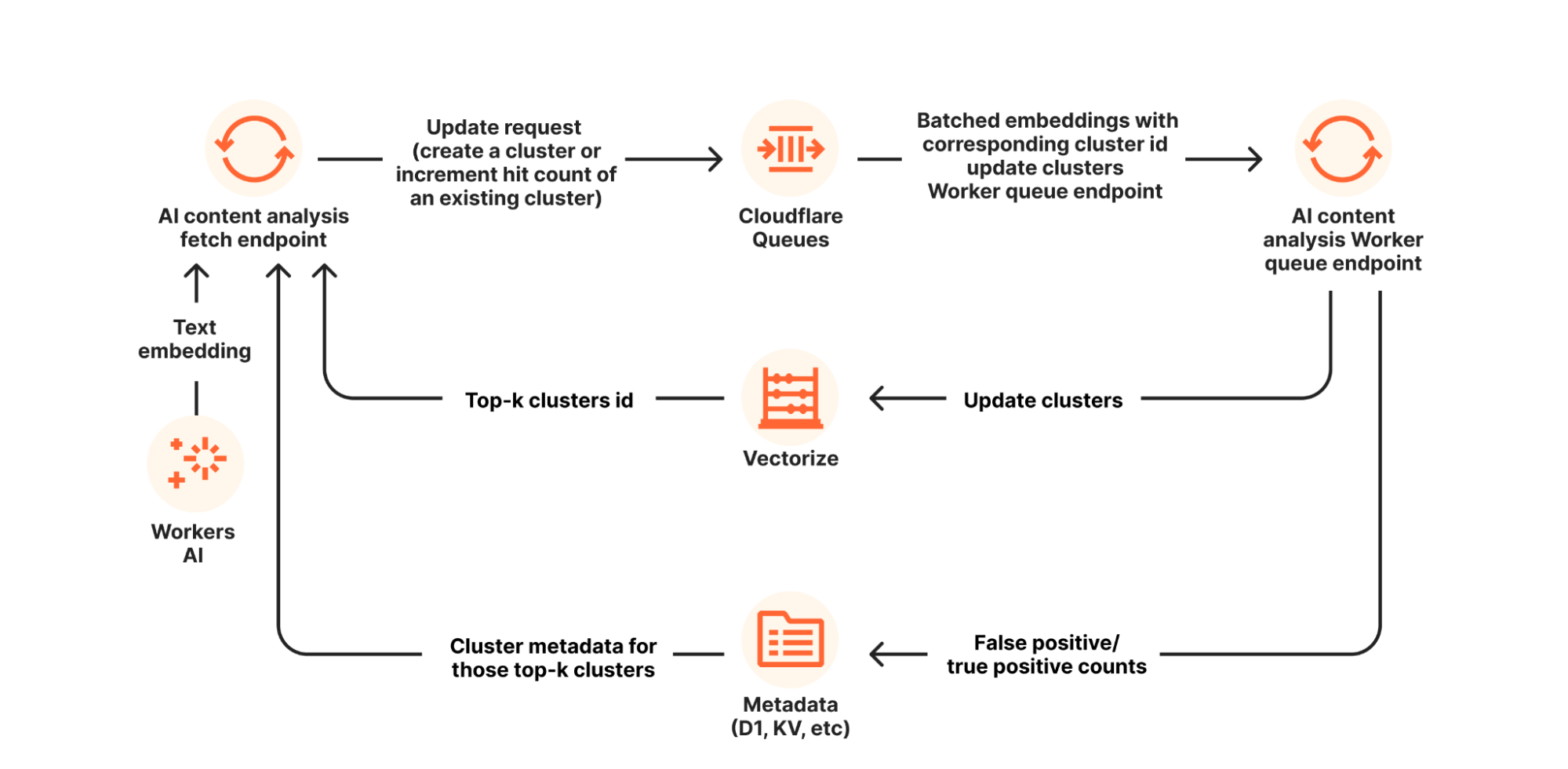
AWS GuardDuty has introduced two powerful new alerts that enhance its threat detection capabilities: “Potential Credential Compromise” and “Potential S3 Data Compromise.” These alerts go beyond traditional threat detection by focusing on attack sequences, providing deeper insights into suspicious activities that may indicate credential misuse or unauthorized data access.
Unlike single-event alerts, these new notifications correlate multiple signals across different timeframes and contexts, helping organizations detect sophisticated attack strategies such as persistence, privilege escalation, and data exfiltration. These advanced alerts represent a significant shift in cloud security, enabling users to take faster, more informed actions against potential threats.
Rapid7’s Managed Threat Complete supports third party cloud security tools, includingAWS GuardDuty alerts, by providing critical capabilities such as alert triage, remediation recommendations, and response actions, helping SOC analysts reduce response time and improve operational efficiency for customers. The Rapid7 SOC has increased their coverage for these new AWS alerts, let’s take a look at each of them and how they work.
AttackSequence:IAM/CompromisedCredentials – Detecting IAM Credential Abuse
The IAM Compromised Credentials alert identifies potential credential theft and abuse within AWS environments by correlating multiple suspicious activities, such as:
Connection attempts from known malicious IP addresses (e.g., Tor exit nodes)
High-risk API calls, including attempts to disable security controls
Actions aligning with multiple MITRE ATT&CK tactics and techniques
Suspicious privilege escalation attempts
This alert tracks the progression of an attack from initial access attempts to defense evasion techniques like CloudTrail deletions. It provides detailed information about the affected IAM entities, specific API calls made, and geographic origins of suspicious connections, enabling security teams to assess and respond rapidly to potential threats.
AttackSequence:S3/CompromisedData – Protecting Your S3 Data
The S3 Compromised Data alert focuses on detecting potential data breach attempts targeting S3 buckets. This detection mechanism monitors for activity sequences that indicate an attacker attempting to locate, access, or exfiltrate sensitive data. Key aspects of this alert include:
Identification of suspicious S3 bucket enumeration activities
Detection of unusual data access patterns
Monitoring of security control modifications
Tracking of potential data exfiltration attempts
By correlating various activities such as ListBuckets, GetObject, and DeleteObject operations—especially when performed from suspicious IP addresses or in conjunction with bucket access modifications—this alert helps security teams identify and respond to potential data breaches before significant damage occurs.
Both of these new alert types represent a major advancement in AWS security monitoring, providing teams with more context-aware and actionable insights. Implementing these alerts allows organizations to better protect their AWS environments from sophisticated attack sequences and potential data breaches.
Rapid7 Managed SOC Powered by CDR & ICS
Rapid7’s expert-driven cloud-ready MDR solution offers 24/7 monitoring and continuous tracking and response to cloud threats in real-time. Rapid7 Exposure Command automatically enriches alerts from third-party detection engines, such as AWS GuardDuty and Azure Microsoft Defender for Cloud, to accelerate SOC investigation and response, ensuring threats are contextualized effectively.
With a proactive approach, Rapid7 SOC analysts manage critical incidents to minimize risk and enhance cloud security by reducing response time through enriched insights provided by ICS. InsightCloudSec delivers comprehensive cloud security, helping organizations:
Stay compliant by enforcing security policies and addressing security gaps
Reduce attack surface by identifying and fixing risky IAM roles, misconfigurations, and unused resources
Eliminate risks by identifying issues early to minimize vulnerabilities and strengthen the cloud environment
Contact us to learn more about how Managed Threat Complete and InsightCloudSec brings enhanced cloud detection and response to help customers command their attack surface.
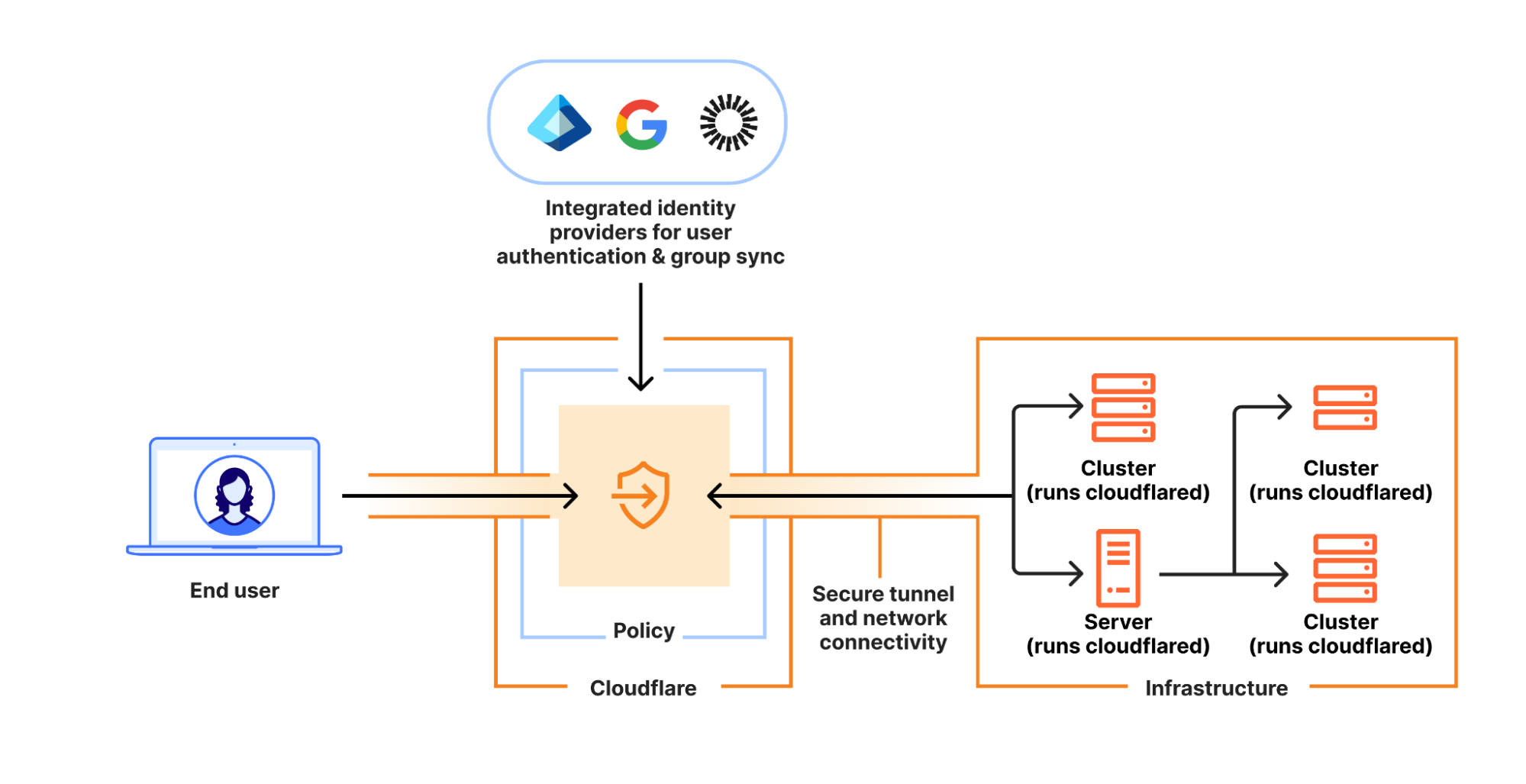
Short-lived SSH access made its debut on Cloudflare’s SASE platform in October 2024. Leveraging the knowledge gained through the BastionZero acquisition, short-lived SSH access enables organizations to apply Zero Trust controls in front of their Linux servers. That was just the beginning, however, as we are thrilled to announce the release of a long-requested feature: clientless, browser-based support for the Remote Desktop Protocol (RDP). Built on top of Cloudflare’s modern proxy architecture, our RDP proxy offers a secure and performant solution that, critically, is also easy to set up, maintain, and use.
Security challenges of RDP
Remote Desktop Protocol (RDP) was born in 1998 with Windows NT 4.0 Terminal Server Edition. If you have never heard of that Windows version, it’s because, well, there’s been 16 major Windows releases since then. Regardless, RDP is still used across thousands of organizations to enable remote access to Windows servers. It’s a bit of a strange protocol that relies on a graphical user interface to display screen captures taken in very close succession in order to emulate the interactions on the remote Windows server. (There’s more happening here beyond the screen captures, including drawing commands, bitmap updates, and even video streams. Like we said — it’s a bit strange.) Because of this complexity, RDP can be computationally demanding and poses a challenge for running at high performance over traditional VPNs.
Beyond its quirks, RDP has also had a rather unsavory reputation in the security industry due to early vulnerabilities with the protocol. The two main offenders are weak user sign-in credentials and unrestricted port access. Windows servers are commonly protected by passwords, which often have inadequate security to start, and worse still, may be shared across multiple accounts. This leaves these RDP servers open to brute force or credential stuffing attacks.
Bad actors have abused RDP’s default port, 3389, to carry out on-path attacks. One of the most severe RDP vulnerabilities discovered is called BlueKeep. Officially known as CVE-2019-0708, BlueKeep is a vulnerability that allows remote code execution (RCE) without authentication, as long as the request adheres to a specific format and is sent to a port running RDP. Worse still, it is wormable, meaning that BlueKeep can spread to other machines within the network with no user action. Because bad actors can compromise RDP to gain unauthorized access, attackers can then move laterally within the network, escalating privileges, and installing malware. RDP has also been used to deploy ransomware such as Ryuk, Conti, and DoppelPaymer, earning it the nickname “Ransomware Delivery Protocol.”
This is a subset of vulnerabilities in RDP’s history, but we don’t mean to be discouraging. Thankfully, due to newer versions of Windows, CVE patches, improved password hygiene, and better awareness of privileged access, many organizations have reduced their attack surface. However, for as many secured Windows servers that exist, there are still countless unpatched or poorly configured systems online, making them easy targets for ransomware and botnets.
The need for a browser-based RDP solution
Despite its security risks, RDP remains essential for many organizations, particularly those with distributed workforces and third-party contractors. It provides value for compute-intensive tasks that require high-powered Windows servers with CPU/GPU resources greater than users’ machines can offer. For security-focused organizations, RDP grants better visibility into who is accessing Windows servers and what actions are taken during those sessions.
Because issuing corporate devices to contractors is costly and cumbersome, many organizations adopt a bring-your-own-device (BYOD) policy. This decision instead requires organizations to provide contractors with a means to RDP to a Windows server with the necessary corporate resources to fulfill their role.
Traditional RDP requires client software on user devices, so this is not an appropriate solution for contractors (or any employees) using personal machines or unmanaged devices. Previously, Cloudflare customers had to rely on self-hosted third-party tools like Apache Guacamole or Devolutions Gateway to enable browser-based RDP access. This created several operational pain points:
Infrastructure complexity: Deploying and maintaining RDP gateways increases operational overhead.
Maintenance burden: Commercial and open-source tools may require frequent updates and patches, sometimes even necessitating custom forks.
Compliance challenges: Third-party software requires additional security audits and risk management assessments, particularly for regulated industries.
Redundancy, but not the good kind – Customers come to Cloudflare to reduce the complexity of maintaining their infrastructure, not add to it.
We’ve been listening. Cloudflare has architectured a high-performance RDP proxy that leverages the modern security controls already part of our Zero Trust Network Access (ZTNA) service. We feel that the “security/performance tradeoff” the industry commonly touts is a dated mindset. With the right underlying network architecture, we can help mitigate RDP’s most infamous challenges.
Introducing browser-based RDP with Access
Cloudflare’s browser-based RDP solution is the newest addition to Cloudflare Access alongside existing clientless SSH and VNC offerings, enabling secure, remote Windows server access without VPNs or RDP clients. Built natively within Cloudflare’s global network, it requires no additional infrastructure.
Our browser-based RDP access combines the power of self-hosted Access applications with the additional flexibility of targets, introduced with Access for Infrastructure. Administrators can enforce:
Authentication: Control how users authenticate to your internal RDP resources with SSO, MFA, and device posture.
Authorization: Use policy-based access control to determine who can access what target and when.
Auditing: Provide Access logs to support regulatory compliance and visibility in the event of a security breach.
Users only need a web browser — no native RDP client is necessary! RDP servers are accessed through our app connector, Cloudflare Tunnel, using a common deployment model of existing Access customers. There is no need to provision user devices to access particular RDP servers, making for minimal setup to adopt this new functionality.
How it works
The client
Cloudflare’s implementation leverages IronRDP, a high-performance RDP client that runs in the browser. It was selected because it is a modern, well-maintained, RDP client implementation that offers an efficient and responsive experience. Unlike Java-based Apache Guacamole, another popular RDP client implementation, IronRDP is built with Rust and integrates very well with Cloudflare’s development ecosystem.
While selecting the right tools can make all the difference, using a browser to facilitate an RDP session faces some challenges. From a practical perspective, browsers just can’t send RDP messages. RDP relies directly on the Layer 4 Transmission Control Protocol (TCP) for communication, and while browsers can use TCP as the underlying protocol, they do not expose APIs that would let apps build protocol support directly on raw TCP sockets.
Another challenge is rooted in a security consideration: the username and password authentication mechanism that is native to RDP leaves a lot to be desired in the modern world of Zero Trust.
In order to tackle both of these challenges, the IronRDP client encapsulates the RDP session in a WebSocket connection. Wrapping the Layer 4 TCP traffic in HTTPS enables the client to use native browser APIs to communicate with Cloudflare’s RDP proxy. Additionally, it enables Cloudflare Access to secure the entire session using identity-aware policies. By attaching a Cloudflare Access authorization JSON Web Token (JWT) via cookie to the WebSocket connection, every inter-service hop of the RDP session is verified to be coming from the authenticated user.
A brief aside into how security and performance is optimized: in conventional client-based RDP traffic, the client and server negotiate a TLS connection to secure and verify the session. However, because the browser WebSocket connection is already secured with TLS to Cloudflare, we employ IronRDP’s RDCleanPath protocol extension to eliminate this second encapsulation of traffic. Removing this redundancy avoids unnecessary performance degradation and increased complexity during session handshakes.
The server
The IronRDP client initiates a WebSocket connection to a dedicated WebSocket proxy, which is responsible for authenticating the client, terminating the WebSocket connection, and proxying tunneled RDP traffic deeper into Cloudflare’s infrastructure to facilitate connectivity. The seemingly simple task of determining how this WebSocket proxy should be built turned out to be the most challengingdecision in the development process.
Our initial proposal was to develop a new service that would run on every server within our network. While this was feasible, operating a new service would introduce a non-trivial maintenance burden, which ultimately turned out to be more overhead than value-add in this case. The next proposal was to build it into Front Line (FL), one of Cloudflare’s oldest services that is responsible for handling tens of millions of HTTP requests per second. This approach would have sidestepped the need to expose new IP addresses and benefitted from the existing scaffolding to let the team move quickly. Despite being promising at first, this approach was decided against because FL is undergoing significant investment, and the team didn’t want to build on shifting sands.
Finally, we identified a solution that implements the proxy service using Cloudflare Workers! Fortunately, Workers automatically scales to massive request rates, which eliminates some of the groundwork we’d lay if we had chosen to build a new service. Candidly, this approach was not initially preferred due to some ambiguities around how Workers communicates with internal Cloudflare services, but with support from the Workers team, we found a path forward.
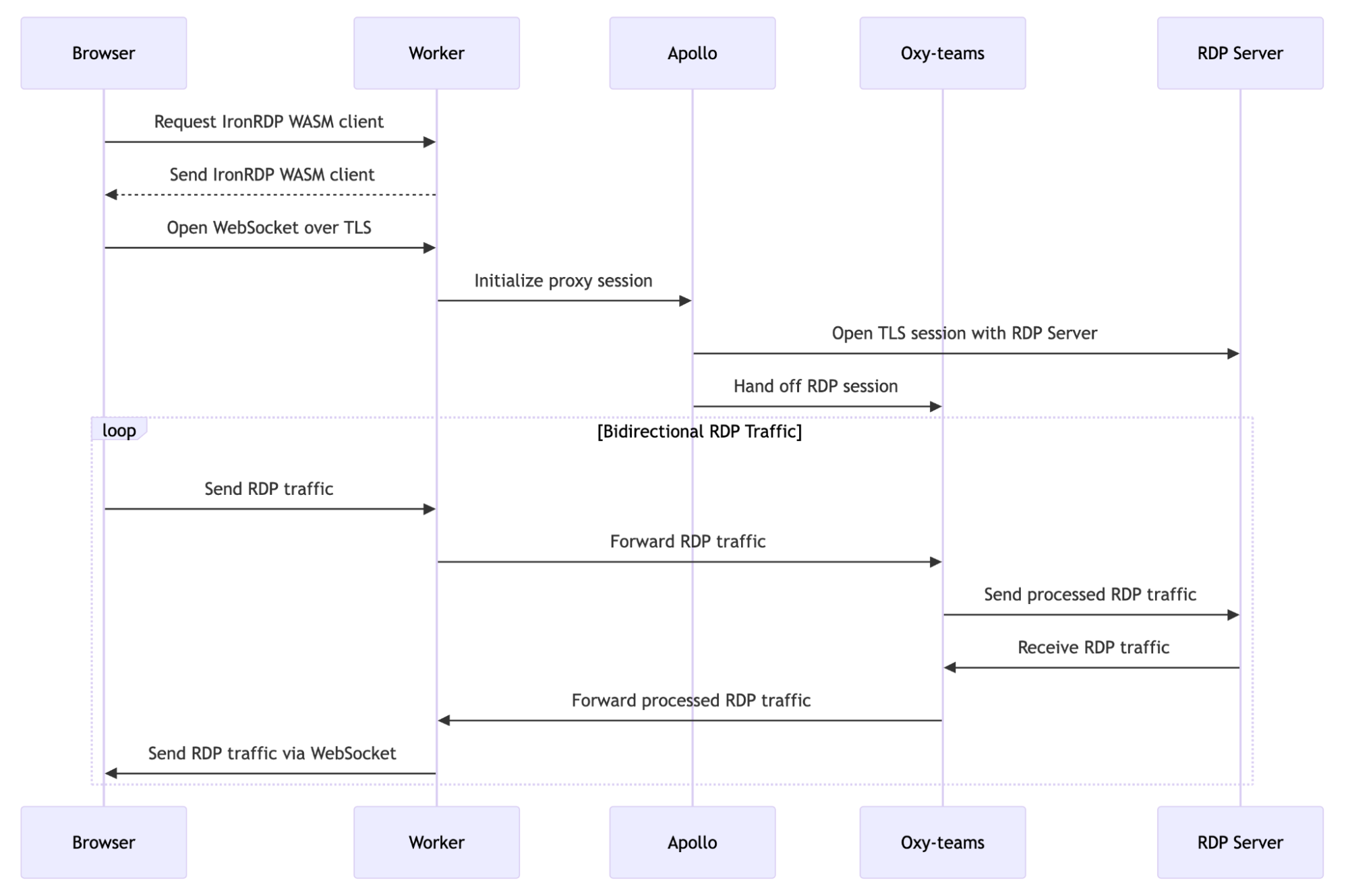
From the WebSocket proxy Worker, the tunneled RDP connection is sent to the Apollo service, which is responsible for routing traffic between on-ramps and off-ramps for Cloudflare Zero Trust. Apollo centralizes and abstracts these complexities to let other services focus on application-specific functionality. Apollo determines which Cloudflare colo is closest to the target Cloudflare Tunnel and establishes a connection to an identical Apollo instance running in that colo. The egressing Apollo instance can then facilitate the final connection to the Cloudflare Tunnel. By using Cloudflare’s global network to traverse the distance between the ingress colo and the target Cloudflare Tunnel, network disruptions and congestion is managed.
Apollo connects to the RDP server and passes the ingress and egress connections to Oxy-teams, the service responsible for inspecting and proxying the RDP traffic. It functions as a pass-through (strictly enabling traffic connectivity) as the web client authenticates to the RDP server. Our initial release makes use of NT Lan Manager (NTLM) authentication, a challenge-response authentication protocol requiring username and password entry. Once the client has authenticated with the server, Oxy-teams is able to proxy all subsequent RDP traffic!
This may sound like a lot of hops, but every server in our network runs every service. So believe it or not, this complex dance takes place on a single server and by using UNIX domain sockets for communication, we also minimize any performance impact. If any of these servers become overloaded, experience a network fault, or have a hardware problem, the load is automatically shifted to a neighboring server with the help of Unimog, Cloudflare’s L4 load balancer.
Putting it all together
User initiation: The user selects an RDP server from Cloudflare’s App Launcher (or accesses it via a direct URL). Each RDP server is associated with a public hostname secured by Cloudflare.
Ingress: This request is received by the closest data center within Cloudflare’s network.
Authentication: Cloudflare Access authenticates the session by validating that the request contains a valid JWT. This token certifies that the user is authorized to access the selected RDP server through the specified domain.
Web client delivery:Cloudflare Workers serves the IronRDP web client to the user’s browser.
Secure tunneling: The client tunnels RDP traffic from the user’s browser over a TLS-secured WebSocket to another Cloudflare Worker.
Traffic routing: The Worker that receives the IronRDP connection terminates the WebSocket and initiates a connection to Apollo. From there, Apollo creates a connection to the RDP server.
Authentication relay: With a connection established, Apollo relays RDP authentication messages between the web client and the RDP server.
Connection establishment: Upon successful authentication, Cloudflare serves as an RDP proxy between the web browser and the RDP server, connecting the user to the RDP server with free-flowing traffic.
Policy enforcement: Cloudflare’s secure web gateway, Oxy-teams, applies Layer 4 policy enforcement and logging of the RDP traffic.
Key benefits of this architecture:
No additional software: Access Windows servers directly from a browser.
Low latency: Cloudflare’s global network minimizes performance overhead.
Enhanced security: RDP access is protected by Access policies, preventing lateral movement.
Integrated logging and monitoring: Administrators can observe and control RDP traffic.
To learn more about Cloudflare’s proxy capabilities, take a look at our related blog post explaining our proxy framework.
Selective, modern RDP authentication
Cloudflare’s browser-based RDP solution exclusively supports modern RDP authentication mechanisms, enforcing best practices for secure access. Our architecture ensures that RDP traffic using outdated or weak legacy security features from older versions of the RDP standard, such as unsecured password-based authentication or RC4 encryption, are never allowed to reach customer endpoints.
Cloudflare supports secure session negotiation using the following principles:
TLS-based WebSocket connection for transport security.
Fine-grained policies that enforce single sign on (SSO), multi-factor authentication (MFA), and dynamic authorization.
Integration with enterprise identity providers via SAML (Security Assertion Markup Language) and OIDC (OpenID Connect).
Every RDP session that passes through Cloudflare’s network is encrypted and authenticated.
What’s next?
This is only the beginning for our browser-based RDP solution! We have already identified a few areas for continued focus:
Enhanced visibility and control for administrators: Because RDP traffic passes through Cloudflare Workers and proxy services, browser-based RDP will expand to include session monitoring. We are also evaluating data loss prevention (DLP) support, such as restricting actions like file transfers and clipboard use, to prevent unauthorized data exfiltration without compromising performance.
Advanced authentication: Long-lived credentials are a thing of the past. Future iterations of browser-based RDP will include passwordless functionality, eliminating the need for end users to remember passwords and administrators from having to manage them. To that end, we are evaluating methods such as client certificate authentication, passkeys and smart cards, and integration with third-party authentication providers via Access.
Compliance and FedRAMP High certification
We plan to include browser-based RDP in our FedRAMP High offering for enterprise and government organizations, a high-priority initiative we announced in early February. This certification will validate that our solution meets the highest standards for:
Data protection
Identity and access management
Continuous monitoring
Incident response
Seeking FedRAMP High compliance demonstrates Cloudflare’s commitment to securing sensitive environments, such as those in the federal government, healthcare, and financial sectors.
By enforcing a modern, opinionated, and secure implementation of RDP, Cloudflare provides a secure, scalable, and compliant solution tailored to the needs of organizations with critical security and compliance mandates.
Get started today
At Cloudflare, we are committed to providing the most comprehensive solution for ZTNA, which now also includes privileged access to sensitive infrastructure like Windows servers over browser-based RDP. Cloudflare’s browser-based RDP solution is in closed beta with new customers being onboarded each week. You can request access here to try out this exciting new feature.
In the meantime, check out ourAccess for Infrastructure documentation to learn more about how Cloudflare protects privileged access to sensitive infrastructure. Access for Infrastructure is currently available free to teams of under 50 users, and at no extra cost to existing pay-as-you-go and Contract plan customers through an Access or Zero Trust subscription. Stay tuned as we continue to natively rebuild BastionZero’s technology into Cloudflare’s Access for Infrastructure service!
Today is the final day of Security Week 2025, and after a great week of blog posts across a variety of topics, we’re excited to share the latest on Cloudflare’s data security products.
This announcement takes us to Cloudflare’s SASE platform, Cloudflare One, used by enterprise security and IT teams to manage the security of their employees, applications, and third-party tools, all in one place.
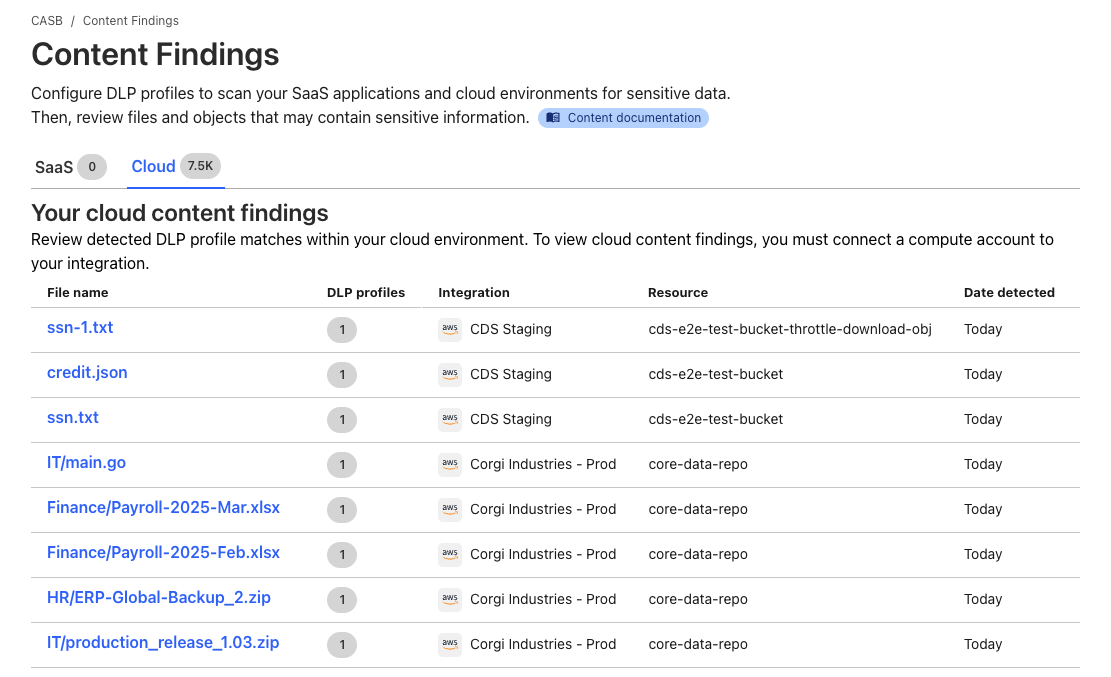
Starting today, Cloudflare One users can now use the CASB (Cloud Access Security Broker) product to integrate with and scan Amazon Web Services (AWS) S3 and Google Cloud Storage, for posture- and Data Loss Prevention (DLP)-related security issues. Create a free account to check it out.
Scanning both point-in-time and continuously, users can identify misconfigurations in Identity and Access Management (IAM), bucket, and object settings, and detect sensitive information, like Social Security numbers, credit card numbers, or any other pattern using regex, in cloud storage objects.
Cloud DLP
Over the last few years, our customers — predominantly security and IT teams — have told us about their appreciation for CASB’s simplicity and effectiveness as a SaaS security product. Its number of supported integrations, its ease of setup, and speed in identifying critical issues across popular SaaS platforms, like files shared publicly in Microsoft 365 and exposed sensitive data in Google Workspace, has made it a go-to for many.
However, as we’ve engaged with customers, one thing became clear: the risks of unmonitored or exposed data at-rest go far beyond just SaaS environments. Sensitive information – whether intellectual property, customer data, or personal identifiers – can wreak havoc on an organization’s reputation and its obligations to its customers if it falls into the wrong hands. For many of our customers, the security of data stored in cloud providers like AWS and GCP is even more critical than the security of data in their SaaS tools.
That’s why we’ve extended Cloudflare CASB to include Cloud DLP (Data Loss Prevention) functionality, enabling users to scan objects in Amazon S3 buckets and Google Cloud Storage for sensitive data matches.
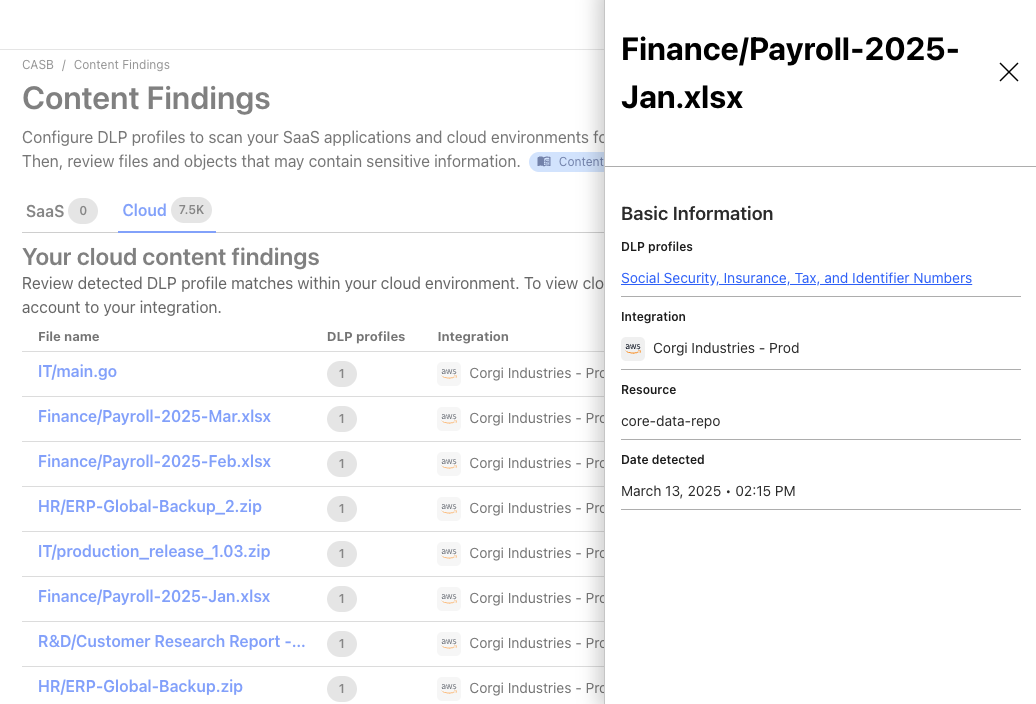
With Cloudflare DLP, you can choose from pre-built detection profiles that look for common data types (such as Social Security Numbers or credit card numbers) or create your own custom profiles using regular expressions. As soon as an object matching a DLP profile is detected, you can dive into the details, understanding the file’s context, seeing who owns it, and more. These capabilities provide the insight needed to quickly protect data and prevent exposure in real time.
And as with all CASB integrations, this new functionality also comes with posture management features, meaning whether you’re using AWS or GCP, we’ll help you identify misconfigurations and other cloud security issues that could leave your data vulnerable, like buckets that are publicly-accessible or have critical logging settings disabled, access keys needing rotation, or users without multi-factor authentication (MFA). It’s all included.
Simple by default, configurable where you want it
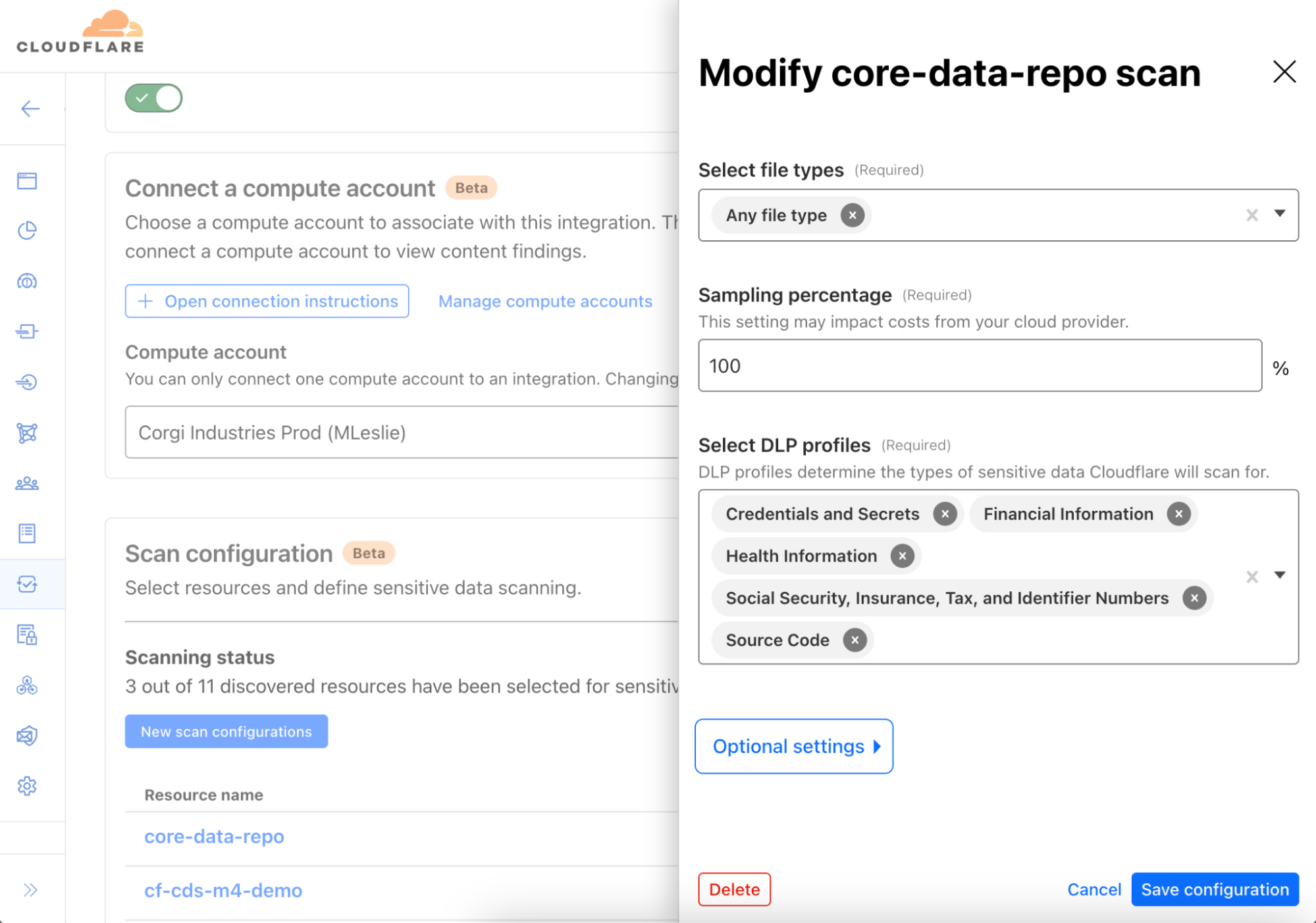
Cloudflare CASB and DLP are simple to use by default, making it easy to get started right away. But it’s also highly configurable, giving you the flexibility to fine-tune the scanning profiles to suit your specific needs.
For example, you can adjust which storage buckets or file types to scan, and even sample only a percentage of objects for analysis. The scanning also runs within your own cloud environment, so your data never leaves your infrastructure. This approach keeps your cloud storage secure and your costs managed while allowing you to tailor the solution to your organization’s unique compliance and security requirements.
Looking ahead, our roadmap also includes expanding support to additional cloud storage environments, such as Azure Blob Storage and Cloudflare R2, further extending our comprehensive, multi-cloud security strategy. Stay tuned for more on that!
How it works
From the start, we knew that to deliver DLP capabilities across cloud environments, it would require an efficient and scalable design to enable real-time detection of sensitive data exposure.
Serverless architecture for streamlined processing
An early design decision was made to leverage a serverless architecture approach to ensure sensitive data discovery is both efficient and scalable. Here’s how it works:
Compute Account: The entire process runs within a cloud account owned by your organization, known as a Compute Account. This design ensures your data remains within your boundaries, avoiding costly cloud egress fees. The Compute Account can be launched in under 15 minutes using a provided Terraform template.
Controller function: Every minute, a lightweight, serverless controller function in your cloud environment communicates with Cloudflare’s APIs, fetching the latest DLP configurations and security profiles from your Cloudflare One account.
Crawler process: The controller triggers an object discovery task, which is processed by a second serverless function known as the Crawler. The Crawler queries cloud storage accounts, like AWS S3 or Google Cloud Storage, via API to identify new objects. Redis is used within the Compute Account to track which objects have yet to be evaluated.
Scanning for sensitive data: Newly discovered objects are sent through a queue to a third serverless function called the Scanner. This function downloads the objects and streams their contents to the DLP engine in the Compute Account, which scans for matches against predefined or custom DLP Profiles.
Finding generation and alerts: If a DLP match is found, metadata about the object, such as context and ownership details, is published to a queue. This data is ingested by a Cloudflare-hosted service and presented in the Cloudflare Dashboard as findings, giving security teams the visibility needed to take swift action.
Scalable and secure design
The DLP pipeline ensures that sensitive data never leaves your cloud environment — a privacy-first approach. All communication between the Compute Account and Cloudflare’s APIs are initiated by the controller, also meaning there is no need to perform any extra configuration to allow ingress traffic.
How to get started
To get started, reach out to your account team to learn more about this new data security functionality and our roadmap. If you want to try this out on your own, you can login to the Cloudflare One dashboard (create a free account here if you don’t have one) and navigate to the CASB page to set up your first integration.
Cloudflare Email Security customers using Microsoft Outlook can now enhance their data protection using our new DLP Assist capability. This application scans emails in real time as users compose them, identifying potential data loss prevention (DLP) violations, such as Social Security or credit card numbers. Administrators can instantly alert users of violations and take action downstream, whether by blocking or encrypting messages, to prevent sensitive information from leaking. DLP Assist is lightweight, easy to deploy, and helps organizations maintain compliance without disrupting workflow.
Making DLP more accessible
After speaking with our customers, we discovered a common challenge: many wanted to implement a data loss prevention policy for Outlook, but found existing solutions either too complex to set up or too costly to adopt.
That’s why we created DLP Assist to be a lightweight application that can be installed in minutes. Unlike other solutions, it doesn’t require changes to outbound email connectors or provide concerns about IP reputation to customers. By fully leveraging the Microsoft ecosystem, DLP Assist makes email DLP accessible to all organizations, whether they have dedicated IT teams or none at all.
We also recognized that traditional DLP solutions often demand significant financial investment in not just software but also in team members to configure and monitor them. DLP Assist aims to eliminate these barriers. Customers can use the application as part of our Email Security product, avoiding the need for additional purchases. Plus, with our DLP engine powered by optical character recognition (OCR), confidence levels, and other detection mechanisms, organizations don’t need a dedicated team to constantly oversee it.
By eliminating the complexities of legacy DLP and email systems, we allow customers to quickly begin preventing the unauthorized egress of sensitive data. With DLP Assist, organizations can be confident in controlling and protecting the information that leaves their environment.
How does it work?
Our DLP Assist is an application that integrates with the Desktop (Mac and Windows) and Web Outlook clients, passively scanning emails as they are composed. Running in the background within Microsoft Outlook, DLP Assist continuously monitors new text and attachments added to emails that users are drafting.
When a customer downloads and installs the application, Cloudflare creates a unique client ID specifically for emails read from the DLP Assist application, which serves as an identifier solely for use by DLP Assist within Cloudflare’s backend. When a user begins drafting a message, the DLP Assist application invokes several Microsoft Outlook APIs to gather information about how the message is changing. These APIs let the Cloudflare application continuously access different parts of the message like subject, body, attachments, etc. While the application is reading the changes within the message, it also establishes a secure, encrypted connection with a Cloudflare Worker.
As raw data about the email and attachments is sent to the Worker, the Worker relays the information to our DLP engine, which is at the heart of our scanning process. It leverages OCR technology to analyze attachments, extract text from images, and detect DLP violations across both email content and embedded data. It also examines raw text to ensure a comprehensive analysis of every part of the email and its attachments. While our engine supports most attachment types, it currently does not process video or audio files.
The DLP engine runs on all of our servers, and we also store the customer DLP profile configuration data on all of our servers. By keeping DLP policy configuration data on all servers alongside our analysis engine, we eliminate the need to reroute requests across our network allowing for low-latency, real-time DLP checks. The customer’s client ID enables us to find and apply their defined DLP profiles and accurately determine policy violations, delivering results directly to the Cloudflare Worker. If a violation is found, the Worker responds to the application to take action within Outlook.
Our architecture ensures real-time scanning with minimal latency, as end users are always near a Cloudflare Worker, regardless of their location. Additionally, this design provides built-in resilience — if a Cloudflare Worker becomes unavailable, another can take over, allowing for uninterrupted DLP enforcement. By scanning in real time, this allows us to provide immediate feedback to the user about any DLP violations that they have within their email, rather than the user having to wait till the message has been sent.
If a violation is detected, the application first displays an insight message — a ribbon notification at the top of the email — alerting the user to the issue. Administrators have full control over this message and can customize it to provide specific guidance or warnings. We find that most of our customers point users to documentation reminding them what is allowed to be sent outside of the organization.
When a DLP violation occurs, DLP Assist also injects a header into the EML file to indicate the violation. If the user removes the content that is in violation, the header is automatically removed as well.
If the violation remains unchanged, DLP Assist invokes a Microsoft Outlook API which prompts the user with a final warning, giving them another opportunity to revise the message before sending.
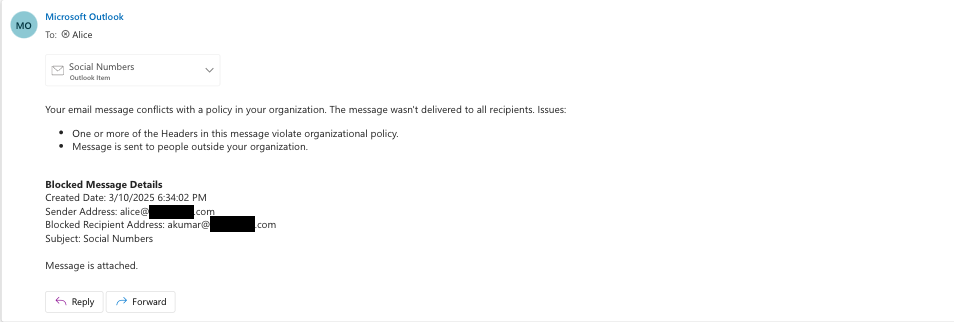
If the user proceeds without making changes, the email will be sent from the client with headers embedded into the EML showing that message contains a DLP violation. Organizations can configure their outbound mail transfer agent (MTA) to take appropriate action based on these headers. For those with Microsoft as their outbound MTA, Cloudflare’s DLP Assist integrates with Microsoft Purview, enabling organizations to block, encrypt, or require approval before sending.
For example, if an organization configures Purview to block the email, users will receive a notification similar to this one.
Violations detected by the DLP Assist application can also be sent externally through our Logpush feature. Customers have the flexibility to integrate this data with SIEM or SOAR platforms for deeper analysis, or store it in bucket storage solutions like Cloudflare R2. Additionally, customers can enhance their reporting capabilities by viewing block data directly within their outbound gateway.
As we continue to improve our DLP engine, we’re introducing more advanced ways to analyze messages. During Security Week 2025, we’re unveiling new AI methodologies that automatically fine-tune DLP confidence levels using machine learning models. Initially, these enhancements will be rolled out for Gateway violations, but we plan to extend them to email scanning in the near future. For more details, see the associated blog post.
Cloudflare One’s DLP Assist is designed for quick deployment, enabling organizations to implement a data loss prevention solution with minimal effort. It allows customers to immediately begin scanning emails for sensitive data and take action to prevent unauthorized sharing, ensuring compliance and security from day one.
How can I start using it?
To get started, navigate to the Zero Trust dashboard and click on the Email Security tab. From there, select the Outbound DLP tab.
To install DLP Assist, organizations can download the manifest file, which provides Microsoft with the necessary instructions to install the application within Outlook. Administrators can then upload this manifest file by going to Integrated Apps within the Microsoft 365 Admin Center and selecting Upload Custom Apps:
This application is best suited for use with OWA (Outlook Web Access) and the desktop (Mac and Windows) Outlook client. Due to Microsoft limitations, a stable experience on mobile devices is not yet available.
We’re continuously expanding our solutions to help organizations protect their data. Exciting new DLP and Email Security features are on the way throughout 2025, so stay tuned for upcoming announcements.
To learn more about our DLP and Email Security solutions, reach out to your Cloudflare representative. Want to see our detections in action? Run a free Retro Scan to uncover any potentially malicious messages hiding in your inbox.
The cryptography that secures the Internet is evolving, and it’s time to catch up. This post is a tutorial on lattice cryptography, the paradigm at the heart of the post-quantum (PQ) transition.
Twelve years ago (in 2013), the revelation of mass surveillance in the US kicked off the widespread adoption of TLS for encryption and authentication on the web. This transition was buoyed by the standardization and implementation of new, more efficient public-key cryptography based on elliptic curves. Elliptic curve cryptography was both faster and required less communication than its predecessors, including RSA and Diffie-Hellman over finite fields.
Today’s transition to PQ cryptography addresses a looming threat for TLS and beyond: once built, a sufficiently large quantum computer can be used to break all public-key cryptography in use today. And we continue to see advancements in quantum-computer engineering that bring us closer to this threat becoming a reality.
Fortunately, this transition is well underway. The research and standards communities have spent the last several years developing alternatives that resist quantum cryptanalysis. For its part, Cloudflare has contributed to this process and is an early adopter of newly developed schemes. In fact, PQ encryption has been available at our edge since 2022 and is used in over 35% of non-automated HTTPS traffic today (2025). And this year we’re beginning a major push towards PQ authentication for the TLS ecosystem.
Lattice-based cryptography is the first paradigm that will replace elliptic curves. Apart from being PQ secure, lattices are often as fast, and sometimes faster, in terms of CPU time. However, this new paradigm for public key crypto has one major cost: lattices require much more communication than elliptic curves. For example, establishing an encryption key using lattices requires 2272 bytes of communication between the client and the server (ML-KEM-768), compared to just 64 bytes for a key exchange using a modern elliptic-curve-based scheme (X25519). Accommodating such costs requires a significant amount of engineering, from dealing with TCP packet fragmentation, to reworking TLS and its public key infrastructure. Thus, the PQ transition is going to require the participation of a large number of people with a variety of backgrounds, not just cryptographers.
The primary audience for this blog post is those who find themselves involved in the PQ transition and want to better understand what’s going on under the hood. However, more fundamentally, we think it’s important for everyone to understand lattice cryptography on some level, especially if we’re going to trust it for our security and privacy.
We’ll assume you have a software-engineering background and some familiarity with concepts like TLS, encryption, and authentication. We’ll see that the math behind lattice cryptography is, at least at the highest level, not difficult to grasp. Readers with a crypto-engineering background who want to go deeper might want to start with the excellent tutorial by Vadim Lyubashevsky on which this blog post is based. We also recommend Sophie Schmieg’s blog on this subject.
While the transition to lattice cryptography incurs costs, it also creates opportunities. Many things we can build with elliptic curves we can also build with lattices, though not always as efficiently; but there are also things we can do with lattices that we don’t know how to do efficiently with anything else. We’ll touch on some of these applications at the very end.
We’re going to cover a lot of ground in this post. If you stick with it, we hope you’ll come away feeling empowered, not only to tackle the engineering challenges the PQ transition entails, but to solve problems you didn’t know how to solve before.
Strap in — let’s have some fun!
Encryption
The most pressing problem for the PQ transition is to ensure that tomorrow’s quantum computers don’t break today’s encryption. An attacker today can store the packets exchanged between your laptop and a website you visit, and then, some time in the future, decrypt those packets with the help of a quantum computer. This means that much of the sensitive information transiting the Internet today — everything from API tokens and passwords to database encryption keys — may one day be unlocked by a quantum computer.
In fact, today’s encryption in TLS is mostly PQ secure: what’s at risk is the process by which your browser and a server establish an encryption key. Today this is usually done with elliptic-curve-based schemes, which are not PQ secure; our goal for this section is to understand how to do key exchange with lattices-based schemes, which are.
We will work through and implement a simplified version of ML-KEM, a.k.a. Kyber, the most widely deployed PQ key exchange in use today. Our code will be less efficient and secure than a spec-compliant, production-quality implementation, but will be good enough to grasp the main ideas.
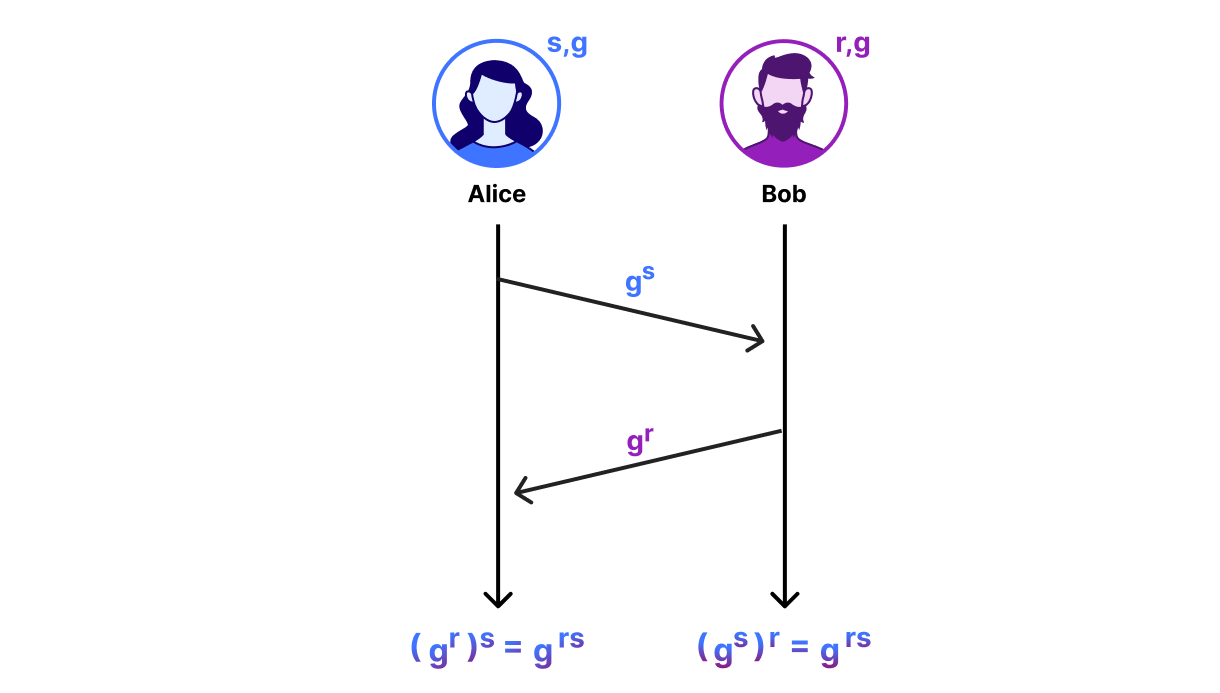
Our starting point is a protocol that looks an awful lot like Diffie-Hellman (DH) key exchange. For those readers unacquainted with DH, the goal is for Alice and Bob to establish a shared secret over an insecure network. To do so, each picks a random secret number, computes the corresponding “key share”, and sends the key share to the other:
Alice’s secret number is $s$ and her key share is $g^s$; Bob’s secret number is $r$ and his key share is $g^r$. Then given their secret and their peer’s key share, each can compute $g^{rs}$. The security of this protocol comes from how we choose $g$, $s$, and $r$ and how we do arithmetic. The most efficient instantiation of DH uses elliptic curves.
In ML-KEM we replace operations on elliptic curves with matrix operations. It’s not quite a drop-in replacement, so we’ll need a little linear algebra to make sense of it. But don’t worry: we’re going to work with Python so we have running code to play with, and we’ll use NumPy to keep things high level.
All the math we’ll need
A matrix is just a two-dimensional array of numbers. In NumPy, we can create a matrix as follows (importing numpy as np):
A = np.matrix([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
This defines A to be the 3-by-3 matrix with entries A[0,0]==1, A[0,1]==2, A[0,2]==3, A[1,0]==4, and so on.
For the purposes of this post, the entries of our matrices will always be integers. Furthermore, whenever we add, subtract, or multiply two integers, we then reduce the result, just like we do with hours on a clock, so that we end up with a number in range(Q) for some positive number Q, called the modulus. The exact value doesn’t really matter now, but for ML-KEM it’s Q=3329, so let’s go with that for now. (The modulus for a clock would be Q=12.)
In Python, we write multiplication of integers a and b modulo Q as c = a*b % Q. Here we compute a*b, divide the result by Q, then set c to the remainder. For example, 42*1337% Q is equal to 2890 rather than 56154. Modular addition and subtraction are done analogously. For the rest of this blog, we will sometimes omit “% Q” when it’s clear in context that we mean modular arithmetic.
Next, we’ll need three operations on matrices.
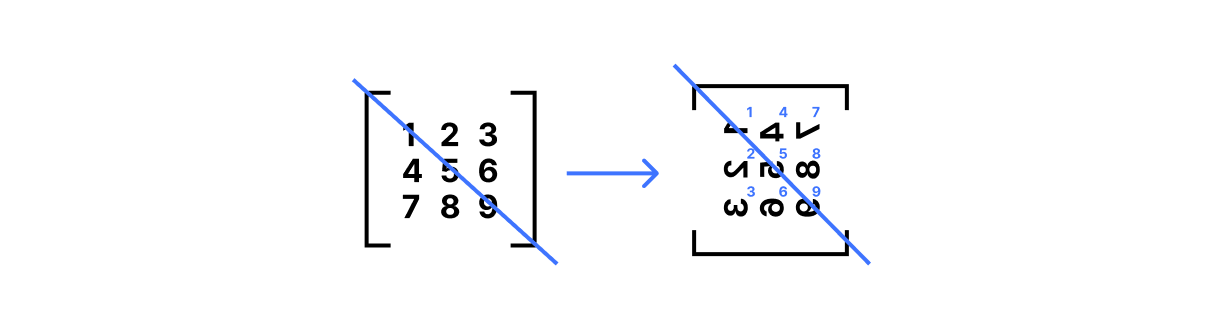
The first is matrix transpose, written A.T in NumPy. This operation flips the matrix along its diagonal so that A.T[j,i] == A[i,j] for all rows i and columns j:
print(A.T)
# [[1 4 7]
# [2 5 8]
# [3 6 9]]
To visualize this, imagine writing down a matrix on a translucent piece of paper. Draw a line from the top left corner to the bottom right corner of that paper, then rotate the paper 180° around that line:
The second operation we’ll need is matrix multiplication. Normally, we will multiply a matrix by a column vector, which is just a matrix with one column. For example, the following 3-by-1 matrix is a column vector:
s = np.matrix([[0],
[1],
[0]])
We can also write s more concisely as np.matrix([[0,1,0]]).T. To multiply a square matrix A by a column vector s, we compute the dot product of each row of A with s. That is, if t = A*s % Q, then t[i] == (A[i,0]*s[0,0] + A[i,1]*s[1,0] + A[i,2]*s[2,0]) % Q for each row i. The output will always be a column vector:
print(A*s % Q)
# [[2]
# [5]
# [8]]
The number of rows of this column vector is equal to the number of rows of the matrix on the left hand side. In particular, if we take our column vector s, transpose it into a 1-by-3 matrix, and multiply it by a 3-by-1 matrix r, then we end up with a 1-by-1 matrix:
r = np.matrix([[1,2,3]]).T
print(s.T*r % Q)
# [[2]]
The final matrix operation we’ll need is matrix addition. If A and B are both N-by-M matrices, then C = (A+B) % Q is the N-by-M matrix for which C[i,j] == (A[i,j]+B[i,j]) % Q. Of course, this only works if the matrices we’re adding have the same dimensions.
Warm up
Enough maths — let’s get to exchanging some keys. We start with the DH diagram from before and swap out the computations with matrix operations. Note that this protocol is not secure, but will be the basis of a secure key exchange mechanism we’ll develop in the next section:
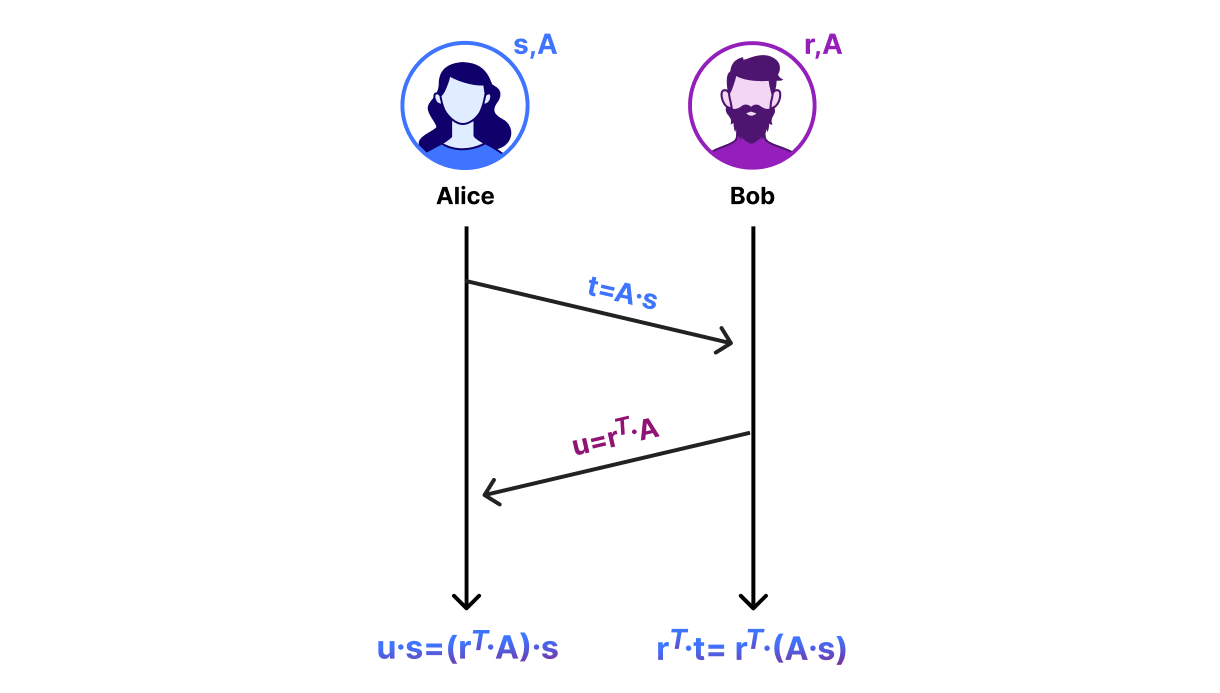
Alice and Bob agree on a public, N-by-N matrix A. This is analogous to the number $g$ that Alice and Bob agree on in the DH diagram.
Alice chooses a random length-N vector s and sends t = A*s % Q to Bob.
Bob chooses a random length-N vector r and sends u = r.T*A % Q to Alice. You can also compute this as (A.T*r).T % Q.
The vectors t and u are analogous to DH key shares. After the exchange of these key shares, Alice and Bob can compute a shared secret. Alice computes the shared secret as u*s % Q and Bob computes the shared secret as r.T*t % Q. To see why they compute the same key, notice that u*s == (r.T*A)*s == r.T*(A*s) == r.T*t.
In fact, this key exchange is essentially what happens in ML-KEM. However, we don’t use this directly, but rather as part of a public key encryption scheme. Public key encryption involves three algorithms:
key_gen(): The key generation algorithm that outputs a public encryption key pk and the corresponding secret decryption key sk.
encrypt(): The encryption algorithm that takes the public key and a plaintext and outputs a ciphertext.
decrypt(): The decryption algorithm that takes the secret key and a ciphertext and outputs the underlying plaintext. That is, decrypt(sk, encrypt(pk, ptxt)) == ptxt for any plaintext ptxt.
We’ll say the scheme is secure if, given a ciphertext and the public key used to encrypt it, no attacker can discern any information about the underlying plaintext without knowledge of the secret key. Once we have this encryption scheme, we then transform it into a key-encapsulation mechanism (the “KEM” in “ML-KEM”) in the last step. A KEM is very similar to encryption except that the plaintext is always a randomly generated key.
Our encryption scheme is as follows:
key_gen(): To generate a key pair, we choose a random, square matrix A and a random column vector s. We set our public key to (A,t=A*s % Q) and our secret key to s. Notice that t is Alice’s key share from the key exchange protocol above.
encrypt(): Suppose our plaintext ptxt is an integer in range(Q). To encrypt ptxt, Bob generates his key share u. He then derives the shared secret and adds it to ptxt. The ciphertext has two components:
u = r.T*A % Q
v = (r.T*t + m) % Q
Here m is a 1-by-1 matrix containing the plaintext, i.e., m = np.matrix([[ptxt]]), and r is a random column vector.
decrypt(): To decrypt, Alice computes the shared secret and subtracts it from v:
m = (v - u*s) % Q
Some readers will notice that this looks an awful lot like El Gamal encryption. This isn’t a coincidence. Good cryptographers roll their own crypto; great cryptographers steal from good cryptographers.
Let’s now put this together into code. The last thing we’ll need is a method of generating random matrices and column vectors. We call this function gen_mat() below. Take a crack at implementing this yourself. Our scheme has two parameters: the modulus Q; and the dimension of N of the matrix and column vectors. The choice of N matters for security, but for now feel free to pick whatever value you want.
def key_gen():
# Here `gen_mat()` returns an N-by-N matrix with entries
# randomly chosen from `range(0, Q)`.
A = gen_mat(N, N, 0, Q)
# Like above except the matrix is N-by-1.
s = gen_mat(N, 1, 0, Q)
t = A*s % Q
return ((A, t), s)
def encrypt(pk, ptxt):
(A, t) = pk
m = np.matrix([[ptxt]])
r = gen_mat(N, 1, 0, Q)
u = r.T*A % Q
v = (r.T*t + m) % Q
return (u, v)
def decrypt(sk, ctxt):
s = sk
(u, v) = ctxt
m = (v - u*s) % Q
return m[0,0]
# Test
assert decrypt(sk, encrypt(pk, 1)) == 1
Making the scheme secure (or “What is a lattice?”)
By now, you might be wondering what on Earth a lattice even is. We promise we’ll define it, but before we do, it’ll help to understand why our warm-up scheme is insecure and what it’ll take to fix it.
Readers familiar with linear algebra may already see the problem: in order for this scheme to be secure, it should be impossible for the attacker to recover the secret key s; but given the public (A,t), we can immediately solve for s using Gaussian elimination.
In more detail, if A is invertible, we can write the secret key as A-1*t == A-1*(A*s) == (A-1*A)*s == s, where A-1 is the inverse of A. (When you multiply a matrix by its inverse, you get the identity matrix I, which simply takes a column vector to itself, i.e., I*s == s.) We can use Gaussian elimination to compute this matrix. Intuitively, all we’re doing is solving a set of linear equations, where the entries of s are the unknown variables. (Note that this is possible even if A is not invertible.)
In order to make this encryption scheme secure, we need to make it a little… “messier”.
Let’s get messy
For starters, we need to make it hard to recover the secret key from the public key. Let’s try the following: generate another random vector e and add it into A*s. Our key generation algorithm becomes:
def key_gen():
A = gen_mat(N, N, 0, Q)
s = gen_mat(N, 1, 0, Q)
e = gen_mat(N, 1, 0, Q)
t = (A*s + e) % Q
return ((A, t), s)
Our formula for the column vector component of the public key, t, now includes an additive term e, which we’ll call the error. Like the secret key, the error is just a random vector.
Notice that the previous attack no longer works: since A-1*t == A-1*(A*s + e) == A-1*(A*s) + A-1*e == s + A-1*e, we need to know e in order to compute s.
Great, but this patch creates another problem. Take a second to plug in this new key generation algorithm into your implementation and test it out. What happens?
You should see that decrypt() now outputs garbage. We can see why using a little algebra:
(v - u*s) == (r.T*t + m) - (r.T*A)*s
== r.T*(A*s + e) + m - (r.T*A)*s
== r.T*(A*s) + r.T*e + m - r.T*(A*s)
== r.T*e + m
The entries of r and e are sampled randomly, so r.T*e is also uniformly random. It’s as if we encrypted m with a one-time pad, then threw away the one-time pad!
Handling decryption errors
What can we do about this? First, it would help if r.T*e were small so that decryption yields something that’s close to the plaintext. Imagine we could generate r and e in such a way that r.T*e were in range(-epsilon, epsilon+1) for some small epsilon. Then decrypt would output a number in range(ptxt-epsilon, ptxt+epsilon+1), which would be pretty close to the actual plaintext.
However, we need to do better than get close. Imagine your browser failing to load your favorite website one-third of the time because of a decryption error. Nobody has time for that.
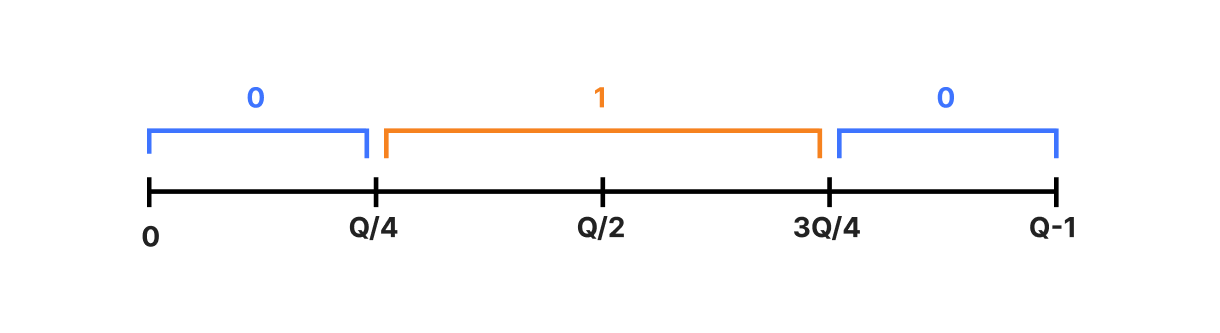
ML-KEM reduces the probability of decryption errors by being clever about how we encode the plaintext. Suppose all we want to do is encrypt a single bit, i.e., ptxt is either 0 or 1. Consider the numbers in range(Q), and split the number line into four chunks of roughly equal length:
Here we’ve labeled the region around zero (-Q/4 to Q/4 modulo Q) with ptxt=0 and the region far away from zero with ptxt=1. To encode the bit, we set it to the integer corresponding to the middle of its range, i.e., m = np.matrix([[ptxt * Q//2]]). (Note the double “//” — this denotes integer division in Python.) To decode, we choose the ptxt corresponding to whatever range m[0,0] is in. That way if the decryption error is small, then we’re highly likely to end up in the correct range.
Now all that’s left is to ensure the decryption error, r.T*e, is small. We do this by sampling short vectors r and e. By “short” we mean the entries of these vectors are sampled from a range that is much smaller than range(Q). In particular, we’ll pick some small positive integer beta and sample entries range(-beta,beta+1).
How do we choose beta? Well, it should be small enough that decryption succeeds with overwhelming probability, but not so small that r and e are easy to guess and our scheme is broken. Take a minute or two to play with this. The parameters we can vary are:
the modulus Q
the dimension of the column vectors N
the shortness parameter beta
For what ranges of these parameters is the decryption error low but the secret vectors are hard to guess? For what ranges is our scheme most efficient, in terms of runtime and communication cost (size of the public key plus the ciphertext)? We’ll give a concrete answer at the end of this section, but in the meantime, we encourage you to play with this a bit.
Gauss strikes back
At this point, we have a working encryption scheme that mitigates at least one key-recovery attack. We’ve come pretty far, but we have at least one more problem.
Take another look at our formula for the ciphertext ctxt = (u,v). What would happen if we managed to recover the random vector r? That would be catastrophic, since v == r.T*t + m, and we already know t (part of the public key) and v (part of the ciphertext).
Just as we were able to compute the secret key from the public key in our initial scheme, we can recover the encryption randomness r from the ciphertext component u using Gaussian elimination. Again, this is just because r is the solution to a system of linear equations.
We can mitigate this plaintext-recovery attack just as before, by adding some noise. In particular, we’ll generate a short vector according to gen_mat(N,1,-beta,beta+1) and add it into u. We also need to add noise to v in the same way, for reasons that we’ll discuss in the next section.
Once again, adding noise increases the probability of a decryption error, but this time the magnitude of the error also depends on the secret key s. To see this, recall that during decryption, we multiply u by s (to compute the shared secret), and the error vector is an additive term. We’ll therefore need s to be a short vector as well.
Let’s now put together everything we’ve learned into an updated encryption scheme. Our scheme now has three parameters, Q, N, and beta, and can be used to encrypt a single bit:
def key_gen():
A = gen_mat(N, N, 0, Q)
s = gen_mat(N, 1, -beta, beta+1)
e1 = gen_mat(N, 1, -beta, beta+1)
t = (A*s + e1) % Q
return ((A, t), s)
def encrypt(pk, ptxt):
(A, t) = pk
m = np.matrix([[ptxt*(Q//2) % Q]])
r = gen_mat(N, 1, -beta, beta+1)
e2 = gen_mat(N, 1, -beta, beta+1)
e3 = gen_mat(1, 1, -beta, beta+1)
u = (r.T*A + e2) % Q
v = (r.T*t + e3 + m) % Q
return (u, v)
def decrypt(sk, ctxt):
s = sk
(u, v) = ctxt
m = (v - u*s) % Q
if m[0,0] in range(Q//4, 3*Q//4):
return 1
return 0
# Test
assert decrypt(sk, encrypt(pk, 0)) == 0
assert decrypt(sk, encrypt(pk, 1)) == 1
Before moving on, try to find parameters for which the scheme works and for which the secret and error vectors seem hard to guess.
Learning with errors
So far we have a functioning encryption scheme for which we’ve mitigated two attacks, one a key-recovery attack and the other a plaintext-recovery attack. There seems to be no other obvious way of breaking our scheme, unless we choose parameters that are so weak that an attacker can easily guess the secret key s or ciphertext randomness r. Again, these vectors need to be short in order to prevent decryption errors, but not so short that they are easy to guess. (Likewise for the error terms.)
Still, there may be other attacks that require a little more sophistication to pull off. For instance, there might be some mathematical analysis we can do to recover, or at least make a good guess of, a portion of the ciphertext randomness. This raises a more fundamental question: in general, how do we establish that cryptosystems like this are actually secure?
As a first step, cryptographers like to try and reduce the attack surface. Modern cryptosystems are designed so that the problem of attacking the scheme reduces to solving some other problem that is easier to reason about.
Our public key encryption scheme is an excellent illustration of this idea. Think back to the key- and plaintext-recovery attacks from the previous section. What do these attacks have in common?
In both instances, the attacker knows some public vector that allowed it to recover a secret vector:
In the key-recovery attack, the attacker knew t for which A*s == t.
In the plaintext-recovery attack, the attacker knew u for which r.T*A == u (or, equivalently, A.T*r == u.T).
The fix in both cases was to construct the public vector in such a manner that it is hard to solve for the secret, namely, by adding an error term. However, ideally the public vector would reveal no information about the secret whatsoever. This ideal is formalized by the Learning With Errors (LWE) problem.
The LWE problem asks the attacker to distinguish between two distributions. Concretely, imagine we flip a coin, and if it comes up heads, we sample from the first distribution and give the sample to the attacker; and if the coin comes up tails, we sample from the second distribution and give the sample to the attacker. The distributions are as follows:
(A,t=A*s + e) where A is a random matrix generated with gen_mat(N,N,0,Q) and s and e are short vectors generated with gen_mat(N,1,-beta,beta+1).
(A,t) where A is a random matrix generated with gen_mat(N,N,0,Q) and t is a random vector generated with gen_mat(N,1,0,Q).
The first distribution corresponds to what we actually do in the encryption scheme; in the second, t is just a random vector, and no longer a secret vector at all. We say that the LWE problem is “hard” if no attacker is able to guess the coin flip with probability significantly better than one-half.
Our encryption is passively secure — meaning the ciphertext doesn’t leak any information about the plaintext — if the LWE problem is hard for the parameters we chose. To see why, notice that both the public key and ciphertext look like LWE instances; if we can replace each instance with an instance of the random distribution, then the ciphertext would be completely independent of the plaintext and therefore leak no information about it at all. Note that, for this argument to go through, we also have to add the error term e3 to the ciphertext component v.
Choosing the parameters
We’ve established that if solving the LWE problem is hard for parameters N, Q, and beta, then so is breaking our public key encryption scheme. What’s left for us to do is tune the parameters so that solving LWE is beyond the reach of any attacker we can think of. This is where lattices come in.
Lattices
A lattice is an infinite grid of points in high-dimensional space. A two-dimensional lattice might look something like this:
The points always follow a clear pattern that resembles “lattice work” you might see in a garden:
For cryptography, we care about a special class of lattices, those defined by a matrix P that “recognizes” points in the lattice. That is, the lattice recognized by P is the set of vectors v for which P*v == 0, where “0” denotes the all-zero vector. The all-zero vector is np.zeros((N,1), dtype=int) in NumPy.
Readers familiar with linear algebra may have a different definition of lattices in mind: in general, a lattice is the set of points obtained by taking linear combinations of some basis. Our lattices can also be formulated in this way, i.e., for a matrix P that recognizes a lattice, we can compute the basis vectors that generate the lattice. However, we don’t much care about this representation here.
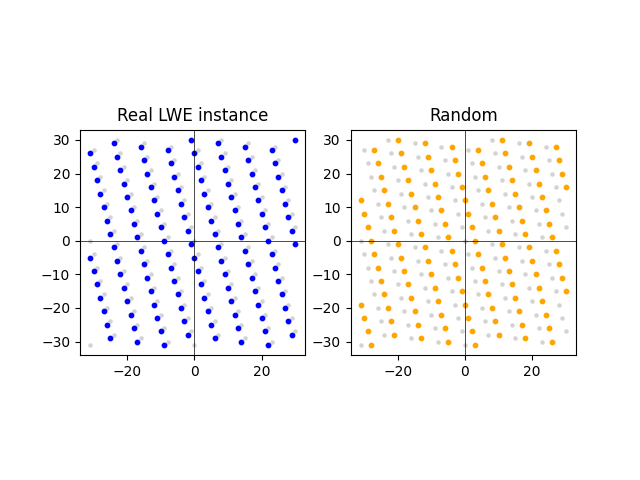
The LWE problem boils down to distinguishing a set of points that are “close to” the lattice from a set of points that are “far away from” the lattice. We construct these points from an LWE instance and a random (A,t) respectively. Here we have an LWE sample (left) and a sample from the random distribution (right):
What this shows is that the points of the LWE instance are much closer to the lattice than the random instance. This is indeed the case on average. However, while distinguishing LWE instances from random is easy in two dimensions, it gets harder in higher dimensions.
Let’s take a look at how we construct these points. First, let’s take an LWE instance (A,t=(A*s + e) % Q) and consider the lattice recognized by the matrix P we get by concatenating A with the identity matrix I. This might look something like this (N=3):
Let z denote this vector and consider the set of points v for which P*v == t. By definition, we say this set of points is “close to” the lattice because z is a short vector. (Remember: by “short” we mean its entries are bounded around 0 by beta.)
Now consider a random (A,t) and consider the set of points v for which P*v == t. We won’t prove it, but it is a fact that this set of points is likely to be “far away from” the lattice in the sense that there is no short vector z for which P*z == t.
Intuitively, solving LWE gets harder as z gets longer. Indeed, increasing the average length of z (by making beta larger) increases the average distance to the lattice, making it look more like a random instance:
On the other hand, making z too long creates another problem.
Breaking lattice cryptography by finding short vectors
Given a random matrix A, the Short Integer Solution (SIS) problem is to find short vectors (i.e., whose entries are bounded by beta) z1 and z2 for which (A*z1 + z2) % Q is zero. Notice that this is equivalent to finding a short vector z in the lattice recognized by P:
z = np.concatenate((z1, z2))
assert np.array_equal((A*z1 + z2) % Q, P*z % Q)
If we had a (quantum) computer program for solving SIS, then we could use this program to solve LWE as well: if (A,t) is an LWE instance, then z1.T*t will be small; otherwise, if (A,t) is random, then z1.T*t will be uniformly random. (You can convince yourself of this using a little algebra.) Therefore, in order for our encryption scheme to be secure, it must be hard to find short vectors in the lattice defined by those parameters.
Intuitively, finding long vectors in the lattice is easier than finding short ones, which means that solving the SIS problem gets easier as beta gets closer to Q. On the other hand, as beta gets closer to 0, it gets easier to distinguish LWE instances from random!
This suggests a kind of Goldilocks zone for LWE-based encryption: if the secret and noise vectors are too short, then LWE is easy; but if the secret and noise vectors are too long, then SIS is easy. The optimal choice is somewhere in the middle.
Enough math, just give me my parameters!
To tune our encryption scheme, we want to choose parameters for which the most efficient known algorithms (quantum or classical) for solving LWE are out of reach for any attacker with as many resources as we can imagine (and then some, in case new algorithms are discovered). But how do we know which attacks to look out for?
Fortunately, the community of expert lattice cryptographers and cryptanalysts maintains a tool called lattice-estimator that estimates the complexity of the best known (quantum) algorithms for lattice problems relevant to cryptography. Here’s what we get when we run this tool for ML-KEM (this requires Sage to run):
The number that we’re most interested in is “rop“, which estimates the amount of computation the attack would consume. Playing with this tool a bit, we eventually find some parameters for our scheme for which the “usvp” and “dual_hybrid” attacks have comparable complexity. However, lattice-estimator identifies an attack it calls “arora-gb” that applies to our scheme, but not to ML-KEM, that has much lower complexity. (N=600, Q=3329, and beta=4):
We’d have to bump the parameters even further to the scheme to a regime that has comparable security to ML-KEM.
Finally, a word of warning: when designing lattice cryptography, determining whether our scheme is secure requires a lot more than estimating the cost of generic attacks on our LWE parameters. In the absence of a mathematical proof of security in a realistic adversarial model, we can’t rule out other ways of breaking our scheme. Tread lightly, fair traveler, and bring a friend along for the journey.
Making the scheme efficient
Now that we understand how to encrypt with LWE, let’s take a quick look at how to make our scheme efficient.
The main problem with our scheme is that we can only encrypt a bit at a time. This is because we had to split the range(Q) into two chunks, one that encodes 1 and another that encodes 0. We could improve the bit rate by splitting the range into more chunks, but this would make decryption errors more likely.
Another problem with our scheme is that the runtime depends heavily on our security parameters. Encryption requires O(N2) multiplications (multiplication is the most expensive part of a secure implementation of modular arithmetic), and in order for our scheme to be secure, we need to make N quite large.
ML-KEM solves both of these problems by replacing modular arithmetic with arithmetic over a polynomial ring. This means the entries of our matrices will be polynomials rather than integers. We need to define what it means to add, subtract, and multiply polynomials, but once we’ve done that, everything else about the encryption scheme is the same.
In fact, you probably learned polynomial arithmetic in grade school. The only thing you might not be familiar with is polynomial modular reduction. To multiply two polynomials $f(X)$ and $g(X)$, we start by multiplying $f(X)\cdot g(X)$ as usual. Then we’re going to divide $f(X)\cdot g(X)$ by some special polynomial — ML-KEM uses $X^{256}+1$ — and take the remainder. We won’t try to explain this algorithm, but the takeaway is that the result is a polynomial with $256$ coefficients, each of which is an integer in range(Q).
The main advantage of using a polynomial ring for arithmetic is that we can pack more bits into the ciphertext. Our formula for the ciphertext is exactly the same (u=r.T*A + e2, v=r.T*t + e3 + m), but this time the plaintext m encodes a polynomial. Each coefficient of the polynomial encodes a bit, and we’ll handle decryption errors just as we did before, by splitting range(Q) into two chunks, one that encodes 1 and another that encodes 0. This allows us to reliably encrypt 256 bits (32 bytes) per ciphertext.
Another advantage of using polynomials is that it significantly reduces the dimension of the matrix without impacting security. Concretely, the most widely used variant of ML-KEM, ML-KEM-768, uses a 3-by-3 matrix A, so just 9 polynomials in total. (Note that $256 \cdot 3 = 768$, hence the name “ML-KEM-768”.) However, note that we have to be careful in how we choose the modulus: $X^{256}+1$ is special in that it does not exhibit any algebraic structure that is known to permit attacks.
The choices of Q=3329 for the coefficient modulus and $X^{256}+1$ for the polynomial modulus have one more benefit. They allow polynomial multiplication to be carried out using the NTT algorithm, which massively reduces the number of multiplications and additions we have to perform. In fact, this optimization is a major reason why ML-KEM is sometimes faster in terms of CPU time than key exchange with elliptic curves.
We won’t get into how NTT works here, except to say that the algorithm will look familiar to you if you’ve ever implemented RSA. In both cases we use the Chinese Remainder Theorem to split multiplication up into multiple, cheaper multiplications with smaller moduli.
From public key encryption to ML-KEM
The last step to build ML-KEM is to make the scheme secure against chosen ciphertext attacks (CCA). Currently, it’s only secure against chosen plaintext attacks (CPA), which basically means that the ciphertext leaks no information about the plaintext, regardless of the distribution of plaintexts. CCA security is stronger in that it gives the attacker access to decryptions of ciphertexts of its choosing. (Of course, it’s not allowed to decrypt the target ciphertext itself.) The specific transform used in ML-KEM results in a CCA-secure KEM (“Key-Encapsulation Mechanism”).
Chosen ciphertext attacks might seem a bit abstract, but in fact they formalize a realistic threat model for many applications of KEMs (and public key encryption for that matter). For example, suppose we use the scheme in a protocol in which the server authenticates itself to a client by proving it was able to decrypt a ciphertext generated by the client. In this kind of protocol, the server acts as a sort of “decryption oracle” in which its responses to clients depend on the secret key. Unless the scheme is CCA secure, this oracle can be abused by an attacker to leak information about the secret key over time, allowing it to eventually impersonate the server.
ML-KEM incorporates several more optimizations to make it as fast and as compact as possible. For example, instead of generating a random matrix A, we can derive it from a random, 32-byte string (called a “seed”) using a hash-based primitive called a XOF (“eXtendable Output Function”), in the case of ML-KEM this XOF is SHAKE128. This significantly reduces the size of the public key.
Another interesting optimization is that the polynomial coefficients (integers in range(Q)) in the ciphertext are compressed by rounding off the least significant bits of each coefficient, thereby reducing the overall size of the ciphertext.
All told, for the most widely deployed parameters (ML-KEM-768), the public key is 1184 bytes and the ciphertext is 1088 bytes. There’s no obvious way to reduce this, except by reducing the size of the encapsulated key or the size of the public matrix A. The former would make ML-KEM useful for fewer applications, and the latter would reduce the security margin.
Note that there are other lattice schemes that are smaller, but they are based on different hardness assumptions and are still undergoing analysis.
Authentication
In the previous section, we learned about ML-KEM, the algorithm already in use to make encryption PQ-secure. However, encryption is only one piece of the puzzle: establishing a secure connection also requires authenticating the server — and sometimes the client, depending on the application.
Authentication is usually provided by a digital signature scheme, which uses a secret key to sign a message and a public key to verify the signature. The signature schemes used today aren’t PQ-secure: a quantum computer can be used to compute the secret key corresponding to a server’s public key, then use this key to impersonate the server.
While this threat is less urgent than the threat to encryption, mitigating it is going to be more complicated. Over the years, we’ve bolted a number of signatures onto the TLS handshake in order to meet the evolving requirements of the web PKI. We have PQ alternatives for these signatures, one of which we’ll study in this section, but so far these signatures and their public keys are too large (i.e., take up too many bytes) to make comfortable replacements for today’s schemes. Barring some breakthrough in NIST’s ongoing standardization effort, we will have to re-engineer TLS and the web PKI to use fewer signatures.
For now, let’s dive into the PQ signature scheme we’re likely to see deployed first: ML-DSA, a.k.a. Dillithium. The design of ML-DSA follows a similar template as ML-KEM. We start by building some intermediate primitive, then we transform that primitive into the primitive we want, in this case a signature scheme.
ML-DSA is quite a bit more involved than ML-KEM, so we’re going to try to boil it down even further and just try to get across the main ideas.
Warm up
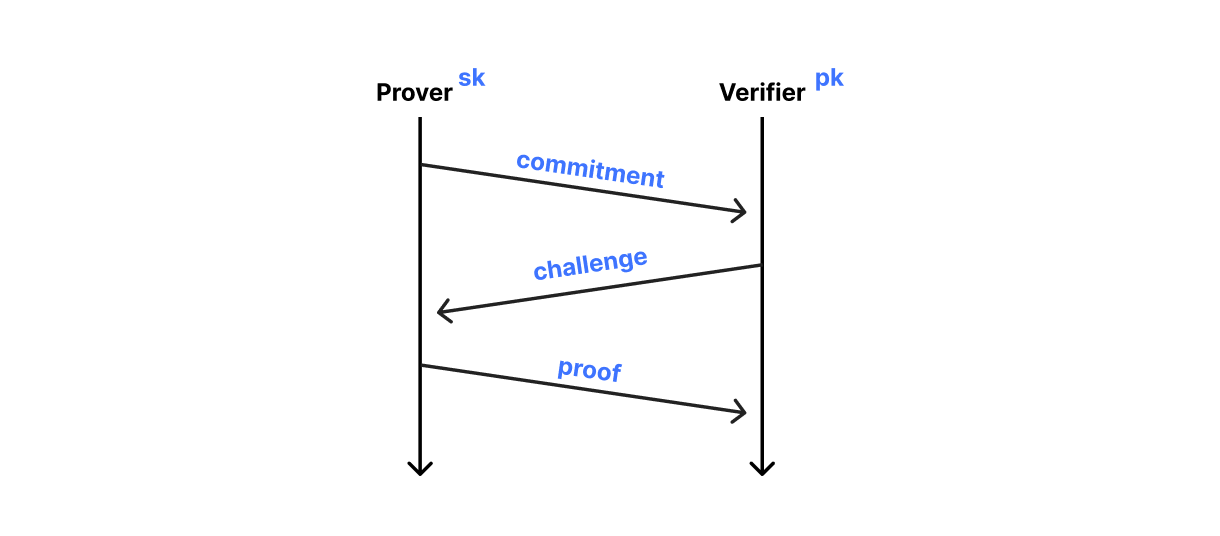
Whereas ML-KEM is basically El Gamal encryption with elliptic curves replaced with lattices, ML-DSA is basically the Schnorr identification protocol with elliptic curves replaced with lattices. Schnorr’s protocol is used by a prover to convince a verifier that it knows the secret key associated with its public key without revealing the secret key itself. The protocol has three moves and is executed with four algorithms:
initialize(): The prover initializes the protocol and sends a commitment to the verifier
challenge(): The verifier receives the commitment and sends the prover a challenge
finish(): The prover receives the challenge and sends the verifier the proof
verify(): Finally, the verifier uses the proof to decide whether the prover knows the secret key
We get the high-level structure of ML-DSA by making this protocol non-interactive. In particular, the prover derives the challenge itself by hashing the commitment together with the message to be signed. The signature consists of the commitment and proof: to verify the signature, the verifier recomputes the challenge from the commitment and message and runs verify()as usual.
Let’s jump right in to building Schnorr’s identification protocol from lattices. If you’ve never seen this protocol before, then this will look a little like black magic at first. We’ll go through it slowly enough to see how and why it works.
Just like for ML-KEM, our public key is an LWE instance (A,t=A*s1 + s2). However, this time our secret key is the pair of short vectors (s1,s2), i.e., it includes the error term. Otherwise, key generation is exactly the same:
To initialize the protocol, the prover generates another LWE instance (A,w=A*y1 + y2). You’ll see why in just a moment. The prover sends the hash of w as its commitment:
Here H is some cryptographic hash function, like SHA-3. The prover stores the secret vectors (y1,y2) for use in its next move.
Now it’s time for the verifier’s challenge. The challenge is just an integer, but we need to be careful about how we choose it. For now let’s just pick it at random:
def challenge():
return random.randrange(0, Q)
Remember: when we turn this protocol into a digital signature, the challenge is derived from the commitment, H(w), and the message. The range of this hash function must be the same as the set of outputs of challenge().
Now comes the fun part. The proof is a pair of vectors (z1,z2) satisfying A*z1 + z2 == c*t + w. We can easily produce this proof if we know the secret key:
z1 = (c*s1 + y1) % Q
z2 = (c*s2 + y2) % Q
Then A*z1 + z2 == A*(c*s1 + y1) + (c*s2 + y2) == c*(A*s1 + s2) + (A*y1 + y2) == c*t + w. Our goal is to design the protocol such that it’s hard to come up with (z1,z2) without knowing (s1,s2), even after observing many executions of the protocol.
Here are the finish() and verify() algorithms for completeness:
Notice that the verifier doesn’t actually check A*z1 + z2 == c*t + w directly; we have to rearrange the equation so that we can set the commitment to H(w) rather than w. We’ll explain the need for hashing in the next section.
Making this scheme secure
The question of whether this protocol is secure boils down to whether it’s possible to impersonate the prover without knowledge of the secret key. Let’s put our attacker hat on and poke around.
Perhaps there’s a way to compute the secret key, either from the public key directly or by eavesdropping on executions of the protocol with the honest prover. If LWE is hard, then clearly there’s no way we’re going to extract the secret key from the public key t. Likewise, the commitment H(w)doesn’t leak any information that would help us extract the secret key from the proof (z1,z2).
Let’s take a closer look at the proof. Notice that the vectors (y1,y2) “mask” the secret key vectors, sort of how the shared secret masks the plaintext in ML-KEM. However, there’s one big exception: we also scale the secret key vectors by the challenge c.
What’s the effect of scaling these vectors? If we squint at a few proofs, we start to see a pattern emerge. Let’s look at z1 first (N=3, Q=3329, beta=4):
Indeed, with enough proof samples, we should be able to make a pretty good guess of the value of s1. In fact, for these parameters, there is a simple statistical analysis we can do to compute s1 exactly. (Hint: Q is a prime number, which means c*pow(c,-1,Q)==1 whenever c>0.) We can also apply this analysis to s2, or compute it directly from t, s1, and A.
The main flaw in our protocol is that, although our secret vectors are short, scaling them makes them so long that they’re not completely masked by (y1,y2). Since c spans the entire range(Q), so do the entries of c*s1. and c*s2, which means in order to mask these entries, we need the entries of (y1,y2) to span range(Q) as well. However, doing this would make solving LWE for (A,w) easy, by solving SIS. We somehow need to strike a balance between the length of the vectors of our LWE instances and the leakage induced by the challenge.
Here’s where things get tricky. Let’s refer to the set of possible outputs of challenge() as the challenge space. We need the challenge space to be fairly large, large enough that the probability of outputting the same challenge twice is negligible.
Why would such a collision be a problem? It’s a little easier to see in the context of digital signatures. Let’s say an attacker knows a valid signature for a message m. The signature includes the commitment H(m), so the attacker also knows the challenge is c == H(H(w),m). Suppose it manages to find a different message m* for which c == H(H(w),m*). Then the signature is also valid for m! And this attack is easy to pull off if the challenge space, that is, the set of possible outputs of H, is too small.
Unfortunately, we can’t make the challenge space larger simply by increasing the size of the modulus Q: the larger the challenge might be, the more information we’d leak about the secret key. We need a new idea.
The best of both worlds
Remember that the hardness of LWE depends on the ratio between beta and Q. This means that y1 and y2 don’t need to be short in absolute terms, but short relative to random vectors.
With that in mind, consider the following idea. Let’s take a larger modulus, say Q=2**31 - 1, and we’ll continue to sample from the same challenge space, range(2**16).
First, notice that z1 is now “relatively” short, since its entries are now in range(-gamma, gamma+1), where gamma = beta*(2**16-1), rather than uniform over range(Q). Let’s also modify initialize() to sample the entries of (y1,y2) from the same range and see what happens:
This is definitely going in the right direction, since there are no obvious correlations between z1 and s1. (Likewise for z2 and s2.) However, we’re not quite there.
One problem is that the challenge space is still quite small. With only 2**16 challenges to choose from, we’re likely to see a collision even after only a handful of protocol executions. We need the challenge space to be much, much larger, say around 2**256. But then Q has to be an insanely large number in order for the beta to Q ratio to be secure.
ML-DSA is able to side step this problem due to its use of arithmetic over polynomial rings. It uses the same modulus polynomial as ML-KEM, so the challenge is a polynomial with 256 coefficients. The coefficients are chosen carefully so that the challenge space is large, but multiplication by the challenge scales the secret vector by a small amount. Note that we still end up using a slightly larger modulus (Q=8380417) for ML-DSA than for ML-KEM, but only by about twelve bits.
However, there is a more fundamental problem here, which is that we haven’t completely ruled out that signatures may leak information about the secret key.
Cause and effect
Suppose we run the protocol a number of times, and in each run, we happen to choose a relatively small value for some entry of y1. After enough runs, this would eventually allow us to reconstruct the corresponding entry of s1. To rule this out as a possibility, we need to make y1 even longer. (Likewise for y2.) But how long?
Suppose we know that the entries of z1 and z2 are always in range(-beta_loose,beta_loose+1) for some beta_loose > beta. Then we can simulate an honest run of the protocol as follows:
This procedure perfectly simulates honest runs of the protocol, in the sense that the output of simulate() is indistinguishable from the transcript of a real run of the protocol with the honest prover. To see this, notice that the w, c, z1, and z2 all have the same mathematical relationship (the verification equation still holds) and have the same distribution.
And here’s the punch line: since this procedure doesn’t use the secret key, it follows that the attacker learns nothing from eavesdropping on the honest prover that it can’t compute from the public key itself. Pretty neat!
What’s left to do is arrange for z1 and z2 to fall in this range. First, we modify initialize() by increasing the range of y1 and y2 by beta_loose:
This ensures the proof vectors z1 and z2 are roughly uniform over range(-beta_loose, beta_loose+1). However, they may fall slightly outside of this range, so need to modify finalize() to abort if not. Correspondingly, verify() should reject proof vectors that are out of range:
def finish(s1, s2, y1, y2, c):
z1 = (c*s1 + y1) % Q
z2 = (c*s2 + y2) % Q
if not in_range(z1, beta_loose) or not in_range(z2, beta_loose):
return (None, None)
return (z1, z2)
def verify(A, t, hw, c, z1, z2):
if not in_range(z1, beta_loose) or not in_range(z2, beta_loose):
return False
return H((A*z1 + z2 - c*t) % Q) == hw
If finish() returns (None,None), then the prover and verifier are meant to abort the protocol and retry until the protocol succeeds:
((A, t), (s1, s2)) = key_gen()
while True:
(hw, (y1, y2)) = initialize(A) # hw: prover -> verifier
c = challenge() # c: verifier -> prover
(z1, z2) = finish(s1, s2, y1, y2, c) # (z1, z2): prover -> verifier
if z1 is not None and z2 is not None:
break
assert verify(A, t, hw, c, z1, z2)
Interestingly, we should expect aborts to be quite common. The parameters of ML-DSA are tuned so that the protocol runs five times on average before it succeeds.
Another interesting point is that the security proof requires us to simulate not only successful protocol runs, but aborted protocol runs as well. More specifically, the protocol simulator must abort with the same probability as the real protocol, which implies that the rejection probability is independent of the secret key.
The simulator also needs to be able to produce realistic looking commitments for aborted transcripts. This is exactly why the prover commits to the hash of w rather than w itself: in the security proof, we can easily simulate hashes of random inputs.
Making this scheme efficient
ML-DSA benefits from many of the same optimizations as ML-KEM, including using polynomial rings, NTT for polynomial multiplication, and encoding polynomials with a fixed number of bits. However, ML-DSA has a few more tricks to make things smaller.
First, in ML-DSA, instead of the pair of short vectors z1 and z2, the proof consists of a single vector z=c*s1 + y, where y was committed to in the previous step. In turn, we only end up with a single proof vector z rather than two as before. Getting this to work requires a special encoding of the commitment so that we can’t compute y from it. ML-DSA uses a related trick to reduce the size of the t vector of the public key, but the details are more complicated.
For the parameters we expect to deploy first (ML-DSA-44), the public key is 1312 bytes long and the signature is a whopping 2420 bytes. In contrast to ML-KEM, it is possible to shave off some more bytes. This does not come for free and requires complicating the scheme. An example is HAETAE, which changes the distributions used. Falcon takes it a step further with even smaller signatures, using a completely different approach, which although elegant is also more complex to implement.
Wrap up
Lattice cryptography underpins the first generation of PQ algorithms to get widely deployed on the Internet. ML-KEM is already widely used today to protect encryption from quantum computers, and in the coming years we expect to see ML-DSA deployed to get ahead of the threat of quantum computers to authentication.
Lattices are also the basis of a new frontier for cryptography: computing on encrypted data.
Suppose you wanted to aggregate some metrics submitted by clients without learning the metrics themselves. With LWE-based encryption, you can arrange for each client to encrypt their metrics before submission, aggregate the ciphertexts, then decrypt to get the aggregate.
Suppose instead that a server has a database that it wants to provide clients access to without revealing to the server which rows of the database the client wants to query. LWE-based encryption allows the database to be encoded in a manner that permits encrypted queries.
These applications are special cases of a paradigm known as FHE (“Fully Homomorphic Encryption”), which allows for arbitrary computations on encrypted data. FHE is an extremely powerful primitive, and the only way we know how to build it today is with lattices. However, for most applications, FHE is far less practical than a special-purpose protocol would be (lattice-based or not). Still, over the years we’ve seen FHE get better and better, and for many applications it is already a decent option. Perhaps we’ll dig into this and other lattice schemes in a future blog post.
We hope you enjoyed this whirlwind tour of lattices. Thanks for reading!
We are excited to announce our latest innovation to Cloudflare’s Data Loss Prevention (DLP) solution: a self-improving AI-powered algorithm that adapts to your organization’s unique traffic patterns to reduce false positives.
Many customers are plagued by the shapeshifting task of identifying and protecting their sensitive data as it moves within and even outside of their organization. Detecting this data through deterministic means, such as regular expressions, often fails because they cannot identify details that are categorized as personally identifiable information (PII) nor intellectual property (IP). This can generate a high rate of false positives, which contributes to noisy alerts that subsequently may lead to review fatigue. Even more critically, this less than ideal experience can turn users away from relying on our DLP product and result in a reduction in their overall security posture.
Built into Cloudflare’s DLP Engine, AI enables us to intelligently assess the contents of a document or HTTP request in parallel with a customer’s historical reports to determine context similarity and draw conclusions on data sensitivity with increased accuracy.
Understanding false positives and their impact on user confidence
Data Loss Prevention (DLP) at Cloudflare detects sensitive information by scanning potential sources of data leakage across various channels such as web, cloud, email, and SaaS applications. While we leverage several detection methods, pattern-based methods like regular expressions play a key role in our approach. This method is effective for many types of sensitive data. However, certain information can be challenging to classify solely through patterns. For instance, U.S. Social Security Numbers (SSNs), structured as AAA-GG-SSSS, sometimes with dashes omitted, are often confused with other similarly formatted data, such as U.S. taxpayer identification numbers, bank account numbers, or phone numbers.
Since announcing our DLP product, we have introduced new capabilities like confidence thresholds to reduce the number of false positives users receive. This method involves examining the surrounding context of a pattern match to assess Cloudflare’s confidence in its accuracy. With confidence thresholds, users specify a threshold (low, medium, or high) to signify a preference for how tolerant detections are to false positives. DLP uses the chosen threshold as a minimum, surfacing only those detections with a confidence score that meets or exceeds the specified threshold.
However, implementing context analysis is also not a trivial task. A straightforward approach might involve looking for specific keywords near the matched pattern, such as “SSN” near a potential SSN match, but this method has its limitations. Keyword lists are often incomplete, users may make typographical errors, and many true positives do not have any identifying keywords nearby (e.g., bank accounts near routing numbers or SSNs near names).
Leveraging AI/ML for enhanced detection accuracy
To address the limitations of a hardcoded strategy for context analysis, we have developed a dynamic, self-improving algorithm that learns from customer feedback to further improve their future experience. Each time a customer reports a false positive via decrypted payload logs, the system reduces its future confidence for hits in similar contexts. Conversely, reports of true positives increase the system’s confidence for hits in similar contexts.
To determine context similarity, we leverage Workers AI. Specifically, a pretrained language model that converts the text into a high-dimensional vector (i.e. text embedding). These embeddings capture the meaning of the text, ensuring that two sentences with the same meaning but different wording map to vectors that are close to each other.
When a pattern match is detected, the system uses the AI model to compute the embedding of the surrounding context. It then performs a nearest neighbor search to find previously logged false or true positives with similar meanings. This allows the system to identify context similarities even if the exact wording differs, but the meaning remains the same.
In our experiments using Cloudflare employee traffic, this approach has proven robust, effectively handling new pattern matches it hadn’t encountered before. When the DLP admin reports false and true positives through the Cloudflare dashboard while viewing the payload log of a policy match, it helps DLP continue to improve, leading to a significant reduction in false positives over time.
Seamless integration with Workers AI and Vectorize
In developing this new feature, we used components from Cloudflare’s developer platform — Workers AI and Vectorize — which helps simplify our design. Instead of managing the underlying infrastructure ourselves, we leveraged Cloudflare Workers as the foundation, using Workers AI for text embedding, and Vectorize as the vector database. This setup allows us to focus on the algorithm itself without the overhead of provisioning underlying resources.
Thanks to Workers AI, converting text into embeddings couldn’t be easier. With just a single line of code we can transform any text into its corresponding vector representation.
const result = await env.AI.run(model, {text: [text]}).data;
This handles everything from tokenization to GPU-powered inference, making the process both simple and scalable.
The nearest neighbor search is equally straightforward. After obtaining the vector from Workers AI, we use Vectorize to quickly find similar contexts from past reports. In the meantime, we store the vector for the current pattern match in Vectorize, allowing us to learn from future feedback.
To optimize resource usage, we’ve incorporated a few more clever techniques. For example, instead of storing every vector from pattern hits, we use online clustering to group vectors into clusters and store only the cluster centroids along with counters for tracking hits and reports. This reduces storage needs and speeds up searches. Additionally, we’ve integrated Cloudflare Queues to separate the indexing process from the DLP scanning hot path, ensuring a robust and responsive system.
Privacy is a top priority. We redact any matched text before conversion to embeddings, and all vectors and reports are stored in customer-specific private namespaces across Vectorize, D1, and Workers KV. This means each customer’s learning process is independent and secure. In addition, we implement data retention policies so that vectors that have not been accessed or referenced within 60 days are automatically removed from our system.
Limitations and continuous improvements
AI-driven context analysis significantly improves the accuracy of our detections. However, this comes at the cost of some increase in latency for the end user experience. For requests that do not match any enabled DLP entries, there will be no latency increase. However, requests that match an enabled entry in a profile with AI context analysis enabled will typically experience an increase in latency of about 400ms. In rare extreme cases, for example requests that match multiple entries, that latency increase could be as high as 1.5 seconds. We are actively working to drive the latency down, ideally to a typical increase of 250ms or better.
Another limitation is that the current implementation supports English exclusively because of our choice of the language model. However, Workers AI is developing a multilingual model which will enable DLP to increase support across different regions and languages.
Looking ahead, we also aim to enhance the transparency of AI context analysis. Currently, users have no visibility on how the decisions are made based on their past false and true positive reports. We plan to develop tools and interfaces that provide more insight into how confidence scores are calculated, making the system more explainable and user-friendly.
With this launch, AI context analysis is only available for Gateway HTTP traffic. By the end of 2025, AI context analysis will be available in both CASB and Email Security so that customers receive the same AI enhancements across their entire data landscape.
Unlock the benefits: start using AI-powered detection features today
DLP’s AI context analysis is in closed beta. Sign up here for early access to experience immediate improvements to your DLP HTTP traffic matches. More updates are coming soon as we approach general availability!
To get access to DLP via Cloudflare One, contact your account manager.
We are excited to announce our public sector suite of services for Australia, Cloudflare for Government – Australia, has been assessed under the Infosec Registered Assessor Program (IRAP) at the PROTECTED level in Australia.
IRAP, established by the Australian government, provides a rigorous, standardized approach to security assessment for cloud products and services. Achieving IRAP PROTECTED assessment reinforces our commitment to providing secure, high-performance solutions for government agencies and highly regulated industries across the globe.
Obtaining our IRAP assessment is one part of our broader strategy to scale out our Cloudflare for Government offering to as many areas of the world as possible. Cloudflare’s global network offers governments and highly regulated customers a unique capability to be within 50ms of 95% of Internet users globally, while also offering robust security for data processing, key management, and metadata storage. Earlier this year, we announced that we completed our ENS certification in Spain, and we are well underway on the development of our FedRAMP High systems in the United States.
Cloudflare’s network spans more than 330 cities in over 120 countries, where we interconnect with approximately 13,000 network providers in order to provide a broad range of services to millions of customers. Our network is our greatest strength to provide resiliency, security, and performance. So, instead of creating a siloed government network that has limited access to our products and services, we decided to build the unique government compliance capabilities directly into our platform from the very beginning. We accomplished this by delivering critical controls in three key areas: traffic processing, management, and metadata storage.
The benefit of running the same software across our entire network is that it enables us to leverage our global footprint, and then make smart choices about how to handle traffic. For instance, Regional Services (our system that ensures that traffic is processed in the correct region) runs globally. Regional Services allows us to do global Layer 3 (network layer) DDoS attack prevention, while still only decrypting traffic inside our IRAP boundary, which includes both US and Australian facilities. This software-defined regionalization approach allows us to get the full benefits of the global network running anycast, while offering highly specific regionalization on the same hardware. We get similar advantages for key management and metadata storage locality.
Network and security services can dramatically improve user experiences, but only when they run as close to the user as possible, even if the user doesn’t live close to a major hub. Leveraging our global network of over 300 data centers to ingest traffic to our network, our private backbone can move traffic to the closest certified processing location that is within the scope of our IRAP system. This enables you to meet the most stringent controls of the IRAP assessment without trading off user experience.
Our single platform strategy enables almost every Cloudflare product and service across all of our solution areas to be included in scope with Cloudflare for Government – Australia. This includes our application security products like our CDN, WAF, API Shield, Rate Limiting, and Bot Management. Our Zero Trust Products like Secure Web Gateway, CASB, Magic Transit, Magic WAN, and Remote Browser Isolation are also in scope, as are developer platform components including Workers, R2, Durable Objects, Stream, and Cache Reserve.
We invite all of our Cloudflare for Government public and private partners to learn more about our capabilities and work with us to develop solutions to meet the security demands required in complex environments. Please reach out to us at [email protected] with any questions.
Когато питонът бавно и методично поглъща някое голямо животно, той разтваря широко челюстите си. Също както олигархът Делян Пеевски поглъща политическото в България – с него и държавността, която институциите олицетворяват.
Пеевщината не е обикновена политическа техника – тя е modus absorbendi (начин на поглъщане), при който бива изсмуквано съдържанието на демокрацията и остава фасадата, докато реалната власт преминава в ръцете на задкулисието. Пеевщината налага своята воля чрез груба сила, но и чрез неизбежност – като тежест, която политическите партии носят дори когато се преструват, че я отхвърлят.
Кръстникът ѝ продължи традицията, заложена от началото на Прехода от висши номенклатури на БКП и Държавна сигурност, но ще се прослави повече от тях, защото ѝ даде името си. Докато другите сключваха сделки в сянка, той превърна сянката в самата сделка. Докато предшествениците му дърпаха конците зад завесата, той доказа, че завесата изобщо не е нужна, след като излезе пред нея.
В хода на този процес едни партии отричат връзките си със санкционирания за корупция от САЩ и Великобритания, други се оправдават с „политическата реалност“, за да се обвържат. Накрая първите се примиряват с присъствието на ДП и се кооперират, а вторите пак излизат на протести със старите нови плакати „Вън Пеевски от властта“.
Асимилацията
Делян Пеевски не нахлу във властта – той я асимилира, докато тя не заприлича на него във всичко: лица, действия, натиск. Тази седмица видяхме едно от многото (му) лица. За съдия в Конституционния съд (КС) ГЕРБ–СДС, БСП – Обединена левица, „Има такъв народ“ и пеевската партия ДПС – Ново началоизбраха асистента по конституционно право в Софийския университет Орлин Колев, номиниран от ГЕРБ. Завършил право в Югозападния университет „Неофит Рилски“ и започнал кариерата си на преподавател в Академията на МВР, Колев спечели срещу подкрепения от утвърдени юристи и предложен от ПП–ДБ бивш съдия на България в Европейския съд по правата на човека Йонко Грозев, за чиято компетентност и професионално развитие не съществуват съмнения – за разлика от Колев, чиято трудова биография е доста по-скромна. Въпреки това Грозев, известен и с работата си като адвокат по дела, свързани с човешките права, получи само 38 гласа – 36 от ПП–ДБ, 1 от ГЕРБ и 1 от „Величие“.
В пленарната зала обаче няколко депутати продължиха с кампанията срещу Йонко Грозев, започната в медиите от кръга на Пеевски, където в същото време беше рекламиран Орлин Колев и всичките му медийни изяви. Представен в парламента от Рая Назарян (ГЕРБ), за която също има спекулации за зависимости от Пеевски, Колев обяви, че „категорично не е обвързан с определени партии и личности“. От ПП–ДБ обаче посочиха, че в КС той ще обслужва интересите на Борисов и Пеевски, а Надежда Йорданова отбеляза, че страхът от Пеевски не е позволил на останалите партии да дадат дори един глас за:
Бойко Борисов под натиска на Делян Пеевски зароби върховенството на правото за пореден път.
Изборът на Орлин Колев е резултат не от правни аргументи и състезание от типа „най-добрият да спечели“, а от политическа аритметика – механика, в която качествата са на втори план, а лоялността и удобството за мнозинството са решаващи. Професионалното развитие на Колев до голяма степен повтаря нашествието на цяла плеяда възпитаници на ЮЗУ и на Академията на МВР в полето на правораздаването, като бившия главен прокурор Иван Гешев и настоящия (и.д.) Борислав Сарафов, друг конституционен съдия, като Анастас Анастасов, вече бившия председател на ВАС Георги Колев и още много прочули се юристи. Практика, утвърдена при управлението на ГЕРБ.
Амбицията на ДП е списъкът на тези въдворители на modus absorbendi –не и навърховенството на правото – да бъде продължен, за да продължи и подчинението на институциите. Едва ли някой приема за истина декларирания предварително отказ от номинации в регулаторите и съдебната власт от страна на Пеевски.
С избора на Колев, а и на управителя на НЗОК Петко Стефановски, също подкрепен от ДПС – Ново начало, бе даден старт на „обновлението“ – 96 нови лица в перманентната власт. Край ще сложи най-трудният избор – за членове на Висшия съдебен съвет (ВСС) и на Инспектората, за които е необходимо мнозинство от 160 гласа. Това е и голямата цел на modus absorbendi: да бъде възпроизведен досегашният модел, който пази върховенството на част от политическия елит и неговите икономически кръгове. Но до средата на годината – възможен хоризонт за правителството, обявен от лидера на ГЕРБ – най-вероятно парламентарната квота във ВСС няма да бъде избрана.
Дотук сметките показват, че в КС има (поне) двама конституционни съдии, лично благодарни на Пеевски, също и на Борисов – Десислава Атанасова и Орлин Колев, но и издигнатият от ПП–ДБ Белослав Белазелков получи същата подкрепа.
Има ли изход?
През 2013–2014 г., когато бяха протестите срещу избора на Пеевски за председател на ДАНС, наложен от БСП и ДПС, към гневната градска десница се присъедини ГЕРБ. Падането на правителството „Орешарски“ изтласка Пеевски обратно в сенките тъкмо когато беше набрал сили за повторно излизане на светло след Тройната коалиция. Но не скъса мрежите му на влияние в съдебната система. И завърналата се на власт ГЕРБ с премиер Бойко Борисов се възползва от тях.
След политическите турбуленции, започнали през 2021 г., през 2023 г. звездата на Пеевски отново изгря на сцената с „конституционно мнозинство“, очертало се като ключова стратегия на ПП–ДБ, обявена още преди изборите през април същата година от съпредседателя на „Демократична България“ Христо Иванов. Целта беше да се постигне широко съгласие за конституционни реформи, които да ограничат влиянието на главния прокурор и да стабилизират съдебната власт. На теория това изискваше разширяване на подкрепата отвъд ПП–ДБ и ГЕРБ, което доведе до преговори и с ДПС.
Така след вота към парламентарното мнозинство на ПП–ДБ и ГЕРБ, разполагащи със 133 мандата, се притуриха и 36-те на все още единното ДПС. И Делян Пеевски влезе в роля, от която не е излязъл – на стожер на управлението и негов некоронован наставник.
На практика обаче балансът на силите се измести – вместо ПП–ДБ да използват ДПС като инструмент за реформа, Пеевски използва „реформаторите“ като инструмент за завръщането си в политическия елит. Това беше видимо още в първите етапи – когато ПП–ДБ не просто толерираха Пеевски като част от процеса, а мълчаливо приеха неговата водеща роля. Докато коалицията с ГЕРБ беше представена като „неизбежен компромис“, съюзът с ДПС нанесе поражения, тъй като разми границите между реформатори и статукво.
Вместо инструмент за съдебна реформа, „конституционното мнозинство“ послужи на олигарха, който иззе инициативата, а ПП–ДБ се оказа в капана на реалността. Резултатът от онова 9-месечно управление е, че значителна част от конституционните промени бяха отменени от Конституционния съд, а то самото се разпадна при планираната правителствена ротация между ПП–ДБ и ГЕРБ. Впоследствие се оказа, че Пеевски е имал свои в кабинета, макар да бе декларирано, че няма да получи назначения. Разчитал е обаче да се снабди със своя квота в регулаторите и ВСС.
Този път шансовете да си я осигури са значително по-големи – в политиката благотворителност не съществува. В настоящата ситуация Пеевски и гласовете на депутатите му (пак) се оказаха насъщни за управляващото мнозинство, заковало се на минимума от 121 гласа заради влизането на „Величие“. В противен случай правителството с мандата на ГЕРБ–СДС ще падне, обясняват задъхано някои анализатори, също и политици като Борисов:
Изобщо не е стабилно правителството, как ще е стабилно? Диаметрално противоположни партии, които събрахме с най-важната цел – да приемем бюджета и еврозоната. Всеки може да клати лодката, както си иска.
Но работата е там, че дори депутатите от ДПС на Ахмед Доган, недоволни от назначения и с неудовлетворени докрай претенции, не искат да клатят тази лодка, защото после не е сигурно дали ще намерят място в нея. Също и другите партньори в управлението, като БСП и ИТН. А с Пеевски, както убеждават едни и същи пророци на ДП, кабинетът има шансове да изкара пълен мандат. Едва ли ще е пълен, но в парламента изглеждат готови да приемат бюджета за 2025 г. и да довършат назначенията.
С гласувания вече бюджет Пеевски получи първия подарък за своята подкрепа от управляващите – с гласовете на ГЕРБ–СДС, ИТН, БСП и на неговата партия бе дадена зелена светлина на веригата държавни магазини за хранителни стоки с надценка до 10%. Поредната хранилка, чрез която с парите на данъкоплатците ще се купуват гласове и ще се финансират обръчи.
При толкова фрагментирана подкрепа в парламента договарянето става все по-трудно, а компромисите – по-големи. Единственият начин да се разпадне коалицията е Борисов да обяви изтеглянето на ГЕРБ. Самият той първоначално обяви хоризонт на кабинета „Желязков“ до влизането в еврозоната, т.е. не повече от година. После скъси наполовина – до излизането на конвергентните доклади през юни. Дотогава регулаторите най-вероятно ще бъдат обновени, но не и ВСС. Лидерът на ГЕРБ може и да изтегли партията си от мнозинството, ако не иска един доминиран от ДП Висш съдебен съвет да избере следващия главен прокурор и цялата власт да се концентрира в едни ръце.
Питонът не бърза, до половината ги е налапал.
* Според една от легендите Лаокоон бил прорицател от Троя, който се опитвал да предупреди съгражданите си, че подаръкът от гърците (Троянският кон) е поредната хитрост на Одисей и ще обрече Троя на гибел. Докато един ден Лаокоон заедно с двамата си сина принасял жертва на Посейдон на брега на морето, от него изскочили две огромни змии и убили децата и бащата. После се скрили в храма на Атина и троянците решили, че това е знамение – Лаокоон не е прав за коня и боговете го наказват. Всички знаем какво става после с коня и с Троя. В статуята „Лаокоон и синовете му“ от Агесандър, Полидор и Атенодор от Родос е увековечена тъкмо тази борба на бащата да спаси децата си от змиите. – Б.р.
The UK’s National Computer Security Center (part of GCHQ) released a timeline—also see their blog post—for migration to quantum-computer-resistant cryptography.
I ran in the “Affiliate district” in the 2025 election for
Board of Directors of the Open Source Initiative (OSI) on
a joint platform for OSI Reform with my colleague, Richard
Fontana (who among other accomplishments, is currently Senior Commercial
Counsel at IBM’s Red Hat).
After voting closed, we received a strange request demanding that we sign
the OSI‘s Board Agreement
within 47 hours — and before we or anyone else (outside of OSI) were
told the election results. This varies from all past elections in OSI’s
history, and instructions that 2025 candidates received in orientation.
Fontana specifically verified with a question during orientation that
candidates need not sign the Board Agreement unless/until we
succeeded in the election and were a true candidate for a Directorship.
Tracy Hinds, then chairperson of OSI’s Board, confirmed this verbally for
all candidates at the orientation. (And, that position is consistent with
logic, since the OSI elections are purely advisory and its Board has
discretion to ignore the election results in any event.
I ran in the “Affiliate district” in the 2025 election for
Board of Directors of the Open Source Initiative (OSI) on
a joint platform for OSI Reform with my colleague, Richard
Fontana (who among other accomplishments, is currently Senior Commercial
Counsel at IBM’s Red Hat).
After voting closed, we received a strange request demanding that we sign
the OSI‘s Board Agreement
within 47 hours — and before we or anyone else (outside of OSI) were
told the election results. This varies from all past elections in OSI’s
history, and instructions that 2025 candidates received in orientation.
Fontana specifically verified with a question during orientation that
candidates need not sign the Board Agreement unless/until we
succeeded in the election and were a true candidate for a Directorship.
Tracy Hinds, then chairperson of OSI’s Board, confirmed this verbally for
all candidates at the orientation. (And, that position is consistent with
logic, since the OSI elections are purely advisory and its Board has
discretion to ignore the election results in any event.
I ran in the “Affiliate district” in the 2025 election for
Board of Directors of the Open Source Initiative (OSI) on
a joint platform for OSI Reform with my colleague, Richard
Fontana (who among other accomplishments, is currently Senior Commercial
Counsel at IBM’s Red Hat).
After voting closed, we received a strange request demanding that we sign
the OSI‘s Board Agreement
within 47 hours — and before we or anyone else (outside of OSI) were
told the election results. This varies from all past elections in OSI’s
history, and instructions that 2025 candidates received in orientation.
Fontana specifically verified with a question during orientation that
candidates need not sign the Board Agreement unless/until we
succeeded in the election and were a true candidate for a Directorship.
Tracy Hinds, then chairperson of OSI’s Board, confirmed this verbally for
all candidates at the orientation. (And, that position is consistent with
logic, since the OSI elections are purely advisory and its Board has
discretion to ignore the election results in any event.
I ran in the “Affiliate district” in the 2025 election for
Board of Directors of the Open Source Initiative (OSI) on
a joint platform for OSI Reform with my colleague, Richard
Fontana (who among other accomplishments, is currently Senior Commercial
Counsel at IBM’s Red Hat).
After voting closed, we received a strange request demanding that we sign
the OSI‘s Board Agreement
within 47 hours — and before we or anyone else (outside of OSI) were
told the election results. This varies from all past elections in OSI’s
history, and instructions that 2025 candidates received in orientation.
Fontana specifically verified with a question during orientation that
candidates need not sign the Board Agreement unless/until we
succeeded in the election and were a true candidate for a Directorship.
Tracy Hinds, then chairperson of OSI’s Board, confirmed this verbally for
all candidates at the orientation. (And, that position is consistent with
logic, since the OSI elections are purely advisory and its Board has
discretion to ignore the election results in any event.
I ran in the “Affiliate district” in the 2025 election for
Board of Directors of the Open Source Initiative (OSI) on
a joint platform for OSI Reform with my colleague, Richard
Fontana (who among other accomplishments, is currently Senior Commercial
Counsel at IBM’s Red Hat).
After voting closed, we received a strange request demanding that we sign
the OSI‘s Board Agreement
within 47 hours — and before we or anyone else (outside of OSI) were
told the election results. This varies from all past elections in OSI’s
history, and instructions that 2025 candidates received in orientation.
Fontana specifically verified with a question during orientation that
candidates need not sign the Board Agreement unless/until we
succeeded in the election and were a true candidate for a Directorship.
Tracy Hinds, then chairperson of OSI’s Board, confirmed this verbally for
all candidates at the orientation. (And, that position is consistent with
logic, since the OSI elections are purely advisory and its Board has
discretion to ignore the election results in any event.
I ran in the “Affiliate district” in the 2025 election for
Board of Directors of the Open Source Initiative (OSI) on
a joint platform for OSI Reform with my colleague, Richard
Fontana (who among other accomplishments, is currently Senior Commercial
Counsel at IBM’s Red Hat).
After voting closed, we received a strange request demanding that we sign
the OSI‘s Board Agreement
within 47 hours — and before we or anyone else (outside of OSI) were
told the election results. This varies from all past elections in OSI’s
history, and instructions that 2025 candidates received in orientation.
Fontana specifically verified with a question during orientation that
candidates need not sign the Board Agreement unless/until we
succeeded in the election and were a true candidate for a Directorship.
Tracy Hinds, then chairperson of OSI’s Board, confirmed this verbally for
all candidates at the orientation. (And, that position is consistent with
logic, since the OSI elections are purely advisory and its Board has
discretion to ignore the election results in any event.
I ran in the “Affiliate district” in the 2025 election for
Board of Directors of the Open Source Initiative (OSI) on
a joint platform for OSI Reform with my colleague, Richard
Fontana (who among other accomplishments, is currently Senior Commercial
Counsel at IBM’s Red Hat).
After voting closed, we received a strange request demanding that we sign
the OSI‘s Board Agreement
within 47 hours — and before we or anyone else (outside of OSI) were
told the election results. This varies from all past elections in OSI’s
history, and instructions that 2025 candidates received in orientation.
Fontana specifically verified with a question during orientation that
candidates need not sign the Board Agreement unless/until we
succeeded in the election and were a true candidate for a Directorship.
Tracy Hinds, then chairperson of OSI’s Board, confirmed this verbally for
all candidates at the orientation. (And, that position is consistent with
logic, since the OSI elections are purely advisory and its Board has
discretion to ignore the election results in any event.
I ran in the “Affiliate district” in the 2025 election for
Board of Directors of the Open Source Initiative (OSI) on
a joint platform for OSI Reform with my colleague, Richard
Fontana (who among other accomplishments, is currently Senior Commercial
Counsel at IBM’s Red Hat).
After voting closed, we received a strange request demanding that we sign
the OSI‘s Board Agreement
within 47 hours — and before we or anyone else (outside of OSI) were
told the election results. This varies from all past elections in OSI’s
history, and instructions that 2025 candidates received in orientation.
Fontana specifically verified with a question during orientation that
candidates need not sign the Board Agreement unless/until we
succeeded in the election and were a true candidate for a Directorship.
Tracy Hinds, then chairperson of OSI’s Board, confirmed this verbally for
all candidates at the orientation. (And, that position is consistent with
logic, since the OSI elections are purely advisory and its Board has
discretion to ignore the election results in any event.
I ran in the “Affiliate district” in the 2025 election for
Board of Directors of the Open Source Initiative (OSI) on
a joint platform for OSI Reform with my colleague, Richard
Fontana (who among other accomplishments, is currently Senior Commercial
Counsel at IBM’s Red Hat).
After voting closed, we received a strange request demanding that we sign
the OSI‘s Board Agreement
within 47 hours — and before we or anyone else (outside of OSI) were
told the election results. This varies from all past elections in OSI’s
history, and instructions that 2025 candidates received in orientation.
Fontana specifically verified with a question during orientation that
candidates need not sign the Board Agreement unless/until we
succeeded in the election and were a true candidate for a Directorship.
Tracy Hinds, then chairperson of OSI’s Board, confirmed this verbally for
all candidates at the orientation. (And, that position is consistent with
logic, since the OSI elections are purely advisory and its Board has
discretion to ignore the election results in any event.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.