Post Syndicated from The Hook Up original https://www.youtube.com/watch?v=OG-UTMriJT8
[$] Safer speculation-free user-space access
Post Syndicated from corbet original https://lwn.net/Articles/1042711/
The Spectre class of hardware vulnerabilities truly is a gift that keeps on
giving. New variants are still being discovered in current CPUs nearly
eight years after the disclosure of this
problem, and developers are still working to minimize the performance costs
that come from defending against it. The masked user-space access
mechanism is a case in point: it reduces the cost of defending against some
speculative attacks, but it brought some challenges of its own that are
only now being addressed.
Btrfs support coming to AlmaLinux 10.1
Post Syndicated from jzb original https://lwn.net/Articles/1043029/
The AlmaLinux project has announced
that the upcoming 10.1 release will include support for
Btrfs:
Btrfs support encompasses both kernel and userspace enablement, and
it is now possible to install AlmaLinux OS with a Btrfs filesystem
from the very beginning. Initial enablement was scoped to the
installer and storage management stack, and broader support within the
AlmaLinux software collection for Btrfs features is forthcoming.Btrfs support in AlmaLinux OS did not happen in isolation. This was
proposed and scoped in RFC 0005, and has been built upon prior efforts
by the Fedora
Btrfs SIG in Fedora Linux and the CentOS Hyperscale SIG
in CentOS Stream.
AlmaLinux OS is designed to be binary compatible with Red Hat
Enterprise Linux (RHEL); Btrfs, however, has never been supported in
RHEL. A technology preview of Btrfs in RHEL 6 and 7 ended with the
filesystem being dropped from RHEL 8 and
onward. AlmaLinux OS 10.1 is currently
in beta.
Security updates for Thursday
Post Syndicated from jzb original https://lwn.net/Articles/1043027/
Security updates have been issued by AlmaLinux (ipa, kernel, and thunderbird), Debian (gdk-pixbuf, gegl, gimp, intel-microcode, raptor2, request-tracker4, and request-tracker5), Fedora (samba and wireshark), Mageia (haproxy, nginx, openssl, and python-django), Oracle (kernel and thunderbird), Red Hat (redis and redis:7), Slackware (bind), SUSE (aws-cli, local-npm-registry, python-boto3, python- botocore, python-coverage, python-flaky, python-pluggy, python-pytest, python- pytest-cov, python-pytest-html, python-pytest-metada, cargo-audit-advisory-db-20251021, fetchmail, git-bug, ImageMagick, istioctl, kernel, krb5, libsoup, libxslt, python-Authlib, and sccache), and Ubuntu (bind9, linux, linux-aws, linux-azure, linux-azure-6.8, linux-gcp, linux-gkeop,
linux-ibm, linux-ibm-6.8, linux-lowlatency, linux-lowlatency-hwe-6.8,
linux-oracle, linux-azure, linux-azure-5.15, linux-gcp-5.15, linux-gcp-6.8, linux-gke, linux-nvidia, linux-nvidia-6.8,
linux-nvidia-lowlatency, and linux-realtime, linux-realtime-6.8).
Serious F5 Breach
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/10/serious-f5-breach.html
This is bad:
F5, a Seattle-based maker of networking software, disclosed the breach on Wednesday. F5 said a “sophisticated” threat group working for an undisclosed nation-state government had surreptitiously and persistently dwelled in its network over a “long-term.” Security researchers who have responded to similar intrusions in the past took the language to mean the hackers were inside the F5 network for years.
During that time, F5 said, the hackers took control of the network segment the company uses to create and distribute updates for BIG IP, a line of server appliances that F5 says is used by 48 of the world’s top 50 corporations. Wednesday’s disclosure went on to say the threat group downloaded proprietary BIG-IP source code information about vulnerabilities that had been privately discovered but not yet patched. The hackers also obtained configuration settings that some customers used inside their networks.
Control of the build system and access to the source code, customer configurations, and documentation of unpatched vulnerabilities has the potential to give the hackers unprecedented knowledge of weaknesses and the ability to exploit them in supply-chain attacks on thousands of networks, many of which are sensitive. The theft of customer configurations and other data further raises the risk that sensitive credentials can be abused, F5 and outside security experts said.
F5 announcement.
18 Minutes From Nuclear Annihilation
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=_woBkRdrxAE
Introducing AWS RTB Fabric for real-time advertising technology workloads
Post Syndicated from Betty Zheng (郑予彬) original https://aws.amazon.com/blogs/aws/introducing-aws-rtb-fabric-for-real-time-advertising-technology-workloads/
Today, we’re announcing AWS RTB Fabric, a fully managed service purpose built for real-time bidding (RTB) advertising workloads. The service helps advertising technology (AdTech) companies seamlessly connect with their supply and demand partners, such as Amazon Ads, GumGum, Kargo, MobileFuse, Sovrn, TripleLift, Viant, Yieldmo and more, to run high-volume, latency-sensitive RTB workloads on Amazon Web Services (AWS) with consistent single-digit millisecond performance and up to 80% lower networking costs compared to standard networking costs.
AWS RTB Fabric provides a dedicated, high-performance network environment for RTB workloads and partner integrations without requiring colocated, on-premises infrastructure or upfront commitments. The following diagram shows the high-level architecture of RTB Fabric.
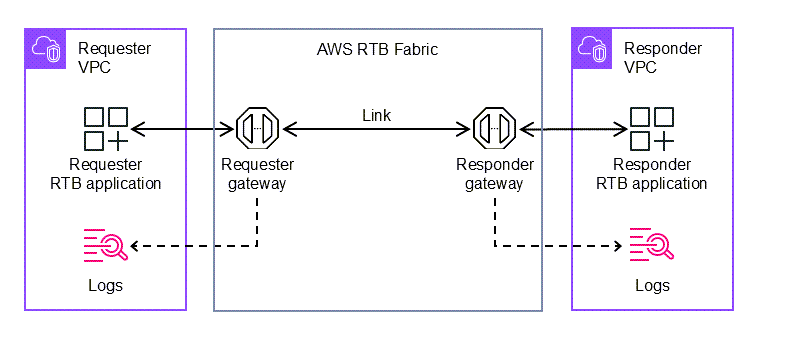
AWS RTB Fabric also includes modules, a capability that helps customers bring their own and partner applications securely into the compute environment used for real-time bidding. Modules support containerized applications and foundation models (FMs) that can enhance transaction efficiency and bidding effectiveness. At launch, AWS RTB Fabric includes modules for optimizing traffic management, improving bid efficiency, and increasing bid response rates, all running inline within the service for consistent low-latency execution.
The growth of programmatic advertising has created a need for low-latency, cost-efficient infrastructure to support RTB workloads. AdTech companies process millions of bid requests per second across publishers, supply-side platforms (SSPs), and demand-side platforms (DSPs). These workloads are highly sensitive to latency because most RTB auctions must complete within 200–300 milliseconds and require reliable, high-speed exchange of OpenRTB requests and responses among multiple partners. Many companies have addressed this by deploying infrastructure in colocation data centers near key partners, which reduces latency but adds operational complexity, long provisioning cycles, and high costs. Others have turned to cloud infrastructure to gain elasticity and scale, but they often face complex provisioning, partner-specific connectivity, and long-term commitments to achieve cost efficiency. These gaps add operational overhead and limit agility. AWS RTB Fabric solves these challenges by providing a managed private network built for RTB workloads that delivers consistent performance, simplifies partner onboarding, and achieves predictable cost efficiency without the burden of maintaining colocation or custom networking setups.
Key capabilities
AWS RTB Fabric introduces a managed foundation for running RTB workloads at scale. The service provides the following key capabilities:
- Simplified connectivity to AdTech partners – When you register an RTB Fabric gateway, the service automatically generates secure endpoints that can be shared with selected partners. Using the AWS RTB Fabric API, you can create optimized, private connections to exchange RTB traffic securely across different environments. External Links are also available to connect with partners who aren’t using RTB Fabric, such as those operating on premises or in third-party cloud environments. This approach shortens integration time and simplifies collaboration among AdTech participants.
- Dedicated network for low-latency advertising transactions – AWS RTB Fabric provides a managed, high-performance network layer optimized for OpenRTB communication. It connects AdTech participants such as SSPs, DSPs, and publishers through private, high-speed links that deliver consistent single-digit millisecond latency. The service automatically optimizes routing paths to maintain predictable performance and reduce networking costs, without requiring manual peering or configuration.
- Pricing model aligned with RTB economics – AWS RTB Fabric uses a transaction-based pricing model designed to align with programmatic advertising economics. Customers are billed per billion transactions, providing predictable infrastructure costs that align with how advertising exchanges, SSPs, and DSPs operate.
- Built-in traffic management modules – AWS RTB Fabric includes configurable modules that help AdTech workloads operate efficiently and reliably. Modules such as Rate Limiter, OpenRTB Filter, and Error Masking help you control request volume, validate message formats, and manage response handling directly in the network path. These modules execute inline within the AWS RTB Fabric environment, maintaining network-speed performance without adding application-level latency. All configurations are managed through the AWS RTB Fabric API, so you can define and update rules programmatically as your workloads scale.
Getting started
Today, you can start building with AWS RTB Fabric using the AWS Management Console, AWS Command Line Interface (AWS CLI), or infrastructure-as-code (IaC) tools such as AWS CloudFormation and Terraform.
The console provides a visual entry point to view and manage RTB gateways and links, as shown on the Dashboard of the AWS RTB Fabric console.
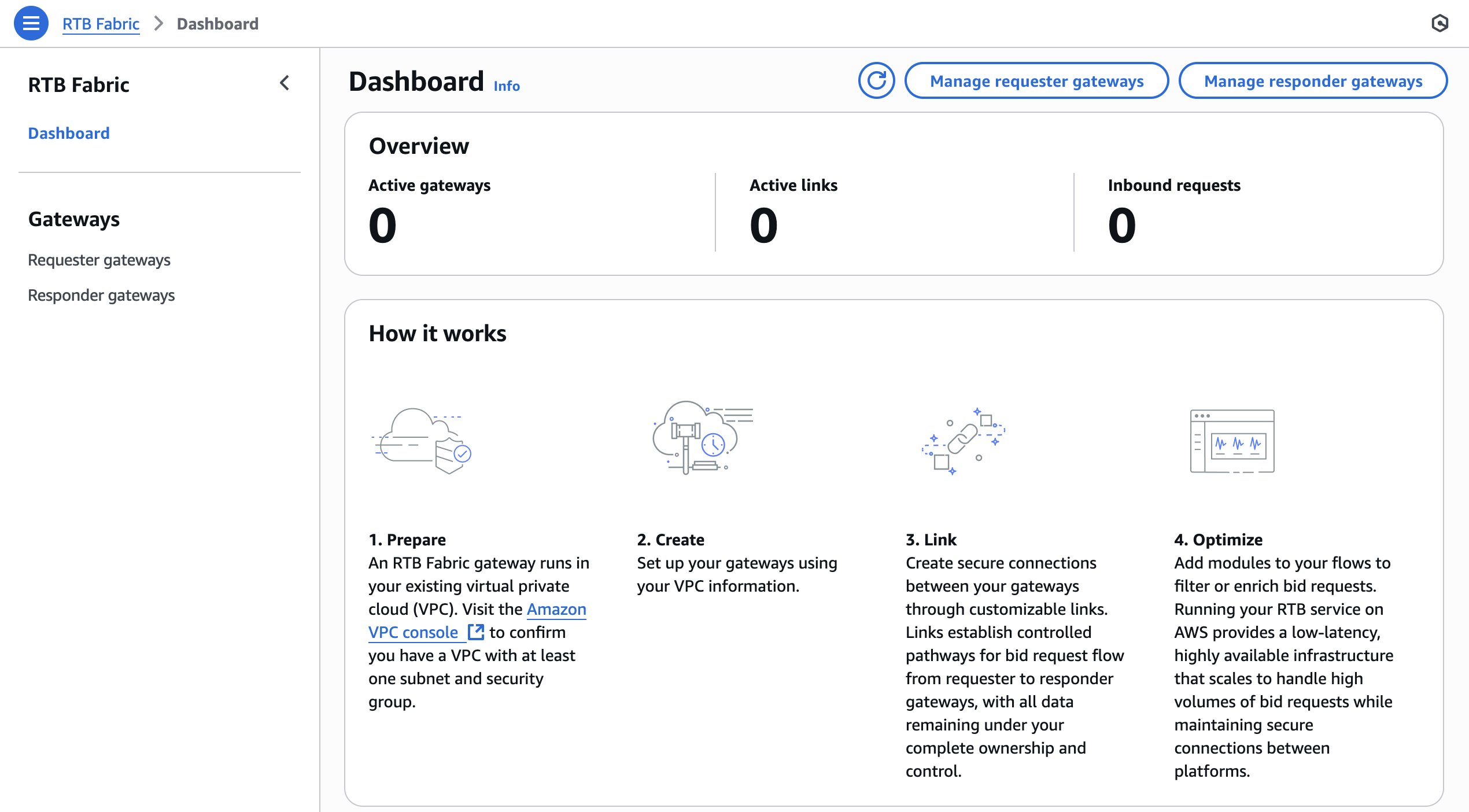
You can also use the AWS CLI to configure gateways, create links, and manage traffic programmatically. When I started building with AWS RTB Fabric, I used the AWS CLI to configure everything from gateway creation to link setup and traffic monitoring. The setup ran inside my Amazon Virtual Private Cloud (Amazon VPC) endpoint while AWS managed the low-latency infrastructure that connected workloads.
To begin, I created a requester gateway to send bid requests and a responder gateway to receive and process bid responses. These gateways act as secure communication points within the AWS RTB Fabric.
# Create a requester gateway with required parameters
aws rtbfabric create-requester-gateway \
--description "My RTB requester gateway" \
--vpc-id vpc-12345678 \
--subnet-ids subnet-abc12345 subnet-def67890 \
--security-group-ids sg-12345678 \
--client-token "unique-client-token-123"
# Create a responder gateway with required parameters
aws rtbfabric create-responder-gateway \
--description "My RTB responder gateway" \
--vpc-id vpc-01f345ad6524a6d7 \
--subnet-ids subnet-abc12345 subnet-def67890 \
--security-group-ids sg-12345678 \
--dns-name responder.example.com \
--port 443 \
--protocol HTTPS
After both gateways were active, I created a link from the requester to the responder to establish a private, low-latency communication path for OpenRTB traffic. The link handled routing and load balancing automatically.
# Requester account creating a link from requester gateway to a responder gateway
aws rtbfabric create-link \
--gateway-id rtb-gw-requester123 \
--peer-gateway-id rtb-gw-responder456 \
--log-settings '{"applicationLogs:{"sampling":"errorLog":10.0,"filterLog":10.0}}'# Responder account accepting a link from requester gateway to responder gateway
aws rtbfabric accept-link \
--gateway-id rtb-gw-responder456 \
--link-id link-reqtoresplink789 \
--log-settings '{"applicationLogs:{"sampling":"errorLog":10.0,"filterLog":10.0}}'I also connected with external partners using External Links, which extended my RTB workloads to on-premises or third-party environments while maintaining the same latency and security characteristics.
# Create an inbound external link endpoint for an external partner to send bid requests to
aws rtbfabric create-inbound-external-link \
--gateway-id rtb-gw-responder456# Create an outbound external link for sending bid requests to an external partner
aws rtbfabric create-outbound-external-link \
--gateway-id rtb-gw-requester123 \
--public-endpoint "https://my-external-partner-responder.com"
To manage traffic efficiently, I added modules directly into the data path. The Rate Limiter module controlled request volume, and the OpenRTB Filter validated message formats inline at network speed.
# Attach a rate limiting module
aws rtbfabric update-link-module-flow \
--gateway-id rtb-gw-responder456 \
--link-id link-toresponder789 \
--modules '{"name":"RateLimiter":"moduleParameters":{"rateLimiter":{"tps":10000}}}'Finally, I used Amazon CloudWatch to monitor throughput, latency, and module performance, and I exported logs to Amazon Simple Storage Service (Amazon S3) for auditing and optimization.
All configurations can also be automated with AWS CloudFormation or Terraform, allowing consistent, repeatable deployment across multiple environments. With RTB Fabric, I could focus on optimizing bidding logic while AWS maintained predictable, single-digit millisecond performance across my AdTech partners.
For more details, refer to the AWS RTB Fabric User Guide.
Now available
AWS RTB Fabric is available today in the following AWS Regions: US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Tokyo), Europe (Frankfurt), and Europe (Ireland).
AWS RTB Fabric is continually evolving to address the changing needs of the AdTech industry. The service expands its capabilities to support secure integration of advanced applications and AI-driven optimizations in real-time bidding workflows that help customers simplify operations and improve performance on AWS. To learn more about AWS RTB Fabric, visit the AWS RTB Fabric page.
– Betty
Научни новини: Нобелови награди 2025
Post Syndicated from Михаил Ангелов original https://www.toest.bg/nauchni-novini-nobelovi-nagradi-2025/
Медицина и физиология


В ежедневието си се срещаме с безброй микроорганизми, които заплашват нашето здраве. Те са навсякъде около нас – във водата, храната, въздуха. За справяне с тях еволюцията ни е предоставила изключително мощно оръжие – имунната ни система, без която не бихме оцелели.
Тя се състои от различни класове клетки, всеки с различна функция. Т-клетките (наречени така, тъй като съзряват в тимуса) са един от класовете и от своя страна се разделя на няколко подкласа. Един от признаците за това разделение са протеините, намиращи се по клетъчната им обвивка: клетки с протеин CD4 (важни за днешната история), които помагат на имунната система, насочвайки другите клетки към проблемни места; клетки убийци с протеин CD8, в състояние да унищожават клетки, в които протичат нежелани процеси; клетки на паметта и други видове.
Много впечатляваща способност на имунната ни система е, че тя успява да бъде изключително специфична – напада само неприятели, които заплашват нашето здраве, но не и здравите клетки на тялото ни. Колкото и да е добра в това обаче, понякога стават грешки и така възникват автоимунните заболявания. Те могат да бъдат изключително тежки, ето защо изясняването как точно се осъществява контролът на имунния отговор занимава учените от дълго време.
Един от процесите, отговорни за това, е т.нар. централен толеранс. Той протича в тимуса, където Т-клетките минават проверка и тези, които биха атакували тялото ни, се отстраняват. Въпреки че механизмът работи в повечето случаи, някои от Т-клетките успяват да се измъкнат, създавайки проблеми в организма. Това кара учените да заподозрат съществуването на допълнителни начини за контрол на тези клетки.
Така се ражда хипотезата за съществуването на „супресорни Т-клетки“, които могат да потиснат имунния отговор. Според нея в генома има участък, кодиращ функционалността на тези клетки. Хипотезата набира скорост през 70-те години на миналия век, но уви, по това време технологиите не позволяват прецизно разделяне на различните видове Т-клетки, поради което публикуваните резултати понякога не съвпадат напълно или дори си противоречат. И когато в началото на 80-те става ясно, че такъв участък в генома не съществува, хипотезата бързо изчезва от вниманието на учените.
По това време японски учени получават интересни резултати – когато тимусната жлеза на тридневни мишлета се премахне оперативно, имунната им система излиза извън контрол, водейки до автоимунно заболяване. Но ако в мишлетата се инжектират помощни Т-клетки от възрастен донор, остават здрави. Това повдига въпроса как помощните Т-клетки, които би трябвало да активират имунната система, я потискат. Може би все пак супресорните Т-клетки съществуват?
Един от тези японски учени е бъдещият нобелов лауреат Сакагучи. Вдъхновен от резултатите, той посвещава следващите над десет години в търсене на тези клетки и през 1995 г. обявява съществуването им. По-късно са наречени „регулаторни“ Т-клетки (Treg), като характерното за тях е, че освен обичайния за помощните Т-клетки протеин CD4 носят още един на повърхността си – CD25. Екипът на Сакагучи демонстрира, че ако експериментът с мишките се повтори, за спиране на автоимунното заболяване е достатъчно инжектирането само на този тип клетки. За съжаление, тъй като CD25 се намира в малки количества и по другите помощни Т-клетки, новооткритите клетки не могат да бъдат напълно отделени от тях. Липсата на специфичен маркер за Treg поставя бариера пред по-нататъшната работа за установяване на тяхната функционалност.
В този момент в историята се включват мишки с далечен прародител, изложен на радиация. По време на разработването на атомната бомба се извършват и експерименти за установяване на ефекта от радиацията върху животни. При някои облъчени мишки се наблюдават проблеми с козината и кожата, в някои вътрешни органи, както и кратък живот. Това заинтригува учените и те създават нова линия мишки с тежко автоимунно заболяване, наречена scurfy. По време на развъждането им се установява, че заболяването се проявява само при мъжките мишки, което насочва учените към мишата X хромозома. Тъй като автоимунното им заболяване засяга множество органи, намирането на причината за възникването му е от голям интерес за учените.
Тук се включва биотехнологичната компания Celltech Chiroscience, и по-конкретно двамата бъдещи нобелови лауреати, които работят там – Брънкау и Рамсдел. Бавно и методично те започват проучване на мишата X хромозома, като успяват да стеснят участъка, където се намира мутацията, до около 500 000 бази от 170-те милиона на цялата хромозома. В този участък те откриват около 20 гена, които са потенциалните виновници за заболяването. След като в продължение на няколко години Брънкау и Рамсдел ги проверяват един по един, последният ген се оказва този, чиято промяна води до силния автоимунен отговор. Непознатият към онзи момент ген е структурно сходен с гените от групата forkhead box, поради което го наричат Forkhead Box P3, или за по-кратко Foxp3.
Щом откриват гена, Брънкау и Рамсдел правят интересен паралел с човешкото автоимунно заболяване IPEX, което също се проявява при момчета и е с генетичен механизъм, локализиран на X хромозомата, като подлежи на терапия чрез трансплантация на стволови клетки. Анализирайки човешкия аналог на Foxp3 при пациенти с IPEX, те потвърждават, че причината е мутация именно в този ген.
След като това става ясно, екипът на Сакагучи бързо прави връзка между двете открития – Foxp3 се активира само в Treg клетките, правейки възможна тяхната уникална функция. Ако генът е повреден, те губят способността си да контролират клетките, изплъзнали се от централния толеранс.
На базата на това познание вече се работи по създаването на нови терапии. Установено е, че туморните образувания привличат множество Treg клетки, за да потиснат активността на имунната система и да се предпазят от нея. В момента се търсят начини, по които да се намали количеството Treg клетки, така че тялото само да се справи със заболелите тъкани. Друго потенциално приложение е терапия на автоимунни заболявания – специфични за пациента Treg клетки се намножават в лаборатория, след което се инжектират отново в него с идеята това да повиши общия им брой в организма. В лабораторията те също могат да се модифицират, така че да бъдат насочени към конкретно място в тялото, например трансплантиран орган, който да бъде предпазен от имунната система.
Освен огромния принос на лабораторните животни към развитието на медицината и науката като цяло, тазгодишната награда за медицина и физиология показва и колко е важно учените да проявяват наблюдателност, постоянство и любопитство. От забелязването и запазването на мишките, страдащи от странно заболяване, през вярата на Сакагучи и плуването му ако не срещу течението, то поне в съседен коридор, до правенето на връзки с човешката генетика и създаването на нови терапии за автоимунни заболявания.
Физика

Квантовите компютри крият голям потенциал, който все още не можем да овладеем напълно. Те са изградени от изключително специфични части, които по същество не се държат както повечето обекти в нашето ежедневие. Нобеловата награда за физика тази година е признание за учените, които вникват в това какви процеси протичат и какво практическо приложение могат да имат в системите, които стават основа на днешните квантови компютри.
За да разберем какво точно е откритието на лауреатите, първо трябва да се вмъкнем в дебрите на квантовата физика и да разгледаме два феномена.
Тунелни преходи
Обикновено когато говорим за квантови ефекти, става дума за процеси, протичащи в невидим за нас свят поради малките си размери. Сред тези квантови ефекти са и т.нар. тунелни преходи, позволяващи преминаването на частици през прегради, което звучи малко научнофантастично. Представете си, че хвърляте топка към стена. Интуицията ви подсказва, че топката ще отскочи обратно. Но ако вместо топка, която се състои от безчет атоми, към стената хвърлим само една частица, има вероятност тя просто да се появи от другата страна.
Обикновено когато говорим за квантови ефекти, става дума за процеси, протичащи в невидим за нас свят поради малките си размери. Сред тези квантови ефекти са и т.нар. тунелни преходи, позволяващи преминаването на частици през прегради, което звучи малко научнофантастично. Представете си, че хвърляте топка към стена. Интуицията ви подсказва, че топката ще отскочи обратно. Но ако вместо топка, която се състои от безчет атоми, към стената хвърлим само една частица, има вероятност тя просто да се появи от другата страна.
Това поведение не е пълна изненада за учените – в края на 20-те години на миналия век става ясно, че то стои зад радиоактивния алфа-разпад на ядрата на тежките елементи. Въпреки че силите в ядрото създават преграда, която би трябвало да спре изстрелването на частиците, те все пак успяват да я прескочат.
Свръхпроводимост
При движението си в обикновените проводници електроните се блъскат в атомите на проводника, като по този начин част от енергията им се отделя под формата на топлина и това води до загуби. Тайната на свръхпроводящите материали е, че когато те се охладят до изключително ниски температури, електроните в тях образуват т.нар. куперови двойки, в които поради квантови ефекти стават неразличими един от друг, макар да остават отделни частици. Така те могат да преминават през материала, без да се удрят в атомите му. Тези материали имат значителен потенциал и правят възможни най-различни технологии, една от които са съвременните свръхчувствителни машини за ядрено-магнитен резонанс.
И двата ефекта протичат в микроскопични мащаби с едни от най-простите частици, изграждащи материята. Пресечната точка между тях е в електрическа схема, наречена контакт на Джоузефсън. Това е система, състояща се от два свръхпроводника, между които е поставена непроводяща бариера. От време на време куперовите двойки успяват да преминат през тази бариера, като прехвърлят квантовото състояние от единия свръхпроводник в другия без подаване на напрежение. За математическото моделиране на процеса Брайън Джоузефсън получава Нобелова награда за физика през 1973 г.
В началото на 80-те години на миналия век възниква въпросът дали в тези контакти може да се наблюдава тунелен преход в макроскопски мащаб – движение на милиарди електрони в синхрон. Предположението е направено от Антъни Легет, който през 2003 г. също получава Нобелова награда за физика. Тази хипотеза заинтригува тримата настоящи лауреати и те се заемат със създаването на специална опитна установка, с която да я изпитат. Поради много ниските температури и случайния характер на прескачането установката трябва да бъде изключително прецизна, за да се изключи влизането на външна енергия в системата, което би дало фалшиво позитивен сигнал.
С помощта на новосъздадения уред триото учени провежда няколко ключови експеримента. При нормална температура системата се придържа към класическите модели – за преминаване на бариерата (протичане на напрежение) е необходимо да се подаде енергия. Но под определена температура тя започва да работи като свръхпроводник и в закономерни интервали през нея протича напрежение. Това ясно потвърждава, че целият контакт на Джоузефсън се държи като една голяма квантова единица – всички куперови двойки в него са квантово идентични. Щом потвърждават хипотезата, учените също показват, че схемата има дискретни нива на енергия, подобно на атомите.
На практика устройството, което създават Джон Кларк, Мишел Деворе и Джон Мартинис, е своеобразен кюбит – градивната единица на квантовите компютри. В последващи експерименти Мартинис показва, че използвайки различните нива на енергия в системата, тя може да съхранява информация под формата на 1 и 0. Това е и фундаменталният практически принос на откритието на лауреатите – те полагат основите за създаване на ново поколение изчислителни машини.
Признание за това са и новите поприща на двама от тях, след като напускат академичните среди – Мартинис е част от екипа на Google, разработващ квантови компютри, в периода от 2014 до 2020 г., след което създава свой стартъп. Деворе поема ръководството на отдела за квантови компютри на технологичния гигант през 2023 г.
Химия

Едно от интересните умения на хората е да черпят вдъхновение от природата и да променят сътвореното от нея. Пример за това са много материали в нашето ежедневие, които сме взели от нея, а после сме ги преработили и подобрили. Но със сигурност не е лесно – измислянето на нов клас материали е постижение, с което не могат да се похвалят мнозина.
Ричард Робсън е един от тях – той е бащата на т.нар. метало-органични структури (МОС). Идеята за създаването им го осенява, докато подготвя модели на молекули за упражнения по химия. Тогава Робсън се замисля как би изглеждала молекула, в която има метални звена, свързани с органични молекули.
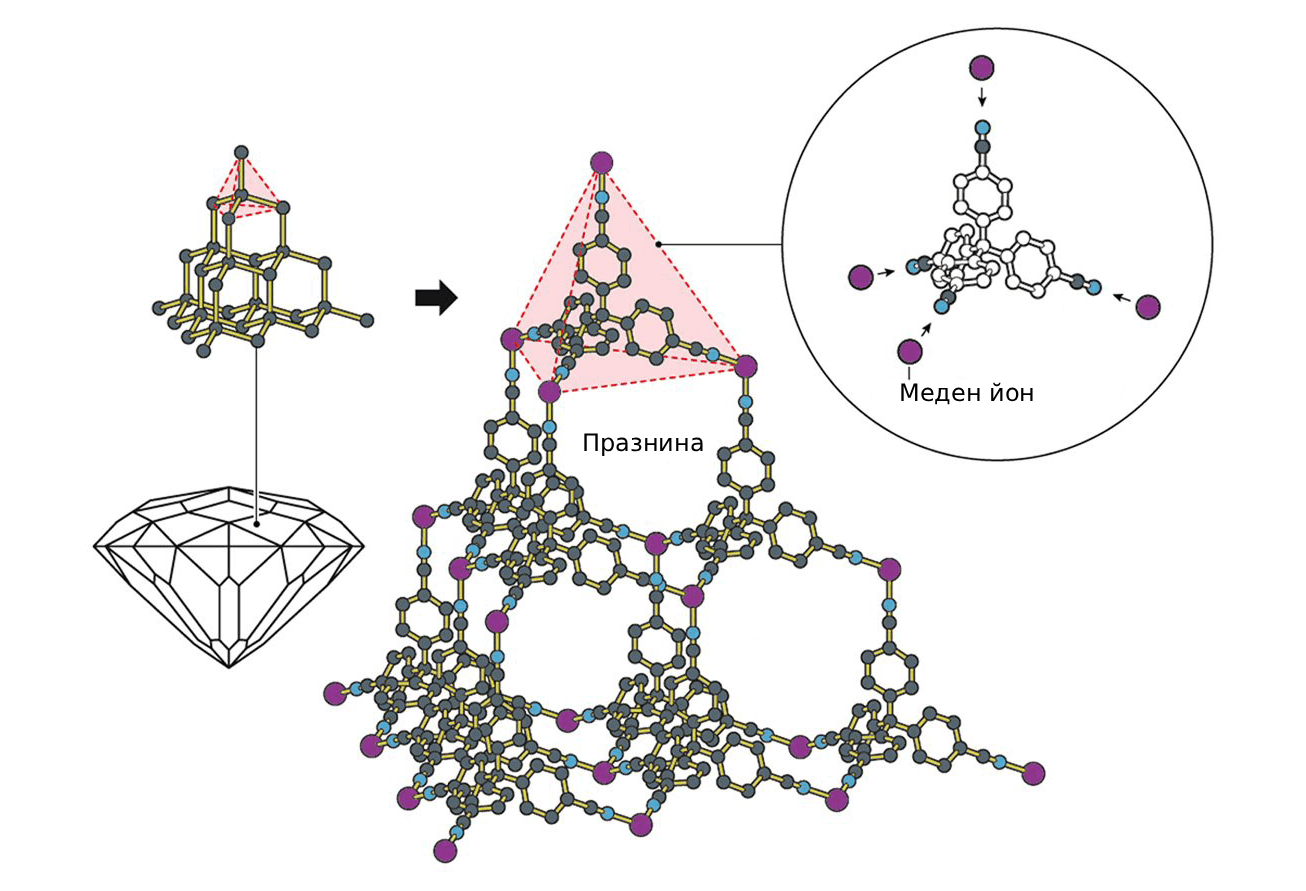
Първата структура, която хрумва на Робсън, е сходна с диамант, в който въглеродните атоми използват четирите си връзки, за да се свържат под формата на пирамида с други въглеродни атоми. За техен аналог той използва медни йони, които също като въглеродните атоми могат да направят четири връзки, а за свързващи звена използва органична молекула с четири „ръце“, които могат да се захванат за четири медни йона.
Една от впечатляващите характеристики на тази структура е, че тъй като отделните метални звена са свързани не директно едно с друго (както е в плътните диаманти), а с по-дълги елементи, в нея има големи празни пространства. Робсън установява, че при образуването на структурата празнините са пълни с разтворителя, в който протича реакцията, но той не е затворен там, а може да се движи през тях.
След като създава първия по вида си нов материал, той продължава с експериментите си, правейки други структури с по-различни свойства – например структура, която може да приема избирателно само определени вещества в празнините си. Като пионер той изказва редица хипотези, които предстои да се потвърдят – това, че структурите могат да запазят формата си, дори и без празнините да са пълни, както и възможността за заключване на молекули, които катализират реакции. Това би ги направило изключително впечатляващи катализатори за химическата индустрия поради избирателната им пропускливост и голямата им площ.
За съжаление, в началото структурите на Робсън не привличат огромно внимание. Те имат интригуващи свойства, но са нестабилни и поради пълната си новост учените могат само да изказват хипотези за потенциалните им приложения.
Тази „безполезност“ привлича Китагава, който смята, че за да бъде нещо интересно, не е задължително да бъде полезно. Това се случва и с първата МОС, създадена от него – двуизмерна структура, в която може да се улавя ацетон и която засега няма особено практическо приложение. Въпреки трудностите с намирането на финансиране той продължава да се занимава с тези структури и след няколко години създава МОС, която може да бъде изсушена и да остане стабилна, а в празнините ѝ да се абсорбират различни газове, като метан, кислород и азот. След това постижение той се концентрира върху създаването на гъвкави МОС. Изградени по подходящ начин, те биха могли да функционират като бял дроб.
Паралелно с японеца работи третият лауреат – Омар Яги. Той е роден в семейство на палестински бежанци в Йордания и когато е на 15 години, заминава за САЩ, където открива любовта си към химията. Докато Китагава се занимава с гъвкавите структури, Яги се фокусира върху създаването на изключително стабилни структури, издържащи на високи температури. Една от тях, която се налага като крайъгълен камък в дизайна на МОС, е MOF-5. Свойствата ѝ са главозамайващи – тя остава стабилна дори при 300℃ и е изключително порьозна. Един грам от нея има площ от 2900 кв.м – представете си как нагъвате половин футболно игрище в зарче.
С времето екипът на Яги създава още по-впечатляващи МОС – например MOF-210 има три пъти по-голяма площ от MOF-5. Някои от тях имат и пряко приложение: една от тях има способността да задържа въглероден двуокис, а друга – да поема влага от въздуха, която после да освободи при нагряване.
Въпреки че все още могат да бъдат описани като „нов материал“, полезните свойства на МОС вече не са под въпрос. Поради богатото разнообразие от молекули и метални йони, от които е възможно да бъдат изградени, те могат да имат изключително различни структури и функционалности, което ги прави ценни за редица индустрии. Сами по себе си МОС биха заинтригували малцина. Но продуктите, на които могат да станат основа (събиране на вода от пустинния въздух, пречистване на вода, съхранение на водород), пленяват вниманието и показват колко обещаващи са всъщност.
Анатомия в огледалото. Естетичната медицина
Post Syndicated from Надежда Цекулова original https://www.toest.bg/anatomiya-v-ogledaloto-estetichnata-meditsina/

Като тийнейджърка се смущавах, че бюстът ми е малък, а носът ми е голям. Живях някак (всъщност доста добре) с „невероятните“ си дефицити и след повече от две десетилетия, тъкмо когато започнах да съществувам в хармония с тия си неравности, четирийсетте ми донесоха нови тревоги – бръчки, отпускане на кожата, пигментни петна.
Всяка сутрин, докато се мажа с крем пред огледалото, се питам искам ли да изглеждам на 25. Няма да ви занимавам с отговора, защото би издал личните ми пристрастия.
Най-близкото обкръжение на американския президент – и мъже, и жени – има сходни лицеви белези: високи, твърди и препълнени скули, опъната кожа, повдигната линия на косата, пълни устни, добре оформени вежди, широки бадемовидни очи, силна челюст, тесен нос и много бели зъби.
Не ги е избирал по хубост.
Няколко месеца след встъпването на Тръмп в длъжност американските медии започнаха да забелязват (и да разказват), че ключовите членове на администрацията му – както и самият Тръмп – си приличат твърде много. Това не е случайно, а причината не е тайна – всички си правят естетични корекции с идентично задание.
Лицето „Мар-а-Лаго“
Лице „Мар-а-Лаго“, наречено на имението на Тръмп в Палм Бийч, „се отнася до разпознаваемо съчетание от черти на лицето и пластични корекции, често моделирани по характерния външен вид на Иванка Тръмп“, казва пластичният хирург Матю Дж. Никиел пред изданието HuffPost.
Постигането на този вид обикновено включва комбинация от хирургични процедури и инжекционни манипулации – фасети, ботокс, лифтинг, операция на клепачите, лазерни процедури и поставяне на филъри. Първоначалното им прилагане струва десетки, понякога дори стотици хиляди долари, а след това е необходима и скъпа поддръжка. Въпреки високата цена моделът се разпространява светкавично и сред поддръжниците на движението MAGA. Лицето „Мар-а-Лаго“ може да се разглежда като част от „по-широки усилия“ за „налагане на строги полови норми“ върху последователите на американския президент с „естетика, която – подобно на политиката на Тръмп – е нелепо директна“, пише лявото издание Mother Jones.
Тази история ми попадна преди време и признавам, шокирах се, че човек може по политически причини да се подложи на серия инвазивни и потенциално рискови процедури, които поставят под въпрос нещо толкова лично, като идентичността му.
Огледалце, огледалце от стената…
Причините, каращи човек да се стреми да изглежда по определен начин, обаче са неизброими.
През последните години в развития свят модата на фрапантните естетични намеси е подложена на преосмисляне в средите на артистичните елити, които преди десетилетия изглеждаха „привилегировани“ в достъпа си до естетични корекции. Иконата на силиконовия бюст Памела Андерсън например не само махна силикона преди две десетилетия, а в момента преживява своето творческо прераждане именно във фокуса на новия си имидж „без грим“ (makeup-free). Темата за правото на жените (и на мъжете, но тази рубрика не се занимава с тях) да остареят достойно става все по-ключова за Холивуд.
В същото време обаче естетичната медицина става все по-достъпна и по-масова. Последният доклад на Международната общност на естетичните пластични хирурзи сочи общ ръст от 40% между 2020 и 2024 г. на хирургичните и нехирургичните процедури. Операцията на клепачите за първи път е най-често срещаната хирургична процедура през 2024 г. (благодарение на ръста си при мъжете), замествайки липосукцията, която остава втора, уголемяването на гърдите, корекцията на белези и ринопластиката. Най-популярните нехирургични процедури са слагане на ботулинов токсин (и при жените, и при мъжете), поставяне на хиалуронова киселина (филър), обезкосмяване, нехирургично стягане на кожата и химически пилинг. Държавите шампионки по брой процедури в света са САЩ, Япония и Бразилия, а в Европа водят Германия и Турция, като Турция е сред световните лидери по брой на чуждестранните пациенти.
В България не се поддържа официална статистика за пазара на естетични услуги. По улиците на българските градове, в българските риалити формати и понякога дори на представителни постове в българските институции обаче достатъчно често се срещат жени, а и мъже с драстични естетични намеси, така че можем да сме уверени в принадлежността си към тези световни тенденции. Изследване на екип на Медицинския университет в София, фокусирано върху клиентите на един център за естетична медицина в София, показва, че възрастовото разпределение в този център не се разминава драстично със световните данни за ползвателите на такива процедури. Клиентите под 18 г. са под 2%, още 14% са до 25-годишна възраст. Преди да повдигнете вежди многозначително, нека отбележим, че сред отчитаните процедури е и лазерното обезкосмяване, и можем да спекулираме, че то добавя клиенти в най-младия сегмент.
„Коя е най-красива на Земята?“
„Младите хора в България днес нямат добри модели, върху които да изградят идентичност“, казва психоложката Александра Петрова за англоезичното издание 3seaseurope.com в статия, посветена на причините за масовото разпространение на естетичните процедури у нас. Според нея, ако прекалено уголемените устни или други части на тялото на човек са успешно позиционирани в социалните мрежи и будят интерес, тогава много бързо се губят балансът и границите и е лесно човек да поиска подобни устни например. Психоложката смята, че младите хора често виждат приказката за Пепеляшка във фантазиите си, свързани с промяната на външния вид – ако отговарям на определени критерии за красота, принцът ще ме забележи, ще танцуваме цяла нощ и след това ще сме щастливи до края на дните си.
Образно казано, но схващате идеята.
Разбира се, в истинския живот рядко става точно така, а и както видяхме от статистиката, младите всъщност са един сравнително малък дял от ползвателите на естетичната медицина.
Мотивите на хората за промяна на външния им вид се изследват от десетилетия, а бумът на естетичните процедури в последните години повишава интереса и към тези изследвания. Някои от тях потвърждават интуитивни хипотези – проучване на екип от University College London през 2012 г. например установява, че по-вероятно е на козметична операция да се подложи човек с ниска самооценка, ниска удовлетвореност от живота, ниско самооценена физическа привлекателност, висока консумация на медии и слаби религиозни убеждения. Или казано по-просто, хората, които не се чувстват добре в кожата си и са недоволни от живота си, са по-склонни да обмислят хирургична промяна на външния си вид, особено ако това често присъства в медийните послания и ако не са религиозни.
В ново проучване от юни тази година международен екип се допитва до над 800 жени от Бразилия, като основните групи са разделени на подкрепящи и на отхвърлящи естетичните процедури. За жените с по-високо ниво на образование, разведени, с по-високи доходи и по-сериозни страхове от остаряването има по-голяма вероятност да се подложат на естетични процедури за лице.
Зад тази социологическа находка стоят психологически явления, стари колкото човечеството – хората се страхуват от остаряването и смъртта, искат да бъдат харесвани и приемани и да принадлежат към общност (за предпочитане – успешна). През последните години обаче към тези стари страхове и към проявленията им в различните епохи се присъединяват технологичният бум и възможността да модифицираме собствения си образ през филтрите за изображения в различни приложения и социални мрежи. Това явление добавя към традиционното влияние на ролевите модели нов недостижим стремеж – да приличаме на едно дигитално модифицирано и частично анимирано аз.
Британското издание The Guardian посвещава редица статии в последните години на този феномен и на все по-често свързваното с него телесно дисморфично разстройство (body dysmorphic disorder) – натрапчиво усещане, че реалното тяло е дефектно. Основната идея, която се налага, е, че филтрираният ни дигитален образ ни създава изкривени очаквания как трябва да изглеждаме, за да се възприемаме положително.
Филтрите за красота в социалните мрежи постепенно променят не само как изглеждаме онлайн, а как възприемаме собственото си лице, обяснява Ракел Джонс в статията „Това аз ли съм? Грозната истина за разкрасителните филтри“ (Is that really me? The ugly truth about beauty filters). Джонс описва как невинните на пръв поглед функции за изглаждане на кожата или за уголемяване на очите създават нов визуален стандарт, с който все повече хора започват да се сравняват в реалния живот. Психоложката Джесика Фардоули предупреждава, че колкото по-недостижим е този стандарт, толкова по-дълбоко се подкопава самочувствието, и няма достатъчно изследвания какви могат да бъдат дългосрочните последици.
Като превенция на психичното ни здраве и риска да се опитаме с естетични корекции да поправим в тялото си проблеми, възникнали в психиката, от Австралийското психологическо дружество препоръчват психосоциална оценка на хората, желаещи да се подложат на козметична процедура. Целта е да се идентифицират пациентите, които са неподходящи за такава интервенция по причини отвъд физическото им състояние, например нестабилно емоционално състояние, телесно дисморфично разстройство или други психиатрични проблеми.
Как започва всичко?
Естетичната хирургия възниква през XIX в. в контекста на възможностите на тогавашната медицина за възстановяване на лица и крайници след травми, изгаряния, инфекции или вродени дефекти. Тази ѝ функция, макар по-малко фамозна, остава ключова и до днес. Когато говорим за жени, най-честата асоциация (и нужда по линия на пластичната хирургия) е реконструкцията на гърда след операция при рак на млечната жлеза.
В България не е ясно точно колко от пациентките, претърпели мастектомия (частично или цялостно отстраняване на млечната жлеза), се подлагат на реконструктивна операция. Както и по много други въпроси, и по този официална статистика липсва. В САЩ например над 40% от жените, които преминават през лечение на карцином на млечната жлеза, включват и реконструктивна хирургия във възстановяването си. Международно проучване сред над 800 хирурзи от 79 държави обаче установява, че различията в практиките в отделните страни са много големи – изводите им сочат, че над 1/3 от хирурзите извършват до 10 реконструктивни операции на година, а други 20% извършват над 50.
Национални особености
Макар склонността ни да драматизираме националното си положение чрез споделяне на клипчета от „Ергенът“ (който иначе „никой“ не гледа) да се е превърнала в част от изконните ни ценности, всъщност бумът на интереса към естетичните процедури и проблемите, които го пораждат (и които предизвиква впоследствие), очевидно не са уникални за страната ни. Все пак е добре да знаем къде се намираме, когато правим избора си дали и какви разкрасителни процедури да предприемем.
Адвокат Вили Костадинова обръща внимание, че пропуски в регулацията на естетичните процедури в България създават допълнителни рискове и нужда от проверка. „На първо място, масово хората не знаят, че всяка процедура, при която се прониква в тялото, е инвазивна, което означава, че може да се извършва само от лекар“, обяснява тя за „Тоест“.
Това включва поставянето на филъри и на нерезорбируеми конци, инжектирането на ботулинов токсин и други процедури, които в момента безконтролно се извършват от хора с квалификация за козметици или фризьори. „Тези процедури са скъпи за клиента и бързи за извършване, което привлича професионалисти от много широк спектър да желаят да ги предлагат“, обяснява адв. Костадинова. По думите ѝ обаче, квалификация за подобна дейност имат не просто лекарите, а лекарите с точно определени специалности.
Това са само дерматолозите и пластичните хирурзи, както и специалистите, чиято специалност е свързана с локацията, на която се прилага дадената процедура. Например акушер-гинеколозите имат квалификация да поставят филъри в интимната област.
Особено внимание трябва да се обръща на прилагането на ботулинов токсин, което според международните изследвания е сред най-популярните процедури. „В България все още човек може сам да си закупи отнякъде ботулинов токсин и да отиде да му го приложат в някой салон за красота. А това е медицинско изделие – както личи и от самото му име „токсин“, – което изисква квалификация и наблюдение“, подчертава адв. Костадинова.
С други думи, макар в набора си от народни мъдрости да имаме и тази, че „красотата иска жертви“, то добре е към жертвите да се пристъпва след внимателно обмисляне, събиране на информация и консултиране с различни специалисти.
„Анатомия на пола: Жена“ разглежда здравето на жените като неразривна част от обществото, историята и културата. В поредицата изследваме как са се променяли нагласите към женското здраве, как медицината е възприемала специфичните потребности на жените и какви процеси са повлияли на достъпа им до качествени здравни грижи. Вглеждаме се в научните открития, но и в културните митове; в официалните политики, но и в личните истории на жени, борещи се за правото си на здраве и достойнство.
NextSilicon Maverick-2 Brings Dataflow and HBM3e to HPC Customers
Post Syndicated from John Lee original https://www.servethehome.com/nextsilicon-maverick-2-brings-dataflow-and-hbm3e-to-hpc-customers/
The NextSilicon Maverick-2 brings dataflow architecture with HBM3E memory to HPC customers, including a Sandia National Labs win
The post NextSilicon Maverick-2 Brings Dataflow and HBM3e to HPC Customers appeared first on ServeTheHome.
[$] LWN.net Weekly Edition for October 23, 2025
Post Syndicated from corbet original https://lwn.net/Articles/1042221/
Inside this week’s LWN.net Weekly Edition:
- Front: Git 3.0 topics; Lazy imports for Python; RubyGems; LLMs for patch review; DebugFS.
- Briefs: Fedora AI policy; OpenBSD 7.8; DigiKam 8.8.0; Forgejo 13.0; KDE Plasma 6.5; RubyGems; Valkey 9.0.0; Quotes; …
- Announcements: Newsletters, conferences, security updates, patches, and more.
Upgrade from Amazon Redshift DC2 node type to Amazon Redshift Serverless
Post Syndicated from Nita Shah original https://aws.amazon.com/blogs/big-data/upgrade-from-amazon-redshift-dc2-node-type-to-amazon-redshift-serverless/
Amazon Redshift is a fully managed, petabyte-scale, cloud data warehouse service. You can use Amazon Redshift to run complex queries against petabytes of structured and semi-structured data quickly and efficiently, integrating seamlessly with other AWS services.
Amazon Redshift Serverless helps you run and scale analytics in seconds without having to set up, manage, or scale data warehouse infrastructure. It automatically provisions data warehouse capacity and intelligently scales the underlying resources to deliver fast performance for demanding workloads and you pay only for the compute capacity you use. Additionally, with Amazon Redshift managed storage, you can further optimize your data warehouse by scaling storage and compute independently and you pay only for the storage you use.
Upgrading your data warehouse from Amazon Redshift dense compute (DC2) instances to Amazon Redshift Serverless unlocks these advantages and provides an enhanced user experience and simplified operations, offering a more efficient, scalable solution for data analytics.
In this post, we show you the upgrade process from DC2 instances to Amazon Redshift Serverless. We’ll cover:
- Assessing your current setup and determining if an upgrade is right for you
- Planning and preparing for the upgrade
- Step-by-step instructions for the upgrade process
- Post-upgrade optimization and best practices
Why upgrade to Amazon Redshift Serverless
By using Amazon Redshift Serverless, you can run and scale analytics without managing data warehouse infrastructure. When you upgrade from DC2 instances to Amazon Redshift Serverless, you get the following benefits:
- Simplified operations: Access and analyze data without needing to set up, tune, and manage compute clusters.
- Automatic performance optimization: Deliver consistently high performance and simplified operations for demanding and volatile workloads with automatic scaling and AI driven scaling and optimization.
- Pay-as-you-go pricing: The flexible pricing structure charges you only during active usage; you pay only for what you use.
- Online maintenance: Amazon Redshift Serverless automatically manages system updates and patches without requiring maintenance windows, helping to facilitate seamless operation of your data warehouse.
- Decoupled storage and compute: Control costs by scaling and paying for compute and storage separately with Amazon Redshift managed storage.
- Access to new capabilities: Use advanced features including data sharing writes, Redshift Streaming Ingestion, zero-ETL, and other capabilities.
Sizing guidance
To upgrade from DC2 to Amazon Redshift Serverless, you need to understand the size equivalency. The following table shows suggested sizing configurations when upgrading from the DC2 node type.
Note that availability of Redshift Processing Unit (RPU) configurations varies by AWS Region.
| Existing node type | Existing number of nodes | Amazon Redshift Serverless upgrade |
| DC2.large | 1–4 | Start with 4 RPUs |
| DC2.large | 5–7 | Start with 8 RPUs |
| DC2.large | 8–32 | Add 8 RPUs per 8 nodes of DC2.large |
| DC2.8xlarge | 2–32 | Add 16 RPUs per node (up to a maximum of 1,024 RPUs) |
These sizing estimates provide a flexible starting point tailored to help you make the most of Amazon Redshift Serverless. The ideal configuration for your needs will depend on factors such as your desired balance of cost and performance and the specific latency and throughput requirements of your workload. To further optimize the sizing based on your specific requirements, you can use one or more of following approaches:
- Test your workload beforehand: Before migrating to Amazon Redshift Serverless, evaluate your workload’s performance requirements in a non-production environment. The Amazon Redshift Test Drive utility simplifies this process by simulating your production workloads across different serverless configurations. You can use the results to help identify the optimal balance between performance and cost and make informed decisions about your configuration. For step-by-step guidance on using the Test Drive utility for DC2 to Serverless upgrades, see the Amazon Redshift Migration Workshop. Running these performance tests before migration helps you to identify any necessary adjustments to your configuration before deploying to production
- Monitor in production: After you’ve deployed your workload, closely monitor the performance and resource utilization for over a period of time that represents your typical workloads. Based on the observed metrics, you can then scale the resources up or down as needed to achieve the best balance of performance and cost.
- AI-driven scaling and optimization: Consider using Amazon Redshift Serverless with AI-driven scaling and optimization to automatically size Amazon Redshift Serverless for your workload needs.
A methodical approach to sizing validation, combining both pre-production testing and ongoing production monitoring, helps ensure your Amazon Redshift Serverless configuration aligns with your workload.
Upgrade to Amazon Redshift Serverless
To upgrade to Amazon Redshift Serverless, you can use a snapshot restore to move directly from Amazon Redshift to Amazon Redshift Serverless, as shown in the following figure. A snapshot restore restores data and objects in addition to users and their associated permissions, configurations, and schema structures. By using snapshot restore for migration, you can validate the target Amazon Redshift Serverless warehouses without impacting your production Amazon Redshift DC2 cluster. You can also use snapshot restore to migrate your Amazon Redshift DC2 workloads to different Regions or Availability Zones.
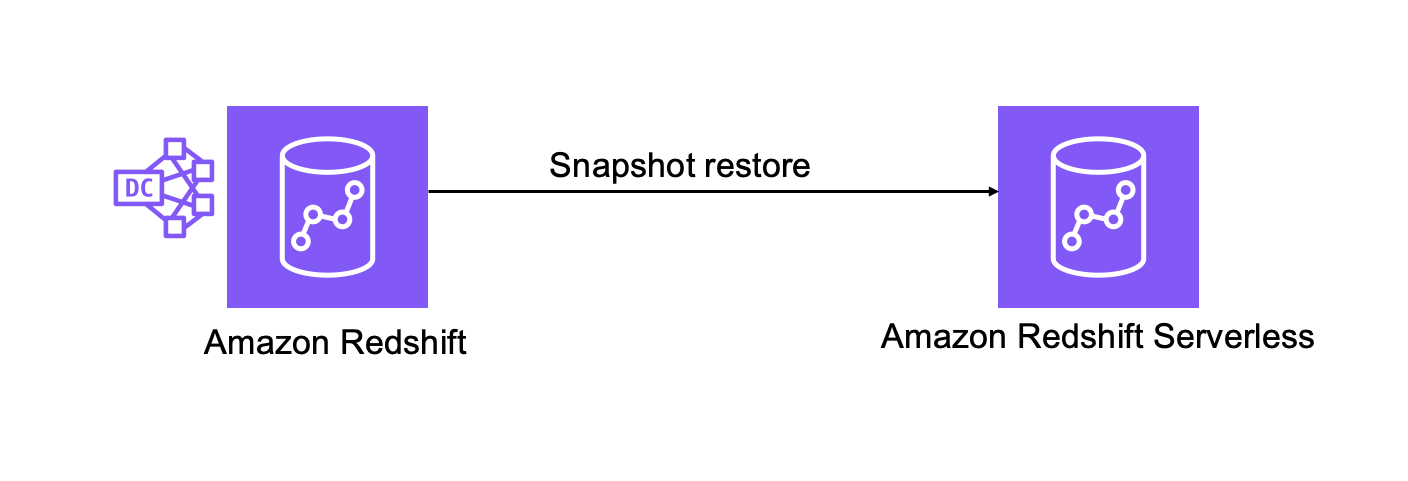
Prerequisites to migrate using a snapshot restore
- Create an Amazon Redshift Serverless workgroup with a namespace. For more information, see creating workgroup with a namespace.
- Amazon Redshift Serverless is encrypted by default. Amazon Redshift Serverless also supports changing the AWS KMS key for the namespace so you can adhere to your organization’s security policies.
- Verify that the Amazon Redshift Serverless namespace you’re trying to restore to is attached to an Amazon Redshift Serverless workgroup.
- To restore from a provisioned Amazon Redshift cluster to Amazon Redshift Serverless, the AWS Identity and Access Management (IAM) user or role must have the following permissions:
redshift-serverless:RestoreFromSnapshot,CreateNamespace, andCreateWorkgroup. For more information, see Amazon Redshift Serverless restore.
Upgrade using the console
Use the following steps in the AWS Management Console for Amazon Redshift to upgrade your DC2 cluster to Amazon Redshift Serverless using the snapshot restore method.
- On the Redshift console, choose Clusters in the navigation pane. Select your cluster and then choose Maintenance.

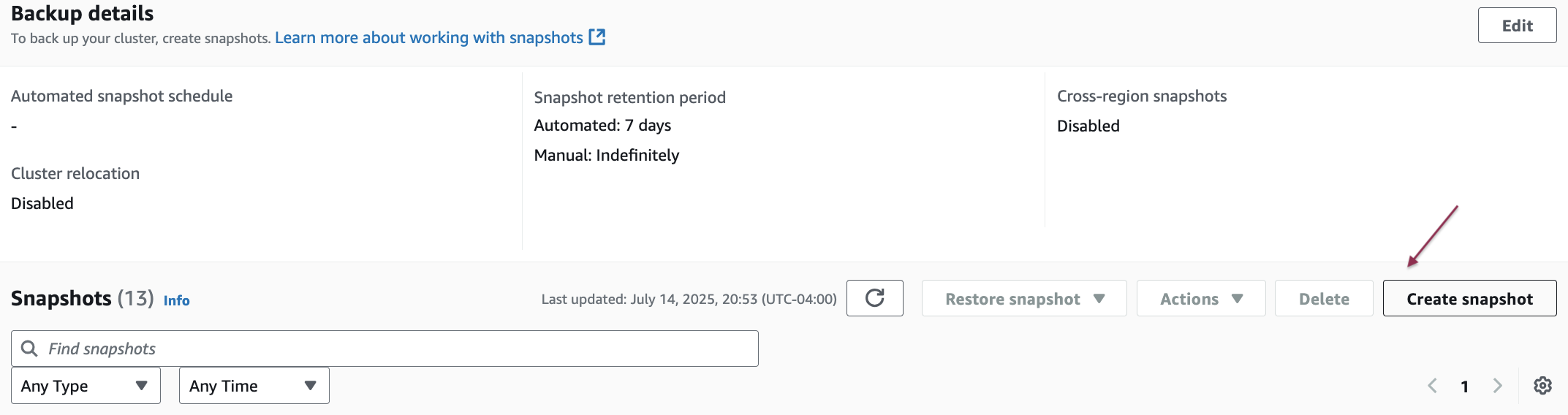
- Choose Create snapshot to create a manual snapshot of the existing Amazon Redshift provisioned cluster.

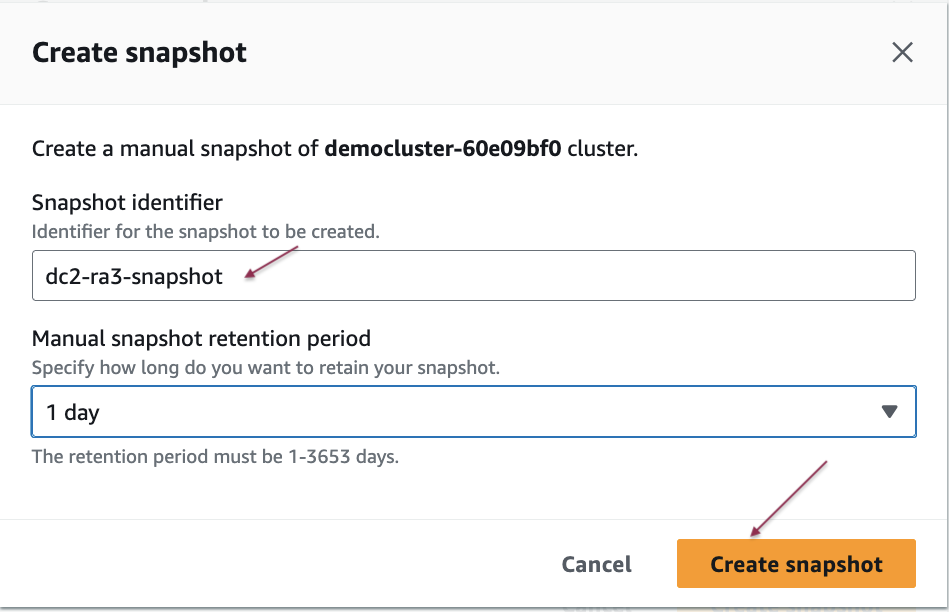
- Enter a snapshot identifier, select the snapshot retention period, and then choose Create snapshot.

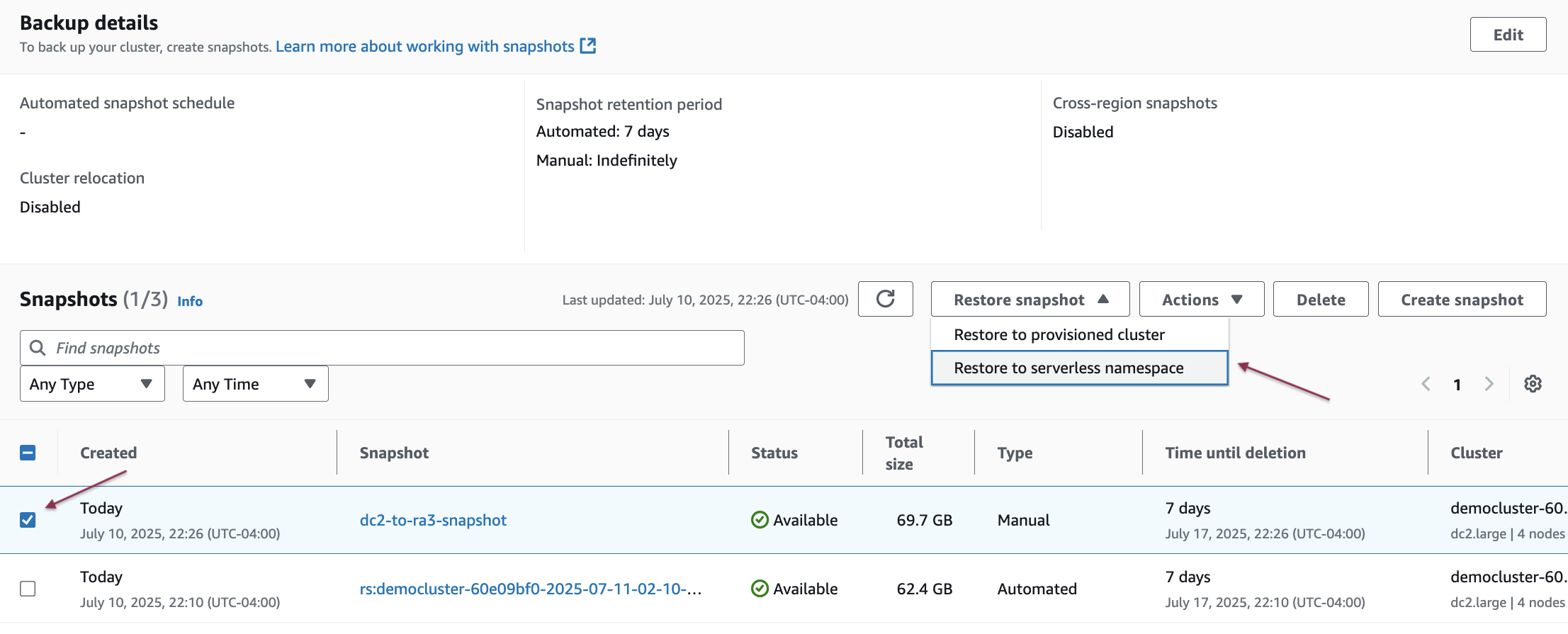
- Select the snapshot you want to restore to Amazon Redshift Serverless from the list and then choose Restore snapshot and select Restore to serverless namespace.

- Under Select namespace, select your target serverless namespace from the dropdown list and then choose Restore.

- The restoration time will vary based on your data volume.

- After the restoration completes, verify your data migration by connecting to your Amazon Redshift Serverless workspace using either the Amazon Redshift Query Editor v2 or your preferred SQL client.
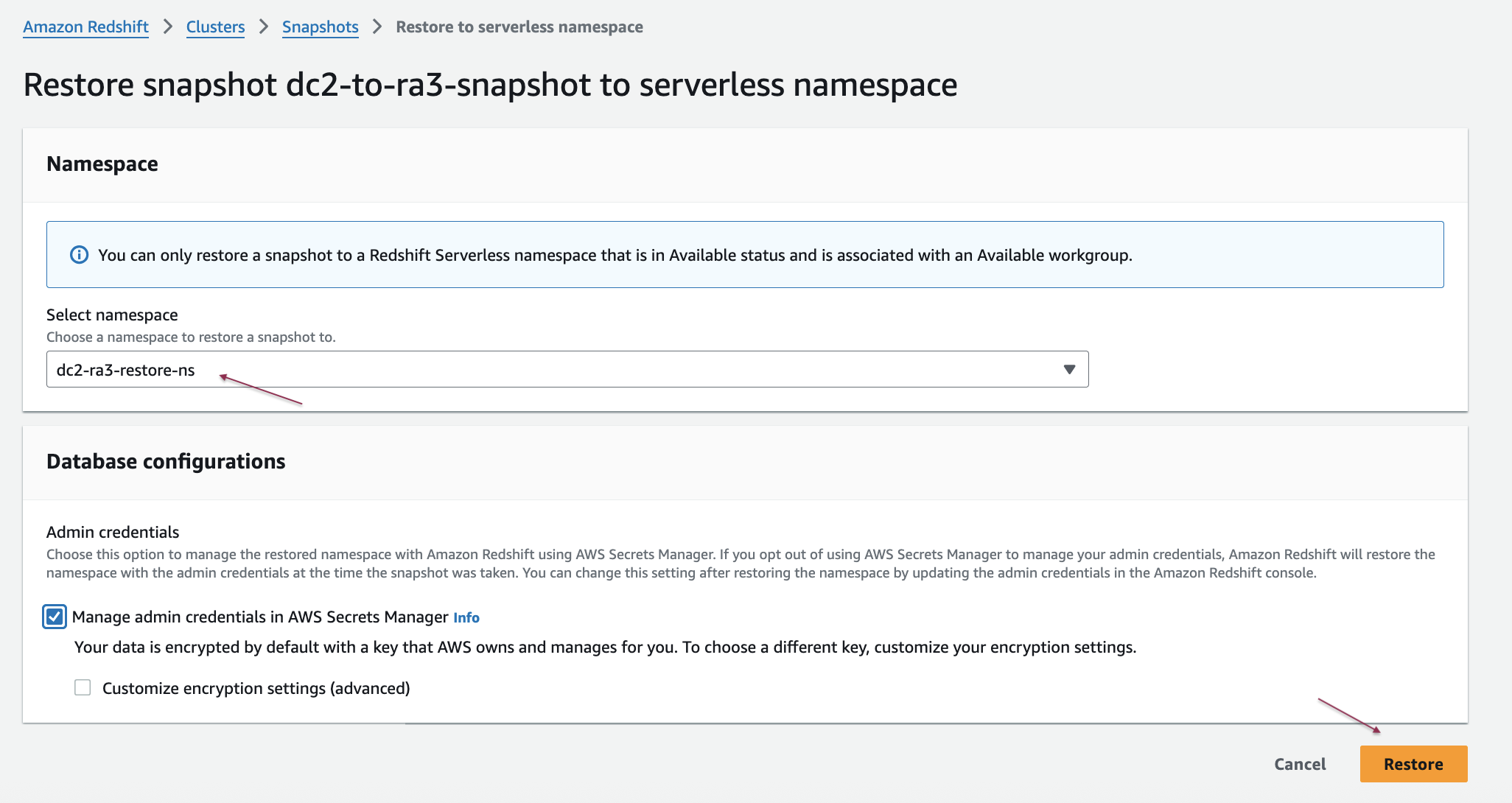

For more information, see Creating a snapshot of your provisioned cluster.
Upgrade using the AWS CLI
Use the following steps in the AWS Command Line Interface (AWS CLI) to upgrade your DC2 cluster to Amazon Redshift Serverless using the snapshot restore method.
- Create a snapshot from the source cluster:
- Verify that the snapshot exists:
- Restore the snapshot to your Amazon Redshift Serverless namespace:
For more information, see Restore from cluster snapshot using AWS CLI.
Best practices for upgrading to Amazon Redshift Serverless
The following are recommended best practices when upgrading from Amazon Redshift to Amazon Redshift Serverless.
- Pre-upgrade:
- Determine a suitable target configuration using the sizing guidance.
- Validate the target configuration by running a proof of concept (POC) using Amazon Redshift Test Drive.
- Consider a CNAME. A Canonical Name (CNAME) record is a type of DNS record that you can use to create an alias for the endpoint of your Amazon Redshift cluster.
- If you use interleaved sort keys, Amazon Redshift automatically converts them to compound keys when you restore a provisioned cluster snapshot to a serverless namespace. For more information, see Considerations when using Amazon Redshift Serverless.
- Some concepts and features are different in Amazon Redshift Serverless than their corresponding feature for an Amazon Redshift provisioned data warehouse. These include differences in system tables and views, audit logging, and endpoint names. For a full list of these differences, see Comparing Amazon Redshift Serverless to an Amazon Redshift provisioned data warehouse.
- Subscribe to the Amazon Redshift Serverless event notifications using Amazon EventBridge to be notified of the events during the migration process
- Post-upgrade:
- Update existing connections: When you migrate to Amazon Redshift Serverless, a new endpoint will be created. Update any existing connections to business intelligence and other reporting tools.
- Observability and monitoring: If you have any data monitoring tools using systems views, verify that there are no open or empty transactions. It’s important as a best practice to end transactions. If you don’t end or roll back open transactions, Amazon Redshift Serverless will continue to use RPUs for those transactions.
- Access: When using IAM authentication with
dbUseranddbGroups, your applications can access the database using the GetCredentials API. For more information, see Connecting using IAM. - System views: Review the list of unified system views available in Amazon Redshift Serverless.
If your workloads aren’t suited for Amazon Redshift Serverless because of their nature or any of the considerations listed in Considerations when using Amazon Redshift Serverless, you can upgrade to Amazon Redshift RA3 instances by following the RA3 sizing guidance.
Cost considerations
In this section, we provide information to help you understand and manage your Amazon Redshift Serverless costs.
- You can reduce your serverless computing costs by reserving capacity in advance when you have predictable usage patterns.
- Amazon Redshift Serverless automatically adjusts capacity based on workload. By setting a maximum RPU limit, you can control costs by capping how much the system can scale up.
- Amazon Redshift Serverless uses RPUs as a compute unit. While it starts with a default of 128 RPUs, you can adjust the base RPU anywhere from 4 to 1,024 RPUs to match your specific workload needs and SLA requirement. For more information, see Billing for Amazon Redshift Serverless.
- Amazon Redshift Serverless automatically creates recovery points every 30 minutes or whenever 5 GB of data changes per node occur, whichever happens first. The minimum interval between recovery points is 15 minutes. All recovery points are retained for 24 hours by default.
If you need to preserve backups for a longer period, you can create manual backups. Manual backups will incur additional storage costs.
- Amazon Redshift Serverless AI-driven scaling and optimization let you reduce costs by easily adjusting compute resources with a simple slider – balancing your budget against performance needs.
Clean up
To avoid incurring future charges, delete the Amazon Redshift Serverless instance or provisioned data warehouse cluster created as part of the prerequisite steps. For more information, see Deleting a workgroup and Shutting down and deleting a cluster.
Conclusion
In this post, we discussed the benefits of upgrading Amazon Redshift DC2 instances to Amazon Redshift Serverless, in addition to the various options for upgrading and some best practices. It is essential to determine the target Amazon Redshift Serverless configuration and validate it using Amazon Redshift Test Drive utility in test and development environments before upgrading.
Get started upgrading to Amazon Redshift Serverless today by implementing the guidance in this post. If you have questions or need assistance, contact AWS Support forarchitectural and design guidance, in addition to support for proofs of concept and implementation.
About the authors
Breaking down monolith workflows: Modularizing AWS Step Functions workflows
Post Syndicated from Sahithi Ginjupalli original https://aws.amazon.com/blogs/compute/breaking-down-monolith-workflows-modularizing-aws-step-functions-workflows/
You can use AWS Step Functions to orchestrate complex business problems. However, as workflows grow and evolve, you can find yourself grappling with monolithic state machines that become increasingly difficult to maintain and update. In this post, we show you strategies for decomposing large Step Functions workflows into modular, maintainable components. We dive deep into architectural patterns like parent-child workflows, domain-based separation, and shared utilities that can help you break down complexity while maintaining business functionality. By implementing these decoupling techniques, you can achieve faster deployments, better error isolation, and reduced operational overhead – all while keeping your workflows scalable and efficient. Whether you’re dealing with payment processing, data transformation, or complex business logic, these patterns will help you build more resilient and manageable Step Functions applications.
The Complexity of Single-State Machine Architectures
While monolithic workflows can be suitable for simple, linear processes with limited states and clear dependencies, they become problematic when handling complex business logic across multiple domains. If your workflow involves more than 15-20 states, crosses multiple business domains, or requires frequent updates from different teams, it’s a strong indicator that you should consider a decomposed approach instead of a monolithic one. However, monolithic workflows remain a valid choice for scenarios with straightforward business logic, single-team ownership, infrequent changes, and workflows with less than 15 states – especially when rapid development and simplified debugging are priorities.
Let’s examine a real-world example of such a monolithic workflow and understand the challenges it presents for development teams, operational efficiency, and business agility. Below is an example of a state machine that is a mix of payment processes, inventory management, and notification mechanisms for an e-commerce implementation:
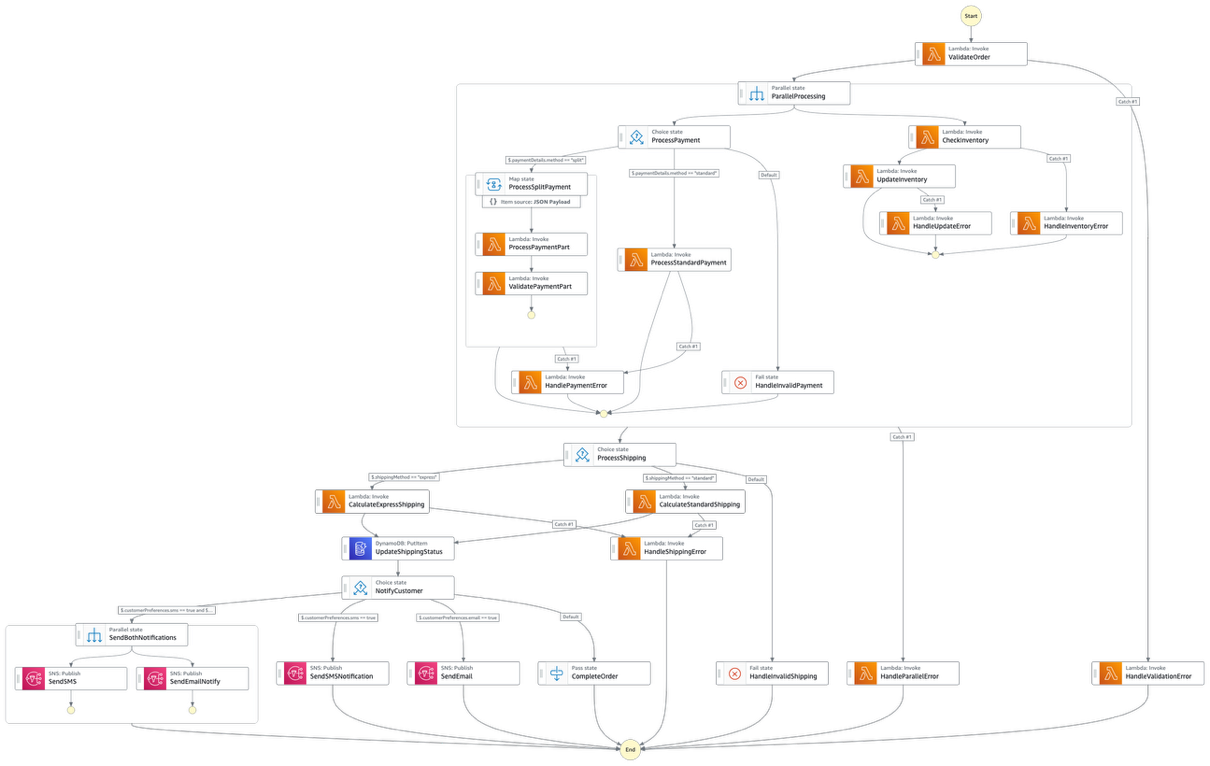
Figure 1: A state machine that is a mix of payment processes, inventory management, and notification mechanisms for an e-commerce implementation
State Explosion
Modifying a single state in a monolithic workflow triggers a cascade of changes across multiple interconnected states due to their tight coupling and dependencies. For example, adding a new payment method would require modifications across various states including validation, processing, and error handling, creating a ripple effect throughout the workflow. This inter dependency makes even simple changes complex and risky, as altering one component can have unintended consequences on other parts of the workflow.
Looking at the provided architecture, we can see a clear example of state explosion where a single workflow handles multiple business processes including order validation, payment processing, inventory management, shipping calculations, and customer notifications. This creates a complex web of dependent states that becomes increasingly difficult to manage. The result is a “spider web” of states that becomes progressively harder to understand, debug, and maintain.
Version Management
Version management in monolithic workflows requires deploying the entire workflow even for minor changes to individual components, making it difficult to isolate and update specific business logic. The provided architecture demonstrates the version management challenge clearly. For instance, if the shipping calculation logic needs an urgent fix, the entire workflow must be redeployed, requiring comprehensive testing of all components, including unmodified ones, to ensure nothing breaks in the process.
Resource Limitations
While not immediately visible in the architecture diagram, Monolithic workflows face operational constraints as they grow in complexity, particularly with state transitions, maximum event payload size, and execution history size. Refer to the Service quotas documentation to understand such limits. These constraints become critical bottlenecks as workflows grow in complexity and handle increased transaction volumes. In the monolithic state machine, long-running operations like payment processing and shipping calculations, combined with multiple state transitions, could approach these limits, especially for high-volume scenarios.
Additionally, we also come across generic design challenges such as error handling. In monolithic approach, workflows leads to redundant try-catch blocks and retry configurations across different operations. This creates challenges in implementing distinct error strategies for different business scenarios and makes it difficult to maintain proper rollback mechanisms when failures occur in middle states.
These challenges collectively highlight the need for a more modular approach to Step Functions workflow design.
Transforming Complex Workflows Through Decomposition
When transforming complex monolithic workflows into more manageable components, you can employ several decomposition strategies to achieve better modularity and maintainability. These strategies include the parent-child pattern, which creates a hierarchical structure of workflows, domain separation that breaks down workflows based on business capabilities, shared utilities that serve as reusable components for common operations, and specialized error workflows for centralized error handling. Each of these strategies can be implemented either individually or in combination, depending on the specific requirements and complexity of the application, allowing organizations to create more efficient, scalable, and maintainable Step Functions workflows while ensuring proper separation of concerns and reduced operational overhead.
Parent-Child Pattern
The parent-child pattern represents a hierarchical approach to workflow organization where a main (parent) workflow orchestrates multiple sub-workflows (children). Parent workflows manage the overall business process and coordination, while child workflows handles specific, short-lived operations. This pattern is particularly effective when you need to balance between orchestration complexity and execution speed.
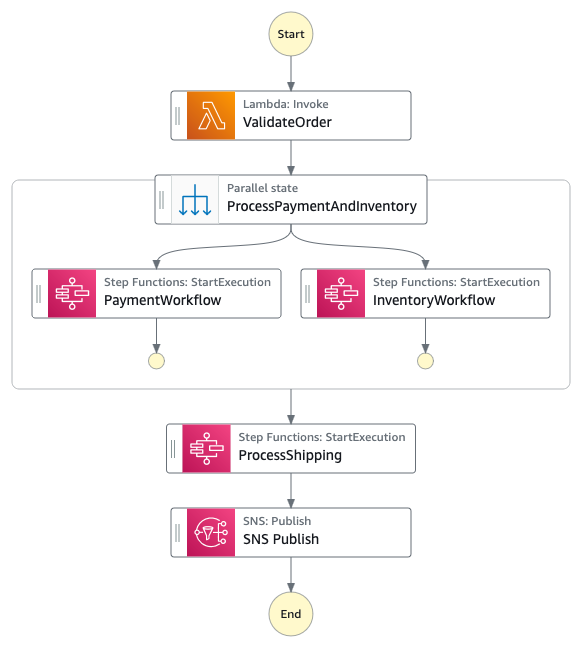
Figure 2 : Decoupled parent state machine
The current monolithic workflow can be restructured by creating a parent workflow focused on order orchestration while delegating specific operations to Express child workflows. The parent workflow would maintain the high-level flow from order validation through completion, while time-sensitive operations like ValidateOrder, ProcessPayment, and ProcessShipping could become Express child workflows.
Kindly note that during an architecture re-vamp, Express workflows are different when compared to Standard Workflows. For example, you cannot have an Express parent workflow invoke a Standard child workflow. Also, an Express workflow does not support Job-run (.sync) or Callback (.waitForTaskToken) service integration patterns. You can refer to the differences between Standard and Express workflows documentation to choose the right architecture pattern.
For instance, the payment processing section could be transformed into a child Express workflow that handles all payment-related states (ProcessPayment, ProcessStandardPayment, ValidatePaymentPart) as a single unit. An express workflow is more suitable for sections like payment processing as their executions complete within 5 minutes. Hence this would also reduce the over-all cost of the workflow. Similarly, the shipping calculation logic involving CalculateExpressShipping and CalculateStandardShipping could be consolidated into another Express child workflow, leading to reduced costs and easier updates to shipping logic.
Domain Separation
Domain separation involves breaking down workflows based on distinct business capabilities or functional areas. Each domain-specific workflow becomes responsible for a complete business function, operating independently while communicating through well-defined interfaces. This approach aligns closely with micro-service architecture principles and domain-driven design. The architecture shows clear boundaries between different business domains that can be separated into independent workflows. Three primary domains emerge:
- Payment Domain: Encompassing ValidateOrder, ProcessPayment, ValidatePaymentPart, and related error handlers
- Inventory Domain: Including CheckInventory, UpdateInventory, and associated states
- Shipping Domain: Containing ProcessShipping, shipping calculations, and shipping status updates
Each domain would become its own workflow, with clear input/output contracts. This separation would allow specialized teams to maintain and deploy updates to their domain workflows independently ensuring implementation of domain-specific retry policies, error handling, and business rules without affecting other domains. For example, the payment team could enhance payment processing logic without impacting shipping or inventory operations.
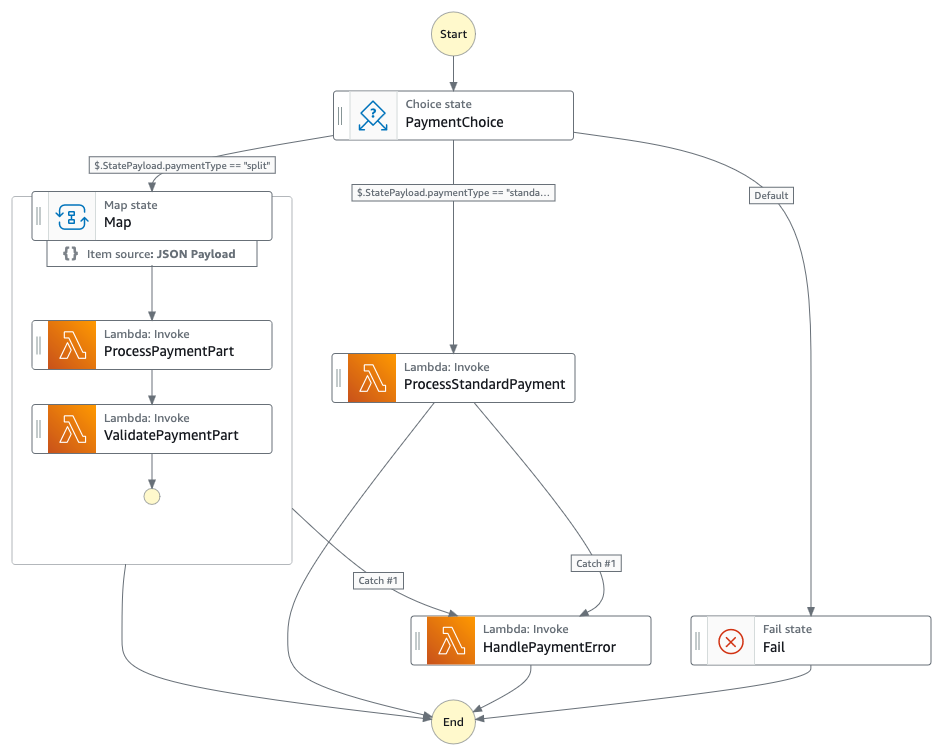
Figure 3 : Child state machine that handles payment workflow
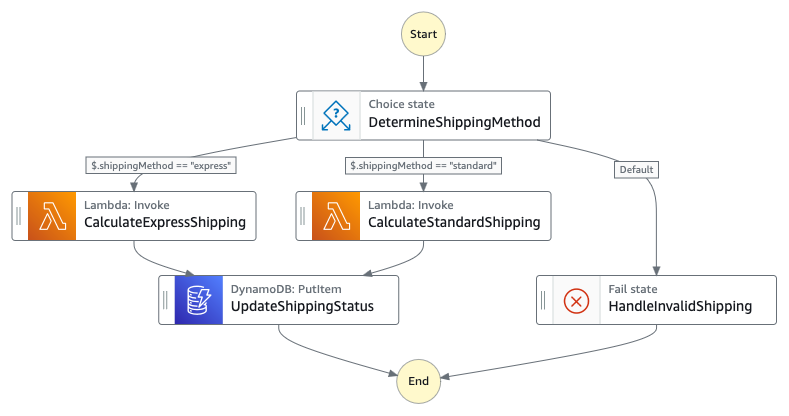
Figure 4 : Child state machine that handles shipping workflow
Shared Utilities
Shared utility workflows serve as reusable components for common operations that appear across multiple business processes. These workflows encapsulate standard functionality like notification handling, data validation, logging, or audit trail creation. By centralizing these common operations, organizations can ensure consistency and reduce duplication across their Step Functions applications.
The current architecture repeats several common patterns that could be extracted into shared utility workflows. Most notably, the notification handling logic (SendEmail, SendSMSNotification, SendPushNotification) appears as a cluster of states at the end of the workflow. This could be consolidated into a single “NotificationManager” utility workflow that handles all types of notifications. These utility workflows could then be called from any other workflow in the system, ensuring consistent behavior and reducing code duplication.
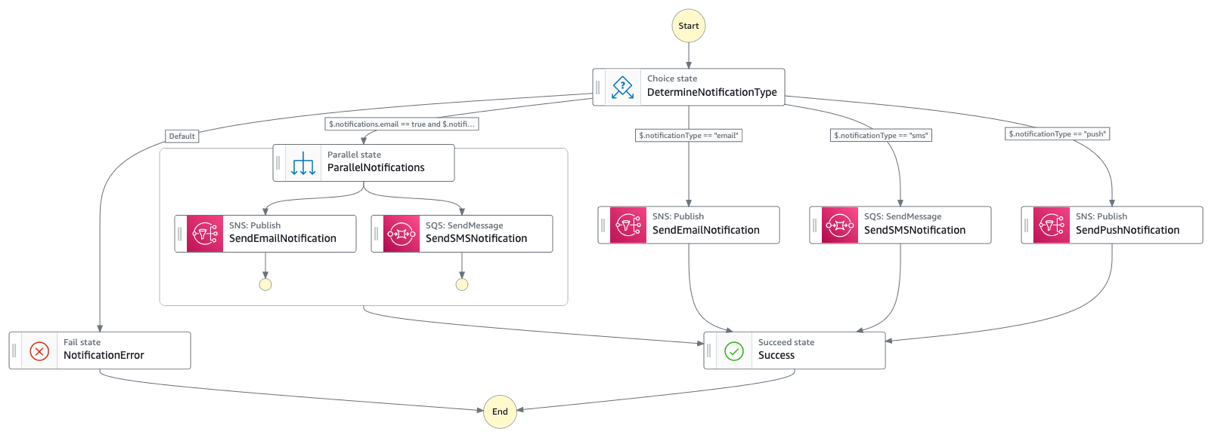
Figure 5 : Re-usable notification workflow
Error Workflows
Error workflows represent a specialized form of decomposition focused on centralizing error handling and recovery logic. Instead of embedding complex error handling in each business workflow, organizations can create dedicated workflows that manage different types of failures, retries, and compensation actions. This approach provides a consistent and maintainable way to handle errors across the application.
Each of these decomposition strategies can be used individually or in combination, depending on the specific needs of your application. For instance, utilization of Domain Separation pattern has resulted in streamlined error workflows. The key is to choose the appropriate combination that provides the right balance of maintainability, scalability, and operational efficiency for your use case. However, implementing all four strategies in a phased approach would provide the most comprehensive solution for long-term maintainability and scalability.
Results:
The comparison between monolithic and decoupled approaches reveals notable differences in performance and operational metrics. In order to emulate similar test environments across monolithic and decomposed state machines, we tested them in us-east-1 AWS region. We made use of the aforementioned workflows, both monolithic and decomposed to achieve a similar end goal. Pricing comparison is based on a monolithic workflow processing 11 state transitions per workflow across 30,000 monthly requests. For the decomposed approach, calculations assume Express child workflows configured with 64MB memory and 100ms execution duration, while the parent workflow handles 8 state transitions per workflow for the same volume of 30,000 monthly requests. AWS Lambda task states in both approaches complete within 2 seconds of execution time.
When decoupled, the workflows can be re-designed to use either Express or Standard mechanisms depending on their execution time and integration pattern requirements. In this use-case, we identified multiple workflows like PaymentProcessing, CalculateExpressShipping that are revamped to use Express workflows as per their requirement. While the monolithic approach shows a slightly faster execution duration of 11.5 seconds compared to 13 seconds in the decomposed approach, the monthly pricing significantly favors the decoupled architecture at $6.37 USD versus $11.90 USD for the monolithic approach. The decoupled approach demonstrates superior debugging capabilities with better error isolation and domain-specific debugging, contrasting with the monolithic approach’s complex debugging challenges due to heavy payloads and middle-state failure tracking. Additionally, the decoupled architecture benefits from smaller payload sizes through distributed data handling, whereas the monolithic workflow carries larger payloads across its 18 state transitions.
| Monolithic Approach | Decoupled Approach | |
| Execution Duration | 11.5 seconds for complete workflow execution | 13 seconds with distributed processing across parent-child workflows |
| Monthly Pricing | $11.90 USD (476,000 billable state transitions) | $6.37 USD (Combined cost of Standard parent workflow and Express child workflows) |
| Debug Effort | High – Complex debugging due to heavy payloads and difficulty in tracking failures in middle states. Cannot effectively use ResultSelector when final notification state needs all details. | Lower – Easier to debug with isolated domains and smaller payloads. Better error isolation and domain-specific debugging. |
| Payload Size | Larger payload size throughout workflow execution as all data needs to be carried across 18 state transitions | Smaller payload size due to domain separation and distributed data handling across parent-child workflows |
Conclusion
The need for decomposing Step Functions workflows becomes evident when you face challenges with monolithic workflows such as state explosion, version management complexities, and resource limitations. These challenges result in reduced operational efficiency, increased debugging complexity, and higher maintenance overhead as demonstrated by the comparison results showing differences in execution duration, pricing, debugging effort, and payload management. Organizations should evaluate workflow decomposition when they observe workflows exceeding 15-20 states, multiple team involvement in workflow maintenance, frequent independent updates across different business domains, complex error handling requirements, and the need for reusable components across workflows. The implementation of decomposition strategies through parent-child pattern for hierarchical workflow organization, domain separation for business capability isolation, shared utilities for common operations, and dedicated error workflows for centralized error handling has shown tangible benefits in terms of reduced costs, better error isolation, and more efficient payload management.
While implementing decomposition strategies, organizations must be cautious to avoid over-decomposition of workflows, maintaining tight coupling between workflows, and ignoring core design principles of loose coupling and single responsibility. This strategic approach to workflow decomposition ultimately leads to more maintainable, scalable, and cost-effective Step Functions applications that better serve business needs while reducing operational overhead. The transformation from monolithic to decomposed workflows represents a significant architectural improvement that enables organizations to better manage complex business processes while maintaining operational efficiency and system reliability.
Contributing writer Jemele Hill answers reader questions
Post Syndicated from The Atlantic original https://www.youtube.com/shorts/2cQ1JFFouvE
How to choose the right AWS service for managing secrets and configurations
Post Syndicated from Zachary Miller original https://aws.amazon.com/blogs/security/how-to-choose-the-right-aws-service-for-managing-secrets-and-configurations/
When building applications on AWS, you often need to manage various types of configuration data, including sensitive values such as API tokens or database credentials. From environment variables and API keys to passwords and endpoints, this configuration data helps determine application behavior. AWS offers managed services that you can use for different aspects of managing secrets and configuration data, in addition to feature flags to adjust application behavior without requiring full code deployments. This post explores AWS Secrets Manager, AWS Systems Manager Parameter Store, and AWS AppConfig, and provides guidance on selecting the right service to help meet your requirements. To summarize: AWS recommends you use AWS Secrets Manager for secrets, Parameter Store for simple storage of key-value pairs, and AWS AppConfig for feature flags and advanced dynamic configuration.
Overview of relevant AWS services
Let’s begin by examining the core services that manage customer secrets and configurations: Secrets Manager, Systems Manager Parameter Store, and AWS AppConfig.
Secrets Manager
Secrets Manager specializes in protecting access to applications, services, and IT resources by managing the lifecycle of secrets. Secrets Manager helps you rotate, manage, and retrieve credentials for databases, API keys, OAuth tokens, JSON Web Tokens (JWTs) and other secrets, securing resources in the AWS Cloud, on-premises, or in multi-cloud environments. Secrets Manager was designed specifically for sensitive credentials such as database passwords and can be used to replicate secrets to other AWS Regions and rotate passwords automatically based on a configurable schedule. Secrets Manager integrates with AWS Key Management Service (AWS KMS) to encrypt secrets you create with a KMS key you own and control—this encryption of secrets cannot be disabled. Additionally, Secrets Manager supports Post-Quantum TLS (PQ TLS) by default for API communications, with select client SDKs also offering PQ TLS protection.
Parameter Store
Parameter Store, a capability within Systems Manager, offers secure, hierarchical storage for configuration data and secure strings. You can store various types of data—from passwords and database strings to AMI IDs and license codes—as parameter values. These values can be stored as either plain text or encrypted data and referenced using unique names. Parameter Store also offers encryption using AWS KMS, but only for a specific parameter type, known as SecureString parameters. SecureString parameters must be encrypted with AWS KMS, but other parameter types can be stored unencrypted.
AWS AppConfig
AWS AppConfig facilitates the creation, management, and deployment of feature flags and application configuration data. It’s designed to support applications of different sizes with controlled deployments and includes robust validation mechanisms and monitoring capabilities. AWS AppConfig works seamlessly with various deployment targets, including Amazon Elastic Compute Cloud (Amazon EC2) instances, AWS Lambda functions, containers, mobile applications, and Internet of Things (IoT) devices. While AWS AppConfig can store configuration data either in its own datastore, using Parameter Store, or using Secrets Manager, it’s primarily designed to help you speed up software release frequency, improve application resiliency, and address emergent issues more quickly using feature flags and dynamic configuration as a powerful DevOps tool.
Service similarities
These services share several common capabilities while maintaining distinct specializations. All three support comprehensive logging through AWS CloudTrail and monitoring through Amazon CloudWatch, can be governed through granular AWS Identity and Access Management (IAM) permissions and service control policies (SCPs), and are available across the commercial Regions. They can store configuration data, though each excels in different scenarios. Parameter Store should be used to store and manage non-sensitive configuration data that doesn’t require frequent rotation or replication across Regions. Secrets Manager focuses on storing and automatically rotating sensitive credentials, offering features like the Secrets Manager Agent for secret caching and retrieval, and integrations with services like Amazon Relational Database Service (Amazon RDS) to reduce the operational overhead of managing admin passwords for databases. AWS AppConfig specializes in managing application configuration and feature flags with deployment safety controls and can be used in conjunction with Parameter Store or Secrets Manager to store and manage sensitive credentials. AWS AppConfig also uses a caching agent for performance and resiliency.
All three services can be used to encrypt your configuration data using AWS KMS. You can use IAM permissions in conjunction with AWS KMS to control access to encrypted values. Parameter Store and Secrets Manager also support resource policies for secrets and parameters that can be used to grant cross-account access and provide another layer of access control in addition to IAM policies.
The services also share an integration with AWS CloudFormation, enabling references to configuration data within templates instead of hardcoding sensitive information. This integration helps maintain security in infrastructure-as-code practices by helping prevent exposure of sensitive data. Additionally, all three services support versioning, though they implement it differently: Secrets Manager creates new versions during rotation or value changes, Parameter Store maintains versions when parameters are edited, and AWS AppConfig tracks versions through configuration profiles and its hosted configuration store.
Service differences
A primary differentiator between these three services is their approach to access control and permissions management. Secrets Manager offers the most comprehensive security controls through multiple layers: resource-based policies (RBPs), resource control policies (RCPs), service control policies (SCPs), attribute-based access control (ABAC), and AWS KMS key policies. By using this multi-layered approach, organizations can implement defense-in-depth strategies and can meet stringent compliance requirements. Additionally, the integration of Secrets Manager with Amazon GuardDuty provides automated secret-specific threat detection, including alerts for potentially malicious API calls or unauthorized access attempts. The direct integration of Secrets Manager with AWS Config and AWS Security Hub enables automated compliance monitoring and reporting across multiple compliance frameworks (such as PCI DSS, HIPAA, and SOC), with built-in controls and continuous assessment capabilities. These comprehensive security and compliance features make Secrets Manager particularly suitable for regulated industries requiring detailed audit trails and compliance reporting.
Another key difference is the ability to replicate secrets and parameters across Regions and automatically rotate secrets to reduce the impact radius of a compromised credential. The built-in automatic rotation functionality of Secrets Manager—using Lambda functions to handle rotation logic with customizable intervals—sets it apart from other services. The service maintains previous versions during rotation to help facilitate system stability. While Parameter Store and AWS AppConfig don’t offer native rotation capabilities, you can reference secrets stored in Secrets Manager as configuration sources, enabling a complementary approach to secrets management.
The services also differ in their logging and observability capabilities. While all three services integrate with CloudTrail for API activity logging, Secrets Manager provides additional detailed logging through CloudWatch Logs for rotation events and secret access patterns. It also offers enhanced monitoring through CloudWatch metrics for tracking secret versions, rotation status, and API usage patterns, providing deeper operational insights compared to Parameter Store and AWS AppConfig.
In terms of resilience, all three services are highly available within a Region, but only Secrets Manager supports the ability to automatically replicate secret values across Regions. For example, if you have a requirement to replicate database passwords to multiple Regions for a global application (or disaster recovery), you can use secret replicas to keep secret values in sync with each other, even when the primary version of the secret is rotated automatically. Parameter Store lacks multi-Region support and only provides cross-account access through resource-based policies, limiting its use to single-Region deployments. This makes Parameter Store suitable for Regional configuration management.
AWS AppConfig distinguishes itself through comprehensive deployment safety mechanisms. It employs validators to help make sure configuration updates are both syntactically and semantically correct, supporting both JSON schema and custom Lambda function validators. The service implements gradual deployment strategies to control configuration change rates and includes automatic rollback capabilities triggered by CloudWatch (and other APM provider) alarms. These features help limit the potential impact of configuration changes, while Parameter Store and Secrets Manager focus primarily on secure storage and retrieval of credentials.
From a pricing perspective, the services have different cost models aligned with their capabilities. Parameter Store offers standard parameters at no additional charge, while advanced parameters cost $0.05 per parameter per month plus API interaction costs. Advanced parameters support larger parameter values (up to 8 KB) and parameter policies, using envelope encryption with the AWS Encryption SDK for SecureString parameters. Secrets Manager charges $0.40 per secret stored plus API calls, reflecting its additional capabilities such as secret replication, automatic rotation, and native integrations with AWS services like Amazon RDS. Its pricing model is designed for storing sensitive credentials that require these advanced features. It maintains versions of secrets throughout their lifecycle, particularly during rotation, and you can retrieve specific versions as needed. AWS AppConfig is priced based on configurations received ($0.0008 per configuration) and configuration requests ($0.0000002 per request), with the flexibility to store configurations directly or reference them from Parameter Store or Secrets Manager. This pricing structure makes Parameter Store optimal for non-sensitive configuration data, Secrets Manager for sensitive credentials requiring rotation, and AWS AppConfig for managing application configurations with deployment controls.
Use case examples
Let’s explore a few common use cases to illustrate when each service proves most valuable.
Non-sensitive key/value pairs that don’t require advanced features
For non-sensitive key/value pairs in applications that don’t require regular rotation, compliance monitoring, or resilience across multiple Regions, Parameter Store will likely be the best choice for most customers. Consider a scenario where an application needs to store a license key for a database, or an AMI ID. Parameter Store is a good choice because the use case doesn’t require rotation or multi-Region replication, the data structure is straightforward, and cost efficiency matters for high-volume retrieval. Encryption with AWS KMS is supported if needed for parameters that might be for internal use only but don’t contain personally identifiable information (PII) or credentials used for authentication. With Parameter Store, you can efficiently manage large sets of parameters while maintaining security controls and organizational structure. Retrieving the values from Parameter Store is straightforward for developers, as shown in the following example (Python):
Database credentials with rotation and multi-Region requirements
For database credentials requiring rotation and multi-Region capabilities, Secrets Manager is the clear choice. Its automatic rotation functionality, multi-Region replication support, and native integration with Amazon RDS and other AWS services make it well-suited for managing complex database credential scenarios. Similarly, you should choose Secrets Manager for sensitive items like API keys and other types of credentials used for authentication. In the following diagram, you can see an example application architecture using Lambda to retrieve database credentials from Secrets Manager, which will be used to authenticate and query information from an RDS instance. Because the RDS instance has a cross-Region read replica, you can replicate the secret to the secondary Region (us-west-2), allowing the Lambda function in us-west-2 to get the secret value and query the read replica, even if the secret in the primary Region (us-east-1) cannot be accessed.
Secrets Manager also makes it straightforward for developers to retrieve secrets in their application, as shown in the following code sample:
While you can directly call the Secrets Manager APIs to retrieve a secret (as shown in the preceding example), Secrets Manager also has a number of features and integrations to improve the developer experience further, including the AWS Secrets Manager Agent, native integrations with Amazon Elastic Container Service (Amazon ECS), and the AWS Secrets and Configuration Provider (ASCP), which complements the CSI Driver utility in Kubernetes.
Secure password generation in CI/CD pipelines
When building applications, you might need to securely generate a password or other type of secret in your continuous integration and delivery (CI/CD) pipeline, without that secret value being exposed to developers or other human users. The ability of Secrets Manager to generate and manage secure passwords without human intervention, combined with its automated rotation capabilities and CI/CD tool integration, makes it the optimal solution. In the following sample, the Secrets Manager API GetRandomPassword is used to securely generate a password with a specific, configurable length without that value being exposed to a human or written to application logs or pipeline artifacts.
Configurable deployment controls
AWS AppConfig shines in scenarios requiring sophisticated deployment controls and validation for configuration changes. Its validation mechanisms, gradual deployment capabilities, and automatic rollback features make it ideal for managing feature flags and application configurations where controlled deployment is crucial. For instance, you might have a configuration file that contains an Allowlist of network environments that should be able to access and use your application; or you could have feature flags that enable use of AI for recommendations, or live-chat with support.
These examples aren’t necessarily sensitive values that require strong access control, encryption, and automatic rotation to reduce the impact radius of a lost credential. This means Secrets Manager wouldn’t be the most cost-effective choice to store these parameters: the additional value provided by features like automatic rotation aren’t needed for this use case. Also, AWS AppConfig is designed to help you validate your configuration changes and deploy them in a controlled way. For a more concrete example, see the following configuration files, which outline a network allowlist and AI configuration data for an example application.
Conclusion
Selecting the appropriate service depends on your specific requirements. Choose Parameter Store when managing basic configuration data, secure strings, or a large volume of secrets that don’t require rotation or multi-Region replication, particularly when cost optimization is important. Opt for Secrets Manager when handling sensitive credentials requiring rotation and cross-account or multi-Region resilience. Select AWS AppConfig when sophisticated deployment controls and validation for configuration changes are essential; and remember that you can use Parameter Store or Secrets Manager to store the actual configuration data, instead of or in addition to the default configuration datastore provided by AWS AppConfig.
These services aren’t mutually exclusive; they can work together as part of a comprehensive configuration management strategy. Many organizations successfully combine Parameter Store for general configuration data, Secrets Manager for sensitive credentials, and AWS AppConfig for feature flags and application configuration deployment. By using this integrated approach, you can take advantage of the strengths of each service while maintaining security and operational efficiency.
To get started, visit the AWS Management Console. Each service discussed in this post provides detailed documentation and getting started guides to help implement the right solution for your specific use case.
Getting Started guides
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Enhance email security using VPC endpoints with Amazon SES
Post Syndicated from Mamadou Ba original https://aws.amazon.com/blogs/messaging-and-targeting/enhance-email-security-using-vpc-endpoints-with-amazon-ses/
Email’s universal adoption and accessibility make Amazon Simple Email Service (Amazon SES) an ideal platform for delivering critical business communications, such as customer notifications or password resets. However, the ubiquity of email also invites bad actors who seek to actively exploit email’s ubiquity to launch sophisticated attacks. Business email transmissions traverse a complex network with potential vulnerabilities, making email systems prime targets for these malicious actors. Common threats include message interception, email spoofing, unauthorized access to sending services, and service disruption attacks.
Amazon SES handles millions of sensitive communications daily. For example, healthcare providers transmit patient data, financial institutions send transaction alerts, and businesses exchange confidential information. Securing this critical infrastructure requires deep expertise in email systems, threat detection, and advanced security protocols to provide message integrity and confidentiality.
In this post, we discuss and guide you in enhancing your email security by using VPC endpoints with Amazon SES.
Common security challenges customers face sending email with Amazon SES
Consider the challenges faced by a large healthcare provider seeking to send automated appointment reminders and confidential lab results. Although Amazon SES meets their email delivery needs, the IT team must implement strict security measures to satisfy industry, government, and internal requirements. These likely include secure SMTP connections, identity-based access controls, and network isolation to safeguard sensitive patient information.
These common security requirements seek to address two critical concerns. First, they aim to prevent unauthorized access to the organization’s Amazon SES accounts, thereby safeguarding sensitive communications from potential breaches. Second, these measures mitigate the risks of bad actors co-opting their Amazon SES accounts to launch sophisticated email spoofing and phishing attacks.
Either breach could compromise trusted domains, undermining the security of the healthcare provider’s email communications and damaging their reputation.
For organizations with specific network security requirements or compliance mandates, Amazon SES offers VPC endpoint integration to provide additional network-level controls. This approach is particularly valuable for customers who prefer to avoid API calls traversing the public internet or need to ensure email processing workflows remain within private network boundaries.
VPC endpoints create a direct connection between your applications and Amazon SES, offering the following capabilities:
- Enhanced network isolation: Keeps email traffic within your private network infrastructure
- Compliance alignment: Supports regulatory frameworks like HIPAA and GDPR that may require additional network controls
- Network-based access controls: Restricts SES access to authorized IP ranges and subnets
- Simplified hybrid connectivity: Leverages existing VPN or Direct Connect infrastructure for seamless integration
- Defense-in-depth architecture: Adds an additional layer of network security to your email infrastructure
Amazon SES VPC endpoints are enabled by AWS PrivateLink for SMTP message traffic. With these VPC endpoints, you can route SMTP email traffic privately within the AWS network between your sending applications, optionally with encryption, and Amazon SES. When using a VPC endpoint, traffic to Amazon SES doesn’t transmit over the internet and never leaves the Amazon network to securely connect your VPC to Amazon SES without availability risks or bandwidth constraints on your network traffic.
At the time of writing, Amazon SES VPC endpoints don’t support API-based email sending (such as SendEmail, SendRawEmail, or SDKs). Amazon SES API traffic should be encrypted and routed using a VPC through a NAT gateway or over the public internet.
Solution overview
Our solution can help you secure your SMTP message traffic by using the following components:
- Authorized SMTP applications that optionally enforce TLS encryption and transport messages only over approved, private networks
- Amazon Virtual Private Cloud (Amazon VPC) endpoints powered by PrivateLink
- AWS security groups to further limit SMTP message traffic to approved network subnets
- AWS Identity and Access Management (IAM) policies to limit Amazon SES usage to only authorized SMTP credentialed accounts
The following diagram illustrates the solution architecture. The architecture assumes you already have connectivity from your on-premises network to your VPC. For instructions to connect your on-premises network to AWS, refer to Hybrid network connections.
For testing purposes, we use connectivity within AWS. The same concept applies if you’re connecting from an on-premises network that is connected to your VPC either through a Virtual Private Network (VPN) or Direct Connect (DX).
The solution workflow consists of the following steps:
- Your SMTP sending applications and services are located on premises or in your data center using two subnets:
- Subnet A (IP range: 10.10.10.50)
- Subnet B (IP range: 10.90.120.50)
- Secure connections are transmitted using AWS Direct Connect or VPN connection to a VPC in the same AWS Region as your Amazon SES account.
- The SMTP message traffic, optionally encrypted, is sent to the Amazon SES VPC endpoints configured to restrict network connections from the VPC to only specific subnets:
- Traffic on approved subnet A (10.10.10.50) is sent to Amazon SES.
- Traffic on denied subnet B (10.90.120.50) is dropped (not sent to Amazon SES).
- SMTP traffic from only the allowed subnet A is further restricted to an IAM policy with valid SMTP credentials.
- Messages that conform to the traffic and authentication policies are passed to Amazon SES for final delivery to recipients.
Prerequisites
To implement this solution, you must have the following prerequisites:
- Amazon SES, configured with at least one verified identity, in the same Region as the VPC.
- An existing VPC in the same Region as Amazon SES. This can be the default VPC. For more information, see Plan your VPC.
- An SMTP sending application (optionally supporting TLS encryption) located in one of the following options:
- On premises or in a data center that is connected to the VPC through a private network connection (such as Direct Connect or VPN). For more details about private network connections to AWS, refer to Network-to-Amazon VPC connectivity options.
- In the VPC running on a compute resource such as Amazon Elastic Compute Cloud (Amazon EC2) or AWS Lambda. For this post, we use an EC2 instance in the VPC and connect to Amazon SES through the VPC endpoint on port 587 with TLS enabled. Note that AWS blocks outbound SMTP traffic on port 25 across most AWS services. Use an alternative TCP port, such as 465, 587, 2465, or 2587. Request port 25 exemption by submitting a request to AWS Support from your AWS account using the “Request to remove email sending limitations” form. This can take upwards of 7 business days to be reviewed; approval is not guaranteed. Amazon SES uses an opportunistic TLS policy by default for encrypting messages when the receiving host supports it. You should use encryption whenever it is available.
- For testing, you can use one of the following options:
- Bash or Windows PowerShell script from on-premises server.
- Use the third-party Sendmail application on an EC2 instance in the VPC. For details, see Integrating Amazon SES with Sendmail.
- PHP or Java on an EC2 instance in the VPC. For details, see Sending emails programmatically through the Amazon SES SMTP interface.
- DNS resolution for resources in the VPC with the Amazon SES VPC endpoints in the source network. To learn more, see Resolving DNS queries between VPCs and your network.
Create security group
The first step is to create a security group with inbound rules that only allow a specific IP range on the appropriate port (host-permitting, 25, 465, 587, 2465, or 2587). In our example, we only allow subnet A (IP range: 10.10.10.50) on port 587. Complete the following steps to create the security group:
- In the navigation pane of the Amazon EC2 console, under Network & Security, choose Security groups.
- Choose Create security group.
- For Security group name, enter a unique name that identifies the security group (we use
ses-vpce-sec-group). - For Description, enter the purpose of the security group.
- For VPC, choose the VPC in which you will host the application that will use Amazon SES.
- Under Inbound rules, choose Add rule.
- For Type, choose Custom TCP.
- For Port range, enter the port number that you want to use to send email. You can choose from 465, 587, 2465, or 2587. For this post, we use 587.
- For Source type, choose Custom.
- Enter the private IP CIDR range for subnet A (IP range: 10.10.10.50), which contains the resources that will use the VPC endpoint to communicate with Amazon SES.
- Choose Create security group.
Create VPC endpoint to connect the VPC to Amazon SES
Complete the following steps to create your VPC endpoint:
- On the Amazon VPC console, in the navigation pane, under PrivateLink and Lattice, choose Endpoints.
- Choose Create endpoint.
- Optionally, under Endpoint settings, create a tag in the Name tag field.
- For Service category, select AWS services.
- For Services, filter for and select
smtp. - For VPC, choose a VPC (for more details, see Prerequisites).
- For Subnets, select Availability Zones and Subnet IDs.
Amazon SES doesn’t support VPC endpoints in the following Availability Zones:use1-az2,use1-az3,use1-az5,usw1-az2,usw2-az4,apne2-az4,cac1-az3, andcac1-az4.
- For Security groups, choose the security group you created earlier.
- Optionally, for Tags, create one or more tags.
- Choose Create endpoint.
 Wait approximately 5 minutes while Amazon VPC creates the endpoint. When the endpoint is ready to use, the value in the Status column changes to Available.
Wait approximately 5 minutes while Amazon VPC creates the endpoint. When the endpoint is ready to use, the value in the Status column changes to Available. - Copy the VPC endpoint ID to your clipboard to use in the next step.
 Wait approximately 5 minutes while Amazon VPC creates the endpoint. When the endpoint is ready to use, the value in the Status column changes to Available.
Wait approximately 5 minutes while Amazon VPC creates the endpoint. When the endpoint is ready to use, the value in the Status column changes to Available.Optionally, you can test the connection to make sure the VPC endpoint is configured properly by using command line tools to send a test email using the Amazon SES SMTP interface from an EC2 instance in the same VPC where you just created the email-smtp VPC endpoint. For more information, see Using the Amazon SES SMTP interface to send email.
Create SMTP credentials in Amazon SES that will be used by sender applications to authenticate
Complete the following steps to create SMTP credentials:
- On the Amazon SES console, choose SMTP Settings in the navigation pane.
- Choose Create SMTP credentials.

- Enter your preferred user name and choose Create user.

- Download the user’s SMTP credentials or copy the credentials to AWS Secrets Manager. (we will use these SMTP credentials in the next step).
- Return to the SES console.
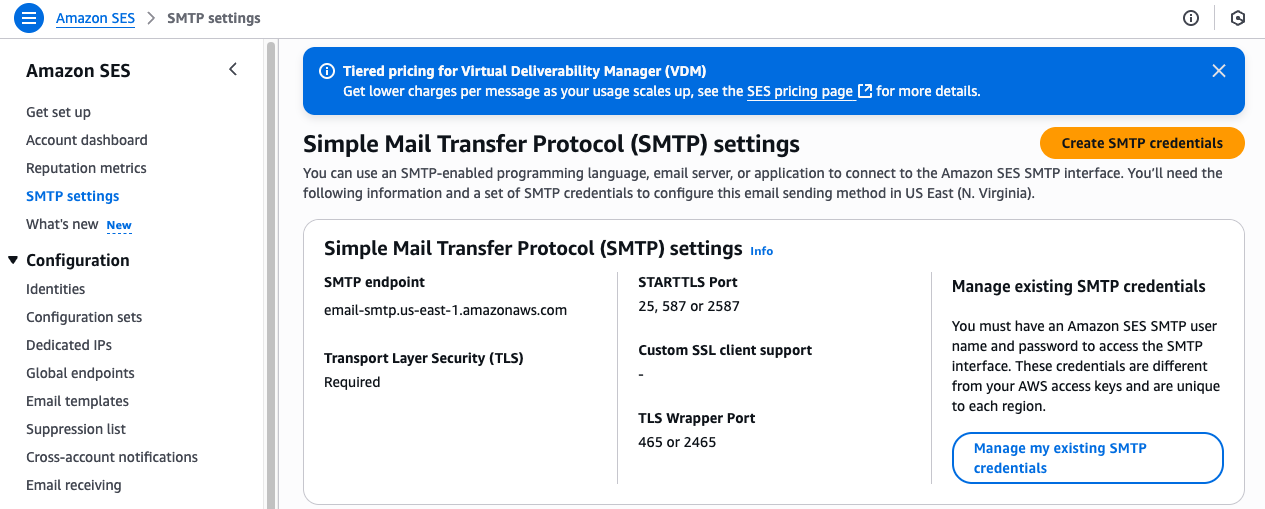
Limit traffic to the Amazon SES VPC endpoint using IAM
In this step, we limit traffic to the Amazon SES VPC endpoint using an IAM policy. The IAM policy has a condition that restricts access to aws:SourceVpce. Complete the following steps:
- On the Amazon SES console, choose SMTP Settings in the navigation pane.
- Choose Manage my existing SMTP credentials.
- Choose the user you created earlier, then choose Permissions.
- Choose the policy name
AmazonSesSendingAccessto go to the IAM policy editor. - Replace the policy content in JSON view with the following policy, which adds the conditions for traffic to come from the Amazon SES VPC endpoint:
- Choose Next.
- Choose Save changes.
As a best practice, rotate your SMTP credentials on a periodic basis and whenever there is concern over the confidentiality of the credentials. For more information, see Automate the Creation & Rotation of Amazon Simple Email Service SMTP Credentials.
Test permissions and connectivity
To test permissions and connectivity by sending a test email, complete the following steps to create an EC2 instance in your VPC:
- On the Amazon EC2 console, create a new EC2 instance.
- Make sure to specify your VPC and subnet. The subnet must be the same as the one selected in previous steps.
- Use the SMTP script in the Amazon SES documentation for testing.
This screenshot shows the test result using the SMTP VPC Endpoint URL.
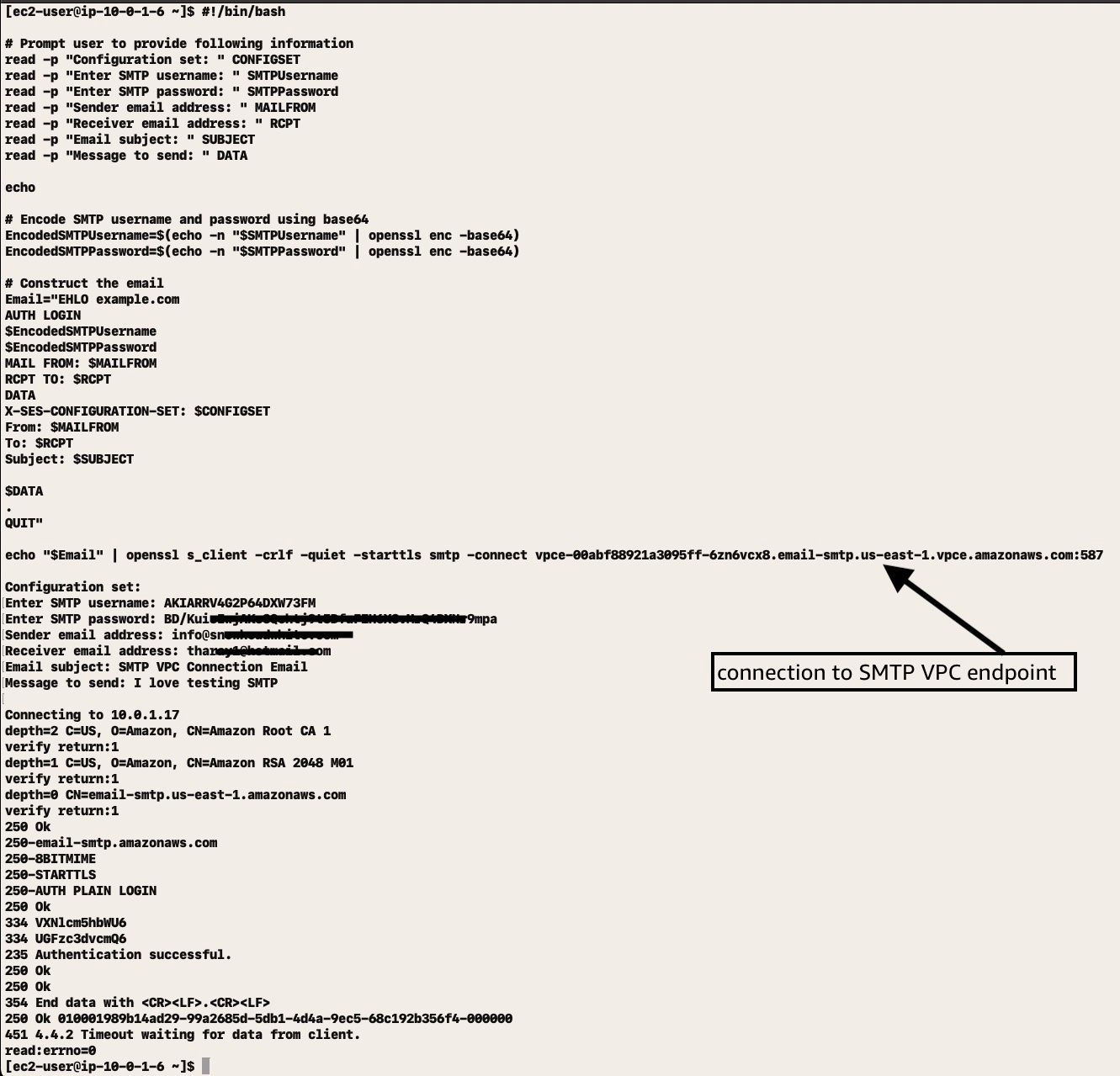
This configuration allows Amazon SES to only accept SMTP message traffic from applications from allowed on-premises subnets with connectivity to AWS and in the VPC that originates from the permitted SMTP IAM identity policy. This design follows the AWS least privilege access approach to security. To learn more, refer to Strategies for achieving least privilege at scale.
Clean up
After testing, if you don’t want to keep these configurations you should delete the EC2 instance, the VPC endpoint, the SMTP credential, and the IAM user.
Conclusion
In this post, we demonstrated how to implement a secure Amazon SES environment by combining multiple AWS security controls. By using Amazon SES VPC endpoints, security groups, and IAM policies, you can create a robust security architecture that restricts email sending capabilities to authorized networks only.
This multi-layered approach addresses critical security challenges by avoiding public internet exposure for SMTP traffic, enabling comprehensive traffic monitoring through VPC flow logs, and establishing defined network boundaries that satisfy strict compliance requirements.
The solution provides significant security benefits while maintaining the scalability and reliability that Amazon SES customers expect. Organizations can effectively protect sensitive email communications, prevent unauthorized access, and maintain compliance with industry regulations like HIPAA and GDPR. This becomes increasingly important as email-based threats continue to evolve and regulatory requirements become more stringent.
Start implementing these security controls today:
- Deploy this solution in your development environment first, testing each component thoroughly
- Review the security best practices for Amazon SES and VPC endpoints
- Validate your implementation against your organization’s security requirements
- Create a detailed migration plan for your production environment
- Monitor and audit your email infrastructure regularly using VPC Flow Logs and Amazon CloudWatch
For additional guidance, consult the Amazon SES documentation, explore the AWS Security Blog for related articles, or engage with AWS Support. Remember to periodically review and update your security configurations as new features and best practices emerge.
About the authors
Radio Atlantic — If the Voting Rights Act Falls
Post Syndicated from The Atlantic original https://www.youtube.com/shorts/EpqhPF8pbS4
Customer Carbon Footprint Tool Expands: Additional emissions categories including Scope 3 are now available
Post Syndicated from Channy Yun (윤석찬) original https://aws.amazon.com/blogs/aws/aws-customer-carbon-footprint-tool-now-includes-scope-3-emissions/
Since it launched in 2022, the Customer Carbon Footprint Tool (CCFT) has supported our customers’ sustainability journey to track, measure, and review their carbon emissions by providing the estimated carbon emissions associated with their usage of Amazon Web Services (AWS) services.
In April, we made major updates in the CCFT, including easier access to carbon emissions data, visibility into emissions by AWS Region, inclusion of location-based emissions (LBM), an updated, independently-verified methodology as well as moving to a dedicated page in the AWS Billing console.
The CCFT is informed by the Greenhouse Gas (GHG) Protocol’s classification of emissions, which classifies a company’s emissions. Today, we’re announcing the inclusion of Scope 3 emissions data and an update to Scope 1 emissions in the CCFT. The new emission categories complement the existing Scope 1 and 2 data, and they’ll give our customers a comprehensive look into their carbon emissions data.
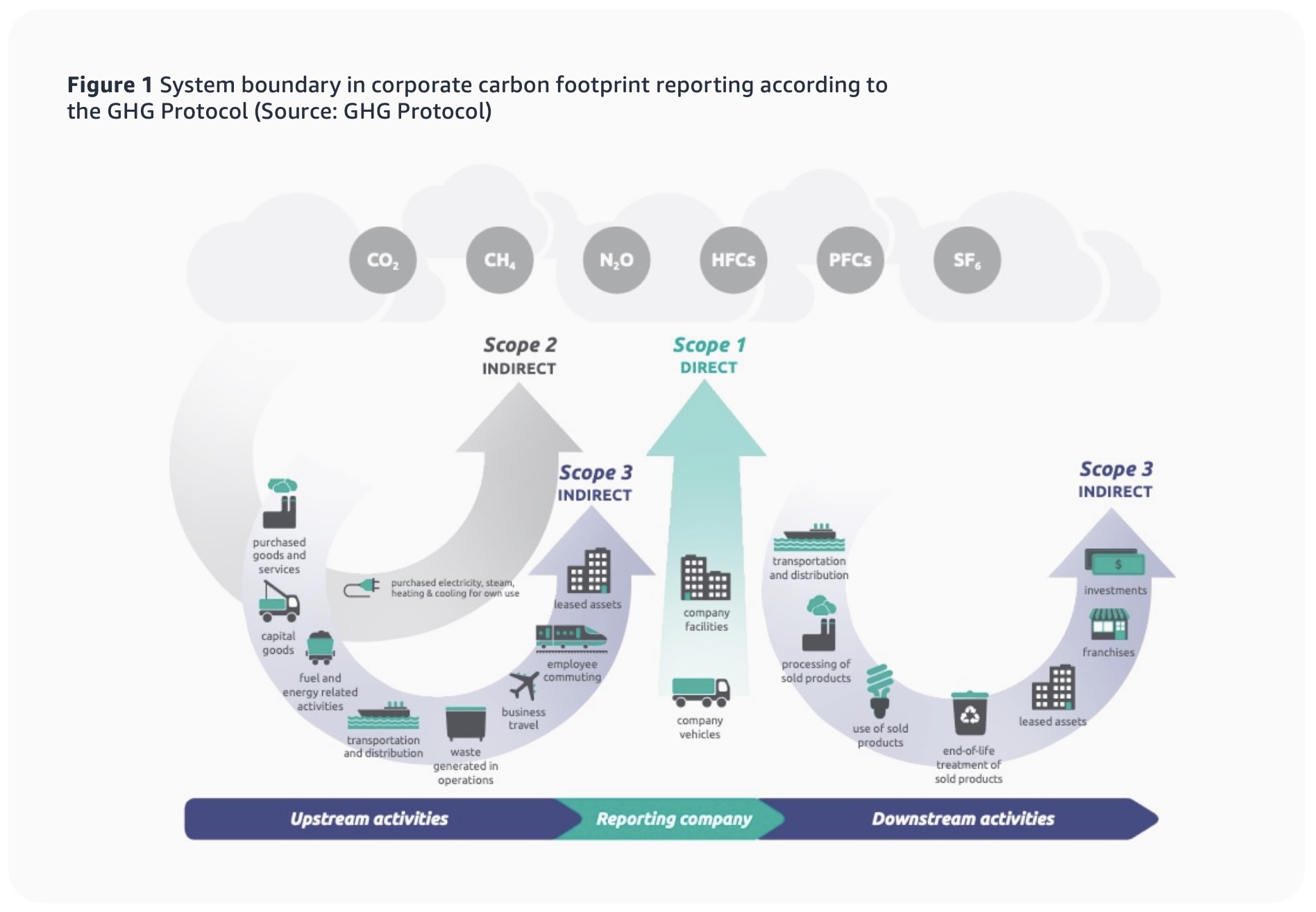
In this updated methodology we incorporate new emissions categories. We’ve added Scope 1 refrigerants and natural gas, alongside the existing Scope 1 emissions from fuel combustion in emergency backup generators (diesel). Although Scope 1 emissions represent a small share of overall emissions, we provide our customers with a complete image of their carbon emissions.
To decide which categories of Scope 3 to include in our model we looked at how material each of them were to the overall carbon impact and confirmed the vast majority of emissions were represented. With that in mind, the methodology now includes:
-
Fuel- and energy-related activities (“FERA” under the GHG Protocol) – This includes upstream emissions from purchased fuels, upstream emissions of purchased electricity, and transmission and distribution (T&D) losses. AWS calculates these emissions using both LBM and the market-based method (MBM).
-
IT hardware – AWS uses a comprehensive cradle-to-gate approach that tracks emissions from raw material extraction through manufacturing and transportation to AWS data centers. We use four calculation pathways: process-based life cycle assessment (LCA) with engineering attributes, extrapolation, representative category average LCA, and economic input-output LCA. AWS prioritizes the most detailed and accurate methods for components that contribute significantly to overall emissions.
-
Buildings and equipment – AWS follows established whole building life cycle assessment (wbLCA) standards, considering emissions from construction, use, and end-of-life phases. The analysis covers data center shells, rooms, and long-lead equipment such as air handling units and generators. The methodology uses both process-based life cycle assessment models and economic input-output analysis to provide comprehensive coverage.
The Scope 3 emissions are then amortized over the assets’ service life (6 years for IT hardware, 50 years for buildings) to calculate monthly emissions that can be allocated to customers. This amortization means that we fairly distribute the total embodied carbon of each asset across its operational lifetime, accounting for scenarios such as early retirement or extended use.
All these updates are part of methodology version 3.0.0 and are explained in detail in our methodology document, which has been independently verified by a third party.
How to access the CCFT
To get started, go to the AWS Billing and Cost Management console and choose Customer Carbon Footprint Tool under Cost and Usage Analysis. You can access your carbon emissions data in the dashboard, download a csv file, or export all data using basic SQL and visualize your data by integrating with AWS Data Exports and Amazon Quick Sight.
To ensure you can make meaningful year-over-year comparisons, we’ve recalculated historical data back to January 2022 using version 3 of the methodology. All the data displayed in the CCFT now uses version 3. To see historical data using v3, choose Create custom data export. A new data export now includes new columns breaking down emissions by Scope 1, 2, and 3.
You can see estimated AWS emissions and estimated emissions savings. The tool shows emissions calculated using the MBM for 38 months of data by default. You can find your emissions calculated using the LBM by choosing LBM in the Calculation method filter on the dashboard. The unit of measurement for carbon emissions is metric tons of carbon dioxide equivalent (MTCO2e), an industry-standard measure.
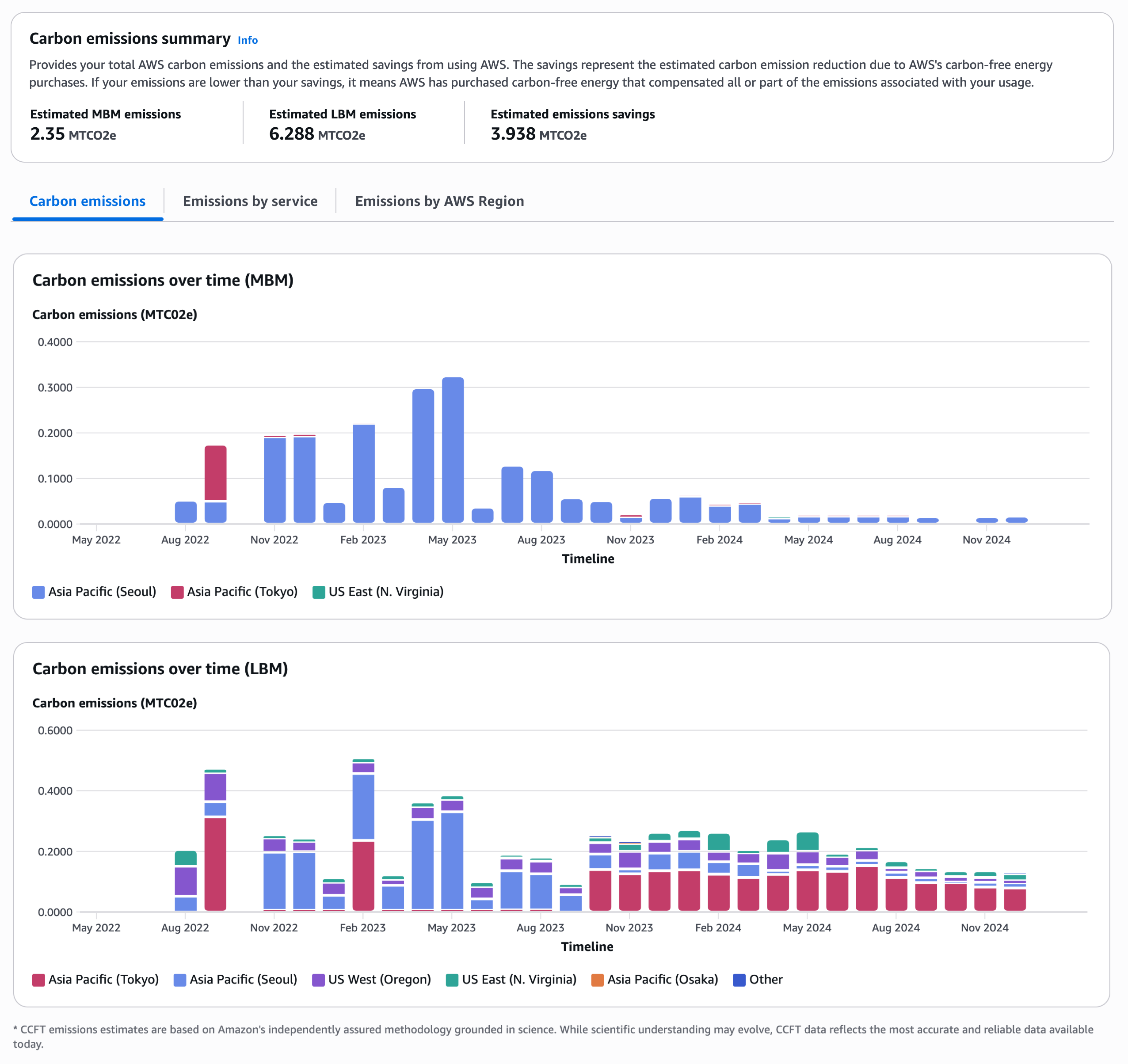
In the Carbon emissions summary, it shows trends of your carbon emissions over time. You can also find emissions resulting from your usage of AWS services and across all AWS Regions. To learn more, visit Viewing your carbon footprint in the AWS documentation.
Voice of the customer
Some of our customers had early access to these updates. This is what they shared with us:
Sunya Norman, senior vice president, Impact at Salesforce shared “Effective decarbonization begins with visibility into our carbon footprint, especially in Scope 3 emissions. Industry averages are only a starting point. The granular carbon data we get from cloud providers like AWS are critical to helping us better understand the actual emissions associated with our cloud infrastructure and focus reductions where they matter most.”
Gerhard Loske, Head of Environmental Management at SAP said “The latest updates to the CCFT are a big step forward in helping us managing SAP’s sustainability goals. With new Region-specific data, we can now see better where emissions are coming from and take targeted action. The upcoming addition of Scope 3 emissions will give us a much fuller picture of our carbon footprint across AWS workloads. These improvements make it easier for us to turn data into meaningful climate action.”
Pinterest’s Global Sustainability Lead, Mia Ketterling highlighted the benefits of the Scope 3 emission data, saying, “By including Scope 3 emissions data in their CCFT, AWS empowers customers like Pinterest to more accurately measure and report the full carbon footprint of our digital operations. Enhanced transparency helps us drive meaningful climate action across our value chain.”
If you’re attending AWS re:Invent in person in December, join technical leaders from AWS, Adobe, and Salesforce as they reveal how the Customer Carbon Footprint Tool supports their environmental initiatives.
Now available
With Scope 1, 2, and 3 coverage in the CCFT, you can track your emissions over time to understand how you’re trending towards your sustainability goals and see the impact of any carbon reduction projects you’ve implemented. To learn more, visit the Customer Carbon Footprint Tool (CCFT) page.
Give these new features a try in the AWS Billing and Cost Management console and send feedback to AWS re:Post for the CCFT or through your usual AWS Support contacts.
— Channy
Fedora Council approves AI-assisted contributions policy
Post Syndicated from jzb original https://lwn.net/Articles/1042947/
The Fedora Council has approved
an AI-assisted
contributions policy. This follows several
weeks of discussion, some of which were covered by LWN on
October 1. The final policy contains substantial differences from
the initial
proposal, and now requires disclosure of AI tools “when the
“.
significant part of the contribution is taken from a tool without
changes
The Triumphs and Tragedies of the American Revolution, with Ken Burns | The David Frum Show
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=vZC6CnGX8qU