Post Syndicated from Betty Zheng (郑予彬) original https://aws.amazon.com/blogs/aws/introducing-aws-rtb-fabric-for-real-time-advertising-technology-workloads/
Today, we’re announcing AWS RTB Fabric, a fully managed service purpose built for real-time bidding (RTB) advertising workloads. The service helps advertising technology (AdTech) companies seamlessly connect with their supply and demand partners, such as Amazon Ads, GumGum, Kargo, MobileFuse, Sovrn, TripleLift, Viant, Yieldmo and more, to run high-volume, latency-sensitive RTB workloads on Amazon Web Services (AWS) with consistent single-digit millisecond performance and up to 80% lower networking costs compared to standard networking costs.
AWS RTB Fabric provides a dedicated, high-performance network environment for RTB workloads and partner integrations without requiring colocated, on-premises infrastructure or upfront commitments. The following diagram shows the high-level architecture of RTB Fabric.
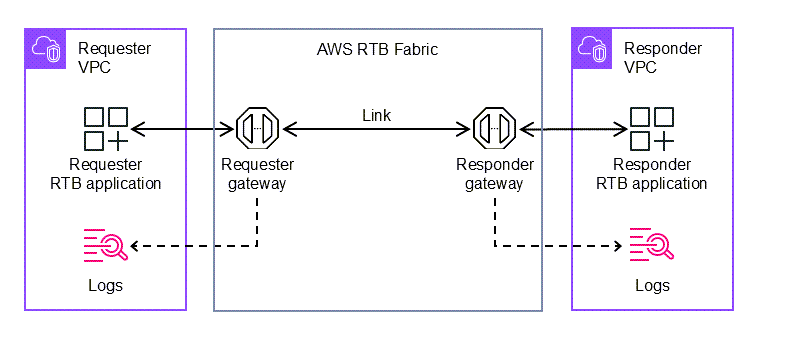
AWS RTB Fabric also includes modules, a capability that helps customers bring their own and partner applications securely into the compute environment used for real-time bidding. Modules support containerized applications and foundation models (FMs) that can enhance transaction efficiency and bidding effectiveness. At launch, AWS RTB Fabric includes modules for optimizing traffic management, improving bid efficiency, and increasing bid response rates, all running inline within the service for consistent low-latency execution.
The growth of programmatic advertising has created a need for low-latency, cost-efficient infrastructure to support RTB workloads. AdTech companies process millions of bid requests per second across publishers, supply-side platforms (SSPs), and demand-side platforms (DSPs). These workloads are highly sensitive to latency because most RTB auctions must complete within 200–300 milliseconds and require reliable, high-speed exchange of OpenRTB requests and responses among multiple partners. Many companies have addressed this by deploying infrastructure in colocation data centers near key partners, which reduces latency but adds operational complexity, long provisioning cycles, and high costs. Others have turned to cloud infrastructure to gain elasticity and scale, but they often face complex provisioning, partner-specific connectivity, and long-term commitments to achieve cost efficiency. These gaps add operational overhead and limit agility. AWS RTB Fabric solves these challenges by providing a managed private network built for RTB workloads that delivers consistent performance, simplifies partner onboarding, and achieves predictable cost efficiency without the burden of maintaining colocation or custom networking setups.
Key capabilities
AWS RTB Fabric introduces a managed foundation for running RTB workloads at scale. The service provides the following key capabilities:
- Simplified connectivity to AdTech partners – When you register an RTB Fabric gateway, the service automatically generates secure endpoints that can be shared with selected partners. Using the AWS RTB Fabric API, you can create optimized, private connections to exchange RTB traffic securely across different environments. External Links are also available to connect with partners who aren’t using RTB Fabric, such as those operating on premises or in third-party cloud environments. This approach shortens integration time and simplifies collaboration among AdTech participants.
- Dedicated network for low-latency advertising transactions – AWS RTB Fabric provides a managed, high-performance network layer optimized for OpenRTB communication. It connects AdTech participants such as SSPs, DSPs, and publishers through private, high-speed links that deliver consistent single-digit millisecond latency. The service automatically optimizes routing paths to maintain predictable performance and reduce networking costs, without requiring manual peering or configuration.
- Pricing model aligned with RTB economics – AWS RTB Fabric uses a transaction-based pricing model designed to align with programmatic advertising economics. Customers are billed per billion transactions, providing predictable infrastructure costs that align with how advertising exchanges, SSPs, and DSPs operate.
- Built-in traffic management modules – AWS RTB Fabric includes configurable modules that help AdTech workloads operate efficiently and reliably. Modules such as Rate Limiter, OpenRTB Filter, and Error Masking help you control request volume, validate message formats, and manage response handling directly in the network path. These modules execute inline within the AWS RTB Fabric environment, maintaining network-speed performance without adding application-level latency. All configurations are managed through the AWS RTB Fabric API, so you can define and update rules programmatically as your workloads scale.
Getting started
Today, you can start building with AWS RTB Fabric using the AWS Management Console, AWS Command Line Interface (AWS CLI), or infrastructure-as-code (IaC) tools such as AWS CloudFormation and Terraform.
The console provides a visual entry point to view and manage RTB gateways and links, as shown on the Dashboard of the AWS RTB Fabric console.
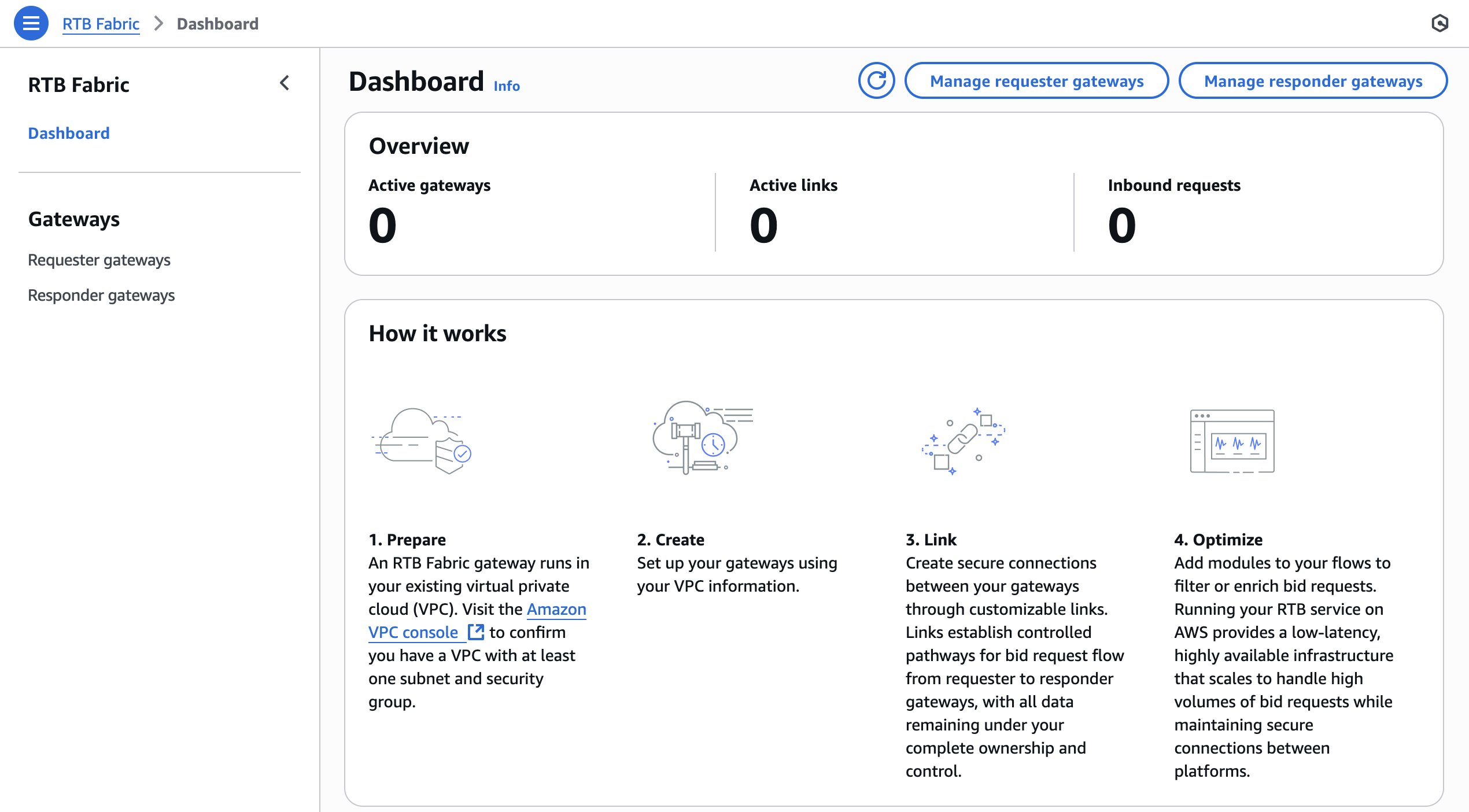
You can also use the AWS CLI to configure gateways, create links, and manage traffic programmatically. When I started building with AWS RTB Fabric, I used the AWS CLI to configure everything from gateway creation to link setup and traffic monitoring. The setup ran inside my Amazon Virtual Private Cloud (Amazon VPC) endpoint while AWS managed the low-latency infrastructure that connected workloads.
To begin, I created a requester gateway to send bid requests and a responder gateway to receive and process bid responses. These gateways act as secure communication points within the AWS RTB Fabric.
# Create a requester gateway with required parameters
aws rtbfabric create-requester-gateway \
--description "My RTB requester gateway" \
--vpc-id vpc-12345678 \
--subnet-ids subnet-abc12345 subnet-def67890 \
--security-group-ids sg-12345678 \
--client-token "unique-client-token-123"
# Create a responder gateway with required parameters
aws rtbfabric create-responder-gateway \
--description "My RTB responder gateway" \
--vpc-id vpc-01f345ad6524a6d7 \
--subnet-ids subnet-abc12345 subnet-def67890 \
--security-group-ids sg-12345678 \
--dns-name responder.example.com \
--port 443 \
--protocol HTTPS
After both gateways were active, I created a link from the requester to the responder to establish a private, low-latency communication path for OpenRTB traffic. The link handled routing and load balancing automatically.
# Requester account creating a link from requester gateway to a responder gateway
aws rtbfabric create-link \
--gateway-id rtb-gw-requester123 \
--peer-gateway-id rtb-gw-responder456 \
--log-settings '{"applicationLogs:{"sampling":"errorLog":10.0,"filterLog":10.0}}'# Responder account accepting a link from requester gateway to responder gateway
aws rtbfabric accept-link \
--gateway-id rtb-gw-responder456 \
--link-id link-reqtoresplink789 \
--log-settings '{"applicationLogs:{"sampling":"errorLog":10.0,"filterLog":10.0}}'I also connected with external partners using External Links, which extended my RTB workloads to on-premises or third-party environments while maintaining the same latency and security characteristics.
# Create an inbound external link endpoint for an external partner to send bid requests to
aws rtbfabric create-inbound-external-link \
--gateway-id rtb-gw-responder456# Create an outbound external link for sending bid requests to an external partner
aws rtbfabric create-outbound-external-link \
--gateway-id rtb-gw-requester123 \
--public-endpoint "https://my-external-partner-responder.com"
To manage traffic efficiently, I added modules directly into the data path. The Rate Limiter module controlled request volume, and the OpenRTB Filter validated message formats inline at network speed.
# Attach a rate limiting module
aws rtbfabric update-link-module-flow \
--gateway-id rtb-gw-responder456 \
--link-id link-toresponder789 \
--modules '{"name":"RateLimiter":"moduleParameters":{"rateLimiter":{"tps":10000}}}'Finally, I used Amazon CloudWatch to monitor throughput, latency, and module performance, and I exported logs to Amazon Simple Storage Service (Amazon S3) for auditing and optimization.
All configurations can also be automated with AWS CloudFormation or Terraform, allowing consistent, repeatable deployment across multiple environments. With RTB Fabric, I could focus on optimizing bidding logic while AWS maintained predictable, single-digit millisecond performance across my AdTech partners.
For more details, refer to the AWS RTB Fabric User Guide.
Now available
AWS RTB Fabric is available today in the following AWS Regions: US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Tokyo), Europe (Frankfurt), and Europe (Ireland).
AWS RTB Fabric is continually evolving to address the changing needs of the AdTech industry. The service expands its capabilities to support secure integration of advanced applications and AI-driven optimizations in real-time bidding workflows that help customers simplify operations and improve performance on AWS. To learn more about AWS RTB Fabric, visit the AWS RTB Fabric page.
– Betty





























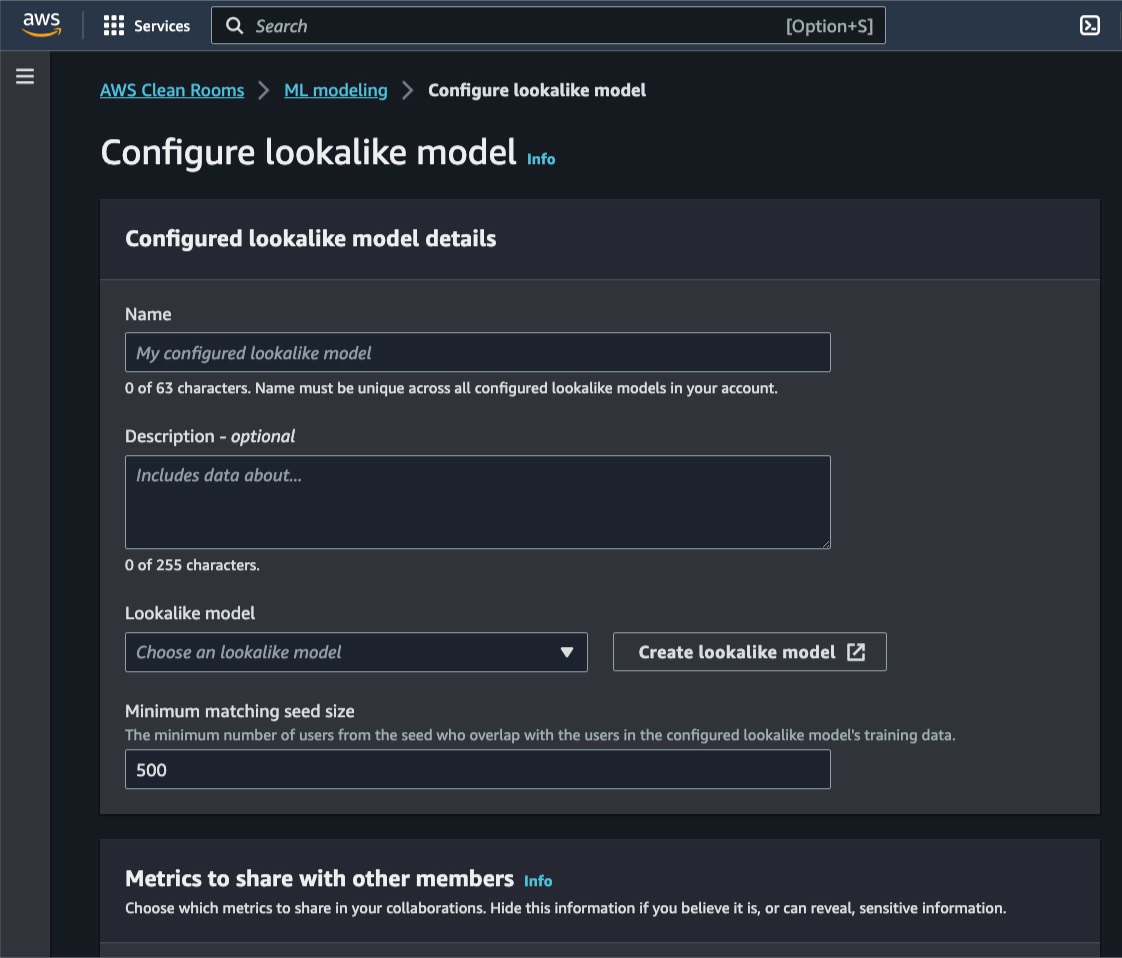
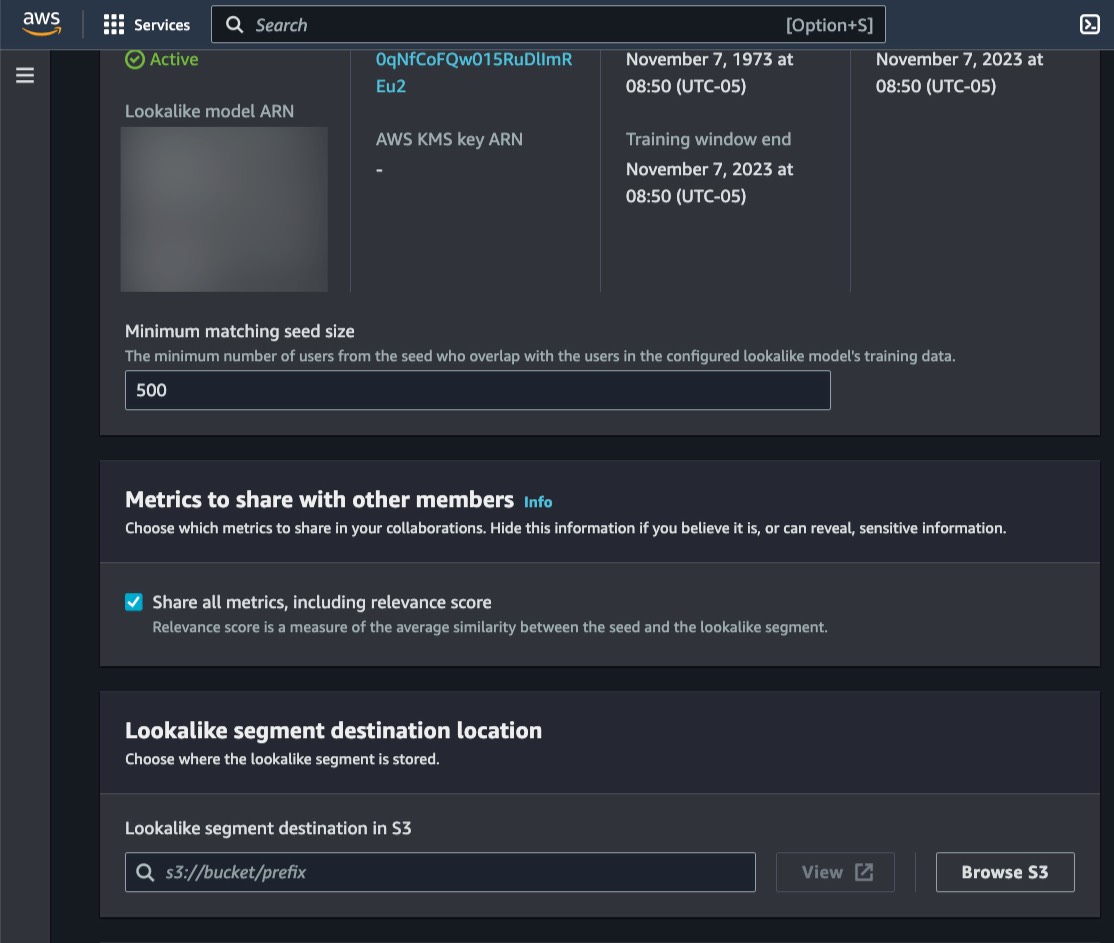

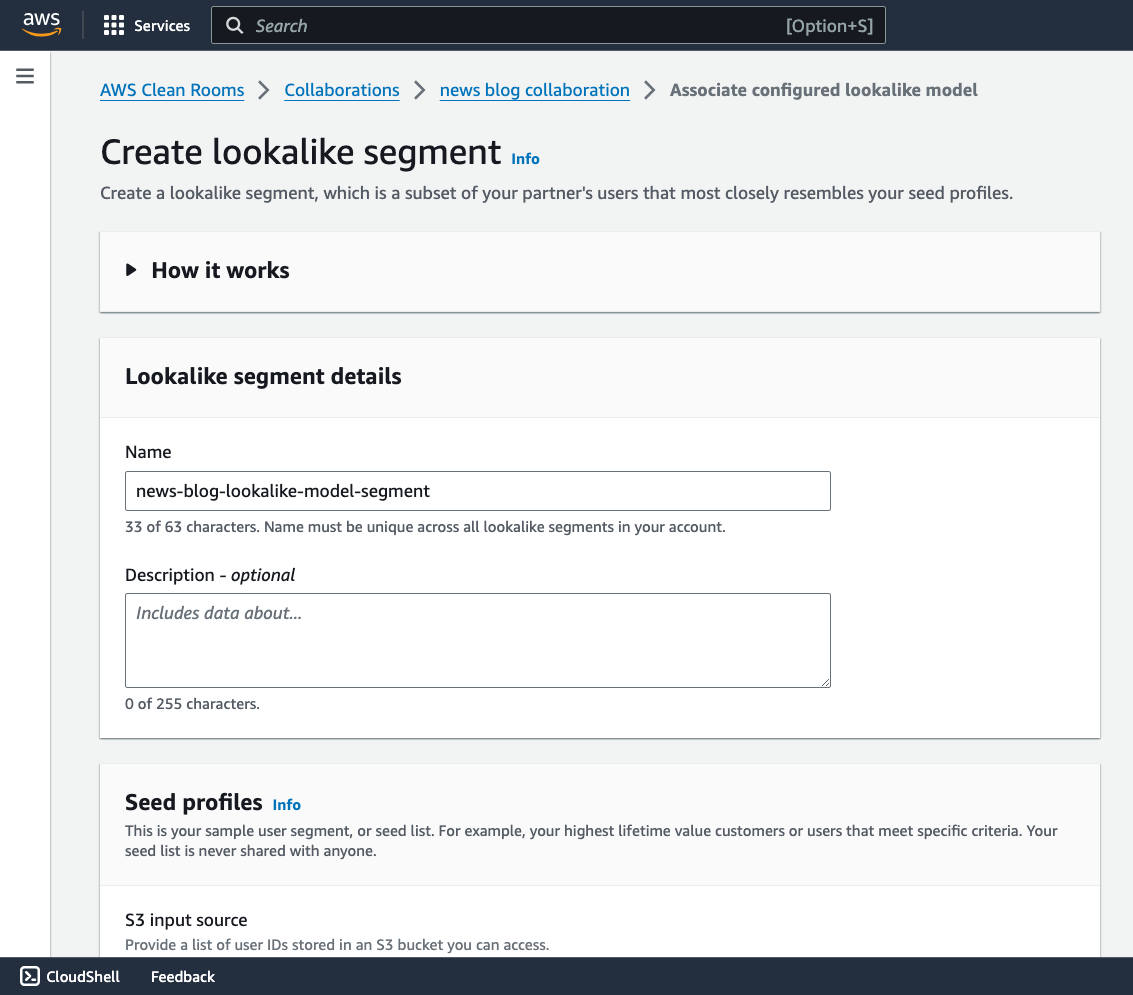

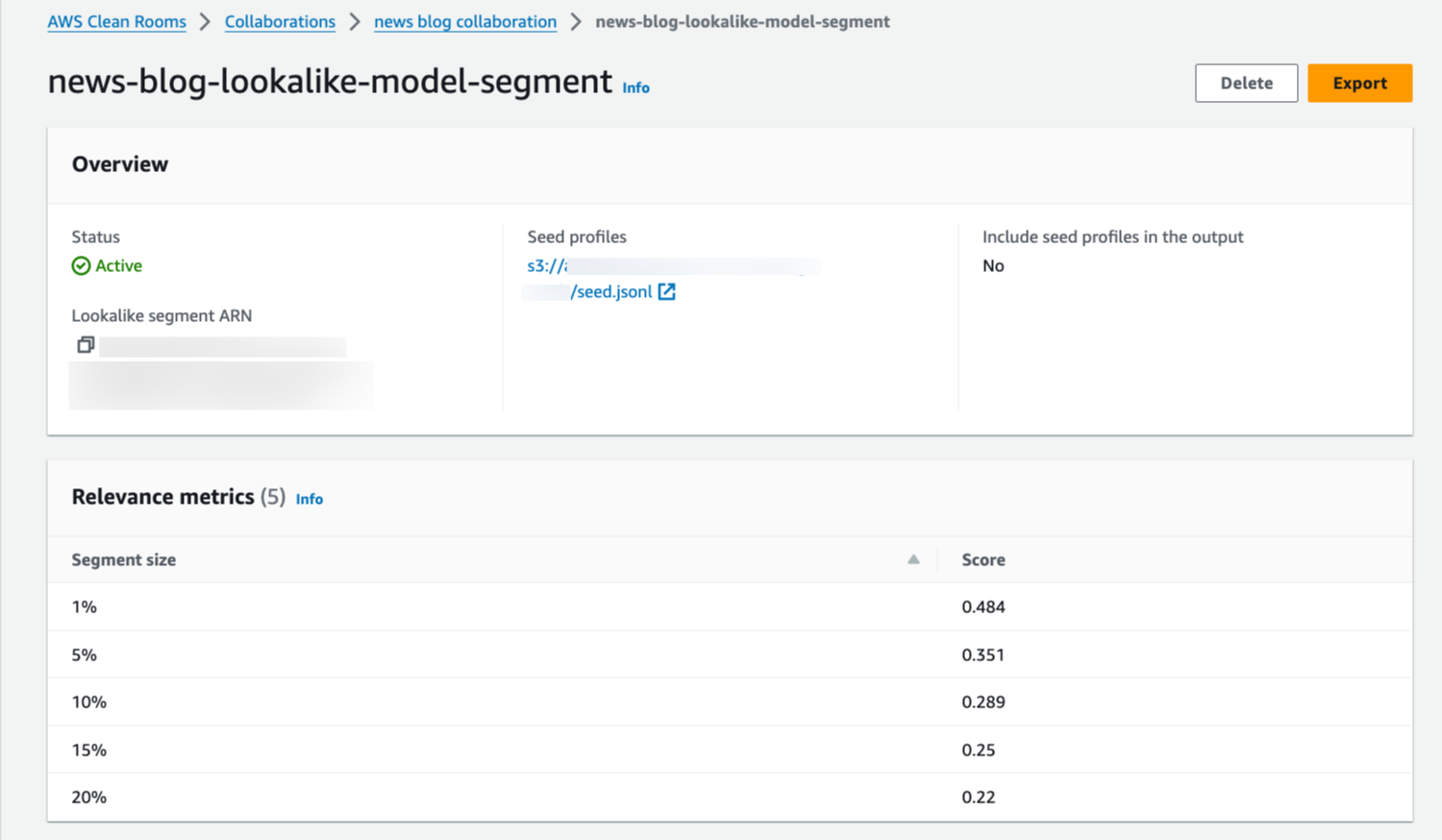












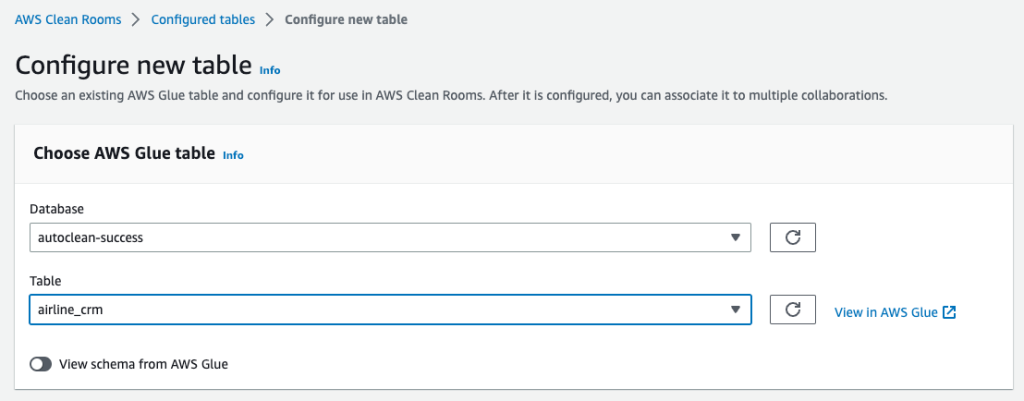
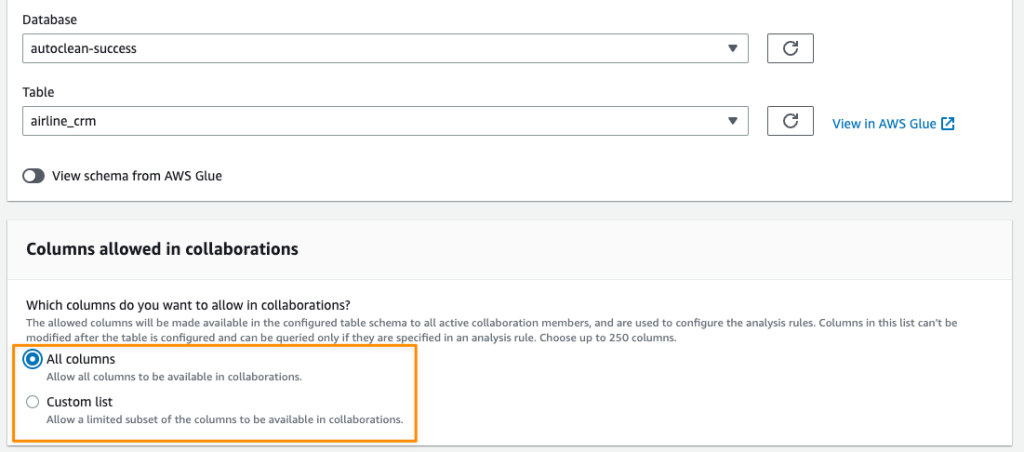
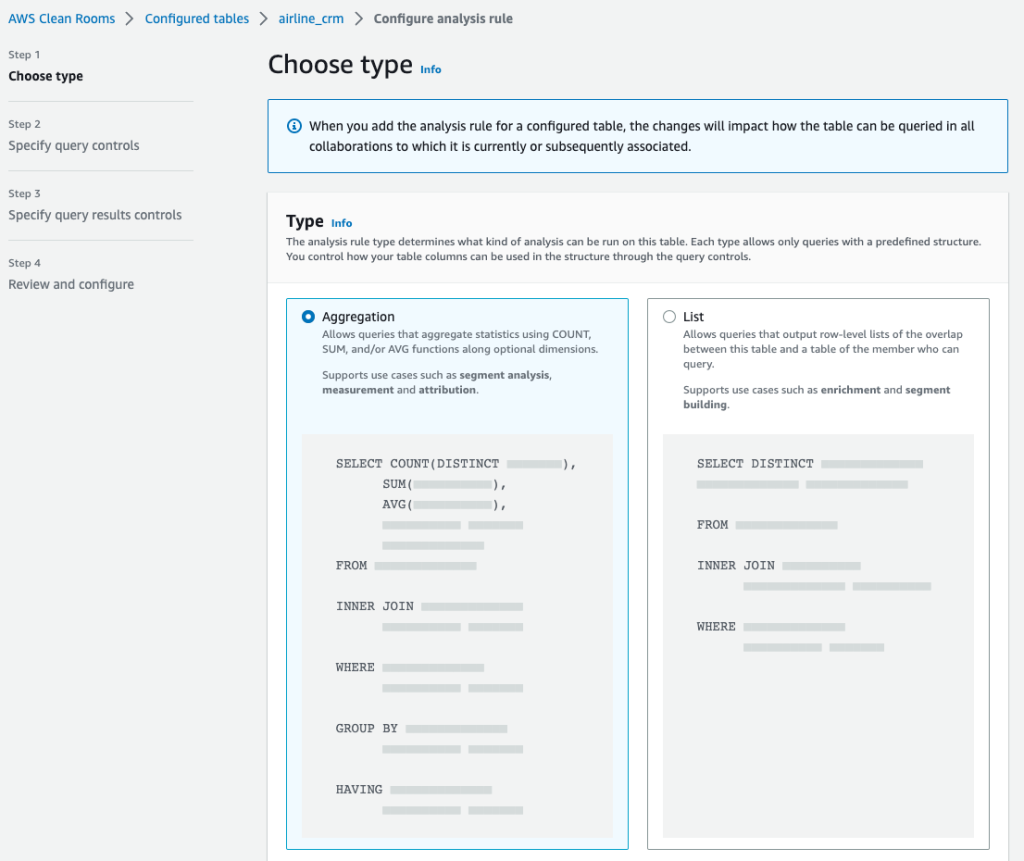
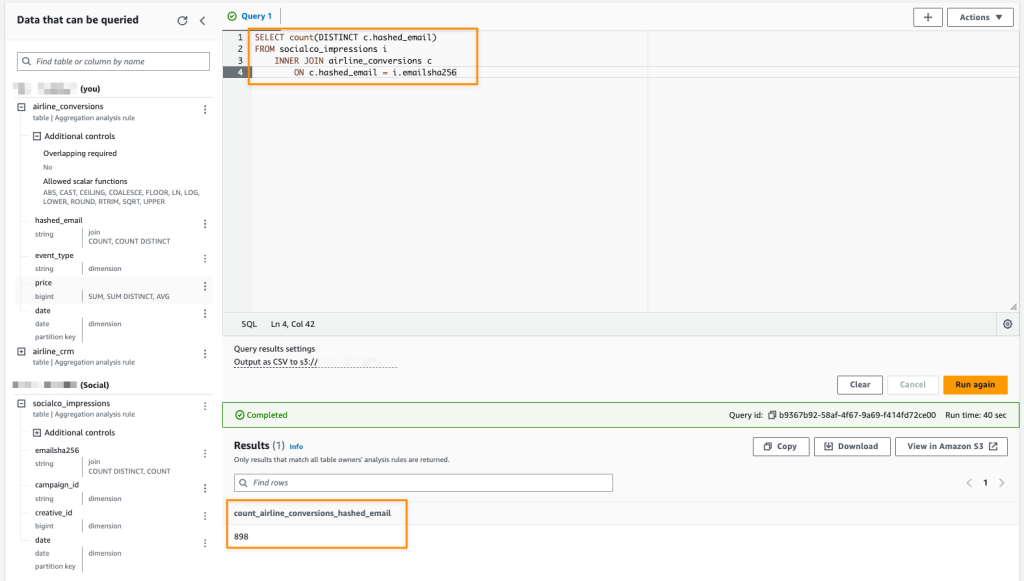
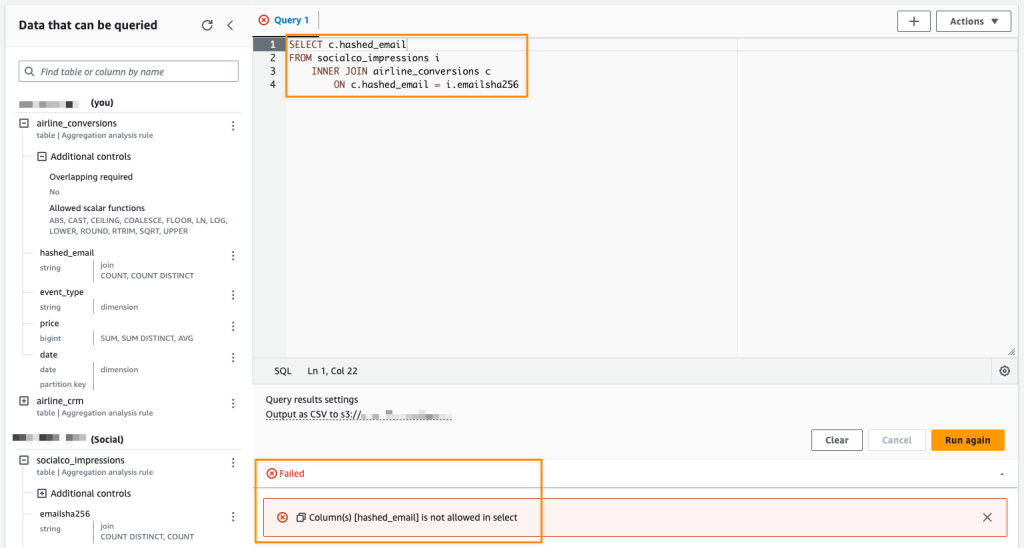
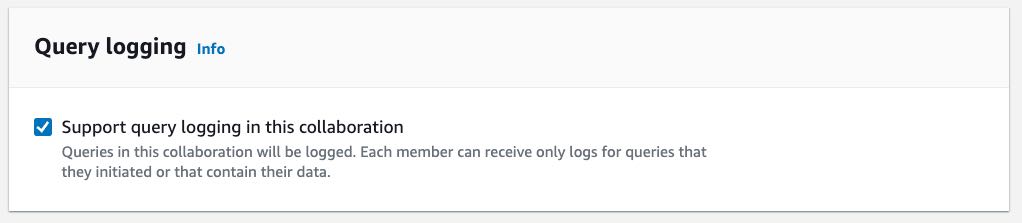
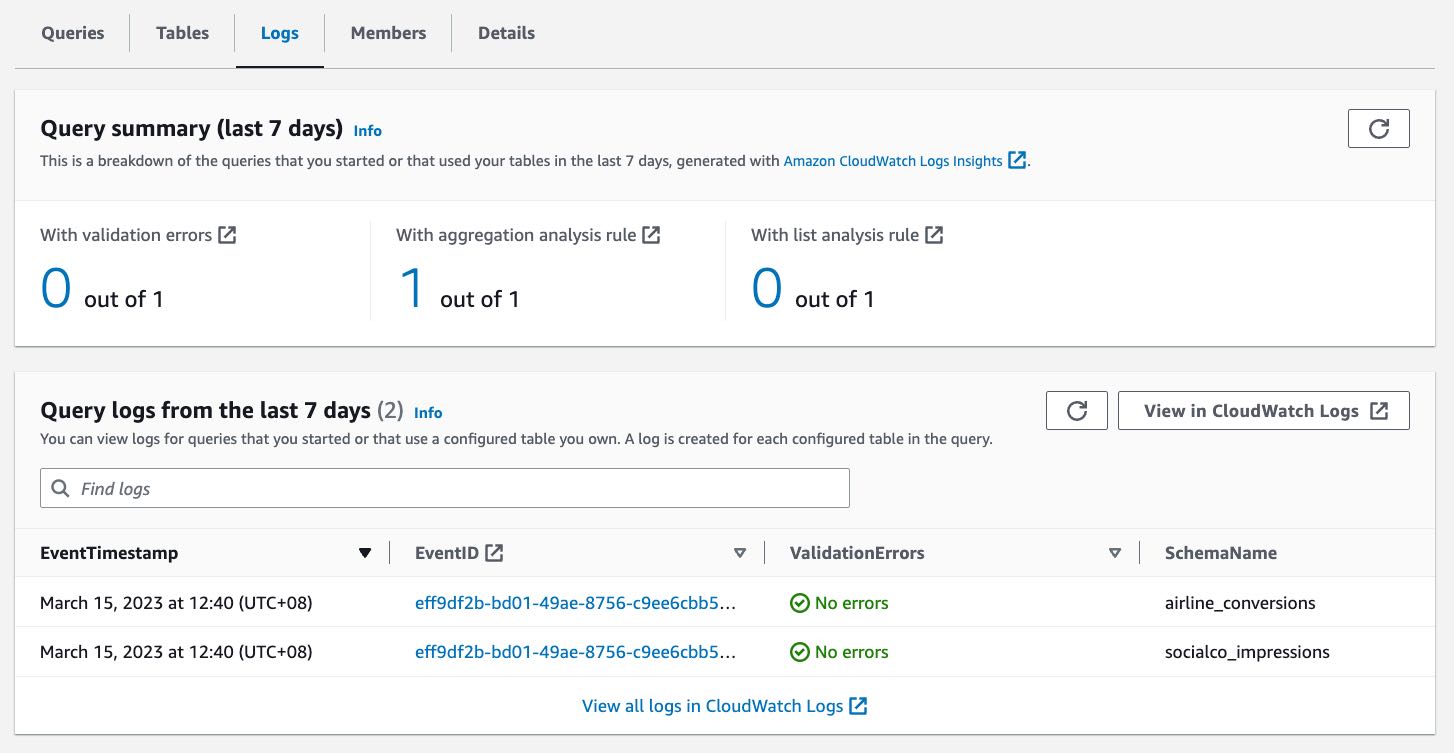
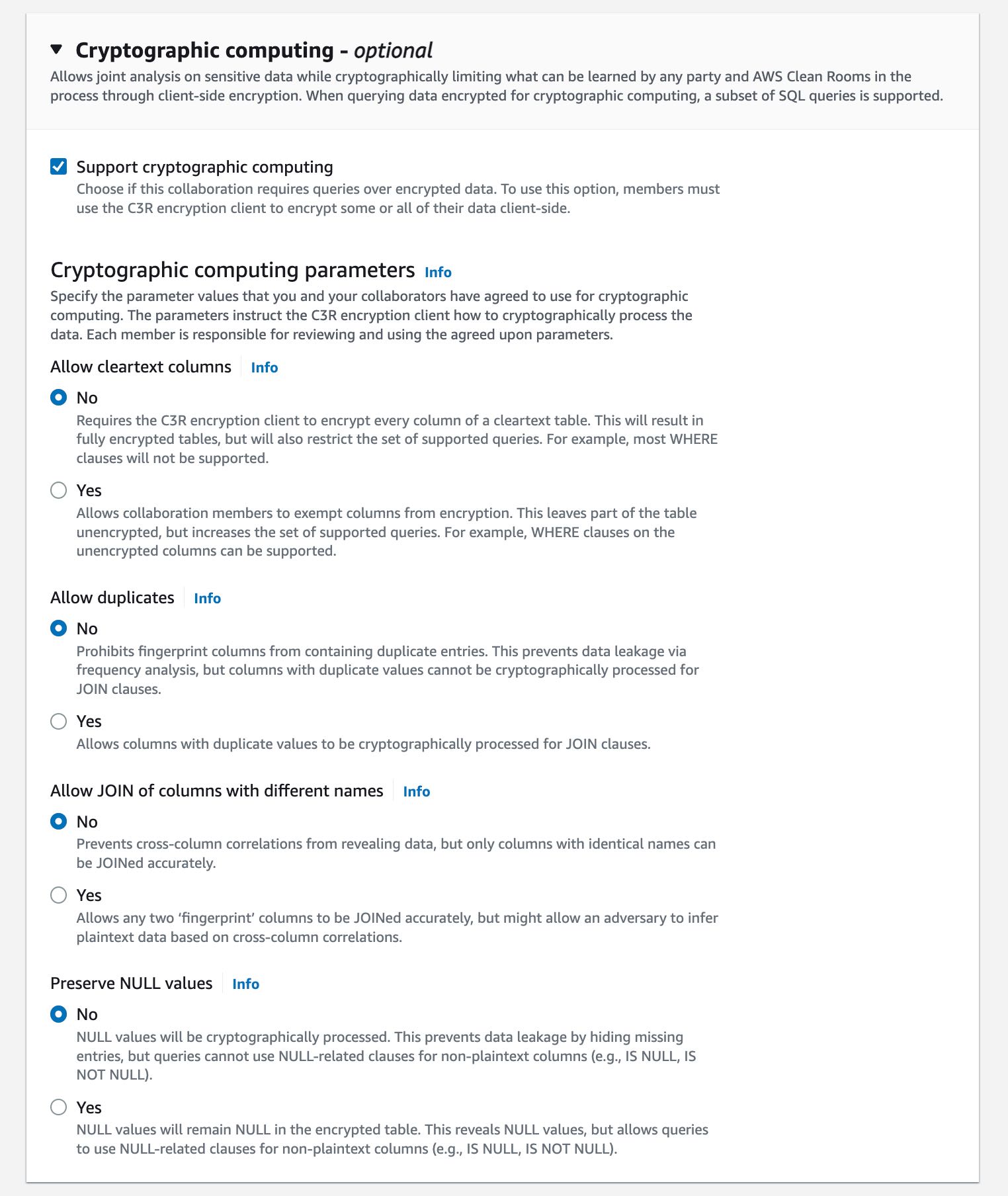


 “Providing marketers with greater control over their own signals while being able to analyze them in conjunction with signals from Amazon Ads is crucial in today’s marketing landscape. By migrating AMC’s compute infrastructure to AWS Clean Rooms under the hood, marketers can use their own signals in AMC without storing or maintaining data outside of their AWS environment. This simplifies how marketers can manage their signals and enables AMC teams to focus on building new capabilities for brands,” said Paula Despins, Vice President of Ads Measurement at Amazon Ads.
“Providing marketers with greater control over their own signals while being able to analyze them in conjunction with signals from Amazon Ads is crucial in today’s marketing landscape. By migrating AMC’s compute infrastructure to AWS Clean Rooms under the hood, marketers can use their own signals in AMC without storing or maintaining data outside of their AWS environment. This simplifies how marketers can manage their signals and enables AMC teams to focus on building new capabilities for brands,” said Paula Despins, Vice President of Ads Measurement at Amazon Ads.