Post Syndicated from Explosm.net original https://explosm.net/comics/gonna-jump
New Cyanide and Happiness Comic
Post Syndicated from Explosm.net original https://explosm.net/comics/gonna-jump
New Cyanide and Happiness Comic
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=hYhgkBfjhAg
Post Syndicated from xkcd.com original https://xkcd.com/2933/

Investigating lateral movements with Amazon Detective investigation and Security Lake integration
Post Syndicated from Yue Zhu original https://aws.amazon.com/blogs/security/investigating-lateral-movements-with-amazon-detective-investigation-and-security-lake-integration/
According to the MITRE ATT&CK framework, lateral movement consists of techniques that threat actors use to enter and control remote systems on a network. In Amazon Web Services (AWS) environments, threat actors equipped with illegitimately obtained credentials could potentially use APIs to interact with infrastructures and services directly, and they might even be able to use APIs to evade defenses and gain direct access to Amazon Elastic Compute Cloud (Amazon EC2) instances. To help customers secure their AWS environments, AWS offers several security services, such as Amazon GuardDuty, a threat detection service that monitors for malicious activity and anomalous behavior, and Amazon Detective, an investigation service that helps you investigate, and respond to, security events in your AWS environment.
After the service is turned on, Amazon Detective automatically collects logs from your AWS environment to help you analyze and investigate security events in-depth. At re:Invent 2023, Detective released Detective Investigations, a one-click investigation feature that automatically investigates AWS Identity and Access Management (IAM) users and roles for indicators of compromise (IoC), and Security Lake integration, which enables customers to retrieve log data from Amazon Security Lake to use as original evidence for deeper analysis with access to more detailed parameters.
In this post, you will learn about the use cases behind these features, how to run an investigation using the Detective Investigation feature, and how to interpret the contents of investigation reports. In addition, you will also learn how to use the Security Lake integration to retrieve raw logs to get more details of the impacted resources.
As a security analyst, one of the common workflows in your daily job is to respond to suspicious activities raised by security event detection systems. The process might start when you get a ticket about a GuardDuty finding in your daily operations queue, alerting you that suspicious or malicious activity has been detected in your environment. To view more details of the finding, one of the options is to use the GuardDuty console.
In the GuardDuty console, you will find more details about the finding, such as the account and AWS resources that are in scope, the activity that caused the finding, the IP address that caused the finding and information about its possible geographic location, and times of the first and last occurrences of the event. To triage the finding, you might need more information to help you determine if it is a false positive.
Every GuardDuty finding has a link labeled Investigate with Detective in the details pane. This link allows you to pivot to the Detective console based on aspects of the finding you are investigating to their respective entity profiles. The finding Recon:IAMUser/MaliciousIPCaller.Custom that’s shown in Figure 1 results from an API call made by an IP address that’s on the custom threat list, and GuardDuty observed it made API calls that were commonly used in reconnaissance activity, which commonly occurs prior to attempts at compromise. To investigate this finding, because it involves an IAM role, you can select the Role session link and it will take you to the role session’s profile in the Detective console.
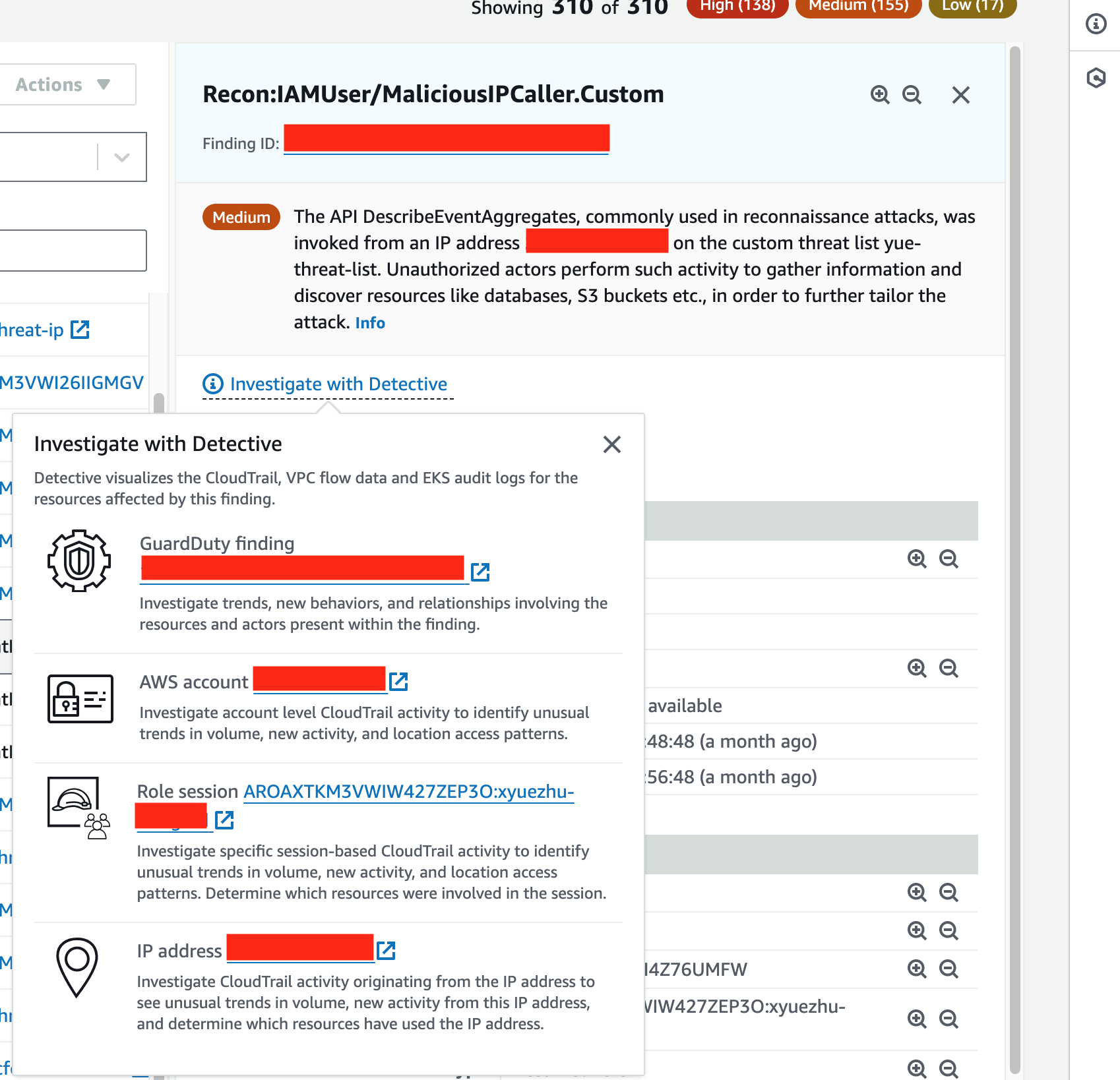
Figure 1: Example finding in the GuardDuty console, with Investigate with Detective pop-up window
Within the AWS Role session profile page, you will find security findings from GuardDuty and AWS Security Hub that are associated with the AWS role session, API calls the AWS role session made, and most importantly, new behaviors. Behaviors that deviate from expectations can be used as indicators of compromises to give you more information to determine if the AWS resource might be compromised. Detective highlights new behaviors first observed during the scope time of the events related to the finding that weren’t observed during the Detective baseline time window of 45 days.
If you switch to the New behavior tab within the AWS role session profile, you will find the Newly observed geolocations panel (Figure 2). This panel highlights geolocations of IP addresses where API calls were made from that weren’t observed in the baseline profile. Detective determines the location of requests using MaxMind GeoIP databases based on the IP address that was used to issue requests.
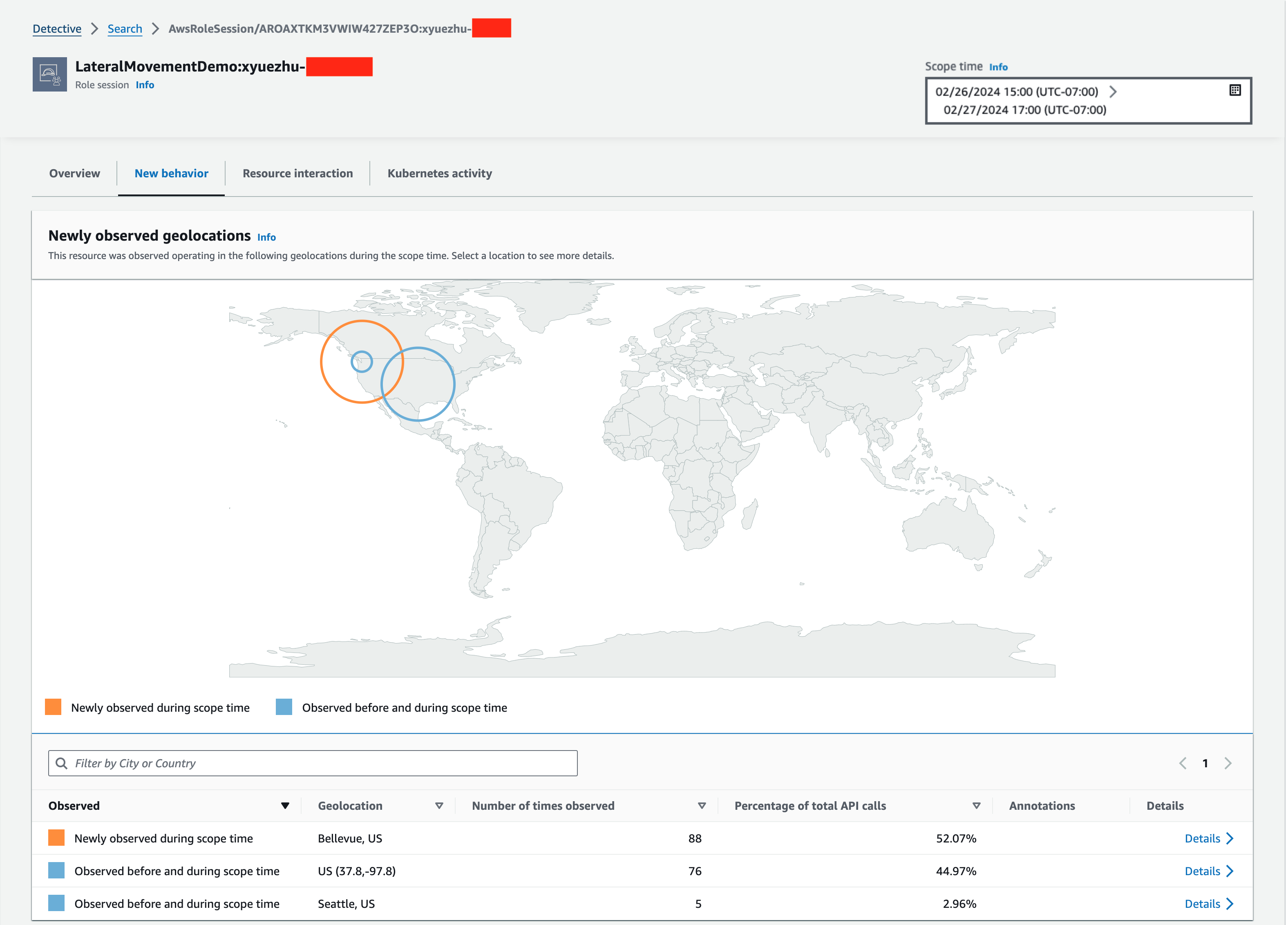
Figure 2: Detective’s Newly observed geolocations panel
If you choose Details on the right side of each row, the row will expand and provide details of the API calls made from the same locations from different AWS resources, and you can drill down and get to the API calls made by the AWS resource from a specific geolocation (Figure 3). When analyzing these newly observed geolocations, a question you might consider is why this specific AWS role session made API calls from Bellevue, US. You’re pretty sure that your company doesn’t have a satellite office there, nor do your coworkers who have access to this role work from there. You also reviewed the AWS CloudTrail management events of this AWS role session, and you found some unusual API calls for services such as IAM.
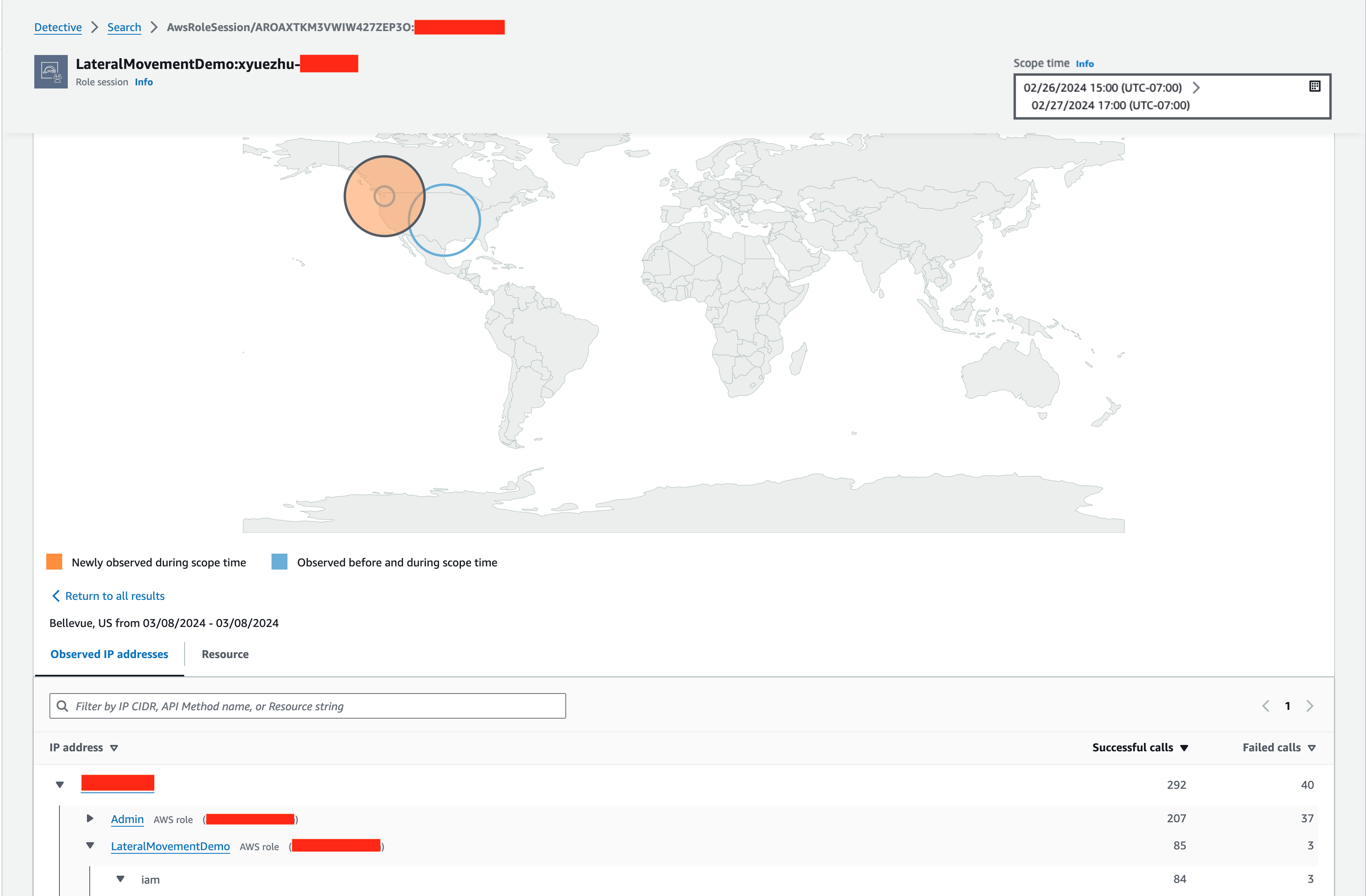
Figure 3: Detective’s Newly observed geolocations panel expanded on details
You decide that you need to investigate further, because this role session’s anomalous behavior from a new geolocation is sufficiently unexpected, and it made unusual API calls that you would like to know the purpose of. You want to gather anomalous behaviors and high-risk API methods that can be used by threat actors to make impacts. Because you’re investigating an AWS role session rather than investigating a single role session, you decide you want to know what happened in other role sessions associated with the AWS role in case threat actors spread their activities across multiple sessions. To help you examine multiple role sessions automatically with additional analytics and threat intelligence, Detective introduced the Detective Investigation feature at re:Invent 2023.
Amazon Detective Investigation uses machine learning (ML) models and AWS threat intelligence to automatically analyze resources in your AWS environment to identify potential security events. It identifies tactics, techniques, and procedures (TTPs) used in a potential security event. The MITRE ATT&CK framework is used to classify the TTPs. You can use this feature to help you speed up the investigation and identify indicators of compromise and other TTPs quickly.
To continue with your investigation, you should investigate the role and its usage history as a whole to cover all involved role sessions at once. This addresses the potential case where threat actors assumed the same role under different session names. In the AWS role session profile page that’s shown in Figure 4, you can quickly identify and pivot to the corresponding AWS role profile page under the Assumed role field.
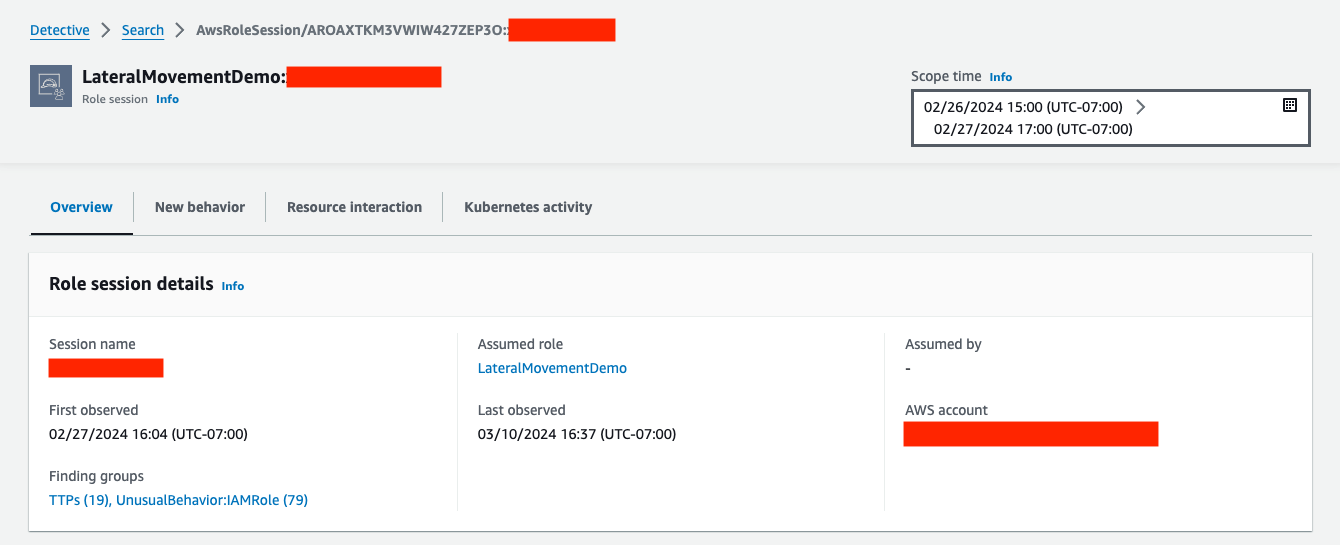
Figure 4: Detective’s AWS role session profile page
After you pivot to the AWS role profile page (Figure 5), you can run the automated investigations by choosing Run investigation.
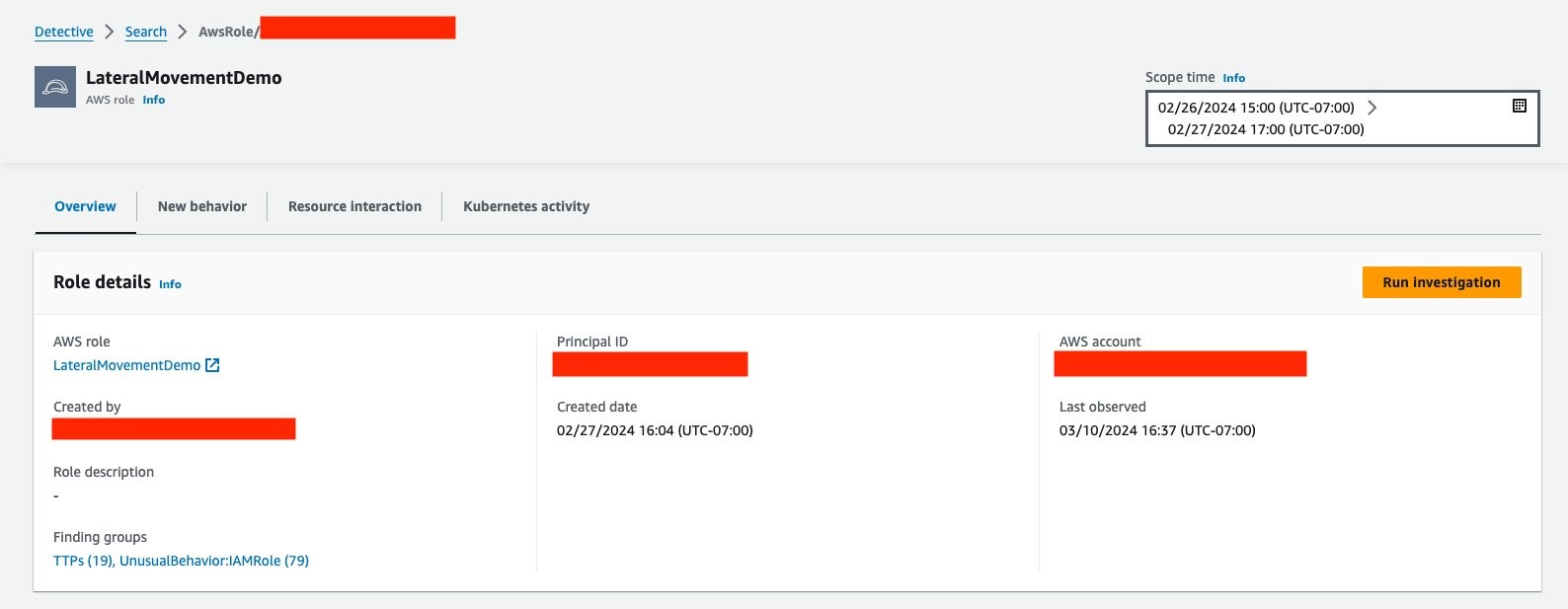
Figure 5: Role profile page, from which an investigation can be run
The first thing to do in a new investigation is to choose the time scope you want to run the investigation for. Then, choose Confirm (Figure 6).
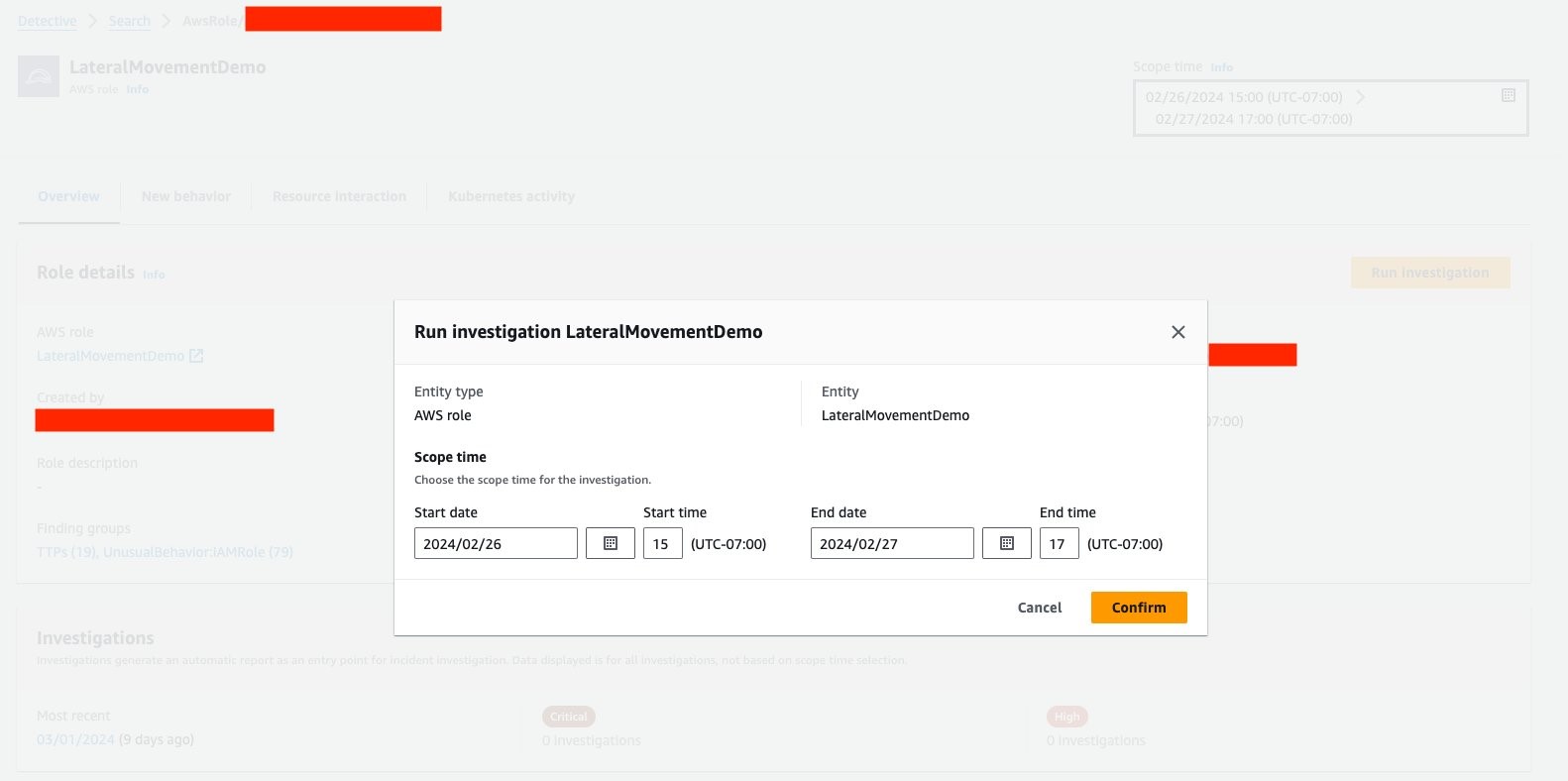
Figure 6: Setting investigation scope time
Next, you will be directed to the Investigations page (Figure 7), where you will be able to see the status of your investigation. Once the investigation is done, you can choose the hyperlinked investigation ID to access the investigation report.
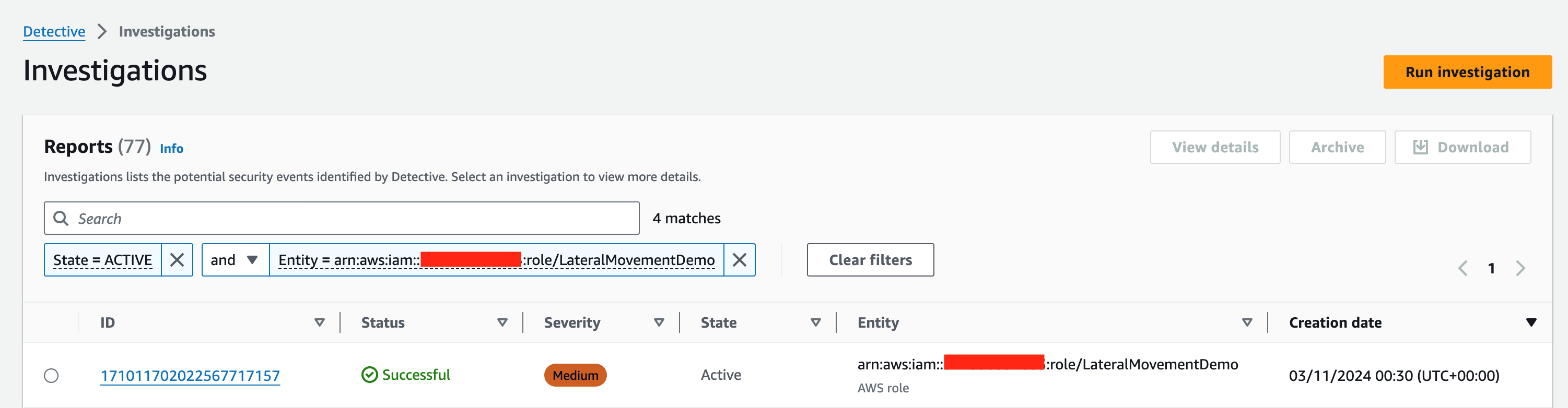
Figure 7: Investigations page, with new report
Another way to run an investigation is to choose Investigations on the left menu panel in the Detective console, and then choose Run investigation. You will then be taken to the page where you will specify the AWS role Amazon Resource Number (ARN) you’re investigating, and the scope time (Figure 8). Then you can choose Run investigation to commence an investigation.
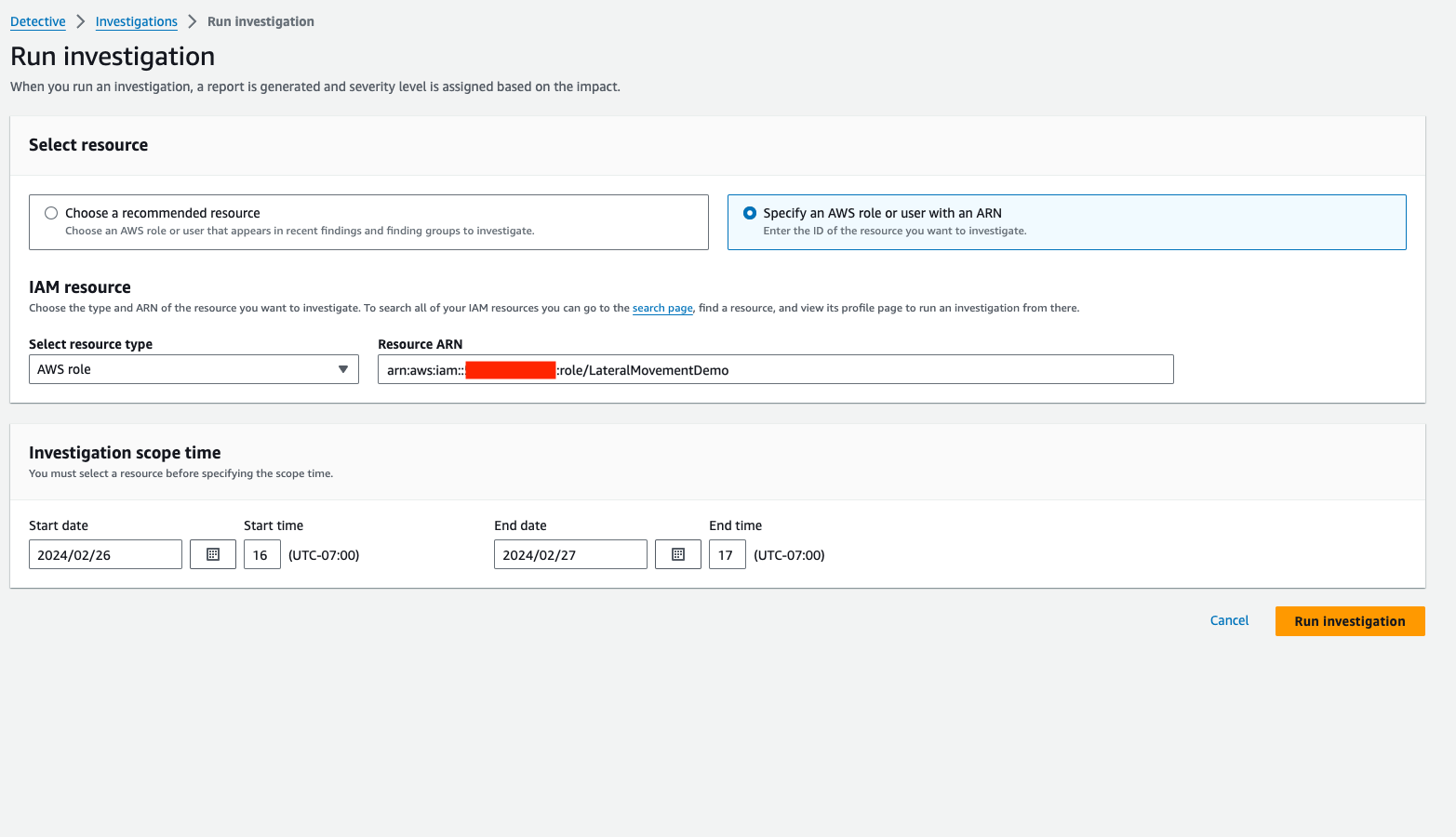
Figure 8: Configuring a new investigation from scratch rather than from an existing finding
Detective also offers StartInvestigation and GetInvestigation APIs for running Detective Investigations and retrieving investigation reports programmatically.
The investigation report (Figure 9) includes information on anomalous behaviors, potential TTP mappings of observed CloudTrail events, and indicators of compromises of the resource (in this example, an IAM principal) that was investigated.
At the top of the report, you will find a severity level computed based on the observed behaviors during the scope window, as well as a summary statement to give you a quick understanding of what was found. In Figure 9, the AWS role that was investigated engaged in the following unusual behaviors:
These indicators of compromise represent unusual behaviors that have either not been observed before in the AWS account involved or that are intrinsically considered high risk. The following summary panel includes the report that shows a detailed breakdown of the investigation results.
Unusual activities are important factors that you should look for during investigations, and sudden behavior change can be a sign of compromise. When you’re investigating an AWS role that can be assumed by different users from different AWS Regions, you are likely to need to examine activity at the granularity of the specific AWS role session that made the APIs calls. Within the report, you can do this by choosing the hyperlinked role name in the summary panel, and it will take you to the AWS role profile page.
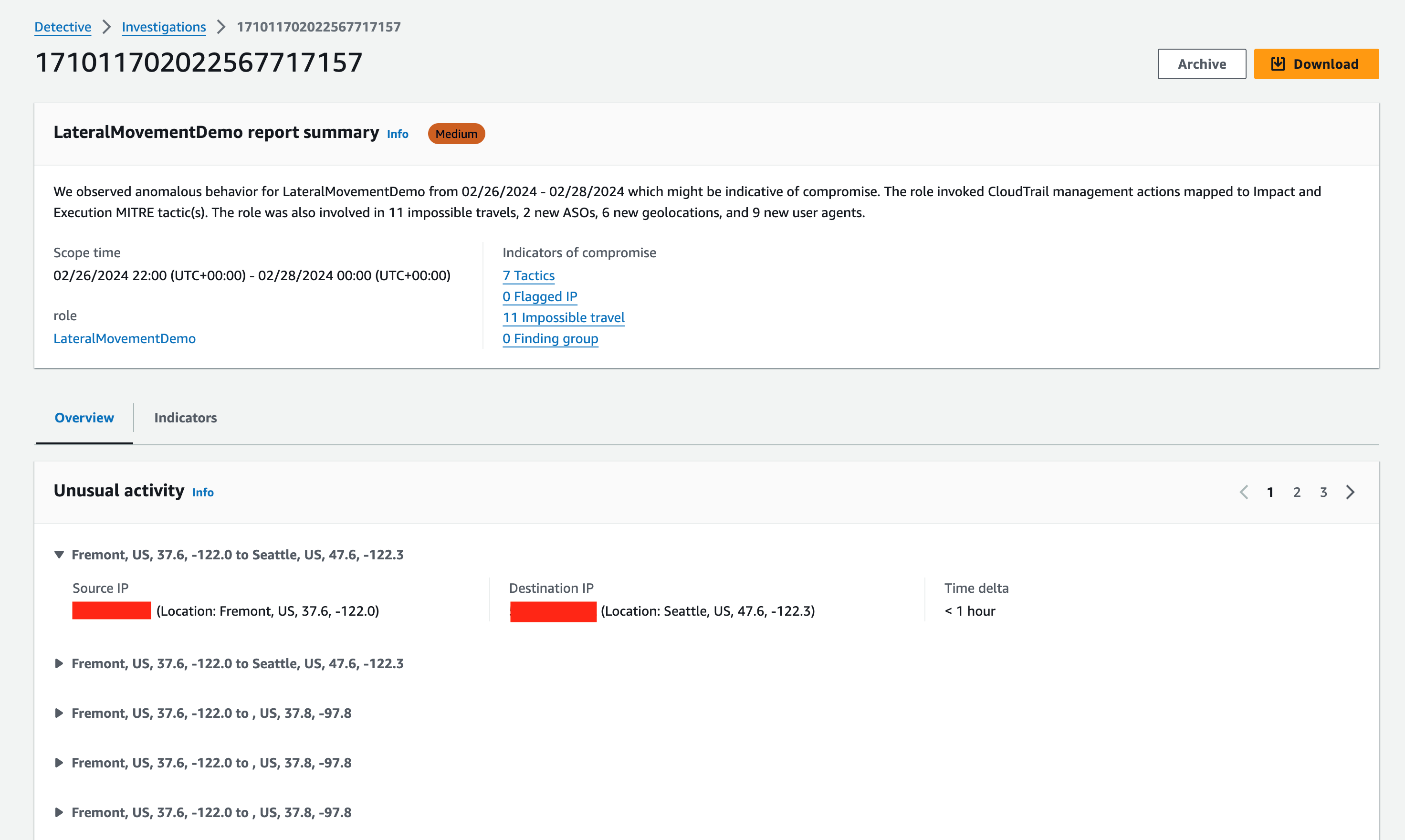
Figure 9: Investigation report summary page
Further down on the investigation report is the TTP Mapping from CloudTrail Management Events panel. Detective Investigations maps CloudTrail events to the MITRE ATT&CK framework to help you understand how an API can be used by threat actors. For each mapped API, you can see the tactics, techniques, and procedures it can be used for. In Figure 10, at the top there is a summary of TTPs with different severity levels. At the bottom is a breakdown of potential TTP mappings of observed CloudTrail management events during the investigation scope time.
When you select one of the cards, a side panel appears on the right to give you more details about the APIs. It includes information such as the IP address that made the API call, the details of the TTP the API call was mapped to, and if the API call succeeded or failed. This information can help you understand how these APIs can potentially be used by threat actors to modify your environment, and whether or not the API call succeeded tells you if it might have affected the security of your AWS resources. In the example that’s shown in Figure 10, the IAM role successfully made API calls that are mapped to Lateral Movement in the ATT&CK framework.
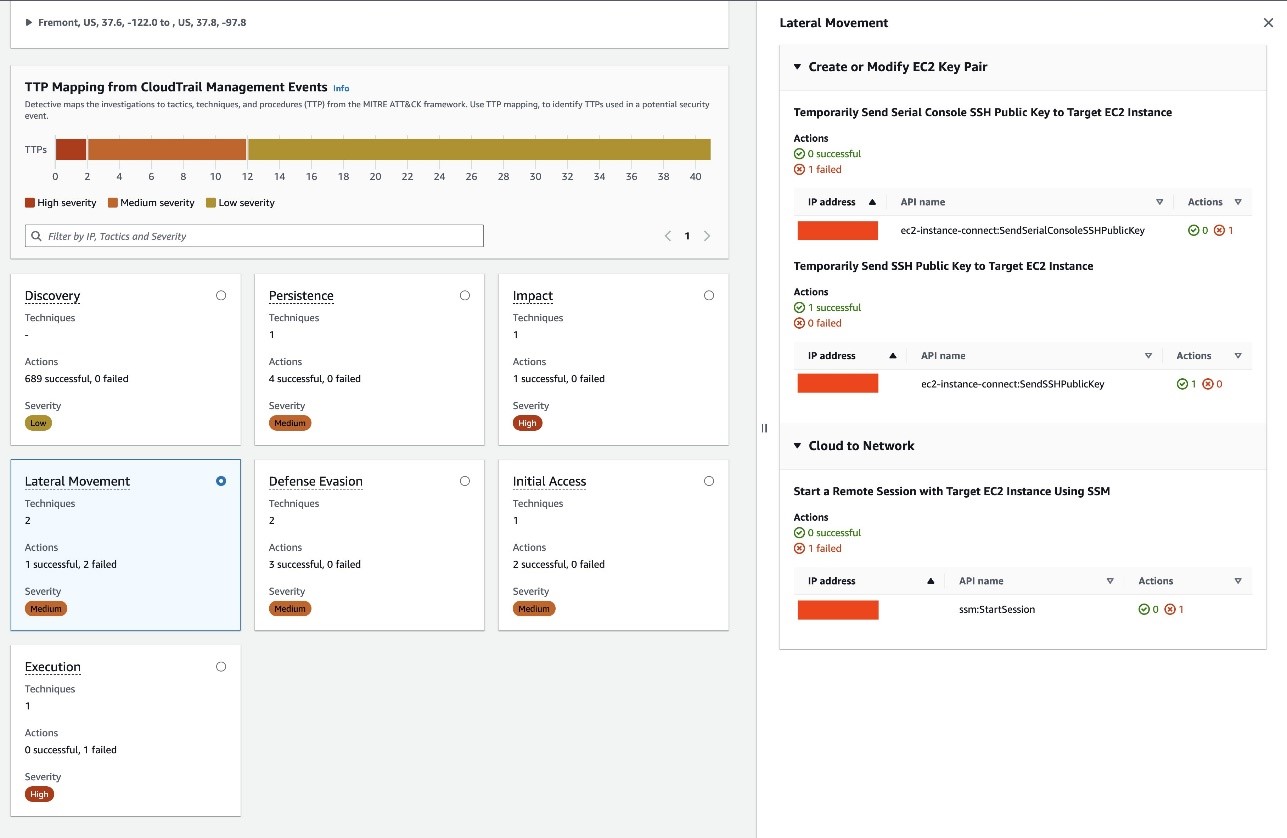
Figure 10: Investigation report page with event ATT CK mapping
The report also includes additional indicators of compromise (Figure 11). You can find these if you select the Indicators tab next to Overview. Within this tab, you can find the indicators identified during the scope time, and if you select one indicator, details for that indicator will appear on the right. In the example in Figure 11, the IAM role made API calls with a user agent that wasn’t used by this IAM role or other IAM principals in this account, and indicators like this one show sudden behavior change of your IAM principal. You should review them and identify the ones that aren’t expected. To learn more about indicators of compromise in Detective Investigation, see the Amazon Detective User Guide.
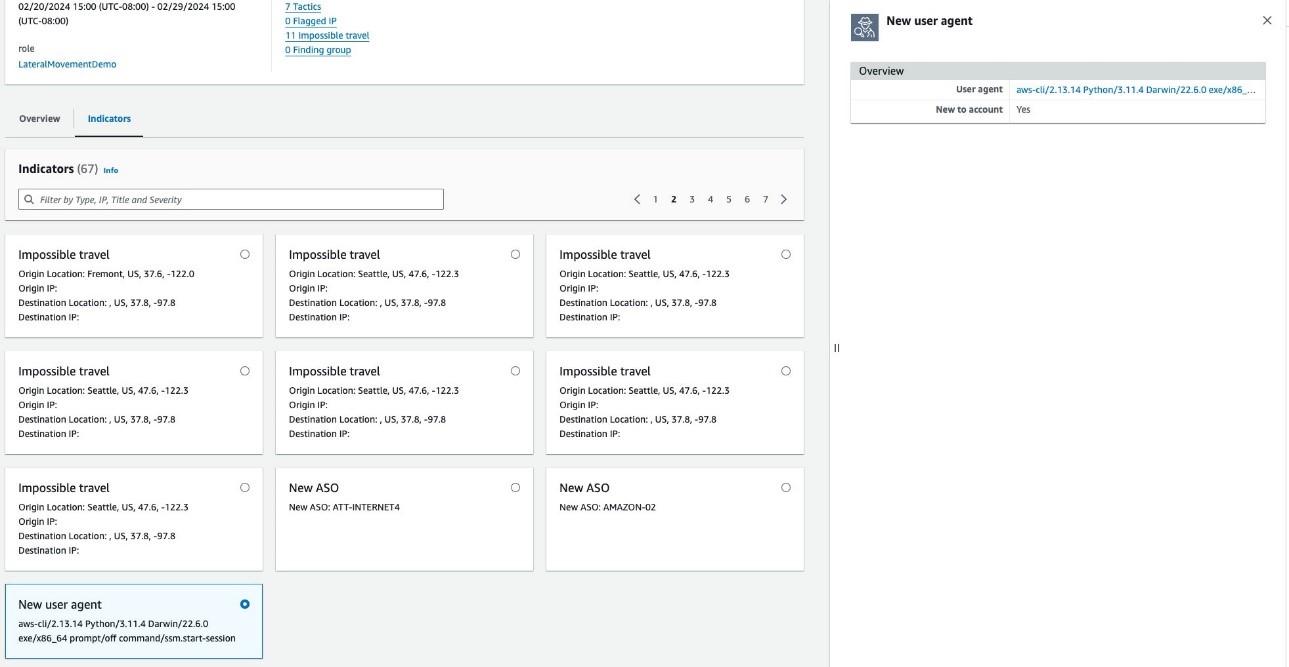
Figure 11: Indicators of compromise identified during scope time
At this point, you’ve analyzed the new and unusual behaviors the IAM role made and learned that the IAM role made API calls using new user agents and from new ASOs. In addition, you went through the API calls that were mapped to the MITRE ATT&CK framework. Among the TTPs, there were three API calls that are classified as lateral movements. These should attract attention for the following reasons: first, the purpose of these API calls is to gain access to the EC2 instance involved; and second, ec2-instance-connect:SendSSHPublicKey was run successfully.
Based on the procedure description in the report, this API would grant threat actors temporary SSH access to the target EC2 instance. To gather original evidence, examine the raw logs stored in Security Lake. Security Lake is a fully managed security data lake service that automatically centralizes security data from AWS environments, SaaS providers, on-premises sources, and other sources into a purpose-built data lake stored in your account.
You can use Security Lake integration to retrieve raw logs from your Security Lake tables within the Detective console as original evidence. If you haven’t enabled the integration yet, you can follow the Integration with Amazon Security Lake guide to enable it. In the context of the example investigation earlier, these logs include details of which EC2 instance was associated with the ec2-instance-connect:SendSSHPublicKey API call. Within the AWS role profile page investigated earlier, if you scroll down to the bottom of the page, you will find the Overall API call volume panel (Figure 12). You can search for the specific API call using the Service and API method filters. Next, choose the magnifier icon, which will initiate a Security Lake query to retrieve the raw logs of the specific CloudTrail event.
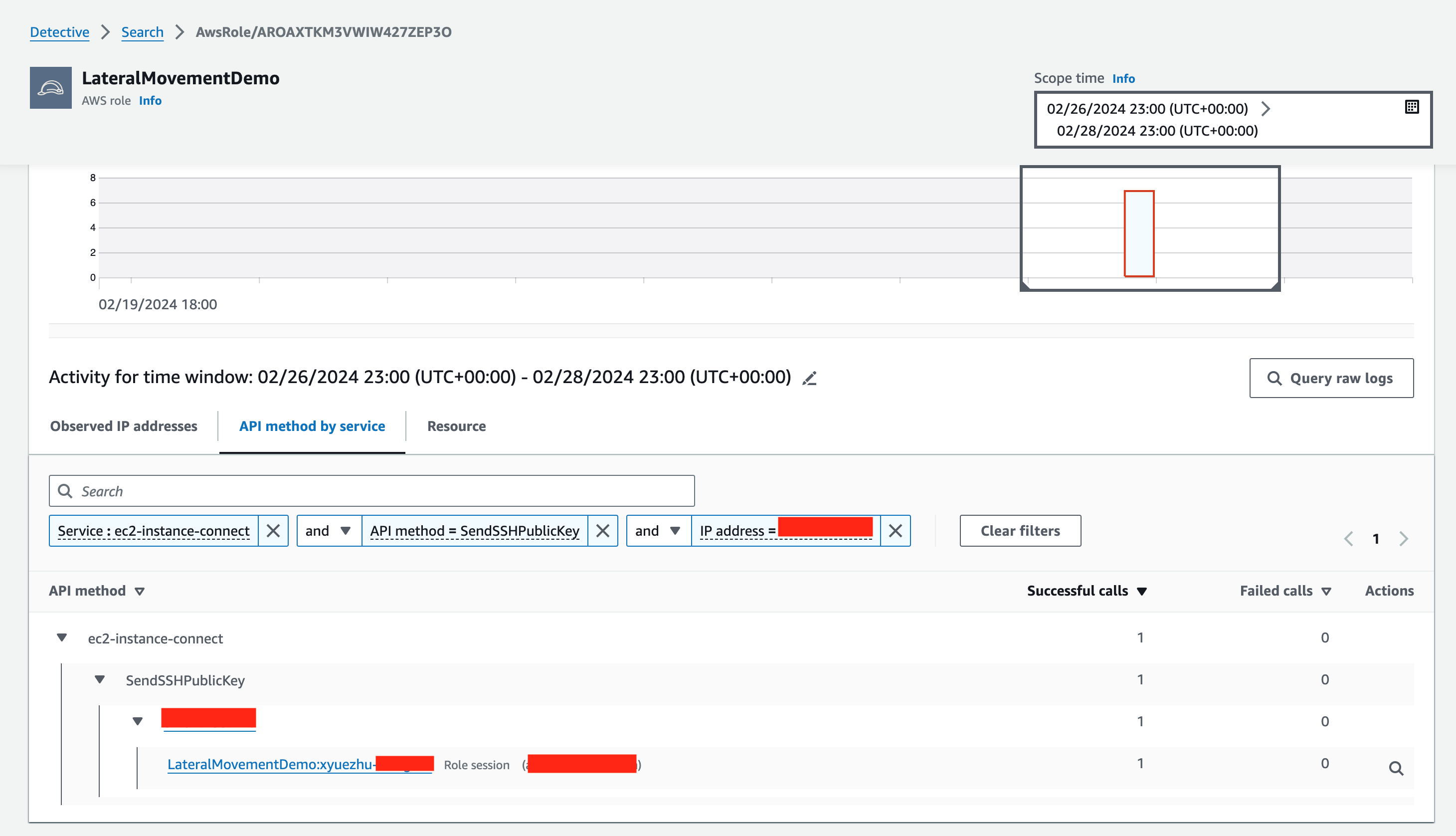
Figure 12: Finding the CloudTrail record for a specific API call held in Security Lake
You can identify the target EC2 instance the API was issued against from the query results (Figure 13). To determine whether threat actors actually made an SSH connection to the target EC2 instance as a result of the API call, you should examine the EC2 instance’s profile page:
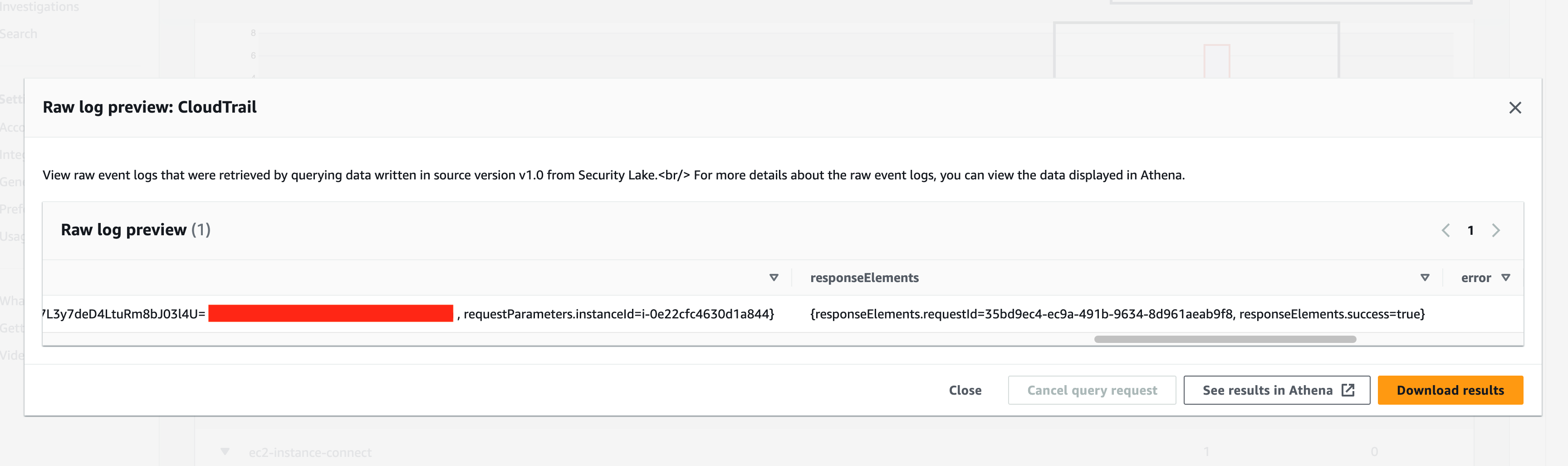
Figure 13: Reviewing a CloudTrail log record from Security Lake
From the profile page of the EC2 instance in the Detective console, you can go to the Overall VPC flow volume panel and filter the Amazon Virtual Private Cloud (Amazon VPC) flow logs using the attributes related to the threat actor identified as having made the SSH API call. In Figure 14, you can see the IP address that tried to connect to 22/tcp, which is the SSH port of the target instance. It’s common for threat actors to change their IP address in an attempt to evade detection, and you can remove the IP address filter to see inbound connections to port 22/tcp of your EC2 instance.
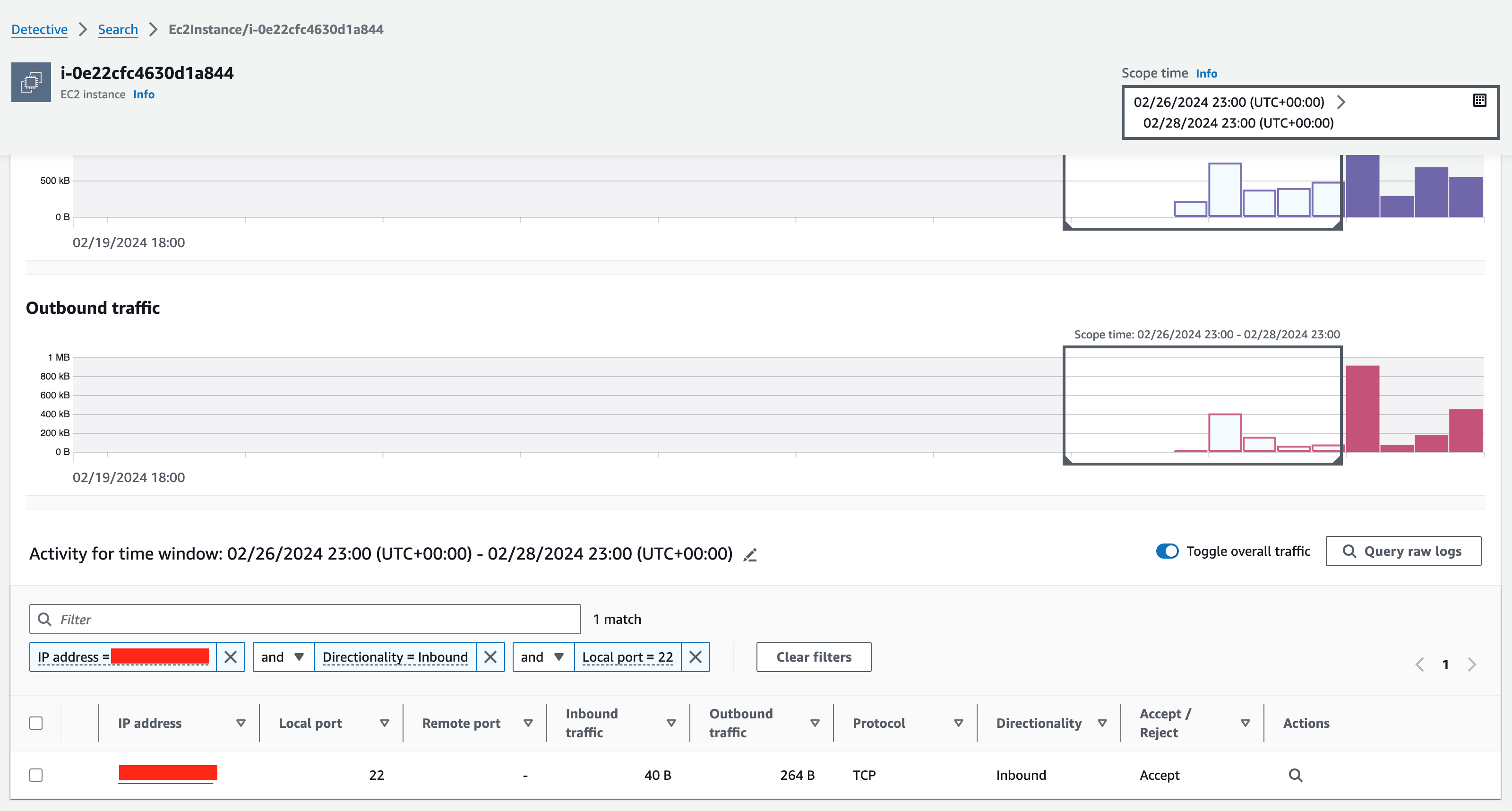
Figure 14: Examining SSH connections to the target instance in the Detective profile page
At this point, you’ve made progress with the help of Detective Investigations and Security Lake integration. You started with a GuardDuty finding, and you got to the point where you were able to identify some of the intent of the threat actors and uncover the specific EC2 instance they were targeting. Your investigation shouldn’t stop here because you’ve successfully identified the EC2 instance, which is the next target to investigate.
You can reuse this whole workflow by starting with the EC2 instance’s New behavior panel, run Detective Investigations on the IAM role attached to the EC2 instance and other IAM principals you think are worth taking a closer look at, then use the Security Lake integration to gather raw logs of the APIs made by the EC2 instance to identify the specific actions taken and their potential consequences.
In this post, you’ve seen how you can use the Amazon Detective Investigation feature to investigate IAM user and role activity and use the Security Lake integration to determine the specific EC2 instances a threat actor appeared to be targeting.
The Detective Investigation feature is automatically enabled for both existing and new customers in AWS Regions that support Detective where Detective has been activated. The Security Lake integration feature can be enabled in your Detective console. If you don’t currently use Detective, you can start a free 30-day trial. For more information on Detective Investigation and Security Lake integration, see Investigating IAM resources using Detective investigations and Security Lake integration.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on X.
Post Syndicated from Adam Barnett original https://blog.rapid7.com/2024/05/14/patch-tuesday-may-2024/

Microsoft is addressing 61 vulnerabilities this May 2024 Patch Tuesday. Microsoft has evidence of in-the-wild exploitation and/or public disclosure for three of the vulnerabilities published today. At time of writing, two of the vulnerabilities patched today are listed on CISA KEV. Microsoft is also patching a single critical remote code execution (RCE) vulnerability today. Six browser vulnerabilities were published separately this month, and are not included in the total.
The first of today’s zero-day vulnerabilities is CVE-2024-30051, an elevation of privilege (EoP) vulnerability in the Windows Desktop Windows Manager (DWM) Core Library which is listed on the CISA KEV list. Successful exploitation grants SYSTEM privileges. First introduced as part of Windows Vista, DWM is responsible for drawing everything on the display of a Windows system.
Reporters Securelist have linked exploitation of CVE-2024-30051 with deployment of QakBot malware, and the vulnerability while investigating a partial proof-of-concept contained within an unusual file originally submitted to VirusTotal by an unknown party. Securelist further notes that the exploitation method for CVE-2024-30051 is identical to a previous DWM zero-day vulnerability CVE-2023-36033, which Microsoft patched back in November 2023.
Courtesy of Microsoft’s recent enhancement of their security advisories to include Common Weakness Enumeration (CWE) data, the mechanism of exploitation is listed as CVE-122: Heap-based Buffer Overflow, which is just the sort of defect which recent US federal government calls for memory safe software development are designed to address.
The Windows MSHTML platform receives a patch for CVE-2024-30040, a security feature bypass vulnerability for which Microsoft has evidence of exploitation in the wild, and which CISA has also listed on KEV.
The advisory states that an attacker would have to convince a user to open a malicious file; successful exploitation bypasses COM/OLE protections in Microsoft 365 and Microsoft Office to achieve code execution in the context of the user.
As Rapid7 has previously noted, MSHTML (also known as Trident) is still fully present in Windows — and unpatched assets are thus vulnerable to CVE-2024-30040 — regardless of whether or not a Windows asset has Internet Explorer 11 fully disabled.
Rounding out today’s trio of zero-day vulnerabilities: a denial of service (DoS) vulnerability in Visual Studio.
Microsoft describes CVE-2024-30046 as requiring a highly complex attack to win a race condition through “[the investment of] time in repeated exploitation attempts through sending constant or intermittent data”. Since all data sent anywhere is transmitted either constantly or intermittently, and the rest of the advisory is short on detail, the potential impact of exploitation remains unclear.
Only Visual Studio 2022 receives an update, so older supported versions of Visual Studio are presumably unaffected.
SharePoint admins are no strangers to patches for critical RCE vulnerabilities. CVE-2024-30044 allows an authenticated attacker with Site Owner permissions or higher to achieve code execution in the context of SharePoint Server via upload of a specially crafted file, followed by specific API calls to trigger deserialization of the file’s parameters.
Microsoft considers exploitation of CVE-2024-30044 more likely, and the low attack complexity and network attack contribute to a relatively high CVSS 3.1 base score of 8.8. The advisory also lists the privileges required vector component as low, which is debatable given the Site Owner authentication requirement for exploitation.
Microsoft has previously published an accessible introduction to deserialization vulnerabilities and the risks of assuming data to be trustworthy, aimed at .NET developers.
Microsoft Excel receives a patch for CVE-2024-30042. Successful exploitation requires that an attacker convince the user to open a malicious file, which leads to code execution, presumably in the context of the user.
Also of interest today: Microsoft is releasing updated patches for three Windows Remote Access Connection Manager information disclosure vulnerabilities originally published in April 2024: CVE-2024-26207, CVE-2024-26217, and CVE-2024-28902. Microsoft states that an unspecified regression introduced by the April patches is resolved by installation of the May patches.
The Windows Mobile Broadband driver receives patches for no fewer than 11 vulnerabilities; for example, CVE-2024-29997. All 11 vulnerabilities appear very similar based on the advisories. In each case, the relatively low CVSS base score of 6.8 reflects that an attacker must be physically present and insert a malicious USB device into the target host.
Back in 2021, Microsoft started publishing the Assigning CNA (CVE Numbering Authority) field on advisories. A welcome trend of publishing advisories for third-party software included in Microsoft products continues this month with two vulnerabilities in MinGit patched as part of the May 2024 Windows security updates. MinGit is published by GitHub and consumed by Visual Studio. CVE-2024-32002 describes a RCE vulnerability on case-insensitive filesystems that support symlinks — macOS APFS comes to mind — and CVE-2024-32004 describes RCE while cloning specially-crafted local repositories.
There are no significant changes to the lifecycle phase of Microsoft products this month.
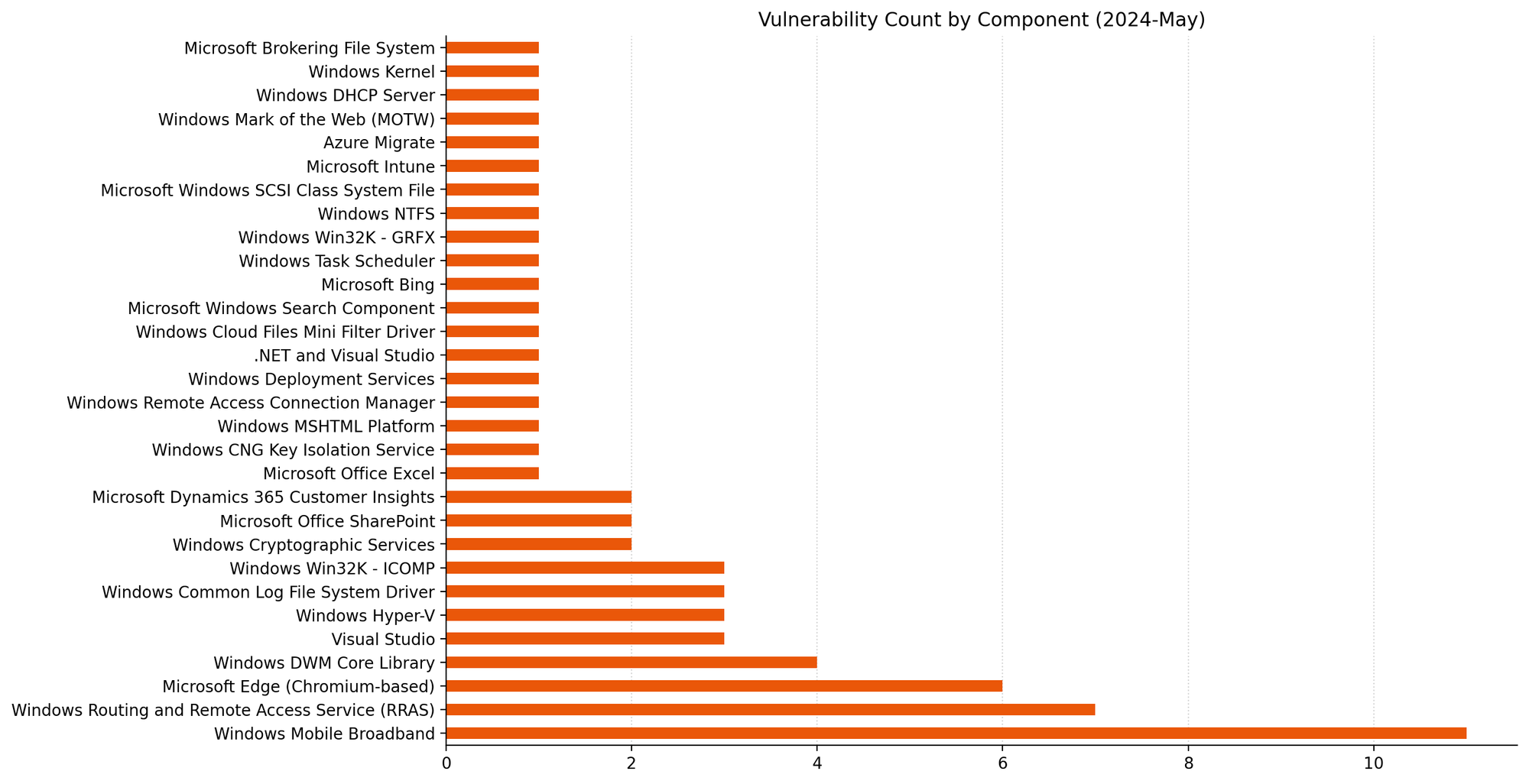
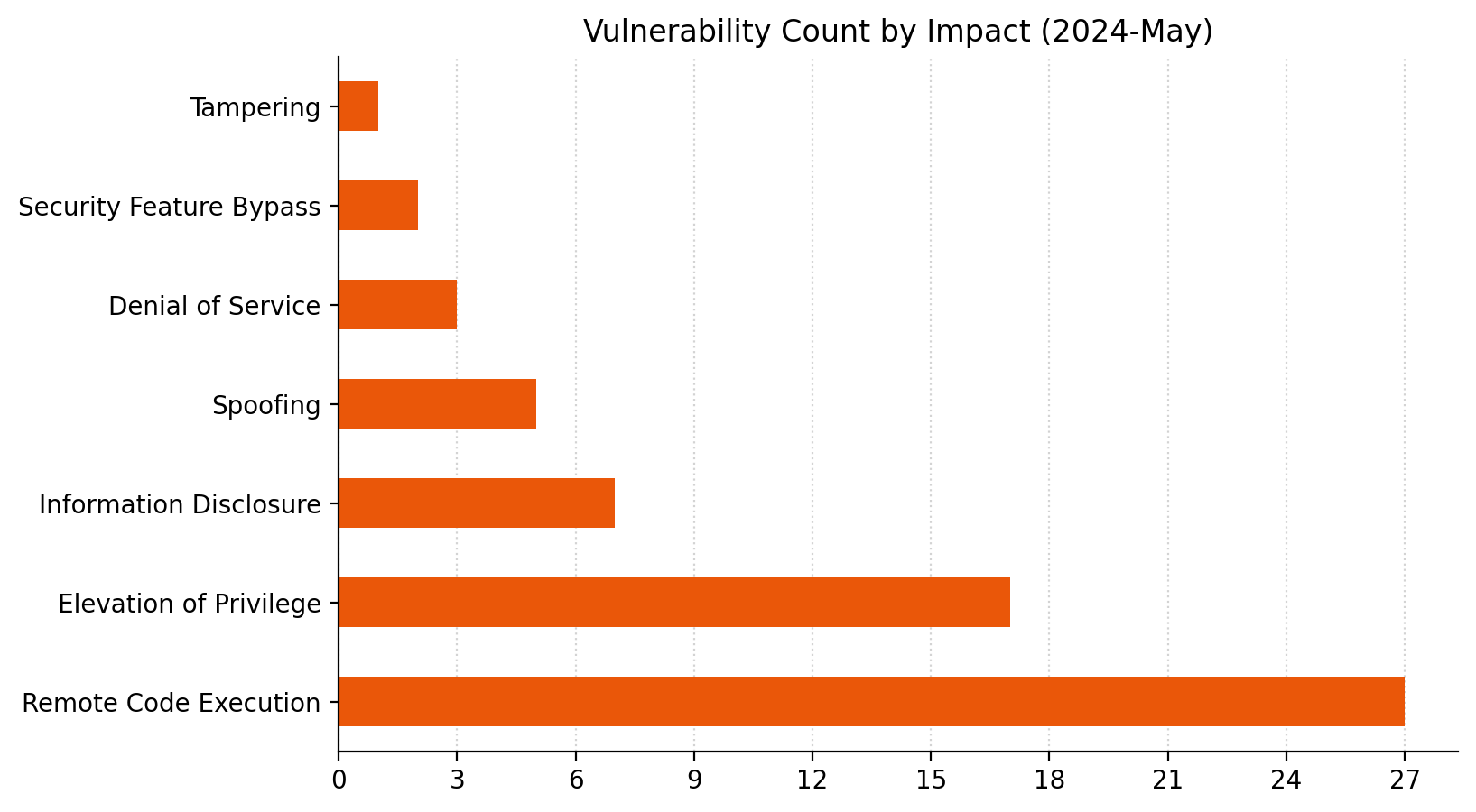
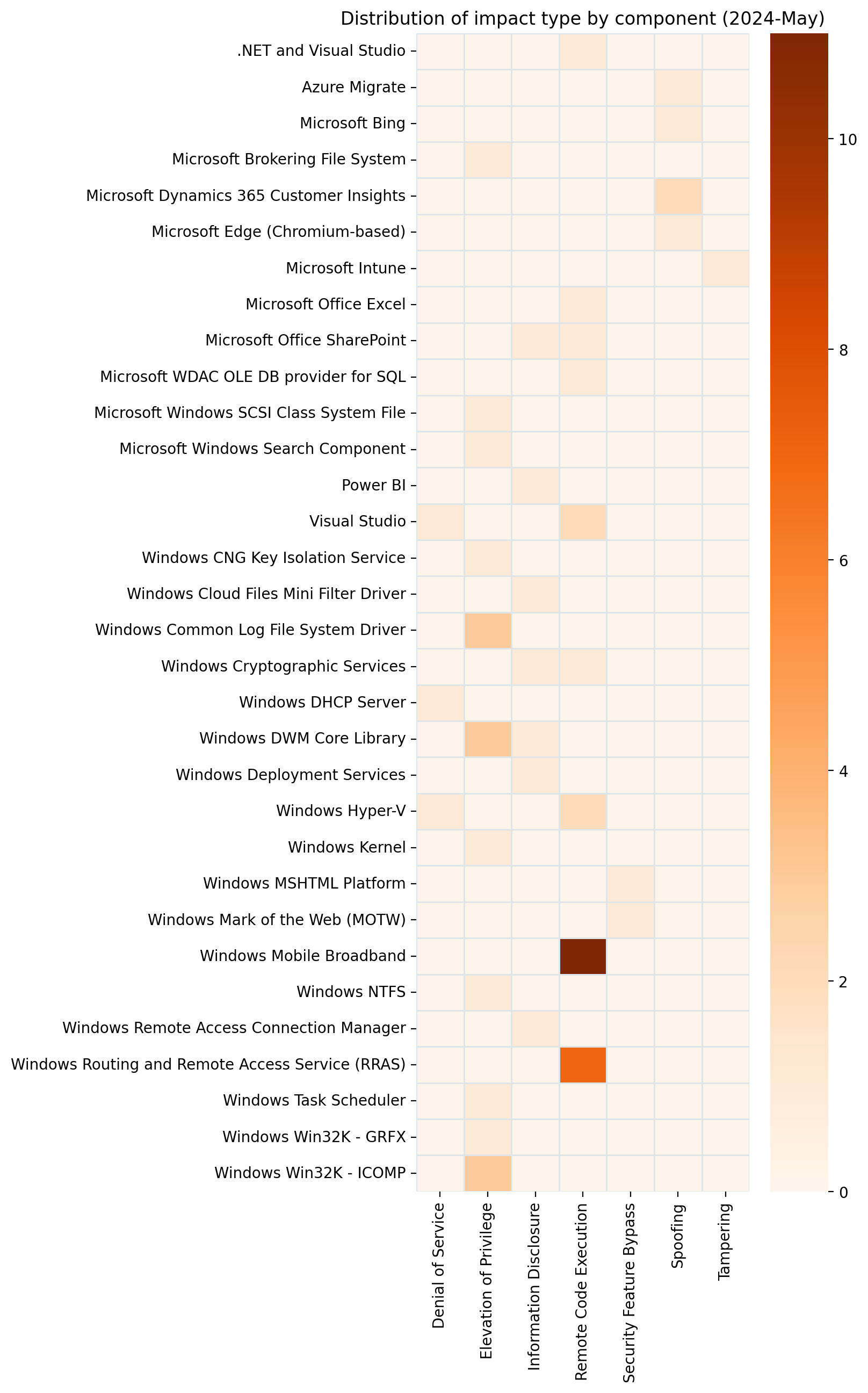
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30059 | Microsoft Intune for Android Mobile Application Management Tampering Vulnerability | No | No | 6.1 |
| CVE-2024-30041 | Microsoft Bing Search Spoofing Vulnerability | No | No | 5.4 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30053 | Azure Migrate Cross-Site Scripting Vulnerability | No | No | 6.5 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30055 | Microsoft Edge (Chromium-based) Spoofing Vulnerability | No | No | 5.4 |
| CVE-2024-4671 | Chromium: CVE-2024-4671 Use after free in Visuals | No | No | N/A |
| CVE-2024-4559 | Chromium: CVE-2024-4559 Heap buffer overflow in WebAudio | No | No | N/A |
| CVE-2024-4558 | Chromium: CVE-2024-4558 Use after free in ANGLE | No | No | N/A |
| CVE-2024-4368 | Chromium: CVE-2024-4368 Use after free in Dawn | No | No | N/A |
| CVE-2024-4331 | Chromium: CVE-2024-4331 Use after free in Picture In Picture | No | No | N/A |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-32002 | CVE-2024-32002 Recursive clones on case-insensitive filesystems that support symlinks are susceptible to Remote Code Execution | No | No | 9 |
| CVE-2024-32004 | GitHub: CVE-2024-32004 Remote Code Execution while cloning special-crafted local repositories | No | No | 8.1 |
| CVE-2024-30045 | .NET and Visual Studio Remote Code Execution Vulnerability | No | No | 6.3 |
| CVE-2024-30046 | Visual Studio Denial of Service Vulnerability | No | Yes | 5.9 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30030 | Win32k Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30009 | Windows Routing and Remote Access Service (RRAS) Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2024-30010 | Windows Hyper-V Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2024-30006 | Microsoft WDAC OLE DB provider for SQL Server Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2024-30020 | Windows Cryptographic Services Remote Code Execution Vulnerability | No | No | 8.1 |
| CVE-2024-30049 | Windows Win32 Kernel Subsystem Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-29996 | Windows Common Log File System Driver Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30025 | Windows Common Log File System Driver Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30031 | Windows CNG Key Isolation Service Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30028 | Win32k Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30038 | Win32k Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30027 | NTFS Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30014 | Windows Routing and Remote Access Service (RRAS) Remote Code Execution Vulnerability | No | No | 7.5 |
| CVE-2024-30015 | Windows Routing and Remote Access Service (RRAS) Remote Code Execution Vulnerability | No | No | 7.5 |
| CVE-2024-30022 | Windows Routing and Remote Access Service (RRAS) Remote Code Execution Vulnerability | No | No | 7.5 |
| CVE-2024-30023 | Windows Routing and Remote Access Service (RRAS) Remote Code Execution Vulnerability | No | No | 7.5 |
| CVE-2024-30024 | Windows Routing and Remote Access Service (RRAS) Remote Code Execution Vulnerability | No | No | 7.5 |
| CVE-2024-30029 | Windows Routing and Remote Access Service (RRAS) Remote Code Execution Vulnerability | No | No | 7.5 |
| CVE-2024-30037 | Windows Common Log File System Driver Elevation of Privilege Vulnerability | No | No | 7.5 |
| CVE-2024-30011 | Windows Hyper-V Denial of Service Vulnerability | No | No | 6.5 |
| CVE-2024-30036 | Windows Deployment Services Information Disclosure Vulnerability | No | No | 6.5 |
| CVE-2024-30019 | DHCP Server Service Denial of Service Vulnerability | No | No | 6.5 |
| CVE-2024-30039 | Windows Remote Access Connection Manager Information Disclosure Vulnerability | No | No | 5.5 |
| CVE-2024-30016 | Windows Cryptographic Services Information Disclosure Vulnerability | No | No | 5.5 |
| CVE-2024-30050 | Windows Mark of the Web Security Feature Bypass Vulnerability | No | No | 5.4 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30047 | Dynamics 365 Customer Insights Spoofing Vulnerability | No | No | 7.6 |
| CVE-2024-30048 | Dynamics 365 Customer Insights Spoofing Vulnerability | No | No | 7.6 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30044 | Microsoft SharePoint Server Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2024-30042 | Microsoft Excel Remote Code Execution Vulnerability | No | No | 7.8 |
| CVE-2024-30043 | Microsoft SharePoint Server Information Disclosure Vulnerability | No | No | 6.5 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30054 | Microsoft Power BI Client JavaScript SDK Information Disclosure Vulnerability | No | No | 6.5 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30040 | Windows MSHTML Platform Security Feature Bypass Vulnerability | Yes | No | 8.8 |
| CVE-2024-30017 | Windows Hyper-V Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2024-30007 | Microsoft Brokering File System Elevation of Privilege Vulnerability | No | No | 8.8 |
| CVE-2024-30018 | Windows Kernel Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30051 | Windows DWM Core Library Elevation of Privilege Vulnerability | Yes | Yes | 7.8 |
| CVE-2024-30032 | Windows DWM Core Library Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30035 | Windows DWM Core Library Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-29994 | Microsoft Windows SCSI Class System File Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-26238 | Microsoft PLUGScheduler Scheduled Task Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30033 | Windows Search Service Elevation of Privilege Vulnerability | No | No | 7 |
| CVE-2024-29997 | Windows Mobile Broadband Driver Remote Code Execution Vulnerability | No | No | 6.8 |
| CVE-2024-29998 | Windows Mobile Broadband Driver Remote Code Execution Vulnerability | No | No | 6.8 |
| CVE-2024-29999 | Windows Mobile Broadband Driver Remote Code Execution Vulnerability | No | No | 6.8 |
| CVE-2024-30000 | Windows Mobile Broadband Driver Remote Code Execution Vulnerability | No | No | 6.8 |
| CVE-2024-30001 | Windows Mobile Broadband Driver Remote Code Execution Vulnerability | No | No | 6.8 |
| CVE-2024-30002 | Windows Mobile Broadband Driver Remote Code Execution Vulnerability | No | No | 6.8 |
| CVE-2024-30003 | Windows Mobile Broadband Driver Remote Code Execution Vulnerability | No | No | 6.8 |
| CVE-2024-30004 | Windows Mobile Broadband Driver Remote Code Execution Vulnerability | No | No | 6.8 |
| CVE-2024-30005 | Windows Mobile Broadband Driver Remote Code Execution Vulnerability | No | No | 6.8 |
| CVE-2024-30012 | Windows Mobile Broadband Driver Remote Code Execution Vulnerability | No | No | 6.8 |
| CVE-2024-30021 | Windows Mobile Broadband Driver Remote Code Execution Vulnerability | No | No | 6.8 |
| CVE-2024-30008 | Windows DWM Core Library Information Disclosure Vulnerability | No | No | 5.5 |
| CVE-2024-30034 | Windows Cloud Files Mini Filter Driver Information Disclosure Vulnerability | No | No | 5.5 |
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/intel-ponte-vecchio-spaceship-gpu-no-longer-hunting-new-clusters/
Intel’s spaceship GPU, Ponte Vecchio, was perhaps too far ahead of its time and the GPU is moving into a support phase ahead of Falcon Shores
The post Intel Ponte Vecchio Spaceship GPU No Longer Hunting New Clusters appeared first on ServeTheHome.
Post Syndicated from Mikayla Wyman original https://blog.rapid7.com/2024/05/14/5-key-mdr-differentiators-to-look-for-to-build-stronger-security-resilience/

Organizations looking to address the skills gap and bring greater efficiency as their business grows and their attack surface sprawls are turning to MDR providers at an accelerated pace. We’ve seen predictions from top analyst firms signaling the rapid rate of adoption of an MDR provider by 2025.
This isn’t just a shift to more organizations using MDR providers — teams are asking their MDRs to do more. More scope, more response, and more coaching along the way.
But with added complexity, identifying the right MDR provider can be harder than ever. In this blog, we’ll explore the top service trends of the most effective MDR providers in the space, and what you should look for to bring increased value to your SOC.
No one knows your environment, your employees, and your business practices like you do. MDR providers who promote a hands-off service delivery are leaving a lot of critical components on the table.
An effective MDR provider should work as an extension of your team, with a unique understanding of your specific environment and who feel accountable for your security outcomes.
One size fits all isn’t an approach that’s scalable over time. A security team that will help you grow, will customize your service, and help guide you to your organization’s specific goals is an essential choice.
The goal of any good MDR is to keep organizations safe from a breach. But breaches are so frequent and ominous, they’re now referred to as inevitable. So what happens when the worst happens, and there’s an active breach in your environment?
Many MDR providers in the space will say it’s time to call in an IR Consulting firm (or pay for theirs) to take over the investigation and breach response. Anyone else hearing the unwelcome chime of a 90s cash register?
The “R” in MDR is important. How will a provider actually respond if there is an active breach? Will they ask for more money to continue their investigation as breach response? Will they pawn you off to someone else? Or will they continue to investigate, providing deep forensic analysis to eradicate the attacker and mitigate data loss or stop ransomware as part of your existing service? We know what we’d choose.
Many MDR providers are built on top of technology. Some monitor the technology you bring to them, while others use a 3rd party tooling set that isn’t accessible to the end user.
When it comes to your organization’s security posture, accessing the technology isn’t just a nice to have. Having transparency into your MDRs operations, and the ability to truly use the tech — building reports, searching logs, customization, and the ability to perform investigations — is an incredibly valuable feature.
Partners who use this model not only bring visibility and access to their customers, they allow their customers to grow their program with their service. Sure, you should be catching attacker behavior in your environment, but the partners who can help build resilience over time, and give access to the technology that they can take over should they want to build their program in-house, becomes another long-term asset.
Knowing where your organization is vulnerable is imperative to keeping it secure. The more proactive you can be, the less you’ll have to respond to, shrinking your attack surface and keeping your team ready to react to the most critical attacker signals.
Including exposure management, by way of vulnerability risk management (VRM) or similar tool sets, provides your team the ability to harden defenses and identify the attacker signals early to prevent a breach before it can execute.
MDR that’s able to strengthen your security posture by staying ahead of emerging threats is going to be the most effective at helping to build your security resilience through its service delivery.
MDR providers who deliver expertise in a multitude of security areas will always be a value driver. All provide D&R capabilities and some provide D&R technology. Others include these components alongside technology and capabilities that traditionally lie outside of the D&R space.
It’s important to evaluate MDRs on the primary use cases they’re able to address within your specific environment. Do you need the ability to automate across security tools and functions? It’d be great if they could include a SOAR solution. Do you want to understand your vulnerability and risk posture across your environment and better arm your D&R program? Having a VRM program as a component of their MDR service becomes a differentiator. Do you want to have the ability to perform forensic hunts and investigations from within the platform? Including a DFIR toolset would tick the box.
When a provider can deliver across your organization’s needs with a connected solution layered with high caliber expertise, the value extends beyond the traditional scope of an MDR solution.
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=9pLWPUss1To
Post Syndicated from jzb original https://lwn.net/Articles/973686/
Version 24.0
of the Arch-based Manjaro distribution is now available with
the 6.9 kernel, GNOME 46, Xfce 4.18, and an update to the
Pamac package
installer. This is also the project’s first release with KDE Plasma 6:
The Plasma edition comes with the latest Plasma 6.0 series and KDE
Gear 24.02. It brings exciting new improvements to your desktop.With Plasma 6, KDE’s technology stack has undergone major upgrades:
a transition to the latest version of application framework, Qt, and
an improved graphics platform when Wayland is used. These changes are
as smooth and unnoticeable to the users as possible. You will see the
same familiar desktop environment that you know and love. But these
under-the-hood upgrades benefit Plasma’s security, efficiency, and
performance, and improve support for modern hardware. Thus Plasma
delivers an overall more reliable user experience, while paving the
way for many more improvements in the future.
The project also offers minimal install images with the 6.6 LTS
and 6.1 LTS kernels to support older hardware.
Post Syndicated from Matheus Guimaraes original https://aws.amazon.com/blogs/aws/new-compute-optimized-c7i-flex-amazon-ec2-flex-instances/
The vast majority of applications don’t run run the CPU flat-out at 100% utilization continuously. Take a web application, for instance. It typically fluctuates between periods of high and low demand, but hardly ever uses a server’s compute at full capacity.

CPU utilization for many common workloads that customers run in the AWS Cloud today. (source: AWS Documentation)
One easy and cost-effective way to run such workloads is to use the Amazon EC2 M7i-flex instances which we introduced last August. These are lower-priced variants of the Amazon EC2 M7i instances offering the same next-generation specs for general purpose compute for the most popular sizes with the added benefit of giving you better price/performance if you don’t need full compute power 100 percent of the time. This makes them a great first choice if you are looking to reduce your running cost while meeting the same performance benchmarks.
This flexibility resonated really well with customers so, today, we are expanding our Flex portfolio by launching Amazon EC2 C7i-flex instances offering similar benefits of price/performance and lower costs for compute-intensive workloads. These are lower-priced variants of the Amazon EC2 C7i instances that offer a baseline level of CPU performance with the ability to scale up to the full compute performance 95% of the time.
C7i-flex instances
C7i-flex offers five of the most common sizes from large to 8xlarge, delivering 19 percent better price performance than Amazon EC2 C6i instances.
| Instance name | vCPU | Memory (GiB) | Instance storage (GB) | Network bandwidth (Gbps) | EBS bandwidth (Gbps) |
|---|---|---|---|---|---|
| c7i-flex.large | 2 | 4 | EBS-only | up to 12.5 | up to 10 |
| c7i-flex.xlarge | 4 | 8 | EBS-only | up to 12.5 | up to 10 |
| c7i-flex.2xlarge | 8 | 16 | EBS-only | up to 12.5 | up to 10 |
| c7i-flex.4xlarge | 16 | 32 | EBS-only | up to 12.5 | up to 10 |
| c7i-flex.8xlarge | 32 | 64 | EBS-only | up to 12.5 | up to 10 |
Should I use C7i-flex or C7i?
Both C7i-flex and C7i are compute-optmized instances powered by custom 4th Generation Intel Xeon Scalable processors which are only available at Amazon Web Services (AWS). They offer up to 15 percent better performance over comparable x86-based Intel processors used by other cloud providers.
They both also use DDR5 memory, feature a 2:1 ratio of memory to vCPU, and are ideal for running applications such as web and application servers, databases, caches, Apache Kafka, and Elasticsearch.
So why would you use one over the other? Here are three things to consider when deciding which one is right for you.
Usage pattern
EC2 flex instances are a great fit for when you don’t need to fully utilize all compute resources.
You can achieve 5 percent better price performance and 5 percent lower prices due to efficient use of compute resources. Typically, this is a great fit for most applications, so C7i-flex instances should be the first choice for compute-intensive workloads.
However, if your application requires continuous high CPU usage, then you should use C7i instances instead. They are likely more suitable for workloads such as batch processing, distributed analytics, high performance computing (HPC), ad serving, highly scalable multiplayer gaming, and video encoding.
Instance sizes
C7i-flex instances offer the most common sizes used by a majority of workloads going up to a maximum of 8xlarge in size.
If you need higher specs, then you should look into the large C7i instances, which include 12xlarge, 16xlarge, 24xlarge, 48xlarge and two bare metal options with metal-24xl and metal-48xl sizes.
Network bandwidth
Larger sizes also offer higher network and Amazon Elastic Block Store (Amazon EBS) bandwidths so you may need to use one of the larger C7i instances depending on your requirements. C7i-flex instances offer up to 12.5 Gbps of network bandwidth and up to 10 Gbps of Amazon Elastic Block Store (Amazon EBS) bandwidth which should be suitable for most applications.
Things to know
Regions – Visit AWS Services by Region to check whether C7i-flex instances are available in your preferred regions.
Purchasing options – C7i-Flex and C7i instances are available in On-Demand, Savings Plan, Reserved Instance, and Spot form. C7i instances are also available in Dedicated Host and Dedicated Instance form.
To learn more visit Amazon EC2 C7i and C7i-flex instances
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=Er_pB4xj6CU
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/05/upcoming-speaking-engagements-36.html
This is a current list of where and when I am scheduled to speak:
The list is maintained on this page.
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=vBphWggSE-E
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=yzR60maM_co
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=ize6nF4fOL8
Post Syndicated from daroc original https://lwn.net/Articles/971195/
Large language models (LLMs) have been the subject of much discussion and
scrutiny recently. Of particular interest to open-source enthusiasts are the
problems with running LLMs on one’s own hardware — especially when doing so
requires NVIDIA’s proprietary CUDA toolkit, which remains unavailable in many
environments.
Mozilla has developed
llamafile as a
potential solution to these problems. Llamafile can compile LLM weights
into portable, native executables for easy integration, archival, or
distribution. These executables can take advantage of supported GPUs when
present, but do not require them.
Post Syndicated from Anandprasanna Gaitonde original https://aws.amazon.com/blogs/security/governing-and-securing-aws-privatelink-service-access-at-scale-in-multi-account-environments/
Amazon Web Services (AWS) customers have been adopting the approach of using AWS PrivateLink to have secure communication to AWS services, their own internal services, and third-party services in the AWS Cloud. As these environments scale, the number of PrivateLink connections outbound to external services and inbound to internal services increase and are spread out across multiple accounts in virtual private clouds (VPCs). While AWS Identity and Access Management (IAM) policies allow you to control access to individual PrivateLink services, customers want centralized governance for the use of PrivateLink in adherence with organizational standards and security needs.
This post provides an approach for centralized governance for PrivateLink based services across your multi-account environment. It provides a way to create preventative controls through the use of service control policies (SCPs) and detective controls through event-driven automation. This allows your application teams to consume internal and external services while adhering to organization policies and provides a mechanism for centralized control as your AWS environment grows.
Figure 1 shows an example customer environment comprising a multi-account structure created through AWS Organizations or using AWS Control Tower. There are separate organizational units (OUs) pertaining to different business units (BUs) with respective accounts. The business services’ account hosts several backend services that are utilized by consuming applications for their functionality. Since these services provide functionality to more than one internal application and will require access across VPC and account boundaries, these are exposed through AWS PrivateLink. One such service is shown in the business services account.
The customer has partners that provide services for integration with the customer’s application stack. The approved partner account provides a service that is approved for use by the cloud administration team. The NotApproved partner account provides services that are not approved within the customer’s organization. The customer has another OU dedicated to application teams. The application 1 account has an application that consumes the business service of the approved partner account. It is also planning to use the service from the NotApproved partner, which should be blocked. The application in the application 2 account is planning on using AWS services through interface endpoints as well as the approved partner account through PrivateLink integration.
Note: Throughout this post, “organization” is used to refer to an organization that you create and manage through AWS Organizations.

Figure 1: A multi-account customer environment
Access to individual PrivateLink connections can be controlled through IAM policies. At scale, however, different teams use and adopt PrivateLink for incoming and outgoing connections, and the number of VPC endpoint policies to create and manage increases. As mentioned in the problem statement presented in the introduction, as the customer environment scales and the number of PrivateLink connections increases, customers want centralized guardrails to manage PrivateLink resources at scale. For our example, the customer would like to put the following controls in place:
Use case 1:
Use case 2:
Use case 3:
Use case 4:
This post presents a solution that uses SCPs, AWS CloudTrail, and AWS Config to achieve governance. When the solution is deployed in your account, the following components are created as part of the architecture, as shown in Figure 2.

Figure 2: Resources deployed in the customer environment by the solution
The following architecture is now in place:
This section walks through each use case and how the solution components are used to address each use case.
Use case 1: Allowing the creation of a VPC endpoint connection to only AWS services and approved internal and third-party PrivateLink services
This solution allows creating a VPC endpoint for only approved partner PrivateLink services, PrivateLink services internal to the organization, and AWS services. This is implemented using an SCP and can be enforced at the individual account or OU. The approved partner services as well as the internal accounts that can host allowed PrivateLink services can be specified during the solution deployment. Application teams operating in AWS accounts within the customer environment can then create VPC endpoints to PrivateLink services of approved partners or AWS services. However, they will not be able to create a VPC endpoint to an unapproved PrivateLink service, for example. This is shown in Figure 3.

Figure 3: Allowed and disallowed paths in PrivateLink connections by SCP
The SCP that allows you to do this preventative control is shown in the following code snippet. In this example SCP policy, AllowedPrivateLinkPartnerService-ServiceName refers to the service name of the allowed partner PrivateLink. Also, the SCP allows the creation of VPC endpoints to internal PrivateLink services that are hosted in AllowedPrivateLinkAccount. Make sure that this SCP does not interfere with the other policies you created within your organization. The solution currently uses ec2:VpceServiceName and ec2:VpceServiceOwner conditions to identify the PrivateLink service of AWS services or a third-party partner. These conditions can be used in an SCP to control the creation of VPC endpoints:
Use case 2: Allow only a cloud admin role to add permissions to connect to an endpoint service
This solution makes sure that PrivateLink services that are owned and created in AWS accounts of the customer cannot be connected to consumers unless it is allowed by the cloud administrator role. The cloud administrator can then make sure that only legitimate internal AWS accounts are allowed access to that service and restrict access from other accounts outside of the customer’s organization. This is achieved through the use of a service control policy that will restrict modifications of permissions of the PrivateLink endpoint service. This makes sure that individual teams are not able to use the Allow principals configuration to open access to other entities directly, and only a cloud administrator role with the right permissions can make that change.
This policy can help in achieving the access control, as shown in Figure 4. The cloud administrator uses the Allow principals configuration of the business services PrivateLink service to provide access only to the application 1 account. The SCP allows only the cloud administrator to make the modification and does not allow another member of the team from bypassing that process and adding a nonapproved client application account to access the internal PrivateLink service.

Figure 4: Centralized control on access to the internal PrivateLink service to the customer’s own accounts
For detective controls, we discuss two use cases that are deployed as part of the solution and can be enabled and disabled based on the test that you want to perform.
Use case 3: Detecting if connections are made by external AWS accounts (not belonging to the customer’s organization) to PrivateLink services exposed by the customer’s AWS accounts
In this use case, the customer would like to detect if connections are made to their business services from accounts outside of its organization. The solution uses individual member account trails for capturing API calls across the multi-account structure and cross-account EventBridge integration. CloudTrail events from member accounts capture events when a PrivateLink service connection is accepted through the API call event AcceptVPCConnectionEndpoint and sent to the event bus in the audit account. This triggers a Lambda function that then captures the information of the entity requesting the connection and details of the PrivateLink service and sends a notification to the cloud administrator. This is shown in Figure 5.

Figure 5: Detecting the creation of a VPC endpoint or accepting a PrivateLink service connection using CloudTrail events in EventBridge
This detective control mechanism works in cases where PrivateLink services are configured to manually accept client connections. If the endpoint is configured to automatically accept connections, CloudTrail will not generate an event when a connection is accepted. AWS PrivateLink allows customers to configure connection notifications to send connection notification events to an Amazon Simple Notification Service (Amazon SNS) topic. Cloud administrators can get the notifications if they are subscribed to the SNS topic. However, if the notification configuration is removed by the member account, there is no way for the cloud administrator to have visibility for new connections and effectively apply governance requirements.
This solution employs an AWS Config rule to detect if PrivateLink services are created with the Auto Accept Connections setting enabled or without a connection notification configuration and flag it as noncompliant.
This is depicted in Figure 6.

Figure 6: Custom AWS Config rule and SNS notification deployed as part of the solution
When a PrivateLink service is created by one of the business services teams, an AWS Config organization rule in the audit account will detect the event, and the custom Lambda function will check if the connection notification configuration is present. If not, then the AWS Config rule will flag the resource as noncompliant. Cloud administrators can view these in the AWS Config dashboard or receive notifications configured through AWS Config.
Use case 4: Detecting if connections are made to PrivateLink services exposed by AWS accounts not belonging to the customer’s organization.
Using the same approach as presented in use case 3, connections made to PrivateLink services exposed by AWS accounts outside of the customer’s organization can be detected through the API call event from CloudTrail CreateVPCEndpoint. This event is sent to the centralized event bus and the Lambda function to check against the criteria and provide notifications to the cloud administrator.
This section walks through how to deploy and test our recommended solution.
To deploy the solution, first follow these steps.

Figure 7: Simulated partner services (approved and not approved) in a separate test account
![]()
CloudFormation stacks can be deployed using the AWS CloudFormation console or using the AWS CLI.
| AWSOrganizationsId | Identifier for your organization. This can be obtained from your management account as described in the AWS Organizations User Guide. |
| AdminRoleArn | Role of the persona who is allowed to modify PrivateLink endpoint permissions. |
| AllowedPrivateLinkAccounts | AWS account IDs of accounts in your OU that host PrivateLink services. |
| AllowedPrivateLinkPartnerServices | Specify the service name of the approved PrivateLink services from partners. If you want to test with a simulated partner PrivateLink, take the service name of PrivateLink services created in Step 4 of the prerequisites as the partner services to which connections should be allowed. The unique service name of the partner’s PrivateLink service is provided by the partner to the customer so that they can connect to it. |
| AuditAccountId | AWS account ID of the audit account in your multi-account environment. |
| PLOrganizationUnit | OU identifier for the organizational unit where the solution will perform preventative and detective control. |

Figure 8: CloudFormation template input parameters for the solution as it appears on the console
Once the solution is deployed successfully, follow these steps to test the solution:
You can delete the solution by following these steps to avoid unnecessary charges:
As customers adopt AWS PrivateLink throughout their environment, the mechanisms discussed in this post provide a way for administrators to govern and secure their PrivateLink services at scale. This approach can help you create a scalable solution where interconnections are aligned to the organization’s guidelines and security requirements. While this solution presents an approach to governance, customers can tailor this solution to their unique organizational requirements.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Post Syndicated from jzb original https://lwn.net/Articles/973667/
Security updates have been issued by Debian (glib2.0 and shim), Fedora (glib2, gnome-shell, tcpdump, tpm2-tools, tpm2-tss, and uriparser), Mageia (mutt), Oracle (git-lfs, glibc, kernel, kernel-container, nodejs:18, nodejs:20, and pcp), SUSE (apache2, opensc, openssl-1_1, openssl-3, perl, python-Pillow, python-pyOpenSSL, python-Werkzeug, SUSE Manager Client Tools Beta, tpm2-0-tss, and tpm2.0-tools), and Ubuntu (sqlparse and strongswan).
Post Syndicated from Brian Batraski original https://blog.cloudflare.com/cloudflares-public-ipfs-gateways-and-supporting-interplanetary-shipyard

IPFS, the distributed file system and content addressing protocol, has been around since 2015, and Cloudflare has been a user and operator since 2018, when we began operating a public IPFS gateway. Today, we are announcing our plan to transition this gateway traffic to the Interplanetary Shipyard (“Shipyard”) team and discussing what it means for users and the future of IPFS gateways.
As announced in April 2024, many of the IPFS core developers and maintainers now work within a newly created, independent entity called Interplanetary Shipyard (“Shipyard”). For IPFS to continue exemplifying the open-source ethos, its core developers will work for Shipyard, rather than Protocol Labs, where IPFS was invented and incubated. By operating as a collective, ongoing maintenance and support of important protocols like IPFS are now even more community-owned and managed. We fully support this “exit to community” and are excited to see Shipyard build more great infrastructure for the open web.
On May 14th, 2024, we will begin to transition traffic that comes to Cloudflare’s public IPFS gateway to Shipyard’s IPFS gateway at ipfs.io or dweb.link. Cloudflare’s public IPFS gateway is just one of many – part of a distributed ecosystem that also includes Pinata, eth.limo, and many more. Visit the IPFS Public Gateway Checker to see the other publicly available IPFS gateways.
Cloudflare believes in helping build a better Internet for all and an accessible and private Internet, principles that Protocol Labs, IPFS, and Shipyard all share. We believe the IPFS gateway transition to Shipyard will boost ecosystem collaboration, increase protocol resiliency, and ensure healthy stewardship and governance. Cloudflare is proud to be a partner of Shipyard in this transition and will continue to help sponsor their work as gateway stewards.
All traffic using the cloudflare-ipfs.com or cf-ipfs.com hostname(s) will continue to work without interruption and be redirected to ipfs.io or dweb.link until August 14th, 2024, at which time the Cloudflare hostnames will no longer connect to IPFS and all users must switch the hostname they use to ipfs.io or dweb.link to ensure no service interruption takes place. If you are using either of the Cloudflare hostnames, please be sure to switch to one of the new ones as soon as possible ahead of the transition date to avoid any service interruptions!
It is important to both Cloudflare and Shipyard that this transition is completed seamlessly and with as little impact to users as possible. With that in mind, there is no change to the amount or type of end user information that is visible to either Cloudflare or Shipyard before or after the completion of this transition.
We’re excited to see further development and projects from the IPFS community and play our part in helping those applications be secure, performant, and reliable!
—
Interplanetary Shipyard is an engineering collective that delivers user agency through technical advancements in IPFS and libp2p. As the core maintainers of open source projects in the Interplanetary Stack (including IPFS and libp2p implementations such as Kubo, Rainbow, Boxo, Helia, and go/js-libp2p/js-libp2p), and supporting performance measurement tooling (Probelab), they are committed to open source innovation and building bridges between traditional web frameworks and the decentralized ecosystem. To achieve this, their engineers work alongside technical teams in web2 and web3 to promote adoption and drive practical applications.
Post Syndicated from Colin Douch original https://blog.cloudflare.com/reclaiming-cpu-for-free-with-pgo

Golang 1.20 introduced support for Profile Guided Optimization (PGO) to the go compiler. This allows guiding the compiler to introduce optimizations based on the real world behaviour of your system. In the Observability Team at Cloudflare, we maintain a few Go-based services that use thousands of cores worldwide, so even the 2-7% savings advertised would drastically reduce our CPU footprint, effectively for free. This would reduce the CPU usage for our internal services, freeing up those resources to serve customer requests, providing measurable improvements to our customer experience. In this post, I will cover the process we created for experimenting with PGO – collecting representative profiles across our production infrastructure and then deploying new PGO binaries and measuring the CPU savings.
PGO itself is not a Go-specific tool, although it is relatively new. PGO allows you to take CPU profiles from a program running in production and use that to optimise the generated assembly for that program. This includes a bunch of different optimisations such as inlining heavily used functions more aggressively, reworking branch prediction to favour the more common branches, and rearranging the generated code to lump hot paths together to save on CPU cache swapping.
The general flow for using PGO is to compile a non-PGO binary and deploy it to production, collect CPU profiles from the binary in production, and then compile a second binary using that CPU profile. CPU Profiles contain samples of what the CPU was spending the most time on when executing a program, which provides valuable context to the compiler when it’s making decisions about optimising a program. For example, the compiler may choose to inline a function that is called many times to reduce the function call overhead, or it might choose to unroll a particularly jump-heavy loop. Crucially, using a profile from production can guide the compiler much more efficiently than any upfront heuristics.
In the Observability team, we operate a system we call “wshim”. Wshim is a service that runs on every one of our edge servers, providing a push gateway for telemetry sourced from our internal Cloudflare Workers. Because this service runs on every server, and is called every time an internal worker is called, wshim requires a lot of CPU time to run. In order to track exactly how much, we put wshim into its own cgroup, and use cadvisor to expose Prometheus metrics pertaining to the resources that it uses.
Before deploying PGO, wshim was using over 3000 cores globally:
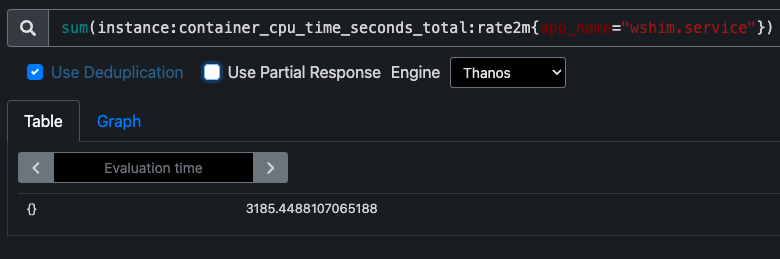
container_cpu_time_seconds is our internal metric that tracks the amount of time a CPU has spent running wshim across the world. Even a 2% saving would return 60 cores to our customers, making the Cloudflare network even more efficient.
The first step in deploying PGO was to collect representative profiles from our servers worldwide. The first problem we run into is that we run thousands of servers, each with different usage patterns at given points in time – a datacenter serving lots of requests during daytime hours will have a different usage pattern than a different data center that locally is in the middle of the night. As such, selecting exactly which servers to profile is paramount to collecting good profiles for PGO to use.
In the end, we decided that the best samples would be from those datacenters experiencing heavy load – those are the ones where the slowest parts of wshim would be most obvious. Even further, we will only collect profiles from our Tier 1 data centers. These are data centers that serve our most heavily populated regions, are generally our largest, and are generally under very heavy loads during peak hours.
Concretely, we can get a list of high CPU servers by querying our Thanos infrastructure:
num_profiles="1000"
# Fetch the top n CPU users for wshim across the edge using Thanos.
cloudflared access curl "https://thanos/api/v1/query?query=topk%28${num_profiles}%2Cinstance%3Acontainer_cpu_time_seconds_total%3Arate2m%7Bapp_name%3D%22wshim.service%22%7D%29&dedup=true&partial_response=true" --compressed | jq '.data.result[].metric.instance' -r > "${instances_file}"
Go makes actually fetching CPU profiles trivial with pprof. In order for our engineers to debug their systems in production, we provide a method to easily retrieve production profiles that we can use here. Wshim provides a pprof interface that we can use to retrieve profiles, and we can collect these again with bash:
# For every instance, attempt to pull a CPU profile. Note that due to the transient nature of some data centers
# a certain percentage of these will fail, which is fine, as long as we get enough nodes to form a representative sample.
while read instance; do fetch-pprof $instance –port 8976 –seconds 30' > "${working_dir}/${instance}.pprof" & done < "${instances_file}"
wait $(jobs -p)
And then merge all the gathered profiles into one, with go tool:
# Merge the fetched profiles into one.
go tool pprof -proto "${working_dir}/"*.pprof > profile.pprof
It’s this merged profile that we will use to compile our pprof binary. As such, we commit it to our repo so that it lives alongside all the other deployment components of wshim:
~/cf-repos/wshim ± master
23/01/2024 10:49:08 AEDT❯ tree pgo
pgo
├── README.md
├── fetch-profiles.sh
└── profile.pprof
And update our Makefile to pass in the -pgo flag to the go build command:
build:
go build -pgo ./pgo/profile.pprof -o /tmp/wshim ./cmd/wshim
After that, we can build and deploy our new PGO optimized version of wshim, like any other version.
Once our new version is deployed, we can review our CPU metrics to see if we have any meaningful savings. Resource usages are notoriously hard to compare. Because wshim’s CPU usage scales with the amount of traffic that any given server is receiving, it has a lot of potentially confounding variables, including the time of day, day of the year, and whether there are any active attacks affecting the datacenter. That being said, we can take a couple of numbers that might give us a good indication of any potential savings.
Firstly, we can look at the CPU usage of wshim immediately before and after the deployment. This may be confounded by the time difference between the sets, but it shows a decent improvement. Because our release takes just under two hours to roll to every tier 1 datacenter, we can use PromQLs `offset` operator to measure the difference:


This indicates that following the release, we’re using ~97 cores fewer than before the release, a ~3.5% reduction. This seems to be inline with the upstream documentation that gives numbers between 2% and 14%.
The second number we can look at is the usage at the same time of day on different days of the week. The average usage for the 7 days prior to the release was 3067.83 cores, whereas the 7 days after the release were 2996.78, a savings of 71 CPUs. Not quite as good as our 97 CPU savings, but still pretty substantial!
This seems to prove the benefits of PGO – without changing the code at all, we managed to save ourselves several servers worth of CPU time.
Looking at these initial results certainly seems to prove the case for PGO – saving multiple servers worth of CPU without any code changes is a big win for freeing up resources to better serve customer requests. However, there is definitely more work to be done here. In particular:
If that sounds interesting to you, we’re hiring in both the USA and EMEA!