Post Syndicated from Bhavani Kanneganti original https://aws.amazon.com/blogs/devops/how-we-sped-up-aws-cloudformation-deployments-with-optimistic-stabilization/
Introduction
AWS CloudFormation customers often inquire about the behind-the-scenes process of provisioning resources and why certain resources or stacks take longer to provision compared to the AWS Management Console or AWS Command Line Interface (AWS CLI). In this post, we will delve into the various factors affecting resource provisioning in CloudFormation, specifically focusing on resource stabilization, which allows CloudFormation and other Infrastructure as Code (IaC) tools to ensure resilient deployments. We will also introduce a new optimistic stabilization strategy that improves CloudFormation stack deployment times by up to 40% and provides greater visibility into resource provisioning through the new CONFIGURATION_COMPLETE status.
AWS CloudFormation is an IaC service that allows you to model your AWS and third-party resources in template files. By creating CloudFormation stacks, you can provision and manage the lifecycle of the template-defined resources manually via the AWS CLI, Console, AWS SAM, or automatically through an AWS CodePipeline, where CLI and SAM can also be leveraged or through Git sync. You can also use AWS Cloud Development Kit (AWS CDK) to define cloud infrastructure in familiar programming languages and provision it through CloudFormation, or leverage AWS Application Composer to design your application architecture, visualize dependencies, and generate templates to create CloudFormation stacks.
Deploying a CloudFormation stack
Let’s examine a deployment of a containerized application using AWS CloudFormation to understand CloudFormation’s resource provisioning.

Figure 1. Sample application architecture to deploy an ECS service
For deploying a containerized application, you need to create an Amazon ECS service. To set up the ECS service, several key resources must first exist: an ECS cluster, an Amazon ECR repository, a task definition, and associated Amazon VPC infrastructure such as security groups and subnets.
Since you want to manage both the infrastructure and application deployments using AWS CloudFormation, you will first define a CloudFormation template that includes: an ECS cluster resource (AWS::ECS::Cluster), a task definition (AWS::ECS::TaskDefinition), an ECR repository (AWS::ECR::Repository), required VPC resources like subnets (AWS::EC2::Subnet) and security groups (AWS::EC2::SecurityGroup), and finally, the ECS Service (AWS::ECS::Service) itself. When you create the CloudFormation stack using this template, the ECS service (AWS::ECS::Service) is the final resource created, as it waits for the other resources to finish creation. This brings up the concept of Resource Dependencies.
Resource Dependency:
In CloudFormation, resources can have dependencies on other resources being created first. There are two types of resource dependencies:
- Implicit: CloudFormation automatically infers dependencies when a resource uses intrinsic functions to reference another resource. These implicit dependencies ensure the resources are created in the proper order.
- Explicit: Dependencies can be directly defined in the template using the DependsOn attribute. This allows you to customize the creation order of resources.
The following template snippet shows the ECS service’s dependencies visualized in a dependency graph:
Template snippet:
ECSService:
DependsOn: [PublicRoute] #Explicit Dependency
Type: 'AWS::ECS::Service'
Properties:
ServiceName: cfn-service
Cluster: !Ref ECSCluster #Implicit Dependency
DesiredCount: 2
LaunchType: FARGATE
NetworkConfiguration:
AwsvpcConfiguration:
AssignPublicIp: ENABLED
SecurityGroups:
- !Ref SecurityGroup #Implicit Dependency
Subnets:
- !Ref PublicSubnet #Implicit Dependency
TaskDefinition: !Ref TaskDefinition #Implicit DependencyDependency Graph:

Figure 2. CloudFormation’s dependency graph for a containerized application
Note: VPC Resources in the above graph include PublicSubnet (AWS::EC2::Subnet), SecurityGroup (AWS::EC2::SecurityGroup), PublicRoute (AWS::EC2::Route)
In the above template snippet, the ECS Service (AWS::ECS::Service) resource has an explicit dependency on the PublicRoute resource, specified using the DependsOn attribute. The ECS service also has implicit dependencies on the ECSCluster, SecurityGroup, PublicSubnet, and TaskDefinition resources. Even without an explicit DependsOn, CloudFormation understands that these resources must be created before the ECS service, since the service references them using the Ref intrinsic function. Now that you understand how CloudFormation creates resources in a specific order based on their definition in the template file, let’s look at the time taken to provision these resources.
Resource Provisioning Time:
The total time for CloudFormation to provision the stack depends on the time required to create each individual resource defined in the template. The provisioning duration per resource is determined by several time factors:
- Engine Time: CloudFormation Engine Time refers to the duration spent by the service reading and persisting data related to a resource. This includes the time taken for operations like parsing and interpreting the CloudFormation template, and for the resolution of intrinsic functions like Fn::GetAtt and Ref.
- Resource Creation Time: The actual time an AWS service requires to create and configure the resource. This can vary across resource types provisioned by the service.
- Resource Stabilization Time: The duration required for a resource to reach a usable state after creation.
What is Resource Stabilization?
When provisioning AWS resources, CloudFormation makes the necessary API calls to the underlying services to create the resources. After creation, CloudFormation then performs eventual consistency checks to ensure the resources are ready to process the intended traffic, a process known as resource stabilization. For example, when creating an ECS service in the application, the service is not readily accessible immediately after creation completes (after creation time). To ensure the ECS service is available to use, CloudFormation performs additional verification checks defined specifically for ECS service resources. Resource stabilization is not unique to CloudFormation and must be handled to some degree by all IaC tools.
Stabilization Criteria and Stabilization Timeout
For CloudFormation to mark a resource as CREATE_COMPLETE, the resource must meet specific stabilization criteria called stabilization parameters. These checks validate that the resource is not only created but also ready for use.
If a resource fails to meet its stabilization parameters within the allowed stabilization timeout period, CloudFormation will mark the resource status as CREATE_FAILED and roll back the operation. Stabilization criteria and timeouts are defined uniquely for each AWS resource supported in CloudFormation by the service, and are applied during both resource create and update workflows.
AWS CloudFormation vs AWS CLI to provision resources
Now, you will create a similar ECS service using the AWS CLI. You can use the following AWS CLI command to deploy an ECS service using the same task definition, ECS cluster and VPC resources created earlier using CloudFormation.
Command:
aws ecs create-service \
--cluster CFNCluster \
--service-name service-cli \
--task-definition task-definition-cfn:1 \
--desired-count 2 \
--launch-type FARGATE \
--network-configuration "awsvpcConfiguration={subnets=[subnet-xxx],securityGroups=[sg-yyy],assignPublicIp=ENABLED}" \
--region us-east-1The following snippet from the output of the above command shows that the ECS Service has been successfully created and its status is ACTIVE.

Figure 3. Snapshot of the ECS service API call
However, when you navigate to the ECS console and review the service, tasks are still in the Pending state, and you are unable to access the application.

Figure 4. ECS console view
You have to wait for the service to reach a steady state before you can successfully access the application.

Figure 5. ECS service events from the AWS console
When you create the same ECS service using AWS CloudFormation, the service is accessible immediately after the resource reaches a status of CREATE_COMPLETE in the stack. This reliable availability is due to CloudFormation’s resource stabilization process. After initially creating the ECS service, CloudFormation waits and continues calling the ECS DescribeServices API action until the service reaches a steady state. Once the ECS service passes its consistency checks and is fully ready for use, only then will CloudFormation mark the resource status as CREATE_COMPLETE in the stack. This creation and stabilization orchestration allows you to access the service right away without any further delays.
The following is an AWS CloudTrail snippet of CloudFormation performing DescribeServices API calls during Stabilization:

Figure 6. Snapshot of AWS CloudTrail event
By handling resource stabilization natively, CloudFormation saves you the extra coding effort and complexity of having to implement custom status checks and availability polling logic after resource creation. You would have to develop this additional logic using tools like the AWS CLI or API across all the infrastructure and application resources. With CloudFormation’s built-in stabilization orchestration, you can deploy the template once and trust that the services will be fully ready after creation, allowing you to focus on developing your application functionality.
Evolution of Stabilization Strategy
CloudFormation’s stabilization strategy couples resource creation with stabilization such that the provisioning of a resource is not considered COMPLETE until stabilization is complete.
Historic Stabilization Strategy
For resources that have no interdependencies, CloudFormation starts the provisioning process in parallel. However, if a resource depends on another resource, CloudFormation will wait for the entire resource provisioning operation of the dependency resource to complete before starting the provisioning of the dependent resource.

Figure 7. CloudFormation’s historic stabilization strategy
The diagram above shows a deployment of some of the ECS application resources that you deploy using AWS CloudFormation. The Task Definition (AWS::ECS::TaskDefinition) resource depends on the ECR Repository (AWS::ECR::Repository) resource, and the ECS Service (AWS::ECS:Service) resource depends on both the Task Definition and ECS Cluster (AWS::ECS::Cluster) resources. The ECS Cluster resource has no dependencies defined. CloudFormation initiates creation of the ECR Repository and ECS Cluster resources in parallel. It then waits for the ECR Repository to complete consistency checks before starting provisioning of the Task Definition resource. Similarly, creation of the ECS Service resource begins only when the Task Definition and ECS Cluster resources have been created and are ready. This sequential approach ensures safety and stability but causes delays. CloudFormation strictly deploys dependent resources one after the other, slowing down deployment of the entire stack. As the number of interdependent resources grows, the overall stack deployment time increases, creating a bottleneck that prolongs the whole stack operation.
New Optimistic Stabilization Strategy
To improve stack provisioning times and deployment performance, AWS CloudFormation recently launched a new optimistic stabilization strategy. The optimistic strategy can reduce customer stack deployment duration by up to 40%. It allows dependent resources to be created in parallel. This concurrent resource creation helps significantly improve deployment speed.

Figure 8. CloudFormation’s new optimistic stabilization strategy
The diagram above shows deployment of the same 4 resources discussed in the historic strategy. The Task Definition (AWS::ECS::TaskDefinition) resource depends on the ECR Repository (AWS::ECR::Repository) resource, and the ECS Service (AWS::ECS:Service) resource depends on both the Task Definition and ECS Cluster (AWS::ECS::Cluster) resources. The ECS Cluster resource has no dependencies defined. CloudFormation initiates creation of the ECR Repository and ECS Cluster resources in parallel. Then, instead of waiting for the ECR Repository to complete consistency checks, it starts creating the Task Definition when the ECR Repository completes creation, but before stabilization is complete. Similarly, creation of the ECS Service resource begins after Task Definition and ECS Cluster creation. The change was made because not all resources require their dependent resources to complete consistency checks before starting creation. If the ECS Service fails to provision because the Task Definition or ECS Cluster resources are still undergoing consistency checks, CloudFormation will wait for those dependencies to complete their consistency checks before attempting to create the ECS Service again.

Figure 9. CloudFormation’s new stabilization strategy with the retry capability
This parallel creation of dependent resources with automatic retry capabilities results in faster deployment times compared to the historical linear resource provisioning strategy. The Optimistic stabilization strategy currently applies only to create workflows with resources that have implicit dependencies. For resources with an explicit dependency, CloudFormation leverages the historic strategy in deploying resources.
Improved Visibility into Resource Provisioning
When creating a CloudFormation stack, a resource can sometimes take longer to provision, making it appear as if it’s stuck in an IN_PROGRESS state. This can be because CloudFormation is waiting for the resource to complete consistency checks during its resource stabilization step. To improve visibility into resource provisioning status, CloudFormation has introduced a new “CONFIGURATION_COMPLETE” event. This event is emitted at both the individual resource level and the overall stack level during create workflow when resource(s) creation or configuration is complete, but stabilization is still in progress.
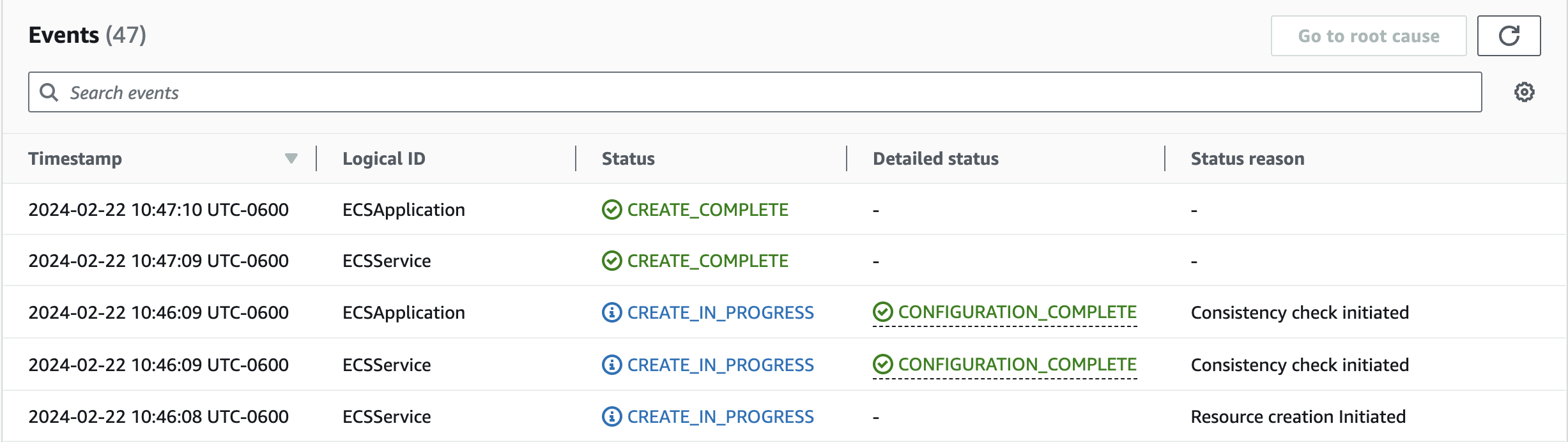
Figure 10. CloudFormation stack events of the ECS Application
The above diagram shows the snapshot of stack events of the ECS application’s CloudFormation stack named ECSApplication. Observe the events from the bottom to top:
- At 10:46:08 UTC-0600, ECSService (AWS::ECS::Service) resource creation was initiated.
- At 10:46:09 UTC-0600, the ECSService has CREATE_IN_PROGRESS status in the Status tab and CONFIGURATION_COMPLETE status in the Detailed status tab, meaning the resource was successfully created and the consistency check was initiated.
- At 10:46:09 UTC-0600, the stack ECSApplication has CREATE_IN_PROGRESS status in the Status tab and CONFIGURATION_COMPLETE status in the Detailed status tab, meaning all the resources in the ECSApplication stack are successfully created and are going through stabilization. This stack level CONFIGURATION_COMPLETE status can also be viewed in the stack’s Overview tab.

Figure 11. CloudFormation Overview tab for the ECSApplication stack
- At 10:47:09 UTC-0600, the ECSService has CREATE_COMPLETE status in the Status tab, meaning the service is created and completed consistency checks.
- At 10:47:10 UTC-0600, ECSApplication has CREATE_COMPLETE status in the Status tab, meaning all the resources are successfully created and completed consistency checks.
Conclusion:
In this post, I hope you gained some insights into how CloudFormation deploys resources and the various time factors that contribute to the creation of a stack and its resources. You also took a deeper look into what CloudFormation does under the hood with resource stabilization and how it ensures the safe, consistent, and reliable provisioning of resources in critical, high-availability production infrastructure deployments. Finally, you learned about the new optimistic stabilization strategy to shorten stack deployment times and improve visibility into resource provisioning.
















