Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/lightsail-containers-an-easy-way-to-run-your-containers-in-the-cloud/
When I am delivering an introduction to the AWS Cloud for developers, I usually spend a bit of time to mention and to demonstrate Amazon Lightsail. It is by far the easiest way to get started on AWS. It allows you to get your application running on your own virtual server in a matter of minutes. Today, we are adding the possibility to deploy your container-based workloads on Amazon Lightsail. You can now deploy your container images to the cloud with the same simplicity and the same bundled pricing Amazon Lightsail provides for your virtual servers.
Amazon Lightsail is an easy-to-use cloud service that offers you everything needed to deploy an application or website, for a cost effective and easy to understand monthly plan. It is ideal to deploy simple workloads, websites, or to get started with AWS. The typical Lightsail customers range from developers to small businesses or startups who are looking to get quickly started in the cloud and AWS. At any time, you can later adopt the broad AWS Services when you are getting more familiar with the AWS cloud.
Under the hood, Lightsail is powered by Amazon Elastic Compute Cloud (EC2), Amazon Relational Database Service (RDS), Application Load Balancer, and other AWS services. It offers the level of security, reliability, and scalability you are expecting from AWS.
When deploying to Lightsail, you can choose between six operating systems (4 Linux distributions, FreeBSD, or Windows), seven applications (such as WordPress, Drupal, Joomla, Plesk…), and seven stacks (such as Node.js, Lamp, GitLab, Django…). But what about Docker containers?
Starting today, Amazon Lightsail offers an simple way for developers to deploy their containers to the cloud. All you need to provide is a Docker image for your containers and we automatically containerize it for you. Amazon Lightsail gives you an HTTPS endpoint that is ready to serve your application running in the cloud container. It automatically sets up a load balanced TLS endpoint, and take care of the TLS certificate. It replaces unresponsive containers for you automatically, it assigns a DNS name to your endpoint, it maintains the old version till the new version is healthy and ready to go live, and more.
Let’s see how it works by deploying a simple Python web app as a container. I assume you have the AWS Command Line Interface (CLI) and Docker installed on your laptop. Python is not required, it will be installed in the container only.
I first create a Python REST API, using the Flask simple application framework. Any programming language and any framework that can run inside a container works too. I just choose Python and Flask because they are simple and elegant.
You can safely copy /paste the following commands:
mkdir helloworld-python
cd helloworld-python
# create a simple Flask application in helloworld.py
echo "
from flask import Flask, request
from flask_restful import Resource, Api
app = Flask(__name__)
api = Api(app)
class Greeting (Resource):
def get(self):
return { "message" : "Hello Flask API World!" }
api.add_resource(Greeting, '/') # Route_1
if __name__ == '__main__':
app.run('0.0.0.0','8080')
" > helloworld.py
Then I create a Dockerfile that contains the steps and information required to build the container image:
# create a Dockerfile
echo '
FROM python:3
ADD helloworld.py /
RUN pip install flask
RUN pip install flask_restful
EXPOSE 8080
CMD [ "python", "./helloworld.py"]
' > Dockerfile
Now I can build my container:
docker build -t lightsail-hello-world .
The build command outputs many lines while it builds the container, it eventually terminates with the following message (actual ID differs):
Successfully built 7848e055edff
Successfully tagged lightsail-hello-world:latest
I test the container by launching it on my laptop:
docker run -it --rm -p 8080:8080 lightsail-hello-world
and connect a browser to localhost:8080

When I am satisfied with my app, I push the container to Docker Hub.
docker tag lightsail-hello-world sebsto/lightsail-hello-world
docker login
docker push sebsto/lightsail-hello-world
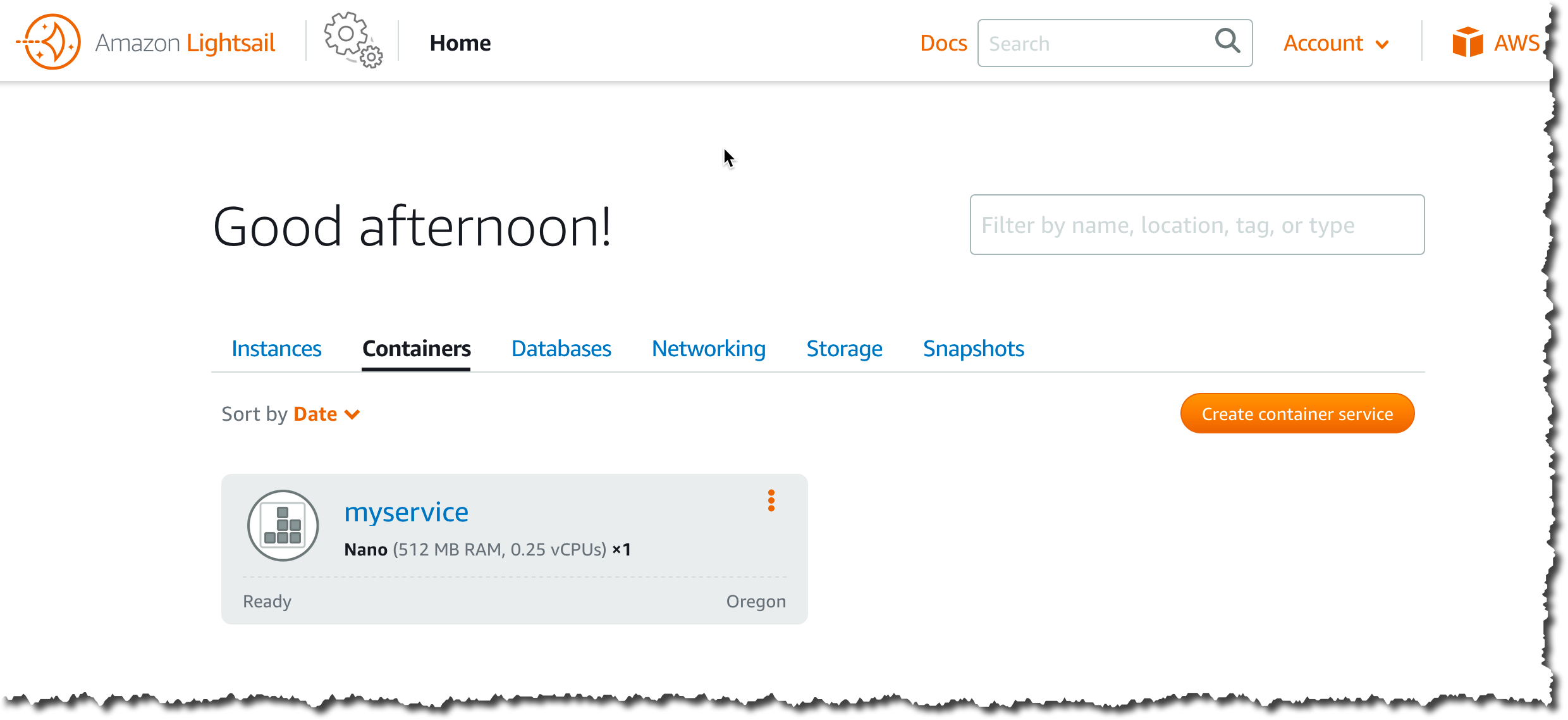
Now that I have a container ready on Docker Hub, let’s create a Lightsail Container Service.
I point my browser to the Amazon Lightsail console. I can see container services already deployed and I can manage them. To create a new service, I click Create container service:
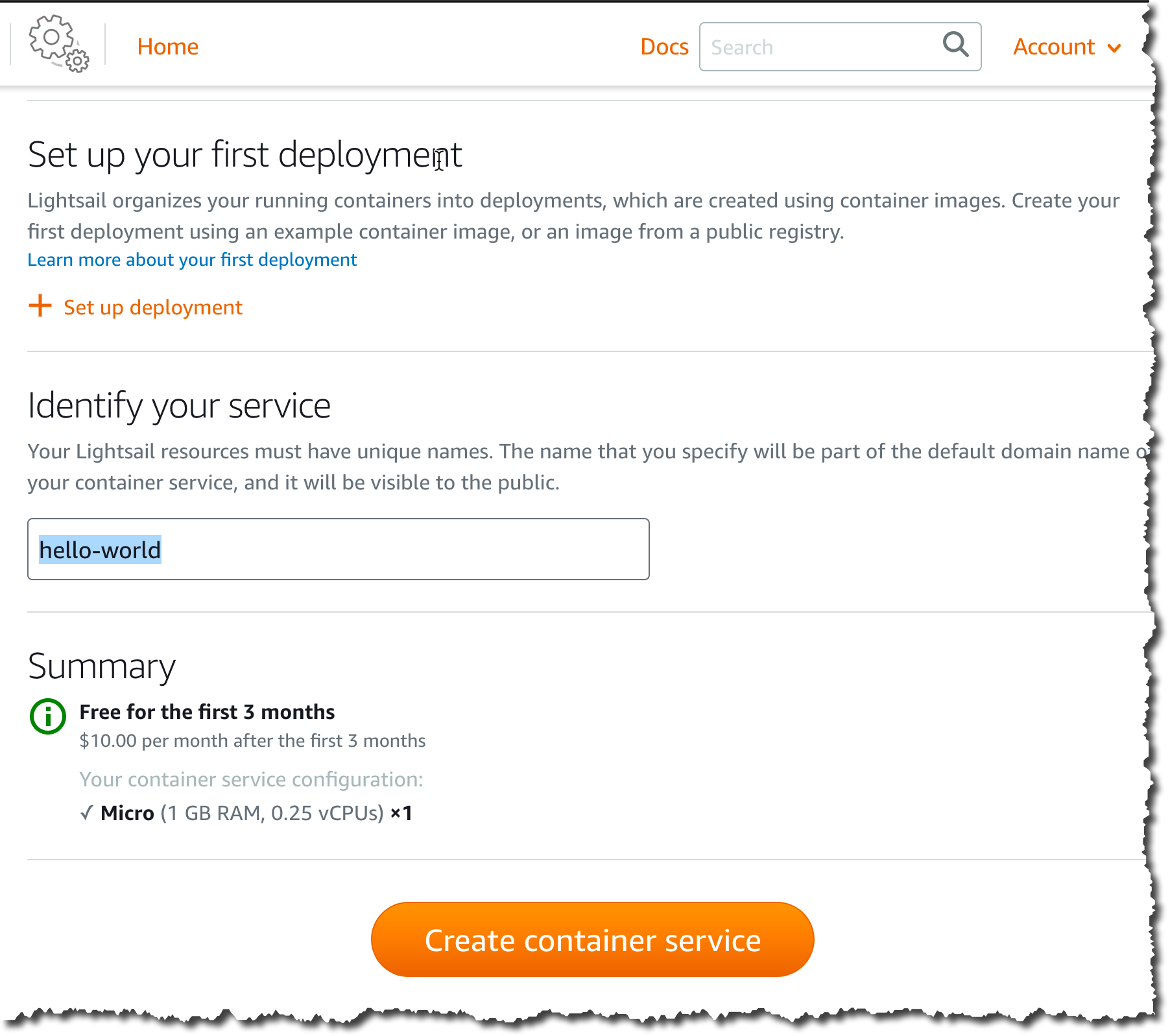
On the next screen, I select the size of the container I want to use, in terms of vCPU and memory available to my application. I also select the number of container instances I want to run in parallel for high availability or scalability reasons. I can change the number of container instances or their power (vCPU and RAM) at any time, without interrupting the service. Both these parameters impact the price AWS charges you per month. The price is indicated and dynamically adjusted on the screen, as shown on the following video.

Slightly lower on the screen, I choose to skip the deployment for now. I give a name for the service (“hello-world“). I click Create container service.

Once the service is created, I click Create your first deployment to create a deployment. A deployment is a combination of a specific container image and version to be deployed on the service I just created.
I chose a name for my image and give the address of the image on Docker Hub, using the format user/<my container name>:tag. This is also where I have the possibility to enter environment variables, port mapping, or a launch command.
My container is offering a network service on port TCP 8080, so I add that port to the deployment configuration. The Open Ports configuration specifies which ports and protocols are open to other systems in my container’s network. Other containers or virtual machines can only connect to my container when the port is explicitly configured in the console or EXPOSE‘d in my Dockerfile. None of these ports are exposed to the public internet.
But in this example, I also want Lightsail to route the traffic from the public internet to this container. So, I add this container as an endpoint of the hello-world service I just created. The endpoint is automatically configured for TLS, there is no certificate to install or manage.
I can add up to 10 containers for one single deployment. When ready, I click Save and deploy.

After a while, my deployment is active and I can test the endpoint.

The endpoint DNS address is available on the top-right side of the console. If I must, I can configure my own DNS domain name.
 I open another tab in my browser and point it at the https endpoint URL:
I open another tab in my browser and point it at the https endpoint URL:
 When I must deploy a new version, I use the console again to modify the deployment. I spare you the details of modifying the application code, build, and push a new version of the container. Let’s say I have my second container image version available under the name
When I must deploy a new version, I use the console again to modify the deployment. I spare you the details of modifying the application code, build, and push a new version of the container. Let’s say I have my second container image version available under the name sebsto/lightsail-hello-world:v2. Back to Amazon Lightsail console, I click Deployments, then Modify your Deployments. I enter the full name, including the tag, of the new version of the container image and click Save and Deploy.
 After a while, the new version is deployed and automatically activated.
After a while, the new version is deployed and automatically activated.

I open a new tab in my browser and I point it to the endpoint URI available on the top-right corner of Amazon Lightsail console. I observe the JSON version is different. It now has a version attribute with a value of 2.

When something goes wrong during my deployment, Amazon Lightsail automatically keeps the last deployment active, to avoid any service interruption. I can also manually activate a previous deployment version to reverse any undesired changes.
I just deployed my first container image from Docker Hub. I can also manage my services and deploy local container images from my laptop using the AWS Command Line Interface (CLI). To push container images to my Amazon Lightsail container service directly from my laptop, I must install the LightSail Controler Plugin. (TL;DR curl, cp and chmod are your friends here, I also maintain a DockerFile to use the CLI inside a container.)
To create, list, or delete a container service, I type:
aws lightsail create-container-service --service-name myservice --power nano --scale 1
aws lightsail get-container-services
{
"containerServices": [{
"containerServiceName": "myservice",
"arn": "arn:aws:lightsail:us-west-2:012345678901:ContainerService/1b50c121-eac7-4ee2-9078-425b0665b3d7",
"createdAt": "2020-07-31T09:36:48.226999998Z",
"location": {
"availabilityZone": "all",
"regionName": "us-west-2"
},
"resourceType": "ContainerService",
"power": "nano",
"powerId": "",
"state": "READY",
"scale": 1,
"privateDomainName": "",
"isDisabled": false,
"roleArn": ""
}]
}
aws lightsail delete-container-service --service myservice
I can also use the CLI to deploy container images directly from my laptop. Be sure lightsailctl is installed.
# Build the new version of my image (v3)
docker build -t sebsto/lightsail-hello-world:v3 .
# Push the new image.
aws lightsail push-container-image --service-name hello-world --label hello-world --image sebsto/lightsail-hello-world:v3
After a while, I see the output:
Image "sebsto/lightsail-hello-world:v3" registered.
Refer to this image as ":hello-world.hello-world.1" in deployments.
I create a lc.json file to hold the details of the deployment configuration. it is aligned to the options I see on the console. I report the name given by the previous command on the image property:
{
"serviceName": "hello-world",
"containers": {
"hello-world": {
"image": ":hello-world.hello-world.1",
"ports": {
"8080": "HTTP"
}
}
},
"publicEndpoint": {
"containerName": "hello-world",
"containerPort": 8080
}
}
Finally, I create a new service version with:
aws lightsail create-container-service-deployment --cli-input-json file://lc.json
I can query the deployment status with
aws lightsail get-container-services
...
"nextDeployment": {
"version": 4,
"state": "ACTIVATING",
"containers": {
"hello-world": {
"image": ":hello-world.hello-world.1",
"command": [],
"environment": {},
"ports": {
"8080": "HTTP"
}
}
},
...
After a while, the status becomes ACTIVE, and I can test my endpoint.
curl https://hello-world.nxxxxxxxxxxx.lightsail.ec2.aws.dev/
{"message": "Hello Flask API World!", "version": 3}
If you plan to later deploy your container to Amazon ECS or Amazon Elastic Kubernetes Service, no changes are required. You can pull the container image from your repository, just like you do with Amazon Lightsail.
You can deploy your containers on Lightsail in all AWS Regions where Amazon Lightsail is available. As of today, this is US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), and Europe (Paris).
As usual when using Amazon Lightsail, pricing is easy to understand and predictable. Amazon Lightsail Containers have a fixed price per month per container, depending on the size of the container (the vCPU/memory combination you use). You are charged on the prorated hours you keep the service running. The price per month is the maximum price you will be charged for running your service 24h/7. The prices are identical in all AWS Regions. They are ranging from $7 / month for a Nano container (512MB memory and 0.25 vCPU) to $160 / month for a X-Large container (8GB memory and 4 vCPU cores). This price not only includes the container itself, but also the load balancer, the DNS, and a generous data transfer tier. The details and prices for other AWS Regions are on the Lightsail pricing page.
I can’t wait to discover what solutions you will build and deploy on Amazon Lightsail Containers!
— seb