Post Syndicated from Mark Calleja original https://www.raspberrypi.org/blog/ready-set-scratch-a-beginners-guide-to-creative-coding/
What is Scratch?
Scratch is a free, beginner-friendly coding platform that allows young people to create animations, games, and interactive stories using simple visual blocks. Scratch removes some of the complexity of coding by replacing syntax-heavy programming languages with intuitive drag-and-drop blocks. This lets creativity take centre stage and makes it the perfect first step for young coders.

Why Scratch is the ideal starting point
Every coding journey begins with a single step. Scratch delivers this first step in a way that is playful, approachable, and empowering. Scratch immediately delivers tangible results that new coders can feel proud of by linking coding to storytelling, design, and play. It also cultivates curiosity, confidence, and resilience — qualities crucial to long-term success in both coding and problem solving.
Most importantly, Scratch emphasises exploration over perfection. It invites young learners to experiment freely, troubleshoot confidently, and express themselves creatively without fear of making mistakes. This exploratory mindset provides the foundation for future technical proficiency and innovation.
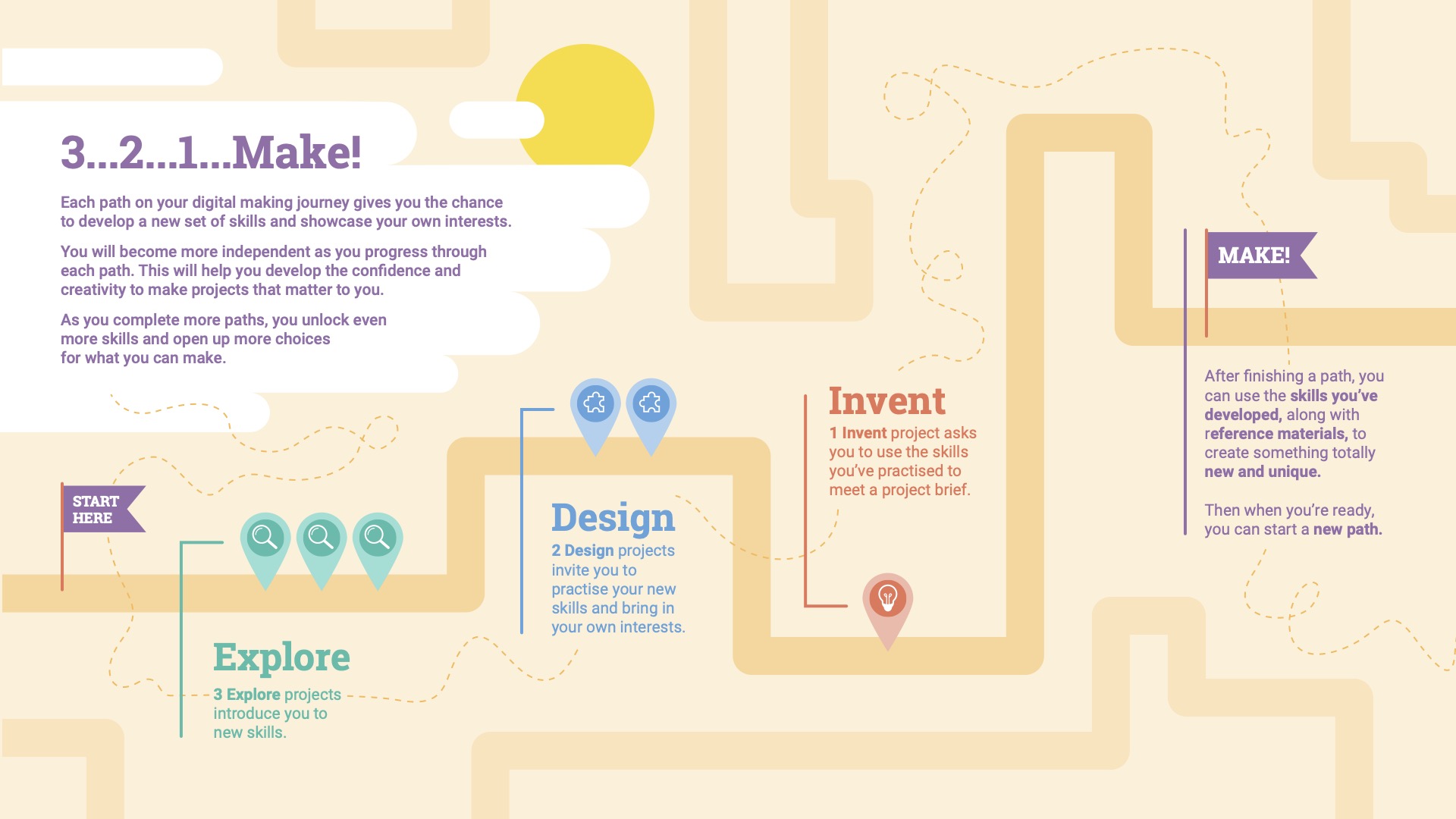
Get started with our free projects
Starting with structured projects helps young learners build solid coding skills while maintaining enthusiasm and enjoyment.
Catch the bus (animation)

In ‘Catch the bus’, coders create an animation featuring a character (called a sprite in Scratch) attempting to catch a departing bus. They learn how to sequence events, switch costumes to simulate movement, and synchronise actions to tell a simple story. This introduces fundamental storytelling and animation skills in Scratch.
What you’ll learn:
- Timing and sequencing actions
- Using costume changes to simulate movement
- Creating narrative animations
Chomp the cheese (interactive)

In ‘Chomp the cheese’, learners use facial recognition tools in Scratch Lab to build an interactive game controlled by mouth movements. Using a webcam, players physically open their mouths to “chomp” virtual cheese snacks on screen. This playful and engaging activity introduces machine learning concepts in a tangible and enjoyable way.
What you’ll learn:
- Using facial recognition in Scratch
- Creating interactive games with webcam input
- Basic concepts of machine learning and interactivity
Boat race (game)

In ‘Boat race’, young coders create a game where players navigate a boat around obstacles, steering using mouse controls. They learn to handle player input, detect collisions, and define conditions for winning. This foundational game-making experience sets the stage for more complex creations in the future.
What you’ll learn:
- Controlling sprites with mouse clicks
- Collision detection between sprites
- Defining goals and win conditions
“The key to sparking a lifelong interest in coding is excitement. When young people are building something they genuinely care about, they’re not worried about getting everything perfect on the first try. They’re chasing their ideas and learning as they go. Scratch creates the ideal environment for this type of messy, brilliant exploration. It provides young coders with the freedom to experiment, persevere, and express themselves — all while enjoying the process,” or so says my amazing colleague Pete Bell, Learning Manager and creator of some of our most engaging content at the Raspberry Pi Foundation. I have to say, I agree with him!
Level up and build momentum
After completing their first projects, young coders can continue to build momentum through several exciting avenues:
- Personalise projects: Encourage learners to remix existing projects by altering characters, backgrounds, and rules. Personalisation deepens learning and fosters ownership of the coding experience.
- Explore Python: Scratch’s block-based coding naturally leads to curiosity about text-based languages like Python, which many learners find an exciting next step.
- Join a Code Club: Coding alongside peers transforms individual learning into a social experience. Code Clubs offer a collaborative environment where learners solve problems together, share creations, and build lasting friendships.
Encouraging personalisation, curiosity, and community involvement keeps learners motivated and engaged on their coding journey.

Conclusion
Scratch is more than just an introductory tool — it’s a creative playground that nurtures curiosity, resilience, and technical skills in equal measure. By guiding young coders through their first steps with engaging projects and supportive encouragement, you lay the foundation for a lifetime of innovation, problem-solving, and creative expression. Ready, set, Scratch! Let’s get started!
The post Ready, set, Scratch: A beginner’s guide to creative coding appeared first on Raspberry Pi Foundation.