Post Syndicated from original https://0pointer.net/blog/linux-boot-partitions.html
💽 Linux Boot Partitions and How to Set Them Up 🚀
Let’s have a look how traditional Linux distributions set up
/boot/ and the ESP, and how this could be improved.
How Linux distributions traditionally have been setting up their
“boot” file systems has been varying to some degree, but the most
common choice has been to have a separate partition mounted to
/boot/. Usually the partition is formatted as a Linux file system
such as ext2/ext3/ext4. The partition contains the kernel images, the
initrd and various boot loader resources. Some distributions, like
Debian and Ubuntu, also store ancillary files associated with the
kernel here, such as kconfig or System.map. Such a traditional
boot partition is only defined within the context of the distribution,
and typically not immediately recognizable as such when looking just
at the partition table (i.e. it uses the generic Linux partition type
UUID).
With the arrival of UEFI a new partition relevant for boot appeared,
the EFI System Partition (ESP). This partition is defined by the
firmware environment, but typically accessed by Linux to install or
update boot loaders. The choice of file system is not up to Linux, but
effectively mandated by the UEFI specifications: vFAT. In theory it
could be formatted as other file systems too. However, this would
require the firmware to support file systems other than vFAT. This is
rare and firmware specific though, as vFAT is the only file system
mandated by the UEFI specification. In other words, vFAT is the only
file system which is guaranteed to be universally supported.
There’s a major overlap of the type of the data typically stored in
the ESP and in the traditional boot partition mentioned earlier: a
variety of boot loader resources as well as kernels/initrds.
Unlike the traditional boot partition, the ESP is easily recognizable
in the partition table via its GPT partition type UUID. The ESP is
also a shared resource: all OSes installed on the same disk will
share it and put their boot resources into them (as opposed to the
traditional boot partition, of which there is one per installed Linux
OS, and only that one will put resources there).
To summarize, the most common setup on typical Linux distributions is
something like this:
| Type | Linux Mount Point | File System Choice |
|---|---|---|
| Linux “Boot” Partition | /boot/ |
Any Linux File System, typically ext2/ext3/ext4 |
| ESP | /boot/efi/ |
vFAT |
As mentioned, not all distributions or local installations agree on
this. For example, it’s probably worth mentioning that some
distributions decided to put kernels onto the root file system of the
OS itself. For this setup to work the boot loader itself [sic!] must
implement a non-trivial part of the storage stack. This may have to
include RAID, storage drivers, networked storage, volume management,
disk encryption, and Linux file systems. Leaving aside the conceptual
argument that complex storage stacks don’t belong in boot loaders
there are very practical problems with this approach. Reimplementing
the Linux storage stack in all its combinations is a massive amount of
work. It took decades to implement what we have on Linux now, and it
will take a similar amount of work to catch up in the boot loader’s
reimplementation. Moreover, there’s a political complication: some
Linux file system communities made clear they have no interest in
supporting a second file system implementation that is not maintained
as part of the Linux kernel.
What’s interesting is that the /boot/efi/ mount point is nested
below the /boot/ mount point. This effectively means that to access
the ESP the Boot partition must exist and be mounted first. A system
with just an ESP and without a Boot partition hence doesn’t fit well
into the current model. The Boot partition will also have to carry an
empty “efi” directory that can be used as the inner mount point, and
serves no other purpose.
Given that the traditional boot partition and the ESP may carry
similar data (i.e. boot loader resources, kernels, initrds) one may
wonder why they are separate concepts. Historically, this was the
easiest way to make the pre-UEFI way how Linux systems were booted
compatible with UEFI: conceptually, the ESP can be seen as just a
minor addition to the status quo ante that way. Today, primarily two
reasons remained:
-
Some distributions see a benefit in support for complex Linux file
system concepts such as hardlinks, symlinks, SELinux labels/extended
attributes and so on when storing boot loader resources. – I
personally believe that making use of features in the boot file
systems that the firmware environment cannot really make sense of is
very clearly not advisable. The UEFI file system APIs know no
symlinks, and what is SELinux to UEFI anyway? Moreover, putting more
than the absolute minimum of simple data files into such file
systems immediately raises questions about how to authenticate them
comprehensively (including all fancy metadata) cryptographically on
use (see below). -
On real-life systems that ship with non-Linux OSes the ESP often
comes pre-installed with a size too small to carry multiple Linux
kernels and initrds. As growing the size of an existing ESP is
problematic (for example, because there’s no space available
immediately after the ESP, or because some low-quality firmware
reacts badly to the ESP changing size) placing the kernel in a
separate, secondary partition (i.e. the boot partition) circumvents
these space issues.
File System Choices
We already mentioned that the ESP effectively has to be vFAT, as that
is what UEFI (more or less) guarantees. The file system choice for the
boot partition is not quite as restricted, but using arbitrary Linux
file systems is not really an option either. The file system must be
accessible by both the boot loader and the Linux OS. Hence only file
systems that are available in both can be used. Note that such
secondary implementations of Linux file systems in the boot
environment – limited as they may be – are not typically welcomed
or supported by the maintainers of the canonical file system
implementation in the upstream Linux kernel. Modern file systems are
notoriously complicated and delicate and simply don’t belong in boot
loaders.
In a trusted boot world, the two file systems for the ESP and the
/boot/ partition should be considered untrusted: any code or
essential data read from them must be authenticated cryptographically
before use. And even more, the file system structures themselves are
also untrusted. The file system driver reading them must be careful
not to be exploitable by a rogue file system image. Effectively this
means a simple file system (for which a driver can be more easily
validated and reviewed) is generally a better choice than a complex
file system (Linux file system communities made it pretty clear that
robustness against rogue file system images is outside of their scope
and not what is being tested for.).
Some approaches tried to address the fact that boot partitions are
untrusted territory by encrypting them via a mechanism compatible to
LUKS, and adding decryption capabilities to the boot loader so it can
access it. This misses the point though, as encryption does not imply
authentication, and only authentication is typically desired. The boot
loader and kernel code are typically Open Source anyway, and hence
there’s little value in attempting to keep secret what is already
public knowledge. Moreover, encryption implies the existence of an
encryption key. Physically typing in the decryption key on a keyboard
might still be acceptable on desktop systems with a single human user
in front, but outside of that scenario unlock via TPM, PKCS#11 or
network services are typically required. And even on the desktop FIDO2
unlocking is probably the future. Implementing all the technologies
these unlocking mechanisms require in the boot loader is not
realistic, unless the boot loader shall become a full OS on its own as
it would require subsystems for FIDO2, PKCS#11, USB, Bluetooth
network, smart card access, and so on.
File System Access Patterns
Note that traditionally both mentioned partitions were read-only
during most parts of the boot. Only later, once the OS is up, write
access was required to implement OS or boot loader updates. In today’s
world things have become a bit more complicated. A modern OS might
want to require some limited write access already in the boot loader,
to implement boot counting/boot assessment/automatic fallback (e.g.,
if the same kernel fails to boot 3 times, automatically revert to
older kernel), or to maintain an early storage-based random seed. This
means that even though the file system is mostly read-only, we need
limited write access after all.
vFAT cannot compete with modern Linux file systems such as btrfs
when it comes to data safety guarantees. It’s not a journaled file
system, does not use CoW or any form of checksumming. This means when
used for the system boot process we need to be particularly careful
when accessing it, and in particular when making changes to it (i.e.,
trying to keep changes local to single sectors). It is essential to
use write patterns that minimize the chance of file system
corruption. Checking the file system (“fsck”) before modification
(and probably also reading) is important, as is ensuring the file
system is put into a “clean” state as quickly as possible after each
modification.
Code quality of the firmware in typical systems is known to not always
be great. When relying on the file system driver included in the
firmware it’s hence a good idea to limit use to operations that have a
better chance to be correctly implemented. For example, when writing
from the UEFI environment it might be wise to avoid any operation that
requires allocation algorithms, but instead focus on access patterns
that only override already written data, and do not require allocation
of new space for the data.
Besides write access from the boot loader code (as described above)
these file systems will require write access from the OS, to
facilitate boot loader and kernel/initrd updates. These types of
accesses are generally not fully random accesses (i.e., never partial
file updates) but usually mean adding new files as whole, and removing
old files as a whole. Existing files are typically not modified once
created, though they might be replaced wholly by newer versions.
Boot Loader Updates
Note that the update cycle frequencies for boot loaders and for
kernels/initrds are probably similar these days. While kernels are
still vastly more complex than boot loaders, security issues are
regularly found in both. In particular, as boot loaders (through
“shim” and similar components) carry certificate/keyring and denylist
information, which typically require frequent updates. Update cycles
hence have to be expected regularly.
Boot Partition Discovery
The traditional boot partition was not recognizable by looking just at
the partition table. On MBR systems it was directly referenced from
the boot sector of the disk, and on EFI systems from information
stored in the ESP. This is less than ideal since by losing this
entrypoint information the system becomes unbootable. It’s typically a
better, more robust idea to make boot partitions recognizable as such
in the partition table directly. This is done for the ESP via the GPT
partition type UUID. For traditional boot partitions this was not done
though.
Current Situation Summary
Let’s try to summarize the above:
-
Currently, typical deployments use two distinct boot partitions,
often using two distinct file system implementations -
Firmware effectively dictates existence of the ESP, and the use of
vFAT -
In userspace view: the ESP mount is nested below the general
Boot partition mount -
Resources stored in both partitions are primarily kernel/initrd, and
boot loader resources -
The mandatory use of vFAT brings certain data safety challenges,
as does quality of firmware file system driver code -
During boot limited write access is needed, during OS runtime
more comprehensive write access is needed (though still not fully
random). -
Less restricted but still limited write patterns from OS
environment (only full file additions/updates/removals, during
OS/boot loader updates) -
Boot loaders should not implement complex storage stacks.
-
ESP can be auto-discovered from the partition table, traditional
boot partition cannot. -
ESP and the traditional boot partition are not protected
cryptographically neither in structure nor contents. It is expected
that loaded files are individually authenticated after being read. -
The ESP is a shared resource — the traditional boot partition a
resource specific to each installed Linux OS on the same disk.
How to Do it Better
Now that we have discussed many of the issues with the status quo ante, let’s see how we can do things better:
-
Two partitions for essentially the same data is a bad idea. Given
they carry data very similar or identical in nature, the common case
should be to have only one (but see below). -
Two file system implementations are worse than one. Given that vFAT
is more or less mandated by UEFI and the only format universally
understood by all players, and thus has to be used anyway, it might
as well be the only file system that is used. -
Data safety is unnecessarily bad so far: both ESP and boot partition
are continuously mounted from the OS, even though access is pretty
restricted: outside of update cycles access is typically not
required. -
All partitions should be auto-discoverable/self-descriptive
-
The two partitions should not be exposed as nested mounts to userspace
To be more specific, here’s how I think a better way to set this all up would look like:
-
Whenever possible, only have one boot partition, not two. On EFI
systems, make it the ESP. On non-EFI systems use an XBOOTLDR
partition instead (see below). Only have both in the case where a
Linux OS is installed on a system that already contains an OS with
an ESP that is too small to carry sufficient kernels/initrds. When a
system contains a XBOOTLDR partition put kernels/initrd on that,
otherwise the ESP. -
Instead of the vaguely defined, traditional Linux “boot” partition
use the XBOOTLDR partition type as defined by the Discoverable
Partitions
Specification. This
ensures the partition is discoverable, and can be automatically
mounted by things like
systemd-gpt-auto-generator. Use
XBOOTLDR only if you have to, i.e., when dealing with systems that
lack UEFI (and where the ESP hence has no value) or to address the
mentioned size issues with the ESP. Note that unlike the traditional
boot partition the XBOOTLDR partition is a shared resource, i.e.,
shared between multiple parallel Linux OS installations on the same
disk. Because of this it is typically wise to place a per-OS
directory at the top of the XBOOTLDR file system to avoid conflicts. -
Use vFAT for both partitions, it’s the only thing
universally understood among relevant firmwares and Linux. It’s
simple enough to be useful for untrusted storage. Or to say this
differently: writing a file system driver that is not easily
vulnerable to rogue disk images is much easier for vFAT than for
let’s say btrfs. – But the choice of vFAT implies some care needs to
be taken to address the data safety issues it brings, see below. -
Mount the two partitions via the “automount”
logic. For example, via systemd’s
automount
units, with a very short idle time-out (one second or so). This
improves data safety immensely, as the file systems will remain
mounted (and thus possibly in a “dirty” state) only for very short
periods of time, when they are actually accessed – and all that
while the fact that they are not mounted continuously is mostly not
noticeable for applications as the file system paths remain
continuously around. Given that the backing file system (vFAT) has
poor data safety properties, it is essential to shorten the access
for unclean file system state as much as possible. In fact, this is
what the aforementionedsystemd-gpt-auto-generator
logic actually does by default. -
Whenever mounting one of the two partitions, do a file system check
(fsck; in fact this is also what
systemd-gpt-auto-generatordoes by default, hooked into
the automount logic, to run on first access). This ensures that even
if the file system is in an unclean state it is restored to be clean
when needed, i.e., on first access. -
Do not mount the two partitions nested, i.e., no
more/boot/efi/. First of all, as mentioned above, it
should be possible (and is desirable) to only have one of the
two. Hence it is simply a bad idea to require the other as well,
just to be able to mount it. More importantly though, by nesting
them, automounting is complicated, as it is necessary to trigger the
first automount to establish the second automount, which defeats the
point of automounting them in the first place. Use the two distinct
mount points/efi/(for the ESP) and
/boot/(for XBOOTLDR) instead. You might have guessed,
but that too is whatsystemd-gpt-auto-generatordoes by
default. -
When making additions or updates to ESP/XBOOTLDR from the OS make
sure to create a file and write it in full, then
syncfs()the whole file system, then rename to give it
its final name, andsyncfs()again. Similar when
removing files. -
When writing from the boot loader environment/UEFI to ESP/XBOOTLDR,
do not append to files or create new files. Instead overwrite
already allocated file contents (for example to maintain a random
seed file) or rename already allocated files to include information
in the file name (and ideally do not increase the file name in
length; for example to maintain boot counters). -
Consider adopting
UKIs,
which minimize the number of files that need to be updated on the
ESP/XBOOTLDR during OS/kernel updates (ideally down to 1) -
Consider adopting
systemd-boot,
which minimizes the number of files that need to be updated on boot
loader updates (ideally down to 1) -
Consider removing any mention of ESP/XBOOTLDR from
/etc/fstab, and just let
systemd-gpt-auto-generatordo its thing. -
Stop implementing file systems, complex storage, disk encryption, …
in your boot loader.
Implementing things like that you gain:
-
Simplicity: only one file system implementation, typically only
one partition and mount point -
Robust auto-discovery of all partitions, no need to even
configure/etc/fstab -
Data safety guarantees as good as possible, given the
circumstances
To summarize this in a table:
| Type | Linux Mount Point | File System Choice | Automount |
|---|---|---|---|
| ESP | /efi/ |
vFAT | yes |
| XBOOTLDR | /boot/ |
vFAT | yes |
A note regarding modern boot loaders that implement the Boot Loader
Specification:
both partitions are explicitly listed in the specification as sources
for both Type #1 and Type #2 boot menu entries. Hence, if you use such
a modern boot loader (e.g. systemd-boot) these two partitions are the
preferred location for boot loader resources, kernels and initrds
anyway.
Addendum: You got RAID?
You might wonder, what about RAID setups and the ESP? This comes up
regularly in discussions: how to set up the ESP so that (software)
RAID1 (mirroring) can be done on the ESP. Long story short: I’d
strongly advise against using RAID on the ESP. Firmware typically
doesn’t have native RAID support, and given that firmware and boot
loader can write to the file systems involved, any attempt to use
software RAID on them will mean that a boot cycle might corrupt the
RAID sync, and immediately requires a re-synchronization after
boot. If RAID1 backing for the ESP is really necessary, the only way
to implement that safely would be to implement this as a driver for
UEFI – but that creates certain bootstrapping issues (i.e., where to
place the driver if not the ESP, a file system the driver is supposed
to be used for), and also reimplements a considerable component of the
OS storage stack in firmware mode, which seems problematic.
So what to do instead? My recommendation would be to solve this via
userspace tooling. If redundant disk support shall be implemented for
the ESP, then create separate ESPs on all disks, and synchronize them
on the file system level instead of the block level. Or in other
words, the tools that install/update/manage kernels or boot loaders
should be taught to maintain multiple ESPs instead of one. Copy the
kernels/boot loader files to all of them, and remove them from all of
them. Under the assumption that the goal of RAID is a more reliable
system this should be the best way to achieve that, as it doesn’t
pretend the firmware could do things it actually cannot do. Moreover
it minimizes the complexity of the boot loader, shifting the syncing
logic to userspace, where it’s typically easier to get right.
Addendum: Networked Boot
The discussion above focuses on booting up from a local disk. When
thinking about networked boot I think two scenarios are particularly
relevant:
-
PXE-style network booting. I think in this mode of operation focus
should be on directly booting a single UKI image instead of a boot
loader. This sidesteps the whole issue of maintaining any boot
partition at all, and simplifies the boot process greatly. In
scenarios where this is not sufficient, and an interactive boot
menu or other boot loader features are desired, it might be a good
idea to take inspiration from the UKI concept, and build a single
boot loader EFI binary (such as systemd-boot), and include the UKIs
for the boot menu items and other resources inside it via PE
sections. Or in other words, build a single boot loader binary that
is “supercharged” and contains all auxiliary resources in its own
PE sections. (Note: this does not exist, it’s an idea I intend to
explore with systemd-boot). Benefit: a single file has to be
downloaded via PXE/TFTP, not more. Disadvantage: unused resources
are downloaded unnecessarily. Either way: in this context there is
no local storage, and the ESP/XBOOTLDR discussion above is without
relevance. -
Initrd-style network booting. In this scenario the boot loader and
kernel/initrd (better: UKI) are available on a local disk. The
initrd then configures the network and transitions to a network
share or file system on a network block device for the root file
system. In this case the discussion above applies, and in fact the
ESP or XBOOTLDR partition would be the only partition available
locally on disk.
And this is all I have for today.
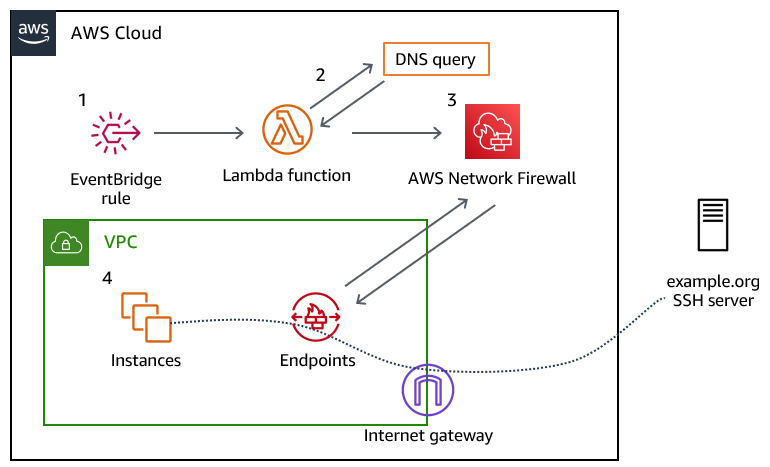








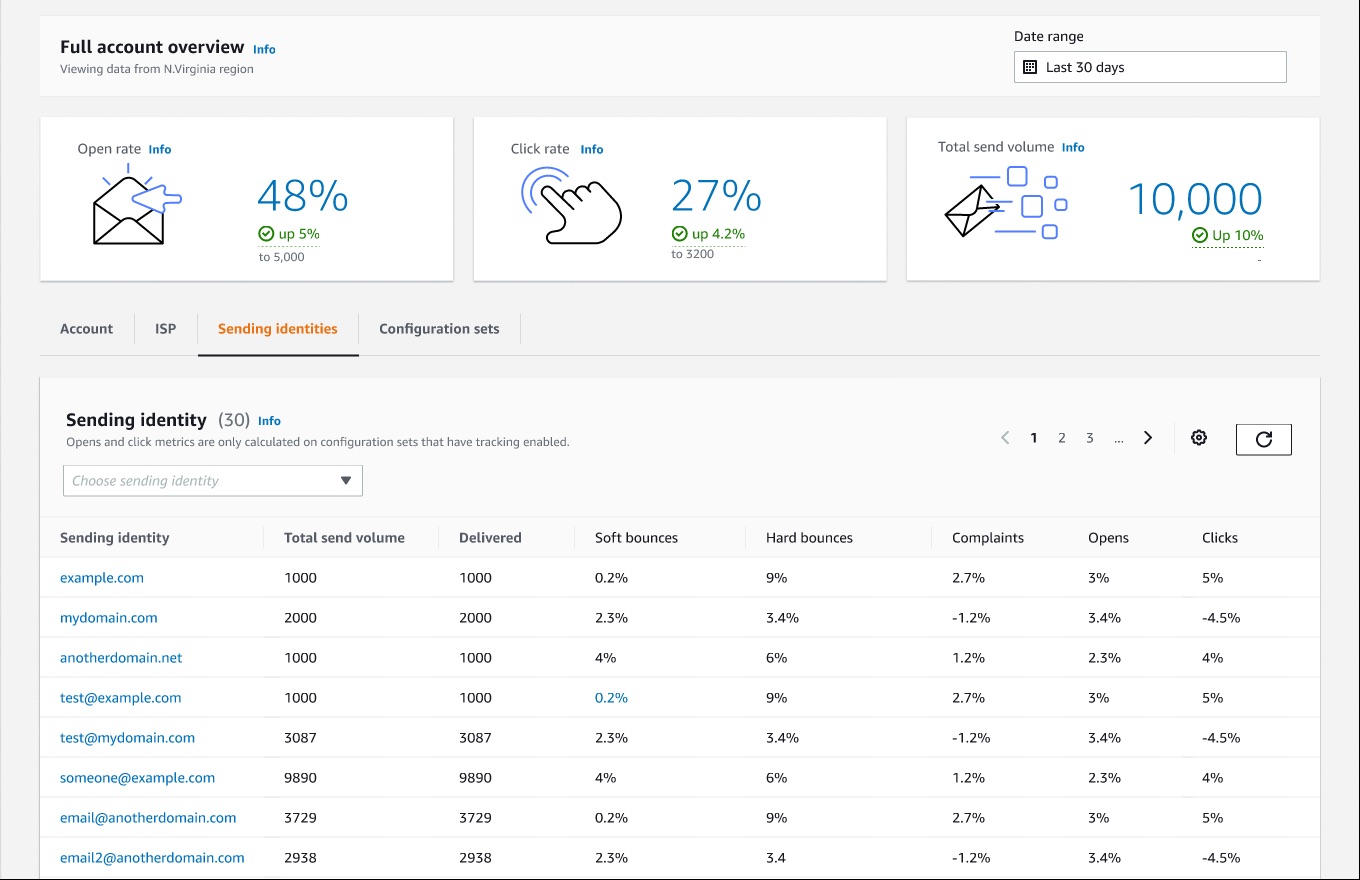
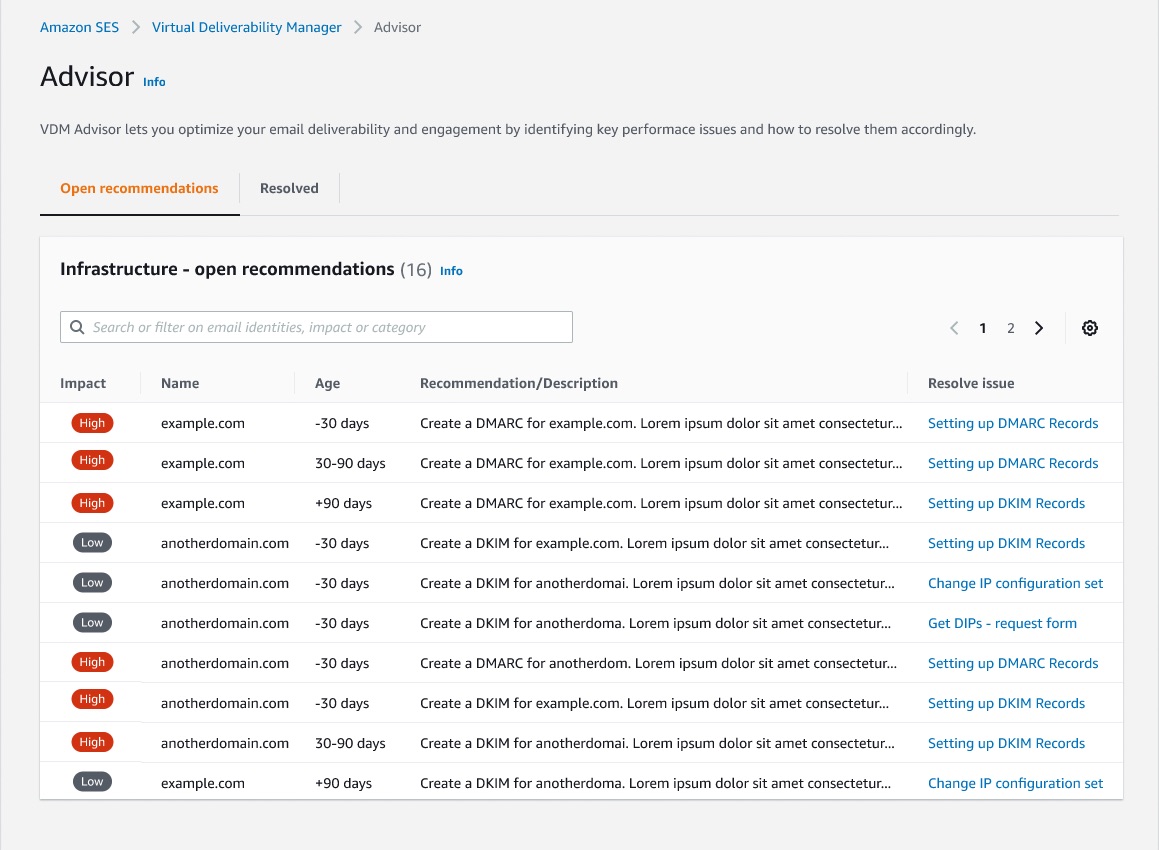 Applying new deliverability features is simple in the AWS console. Senders can log into their SES account dashboard to enable the virtual deliverability manager features. The features are billed as monthly subscription and can be turned on or off at any time. Once the features are activated, SES provides deliverability insights and recommendations in real time, allowing senders to improve performance of future sending batches or campaigns. Senders using Simple Email Service (SES) get reliable, scalable email at the lowest industry prices. SES is backed by AWS’ data security, and email through SES supports compliance with HIPAA-eligible, FedRAMP-, GDPR-, and ISO-certified options.
Applying new deliverability features is simple in the AWS console. Senders can log into their SES account dashboard to enable the virtual deliverability manager features. The features are billed as monthly subscription and can be turned on or off at any time. Once the features are activated, SES provides deliverability insights and recommendations in real time, allowing senders to improve performance of future sending batches or campaigns. Senders using Simple Email Service (SES) get reliable, scalable email at the lowest industry prices. SES is backed by AWS’ data security, and email through SES supports compliance with HIPAA-eligible, FedRAMP-, GDPR-, and ISO-certified options.