Post Syndicated from LastWeekTonight original https://www.youtube.com/shorts/2fH8RYbqSj8
Build scalable REST APIs using Amazon API Gateway private integration with Application Load Balancer
Post Syndicated from Christian Silva original https://aws.amazon.com/blogs/compute/build-scalable-rest-apis-using-amazon-api-gateway-private-integration-with-application-load-balancer/
This post is written by Vijay Menon, Principal Solutions Architect, and Christian Silva, Senior Solutions Architect.
Today, we announced Amazon API Gateway REST API’s support for private integration with Application Load Balancers (ALBs). You can use this new capability to securely expose your VPC-based applications through your REST APIs without exposing your ALBs to the public internet.
Prior to this launch, if you wanted to connect API Gateway to private ALBs, you would have had to use a Network Load Balancer (NLB) as an intermediary, increasing cost and complexity. Now, you can directly integrate API Gateway with private ALBs without requiring an NLB, reducing operational overhead and optimizing cost.
Previous architecture: Connecting API Gateway to private ALBs
Before this launch, API Gateway REST APIs connect to private ALB resources through an NLB positioned in front of the ALB. Many customers have successfully built and operated production workloads using this architecture, demonstrating its reliability for business-critical applications. The following architecture demonstrates this setup.
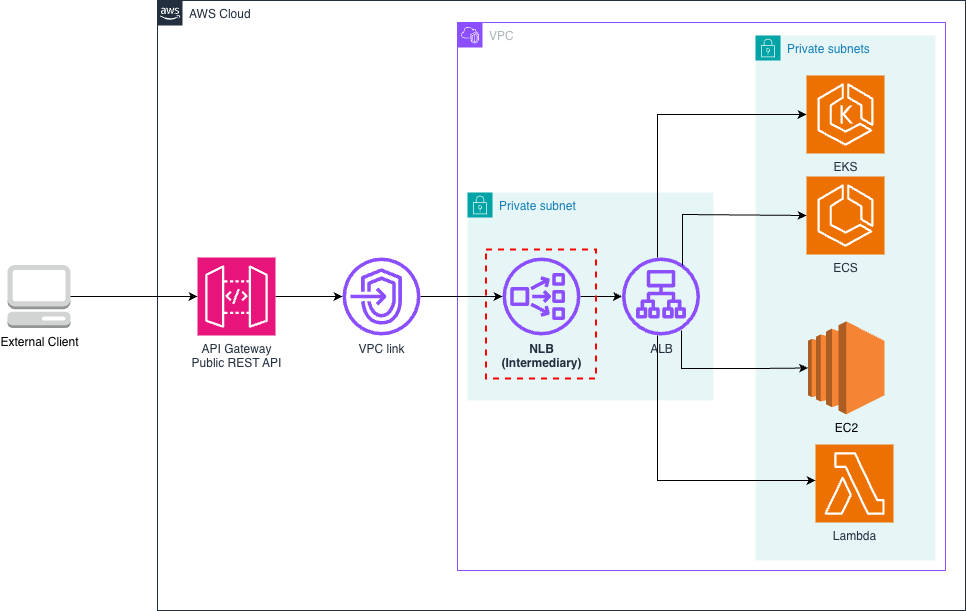
Figure 1. Previous architecture: API Gateway to private ALB via intermediary NLB
In response to customer feedback for a simplified architecture and reduced costs, we’ve extended VPC link v2 support to REST APIs. This feature now enables direct private ALB integration for REST APIs, eliminating the need for an intermediary NLB.
New architecture: Connecting API Gateway to private ALBs
With direct private ALB integration, this architecture becomes simpler and more efficient. The integration removes the need for an intermediate NLB, reducing the number of hops between client and your services. This streamlined setup simplifies the architecture for applications, allowing more efficient use of ALB’s layer-7 load-balancing capabilities, authentication, and authorization features. While these ALB features were technically accessible before, the new architecture removes the overhead and complexity of managing an additional NLB. Here’s how the simplified architecture looks now:
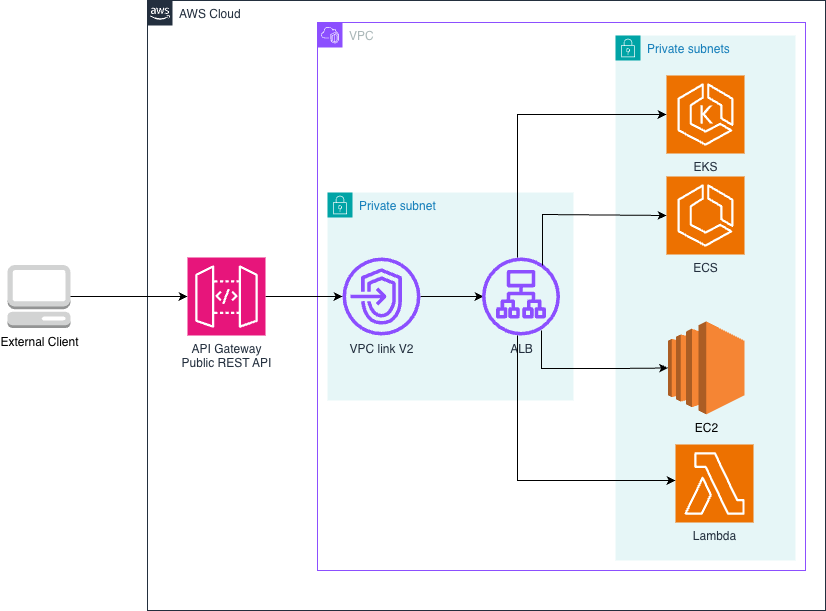
Figure 2. Direct integration between API Gateway and private ALB
Benefits of a direct integration between your API Gateway endpoint and your private ALB
- Architectural simplification and operational excellence: Now that your API Gateway can directly connect to your private ALB, you no longer need an NLB to act as a bridge between your API Gateway and your private ALB. This eliminates the need to provision, configure, manage, or monitor an intermediate load balancer. The reduction in infrastructure components translates to reduced operational overhead and fewer potential failure points. Traffic flows directly from API Gateway to your ALB within the Amazon Web Services (AWS) network, reducing network hops and latency.
- Improved scalability: VPC link v2 supports a one-to-many relationship with load balancers. A single VPC link v2 allows API Gateway to integrate with multiple ALBs or NLBs within your VPC. This architectural advantage is particularly valuable for organizations managing complex applications with multiple microservices, each potentially behind its own ALB, or those running numerous APIs. The ability to consolidate multiple load balancer connections through a single VPC link not only reduces administrative overhead but also provides greater flexibility in scaling your architecture. As your application grows and you add more services or load balancers, you won’t need to provision additional VPC links, making it easier to expand your infrastructure while maintaining operational efficiency.
- Cost optimization: You can remove the NLB from your architecture and thereby eliminate both the hourly charges for running the NLB and the associated Network Load Balancer Capacity Units (NLCU) used per hour. For organizations running multiple environments or numerous APIs, these savings can accumulate to thousands of dollars annually. Moreover, your data transfer patterns become more efficient. Traffic flows directly from API Gateway to your ALB within the AWS network, which avoids any unnecessary hops that could incur more data transfer charges. This streamlined path not only reduces costs but also improves performance by minimizing network latency.
Getting started
This tutorial demonstrates the setup using both the AWS Management Console and AWS Command Line Interface (AWS CLI). Before you begin, make sure that you have an internal ALB configured in your VPC. For resources that need naming, use appropriate names for your environment.
Step 1: Create a VPC link v2
The first step in our process is to create a VPC link v2, which will enable API Gateway to route traffic to your internal ALB. Here’s how to set it up:
- Navigate to the API Gateway console.
- In the left navigation pane, choose VPC links.
- Choose Create VPC link.
- Choose VPC link v2 as the VPC link type.
- Provide a descriptive name for your VPC link.
- Choose your VPC and subnets where your ALB resides. For high availability, choose subnets in multiple AWS Availability Zones (AZs) that match your ALB configuration.
- Assign one or more security groups to your VPC link. These security groups will control the traffic flow between API Gateway and your VPC.
- Choose Create and wait for the VPC link status to become Available. This process can take a few minutes.
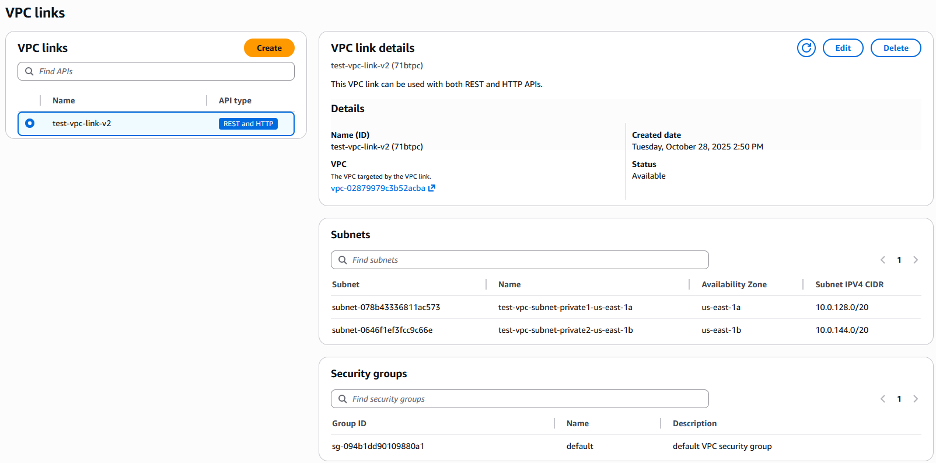
Alternatively, you can create a VPC link v2 using the AWS CLI:
# Create VPC link v2
aws apigatewayv2 create-vpc-link \
--name "test-vpc-link-v2" \
--subnet-ids "<your-subnet1-id>" "<your-subnet2-id>" \
--security-group-ids "<your-security-group-id>" \
--region <your-AWS-region>
# Check VPC link v2 status
aws apigatewayv2 get-vpc-link \
--vpc-link-id "<your-vpc-link-v2-id>" \
--region <your-AWS-region>
Step 2: Create a REST API and configure integration
With your VPC link v2 now available, the next step is to create a REST API and configure it to use the VPC Link. This process involves creating the API, setting up resources and methods, and configuring the integration with your internal ALB.
- In the API Gateway console, choose Create API.
- Choose REST API.
- Enter an API name and choose Create API.
- Create a new resource by choosing Actions, then choose Create resource. This resource will represent the endpoint for your API.
- Create a method by choosing Actions, then choose Create method. The method defines the type of request your API will accept (GET, POST, etc.).
- Now, configure the integration. This is where you’ll connect your API to your internal ALB via the VPC link v2:
- Choose VPC link as the integration type.
- Choose the HTTP method for your backend integration.
- Choose your newly created VPC link v2.
- Specify your ALB as the Integration target.
- Enter the endpoint URL for your integration. The port specified in the URL is used to route requests to the backend.
- Set the Integration timeout.
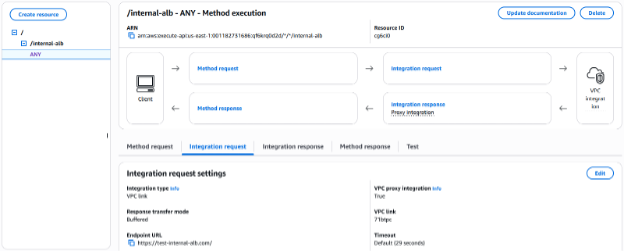
Using the AWS CLI:
# Create REST API
aws apigateway create-rest-api \
--name "test-rest-api" \
--description "REST API integration with internal ALB via VPC link v2" \
--region <your-AWS-region>
# Get REST API’s root resource ID
aws apigateway get-resources \
--rest-api-id "<your-rest-api-id>" \
--region <your-AWS-region>
# Create a new resource
aws apigateway create-resource \
--rest-api-id "<your-rest-api-id>" \
--parent-id "<your-parent-id>" \
--path-part "internal-alb" \
--region <your-AWS-region>
# Create a new method
aws apigateway put-method \
--rest-api-id "<your-rest-api-id>" \
--resource-id "<your-resource-id>" \
--http-method ANY \
--authorization-type NONE \
--region <your-AWS-region>
# Create the integration
aws apigateway put-integration \
--rest-api-id "<your-rest-api-id>" \
--resource-id "<your-resource-id>" \
--http-method ANY \
--type HTTP_PROXY \
--integration-http-method ANY \
--uri "http://test-internal-alb.com/test" \
--connection-type VPC_LINK \
--connection-id "<your-vpc-link-v2-id>" \
--integration-target "<your-ALB-arn>" \
--region <your-AWS-region>
Step 3: Deploy and test
With your API configured, it’s time to deploy it and verify that it’s working correctly.
- Choose Deploy API to create a new deployment of your API.
- Create a new stage (for example “test”). Stages allow you to manage multiple versions of your API.
- After deployment, you’ll receive an API endpoint URL. Copy this URL as you’ll need it for testing.
Test your API using your preferred API client or a simple curl command.
Using the AWS CLI:
# Create a new deployment to a test stage
aws apigateway create-deployment \
--rest-api-id "<your-rest-api-id>" \
--stage-name "test" \
--region <your-AWS-region>
Test your API integration using a curl command:
curl https://<rest-api-id>.execute-api.<your-aws-region>.amazonaws.com/internal-alb
{"message": "Hello from internal ALB"}
Step 4: Scale your VPC link v2
A single VPC link can now connect to multiple ALBs or NLBs within your VPC, simplifying infrastructure management. This AWS CLI snippet demonstrates API Gateway integrating with multiple internal services, for example orders and payments services, each behind its own ALB, using a single VPC link v2. Note how the same VPC link ID is used across both integrations.
# Orders service integration (ALB-1)
aws apigateway put-integration \
--rest-api-id "<your-rest-api-id>" \
--resource-id "<orders-resource-id>" \
--http-method ANY \
--type HTTP_PROXY \
--integration-http-method ANY \
--uri "<your-orders-alb-endpoint>" \
--connection-type VPC_LINK \
--connection-id "<your-vpc-link-v2-id>" \
--integration-target "<your-orders-alb-arn>" \
--region "<your-aws-region>"
# Payments service integration (ALB-2)
aws apigateway put-integration \
--rest-api-id "<your-rest-api-id>" \
--resource-id "<payments-resource-id>" \
--http-method ANY \
--type HTTP_PROXY \
--integration-http-method ANY \
--uri "<your-payments-alb-endpoint>" \
--connection-type VPC_LINK \
--connection-id "<your-vpc-link-v2-id>" \
--integration-target "<your-payments-alb-arn>" \
--region "<your-aws-region>"For a detailed, step-by-step guide, please see our official documentation in the API Gateway Developer Guide.
Use cases
Private ALB integration with API Gateway enables architectural patterns that solve enterprise challenges. These are three key scenarios where organizations can use this new capability:
- Microservices on Amazon ECS and Amazon EKS: Exposing microservices running on Amazon ECS or Amazon EKS becomes simpler with this integration. It allows secure, path-based routing to different services without exposing your ALB to the public internet or using complex NLB proxy patterns.
- Hybrid cloud architectures: Seamless and secure connectivity between cloud-native APIs and on-premises resources is achieved via AWS Direct Connect or AWS Site-to-Site VPN. This setup allows flexible routing based on HTTP methods and headers to various internal systems.
- Enterprise modernization: Gradual application modernization is facilitated by enabling phased migration from monolithic architectures to microservices. Organizations can route traffic between legacy and new components while maintaining operational continuity and minimizing risk.
Conclusion
Direct private integration between API Gateway REST APIs and ALBs enhances API architecture on AWS. By simplifying infrastructure and reducing operational overhead, this capability improves performance and efficiency for API-driven applications.
This feature is available today in all AWS Regions where VPC link v2 and ALBs are present. We can’t wait to see what you build with it and how it transforms your API architectures. Get started now by visiting the API Gateway console and creating your first VPC link v2 for direct ALB integration.
For more information, visit the API Gateway product page, review our pricing details, and explore the comprehensive developer documentation to learn about all the powerful features available to help you build world-class APIs on AWS.
More on Rewiring Democracy
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/11/71226.html
It’s been a month since Rewiring Democracy: How AI Will Transform Our Politics, Government, and Citizenship was published. From what we know, sales are good.
Some of the book’s forty-three chapters are available online: chapters 2, 12, 28, 34, 38, and 41.
We need more reviews—six on Amazon is not enough, and no one has yet posted a viral TikTok review. One review was published in Nature and another on the RSA Conference website, but more would be better. If you’ve read the book, please leave a review somewhere.
My coauthor and I have been doing all sort of book events, both online and in person. This book event, with Danielle Allen at the Harvard Kennedy School Ash Center, is particularly good. We also have been doing a ton of podcasts, both separately and together. They’re all on the book’s homepage.
There are two live book events in December. If you’re in Boston, come see us at the MIT Museum on 12/1. If you’re in Toronto, you can see me at the Munk School at the University of Toronto on 12/2.
I’m also doing a live AMA on the book on the RSA Conference website on 12/16. Register here.
Accelerate investigations with AWS Security Incident Response AI-powered capabilities
Post Syndicated from Daniel Begimher original https://aws.amazon.com/blogs/security/accelerate-investigations-with-aws-security-incident-response-ai-powered-capabilities/
If you’ve ever spent hours manually digging through AWS CloudTrail logs, checking AWS Identity and Access Management (IAM) permissions, and piecing together the timeline of a security event, you understand the time investment required for incident investigation. Today, we’re excited to announce the addition of AI-powered investigation capabilities to AWS Security Incident Response that automate this evidence gathering and analysis work.
AWS Security Incident Response helps you prepare for, respond to, and recover from security events faster and more effectively. The service combines automated security finding monitoring and triage, containment, and now AI-powered investigation capabilities with 24/7 direct access to the AWS Customer Incident Response Team (CIRT).
While investigating a suspicious API call or unusual network activity, scoping and validation require querying multiple data sources, correlating timestamps, identifying related events, and building a complete picture of what happened. Security operations center (SOC) analysts devote a significant amount of time to each investigation, with roughly half of that effort spent manually gathering and piecing together evidence from various tools and complex logs. This manual effort can delay your analysis and response.
AWS is introducing an investigative agent to Security Incident Response, changing this paradigm and adding layers of efficiency. The investigative agent helps you reduce the time required to validate and respond to potential security events. When a case for a security concern is created, either by you or proactively by Security Incident Response, the investigative agent asks clarifying questions to make sure it understands the full context of the potential security event. It then automatically gathers evidence from CloudTrail events, IAM configurations, and Amazon Elastic Compute Cloud (Amazon EC2) instance details and even analyzes cost usage patterns. Within minutes, it correlates the evidence, identifies patterns, and presents you with a clear summary.
How it works in practice
Before diving into an example, let’s paint a clear picture of where the investigative agent lives, how it’s accessed, and its purpose and function. The investigative agent is built directly into Security Incident Response and is automatically available when you create a case. Its purpose is to act as your first responder—gathering evidence, correlating data across AWS services, and building a comprehensive timeline of events so you can quickly move from detection to recovery.
For example: you discover that AWS credentials for an IAM user in your account were exposed in a public GitHub repository. You need to understand what actions were taken with those credentials and properly scope the potential security event, including lateral movement and reconnaissance operations. You need to identify persistence mechanisms that might have been created and determine the appropriate containment steps. To get started, you create a case in the Security Incident Response console and describe the situation.
Here’s where the agent’s approach differs from traditional automation: it asks clarifying questions first. When were the credentials first exposed? What’s the IAM user name? Have you already rotated the credentials? Which AWS account is affected?
This interactive step gathers the appropriate details and metadata before it starts gathering evidence. Specifically, you’re not stuck with generic results—the investigation is tailored to your specific concern.
After the agent has what it needs, it investigates. It looks up CloudTrail events to see what API calls were made using the compromised credentials, pulls IAM user and role details to check what permissions were granted, identifies new IAM users or roles that were created, checks EC2 instance information if compute resources were launched, and analyzes cost and usage patterns for unusual resource consumption. Instead of you querying each AWS service, the agent orchestrates this automatically.
Within minutes, you get a summary, as shown in the following figure. The investigation summary includes a high-level summary and critical findings, which include the credential exposure pattern, observed activity and the timeframe, affected resources, and limiting factors.
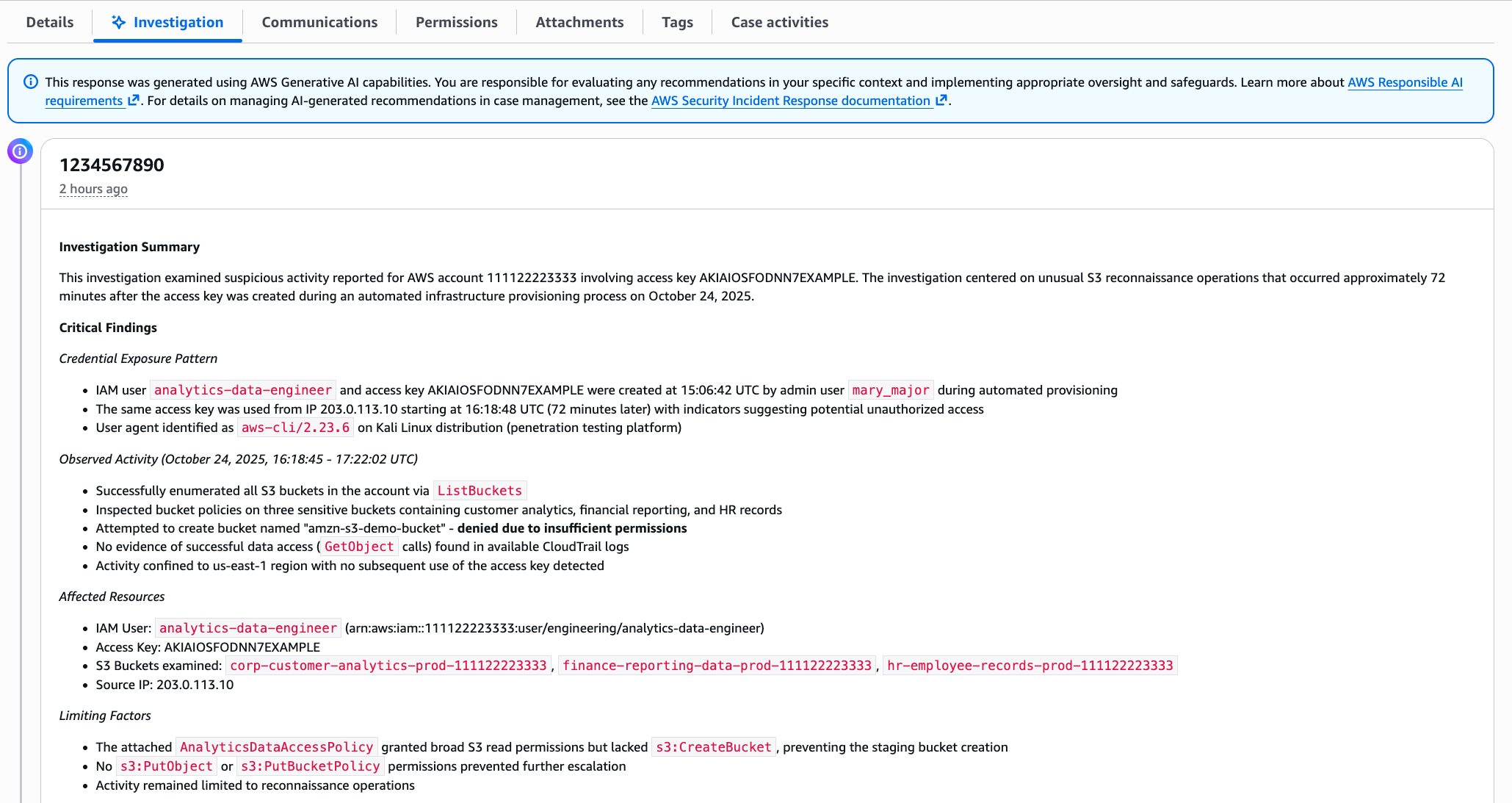
This response was generated using AWS Generative AI capabilities. You are responsible for evaluating any recommendations in your specific context and implementing appropriate oversight and safeguards. Learn more about AWS Responsible AI requirements.
Note: The preceding example is representative output. Exact formatting will vary depending on findings.
The investigation summary includes various tabs for detailed information, such as technical findings with an events timeline, as shown in the following figure:

Figure 2 – Security event timeline
When seconds count, this transparency is paramount to a quick, high-fidelity, and accurate response—especially if you need to escalate to the AWS CIRT, a dedicated group of AWS security experts, or explain your findings to leadership, creating a single lens for stakeholders to view the incident.
When the investigation is complete, you have a high-resolution picture of what happened and can make informed decisions about containment, eradication, and recovery. For the preceding exposed credentials scenario, you might need to:
- Delete the compromised access keys
- Remove the newly created IAM role
- Terminate the unauthorized EC2 instances
- Review and revert associated IAM policy changes
- Check for additional access keys created for other users.
When you engage with the CIRT, they can provide additional guidance on containment strategies based on the evidence the agent gathered.
What this means for your security operations
The leaked credentials scenario shows what the agent can do for a single incident. But the bigger impact is on how you operate day-to-day:
- You spend less time on evidence collection. The investigative agent automates the most time-consuming part of investigations—gathering and correlating evidence from multiple sources. Instead of spending an hour on manual log analysis, you can spend most of that time on making containment decisions and preventing recurrence.
- You can investigate in plain language. The investigative agent uses natural language processing (NLP), which you can use to describe what you’re investigating in plain language, such as
unusual API calls from IP address Xordata access from terminated employee’s credentials, and the agent translates that into the technical queries needed. You don’t need to be an expert in AWS log formats or know the exact syntax for querying CloudTrail. - You get a foundation for high-fidelity and accurate investigations. The investigative agent handles the initial investigation—gathering evidence, identifying patterns, and providing a comprehensive summary. If your case requires deeper analysis or you need guidance on complex scenarios, you can engage with the AWS CIRT, who can immediately build on the work the agent has already done, speeding up their response time. They see the same evidence and timeline, so they can focus on advanced threat analysis and containment strategies rather than starting from scratch.
Getting started
If you already have Security Incident Response enabled, the AI-powered investigation capabilities are available now—no additional configuration needed. Create your next security case and the agent will start working automatically.
If you’re new to Security Incident Response, here’s how to set it up:
- Enable Security Incident Response through your AWS Organizations management account. This takes a few minutes through the AWS Management Console and provides coverage across your accounts.
- Create a case. Describe what you’re investigating; you can do this through the Security Incident Response console or an API, or set up automatic case creation from Amazon GuardDuty or AWS Security Hub alerts.
- Review the analysis. The agent presents its findings through the Security Incident Response console, or you can access them through your existing ticketing systems such as Jira or ServiceNow.
The investigative agent uses the AWS Support service-linked role to gather information from your AWS resources. This role is automatically created when you set up your AWS account and provides the necessary access for Support tools to query CloudTrail events, IAM configurations, EC2 details, and cost data. Actions taken by the agent are logged in CloudTrail for full auditability.
The investigative agent is included at no additional cost with Security Incident Response, which now offers metered pricing with a free tier covering your first 10,000 findings ingested per month. Beyond that, findings are billed at rates that decrease with volume. With this consumption-based approach, you can scale your security incident response capabilities as your needs grow.
How it fits with existing tools
Security Incident Response cases can be created by customers or proactively by the service. The investigative agent is automatically triggered when a new case is created, and cases can be managed through the console, API, or Amazon EventBridge integrations.
You can use EventBridge to build automated workflows that route security events from GuardDuty, Security Hub, and Security Incident Response itself to create cases and initiate response plans, enabling end-to-end detection-to-investigation pipelines. Before the investigative agent begins its work, the service’s auto-triage system monitors and filters security findings from GuardDuty and third-party security tools through Security Hub. It uses customer-specific information, such as known IP addresses and IAM entities, to filter findings based on expected behavior, reducing alert volume while escalating alerts that require immediate attention. This means the investigative agent focuses on alerts that actually need investigation.
Conclusion
In this post, I showed you how the new investigative agent in AWS Security Incident Response automates evidence gathering and analysis, reducing the time required to investigate security events from hours to minutes. The agent asks clarifying questions to understand your specific concern, automatically queries multiple AWS data sources, correlates evidence, and presents you with a comprehensive timeline and summary while maintaining full transparency and auditability.
With the addition of the investigative agent, Security Incident Response customers now get the speed and efficiency of AI-powered automation, backed by the expertise and oversight of AWS security experts when needed.
The AI-powered investigation capabilities are available today in all commercial AWS Regions where Security Incident Response operates. To learn more about pricing and features, or to get started, visit the AWS Security Incident Response product page.
If you have feedback about this post, submit comments in the Comments section below.
GL.iNet Comet PoE 4K Remote KVM Mini Review
Post Syndicated from Eric Smith original https://www.servethehome.com/gl-inet-comet-poe-4k-remote-kvm-review-gl-rm1pe/
We take a look at the GL.iNet Comet GL-RM1PE, a little PoE-powered box that lets you easily remotely manage systems as if you were sitting next to them
The post GL.iNet Comet PoE 4K Remote KVM Mini Review appeared first on ServeTheHome.
Sports-gambling Sites Aren’t Playing the Long Game
Post Syndicated from The Atlantic original https://www.youtube.com/shorts/VRTKDBeSOzc
Pablo Torre on the Gambling Boom That Could Break Sports
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=7XYpenjgxZw
Introducing Cluster insights: Unified monitoring dashboard for Amazon OpenSearch Service clusters
Post Syndicated from Siddhant Gupta original https://aws.amazon.com/blogs/big-data/introducing-cluster-insights-unified-monitoring-dashboard-for-amazon-opensearch-service-clusters/
Amazon OpenSearch Service clusters offer a wealth of operational metrics accessible through CloudWatch and the Amazon OpenSearch Service console to support effective performance monitoring and alert creation. Yet, pinpointing resiliency and performance challenges within your cluster can prove daunting. The process of identifying resource-intensive queries or understanding performance degradation trends can be time-consuming.
To address these challenges, we launched Cluster insights, which presents a unified dashboard delivering curated insights along with actionable mitigation steps. The dashboard displays detailed metrics at the node, index, and shard levels, coupled with a concise summary of security and resiliency best practices to uphold peak resiliency and availability.
This blog will guide you through setting up and using Cluster Insights, including key features and metrics. By the conclusion, you’ll understand how to use Cluster insights to recognize and address performance and resiliency issues within your OpenSearch Service clusters.
Getting Started with Cluster insights
Cluster insights is available at no additional cost to OpenSearch Service users running OpenSearch version 2.17 or later. Accessing Cluster insights requires admin-level permissions for your OpenSearch domain. Cluster insights is available only through the OpenSearch UI. OpenSearch UI offers support to multiple data sources, zero downtime upgrades for your dashboard experience, and curated workspaces for effective team collaborations. You first need to associate a data source (your clusters) with an OpenSearch UI application. Detailed steps are described in the user guide. Your OpenSearch UI console experience will look like following screenshots.
To access Cluster insights using the OpenSearch UI application:
- In the Amazon OpenSearch Service console, navigate to OpenSearch UI (Dashboards) and choose the Application URL to access your OpenSearch UI application.

- OpenSearch UI application, choose the settings icon at the left-bottom corner, then choose Data administration.
- On the Data administration overview page, or under Manage data in the left navigation, select Cluster insights.
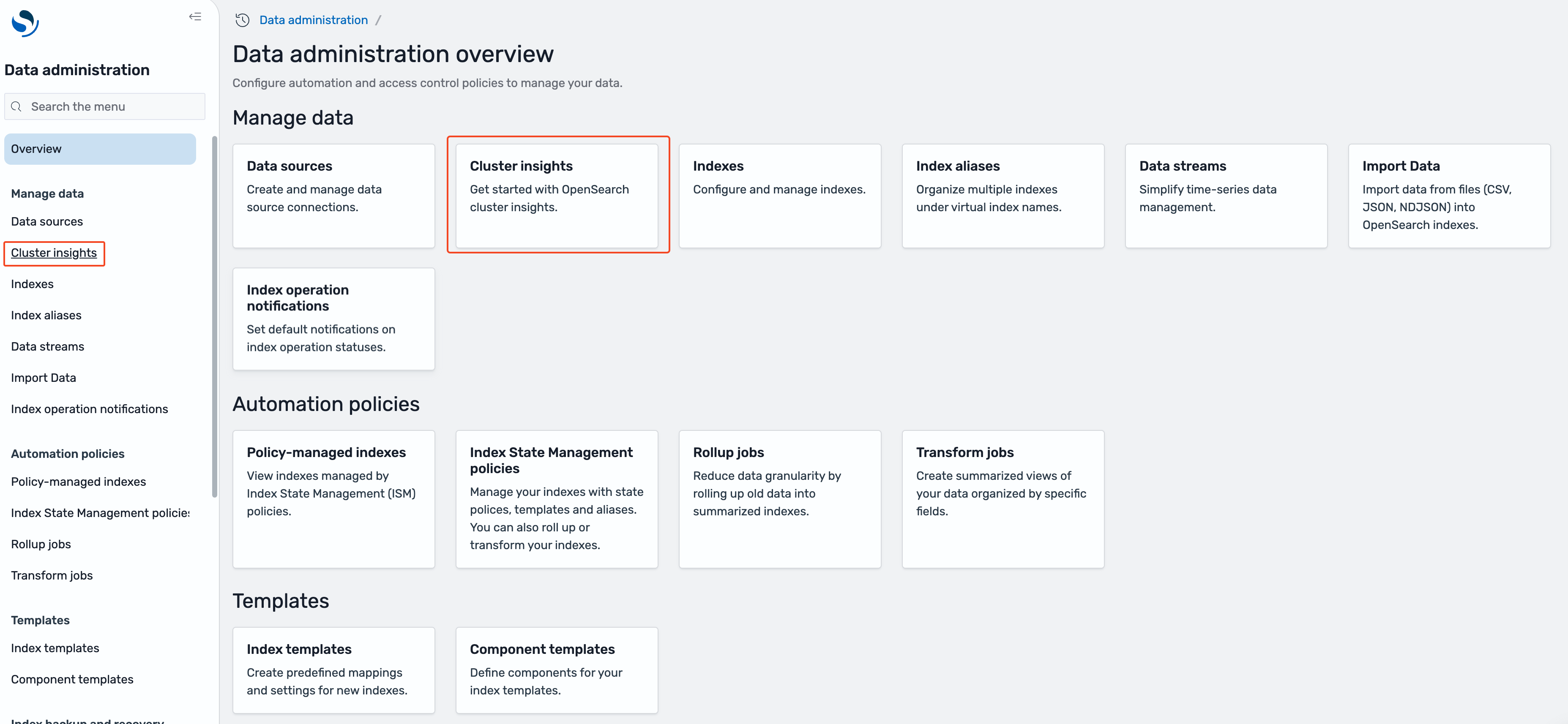
Cluster insights overview
The Cluster insights – Overview acts as a landing page to show health and insights for all connected OpenSearch domains. It is organized into five sections:
- Current cluster status – Displays cluster health status (Green, Yellow, and Red) in a donut chart.
- Insights trend – Tracks issue patterns over the past 30 days, helping you identify emerging problems and track resolution progress. This trend analysis becomes particularly valuable when monitoring the impact of operational changes or troubleshooting recurring issues.
- Current open insights – Shows the count and severity breakdown of currently active insights across your clusters.
- OpenSearch service clusters – Lists all domains with their vital statistics such as health status, insights count, nodes, shards, and active queries.
- Top insights by severity – Prioritizes issues that need immediate attention. Each insight comes with a clear description and specific recommendations, transforming complex monitoring data into actionable tasks. This prioritized view helps teams can focus on critical issues first, whether they’re addressing shard size problems, disk space issues, or performance bottlenecks.
Together, these sections provide a comprehensive view of your OpenSearch Service infrastructure so you can assess cluster health, identify trends, and take action on critical issues from a single dashboard.
Cluster health
When you choose a specific cluster from the OpenSearch domains on the Cluster insights – Overview page, you will see cluster-specific details including health status, active insights, and performance metrics. The overview section displays cluster health along with essential metrics including count of shards, nodes, indices, and a total document size. You can also review the configuration best practices followed by domain across resiliency and security areas.
The lower section contains a table of actionable insights that presents a detailed view of current issues. This table mirrors the insights from the landing page but focuses specifically on issues affecting the selected cluster. You can observe high-severity issues such as low disk space and shard count problems, as well as medium-severity concerns that may impact cluster performance.
Each insight entry serves as an interactive element – selecting any issue reveals an in-depth analysis complete with root cause identification and specific remediation steps. The table includes important metadata such as generation timestamps, severity levels, recommendation counts, and current status, so users can prioritize and address issues effectively.
Insight details
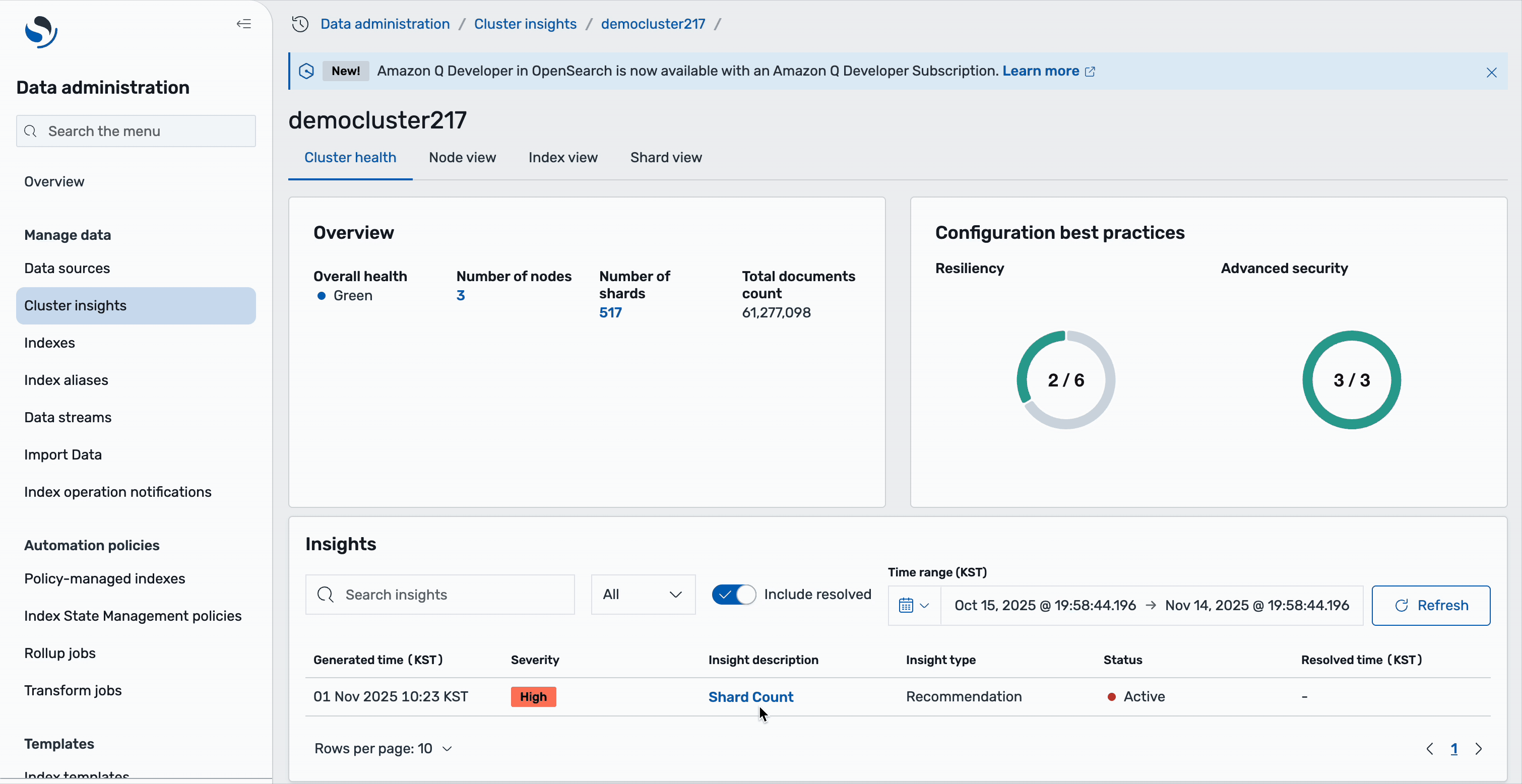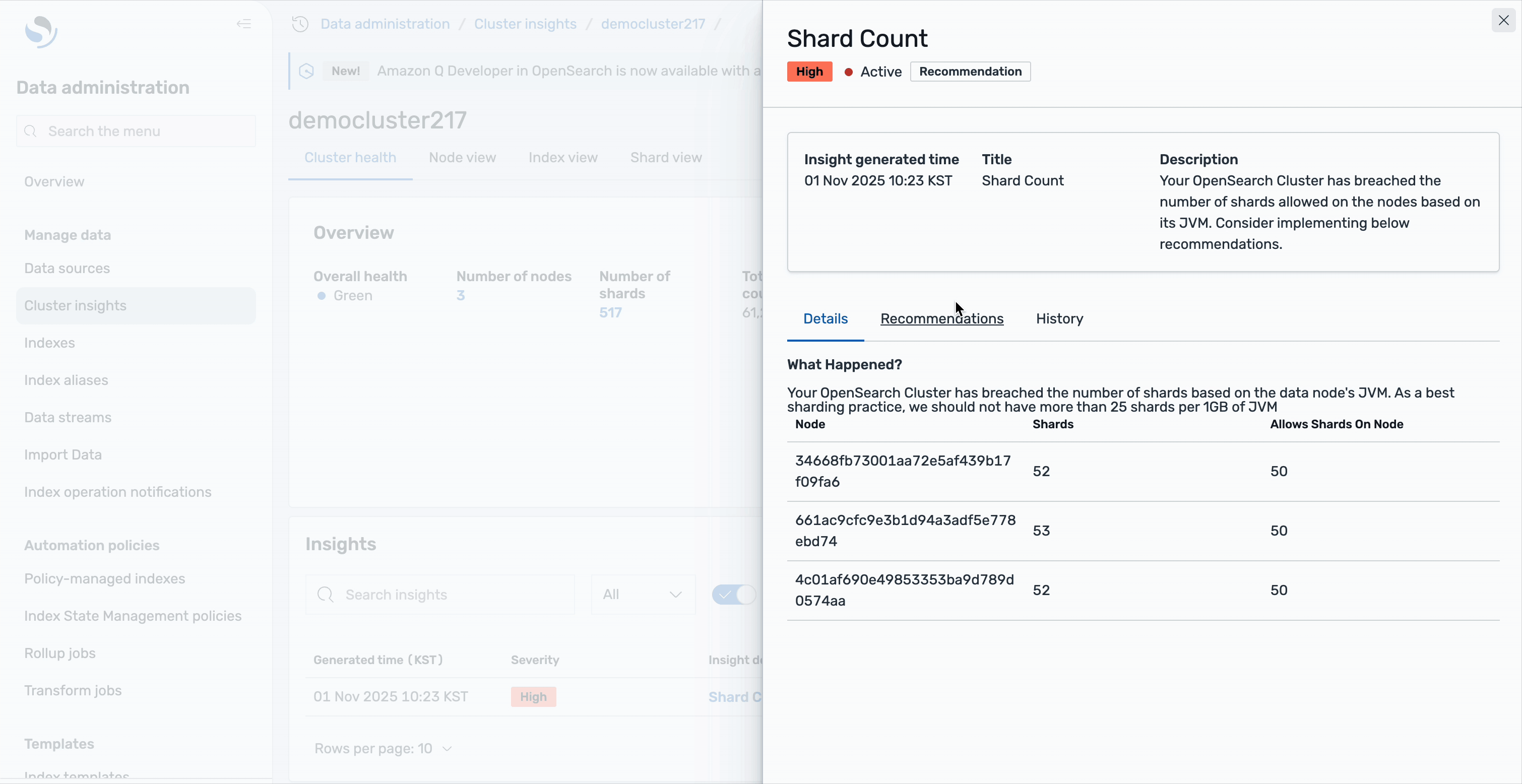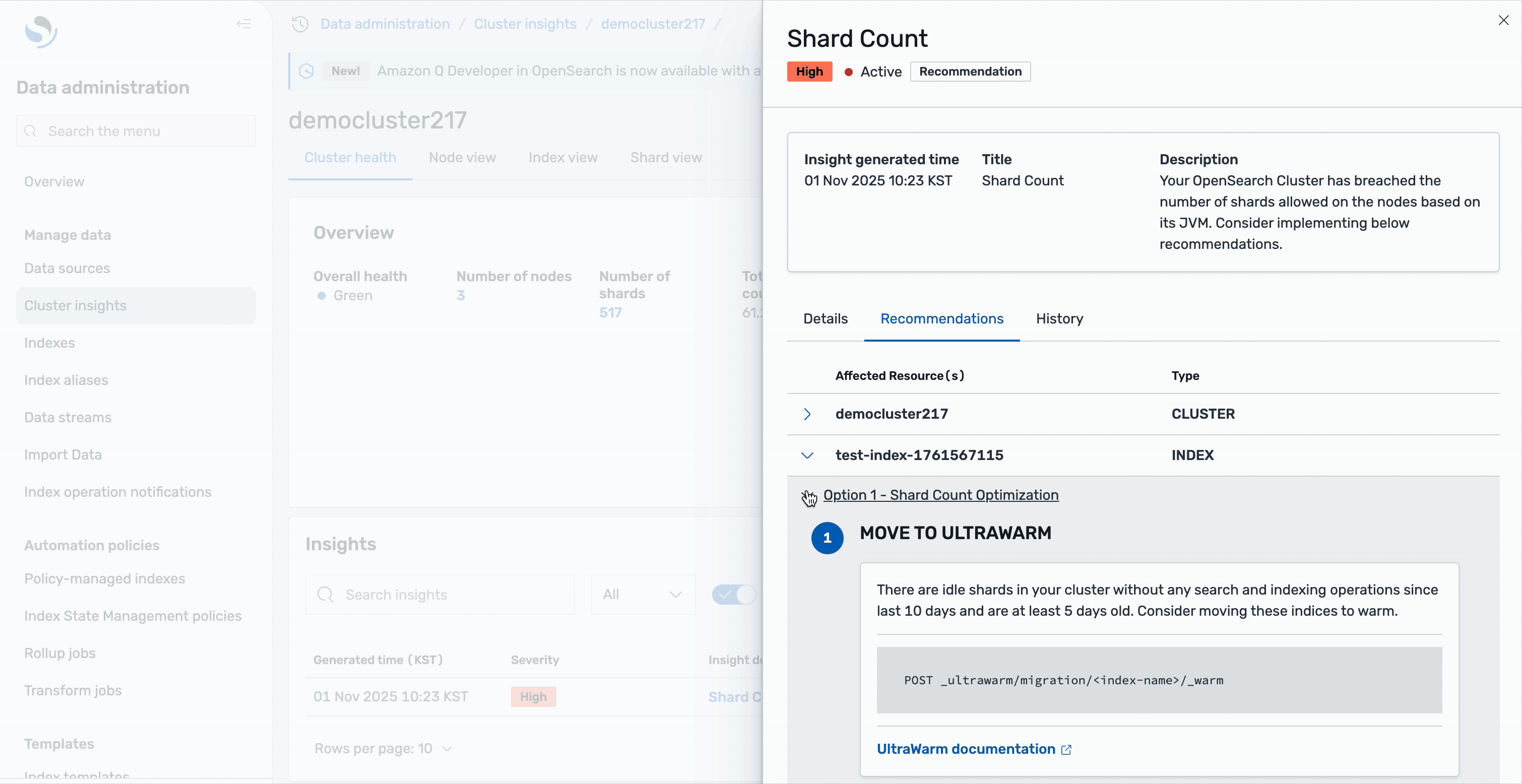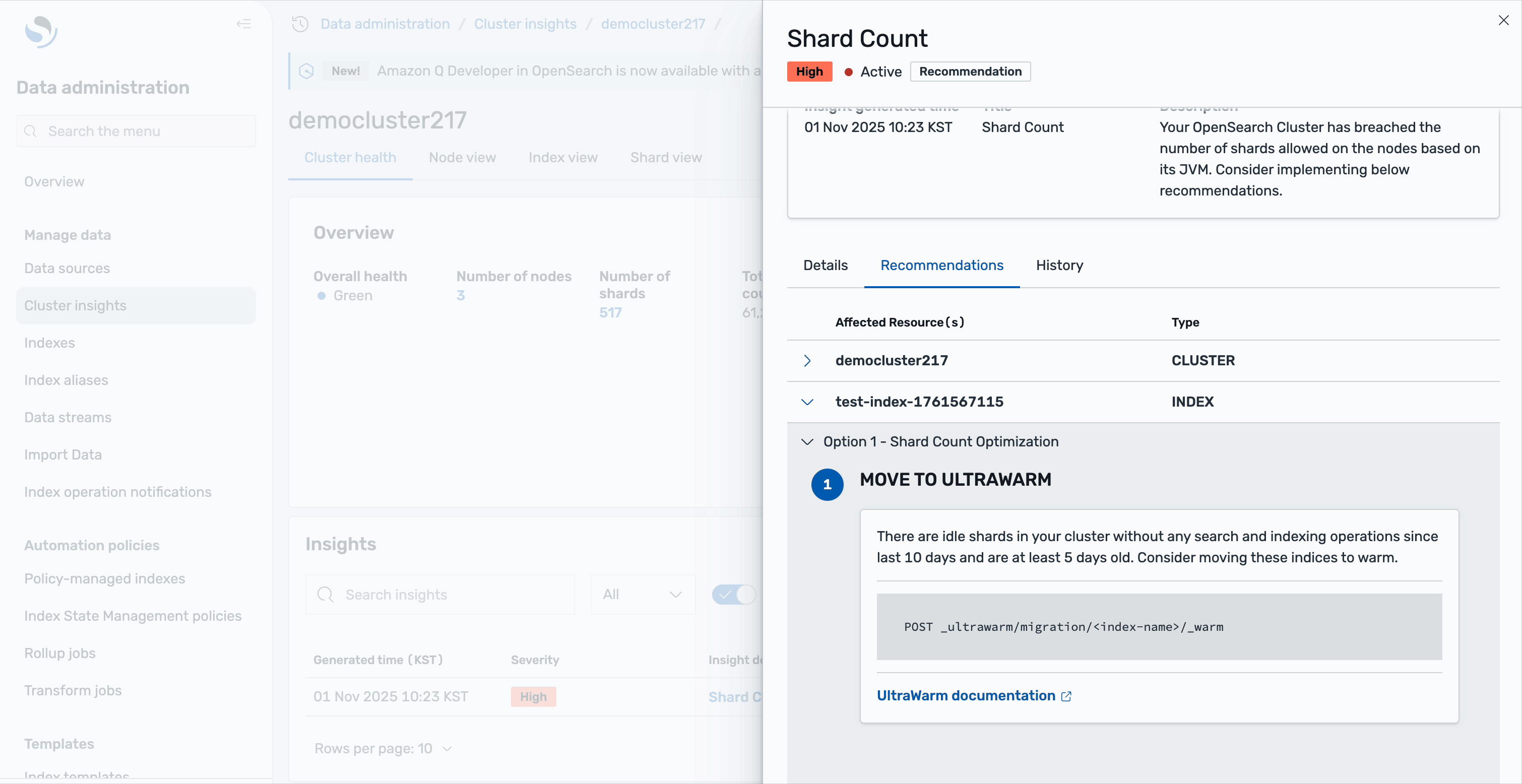
Every insight offers detailed analysis and actionable recommendations. Take the Shard Count insight as an example: selecting it reveals a comprehensive breakdown of the issue. You’ll see that your OpenSearch cluster has breached the number of shards allowed on the nodes based on its JVM heap size, along with a detailed list of affected resources.

The detailed view includes a resource map that precisely identifies each impacted node and index, displaying critical information such as node IDs, shard counts, and the indices contributing to the issue.
The recommendations are organized into two levels: cluster-level recommendations address overall architecture improvements, such as scaling your cluster or adjusting global shard allocation settings. Index-level recommendations provide specific actions for individual indices—for example, you might see suggestions to move idle shards to UltraWarm storage. These are shards without any search or indexing operations for the last 10 days and are at least 5 days old, making them ideal candidates for warm storage to reduce the active shard count. All of this guidance is available directly within the Cluster insights interface, eliminating the need to switch between different tools or consoles.
Node, Index, Shard, and Query view
Next to cluster health, you can review Node, Index, Shard, and Query details for a specific cluster. These views present critical metrics such as resource (CPU, memory, disk) utilization, search and index latency.
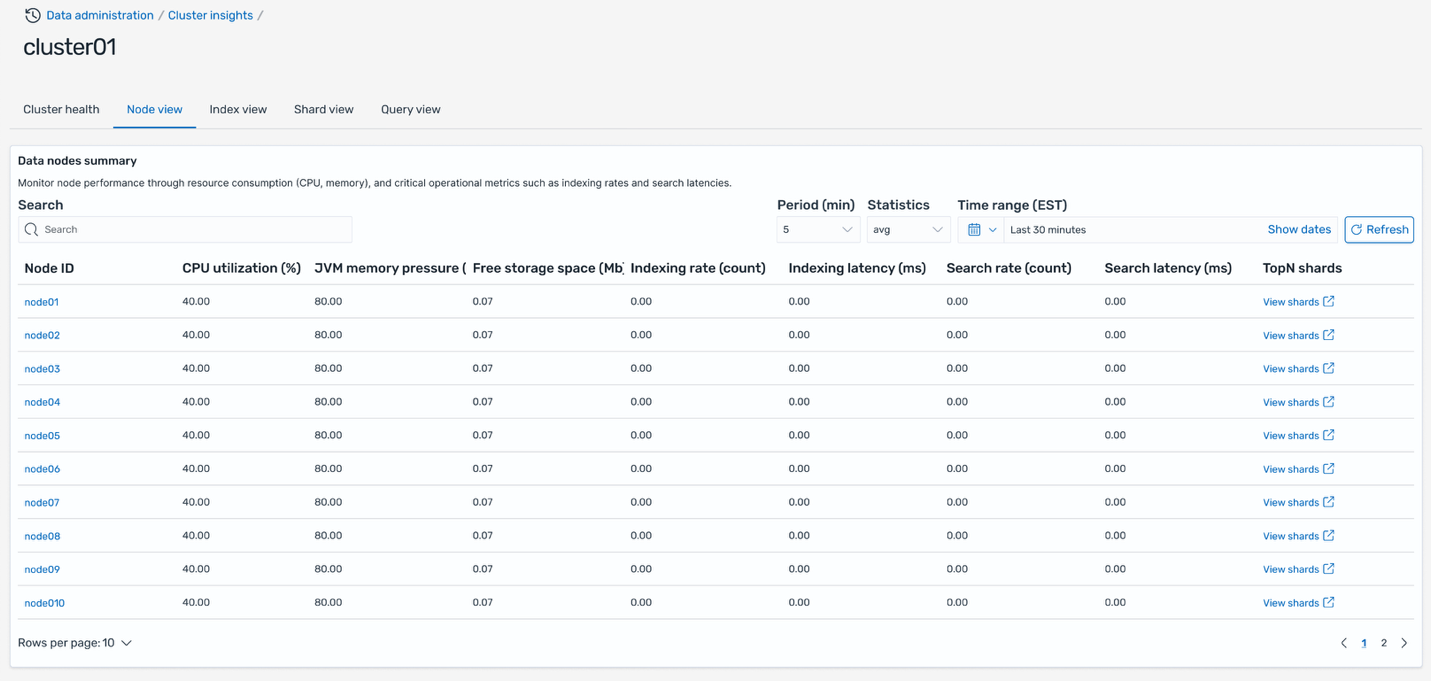
Node view
The Node view tab provides a comprehensive view of individual node performance across your cluster. This table displays critical metrics for each node including heat score indicating overall node health, resource utilization (CPU, memory, disk), search and indexing latency and rates, along with quick links to view top N shards and queries running on each node.
This view helps you identify nodes experiencing high resource utilization or performance degradation. You can drill deeper into each node by clicking on the node ID to view detailed time-based metrics showing resource usage trends over time. Additionally, you can click the top N shards link to navigate directly to the Shard View, automatically filtered to show only the shards running on the selected node, allowing you to pinpoint which specific shards are contributing to performance issues.
Index view
The Index view tab shows performance metrics aggregated at the index level. For each index, you can monitor document count and storage size, search latency and rate, indexing latency and rate, and access top N queries affecting the index. This perspective is valuable for understanding which indices are driving cluster load and identifying optimization opportunities at the index configuration level.

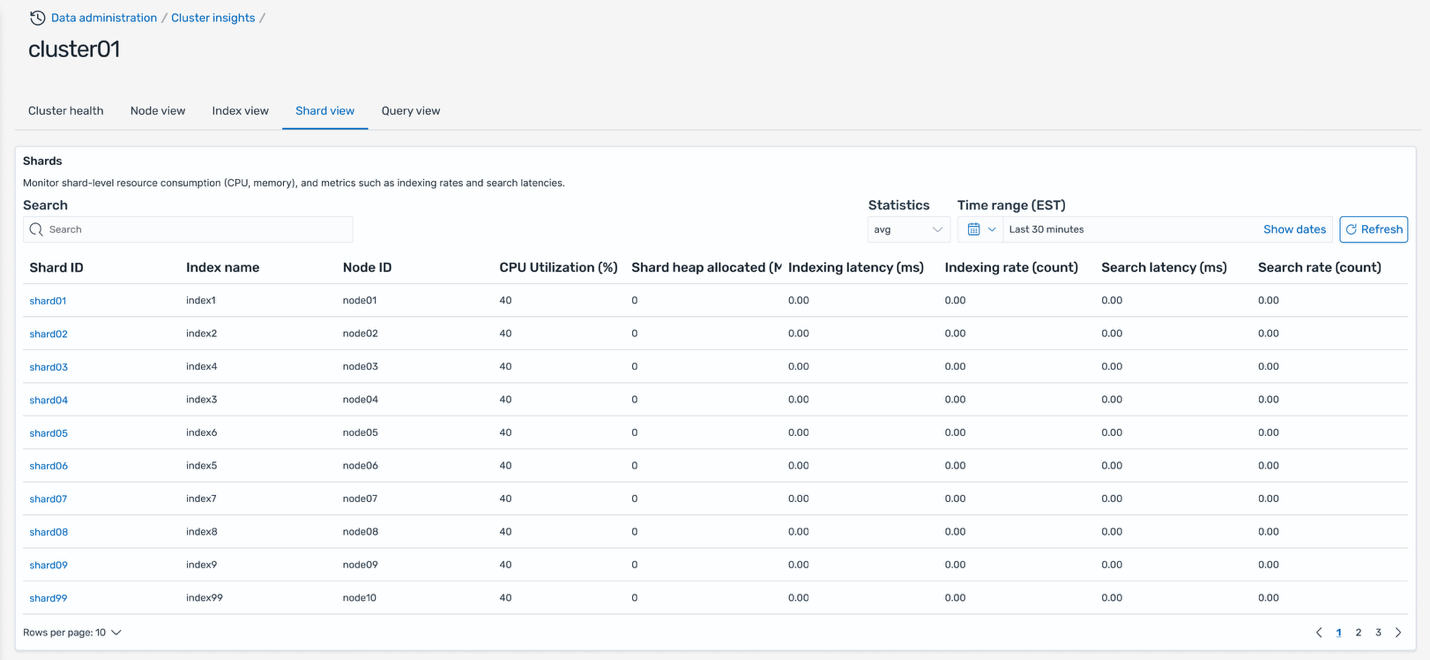
Shard view
The Shard view tab offers the most granular view of cluster performance by displaying metrics for individual shards. Each row shows shard ID and its assigned node, index association and resource pressure metrics (CPU, memory), along with search and indexing latency per shard. This detailed view enables you to pinpoint specific shards causing performance issues, identify shard placement imbalances, and take targeted remediation actions.
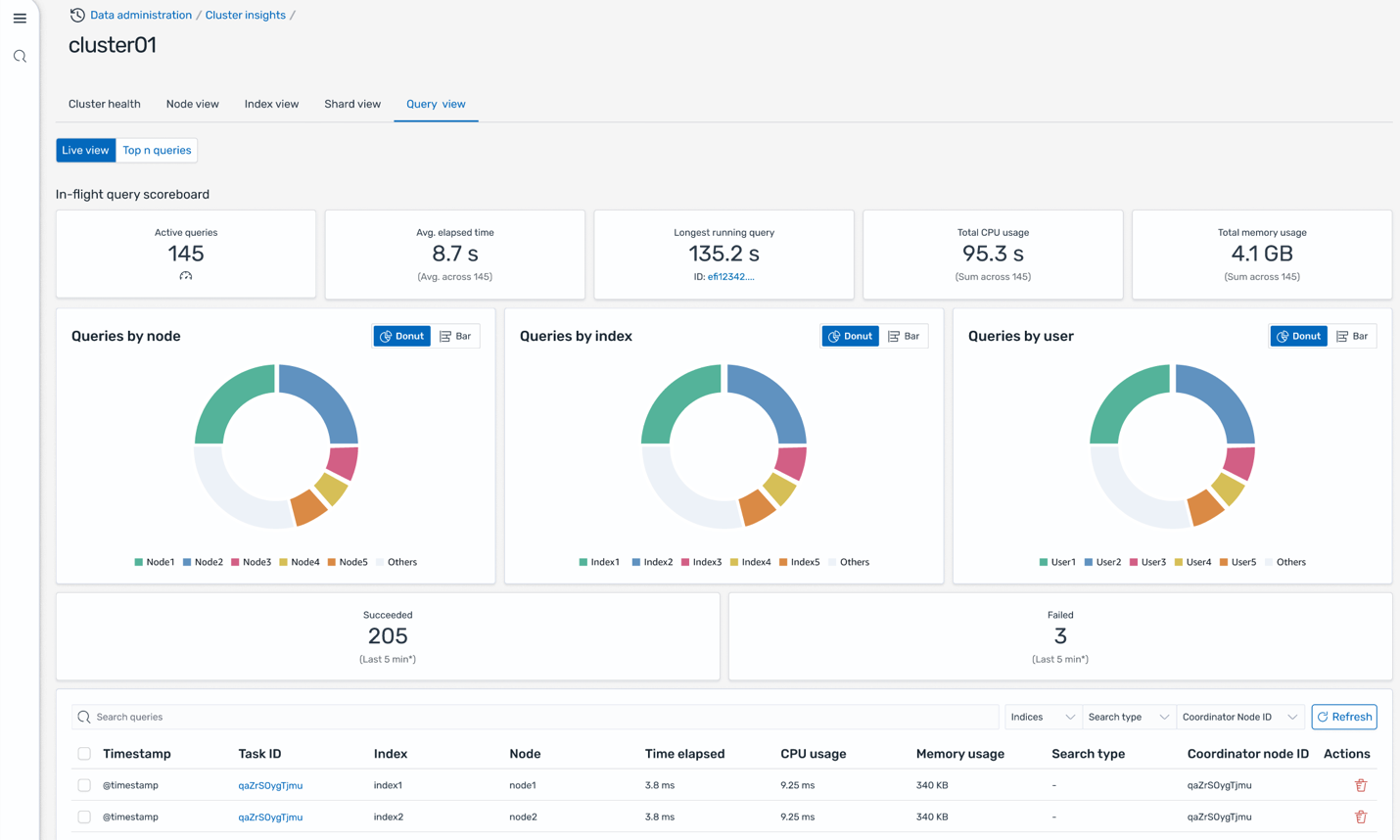
Query view
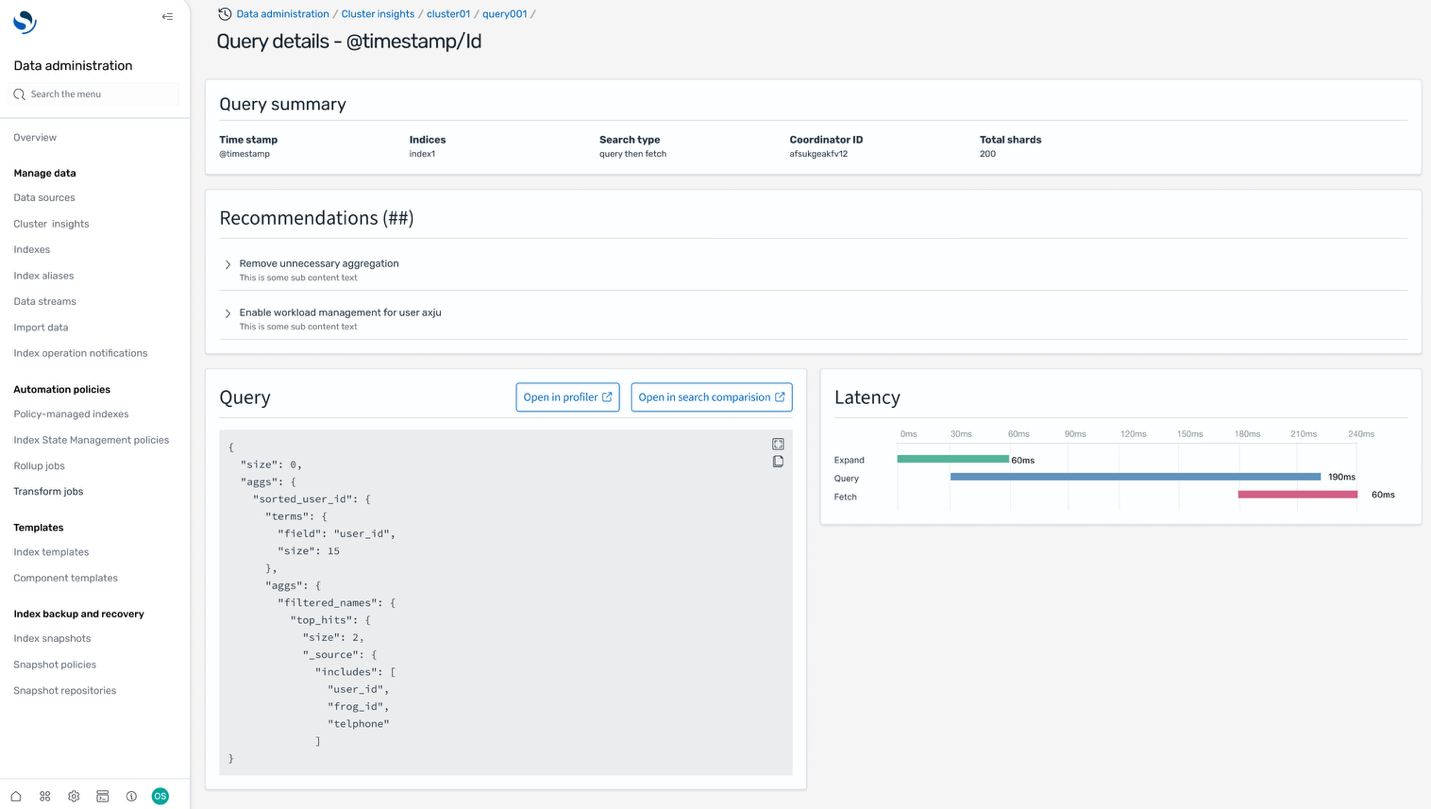
The Query view on the Cluster insights page solves presents live dashboards that break down execution stats, CPU and memory usage, and completion progress for every query. This helps monitor which queries are driving the biggest resource consumption (the Top-N queries). With intuitive donut charts and scoreboards showing distribution by node, index, and user, this interface helps operators to quickly pinpoint performance bottlenecks and heavy workloads, supporting targeted optimization and confident scaling decisions.
Query insights
In addition to Cluster insights, you can also get Query insights to view the exact queries running and latencies across Expand, Query, and Fetch phases that provides valuable insights for search developers to further fine-tune their queries.
Conclusion
Cluster insights transforms OpenSearch Service cluster management from reactive troubleshooting to proactive optimization. By providing unified dashboards with heat score, and best practices across stability, resiliency, and security pillars, it offers visibility into your search infrastructure at the account level.
The actionable recommendations and step-by-step remediation guidance help users of all experience levels effectively resolve complex issues like shard imbalances and resource bottlenecks.
The integration with Query insights delivers real-time visibility into resource consumption patterns so that teams can identify and optimize performance-critical queries through detailed profiling and latency analysis.
For more information, see the AWS OpenSearch Service User Guide for additional details.
About the authors
Introducing VPC encryption controls: Enforce encryption in transit within and across VPCs in a Region
Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/introducing-vpc-encryption-controls-enforce-encryption-in-transit-within-and-across-vpcs-in-a-region/
Today, we’re announcing virtual private cloud (VPC) encryption controls, a new capability of Amazon Virtual Private Cloud (Amazon VPC) that helps you audit and enforce encryption in transit for all traffic within and across VPCs in a Region.
Organizations across financial services, healthcare, government, and retail face significant operational complexity in maintaining encryption compliance across their cloud infrastructure. Traditional approaches require piecing together multiple solutions and managing complex public key infrastructure (PKI), while manually tracking encryption across different network paths using spreadsheets—a process prone to human error that becomes increasingly challenging as infrastructure scales.
Although AWS Nitro based instances automatically encrypt traffic at the hardware layer without affecting performance, organizations need simple mechanisms to extend these capabilities across their entire VPC infrastructure. This is particularly important for demonstrating compliance with regulatory frameworks such as Health Insurance Portability and Accountability (HIPAA), Payment Card Industry Data Security Standard (PCI DSS), and Federal Risk and Authorization Management Program (FedRAMP), which require proof of end-to-end encryption across environments. Organizations need centralized visibility and control over their encryption status, without having to manage performance trade-offs or complex key management systems.
VPC encryption controls address these challenges by providing two operational modes: monitor and enforce. In monitor mode, you can audit the encryption status of your traffic flows and identify resources that allow plaintext traffic. The feature adds a new encryption-status field to VPC flow logs, giving you visibility into whether traffic is encrypted using Nitro hardware encryption, application-layer encryption (TLS), or both.
After you’ve identified resources that need modification, you can take steps to implement encryption. AWS services, such as Network Load Balancer, Application Load Balancer, and AWS Fargate tasks, will automatically and transparently migrate your underlying infrastructure to Nitro hardware without any action required from you and with no service interruption. For other resources, such as the previous generation of Amazon Elastic Compute Cloud (Amazon EC2) instances, you will need to switch to modern Nitro based instance types or configure TLS encryption at application level.
You can switch to enforce mode after all resources have been migrated to encryption-compliant infrastructure. This migration to encryption-compliant hardware and communication protocols is a prerequisite for enabling enforce mode. You can configure specific exclusions for resources such as internet gateways or NAT gateways, that don’t support encryption (because the traffic flows outside of your VPC or the AWS network).
Other resources must be encryption-compliant and can’t be excluded. After activation, enforce mode provides that all future resources are only created on compatible Nitro instances, and unencrypted traffic is dropped when incorrect protocols or ports are detected.
Let me show you how to get started
For this demo, I started three EC2 instances. I use one as a web server with Nginx installed on port 80, serving a clear text HTML page. The other two are continuously making HTTP GET requests to the server. This generates clear text traffic in my VPC. I use the m7g.medium instance type for the web server and one of the two clients. This instance type uses the underlying Nitro System hardware to automatically encrypt in-transit traffic between instances. I use a t4g.medium instance for the other web client. The network traffic of that instance is not encrypted at the hardware level.
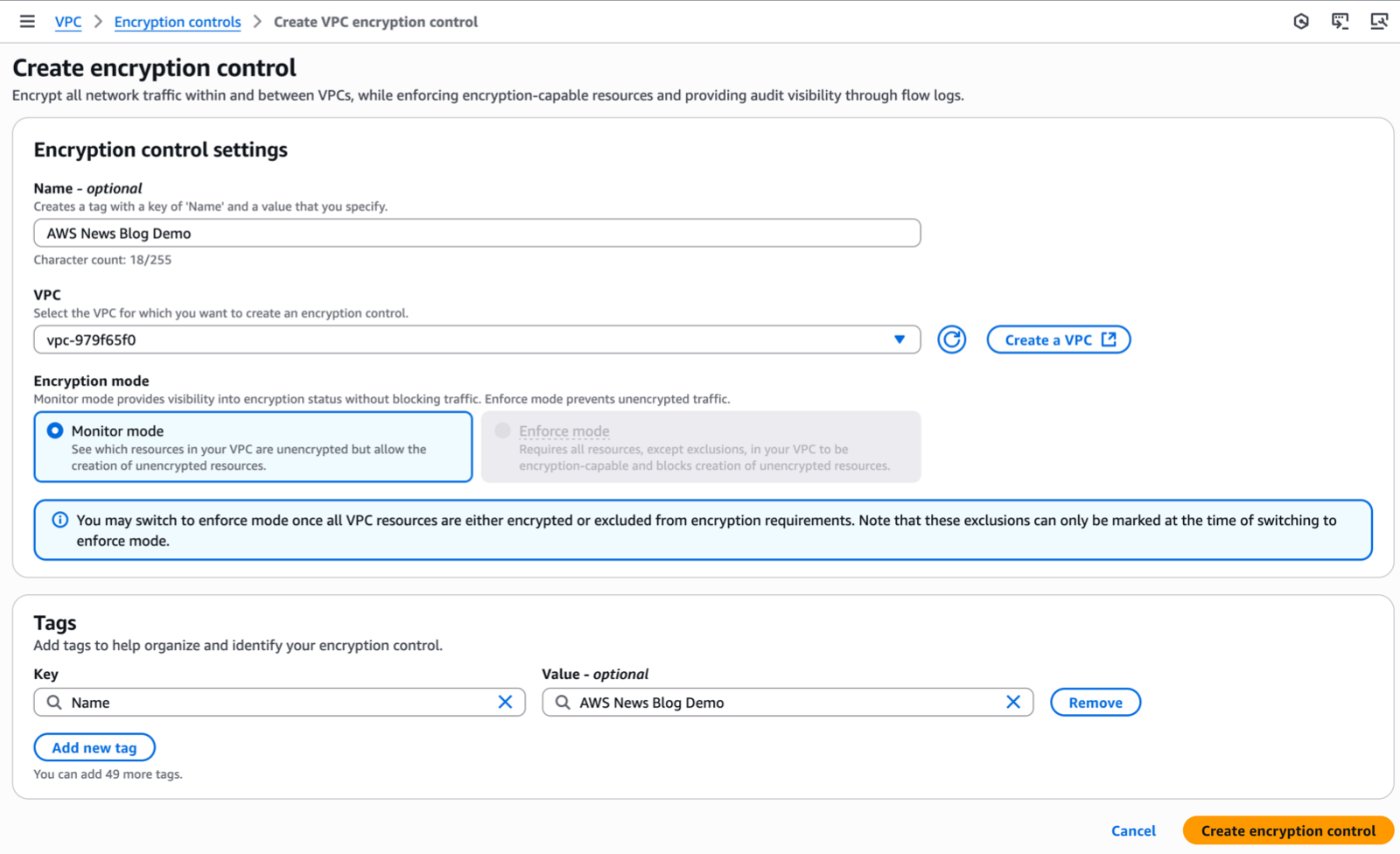
To get started, I enable encryption controls in monitor mode. In the AWS Management Console, I select Your VPCs in the left navigation pane, then I switch to the VPC encryption controls tab. I choose Create encryption control and select the VPC I want to create the control for.
Each VPC can have only one VPC encryption control associated with it, creating a one-to-one relationship between the VPC ID and the VPC encryption control Id. When creating VPC encryption controls, you can add tags to help with resource organization and management. You can also activate VPC encryption control when you create a new VPC.

I enter a Name for this control. I select the VPC I want to control. For existing VPCs, I have to start in Monitor mode, and I can turn on Enforce mode when I’m sure there is no unencrypted traffic. For new VPCs, I can enforce encryption at the time of creation.
Optionally, I can define tags when creating encryption controls for an existing VPC. However, when enabling encryption controls during VPC creation, separate tags can’t be created for VPC encryption controls—because they automatically inherit the same tags as the VPC. When I’m ready, I choose Create encryption control.
 Alternatively, I can use the AWS Command Line Interface (AWS CLI):
Alternatively, I can use the AWS Command Line Interface (AWS CLI):
aws ec2 create-vpc-encryption-control --vpc-id vpc-123456789Next, I audit the encryption status of my VPC using the console, command line, or flow logs:
aws ec2 create-flow-logs \
--resource-type VPC \
--resource-ids vpc-123456789 \
--traffic-type ALL \
--log-destination-type s3 \
--log-destination arn:aws:s3:::vpc-flow-logs-012345678901/vpc-flow-logs/ \
--log-format '${flow-direction} ${traffic-path} ${srcaddr} ${dstaddr} ${srcport} ${dstport} ${encryption-status}'
{
"ClientToken": "F7xmLqTHgt9krTcFMBHrwHmAZHByyDXmA1J94PsxWiU=",
"FlowLogIds": [
"fl-0667848f2d19786ca"
],
"Unsuccessful": []
}After a few minutes, I see this traffic in my logs:
flow-direction traffic-path srcaddr dstaddr srcport dstport encryption-status
ingress - 10.0.133.8 10.0.128.55 43236 80 1 # <-- HTTP between web client and server. Encrypted at hardware-level
egress 1 10.0.128.55 10.0.133.8 80 43236 1
ingress - 10.0.133.8 10.0.128.55 36902 80 1
egress 1 10.0.128.55 10.0.133.8 80 36902 1
ingress - 10.0.130.104 10.0.128.55 55016 80 0 # <-- HTTP between web client and server. Not encrypted at hardware-level
egress 1 10.0.128.55 10.0.130.104 80 55016 0
ingress - 10.0.130.104 10.0.128.55 60276 80 0
egress 1 10.0.128.55 10.0.130.104 80 60276 010.0.128.55is the web server with hardware-encrypted traffic, serving clear text traffic at application level.10.0.133.8is the web client with hardware-encrypted traffic.10.0.130.104is the web client with no encryption at the hardware level.
The encryption-status field tells me the status of the encryption for the traffic between the source and destination address:
- 0 means the traffic is in clear text
- 1 means the traffic is encrypted at the network layer (Level 3) by the Nitro system
- 2 means the traffic is encrypted at the application layer (Level7, TCP Port 443 and TLS/SSL)
- 3 means the traffic is encrypted both at the application layer (TLS) and the network layer (Nitro)
- “-” means VPC encryption controls are not enabled, or AWS Flow Logs don’t have the status information.
The traffic originating from the web client on the instance that isn’t Nitro based (10.0.130.104), is flagged as 0. The traffic initiated from the web client on the Nitro- ased instance (10.0.133.8) is flagged as 1.
I also use the console to identify resources that need modification. It reports two nonencrypted resources: the internet gateway and the elastic network interface (ENI) of the instance that isn’t based on Nitro.
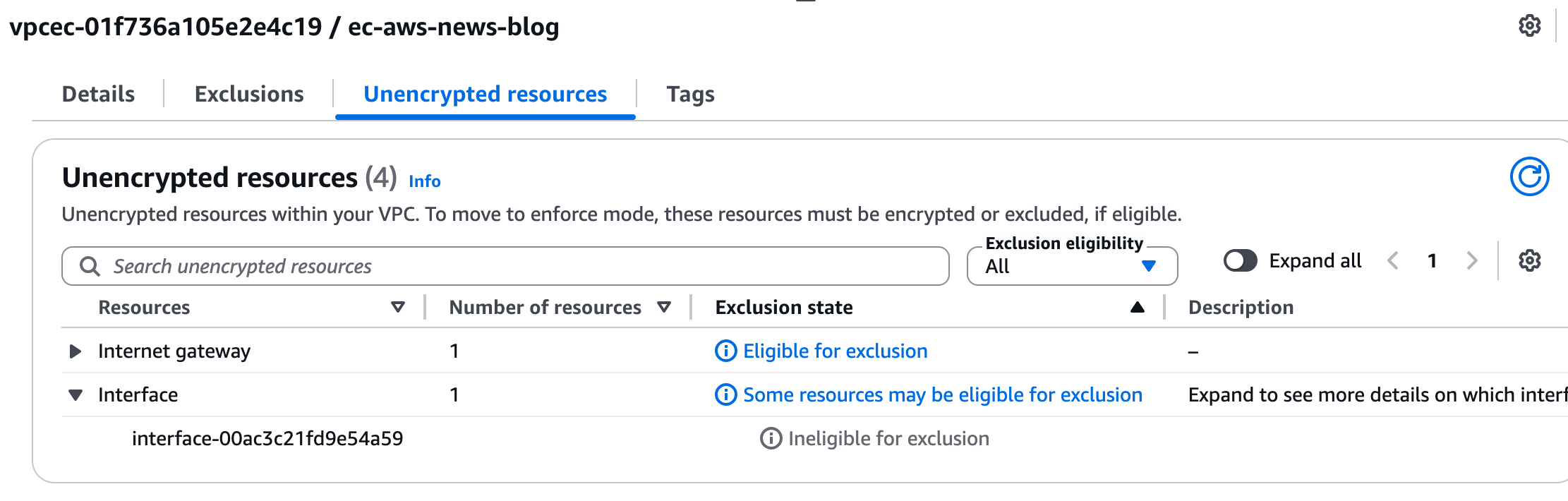 I can also check for nonencrypted resources using the CLI:
I can also check for nonencrypted resources using the CLI:
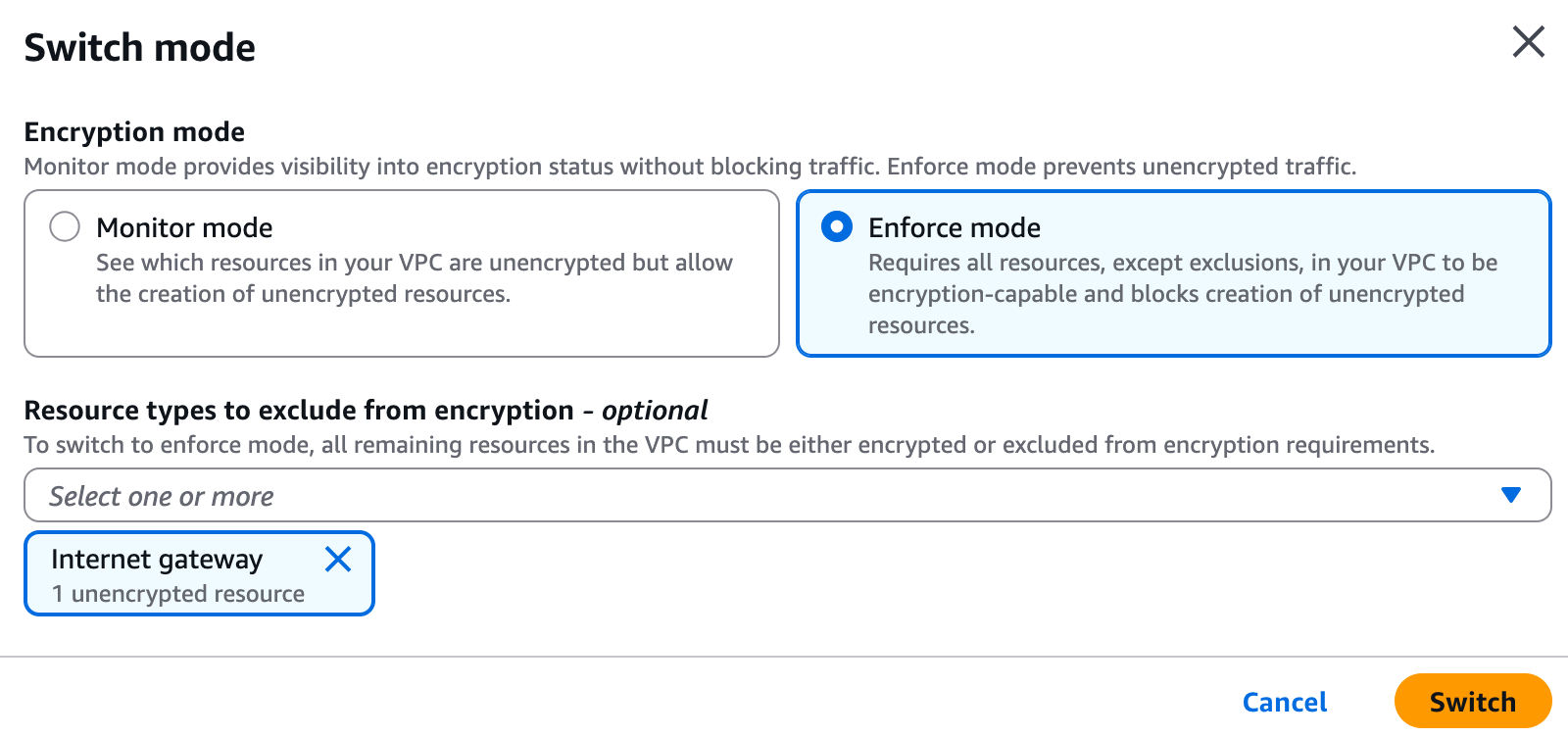
aws ec2 get-vpc-resources-blocking-encryption-enforcement --vpc-id vpc-123456789After updating my resources to support encryption, I can use the console or the CLI to switch to enforce mode.
In the console, I select the VPC encryption control. Then, I select Actions and Switch mode.
 Or the equivalent CLI:
Or the equivalent CLI:
aws ec2 modify-vpc-encryption-control --vpc-id vpc-123456789 --mode enforceHow to modify the resources that are identified as nonencrypted?
All your VPC resources must support traffic encryption, either at the hardware layer or at the application layer. For most resources, you don’t need to take any action.
AWS services accessed through AWS PrivateLink and gateway endpoints automatically enforce encryption at the application layer. These services only accept TLS-encrypted traffic. AWS will automatically drop any traffic that isn’t encrypted at the application layer.
When you enable monitor mode, we automatically and gradually migrate your Network Load Balancers, Application Load Balancers, AWS Fargate clusters, and Amazon Elastic Kubernetes Service (Amazon EKS) clusters to hardware that inherently supports encryption. This migration happens transparently without any action required from you.
Some VPC resources require you to select the underlying instances that support modern Nitro hardware-layer encryption. These include EC2 Instances, Auto Scaling groups, Amazon Relational Database Service (Amazon RDS) databases (including Amazon DocumentDB), Amazon ElastiCache node-based clusters, Amazon Redshift provisioned clusters, EKS clusters, ECS with EC2 capacity, MSK Provisioned, Amazon OpenSearch Service, and Amazon EMR. To migrate your Redshift clusters, you must create a new cluster or namespace from a snapshot.
If you use newer-generation instances, you likely already have encryption-compliant infrastructure because all recent instance types support encryption. For older-generation instances that don’t support encryption-in transit, you’ll need to upgrade to supported instance types.
Something to know when using AWS Transit Gateway
When creating a Transit Gateway through AWS CloudFormation with VPC encryption enabled, you need two additional AWS Identity and Access Management (IAM) permissions: ec2:ModifyTransitGateway and ec2:ModifyTransitGatewayOptions. These permissions are required because CloudFormation uses a two-step process to create a Transit Gateway. It first creates the Transit Gateway with basic configuration, then calls ModifyTransitGateway to enable encryption support. Without these permissions, your CloudFormation stack will fail during creation when attempting to apply the encryption configuration, even if you’re only performing what appears to be a create operation.
Pricing and availability
You can start using VPC encryption controls today in these AWS Regions: US East (Ohio, N. Virginia), US West (N. California, Oregon), Africa (Cape Town), Asia Pacific (Hong Kong, Hyderabad, Jakarta, Melbourne, Mumbai, Osaka, Singapore, Sydney, Tokyo), Canada (Central), Canada West (Calgary), Europe (Frankfurt, Ireland, London, Milan, Paris, Stockholm, Zurich), Middle East (Bahrain, UAE), and South America (São Paulo).
VPC encryption controls is free of cost until March 1, 2026. The VPC pricing page will be updated with details as we get closer to that date.
To learn more, visit the VPC encryption controls documentation or try it out in your AWS account. I look forward to hearing how you use this feature to strengthen your security posture and help you meet compliance standards.
Ubiquiti Black Friday Deals: The Best Discounts You Need to See
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=5MGe3BKtp38
[$] Unpacking for Python comprehensions
Post Syndicated from jake original https://lwn.net/Articles/1046216/
Unpacking Python iterables of various sorts, such as dictionaries or lists,
is useful in a number of contexts, including for function arguments, but
there has long been a call for extending that capability to comprehensions. PEP 798 (“Unpacking in
Comprehensions”) was first proposed in June 2025 to fill that gap. In early
November, the steering council accepted
the PEP, which means that the feature will be coming to Python 3.15 in
October 2026. It may be something of a niche feature, but it is an
inconsistency
that has been apparent for a while—to the point that some Python programmers
assume that it is already present in the language.
PHP 8.5.0 released
Post Syndicated from corbet original https://lwn.net/Articles/1047429/
Version
8.5.0 of the PHP language has been released. Changes include a new
“|>” operator that, for some reason, makes these two lines
equivalent:
$result = strlen("Hello world");
$result = "Hello world" |> strlen(...);
Other changes include a new function attribute, “#[\NoDiscard]” to
indicate that the return value should be used, attributes on constants, and
more; see the
migration guide for details.
The Agentic AI Security Scoping Matrix: A framework for securing autonomous AI systems
Post Syndicated from Aaron Brown original https://aws.amazon.com/blogs/security/the-agentic-ai-security-scoping-matrix-a-framework-for-securing-autonomous-ai-systems/
As generative AI became mainstream, Amazon Web Services (AWS) launched the Generative AI Security Scoping Matrix to help organizations understand and address the unique security challenges of foundation model (FM)-based applications. This framework has been adopted not only by AWS customers across the globe, but also widely referenced by organizations such as OWASP, CoSAI, and other industry standards bodies, partners, systems integrators (SIs), analysts, auditors, and more. Now, as long-running, function-calling agentic AI systems emerge with capabilities for autonomous decision-making, we’re creating an additional framework to address an entirely new set of security challenges.
Agentic AI systems can autonomously execute multi-step tasks, make decisions, and interact with infrastructure and data. This is a paradigm shift, and organizations must adapt to it. Unlike traditional FMs that operate in stateless request-response patterns, agentic AI systems introduce autonomous capabilities, persistent memory, tool orchestration, identity and agency challenges, and external system integration, expanding the risks that organizations must address.
Working with customers deploying these systems, we’ve observed that traditional AI security frameworks don’t always extend into the agentic space. The autonomous nature of agentic systems requires fundamentally different security approaches. To address this gap, we’ve developed the Agentic AI Security Scoping Matrix, a mental model and framework that categorizes four distinct agentic architectures based on connectivity and autonomy levels, mapping critical security controls across each.
Understanding the agentic paradigm shift
FM-powered applications operate in a now well-understood, predictable pattern even though the responses that an FM produces are non-deterministic and stateless. These applications, in their most basic form receive a prompt or instruction, generate a response, then terminate the session. Security and safety controls focus on basic measures such as input validation, output filtering, and content moderation guardrails, while governance focuses on the overall risk profiles and the resilience of models. This model works because security failures have limited scope: a compromised interaction affects only that specific request and response, without persisting or propagating to other systems or users.
Agentic AI systems fundamentally change this security model through several key capabilities:
Autonomous execution and agency: Agents initiate actions based on goals and environmental triggers that might, or might not, require human prompts or approval. This creates risks of unauthorized actions, runaway processes, and decisions that exceed intended boundaries when agents misinterpret objectives or operate on compromised instructions.
When AI agents are given instructions or permissions to act based on the data, parameters, instructions, and responses given to them, the boundaries of independence or autonomy they are permitted to act within are important to define. In discussing agentic AI systems, it’s important to clarify the distinction between agency and autonomy, because these related but different concepts inform our security approach.
Agency refers to the scope of actions an AI system is permitted and enabled to take within the operating environment, and how much a human bounds an agent’s actions or capabilities. This includes what systems it can interact with, what operations it can perform, and what resources it can modify. Agency is fundamentally about capabilities and permissions—what the system is allowed to do within its operational environment. For example, an AI agent with no agency would be guided by human-defined workflow, process, tools, or orchestration compared to an AI agent with full agency that can self-determine how to accomplish a human-defined goal.
Autonomy, in contrast, refers to the degree of independent decision-making and action the system can take without human intervention. This includes when it operates, how it chooses between available actions, and whether it requires human approval for execution. Autonomy is about independence in decision-making and execution—how freely the system can act within its granted agency. For example, an AI agent might have high agency (able to perform many actions) but low autonomy (requiring human approval for each action), or vice versa.
Understanding this distinction is crucial for implementing appropriate security controls. Agency requires boundaries and permission systems, while autonomy requires oversight mechanisms and behavioral controls. Both dimensions must be carefully managed to create secure agentic AI systems.
It’s important to determine how much agency and autonomy you want to permit and grant your AI agents to act within. After you have determined the appropriate level that any given agent should operate within, you can then evaluate the appropriate security controls to put in place to restrict the agency to a permissible risk tolerance for your agentic-based application and your organization.
Persistent memory: Agents often benefit from maintaining context and learned behaviors across sessions, building knowledge bases that inform future decisions in the form of short- and long-term memory. This data persistence introduces additional data protection requirements and can add new risk vectors such as memory poisoning attacks where adversaries inject false information that corrupts decision-making across multiple interactions and users.
Tool orchestration: Agents directly integrate via functions with connections to databases, APIs, services, and potentially other agents or orchestration components to execute complex tasks autonomously depending on the tool abstraction level. This expanded attack surface creates risks of cascading compromises where a single agent breach can propagate through connected systems, multi-agent workflows, and downstream services and data stores.
External connectivity: Agents operate across network boundaries, accessing internet resources, third-party APIs, and enterprise systems. Like traditional non-agentic systems, expanded connectivity can help unlock new business value, but this access should be designed with security controls that limit risks such as data exfiltration, lateral movement, and external manipulation. Threat modeling your agentic AI applications should be a high priority and can help directly align security controls that assist your implementation of zero-trust principles into your strategy.
Self-directed behavior: Advanced agents can initiate activities based on environmental monitoring, scheduling, or learned patterns without human instantiation or review, depending on configuration. This self-direction introduces risks of uncontrolled operations, explainability, and auditability, and makes it difficult to maintain predictable security boundaries.
These capabilities transform security from a boundary problem to a continuous monitoring and control challenge. A compromised agent doesn’t just leak information—it could autonomously execute unauthorized transactions, modify critical infrastructure, or operate maliciously for extended periods without detection.
The Agentic AI Security Scoping Matrix
Working with customers and the community, we’ve identified four architectural scopes that represent the evolution of agentic AI systems based on two critical dimensions: level of human oversight compared with autonomy and the level of agency the AI system is permitted to act within. Each scope introduces new capabilities—and corresponding security requirements—that organizations must prioritize when addressing agentic AI risk. Figure 1 shows the Agentic AI Security Scoping Matrix.
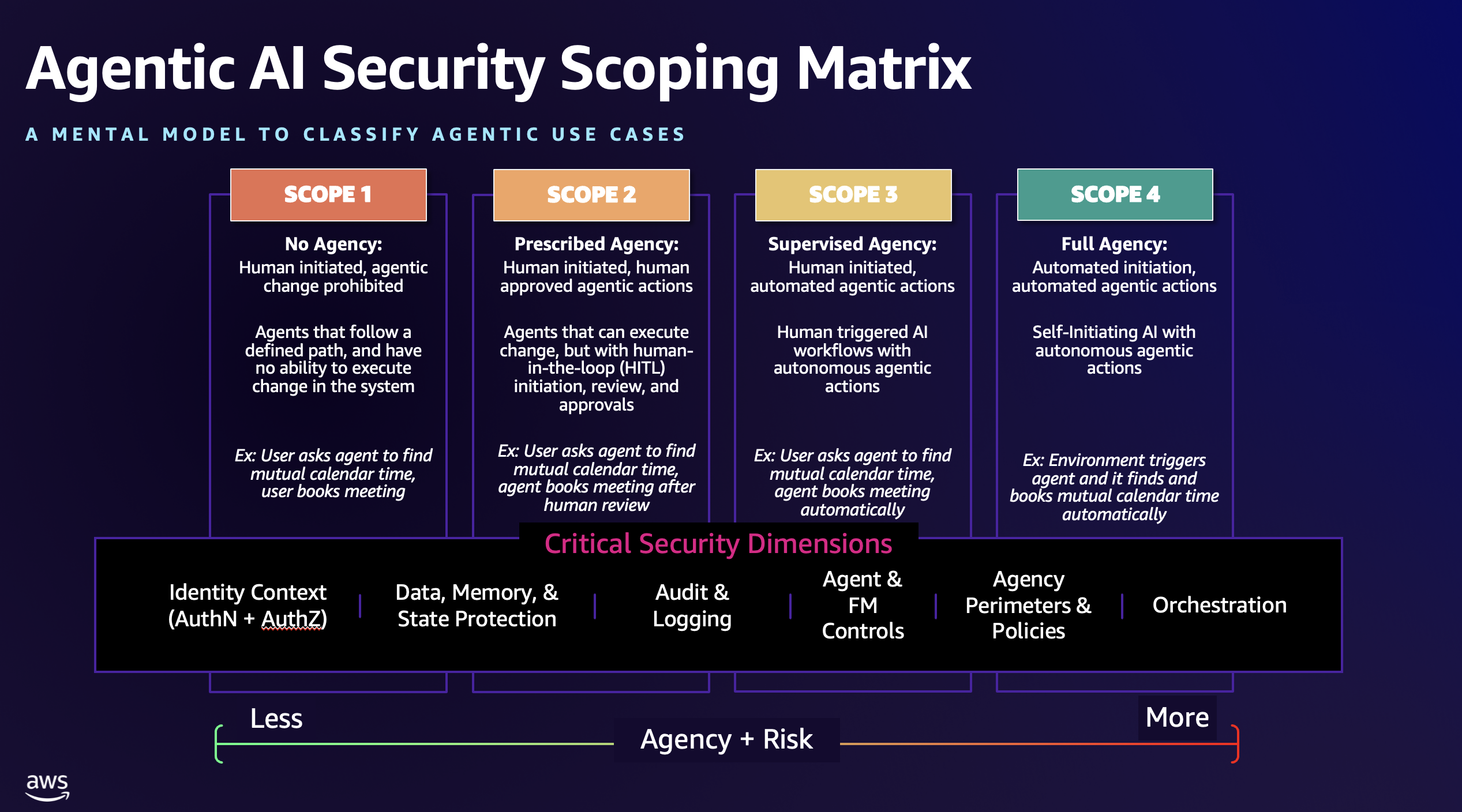
Figure 1 – The Agentic AI Security Scoping Matrix
Scope 1: No agency
In this most basic scope, systems operate with human-initiated processes and no autonomous or even human-approved change capabilities through the agent itself. The agents are, essentially, read-only. These systems follow predefined execution paths and operate under strict human-triggered workflows, which are usually predefined and follow discrete steps, but could be augmented with non-deterministic outputs from an FM. Security focuses primarily on process integrity and boundary enforcement, helping operations remain within predetermined limits and agents are highly controlled and prohibited from change execution and unbounded actions.
Key characteristics:
- Agents can’t directly execute change in the environment
- Fixed step-by-step execution following predetermined paths
- Generative AI components process data within individual workflow nodes
- Conditional branching only where explicitly designed into the workflow
- No dynamic planning or autonomous goal-seeking behavior
- State persistence limited to workflow execution context
- Tool access restricted to specific predefined workflow steps
Security focus: Protecting data integrity within the environment and restricting agents to not exceed their boundaries, especially limits around environment and data modification. Primary concerns include securing state transitions between steps, validating data passed between workflow nodes, and preventing AI components from modifying the orchestration logic or escaping their designated boundaries within the workflow.
Example: We will use a very simplistic example, across all four scopes, of a use case for an agent that is designed to help you create calendar invites. Let’s say you need to book a meeting with another colleague. In Scope 1, you might have an agent that you instantiate through a workflow or prompt to look at your calendar and your colleague’s calendar for available meeting times. In this case, you initiate the request, and the agent executes a contextual search using a Model Context Protocol (MCP) server connected to your enterprise calendaring application. The agent is only allowed to look at available times, analyze the best times to meet, and provide a response back, which a human can then use to manually set up a meeting. In this example, the human defines specific workflows and orchestrations (no agency) and reviews and approves the actions taken (no autonomous change).
Scope 2: Prescribed agency
Moving up in agency and risk, Scope 2 systems also are instantiated by a human, but now have the potential to perform actions—limited agency—that could change the environment. However, all actions taken by an agent require explicit human approval for all actions of consequence—commonly referred to as human in the loop or HITL. These systems can gather information, analyze data, and prepare recommendations, but cannot execute actions that modify external systems or access sensitive resources without human authorization. Agents can also request human input to clarify ambiguities, provide missing context, or optimize their approach before presenting recommendations.
Key characteristics:
- Agents can execute change in the environment with human review and approval
- Real-time human oversight with approval workflows
- Bidirectional human interaction—agents can query humans for context
- Limited autonomous actions restricted to read-only operations (such as, querying data, running analysis jobs, and so on)
- Agent-initiated requests for clarification or additional information
- Audit trails of all human approval decisions and context exchanges
Security focus: Implementing robust approval workflows and preventing agents from bypassing human authorization controls. Key concerns include preventing privilege escalation, enforcing appropriate identity contexts, securing the approval process itself, validating human-provided context to prevent injection attacks, and maintaining visibility into all agent recommendations and their rationale.
Example: In our calendaring example, a Scope 2 agentic system is instantiated by a human. The agent then looks up the stakeholders’ calendar availability, does its analysis, returns a recommendation for a meeting time to the user, and asks the user if they want the agent to send the invitation out on their behalf. The user looks at the response and recommendation of the agent, validates that it meets their requirements, and then acknowledges and approves the agent’s request to modify the calendars and send the invitation. In this example, the human orchestrates a structured workflow, but the agent now can instantiate human reviewed change through bounded actions (limited agency and limited autonomy).
Scope 3: Supervised agency
In Scope 3, we expand the agency to allow for a greater sense of agentic autonomy—high agency—in execution. These are AI systems that execute complex autonomous tasks that are initiated by humans (or at least from an upstream human-managed workflow), with the ability to make decisions and take actions to connected systems without further approval or HITL mechanisms. Humans define the objectives and trigger execution, but agents operate independently to achieve goals through dynamic planning and tool usage. During execution, agents can request human guidance to optimize trajectory or handle edge cases, though they can continue operating without it.
Key characteristics:
- Agents can execute change in the environment, with no (or optional) human interaction or review
- Human-triggered execution with autonomous task completion
- Dynamic planning and decision-making during execution
- Optional human intervention points for trajectory optimization
- Human ability to adjust parameters or provide context mid-execution
- Direct access to external APIs and systems for task completion
- Persistent memory across extended execution sessions
- Autonomous tool selection and orchestration within defined boundaries
Security focus: Implementing comprehensive monitoring of agent actions during autonomous execution phases and establishing clear agency boundaries for agent operations—the bounds you’re willing to let the agents operate within, and actions that would be out of bounds and must be prevented. Critical concerns include securing the human intervention channel to prevent unauthorized modifications, preventing scope creep during task execution, implementing trusted identity propagation constructs, monitoring for behavioral anomalies, and validating that agents remain aligned with original human intent throughout extended operations even when trajectory adjustments are made.
Example: In our calendaring example, a Scope 3 agentic system can still be instantiated by a human. The agent then looks up the stakeholders’ calendar availability, does its analysis, and returns a recommendation for a meeting time to the user; however, it’s within the agent’s bounds to act upon its own recommendation on behalf of the user to automatically book the best available slot. The user is not prompted or expected to give the agent permission to do so prior to its actions. The result is that all stakeholders have a calendar entry added to their calendar in the context of the calling human user. In this example, the human defines an outcome but with more freedom for the agent to determine how to achieve that goal, and the agent now can take autonomous action without human review (high agency and high autonomy).
Scope 4: Full agency
Scope 4 includes fully autonomous AI systems that can initiate their own activities based on environmental monitoring, learned patterns, or predefined conditions, and execute complex tasks without human intervention. These systems represent the highest level of AI agency, operating continuously and making independent decisions about when and how to act. It’s key to note that AI systems within Scope 4 could have full agency when executing within their designed bounds; therefore, it’s critical that humans maintain supervisory oversight with the ability to provide strategic guidance, course corrections, or interventions when needed. Continuous compliance, auditing, and full-lifecycle management mechanisms, both human and automated reviews, which could also be aided by AI, are critical to successfully securing and governing Scope 4 agentic AI systems while limiting risk.
Key characteristics:
- Self-directed activity initiation based on environmental triggers
- Continuous operation with minimal human oversight or HITL processes during execution
- Human ability to inject strategic guidance without disrupting operations
- High to full degrees of autonomy in goal setting, planning, and execution
- Dynamic interaction with multiple external systems and agents
- Capability for recursive self-improvement and capability expansion
Security focus: Implementing advanced guardrails for behavioral monitoring, anomaly detection, scope-based tool access controls, and fail-safe mechanisms to prevent runaway operations. Primary concerns include maintaining alignment with organizational objectives, securing human intervention channels against adversarial manipulation, preventing unauthorized capability expansion, preventing human oversight mechanisms from being disabled by the agent, and enabling graceful degradation when agents encounter unexpected situations.
Example: Let’s look at how we might deploy our AI calendaring example in Scope 4. Let’s say you have implemented a generative AI meeting summarizer. This agent is automatically enabled when you host a web conference. At the conclusion of the meeting, the calendaring agent sees a new meeting occurred from the meeting summarizer agent. It looks at the action items that were summarized and determines that six people agreed to a whiteboard session on Friday. The calendaring agent might either have a statically defined API configuration or leverage dynamic discovery on MCP servers to help with calendaring. It then finds availability for the six identified resources and books the best available slot. It then uses the appropriate identity context of the user who is asking for the meeting to book the meeting autonomously. At no point does a user directly instantiate the request for calendaring; it is fully automated and driven off environment changes that the agent is instructed to look for (full agency and full autonomy).
Scope comparison across the scopes
In the context of the security scoping matrix, let’s compare how autonomy and agency characteristics shift depending on the scope:
Table 1 – Scope impacts on agency and autonomy levels
Critical security dimensions
|
Scope |
Agency level |
Agency characteristics |
Autonomy level |
Autonomy characteristics |
|
Scope 1: No agency |
None |
|
None |
|
|
Scope 2: Prescribed agency |
Limited |
|
Limited |
|
|
Scope 3: Supervised agency |
High |
|
High |
|
|
Scope 4: Full agency |
Full |
|
Full |
|
Each architectural scope requires specific security controls and considerations across six critical dimensions. Table 2 illustrates how security requirements escalate with increasing agency and autonomy:
|
Security dimension |
Scope 1: No agency |
Scope 2: Prescribed agency |
Scope 3: Supervised agency |
Scope 4: Full agency |
|
Identity context (authN and authZ) |
|
|
|
|
|
Data, memory, and state protection |
|
|
|
|
|
Audit and logging |
|
|
|
|
|
Agent and FM controls |
|
|
|
|
|
Agency perimeters and policies |
|
|
|
|
|
Orchestration |
|
|
|
|
Table 2 — Critical security dimensions per scope
Security implementation by scope
Now that we’ve outlined each of the scopes and the associated levels of agency and autonomy, let’s discuss some primary security challenges per scope and key considerations that should be taken to address the associated risks.
Scope 1: No agency
Primary security challenges: Protecting workflow integrity, preventing prompt injection from breaking predetermined flows, and maintaining isolation between workflow executions.
Implementation considerations:
- Comprehensive monitoring with anomaly detection
- Strict data validation and integrity checking
- Input validation at each workflow step boundary
- Immutable workflow definitions with version control
- State encryption and validation between workflow nodes
- Monitoring for attempts to escape workflow boundaries
- Segregation between different workflow executions
- Fixed timeout and resource limits per workflow step
- Audit trails showing actual compared to expected execution paths
Scope 2: Prescribed agency
Primary security challenges: Securing approval workflows, preventing human authorization bypass, and maintaining oversight effectiveness.
Implementation considerations:
- Multi-factor authentication for all human approvers
- Cryptographically signed approval decisions
- Securing bidirectional human-agent communication channels
- Time-bounded approval tokens with automatic expiration
- Comprehensive logging of all approval interactions
- Regular training for human approvers on agent capabilities and risks
Scope 3: Supervised agency
Primary security challenges: Maintaining control during autonomous execution, scope management, explainability and auditability, and behavioral monitoring.
Implementation considerations:
- Clear execution boundaries defined at initiation
- Real-time monitoring of agent actions during execution
- Automated kill switches for runaway processes
- Non-blocking intervention mechanisms
- Behavioral baselines for normal agent operations
- Regular validation of agent alignment with original objectives
Scope 4: Full agency
Primary security challenges: Continuous behavioral validation, enforcing agency boundaries, preventing capability drift, and maintaining organizational alignment.
Implementation considerations:
- Advanced AI safety techniques including reward modeling
- Continuous monitoring with machine learning-based anomaly detection
- Automated response systems for behavioral deviations
- Regular alignment validation through systematic testing
- Tamper-proof human override mechanisms
- Failsafe mechanisms that can halt operations when confidence drops
Key architectural patterns
Successful agentic deployments share common patterns that balance autonomy with control.
Progressive autonomy deployment: Start with Scope 1 or 2 implementations and gradually advance through the scopes as organizational confidence and security capabilities mature. This approach minimizes risk while building operational experience. Be cautious and selective when analyzing use cases and bounding controls for Scope 4 implementations and review your ability to address risks at the lower scopes and how risks increase as you move further up the levels.
Layered security architecture: Implement defense-in-depth with security controls at multiple levels—network, application, agent, and data layers—to safeguard that compromise at one level doesn’t lead to complete system failure. Although the combination of these controls is what enables a high security bar, be sure to spend considerable efforts on making sure that identity and authorization concerns are addressed—for both machines and humans. This helps prevent issues such as the confused deputy problem—when a human or service with lesser permissions is able to elevate permissions through agents that might themselves have more entitlements and privileges.
Continuous validation loops: Establish automated systems that continuously verify agent behavior against expected patterns, and that have escalation procedures for when deviations are detected. Auditability and explainability are key requirements to confirm that agents are performing within the bounds intended and to help you determine control effectiveness, adjust parameters, and validate your orchestration workflows.
Human oversight integration: Even in highly autonomous systems, maintain meaningful human oversight through strategic checkpoints, behavioral reporting, and manual override capabilities. It might be reasonable to assume that human oversight reduces when moving from Scope 1 to Scope 4 agency, but the truth is that it simply shifts focus. For example, the human requirement to instantiate, review, and approve certain agentic actions is higher in Scopes 1 and 2 and lower in Scopes 3 and 4; however, the human requirement to audit, assess, validate, and implement more complex security and operational controls is much higher in Scopes 4 and 3 than they are in Scopes 2 and 1.
Graceful degradation: Design systems to automatically reduce autonomy levels when security events are detected, allowing operations to continue safely while human operators investigate. If your agents start to act in ways that go beyond the intended bounds of their design, anomalous behavior is detected, or they begin to perform actions deemed particularly risky or sensitive to your business, then consider having detective controls that will automatically inject tighter restrictions such as requiring more HITL or reducing the actions an agent can take. You might do this as incremental degradation or, you might choose to disable the agent if it’s acting in ways that negatively impact the environment. These agentic safety mechanisms that can implement additional restrictions or even disable an agent should be considered when building or deploying agents.
Conclusion
The Agentic AI Security Scoping Matrix provides a structured mental model and framework for understanding and addressing the security challenges of autonomous agentic AI systems across four distinct scopes. By accurately assessing your current scope and implementing appropriate controls across all six security dimensions, organizations can confidently deploy agentic AI while managing the landscape of associated risks.
The progression from basic and highly constrained agents to fully autonomous and even self-directing agents represents a fundamental shift in how we approach AI security. Each scope requires specific security capabilities, and organizations must build these capabilities systematically to support their agentic ambitions safely.
Next steps
To implement the Agentic AI Security Scoping Matrix in your organization:
- Assess your current agentic use cases and maturity against the four scopes to understand your security requirements and associated risks. Integrate it into your procurement and SDLC processes.
- Identify capability gaps across the six security dimensions for your target scope.
- Develop a progressive deployment strategy that builds security capabilities as you advance through scopes.
- Implement continuous monitoring and behavioral analysis appropriate for your scope level.
- Establish governance processes for scope progression and security validation.
- Train your teams on the unique security challenges of each scope.
You can find additional information on the Agentic AI Security Scoping matrix here, along with additional information on AI security topics. For additional resources on securing AI workloads, see the AI for security and security for AI: Navigating Opportunities and Challenges whitepaper and explore purpose-built platforms designed for the unique challenges of agentic AI.
If you have feedback about this post, submit comments in the Comments section below.
Security updates for Friday
Post Syndicated from jzb original https://lwn.net/Articles/1047386/
Security updates have been issued by AlmaLinux (delve and golang), Debian (webkit2gtk), Oracle (expat and thunderbird), Red Hat (kernel), Slackware (openvpn), SUSE (chromium, grub2, and kernel), and Ubuntu (cups-filters, imagemagick, and libcupsfilters).
What’s in a name? History
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=zMqRLRLe7ZE
Nikon’s Coolest Camera just got a major update
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=XV7qEfmsipU
AI as Cyberattacker
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/11/ai-as-cyberattacker.html
From Anthropic:
In mid-September 2025, we detected suspicious activity that later investigation determined to be a highly sophisticated espionage campaign. The attackers used AI’s “agentic” capabilities to an unprecedented degree—using AI not just as an advisor, but to execute the cyberattacks themselves.
The threat actor—whom we assess with high confidence was a Chinese state-sponsored group—manipulated our Claude Code tool into attempting infiltration into roughly thirty global targets and succeeded in a small number of cases. The operation targeted large tech companies, financial institutions, chemical manufacturing companies, and government agencies. We believe this is the first documented case of a large-scale cyberattack executed without substantial human intervention.
[…]
The attack relied on several features of AI models that did not exist, or were in much more nascent form, just a year ago:
- Intelligence. Models’ general levels of capability have increased to the point that they can follow complex instructions and understand context in ways that make very sophisticated tasks possible. Not only that, but several of their well-developed specific skills—in particular, software coding—lend themselves to being used in cyberattacks.
- Agency. Models can act as agents—that is, they can run in loops where they take autonomous actions, chain together tasks, and make decisions with only minimal, occasional human input.
- Tools. Models have access to a wide array of software tools (often via the open standard Model Context Protocol). They can now search the web, retrieve data, and perform many other actions that were previously the sole domain of human operators. In the case of cyberattacks, the tools might include password crackers, network scanners, and other security-related software.
Comic for 2025.11.21 – Five Finger
Post Syndicated from Explosm.net original https://explosm.net/comics/five-finger
New Cyanide and Happiness Comic
Гневни ли сте?
Post Syndicated from Емилия Милчева original https://www.toest.bg/gnevni-li-ste/

Какво очаква председателят на „Продължаваме промяната“ Асен Василев, призовавайки за окупация на парламента на 25 ноември, когато ще се обсъжда бюджетът за 2026-та?
Да окупираме парламента идния вторник, когато се приема бюджетът и да не позволим на прасетата да го приемат. Защото после трудно ще е връщането назад.
Окупацията няма да попречи на ГЕРБ–СДС, БСП, „Има такъв народ“ и ДПС – Ново начало да гласуват бюджета. Освен ако в нея не се включат синдикати, бизнес – изобщо всички недоволни от този бюджет, и не щурмуват парламента. Тоест да се повтори 10 януари 1997 г.
Но това няма да се случи и Асен Василев е наясно. А той готов ли е да поведе щурм? Едно е да поставиш фигура на розово прасе касичка пред Народното събрание, съвсем друго да предвождаш разгневени хора.
Но подобни призиви не са прецедент и показват, че демократични партии адаптират методи, типични за радикалния популизъм, за да постигнат своите цели. Гневът вече не е монопол на екстремистите или националистите, а се превръща в инструмент за мобилизация и натиск.
10 януари няма да се повтори
В действителност Асен Василев не призовава към 10 януари, просто дава сигнал. Политически жест – комуникационен, не революционен, който вдига адреналина на симпатизанти и избиратели, но без реален риск да запали улицата.
Общественият гняв днес е „разреден“ – хората скандират „Свобода!“ и са недоволни, но не са в онзи стадий на екзистенциален страх и отчаяние от 1996–1997 г., когато икономическата катастрофа засегна почти всички. Да, храните поскъпват, бюджетът е силно популистки, но няма хиперинфлация, празни магазини, фалирали банки и масова безизходица. След 40 дни България ще е в еврозоната. Стандартът на живот все още изостава от средните нива за ЕС, но се е подобрил.
Тоест няма маса от десетки хиляди хора, готови да протестират с риск от сблъсък с полицията или арест. През зимата на 1997 г. блокади и протести имаше в цяла България и всички, излезли на улицата, искаха едно: правителството на Жан Виденов и БСП да падне от власт.
За третото тримесечие на 2025 г. индексът на обществено напрежение, който измерва Центърът за анализ и кризисни комуникации заедно със Социологическа агенция „Мяра“, е 6,09 по скалата от 0 до 10. Тази стойност се формира от 21 показателя, сред които държавност и среда, където са всички показатели за политическата ситуация и външните катаклизми, благосъстояниe, публичност и др. Според социолозите 6,09 е в зоната „високо напрежение, трудно контролируем риск“ – или една стъпка дели обществото от „почти неуправляема ситуация“.
При това в края на септември дори не беше внесен спорният бюджет за 2026 г. и все още имаше шанс мярката за неотклонение на кмета на Варна Благомир Коцев да бъде променена в по-лека – от задържане под стража в домашен арест.
Разнопосочни недоволства
Въпреки че данните показват висок индекс на обществено напрежение, липсва колективен фокус. За сериозна окупация са необходими общ враг и общ мотив, а в момента има само разнопосочни недоволства. Едни са гневни заради несправедливото правосъдие и институциите бухалки. Няколко хиляди души в София, Варна и Пловдив се отзоваха на призива на ПП–ДБ за протести в защита на варненския кмет Благомир Коцев, който е 130 дни в ареста. Шествието под наслов „Свобода за политическите затворници“ стигна и до централата на ДПС на ул. „Врабча“.
Тази седмица делото срещу Коцев взе нов обрат. Върховният касационен съд се произнесе по спора кой съд е компетентен да го гледа – Софийският градски или Окръжният във Варна, и го прати на местния съд.
Петимата обвиняеми са от Варна, както и 25 от 28 свидетели, твърди се, че престъпленията са извършени във Варна – значи процесът трябва да се разглежда там.
Включването на неизвестно лице, за което е налице единствено твърдение, че разполага с имунитет, което твърдение не може да бъде проверено по съответния процесуален ред, не е достатъчно, за да обуслови наличието на специална подсъдност […].
Партиите не искат ескалация, затова и не се чуват отчетливи призиви за оставка. Дори симпатизантите на протестните формации са предпазливи към „революционни“ жестове, които могат да бъдат използвани срещу тях. А без политическа коалиция няма критична маса на улицата – правило, доказано от всички протести в най-новата история.
Бизнесът е недоволен заради вдигането на осигуровките с 2 процентни пункта, което е над 10%, и заради данък дивидент, но настоява за преговори, не за барикади. Нито една работодателска организация няма да подкрепи окупация, за да си остави врата за преговори – макар че от години не е имало такъв разрив между управляващите и организациите на предприемачите заради разходите на държавата. Асоциацията на индустриалния капитал в България определи бюджета като „безнадеждно неадекватен“, а Българската работодателска асоциация иновативни технологии предупреди за ефект от забавяне на растежа и отлагане на инвестиции.
В БСП зрее недоволство заради „безгръбначното поведение на ръководството пред Борисов и Пеевски“. ИТН са раздразнени от растящото влияние на Пеевски. Синдикатите пък, в началото гневни заради минималната работна заплата, впоследствие се разбраха с управляващите – както винаги впрочем.
Но пък стотици софиянци са ядосани заради обявената от Столичната община „реформа“, която разширява синята и зелената зона и удвоява цените на платеното почасово паркиране. Кметът Васил Терзиев намери няколко аргумента, за да оправдае действията – корекции на цените не са правени повече от 10 години, мерките ще внесат повече ред, а получените приходи ще се реинвестират в районите. Липсват обаче разчети за прогнозните приходи, какви проекти са подготвени срещу тях, а и как ще се договаря с Центъра за градска мобилност каква част да отива за районните кметства, защото средствата постъпват най-напред в него.
Гневът не преминава в действие
За да стане гневът действие, са необходими ясна цел, усещане, че промяна на системата е възможна – значи има алтернатива, лидерство и готовност да се поеме колективен риск. В момента никоя от парламентарно представените партии не се осмелява да се заяви като алтернатива. Рисковете са прекалено големи – несигурността на пазара на горива, предстоящата смяна на валутата, натискът върху публичните разходи. Затова и предпочитат по-скоро да поддържат огъня, отколкото да вадят кестени от него.
А когато гневът не води до решаване на проблема или преодоляване на препятствието, постепенно се трансформира във фрустрация – усещане за безсилие, разочарование, вътрешно напрежение.
Така че буревестници още няма. Политиците се надвикват, но никой не води.
Истинският въпрос не е „Гневни ли сте?“. Истинският въпрос е кой е способен да превърне гнева в действие, не в динамит.
Т.Е. от Е.Т. – епизод 32
Post Syndicated from Тоест original https://www.toest.bg/t-e-ot-e-t-epizod-32/

В този епизод вървим. Към извънредно положение, институционална катастрофа, обществена ентропия, личностен разпад – кой каквото си избере. А иначе като цяло вървим на майната си.
Следете видеорубриката на Елена Телбис за „Тоест“ и във Facebook, Instagram и TikTok.