Post Syndicated from Raji Sivasubramaniam original https://aws.amazon.com/blogs/big-data/embed-multi-tenant-dashboards-in-saas-apps-using-amazon-quicksight-without-provisioning-or-managing-users/
Amazon QuickSight is a fully-managed, cloud-native business intelligence (BI) service that makes it easy to connect to your data, create interactive dashboards, and share these with tens of thousands of users, either within QuickSight itself, or embedded in software as a service (SaaS) apps.
QuickSight Enterprise Edition recently added row-level security (RLS) using tags, a new feature that allows developers to share a single dashboard with tens of thousands of users, while ensuring that each user can only see and have access to particular data. This means that when an independent software vendor (ISV) adds a QuickSight-embedded dashboard in their app, they don’t have to provision their end-users in QuickSight, and can simply set up tags to filter data based on who the dashboard is being served to. For example, if an ISV wanted to set up a dashboard that was to be shared with 20,000 users across 100 customers of an app, with all users within a customer having access to identical data, this new feature allows you to share a single dashboard for all users, without having to set up or manage the 20,000 users in QuickSight.
RLS enforced using tags makes sure that each end-user only sees data that is relevant to them, while QuickSight automatically scales to meet user concurrency to ensure every end-user sees consistently fast performance. In this post, we look at how this can be implemented.
Solution overview
To embed dashboards without user provisioning, we use the API GenerateEmbedURLForAnonymousUser, which works with QuickSight’s session capacity pricing. With this API, the embedding server (logic in the SaaS app) determines and manages the identity of the user to whom the dashboard is being displayed (as opposed to this identity being provisioned and managed within QuickSight).
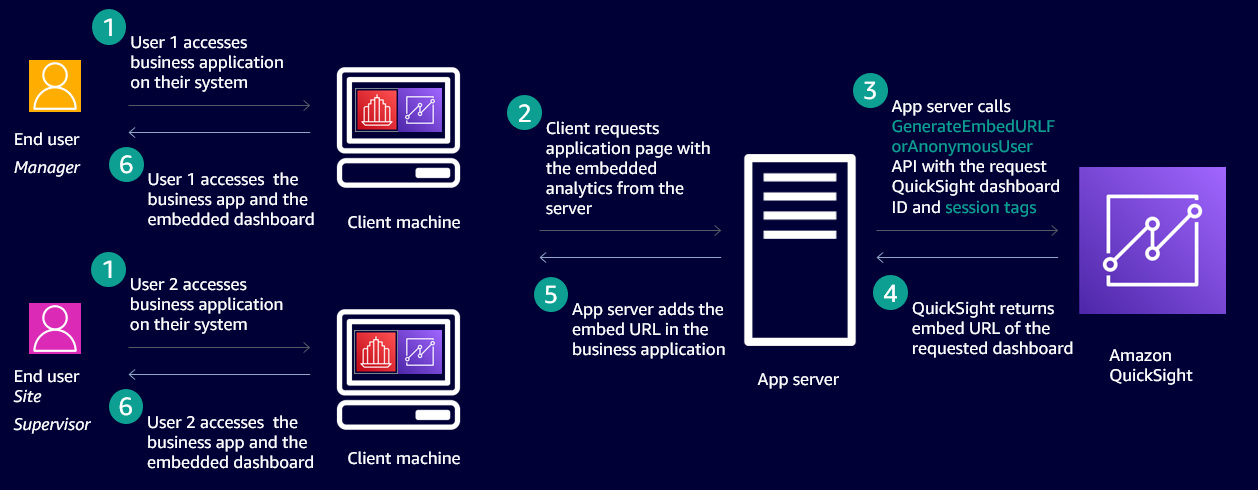
The following diagram shows an example workflow of embedded dashboards that secures data based on who is accessing the application using RLS with tags.

In this case, an ISV has a SaaS application that is accessed by two end-users. One is a manager and other is a site supervisor. Both users access the same application and the same QuickSight dashboard embedded in the application and they’re not provisioned in QuickSight. When the site supervisor accesses the dashboard, they only see data pertaining to their site, and when the manager accesses the dashboard, they see data pertaining to all the sites they manage.
To achieve this behavior, we use a new feature that enables configuring the row-level security using tags. This method of securing data on embedded dashboards works only when dashboards are embedded without user provisioning (also called anonymous embedding). The process includes two steps:
- Set up tag keys on the columns of the datasets used to build the dashboard.
- Set values for the tag keys at runtime when embedding the dashboard anonymously.
Set up tag keys on columns in the datasets used to build the dashboard
ISVs or developers can set columns on the datasets using the CreateDataset or UpdateDataset APIs as follows:
create-data-set
--aws-account-id
--data-set-id
--name
--physical-table-map
[--logical-table-map ]
--import-mode
[--column-groups ]
[--field-folders ]
[--permissions ]
[--row-level-permission-data-set ]
[--column-level-permission-rules ]
[--tags ]
[--cli-input-json ]
[--generate-cli-skeleton ]
[--row-level-permission-tag-configuration //upto 50 tagkeys can be added at this time
'{
"Status": "ENABLED",
"TagRules":
[
{
"TagKey": "tag_name_1", //upto 128 characters
"ColumnName": "column_name_1",
"TagMultiValueDelimiter": ",",
"MatchAllValue": "*"
},
{
"TagKey": "tag_name_2", //upto 128 characters
"ColumnName": "column_name_2"
}
]
}'
]
update-data-set
--aws-account-id <value>
--data-set-id <value>
--name <value>
--physical-table-map <value>
[--logical-table-map <value>]
--import-mode <value>
[--column-groups <value>]
[--field-folders <value>]
[--row-level-permission-data-set <value>]
[--column-level-permission-rules <value>]
[--cli-input-json <value>]
[--generate-cli-skeleton <value>]
[--row-level-permission-tag-configuration //upto 50 tagkeys can be added at this time
'{
"Status": "ENABLED",
"TagRules":
[
{
"TagKey": "tag_name_1", //upto 128 characters
"ColumnName": "column_name_1",
"TagMultiValueDelimiter": ",",
"MatchAllValue": "*"
},
{
"TagKey": "tag_name_2", //upto 128 characters
"ColumnName": "column_name_2",
"MatchAllValue": "*"
},
{
"TagKey": "tag_name_3", //upto 128 characters
"ColumnName": "column_name_3"
}
]
}'
]
In the preceding example code, row-level-permission-tag-configuration is the element that you can use to define tag keys on the columns of a dataset. For each tag, you can define the following optional items:
- TagMultiValueDelimiter – This option when set on a column enables you to pass more than one value to the tag at runtime, and the values are delimited by the string set for this option. In this sample, a comma is set as a delimiter string.
- MatchAllValue – This option when set on a column enables you to pass all values of a column at runtime, and the values are represented by the string set for this option. In this sample, an asterisk is set as a match all string.
After we define our tags, we can enable or disable these rules using the Status element of the API. In this case the value is set to ENABLED. To disable the rules, the value is DISABLED. After the tags are enabled, we can pass values to the tags at runtime to secure the data displayed based on who is accessing the dashboard.
Each dataset can have up to 50 tag keys.
We receive the following response for the CreateDataset or UpdateDataset API:
{
"Status": 201,
“Arn”: “string”, //ARN of the dataset
“DataSetId”: “string”, //ID of the dataset
“RequestId”: “string”
}
Enable authors to access data protected by tag keys when authoring analysis
After tags keys are set and enabled on the dataset, it is secured. Authors when using this dataset to author a dashboard don’t see any data. They must be given permissions to see any of the data in the dataset when authoring a dashboard. To give QuickSight authors permission to see data in the dataset, create a permissions file or a rules dataset. For more information, see Creating Dataset Rules for Row-Level Security. The following is an example rules dataset.
| UserName |
column_name_1 |
column_name_2 |
column_name_3 |
| admin/sampleauthor |
In this sample dataset, we have the author’s username listed in the UserName column. The other three columns are the columns from the dataset on which we set tag keys. The values are left empty for these columns for the author added to this table. This enables the author to see all the data in these columns without any restriction when they’re authoring analyses.
Set values to the tag keys at runtime when embedding the dashboard
After the tag keys are set for columns of the datasets, developers set values to the keys at runtime when embedding the dashboard. Developers call the API GenerateDashboardEmbedURLForAnonymousUser to embed the dashboard and pass values to the tag keys in the element SessionTags, as shown in the following example code:
POST /accounts//embed-url/anonymous-user HTTP/1.1
Content-type: application/json
{
"AwsAccountId": "string",
"SessionLifetimeInMinutes": integer,
"Namespace": "string",
"SessionTags":
[
{
"Key": "tag_name_1", // Length: [1-128]
"Value": "value1, value2" // Length: [0-256]
}
{
"Key": "tag_name_2", // Length: [1-128]
"Value": "*" // Length: [0-256]
}
{
"Key": "tag_name_3", // Length: [1-128]
"Value": "value3" // Length: [0-256]
}
],
"AuthorizedResourceArns":
[
// Length: [1-25]
// Dashboard ARNs in the same AWS Account
"string"
],
"ExperienceConfiguration":
{
"Dashboard":
{
"InitialDashboardId": "string"
}
}
}
}
Because this feature secures data for users not provisioned in QuickSight, the API call is for AnonymousUser only and therefore this feature works only with the API GenerateDashboardEmbedURLForAnonymousUser.
The preceding example code has the following components:
- For
tag_name_1, you set two values (value1 and value2) using the TagMultiValueDelimiter defined when setting the tag keys (in this case, a comma).
- For
tag_name_2, you set one value as an asterisk. This enables this tag key to have all values for that column assigned because we defined asterisk as the MatchAllValue when setting a tag key on the column earlier.
- For
tag_name_3, you set one value (value3).
API response definition
The response of the API has the EmbedURL, Status, and RequestID. You can embed this URL in your HTML page. Data in this dashboard is secured based on the values passed to the tag keys when calling the embedding API GenerateDashboardEmbedURLForAnonymousUser:
- EmbedUrl (string) – A single-use URL that you can put into your server-side webpage to embed your dashboard. This URL is valid for 5 minutes. The API operation provides the URL with an
auth_code value that enables one (and only one) sign-on to a user session that is valid for up to 10 hours. This URL renders the dashboard with RLS rules applied based on the values set for the RLS tag keys.
- Status (integer) – The HTTP status of the request.
- RequestId (string) – The AWS request ID for this operation.
Fine-grained access control
You can achieve fine-grained access control by using dynamic AWS Identity and Access Management (IAM) policy generation. For more information, see Isolating SaaS Tenants with Dynamically Generated IAM Policies. When using the GenerateEmbedUrlForAnonymousUser API for embedding, you need to mention two resource types in the IAM policy: the namespace ARNs your anonymous users virtually belong to, and the dashboard ARNs that can be used in the AuthorizedResourceArns input parameter value. The sessions generated using this API can access the authorized resources and the ones (dashboards) shared with the namespace.
Because anonymous users are part of a namespace, any dashboards shared with the namespace are accessible to them, regardless of whether they are passed explicitly via the AuthorizedResourceArns parameter.
To allow the caller identity to generate a URL for any user and any dashboard, the Resource block of the policy can be set to *. To allow the caller identity to generate a URL for any anonymous user in a specific namespace (such as Tenant1), the Resource part of the policy can be set to arn:aws:quicksight:us-east-1:<YOUR_AWS_ACCOUNT_ID>:namespace/Tenant1. This is the same for the dashboard ID. For dynamic policy generation, you can also use placeholders for the namespace and users.
The following code is an example IAM policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "QuickSightEmbeddingRole",
"Effect": "Allow",
"Action": [
"quicksight:GenerateEmbedUrlForAnonymousUser"
],
"Resource": [
"arn:aws:quicksight:us-east-1::namespace/tenant1",
"arn:aws:quicksight:us-east-1::dashboard/dashboard-id-123"
// You can add specific Namespace IDs (tenant IDs), or namespace prefixes here
// e.g. "arn:aws:quicksight:us-east-1::namespace/{{tenant-id}}" will allow the role to
// generate embedding URL for namespace dynamically substituted
// into the placeholder {{tenant-id}}
// or "arn:aws:quicksight:us-east-1::namespace/MyTenantIdPrefix*" will allow the role to
// generate embedding URL for namespaces having prefix MyTenantIdPrefix.
// You can add specific Dashboard IDs, or ID prefixes here
// e.g. "arn:aws:quicksight:us-east-1::dashboard/{{dashboard-id}}" will allow the role to
// generate embedding URL for dashboard dynamically substituted
// into the placeholder {{dashboard-id}}
// or "arn:aws:quicksight:us-east-1::dashboard/MyDashboardIdPrefix*" will allow the role to
// generate embedding URL for namespaces having prefix MyDashboardIdPrefix.
]
}
]
}
Use case
OkTank is an ISV in the healthcare space. They have a SaaS application that is used by different hospitals across different regions of the country to manage their revenue. OkTank has thousands of healthcare employees accessing their application and has embedded operations related to their business in a QuickSight dashboard in their application. OkTank doesn’t want to manage their users in QuickSight separately, and wants to secure data based on which user from which hospital is accessing their application. OkTank is securing the data on the dashboards at runtime using row-level security using tags.
OkTank has hospitals (North Hospital, South Hospital, and Downtown Hospital) in regions Central, East, South, and West.
In this example, the following users access OkTank’s application and the embedded dashboard. Each user has a certain level of restriction rules that define what data they can access in the dashboards. PowerUser is a super user that can see the data for all hospitals and regions.
| OkTank’s application’s user |
Hospital |
Region |
| NorthUser |
North Hospital |
Central and East |
| NorthAdmin |
North Hospital |
All regions |
| SouthUser |
South Hospital |
South |
| SouthAdmin |
South Hospital |
All regions |
| PowerUser |
All hospitals |
All regions |
None of these users have been provisioned in QuickSight. OkTank manages these users in its own application and therefore knows which region and hospital each user belongs to. When any of these users access the embedded QuickSight dashboard in the application, OkTank must secure the data on the dashboard so that users can only see the data for their region and hospital.
First, OkTank created tag keys on the dataset they’re using to power the dashboard. In their UpdateDataset API call, the RowLevelPermissionTagConfiguration element on the dataset is as follows:
"RowLevelPermissionTagConfiguration":
{
"Status": "ENABLED",
"TagRules": [
{
"TagKey": "customer_region",
"ColumnName": "region",
"TagMultiValueDelimiter": ",",
"MatchAllValue": "*"
},
{
"TagKey": "customer_hospital",
"ColumnName": "hospital",
"TagMultiValueDelimiter": ",",
"MatchAllValue": "*"
}
]
}
Second, at runtime when embedding the dashboard via the GenerateDashboardEmbedURLForAnonymousUser API, they set SessionTags for each user.
SessionTags for NorthUser in the GenerateDashboardEmbedURLForAnonymousUser API call are as follows:
"SessionTags":
[
{
"Key": "customer_hospital",
"Value": "North Hospital"
},
{
"Key": " customer_region",
"Value": "Central, East"
}
]
SessionTags for NorthAdmin are as follows:
"SessionTags":
[
{
"Key": " customer_hospital",
"Value": "North Hospital"
},
{
"Key": " customer_region",
"Value": "*"
}
]
SessionTags for SouthUser are as follows:
"SessionTags":
[
{
"Key": " customer_hospital",
"Value": "South Hospital"
},
{
"Key": " customer_region",
"Value": "South"
}
]
SessionTags for SouthAdmin are as follows:
"SessionTags":
[
{
"Key": " customer_hospital",
"Value": "South Hospital"
},
{
"Key": " customer_region",
"Value": "*"
}
]
SessionTags for PowerUser are as follows:
"SessionTags":
[
{
"Key": " customer_hospital",
"Value": "*"
},
{
"Key": " customer_region",
"Value": "*"
}
]
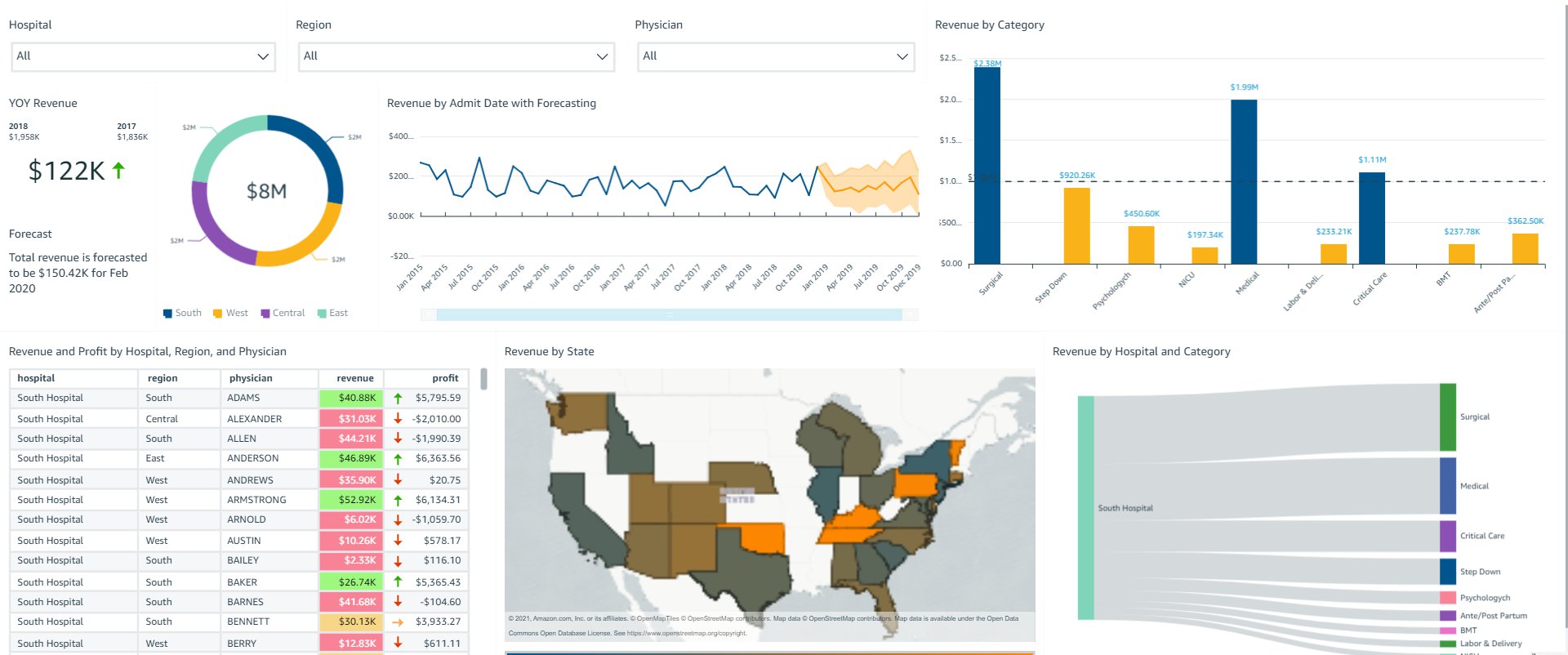
The following screenshot shows what SouthUser sees pertaining to South Hospital in the South region.

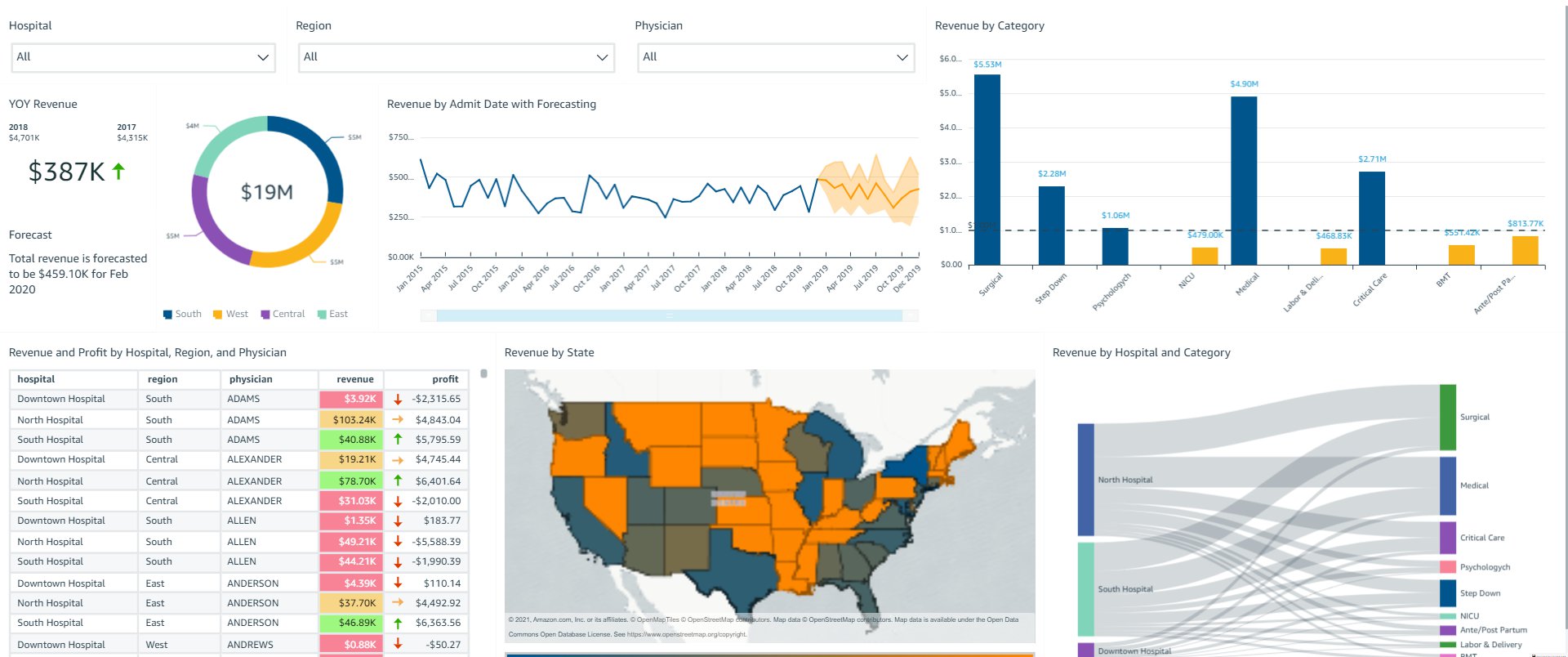
The following screenshot shows what SouthAdmin sees pertaining to South Hospital in all regions.

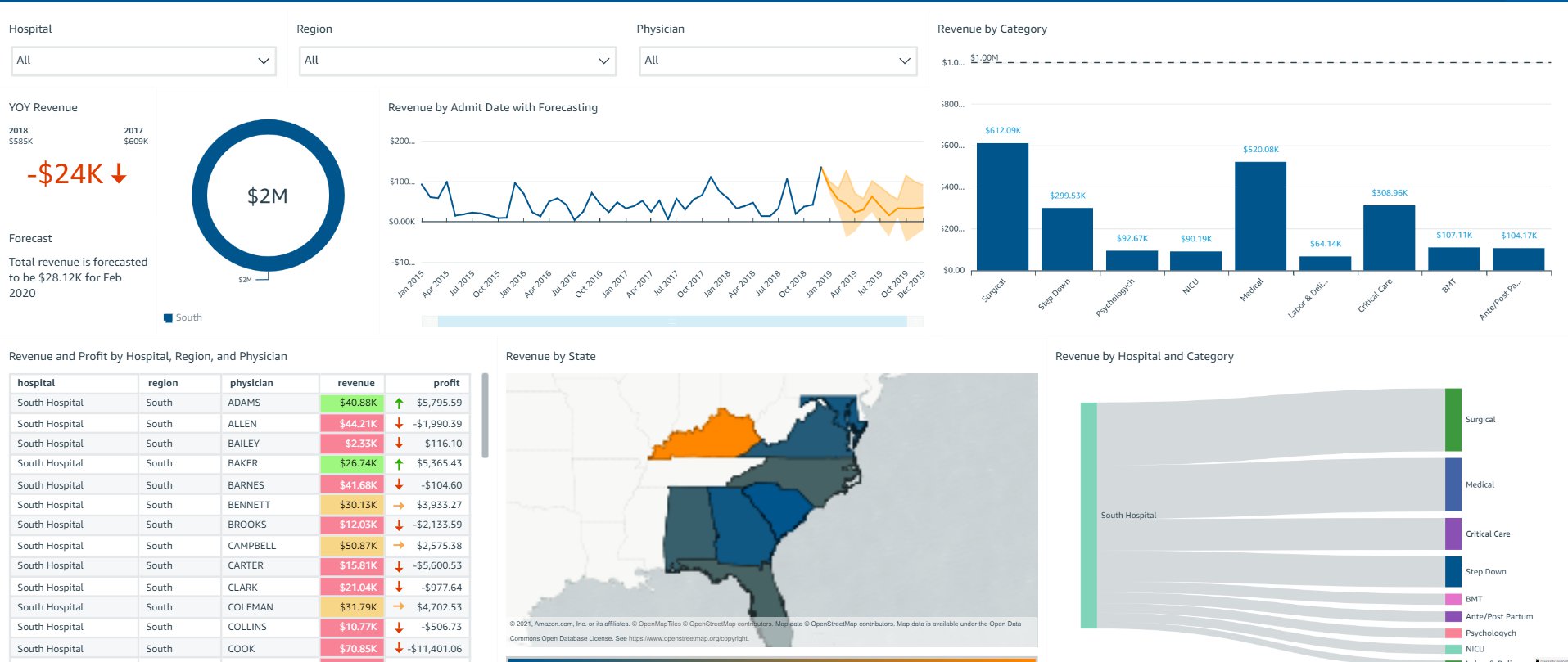
The following screenshot shows what PowerUser sees pertaining to all hospitals in all regions.

Based on session tags, OkTank has secured data on the embedded dashboards such that each user only sees specific data based on their access. You can access the dashboard as one of the users (by changing the user in the drop-down menu on the top right) and see how the data changes based on the user selected.
Overall, with row-level security using tags, OkTank is able to provide a compelling analytics experience within their SaaS application, while making sure that each user only sees the appropriate data without having to provision and manage users in QuickSight. QuickSight provides a highly scalable, secure analytics option that you can set up and roll out to production in days, instead of weeks or months previously.
Conclusion
The combination of embedding dashboard for users not provisioned in QuickSight and row-level security using tags enables developers and ISVs to quickly and easily set up sophisticated, customized analytics for their application users—all without any infrastructure setup or management while scaling to millions of users. For more updates from QuickSight embedded analytics, see What’s New in the Amazon QuickSight User Guide.
About the Authors
Raji Sivasubram aniam is a Specialist Solutions Architect at AWS, focusing on Analytics. Raji has 20 years of experience in architecting end-to-end Enterprise Data Management, Business Intelligence and Analytics solutions for Fortune 500 and Fortune 100 companies across the globe. She has in-depth experience in integrated healthcare data and analytics with wide variety of healthcare datasets including managed market, physician targeting and patient analytics. In her spare time, Raji enjoys hiking, yoga and gardening.
aniam is a Specialist Solutions Architect at AWS, focusing on Analytics. Raji has 20 years of experience in architecting end-to-end Enterprise Data Management, Business Intelligence and Analytics solutions for Fortune 500 and Fortune 100 companies across the globe. She has in-depth experience in integrated healthcare data and analytics with wide variety of healthcare datasets including managed market, physician targeting and patient analytics. In her spare time, Raji enjoys hiking, yoga and gardening.
 Srikanth Baheti is a Specialized World Wide Sr. Solution Architect for Amazon QuickSight. He started his career as a consultant and worked for multiple private and government organizations. Later he worked for PerkinElmer Health and Sciences & eResearch Technology Inc, where he was responsible for designing and developing high traffic web applications, highly scalable and maintainable data pipelines for reporting platforms using AWS services and Serverless computing.
Srikanth Baheti is a Specialized World Wide Sr. Solution Architect for Amazon QuickSight. He started his career as a consultant and worked for multiple private and government organizations. Later he worked for PerkinElmer Health and Sciences & eResearch Technology Inc, where he was responsible for designing and developing high traffic web applications, highly scalable and maintainable data pipelines for reporting platforms using AWS services and Serverless computing.
Kareem Syed-Mohammed is a Product Manager at Amazon QuickSight. He focuses on embedded analytics, APIs, and developer experience. Prior to QuickSight he has been with AWS Marketplace and Amazon retail as a PM. Kareem started his career as a developer and then PM for call center technologies, Local Expert and Ads for Expedia. He worked as a consultant with McKinsey and Company for a short while.












 Kareem Syed-Mohammed is a Product Manager at Amazon QuickSight. He focuses on embedded analytics, APIs, and developer experience. Prior to QuickSight he has been with AWS Marketplace and Amazon retail as a PM. Kareem started his career as a developer and then PM for call center technologies, Local Expert and Ads for Expedia. He worked as a consultant with McKinsey and Company for a short while.
Kareem Syed-Mohammed is a Product Manager at Amazon QuickSight. He focuses on embedded analytics, APIs, and developer experience. Prior to QuickSight he has been with AWS Marketplace and Amazon retail as a PM. Kareem started his career as a developer and then PM for call center technologies, Local Expert and Ads for Expedia. He worked as a consultant with McKinsey and Company for a short while.