Post Syndicated from Geographics original https://www.youtube.com/watch?v=3zhGduDRXOc
Voice – Chapter 9
Post Syndicated from Home Assistant original https://www.youtube.com/watch?v=k6VvzDSI8RU
Freedesktop looking for new home for its GitLab instance
Post Syndicated from jake original https://lwn.net/Articles/1007032/
Visitors to the freedesktop.org
GitLab instance are currently being greeted with a message noting that
the company who has been hosting it for free for nearly five years, Equinix, has
asked that it be moved (or start being paid for) by the end of April. The
issue
ticket opened by Benjamin Tissoires in order to track the planning of a move is clear that the project is grateful for
the gift:
“First, I’d like to thank Equinix Metal for the years of support they gave us. They were very kind and generous with us and even if it’s a shame we have to move out on a short notice, all things come to an end.
”
The current cost for the services, much of which is for 50TB of bandwidth data transfer
per month and a half-dozen beefy servers for running continuous-integration
(CI) jobs, comes to around $24,000 per month. Tissoires believes that the
project should start paying for service somewhere, in order to avoid
upheaval of this sort, sometimes on short or no notice. “I personally
” Various options are
think we better have fd.o pay for its own servers, and then have sponsors
chip in. This way, when a sponsor goes away, it’s technically much simpler
to just replace the money than change datacenter.
being discussed there, but any move is likely to disrupt normal services
for a week or more.
git submodules adoption flow
Post Syndicated from turnoff.us original http://turnoff.us/geek/git-submodules/

GNU C Library 2.41 released
Post Syndicated from corbet original https://lwn.net/Articles/1007024/
Version 2.41 of the GNU
C Library has been released. Changes include a number of test-suite
improvements, strict-error support in the DNS stub resolver, wrappers for
the the sched_setattr()
and sched_getattr() system calls,
Unicode 16.0.0 support,
improved C23 support,
support for extensible restartable
sequences,
Guarded Control Stack support on 64-bit Arm systems,
and more.
Run Deepseek Locally for Free!
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=pbCQnDDj-bo
Security updates for Thursday
Post Syndicated from jake original https://lwn.net/Articles/1006978/
Security updates have been issued by AlmaLinux (redis:7), Debian (bind9, chromium, flightgear, pam-u2f, and simgear), Red Hat (fence-agents, git-lfs, libsoup, python3.9, rsync, and traceroute), Slackware (bind), SUSE (apache2-mod_security2, corepack22, go1.24, hplip, ignition, iperf, kernel, kernel-devel-longterm, nginx, nodejs22, openvpn, owasp-modsecurity-crs, and shadow), and Ubuntu (bind9, jinja2, libxml2, linux-lowlatency-hwe-6.8, php7.0, tomcat6, and vlc).
Thunderbird moving to monthly updates in March
Post Syndicated from jzb original https://lwn.net/Articles/1006917/
The Thunderbird project has announced
that it is making its Release
channel the default download beginning with the 135.0 release in
March. This will move users to major monthly releases instead of the
annual major Extended Support Release (ESR) that is the current
default.
One of our goals for 2025 is to increase active installations on the
release channel to at least 20% of the total installations. At last
check, we had 29,543 active installations on the release channel,
compared to 20,918 on beta, and 5,941 on daily. The release channel
installations currently account for 0.27% of the 10,784,551 total
active installations tracked on stats.thunderbird.net.
Paying It Forward: Giving and Receiving Mentorship in Tech
Post Syndicated from Rapid7 original https://blog.rapid7.com/2025/01/30/paying-it-forward-giving-and-receiving-mentorship-in-tech/

I’ve never actually seen the 2000 romantic drama Pay It Forward, but the movie’s core idea has stayed with me since I first heard of it:
The best way to repay a favor or good deed is to do one for someone else. You ‘pay it forward,’ and ask that person to do likewise, creating an expanding web of positivity and goodwill.
Cliche as it may sound, it’s served me well over my career. I’ve had many roles over the past 20 years, starting as a junior engineer and progressing into management. My own mentors and coaches shaped my experiences along the way, contributing to that growth.
In return, I try to do the same for others.
Mentorship vs. coaching
I want to briefly look at ‘mentorship’ versus ‘coaching,’ as they are often conflated. There is certainly overlap, but the approach and impetus differs.
Mentorship involves dedicated guidance and support over time. The mentee drives the relationship, the ultimate goal, and the current focus. The mentor maps a path to the goal, and offers personalized knowledge and experience on a one-to-one basis.
Coaching is a more structured approach,primarily driven by the coach. It normally involves specific skill or knowledge training, and often isn’t personalized; it can be extended to groups with minimal change.
I believe that successful learning relationships operate on a spectrum between mentorship and coaching. Particularly in tech, where so-called ‘hard’ and ‘soft’ skills carry equal weight, the focus is a sliding scale over time.
For this article, I’ll focus on the ‘mentor’ and ‘mentee’ roles for simplicity.
Why do people seek mentorship?
Mentee-mentor relationships are inherently transactional – and that’s okay! The mentee has a goal to achieve, and wants help to get there. So what’s in it for both parties?
For mentees, it’s fairly obvious:
- Skills and experience growth
- Career advancement
- Increased profile and exposure
- Personalized individual guidance
The mentor – wanting to be diligent and accurate with their guidance – sees their own skills and knowledge reinforced. Communication and teaching skills grow. Their ability to elevate others is advantageous for their own career aspirations.
It’s okay to feel good about this – it’s a good thing.
Mentorship and career growth
As you climb the ladder in your career, you will find yourself gaining:
- The ability to handle increasing ambiguity, complexity, and scope
- Knowledge and experience you can share with others
Obviously you also have to deliver value, but I see that as a function of the above, plus institutional factors. Your increasing capacity to navigate complex or ambiguous environments, paired with an advanced set of skills, is what propels you from wide-eyed junior to seasoned veteran.
We’re all walking this path in some form. Juniors often need direction on what to do and how to do it. With more experience, there is less direction needed for ‘how’ and more focus on ‘what’ and ‘why.’ You start to own features and systems, and can guide others.
In higher roles, strategy comes to the forefront as you become more aware of business needs, customer requirements, and wider technical challenges. You’ve gone from ‘change this line of code’ to ‘increase this KPI by 20%’. Ambiguity, complexity, and scope all go up as a result..
In addition to changes in your deliverables, success also becomes measured by how well you can elevate others around you. At Rapid7, we look at leaders to be impact multipliers, meaning they have the capacity to drive impact not only in their own roles, but how they support those around them to be successful.
Additionally, you don’t have to wait to be in an official people leader role to have this kind of impact. Being a mentor and elevating others can happen regardless of where you are in your career journey.
Mentoring someone is an investment in the future. You chart a path to success, act as a role model, and in some ways shape the industry to come.
Getting started
Whether you’re looking to become a mentor – or seeking guidance as a mentee – the keys to getting started are relatively similar.
Seeking the right opportunities
- Take stock of where you have existing relationships to build off of, and ask for guidance while sharing what your goals are for entering into a mentorship relationship. – Let your colleagues and manager know that you’re available. Sharing your goals with your manager can help incorporate your mentor experience into your personal development plan, and they may even have recommendations on how to get started. Colleagues can be great mentors/mentees, and may also be able to help point you in the right direction to connect with someone. Seek opportunities on Slack, Discord, and other community channels. Going beyond your current employer can expose you to different practices and philosophies that exist within the same field or area of focus.
- Attend meetups and conferences to network and find opportunities. The goal of attending an event is often to gain knowledge and share best practices, so this is a great audience for you to find your mentor/mentee match.
Establishing guidelines and expectations
It’s important for both parties to agree on some foundational principles, which for me are:
- Mutual trust and respect
- Adequate investment of time, effort, and care
- Fluidity and flexibility
- Transparency, honesty, and accountability
Maintaining effective mentorships
Let’s look at some other factors to consider and watch for as the relationship evolves:
- Don’t over-prescribe structure or get bogged down in note-taking – keep it light and fluid to encourage maximum flexibility.
- There are no ‘stupid questions’ – don’t apologize as a mentee for asking!
- Leave ego at the door – embrace honest feedback and mutual respect at all times.
- Safety and trust are essential – but avoid getting too personal in ways that hinder your ability to be honest and open.
- Mentorship is a vital tool for managers – but transparency can suffer when the mentee is also a direct report. Peer relationships without these power structures can feel ‘safer’ and encourage better transparency.
Conclusion
When it comes to mentorship, my core point is this:
Helping people is good, and you can (and should) do it.
As a mentor, you have the opportunity to shape someone’s career and experience while galvanizing your own skills and future prospects. Start today, in whatever form you can.
As a mentee benefitting from guidance and support in pursuit of your goals, try not to forget to pay it forward. Find someone to guide and help on their journey, as you yourself have been.
Comic for 2025.01.31 – Jedi
Post Syndicated from Explosm.net original https://explosm.net/comics/jedi
New Cyanide and Happiness Comic
How Open Universities Australia modernized their data platform and significantly reduced their ETL costs with AWS Cloud Development Kit and AWS Step Functions
Post Syndicated from Michael Davies original https://aws.amazon.com/blogs/big-data/how-open-universities-australia-modernized-their-data-platform-and-significantly-reduced-their-etl-costs-with-aws-cloud-development-kit-and-aws-step-functions/
This is a guest post co-authored by Michael Davies from Open Universities Australia.
At Open Universities Australia (OUA), we empower students to explore a vast array of degrees from renowned Australian universities, all delivered through online learning. We offer students alternative pathways to achieve their educational aspirations, providing them with the flexibility and accessibility to reach their academic goals. Since our founding in 1993, we have supported over 500,000 students to achieve their goals by providing pathways to over 2,600 subjects at 25 universities across Australia.
As a not-for-profit organization, cost is a crucial consideration for OUA. While reviewing our contract for the third-party tool we had been using for our extract, transform, and load (ETL) pipelines, we realized that we could replicate much of the same functionality using Amazon Web Services (AWS) services such as AWS Glue, Amazon AppFlow, and AWS Step Functions. We also recognized that we could consolidate our source code (much of which was stored in the ETL tool itself) into a code repository that could be deployed using the AWS Cloud Development Kit (AWS CDK). By doing so, we had an opportunity to not only reduce costs but also to enhance the visibility and maintainability of our data pipelines.
In this post, we show you how we used AWS services to replace our existing third-party ETL tool, improving the team’s productivity and producing a significant reduction in our ETL operational costs.
Our approach
The migration initiative consisted of two main parts: building the new architecture and migrating data pipelines from the existing tool to the new architecture. Often, we would work on both in parallel, testing one component of the architecture while developing another at the same time.
From early in our migration journey, we began to define a few guiding principles that we would apply throughout the development process. These were:
- Simple and modular – Use simple, reusable design patterns with as few moving parts as possible. Structure the code base to prioritize ease of use for developers.
- Cost-effective – Use resources in an efficient, cost-effective way. Aim to minimize situations where resources are running idly while waiting for other processes to be completed.
- Business continuity – As much as possible, make use of existing code rather than reinventing the wheel. Roll out updates in stages to minimize potential disruption to existing business processes.
Architecture overview
The following Diagram 1 is the high-level architecture for the solution.

Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3
The following AWS services were used to shape our new ETL architecture:
- Amazon Redshift – A fully managed, petabyte-scale data warehouse service in the cloud. Amazon Redshift served as our central data repository, where we would store data, apply transformations, and make data available for use in analytics and business intelligence (BI). Note: The provisioned cluster itself was deployed separately from the ETL architecture and remained unchanged throughout the migration process.
- AWS Cloud Development Kit (AWS CDK) – The AWS Cloud Development Kit (AWS CDK) is an open-source software development framework for defining cloud infrastructure in code and provisioning it through AWS CloudFormation. Our infrastructure was defined as code using the AWS CDK. As a result, we simplified the way we defined the resources we wanted to deploy while using our preferred coding language for development.
- AWS Step Functions – With AWS Step Functions, you can create workflows, also called State machines, to build distributed applications, automate processes, orchestrate microservices, and create data and machine learning pipelines. AWS Step Functions can call over 200 AWS services including AWS Glue, AWS Lambda, and Amazon Redshift. We used the AWS Step Function state machines to define, orchestrate, and execute our data pipelines.
- Amazon EventBridge – We used Amazon EventBridge, the serverless event bus service, to define the event-based rules and schedules that would trigger our AWS Step Functions state machines.
- AWS Glue – A data integration service, AWS Glue consolidates major data integration capabilities into a single service. These include data discovery, modern ETL, cleansing, transforming, and centralized cataloging. It’s also serverless, which means there’s no infrastructure to manage. includes the ability to run Python scripts. We used it for executing long-running scripts, such as for ingesting data from an external API.
- AWS Lambda – AWS Lambda is a highly scalable, serverless compute service. We used it for executing simple scripts, such as for parsing a single text file.
- Amazon AppFlow – Amazon AppFlow enables simple integration with software as a service (SaaS) applications. We used it to define flows that would periodically load data from selected operational systems into our data warehouse.
- Amazon Simple Storage Service (Amazon S3) – An object storage service offering industry-leading scalability, data availability, security, and performance. Amazon S3 served as our staging area, where we would store raw data prior to loading it into other services such as Amazon Redshift. We also used it as a repository for storing code that could be retrieved and used by other services.
Where practical, we made use of the file structure of our code base for defining resources. We set up our AWS CDK to refer to the contents of a specific directory and define a resource (for example, an AWS Step Functions state machine or an AWS Glue job) for each file it found in that directory. We also made use of configuration files so we could customize the attributes of specific resources as required.
Details on specific patterns
In the above architecture Diagram 1, we showed multiple flows by which data could be ingested or unloaded from our Amazon Redshift data warehouse. In this section, we highlight four specific patterns in more detail which were utilized in the final solution.
Pattern 1: Data transformation, load, and unload
Several of our data pipelines included significant data transformation steps, which were primarily performed through SQL statements executed by Amazon Redshift. Others required ingestion or unloading of data from the data warehouse, which could be performed efficiently using COPY or UNLOAD statements executed by Amazon Redshift.
In keeping with our aim of using resources efficiently, we sought to avoid running these statements from within the context of an AWS Glue job or AWS Lambda function because these processes would remain idle while waiting for the SQL statement to be completed. Instead, we opted for an approach where SQL execution tasks would be orchestrated by an AWS Step Functions state machine, which would send the statements to Amazon Redshift and periodically check their progress before marking them as either successful or failed. The following Diagram 2 shows this workflow.

Diagram 2: Data transformation, load, and unload pattern using Amazon Lambda and Amazon Redshift within an AWS Step Function
Pattern 2: Data replication using AWS Glue
In cases where we needed to replicate data from a third-party source, we used AWS Glue to run a script that would query the relevant API, parse the response, and store the relevant data in Amazon S3. From here, we used Amazon Redshift to ingest the data using a COPY statement. The following Diagram 3 shows this workflow.

Diagram 3: Copying from external API to Redshift with AWS Glue
Note: Another option for this step would be to use Amazon Redshift auto-copy, but this wasn’t available at time of development.
Pattern 3: Data replication using Amazon AppFlow
For certain applications, we were able to use Amazon AppFlow flows in place of AWS Glue jobs. As a result, we could abstract some of the complexity of querying external APIs directly. We configured our Amazon AppFlow flows to store the output data in Amazon S3, then used an EventBridge rule based on an End Flow Run Report event (which is an event which is published when a flow run is complete) to trigger a load into Amazon Redshift using a COPY statement. The following Diagram 4 shows this workflow.
By using Amazon S3 as an intermediate data store, we gave ourselves greater control over how the data was processed when it was loaded into Amazon Redshift, when compared with loading the data directly to the data warehouse using Amazon AppFlow.

Diagram 4: Using Amazon AppFlow to integrate external data to Amazon S3 and copy to Amazon Redshift
Pattern 4: Reverse ETL
Although most of our workflows involve data being brought into the data warehouse from external sources, in some cases we needed the data to be exported to external systems instead. This way, we could run SQL queries with complex logic drawing on multiple data sources and use this logic to support operational requirements, such as identifying which groups of students should receive specific communications.
In this flow, shown in the following Diagram 5, we start by running an UNLOAD statement in Amazon Redshift to unload the relevant data to files in Amazon S3. From here, each file is processed by an AWS Lambda function, which performs any necessary transformations and sends the data to the external application through one or more API calls.

Diagram 5: Reverse ETL workflow, sending data back out to external data sources
Outcomes
The re-architecture and migration process took 5 months to complete, from the initial concept to the successful decommissioning of the previous third-party tool. Most of the architectural effort was completed by a single full-time employee, with others on the team primarily assisting with the migration of pipelines to the new architecture.
We achieved significant cost reductions, with final expenses on AWS native services representing only a small percentage of projected costs compared to continuing with the third-party ETL tool. Moving to a code-based approach also gave us greater visibility of our pipelines and made the process of maintaining them quicker and easier. Overall, the transition was seamless for our end users, who were able to view the same data and dashboards both during and after the migration, with minimal disruption along the way.
Conclusion
By using the scalability and cost-effectiveness of AWS services, we were able to optimize our data pipelines, reduce our operational costs, and improve our agility.
Pete Allen, an analytics engineer from Open Universities Australia, says, “Modernizing our data architecture with AWS has been transformative. Transitioning from an external platform to an in-house, code-based analytics stack has vastly improved our scalability, flexibility, and performance. With AWS, we can now process and analyze data with much faster turnaround, lower costs, and higher availability, enabling rapid development and deployment of data solutions, leading to deeper insights and better business decisions.”
Additional resources
- Orchestrate Amazon Redshift based ETL workflows with AWS Step Functions and AWS Glue
- Best practices for developing and deploying cloud infrastructure with the AWS CDK
- redshift-data-api-with-step-functions-sample
About the Authors
 Michael Davies is a Data Engineer at OUA. He has extensive experience within the education industry, with a particular focus on building robust and efficient data architecture and pipelines.
Michael Davies is a Data Engineer at OUA. He has extensive experience within the education industry, with a particular focus on building robust and efficient data architecture and pipelines.
 Emma Arrigo is a Solutions Architect at AWS, focusing on education customers across Australia. She specializes in leveraging cloud technology and machine learning to address complex business challenges in the education sector. Emma’s passion for data extends beyond her professional life, as evidenced by her dog named Data.
Emma Arrigo is a Solutions Architect at AWS, focusing on education customers across Australia. She specializes in leveraging cloud technology and machine learning to address complex business challenges in the education sector. Emma’s passion for data extends beyond her professional life, as evidenced by her dog named Data.
Fake Reddit and WeTransfer Sites are Pushing Malware
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/01/fake-reddit-and-wetransfer-sites-are-pushing-malware.html
There are thousands of fake Reddit and WeTransfer webpages that are pushing malware. They exploit people who are using search engines to search sites like Reddit.
Unsuspecting victims clicking on the link are taken to a fake WeTransfer site that mimicks the interface of the popular file-sharing service. The ‘Download’ button leads to the Lumma Stealer payload hosted on “weighcobbweo[.]top.”
Boingboing post.
The War for Your Attention
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=MRDqQ8-HiwM
Migration to Zabbix 7.0
Post Syndicated from Rogerio Batista original https://blog.zabbix.com/migration-to-zabbix-7-0/29594/
Based in northern Brazil, TO HOST Data Centers provides regional cloud services with a focus on cloud computing, colocation, and infrastructure management. With 35 suppliers and partners and over 5,000 monitored assets, their mission is to provide innovative IT infrastructure products and services with a high level of proficiency, in order to meet the high standards required by their clients and partners. To do this, they need to monitor internal applications, data center assets, devices, and customer environments, ensuring high availability and optimal performance.

The challenge:
TO HOST’s monitoring environment included a standalone server (Zabbix, FrontEnd, Database) with the following:
- Hosts: ~600
- Itens/Metrics: ~90.000
- Average period for history table: 45~60 days
- Average period for trends table: 365 days
- Average period for events table: 365 days
- 3 Internal Proxies
- 8 Client Proxies
- ~30 External Active Agents
TO HOST needed a clean installation of Zabbix Server and Zabbix Proxy version 7.0.x on separate virtual machines with an updated operating system (Oracle 9), plus a migration of the current monitoring environment database to the new version, while preserving history and data integrity.
Their production servers were outdated, featuring a CentOS 7 version that was originally installed with Zabbix version 5.2.x and updated to version 6.0.x in 2022. The migration needed to retain historical data and ensure compatibility with Zabbix 7.0.x, while keeping service interruptions to a minimum.
A number of risks were anticipated and planned for – during the data migration process, it was understood that there may be failures in migrating the database due to version incompatibility and that there was a distinct possibility of collection failures that would require corrections after migration, if any data sources were not properly mapped.
All graphs needed to be reviewed and optimized to take advantage of the new widget models and improvements in Zabbix 7.0. Due to the changes in data sources (and because of the migration to a new operating system and a new version of the Zabbix Server) there was potential version incompatibility.
Directories containing custom scripts and images were mapped and files were copied in order to ensure integrity, and the TO HOST team was prepared for possible service interruptions during the upgrade process, standing ready to notify users about the planned maintenance and creating procedures to minimize the impact.
The solution:
Step one was to make sure that the change to Zabbix 7.0 was appropriately planned. A change schedule was created, and all relevant stakeholders were notified of the operation. A virtualized environment was then set up on Oracle 9, in order to guarantee a clean installation.
Once that was done, Zabbix 7.0 was installed, keeping in mind that the imported database could not exist on the new server. Next up was a full backup and the cloning of the database for integrity validation pre-migration. At this point, the To Host team stopped the data collection service, started the backup, and started restore.
From that point, it became a simple matter of carrying out automated database versioning and data source mapping corrections. The data mapping during the Zabbix 7.0 migration involved updating the database structure to meet the new version’s requirements, such as changes to MySQL instances, fields, and storage formats.
Data mapping in the Zabbix migration process involved the following:
- Database Version: During migration, the database structure changed to align with the requirements of Zabbix 7.0. This included different versioning of MySQL instances, as well as modifications to fields, tables, and storage formats within the database.
- Import and Update Process: The legacy database (version 6) was exported and then imported into the new Zabbix 7.0 installation. During the process, Zabbix ran automatic update scripts to convert the old database into the new format.
- Data Sources: Each item monitored in Zabbix was associated with a unique key (item key) that defined how data was collected and processed. No changes were identified in this process.
- Tools and Validations: Mapping validation was performed during the import/restore process, where error logs indicated inconsistencies. During testing, inconsistencies were found in the validation, requiring a command to update the keys replicated on the migration.
Data collection services were then restarted, and all stakeholders were notified of the completion of the change.
The results:
Zabbix 7.0’s new dashboards and improved visual configuration have increased the satisfaction of internal customers, while having a tangible impact on operational efficiency and customer satisfaction.
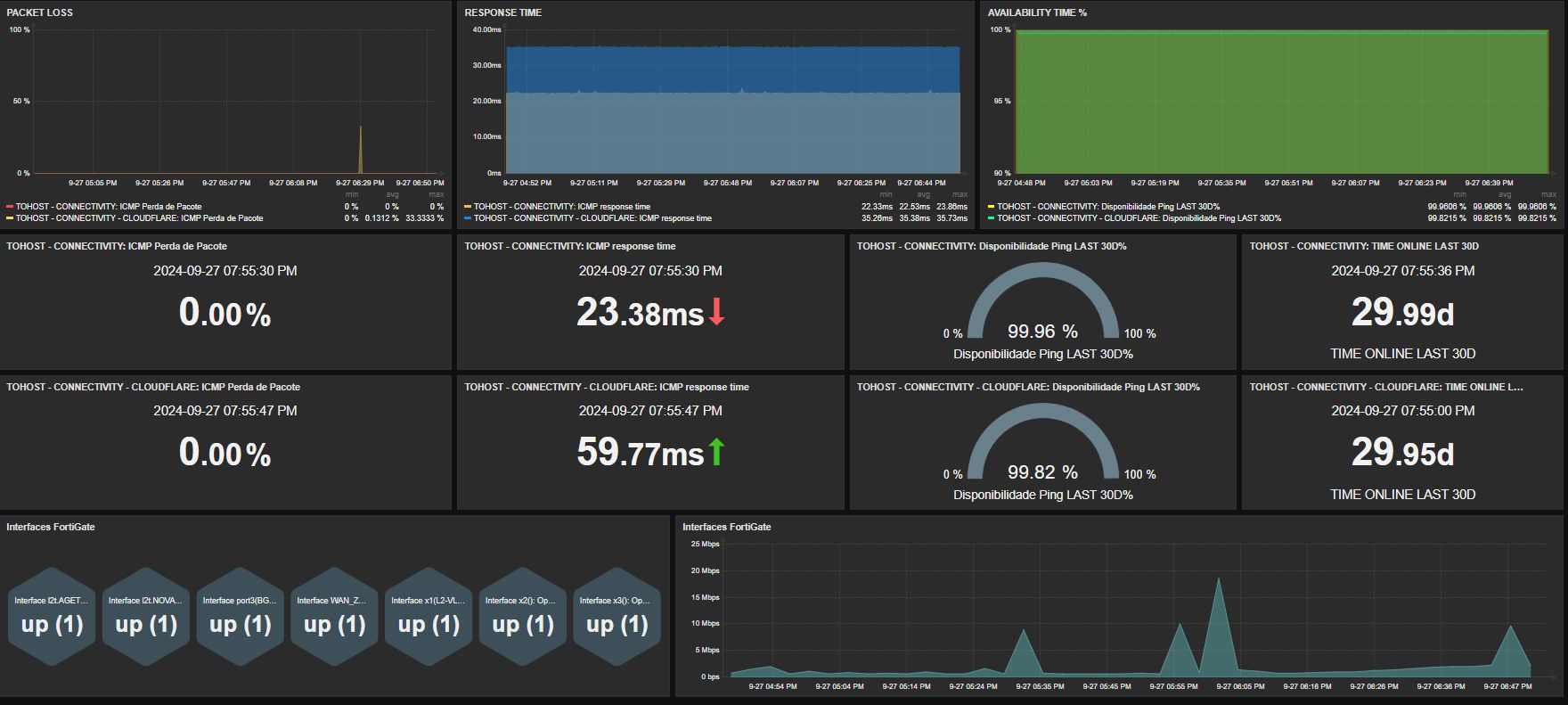
The implementation and management of Zabbix 7.0 has enhanced the continuous visibility and integrity of TO HOST’s IT systems, enabling real-time monitoring and alerting, facilitating proactive issue resolution, and guaranteeing optimal infrastructure performance.
Many users have noted that the asynchronous polling method used in Zabbix 7.0 significantly reduces the time taken for metric collection. This allows for faster incident detection and resolution in TO HOST’s critical environment, while the addition of multi-factor authentication and improved access controls has helped to enhance security in monitoring environments and keep cyber threats at bay.
TO HOST’s future plans include exploring advanced Zabbix 7.0 features and continuous performance monitoring. A roadmap is already in place to leverage the additional automation and security enhancements that Zabbix 7.0 can provide.
The post Migration to Zabbix 7.0 appeared first on Zabbix Blog.
За 20-те% истина в говоренето за строежит
Post Syndicated from Боян Юруков original https://yurukov.net/blog/2025/istinata-za-stroejite/
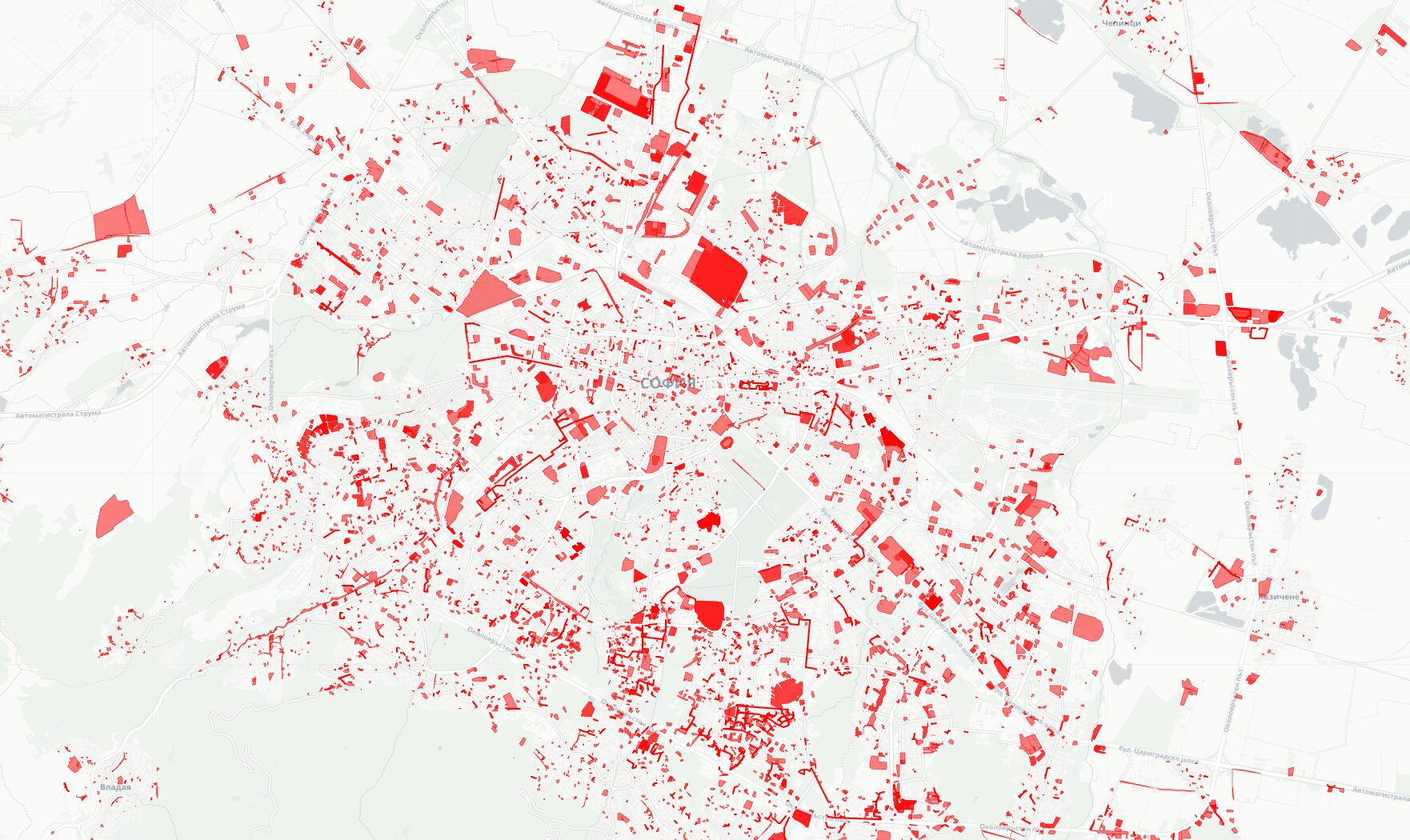
Темата за градоустройството и разрешителните за стоеж в София отново се завъртя в ефира. Хвърлят се твърдения, протести, документи. Истината е, че имаме пълното право да сме недоволни, още повече като ни кажат, че мачът е свирен за много от наболелите теми.
Също толкова обаче е вярно, че над 80% от твърденията, които четем в медиите за градоустройството и конкретни строежи не са верни. Защо твърдя това? Не съм архитект, не работя в общината или строителна компания. Това, което правя обаче е от години е да следя документите, процесите, да изследвам, аргументирам, да обсъждам както с архитекти отчаяни от гилдията си, така и от чиновници в местната администрация и служители в инвеститори в строителството, на които също им е писнало вече.
Първото общо между тях е, че ги е страх да излязат с имената си. Страх ги е от самите инвеститори и финансовите интереси. Страх ги е също от Камарата на архитектите и политически машинации, което обаче пак идва от въпросните инвеститори. Другото общо обаче е, че покрай описанията им за аспекти от проблемите, нарочен саботаж и укриване от служители в администрацията, кадруване и конфликт на интереси в общината и ДНСК, лобизъм и корупция както в местната власт, така и в НС, говорят, че никой не разбира цялата картина. Толкова е обширна темата, че никой няма поглед над дори половината от заровените скелети по устройствени планове, решения и параметри заложени години назад. Същото съм забелязал и аз в разговорите и когато съм се заемал да оборвам с документи твърдения на строители, районни кметове и общински съветници.
Та ако някой ви каже, че знае точно какъв е проблемът, то знайте, че лъже. Тези, които знаят най-много, обикновено публично говорят друго и умишлено отклоняват вниманието атакувайки опитите да се разплете тази каша бидейки в голяма степен сред „архитектите“ на сегашния хаос.
Това също позволява на много да подвеждат и откровено да лъжат с определени обекти, как се е стигнало до строеж или събаряне. Че не са знаели, че са нямали полезни ходове преди и прочие. Всъщност, всеки документ, който виждате публикуван, включително от мен, е предшестван от множество комисии, уведомления към районни кметове, експерти и прочие. Дали е обърнато внимание и дали са имали капацитет да обърнат внимание е важна тема, която трябва да се засегне, но не го правим.
Та призивът ми е да не забравяме, че всяко нещо, което някой пуска като сензация, пряко или прикрито обвинение и протест, показва не повече от 20% от истината. Останалото е или измислено, или подвеждащо, или премълчано. И да, в това число включвам както Балкантон, така и няколкото нашумели обекти в Изгрев, високи сгради по Черни връх и Симеоново и прочие. Включително аз пускам съобщения за нови строежи и ги придружавам с документите. Като правило в заповедите и разрешенията за строеж пише коя комисия го е предложила и аргументирала, кой е протестирал и как, какви дела са били загубени от общината и прочие.
Четете, ако ви е грижа. Шаренията по картата ми може да покаже само къде да насочите вниманието си, но се иска следващи стъпки.
The post За 20-те% истина в говоренето за строежит first appeared on Блогът на Юруков.
[$] LWN.net Weekly Edition for January 30, 2025
Post Syndicated from corbet original https://lwn.net/Articles/1005953/
Inside this week’s LWN.net Weekly Edition:
- Front: Go vendoring in Fedora; Rust 2024 edition; 6.14 Merge window; uretprobe(); FOSDEM keynote; Earthstar.
- Briefs: Git security; Ubuntu discussion; LWN EPUBs; Facebook moderation; Quotes; …
- Announcements: Newsletters, conferences, security updates, patches, and more.
Kioxia AiSAQ SSD-backed RAG Open Sourced
Post Syndicated from Cliff Robinson original https://www.servethehome.com/kioxia-aisaq-ssd-backed-rag-open-sourced/
Kioxia AiSAQ is designed to replace DRAM with lower-cost flash in RAG applications. It is now open-sourced and available on Github
The post Kioxia AiSAQ SSD-backed RAG Open Sourced appeared first on ServeTheHome.
The "Wagtail"
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=H1-5i70bkko
Scaling Our Rate Limits to Prepare for a Billion Active Certificates
Post Syndicated from Let's Encrypt original https://letsencrypt.org/2025/01/30/scaling-rate-limits/
Let’s Encrypt protects a vast portion of the Web by providing TLS certificates to over 550 million websites—a figure that has grown by 42% in the last year alone. We currently issue over 64,000 certificates per hour. To manage this immense traffic and maintain responsiveness under high demand, our infrastructure relies on rate limiting. In 2015, we introduced our first rate limiting system, built on MariaDB. It evolved alongside our rapidly growing service but eventually revealed its limits: straining database servers, forcing long reset times on subscribers, and slowing down every request.
We needed a solution built for the future—one that could scale with demand, reduce the load on MariaDB, and adapt to real-world subscriber request patterns. The result was a new rate limiting system powered by Redis and a proven virtual scheduling algorithm from the mid-90s. Efficient and scalable, and capable of handling over a billion active certificates.
Rate Limiting a Free Service is Hard
In 2015, Let’s Encrypt was in early preview, and we faced a unique challenge. We were poised to become incredibly popular, offering certificates freely and without requiring contact information or email verification. Ensuring fair usage and preventing abuse without traditional safeguards demanded an atypical approach to rate limiting.
We decided to limit the number of certificates issued—per week—for each registered domain. Registered domains are a limited resource with real costs, making them a natural and effective basis for rate limiting—one that mirrors the structure of the Web itself. Specifically, this approach targets the effective Top-Level Domain (eTLD), as defined by the Public Suffix List (PSL), plus one additional label to the left. For example, in new.blog.example.co.uk, the eTLD is .co.uk, making example.co.uk the eTLD+1.
Counting Events Was Easy
For each successfully issued certificate, we logged an entry in a table that recorded the registered domain, the issuance date, and other relevant details. To enforce rate limits, the system scanned this table, counted the rows matching a given registered domain within a specific time window, and compared the total to a configured threshold. This simple design formed the basis for all future rate limits.
Counting a Lot of Events Got Expensive
By 2019, we had added six new rate limits to protect our infrastructure as demand for certificates surged. Enforcing these limits required frequent scans of database tables to count recent matching events. These operations, especially on our heavily-used authorizations table, caused significant overhead, with reads outpacing all other tables—often by an order of magnitude.
Rate limit calculations were performed early in request processing and often. Counting rows in MariaDB, particularly for accounts with rate limit overrides, was inherently expensive and quickly became a scaling bottleneck.
Adding new limits required careful trade-offs. Decisions about whether to reuse existing schema, optimize indexes, or design purpose-built tables helped balance performance, complexity, and long-term maintainability.
Buying Runway — Offloading Reads
In late 2021, we updated our control plane and Boulder—our in-house CA software—to route most API reads, including rate limit checks, to database replicas. This reduced the load on the primary database and improved its overall health. At the same time, however, latency of rate limit checks during peak hours continued to rise, highlighting the limitations of scaling reads alone.
Sliding Windows Got Frustrating
Subscribers were frequently hitting rate limits unexpectedly, leaving them unable to request certificates for days. This issue stemmed from our use of relatively large rate limiting windows—most spanning a week. Subscribers could deplete their entire limit in just a few moments by repeating the same request, and find themselves locked out for the remainder of the week. This approach was inflexible and disruptive, causing unnecessary frustration and delays.
In early 2022, we patched the Duplicate Certificate limit to address this rigidity. Using a naive token-bucket approach, we allowed users to “earn back” requests incrementally, cutting the wait time—once rate limited—to about 1.4 days. The patch worked by fetching recent issuance timestamps and calculating the time between them to grant requests based on the time waited. This change also allowed us to include a Retry-After timestamp in rate limited responses. While this improved the user experience for this one limit, we understood it to be a temporary fix for a system in need of a larger overhaul.
When a Problem Grows Large Enough, It Finds the Time for You
Setting aside time for a complete overhaul of our rate-limiting system wasn’t easy. Our development team, composed of just three permanent engineers, typically juggles several competing priorities. Yet by 2023, our flagging rate limits code had begun to endanger the reliability of our MariaDB databases.
Our authorizations table was now regularly read an order of magnitude more than any other. Individually identifying and deleting unnecessary rows—or specific values—had proved unworkable due to poor MariaDB delete performance. Storage engines like InnoDB must maintain indexes, foreign key constraints, and transaction logs for every deletion, which significantly increases overhead for concurrent transactions and leads to gruelingly slow deletes.
Our SRE team automated the cleanup of old rows for many tables using the PARTITION command, which worked well for bookkeeping and compliance data. Unfortunately, we couldn’t apply it to most of our purpose-built rate limit tables. These tables depend on ON DUPLICATE KEY UPDATE, a mechanism that requires the targeted column to be a unique index or primary key, while partitioning demands that the primary key be included in the partitioning key.
Indexes on these tables—such as those tracking requested hostnames—often grew larger than the tables themselves and, in some cases, exceeded the memory of our smaller staging environment databases, eventually forcing us to periodically wipe them entirely.
By late 2023, this cascading confluence of complexities required a reckoning. We set out to design a rate limiting system built for the future.
The Solution: Redis + GCRA
We designed a system from the ground up that combines Redis for storage and the Generic Cell Rate Algorithm (GCRA) for managing request flow.
Why Redis?
Our engineers were already familiar with Redis, having recently deployed it to cache and serve OCSP responses. Its high throughput and low latency made it a candidate for tracking rate limit state as well.
By moving this data from MariaDB to Redis, we could eliminate the need for ever-expanding, purpose-built tables and indexes, significantly reducing read and write pressure. Redis’s feature set made it a perfect fit for the task. Most rate limit data is ephemeral—after a few days, or sometimes just minutes, it becomes irrelevant unless the subscriber calls us again. Redis’s per-key Time-To-Live would allow us to expire this data the moment it was no longer needed.
Redis also supports atomic integer operations, enabling fast, reliable counter updates, even when increments occur concurrently. Its “set if not exist” functionality ensures efficient initialization of keys, while pipeline support allows us to get and set multiple keys in bulk. This combination of familiarity, speed, simplicity, and flexibility made Redis the natural choice.
Why GCRA?
The Generic Cell Rate Algorithm (GCRA) is a virtual scheduling algorithm originally designed for telecommunication networks to regulate traffic and prevent congestion. Unlike traditional sliding window approaches that work in fixed time blocks, GCRA enforces rate limits continuously, making it well-suited to our goals.
A rate limit in GCRA is defined by two parameters: the emission interval and the burst tolerance. The emission interval specifies the minimum time that must pass between consecutive requests to maintain a steady rate. For example, an emission interval of one second allows one request per second on average. The burst tolerance determines how much unused capacity can be drawn on to allow short bursts of requests beyond the steady rate.
When a request is received, GCRA compares the current time to the Theoretical Arrival Time (TAT), which indicates when the next request is allowed under the steady rate. If the current time is greater than or equal to the TAT, the request is permitted, and the TAT is updated by adding the emission interval. If the current time plus the burst tolerance is greater than or equal to the TAT, the request is also permitted. In this case, the TAT is updated by adding the emission interval, reducing the remaining burst capacity.
However, if the current time plus the burst tolerance is less than the TAT, the request exceeds the rate limit and is denied. Conveniently, the difference between the TAT and the current time can then be returned to the subscriber in a Retry-After header, informing their client exactly how long to wait before trying again.
To illustrate, consider a rate limit of one request per second (emission interval = 1s) with a burst tolerance of three requests. Up to three requests can arrive back-to-back, but subsequent requests will be delayed until “now” catches up to the TAT, ensuring that the average rate over time remains one request per second.
What sets GCRA apart is its ability to automatically refill capacity gradually and continuously. Unlike sliding windows, where users must wait for an entire time block to reset, GCRA allows users to retry as soon as enough time has passed to maintain the steady rate. This dynamic pacing reduces frustration and provides a smoother, more predictable experience for subscribers.
GCRA is also storage and computationally efficient. It requires tracking only the TAT—stored as a single Unix timestamp—and performing simple arithmetic to enforce limits. This lightweight design allows it to scale to handle billions of requests, with minimal computational and memory overhead.
The Results: Faster, Smoother, and More Scalable
The transition to Redis and GCRA brought immediate, measurable improvements. We cut database load, improved response times, and delivered consistent performance even during periods of peak traffic. Subscribers now experience smoother, more predictable behavior, while the system’s increased permissiveness allows for certificates that the previous approach would have delayed—all achieved without sacrificing scalability or fairness.
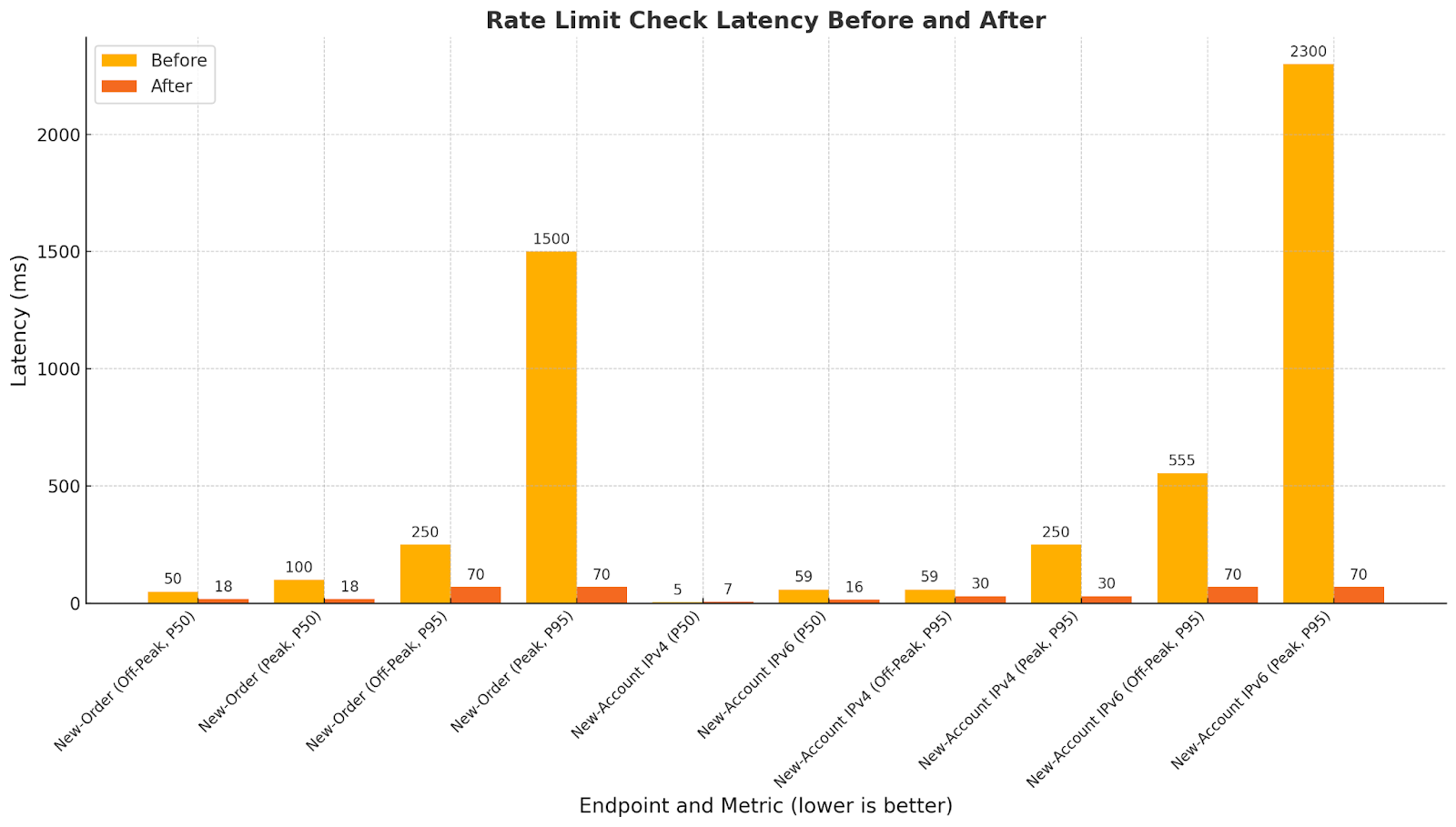
Rate Limit Check Latency
Check latency is the extra time added to each request while verifying rate limit compliance. Under the old MariaDB-based system, these checks slowed noticeably during peak traffic, when database contention caused significant delays. Our new Redis-based system dramatically reduced this overhead. The high-traffic “new-order” endpoint saw the greatest improvement, while the “new-account” endpoint—though considerably lighter in traffic—also benefited, especially callers with IPv6 addresses. These results show that our subscribers now experience consistent response times, even under peak load.
Database Health
Our once strained database servers are now operating with ample headroom. In total, MariaDB operations have dropped by 80%, improving responsiveness, reducing contention, and freeing up resources for mission-critical issuance workflows.

Buffer pool requests have decreased by more than 50%, improving caching efficiency and reducing overall memory pressure.

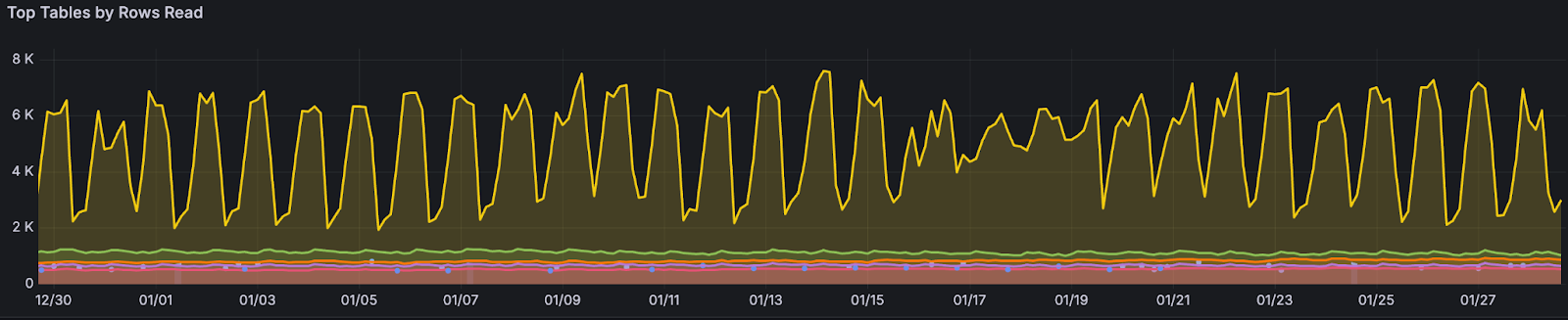
Reads of the authorizations table—a notorious bottleneck—have dropped by over 99%. Previously, this table outpaced all others by more than two orders of magnitude; now it ranks second (the green line below), just narrowly surpassing our third most-read table.
Tracking Zombie Clients
In late 2024, we turned our new rate limiting system toward a longstanding challenge: “zombie clients.” These requesters repeatedly attempt to issue certificates but fail, often because of expired domains or misconfigured DNS records. Together, they generate nearly half of all order attempts yet almost never succeed. We were able to build on this new infrastructure to record consecutive ACME challenge failures by account/domain pair and automatically “pause” this problematic issuance. The result has been a considerable reduction in resource consumption, freeing database and network capacity without disrupting legitimate traffic.
Scalability on Redis
Before deploying the limits to track zombie clients, we maintained just over 12.6 million unique TATs across several Redis databases. Within 24 hours, that number more than doubled to 26 million, and by the end of the week, it peaked at over 30 million. Yet, even with this sharp increase, there was no noticeable impact on rate limit responsiveness. That’s all we’ll share for now about zombie clients—there’s plenty more to unpack, but we’ll save those insights and figures for a future blog post.
What’s Next?
Scaling our rate limits to keep pace with the growth of the Web is a huge achievement, but there’s still more to do. In the near term, many of our other ACME endpoints rely on load balancers to enforce per-IP limits, which works but gives us little control over the feedback provided to subscribers. We’re looking to deploy this new infrastructure across those endpoints as well. Looking further ahead, we’re exploring how we might redefine our rate limits now that we’re no longer constrained by a system that simply counts events between two points in time.
By adopting Redis and GCRA, we’ve built a flexible, efficient rate limit system that promotes fair usage and enables our infrastructure to handle ever-growing demand. We’ll keep adapting to the ever-evolving Web while honoring our primary goal: giving people the certificates they need, for free, in the most user-friendly way we can.
Cyber Security Cloud, Inc. accelerates sales with CloudSmart Insights and Amazon SES
Post Syndicated from Anne Grahn original https://aws.amazon.com/blogs/messaging-and-targeting/cyber-security-cloud-inc-accelerates-sales-with-cloudsmart-insights-and-amazon-ses/
In today’s rapidly evolving digital landscape, effective content curation is essential for businesses to stand out and connect with their target audience.
Optimizing customer outreach can be a difficult task. Sales intelligence can help you use data to understand customer behavior, attract prospects with relevant messaging, and focus sales and marketing efforts where they’ll make the most impact.
Web security service provider Cyber Security Cloud Inc. (CSC) is using CloudSmart Insights and Amazon Simple Email Service (SES) to curate and deliver targeted content, and to drive sales of its web application firewall (WAF) automation service, WafCharm.
What is CloudSmart Insights?
CloudSmart Insights is a go-to-market (GTM) and co-sell intelligence solution for Amazon Web Services (AWS) Marketplace sellers. CloudSmart Insights helps remove guesswork, and the need for manual authoring and analyzing of reports from AWS Marketplace seller operations. With CloudSmart Insights, AWS Marketplace sellers can easily visualize sales and forecasts without the need for custom coding, business intelligence (BI) authoring, or data science skills.
CloudSmart Insights’ private offer feature on the AWS Marketplace empowers other Marketplace sellers to deliver personalized customer experiences tailored to individual needs. By curating targeted messages, CloudSmart Insights can provide their customers with valuable resources, guidance, and access to relevant features, helping to maximize investments from the outset. The feature allows CloudSmart Insights’ customers to create customized rules for cost, quantity, and duration, streamlining both single private offers and large-scale sales plays.
What is Amazon SES?
Amazon Simple Email Service (Amazon SES) is a cloud-based email service provider that can integrate into any application for high-volume email automation. Amazon SES supports a variety of deployments including dedicated, shared, or owned IP addresses. Reports on sender statistics and email deliverability tools can help you make every email count. Whether you use an email software to send transactional emails, marketing emails, or promotional emails, you pay only for what you use.
Who is Cyber Security Cloud, Inc.?
CSC provides web application security services powered by advanced artificial intelligence (AI) and global threat intelligence. CSC’s WafCharm is a managed cloud-based web application firewall (WAF) service that seamlessly integrates with AWS WAF to enhance the security of web applications deployed on AWS. WafCharm simplifies the process of configuring, managing, and updating AWS WAF rules, making it easier for your organization to protect web applications from threats.
The opportunity
CSC wanted to increase customer engagement and provide detailed guidance to facilitate the acceptance of private offers from AWS Marketplace. Delivering curated content was a central objective to increase the efficacy of communications. CSC turned to CloudSmart Insights to support customized messaging built on Amazon SES.
The solution
CSC chose CloudSmart Insights’ private offer curation feature to engage with existing and prospective customers using AWS Marketplace. Customers who discover, purchase, and deploy CSC WafCharm now receive personalized communications directly from CloudSmart Insights through Amazon SES.
CSC uses the CloudSmart insight offer report to preview upcoming renewals, and creates curated messages via the CloudSmart private offer messaging feature. The integration with Amazon SES allows transactional messages to be curated to the customer’s needs, providing additional instructions, resources, and details of the offer. With this flexibility, CSC can manage renewals efficiently and deploy targeted promotional offers that increase engagement with buyers. Amazon SES also allows CSC to confirm that messages are sent from a trusted source.
CloudSmart Insights uses an Amazon QuickSight serverless architecture to allow automatic scaling and meet user requirements, without manual server management. This architecture helps keep dashboards responsive during peak usage periods.
By embedding Amazon QuickSight into CloudSmart Insights, CSC uses the systems they have already found to be effective and decreases the amount of individual configuration needed to examine data. AWS Marketplace provides CSC with APIs for creating and managing catalog products, offers, and agreements. The APIs also provide read-and-write actions to create, list, and manage private offers.
The steps for creating a custom private offer with CloudSmart Insights are fully detailed in this blog post.
The outcome
Integrating CloudSmart Insights with Amazon SES allowed CSC to target specific customer segments based on their interests, purchasing behavior, or demographics, reducing the time taken to send private offers from one hour to 5 minutes per offer extended.
| “With CloudSmart Insights, CSC was able to incorporate Amazon SES features such as verified identities into their sales cycle for WafCharm. This helped to improve email deliverability by establishing the authenticity of sellers’ emails, and enhance security by protecting accounts from unauthorized use.” – Takashi Yoshimi, U.S. COO, Cyber Security Cloud Inc. |
By tailoring email messages to provide acceptance instructions for individual recipients, CSC increased their closure rate by 5%. Automated email workflows allowed them to nurture leads and drive sales, making it easier for customers to understand the capabilities of WafCharm.
Errors and repetitive work within the CSC marketplace deal desk were reduced, allowing CSC’s customer satisfaction, marketing, and sales teams to gather and analyze areas of customer improvement more efficiently.
Reach the right targets
CloudSmart Insights is available through AWS Marketplace to help your organization create curated private offers, and enhance your AWS Marketplace journey. Visit AWS Marketplace for more information.
To learn more about optimizing email sending, visit Amazon SES. To learn more about CSC WafCharm, please visit the WafCharm website or contact Anri Nakayama, Vice President, Partner Relations at CSC.