Post Syndicated from LGR original https://www.youtube.com/watch?v=abmiv22Q7xA
Community Update: empowering startups building on Cloudflare and creating an inclusive community
Post Syndicated from Ricky Robinett original https://blog.cloudflare.com/2024-community-update

With millions of developers around the world building on Cloudflare, we are constantly inspired by what you all are building with us. Every Developer Week, we’re excited to get your hands on new products and features that can help you be more productive, and creative, with what you’re building. But we know our job doesn’t end when we put new products and features in your hands during Developer Week. We also need to cultivate welcoming community spaces where you can come get help, share what you’re building, and meet other developers building with Cloudflare.
We’re excited to close out Developer Week by sharing updates on our Workers Launchpad program, our latest Developer Challenge, and the work we’re doing to ensure our community spaces – like our Discord and Community forums – are safe and inclusive for all developers.
Helping startups go further with Workers Launchpad

In late 2022, we initiated the $2 billion Workers Launchpad Funding Program aimed at aiding the more than one million developers who use Cloudflare’s Developer Platform. This initiative particularly benefits startups that are investing in building on Cloudflare to propel their business growth.
The Workers Launchpad Program offers a variety of resources to help builders scale faster and reach more customers. The program includes, but is not limited to:
- Fostering a community of like-minded founders
- Facilitating introductions to the Launchpad’s VC partner network of 40+ leading investors
- Company-building support and mentorship through virtual Founders Bootcamp sessions
- Organizing technical office hours with our engineers
- Access to preview upcoming Cloudflare products and Product Managers
- Culminating in a Demo Day, for participants to share their stories globally with investors and prospective customers.
So far, 50 amazing startups from 13 countries have successfully graduated from the Workers Launchpad program. We finished up Cohort #1 in March 2023, and Cohort #2 wrapped up August 2023.
Meet Cohort #3 of the Workers Launchpad!
Since the end of Cohort #2, we have received hundreds of new applications from startups across the globe. Startup applicants showcased incredible tools and software across a variety of industries, including AI, SaaS, Supply Chain, Media, Gaming, Hospitality, and Developer Productivity. While we were encouraged by this wave of applicants’ ability to build amazing technology, there were a few that stood out that are leveraging Cloudflare’s Developer Suite to scale their business.
With that being said, we would like to introduce you to the 29 startups that have been chosen to participate in Cohort #3 of Workers Launchpad:

Below, you will find a brief summary of what problems these startups are looking to solve:
| Autoblocks AI | Evaluation & testing platform to improve AI product quality. |
|---|---|
| BEAM (By Mass Luminosity) | A next-gen live streaming platform that elevates creator-viewer interactions to the next level. |
| BentoML | Run any AI model in your cloud. |
| bohr.io | An easy and fast development platform. |
| Cloneable | Provides low/no-code tools to build and deploy applications to any device, instantly. |
| CleverEV | Manage EV charging infrastructure and experience for clients. |
| Dulia | Managed edge powered serverless AI platform. |
| Erxes | Open-source experience operating system empowering businesses. |
| Exporio | AI-first A/B testing and personalization platform. |
| Helicone | GenAI observability platform built for developers. |
| Houdini | An end-to-end solution for building and deploying GraphQL applications. |
| Intelligage | Humanize your AI for customers. |
| Langbase | Ship hyper-personalized AI apps in seconds — any LLM, any data, any developer. |
| Milkshake | Create websites via mobile within minutes. |
| Nadrama | Kubernetes PaaS in your cloud account, in minutes. |
| NuxtHub (by NuxtLabs) | Build full-stack applications on Cloudflare with zero configuration. |
| Panaptico | High performance networking fabrics for specialized workloads. |
| Playroom | Platform for game developers to build multiplayer games in minutes. |
| Puzzle Labs | P2P, prompt-first knowledge base for teams to collaborate with AI. |
| Resilis | Intelligent edge caching for REST APIs. |
| Scrappi | A better way to collect, create and collaborate. |
| Starlight Labs | AI native game studio. |
| T4 Stack | Ship feature parity on universal apps. |
| TextCortex AI | AI copilot platform to leverage the power of easy customization and integration. |
| Toothless | Build GenAI-powered workflow automation and internal tools in minutes. |
| Unfetch | Generate and run scripts with AI to complete tasks within seconds. |
| Unkey | Redefines API management for developers. Add authentication, analytics, and rate-limiting to your APIs in minutes. |
| Unnug | Transformative cloud compiler with an emphasis on user on-premises, cloud, and edge resources. |
| Wope | AI-powered marketing agent that leverages Gen AI to optimize businesses’ online presence and drive more traffic. |
The Cloudflare team is looking forward to working with Cohort #3 participants and sharing what they are building on Cloudflare. To follow along with Cohort #3 of Workers Launchpad, follow @CloudflareDev and join our Developer Discord server.
Are you a startup and interested in joining Cohort #4? Apply here!
AI developer challenge

Now that Workers AI is GA, we’re excited to see what our community can build. We’ve teamed up with our friends at DEV who will be running an AI Developer challenge, which officially launched on Wednesday, April 3, and runs until Sunday, April 14, 2024, when submissions close.
For this challenge, you will build a Workers AI application that makes use of AI task types from Cloudflare’s growing catalog of Open Models. Apps will be evaluated on innovation, creativity, and demonstration of underlying technology with prizes awarded by DEV for the best overall app, as well as projects leveraging multiple models and tasks. For more information and details on how to participate, including DEV’s rules and requirements, head over to the official challenge page.
Creating an inclusive community
Our community has been growing really fast over the past year, so fast that it’s becoming more difficult to welcome each new member that joins our Discord server every day, and Developer Week has always been one of the main drivers of this growth.
When you come into the Cloudflare developer community, it’s important to us that you’re entering a space that is safe and welcoming. Even though we already have rules for the server and community forums, we needed guidelines for our community programs, so that’s why we’ve created a new Code of Conduct that promotes inclusivity, respect, and will help us create a better community for everyone.
Do you want to be part of this and help us create a more inclusive and helpful community? Then please share your feedback and tell us what you would like to see improved in our community and our Discord server in this thread.
The Great Onion Scandal
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=aIaBowKg6tU
The Ultimate Review: Testing the SLZB-06M from SmartLight
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=9PhLqveokck
The Great Onion Scandal
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=WuiREF2e-Ps
Maybe the Phone System Surveillance Vulnerabilities Will Be Fixed
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/04/maybe-the-phone-system-surveillance-vulnerabilities-will-be-fixed.html
It seems that the FCC might be fixing the vulnerabilities in SS7 and the Diameter protocol:
On March 27 the commission asked telecommunications providers to weigh in and detail what they are doing to prevent SS7 and Diameter vulnerabilities from being misused to track consumers’ locations.
The FCC has also asked carriers to detail any exploits of the protocols since 2018. The regulator wants to know the date(s) of the incident(s), what happened, which vulnerabilities were exploited and with which techniques, where the location tracking occurred, and if known the attacker’s identity.
This time frame is significant because in 2018, the Communications Security, Reliability, and Interoperability Council (CSRIC), a federal advisory committee to the FCC, issued several security best practices to prevent network intrusions and unauthorized location tracking.
Всичко е избори. Другото чака
Post Syndicated from Емилия Милчева original https://www.toest.bg/vsichko-e-izbori-drugoto-chaka/

В следващите два месеца всичко е избори – работата на парламента, действията на служебното правителство, комуникацията на президента Румен Радев и подновените му участия в заседанията на Европейския съвет в Брюксел, акциите на службите, МВР и антикорупционната комисия.
Единствено Конституционният съд (КС) не участва в тази какофония, но със сигурност ще допринесе, тъй като се очаква решението му по конституционните промени, оспорени от Радев и от две партии – „Възраждане“ и „Има такъв народ“. Каквото и да е то, също ще влезе в предизборна употреба от едната или от другата страна.
Дори и истини да чуем, ще имаме едно наум, че това все пак е рекламната пауза,
коментира по БНР социологът Първан Симеонов, директор на „Галъп интернешънъл болкан“.
Каквито и истини да се чуят в следващите седмици, до една ще са закъснели. Партньорите в доскорошното управляващо мнозинство – ПП–ДБ, ГЕРБ–СДС и ДПС, са разделени и изпокарани. А политолози пробват с хипотези за формулата на властта след юнските предсрочни парламентарни избори и европейския вот – ще преговарят ли отново трите формации за съвместно управление и изобщо кой ще преговаря, възможно ли е да има трети различен или дори четвърти… Тази седмица лидерът на ГЕРБ Бойко Борисов коментира, че „в едно парламентарно мнозинство [в 50-тия парламент – б.а.] трябва да има по-широка палитра на подкрепа“.
Анализите и прогнозите оформят три опции:
- всичко ще е както преди; дори и да има промяна в числеността на парламентарните групи, ще е незначителна;
- нищо няма да е както преди, защото съотношението на силите ще е силно променено, което ще промени и договорките и разпределението на властта;
- няма време за нов силен играч на политическата сцена – да се разбира, че евентуалният президентски проект ще прескочи и този вот.
Едно наум за парламента
В 49-тия парламент, който ще работи още месец, се раждат единствено временни комисии, които депутатите ще използват в предизборната кампания. Тези формирования ще произведат единствено послания за предизборна агитация и пропаганда. Времето няма да им стигне, за да проучат задълбочено проблема, заради който е формирана съответната комисия, а депутатите получават допълнителни средства върху възнагражденията си.
Народните представители дори не са приключили работата в създадени по-рано други шест временни комисии – за сигурността на машинното гласуване; за защита на правата на психично болните пациенти и изготвяне на законодателни промени, които да ги гарантират; за сделката между „Булгаргаз“ и турската държавна компания „Боташ“; за аферата „Нотариуса“, за дейността на Глеб Мишин, едно от главните действащи лица в престъпни схеми за придобиване на българско гражданство.
Единствената комисия, върху която са се съсредоточили управляващите, е за Нотариуса. При изслушването си тази седмица обаче вътрешният министър Калин Стоянов отново е отказал да съобщи/потвърди вече известния факт, че убитият дилър на правосъдие Мартин Божанов – Нотариуса е бил доверено лице и сътрудник на МВР. (Информацията обяви във Facebook журналистът от Антикорупционния фонд Николай Стайков, както и името на човека, вербувал го през 2005 г. – Виктор Младенов от Трето РПУ в София, „извършвал множество нерегламентирани справки в базите данни на МВР по отношение на лица, оперативно интересни за Нотариуса, включително за свидетели срещу него“.)
Да не забравяме и временната комисия, която разследваше полицейското насилие на протеста срещу БФС и чиято работа официално приключи в средата на март, но липсват заключенията.
Сега тази бройка се попълва с нови три комисии, гласувани в полунощ на трети срещу четвърти април, всички със срок на действие от месец. Едната, предложена от ИТН, е за проучване на корупционни практики в Агенция „Митници“ и евентуалната роля на министъра на финансите Асен Василев в тях. Комисията ще бъде оглавена от Тошко Йорданов от ИТН. За другите две председатели така и не бяха избрани – преди всяко тяхно заседание председателят на парламента ще решава кой да ги ръководи.
Най-много парламентарно време отнеха дискусиите и гласуването на предложена от ПП–ДБ комисия за изчезналата пътна карта за реализацията и преминаването на газопровода „Турски поток“ през България (разширение на газопреносната мрежа, под каквото име е известен проектът). Документът описва етапите на изпълнение на тръбопровода, който транзитира природен газ за Сърбия, Австрия и Унгария. Вероятно копие на пътната карта се появи в кореспонденция от хакнатата от украинци поща на Евгений Зобин, помощник на високопоставения руски политик Александър Бабаков. Бившата министърка на енергетиката Теменужка Петкова (ГЕРБ), подписала пътната карта през 2017 г. заедно с шефа на „Газпром“ Алексей Милер, отговори така на въпроса на ПП–ДБ къде е оригиналът:
Пътната карта ви е предоставена по времето на управлението на Кирил Петков, от ДАНС ви е предоставено копие.
Третата комисия е за необходимостта от дерогацията на „Лукойл“ и ефекта върху потребителите и режима в Русия.
Наред с комисиите обаче парламентът прие безпрецедентно решение, с което на практика забрани на финансовия министър в оставка Асен Василев да харчи пари от бюджета, освен за пенсии, заплати, неотложни социални плащания и падежиращи плащания по държавния дълг – до назначаване на служебно правителство. Предложението на ГЕРБ–СДС и ДПС e поредното, с което парламентът „трича“, по определението на ClubZ, Василев, когото ще задължи да изплати по 75 лв. за великденски добавки на над 500 000 пенсионери с пенсия до линията на бедност от 526 лв. Идеята е пак на ГЕРБ и ДПС.
Приемайки друго предложение на ГЕРБ, депутатите задължиха Министерството на финансите да внесе до края на март 1 млрд. лв. във фонд „Сигурност на електроенергийната система“. Решение, което правителството в оставка даде на КС с мотива, че плащането е трябвало да бъде записано в Закона за държавния бюджет. На КС е дадено и ограничението, наложено на финансовия министър, да прави разходи извън тези, които му разреши парламентът.
Ще бъде чудо, ако 49-тият парламент свърши и друга работа, освен предизборната агитация, в оставащия му не повече от месец. Например да приеме законопроекта за еврото, който мина обществено обсъждане и е важен в контекста на целта за присъединяване към еврозоната през 2025 г.
Пътната карта за „Турски поток“ vs. дерогацията за „Лукойл“
Дискусиите по създаването на комисиите се превърнаха в предизборен диспут. Нито една от двете политически сили не предложи създаването им, когато се „сглобяваха“. Сега Венко Сабрутев от ПП гръмовно пита от трибуната: „Кой и колко открадна от изграждането на „Турски поток“? Кой позволи българската енергетика да бъде поета на управление от Москва? Нямам търпение да ви видя физиономиите, когато пратиме [sic!] документа на прокуратурата“, предизвиквайки отговори в същия натюрел от ГЕРБ.
На 6 март с колегите сме задали въпрос към енергийния министър дали пътната карта, показана на обществото и изкарана от хакнат имейл на сътрудник на руски депутат, е истинската пътна карта и е била в Енергийното министерство. Питали сме като народни представители къде е пътната карта, имаше и разследване на ДАНС. Отговорът на самото министерство е, че самото министерство не е убедено каква е пътната карта и откъде е,
каза депутатът от ПП–ДБ Ивайло Мирчев. От ГЕРБ–СДС не им останаха длъжни.
Разликата между на „Лукойл“ дерогацията и „Булгартрансгаз“ е една основна. Единият проект генерира печалба, генерира приходи. Другият проект – точно обратното, пълни гушата на така наречения „омразен режим“ на Путин,
заяви народният представител Александър Ненков.
Според бившата енергийна министърка Теменужка Петкова, настояща депутатка от ГЕРБ–СДС, има паметна записка за проекта в ДАНС и всеки журналист можел да я поиска. От предоставените на Mediapool.bg данни от „Булгартрансгаз“ става ясно, че от пускането в експлоатация на продължението на „Турски поток“ през българска територия приходите от резервирани капацитети и пренесени количества природен газ са 1,308 млрд. лв. Тоест съоръжението, построено, за да бъде заобиколена Украйна като основна страна за транзита на руски газ, е изплатило над половината от направената от „Булгартрансгаз“ инвестиция. (От 1 януари 2025 г. Киев спира транзита на руски газ през своя територия и „Турски поток“ през България е един от двата варианта за доставки на синьо гориво за Централна Европа заедно с „Ямал“ през Германия.)
Две наум, три наум
Какъвто и да е съставът на служебното правителство с премиер председателя на Сметната палата Димитър Главчев, който излиза в неплатен отпуск, несъмнено ГЕРБ ще има влияние в него. Преди да бъде избран начело на държавните одитори, Главчев беше председател на Контролната комисия на ГЕРБ, депутат от ГЕРБ в няколко парламента и за кратко председател на Народното събрание. Своята кариера и съответстващата ѝ тежест в обществото той дължи на партията, направила толкова много за него.
Макар да обеща на президента Радев неутрални и равно отдалечени експерти за министри, самият той не минава за такъв. Но въпреки че е невидима за обществото, комуникацията му с държавния глава, а защо не и с Бойко Борисов, със сигурност не престава, за да няма сътресения при указа за назначаване на служебния кабинет.
Служебният кабинет на Димитър Главчев, освен с наклон към ГЕРБ, се оказа и с реверанс към президента. Людмила Петкова – вицепремиер и министър на финансите, експерт с дълъг опит, свързват я с ДПС. Калин Стоянов – министър на вътрешните работи, най-спорното име в този кабинет, предизвикало остра реакция в ПП–ДБ. Виолета Коритарова – министър на регионалното развитие и благоустройството, оглавила Агенцията по геодезия, картография и кадастър в третия кабинет на ГЕРБ.
Ивайло Иванов, който е избран за министър на труда и социалната политика, също е кадър на ГЕРБ. Министърът на отбраната Атанас Запрянов досега беше заместник-министър. Министърът на външните работи Ивайло Ценов е бил 15 години консул на България във Виена. За министър на правосъдието обаче е избран заместник на Борислав Сарафов – Мария Павлова.
Министър на образованието остава проф. Галин Цоков, един от хората, за които премиерът в оставка Николай Денков каза, че е бил номинация на ГЕРБ.
Министър на здравеопазването е Галя Кондева, изпълнителна директорка на болницата по хематология. За министър на културата Главчев връща министър от служебните кабинети на президента – Найден Тодоров. Министър на околната среда и водите става един от заместник-министрите – Петър Димитров. Министър на земеделието остава Кирил Вътев. Георги Гвоздейков също запазва поста си като министър на транспорта, заради което ще бъде изключен от ПП.
За министър на иновациите и растежа е избран дългогодишният председател на Комисията за защита на конкуренцията Петко Николов, а за министър на иновациите и растежа – Росен Карадимов, до момента председател на надзора на Българска банка за развитие. Карадимов е свързван с новото ляво, което се опитват да изградят отцепници от БСП. Шефът на „Булгартрансгаз“ Владимир Малинов става министър на енергетиката, за министър на електронното управление е избран Валентин Мундров, който и по време на преговорите за ротация беше предложен от ГЕРБ за позицията, а сега е заместник-министър. За министър на туризма е предложен шоуменът и продуцент Евтим Милошев, а за министър на младежта и спорта – Георги Глушков, първият българин, играл в NBA.
Прегрупирането на политическата сцена между доскорошни яростни противници, които създават временни съюзи, вече не изненадва никого. Интересите на първо място.
ПП–ДБ пак се фокусират върху отколешния си политически враг – ДПС и санкционирания за корупция от САЩ и Великобритания Пеевски, обявявайки, че съпредседателят на ДПС е в основата на дирижирана атака срещу тях, при която са задействани всички „бухалки“. (Все пак с ГЕРБ ще търсят обща платформа след изборите през юни.) Съпредседателят на ДБ Христо Иванов повтори, че разривът при ротацията е настъпил, тъй като Пеевски не е получил исканото. А премиерът в оставка Николай Денков определи посочения от Доган за лидер на ДПС така:
Делян Пеевски в момента е най-голямото зло, което се случва в България.
Четвърт век по-рано тогавашният премиер Иван Костов каза същото за Ахмед Доган: „Доган е проклятието на България.“
В антракта между две правителства
Шумната акция на ДАНС със 72-часовото задържане на назначената преди месец и половина шефка на Агенция „Митници“ Петя Банкова и заместника ѝ Людмил Маринов се състоя в антракта между две правителства – кабинета в оставка на Николай Денков и служебния с премиер Димитър Главчев. Банкова вече е с повдигнато обвинение за участие в организирана престъпна група, действала от 2022 г. и занимавала се с търговия с влияние, подкупи и контрабанда.
Публикуваната на сайта на Агенция „Митници“ нейна биография е постна – съдържа данни за образованието, но не и за конкретните длъжности и институции, в които е работила през годините, освен споменатата ДАНС, но без уточняване на периода. (Кадър на ДАНС – Плевен е и Маринов, когото тя е довела в агенцията.) Завършила е Академията на МВР, право в Югозападния университет и докторантура в УНИБИТ, т.нар. Библиотекарски институт – визитка, която повече подхожда за кадър на ГЕРБ или ДПС. Банкова няма опит в Агенция „Митници“, където Асен Василев я назначава първо за заместник-директор, а от края на февруари т.г. и за директор.
Медиите веднага припомниха, че нейният брат Стефан Банков оглавяваше „частната ДАТО“ на бившите вече главни прокурори Сотир Цацаров и Иван Гешев и беше началник на „Вътрешна сигурност“ на МВР. Разследващият сайт BIRD припомня, че той беше уволнен от вътрешния министър Бойко Рашков заради масовите подслушвания на протестите през 2020 г. Съдът обаче го върна, а въпреки че МВР обжалва, после „забрави“ да плати държавната такса от 70 лв. и така делото беше прекратено.
Сега Банков е прокурорски помощник на Сотир Цацаров, който след мандата си на главен прокурор и работата като председател на КПКОНПИ се върна във Върховната касационна прокуратура. В повечето публикации се споменава една и съща информация – че братът и сестрата не поддържат връзка помежду си, без източник за тези подробности.
Назначението на Банкова бе в момент, в който Асен Василев изненадващо обяви сливане на Агенция „Митници“ и НАП – инициатива, която не присъства в одобрената управленска програма на правителството до края на 2024 г. Стъпки в посока на реално сливане не бяха предприети, освен кадрови смени.
Една версия срещу друга версия
Банкова е задържана заедно с други шестима, а версиите са различни. Управляващите и тя самата казват, че акцията е заради нейната добра работа срещу контрабандните канали, контактите с международни партньори и силно увеличените приходи (за последното не са предоставени данни, а и тя е на поста малко повече от месец). Изтъква се и заловена наскоро пратка от 180 кг кокаин в хладилен контейнер с банани на пристанище Бургас – по сигнал от австрийските служби.
На тези твърдения се противопоставя разследването, което се води срещу организирана престъпна група за контрабанда, пране на пари, подкуп и длъжностни престъпления, започнато в условията на неотложност. В медии се появява контролирана информация от разследването, например че висш полицай е станал анонимен свидетел по делото срещу шефа на Агенция „Митници“, промъкват се и данни за контрабанда на цигари в големи количества. Все още обаче няма официални изявления от МВР, ДАНС и КПКОНПИ, за чиято първа жертва се обяви Банкова.
„Както знаете, в момента на ГКПП „Капитан Андреево“ има служители на САЩ и това е изцяло по моя инициатива и по тяхна партньорска инициатива“, заяви пред журналисти Петя Банкова преди задържането ѝ. В пост в социалните мрежи бивш заместник-министър на финансите с ресор митници – Георги Кадиев, заяви, че става въпрос за един-единствен служител на САЩ, изпратен на пристанище Бургас.
Цялата информация за акцията срещу Петя Банкова е оскъдна – къде е истината и дали става въпрос за реална битка срещу контрабанда, или за опит за овладяване от кръгове, чиито интереси са нарушени, обществото няма как да прецени. Фактът, че се прави точно сега, показва предизборни усилия. А поради липса на разбирателство в управлявалата доскоро сглобка ПП–ДБ пък не успяха да наложат искането си за смяна на шефовете на служби, назначени при служебното управление на президента. Според ГЕРБ и ДПС те работели чудесно.
Предизборната кампания започна и гражданите са облъчвани с истини, полуистини и откровени лъжи. На изпроводяк премиерът в оставка най-сетне каза и кои са министрите в правителството, предложени от ГЕРБ чрез Мария Габриел. Това са министърът на културата Кръстьо Кръстев, на образованието – Галин Цоков, на иновациите и растежа – Милена Стойчева и на туризма – Зарица Динкова.
Изглежда, че вътрешният министър Калин Стоянов и министърът на електронното управление Александър Йоловски са се „обърнали“ на другата страна по време на 9-те месеца. А след като ПП–ДБ поискаха оставката на Стоянов, той е в открит конфликт с тях и дори обяви как съпредседателят на ПП Кирил Петков поискал от него да назначи Кирил Ценкин за шеф на предизборния щаб. (Служителят на НСО Ценкин стана зам.-министър на вътрешните работи по предложение на Петков.)
Всичко е избори.
На второ четене: „Цялото наше безумство“
Post Syndicated from original https://www.toest.bg/na-vtoro-chetene-cyaloto-nashe-bezumstvo/
„Цялото наше безумство“ от Ши-Ли Коу

превод от английски Светослава Павлова, изд. „Алтера“, 2022
Обикновено има или целенасочен интерес и изрично любопитство, или някаква странна съпротива и съмнение, когато човек посяга към литература от автори, принадлежащи на крайно далечна от нас култура. Признавам си, че зачетох „Цялото наше безумство“ на малайската авторка Ши-Ли Коу по втория начин само за да установя
колко изумително сходен на нашия е светът, който тя описва –
в устройството на обществото и специфичните му недъзи; в хитрите и често смехотворни преки към справянето с бита, спецификата на отношенията и живописните характери в провинцията; в противопоставянето на глобалния мегаполис и справянето с неумолимо настъпващия „прогрес“; в шегите и езика.
Романът представлява двугласен хор от разкази в първо лице, като едното повествование се води от възрастен етнически китаец, а другото – от подрастващо християнско момиче.
Съдбата на двамата се преплита, когато момичето бива осиновено след катастрофа от близката на мъжа – малайката Мами Биви. Жена, която като че ли сме срещали в редица други любими книги: самодостатъчна особнячка, самотна и самобитна, чудата и доизмисляща истории, всяка от които започва с „Беше/Имаше неестествен…“. Тази дума – неестествен, ще бележи всичко случващо се в измисления градец Лубок Сайонг в щата Перак, така че дори нормалните и обичайни неща ще придобият някакъв друг, извънвремеви и леко магичен привкус. Така както някои от героите ще виждат неспокойни мъртви или ангели, рибите ще имат съзнание, а част от събитията ще се случват като че ли по неведомо съвпадение.
Не, романът далеч не е в традицията на латиноамериканския магически реализъм, макар тук-там да има подобни краски.
Разказът е изключително земен, изпълнен със сладостна ирония и ярък социален сарказъм.
Книгата не представлява също така нито мемоари на възрастния мъж (макар и донякъде да наподобява градски летописи, водени в ние-форма), нито роман на израстването в аз-форма, както се споменава в анотацията. Може би защото героите разказвачи не са наистина важните, фокусът не е тяхната промяна или израстване, те не са в центъра на събитията.
Големият герой на този роман е всъщност самият градец, както и неговите типажи, чешити, местни и случайно приходящи. Това неголямо и не особено уредено място няма как да не ви се стори безкрайно познато – то все още е далеч от инфраструктурата, привилегиите и шаблонния лукс на глобалното, макар „прогресът“ по един или друг начин да пълзи към него. Иска ли питане, че политиците минават през него инцидентно преди избори и с известна погнуса, а ежегодните наводнения са нещо, което жителите са приели като природна даденост, както – уви – често се случва и у нас:
В Лубок Сайонг не виним пътното строителство, обезлесяването, затинените реки, запушените отводнителни тръби или универсалния виновник, корумпираните бюрократи, които работят в отделите, отговарящи за гореспоменатите пътища, гори, реки и тръби.
В този град, където всичко е едно – една болница, едно полицейско управление, една бензиностанция и така нататък – легендата е най-близката възможност за преодоляване на нелицеприятната и скучна истина за реалността такава, каквато е. Дори и тя обаче е оскъдна и не особено атрактивна, за да привлича достатъчно интерес към града, или както разказвачът описва местното предлагане на легендите –
хладни и слабо гарнирани, на порции, недостатъчни да задоволят апетита или въображението.
Ши-Ли Коу е изключително забавна в начина, по който кара разказвача си да (само)иронизира местните поверия, да „героизира“ на шега обикновеното, докато подкача „автентичното“ и „традиционното“, да извежда на преден план смешното, като същевременно буди у нас симпатия към него.
Съпоставяйки от време на време живота с този в столицата Куала Лумпур, авторката очертава ясни дихотомии, без нито за миг да бъде мелодраматична или да идеализира едното за сметка на другото: уж автентичното ръчно труд-и-творчество (често „подпомагано“ от поръчаните в Китай масовки) срещу индустриализацията и големите фабрики, в които в крайна сметка работят същите „мързеливи, глупави и злочести хора, които просто се опитват да си изкарат прехраната“; неугледния локален туризъм, на който се отдават само случайно изпаднали авантюристи, срещу маститите спа комплекси за добре плащащите чуждестранни гости; местната храна, която може да предизвика позиви за често ходене до тоалетната, срещу безличните световни вериги, като „Старбъкс“ и „Макдоналдс“; самодоволните доброволци от големия град и свикналите с бедствията провинциалисти, които се дразнят от тяхната жизнерадостна и клиширана помощ; забавната неприветливост на самобитното срещу абсурда на привнесеното; традиционните ислямски закони и илюзорното приличие срещу реалното съществуване на травестити и други сексуални и личностни свободи зад кулисите.
Възможно е тогава да се каже, че „Цялото наше безумство“ може да се чете като своеобразна социална сатира,
тъй като във всяка възможна ситуация и чрез куп метафори Ши Ли-Коу не пропуска да ни напомни за обществените реалности. Макар и история на един отделно взет малък град, тя е история на съвременна Малайзия встрани от лъскавите туристически брошури. Ши Ли-Коу очертава ежедневието на земния, обикновен човек (чиято практичност измества дори въпросите на живот и смърт) чрез поредица от забавни, полукомични и леко тъжни случки. Ще научим как се клинчи от час, как се спасяват пиявици, как се превъзпитават травестити, как се прави мост в нищото и т.н. И във всичко това ще личи носталгията по непревзетото от глобализма, по малкия град, по твърде човешкото.
Тази книга наистина е изпълнена с неподправено човеколюбие,
с великодушно снизхождение към кривиците и недостатъците на всеки и с обич към доброто и достойното у всеки – независимо от неговата етническа, верска, сексуална и друга принадлежност. В мешавицата от етноси, която Ши-Ли Коу забърква – малайци, индийци, китайци, индонезийци, – човекът в която и да е координатна точка на споменатото в горния абзац остава просто човек: погрешим, в никога незавършен процес на себесъздаване, очарователно комичен. Важното е, че той не е сам за себе си – героите на романа неизбежно намират път един към друг, колкото и криволичещ да е той, образуват сложни, но автентични връзки и в крайна сметка една истинска човечна общност в епруветката на измисления Лубок Сайонг.

В „Цялото наше безумство“ няма поука, както признава чрез героите си авторката:
Искам да кажа на тези, които идват, на всеки, който би ме чул, че урокът не е в разказа, а в живота.
И за да затворим кръга към далечното, което особено на нас, българите, ще ни се стори безкрайно познато, ще ви оставя
кратък списък с някои неща от ежедневния дискурс, които веднага ще разпознаете като родни
и които присъстват в книгата:
- всичко е политика;
- таксиметровите шофьори се оплакват, че държавата е съсипана и никой не се грижи за тях, а всички искат да ги прецакат;
- всичко гнило идва от Китай – отровено мляко за кърмачета, консервирана храна с живак, масово произведените сувенири;
- всички гледат ужасно дублирани сапунени опери;
- хората в крайна сметка си предпочитат съмнителната и мързелива помощ на корумпираните институции;
- те споделят тихото чакане и кротката търпимост по отношение на некадърността, защото общата мизерия свързва;
- политиците раздават пари на калпак преди избори на всички социално ощетени групи освен данъкоплатците на платена работа;
- природните бедствия са по вина на корупцията и нехайството, но са представяни като добри за нацията, защото карат обществото да се обединява около обща кауза;
- младите, които все пак остават в малкия град, просто твърде много обичат мързеливия си живот, за да се бъхтят на някаква работа;
- прогресът не е исторически, а преди всичко търговски и се измерва с потреблението на куп жалонни боклуци.
Завършвам с една присъда на Мама Биви:
Вие сте тези, които погубихте Куала Лумпур. Продължихте да строите магазини, офиси, жилищни сгради и огромни молове. Живеехте си в множеството ви мезонети и вили и те пак не ви бяха достатъчни. Строите още по-големи сгради, за да продавате все повече неща. Настоявате за все повече чуждестранни майстори готвачи и лъскави ресторанти, които трябва да се обновяват на всеки три години. Построихте още пътища за шестте ви коли, с които задушавате града, защото много ще се изпотите, ако се качите в метрото или автобуса. И се оплаквате, че градът бил загубил чара си?
Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Антония Апостолова, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.
ASRock Rack MECAI-GH200 Short-Depth NVIDIA Grace Hopper Server
Post Syndicated from Cliff Robinson original https://www.servethehome.com/asrock-rack-mecai-gh200-short-depth-nvidia-grace-hopper-server-arm/
The ASRock Rack MECAI-GH200 is a short-depth NVIDIA Grace Hopper (GH200) server with lots of I/O and designed for single aisle servicing
The post ASRock Rack MECAI-GH200 Short-Depth NVIDIA Grace Hopper Server appeared first on ServeTheHome.
Comic for 2024.04.05 – Grieving Friend
Post Syndicated from Explosm.net original https://explosm.net/comics/grieving-friend
New Cyanide and Happiness Comic
Machine
Post Syndicated from xkcd.com original https://xkcd.com/2916/

Reverse Searching Netflix’s Federated Graph
Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/reverse-searching-netflixs-federated-graph-222ac5d23576
By Ricky Gardiner, Alex Hutter, and Katie Lefevre
Since our previous posts regarding Content Engineering’s role in enabling search functionality within Netflix’s federated graph (the first post, where we identify the issue and elaborate on the indexing architecture, and the second post, where we detail how we facilitate querying) there have been significant developments. We’ve opened up Studio Search beyond Content Engineering to the entirety of the Engineering organization at Netflix and renamed it Graph Search. There are over 100 applications integrated with Graph Search and nearly 50 indices we support. We continue to add functionality to the service. As promised in the previous post, we’ll share how we partnered with one of our Studio Engineering teams to build reverse search. Reverse search inverts the standard querying pattern: rather than finding documents that match a query, it finds queries that match a document.
Intro
Tiffany is a Netflix Post Production Coordinator who oversees a slate of nearly a dozen movies in various states of pre-production, production, and post-production. Tiffany and her team work with various cross-functional partners, including Legal, Creative, and Title Launch Management, tracking the progression and health of her movies.
So Tiffany subscribes to notifications and calendar updates specific to certain areas of concern, like “movies shooting in Mexico City which don’t have a key role assigned”, or “movies that are at risk of not being ready by their launch date”.
Tiffany is not subscribing to updates of particular movies, but subscribing to queries that return a dynamic subset of movies. This poses an issue for those of us responsible for sending her those notifications. When a movie changes, we don’t know who to notify, since there’s no association between employees and the movies they’re interested in.
We could save these searches, and then repeatedly query for the results of every search, but because we’re part of a large federated graph, this would have heavy traffic implications for every service we’re connected to. We’d have to decide if we wanted timely notifications or less load on our graph.
If we could answer the question “would this movie be returned by this query”, we could re-query based on change events with laser precision and not impact the broader ecosystem.
The Solution
Graph Search is built on top of Elasticsearch, which has the exact capabilities we require:
- percolator fields that can be used to index Elasticsearch queries
- percolate queries that can be used to determine which indexed queries match an input document.
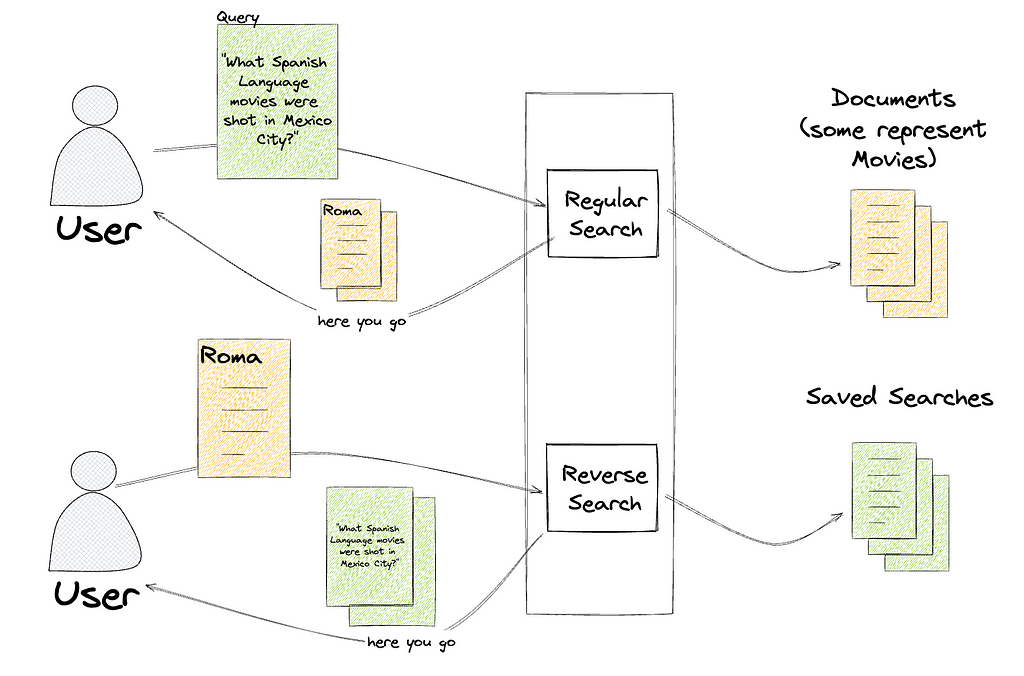
Instead of taking a search (like “spanish-language movies shot in Mexico City”) and returning the documents that match (One for Roma, one for Familia), a percolate query takes a document (one for Roma) and returns the searches that match that document, like “spanish-language movies” and “scripted dramas”.
We’ve communicated this functionality as the ability to save a search, called SavedSearches, which is a persisted filter on an existing index.
type SavedSearch {
id: ID!
filter: String
index: SearchIndex!
}
That filter, written in Graph Search DSL, is converted to an Elasticsearch query and indexed in a percolator field. To learn more about Graph Search DSL and why we created it rather than using Elasticsearch query language directly, see the Query Language section of “How Netflix Content Engineering makes a federated graph searchable (Part 2)”.
We’ve called the process of finding matching saved searches ReverseSearch. This is the most straightforward part of this offering. We added a new resolver to the Domain Graph Service (DGS) for Graph Search. It takes the index of interest and a document, and returns all the saved searches that match the document by issuing a percolate query.
"""
Query for retrieving all the registered saved searches, in a given index,
based on a provided document. The document in this case is an ElasticSearch
document that is generated based on the configuration of the index.
"""
reverseSearch(
after: String,
document: JSON!,
first: Int!,
index: SearchIndex!): SavedSearchConnection
Persisting a SavedSearch is implemented as a new mutation on the Graph Search DGS. This ultimately triggers the indexing of an Elasticsearch query in a percolator field.
"""
Mutation for registering and updating a saved search. They need to be updated
any time a user adjusts their search criteria.
"""
upsertSavedSearch(input: UpsertSavedSearchInput!): UpsertSavedSearchPayload
Supporting percolator fields fundamentally changed how we provision the indexing pipelines for Graph Search (see Architecture section of How Netflix Content Engineering makes a federated graph searchable). Rather than having a single indexing pipeline per Graph Search index we now have two: one to index documents and one to index saved searches to a percolate index. We chose to add percolator fields to a separate index in order to tune performance for the two types of queries separately.
Elasticsearch requires the percolate index to have a mapping that matches the structure of the queries it stores and therefore must match the mapping of the document index. Index templates define mappings that are applied when creating new indices. By using the index_patterns functionality of index templates, we’re able to share the mapping for the document index between the two. index_patterns also gives us an easy way to add a percolator field to every percolate index we create.
Example of document index mapping
Index pattern — application_*
{
"order": 1,
"index_patterns": ["application_*"],
"mappings": {
"properties": {
"movieTitle": {
"type": "keyword"
},
"isArchived": {
"type": "boolean"
}
}
}
Example of percolate index mappings
Index pattern — *_percolate
{
"order": 2,
"index_patterns": ["*_percolate*"],
"mappings": {
"properties": {
"percolate_query": {
"type": "percolator"
}
}
}
}
Example of generated mapping
Percolate index name is application_v1_percolate
{
"application_v1_percolate": {
"mappings": {
"_doc": {
"properties": {
"movieTitle": {
"type": "keyword"
},
"isArchived": {
"type": "boolean"
},
"percolate_query": {
"type": "percolator"
}
}
}
}
}
}
Percolate Indexing Pipeline
The percolate index isn’t as simple as taking the input from the GraphQL mutation, translating it to an Elasticsearch query, and indexing it. Versioning, which we’ll talk more about shortly, reared its ugly head and made things a bit more complicated. Here is the way the percolate indexing pipeline is set up.
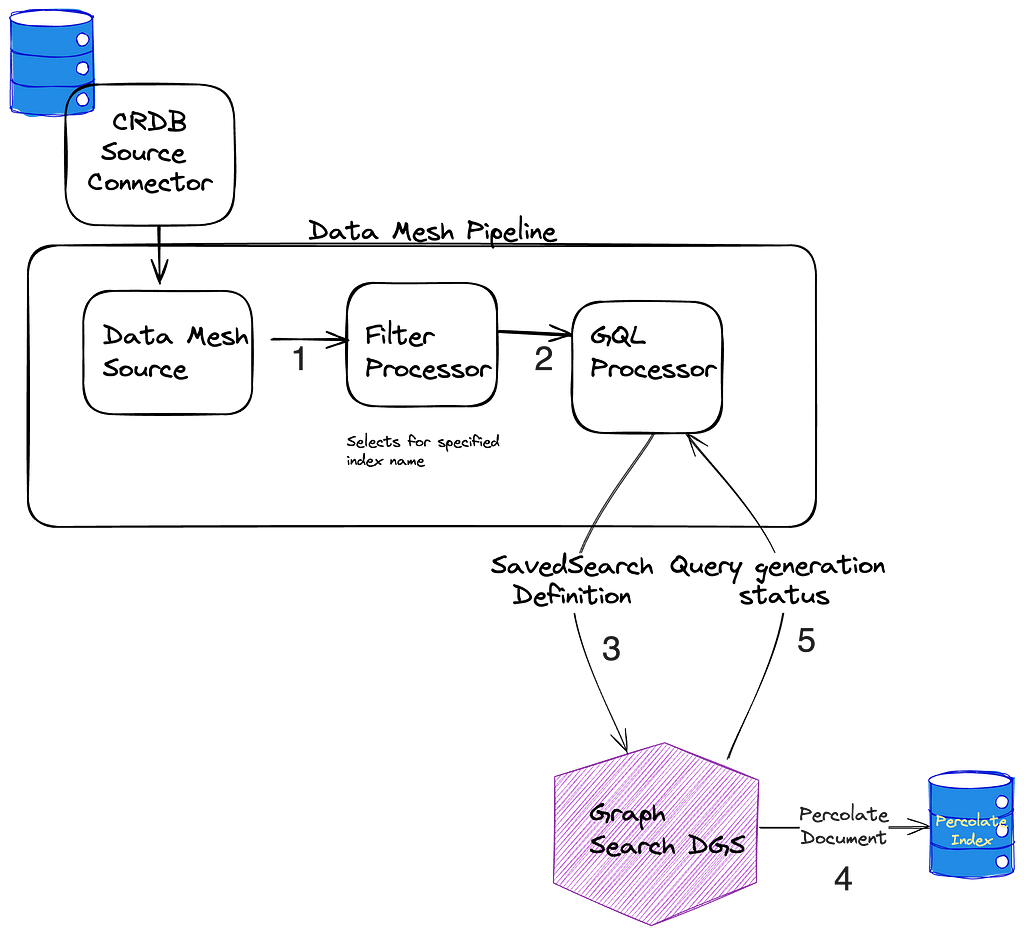
- When SavedSearches are modified, we store them in our CockroachDB, and the source connector for the Cockroach database emits CDC events.
- A single table is shared for the storage of all SavedSearches, so the next step is filtering down to just those that are for *this* index using a filter processor.
- As previously mentioned, what is stored in the database is our custom Graph Search filter DSL, which is not the same as the Elasticsearch DSL, so we cannot directly index the event to the percolate index. Instead, we issue a mutation to the Graph Search DGS. The Graph Search DGS translates the DSL to an Elasticsearch query.
- Then we index the Elasticsearch query as a percolate field in the appropriate percolate index.
- The success or failure of the indexing of the SavedSearch is returned. On failure, the SavedSearch events are sent to a Dead Letter Queue (DLQ) that can be used to address any failures, such as fields referenced in the search query being removed from the index.
Now a bit on versioning to explain why the above is necessary. Imagine we’ve started tagging movies that have animals. If we want users to be able to create views of “movies with animals”, we need to add this new field to the existing search index to flag movies as such. However, the mapping in the current index doesn’t include it, so we can’t filter on it. To solve for this we have index versions.

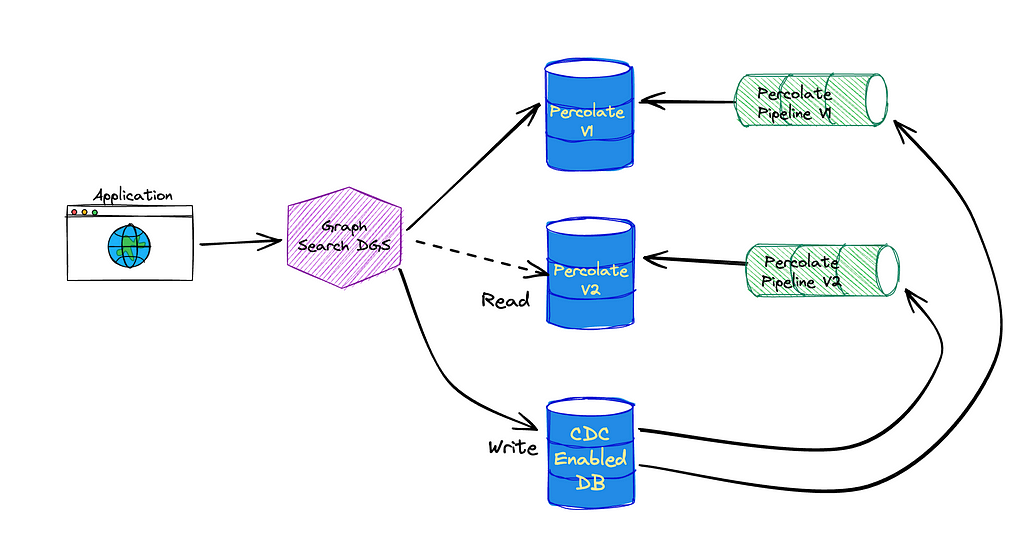
When a change is made to an index definition that necessitates a new mapping, like when we add the animal tag, Graph Search creates a new version of the Elasticsearch index and a new pipeline to populate it. This new pipeline reads from a log-compacted Kafka topic in Data Mesh — this is how we can reindex the entire corpus without asking the data sources to resend all the old events. The new pipeline and the old pipeline run side by side, until the new pipeline has processed the backlog, at which point Graph Search cuts over to the version using Elasticsearch index aliases.
Creating a new index for our documents means we also need to create a new percolate index for our queries so they can have consistent index mappings. This new percolate index also needs to be backfilled when we change versions. This is why the pipeline works the way it does — we can again utilize the log compacted topics in Data Mesh to reindex the corpus of SavedSearches when we spin up a new percolate indexing pipeline.
Another Use Case
We hoped reverse search functionality would eventually be useful for other engineering teams. We were approached almost immediately with a problem that reverse searching could solve.
The way you make a movie can be very different based on the type of movie it is. One movie might go through a set of phases that are not applicable to another, or might need to schedule certain events that another movie doesn’t require. Instead of manually configuring the workflow for a movie based on its classifications, we should be able to define the means of classifying movies and use that to automatically assign them to workflows. But determining the classification of a movie is challenging: you could define these movie classifications based on genre alone, like “Action” or “Comedy”, but you likely require more complex definitions. Maybe it’s defined by the genre, region, format, language, or some nuanced combination thereof. The Movie Matching service provides a way to classify a movie based on any combination of matching criteria. Under the hood, the matching criteria are stored as reverse searches, and to determine which criteria a movie matches against, the movie’s document is submitted to the reverse search endpoint.
In short, reverse search is powering an externalized criteria matcher. It’s being used for movie criteria now, but since every Graph Search index is now reverse-search capable, any index could use this pattern.
A Possible Future: Subscriptions
Reverse searches also look like a promising foundation for creating more responsive UIs. Rather than fetching results once as a query, the search results could be provided via a GraphQL subscription. These subscriptions could be associated with a SavedSearch and, as index changes come in, reverse search can be used to determine when to update the set of keys returned by the subscription.
![]()
Reverse Searching Netflix’s Federated Graph was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Knickerbocker Athletic Club Murders
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=Ea-iGLtkB_c
Stable kernels 6.8.4 and 6.6.25
Post Syndicated from jake original https://lwn.net/Articles/968468/
The 6.8.4 and 6.6.25 stable kernels have been released.
They both contain 11 reversions of workqueue patches.
UniFi Protect Hidden Feature! #shorts #unifi #surveillance
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=qERsMtIZeaw
V8 incorporates new sandbox
Post Syndicated from daroc original https://lwn.net/Articles/968429/
V8, the JavaScript engine used in Chrome,
announced
that its memory sandbox is no longer experimental.
Chrome 123 could therefore be considered to be a sort of “beta”
release for the sandbox. This blog post uses this opportunity to
discuss the motivation behind the sandbox, show how it prevents
memory corruption in V8 from spreading within the host process, and
ultimately explain why it is a necessary step towards memory safety.
[$] A focus on FOSS funding
Post Syndicated from jzb original https://lwn.net/Articles/967001/
Among the numerous approaches to funding the development and advancement of
open-source software, corporate sponsorship in the form of donations to umbrella
organizations is perhaps the most visible. At SCALE21x in Pasadena, California, Duane O’Brien
presented
a slice of his recent research into the landscape of such sponsorship arrangements,
with an overview of the identifiable trends of the past ten years and some initial
insights he hopes are valuable for sponsors and community members alike.
How Aura from Unity revolutionized their big data pipeline with Amazon Redshift Serverless
Post Syndicated from Yonatan Dolan original https://aws.amazon.com/blogs/big-data/how-aura-from-unity-revolutionized-their-big-data-pipeline-with-amazon-redshift-serverless/
This post is co-written with Amir Souchami and Fabian Szenkier from Unity.
Aura from Unity (formerly known as ironSource) is the market standard for creating rich device experiences that engage and retain customers. With a powerful set of solutions, Aura enables complete digital transformation, letting operators promote key services outside the store, directly on-device.
Amazon Redshift is a recommended service for online analytical processing (OLAP) workloads such as cloud data warehouses, data marts, and other analytical data stores. You can use simple SQL to analyze structured and semi-structured data, operational databases, and data lakes to deliver the best price/performance at any scale. The Amazon Redshift data sharing feature provides instant, granular, and high-performance access without data copies and data movement across multiple Redshift data warehouses in the same or different AWS accounts and across AWS Regions. Data sharing provides live access to data so that you always see the most up-to-date and consistent information as it’s updated in the data warehouse.
Amazon Redshift Serverless makes it straightforward to run and scale analytics in seconds without the need to set up and manage data warehouse clusters. Redshift Serverless automatically provisions and intelligently scales data warehouse capacity to deliver fast performance for even the most demanding and unpredictable workloads, and you pay only for what you use. You can load your data and start querying right away in the Amazon Redshift Query Editor or in your favorite business intelligence (BI) tool and continue to enjoy the best price/performance and familiar SQL features in an easy-to-use, zero administration environment.
In this post, we describe Aura’s successful and swift adoption of Redshift Serverless, which allowed them to optimize their overall bidding advertisement campaigns’ time to market from 24 hours to 2 hours. We explore why Aura chose this solution and what technological challenges it helped solve.
Aura’s initial data pipeline
Aura is a pioneer in using Redshift RA3 clusters with data sharing for extract, transform, and load (ETL) and BI workloads. One of Aura’s operations is bidding advertisement campaigns. These campaigns are optimized by using an AI-based bid process that requires running hundreds of analytical queries per campaign. These queries are run on data that resides in an RA3 provisioned Redshift cluster.
The integrated pipeline is comprised of various AWS services:
- Amazon Elastic Container Registry (Amazon ECR) for storing Amazon Elastic Kubernetes Service (Amazon EKS) Docker images
- Amazon Managed Workflows for Apache Airflow (Amazon MWAA) for pipeline orchestration
- Amazon DynamoDB for storing job-related configuration such as service connection strings and batch sizes
- Amazon Managed Streaming for Apache Kafka (Amazon MSK) for streaming last changed and added advertisement campaigns
- EKSPodOperator in Amazon MWAA for triggering an EKS pod task that runs the data preparation queries for each ad campaign on Aura’s main Redshift provisioned cluster
- Amazon Redshift provisioned for running ETL jobs, a BI layer, and analytical queries per ad campaign
- An Amazon Simple Storage Service (Amazon S3) bucket for storing the Redshift query results
- Amazon MWAA with Amazon EKS for running machine learning (ML) training on the query results using a Python-based ML algorithm
The following diagram illustrates this architecture.

Challenges of the initial architecture
The queries for each campaign run in the following manner:
First, a preparation query filters and aggregates raw data, preparing it for the subsequent operation. This is followed by the main query, which carries out the logic according to the preparation query result set.
As the number of campaigns grew, Aura’s Data team was required to run hundreds of concurrent queries for each of these steps. Aura’s existing provisioned cluster was already heavily utilized with data ingestion, ETL, and BI workloads, so they were looking for cost-effective ways to isolate this workload with dedicated compute resources.
The team evaluated a variety of options, including unloading data to Amazon S3 and a multi-cluster architecture using data sharing and Redshift serverless. The team gravitated towards the multi-cluster architecture with data sharing, as it requires no query rewrite, allows for dedicated compute for this specific workload, avoids the need to duplicate or move data from the main cluster, and provides high concurrency and automatic scaling. Lastly, it’s billed in a pay-for-what-you-use model, and provisioning is straightforward and quick.
Proof of concept
After evaluating the options, Aura’s Data team decided to conduct a proof of concept using Redshift Serverless as a consumer of their main Redshift provisioned cluster, sharing just the relevant tables for running the required queries. Redshift Serverless measures data warehouse capacity in Redshift Processing Units (RPUs). A single RPU provides 16 GB of memory and a serverless endpoint can range from 8 RPU to 512 RPU.
Aura’s Data team started the proof of concept using a 256 RPU Redshift Serverless endpoint and gradually lowered the RPU to reduce costs while making sure the query runtime was below the required target.
Eventually, the team decided to use a 128 RPU (2 TB RAM) Redshift Serverless endpoint as the base RPU, while using the Redshift Serverless auto scaling feature, which allows hundreds of concurrent queries to run by automatically upscaling the RPU as needed.
Aura’s new solution with Redshift Serverless
After a successful proof of concept, the production setup included adding code to switch between the provisioned Redshift cluster and the Redshift Serverless endpoint. This was done using a configurable threshold based on the number of queries waiting to be processed in a specific MSK topic consumed at the beginning of the pipeline. Small-scale campaign queries would still run on the provisioned cluster, and large-scale queries would use the Redshift Serverless endpoint. The new solution uses an Amazon MWAA pipeline that fetches configuration information from a DynamoDB table, consumes jobs that represent ad campaigns, and then runs hundreds of EKS jobs triggered using EKSPodOperator. Each job runs the two serial queries (the preparation query followed by a main query, which outputs the results to Amazon S3). This happens several hundred times concurrently using Redshift Serverless compute resources.
Then the process initiates another set of EKSPodOperator operators to run the AI training code based on the data result that was saved on Amazon S3.
The following diagram illustrates the solution architecture.

Outcome
The overall runtime of the pipeline was reduced from 24 hours to just 2 hours, a 12-times improvement. This integration of Redshift Serverless, coupled with data sharing, led to a 90% reduction in pipeline duration, negating the necessity for data duplication or query rewriting. Moreover, the introduction of a dedicated consumer as an exclusive compute resource significantly eased the load of the producer cluster, enabling running small-scale queries even faster.
“Redshift Serverless and data sharing enabled us to provision and scale our data warehouse capacity to deliver fast performance, high concurrency and handle challenging ML workloads with very minimal effort.”
– Amir Souchami, Aura’s Principal Technical Systems Architect.
Learnings
Aura’s Data team is highly focused on working in a cost-effective manner and has therefore implemented several cost controls in their Redshift Serverless endpoint:
- Limit the overall spend by setting a maximum RPU-hour usage limit (per day, week, month) for the workgroup. Aura configured that limit so when it is reached, Amazon Redshift will send an alert to the relevant Amazon Redshift administrator team. This feature also allows writing an entry to a system table and even turning off user queries.
- Use a maximum RPU configuration, which defines the upper limit of compute resources that Redshift Serverless can use at any given time. When the maximum RPU limit is set for the workgroup, Redshift Serverless scales within that limit to continue to run the workload.
- Implement query monitoring rules that prevent wasteful resource utilization and runaway costs caused by poorly written queries.
Conclusion
A data warehouse is a crucial part of any modern data-driven company, enabling you to answer complex business questions and provide insights. The evolution of Amazon Redshift allowed Aura to quickly adapt to business requirements by combining data sharing between provisioned and Redshift Serverless data warehouses. Aura’s journey with Redshift Serverless underscores the vast potential of strategic tech integration in driving efficiency and operational excellence.
If Aura’s journey has sparked your interest and you are considering implementing a similar solution in your organization, here are some strategic steps to consider:
- Start by thoroughly understanding your organization’s data needs and how such a solution can address them.
- Reach out to AWS experts, who can provide you with guidance based on their own experiences. Consider engaging in seminars, workshops, or online forums that discuss these technologies. The following resources are recommended for getting started:
- An important part of this journey would be to implement a proof of concept. Such hands-on experience will provide valuable insights before moving to production.
Elevate your Redshift expertise. Already enjoying the power of Amazon Redshift? Enhance your data journey with the latest features and expert guidance. Reach out to your dedicated AWS account team for personalized support, discover cutting-edge capabilities, and unlock even greater value from your data with Amazon Redshift.
About the Authors
 Amir Souchami, Chief Architect of Aura from Unity, focusing on creating resilient and performant cloud systems and mobile apps at major scale.
Amir Souchami, Chief Architect of Aura from Unity, focusing on creating resilient and performant cloud systems and mobile apps at major scale.
 Fabian Szenkier is the ML and Big Data Architect at Aura by Unity, works on building modern AI/ML solutions and state of the art data engineering pipelines at scale.
Fabian Szenkier is the ML and Big Data Architect at Aura by Unity, works on building modern AI/ML solutions and state of the art data engineering pipelines at scale.
 Liat Tzur is a Senior Technical Account Manager at Amazon Web Services. She serves as the customer’s advocate and assists her customers in achieving cloud operational excellence in alignment with their business goals.
Liat Tzur is a Senior Technical Account Manager at Amazon Web Services. She serves as the customer’s advocate and assists her customers in achieving cloud operational excellence in alignment with their business goals.
 Adi Jabkowski is a Sr. Redshift Specialist in EMEA, part of the Worldwide Specialist Organization (WWSO) at AWS.
Adi Jabkowski is a Sr. Redshift Specialist in EMEA, part of the Worldwide Specialist Organization (WWSO) at AWS.
 Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. He is located in Israel and helps customers harness AWS analytical services to leverage data, gain insights, and derive value.
Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. He is located in Israel and helps customers harness AWS analytical services to leverage data, gain insights, and derive value.
Automate large-scale data validation using Amazon EMR and Apache Griffin
Post Syndicated from Dipal Mahajan original https://aws.amazon.com/blogs/big-data/automate-large-scale-data-validation-using-amazon-emr-and-apache-griffin/
Many enterprises are migrating their on-premises data stores to the AWS Cloud. During data migration, a key requirement is to validate all the data that has been moved from source to target. This data validation is a critical step, and if not done correctly, may result in the failure of the entire project. However, developing custom solutions to determine migration accuracy by comparing the data between the source and target can often be time-consuming.
In this post, we walk through a step-by-step process to validate large datasets after migration using a configuration-based tool using Amazon EMR and the Apache Griffin open source library. Griffin is an open source data quality solution for big data, which supports both batch and streaming mode.
In today’s data-driven landscape, where organizations deal with petabytes of data, the need for automated data validation frameworks has become increasingly critical. Manual validation processes are not only time-consuming but also prone to errors, especially when dealing with vast volumes of data. Automated data validation frameworks offer a streamlined solution by efficiently comparing large datasets, identifying discrepancies, and ensuring data accuracy at scale. With such frameworks, organizations can save valuable time and resources while maintaining confidence in the integrity of their data, thereby enabling informed decision-making and enhancing overall operational efficiency.
The following are standout features for this framework:
- Utilizes a configuration-driven framework
- Offers plug-and-play functionality for seamless integration
- Conducts count comparison to identify any disparities
- Implements robust data validation procedures
- Ensures data quality through systematic checks
- Provides access to a file containing mismatched records for in-depth analysis
- Generates comprehensive reports for insights and tracking purposes
Solution overview
This solution uses the following services:
- Amazon Simple Storage Service (Amazon S3) or Hadoop Distributed File System (HDFS) as the source and target.
- Amazon EMR to run the PySpark script. We use a Python wrapper on top of Griffin to validate data between Hadoop tables created over HDFS or Amazon S3.
- AWS Glue to catalog the technical table, which stores the results of the Griffin job.
- Amazon Athena to query the output table to verify the results.
We use tables that store the count for each source and target table and also create files that show the difference of records between source and target.
The following diagram illustrates the solution architecture.

In the depicted architecture and our typical data lake use case, our data either resides n Amazon S3 or is migrated from on premises to Amazon S3 using replication tools such as AWS DataSync or AWS Database Migration Service (AWS DMS). Although this solution is designed to seamlessly interact with both Hive Metastore and the AWS Glue Data Catalog, we use the Data Catalog as our example in this post.
This framework operates within Amazon EMR, automatically running scheduled tasks on a daily basis, as per the defined frequency. It generates and publishes reports in Amazon S3, which are then accessible via Athena. A notable feature of this framework is its capability to detect count mismatches and data discrepancies, in addition to generating a file in Amazon S3 containing full records that didn’t match, facilitating further analysis.
In this example, we use three tables in an on-premises database to validate between source and target : balance_sheet, covid, and survery_financial_report.
Prerequisites
Before getting started, make sure you have the following prerequisites:
- An AWS account with access to AWS services
- A VPC with private subnet
- An Amazon Elastic Compute Cloud (Amazon EC2) key pair
- An AWS Identity and Access Management (IAM) policy for AWS Secrets Manager permissions
- IAM roles
EMR_DefaultRoleandEMR_EC2_DefaultRoleavailable in your account - A SQL editor to connect to the source database
- The AWS Command Line Interface (AWS CLI) set up to run AWS commands locally:
- Create an IAM policy have access to specific S3 buckets with actions s3:PutObject and s3:GetObject , and an IAM policy to use an AWS CloudFormation template with desired permissions
- Create an IAM user
- Create an IAM role and attach the IAM S3 policy and CloudFormation policies
- Configure ~/.aws/config to use the IAM role and user
Deploy the solution
To make it straightforward for you to get started, we have created a CloudFormation template that automatically configures and deploys the solution for you. Complete the following steps:
- Create an S3 bucket in your AWS account called
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}(provide your AWS account ID and AWS Region). - Unzip the following file to your local system.
- After unzipping the file to your local system, change <bucket name> to the one you created in your account (
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}) in the following files:bootstrap-bdb-3070-datavalidation.shValidation_Metrics_Athena_tables.hqldatavalidation/totalcount/totalcount_input.txtdatavalidation/accuracy/accuracy_input.txt
- Upload all the folders and files in your local folder to your S3 bucket:
- Run the following CloudFormation template in your account.
The CloudFormation template creates a database called griffin_datavalidation_blog and an AWS Glue crawler called griffin_data_validation_blog on top of the data folder in the .zip file.
- Choose Next.

- Choose Next again.
- On the Review page, select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.

You can view the stack outputs on the AWS Management Console or by using the following AWS CLI command:
- Run the AWS Glue crawler and verify that six tables have been created in the Data Catalog.
- Run the following CloudFormation template in your account.
This template creates an EMR cluster with a bootstrap script to copy Griffin-related JARs and artifacts. It also runs three EMR steps:
- Create two Athena tables and two Athena views to see the validation matrix produced by the Griffin framework
- Run count validation for all three tables to compare the source and target table
- Run record-level and column-level validations for all three tables to compare between the source and target table
- For SubnetID, enter your subnet ID.
- Choose Next.

- Choose Next again.
- On the Review page, select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.

You can view the stack outputs on the console or by using the following AWS CLI command:
It takes approximately 5 minutes for the deployment to complete. When the stack is complete, you should see the EMRCluster resource launched and available in your account.
When the EMR cluster is launched, it runs the following steps as part of the post-cluster launch:
- Bootstrap action – It installs the Griffin JAR file and directories for this framework. It also downloads sample data files to use in the next step.
- Athena_Table_Creation – It creates tables in Athena to read the result reports.
- Count_Validation – It runs the job to compare the data count between source and target data from the Data Catalog table and stores the results in an S3 bucket, which will be read via an Athena table.
- Accuracy – It runs the job to compare the data rows between the source and target data from the Data Catalog table and store the results in an S3 bucket, which will be read via the Athena table.

When the EMR steps are complete, your table comparison is done and ready to view in Athena automatically. No manual intervention is needed for validation.
Validate data with Python Griffin
When your EMR cluster is ready and all the jobs are complete, it means the count validation and data validation are complete. The results have been stored in Amazon S3 and the Athena table is already created on top of that. You can query the Athena tables to view the results, as shown in the following screenshot.
The following screenshot shows the count results for all tables.

The following screenshot shows the data accuracy results for all tables.

The following screenshot shows the files created for each table with mismatched records. Individual folders are generated for each table directly from the job.

Every table folder contains a directory for each day the job is run.

Within that specific date, a file named __missRecords contains records that do not match.

The following screenshot shows the contents of the __missRecords file.

Clean up
To avoid incurring additional charges, complete the following steps to clean up your resources when you’re done with the solution:
- Delete the AWS Glue database
griffin_datavalidation_blogand drop the databasegriffin_datavalidation_blogcascade. - Delete the prefixes and objects you created from the bucket
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}. - Delete the CloudFormation stack, which removes your additional resources.
Conclusion
This post showed how you can use Python Griffin to accelerate the post-migration data validation process. Python Griffin helps you calculate count and row- and column-level validation, identifying mismatched records without writing any code.
For more information about data quality use cases, refer to Getting started with AWS Glue Data Quality from the AWS Glue Data Catalog and AWS Glue Data Quality.
About the Authors
 Dipal Mahajan serves as a Lead Consultant at Amazon Web Services, providing expert guidance to global clients in developing highly secure, scalable, reliable, and cost-efficient cloud applications. With a wealth of experience in software development, architecture, and analytics across diverse sectors such as finance, telecom, retail, and healthcare, he brings invaluable insights to his role. Beyond the professional sphere, Dipal enjoys exploring new destinations, having already visited 14 out of 30 countries on his wish list.
Dipal Mahajan serves as a Lead Consultant at Amazon Web Services, providing expert guidance to global clients in developing highly secure, scalable, reliable, and cost-efficient cloud applications. With a wealth of experience in software development, architecture, and analytics across diverse sectors such as finance, telecom, retail, and healthcare, he brings invaluable insights to his role. Beyond the professional sphere, Dipal enjoys exploring new destinations, having already visited 14 out of 30 countries on his wish list.
 Akhil is a Lead Consultant at AWS Professional Services. He helps customers design & build scalable data analytics solutions and migrate data pipelines and data warehouses to AWS. In his spare time, he loves travelling, playing games and watching movies.
Akhil is a Lead Consultant at AWS Professional Services. He helps customers design & build scalable data analytics solutions and migrate data pipelines and data warehouses to AWS. In his spare time, he loves travelling, playing games and watching movies.
 Ramesh Raghupathy is a Senior Data Architect with WWCO ProServe at AWS. He works with AWS customers to architect, deploy, and migrate to data warehouses and data lakes on the AWS Cloud. While not at work, Ramesh enjoys traveling, spending time with family, and yoga.
Ramesh Raghupathy is a Senior Data Architect with WWCO ProServe at AWS. He works with AWS customers to architect, deploy, and migrate to data warehouses and data lakes on the AWS Cloud. While not at work, Ramesh enjoys traveling, spending time with family, and yoga.
Voice Assistant Contest Winners livestream
Post Syndicated from Home Assistant original https://www.youtube.com/watch?v=eOfV3vDyhLU