Python functions can use both positional and keyword arguments; the latter
provide a certain level of documentation for an argument and its meaning,
while allowing them to be given in any order in a call. But it is often
the case that the name of the local variable to be passed is the same as
the keyword, which can lead to overly repetitive argument lists, at least
in some eyes. A recent proposal to shorten the syntax for calls with
these duplicate names seems to be gaining some steam—a Python Enhancement
Proposal (PEP) is forthcoming—though there are some who find it to be an
unnecessary and unwelcome complication for the language.
Amazon Redshift ML allows data analysts, developers, and data scientists to train machine learning (ML) models using SQL. In previous posts, we demonstrated how you can use the automatic model training capability of Redshift ML to train classification and regression models. Redshift ML allows you to create a model using SQL and specify your algorithm, such as XGBoost. You can use Redshift ML to automate data preparation, preprocessing, and selection of your problem type (for more information, refer to Create, train, and deploy machine learning models in Amazon Redshift using SQL with Amazon Redshift ML). You can also bring a model previously trained in Amazon SageMaker into Amazon Redshift via Redshift ML for local inference. For local inference on models created in SageMaker, the ML model type must be supported by Redshift ML. However, remote inference is available for model types that are not natively available in Redshift ML.
Over time, ML models grow old, and even if nothing drastic happens, small changes accumulate. Common reasons why ML models needs to be retrained or audited include:
Data drift – Because your data has changed over time, the prediction accuracy of your ML models may begin to decrease compared to the accuracy exhibited during testing
Concept drift – The ML algorithm that was initially used may need to be changed due to different business environments and other changing needs
You may need to refresh the model on a regular basis, automate the process, and reevaluate your model’s improved accuracy. As of this writing, Amazon Redshift doesn’t support versioning of ML models. In this post, we show how you can use the bring your own model (BYOM) functionality of Redshift ML to implement versioning of Redshift ML models.
We use local inference to implement model versioning as part of operationalizing ML models. We assume that you have a good understanding of your data and the problem type that is most applicable for your use case, and have created and deployed models to production.
Solution overview
In this post, we use Redshift ML to build a regression model that predicts the number of people that may use the city of Toronto’s bike sharing service at any given hour of a day. The model accounts for various aspects, including holidays and weather conditions, and because we need to predict a numerical outcome, we used a regression model. We use data drift as a reason for retraining the model, and use model versioning as part of the solution.
After a model is validated and is being used on a regular basis for running predictions, you can create versions of the models, which requires you to retrain the model using an updated training set and possibly a different algorithm. Versioning serves two main purposes:
You can refer to prior versions of a model for troubleshooting or audit purposes. This enables you to ensure that your model still retains high accuracy before switching to a newer model version.
You can continue to run inference queries on the current version of a model during the model training process of the new version.
At the time of this writing, Redshift ML doesn’t have native versioning capabilities, but you can still achieve versioning by implementing a few simple SQL techniques by using the BYOM capability. BYOM was introduced to support pre-trained SageMaker models to run your inference queries in Amazon Redshift. In this post, we use the same BYOM technique to create a version of an existing model built using Redshift ML.
The following figure illustrates this workflow.
In the following sections, we show you how to can create a version from an existing model and then perform model retraining.
We use the regression model created in the post Build regression models with Amazon Redshift ML. We assume that it is already been deployed and use this model to create new versions and retrain the model.
Create a version from the existing model
The first step is to create a version of the existing model (which means saving developmental changes of the model) so that a history is maintained and the model is available for comparison later on.
The following code is the generic format of the CREATE MODEL command syntax; in the next step, you get the information needed to use this command to create a new version:
Next, we collect and apply the input parameters to the preceding CREATE MODEL code to the model. We need the job name and the data types of the model input and output values. We collect these by running the show model command on our existing model. Run the following command in Amazon Redshift Query Editor v2:
show model predict_rental_count;
Note the values for AutoML Job Name, Function Parameter Types, and the Target Column (trip_count) from the model output. We use these values in the CREATE MODEL command to create the version.
The following CREATE MODEL statement creates a version of the current model using the values collected from our show model command. We append the date (the example format is YYYYMMDD) to the end of the model and function names to track when this new version was created.
CREATE MODEL predict_rental_count_20230706
FROM 'redshiftml-20230706171639810624'
FUNCTION predict_rental_count_20230706 (int4, int4, int4, int4, int4, int4, int4, numeric, numeric, int4)
RETURNS float8
IAM_ROLE default
SETTINGS (
S3_BUCKET '<<your S3 Bucket>>');
This command may take few minutes to complete. When it’s complete, run the following command:
show model predict_rental_count_20230706;
We can observe the following in the output:
AutoML Job Name is the same as the original version of the model
Function Name shows the new name, as expected
Inference Type shows Local, which designates this is BYOM with local inference
You can run inference queries using both versions of the model to validate the inference outputs.
The following screenshot shows the output of the model inference using the original version.
The following screenshot shows the output of model inference using the version copy.
As you can see, the inference outputs are the same.
You have now learned how to create a version of a previously trained Redshift ML model.
Retrain your Redshift ML model
After you create a version of an existing model, you can retrain the existing model by simply creating a new model.
You can create and train a new model using same CREATE MODEL command but using different input parameters, datasets, or problem types as applicable. For this post, we retrain the model on newer datasets. We append _new to the model name so it’s similar to the existing model for identification purposes.
In the following code, we use the CREATE MODEL command with a new dataset available in the training_data table:
CREATE MODEL predict_rental_count_new
FROM training_data
TARGET trip_count
FUNCTION predict_rental_count_new
IAM_ROLE 'arn:aws:iam::<accountid>:role/RedshiftML'
PROBLEM_TYPE regression
OBJECTIVE 'mse'
SETTINGS (s3_bucket 'redshiftml-<your-account-id>',
s3_garbage_collect off,
max_runtime 5000);
Run the following command to check the status of the new model:
show model predict_rental_count_new;
Replace the existing Redshift ML model with the retrained model
The last step is to replace the existing model with the retrained model. We do this by dropping the original version of the model and recreating a model using the BYOM technique.
First, check your retrained model to ensure the MSE/RMSE scores are staying stable between model training runs. To validate the models, you can run inferences by each of the model functions on your dataset and compare the results. We use the inference queries provided in Build regression models with Amazon Redshift ML.
After validation, you can replace your model.
Start by collecting the details of the predict_rental_count_new model.
Note the AutoML Job Name value, the Function Parameter Types values, and the Target Column name in the model output.
Replace the original model by dropping the original model and then creating the model with the original model and function names to make sure the existing references to the model and function names work:
drop model predict_rental_count;
CREATE MODEL predict_rental_count
FROM 'redshiftml-20230706171639810624'
FUNCTION predict_rental_count(int4, int4, int4, int4, int4, int4, int4, numeric, numeric, int4)
RETURNS float8
IAM_ROLE default
SETTINGS (
S3_BUCKET ’<<your S3 Bucket>>’);
The model creation should complete in a few minutes. You can check the status of the model by running the following command:
show model predict_rental_count;
When the model status is ready, the newer version predict_rental_count of your existing model is available for inference and the original version of the ML model predict_rental_count_20230706 is available for reference if needed.
Please refer to this GitHub repository for sample scripts to automate model versioning.
Conclusion
In this post, we showed how you can use the BYOM feature of Redshift ML to do model versioning. This allows you to have a history of your models so that you can compare model scores over time, respond to audit requests, and run inferences while training a new model.
For more information about building different models with Redshift ML, refer to Amazon Redshift ML.
About the Authors
Rohit Bansal is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build next-generation analytics solutions using other AWS Analytics services.
Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse.
Multiple Cloudflare services were unavailable for 37 minutes on October 30, 2023. This was due to the misconfiguration of a deployment tool used by Workers KV. This was a frustrating incident, made more difficult by Cloudflare’s reliance on our own suite of products. We are deeply sorry for the impact it had on customers. What follows is a discussion of what went wrong, how the incident was resolved, and the work we are undertaking to ensure it does not happen again.
Workers KV is our globally distributed key-value store. It is used by both customers and Cloudflare teams alike to manage configuration data, routing lookups, static asset bundles, authentication tokens, and other data that needs low-latency access.
During this incident, KV returned what it believed was a valid HTTP 401 (Unauthorized) status code instead of the requested key-value pair(s) due to a bug in a new deployment tool used by KV.
These errors manifested differently for each product depending on how KV is used by each service, with their impact detailed below.
What was impacted
A number of Cloudflare services depend on Workers KV for distributing configuration, routing information, static asset serving, and authentication state globally. These services instead received an HTTP 401 (Unauthorized) error when performing any get, put, delete, or list operation against a KV namespace.
Customers using the following Cloudflare products would have observed heightened error rates and/or would have been unable to access some or all features for the duration of the incident:
Product
Impact
Workers KV
Customers with applications leveraging KV saw those applications fail during the duration of this incident, including both the KV API within Workers, and the REST API. Workers applications not using KV were not impacted.
Pages
Applications hosted on Pages were unreachable for the duration of the incident and returned HTTP 500 errors to users. New Pages deployments also returned HTTP 500 errors to users for the duration.
Access
Users who were unauthenticated could not log in; any origin attempting to validate the JWT using the /certs endpoint would fail; any application with a device posture policy failed for all users. Existing logged-in sessions that did not use the /certs endpoint or posture checks were unaffected. Overall, a large percentage of existing sessions were still affected.
WARP / Zero Trust
Users were unable to register new devices or connect to resources subject to policies that enforce Device Posture checks or WARP Session timeouts. Devices already enrolled, resources not relying on device posture, or that had re-authorized outside of this window were unaffected.
Images
The Images API returned errors during the incident. Existing image delivery was not impacted.
Cache Purge (single file)
Single file purge was partially unavailable for the duration of the incident as some data centers could not access configuration data in KV. Data centers that had existing configuration data locally cached were unaffected. Other cache purge mechanisms, including purge by tag, were unaffected.
Workers
Uploading or editing Workers through the dashboard, wrangler or API returned errors during the incident. Deployed Workers were not impacted, unless they used KV.
AI Gateway
AI Gateway was not able to proxy requests for the duration of the incident.
Waiting Room
Waiting Room configuration is stored at the edge in Workers KV. Waiting Room configurations, and configuration changes, were unavailable and the service failed open. When access to KV was restored, some Waiting Room users would have experienced queuing as the service came back up.
Turnstile and Challenge Pages
Turnstile’s JavaScript assets are stored in KV, and the entry point for Turnstile (api.js) was not able to be served. Clients accessing pages using Turnstile could not initialize the Turnstile widget and would have failed closed during the incident window. Challenge Pages (which products like Custom, Managed and Rate Limiting rules use) also use Turnstile infrastructure for presenting challenge pages to users under specific conditions, and would have blocked users who were presented with a challenge during that period.
Cloudflare Dashboard
Parts of the Cloudflare dashboard that rely on Turnstile and/or our internal feature flag tooling (which uses KV for configuration) returned errors to users for the duration.
Timeline
All timestamps referenced are in Coordinated Universal Time (UTC).
Time
Description
2023-10-30 18:58 UTC
The Workers KV team began a progressive deployment of a new KV build to production.
2023-10-30 19:29 UTC
The internal progressive deployment API returns staging build GUID to a call to list production builds.
2023-10-30 19:40 UTC
The progressive deployment API was used to continue rolling out the release. This routed a percentage of traffic to the wrong destination, triggering alerting and leading to the decision to roll back.
2023-10-30 19:54 UTC
Rollback via progressive deployment API attempted, traffic starts to fail at scale. — IMPACT START —
2023-10-30 20:15 UTC
Cloudflare engineers manually edit (via break glass mechanisms) deployment routes to revert to last known good build for the majority of traffic.
2023-10-30 20:29 UTC
Workers KV error rates return to normal pre-incident levels, and impacted services recover within the following minute.
2023-10-30 20:31 UTC
Impact resolved — IMPACT END —
As shown in the above timeline, there was a delay between the time we realized we were having an issue at 19:54 UTC and the time we were actually able to perform the rollback at 20:15 UTC.
This was caused by the fact that multiple tools within Cloudflare rely on Workers KV including Cloudflare Access. Access leverages Workers KV as part of its request verification process. Due to this, we were unable to leverage our internal tooling and had to use break-glass mechanisms to bypass the normal tooling. As described below, we had not spent sufficient time testing the rollback mechanisms. We plan to harden this moving forward.
Resolution
Cloudflare engineers manually switched (via break glass mechanism) the production route to the previous working version of Workers KV, which immediately eliminated the failing request path and subsequently resolved the issue with the Workers KV deployment.
Analysis
Workers KV is a low-latency key-value store that allows users to store persistent data on Cloudflare’s network, as close to the users as possible. This distributed key-value store is used in many applications, some of which are first-party Cloudflare products like Pages, Access, and Zero Trust.
The Workers KV team was progressively deploying a new release using a specialized deployment tool. The deployment mechanism contains a staging and a production environment, and utilizes a process where the production environment is upgraded to the new version at progressive percentages until all production environments are upgraded to the most recent production build. The deployment tool had a latent bug with how it returns releases and their respective versions. Instead of returning releases from a single environment, the tool returned a broader list of releases than intended, resulting in production and staging releases being returned together.
In this incident, the service was deployed and tested in staging. But because of the deployment automation bug, when promoting to production, a script that had been deployed to the staging account was incorrectly referenced instead of the pre-production version on the production account. As a result, the deployment mechanism pointed the production environment to a version that was not running anywhere in the production environment, effectively black-holing traffic.
When this happened, Workers KV became unreachable in production, as calls to the product were directed to a version that was not authorized for production access, returning a HTTP 401 error code. This caused dependent products which stored key-value pairs in KV to fail, regardless of whether the key-value pair was cached locally or not.
Although automated alerting detected the issue immediately, there was a delay between the time we realized we were having an issue and the time we were actually able to perform the roll back. This was caused by the fact that multiple tools within Cloudflare rely on Workers KV including Cloudflare Access. Access uses Workers KV as part of the verification process for user JWTs (JSON Web Tokens).
These tools include the dashboard which was used to revert the change, and the authentication mechanism to access our continuous integration (CI) system. As Workers KV was down, so too were these services. Automatic rollbacks via our CI system had been successfully tested previously, but the authentication issues (Access relies on KV) due to the incident made accessing the necessary secrets to roll back the deploy impossible.
The fix ultimately was a manual change of the production build path to a previous and known good state. This path was known to have been deployed and was the previous production build before the attempted deployment.
Next steps
As more teams at Cloudflare have built on Workers, we have “organically” ended up in a place where Workers KV now underpins a tremendous amount of our products and services. This incident has continued to reinforce the need for us to revisit how we can reduce the blast radius of critical dependencies, which includes improving the sophistication of our deployment tooling, its ease-of-use for our internal teams, and product-level controls for these dependencies. We’re prioritizing these efforts to ensure that there is not a repeat of this incident.
This also reinforces the need for Cloudflare to improve the tooling, and the safety of said tooling, around progressive deployments of Workers applications internally and for customers.
This includes (but is not limited) to the below list of key follow-up actions (in no specific order) this quarter:
Onboard KV deployments to standardized Workers deployment models which use automated systems for impact detection and recovery.
Ensure that the rollback process has access to a known good deployment identifier and that it works when Cloudflare Access is down.
Add pre-checks to deployments which will validate input parameters to ensure version mismatches don’t propagate to production environments.
Harden the progressive deployment tooling to operate in a way that is designed for multi-tenancy. The current design assumes a single-tenant model.
Add additional validation to progressive deployment scripts to verify that the deployment matches the app environment (production, staging, etc.).
Again, we’re extremely sorry this incident occurred, and take the impact of this incident on our customers extremely seriously.
LWN editor Jonathan Corbet was asked to give a brief talk about kernel
maintainership at the recently concluded Linux
Foundation Member Summit. That talk was recorded and has now been made available
on YouTube. There is little in it that will be news to regular LWN
readers, but it may be instructive to folks who are less well versed in how
kernel development works.
There’s an alternative universe where we decided to teach the
kernel about every piece of hardware it should run on. Fortunately
(or, well, unfortunately) we’ve seen that in the ARM world. Most
device-specific simply never reaches mainline, and most users are
stuck running ancient kernels as a result. Imagine every x86 device
vendor shipping their own kernel optimised for their hardware, and
now imagine how well that works out given the quality of their
firmware. Does that really seem better to you?
If you’re looking to enhance the security of your containers on Amazon Elastic Container Service (Amazon ECS), you can begin with the six tips that we’ll cover in this blog post. These curated best practices are recommended by Amazon Web Services (AWS) container and security subject matter experts in order to help raise your container security posture.
Before we jump into best practices, let’s look at the how the shared responsibility model works for Amazon ECS hosted on Amazon Elastic Compute Cloud (Amazon EC2) infrastructure compared to AWS Fargate. The security and compliance of a managed service like Amazon ECS is a shared responsibility between you and AWS. Generally speaking, AWS is responsible for security of the cloud whereas you, the customer, are responsible for security in the cloud. AWS is responsible for the management of the Amazon ECS control plane, including the infrastructure that’s needed to deliver a secure and reliable service. In this post, we’re going to focus on the areas of ECS security that you will be responsible for and provide guidance on what you need to do to adhere to these ECS security best practices.
Figure 1 shows the shared responsibility model for Amazon ECS hosted on an EC2 instance, in which the customer has more security responsibility to cover than when using ECS on Fargate. For example, the ECS agent and the worker node configuration is the customer’s responsibility to govern, because the customer is managing the EC2 instance. Therefore, the customer will have to manage the ECS agent and worker node as part of their configuration and management operations.
Figure 1: Responsibility model for Amazon ECS hosted on an Amazon EC2 instance
AWS assumes greater responsibility for infrastructure security for Fargate, as shown in Figure 2.
Figure 2: Responsibility model for Amazon ECS hosted on Fargate
In Fargate, each task runs in its own virtual machine (VM). No two tasks share the operating system or kernel resources. With Fargate, AWS manages the security of the underlying instance in the cloud and the runtime that’s used to run your tasks. It also automatically scales your infrastructure on your behalf, which is something you should take into consideration if you’re starting your container journey and deciding on your infrastructure options.
With that, let’s go through these six Amazon ECS security best practices.
Enforce least privilege when setting up policies for Amazon ECS resources – Use resource-level permissions to specify upon which resources you want to allow particular actions. For example, only allow a specific IAM user to stop a task that uses a specific task definition family on a specific ECS cluster.
Specify your task’s role – Make sure to define the right task role in your ECS task definition. The task role is used by your application in the task to make API calls to AWS services like Amazon Simple Storage Service (Amazon S3). This allows you to run your tasks by using an IAM role that has only the necessary permissions, without complete access to all services and resources within your account.
Create automated pipelines – Use Amazon CodePipeline or one of your other preferred continuous integration and continuous delivery (CI/CD) solutions to create pipelines that package and deploy your applications into ECS clusters. This way, you limit the users’ actions and delegate them to the automated pipeline. For an example of how to create pipelines, see Automatically build CI/CD pipelines and Amazon ECS clusters for microservices using AWS CDK.
Audit Amazon ECS API access – Track and monitor your AWS CloudTrail logs to identify who has access to your Amazon ECS APIs and whether that access is still warranted. You can then delete the IAM users, roles, and groups that aren’t in use and review the policies that are in place. For more information, see the AWS security audit guidelines.
2 – Secure your ECS network
Network security is an important item to work on as part of applying best practices to secure your Amazon ECS environment. This area includes several sub-areas such as firewalling, traffic routing, and network observability. Here’s what we recommend:
Network segmentation and isolation – Amazon ECS tasks are configured to operate in different network modes. AWS recommends the use of awsvpc as the preferred network mode. This is because it’s the only mode that you can use to assign security groups to tasks. After you configure your task to use this mode, the ECS agent automatically provisions and attaches an elastic network interface (ENI) to the task. When the ENI is provisioned, the task is enrolled in an AWS security group. The security group acts as a virtual firewall that you can use to control inbound and outbound traffic. It’s also the only mode that’s available for Fargate tasks on ECS if you choose to go that route.
Use network encryption where applicable – Encrypting network traffic helps prevent unauthorized users from intercepting and reading data when that data is transmitted across a network. With Amazon ECS, you can implement network encryption in different ways, such as with a service mesh (TLS), using AWS Nitro system instances, using server name indication (SNI) with an application load balancer, or end-to-end encryption with TLS certificates. If your service is fronted by a public-facing load balancer, use TLS/SSL to encrypt the traffic from the client’s browser to the load balancer and re-encrypt traffic to the backend if warranted. For more information, see Amazon ECS encryption in transit.
Create clusters in separate VPCs when network traffic needs to be strictly isolated – You should create clusters in separate virtual private clouds (VPCs) when network traffic needs to be strictly isolated. Avoid running workloads that have strict security requirements on clusters with workloads that don’t have to adhere to those requirements. When strict network isolation is mandatory, create clusters in separate VPCs and selectively expose services to other VPCs by using VPC endpoints. For more information, see VPC endpoints.
Secrets, such as API keys and database credentials, are frequently used by applications to gain access to other systems. They often consist of a username and password, a certificate, or an API key. Access to these secrets should be restricted to specific IAM principals that are using IAM and injected into containers at runtime. Here’s what we recommend:
Use Secrets Manager or Amazon EC2 Systems Manager Parameter Store for storing secret materials – Securely storing API keys, database credentials, and other secret materials is crucial to help prevent accidental exposure and unauthorized access. AWS recommends that you store these secrets in Secrets Manager or as an encrypted parameter in Amazon EC2 Systems Manager Parameter Store. These services are similar because they’re both managed key-value stores that use AWS Key Management Service (AWS KMS) to encrypt sensitive data. Secrets Manager, however, also includes the ability to automatically rotate secrets, generate random secrets, and share secrets across AWS accounts. Additionally, Amazon ECS does not support versioned parameters in Parameter Store. If you need to implement any of these features, use Secrets Manager; otherwise, use encrypted parameters. Also, you can use tools like Chamber to manage secrets. For more information, see this Knowledge Center article.
Mount the secret to a volume by using a sidecar container – Considering the elevated risk of data leakage with environmental variables, it’s recommended that you run a sidecar container that reads your secrets from Secrets Manager and writes them to a shared volume. This container can run and exit before the application container by using Amazon ECS container ordering. When you do this, the application container subsequently mounts the volume where the secret was written. This will help isolate secret management concerns and facilitates dynamic secret handling. For example, your application should be written to read the secret from the shared volume. Then, because the volume is scoped to the task, the volume is automatically deleted after the task stops. For more details about sidecar containers, see the aws-secret-sidecar-injector project in GitHub.
4 – Secure the ECS task and runtime
You should consider the container image as your first line of defense. An insecure, poorly constructed image can allow users to escape the bounds of the container and gain access to the host. You should do the following to mitigate the chances of this happening:
Secure your container’s images – Escape to host is a well-known container threat technique where bad actors use unsecured container images to escape the bounds of a container and gain access to the underlying host. We recommend that you scan your container’s images before deployment. For images stored on Amazon ECR, you can use Amazon Inspector to scan your images, along with Amazon EventBridge to be notified to take actions to either delete or rebuild insecure images. This process is shown in the architecture in Figure 3. You can find more details on how to create custom responses to Amazon Inspector findings with Amazon EventBridge in the Amazon Inspector User Guide.
Figure 3: Sample architecture showing how to get notified of Amazon Inspector findings on a container’s image
Enable the ECR tag immutability feature – Threat actors could also try to push a compromised version of a container image into your Amazon ECR repository with an identical tag. A solution for this is to force a new tag for each new version of your image. You can do this by enabling the image tag mutability feature for your ECR repositories. You can find the Tag immutability setting on the Create repository page in the Amazon ECR console, under General settings, as shown in Figure 4.
Figure 4: Enabling the tag immutability feature for your Amazon ECR repository
Secure your containers and tasks
Define the USER parameter to use inside your container – Containers run by default as the root user, which doesn’t adhere to the principle of least privilege and can be misused. One recommendation is to make sure to run your containers as a non-root user by specifying the USER directive in your Dockerfile. You can enforce this when using a CI/CD pipeline by configuring the pipeline to fail the build if the USER directive is missing.
Don’t run your containers in privileged mode – Make sure to not run your containers in privileged mode, which can be a potential gap that allows unauthorized users to run commands within a container. You can use AWS Security Hub to detect containers that are running in privileged mode. Alternatively, you can use AWS Lambda to scan your task definitions for the use of the privileged parameter. Security Hub has a built-in control (ECS.4) to check whether the privileged parameter in the container definition of Amazon ECS task definitions is set to true.
Disable ECS Exec – Customers should disable the ECS Execute condition key for production environments. Disabling the key provides access control that can help prevent SSH access into running containers. You can do this by disabling the ECS:Enable-Execute-Command condition key.
Secure runtime – For Linux containers, make sure to add or drop Linux kernel capabilities in the task definition. You can do this either by using linuxParameters and applying SELinux labels or by using the AppArmor profile, which is a Linux security module that restricts a container’s capabilities, such as accessing parts of the file system. When you’re using the Fargate launch type, each Fargate task has its own isolation boundary and does not share the underlying kernel, CPU resources, memory resources, or elastic network interface with another task.
5 – ECS logging and monitoring
Logging and monitoring your container’s activity can help you quickly identify and investigate security incidents in your AWS environments. For example, threat actors might have escalated permissions and have access to your root user. Here’s what we recommend:
Monitor changes to your tasks and containers – Put appropriate events rules in place in Amazon EventBridge for the creation of and changes to your tasks and containers.
Monitor Amazon ECS scheduled tasks – If threat actors have enough privileges, they can abuse the ECS task scheduling feature to deploy containers that would run malicious code. Monitor this type of activity by using Amazon CloudTrail logs and get notifications. For more information about scheduling ECS tasks, see the Amazon ECS Developer Guide.
Monitor your container’s activity metrics – Another recommendation is to enable logging for your container and use Amazon CloudWatch to track activity metrics on your containers, such as CPU and memory utilization. This can help you detect if your resources are accessed and being used for malicious activities, such as launching DoS attacks. See Amazon ECS CloudWatch Container Insights for more information.
Use Amazon VPC Flow Logs to analyze the traffic to and from long-running tasks – You should use Amazon VPC Flow Logs to analyze the traffic to and from long-running tasks. Tasks that use awsvpc network mode get their own ENI. By setting tasks to use this mode, you can use VPC flow logs to monitor traffic that goes to and from individual tasks. A recent update to Amazon VPC Flow Logs (v3) enriches the logs with traffic metadata, including the VPC ID, subnet ID, and the instance ID. You can use this metadata to help narrow an investigation. For more information, see Amazon VPC Flow Logs. AWS cloud-native tools like Amazon GuardDuty inspect VPC flow logs and generate alerts and findings if unusual activity is detected.
6 – ECS security compliance
When using Amazon ECS, your compliance responsibility is determined by the sensitivity of your data, the compliance objectives of your company, and applicable laws and regulations. For example, with regards to the Payment Card Industry Data Security Standard (PCI-DSS), it’s important that you understand the complete flow of cardholder data (CHD) within your environment.
The temporary nature of containerized applications provides additional complexities when auditing configurations. As a result, customers need to maintain an awareness of all container configuration parameters, to make sure that compliance requirements are addressed throughout the phases of a container lifecycle. For additional information on adhering to PCI DSS compliance on Amazon ECS, see the Architecting on Amazon ECS for PCI DSS Compliance whitepaper.
One service that can help with monitoring Amazon ECS compliance is AWS Security Hub. You can use this service to monitor your usage of ECS as it relates to security best practices. Security Hub uses controls to evaluate resource configurations and security standards to help you comply with various compliance frameworks. For more information about using Security Hub to evaluate ECS resources, see Amazon ECS controls in the AWS Security Hub User Guide.
Conclusion
In this blog post, we presented a curated list of best practices for securing your Amazon ECS implementation. You can use these best practices as a starting point to increase the security posture of your ECS environment. You can always add, remove, or prioritize the best practice items based on your business needs and requirements. If you’re looking for more detailed guidance on securing ECS in your environment, we suggest that you take a look at Amazon ECS Security Best Practices.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on AWS re:Post or contact AWS Support.
Сега когато предизборната кампнаия премина и вотът на Хората от Община Родопи беше повече от ясен е време да се отърсим от предизборното говорене и да започнем да мислим трезво.
Първо да честитим на г-н Павел Михайлов новия мандат и наред с това да започнем да обръщаме внимание на злободневните проблеми.
От толкова много послания, хората не обърнаха внимание на факта, че на всички местни избори става въпрос единствено за борба за разпределение на бюджета на общината, мисля да пускам по някой пост от време на време, за да повищаваме финансовата култура.
Все пак бюджета е най-големия инвеститор в нашата община и без неговите средства няма да имаме нито нови улици, нито друга инфраструктура.
Тази година той беше планиран в размер на 55.7 млн лева.
Миналата година беше в размер на 44.8 млн лева.
Миналата година беше в размер на 44.8 млн лева.
Как обаче се прави връзка между двата бюджета? Разбира се чрез изпълнението. Защото ако нямаме изпълнение, единствения начин е да изпълним обещанията чрез теглене на кредит, както го и направихме.
Бюджет 2022 беше изпълнен на 55%. Прилагам някой снимки.
Пимерно в Бюджет 2022, приходите от данък МПС са заложени 2.2 млн, от който сме изпълнили 2.1 млн. Смея да твърдя доста добро изпълнение. Знаете ли защо? Защото не можете да минете преглед, ако не сте си платили данъка. Този данък е доста добре прогнозируем по тази причина. Затова за 2023г. общината е заложила 3.1 млн. приходи.
Преведено на прост език – ще увеличим данъка или очакваме в рамките на една година, автомобилите да се увеличат с 50%. Тоест всяко второ семейство да си купи по още един автомобил, без да спира от движение съществуващия.
Или разбира се да се почви инвеститор, който да регистрира фирмата си с хиляди автомобили в Общиа Родопи. Ще бъде интересно да видим отчета за 2023 на тези приходи.
Сега като видяхме как работи принципа на оценка на бюджета, нека се фокусираме върху някое друго приходно перо. Примерно „Приходи и доходи от собственост”. Тук вече приходите са изцяло зависими от работата на администрацията. Ако не работиш – няма да имаш приходи, следователно за да изпълниш обещаното ще трябва пак кредит.
За 2022г са планирани 701 500лв, събрани са 181 900 лева, тоест едва 26%. Пак казвам, тук събираемостта е пряко свързана с дейността на администрацията. Въпреки тази ниска събираемост за 2023 сме заложили приходи от 746 600 лв. Тоест увеличение на приходите с 6% при положение, че предходната година си събрал едва 26% от планираното.
С нетърпение очаквам да ме опровергаят в очакванията ми, че тази година по това перо пак изпълнението ще бъде близко до 26%, че и по-малко.
Ето така се раздува бюджета – със заложени неизпълними приходи. Понеже няма санкция за неизпълнението, а само аз задавам някакви въпроси на обсъжданията, администрацията може да си позволи да не си дава много зор в изпълнението. Все пак кредита в края на мандата винаги е опция. Поне до едно време, когато станем свръхзадлъжнели, но до този момент има още време.
Едно е сигурно – следващата година няма да има много нови улици и LED лампи. Поне не без кредит. Виж ако изтеглим още 7 млн. ще е различно.
А Брестовчани могат да си чакат техните 25 млн за смяна на водопроводната мрежа. При този бюджет и това изпълнение аз не го виждам. Освен ако разбира се държавата не помогне. Но при Централна власт доминирана от ГЕРБ и ПП-ДБ, и при кмет на Родопи от БСП, това ще е малко вероятно според мен. Още повече, че Брестовица са се засилили да изберат и селски кмет също от БСП.
Както се казва дано да греша и централната власт да не работи на принципа – Отпускам пари само ако мога да си направя PR или ако са гласували за мен. Дано също така да са сменени тръбите под новия площад в Брестовица, че ако трябва после да го копаем… язък ни за барута.
Та това е начина на оценка на бюджета – колко е добър и колко е ефективен. Ще понапиша и за някои други връзки в общинския бюджет, защото дали разбирате или не, всичко за което поискате пари от кметството, трябва да го има заложено в бюджета и съответно да са осигурени пари за него. Дали от кредити, дали от централната власт или от работата на общинските служители, без пари не става!
Следвайте ме за още финансови уроци, свързани с бюджета на китната Община Родопи
Активно мероприятие е нещо (събитие, процес, движение, организация скандал, конфликт, протест и пр.), което изглежда автентично, но в действителност е дело на специалните служби. Или на хора, които владеят методите на службите. Терминът има съветски произход. Някои участници в активните мероприятия са наясно, че са част от специализирана операция, но много други дори не си дават сметка, че са кукли на конци.
И ето че „активно мероприятие“ се превърна в словосъчетанието на седмицата. Ако не и на годината. Този път вече стана очевидно – поне за хората с критично мислене, – че е в ход огромна, добре обмислена и координирана манипулация. Поводът за нея е толкова нелеп, колкото да ви обвинят, че сте снимали светофар, и заради това да го махнат, като оставят само пешеходната пътека, ако използваме сравнението на главната редакторка на „Свободна Европа“ Татяна Ваксберг.
Целта, която активното мероприятие успя да постигне, е да се променят изборните правила за първия тур на местните избори. Независимо от „дребни подробности“ като закон, съд, парламент и правителство. И с явното участие на службите (ДАНС), които, изглежда, имат интерес да действат срещу правителството. Защото то иска да ги прочисти от ченгеджийството, свързано с остатъците от тоталитарната Държавна сигурност. А това не е лесна задача – дори да се сменят хората, чиито кариери имат корени в ДС, те са се възпроизвели многократно, възпитавайки за повече от 30 години поколения оперативни работници, разузнавачи, контраразузнавачи и пр.
Може би се питате за какво му е било на зам.-министъра Михаил Стойнов да снима (публичен) код с телефона си, и си задавате въпроси и за други странности, съпровождащи скандала. Но мислите ли, че една акция, при която действат в синхрон ДАНС, 5 от 6 парламентарно представени партии и ЦИК, нямаше да се осъществи, ако Стойнов не беше снимал? Тогава щеше да има нещо друго, независимо колко нелепо. Например бръкнал си е в джоба, където може би крие нещо, заплашващо сигурността на вота, а с това и цялата национална сигурност. Ето, Върховният административен съд видя различен проблем – машините за гласуване не били удостоверени от когото трябва.
История за университет, джоб и инфаркт
Дадох пример с бъркане в джоба, защото си припомних една история отпреди 15 години. На пръв поглед тя е много различна от случката със снимането на хешкода на машините за гласуване. Но механизмът е аналогичен.
И така, годината е 2008-ма, мястото е Югозападният университет (ЮЗУ) в Благоевград. Съдът тъкмо е отменил второто уволнение на преподавател на име Петър Дошков. Него все го уволняват, защото е чепат и се бори с корупцията в университета. Особено с вече покойния декан на Правно-историческия факултет Александър Воденичаров, който де факто управлява университета. Между другото, продукт на същия факултет е и Делян Пеевски. Към онзи момент Воденичаров е бивш говорител на Висшия съдебен съвет и виден тимаджия, има свое лоби в парламента и кара незаконен трети мандат.
Колегите на Дошков са в ужас от възстановяването му на работа. Когато секретарката го вижда да влиза в кабинета, с ръка в джоба на черното си дънково яке, губи ума и дума. Решава, че в този джоб може да има пистолет, и споделя опасението си с декана. Свиква се заседание, на което се решава Дошков да не бъде допускан в университета въпреки съдебното решение, защото е опасен, може да носи пистолет и да го използва срещу студентите.
На следващия ден Петър Дошков не е допуснат в университета от охраната с аргумента, че носи пистолет, макар никой да не го проверява. Същото се случва и пред вратата на Благоевградския съд, чиито охранители своевременно са информирани за пистолета, който никой не е виждал и никой не желае да потърси.
Ден по-късно полицаи спохождат Дошков и му задават въпроса защо пребивава в града, без да се е регистрирал. Мнозина в България живеят с години без регистрация, да не говорим за почивки и командировки, но за Дошков и два дни се оказват проблем. Освен филолог обаче, преподавателят е също юрист и си знае правата. Отговаря, че има право да пребивава три дни без регистрация, а са минали само два.
На третия ден Петър Дошков се връща в родното си село, където в следващите три години продължава битките си с ЮЗУ. Докато един ден просто получава инфаркт и умира на 50-годишна възраст.
Да целиш танк с прашка
Няма смисъл да продължаваме да обсъждаме конкретното активно мероприятие със зам.-министъра Михаил Стойнов. Проблемът не е какво е направил или не е направил той, а защо не можем ефективно да се противопоставяме на активните мероприятия.
Да вземем за пример друго такова мероприятие – кампанията срещу Истанбулската конвенция. Колкото и логични аргументи да се привеждаха и колкото и да се обясняваше абсурдността на превратното тълкуване на термина „джендър“, всички усилия останаха глас в пустиня. Стигна се до три решения на две висши съдилища – две на Конституционния и едно на Върховния касационен съд, които юридически бетонираха целия нонсенс. От това пострадаха не само преживелите домашно насилие и ЛГБТ+ хората, а и неправителственият сектор и академичните изследователи, работещи в до този момент безобидна област, която внезапно беше превърната в скандална и незаконна.
Работата е там, че активните мероприятия трудно могат да бъдат оборени с разумни аргументи, защото действат на друго равнище. Те успяват именно защото често хората отказват да мислят критично. Хората не са машини, а емоционални същества. И когато с професионална прецизност се въздейства върху емоциите им – всява се страх, насажда се омраза, предизвиква се гняв и т.н., – те стават податливи на манипулации. Колкото и да се смятаме за рационални и критично мислещи, вероятно на всеки от нас му се е случвало поне веднъж да се „върже“ на активно мероприятие.
Последствията от затварянето на очите
Не всички общества са еднакво податливи на активни мероприятия. Те намират по-благодатна почва там, където не срещат достатъчно съпротива от медии, политици и други публични личности. В България е практика политическите партии и публичните личности да не се противопоставят решително на активните мероприятия, за да не загубят популярност.
Трудно можем да се сетим не само за партия, а дори за политик (изключенията са единични), който да призовава за по-скорошно влизане на Македония в ЕС например, защото темата е превърната в масова истерия и не им се „бута между шамарите“. ПП–ДБ чакаха до последния възможен момент, преди да проявят решителност и да кажат, че въглищните централи все някога трябва да бъдат затворени. А за колко публични личности се сещате, които открито заявяват позициите си и се противопоставят на пропагандата?
Също толкова сериозен проблем е безкритичността на голяма част от медиите, особено на най-популярните от тях – националните телевизии. Ретранслирането на опорните точки на силните на деня без контекст, без проверка на фактите, без въпроси не е журналистика. Нито „отразяването“ на една и съща новина от максимален брой репортери, без нито един от тях да се опитва да разбере и покаже нещо повече от това, което официално му се казва. Още по-малко пък демонстративният отказ да се разберат елементарни неща, ако те противоречат на актуалната популистка реторика. Така например вече 15 години преди всеки „София прайд“ активисти трябва да отговарят в едни и същи телевизионни студиа на водещи, които казват: „Не разбирам защо парадирате.“
Ето така, като няма кой да се противопоставя, активните мероприятия се множат и стават все по-безочливи.
Този път е по-различно
Активното мероприятие за отмяна на машинното гласуване обаче не успя напълно. Това, в което успя, беше непосредствената му цел – да не се гласува с машини поне на първия тур на местните избори. Провали се обаче в опита си да бъде убедена критична част от обществото, че софтуерът на машините действително е компрометиран и затова е по-добре изобщо да няма машинно гласуване.
Мероприятието се провали, защото беше твърде плоско скалъпено. Абсурдността на тиражираните обвинения станаха очевадни, а синхронът между ДАНС, 5 от 6-те парламентарно представени партии и ЦИК – подозрителен. Да, ние, хората, сме лесно манипулируеми, но като разберем, че ни правят на глупаци, не ни става приятно.
Този път приятна изненада станаха и мейнстрийм медиите, които влязоха в ролята си на четвърта власт. Водещите и репортерите задаваха точните въпроси и подлагаха опорните точки на съмнение. Изглежда, прагът на поносимост беше прехвърлен и при тях.
И така, вместо за пореден път да затъваме в познатото активномероприятийно блато, ефектът беше по-скоро на свеж въздух. И на събуждане. Колко ще продължи той, е друг въпрос.
Поуката
Вероятно сте чували известното стихотворение на германския богослов Мартин Нимьолер „Когато нацистите дойдоха за мен“. Активните мероприятия следват същия принцип – първите потърпевши са представителите на някоя дискриминирана група, после – на друга, после се минава към професионални съсловия и т.н. Без да забравяме и дишащите канцерогенен въздух, за да се угоди на нечии интереси, маскирани като национални. Докато накрая жертви станем всички.
Този път беше злоупотребено с правото ни на глас. Ако номерът беше минал и активните мероприятия продължаваха да се провеждат без никаква съпротива, рано или късно щеше да се стигне до отмяна на правото на демократични избори – под една или друга форма.
Единственият начин това да не стане е, ако използваме думите на Стивън Хокинг, да продължаваме да говорим. Нека си припомним изговорените с електронния му глас думи, станали част от песента „Keep Talking“ на Pink Floyd:
Милиони години човечеството е живяло точно като животните. После се е случило нещо, което е отприщило силата на въображението ни. Научили сме се да говорим […] и сме се научили да слушаме. Речта е позволила обмена на идеи, давайки възможност на човешките същества да работят заедно, за да изградят невъзможното. Най-великите постижения на човечеството са дошли заради говоренето, а неговите най-велики провали – от липсата на говорене. […] Всичко, от което имаме нужда, е да се уверим, че продължаваме да говорим.
Преди „Хага“ по-скоро не сте правил политически театър?
Не, поне не мога да се сетя, не съм си поставял въпроса за политически театър и какво представлява. Това е и чисто поколенчески въпрос. Израснах във време, в което говоренето за политика, в късния соц, беше безсмислено занимание.
Защо?
Тогава бяхме тийнейджъри и това е моментът, в който започваш да си задаваш малко по-конкретни въпроси: в какво живееш, в какъв тип общество и политическа среда? По онова време имаше няколко интересни движения, свързани най-вече с „Екогласност“, с дисидентската идея, и на тази възраст на човек му става интересно да се порови малко повече. Имах шанса да бъда част от поколение, което се оказа на площадката, когато една система сменяше друга, и ние бяхме абсолютно неподготвени, нямахме абсолютно никаква политическа култура. Населението масово нямаше такава. Имаше идеологеми, които не се поставяха под въпрос. Сблъскахме се с нов начин, по който трябваше да декодираме света и да се учим да бъдем свободни.
Това незнание даде ли повече свобода?
Свобода – трудно мога да кажа, имаше нюанси на свобода, имаше много повече слободия. Имаше и едно парадоксално отдръпване от всичко политическо, защото, когато моето поколение започна да работи, нещото, което можехме да предложим в момент на пълен разпад на системата, се оказа някакъв краен индивидуализъм, който тогава изглеждаше доста симпатичен. Говоря за първите ни работи. За самоосъзнаване и конструиране на политическа култура и политическо говорене отива много време, аз мисля, че все още се уча.
Как протече за Вас този период на учене от 90-те до днес?
Беше дълго пътуване, свързано и с това, че някъде от началото на века прекарвах повече време извън България. Съвпадна и с отварянето на границите, и със сблъсъка с друга култура и с друга политическа култура. Със сблъсъка с т.нар. свободен свят, който не познавахме, но проектирахме върху него, правехме пренос върху него на всичко, което ни липсваше в нашия си контекст. В нашите – по онова време – объркани и незрели мозъци всичко хубаво и адекватно се случваше отвъд желязната завеса, а всичко лошо и нефункциониращо ставаше у нас.
Този сблъсък със свободния свят – защото прекарах доста време в Англия, Германия, Белгия и Франция – също разтърси едни дълбоки устои и представи, които имах, за това кои сме ние, къде сме, за какво се борим и към какво се стремим.
Помня първото ми излизане, имах по-дълъг престой в Англия още като студент. Беше голям шок. Имах ясното чувство, че светът се е придвижил напред, а ние сме гледали в обратната посока и сме изпуснали всички тези процеси. Не съм сигурен, че мога да бъда представителна извадка, но ми се наложи да преразгледам основите на това що е политика и говорене за нея и дали имат въобще място в театъра.
Днес възможно ли е това наваксване, ако погледът е обърнат в по-човешка и морална посока?
Да, мисля, че нещата са свързани, мисля, че има по-различно ниво на осъзнатост. То е свързано и с факта, че имах възможност да прекарам време в истински граждански общества и да наблюдавам как те могат да моделират и модифицират политиката. Нещо, което в България беше трудно да си представя. От друга страна, при мен се връща със задна дата това, което бих могъл да определя като травматична опитност от соца, която тогава не съм можел нито да формулирам като такава, нито да обясня, но в чисто човешки план се е трупала някаква непоносимост към това време и към начина, по който системата третира човека. И днес, на стари години, мисля, че успях да намеря пресечни точки между тази стара травма и фрустрация, която нося в себе си, и едно по-различно самоосъзнаване в рамките на политическата ситуация днес.
Може ли да се каже, че хвърляте мост между израстването си по време на социализма и казването на истината от устата и въображението на дете, на тийнейджър, в лицето на тирана, както е в „Хага“?
Точно така, да, в този смисъл, предполагам, има и някакъв психоаналитичен момент, но не е нужно да навлизаме и в него. Иначе, ако махнем склонността ни към черногледство и оплакване, мисля, че България доста е еволюирала от 90-те, и намирам това за положително. Днешна България не е тази отпреди трийсетина години. Това е свързано най-вече с интегрирането ни в съюзи, изградени на други принципи, различни от принципите на соца – Европейския съюз, на първо място, и НАТО. Това е шок, разбира се, за голяма част от обществото, най-вече за по-възрастните. Но интеграцията поставя страната и обществото на друг път и задава други посоки. Въпросът вече е доколко обществото е готово за тези нови посоки, да участва в говоренето за тях и да се самоосъзнае като свободно общество в рамките на демократичния консенсус. И оттук насетне да поеме отговорност за собственото си развитие в този контекст.
В този ред на мисли според Вас към днешна дата България колонизирана, деколонизирана или държава в процес на деколонизация е?
Сложен въпрос. Имаше моменти, в които бяхме убедени, че България е свободна държава, за да осъзнаем, десетилетие или две по-късно, че всъщност е колония и винаги е била такава. Има моменти, в които си казваме, че деконструираме нещо и се изправяме пред огромна агентурна армия, която се занимава със запазването на хайката, със запазването на ретроградния тип мислене и позиции. Днес ние не сме по-различни от всичко, което се случва в света в момента. Имаме пълна фрагментираност на обществото и балони, в които се говори на определен език, но тези езици не комуникират помежду си. Няма вертикала, към която да се закачим и по която да се съизмерим, но тези процеси протичат и на световно ниво. България не прави изключение.
А театърът като колективно изкуство и жива среща, които създават пространство за различни версии, истини и перспективи за света, начин за интеграция на това общество ли е?
Да, това е много интересното, върху което експериментирам с „Хага“. Да открием виталната роля на театъра – отвъд буржоазната дефиниция, която той получава, отвъд това – не че в България говорим за него, – че така или иначе, няма изследване, което да покаже какъв тип публика ходи на театър – разбира се, една малка част от обществото. И когато намерим начин да провокираме дебат, изненада или шок през театрални средства и те успеят да докоснат по-дълбоко от повърхностната естетика или от доброто прекарване на вечерта в театъра, тогава вече играта започва да става интересна, защото театърът изведнъж показва страни или сили в себе си, надхвърлящи ролята, която сме му определили в общия пъзел.
Каква би била разликата между постановки на „Хага“ във Франция и в България?
Разликата е най-вече в това към кого се обръщаш, на кого говориш, каква е публиката. Това биха били две различни представления може би, не знам, защото хората, на които ще разказвам, са различни, с различен бекграунд и багаж, с различни контексти и история. Във Франция хората нямат особени съмнения кой кого е нападнал, оттам картинката е много ясна. Там хората не могат да разберат как може една държава да се докара до това положение и да извърши такъв акт на агресия. Те биха гледали това с желание да разберат, биха изследвали, биха гледали пътуването на детето през тази история, все едно са на сафари.
Като урок по човекознание, като антропология?
Да, точно така, докато в България заради идеята, че сме проксита на путинския режим, „Хага“ всъщност поставя зрителя в много по-дестабилизираща ситуация. Защото, освен че „Хага“ би разказала какво се случва в Украйна и какво се случва в Руската федерация, тя би разказвала и неща, които дебатират нашата идентичност като българи, като нация, като история и като митологеми, които сами сме изградили и сме пуснали в собствената си градина и които в един момент започват да ни моделират и управляват вместо ние тях.
Разказвачът в „Хага“ е дете, тийнейджър може би, но е и нещо повече, нали?
Да, разказвачът е събирателен образ на много деца, с които авторката се е срещала или е говорила, или е правила проучвания за историите им. Има нещо, което е хубаво да се знае и не съм казвал досега. Има момент в представлението, когато детето запява украинския химн. Някои от зрителите възприемат това като акт на чиста пропаганда, без да знаят, че зад тази сцена стои конкретна история. Разказ на едно от децата, които са били откарани на територията на Руската федерация за осиновяване. Та това дете, според разказа му, е претърпяло огромен тормоз, психически най-вече, и то споделя, че единствените моменти, в които е можело да се задържи в кондиция и без да се разпадне психически, са били, когато са го заключвали в тъмна стая, наказвали са го, защото отказва да говори на руски, и то тихо е пяло химна на Украйна. Тази сцена, както и повечето други, има скрита история, има реален аватар в действителността.
Как бихте разказал за какво става въпрос в „Хага“, на български или руски тийнейджър, или на дете?
Бих казал, че това е история за порастването, за превръщането на детето във възрастен, което при нормални условия се случва за няколко десетилетия, а в условия на война – в рамките на дни, понякога и на часове. Порастването е болезнен процес. Така както детето страда, за да стане възрастен, да научи достатъчно и да има опит, така и човешкото същество страда, за да може да се изкачи на някакво по-високо ниво на развитие. Това би било приказка за порастването, в която всички елементи, като понятията за добро и зло, са разместени и объркани до такава степен, че няма кой да ги преподреди и върне на местата им, освен най-слабия и най-чистия. Това е един от основните митове на човечеството. Популярен пример, за който сега се сещам, е „Властелинът на пръстените“. Там Фродо е натоварен с най-непосилната задача, която не може да бъде изпълнена от никого от по-зрелите и по-магични същества, защото те знаят, че ще се провалят в тази мисия. Те няма да могат да устоят на изкушението. Единственият, който може, е най-наивният, най-непредубеденият. Във „Властелинът“ това е Фродо, в „Хага“ това е детето.
Бихте ли правил отново политически театър в България?
Имам доста класическо театрално образование и изборите при мен са свързани и тръгват най-вече от срещата ми с текст или тема, която да ме вълнува и да влиза в резонанс с днешния ден и с това, което преживяваме на социално и интимно ниво.
Има текстове като „Образ и подобие“ на Радичков или „Персифедрон“ на Константин Павлов, но сякаш политическият театър и драматургия в България все още остават периферни?
Да, ние нямаме почти никаква традиция в това. Има такива светли примери, но те се броят на пръсти. Продължавам да мисля, че „Образ и подобие“ е великолепен текст и идея за проект; в главата ми тя беше свързана дълго време със ситуацията на дванайсетгодишното управление на ГЕРБ, примерно. Сега нещата малко се промениха, но Радичков е автор великан и дори когато пише политическа сатира, той успява да я пласира в едни метафизически пластове на съзнанието. Затова мисля, че и днес този текст би бил изключително силен, ако бъде насочен да говори за нашата дълбока идентичност и за кризата ѝ. След падането на Берлинската стена обществото ни продължава да търси своята идентичност и в него има отделни фракции, които си я представят по много различен начин. Тази фрагментация днес е изключително силно изявена, конфликтите са крайно изострени и на ментално ниво нашето общество е в състояние на война, макар че все още нямаме сили да си го признаем. А в състояние на война правилата се променят.
Как тогава може да съществува мир в България?
Не знам дали мога да отговоря, но мирът винаги е бил нещо, към което всички се стремят. Само че периодът, през който ние като общество преминаваме и който човечеството също прекосява днес, е период на огромни размествания, срутвания на някои устойчиви пластове и всъщност е момент на криза, която неминуемо ще ни задължи да преразгледаме основните си постулати за това как да се ориентираме и какво бъдеще искаме да имаме.
В политически план цялата световна система за сигурност също ще бъде преразгледана. Ние сме на прага на огромни промени и въпросът е дали в колективния облак и в колективното съзнание желанието за катастрофа е по-голямо от желанието за мир. В момента имам чувството, че желанието за катастрофа е по-голямо, а ако това е така, то катастрофа ще има. Не мога да предвидя под каква форма, но единствената надежда в случая е, че катастрофата е нещо, през което трябва да се премине. Тя е един вид месомелачка, стъргало, и тези, които успеят да преминат през нея и да запазят човешката си същност, ще трябва да се борят с ясно очертаващи се фракции в световен мащаб, работещи за пълно обезчовечаване, и техните проксита и в българския социален живот… Тук вече въпросът е дали ще излезем от този период абсолютно обезчовечени, или ще сме разбрали базисни неща и ще градим някаква обща визия за бъдеще.
Да разбираме, че Вие сте – по някакъв начин – стоически обнадежден?
Да, нямам и друг избор. Другото е да се хвърля в античен трагически плач, но такъв вече има достатъчно и няма защо да се прибавя към него. Мисля, че имаме остра нужда от яснота и проницателност, които да ни позволят да провидим бъдеще и надежда.
И от честност и искреност може би?
Това е задължително условие, но то влиза в рамките на личния живот на всеки един индивид и в този смисъл всеки, рано или късно, ще бъде поставен пред избор. И ще трябва да се определи, защото в състояние на война двете страни трябва да прегледат армиите и силите си.
“Why does ACPI exist” – – the greatest thread in the history of forums, locked by a moderator after 12,239 pages of heated debate, wait no let me start again.
Why does ACPI exist? In the beforetimes power management on x86 was done by jumping to an opaque BIOS entry point and hoping it would do the right thing. It frequently didn’t. We called this Advanced Power Management (Advanced because before this power management involved custom drivers for every machine and everyone agreed that this was a bad idea), and it involved the firmware having to save and restore the state of every piece of hardware in the system. This meant that assumptions about hardware configuration were baked into the firmware – failed to program your graphics card exactly the way the BIOS expected? Hurrah! It’s only saved and restored a subset of the state that you configured and now potential data corruption for you. The developers of ACPI made the reasonable decision that, well, maybe since the OS was the one setting state in the first place, the OS should restore it.
So far so good. But some state is fundamentally device specific, at a level that the OS generally ignores. How should this state be managed? One way to do that would be to have the OS know about the device specific details. Unfortunately that means you can’t ship the computer without having OS support for it, which means having OS support for every device (exactly what we’d got away from with APM). This, uh, was not an option the PC industry seriously considered. The alternative is that you ship something that abstracts the details of the specific hardware and makes that abstraction available to the OS. This is what ACPI does, and it’s also what things like Device Tree do. Both provide static information about how the platform is configured, which can then be consumed by the OS and avoid needing device-specific drivers or configuration to be built-in.
The main distinction between Device Tree and ACPI is that Device Tree is purely a description of the hardware that exists, and so still requires the OS to know what’s possible – if you add a new type of power controller, for instance, you need to add a driver for that to the OS before you can express that via Device Tree. ACPI decided to include an interpreted language to allow vendors to expose functionality to the OS without the OS needing to know about the underlying hardware. So, for instance, ACPI allows you to associate a device with a function to power down that device. That function may, when executed, trigger a bunch of register accesses to a piece of hardware otherwise not exposed to the OS, and that hardware may then cut the power rail to the device to power it down entirely. And that can be done without the OS having to know anything about the control hardware.
How is this better than just calling into the firmware to do it? Because the fact that ACPI declares that it’s going to access these registers means the OS can figure out that it shouldn’t, because it might otherwise collide with what the firmware is doing. With APM we had no visibility into that – if the OS tried to touch the hardware at the same time APM did, boom, almost impossible to debug failures (This is why various hardware monitoring drivers refuse to load by default on Linux – the firmware declares that it’s going to touch those registers itself, so Linux decides not to in order to avoid race conditions and potential hardware damage. In many cases the firmware offers a collaborative interface to obtain the same data, and a driver can be written to get that. this bug comment discusses this for a specific board)
Unfortunately ACPI doesn’t entirely remove opaque firmware from the equation – ACPI methods can still trigger System Management Mode, which is basically a fancy way to say “Your computer stops running your OS, does something else for a while, and you have no idea what”. This has all the same issues that APM did, in that if the hardware isn’t in exactly the state the firmware expects, bad things can happen. While historically there were a bunch of ACPI-related issues because the spec didn’t define every single possible scenario and also there was no conformance suite (eg, should the interpreter be multi-threaded? Not defined by spec, but influences whether a specific implementation will work or not!), these days overall compatibility is pretty solid and the vast majority of systems work just fine – but we do still have some issues that are largely associated with System Management Mode.
One example is a recent Lenovo one, where the firmware appears to try to poke the NVME drive on resume. There’s some indication that this is intended to deal with transparently unlocking self-encrypting drives on resume, but it seems to do so without taking IOMMU configuration into account and so things explode. It’s kind of understandable why a vendor would implement something like this, but it’s also kind of understandable that doing so without OS cooperation may end badly.
This isn’t something that ACPI enabled – in the absence of ACPI firmware vendors would just be doing this unilaterally with even less OS involvement and we’d probably have even more of these issues. Ideally we’d “simply” have hardware that didn’t support transitioning back to opaque code, but we don’t (ARM has basically the same issue with TrustZone). In the absence of the ideal world, by and large ACPI has been a net improvement in Linux compatibility on x86 systems. It certainly didn’t remove the “Everything is Windows” mentality that many vendors have, but it meant we largely only needed to ensure that Linux behaved the same way as Windows in a finite number of ways (ie, the behaviour of the ACPI interpreter) rather than in every single hardware driver, and so the chances that a new machine will work out of the box are much greater than they were in the pre-ACPI period.
There’s an alternative universe where we decided to teach the kernel about every piece of hardware it should run on. Fortunately (or, well, unfortunately) we’ve seen that in the ARM world. Most device-specific simply never reaches mainline, and most users are stuck running ancient kernels as a result. Imagine every x86 device vendor shipping their own kernel optimised for their hardware, and now imagine how well that works out given the quality of their firmware. Does that really seem better to you?
It’s understandable why ACPI has a poor reputation. But it’s also hard to figure out what would work better in the real world. We could have built something similar on top of Open Firmware instead but the distinction wouldn’t be terribly meaningful – we’d just have Forth instead of the ACPI bytecode language. Longing for a non-ACPI world without presenting something that’s better and actually stands a reasonable chance of adoption doesn’t make the world a better place.
Recent advancements in machine learning (ML) have unlocked opportunities for customers across organizations of all sizes and industries to reinvent new products and transform their businesses. However, the growth in demand for GPU capacity to train, fine-tune, experiment, and inference these ML models has outpaced industry-wide supply, making GPUs a scarce resource. Access to GPU capacity is an obstacle for customers whose capacity needs fluctuate depending on the research and development phase they’re in.
Today, we are announcing Amazon Elastic Compute Cloud (Amazon EC2)Capacity Blocks for ML, a new Amazon EC2 usage model that further democratizes ML by making it easy to access GPU instances to train and deploy ML and generative AI models. With EC2 Capacity Blocks, you can reserve hundreds of GPUs collocated in EC2 UltraClusters designed for high-performance ML workloads, using Elastic Fabric Adapter (EFA) networking in a peta-bit scale non-blocking network, to deliver the best network performance available in Amazon EC2.
This is an innovative new way to schedule GPU instances where you can reserve the number of instances you need for a future date for just the amount of time you require. EC2 Capacity Blocks are currently available for Amazon EC2 P5 instances powered by NVIDIA H100 Tensor Core GPUs in the AWS US East (Ohio) Region. With EC2 Capacity Blocks, you can reserve GPU instances in just a few clicks and plan your ML development with confidence. EC2 Capacity Blocks make it easy for anyone to predictably access EC2 P5 instances that offer the highest performance in EC2 for ML training.
EC2 Capacity Block reservations work similarly to hotel room reservations. With a hotel reservation, you specify the date and duration you want your room for and the size of beds you’d like─a queen bed or king bed, for example. Likewise, with EC2 Capacity Block reservations, you select the date and duration you require GPU instances and the size of the reservation (the number of instances). On your reservation start date, you’ll be able to access your reserved EC2 Capacity Block and launch your P5 instances. At the end of the EC2 Capacity Block duration, any instances still running will be terminated.
You can use EC2 Capacity Blocks when you need capacity assurance to train or fine-tune ML models, run experiments, or plan for future surges in demand for ML applications. Alternatively, you can continue using On-Demand Capacity Reservations for all other workload types that require compute capacity assurance, such as business-critical applications, regulatory requirements, or disaster recovery.
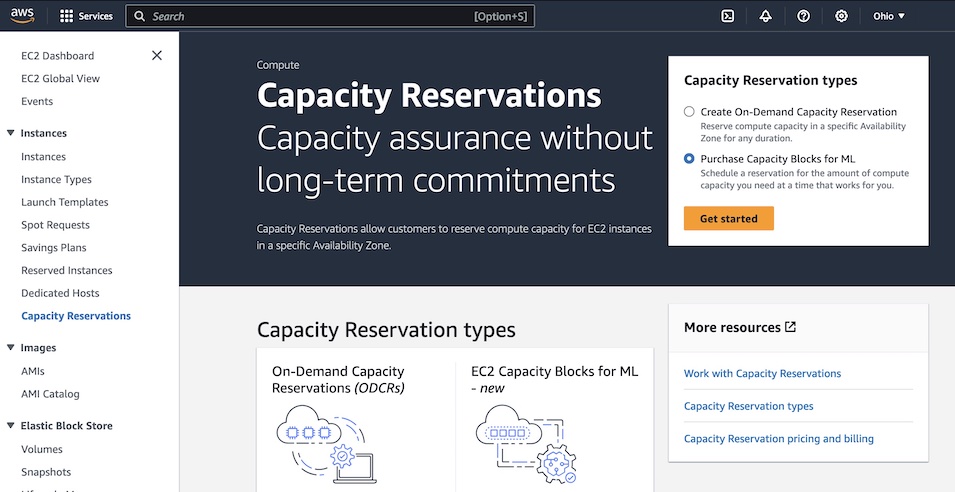
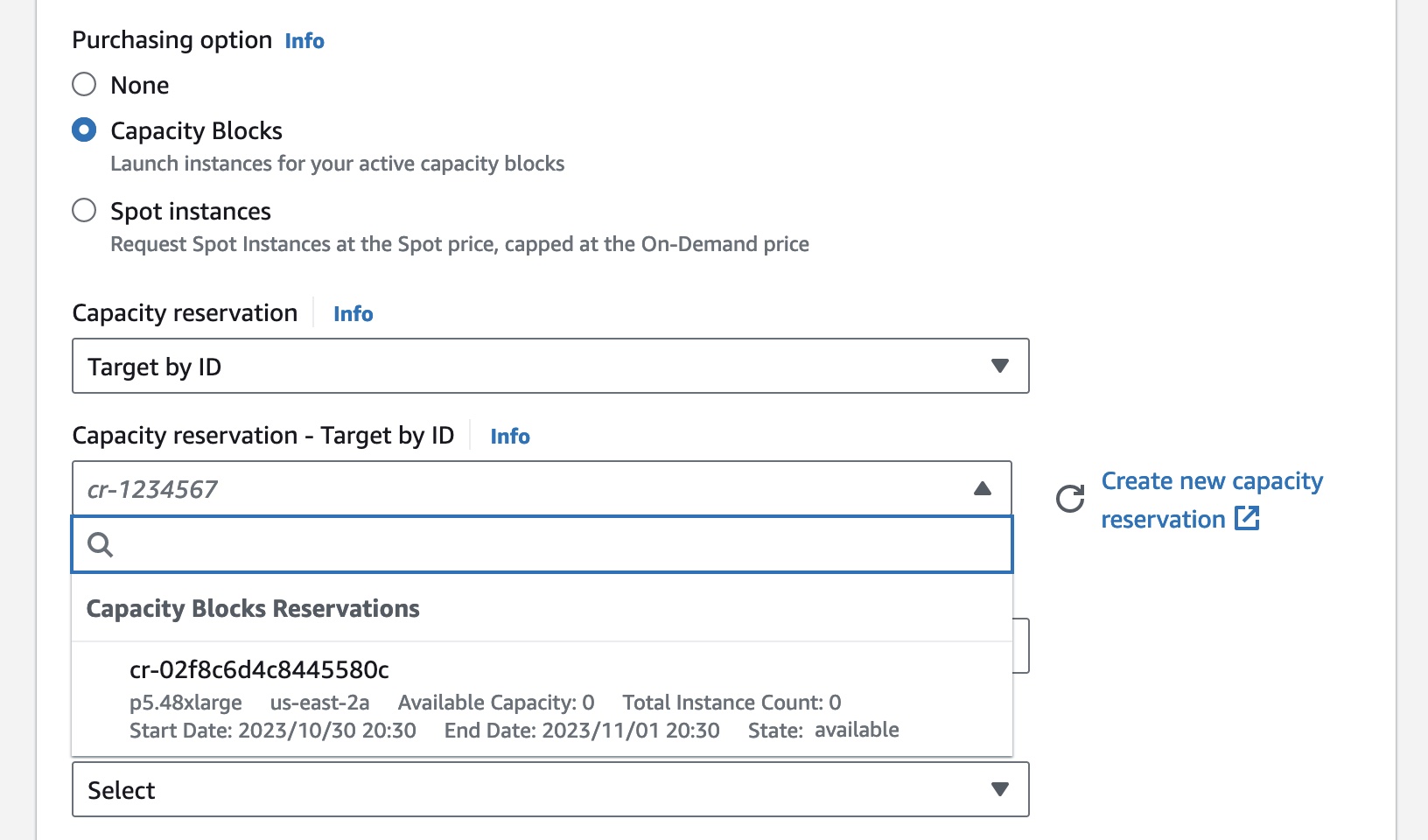
Getting started with Amazon EC2 Capacity Blocks for ML To reserve your Capacity Blocks, choose Capacity Reservations on the Amazon EC2 console in the US East (Ohio) Region. You can see two capacity reservation options. Select Purchase Capacity Blocks for ML and then Get started to start looking for an EC2 Capacity Block.
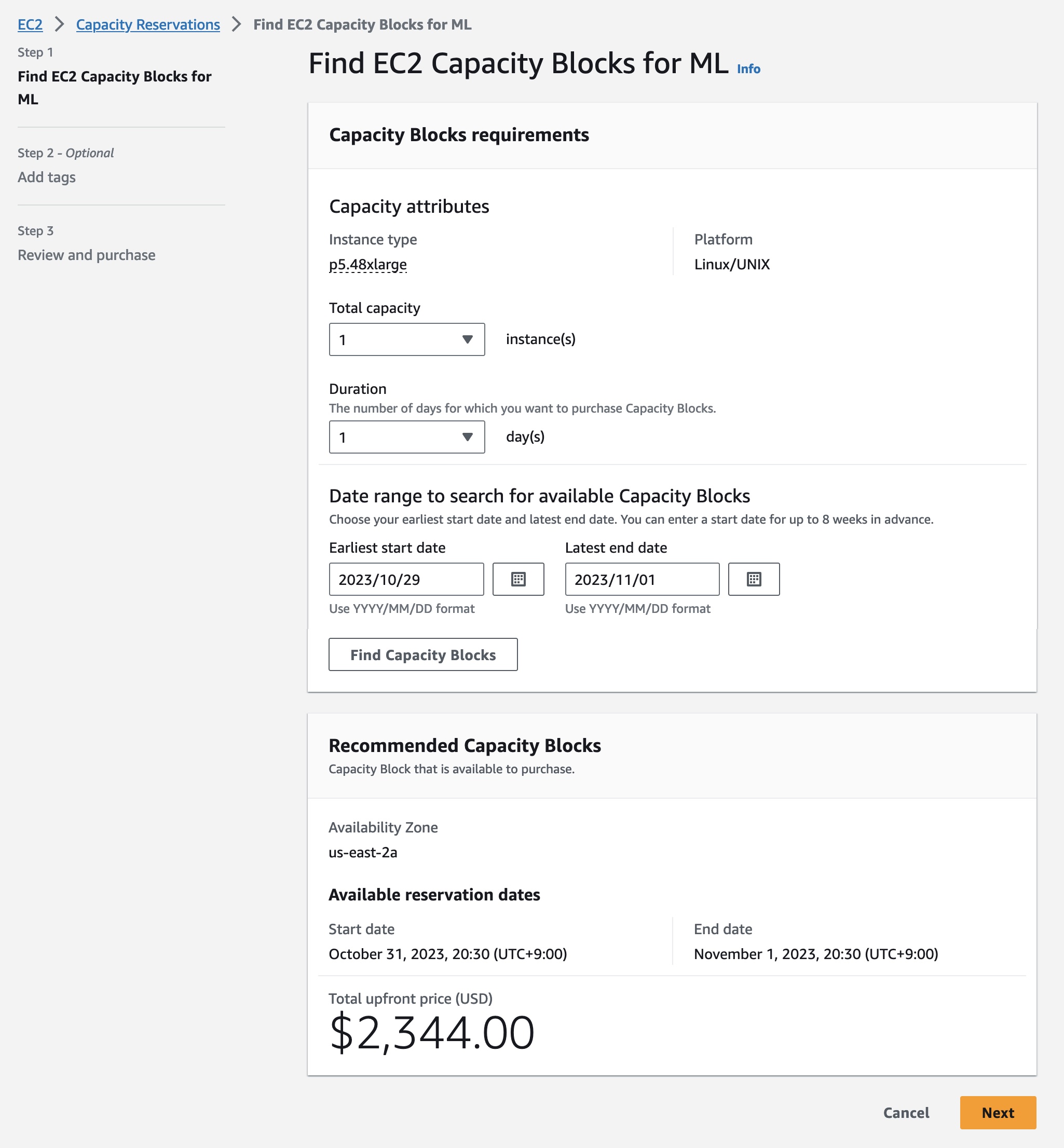
Choose your total capacity and specify how long you need the EC2 Capacity Block. You can reserve an EC2 Capacity Block in the following sizes: 1, 2, 4, 8, 16, 32, or 64 p5.48xlarge instances. The total number of days that you can reserve EC2 Capacity Blocks is 1– 14 days in 1-day increments. EC2 Capacity Blocks can be purchased up to 8 weeks in advance.
EC2 Capacity Block prices are dynamic and depend on total available supply and demand at the time you purchase the EC2 Capacity Block. You can adjust the size, duration, or date range in your specifications to search for other EC2 Capacity Block options. When you select Find Capacity Blocks, AWS returns the lowest-priced offering available that meets your specifications in the date range you have specified. At this point, you will be shown the price for the EC2 Capacity Block.
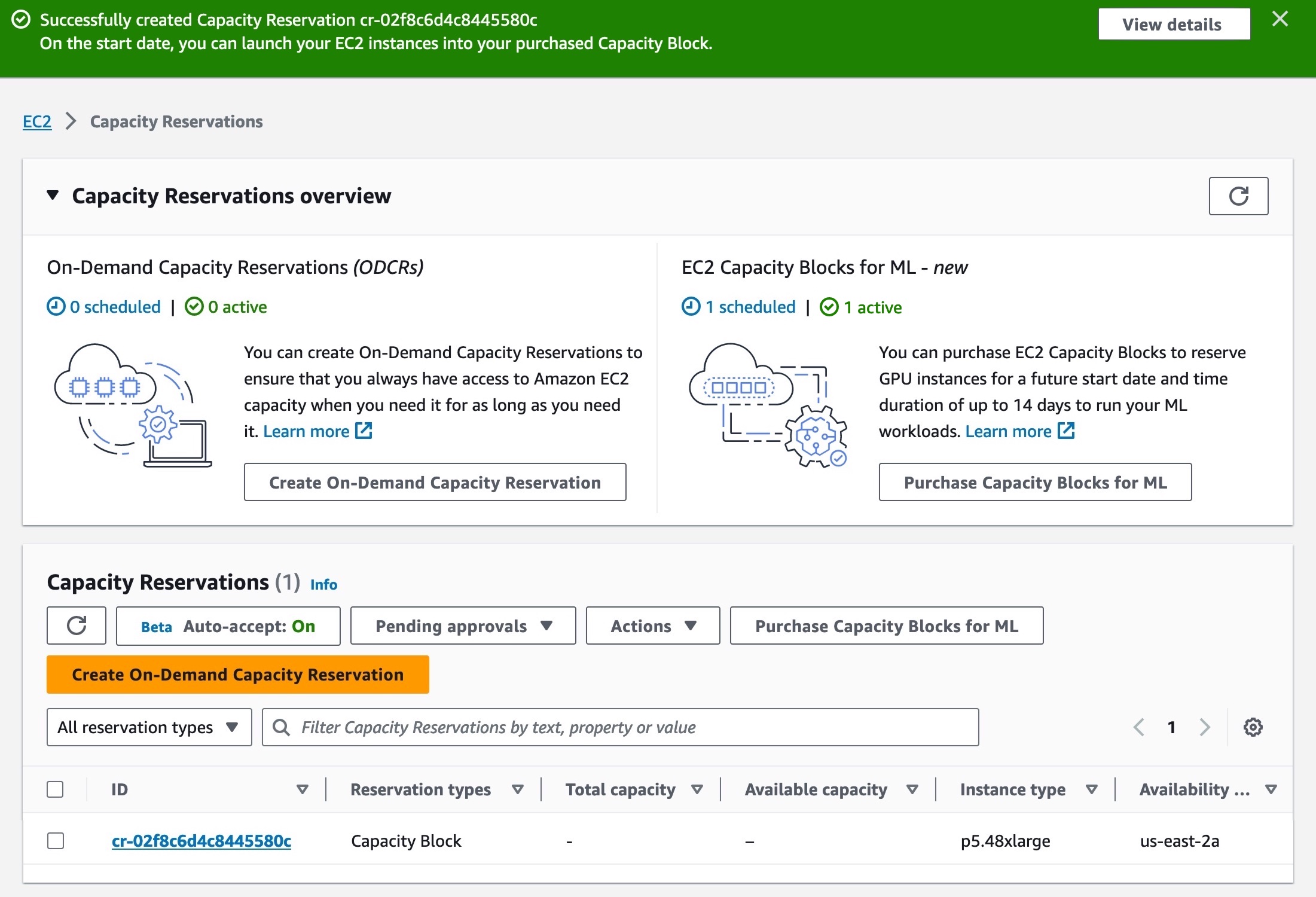
After reviewing EC2 Capacity Blocks details, tags, and total price information, choose Purchase. The total price of an EC2 Capacity Block is charged up front, and the price does not change after purchase. The payment will be billed to your account within 12 hours after you purchase the EC2 Capacity Blocks.
All EC2 Capacity Blocks reservations start at 11:30 AM Coordinated Universal Time (UTC). EC2 Capacity Blocks can’t be modified or canceled after purchase.
You can also use AWS Command Line Interface (AWS CLI) and AWS SDKs to purchase EC2 Capacity Blocks. Use the describe-capacity-block-offerings API to provide your cluster requirements and discover an available EC2 Capacity Block for purchase.
After you find an available EC2 Capacity Block with the CapacityBlockOfferingId and capacity information from the preceding command, you can use purchase-capacity-block-reservation API to purchase it.
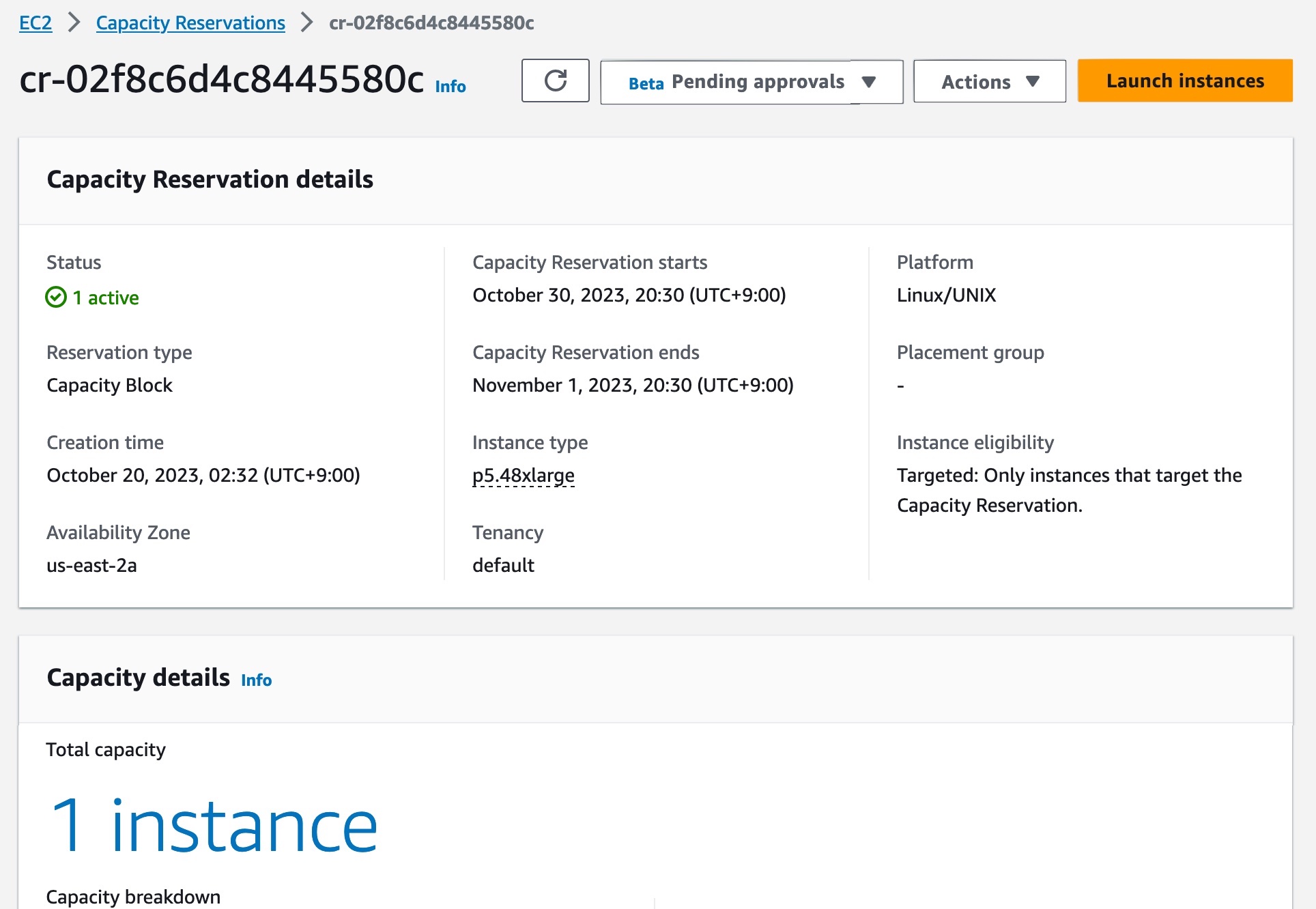
Your EC2 Capacity Block has now been scheduled successfully. On the scheduled start date, your EC2 Capacity Block will become active. To use an active EC2 Capacity Block on your starting date, choose the capacity reservation ID for your EC2 Capacity Block. You can see a breakdown of the reserved instance capacity, which shows how the capacity is currently being utilized in the Capacity details section.
To launch instances into your active EC2 Capacity Block, choose Launch instances and follow the normal process of launching EC2 instances and running your ML workloads.
In the Advanced details section, choose Capacity Blocks as the purchase option and select the capacity reservation ID of the EC2 Capacity Block you’re trying to target.
As your EC2 Capacity Block end time approaches, Amazon EC2 will emit an event through Amazon EventBridge, letting you know your reservation is ending soon so you can checkpoint your workload. Any instances running in the EC2 Capacity Block go into a shutting-down state 30 minutes before your reservation ends. The amount you were charged for your EC2 Capacity Block does not include this time period. When your EC2 Capacity Block expires, any instances still running will be terminated.
Now available Amazon EC2 Capacity Blocks are now available for p5.48xlarge instances in the AWS US East (Ohio) Region. You can view the price of an EC2 Capacity Block before you reserve it, and the total price of an EC2 Capacity Block is charged up-front at the time of purchase. For more information, see the EC2 Capacity Blocks pricing page.
Във връзка с твърденията, че заедно с Кирил Петков съм притискал или заплашвал министъра на електронното управление за поръчки, искам да кажа няколко неща:
1. Това са абсолютни лъжи. Никога не е имало такъв разговор – нито сме обсъждали поръчки, нито е имало заплахи за каквото и да било.
2. Ще съдействам максимално на компетентните органи за установяване на истината.
3. Нямам никаква представа каква е причината за такива твърдения. Надявам се всичко това да е нелепо недоразумение, а не част от политически сценарий.
4. 640 милиона са много пари, които няма как да се изхарчат за краткия хоризонт на правителството. Министерството, а по-рано държавната агенция, за цялото си съществуване от 2016 г. досега са похарчили общо около 135 милиона (по данни от СЕБРА).
5. Министерството не може да не прилага Закона за обществените поръчки, с изключение на ограничени случаи, в които възлага на Информационно обслужване, което е държавно. (Преразказът на разговора включва обвинение, че натискът е бил за това парите да се харчат без обществени поръчки)
Приел съм, че ще бъда обект на абсурдни политически атаки. Те са очаквани в предизборна обстановка и са част от калния терен, на който се намираме, докато опитваме да променим България.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.







 Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse.
Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse.





 Сега когато предизборната кампнаия премина и вотът на Хората от Община Родопи беше повече от ясен е време да се отърсим от предизборното говорене и да започнем да мислим трезво.
Сега когато предизборната кампнаия премина и вотът на Хората от Община Родопи беше повече от ясен е време да се отърсим от предизборното говорене и да започнем да мислим трезво.











 the black hole in V404 Cygni passes over you each day. On Christmas Day it will be directly overhead around 2pm.")