Post Syndicated from Veronica Cucuiat original https://www.raspberrypi.org/blog/explaining-ai-terms-young-people-educators/
What do we talk about when we talk about artificial intelligence (AI)? It’s becoming a cliche to point out that, because the term “AI” is used to describe so many different things nowadays, it’s difficult to know straight away what anyone means when they say “AI”. However, it’s true that without a shared understanding of what AI and related terms mean, we can’t talk about them, or educate young people about the field.

So when we started designing materials for the Experience AI learning programme in partnership with leading AI unit Google DeepMind, we decided to create short explanations of key AI and machine learning (ML) terms. The explanations are doubly useful:
- They ensure that we give learners and teachers a consistent and clear understanding of the key terms across all our Experience AI resources. Within the Experience AI Lessons for Key Stage 3 (age 11–14), these key terms are also correlated to the target concepts and learning objectives presented in the learning graph.
- They help us talk about AI and AI education in our team. Thanks to sharing an understanding of what terms such as “AI”, “ML”, “model”, or “training” actually mean and how to best talk about AI, our conversations are much more productive.
As an example, here is our explanation of the term “artificial intelligence” for learners aged 11–14:
Artificial intelligence (AI) is the design and study of systems that appear to mimic intelligent behaviour. Some AI applications are based on rules. More often now, AI applications are built using machine learning that is said to ‘learn’ from examples in the form of data. For example, some AI applications are built to answer questions or help diagnose illnesses. Other AI applications could be built for harmful purposes, such as spreading fake news. AI applications do not think. AI applications are built to carry out tasks in a way that appears to be intelligent.
You can find 32 explanations in the glossary that is part of the Experience AI Lessons. Here’s an insight into how we arrived at the explanations.
Reliable sources
In order to ensure the explanations are as precise as possible, we first identified reliable sources. These included among many others:
- The Oxford English Dictionary
- Google’s Machine Learning Glossary
- The Alan Turing Institute’s data science and AI glossary
- Well-recognised AI courses, such as Andrew Ng’s AI for Everyone
- Articles included in the AITopics publication of the AAAI
Explaining AI terms to Key Stage 3 learners: Some principles
Vocabulary is an important part of teaching and learning. When we use vocabulary correctly, we can support learners to develop their understanding. If we use it inconsistently, this can lead to alternate conceptions (misconceptions) that can interfere with learners’ understanding. You can read more about this in our Pedagogy Quick Read on alternate conceptions.
Some of our principles for writing explanations of AI terms were that the explanations need to:
- Be accurate
- Be grounded in education research best practice
- Be suitable for our target audience (Key Stage 3 learners, i.e. 11- to 14-year-olds)
- Be free of terms that have alternative meanings in computer science, such as “algorithm”
We engaged in an iterative process of writing explanations, gathering feedback from our team and our Experience AI project partners at Google DeepMind, and adapting the explanations. Then we went through the feedback and adaptation cycle until we all agreed that the explanations met our principles.

An important part of what emerged as a result, aside from the explanations of AI terms themselves, was a blueprint for how not to talk about AI. One aspect of this is avoiding anthropomorphism, detailed by Ben Garside from our team here.
As part of designing the the Experience AI Lessons, creating the explanations helped us to:
- Decide which technical details we needed to include when introducing AI concepts in the lessons
- Figure out how to best present these technical details
- Settle debates about where it would be appropriate, given our understanding and our learners’ age group, to abstract or leave out details
Using education research to explain AI terms
One of the ways education research informed the explanations was that we used semantic waves to structure each term’s explanation in three parts:
- Top of the wave: The first one or two sentences are a high-level abstract explanation of the term, kept as short as possible, while introducing key words and concepts.
- Bottom of the wave: The middle part of the explanation unpacks the meaning of the term using a common example, in a context that’s familiar to a young audience.
- Top of the wave: The final one or two sentences repack what was explained in the example in a more abstract way again to reconnect with the term. The end part should be a repeat of the top of the wave at the beginning of the explanation. It should also add further information to lead to another concept.
Most explanations also contain ‘middle of the wave’ sentences, which add additional abstract content, bridging the ‘bottom of the wave’ concrete example to the ‘top of the wave’ abstract content.
Here’s the “artificial intelligence” explanation broken up into the parts of the semantic wave:
- Artificial intelligence (AI) is the design and study of systems that appear to mimic intelligent behaviour. (top of the wave)
- Some AI applications are based on rules. More often now, AI applications are built using machine learning that is said to ‘learn’ from examples in the form of data. (middle of the wave)
- For example, some AI applications are built to answer questions or help diagnose illnesses. Other AI applications could be built for harmful purposes, such as spreading fake news (bottom of the wave)
- AI applications do not think. (middle of the wave)
- AI applications are built to carry out tasks in a way that appears to be intelligent. (top of the wave)

Was it worth our time?
Some of the explanations went through 10 or more iterations before we agreed they were suitable for publication. After months of thinking about, writing, correcting, discussing, and justifying the explanations, it’s tempting to wonder whether I should have just prompted an AI chatbot to generate the explanations for me.

I tested this idea by getting a chatbot to generate an explanation of “artificial intelligence” using the prompt “Explain what artificial intelligence is, using vocabulary suitable for KS3 students, avoiding anthropomorphism”. The result included quite a few inconsistencies with our principles, as well as a couple of technical inaccuracies. Perhaps I could have tweaked the prompt for the chatbot in order to get a better result. However, relying on a chatbot’s output would mean missing out on some of the value of doing the work of writing the explanations in collaboration with my team and our partners.
The visible result of that work is the explanations themselves. The invisible result is the knowledge we all gained, and the coherence we reached as a team, both of which enabled us to create high-quality resources for Experience AI. We wouldn’t have gotten to know what resources we wanted to write without writing the explanations ourselves and improving them over and over. So yes, it was worth our time.
What do you think about the explanations?
The process of creating and iterating the AI explanations highlights how opaque the field of AI still is, and how little we yet know about how best to teach and learn about it. At the Raspberry Pi Foundation, we now know just a bit more about that and are excited to share the results with teachers and young people.
You can access the Experience AI Lessons and the glossary with all our explanations at experience-ai.org. The glossary of AI explanations is just in its first published version: we will continue to improve it as we find out more about how to best support young people to learn about this field.
Let us know what you think about the explanations and whether they’re useful in your teaching. Onwards with the exciting work of establishing how to successfully engage young people in learning about and creating with AI technologies.
The post How we’re learning to explain AI terms for young people and educators appeared first on Raspberry Pi Foundation.








 Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product.
Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product. Raji Sivasubramaniam is a Sr. Solutions Architect at AWS, focusing on Analytics. Raji is specialized in architecting end-to-end Enterprise Data Management, Business Intelligence and Analytics solutions for Fortune 500 and Fortune 100 companies across the globe. She has in-depth experience in integrated healthcare data and analytics with wide variety of healthcare datasets including managed market, physician targeting and patient analytics.
Raji Sivasubramaniam is a Sr. Solutions Architect at AWS, focusing on Analytics. Raji is specialized in architecting end-to-end Enterprise Data Management, Business Intelligence and Analytics solutions for Fortune 500 and Fortune 100 companies across the globe. She has in-depth experience in integrated healthcare data and analytics with wide variety of healthcare datasets including managed market, physician targeting and patient analytics. Srikanth Baheti is a Specialized World Wide Principal Solution Architect for Amazon QuickSight. He started his career as a consultant and worked for multiple private and government organizations. Later he worked for PerkinElmer Health and Sciences & eResearch Technology Inc, where he was responsible for designing and developing high traffic web applications, highly scalable and maintainable data pipelines for reporting platforms using AWS services and Serverless computing.
Srikanth Baheti is a Specialized World Wide Principal Solution Architect for Amazon QuickSight. He started his career as a consultant and worked for multiple private and government organizations. Later he worked for PerkinElmer Health and Sciences & eResearch Technology Inc, where he was responsible for designing and developing high traffic web applications, highly scalable and maintainable data pipelines for reporting platforms using AWS services and Serverless computing.





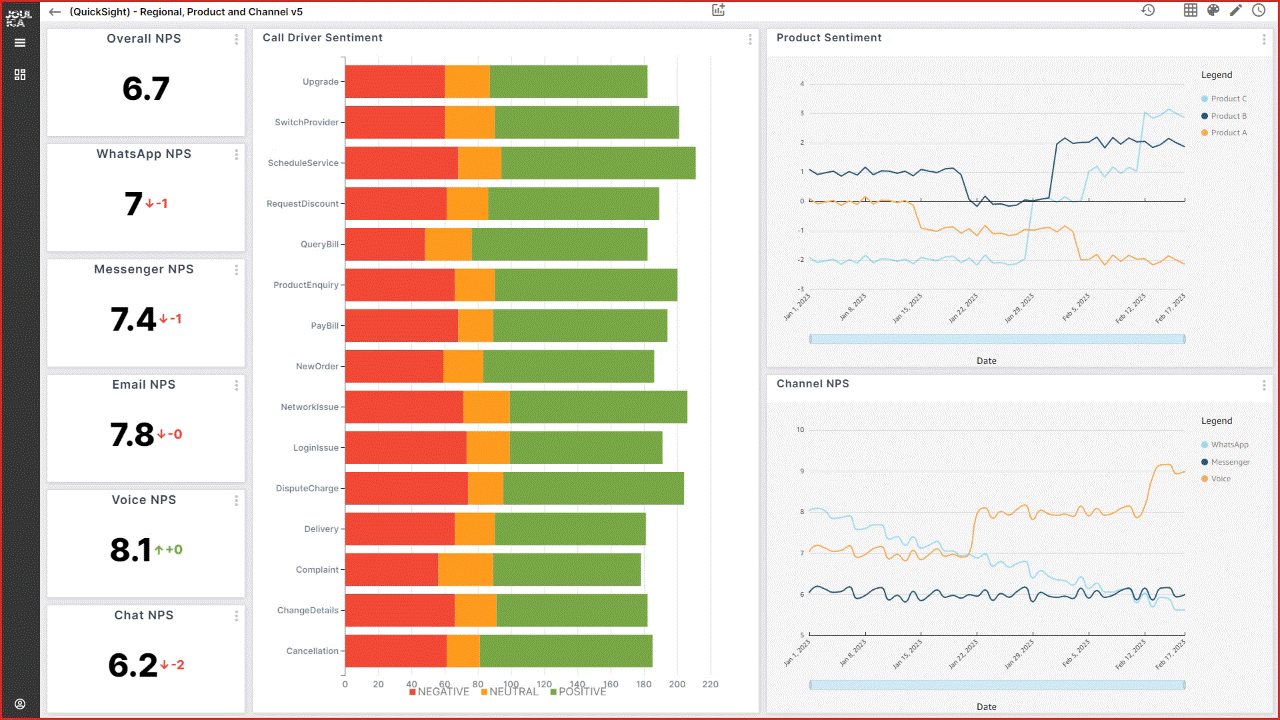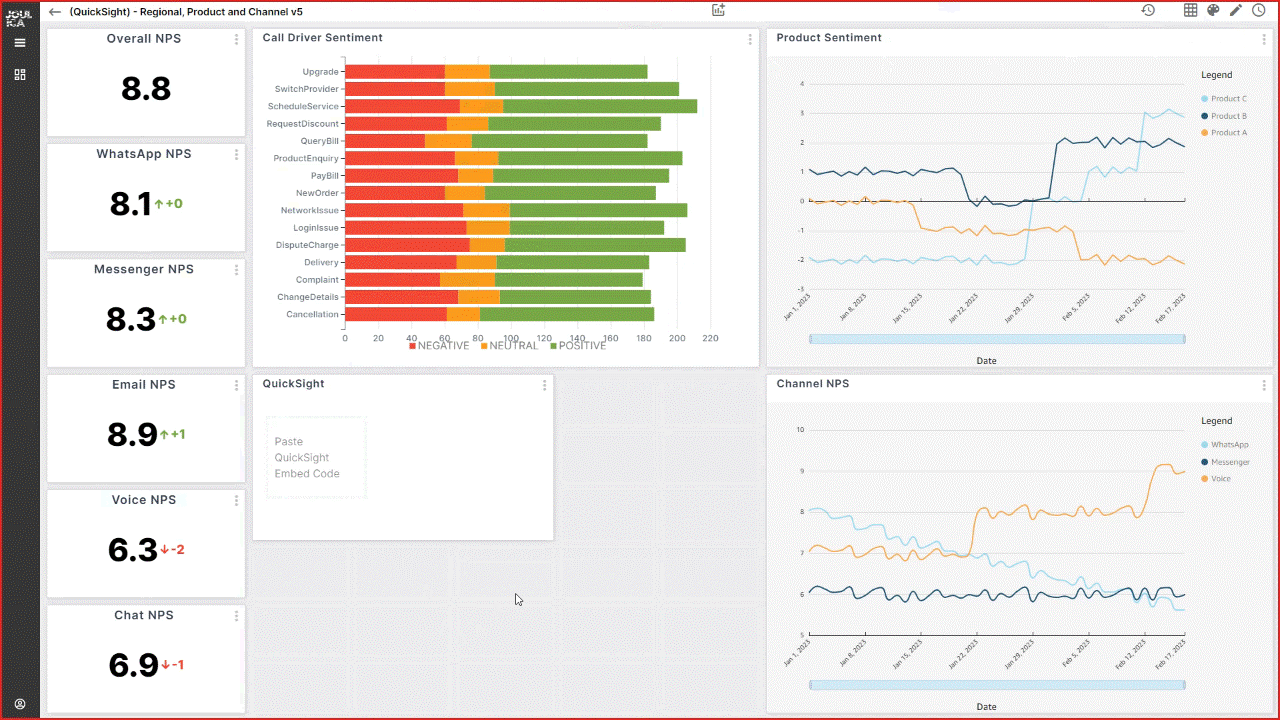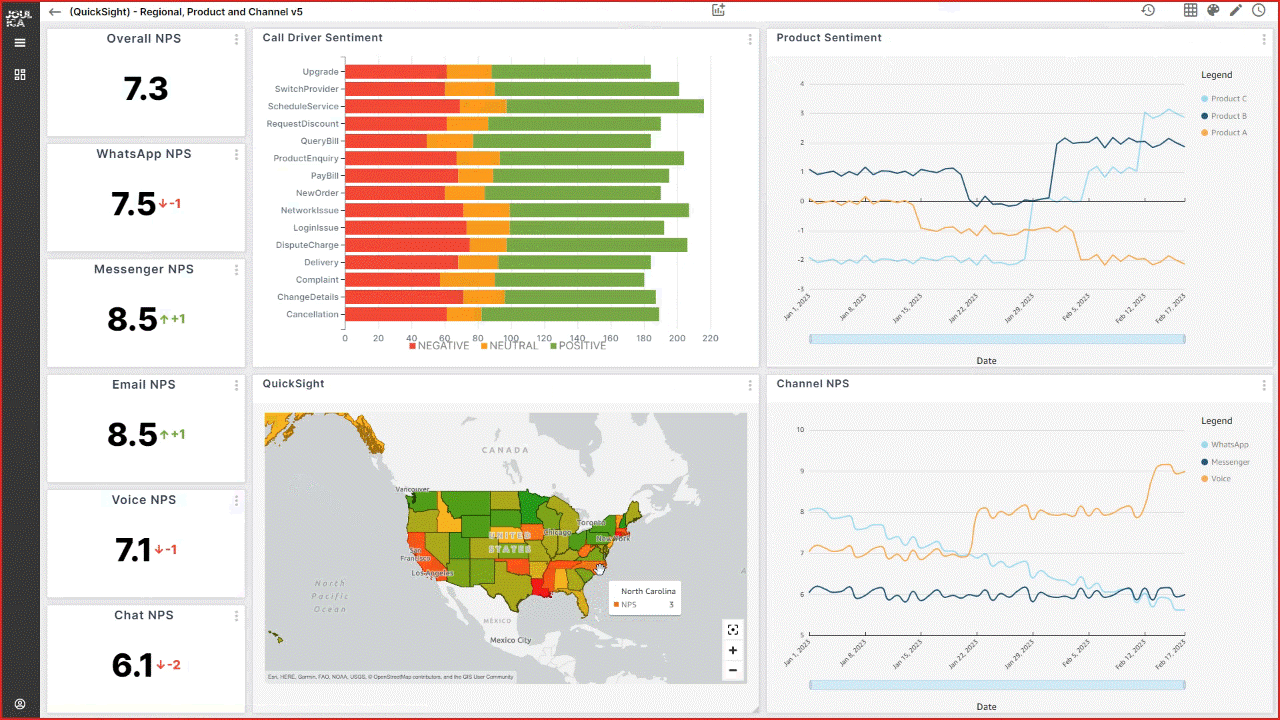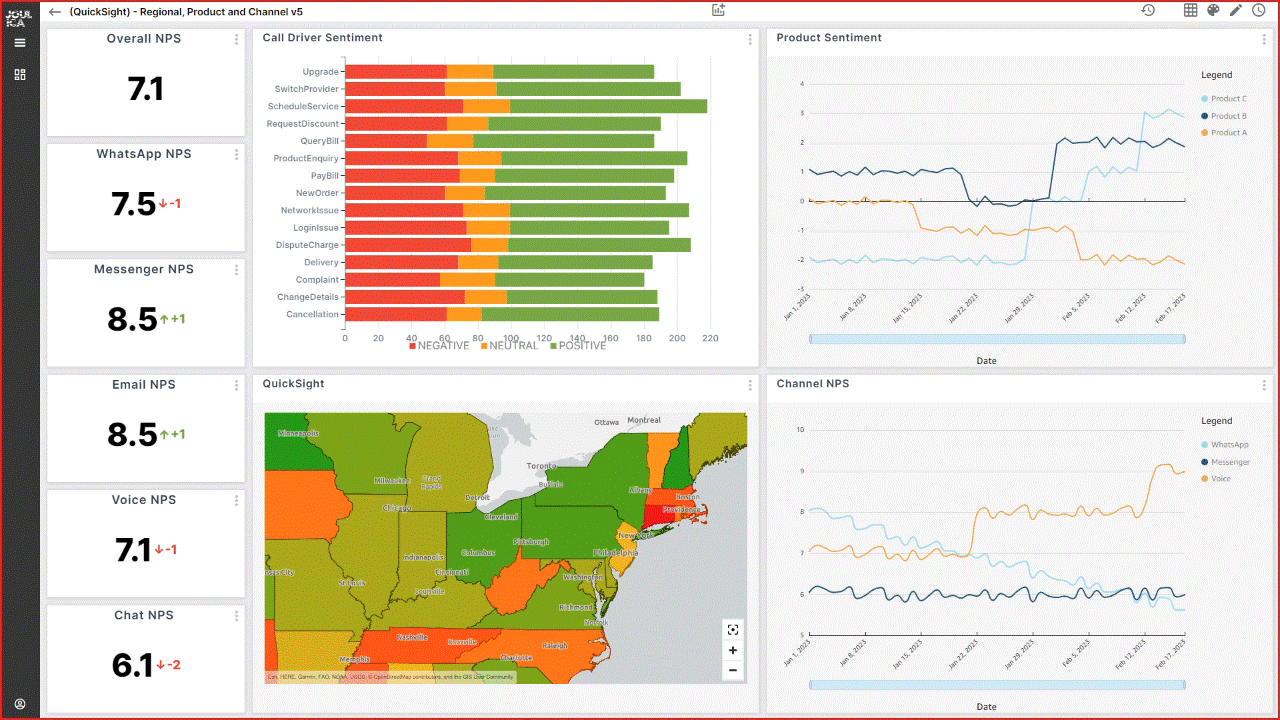
 Tony McCormack is the CEO and Co-founder of Joulica. Based in Galway, Ireland, he is focused on providing enterprise-grade reporting and analytics for Amazon Connect, Salesforce Service Cloud, and other platforms in the customer experience market. He has extensive experience in the contact center domain, with a passion for real-time analytics and their integration into end-user applications.
Tony McCormack is the CEO and Co-founder of Joulica. Based in Galway, Ireland, he is focused on providing enterprise-grade reporting and analytics for Amazon Connect, Salesforce Service Cloud, and other platforms in the customer experience market. He has extensive experience in the contact center domain, with a passion for real-time analytics and their integration into end-user applications.