Post Syndicated from Trevor Schiavone original https://aws.amazon.com/blogs/security/well-architected-best-practices-for-software-supply-chain-security/
There have been multiple notable supply chain attacks using the npm Registry since September: Shai-Hulud, Chalk/Debug, one abusing tea.xyz tokens, and recently axios. Thanks to community efforts involving the Amazon Inspector team, the Open Source Security Foundation, and others, the affected packages were quickly flagged, which reduced the impact of these incidents.
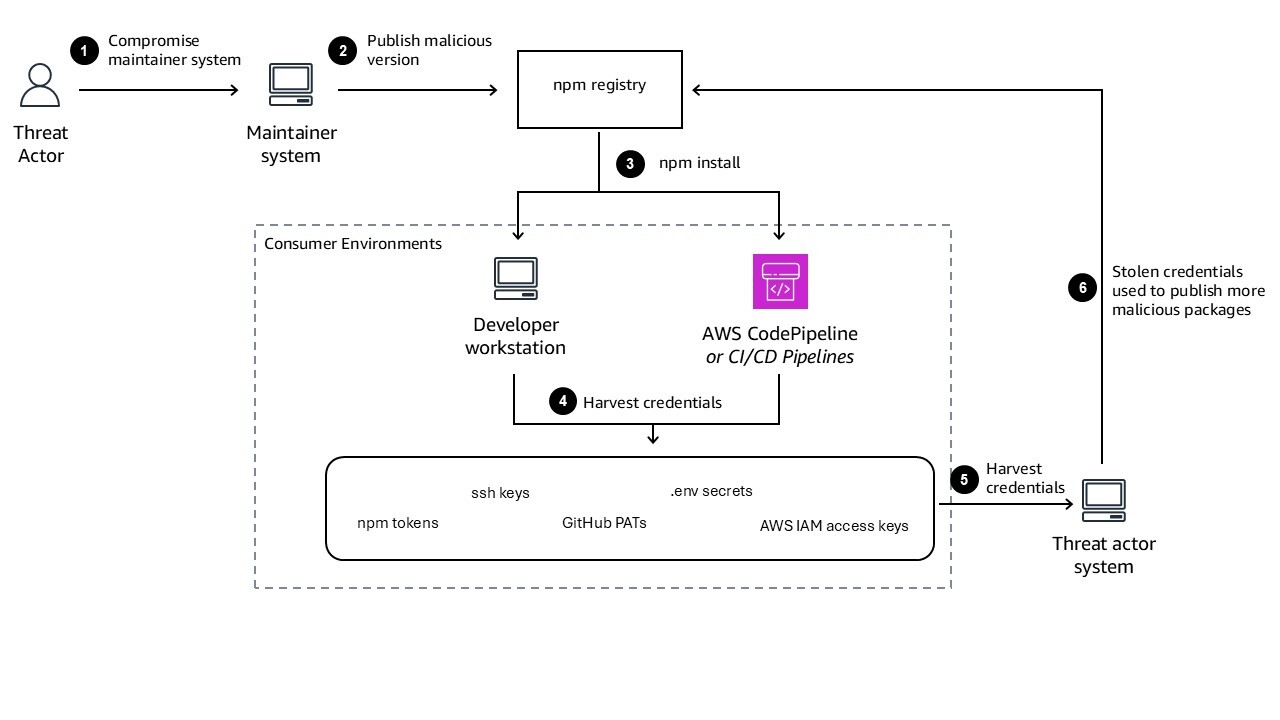
Supply chain attacks like Shai-Hulud exploit vulnerabilities on two fronts: compromised maintainer accounts that publish malicious packages, and consumer environments that download and execute those packages. The Shai-Hulud attack, shown in Figure 1, succeeded because maintainer credentials were compromised through phishing, enabling threat actors to publish malicious versions of popular packages. Incidents like these highlight the need for strong security practices within the software supply chain, and effective defense requires addressing both sides. Package maintainers need protections that prevent account compromise and limit sprawl when credentials are stolen. Package consumers need layered defenses that detect malicious packages, prevent their deployment, and limit damage when compromise occurs.
In this post, we explore best practices for package consumers. These practices are aligned with the AWS Well-Architected Framework – Security Pillar and you can use them to reduce exposure to similar threats and limit their impact if they occur.

Figure 1: Architecture diagram showing Shai-Hulud attack flow
Use temporary credentials and grant least privilege
When Shai-Hulud executed in developer environments and continuous integration and delivery (CI/CD) pipelines, it scanned for secrets such as npm tokens, GitHub tokens, and AWS Identity and Access Management (IAM) access keys. Long-term credentials exposed in this way enabled threat actors to propagate the malware further and access cloud resources. Recent incidents have shown organizations discovering multiple leaked IAM credential pairs, with concerns about additional exposed credentials and potential compromise of CI/CD pipelines.
Removing long-lived credentials from your developer environments and CI/CD pipelines reduces the scope of exposure in the event a system is compromised. For developers working locally, the new AWS CLI login command (aws login) simplifies the process of acquiring short-lived CLI credentials and removes the need to store long-lived credentials in configuration files. AWS IAM Identity Center also provides a straightforward way to acquire temporary credentials that expire automatically. For CI/CD pipelines, OpenID Connect (OIDC) federation with GitHub Actions, GitLab CI, or other platforms provide temporary credentials for each job without storing long-lived tokens. IAM can also federate AWS Identities to external services, allowing your AWS workloads to securely access external services without using long-term credentials. Temporary credentials expire automatically, limiting the window of exposure if a pipeline is compromised.
If you’re interacting with a third-party service that doesn’t support temporary credentials, consider storing the credentials to centralized storage using AWS Secrets Manager or AWS Systems Manager Parameter Store. Limit access to these secrets, require the use of temporary credentials, and apply automatic rotation and audit logging to reduce the risk of exposure of these credentials.
To reduce risk from credential exposure:
In the event of a security incident where credentials might be exposed, immediately rotate all long-term credentials to limit the scope of impact. Use Amazon GuardDuty and AWS CloudTrail to detect abnormal IAM activity and identify which credentials might have been compromised.
Implement defense in depth
Even with temporary credentials and least privilege, a single compromised account can enable threat actors to publish malicious packages or access sensitive resources. Defense in depth creates multiple layers of protection that work together to prevent sprawl after initial compromise. While adding approval workflows to every operation would dramatically decrease deployment speed, implementing them strategically for sensitive workloads provides balanced security.
The key principle is to ensure that if one credential or account is compromised, additional controls prevent that compromise from spreading across your organization. This includes multi-factor authentication (MFA) for access combined with different IAM roles for sensitive workloads. For single-developer open source projects, MFA becomes even more critical because there’s no separation of duties through multiple maintainers.
For package maintainers working in team environments, requiring multiple approvers to release packages to production creates separation of duties. However, developers can still trigger merge requests that initiate deployment pipelines, so multi-party approval should be implemented within the pipeline itself for sensitive deployments. This ensures that even if a developer’s credentials are compromised and they trigger a deployment, the pipeline requires additional approval before releasing to production.
For package consumers, multi-approval workflows in deployment pipelines help ensure that if a malicious package passes initial scanning, human review can catch suspicious changes before production deployment. Artifact signing provides a complementary cryptographic layer that works alongside these process controls.
The Shai-Hulud attack succeeded because compromised maintainer credentials allowed threat actors to publish malicious packages directly to the public npm registry. For package consumers, the defense is ensuring that packages pulled from public registries cannot reach production without verification. Artifact signing is one concrete implementation of this layered approach. By cryptographically binding a package or container image to the identity that produced it, signing creates a verification layer that is independent of the credential used to trigger the build—meaning a compromised developer credential alone isn’t sufficient to introduce an unverified artifact into your deployment pipeline.
Artifact signing as part of defense in depth
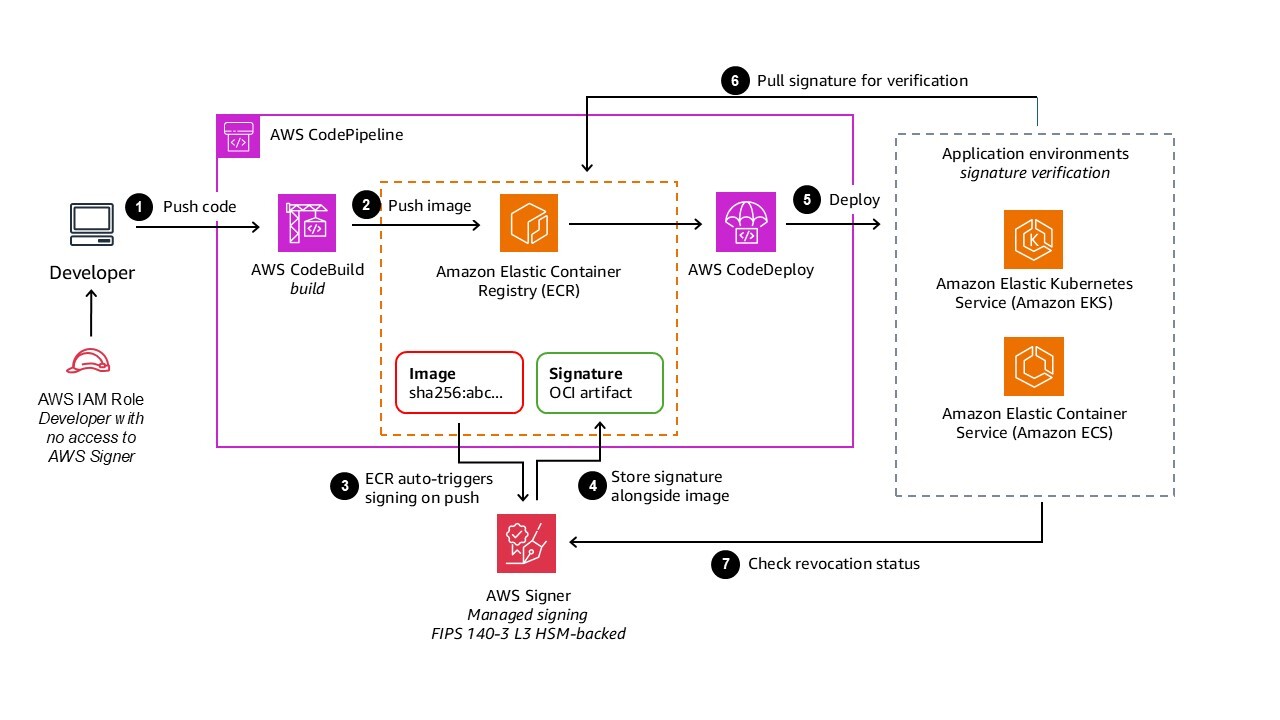
AWS Signer provides cryptographic signing for packages, creating an additional verification layer within your defense in depth strategy. The signing authorization model separates concerns: developer credentials shouldn’t have signing permissions. Only CI/CD pipeline roles should have signing permissions through the signer:StartSigningJob API. Signer uses FIPS 140-3 Level 3 validated hardware security modules (HSMs) to store signing keys, providing strong cryptographic protection.
The container image signing workflow, shown in Figure 2, demonstrates how signing integrates seamlessly into existing processes:
Figure 2: Diagram showing Signer signing workflow
The benefits of Signer compared to building custom signing infrastructure include:
- Fully managed: No need to build custom signing infrastructure or manage certificate lifecycle
- Automated: Amazon ECR managed signing happens automatically on image push without manual steps
- Centralized governance: Single signing profile can be used across multiple accounts and pipelines
- Native integration: Built-in integration with Notation and Kyverno for signature verification in Amazon EKS
- FIPS 140-3 Level 3 compliance: Meets stringent regulatory requirements for cryptographic operations
Audit logging for all signing operations enables detection of unusual patterns such as signing from new IP addresses, unusual times, or rapid succession of signing jobs. For every credential in your system, consider who can access what, how they prove their identity, and what second layer prevents sprawl if that credential is compromised. Artifact signing, combined with centralized storage and Software Bills of Materials (SBOMs), provides layered protection against tampering and malicious packages.
Centralize dependency management
By centralizing package and dependency management, you can validate and approve dependencies before they’re used in applications and quickly audit dependencies in the event of a supply chain security incident. Recent incidents have shown organizations discovering compromised npm packages in their internal artifact repositories, requiring rapid assessment of which applications might be affected.
On AWS, you can use AWS CodeArtifact to host and manage your organization’s software packages. You can use the package group configuration to define an approved list of upstream sources and block access to all others—a direct control against typosquatting attacks, where malicious packages are published under names that closely resemble legitimate ones. Rather than relying on developers to identify suspicious package names at install time, package group configuration enforces the boundary at the repository level. Centralization also helps you pin versions of dependencies to prevent automatic updates from pulling in malicious versions and quickly remove compromised dependencies across your software portfolio when an incident occurs.
For container images, Amazon ECR provides centralized image storage with AWS Key Management Service (AWS KMS) encryption and lifecycle policies. Combine Amazon ECR with Amazon Inspector scanning to continuously validate image integrity.
For additional guidance see SEC11-BP05: Centralize services for packages and dependencies.
npm provenance attestation
For npm packages specifically, provenance attestations provide a complementary control on the consumer side. Available since npm 9.5, npm provenance links a published package to the specific source repository and CI/CD workflow that produced it, using Sigstore as the underlying signing infrastructure. When a package is installed, the npm CLI can verify that the published artifact matches the attested build provenance—providing confidence that the package wasn’t tampered with between build and publication. For organizations consuming open source npm packages, checking for provenance attestations before adding a new dependency is a low-friction signal of supply chain integrity. Package maintainers publishing to npm can enable provenance by running npm publish with the –provenance flag from a supported CI/CD environment such as GitHub Actions.
For additional guidance see SEC11-BP06: Deploy software programatically and, from the DevOps Lens of the AWS Well-Architected Framework, DL.CS.2: Sign code artifacts after each build
Scan dependencies throughout the software development lifecycle
AWS provides services to help you scan dependencies continuously, from development through deployment:
- In development: Kiro can perform software composition analysis during code reviews to identify vulnerable third-party code.
- In code repositories and pipelines: Amazon Inspector scans first-party code, third-party dependencies, and Infrastructure as Code for vulnerabilities.
- For container images: Amazon Inspector provides continuous vulnerability scanning of Amazon ECR images. Amazon Inspector can also be integrated directly into CI/CD pipelines to scan images before they are pushed to Amazon ECR or deployed, helping you block compromised dependencies earlier in the release cycle.
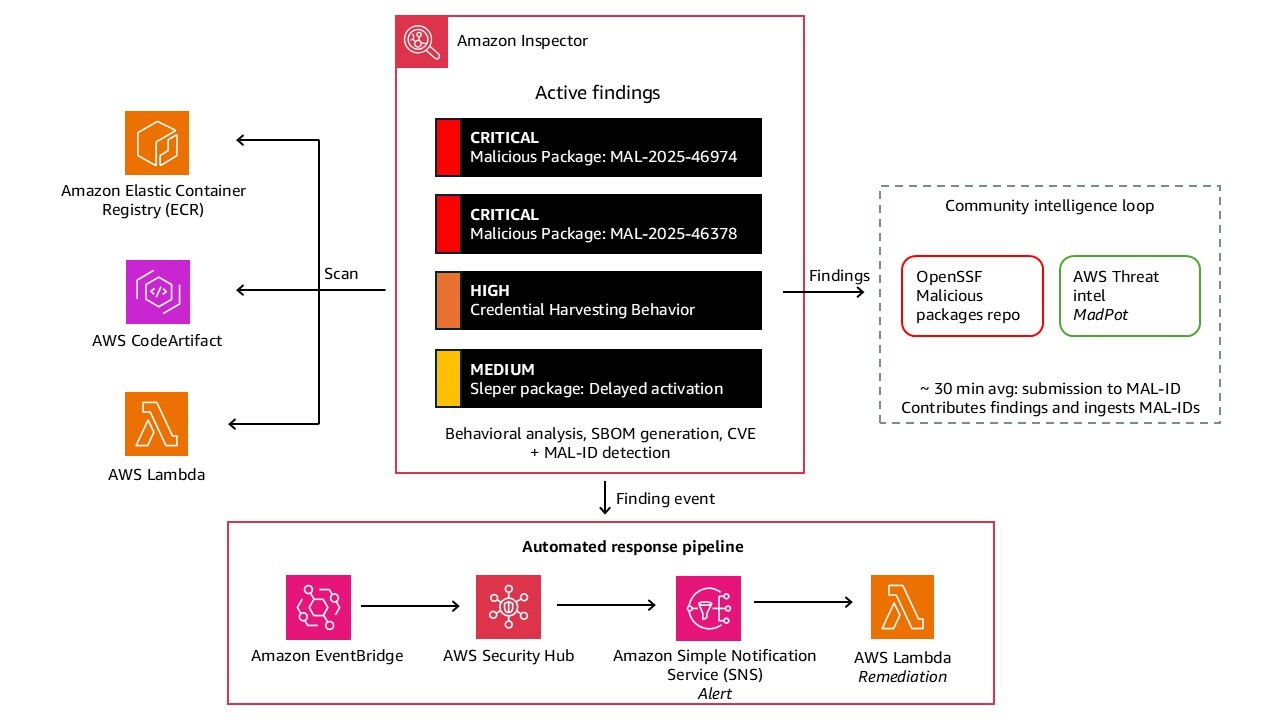
Traditional vulnerability scanners focus on known CVEs—publicly disclosed vulnerabilities with assigned identifiers. Supply chain attacks like Shai-Hulud involve malicious packages that function as zero-days: they’re intentionally crafted by threat actors and actively exploited before a CVE is assigned. Traditional vulnerability scanners that rely on CVE databases won’t detect these packages until they’ve been formally identified and catalogued, which can take days or weeks.
Detecting these requires behavioral analysis at scale and community collaboration, not just static signature matching. The operational scale of AWS—with threat intelligence from sources like MadPot and incident response data across millions of customers—enables detection of suspicious package behavior across multiple environments simultaneously. When a newly published package exhibits credential-harvesting behavior in multiple customer accounts within hours of publication, that cross-account signal enables rapid identification. These findings are contributed to community-maintained databases like the OpenSSF Malicious Packages Repository (github.com/ossf/malicious-packages), which assigns a formal identifier (MAL-ID) and shares it across the security community. For the tea.xyz token farming campaign, the average time from submission to formal identification was approximately 30 minutes. AWS services like Amazon Inspector participate in this community loop, contributing findings and ingesting newly assigned MAL-IDs to surface threats in your environment.
A related threat model worth understanding is the sleeper package: a package that appears benign at publication and activates malicious behavior only after a delay or trigger condition. Static analysis alone is insufficient to catch these packages because the malicious payload isn’t present or active at install time. Amazon Inspector behavioral analysis is specifically designed to detect this class of threat, complementing static vulnerability scanning.
Software Bills of Materials (SBOMs) in SPDX or CycloneDX format enable you to quickly assess exposure during incidents. When responding to supply chain incidents, use SBOMs to identify which applications contain compromised packages, prioritize remediation, and assess blast radius. In the Shai-Hulud incident, the compromised packages (MAL-2025-46974 and CVE-2025-59144) were identified early, providing actionable findings that customers could remediate quickly. Organizations that had scanning enabled but experienced alert fatigue may have missed critical alerts, highlighting the importance of proper alert routing and prioritization.
Figure 3: Screenshot of Amazon Inspector console showing malicious package findings
For additional guidance see SEC11-BP02: Automate testing throughout the development and release lifecycle.
Configure logging and monitoring
Visibility into activity is essential to detect anomalous behavior early. Configure logging and centralize those logs for analysis:
- Enable application and service logging
- Centralize and monitor logs across accounts
- Use GuardDuty to continuously monitor for malicious activity and anomalous API calls
- Aggregate findings with AWS Security Hub and enforce configuration best practices with AWS Config
CloudTrail logging provides audit trails for credential access and API activity. When responding to supply chain incidents, review CloudTrail logs for specific events that indicate credential compromise or malicious activity: sts:AssumeRole calls from unexpected IP addresses or regions, secretsmanager:GetSecretValue or ssm:GetParameter calls from unfamiliar sources, ecr:PutImage from developer workstations bypassing CI/CD pipelines, lambda:UpdateFunctionCode outside normal deployment windows, iam:CreateAccessKey followed by immediate API activity, and codecommit:GitPush or codebuild:StartBuild from unusual IP addresses. When combined with Amazon EventBridge rules, you can trigger automated responses when Amazon Inspector detects malicious packages or when these unusual credential access patterns occur.
Organizations affected by recent supply chain attacks have used CloudTrail analysis to determine the scope of credential exposure and identify which resources might have been accessed by compromised credentials. This forensic capability is essential for understanding blast radius and ensuring complete remediation.
For additional guidance see the best practices in SEC04: Detection.
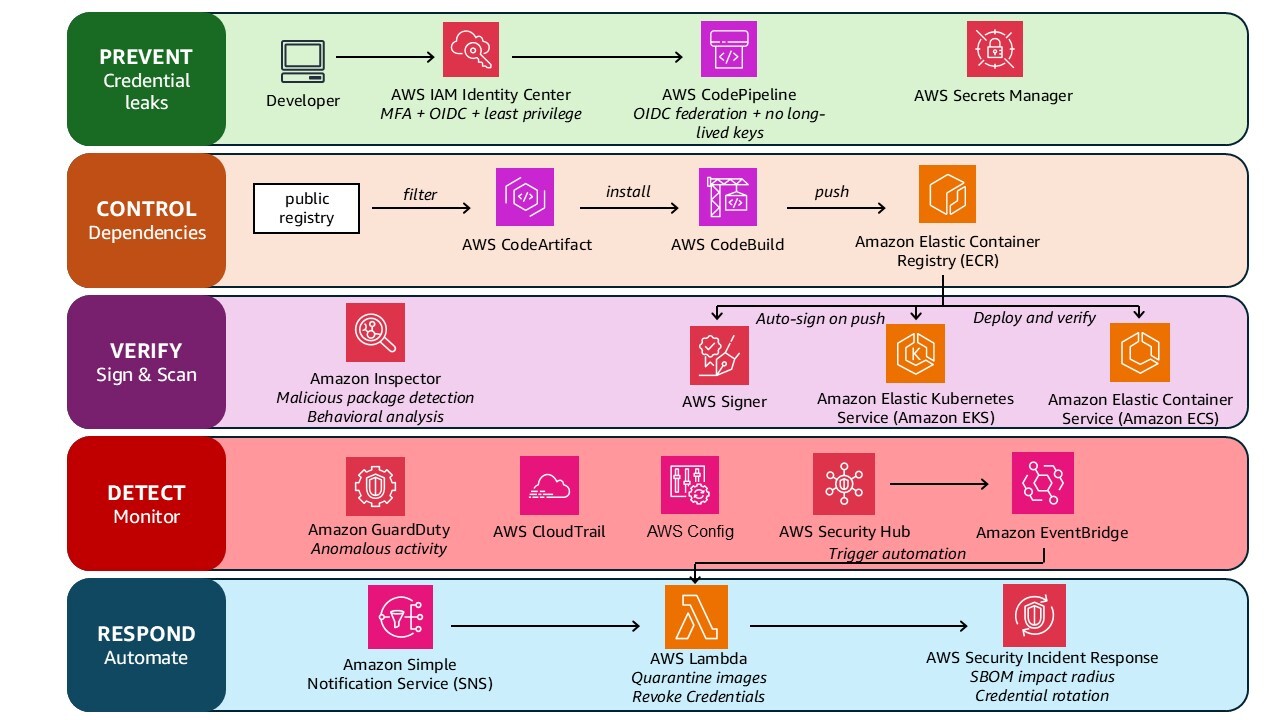
These components of a defense in depth strategy work together to prevent sprawl after initial compromise and help you to detect and respond to the event. Figure 4. shows how these fit together.
Figure 4: Architecture diagram showing defense architecture
Additional best practices
The Security pillar of the Well-Architected Framework also provides organizational best practices that are applicable to improving security processes across all dimensions of your organization. Relevant best practices include SEC11-BP01: Train for application security; SEC11-BP08: Build a program that embeds security ownership in workload teams; and SEC10: Incident Response.
Conclusion
Recent incidents including Shai-Hulud, Chalk/Debug, and tea.xyz reflect ongoing efforts by threat actors to target the the package registries, CI/CD pipelines, and developer credentials for increased attack surface and propagation. A single compromised maintainer account or malicious package can propagate across thousands of consumer environments simultaneously. The controls described in this post are designed with that threat model in mind. Temporary credentials limit the value of stolen tokens, centralized dependency management and upstream blocking reduce the attack surface at the registry level, artifact signing ensures that even if a build pipeline is compromised, unsigned artifacts cannot reach production, and dependency scanning throughout your software lifecycle helps you identify compromised packages early, before they can impact you. Each layer narrows the window of opportunity for a threat actor.
Learn more
See the following blogs and workshops to dive deeper on this topic:
If you have feedback about this post, submit comments in the Comments section below.
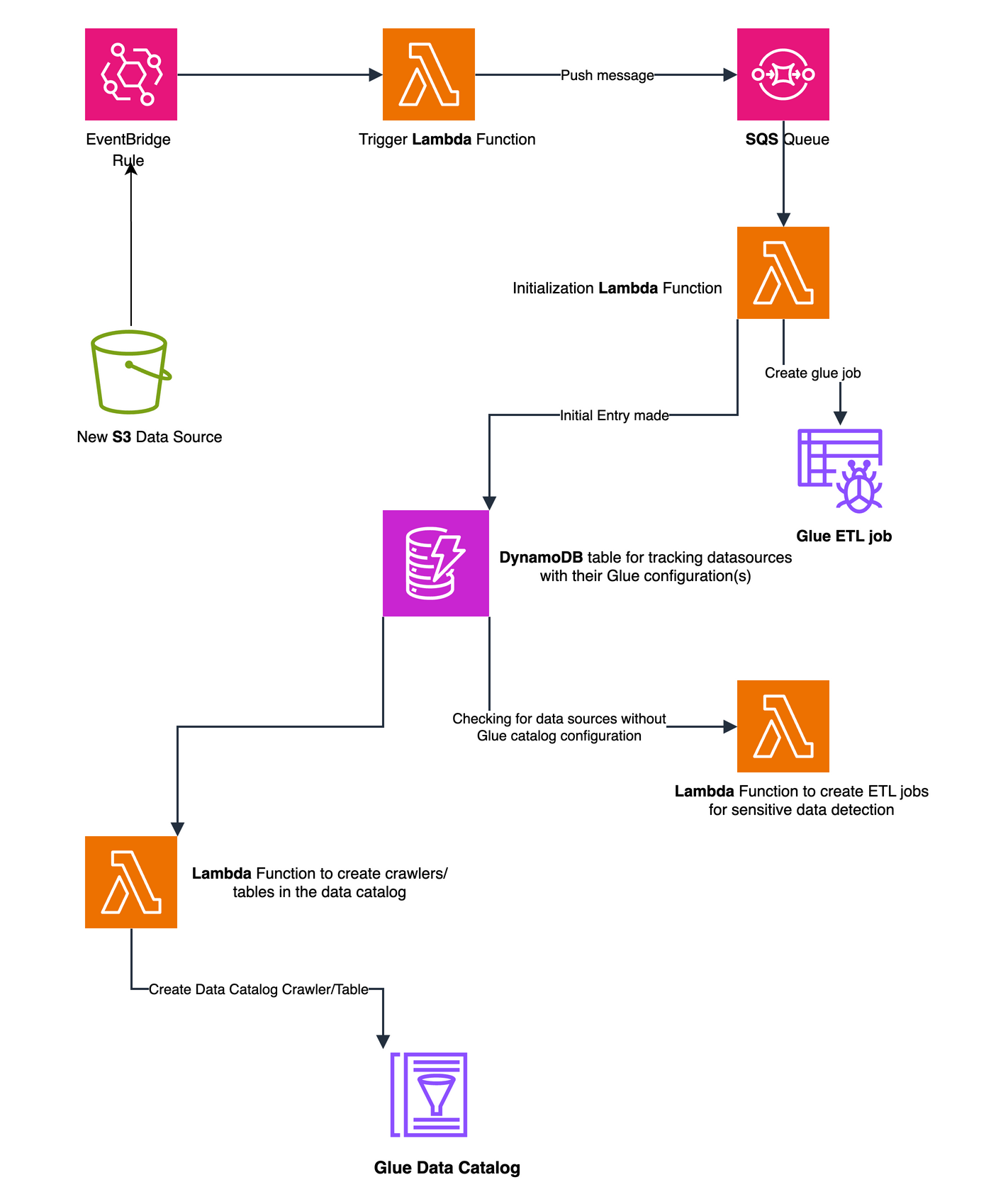
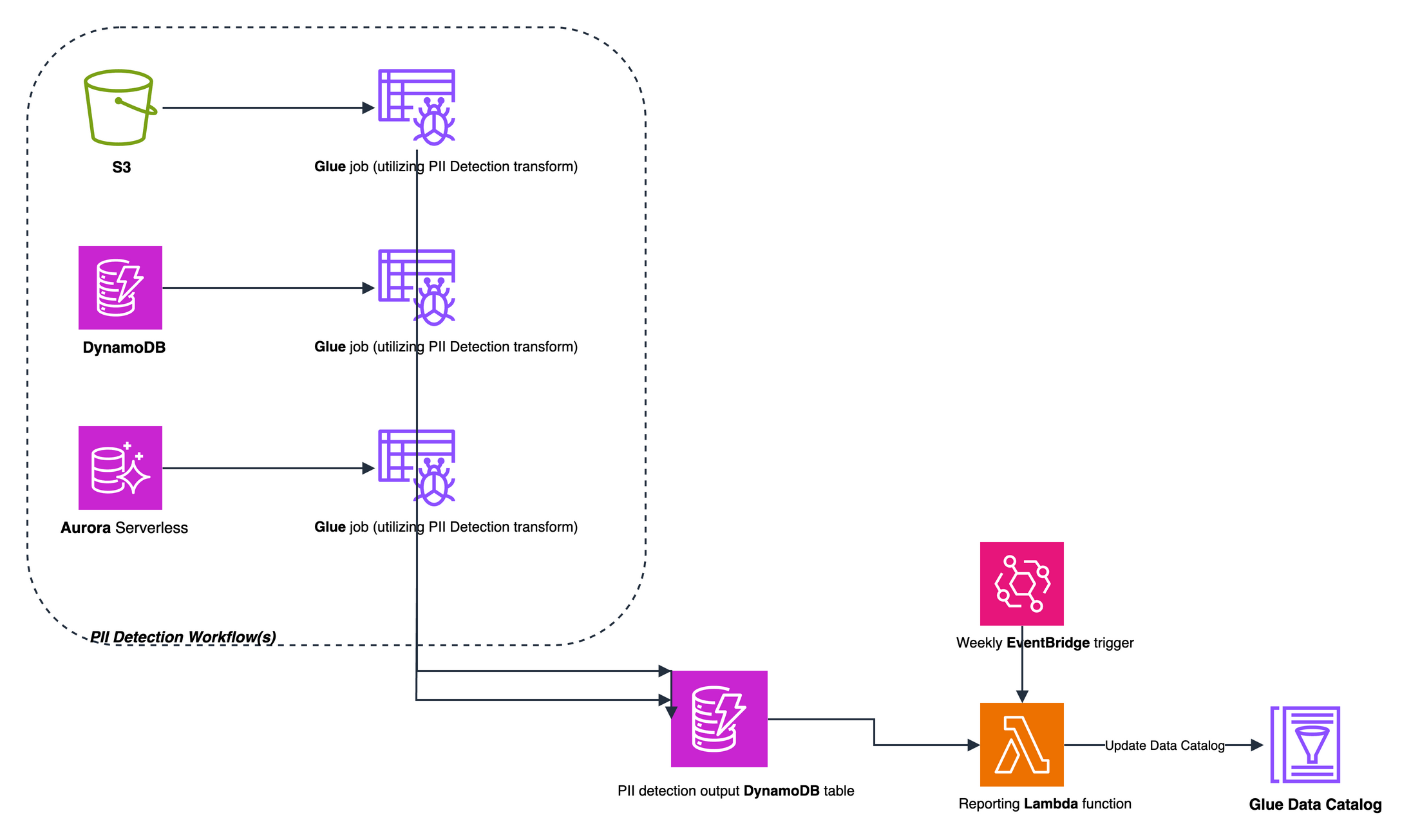
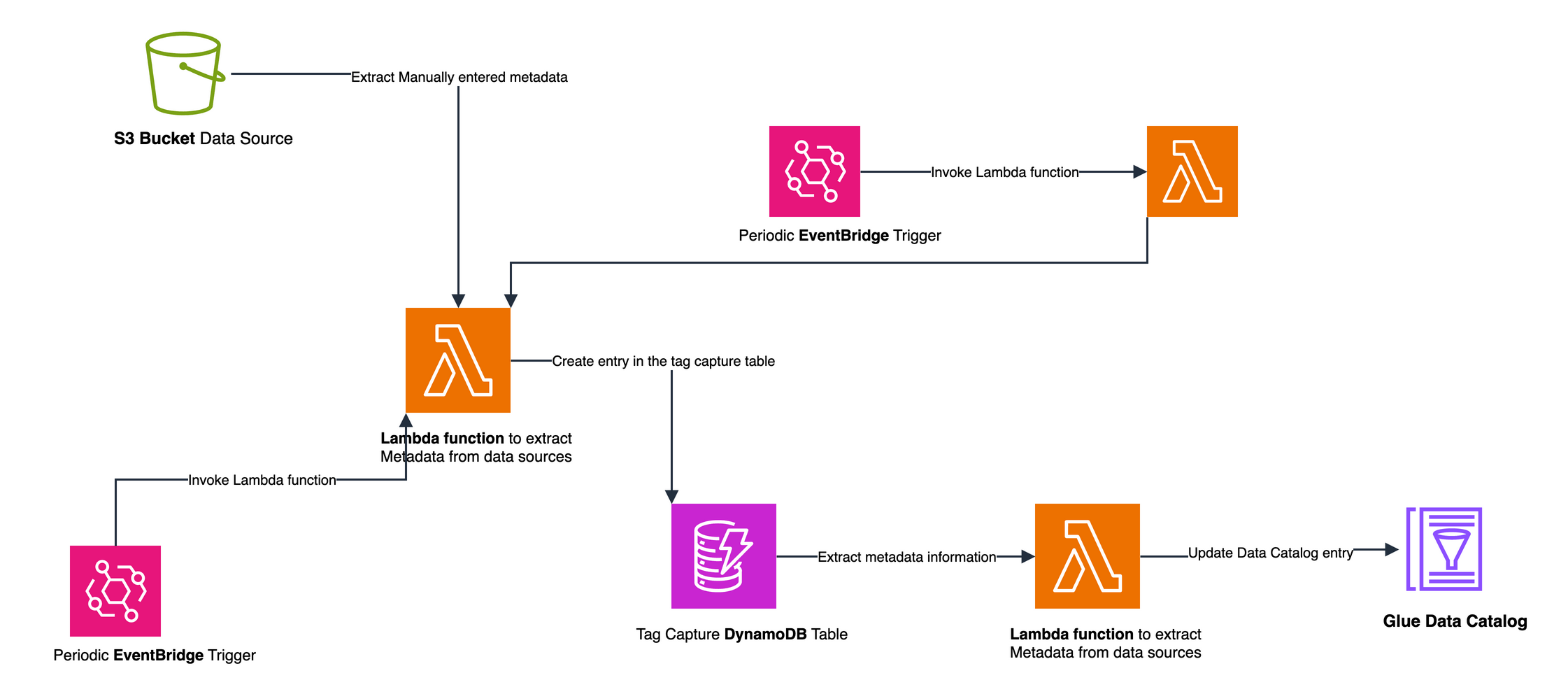
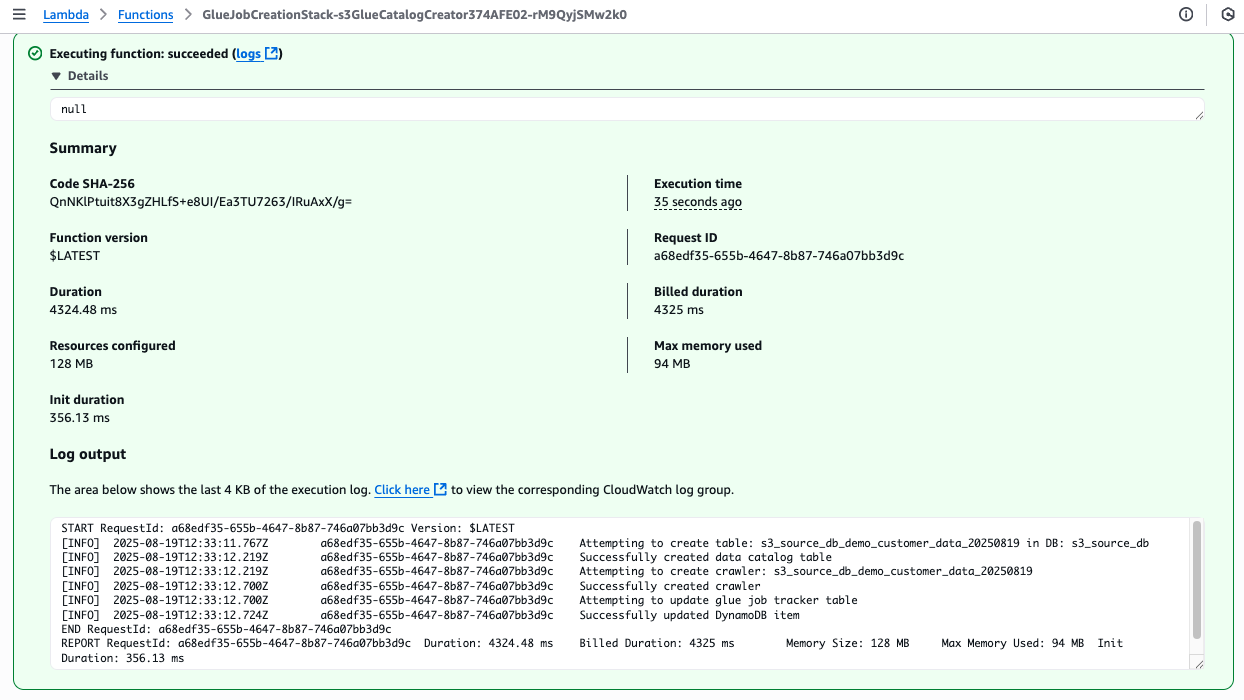
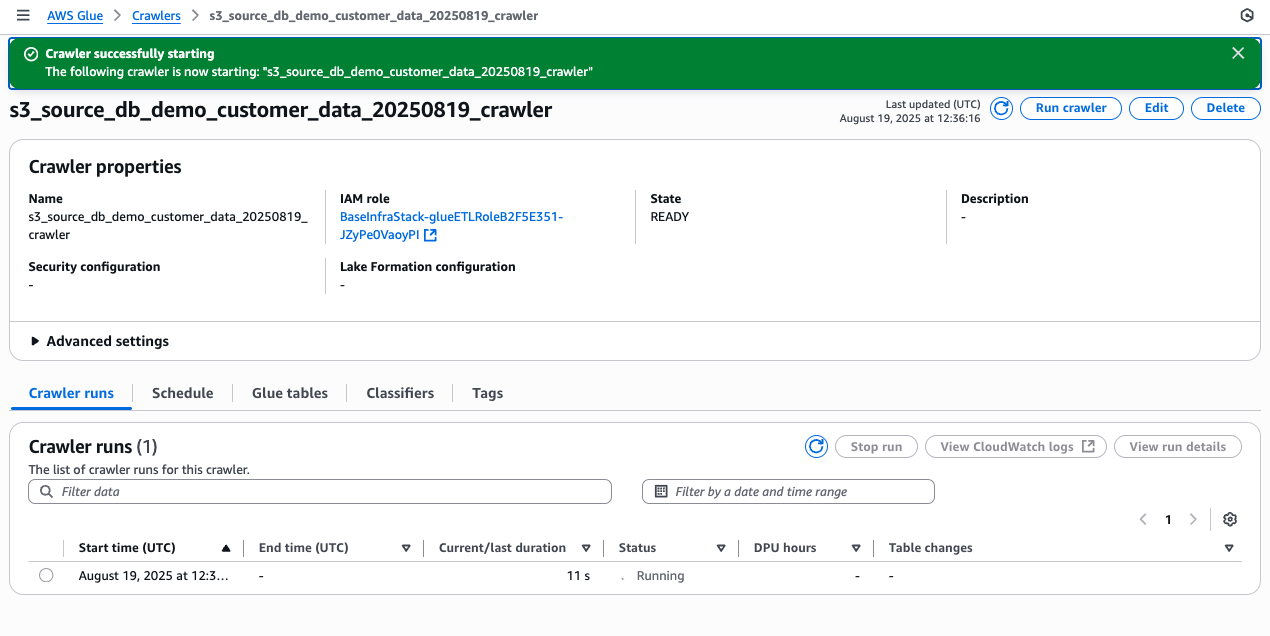
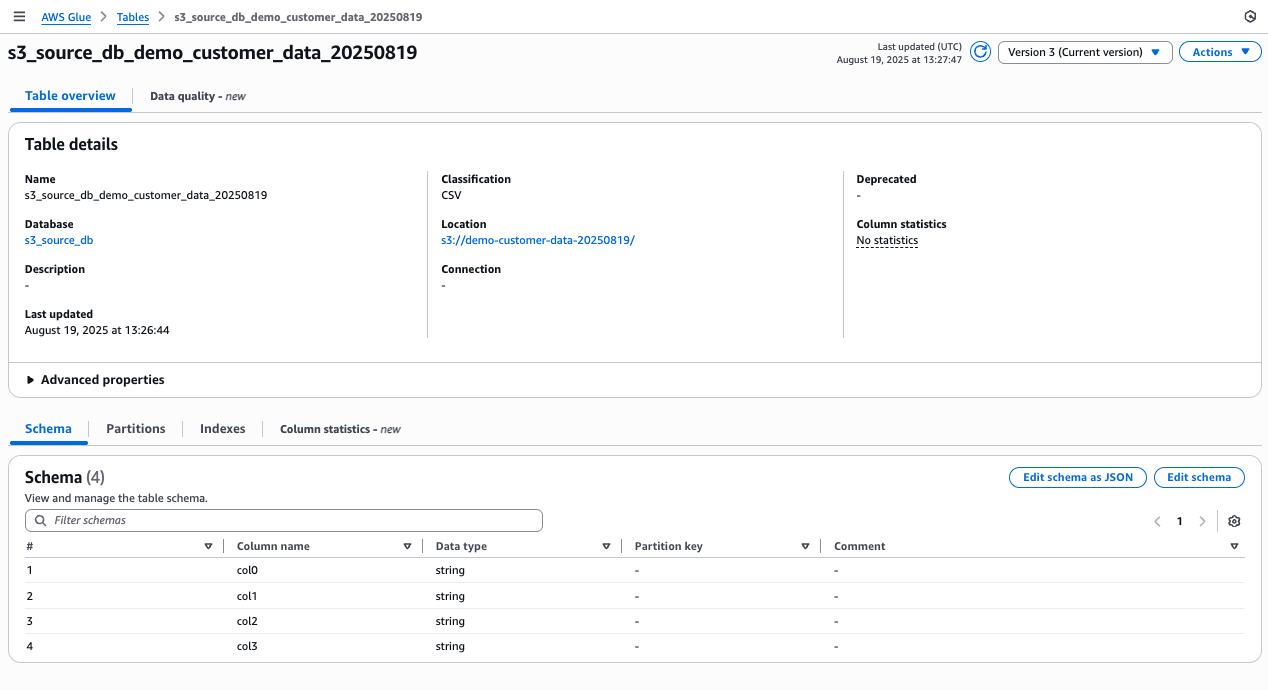
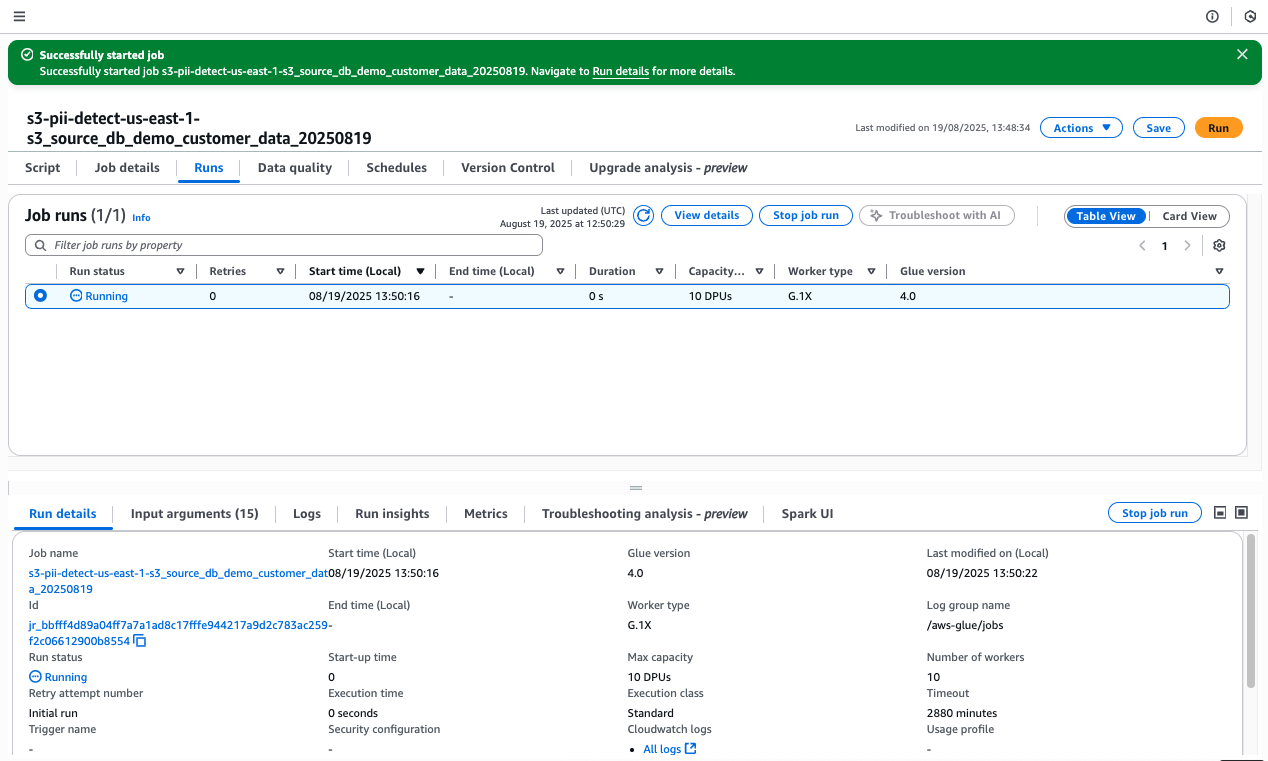
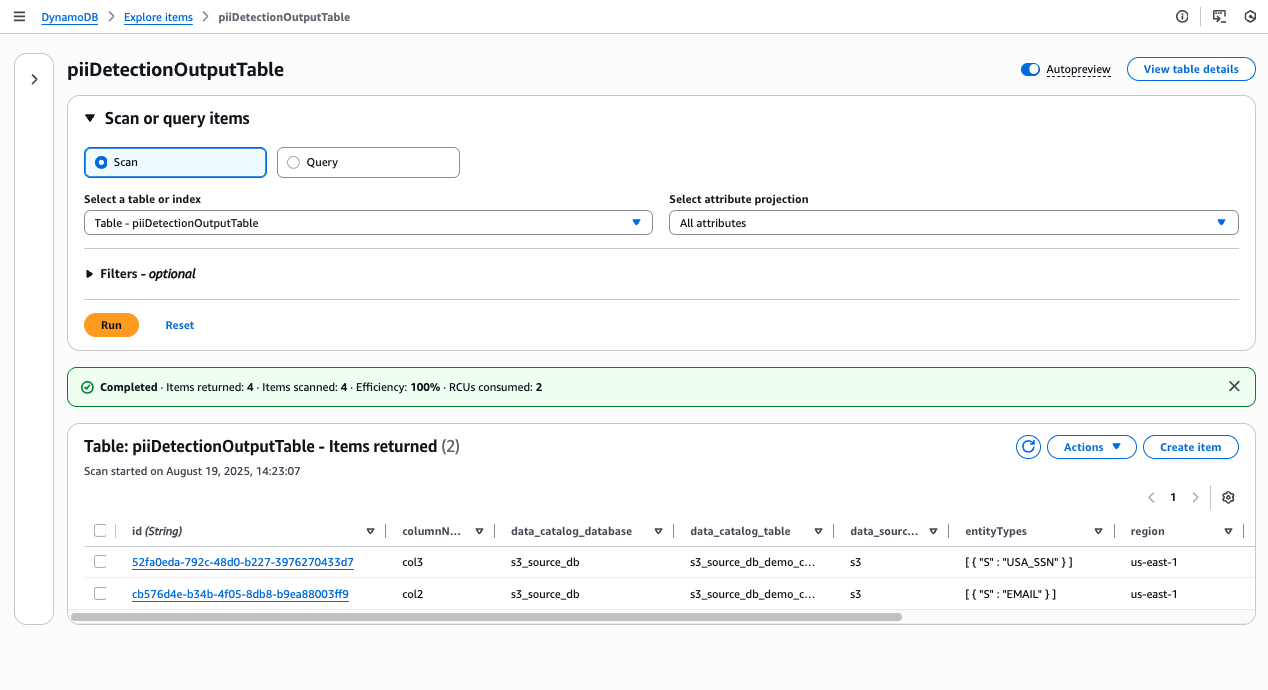
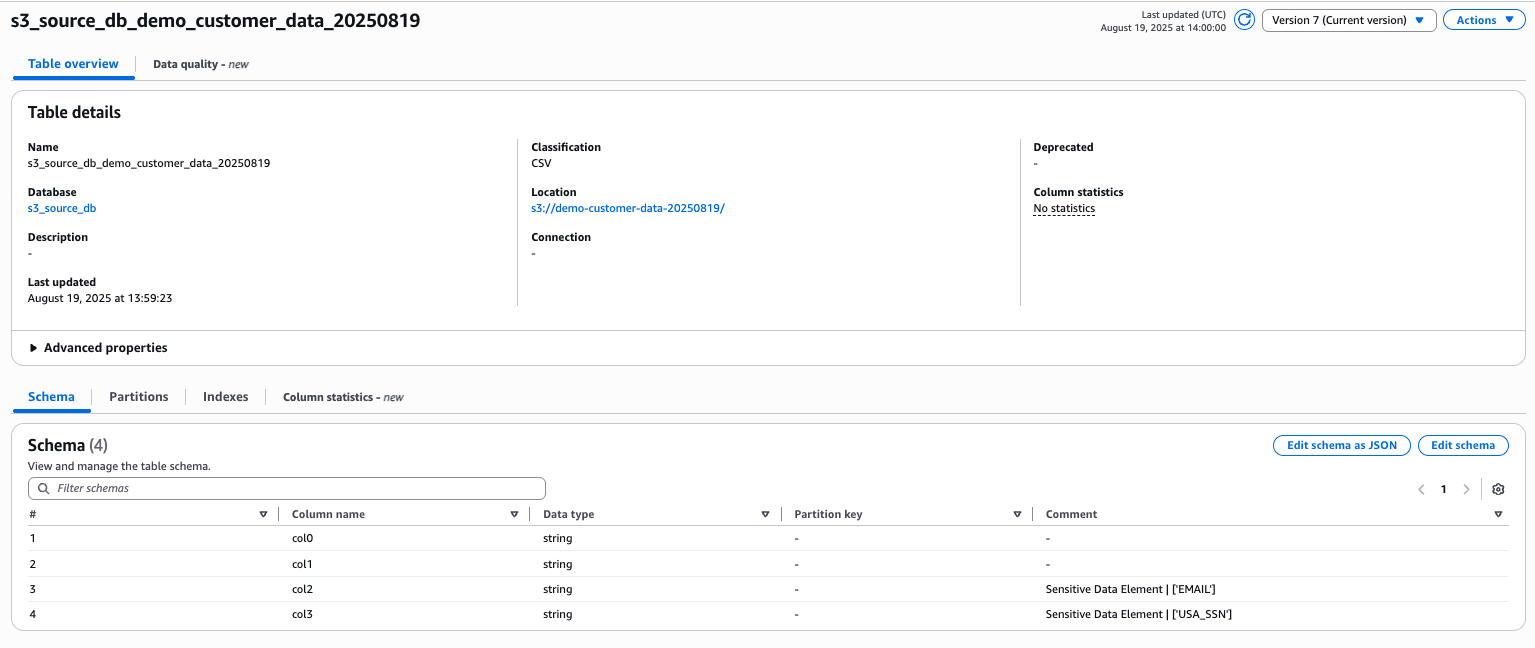
 There’s something genuinely energizing about working with startups — something I’ve been doing intensely for more than two years now. Startups operate at a different frequency: the urgency is real, the constraints are tight, and the stakes are personal. Helping them navigate the challenge of proving their business model requires not just technical depth but a willingness to move fast, challenge assumptions, and make bets on the right architecture before the perfect data exists.
There’s something genuinely energizing about working with startups — something I’ve been doing intensely for more than two years now. Startups operate at a different frequency: the urgency is real, the constraints are tight, and the stakes are personal. Helping them navigate the challenge of proving their business model requires not just technical depth but a willingness to move fast, challenge assumptions, and make bets on the right architecture before the perfect data exists.



