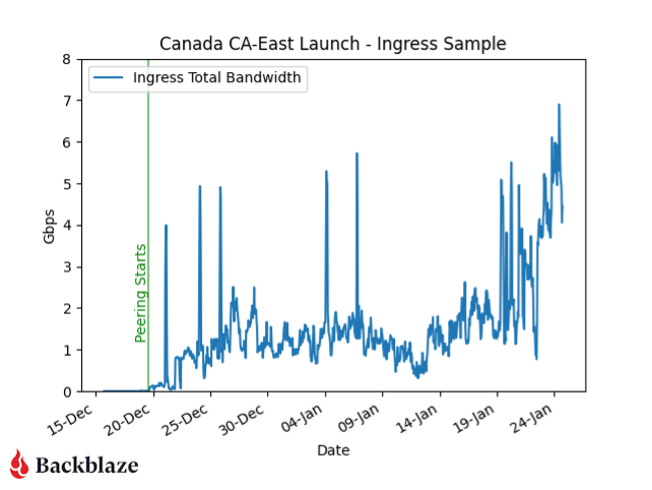
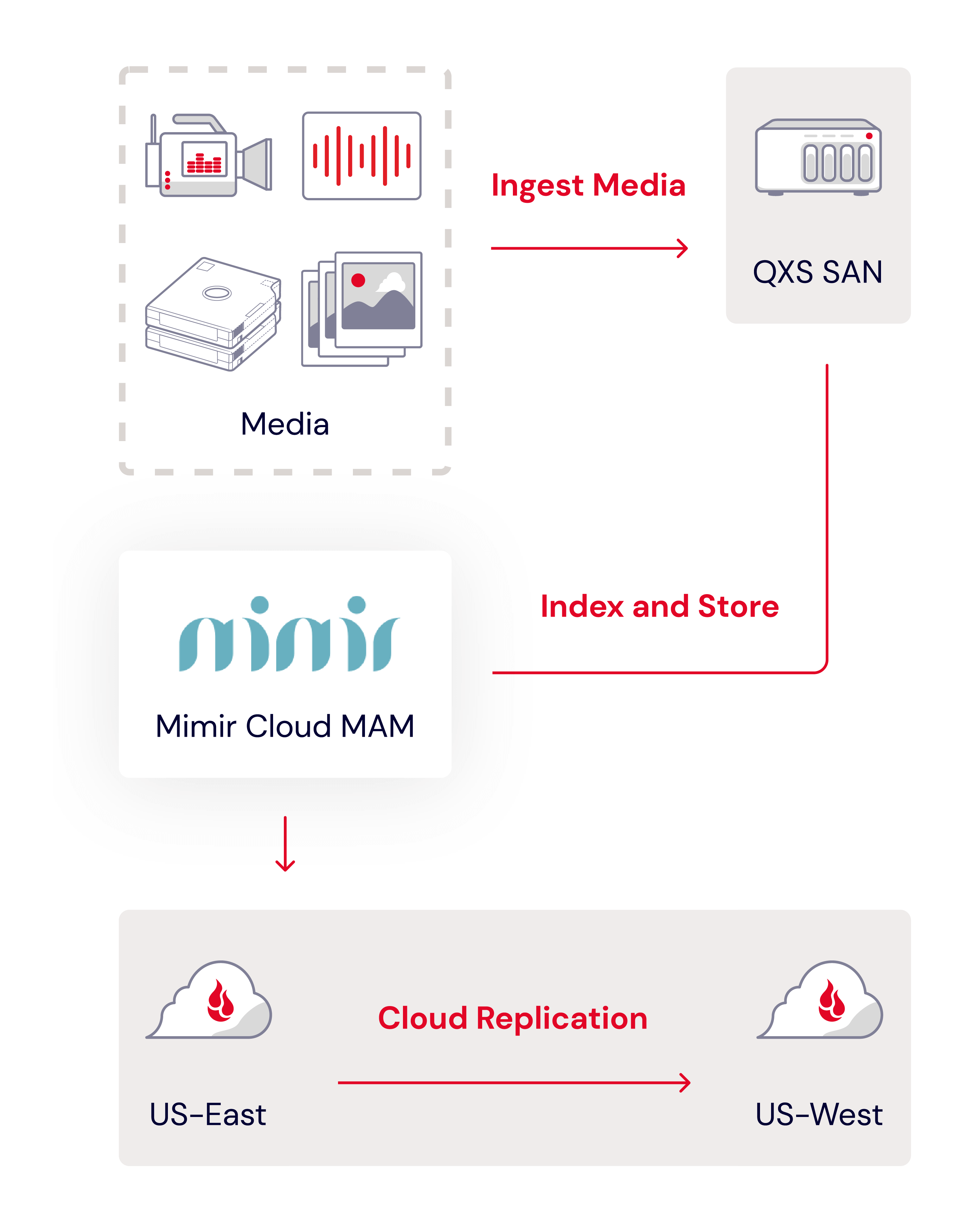
Everyone’s chasing the next breakthrough in AI, pouring money into bigger models and faster chips. But there’s one innovation killer no one’s talking about, and it isn’t compute limits—it’s vendor lock-in.
While you’re optimizing your algorithms, your infrastructure is quietly draining your budget and tying your roadmap to someone else’s agenda. Open cloud providers help you create an ecosystem where data flows freely, innovation isn’t throttled, and every component works harmoniously to drive progress. Yet, for many organizations, vendor lock-in with hyperscalers costs more than just dollars: it comes at the expense of the freedom to innovate on your own terms.
Today, I’m talking through how AI organizations end up locked in with hyperscalers and how to avoid that trap.
Download the ebook
Struggling to keep AI storage costs under control? Download our free ebook to discover how to optimize cloud storage for AI workloads—without compromising performance.
The three pillars of AI infrastructure
At its heart, AI infrastructure rests on three essential pillars:
Compute: The engines powering your models and training processes.
Data management: The systems that capture, store, and organize the massive volumes of data your projects depend on.
Integration and flexibility: The ability to move data seamlessly between various platforms and cloud environments without being tied to a single provider.
When any of these pillars are compromised by vendor lock-in, the consequences are immediate and costly:
Can you freely move workloads between environments?
Are you paying premium prices for basic data transfers?
Is your team spending more time managing infrastructure than building innovative solutions?
These challenges directly hinder your team’s ability to deliver the AI breakthroughs your organization expects.
Understanding vendor lock-in
Vendor lock-in occurs when an organization becomes overly dependent on a single vendor’s products or services, making it difficult—or costly—to switch to alternative solutions. This dependency can manifest in several ways:
Proprietary technologies: When a vendor’s system uses exclusive formats or interfaces, integrating new tools becomes challenging.
Complex pricing: Long-term agreements with rigid terms and hidden fees may restrict flexibility and force you to absorb unexpected costs.
Ecosystem dependence: Relying on one provider’s suite of services can limit your ability to adopt innovative, best-of-breed solutions from other vendors.
In practice, vendor lock-in can hurt innovation by restricting your options, slowing down the pace at which you can adopt new technologies, and diverting resources to manage and maintain a closed system rather than driving creative breakthroughs.
The hidden costs of vendor lock-in
Imagine scaling your AI project only to discover, as Decart did, that egress fees essentially hold your data hostage. Their team needed to train models across multiple GPU clusters simultaneously—a scenario that would have incurred crippling costs with their previous provider. Or consider Grass Network, who found their ability to serve Fortune 1000 clients fundamentally undermined by their cloud vendor’s pricing structure, with egress and deletion fees that made their business model unsustainable at scale.
The pattern is clear: Organizations trapped in vendor-locked systems end up diverting precious resources—both financial and human—away from innovation and toward infrastructure management. This results in delayed training cycles, slower model iterations, and missed market opportunities as engineering talent gets consumed by working around limitations rather than building competitive advantages.
A holistic look at open AI infrastructure
While compute power and advanced analytics often grab headlines, the true strength of an AI system lies in the seamless integration of all its components. An open AI infrastructure can deliver:
Enhanced agility: With a flexible, multi-cloud approach, you can rapidly adopt new tools and technologies without being bound by a single provider’s limitations.
Optimized performance: When data flows effortlessly between compute clusters, storage systems, and analytics platforms, every part of your infrastructure can perform at its peak.
Cost efficiency: Transparent pricing and predictable billing ensure that hidden fees—like those associated with storage tiers and egress—don’t eat into your budget.
Future-proofing: By avoiding proprietary ecosystems, you build an infrastructure that is resilient and adaptable, giving you the freedom to experiment and innovate.
Rethinking storage as the strategic backbone
Among all the components, storage plays a uniquely critical role—it’s the circulatory system that keeps your data moving throughout the AI workflow. The right storage foundation doesn’t just warehouse data; it becomes a strategic asset that enables multi-cloud workflows, maintains cost predictability, and prevents vendor lock-in by allowing seamless integration with different compute engines, GPU clusters, and software platforms. Forward-thinking organizations are increasingly viewing storage not as a commodity, but as the linchpin of AI infrastructure strategy.
Backblaze B2: A foundation for multi cloud storage
Within this framework, Backblaze B2 serves as a robust storage foundation that transforms how AI teams approach multi-cloud workflows. Rather than trying to be everything to everyone, B2 Cloud Storage focuses exclusively on being the best at what matters most for your data: performance, scalability, and predictability.
It effortlessly scales from terabytes to petabytes, accommodating everything from raw training data to archived model outputs without performance degradation. S3 compatibility means it integrates easily with virtually any AI pipeline or tool. Perhaps most importantly, it keeps costs transparent and predictable with straightforward pricing that eliminates the “sticker shock” that plagues many AI projects.
A reliable, independent storage layer doesn’t just help you sidestep the pitfalls of vendor lock-in—it fundamentally changes how your team approaches innovation by removing the technical and financial barriers that traditionally constrain experimentation.
See the open cloud in action
Your company’s data is a powerful resource—learn how to harness it with an AI agent designed to generate meaningful insights. In this deep dive, Backblaze’s Pat Patterson and Jeronimo De Leon will demonstrate how to build an AI agent that can query, analyze, and generate insights from company-specific data—all powered by cost-efficient, scalable cloud storage.
Charting a new course for innovation
Breaking free from vendor lock-in isn’t merely about cutting costs—it’s about reclaiming control over your entire AI infrastructure and accelerating your path to results. When every component, from compute to storage and integration, is designed to be open and flexible, your organization gains the freedom to experiment, iterate, and push the boundaries of what’s possible.
The most successful AI teams we’ve observed are those building on strong, multi-cloud-friendly foundations where data flows without friction or penalty. They’re the ones asking tough questions about their infrastructure choices today to ensure maximum flexibility tomorrow.
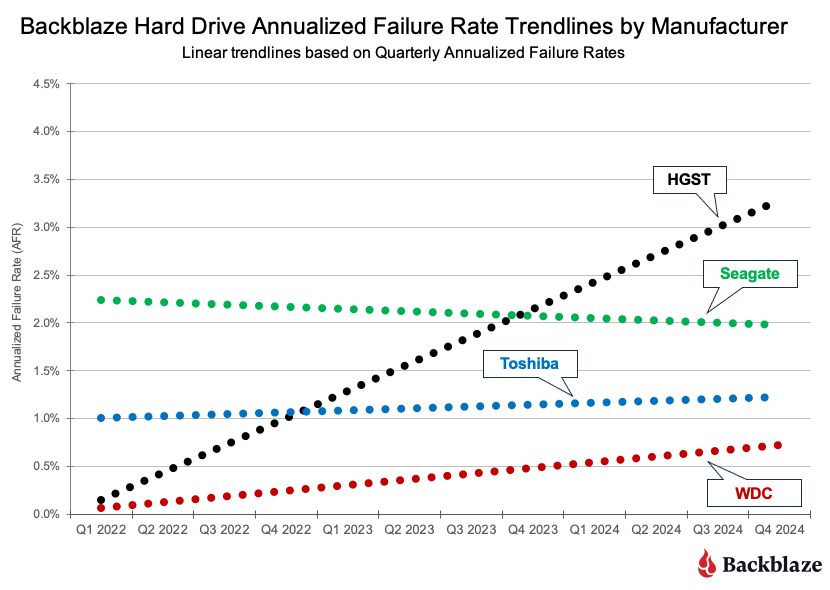
Welcome to the first Drive Stats of 2025. In case you missed it, the 2024 Drive Stats report was the last for long-time Drive Stats guru, Andy Klein, who is happily retired—off putting the “green” in greener pastures by working on his golf game. We–being Backblaze staff writer Stephanie Doyle and Chief Technical Evangelist Pat Patterson–are picking up where Andy left off, bringing you the metrics and analysis you know and love. Now, on to the numbers!
As of March 31, 2025, we had 312,831 drives under management. Of that total, there were 3,970 boot drives and 308,861 data drives. We’ll review their annualized failure rates (AFRs) as of Q1 2025, and we’ll dig into the average age of drive failure by model, drive size, and more. Along the way, we’ll share our observations and insights on the data presented and, this time around, we’ve got some exciting updates to share about how we produce Drive Stats. (Stay tuned, fellow Snowflake fans.)
As always, we look forward to your thoughts—we’ll see you in the comments section.
Sign up for the Drive Stats LinkedIn Live
Ready to dive deeper into the data? Tune in Thursday, May 15, 2025 at 10:00 a.m. PT, to query the new Drive Stats team, Stephanie Doyle and Pat Patterson. Feel free to drop us a line with any questions you want us to answer.
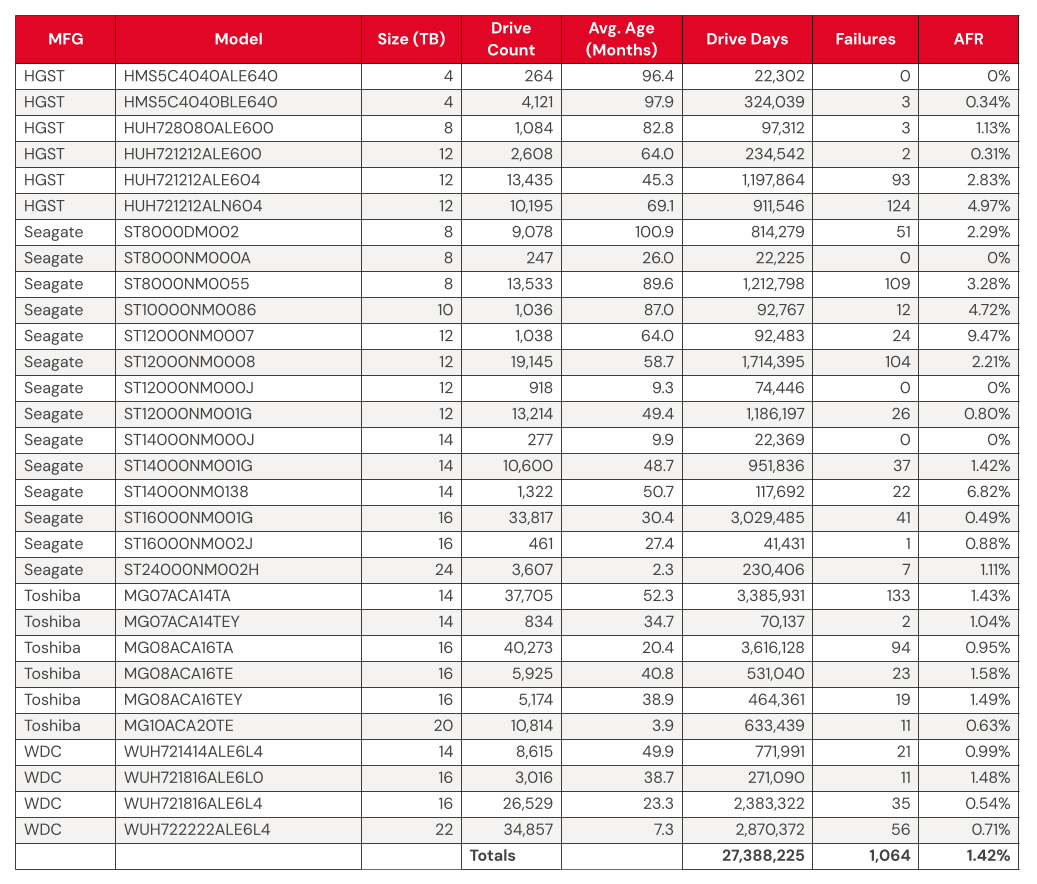
Q1 2025 hard drive failure rates
As mentioned above, at the end of Q1 2025, we were running 312,831 drives. During the quarter as a whole, however, we were monitoring a total of 318,426 drives; this count includes those that were taken out of service during the quarter, either because they failed or were only used temporarily.
We’ll discuss the criteria we used in the next section of this report. Removing these drives leaves us with 317,833 hard drives to analyze. The table below shows the annualized failure rates (AFR) for Q1 2025 for this collection of drives.
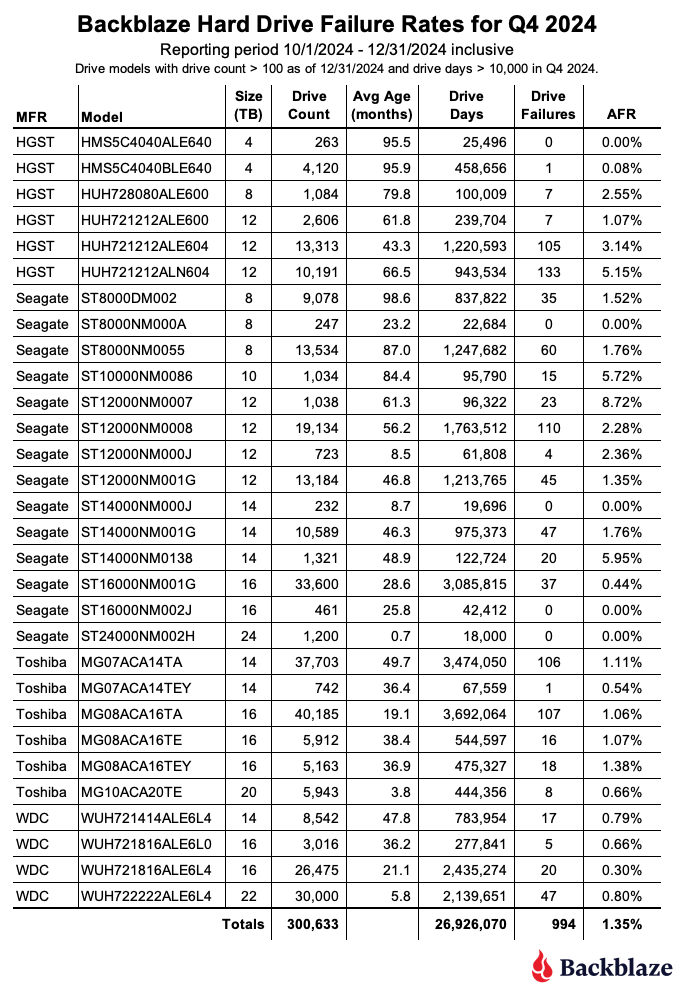
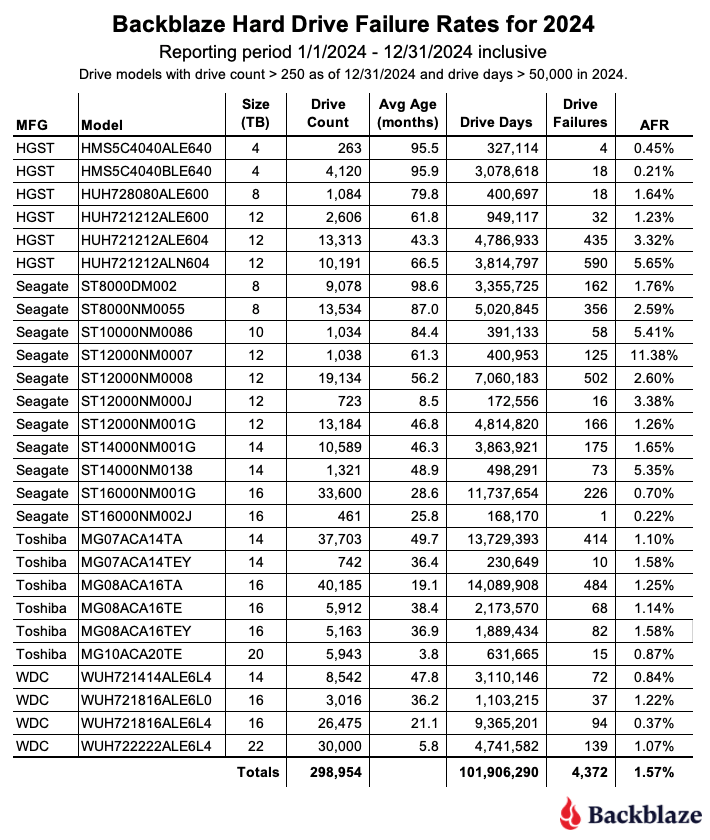
Backblaze Hard Drive Failure Rates for Q1 2025
Reporting period January 1, 2025–March 31, 2025 inclusive Drive models with drive count > 100 as of March 31, 2025 and drive days > 10,000 in Q1 2025.
Notes and observations
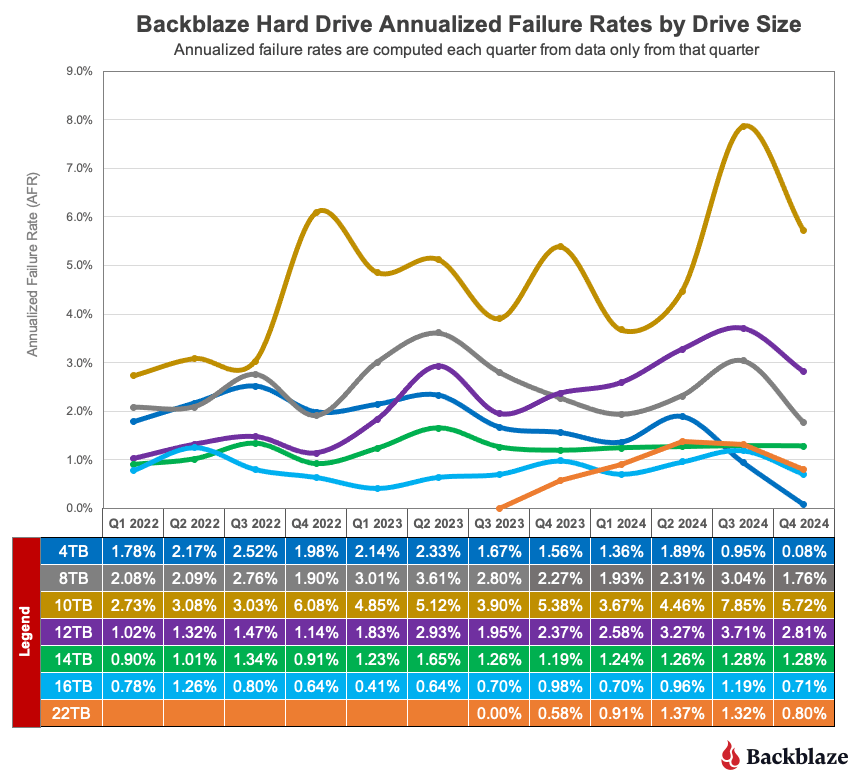
The 4TB drives are hanging on and finishing strong. Good news: We have another quarter’s worth of data on our beloved 4TB drives (though the planned migration is well underway). True to their history, the 4TB drives showed wonderfully low failure rates, with yet another quarter of zero failures from model HMS5C4040ALE640 and 0.34% AFR from model HMS5C4040BLE640.
Keeping an eye on the 20TB+ pool. The 24TB Seagate (model ST24000NM002H) no longer has a perfect record, with eight failures for the quarter. Still, the drives put up a respectable 1.00% AFR. Meanwhile, the 20TB+ drives as a pool are averaging a 0.72% AFR, coming in lower than the overall failure rates—always a promising sign.
Zero failures for the quarter. Four drives get a gold star for zero failures this quarter:
The 4TB HGST (model HMS5C4040ALE640)
The Seagate 8TB (model ST8000NM000A)
Seagate 12TB (model ST12000NM000J)
Seagate 14TB (model ST14000NM000J)
Three out of the four also had zero failures last quarter, all but the Seagate 12TB.
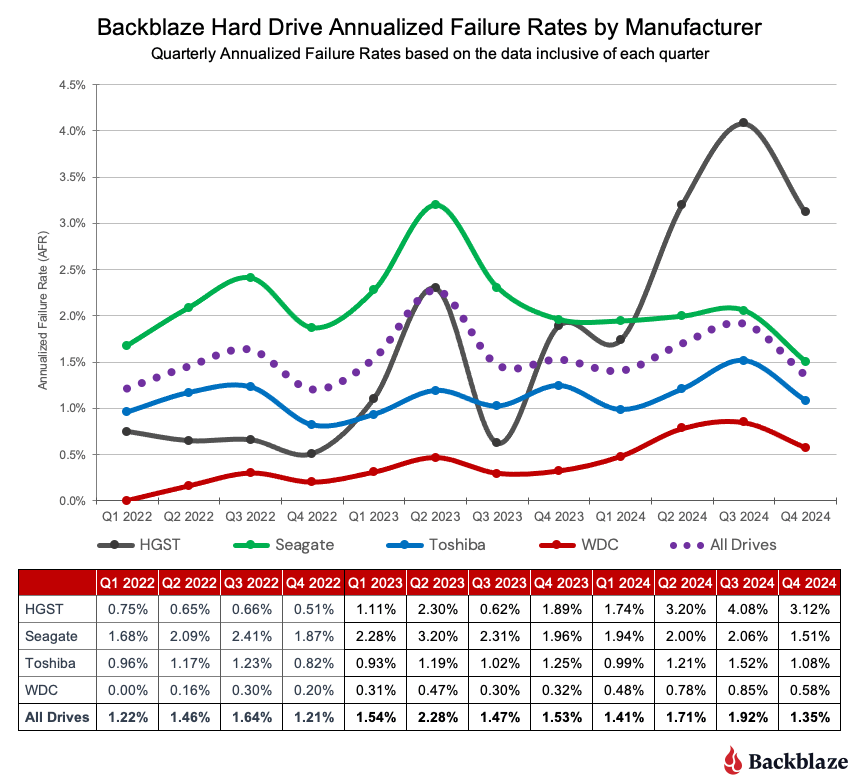
The quarterly failure rate is slightly higher. The quarterly failure rate went up from 1.35% to 1.42%. As with the zero-failure club, our higher-end outlier AFRs show some of the usual suspects:
We noted earlier we removed 593 drives from consideration when we produced the table above covering Q4 2024. There are two primary reasons we did not consider these drive models.
Testing. These are drives of a given model that we monitor and collect Drive Stats data on, but are not considered production drives at this time. For example, drives undergoing certification testing to determine if they are performant enough for our environment are not included in our Drive Stats calculations.
Insufficient data points. When we calculate the annualized failure rate for a drive model for a given period of time (quarterly, annual, or lifetime), we want to ensure we have enough data to reliably do so. Therefore we have defined criteria for a drive model to be included in the tables and charts for the specified period of time. Models that do not meet these criteria are not included in the tables and charts for the period in question.
Regardless of whether or not a given drive model is included in the charts and tables, all of the data for all of the drives we use is included in our Drive Stats dataset which you can download by visiting our Drive Stats page.
As with the Q4 quarterly results, we will apply these criteria to the annual and lifetime charts that follow in this report.
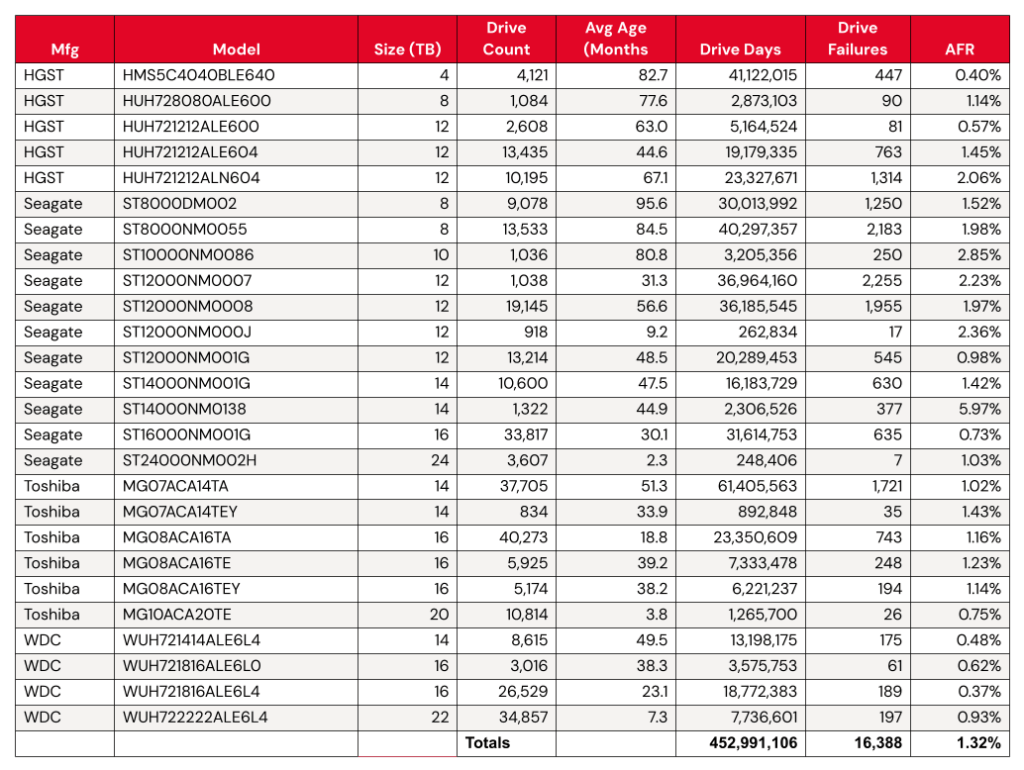
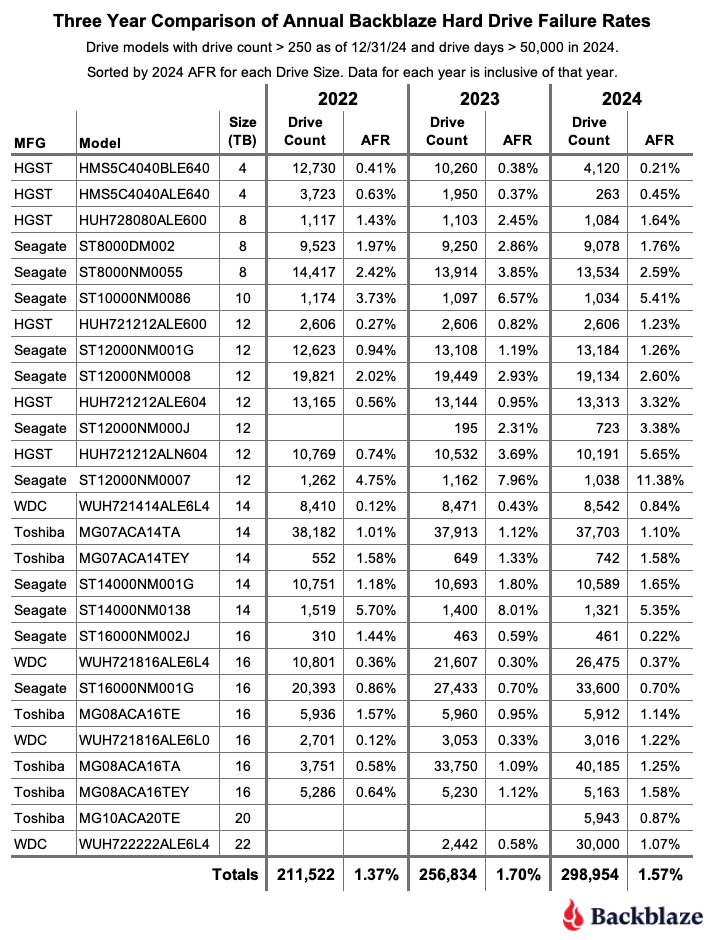
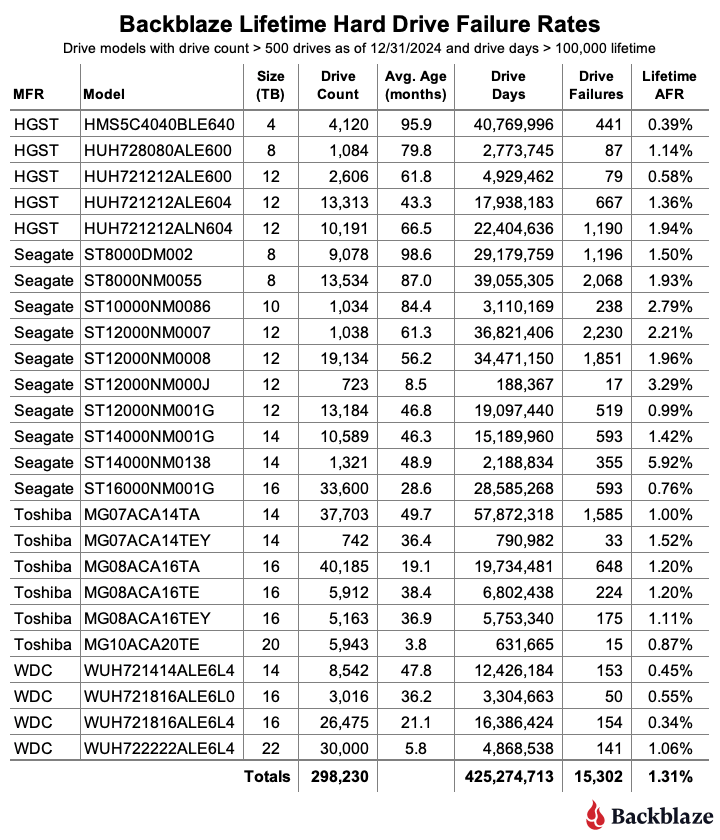
Lifetime hard drive failure rates
As of the end of Q1 2025, we were tracking 312,831 data hard drives. To be considered for the lifetime review, a drive model was required to have 500 or more drives as of the end of Q1 2025 and have over 100,000 accumulated drive days during their lifetime. When we removed those drive models which did not meet the lifetime criteria, we had 312,493 drives grouped into 26 models remaining for analysis as shown in the table below.
Backblaze Lifetime Hard Drive Failure Rates
Reporting period ending March 31, 2025 inclusive Drive models with > 500 drives and > 100,000 lifetime drive days
Notes and observations
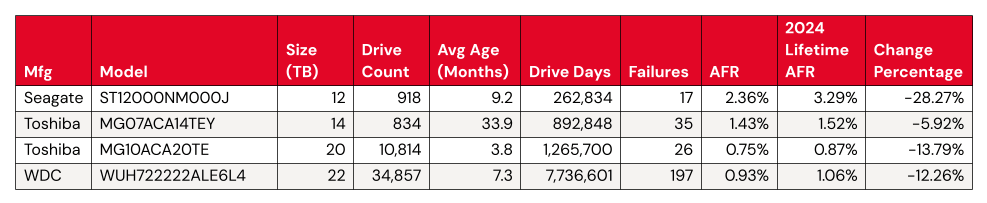
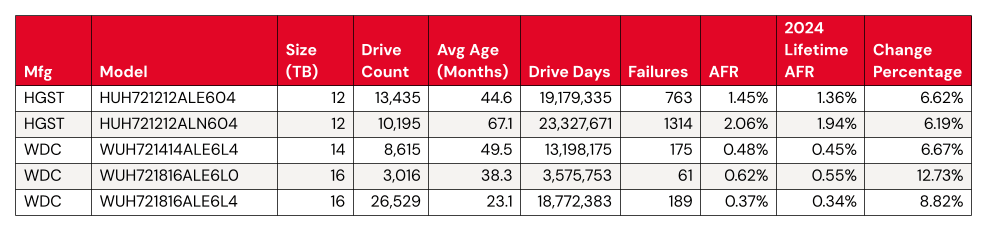
The lifetime AFR remains steady, despite some drives having significant change. We see virtually no change in our overall lifetime AFR, which we last tracked at 1.31% in the 2024 Year-End Drive Stats Report. But, with some drive models showing significant change in year-over-year AFR, it’s worth digging in a little deeper.
Statistically significant improved AFRs:
Both the 12TB and the 14TB had the same number of failures (or nearly so). Meanwhile, the Toshiba 20TB and WDC 22TB had more failures, but added a significant number of drives to the fleet. Both of these activities increase the number of drive days we tracked for the model’s drive pool, so these results are unsurprising.
Statistically significant worsened AFRs:
Meanwhile, we have a few things happening for the significantly worsened AFRs. The WDC drive models are all top performers from a failure perspective, even a change from .45 to .48 shows up in the numbers.
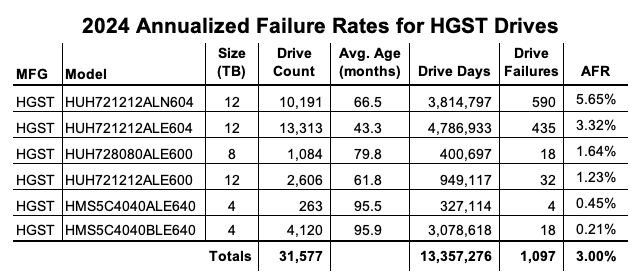
That leaves us with two HGST 12TB drives. Both come in above the average failure rate, at 1.45% (model: HUH721212ALE604) and 2.06% (model: HUH721212ALN604). We can give HUH721212ALE604 a pass—with the drive pool showing an average age of 67.1 months, or about five and a half years, it’s firmly on track with the expected pattern defined by the bathtub curve.
Where does that leave us with model HUH721212ALE604? We’ll keep an eye on it. Given that its AFR rate isn’t too far off from the total AFR of the Backblaze drive fleet, it’s not hugely concerning unless we see the rate of change continue.
What’s new with Drive Stats?
In taking on this report, our main focus was to ensure continuity with our decades-old dataset. That said, we also saw some opportunities to streamline the process of data collection, a continuation of the work that David Winings talked about in Overload to Overhaul: How We Upgraded the Drive Stats Data and Drive Stats Data Deep Dive: The Architecture. All of these things set us up for not just an easier time generating this report, but some bigger plans in the future. (We won’t tip our hand yet—but stay tuned.)
Drive Stats gets a Snowflake upgrade
When we first started tracking Drive Stats way back in 2013, data collection was very ad hoc. For the first few years, when Brian Beach was at the helm, we published stats once a year. When Andy took over in 2015, he moved to publishing quarterly data (starting in 2016). As the dataset grew, and Andy’s collection of lightweight desktop apps started to run out of steam, it became apparent that we needed to upgrade to more capable analytical tooling. For a variety of operational reasons, Andy was gamely running SQL queries against CSV data imported into a MySQL instance running on his laptop—and having to do a ton of manual data cleanup to boot. (Pun obviously intended.)
This year, with the help of our colleagues on the database engineering team (shoutout to Tom Roden—thanks so much!), we were able to get the Drive Stats data included in the Backblaze Snowflake instance. Gone are the days of us bugging folks for exports that take hours to process! We can run lightweight queries against a cached, structured table.
We started from Andy’s SQL queries and tweaked them a bit to match the logic and nomenclature of Snowflake fields. Once we had that worked out, the first thing we did was validate our methodology by running the Q4 Drive Stats numbers and comparing them to Andy’s—success.
It helps that Pat has experimented with our Drive Stats dataset in Trino and other analytical tools like Apache Iceberg, so it’s certainly not the first time he’s considered methodology and tooling for this problem. Going forward, we may further refine the process, but for now, the migration to Snowflake saved us a ton of time and manual data cleanup.
The Hard Drive Stats data
The complete dataset used to create the tables and charts in this report is available on our Hard Drive Test Data page. You can download and use this data for free for your own purpose. All we ask are three things: 1) you cite Backblaze as the source if you use the data, 2) you accept that you are solely responsible for how you use the data, and 3) you do not sell this data itself to anyone; it is free.
Good luck, and let us know if you find anything interesting.
When you’re moving exabytes of data, every network request, every CPU cycle, every byte matters. Recently, I had the chance to revisit a part of our system that’s been quietly humming along for years. With one small rethink, we helped give our download performance a serious boost.
The idea was almost laughably simple: combine two separate requests into one. But when you’re operating at massive scale, even a “simple” change can make a huge difference.
The challenge: Why we had 40 requests per download
Before the change, downloading a file meant:
A “download coordinator” pod would reach out across the 20 pods that make up a Vault to grab metadata.
Once it had those, it would figure out where the needed bytes lived.
Then it would go back and request the actual data.
That meant 40 separate requests just to get the ball rolling on every download.
The fix: Smarter reads with half the overhead
At some point, it clicked for me: why were we doing this in two steps? The original setup only pulled the bare minimum of data. But what if we just grabbed everything we needed at once? There wasn’t a good reason not to. So I refactored the process so that a pod could grab both the shard header and the data in a single request.
Now:
The coordinator still orchestrates the work.
The receiving pod reads the header, figures out what it needs, and pulls the data—all internally. By shifting this responsibility to the receiving pod, we eliminate a network round trip per pod—20 round trips in total.
The combined result is sent back to the coordinator in a single step.
After the fix, we’re still reading the same amount of data from disk, so disk I/O remains unchanged, but network performance improved significantly. Instead of kicking off 40 network operations, we’re down to about half that. Less traffic, less overhead, faster performance.
It was a simple fix, but the project required a significant amount of software engineering work as well. By shifting responsibilities to the “receiving pod” the coordinator needed to learn to perform lots of just-in-time reasoning about the nature of the download, which required rethinking how we architected portions of the download code.
Why it didn’t just instantly double download performance
If you’re thinking, “shouldn’t that make downloads twice as fast?”—not quite.
Here’s why: Big files get broken into “stripes” during download, and my change only optimizes the first stripe request. Smaller files (a big chunk of our traffic) see the full benefit because they often fit into a single stripe. For larger files, though, the improvement only affects a small part of the overall download, so the impact is more limited.
How we measured the impact
Measuring the real-world effect turned out to be trickier than I expected. Our download traffic isn’t steady; it’s spiky. Under normal conditions, our system wasn’t hitting capacity limits which made it hard to clearly see changes in download performance.
But in our dedicated performance testing environment, where we could send a controlled load of downloads, the improvement was crystal clear. With this change, our system could handle a much higher peak load—great news for handling things like backup surges, AI training runs, and large enterprise downloads.
Beyond download performance: System-wide benefits
One of the coolest side effects? This doesn’t just help customer downloads. It also speeds up internal operations like vault recomputing data drives and server-side copies.
By freeing up CPU cycles that used to be wasted on multiple requests, we open the door for better performance everywhere. And hey, maybe even some minor energy savings—less CPU load means less heat, less power.
What this taught me about optimization
When you’re trying to optimize a massive system, it’s tempting to chase performance with complicated solutions: more threads, smarter caches, fancier hardware.
But sometimes, the real win is just about thinking differently. Questioning assumptions. Asking, “Wait, why are we doing it this way?”
For me, this project was a great reminder that even at exabyte scale, the simplest solution can be the most impactful.
If you work with cloud storage and data lakes, you’re likely hearing the word “Iceberg” with increasing frequency, occasionally prefixed by “Apache”. What is Apache Iceberg, and how can you leverage it to efficiently store data in object stores such as Backblaze B2 Cloud Storage? I’ll answer both of those questions in this blog post.
But, first, join me on a brief trip back in time to the beginning of the twenty-first century, a long-ago time before the emergence of big data and cloud computing.
A timely shoutout to the Data Council conference
We recently attended the 2025 Data Council conference and caught Ryan Blue, co-creator of Apache Iceberg’s excellent presentation (featuring some very entertaining slides).
If you want to hear more about topics like this one, feel free to join us at Backblaze Weekly, an ongoing webinar series where we discuss all things Backblaze.
Ryan Blue speaking at the 2025 Data Council conference. Note: His shirt says “the future is open”. We agree!
CSV: The lingua franca of tabular data
In the early 2000s, if you were working with tabular data, you were likely using either a relational database management system (RDBMS), such as Oracle Database, or a spreadsheet, likely Microsoft Excel.
Data stored in an RDBMS is highly structured, meaning that it MUST conform to a predefined schema. For example, you might create an employee table with columns such as first name, last name, date of birth, hire date, and so on. The database schema holds metadata such as the name and data type of each column, whether that column must have a value, relationships between tables, and so on.
A spreadsheet, on the other hand, has some structure—data is arranged in rows and columns, similarly to an RDBMS–but each cell can contain anything: text, a number, a formula referencing other cells, even an image in today’s spreadsheets. We say that a spreadsheet is semi-structured data.
At the turn of the century, each database and spreadsheet had its own proprietary file format, optimized for its own requirements, and often not at all publicly documented, but the need to be able to exchange data between applications led to broad adoption of a file format to allow just that: comma-separated values, or CSV.
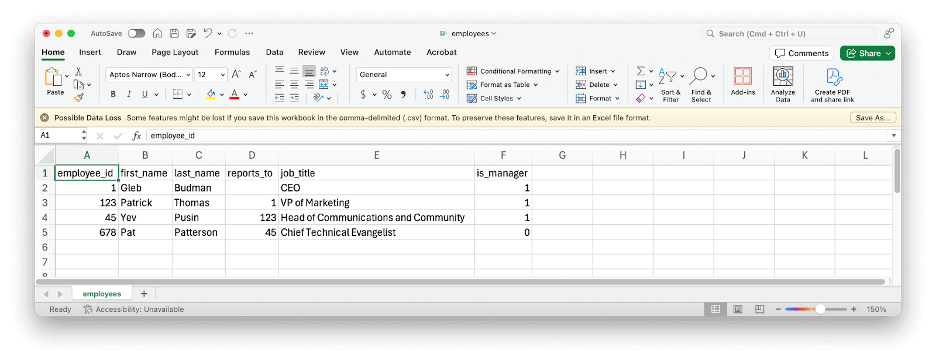
Here’s a simple example of some tabular data represented as CSV:
employee_id,first_name,last_name,reports_to,job_title,is_manager 1,Gleb,Budman,,CEO,1 123,Patrick,Thomas,1,"VP of Marketing",1 45,Yev,Pusin,123,"Head of Communications and Community",1 678,Pat,Patterson,45,"Chief Technical Evangelist",0
CSV is simple and flexible enough that it was easy for me to type that example up manually and import it into Microsoft Excel with no problems at all. Note that, as well as the commas, the double quotes in the CSV data are part of the file format, and do not appear in the imported data:
CSV has a lot of advantages: It’s simple; flexible; widely understood; the optional header line means that data can be somewhat self-describing; and it’s not controlled by any single vendor.
CSV does, however, also have a few disadvantages, including:
There’s no schema; nothing in that file expresses that the values in the first column, apart from the header, must be integers.
It’s difficult to represent complex or hierarchical datasets.
Data is stored as text, which is inefficient for numerical and repetitive data. Text representations of numbers occupy more storage than binary, and applications must convert them to binary when loading the file and convert them back to text when saving it.
Avro, Parquet and ORC: File formats for big data
The emergence of open-source distributed computing frameworks such as Apache Hadoop and, later, Apache Spark, in the first two decades of this century drove the creation and adoption of more efficient ways of storing tabular data. Avro, Parquet and ORC, all Apache projects, are binary file formats that address shortcomings of CSV, such as encapsulating schema alongside the data.
Avro, like CSV, is designed for row-oriented data, which makes it well-suited to use cases that involve appending new data to files. Parquet and ORC, in contrast, are column-oriented file formats, perfect for online analytical processing (OLAP) use cases where, for example, an application might read an entire column from a table to calculate the sum of its values. As well as storing numbers in a binary representation, Parquet and ORC can also reduce file size through compression strategies such as run-length encoding.
Here’s a concrete example: The Drive Stats data set for December 2024 occupies 3.7GB of storage in CSV format. As Parquet, the same data consumes just 242MB, a data compression ratio of more than 15:1.
Why does it matter if your dataset is smaller? Well, beyond just cost savings, which are amplified when dealing with huge datasets, smaller files mean that running queries against full datasets takes less time, which reduces server load, compute costs, and so on.
From file formats to table formats and data lakes
Apache Hadoop’s original use case was as an implementation of MapReduce, a programming model for manipulating large datasets. Engineers at Facebook, tasked with allowing SQL queries over datasets generated by Hadoop, created Apache Hive, and, with it, the Hive table format, which specified how to view a collection of files as a single logical table. The Hive table format in turn allowed organizations to create data lakes, repositories that store structured and semi-structured data in their original format for analysis by a wide range of tools, and, later, data lakehouses, which aim to combine the benefits of data lakes and traditional data warehouses by storing structured data using data lake tools and technologies.
A key concept of the Hive table format is partitioning, a way of organizing files to reduce the amount of data that must be read to process a query. Taking the Drive Stats dataset as an example, we can partition the files by year and month, so that each file has a prefix of the form:
/drivestats/year={year}/month={month}/
For example:
/drivestats/year=2024/month=12/
With this partitioning scheme, a system processing a query for hard drive statistics for, say, December 12, 2024, need only retrieve files with the above prefix. You might be wondering, “Why not partition the data on day, also, to further reduce the number of files that must be retrieved?” The answer depends on the data volume and access patterns. It’s much more efficient to partition data into fewer large files than many small files, so overly granular partitioning can actually impair performance.
It’s worth mentioning that file formats and table formats are largely independent of each other. You can use Avro, Parquet, ORC, or even CSV files with the Hive table format.
While the Hive table format served the big data community well for several years, it had a number of shortcomings:
Every query incurs a file list (“list objects”, in S3 API terms) operation, which is particularly expensive with cloud object storage, both in terms of time and API transaction charges.
Deleting or modifying data typically implies rewriting an entire data file, even if only a single row was affected.
Hive can only partition datasets on columns that are in the table schema. For example, the Drive Stats data set includes a date column, so to use it with Hive, we had to create additional, redundant, year and month columns.
Any changes to the data schema or partitioning strategy require affected files to be rewritten, making schema evolution problematic, if not infeasible, for large datasets.
As a result, vendors and the broader big data community formed a number of projects to define new table formats to succeed Hive, including Apache Iceberg, Apache Hudi, and Delta Lake, a Linux Foundation project.
Iceberg‘s features allow it to be used to organize huge data sets, efficiently and flexibly:
Table metadata including the list of files that comprise a table is stored as JSON data alongside the data files, eliminating the need to run an expensive list object operation for every query.
Schema evolution allows you to add, drop, update, or rename columns.
Hidden partitioning decouples partitioning from the table schema. For example, you can partition data like the Drive Stats dataset by year and month based on the existing date values, without creating additional columns.
Partition layout evolution allows you to modify your partitioning strategy as data volume or access patterns change.
Time travel allows you to query table snapshots.
Serializable isolation provides atomic table changes, ensuring readers never see inconsistent data.
Multiple concurrent writers use optimistic concurrency, retrying to ensure that compatible updates succeed while detecting conflicting writes.
Iceberg is widely supported across the big data ecosystem, with many applications and tools allowing you to store Iceberg tables in S3 compatible cloud object storage such as Backblaze B2. In this article, I’ll look at the simplest use case, running queries against the Drive Stats dataset, with three representative examples: Snowflake, Trino, and DuckDB.
Writing Iceberg data to Backblaze B2
I wrote a simple Python application, drivestats2iceberg, using the PyIceberg library, that converts the Drive Stats dataset from the zipped CSV files we publish to Parquet files in an Iceberg table stored in a Backblaze B2 Bucket. There are some useful techniques in drivestats2iceberg, and it is published on GitHub as open source, under the MIT license, so feel free to use it as a starting point for your own data conversion apps.
Querying Iceberg tables in Backblaze B2 from Snowflake
Snowflake is a data-as-a-service platform addressing a wide variety of use cases, including artificial intelligence (AI), machine learning (ML), collaboration across organizations, and data lakes.
As I mentioned above, Snowflake announced general availability of its Iceberg tables offering in June 2024, allowing you to manipulate Iceberg tables located on external volumes, outside your Snowflake warehouse, and query them alongside data in Snowflake-managed tables.
Snowflake’s Iceberg implementation is quite complicated, with different capabilities according to your choice of cloud object storage provider and whether you want Snowflake to manage your Iceberg catalog or use a catalog integration.
For our simple use case, where the Iceberg metadata and data files already exist in a Backblaze B2 Bucket, the first step is to create a Snowflake external volume, configuring it with suitable credentials and the location of the Drive Stats data.
Note: the application key shown in this Snowflake statement has read-only access to the drivestats-iceberg bucket. You can use it to query the Drive Stats data set from your own Snowflake instance or from other environments.
Next, you must create a catalog integration. The object store catalog integration simply reads Iceberg metadata from an external (to Snowflake) cloud storage location:
Now you can create an Iceberg table object that references the existing dataset. Note that Snowflake requires you to explicitly specify the metadata file to use for column definitions; this is typically the most recently created JSON file under the metadata prefix.
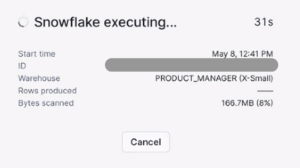
My x-small Snowflake warehouse executed the first three queries in a fraction of a second. As you might expect from its additional complexity, the last query took longer: 16 seconds.
Querying Iceberg tables in Backblaze B2 from Trino
To access the Drive Stats data set from Trino, you must configure its Iceberg connector with a catalog properties file. For example, to configure a catalog named drivestats_b2, create a file etc/catalog/drivestats_b2.properties:
Note that the above configuration file uses the same read-only credentials as the Snowflake example. You can use this configuration file as-is to explore the Drive Stats dataset using Trino.
Start the Trino server and CLI, then create a Trino schema with the location of the data, and set it as the default schema for subsequent queries:
CREATE SCHEMA drivestats_b2.ds_schema WITH (location = 's3://drivestats-iceberg/'); USE drivestats_b2.ds_schema;
The Trino Iceberg connector provides the register_table procedure for registering existing Iceberg tables into the metastore. Optionally, you can provide an additional metadata_file_name parameter if you wish to register the table with some specific table state, or if the connector cannot automatically figure out the metadata version to use.
Since you can query the table using the exact same SQL queries as in the Snowflake example, producing the exact same results, I won’t reproduce them here. Running Trino in a Docker container on my MacBook Pro, the first three queries executed in less than three seconds, the fourth took just over a minute.
Querying Iceberg tables in Backblaze B2 from DuckDB
DuckDB is an open-source column-oriented RDBMS, intended for in-process use: embedded in applications. There are DuckDB client APIs (also known as drivers) for many programming languages, including Python, Java, JavaScript (Node.js) and Go.
DuckDB is focused on the same kinds of use cases as Snowflake and Trino; it is effectively the OLAP equivalent to SQLite, which targets online transaction processing (OLTP) workloads.
To work with Iceberg tables in cloud object storage, you must install and load the httpfs and iceberg DuckDB extensions:
Now, you need to create a secret with your Backblaze B2 credentials.
Again, the application key shown here has read-only access to the Drive Stats dataset; you can use it to explore the data yourself if you like.
CREATE SECRET secret ( TYPE s3, KEY_ID '0045f0571db506a0000000017', SECRET 'K004Fs/bgmTk5dgo6GAVm2Waj3Ka+TE', REGION 'us-west-004', ENDPOINT 's3.us-west-004.backblazeb2.com' );
By default, queries against Iceberg tables in DuckDB use a SELECT ... FROM iceberg_scan(...) syntax, but you can define a schema and a view so that you can use the same SQL queries as with Snowflake and Trino:
First, a schema:
CREATE SCHEMA ds_schema; USE ds_schema;
Then, a view:
CREATE VIEW drivestats AS SELECT * FROM iceberg_scan( 's3://drivestats-iceberg/drivestats', version = '?', allow_moved_paths = true );
Note: the version = '?' parameter tells DuckDB to examine the table’s metadata files and “guess” which one corresponds to the latest version. This behavior is not enabled by default, so you must set unsafe_enable_version_guessing to true before you query the data, like this:
SET unsafe_enable_version_guessing = true;
That done, you can query the table using the exact same SQL queries as with Snowflake and Trino, with the exact same results. With DuckDB on my MacBook Pro, the first three queries took about 15–25 seconds; the fourth about 90 seconds.
Note that Snowflake, Trino and DuckDB are very different systems, with different trade-offs between cost, performance, and flexibility. I’ve included the execution times I saw to set your expectations when working with these tools, rather than as a point of comparison between them.
What’s next for Apache Iceberg?
Apache Iceberg is much more than a table format specification; it’s a broad, thriving ecosystem that is constantly innovating new features, tracking progress via its own GitHub repository. Here are a few technologies that are currently in active development:
Variant Data Type Support will offer a more efficient, versatile approach to managing hierarchical, JSON-like data, aligning with Apache Spark’s variant format.
Materialized Views will allow you to define a view as you usually would, in terms of a query against one or more existing views or tables, that is able to store data, like a table. On creation, the materialized view is populated with data and functions as a cache, serving its data in response to queries. The materialized view can be periodically refreshed to keep it in sync with its sources.
Geospatial Support will add Iceberg-native data types and operations storage and analysis of geospatial data, allowing you to define columns as points, lines and polygons, and use conditions such as “intersects” in queries.
I’ve only scratched the surface of Apache Iceberg in this blog post. Stay tuned for deeper dives into using Snowflake, Trino, DuckDB and more platforms and tools with the Iceberg table format and Backblaze B2 Cloud Storage.
If you’re wrangling massive datasets for AI, machine learning (ML), high-performance compute (HPC), content delivery networks (CDNs), or analytics, you’re familiar with the trade-off: Pay a premium for the highest speeds, or compromise on performance to keep costs manageable.
Backblaze B2 Overdrive changes that. You can now move exabyte-scale datasets at up to terabit speeds without the eye-watering price tag. Starting at $15 per terabyte per month, Backblaze B2 Overdrive gives you the power to run data-intensive workloads at peak performance, with unlimited free egress and private networking options that keep things fast, secure, and predictable.
See it in action
Join our upcoming webinar with Pat Patterson, Chief Technical Evangelist and Dave Ngo, Chief Product Officer, to learn more about how B2 Overdrive supercharges your data.
What makes B2 Overdrive different?
B2 Overdrive offers a specialized cloud object storage solution at a fraction of competitors’ costs. Here’s what you get:
Up to 1Tbps throughput: In other words, the kind of speed that lets you move petabytes of data fast without complex architecture.
Unlimited free egress: Move as much data as you want, whenever you want, to wherever you want. Egress is totally free.
Private networking support: Transfer data at maximum speed through secure private networking connections to your infrastructure.
It’s built on the foundation of our always-hot cloud storage infrastructure, with no minimum file size requirements, no deletion fees, and powerful features like Event Notifications so you can build responsive and automated workflows. We’ll be sharing some of the innovations under the hood in the coming months—so, stay tuned to our series on the engineering behind performance.
Who’s it for?
The simple answer: The status quo isn’t cutting it. Today’s workloads demand both the ability to move massive datasets and predictable economics that don’t penalize success. B2 Overdrive challenges the assumption that mind-bending performance has to come with mind-boggling prices.
We need to store an insane amount of data and, at the same time, download it to different GPU clusters around the world, and for all that to not cost an insane amount of money. That’s why we chose Backblaze.
—Dean Leitersdorf, CEO and Co-Founder, Decart
Ready to go?
Backblaze B2 Overdrive is generally available today for organizations with multi-petabyte storage instances and workloads.
Want to learn more or see if it’s the right fit for your team? Get in touch with our Sales team—we’d love to talk about how we can help you ditch the trade-offs and go full speed ahead.
You’ve always had insight into the buckets in your B2 Cloud Storage account, and now you can go deeper. With Bucket Access Logs, it’s possible to see a detailed record of operations performed against objects inside of a bucket. Whether you’re managing a growing archive, running audits, or troubleshooting automated workflows, these logs can provide the transparency needed to stay in control.
Starting today, Bucket Access Logs are available in limited preview. If you are interested, reach out to Support for more information.
What you can track with Bucket Access Logs
Once enabled, Bucket Access Logs record a range of operations performed on the objects in a bucket. That includes:
Every log entry includes details like the timestamp, operation type, and the object involved. If you’ve ever wished you had a record of what happened—and when—it’s now within reach.
Easy to configure: User interface (UI) and APIs
Bucket Access Logs are fully S3 compatible. You can configure logging through the Backblaze B2 web UI or programmatically via the S3 API using standard tools or SDKs. This makes it easy to integrate logging into your existing workflows and infrastructure without needing to learn anything new.
Because B2’s Bucket Access Logs are S3 compatible, your existing S3 log management tools will work seamlessly with B2 Logs. This allows you to use the same tools and processes you already have in place for monitoring, analyzing, and storing logs.
Important: Don’t enable access logging on the same bucket that you use as the log destination. This can result in an endless loop of logs generating more logs.
Once configured, you’ll begin to see new log objects arrive in the destination bucket as activity occurs in the source bucket. From there, you can analyze, archive, or pipe the data into other systems for further processing.
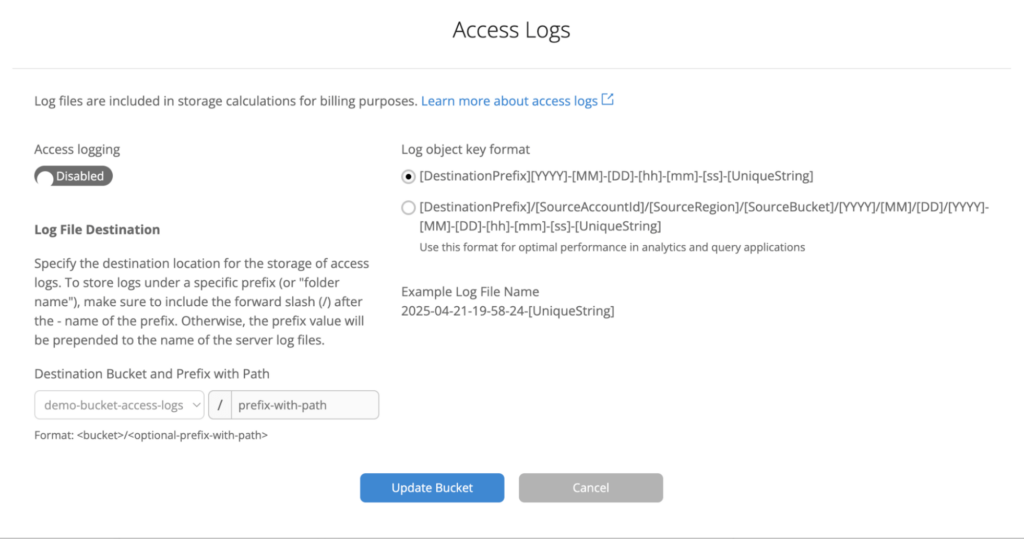
Preview: Configuring Bucket Access Logs in the UI
Here’s a preview of how you will be able to configure Bucket Access Logs via the user interface:
This simple, intuitive interface lets you easily configure your logging settings, choose a destination bucket, and start tracking operations on your objects. Once enabled, you’ll have access to the logs directly in the destination bucket, with the details you need to monitor and analyze your data access patterns.
Use cases for Bucket Access Logs
Bucket Access Logs unlock a broad set of security, privacy, and operational workflows. Here are just a few examples of how you can use them:
1. Security and privacy monitoring
Organizations storing sensitive data—like security footage, personal files, or customer assets—often need detailed audit trails for compliance and accountability.
Log object access activity through pre-signed URLs and correlate access with specific users.
Track access times, IP addresses, and user actions to meet reporting requirements or identify suspicious behavior.
Detect potentially compromised application keys by analyzing activity patterns without disrupting all keys in use.
Enforce privacy policies by monitoring the source IP addresses of requests and verifying they match allowed sources.
Analyze latency and bandwidth metrics across object access requests to optimize data delivery.
2. Infrastructure and traffic control
When storage access is tightly integrated with content delivery networks (CDNs) or other network layers, it’s important to confirm that traffic flows through the correct paths.
Validate that object uploads originate only from approved CDNs or endpoints, not directly from unauthorized sources.
Detect misconfigurations early by comparing traffic origins to expected network patterns.
3. Usage tracking and audit trails
Understanding how data moves through your system can help with cost management, client reporting, and internal transparency.
Monitor object uploads and deletions that impact billing to better forecast and control storage costs.
Maintain a historical record of object activity for clients or partners who require verifiable data access trails.
Troubleshoot issues in automated workflows by reviewing the sequence of operations on specific objects.
Across these use cases, a common thread emerges: the need to know when, what, and where for activity happening inside your buckets.
Get started with Bucket Access Logs
Bucket Access Logs are available today in preview. To try it out, contact Support for more information.
For more detailed instructions and guidance on configuring and using Bucket Access Logs, check out the official Bucket Access Logs documentation.
Whether you’re building for compliance, monitoring security, or just want better observability into your workflows, Bucket Access Logs give you the visibility you need—right where your data lives.
When you’re operating a data storage platform at exabyte scale, even small inefficiencies become big problems. With billions of files flowing through our systems, performance isn’t something we think about after the fact—it’s something we constantly chase, measure, and optimize.
But before you can improve cloud performance, you have to know where to look. When we were working on improving small file uploads, I was tasked with taking a closer look at our file upload pipeline to see if we could make it faster.
The path from that general idea to hitting a clear performance goal taught me a lot—not just about our systems, but about how to approach performance work in a principled, strategic way. Here’s how it unfolded, and what you can apply to your own environment.
Step one: Define the problem
The initial ask from our Product team was pretty familiar: “Can we make uploads faster?” It’s a fair question, but not a very actionable one. So we worked with our Product team to define our success criteria. Here are some of the questions we asked to get to specific, actionable goals:
“What do we mean by faster? Do we want to improve latency or throughput?”
“Do we want to improve all uploads? Just big files? Just small files? “What qualifies as a small upload?”
After some back and forth, we landed on a clear, measurable target: Process file uploads of 1MB or less via our B2 API in under 40 milliseconds. That specificity made a huge difference:
With a goal of 40 milliseconds, we had a stopping point. We would know when we’d done enough.
We had a bar to measure against and a way to identify what was worth optimizing. If something took two milliseconds, we could leave it alone. If it took 30, it became the focus.
We could scope effort. There’s a big difference between getting something under 40 milliseconds versus 200.
Step two: Use the right tools for the job if you possibly can
Analyzing performance without proper tooling means doing a lot of heavy lifting by hand. We had to drop custom instrumentation throughout the stack, create metric-collecting objects, and pass them all the way down the call stack so we could get timing data from different parts of the upload path.
The upload flow touches more than 20 storage pods and services, so we also built a lightweight sampling system to keep from flooding our metrics pipeline. The data went into an open-source search and analytics suite, and from there we built dashboards to try to make sense of it all.
It was time-consuming. Painfully so. But it worked.
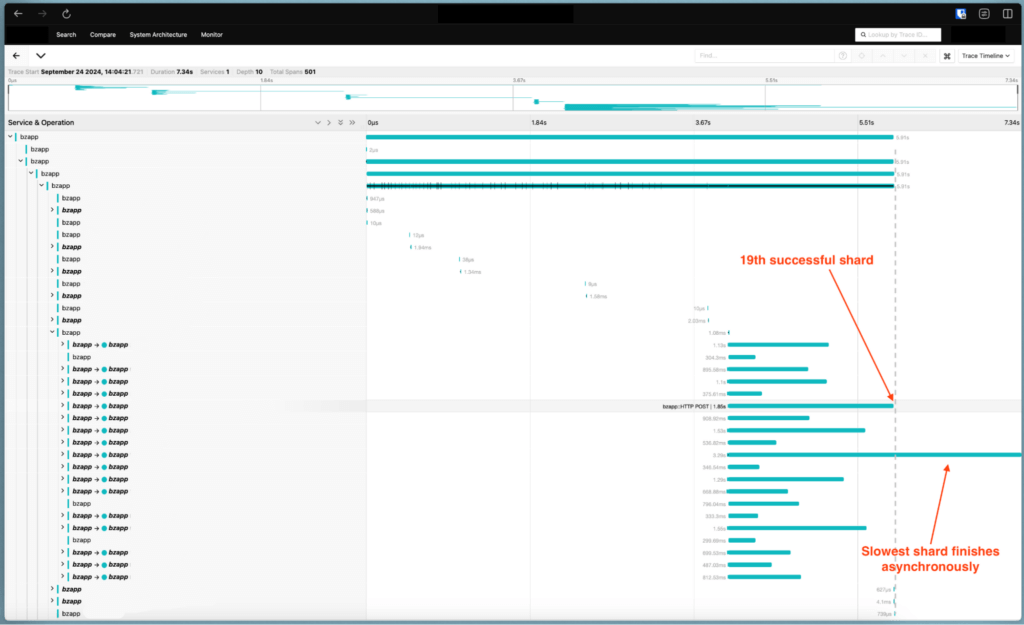
I could now compare fast and slow uploads, identify patterns, and—most importantly—see where time was actually being spent. That’s how we discovered that fsync was dominating our performance profile, captured in the screenshot below. We measured each sub-operation that comprises our drive write operations, and grouped them by the total time they took to complete. You can see the process fsync sub-operation dominates in every group. Removing or optimizing around it offered a 10x speedup. But it took weeks of manual effort to get to that insight.
Drive write operations grouped by the time they took to complete.
Enter: Tracing at scale
Eventually, we brought in more powerful tooling, including an open source distributed tracing system. It was a game changer.
What used to take dozens of lines of code and a lot of custom wiring now took a single annotation. More importantly, it gave us something we couldn’t get otherwise: a way to see activity across services, systems, and pods—all in one view.
It allowed us to correlate events happening across different physical machines, trace performance end-to-end, and understand the impact of specific changes in real time.
At one point, we were debating whether a particular optimization would get us across the finish line. This optimization allows the slowest shard to store asynchronously if and only if all others had been successfully and durably stored. This prevents a single slow shard from slowing down the entire upload. Thanks to the new tooling, we didn’t have to guess—we could see that once we flipped the switch, we’d hit our 40ms goal (and it would help all other uploads as well, not just small uploads). That let us focus on getting that one feature ready for production, confident that it would move the needle.
Visualization demonstrating one of our upload optimizations, this time for a slower upload. The first 19 shards to complete were stored successfully and durably, so we stop waiting for the last shard, return a 200 status code to the customer (indicated by the dotted line), and allow the 20th shard to finish asynchronously.
Step three: Optimize with intent
One of the biggest lessons I learned through this process is that you can spend weeks optimizing the wrong thing if you’re not careful. That’s why measurement has to come first.
Don’t guess. Instrument. Don’t tweak randomly. Set a baseline and track deltas. Performance work is iterative. You’ll fix one bottleneck, only to reveal the next one lurking beneath it. That’s the job.
In hindsight, one of the smartest things we did was setting a clear performance goal at the start of the project. It didn’t just help us focus—it told us when we were done. You can optimize forever. Knowing when to stop is just as important as knowing where to begin.
Step four: Tool up for the future
The tracing tool has made life a lot easier, but it’s not the only tool we use. Our analytics suite still plays a big role when we want to analyze aggregate data, or need the flexibility to slice and dice data. The two complement each other nicely.
There’s no one-size-fits-all solution—it’s more like a toolbox. And like any good toolbox, it keeps growing with our needs.
Advice from the trenches
If you’re running distributed systems or chasing performance in your own stack, here’s what I’d suggest:
Start with a clear goal. Know exactly what “faster” means, and write it down.
Measure before you optimize. Otherwise, you’re flying blind.
Pick the right tool for the job. Tracing, metrics, logs—they all have their place.
Don’t wait to build your tools. Invest in observability early.
Know when to stop. The ROI of performance work diminishes fast if you’re not careful.
And maybe give your helper methods better names than DoSomeWork. Or don’t. It makes the code reviews a little more entertaining.
AI is rewriting the rules of technology, for better or worse. Arguably one of the most “for better and worse” areas? Ransomware. It’s a full blown billion dollar business, and AI is supercharging both the offense and defense.
Not only are we seeing AI give bad actors more sophisticated tools and campaigns to target business and consumers alike, we’re also seeing mitigation techniques and technologies deployed by good actors gain equally compelling AI-powered improvements.
In other words, welcome to the future—where your data is the hostage and the bots are negotiating. Let’s dig in.
Some stage-setting: How much is ransomware costing us?
Despite ransomware payments exceeding an eye-watering $1 billion in 2023—and despite some high profile attacks in 2024, one of which extracted $75 million from a single victim—ransomware attacks actually fell overall in 2024. High profile law enforcement activity, like those against LockBit and BlackCat contributed to a huge drop in the second half of 2024.
Don’t get too excited though: According to cryptocurrency tracing firm Chainanalysis, that still meant $814 million in 2024. And, the true cost of ransomware includes more than just payments extracted under threat.
The economic ripple effects of a ransomware attack can include losing C-level talent, having to lay off employees, and ongoing downtime or business closure. Industry-wide, cyber insurance is a growing industry, and 2024 saw a staggering 31% of claims come from third-party risk.
Perhaps most concerningly, ransomware attackers are increasingly using exfiltration as a tactic to double and triple extortion, even using exfiltration data to launch targeted distributed denial-of-service (DDoS) attacks. According to a Check Point’s 2025 Cyber Security Report, some new actors have emerged as exclusively “data-selling platforms,” hosting dedicated data leak sites (DLS) and negotiation platforms.
The good news
Machine learning (ML) tools have underpinned modern cyber security techniques for years now—with excellent results.
Sophisticated monitoring tools give us far more granular insights and alerts.
AI-driven behavioral analysis is making it easier to detect anomalies and preempt attacks before they escalate.
What does this mean for defending against ransomware attacks?
Enterprises now have access to security platforms that analyze network behavior in real time, flagging unusual access patterns or lateral movement before a full ransomware payload can deploy. These platforms rely on machine learning models trained on massive datasets of known attack vectors, which allows them to flag and quarantine suspicious activity with impressive accuracy.
The interesting thing is that common knowledge says that “the AI revolution” has been happening recently, and quickly. But, when it comes to cybersecurity defense, many tools have been using ML algorithms for at least two decades. Palo Alto Networks (WildFire), for example, has been using ML since 2003.
The line between “processing massive datasets and acting up on that info based on programmed parameters” and machine learning is subtle, but important. While the former follows set parameters, machine learning identifies patterns in data—sometimes with human guidance—to decide from multiple possible actions.
It’s like teaching an assistant a series of tasks they can eventually do on their own. When you think about the progression from basic automation to ML, AI, and deep learning, the shift from rule-based actions to autonomous, chained decisions starts to make a lot of sense.
Zero trust architecture, enhanced by AI, is also gaining momentum. Instead of relying on perimeter-based defenses, AI-enhanced systems enforce granular access controls and continuously verify user and device trust levels. In practice, what this means is that systems no longer assume that you are you on the other end—not without evidence. Combine this with real-time threat intelligence sharing and automated incident response, and enterprises can shorten the window between detection and mitigation drastically.
The bad news
Deep fakes are more convincing.
The ability to generate code means there are more attacks, and those attacks are more sophisticated and responsive.
Cyber criminals of all skill levels have access to more technical tools, including some that are specialized in malware.
Enterprises are adjusting to a new way of working, which can create vulnerabilities.
Generative AI, phishing, and deep fakes
The low-hanging fruit in this discussion is that it’s easy to use generative AI to create more convincing phishing attacks. In the past, bad grammar or non-localized language choices have been an easy way to quickly identify a phishing attack.
Assisted by generative AI, deep fakes of both the voice and video flavor are getting increasingly difficult to spot—so, while you know your CEO isn’t likely to text you to get a bunch of gift cards or send them company funds via Bitcoin or PayPal, you might believe a video of your CFO or a call from your CEO asking you to transfer funds to accounts that turn out to not be legitimate.
How is generated code being used by ransomware bad actors?
Just as generative AI models have made everyone a poet, they’re also widely used to generate code. Tools like GitHub Copilot have seen wide adoption amongst enterprises looking to generate and test code. Gartner reports that by 2027, 70% of professional developers will use AI-powered coding tools, up from less than 10% in 2023.
Given how AI code generation has made code generation easier on enterprises, it’s no surprise that the ransomware industry is following the same adoption trends. By January 2023, this had gone from a hypothetical to a reality, with ransomware bad actors of low levels of technical skill able to leverage LLMs to create malware scripts.
By July 2023, cybercriminals were already discussing WormGPT, a malicious chatbot trained on ChatGPT which removed standard guardrails against creating illegal or inappropriate content. And, cybersecurity protection firms had executed a proof of concept to demonstrate that AI could generate truly polymorphic code on the fly—a technique used to make it much easier to evade detection by antivirus programs. By July 2024, one study showed that ChatGPT 4 was able to exploit 87% of one-day vulnerabilities.
Couple that with the fact that ransomware bad actors have opposite success metrics vs. enterprises. Cyber criminals rely on enacting as many attacks as possible, and it only takes one of those attacks succeeding to see a significant upside. Enterprises, on the other hand, only need one failure to see a huge negative impact on their businesses.
What things can you implement to be ransomware ready?
Some of these recommendations are things that users can do on every platform they interact with, such as:
Creating good, strong, unique passwords, and preferably using a password manager: A good password manager reduces password reuse and helps ensure best practices are followed enterprise-wide.
Enabling multifactor authentication (MFA): Multi-factor authentication remains one of the strongest lines of defense, especially when paired with device verification and biometric options.
On the enterprise side of the house, frameworks like cyber resilience help teams protect data they’ve been entrusted with. And, AI-powered cyber security tools can be a powerful tool in any business’s toolbox. That can look like a number of different things, including:
Investing in AI-powered endpoint detection and response (EDR). These tools continuously monitor and analyze endpoint activities, flagging unusual behavior and isolating threats automatically.
Training teams on recognizing deep fakes and AI-enhanced phishing attempts. Security awareness training is evolving fast. Focused, frequent, and AI-aware sessions are critical for employees across departments.
Leveraging deception technology. Deploying decoy systems, fake credentials, and honeypots can help trap attackers early and gather valuable intel on their tactics.
Running tabletop simulations. Practicing breach scenarios—especially those involving AI-enabled threats—prepares teams to act decisively when seconds matter.
Cyber resilience isn’t static, and neither are the tools and tactics. One of the most important areas an enterprise can invest in is ongoing security and research. Enterprise leaders need to prioritize proactive measures. That means ongoing AI model audits, being nimble in response to new and changing best practices, and investing in cross-functional teams that bring together infosec, legal, and operational leadership.
The future of AI and ransomware
Let’s level with each other—separately, the AI and ransomware spaces are both changing quickly. When you combine AI and ransomware and try to define how they’re affecting each other, you’re on pretty slippery ground.
What we’re trying to do here is identify patterns that affect our everyday lives—but we’re also taking a peek at what folks are studying in the research realm, because quantum is just around the corner, and, frankly, too impactful to ignore.
So, tell us if we need an update, or if you have another opinion! The comments section is open and we’re happy to chat.
At Backblaze, we’re in the business of building a storage platform that can handle billions of operations a day—reliably, predictably, and fast. That means digging deep into low-level architecture, optimizing what most people overlook, and constantly balancing trade-offs between performance, cost, and scale.
Today, we’re kicking off a new blog series that showcases the platform-level work our Engineering team has been doing to build and run a modern cloud storage platform. The kind of work that usually stays buried in Jira tickets and internal docs, but that makes all the difference when you’re serving exabytes at scale.
What it really means to build a modern cloud storage platform
When people talk about cloud storage, they usually focus on capacity, availability, and price. This includes the systems, tools, and architectural decisions that enable our infrastructure to scale reliably while handling billions of operations per day.
We’re crafting a dynamic, evolving platform that handles exabytes of data with reliability and efficiency. We’re a platform that developers and businesses build on. That means durability, performance, uptime, and predictability aren’t just nice-to-haves—they’re fundamental requirements. As Senior Vice President of Engineering, I’m excited to pull back the curtain and offer a glimpse into the ongoing engineering efforts that power our platform.
Building for simple is more complex than it seems
One of our core engineering philosophies is this: Complexity should serve simplicity. For example, changing how we handle request headers might sound like a small thing, but when you operate a distributed system at scale, even tiny inefficiencies can multiply quickly. A 5% improvement in API response time might not sound dramatic, but at exabyte scale, that translates to millions of faster interactions per day, less CPU usage, and better customer experiences across the board.
Our Engineering team is always thinking about those compound effects. Sometimes that means rewriting parts of a system that have been stable for years. Other times it means saying no to flashy solutions and choosing battle-tested designs that will hold up under load.
Our goal, in addition to talking about the individual stories, is to start talking about some of the throughlines—when one project spawns another, or how we decide which project to pursue when there are competing priorities.
These projects don’t usually make headlines on their own, but taken together, they form the backbone of what makes Backblaze perform the way it does. They’ll become part of our regularly scheduled programming, and we’ll drop them in our Tech Lab category so you can find them easily.
Sign up for the Developer newsletter
Sign up for the Backblaze Developer Newsletter to receive a monthly roundup of articles and news for everyone developing on Backblaze B2 Cloud Storage.
See you on the next one—and let us know if you have questions
We’re proud of the work our engineers are doing, but more than that, we think it’s worth sharing. Whether you’re a fellow cloud architect, a developer using our platform, or just someone curious about what it takes to run cloud infrastructure at scale, we hope this series offers something insightful.
Technology doesn’t stand still, and neither do we. The more efficient our platform becomes, the better we can serve our customers—and the more we can invest in new ideas. So stay tuned. We’re kicking things off in this content series in the next few weeks, and we look forward to hearing your thoughts!
As the saying goes, no one ever got fired for using AWS—but we should revisit that truism. In the era of the open cloud, smart enterprise-level companies are leveraging best-of-breed cloud providers to reduce costs and enhance their cloud stack with specialists. What does that mean, practically speaking? The ability to reduce one of your biggest line item expenses by up to 80%.
As a CFO, I’m focused on strategically balancing operational expenses (OpEx) with a constant zero-based budgeting approach so my capital either fuels profitable growth or flows to free cash flows so I can drive shareholder value. Cloud storage, while essential, can be a significant cost center, and its billing structures often lack the transparency you need for effective financial management. My goal here is to demystify cloud storage costs, with a particular emphasis on the often-overlooked egress fees, and outline strategies for controlling these expenses.
Understanding the true cost of the cloud
The cost of cloud storage involves paying for data storage. However, the nuances of billing can vary significantly depending on usage patterns. We call an AWS bill a “cloud storage” bill, but it also includes a wide variety of configurable services, including compute, security, networking, analytics, database, and AI and machine learning (AI/ML) tools.
Consider a company that relies heavily on streaming media. Their primary cost driver is supporting a vast library of content for on-demand streaming. According to EY, cloud hosting for a typical software as a service (SaaS) company costs usually account for 6%-12% of revenue. For businesses with substantial video media assets, just storage expenses can consume a considerable portion of revenue. According to Coughlin and Associates, archiving and preservation accounts for the highest slice of cloud storage spending in the media and entertainment space.
Understanding your cloud bill is easier said than done
Crucial—but difficult to actualize. Cloud storage bills from providers like Amazon are so complex they’re regularly 40+ pages. According to a report from CloudZero, when asked how well they can attribute cloud spend to different aspects of their business (e.g., customers, products, features), 42% of respondents said they’re only able to give an estimate. Even worse, over 20% said they have little to no idea how much different aspects of their business cost.
This complexity has spawned an entire industry specialized in reducing cloud bills, and many enterprise companies have a job role dedicated to it. In my experience, even the best of those that occupy that job role have difficulty parsing the complexity.
Egress fees and other hidden charges: Unveiling the financial drain
While storage costs are relatively straightforward, it’s the hidden fees that can significantly impact the bottom line. Egress fees, incurred when data is transferred out of the cloud, are a prime example. These fees often lack transparency, making accurate budgeting and forecasting difficult. And, if you’re running applications in the cloud, you can’t avoid them: Users need to be able to move their data around. A recent survey indicated that 56% of IT professionals consider egress fees excessive, highlighting a widespread concern within the industry. At Backblaze, over 94% of our cloud storage customers were not charged any egress fees in 2024.
Beyond egress fees, other charges can further complicate cloud billing. These include minimum storage duration fees and tiered pricing models. I’ve seen firsthand how a lack of clarity can hinder financial planning. As I often say to my team, “We can’t optimize what we can’t understand.”
Overcoming cloud migration obstacles: A financial perspective
Given these cost considerations, exploring alternative cloud providers is a financially prudent strategy. I recognize that change can be perceived as disruptive. There’s often a concern about migration complexity and potential risks. Some organizations become so entrenched with a particular provider that they’re hesitant to consider alternatives, even when faced with substantial cost disadvantages in their steady-state cloud bills.
But, why the specific fear of cloud migration? There are always ways to manage the risk. In the grander scheme of IT and tech complexity, re-pointing an S3 standard API is considered an extremely low risk and low complexity effort. This is not like implementing a new ERP or data warehouse. It’s pretty straight forward, and your tech teams will have to make some time for a proof of concept and some testing.
The second big blocker is understanding who you are working with from a reputational and security standpoint. Data is the most precious asset for most companies nowadays. How long has the company been around? How many customers do they have? What is the net retention revenue (NRR)? Any history of cyber breaches? And which information security programs and certifications are in place?
Moving to the economics, the back-of-napkin math on the potential financial benefits of switching providers can be substantial. Reducing cloud storage costs directly impacts profitability. For example, if a video media company with storage costs representing 6% of revenue could cut those costs by 80%, that would translate to a 4.8% reduction in overall revenue costs. For a company with a 10% operating margin, this could increase it to 14.8%. That is a very substantial profitability improvement!
I have personally operated and advised companies with hyperscaler invoices from the likes of AWS ranging from $4 million to $7 million annually. Reducing those expenses isn’t just incremental improvement; it’s a game-changer. In some cases, the return on investment (ROI) from migrating to a more cost-effective solution, including reduced egress fees, can be realized in as little as one quarter.
Driving financial performance through cloud optimization
As CFOs, we have a responsibility to scrutinize cloud spending and ensure it aligns with our financial objectives. This requires a deep understanding of cloud billing models, particularly the impact of egress fees. By demanding transparency, rigorously evaluating alternatives, and embracing change, we can effectively manage cloud costs and enhance shareholder value. It’s imperative to foster a culture of agility within our organizations to facilitate necessary changes. The potential financial rewards are significant, and proactive cloud cost management is a key driver of improved financial performance.
Creating clear goals is inevitably part of any business strategy. You’ve likely heard of the acronym SMART—specific, measurable, actionable, realistic, and time-bound—when it comes to goal setting. As a business leader in information technology or a related business unit, you’re responsible for developing sound goals for business technology, data protection, and disaster recovery.
Two key metrics that feed into those strategies are your recovery time objective (RTO) and recovery point objective (RPO). Like all the other goals your business sets, the RTO and RPO should also be SMART goals.
So, how can you set meaningful RTO and RPO objectives for your business? And how can the cloud help you achieve or improve on those objectives? Today I’ll talk about how to smarten up these objectives to lead to better business continuity (BC) and a more effective disaster recovery (DR) plan.
The Essential Guide to Disaster Recovery Planning
Read more about how to build a disaster recovery plan for your organization.
Why do RTO and RPO matter?
RTO and RPO are two fundamental inputs to a comprehensive disaster recovery plan. They also very much guide how you’ll structure your backup strategy and engineer your backup architecture.
RTO is a business metric that states the maximum length of time a business can tolerate for recovery. It’s important to note the difference between recovery and restoration of data here. Restoring data is just one part of a recovery.
Recovery means systems are back up and running—fully functional—with users (employees, customers, etc.) able to utilize them in the same manner as before the data incident occurred.
RPO measures the maximum amount of data a company can afford to lose (or is willing to lose), measured in units of time. For instance, an RPO of 12 hours means that the company can accept the risk (financial risk, risk to the brand, etc.) of having lost 12 hours worth of data. So, if you run backups every 11 hours, you will be able to meet your RPO.
How to set RTO and RPO
Creating these objectives is a business decision—not an IT decision. If you’re an IT leader, your job is to work with your internal stakeholders to fully understand the business and the criticality of various applications and services in order to help define the RTO and RPO.
Put another way: The decision about what standard to meet is a shared responsibility. And those standards (recovery time, file durability, etc.) are the targets that IT and infrastructure providers teams must meet.
RTO and RPO may be different from one system to another. Some applications are more important than others.
Keep in mind that it’s likely that department heads will all say their services are the most important to immediately recover. But if everything is deemed critical, then nothing is.
Discuss how data loss and time to recovery impact the business in quantifiable details—revenue lost, number of customers affected, etc.—in order to truly prioritize systems and set appropriate RTOs and RPOs.
Making your RTOs and RPOs SMART
Remember that your objectives should be SMART:
Specific: Think through how granular your RTOs and RPOs should be. In addition to different RTOs and RPOs per application, you may also need different RTOs and RPOs per scenario. For example, the RTO for a ransomware attack is much different than that for hardware failure.
Measurable: One good way of measuring the efficacy of your RTOs and RPOs is by conducting DR testing. Run fire drills and conduct tabletop exercises. Practice restoring data. These inputs will help you understand if your objectives are meaningful and obtainable.
Actionable: Document your RTO and RPO in your DR plans and ensure they align with any business continuity risk management plans or goals around maximum allowable risk tolerance. You may also want to document the assumptions and inputs that formed the RTO and RPO. For instance, how much revenue is lost when a given system is down? Explain how that factor drives your RTO.
Realistic: Don’t let your stakeholders set unachievable objectives. If there is an ask for a very low RTO and/or RPO, help your stakeholder understand exactly what it will take—and how much it will cost—to implement that objective.
Time-bound: The RTO can be defined in seconds up to weeks. The shorter the RTO, the more expensive the investment will be to meet it.
Remember that you’re always balancing RTO and RPO against an unachievable “perfect” state. For instance, you would likely need multiple failover hot sites with replicated data to meet an RTO of seconds of downtime.
RTO is a forward-looking measurement; RPO is a backward-looking measurement that essentially represents the frequency of your backups.
A short RPO means more recent backup data is needed, and, yes, that also means greater investment. RPOs measured in seconds may require high-speed backup technology like continuous replication.
How to discuss RTO and RPO with business leaders
Discussing technical concepts with internal stakeholders can be challenging. To guide the objective-setting discussion with stakeholders, use the following questions as a guide:
Where and how do you store data?
How often does your data change?
What would a minute of downtime cost your department, in terms of revenue, risk, loss of productivity, impact to customers, etc.?
What are the compliance or industry requirements for maintaining sensitive data?
Do you have a way of manually transacting business if service is down?
Your IT department may already be well aware of many of these goals, but it’s good to do a fresh and full inventory of data and data management procedures. For example, even with the rise of shared drives, many employees still save important data locally. Or, there may be business-critical data being saved in services like Microsoft 365 or Kubernetes—and those services are often not adequately backed up.
How do RTO and RPO affect backup strategy?
Your RPO is often more directly related to backup strategy, although RTO certainly informs backup strategy. If you need a very low RPO (i.e., the business can tolerate very little data loss), you must plan to run backups more frequently. This ensures you always have very recent data to recover.
RTO, however, relates more to systems and infrastructure—again, because the objective is about recovery and not just restoring data. RTO will drive investment decisions around backup and DR architecture.
Your backup strategy or tech stack should not dictate either your RTO or your RPO.
First, you should define your RTO and RPO, and then you must determine if changes in backup policy are needed or if you need to update any backup systems in order to reach desired RTOs and RPOs.
Your RTO will drive decisions around backup and DR infrastructure; your RPO will drive decisions around frequency of backup and type of backup.
How does the cloud help companies meet RTO and RPO goals?
Using a public cloud for backup and archive can help you achieve your desired RTO and/or RPO. An obvious example is using cloud to replace LTO tape backup. Tape backup has some of the worst (maybe the worst) RTOs and RPOs. It takes an extraordinarily long time to recover from tape, and backups are likely not as frequent as they should be because tape is often not properly maintained. Migrating your tape backups to a public cloud like Backblaze B2 Cloud Storage is still cost-effective and it will drastically improve RTO and RPO.
If you’re using a hyperscaler like AWS, you may have had to cut back on frequency of backup or needed retention periods due to exorbitant fees. Shifting your backups to Backblaze B2 can help you achieve your goals: Backblaze B2 is one-fifth the cost of AWS S3, you can afford to run and save more frequent backups, thus lowering your overall RPO.
Replication is another technology that can help reduce RTOs. Many enterprise businesses will already have a failover site, but keeping an extra copy of your data in the cloud ensures you can still meet your desired RTO in the case of a DR site or production facility takeout. This is exactly what brought SaaS platform Centerbase to Backblaze.
More commonly, if it’s inordinately expensive to own your own DR site, you can store your backups in Backblaze B2 and utilize Cloud Replication for added redundancy.
RTO and RPO and your business
Ultimately, you should frame your RTO and RPO in terms of business impact. Then, reverse engineer your backup and DR infrastructure to support those objectives. Next, identify the storage systems for your data based on its business criticality and desired RTO and RPO.
Depending on your business goals, you’ll likely use cloud storage services, on-premises storage, or some combination of the two. Regardless of the type of business you run, demonstrating that you have an airtight DR plan with SMART RTO and RPO goals will instill confidence in your business partners, help with cyber insurance eligibility, and shore up your organization’s ability to withstand data disasters.
A well-defined disaster recovery (DR) plan relies heavily on a coordinated incident response team. Think of your incident response team like a pit crew. It’s easy to assume you’ll have a good race when everything is performing smoothly, but the real test comes when something goes wrong—maybe a tire blows or the engine overheats. In those moments, success isn’t about having the best tools in the garage; it’s about having the right team, working together, to quickly solve problems and get back on track.
When your team is facing a disaster recovery scenario, whether it’s a cyber attack, natural disaster, outage, or data breach, the speed and coordination of your team determines how quickly and how well you can move forward. In this post, I’m breaking down how to assemble a team that can respond with precision, minimize downtime, and keep your organization running smoothly when unexpected issues arise.
Establishing key team members, roles, and hierarchy
The incident response team (IRT) is the backbone of your DR response and is responsible for leading the recovery efforts during a disaster. Here’s a breakdown of possible key IRT roles:
Incident commander: Oversees the entire incident response process, making critical decisions and delegating tasks to team members.
Communications lead: Handles external and internal communication, ensuring timely updates for stakeholders and mitigating potential reputational damage.
Documentation lead: Maintains the DR runbook, ensuring its accuracy and updating it with post-incident findings.
Legal counsel: Provides legal guidance and ensures compliance with relevant regulations during the response and recovery process.
Building redundancy
Building redundancy in your IRT allows you to account for team member absences. This includes IT leadership; don’t assume you’ll be in the office when a disaster happens. Assign backup personnel for critical roles within the team to ensure continuity in the event of unforeseen circumstances.
Establish a clear succession plan for leadership roles within the IRT. This ensures a smooth transition if the primary incident commander or other key personnel become unavailable during a disaster.
Establishing a reporting hierarchy
Clearly define a reporting hierarchy within the IRT, outlining who reports to whom and the escalation process for making critical decisions. A clear chain of command during a crisis prevents confusion and delays that could result in prolonged downtime and increased risks.
The importance of clear communication
A critical component of any DR plan is clear communication to employees and executives regarding their specific roles during a security incident. This ensures that the assigned team leader can coordinate a unified response. Remember to include guidelines about incident escalation, as well as agreed-upon methods of communication (e.g., email, direct messaging, video calls, etc.).
Executive sponsorship: Beyond awareness
Executive buy-in is paramount for a successful DR strategy. While awareness of the impact of ransomware attacks has grown over the years, contextualizing DR plans with historical financial impacts, downtime implications, and reputational risk associated with such attacks can help to communicate why DR is a top-line priority.
Tip: Educating executives
Framing the DR plan in terms of cost avoidance, user downtime minimization, and reputational risk mitigation can resonate better with executives. Quantify the potential financial losses from data breaches and system outages to garner executive support for DR initiatives.
Beyond cell phones: Communication channels
Disasters can disrupt traditional communication methods like cell phone service. Develop alternative communication channels for the IRT, such as designated email threads, satellite phones, or pre-arranged conference call bridges. It is imperative to include this information and contact details in your DR runbook for immediate accessibility during crises.
By establishing a well-defined team structure with clear roles, communication protocols, and redundancy measures, enterprise businesses can ensure a coordinated and efficient response to data disasters.
A well-prepared team leads to a resilient recovery
Your DR strategy is only as effective as the team behind it. By defining clear roles, building in redundancy, and establishing a reporting hierarchy, IT leaders can eliminate confusion and accelerate recovery efforts. Moreover, securing executive sponsorship and ensuring clear communication strengthens your ability to respond effectively. DR isn’t just about the plan on paper. It’s about how you execute that plan and set your team up for success.
Media workflows have always been complex, requiring seamless collaboration, robust storage, and advanced systems integration. Today, with the explosion of content demands and rapid technological advancements, media organizations need solutions that can scale, innovate, and empower teams to deliver faster and better.
Backblaze and CHESA, long-standing partners and leaders in media workflow solutions, are doubling down on their relationship with CHESA to elevate creative workflows with a joint go-to-market partnership. This enhanced partnership builds on years of success, combining Backblaze’s high-performance, secure cloud storage with CHESA’s expertise in media technology systems integration to provide even more impactful solutions tailored to the needs of modern media-driven organizations.
Together, we’re continuing to make it easier than ever for organizations to streamline content production, enhance accessibility, and achieve business objectives with greater efficiency. In this blog, I’ll explain the key benefits of this expanded collaboration and highlight how it’s already driving transformative results for clients like the Philadelphia Eagles.
The media workflow challenge
From production studios and broadcasters to professional sports teams and creative agencies, media organizations face a growing list of challenges:
Massive data volumes: Video, audio, and other rich media assets require scalable and secure storage solutions to handle terabytes or even petabytes of data.
Fragmented workflows: Teams often juggle multiple tools and platforms, leading to inefficiencies and bottlenecks.
Budget constraints: Organizations need cost-effective solutions that don’t compromise performance or security.
The expanded partnership between Backblaze and CHESA continues to address these pain points head-on by combining best-in-class cloud storage with tailored workflow solutions.
The Backblaze + CHESA solution
Real-world success: The Philadelphia Eagles
One of the most compelling examples of the Backblaze + CHESA partnership is the Philadelphia Eagles’ transition from traditional LTO tape storage to a cloud-based media workflow. With over 800TB under management, switching to cloud storage meant that the team instantly made their data more agile, scoring immediate access to faster content creation and remote workflows.
“Now I can easily share entire broadcasts by copying and sharing a link from our MAM. No need for FTP downloads or uploading to other platforms. It’s fast, seamless, and ensures everyone can view the content without issues.” —Stacy Kelleher, Director of Production, Philadelphia Eagles
Backblaze B2 integrated seamlessly with the Eagles’ preferred tech stack, which leverages a Quantum QXS storage area network (SAN) and Mimir, a cloud-based video production platform.
The challenge
The Eagles faced significant challenges with their legacy storage system:
Limited accessibility: LTO tape storage made it difficult to access archived footage, which hindered content production timelines quickly.
Time-consuming processes: Retrieving footage from physical tapes was manual and slow.
Scaling limitations: As the team’s content library grew, so did the complexity and cost of managing tape storage.
The solution
By leveraging the expanded capabilities of Backblaze and CHESA’s partnership, the Eagles:
Transitioned their extensive media library to Backblaze B2 Cloud Storage.
Integrated CHESA’s tailored media workflow solutions for seamless access and collaboration.
Gained immediate access to decades of archived footage, enabling faster content creation and improved fan engagement.
The results
The Eagles’ media team now enjoys:
Accelerated content production: Instant access to archived footage has streamlined workflows, allowing the team to create engaging content more efficiently.
Enhanced scalability: With Backblaze B2, the Eagles can easily scale their storage as their content library grows.
Improved fan engagement: Faster production timelines enable the team to deliver high-quality content that keeps fans connected and engaged.
Peripheral content drives revenue through monetized clicks like highlights and select moments. Quick sharing and streamlined proof-of-performance delivery keep sponsors satisfied.” —Ryan Lakey, Principal Lead, Solutions, CHESA
Accelerated media workflows
Integrating Backblaze B2 Cloud Storage with CHESA’s media workflow expertise has long been a cornerstone of success for media teams. By enhancing this integration, media teams can experience even faster workflows, immediate asset access, and seamless collaboration across tools and teams. By eliminating the delays associated with traditional storage methods, teams can:
Share assets effortlessly with collaborators anywhere in the world.
Spend less time managing infrastructure and more time creating impactful content.
Backblaze + CHESA benefits
Scalable and cost-effective storage
Backblaze B2 Cloud Storage offers always-hot, S3 compatible object storage at a fraction of the cost of traditional providers like Amazon S3. This cost-effectiveness, combined with CHESA’s expertise in designing and integrating scalable systems, ensures organizations can:
Scale their storage needs as projects grow or shrink.
Optimize budgets without compromising on performance.
Rely on predictable pricing that avoids surprise costs.
Enhanced data security and accessibility
In the media world, accessibility and security are paramount. Backblaze and CHESA provide solutions that keep media assets safe while ensuring real-time access for production teams. Key benefits include:
Secure, encrypted storage to protect sensitive media.
High availability for instant access to files when needed.
Resiliency and redundancy to ensure data integrity, even in the face of unexpected disruptions.
These capabilities have been critical for clients like professional sports teams, broadcasters, and creative agencies that manage vast libraries of high-value media content.
Comprehensive support and maintenance
CHESA’s dedicated support services and Backblaze’s reliable cloud infrastructure ensure organizations experience minimal downtime and sustained operational efficiency. This comprehensive support includes:
Proactive monitoring and maintenance.
Remote and onsite assistance for hardware, software, and workflows.
Consistent communication to address issues before they impact production.
Why this partnership matters
The expanded Backblaze and CHESA partnership is more than just a collaboration—it’s a commitment to empowering media organizations with innovative, efficient, and secure solutions. Here’s why it stands out:
Deeply customized solutions: Every organization’s needs are unique. Backblaze Solution Engineers and CHESA Workflow Engineers dive deep into clients’ specific workflows and objectives to design and implement solutions specifically tailored to their needs.
Unrivaled expertise, built over decades: Rely on the combined power of Backblaze and CHESA’s deep-rooted experience in cloud storage and media technology.
Your future-proof media strategy: Navigate the changing media landscape with confidence, leveraging our scalable and cutting-edge solutions.
Take the next step
Whether you’re a professional sports team looking to enhance fan engagement, a broadcaster aiming to streamline production, or a creative agency seeking cost-effective storage, Backblaze and CHESA are here to help.
Discover how our expanded solutions can revolutionize your media workflows. Visitour dedicated solution page to learn more and to schedule a consultation tailored to your organization’s needs.
Over the past few years, Backblaze has expanded our regional footprint, adding capacity in the US-West region, growing in our EU-Central locale, opening a new US-East presence, and, most recently, moving into Canada with CA-East with an initial storage capacity of just under 60PB.
We approached our most recent expansion into Canada a bit differently, and today, I want to cover some of the new processes and efficiencies that we adopted for this project and how we’re well positioned to serve the Canadian market based on our network connections.
Backblaze deployment team lands in Toronto.
Scaling infrastructure and calling in the reinforcements
The CA-East data region deployment was our fastest to date, cutting the deployment life cycle (“the ink is signed” to a live production system) down in time by 50%. In this deployment cycle we worked with a third party integrator to help us streamline the process and also leveled up our automation procedures for installing operating systems and our storage software stack.
Historically we’ve drop-shipped all our equipment such as the networking gear, servers, hard drives, cables, and tools to the destination site for our deployment team to inventory, unbox, and physically install. It’s fun. It’s controlled chaos (if you like that sort of thing)—but for this build cycle we wanted to iterate our process further to ease and enable future growth in a more predictable and scalable fashion by working with a third party to assist with the initial physical build of the racked equipment.
On our end, there’s up-front engineering time documenting how all the fiber, copper, and power cables are organized. We have a cable map for every device, every cable, and every location as well as how it should be connected. It’s heavy on the paperwork side, but it’s time well spent. It allows us to template and stamp out future cabinets with ease. When we need more storage-focused cabinets to deploy additional storage, that’s a cabinet standard. If we need more compute, that’s also a cabinet that can be easily built out from a template.
The workload on the third party integrator side consists of taking our directions and performing all the physical racking and wiring. Handling all of these tasks takes time. You wouldn’t believe the amount of cardboard and packaging material that you need to process! Unboxing over a hundred servers, thousands of hard drives, and hundreds of fiber and copper cables is no small feat. (Apologies in hindsight for not giving you a marathon unboxing video.) They received all our packaging, then racked and cabled up everything according to our specifications. After inspection and quality control, everything was securely sealed in crates and shipped off to Canada.
Initial setup and bootstrapping of CA-East cluster at the integrator site.
Almost ready for QA and final inspection before shipping to the data center.
Automate all the things
Perform a process once? Sure. Have to do it more than twice? Automate it!
Before shipment out to the data center location, we sent a small team to the integrator site to perform a physical quality assessment of the build and set up remote access, which allowed us to bootstrap the platform as we had access to power and an internet connection.
Internally, we have a system that has a record of machine serial numbers and their roles (e.g., storage, api, database, etc). When a new machine boots up for the first time on our network, it gets a vanilla operating system installed via our PXE services. This is all parallelized, meaning that we were able to have systems to log in to within a few hours for the entire server set.
It’s a lot of fun toggling the power buttons one-by-one on over 90 servers, the PXE server network link running hot, and having an entire fleet of servers automatically install an operating system and be ready for further administration within minutes. Quite different from my days of performing floppy disk installs of Windows 95!
With a final inspection and software pass, everything was approved for shipment. The integrators securely boxed up our cabinets and they were on their way to Canada.
CA-East setup
Arriving at the destination site, everything was brought to the data center floor, bolted down, grounded, and energized. Within four hours we had network connectivity with our internet carriers and had set up our secure connections back to our production network to start our Backblaze software installation with our various internal teams. Within a few days, we had around 90 servers running and ready for our Quality Assurance team to start running tests to simulate client activity.
We partnered with Cologix, a leading network-neutral interconnection and hyperscale edge data center provider in North America, as our Canadian data center facility operator for this deployment. Cologix’s digital edge data center is a 20,000-square-foot, Tier III facility with two megawatts of power. It is a highly secure and efficient colocation and interconnection hub that features industry leading cooling designs, robust 24/7 security with biometric dual authentication access, and compliance with SOC 1, SOC 2, HIPAA and PCI-DSS as well as ISO 27001 certification by Schellman.
Storage Pods with a few compute servers at the top of each cabinet.
CA-East: Network and compute cabinets with room to grow.
Connectivity
Our standard connectivity posture is to connect to three global carriers for the most expansive reach to every network possible, and also to join a local internet exchange (IX) for exchanging traffic between other IX members locally within the same data center or metro region for low-latency efficiency. Additionally, for this site, we also are connected to a large Canadian regional carrier to bring us in close proximity to Canadian-sourced traffic.
With low-latency and diverse dark fiber connectivity between Cologix’s data centers, including Canada’s largest and most important carrier hotel, the facility offers access to 160+ networks, TORIX, and 50+ cloud providers.
Overall that makes our CA-East connectivity map look like this.
Option 1: Global Carriers. Option 2: Regional ISP. Option 3: IX Traffic.
Joining TorIX
The local internet exchange for this site is Toronto Internet Exchange (TorIX), the leading Canadian internet exchange point (IXP) and one of the largest in the world. At the time of this post, more than 250 organizations exchange on average over 1.3 Terabits per second (Tbit/s) of traffic every day between each other locally.
Connecting to TorIX allows low latency transit between us and internet service providers (ISPs), other clouds, partner content delivery networks (CDNs), other enterprise networks, and hosting providers that provide compute services.
Go live
I’ve been at Backblaze for four years now and have been able to participate on builds to expand our US-West, US-East, and now CA-East regions. Turning on the metaphoric “switch” to make the site live is a little anticlimactic—from a network point of view, the only traffic we see at the start of a new region is our monitoring, internal jobs, and some soft-launched testing or proof of concept (PoC) accounts.
Here’s a sample of the network traffic from when we brought up peering with our carriers and soft launched the data region for our internal QA teams.
Initial traffic into CA-East at time of launch.
Where is the initial network traffic coming from? With our network telemetry monitoring, we’re able to see the flows in traffic in and out of our network. That network traffic information is enriched with data that adds context to allow us to see how much traffic is coming to or from a particular upstream provider or geographical region.
Here’s a Sankey diagram that shows a snapshot of current traffic from Canadian provinces over different service providers to the Backblaze network, where the larger lines mean more traffic is seen from that particular province or network. Expectedly, Ontario and British Columbia are the two largest sources of traffic.
Ingress traffic by province and carrier networks to Backblaze network (BGP AS40401).
Canada is open for business
As the months progress, and as more customers create their accounts in this new data region and point their workloads at this location, we’ll see more traffic. We’ll be excited to see what fun insights we can glean, which we’ll keep you updated on in our Network Stats series.
As Backblaze continues to grow its network, we’re excited to continue to iterate on our buildouts to make them more efficient. Ultimately, it lets us be more responsive to customer needs quickly. Same great network—just more locations.
We’re excited to have a footprint in Canada and welcome your storage needs! If you’re interested in learning more about storing your data in Canada, you can read the go-live announcement here.
Ready to store data in CA East?
The new data region is available to customers now, and you can create an account there by selecting “CA East” in the region drop-down when creating a Backblaze account. Already storing data with Backblaze and want to keep a Canadian copy? Leverage our Cloud Replication feature and diversify your storage.
As we explained in our recent blog post, AI Reasoning Models: OpenAI o3-mini, o1-mini, and DeepSeek R1, Chinese startup DeepSeek caused a stir when it released its R1 reasoning model in January of this year. Interestingly, DeepSeek R1 has an OpenAI-compatible API, so applications written for OpenAI should work with DeepSeek R1 with just a configuration change. Since I had a suitable sample app all ready to go, I decided to put their claim to the test.
Why, and why not, use DeepSeek?
A major difference between DeepSeek and OpenAI is cost. At the time of writing, DeepSeek charges $0.55 per million input tokens and $2.19 per million output tokens for its R1 model. That’s about 3.6% of OpenAI’s $15.00 per million input tokens and $60.00 per million output tokens for its flagship o1 reasoning model, and about half of o3-mini’s $1.10 per million input tokens and $4.40 per million output tokens.
Set against this is the fact that, in using the DeepSeek platform’s API, you are sending your data to a startup located in China that has been accused by OpenAI of “inappropriately” basing its work on the output of OpenAI’s models. It’s up to you, and your organizations’ data governance policy, whether the trade-off is worthwhile.
Another consideration is the ability to run DeepSeek’s models locally, on your own infrastructure, or, more likely, your chosen provider’s infrastructure, rather than sending requests to the DeepSeek platform. Spinning up my own DeepSeek instance was out of scope for this blog post, but I’ll likely return to it in a future blog post.
Swapping OpenAI for DeepSeek
Last month, I explained how you can build an AI agent with Backblaze B2, LangChain, and Drive Stats, walking you through a simple chatbot that can answer questions based on our Drive Stats data set—11 years of metrics gathered from the Backblaze B2 Cloud Storage platform’s fleet of hard drives. In that example, the chatbot accepted a natural language question, used OpenAI’s GPT‑4o mini large language model (LLM) to generate a SQL query that might help provide an answer, executed the query against the Drive Stats data set via the Trino SQL engine, and then used OpenAI again to interpret the result set and either repeat the query-interpret cycle, or generate a natural language answer.
I copied the Jupyter notebook from that example and used it as the basis for investigating the feasibility of swapping out OpenAI for DeepSeek. The DeepSeek version of the notebook contains the full source code of my experiments; I’ll include relevant extracts here, edited for clarity.
Since I used the LangChain AI framework, which provides a layer above a range of AI models, the only place that OpenAI surfaced in my code was in creating an instance of LangChain’s ChatOpenAI wrapper:
# OPENAI_API_KEY must be defined in the .env file load_dotenv() llm = ChatOpenAI(model="gpt-4o-mini")
The ChatOpenAI class contains all the code required to communicate with OpenAI via its API.
Provide your DeepSeek API key in the same OPENAI_API_KEY environment variable.
Set the API base URL to https://api.deepseek.com.
Provide a DeepSeek model name in place of the OpenAI one.
If this reminds you of the steps for using Backblaze B2’s S3-compatible API, you’re not alone. The OpenAI API has become a de facto standard for integrating with LLMs in much the same way as Amazon’s S3 API allows an ecosystem of apps and tools to interoperate with object storage systems from a variety of vendors.
Looking at the DeepSeek documentation, you can use one of two models, deepseek-reasoner (aka DeepSeek R1) or deepseek-chat. Let’s see what the much-talked-about DeepSeek R1 came up with.
Using DeepSeek R1 in the AI agent
To make it easy to use both the OpenAI and DeepSeek notebooks, I created a second entry in the .env file for the DeepSeek API key, and copied it to the OpenAI environment variable in the notebook code:
# The .env file needs at least DEEPSEEK_API_KEY, and may also contain # OPENAI_API_KEY. Move the DeepSeek API key to the OpenAI environment # variable load_dotenv()
As I set about repeating the steps from the Jupyter notebook that supported my previous blog post, I was disappointed to see DeepSeek fall at the very first hurdle: generating a SQL query for a simple natural language question. Here is the code:
question = {"question": "How many drives are there?"}
write_query(question)
Looking back at the original notebook, OpenAI’s response was valid SQL, although it didn’t have enough information to construct the correct query:
{'query': 'SELECT COUNT(*) AS drive_count FROM drivestats'}
DeepSeek, on the other hand, responded with a Python stack trace and this error:
openai.UnprocessableEntityError: Failed to deserialize the JSON body into the target type: response_format: response_format.type `json_schema` is unavailable now at line 1 column 13827
What went wrong? Searching for the error turns up a comment from a LangChain engineer explaining that we should use BaseChatOpenAI rather than ChatOpenAI since it “[…] accommodates many APIs that are similar to OpenAI. It uses tool calling for structured output by default.”
So, we can redefine llm accordingly, and try generating a query again:
BadRequestError: Error code: 400 - {'error': {'message': 'The last message of deepseek-reasoner must be a user message, or an assistant message with prefix mode on (refer to https://api-docs.deepseek.com/guides/chat_prefix_completion).', 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_request_error'}}
Looking back at the AI agent code, we can see that we used an off-the-shelf prompt from the LangChain Prompt Hub that provides the model with a single, system, message:
================================ System Message ================================
Given an input question, create a syntactically correct {dialect} query to run to help find the answer. Unless the user specifies in his question a specific number of examples they wish to obtain, always limit your query to at most {top_k} results. You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for a few relevant columns given the question.
Pay attention to use only the column names that you can see in the schema description. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Only use the following tables: {table_info}
Question: {input}
Does this mean that DeepSeek is not, in fact, API-compatible with OpenAI? I would argue that it does not. DeepSeek implements the same API request/response syntax as OpenAI, but it is a different platform. Some variation in semantics is to be expected. We see similar variations between Backblaze B2 and Amazon S3; for example, the S3 PutObjectAcl operation sets the access control list (ACL) for an object in a bucket. Amazon S3’s access management model allows you to manipulate an object’s ACL independently of its bucket—for example, you can put a private object in a public bucket, and vice versa.
This flexibility comes with a cost: It becomes difficult to reason about the visibility of data. In fact, AWS now recommends “that you keep ACLs disabled, except in unusual circumstances where you need to control access for each object individually.”
Backblaze B2’s model is much simpler: You control access at the bucket level, and all objects have the same ACL as their bucket. Backblaze B2 implements the PutObjectAcl operation, but, if you try to set an object’s ACL to any other value than its bucket’s ACL, the service responds with an error.
Returning to the AI agent code, we can replace the single-system-message prompt with one that combines a system message with a user message:
import textwrap from langchain_core.prompts import ChatPromptTemplate
query_prompt_template = ChatPromptTemplate([ ("system", textwrap.dedent("""Given an input question, create a syntactically correct {dialect} query to run to help find the answer. Unless the user specifies in his question a specific number of examples they wish to obtain, always limit your query to at most {top_k} results. You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for a the few relevant columns given the question.
Pay attention to use only the column names that you can see in the schema description. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Only use the following tables: {table_info}""")), ("human", "Question: {input}"), ])
Trying the write_query() call for a third time, this is the response:
BadRequestError: Error code: 400 - {'error': {'message': 'deepseek-reasoner does not support Function Calling', 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_request_error'}}
Function calling is a powerful capability that enables Large Language Models (LLMs) to interact with your code and external systems in a structured way. Instead of just generating text responses, LLMs can understand when to call specific functions and provide the necessary parameters to execute real-world actions.
Unfortunately, that is exactly our use case. It’s becoming clear that DeepSeek R1 is not the correct tool for implementing an AI agent—we’ve been trying to use a chisel as a screwdriver!
DeepSeek-V3: A better fit
As its name suggests, the deepseek-chat model is more appropriate for this application. The DeepSeek documentation tells us that it is based on DeepSeek-V3, released in December 2024. DeepSeek-V3 is priced at $0.27 per million input tokens and $1.10 per million output tokens; this is actually more expensive than the GPT-4o mini model I used for the OpenAI agent example ($0.15 per million input tokens, $0.600 per million output tokens), but how does it compare? Let’s take a look.
First, we need to edit the LLM creation code again to set the model name:
Now we can run write_query() again. It’s immediately clear that it’s a better fit than its “big brother:”
{'query': 'SELECT COUNT(*) AS total_drives FROM drivestats LIMIT 10'}
As with the OpenAI agent, this query is well-formed SQL, but it’s not answering the question we set—it’s giving us the total number of rows in the dataset, rather than the number of drives. Also, it’s a little odd to have a LIMIT clause in a SELECT COUNT(*) query, but it’s legal SQL, and the agent is following its instructions very literally: always limit your query to at most {top_k} results, where we set top_k to 10.
question = {"question": "Each drive has its own serial number. How many drives are there?"}
query = write_query(question)
{'query': 'SELECT COUNT(DISTINCT serial_number) AS total_drives FROM drivestats'}
So far, so good!
I’ll skip some intermediate steps here—they are all in the Jupyter notebook if you want to review them, or run them for yourself—and look at how a simple LangChain graph, built on the DeepSeek LLM, answered the question: “Each drive has its own serial number. How many drives did each data center have on 9/1/2024?”
The OpenAI version generated an invalid query, comparing the date column with the string ’2024-09-01’ without using the required DATE type identifier, but DeepSeek generates a correct SQL query and provides a useful natural language response:
/SELECT datacenter, COUNT(DISTINCT serial_number) AS drive_count FROM drivestats WHERE date = DATE ‘2024-09-01’ GROUP BY datacenter ORDER BY drive_count DESC LIMIT 10
On September 1, 2024, the data centers had the following number of drives:
phx1: 89,477 drives
sac0: 78,444 drives
sac2: 60,775 drives
(empty datacenter): 24,080 drives
iad1: 22,800 drives
ams5: 16,139 drives
These are the top data centers with the highest drive counts on that date.
DeepSeek scores a point!
Moving on to the ReAct AI Agent, which allows the LLM to perform multiple SQL queries in generating an answer to a question, DeepSeek performs similarly to OpenAI. Given the question, “Each drive has its own serial number. What is the annualized failure rate of the ST4000DM000 drive model?”, the DeepSeek agent provides the overall failure rate rather than the annualized failure rate (AFR).
When we provide explicit instructions for calculating AFR in its prompt, the DeepSeek agent provides the correct result, identical, in fact, to the OpenAI agent’s response:
The annual failure rate (AFR) for the ST4000DM000 drive model is approximately 2.63%.
However, when given the question, “What was the annual failure rate of the ST8000NM000A drive model in Q3 2024?”, the DeepSeek agent gives us:
[(1.6100573445081607,)]
While OpenAI responds:
The annual failure rate (AFR) of the ST8000NM000A drive model in Q3 2024 is approximately 1.61%.
Wrapping up the investigation, the final question from the OpenAI notebook is more complex:
Considering only drive models which had at least 100 drives in service at the end of the quarter and which accumulated 10,000 or more drive days during the quarter, which drive had the most failures in Q3 2024, and what was its failure rate?
Impressively, the OpenAI agent constructed a well-formed SQL query and provided the correct response:
The drive model with the most failures in Q3 2024 is the TOSHIBA MG08ACA16TA, which had 181 failures. Its failure rate during this period was approximately 1.84%.
BadRequestError: Error code: 400 - {'error': {'message': "An assistant message with 'tool_calls' must be followed by tool messages responding to each 'tool_call_id'. (insufficient tool messages following tool_calls message)", 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_request_error'}} During task with name 'agent' and id '0aa26ba6-a3ee-ced1-de4d-b60ed7fbca99'
The phrase “insufficient tool messages” suggested that the DeepSeek LLM might need to be reconfigured to allow more tokens. According to the documentation on models and pricing, the deepseek-chat model supports a maximum of 8K output tokens, but defaults to 4K if max_tokens is not specified.
Recreating the DeepSeek wrapper object and agent accordingly, I gave it the last question again:
response = agent_executor.invoke( {"messages": [{"role": "user", "content": "Considering only drive models which had at least 100 drives in service at the end of the quarter and which accumulated 10,000 or more drive days during the quarter, which drive had the most failures in Q3 2024, and what was its failure rate?"}]} )
# Show the SQL query sent to the database print(response['messages'][-3].tool_calls[0]['args']['query'])
# Show the final response message display_markdown(response['messages'][-1].content, raw=True)
This time, DeepSeek was able to generate a similar SQL query to OpenAI:
WITH drive_counts AS ( SELECT model, COUNT(DISTINCT serial_number) AS drive_count FROM drivestats WHERE date >= DATE '2024-07-01' AND date <= DATE '2024-09-30' GROUP BY model HAVING COUNT(DISTINCT serial_number) >= 100 ), drive_days AS ( SELECT model, COUNT(*) AS total_drive_days FROM drivestats WHERE date >= DATE '2024-07-01' AND date <= DATE '2024-09-30' GROUP BY model HAVING COUNT(*) >= 10000 ), failures AS ( SELECT model, COUNT(*) AS failure_count FROM drivestats WHERE date >= DATE '2024-07-01' AND date <= DATE '2024-09-30' AND failure = 1 GROUP BY model ) SELECT d.model, f.failure_count, 100 * (CAST(f.failure_count AS DOUBLE) / (CAST(d.total_drive_days AS DOUBLE) / 365)) AS annual_failure_rate FROM drive_days d JOIN failures f ON d.model = f.model JOIN drive_counts dc ON d.model = dc.model ORDER BY f.failure_count DESC LIMIT 1
With a correct response:
To answer the question:
The drive model with the most failures in Q3 2024 is TOSHIBA MG08ACA16TA, which had 181 failures. The annualized failure rate (AFR) for this model during that quarter was 1.84%.
Success! But, unfortunately, this isn’t the whole story.
DeepSeek Reliability
I originally set out to write this blog post at the end of January, but the DeepSeek platform website had gone offline by January 30, so I couldn’t even start until I was able to sign up for an API key on February 5.
Given my shiny new API key, and DeepSeek’s claims of OpenAI API compatibility, I naïvely expected to be able to work through my earlier OpenAI notebook and write up the results in a couple of days. The reality was more like two weeks.
In this blog post I’ve detailed some of the error messages I encountered along the way, but I saw many more that pointed to the DeepSeek API simply being overwhelmed with traffic. For example, for over a day, when the status page reported no issues, most API requests to DeepSeek terminated after a minute with the error message:
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
A time-consuming investigation revealed that this was caused by the DeepSeek API returning the 200 status code and headers as if the request was successful, then hanging for a minute before terminating the connection without returning any actual data. The calling code saw the 200 as success and tried to decode the non-existent API response body, resulting in the error.
I saw several more instances of intermittent errors that all seemed to point in the same direction: DeepSeek needs to add capacity to its API platform. Notably, the platform seemed faster and more stable on a Saturday morning, U.S. Pacific time, the early hours of Sunday morning in China.
Final thoughts
At present, I would have to classify the DeepSeek-V3 API as “promising, but somewhat flaky.” An agent invocation that succeeds one minute could fail the next with any of a range of error messages. That’s a shame, since when it does work, for instance, in creating the SQL query for the final question above, it tends to work very well.
One final caveat: This is a dynamic field; frameworks and services are literally being updated on a daily basis. For example, since yesterday, as I write this, four of the notebook’s module dependencies have been updated. I encourage you to experiment for yourself as your mileage will almost certainly vary, hopefully in a positive direction.
I’ve heard the horror stories, and I’m sure you have too. A company thinks they’re covered because they have replication running, only to realize too late that replication doesn’t protect against data corruption or ransomware. In a disaster scenario, every copy of their critical data is compromised. And then comes the dreaded question: Do we have a backup?
Many teams—even those with seasoned IT professionals—misunderstand the fundamental difference between backup and replication for disaster recovery (DR). Replication is about availability, or keeping systems running with minimal downtime. Backup is about recoverability, or ensuring you can go back to a known good state.
This post breaks down replication, backup, and their respective roles in disaster recovery in a way that’s easy to share with your team, helping to prevent costly misunderstandings.
What is data replication?
Data replication involves copying and synchronizing data between your primary site and the DR destination in real-time or near real-time. It offers fast failover capabilities as the replicated data at the DR site is constantly updated. However, if malware infects your primary site, it might also replicate to the DR site, rendering the backup compromised.
What is data backup?
Data backup involves creating full and incremental copies of your data and storing them in a separate location from your primary system, typically on a scheduled basis, to prevent loss, corruption, or disasters. A couple key points:
Incremental backups capture changes in data, thus offering a point-in-time recovery option.
Ideally, backups are immutable, meaning they can’t be altered, in order to protect against malware and ransomware by making files and images read-only for safe recovery.
Air-gapped and offline backups can further help resist malware and ransomware attacks by creating a virtual or physical separation from the production network.
Cloud-based backups are a great option for addressing these requirements while offering affordable scaling options as the environment grows.
Replicating backups
A hybrid approach involves replicating your backups to a secondary location, offering a balance between data protection and recovery time. This can be between on-premises and cloud environments, or across multiple cloud targets.
While replicating backups offers additional protection and accessibility for online recovery, the backup images are still subject to ransomware infection. Using immutable backups helps prevent the spread of the infection to recovery sites and backup repositories.
Data backups paired with replication can be an ideal strategy. Full and incremental backups with point-in-time snapshots can provide regular recovery points with replicated copies for remote recovery and additional protection.
Cloud Replication
Backblaze B2 Cloud Replication enables your data to be automatically copied from one location to another for redundancy, compliance, and fast local access. Create 2x backups for a stronger disaster recovery posture. Replicating your Backblaze data is easy and free—no service or egress fees—just the standard Backblaze B2 Cloud Storage rates.
Disaster recovery and backups: Factors to consider when choosing the right approach
The optimal approach to disaster recovery backup and when and how you use replication depends on your specific needs.
For frequently accessed data requiring near-instantaneous recovery, consider a combination of a hot site methodology and real-time data replication. This offers the fastest failover, but can come at a higher cost.
For critical data with acceptable downtime, a warm site with replicated immutable backups at a secondary location (either on-premises or in the cloud) provides a good balance between cost and recovery time. While requiring some manual intervention, it offers protection against malware replicating to the DR site.
For less critical data or archival purposes, cold storage with periodic backups is a cost-effective option. Backups offer a historical record and are less susceptible to malware infection compared to replicated data, particularly if Object Lock is enabled for immutability.
Data replication is important, but it should not be seen as a substitute for backups. Backups offer a required safety net, providing a point-in-time recovery option even if the replicated data is compromised. Selecting the right disaster recovery backup strategy depends on a careful evaluation of your company’s specific needs, budget, and risk tolerance.
By understanding the pros and cons of each option, you can make an informed decision that ensures optimal protection for your critical data in the face of unforeseen disruptions.
Media asset management systems (MAM) have become a standard tool in the tech stack of many media organizations. MAM systems have evolved from basic file storage to sophisticated platforms with advanced organization features, increasing efficiency, collaboration, and distribution speeds.
In this post, I’ll explain some media asset management basics and introduce five key plays you can put into practice to get the most out of your assets, including how to move them into a MAM system or migrate from an older system to a new one.
Why do you need a MAM system?
As a media professional, I’ve come across some, let’s say, creative file naming conventions in my day. While it’s hilarious, “Episode6-Final-final-v2.3_OH_YEAH_THIS_IS_DEFINITELY_THE_FINAL_ONE_2_LOL.mp4” isn’t going to be the easiest thing to find years later when you’re searching through hundreds of files for the (for real) final one.
Whether you make videos, images, or music, the more you produce, the more difficult those assets become to manage, organize, find, and protect. Managing files by carefully placing them in specific folders and implementing more logical naming conventions can only get you so far. At some point, as the scale of your business grows, you’ll find your current way of organizing and searching for assets can’t keep up. That’s where media asset management systems come in.
MAM systems explained: Key concepts
Before you start building a playbook to get the most from your creative assets, let’s review a few key concepts.
Assets and metadata
Asset: A rich media file with intrinsic metadata.
An asset is simply a file that is the result of your creative operation. Most often, it is a rich media file like an image or a video. Typically, these files are captured or created in a raw state, then your creative team adds value to that raw asset by editing it and creating a finished story that in turn, becomes another asset to manage.
Metadata: Information about a file, either embedded within the file itself or associated with the file by another system, typically a MAM application.
Any given file carries information about itself that can be understood by your laptop or workstation’s operating system. Some of these seem obvious, like the name of the file, how much storage space it occupies, when it was first created, and when it was last modified. These would all be helpful ways to try to find one particular file you are looking for among thousands just using the tools available in your OS’s file manager.
File metadata: Information about a file specifically pertaining to the technical attributes of the file.
There’s usually another level of metadata embedded in media files that is not so obvious but potentially enormously useful: Metadata embedded in the file when it’s created by a camera, film scanner, or output by a program.
An example of metadata embedded in a rich media file.
For example, this image taken in Backblaze’s data center carries all kinds of interesting information. When I inspect the file, I can see a wealth of information. I now know the image’s dimensions and when the image was taken, as well as exactly what kind of camera took this picture and the lens settings that were used.
As you can see, this metadata could be very useful if you want to find all images taken on that day, or even images taken with that same camera, focal length, F-stop, or exposure.
Going through files one at a time to find the one you need is incredibly inefficient. Yet that’s how things still work in many creative environments—an ad hoc system of folders plus the memory of whoever’s been with the team longest. Files are often kept on the same storage used for production or even on an external hard drive.
Teams quickly outgrow that system when they find themselves juggling multiple hard drives or they run out of space on production storage. Worst of all, assets kept on a single hard drive are vulnerable to disk damage or to being accidentally copied or overwritten. Even if standard protocol is a redundant backup process, natural disasters can become a serious threat depending on the location of the physical tapes or drives.
Why your assets need to be managed
To meet this challenge, creative teams have often turned to MAMs. A MAM automatically extracts all of the assets’ inherent metadata, helps move files to protected storage, and makes them instantly available to MAM users. As time has gone on, we’ve seen MAM systems be powerfully enhanced by AI. In a way, these MAMs become a private media search engine where any file attribute can be a search query to instantly uncover the needed files in even the largest media asset libraries.
Beyond that, asset management systems are rapidly becoming highly effective collaboration and workflow tools. For example, tagging a series of files as Field Interviews — April 2019, or flagging an edited piece of content as HOLD — do not show customer can be very useful indeed.
Inner workings of a media asset manager
When you add files into an asset management system, the application inspects each file, extracting every available bit of information about the file, noting the file’s location on storage, and often creating a proxy version of the file that is easier to present to users.
To keep track of this information, asset manager applications employ a database and keep information about your files in it. This way, when you’re searching for a particular set of files among your entire asset library, you can simply make a query of your asset manager’s database in an instant rather than rifling through your entire asset library storage system. The application takes the results of that database query and retrieves the files you need.
A MAM Case Study: Complex Networks
Complex Networks was running out of space. Whenever local shared storage filled up, they had to pull assets off to give everybody enough room to continue working. They moved all of their assets to iconik media asset management software and backed them all up to the Backblaze B2 Cloud Storage. They’re now free to focus on what they do best—making culture-defining content—rather than spending time searching for assets.
Asset migration playbook
Whether you need to move from a file and folder based system to a new asset manager, or have been using an older system and want to move to a new one without losing all of the metadata that you have painstakingly developed, a sound playbook for migrating your assets can help guide you. Below we’ll explain five plays you can use to approach your asset management journey:
Play 1: Protecting assets saved in a folder hierarchy without an asset management system
In this scenario, your assets are in a set of files and folders, and you aren’t ready to implement your asset management system yet.
The first consideration is for the safety of the assets—backup and archive. Files on a single hard drive are vulnerable, so if you are not ready to choose an asset manager your first priority should be to get those files into a secure cloud storage service like Backblaze B2.
Then, when you have chosen an asset management system, you can simply point the system at your cloud-based asset storage to extract the metadata out of the files and populate the asset information in your asset manager.
How to run it:
Get assets archived or moved to cloud storage.
Choose your asset management system.
Ingest assets directly from your cloud storage.
Play 2: Moving assets saved in a folder hierarchy into your asset management system and archiving in cloud storage
In this scenario, you’ve chosen your asset management system, and need to get your local assets in files and folders ingested and protected in the most efficient way possible.
You’ll ingest all of your files into your asset manager from local storage, then back them up to cloud storage. Once your asset manager has been configured with your cloud storage credentials, it can automatically move a copy of local files to the cloud for you. Later, when you have confirmed that the file has been copied to the cloud, you can safely delete the local copy.
How to run it:
Ingest assets from local storage directly into your asset manager system.
From within your asset manager system archive a copy of files to your cloud storage.
Once safely archived, the local copy can be deleted.
Play 3: Getting a lot of assets on local storage into your asset management system and backing up to cloud storage
If you have a lot of content, more than say, 20TB, you will want to use a rapid ingest service similar to the Backblaze Fireball system. You copy the files to the Backblaze Fireball, Backblaze puts them directly into your asset management bucket, and the asset manager is then updated with the file’s new location in your Backblaze B2 account.
This can be a manual process, or can be done with scripting to make the process faster.
How to run it:
Ingest assets from local storage directly into your asset manager system.
Archive your local assets to Fireball (up to 90TB at a time).
Once the files have been uploaded by Backblaze, relink the new location of the cloud copy in your asset management system.
Play 4: Moving from one asset manager system to another without losing metadata
In this scenario you have an existing asset management system and need to move to a new one as efficiently as possible. You want to take advantage of your new system’s features and safeguard in cloud storage in a way that does not impact your existing production.
Some asset management systems will allow you to export the database contents in a format that can be imported by a new system. Some older systems may not have that feature and will require the expertise of a database expert to manually extract the metadata. Either way, you can expect to need to map the fields from the old system to the fields in the new system.
Making a copy of your old database is a must. Don’t work on the primary copy, and be sure to conduct tests on small groups of files as you’re migrating from the older system to the new. You need to ensure that the metadata is correct in the new system, with special attention that the actual file location is mapped properly. It’s wise to keep the old system up and running for a while before completely phasing it out.
How to run it:
Export the database from the old system.
Import the records into the new system.
Ensure that the metadata is correct in the new system and file locations are working properly.
Make archive copies of your files to cloud storage.
Once the new system has been running through a few production cycles, it’s safe to power down the old system.
Play 5: Moving quickly from a MAM on local storage to a cloud-based system
In this variation of Play 4, you can move content to object storage with a rapid ingest service like Backblaze Fireball at the same time that you migrate to a cloud-based system. This step will benefit from scripting to create records in your new system with all of your metadata, then relink with the actual file location in your cloud storage all in one pass.
You should test that your asset management system can recognize a file already in the system without creating a duplicate copy of the file. This is done differently by each asset management system.
How to run it:
Export the database from the old system.
Import the records into the new system while creating placeholder records with the metadata only.
Archive your local assets to the Backblaze Fireball (up to 90TB at a time).
Once the files have been uploaded by Backblaze, relink the cloud based location to the asset record.
Bonus play: Using cloud storage to scale a media heavy workload
Fortune Media’s tech stack was expensive, difficult to use, and not 100% reliable. They migrated over 300TB of data, mainly video files, to Backblaze B2 Cloud Storage, which integrated with their preferred MAM system, Primestream Xchange, removing the need for archiving middleware and simplifying the tech stack.
Wrapping up
Every creative environment is different, but all need the same thing: to be able to find assets fast and organize content to enhance productivity and rest easy knowing that content is safe.
With these plays, you can take that step and be ready for any future production challenges and opportunities.
Not many companies run exabyte scale data platforms, and not many companies open source their drive data—at Backblaze, we do both. From that perch, I’m sharing how I think about buying hard drives at exabyte scale, including the intentional design decisions and trade-offs I make as an expert in the field, and what you can apply to your own operations whether you’re running a couple hundred terabytes or petabytes on-premises.
TL/DR: Bigger drives aren’t always better
You’d think, as a cloud platform managing massive amounts of data, we’d be delighted that drive density continues to grow. But it’s not as simple as that. While we do run cohorts of 20TB+ drives in our environment, there are a few reasons it doesn’t always make sense to fill our servers up with the densest drives we can buy.
Drive size and IOPS starvation
Drives have a finite amount of capacity to perform input/output operations per second (IOPS). The larger the drive, the more those IOPS become a contentious consumable—creating a triangle of tension between storage capacity, reading, and writing. You can store more data on a 20TB drive, but you can only read and write as fast as that one drive allows. Conversely, you can store the same amount of data on five 4TB drives and 5x your IOPS capacity through concurrency.
For high demand workloads with high concurrency requirements for reading and writing files—like AI inferencing, for example—you’ll want to carefully consider the balance point between the right drive size and the performance you need to get out of the system. The ability to read, write, or delete content has to peacefully coexist with the ability for your storage infrastructure to service any of those three needs. Now, you might be thinking: If that’s a constraint, what about SSDs? I’ll get to that down below.
Drive size and rebuilds
When managing large data at scale we employ Reed-Solomon erasure coding to rebuild drives upon failure to maintain data durability. The larger the drive, the more painful and slow the rebuild when that drive eventually fails. The rebuild process can take hours or even days, depending on the size of the drive and the workload on the system. That can impact performance, especially if the storage system is already under heavy use, and increases the risk of another failure while the rebuild is in progress. While we mitigate that risk in a variety of ways, it may not be feasible for smaller shops to do so.
If you’re in a business that relies on real-time data access—financial institutions, healthcare providers, e-commerce platforms, for example—you need drives that balance capacity and rebuild speed. Higher-capacity drives may offer better storage density but smaller or enterprise-grade drives with faster rebuild times and higher endurance may be a better choice for businesses where continuous uptime and/or durability is critical.
HDD vs. SSD: Unit economics
The moral of the story is that the way you invest in drives, and how much you take things like drive size, drive type, and the failure rates we publish into consideration absolutely depends on your use case. It’s not as simple as looking at our Drive Stats and picking the drive with the lowest annualized failure rate.
In Backblaze’s early days, when we were focused on consumer backup, drive density and durability were the most important part of the equipment for us. We didn’t care about speed. As our customers increasingly bring us newer and more demanding use cases, our calculus for the kinds of drives we fill our data centers with will change with them.
As of December 31, 2024, we had 305,180 drives under management. Of that number, there were 4,060 boot drives and 301,120 data drives. This report will focus on those data drives as we review the Q4 2024 annualized failure rates (AFR), the 2024 failure rates, and the lifetime failure rates for the drive models in service as of the end of 2024. Along the way, we’ll share our observations and insights on the data presented, and, as always, we look forward to you doing the same in the comments section at the end of the post.
Sign up for the Drive Stats webinar
Tune in to ask those questions you’ve had spinning ‘round your head like so many drives, and meet the new Drive Stats team—Stephanie Doyle and David Johnson of Backblaze Blog fame. Yes, you heard that right: It’s my last Drive Stats before I head off to retirement (but more on that later in the report). Read on, and sign up, for analysis and insights from the 2024 report.
Q4 2024 hard drive failure rates
As of the end of 2024, Backblaze was monitoring 301,120 hard drives used to store data. For our evaluation, we removed from consideration 487 drives, as they did not meet the criteria to be included. We’ll discuss the criteria we used in the next section of this report. Removing these drives leaves us with 300,633 hard drives to analyze. The table below shows the annualized failure rates for Q4 2024 for this collection of drives.
Notes and observations
24TB drives are here. Seagate 24TB drives (model: ST24000NM002H) arrived in early December. The 1,200 drives filled one Backblaze Vault with no failed drives through the end of Q4. The 24TB Seagate drives join the 20TB Toshiba and 22TB WDC drive models in the 20-plus capacity club as we continue to dramatically increase storage capacity while optimizing existing storage server space.
Zero failures for the quarter. Five drive models had zero failures for the quarter starting with the 24TB Seagate drive model noted above. The others are the 4TB HGST (model: HMS5C4040ALE640), the 8TB Seagate (model: ST8000NM000A), the 14TB Seagate (model: ST14000NM000J), and the 16TB Seagate (model: ST16000NM002J). All of the zeroes come with the caveat of having a relatively small number of drives and drive days, but zero failures in a quarter is always a good thing.
The 4TB drives are nearly extinct. The 4TB drive count decreased by another 1,774 drives in Q4. (I discussed exactly how we migrate them in more detail if you want to dig in.) The remaining ~4,000 drives should be gone by the end of Q1 2025. They will be replaced by the incoming 20TB, 22TB, and 24TB drives. It should be noted that out of the 4TB drives in operation in Q4, only one failed, so those 20-plus TB drives have a lot to live up to from a failure perspective.
The quarterly failure rate is down. The AFR for Q4 dropped from 1.89% in Q3 to 1.35% in Q4. While all drive sizes delivered some improvement from Q3 to Q4, one of the primary drivers is the addition of over 14,000 new 20-plus TB drives. As a group, these drives delivered an AFR of 0.77% for the quarter.
Drive model criteria
We noted earlier we removed 487 drives from consideration when we produced the table above covering Q4 2024. There are two primary reasons we did not consider these drive models.
Testing. These are drives of a given model that we monitor and collect Drive Stats data on, but are not considered production drives at this time. For example, drives undergoing certification testing to determine if they are performant enough for our environment are not included in our Drive Stats calculations.
Insufficient data points. When we calculate the annualized failure rate for a drive model for a given period of time (quarterly, annual, or lifetime), we want to ensure we have enough data to reliably do so. Therefore we have defined criteria for a drive model to be included in the tables and charts for the specified period of time. Models that do not meet these criteria are not included in the tables and charts for the period in question.
Period
Drive Count
Drive Days
Quarterly
> 100
> 10,000
Annual
> 250
> 50,000
Lifetime
> 500
>100,000
Regardless of whether or not a given drive model is included in the charts and tables, all of the data for all of the drives we use is included in our Drive Stats dataset which you can download by visiting our Drive Stats page.
As with the Q4 quarterly results, we will apply these criteria to the annual and lifetime charts that follow in this report.
2024 annual hard drive failure rates
As of the end of 2024, Backblaze was monitoring 301,120 hard drives used to store data. We removed nine drive models consisting of 2,012 drives from consideration as they did not meet the annual criteria we have defined. This leaves us with 298,954 drives divided across 27 different drive models. The table below shows the AFRs for 2024 for this collection of drives.
Notes and observations
No zeros for the year. There were no qualifying drive models with zero failures in 2024. That said, the 16TB Seagate (model: ST16000NM002J) got close by recording just one drive failure back in Q3, giving the drive an AFR of 0.22% for 2024.
Busy data center techs. During 2024, our data center techs installed 53,337 drives. If we assume there are 2,080 work hours a year (52 weeks times 40 hours), that math is 53,337/2,080, and that means our intrepid DC techs installed 26 drives per hour. Busy, busy, busy!
The 24TB Seagate drives? While there were 1,200 new 24TB Seagate drives added in 2024, they were installed in early December and did not accumulate enough drive days to make the cut for the annual, or lifetime, tables. Including the 24TB Seagate drive, there were three models that missed out on being included in the 2024 annual tables, these drive models are listed below.
MFG
Model
Drive Count
Drive Days
2024 AFR
Seagate
ST8000NM000A
247
22,684
0.84%
Seagate
ST14000NM000J
232
19,696
1.32%
Seagate
ST24000NM002H
1,200
18,000
0.00%
As a reminder, a drive model needs to have over 250 drives by the end of Q4 and accumulate at least 50,000 drive days during 2024 to be included in the annual tables.
Comparing Drive Stats for 2022, 2023, and 2024
The table below compares the annual failure rates by drive model for each of the last three years. The table includes just those drive models which met the annual criteria as of the end of 2024. The data for each year is inclusive of that year only for the operational drive models present at the end of each year. The table is sorted by drive size and then AFR.
Notes and observations
The annual AFR is down. The 2024 AFR for all drives listed was 1.57%, this is down from 1.70% in 2023. We expect the overall failure rates to continue to fall in 2025, but we will be watching the following for indicators.
The failure rates of the 8TB and 12TB drive models. All of the models will exceed their five years of service. In general, the failure rate will noticeably increase as the drives exceed five years of service. And, while there are outliers like the current HGST 4TB drives, you can’t assume that will happen.
The failure rates of the 14TB and 16TB drive models. These models are approaching middle age—three to five years in operation. This is where, according to the bathtub curve, their failure rates could gradually increase—but not as severely as when they exceed five years.
The failure rates for the 20TB, 22TB, and 24TB drives models. These drives will enter the flat portion of the bathtub curve, that is where their failure rate should be the lowest.
Annualized failure rates vs. drive size
Now, we can dig into the numbers to see what else we can learn. We’ll start by looking at the quarterly annualized failure rate by drive size over the last three years.
Let’s take a look at the different drive sizes and how they affect the overall annualized failure rate over time.
Minimal impact. The 4TB (blue line) drives and 10TB (gold line) drives have had little impact over the last year on the overall failure rate as each finished the year with a relatively small number of drives. Still, the wild ride delivered by the 10TB drives keeps our DC techs on their toes.
Older drives. The 8TB (gray line) drives and 12TB (purple line) drives range in age from five to eight years and as such their overall failure rates should be increasing over time. The 12TB drives are following that pattern moving up from about 1% AFR back in 2021 to just about 3% in 2024. The failure rates of the 8TB drives, while erratic from quarter-to-quarter, have a nearly flat trendline over the same period.
Workhorse drives. The 14TB (green line) and 16TB (azure* line) drives comprise 57% of the drives in service and on average they range in age from two to four years. They are in the prime of their working lives. As such, they should have low and stable failure rates, and as you can see, they do.
* Maybe azure isn’t quite right, but robin’s egg blue seemed a bit pretentious.
New drives on the block. The 22TB (orange line) drives are in their early days as we continue to add more drives on a regular basis. Once the drive population settles down, we’ll have a better sense of the AFR direction. Still, the early results are solid with a lifetime AFR of 1.06%.
Annualized failure rates vs. manufacturer
One of the more popular ways we can look at this data is by the drive manufacturer as we’ve done below.
To complete the picture, the chart below uses the same data, but displays just the linear trendlines for each of the manufacturers over the same three-year period.
HGST. While the HGST trendline is not pretty, it doesn’t tell the entire story. Looking at the first chart, until Q4 2023, the HGST drives were at or below the average for all of the drives, that is all manufacturers. At that point, HGST has exceeded the average, and then some. The table below contains results for just the HGST drives for 2024. We’ve sorted them, high to low, by the 2024 AFR.
As you can see, there are two 12TB drive models driving the high AFR for the HGST drives. The HUH721212ALN604 model began showing signs of an increased quarterly AFR in Q1 2023 and the HUH721212ALE604 model followed suit in Q3 2024. Without these drive models, the 2024 AFR for HGST drive would be 0.55%.
Seagate. The quarterly AFR trendline decreased for the Seagate drives from 2022 through 2024. While the decrease was slight, from 2.25% to 2.0%, Seagate was the only manufacturer to do so. The decrease appears, at least in part, to be due to the removal of the Seagate 4TB drives during that period.
Toshiba. Over the 2022 to 2024 period, the quarterly AFR for the Toshiba drive models varied within a fairly narrow range between 0.80% and 1.52%, with most quarters hovering slightly around 1.2%. Most importantly, none of the individual drive models were outliers, as the highest quarterly AFR for any Toshiba drive model was 1.58%. We like consistency.
WDC. While WDC drive models delivered a similar level of consistency as the Toshiba models, they did so with a lower AFR each quarter. From 2022 through 2024, the range of quarterly AFR values for the WDC models was 0.0% to 0.85%. The 0.0% AFR was in Q1 2022 when none of the 12,207 WDC drives in operation failed during that quarter.
Lifetime hard drive stats
As of the end of 2024, Backblaze was monitoring 301,120 hard drives used to store data. Applying our drive criteria noted above for the lifetime period, we removed 11 drive models consisting of 2,736 drives from consideration as they did not meet the lifetime criteria we defined. This leaves us with 298,230 drives divided across 25 different drive models. The table below shows the lifetime AFRs for this collection of drives.
The current lifetime AFR for all of the drives is 1.31%. This is down from 1.46% in 2023. The drop is primarily due to the completion of the migration of the 4TB Seagate drives in 2024, which left us with only two of these drives still in operation as of the end of 2024. As a consequence, the 79 million drive days and over 5,600 drive failures racked up by the 4TB Seagate drives by the end of 2023 are not included in the data presented in the 2024 lifetime table above.
In the final table below, we’ve taken the lifetime table and sorted out the drive models that have a lifetime AFR of 1.50% or less by drive size.
A couple of caveats as you review the table.
There is enough data for each model to say the AFR values are solid. That said, everything could change tomorrow. In general, the hard drive failure rate follows the bathtub curve as the drives age—unless it doesn’t. Some drives refuse to fail as they age, like the 4TB HGST drives. Other drives are great, and then “hit the wall” and bend the failure curve upward, fast.
A drive model with a 1% annualized failure rate means that you can expect one drive out of 100 to fail in a year. If you’re a personal drive user, that one drive could be yours. If you have exactly one drive, your personal annualized failure rate is 100%. In other words, always have a backup, and don’t forget to test it.
Migration time
I have been authoring the various Drive Stats reports for the past ten years and this will be my last one. I am retiring, or perhaps in Drive Stats vernacular, it would be “migrating.” Either way, after 10 years in the U.S. Air Force and 30+ years in Silicon Valley Tech, it is time. Drive Stats will continue with Stephanie Doyle and David Johnson as the replacement drive models beginning with the Q1 2025 report. I wish them well.
I want to say thank you to each of you who have taken your time to peruse and engage with the Drive Stats reports and data over the last 10 years. And, thank you as well for the comments, questions, and discussions that raced and raged across the various communities that care about something as mundane and awesome as a hard drive. It has been quite the ride—thanks again.
The Hard Drive Stats data
The complete data set used to create the tables and charts in this report is available on our Hard Drive Test Data page. You can download and use this data for free for your own purpose. All we ask are three things: 1) you cite Backblaze as the source if you use the data, 2) you accept that you are solely responsible for how you use the data, and 3) you do not sell this data itself to anyone; it is free.
Good luck, and let us know if you find anything interesting.
Media and entertainment professionals have long debated how and where cloud services best fit in their workflows. Archive was initially seen as the most natural fit. But end-to-end cloud workflows and cloud-based production were viewed with skepticism due to the network bandwidth required to edit full resolution content. Now, as more organizations lean into REMI workflows, and new cloud-oriented creative tools enable real-time content production, the cloud is playing a role at every step of creative workflows.
Of course, it’s one thing to talk about real-time production in the cloud and it’s another thing to show how the cloud has transformed an actual workflow from end-to-end. But that’s exactly what the Philadelphia Eagles media team did by building a streamlined work-from-anywhere solution with cloud storage and cloud-delivered asset management. The best part was that rolling out the new cloud workflow was just as painless as it was transformative for their business.
We went from frequent LTO crashes and long restore times to near-instant access for every stored clip.
—Stacy Kelleher, Director of Production, Philadelphia Eagles
Archive availability sidelines production efforts
The Eagles were using a portfolio of different storage systems to store petabytes of content with different availability for each tier. The best they could hope for when restoring clips from LTO, for example, was half real-time. So, a three hour clip might take an hour and half to restore—and that’s if the LTO system was working at all. It became so problematic that they stopped archiving content to LTO altogether, opting to max out their SAN to ensure fast access.
The desire for faster file-sharing led the business requirements for overhauling their storage infrastructure. They needed to:
Consolidate their storage infrastructure.
Improve remote access faster for sharing content internally or even monetizing it outside the organization.
Improve the reliability of their backup and archive solution.
But migrating data and setting up a new system is no small feat.
Migration can’t run down the clock
Anyone who’s ever done a legacy migration knows moving to a new system is a quagmire. You can’t tell IT: You need to stop syncs and backups for three weeks while we do a migration.
There’s a reason folks in the media and entertainment space dread a migration. It’s slow. It’s semi-painful. And, everything has to port over correctly.
The Eagles approached their migration in the off season. They needed some flexibility to consolidate their multiple SANs, stadium production operations, and LTO system into something that helped them fly higher.
They consolidated the data into one single tier with a Quantum QSX on site for nearline storage and shifted hundreds of terabytes from their SAN and LTO system to Backblaze as their off-site storage for backup and archive.
Cloud MAM for the win
With storage sorted, the Eagles then integrated Mimir, a video collaboration and production platform that includes production asset management, archive, and object-store integration, to keep everything organized and on time. Whenever a file is uploaded to Mimir, it’s automatically stored in Backblaze B2 via Mimir’s file indexer system Kelda. This covered the game day action—their production team had fast access to recently recorded content, providing flexibility to work from home after those late night games.
Getting our sponsored, highest-performing content out quickly drives more views and boosts revenue, so efficiency on game day is critical. Our newly streamlined workflows ensure our editors can deliver while the content is still relevant and engaging.
—Stacy Kelleher, Director of Production, Philadelphia Eagles
The final score
The new system empowers their production team by giving them instant access and fast workflows so they can work without slowdowns. Kelleher noted that restoring a clip is nearly instant.
They have the ability to share links directly from Mimir to users outside the organization for things like pre-season broadcasts, which comes in handy especially when those users don’t want, need, or have the equipment to download the entire broadcast file. Stacy can just copy and paste a Mimir link into an email, and outside agencies or users can watch entire games at speed.
Finally, they freed up IT staff time spent managing all that tape and old hardware, not to mention physical space. It all added up to a big win for the IT team, the franchise, and the fans.
Now I can easily share entire broadcasts by copying and sharing a link from our MAM. No need for FTP downloads or uploading to other platforms. It’s fast, seamless, and ensures everyone can view the content without issues.
—Stacy Kelleher, Director of Production, Philadelphia Eagles
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.