Post Syndicated from Alex Casalboni original https://aws.amazon.com/blogs/aws/announcing-aws-lambda-function-urls-built-in-https-endpoints-for-single-function-microservices/
Organizations are adopting microservices architectures to build resilient and scalable applications using AWS Lambda. These applications are composed of multiple serverless functions that implement the business logic. Each function is mapped to API endpoints, methods, and resources using services such as Amazon API Gateway and Application Load Balancer.
But sometimes all you need is a simple way to configure an HTTPS endpoint in front of your function without having to learn, configure, and operate additional services besides Lambda. For example, you might need to implement a webhook handler or a simple form validator that runs within an individual Lambda function.
Today, I’m happy to announce the general availability of Lambda Function URLs, a new feature that lets you add HTTPS endpoints to any Lambda function and optionally configure Cross-Origin Resource Sharing (CORS) headers.
This lets you focus on what matters while we take care of configuring and monitoring a highly available, scalable, and secure HTTPS service.
How Lambda Function URLs Work
Create a new function URL and map it to any function. Each function URL is globally unique and can be associated with a function’s alias or the function’s unqualified ARN, which implicitly invokes the $LATEST version.
For example, if you map a function URL to your $LATEST version, each code update will be available immediately via the function URL. On the other hand, I’d recommend mapping a function URL to an alias, so you can safely deploy new versions, perform some integration tests, and then update the alias when you’re ready. This also lets you implement weighted traffic shifting and safe deployments.
Function URLs are natively supported by the Lambda API, and you can start using it via the AWS Management Console or AWS SDKs, as well as infrastructure as code(IaC) tools such as AWS CloudFormation, AWS SAM, or AWS Cloud Development Kit (AWS CDK).
Lambda Function URLs in Action
You can configure a function URL for a new or an existing function. Let’s see how to implement a new function to handle a webhook.
When creating a new function, I check Enable function URL in Advanced Settings.
Here, I select Auth type: AWS_IAM or NONE. My webhook will use custom authorization logic based on a signature provided in the HTTP headers. Therefore, I’ll choose AuthType None, which means Lambda won’t check for any AWS IAM Sigv4 signatures before invoking my function. Instead, I’ll extract and validate a custom header in my function handler for authorization.

Please note that when using AuthType None, my function’s resource-based policy must still explicitly allow for public access. Otherwise, unauthenticated requests will be rejected. You can add permissions programmatically using the AddPermission API. In this case, the Lambda console automatically adds the necessary policy for me, as the IAM role I’m using is authorized to call the AddPermission API in my account.
With one click, I can also enable CORS. The default CORS configuration will allow all origins. Then, I’ll add more granular controls after creating the function. In case you’re not familiar with CORS, it’s a header-based security mechanism implemented by browsers to make sure that only certain hosts are allowed to load resources and invoke APIs. If a website is allowed to consume your API, you’ll need to include a few CORS headers that declare which origins, methods, and custom headers are allowed. The new function URLs take care of it for you, so you don’t have to implement all of this in your Lambda handler.
A few seconds later, the function URL is available. I can also easily find and copy it in the Lambda console.
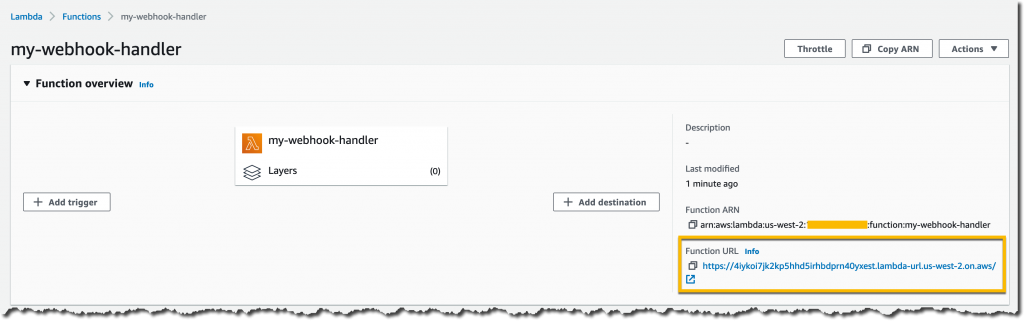
The function code that handles my webhook in Node.js looks like this:
exports.handler = async (event) => {
// (optional) fetch method and querystring
const method = event.requestContext.http.method;
const queryParam = event.queryStringParameters.myCustomParameter;
console.log(`Received ${method} request with ${queryParam}`)
// retrieve signature and payload
const webhookSignature = event.headers.SignatureHeader;
const webhookPayload = JSON.parse(event.body);
try {
validateSignature(webhookSignature); // throws if invalid signature
handleEvent(webhookPayload); // throws if processing error
} catch (error) {
console.error(error)
return {
statusCode: 400,
body: `Cannot process event: ${error}`,
}
}
return {
statusCode: 200, // default value
body: JSON.stringify({
received: true,
}),
};
};
The code is extracting a few parameters from the request headers, query string, and body. If you’re already familiar with the event structure provided by API Gateway or Application Load Balancer, this should look very familiar.
After updating the code, I decide to test the function URL with an HTTP client.
For example, here’s how I’d do it with curl:
$ curl "https://4iykoi7jk2kp5hhd5irhbdprn40yxest.lambda-url.us-west-2.on.aws/?myCustomParameter=squirrel"
-X POST
-H "SignatureHeader: XYZ"
-H "Content-type: application/json"
-d '{"type": "payment-succeeded"}'Or with a Python script:
import json
import requests
url = "https://4iykoi7jk2kp5hhd5irhbdprn40yxest.lambda-url.us-west-2.on.aws/"
headers = {'SignatureHeader': 'XYZ', 'Content-type': 'application/json'}
payload = json.dumps({'type': 'payment-succeeded'})
querystring = {'myCustomParameter': 'squirrel'}
r = requests.post(url=url, params=querystring, data=payload, headers=headers)
print(r.json())Don’t forget to set the request’s Content-type to application/json or text/* in your tests, otherwise, the body will be base64-encoded by default, and you’ll need to decode it in the Lambda handler.
Of course, in this case we’re talking about a webhook, so this function will receive requests directly from the external system that I’m integrating with. I only need to provide them with the public function URL and start receiving events.
For this specific use case, I don’t need any CORS configuration. In other cases where the function URL is called from the browser, I’d need to configure a few more CORS parameters such as Access-Control-Allow-Origin, Access-Control-Allow-Methods, and Access-Control-Expose-Headers. I can easily review and edit these CORS parameters in the Lambda console or in my IaC templates. Here’s what it looks like in the console:
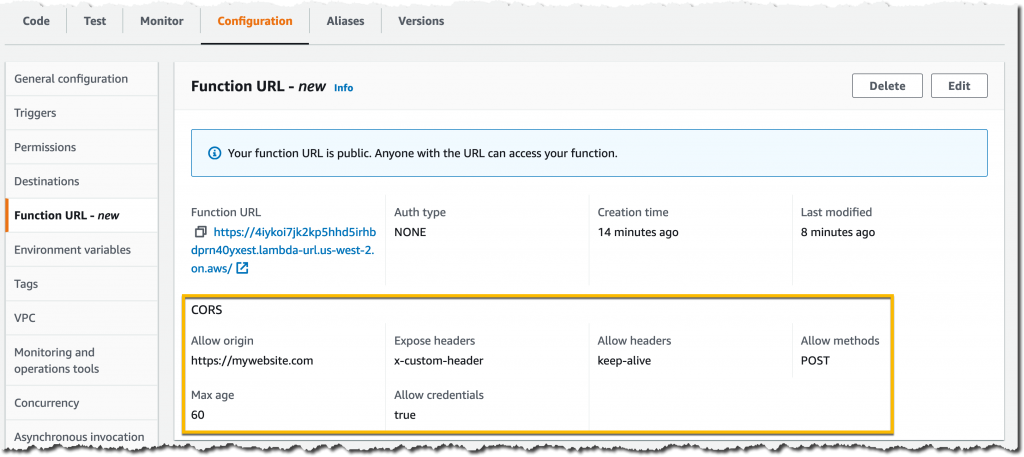
Also, keep in mind that each function URL is unique and mapped to a specific alias or the $LATEST version of your function. This lets you define multiple URLs for the same function. For example, you can define one for testing the $LATEST version during development and one for each stage or alias, such as staging, production, and so on.
Support for Infrastructure as Code (IaC)
You can start configuring Lambda Function URLs directly in your IaC templates today using AWS CloudFormation, AWS SAM, and AWS Cloud Development Kit (AWS CDK).
For example, here’s how to define a Lambda function and its public URL with AWS SAM, including the alias mapping:
WebhookFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: webhook/
Handler: index.handler
Runtime: nodejs14.x
AutoPublishAlias: live
FunctionUrlConfig:
AuthType: NONE
Cors:
AllowOrigins:
- "https://example.com"If you have existing Lambda functions in your IaC templates, you can define a new function URL with a few lines of code.
Function URL Pricing
Function URLs are included in Lambda’s request and duration pricing. For example, let’s imagine that you deploy a single Lambda function with 128 MB of memory and an average invocation time of 50 ms. The function receives five million requests every month, so the cost will be $1.00 for the requests, and $0.53 for the duration. The grand total is $1.53 per month, in the US East (N. Virginia) Region.
When to use Function URLs vs. Amazon API Gateway
Function URLs are best for use cases where you must implement a single-function microservice with a public endpoint that doesn’t require the advanced functionality of API Gateway, such as request validation, throttling, custom authorizers, custom domain names, usage plans, or caching. For example, when you are implementing webhook handlers, form validators, mobile payment processing, advertisement placement, machine learning inference, and so on. It is also the simplest way to invoke your Lambda functions during research and development without leaving the Lambda console or integrating additional services.
Amazon API Gateway is a fully managed service that makes it easy for you to create, publish, maintain, monitor, and secure APIs at any scale. Use API Gateway to take advantage of capabilities like JWT/custom authorizers, request/response validation and transformation, usage plans, built-in AWS WAF support, and so on.
Generally Available Today
Function URLs are generally available today in all AWS Regions where Lambda is available, except for the AWS China Regions. Support is also available through many AWS Lambda Partners such as Datadog, Lumigo, Pulumi, Serverless Framework, Thundra, and Dynatrace.
I’m looking forward to hearing how you’re using this new functionality to simplify your serverless architectures, especially in single-function use cases where you want to keep things simple and cost-optimized.
Check out the new Lambda Function URLs documentation.
— Alex












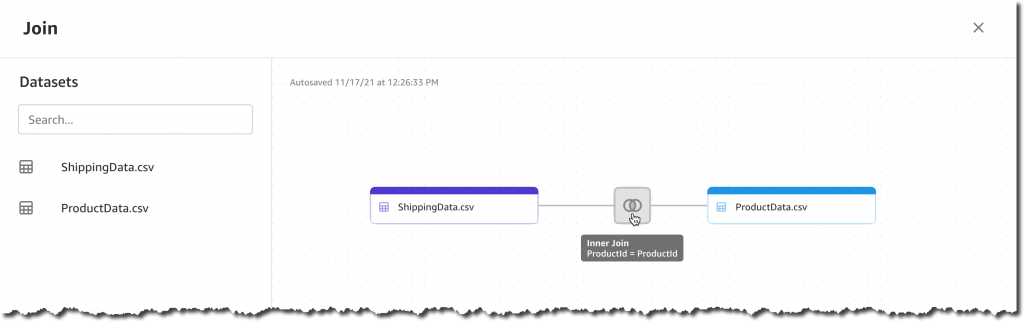

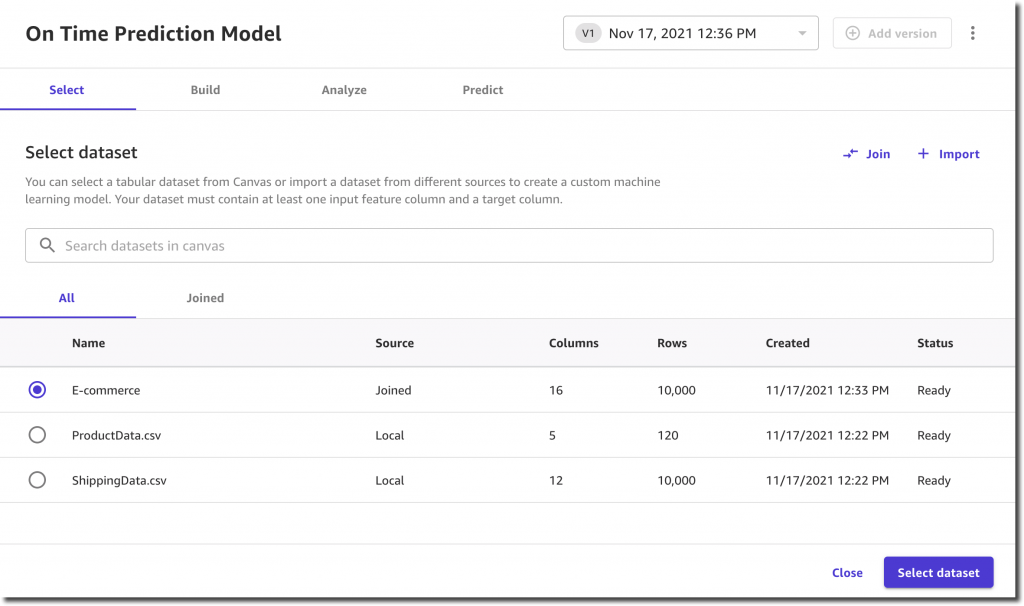



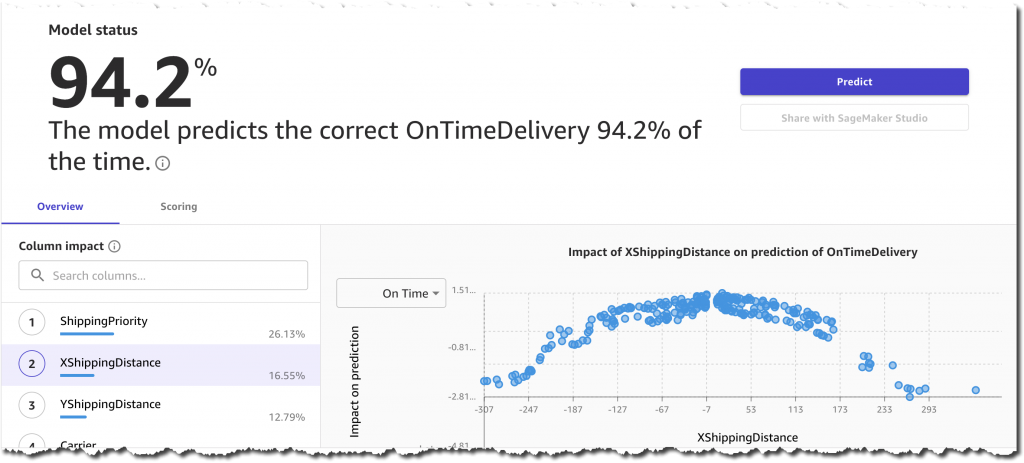































 Traditionally, organizations rely on manual audits of large amounts of data, which is not scalable and is prone to human error. Others use rule-based methods based on arbitrary ranges, which are often static, do not easily adapt to seasonality changes, and lead to too many false detections.
Traditionally, organizations rely on manual audits of large amounts of data, which is not scalable and is prone to human error. Others use rule-based methods based on arbitrary ranges, which are often static, do not easily adapt to seasonality changes, and lead to too many false detections.