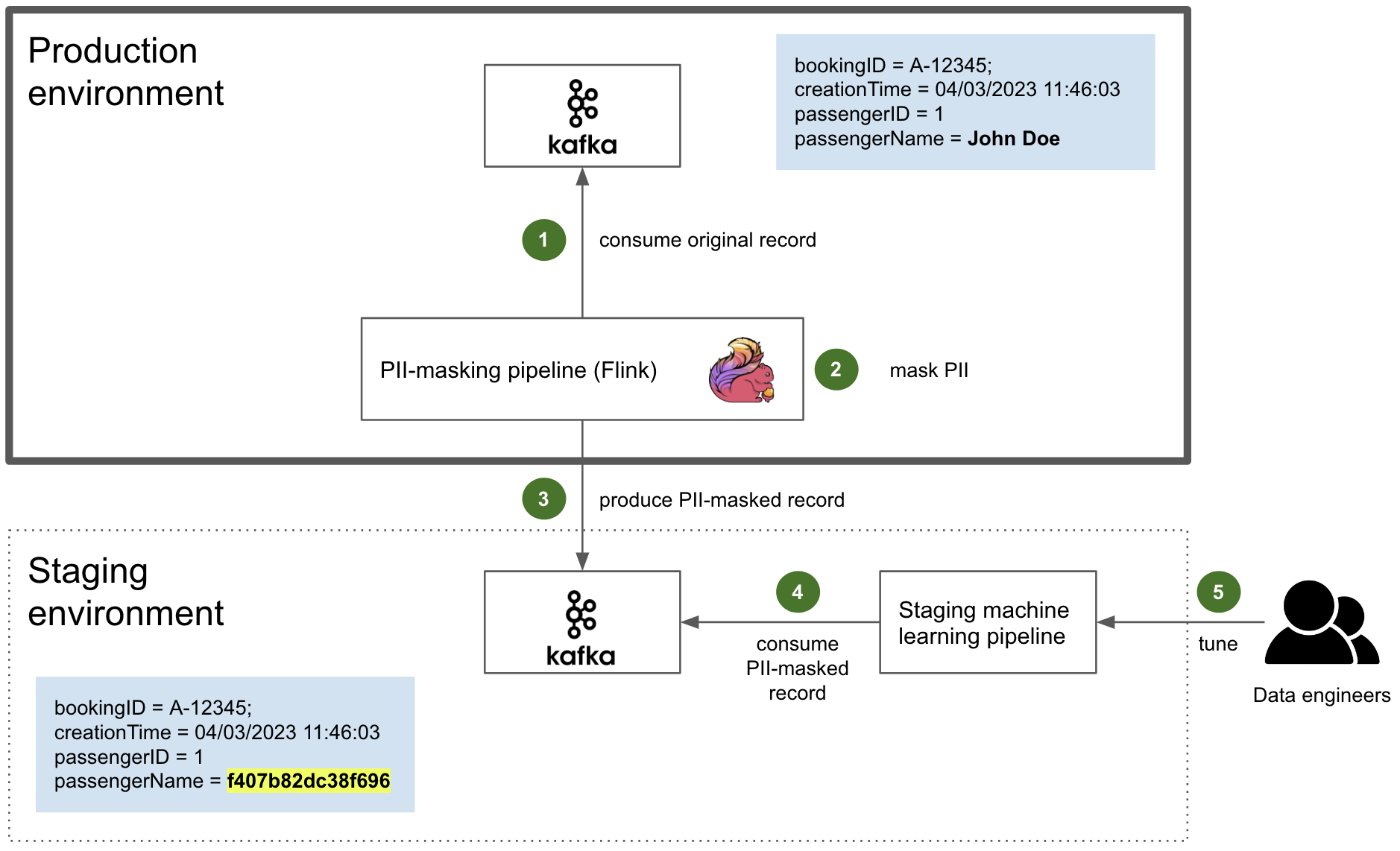
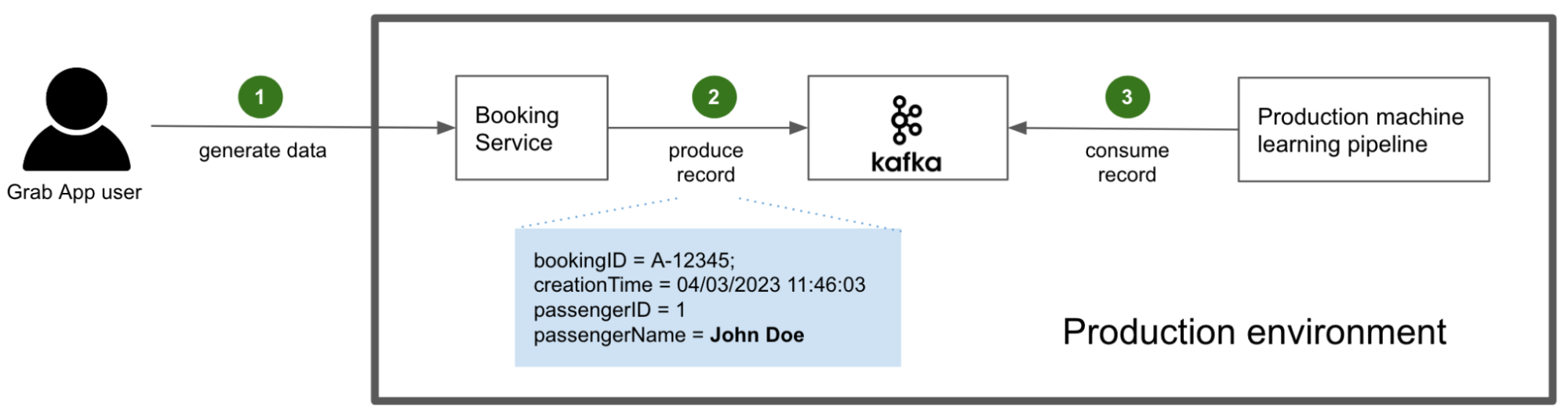
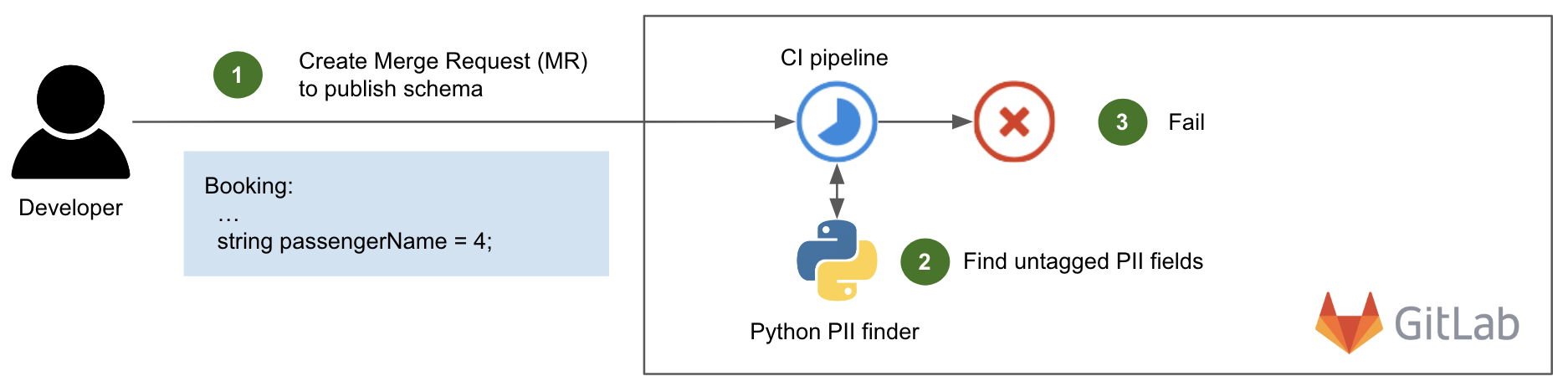
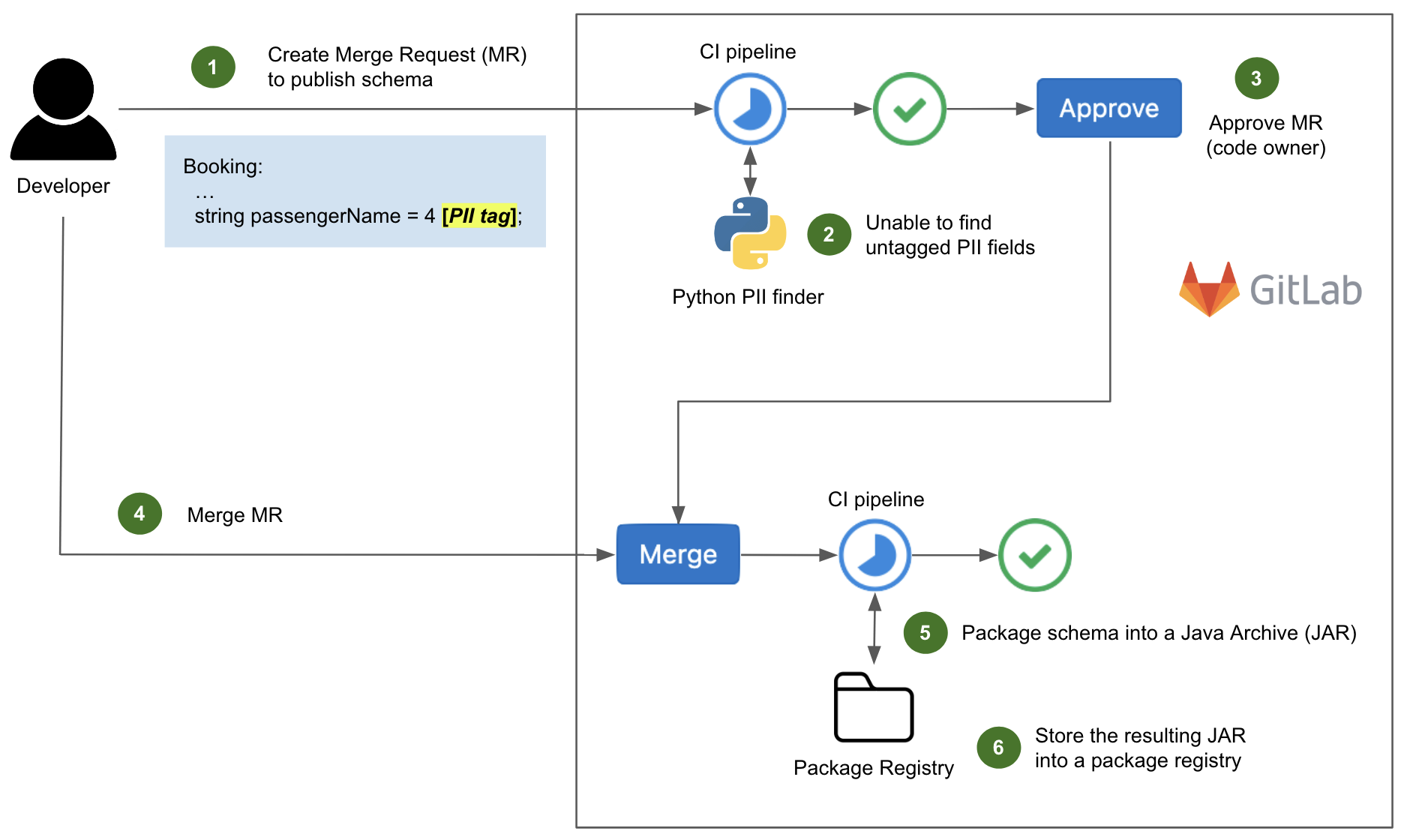
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/06/snowden-ten-years-later.html
In 2013 and 2014, I wrote extensively about new revelations regarding NSA surveillance based on the documents provided by Edward Snowden. But I had a more personal involvement as well.
I wrote the essay below in September 2013. The New Yorker agreed to publish it, but the Guardian asked me not to. It was scared of UK law enforcement, and worried that this essay would reflect badly on it. And given that the UK police would raid its offices in July 2014, it had legitimate cause to be worried.
Now, ten years later, I offer this as a time capsule of what those early months of Snowden were like.
It’s a surreal experience, paging through hundreds of top-secret NSA documents. You’re peering into a forbidden world: strange, confusing, and fascinating all at the same time.
I had flown down to Rio de Janeiro in late August at the request of Glenn Greenwald. He had been working on the Edward Snowden archive for a couple of months, and had a pile of more technical documents that he wanted help interpreting. According to Greenwald, Snowden also thought that bringing me down was a good idea.
It made sense. I didn’t know either of them, but I have been writing about cryptography, security, and privacy for decades. I could decipher some of the technical language that Greenwald had difficulty with, and understand the context and importance of various document. And I have long been publicly critical of the NSA’s eavesdropping capabilities. My knowledge and expertise could help figure out which stories needed to be reported.
I thought about it a lot before agreeing. This was before David Miranda, Greenwald’s partner, was detained at Heathrow airport by the UK authorities; but even without that, I knew there was a risk. I fly a lot—a quarter of a million miles per year—and being put on a TSA list, or being detained at the US border and having my electronics confiscated, would be a major problem. So would the FBI breaking into my home and seizing my personal electronics. But in the end, that made me more determined to do it.
I did spend some time on the phone with the attorneys recommended to me by the ACLU and the EFF. And I talked about it with my partner, especially when Miranda was detained three days before my departure. Both Greenwald and his employer, the Guardian, are careful about whom they show the documents to. They publish only those portions essential to getting the story out. It was important to them that I be a co-author, not a source. I didn’t follow the legal reasoning, but the point is that the Guardian doesn’t want to leak the documents to random people. It will, however, write stories in the public interest, and I would be allowed to review the documents as part of that process. So after a Skype conversation with someone at the Guardian, I signed a letter of engagement.
And then I flew to Brazil.
I saw only a tiny slice of the documents, and most of what I saw was surprisingly banal. The concerns of the top-secret world are largely tactical: system upgrades, operational problems owing to weather, delays because of work backlogs, and so on. I paged through weekly reports, presentation slides from status meetings, and general briefings to educate visitors. Management is management, even inside the NSA Reading the documents, I felt as though I were sitting through some of those endless meetings.
The meeting presenters try to spice things up. Presentations regularly include intelligence success stories. There were details—what had been found, and how, and where it helped—and sometimes there were attaboys from “customers” who used the intelligence. I’m sure these are intended to remind NSA employees that they’re doing good. It definitely had an effect on me. Those were all things I want the NSA to be doing.
There were so many code names. Everything has one: every program, every piece of equipment, every piece of software. Sometimes code names had their own code names. The biggest secrets seem to be the underlying real-world information: which particular company MONEYROCKET is; what software vulnerability EGOTISTICALGIRAFFE—really, I am not making that one up—is; how TURBINE works. Those secrets collectively have a code name—ECI, for exceptionally compartmented information—and almost never appear in the documents. Chatting with Snowden on an encrypted IM connection, I joked that the NSA cafeteria menu probably has code names for menu items. His response: “Trust me when I say you have no idea.”
Those code names all come with logos, most of them amateurish and a lot of them dumb. Note to the NSA: take some of that more than ten-billion-dollar annual budget and hire yourself a design firm. Really; it’ll pay off in morale.
Once in a while, though, I would see something that made me stop, stand up, and pace around in circles. It wasn’t that what I read was particularly exciting, or important. It was just that it was startling. It changed—ever so slightly—how I thought about the world.
Greenwald said that that reaction was normal when people started reading through the documents.
Intelligence professionals talk about how disorienting it is living on the inside. You read so much classified information about the world’s geopolitical events that you start seeing the world differently. You become convinced that only the insiders know what’s really going on, because the news media is so often wrong. Your family is ignorant. Your friends are ignorant. The world is ignorant. The only thing keeping you from ignorance is that constant stream of classified knowledge. It’s hard not to feel superior, not to say things like “If you only knew what we know” all the time. I can understand how General Keith Alexander, the director of the NSA, comes across as so supercilious; I only saw a minute fraction of that secret world, and I started feeling it.
It turned out to be a terrible week to visit Greenwald, as he was still dealing with the fallout from Miranda’s detention. Two other journalists, one from the Nation and the other from the Hindu, were also in town working with him. A lot of my week involved Greenwald rushing into my hotel room, giving me a thumb drive of new stuff to look through, and rushing out again.
A technician from the Guardian got a search capability working while I was there, and I spent some time with it. Question: when you’re given the capability to search through a database of NSA secrets, what’s the first thing you look for? Answer: your name.
It wasn’t there. Neither were any of the algorithm names I knew, not even algorithms I knew that the US government used.
I tried to talk to Greenwald about his own operational security. It had been incredibly stupid for Miranda to be traveling with NSA documents on the thumb drive. Transferring files electronically is what encryption is for. I told Greenwald that he and Laura Poitras should be sending large encrypted files of dummy documents back and forth every day.
Once, at Greenwald’s home, I walked into the backyard and looked for TEMPEST receivers hiding in the trees. I didn’t find any, but that doesn’t mean they weren’t there. Greenwald has a lot of dogs, but I don’t think that would hinder professionals. I’m sure that a bunch of major governments have a complete copy of everything Greenwald has. Maybe the black bag teams bumped into each other in those early weeks.
I started doubting my own security procedures. Reading about the NSA’s hacking abilities will do that to you. Can it break the encryption on my hard drive? Probably not. Has the company that makes my encryption software deliberately weakened the implementation for it? Probably. Are NSA agents listening in on my calls back to the US? Very probably. Could agents take control of my computer over the Internet if they wanted to? Definitely. In the end, I decided to do my best and stop worrying about it. It was the agency’s documents, after all. And what I was working on would become public in a few weeks.
I wasn’t sleeping well, either. A lot of it was the sheer magnitude of what I saw. It’s not that any of it was a real surprise. Those of us in the information security community had long assumed that the NSA was doing things like this. But we never really sat down and figured out the details, and to have the details confirmed made a big difference. Maybe I can make it clearer with an analogy. Everyone knows that death is inevitable; there’s absolutely no surprise about that. Yet it arrives as a surprise, because we spend most of our lives refusing to think about it. The NSA documents were a bit like that. Knowing that it is surely true that the NSA is eavesdropping on the world, and doing it in such a methodical and robust manner, is very different from coming face-to-face with the reality that it is and the details of how it is doing it.
I also found it incredibly difficult to keep the secrets. The Guardian’s process is slow and methodical. I move much faster. I drafted stories based on what I found. Then I wrote essays about those stories, and essays about the essays. Writing was therapy; I would wake up in the wee hours of the morning, and write an essay. But that put me at least three levels beyond what was published.
Now that my involvement is out, and my first essays are out, I feel a lot better. I’m sure it will get worse again when I find another monumental revelation; there are still more documents to go through.
I’ve heard it said that Snowden wants to damage America. I can say with certainty that he does not. So far, everyone involved in this incident has been incredibly careful about what is released to the public. There are many documents that could be immensely harmful to the US, and no one has any intention of releasing them. The documents the reporters release are carefully redacted. Greenwald and I repeatedly debated with Guardian editors the newsworthiness of story ideas, stressing that we would not expose government secrets simply because they’re interesting.
The NSA got incredibly lucky; this could have ended with a massive public dump like Chelsea Manning’s State Department cables. I suppose it still could. Despite that, I can imagine how this feels to the NSA. It’s used to keeping this stuff behind multiple levels of security: gates with alarms, armed guards, safe doors, and military-grade cryptography. It’s not supposed to be on a bunch of thumb drives in Brazil, Germany, the UK, the US, and who knows where else, protected largely by some random people’s opinions about what should or should not remain secret. This is easily the greatest intelligence failure in the history of ever. It’s amazing that one person could have had so much access with so little accountability, and could sneak all of this data out without raising any alarms. The odds are close to zero that Snowden is the first person to do this; he’s just the first person to make public that he did. It’s a testament to General Alexander’s power that he hasn’t been forced to resign.
It’s not that we weren’t being careful about security, it’s that our standards of care are so different. From the NSA’s point of view, we’re all major security risks, myself included. I was taking notes about classified material, crumpling them up, and throwing them into the wastebasket. I was printing documents marked “TOP SECRET/COMINT/NOFORN” in a hotel lobby. And once, I took the wrong thumb drive with me to dinner, accidentally leaving the unencrypted one filled with top-secret documents in my hotel room. It was an honest mistake; they were both blue.
If I were an NSA employee, the policy would be to fire me for that alone.
Many have written about how being under constant surveillance changes a person. When you know you’re being watched, you censor yourself. You become less open, less spontaneous. You look at what you write on your computer and dwell on what you’ve said on the telephone, wonder how it would sound taken out of context, from the perspective of a hypothetical observer. You’re more likely to conform. You suppress your individuality. Even though I have worked in privacy for decades, and already knew a lot about the NSA and what it does, the change was palpable. That feeling hasn’t faded. I am now more careful about what I say and write. I am less trusting of communications technology. I am less trusting of the computer industry.
After much discussion, Greenwald and I agreed to write three stories together to start. All of those are still in progress. In addition, I wrote two commentaries on the Snowden documents that were recently made public. There’s a lot more to come; even Greenwald hasn’t looked through everything.
Since my trip to Brazil [one month before], I’ve flown back to the US once and domestically seven times—all without incident. I’m not on any list yet. At least, none that I know about.
As it happened, I didn’t write much more with Greenwald or the Guardian. Those two had a falling out, and by the time everything settled and both began writing about the documents independently—Greenwald at the newly formed website the Intercept—I got cut out of the process somehow. I remember hearing that Greenwald was annoyed with me, but I never learned the reason. We haven’t spoken since.
Still, I was happy with the one story I was part of: how the NSA hacks Tor. I consider it a personal success that I pushed the Guardian to publish NSA documents detailing QUANTUM. I don’t think that would have gotten out any other way. And I still use those pages today when I teach cybersecurity to policymakers at the Harvard Kennedy School.
Other people wrote about the Snowden files, and wrote a lot. It was a slow trickle at first, and then a more consistent flow. Between Greenwald, Bart Gellman, and the Guardian reporters, there ended up being steady stream of news. (Bart brought in Ashkan Soltani to help him with the technical aspects, which was a great move on his part, even if it cost Ashkan a government job later.) More stories were covered by other publications.
It started getting weird. Both Greenwald and Gellman held documents back so they could publish them in their books. Jake Appelbaum, who had not yet been accused of sexual assault by multiple women, was working with Laura Poitras. He partnered with Spiegel to release an implant catalog from the NSA’s Tailored Access Operations group. To this day, I am convinced that that document was not in the Snowden archives: that Jake got it somehow, and it was released with the implication that it was from Edward Snowden. I thought it was important enough that I started writing about each item in that document in my blog: “NSA Exploit of the Week.” That got my website blocked by the DoD: I keep a framed print of the censor’s message on my wall.
Perhaps the most surreal document disclosures were when artists started writing fiction based on the documents. This was in 2016, when Poitras built a secure room in New York to house the documents. By then, the documents were years out of date. And now they’re over a decade out of date. (They were leaked in 2013, but most of them were from 2012 or before.)
I ended up being something of a public ambassador for the documents. When I got back from Rio, I gave talks at a private conference in Woods Hole, the Berkman Center at Harvard, something called the Congress and Privacy and Surveillance in Geneva, events at both CATO and New America in DC, an event at the University of Pennsylvania, an event at EPIC and a “Stop Watching Us” rally in DC, the RISCS conference in London, the ISF in Paris, and…then…at the IETF meeting in Vancouver in November 2013. (I remember little of this; I am reconstructing it all from my calendar.)
What struck me at the IETF was the indignation in the room, and the calls to action. And there was action, across many fronts. We technologists did a lot to help secure the Internet, for example.
The government didn’t do its part, though. Despite the public outcry, investigations by Congress, pronouncements by President Obama, and federal court rulings, I don’t think much has changed. The NSA canceled a program here and a program there, and it is now more public about defense. But I don’t think it is any less aggressive about either bulk or targeted surveillance. Certainly its government authorities haven’t been restricted in any way. And surveillance capitalism is still the business model of the Internet.
And Edward Snowden? We were in contact for a while on Signal. I visited him once in Moscow, in 2016. And I had him do an guest lecture to my class at Harvard for a few years, remotely by Jitsi. Afterwards, I would hold a session where I promised to answer every question he would evade or not answer, explain every response he did give, and be candid in a way that someone with an outstanding arrest warrant simply cannot. Sometimes I thought I could channel Snowden better than he could.
But now it’s been a decade. Everything he knows is old and out of date. Everything we know is old and out of date. The NSA suffered an even worse leak of its secrets by the Russians, under the guise of the Shadow Brokers, in 2016 and 2017. The NSA has rebuilt. It again has capabilities we can only surmise.
This essay previously appeared in an IETF publication, as part of an Edward Snowden ten-year retrospective.
EDITED TO ADD (6/7): Conversation between Snowden, Greenwald, and Poitras.