US law enforcement can access details of money transfers without a warrant through an obscure surveillance program the Arizona attorney general’s office created in 2014. A database stored at a nonprofit, the Transaction Record Analysis Center (TRAC), provides full names and amounts for larger transfers (above $500) sent between the US, Mexico and 22 other regions through services like Western Union, MoneyGram and Viamericas. The program covers data for numerous Caribbean and Latin American countries in addition to Canada, China, France, Malaysia, Spain, Thailand, Ukraine and the US Virgin Islands. Some domestic transfers also enter the data set.
[…]
You need to be a member of law enforcement with an active government email account to use the database, which is available through a publicly visible web portal. Leber told The Journal that there haven’t been any known breaches or instances of law enforcement misuse. However, Wyden noted that the surveillance program included more states and countries than previously mentioned in briefings. There have also been subpoenas for bulk money transfer data from Homeland Security Investigations (which withdrew its request after Wyden’s inquiry), the DEA and the FBI.
According to the complaint against him, Al-Azhari allegedly visited a dark web site that hosts “unofficial propaganda and photographs related to ISIS” multiple times on May 14, 2019. In virtue of being a dark web site—that is, one hosted on the Tor anonymity network—it should have been difficult for the site owner’s or a third party to determine the real IP address of any of the site’s visitors.
Yet, that’s exactly what the FBI did. It found Al-Azhari allegedly visited the site from an IP address associated with Al-Azhari’s grandmother’s house in Riverside, California. The FBI also found what specific pages Al-Azhari visited, including a section on donating Bitcoin; another focused on military operations conducted by ISIS fighters in Iraq, Syria, and Nigeria; and another page that provided links to material from ISIS’s media arm. Without the FBI deploying some form of surveillance technique, or Al-Azhari using another method to visit the site which exposed their IP address, this should not have been possible.
There are lots of ways to de-anonymize Tor users. Someone at the NSA gave a presentation on this ten years ago. (I wrote about it for the Guardian in 2013, an essay that reads so dated in light of what we’ve learned since then.) It’s unlikely that the FBI uses the same sorts of broad surveillance techniques that the NSA does, but it’s certainly possible that the NSA did the surveillance and passed the information to the FBI.
With the release of ChatGPT, I’ve read many random articles about this or that threat from the technology. This paper is a good survey of the field: what the threats are, how we might detect machine-generated text, directions for future research. It’s a solid grounding amongst all of the hype.
Machine Generated Text: A Comprehensive Survey of Threat Models and Detection Methods
Abstract: Advances in natural language generation (NLG) have resulted in machine generated text that is increasingly difficult to distinguish from human authored text. Powerful open-source models are freely available, and user-friendly tools democratizing access to generative models are proliferating. The great potential of state-of-the-art NLG systems is tempered by the multitude of avenues for abuse. Detection of machine generated text is a key countermeasure for reducing abuse of NLG models, with significant technical challenges and numerous open problems. We provide a survey that includes both 1) an extensive analysis of threat models posed by contemporary NLG systems, and 2) the most complete review of machine generated text detection methods to date. This survey places machine generated text within its cybersecurity and social context, and provides strong guidance for future work addressing the most critical threat models, and ensuring detection systems themselves demonstrate trustworthiness through fairness, robustness, and accountability.
Brian Krebs is reporting on a vulnerability in Experian’s website:
Identity thieves have been exploiting a glaring security weakness in the website of Experian, one of the big three consumer credit reporting bureaus. Normally, Experian requires that those seeking a copy of their credit report successfully answer several multiple choice questions about their financial history. But until the end of 2022, Experian’s website allowed anyone to bypass these questions and go straight to the consumer’s report. All that was needed was the person’s name, address, birthday and Social Security number.
At over thirty years old, HTTP is still the foundation of the web and one of the Internet’s most popular protocols—not just for browsing, watching videos and listening to music, but also for apps, machine-to-machine communication, and even as a basis for building other protocols, forming what some refer to as a “second waist” in the classic Internet hourglass diagram.
What makes HTTP so successful? One answer is that it hits a “sweet spot” for most applications that need an application protocol. “Building Protocols with HTTP” (published in 2022 as a Best Current Practice RFC by the HTTP Working Group) argues that HTTP’s success can be attributed to factors like:
– familiarity by implementers, specifiers, administrators, developers, and users; – availability of a variety of client, server, and proxy implementations; – ease of use; – availability of web browsers; – reuse of existing mechanisms like authentication and encryption; – presence of HTTP servers and clients in target deployments; and – its ability to traverse firewalls.
Another important factor is the community of people using, implementing, and standardising HTTP. We work together to maintain and develop the protocol actively, to assure that it’s interoperable and meets today’s needs. If HTTP stagnates, another protocol will (justifiably) replace it, and we’ll lose all the community’s investment, shared understanding and interoperability.
Cloudflare and many others do this by sending engineers to participate in the IETF, where most Internet protocols are discussed and standardised. We also attend and sponsor community events like the HTTP Workshop to have conversations about what problems people have, what they need, and understand what changes might help them.
So what happened at all of those working group meetings, specification documents, and side events in 2022? What are implementers and deployers of the web’s protocol doing? And what’s coming next?
New Specification: HTTP/3
Specification-wise, the biggest thing to happen in 2022 was the publication of HTTP/3, because it was an enormous step towards keeping up with the requirements of modern applications and sites by using the network more efficiently to unblock web performance.
Way back in the 90s, HTTP/0.9 and HTTP/1.0 used a new TCP connection for each request—an astoundingly inefficient use of the network. HTTP/1.1 introduced persistent connections (which were backported to HTTP/1.0 with the `Connection: Keep-Alive` header). This was an improvement that helped servers and the network cope with the explosive popularity of the web, but even back then, the community knew it had significant limitations—in particular, head-of-line blocking (where one outstanding request on a connection blocks others from completing).
That didn’t matter so much in the 90s and early 2000s, but today’s web pages and applications place demands on the network that make these limitations performance-critical. Pages often have hundreds of assets that all compete for network resources, and HTTP/1.1 wasn’t up to the task. After some false starts, the community finally addressed these issues with HTTP/2 in 2015.
However, removing head-of-line blocking in HTTP exposed the same problem one layer lower, in TCP. Because TCP is an in-order, reliable delivery protocol, loss of a single packet in a flow can block access to those after it—even if they’re sitting in the operating system’s buffers. This turns out to be a real issue for HTTP/2 deployment, especially on less-than-optimal networks.
HTTP/3 is the version of HTTP that uses QUIC. While the working group effectively finished it in 2021 along with QUIC, its publication was held until 2022 to synchronise with the publication of other documents (see below). 2022 was also a milestone year for HTTP/3 deployment; Cloudflare saw increasing adoption and confidence in the new protocol.
While there was only a brief gap of a few years between HTTP/2 and HTTP/3, there isn’t much appetite for working on HTTP/4 in the community soon. QUIC and HTTP/3 are both new, and the world is still learning how best to implement the protocols, operate them, and build sites and applications using them. While we can’t rule out a limitation that will force a new version in the future, the IETF built these protocols based upon broad industry experience with modern networks, and have significant extensibility available to ease any necessary changes.
New specifications: HTTP “core”
The other headline event for HTTP specs in 2022 was the publication of its “core” documents — the heart of HTTP’s specification. The core comprises: HTTP Semantics – things like methods, headers, status codes, and the message format; HTTP Caching – how HTTP caches work; HTTP/1.1 – mapping semantics to the wire, using the format everyone knows and loves.
Additionally, HTTP/2 was republished to properly integrate with the Semantics document, and to fix a few outstanding issues.
This is the latest in a long series of revisions for these documents—in the past, we’ve had the RFC 723x series, the (perhaps most well-known) RFC 2616, RFC 2068, and the grandparent of them all, RFC 1945. Each revision has aimed to improve readability, fix errors, explain concepts better, and clarify protocol operation. Poorly specified (or implemented) features are deprecated; new features that improve protocol operation are added. See the ‘Changes from…’ appendix in each document for the details. And, importantly, always refer to the latest revisions linked above; the older RFCs are now obsolete.
Deploying Early Hints
HTTP/2 included server push, a feature designed to allow servers to “push” a request/response pair to clients when they knew the client was going to need something, so it could avoid the latency penalty of making a request and waiting for the response.
After HTTP/2 was finalised in 2015, Cloudflare and many other HTTP implementations soon rolled out server push in anticipation of big performance wins. Unfortunately, it turned out that’s harder than it looks; server push effectively requires the server to predict the future—not only what requests the client will send but also what the network conditions will be. And, when the server gets it wrong (“over-pushing”), the pushed requests directly compete with the real requests that the browser is making, representing a significant opportunity cost with real potential for harming performance, rather than helping it. The impact is even worse when the browser already has a copy in cache, so it doesn’t need the push at all.
As a result, Chrome removed HTTP/2 server push in 2022. Other browsers and servers might still support it, but the community seems to agree that it’s only suitable for specialised uses currently, like the browser notification-specific Web Push Protocol.
That doesn’t mean that we’re giving up, however. The 103 (Early Hints) status code was published as an Experimental RFC by the HTTP Working Group in 2017. It allows a server to send hints to the browser in a non-final response, before the “real” final response. That’s useful if you know that the content is going to include some links to resources that the browser will fetch, but need more time to get the response to the client (because it will take more time to generate, or because the server needs to fetch it from somewhere else, like a CDN does).
Early Hints can be used in many situations that server push was designed for — for example, when you have CSS and JavaScript that a page is going to need to load. In theory, they’re not as optimal as server push, because they only allow hints to be sent when there’s an outstanding request, and because getting the hints to the client and acted upon adds some latency.
In practice, however, Cloudflare and our partners (like Shopify and Google) spent 2022 experimenting with Early Hints and finding them much safer to use, with promising performance benefits that include significant reductions in key web performance metrics.
We’re excited about the potential that Early Hints show; so excited that we’ve integrated them into Cloudflare Pages. We’re also evaluating new ways to improve performance using this new capability in the protocol.
Privacy-focused intermediation
For many, the most exciting HTTP protocol extensions in 2022 focused on intermediation—the ability to insert proxies, gateways, and similar components into the protocol to achieve specific goals, often focused on improving privacy.
The MASQUE Working Group, for example, is an effort to add new tunneling capabilities to HTTP, so that an intermediary can pass the tunneled traffic along to another server.
While CONNECT has enabled TCP tunnels for a long time, MASQUE enabled UDP tunnels, allowing more protocols to be tunneled more efficiently–including QUIC and HTTP/3.
At Cloudflare, we’re enthusiastic to be working with Apple to use MASQUE to implement iCloud Private Relay and enhance their customers’ privacy without relying solely on one company. We’re also very interested in the Working Group’s future work, including IP tunneling that will enable MASQUE-based VPNs. Another intermediation-focused specification is Oblivious HTTP (or OHTTP). OHTTP uses sets of intermediaries to prevent the server from using connections or IP addresses to track clients, giving greater privacy assurances for things like collecting telemetry or other sensitive data. This specification is just finishing the standards process, and we’re using it to build an important new product, Privacy Gateway, to protect the privacy of our customers’ customers.
We and many others in the Internet community believe that this is just the start, because intermediation can partition communication, a valuable tool for improving privacy.
Protocol security
Finally, 2022 saw a lot of work on security-related aspects of HTTP. The Digest Fields specification is an update to the now-ancient `Digest` header field, allowing integrity digests to be added to messages. The HTTP Message Signatures specification enables cryptographic signatures on requests and responses — something that has widespread ad hoc deployment, but until now has lacked a standard. Both specifications are in the final stages of standardisation.
A revision of the Cookie specification also saw a lot of progress in 2022, and should be final soon. Since it’s not possible to get rid of them completely soon, much work has taken place to limit how they operate to improve privacy and security, including a new `SameSite` attribute.
Another set of security-related specifications that Cloudflare has invested in for many years is Privacy Pass also known as “Private Access Tokens.” These are cryptographic tokens that can assure clients are real people, not bots, without using an intrusive CAPTCHA, and without tracking the user’s activity online. In HTTP, they take the form of a new authentication scheme.
While Privacy Pass is still not quite through the standards process, 2022 saw its broad deployment by Apple, a huge step forward. And since Cloudflare uses it in Turnstile, our CAPTCHA alternative, your users can have a better experience today.
At the 2022 HTTP Workshop, the community also talked about what new work we can take on to improve the protocol. Some ideas discussed included improving our shared protocol testing infrastructure (right now we have a few resources, but it could be much better), improving (or replacing) Alternative Services to allow more intelligent and correct connection management, and more radical changes, like alternative, binary serialisations of headers.
There’s also a continuing discussion in the community about whether HTTP should accommodate pub/sub, or whether it should be standardised to work over WebSockets (and soon, WebTransport). Although it’s hard to say now, adjacent work on Media over QUIC that just started might provide an opportunity to push this forward.
Of course, that’s not everything, and what happens to HTTP in 2023 (and beyond) remains to be seen. HTTP is still evolving, even as it stays compatible with the largest distributed hypertext system ever conceived—the World Wide Web.
Today, we’re excited to announce that Cloudflare is participating in the AS112 project, becoming an operator of this community-operated, loosely-coordinated anycast deployment of DNS servers that primarily answer reverse DNS lookup queries that are misdirected and create significant, unwanted load on the Internet.
With the addition of Cloudflare global network, we can make huge improvements to the stability, reliability and performance of this distributed public service.
What is AS112 project
The AS112 project is a community effort to run an important network service intended to handle reverse DNS lookup queries for private-only use addresses that should never appear in the public DNS system. In the seven days leading up to publication of this blog post, for example, Cloudflare’s 1.1.1.1 resolver received more than 98 billion of these queries — all of which have no useful answer in the Domain Name System.
Some history is useful for context. Internet Protocol (IP) addresses are essential to network communication. Many networks make use of IPv4 addresses that are reserved for private use, and devices in the network are able to connect to the Internet with the use of network address translation (NAT), a process that maps one or more local private addresses to one or more global IP addresses and vice versa before transferring the information.
Your home Internet router most likely does this for you. You will likely find that, when at home, your computer has an IP address like 192.168.1.42. That’s an example of a private use address that is fine to use at home, but can’t be used on the public Internet. Your home router translates it, through NAT, to an address your ISP assigned to your home and that can be used on the Internet.
Here are the reserved “private use” addresses designated in RFC 1918.
Address block
Address range
Number of addresses
10.0.0.0/8
10.0.0.0 – 10.255.255.255
16,777,216
172.16.0.0/12
172.16.0.0 – 172.31.255.255
1,048,576
192.168.0.0/16
192.168.0.0 – 192.168.255.255
65,536
(Reserved private IPv4 network ranges)
Although the reserved addresses themselves are blocked from ever appearing on the public Internet, devices and programs in private environments may occasionally originate DNS queries corresponding to those addresses. These are called “reverse lookups” because they ask the DNS if there is a name associated with an address.
Reverse DNS lookup
A reverse DNS lookup is an opposite process of the more commonly used DNS lookup (which is used every day to translate a name like www.cloudflare.com to its corresponding IP address). It is a query to look up the domain name associated with a given IP address, in particular those addresses associated with routers and switches. For example, network administrators and researchers use reverse lookups to help understand paths being taken by data packets in the network, and it’s much easier to understand meaningful names than a meaningless number.
A reverse lookup is accomplished by querying DNS servers for a pointer record (PTR). PTR records store IP addresses with their segments reversed, and by appending “.in-addr.arpa” to the end. For example, the IP address 192.0.2.1 will have the PTR record stored as 1.2.0.192.in-addr.arpa. In IPv6, PTR records are stored within the “.ip6.arpa” domain instead of “.in-addr.arpa.”. Below are some query examples using the dig command line tool.
# Lookup the domain name associated with IPv4 address 172.64.35.46
# “+short” option make it output the short form of answers only
$ dig @1.1.1.1 PTR 46.35.64.172.in-addr.arpa +short
hunts.ns.cloudflare.com.
# Or use the shortcut “-x” for reverse lookups
$ dig @1.1.1.1 -x 172.64.35.46 +short
hunts.ns.cloudflare.com.
# Lookup the domain name associated with IPv6 address 2606:4700:58::a29f:2c2e
$ dig @1.1.1.1 PTR e.2.c.2.f.9.2.a.0.0.0.0.0.0.0.0.0.0.0.0.8.5.0.0.0.0.7.4.6.0.6.2.ip6.arpa. +short
hunts.ns.cloudflare.com.
# Or use the shortcut “-x” for reverse lookups
$ dig @1.1.1.1 -x 2606:4700:58::a29f:2c2e +short
hunts.ns.cloudflare.com.
The problem that private use addresses cause for DNS
The private use addresses concerned have only local significance and cannot be resolved by the public DNS. In other words, there is no way for the public DNS to provide a useful answer to a question that has no global meaning. It is therefore a good practice for network administrators to ensure that queries for private use addresses are answered locally. However, it is not uncommon for such queries to follow the normal delegation path in the public DNS instead of being answered within the network. That creates unnecessary load.
By definition of being private use, they have no ownership in the public sphere, so there are no authoritative DNS servers to answer the queries. At the very beginning, root servers respond to all these types of queries since they serve the IN-ADDR.ARPA zone.
Over time, due to the wide deployment of private use addresses and the continuing growth of the Internet, traffic on the IN-ADDR.ARPA DNS infrastructure grew and the load due to these junk queries started to cause some concern. Therefore, the idea of offloading IN-ADDR.ARPA queries related to private use addresses was proposed. Following that, the use of anycast for distributing authoritative DNS service for that idea was subsequently proposed at a private meeting of root server operators. And eventually the AS112 service was launched to provide an alternative target for the junk.
The AS112 project is born
To deal with this problem, the Internet community set up special DNS servers called “blackhole servers” as the authoritative name servers that respond to the reverse lookup of the private use address blocks 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16 and the link-local address block 169.254.0.0/16 (which also has only local significance). Since the relevant zones are directly delegated to the blackhole servers, this approach has come to be known as Direct Delegation.
The first two blackhole servers set up by the project are: blackhole-1.iana.org and blackhole-2.iana.org.
Any server, including DNS name server, needs an IP address to be reachable. The IP address must also be associated with an Autonomous System Number (ASN) so that networks can recognize other networks and route data packets to the IP address destination. To solve this problem, a new authoritative DNS service would be created but, to make it work, the community would have to designate IP addresses for the servers and, to facilitate their availability, an AS number that network operators could use to reach (or provide) the new service.
The selected AS number (provided by American Registry for Internet Numbers) and namesake of the project, was 112. It was started by a small subset of root server operators, later grown to a group of volunteer name server operators that include many other organizations. They run anycasted instances of the blackhole servers that, together, form a distributed sink for the reverse DNS lookups for private network and link-local addresses sent to the public Internet.
A reverse DNS lookup for a private use address would see responses like in the example below, where the name server blackhole-1.iana.org is authoritative for it and says the name does not exist, represented in DNS responses by NXDOMAIN.
At the beginning of the project, node operators set up the service in the direct delegation fashion (RFC 7534). However, adding delegations to this service requires all AS112 servers to be updated, which is difficult to ensure in a system that is only loosely-coordinated. An alternative approach using DNAME redirection was subsequently introduced by RFC 7535 to allow new zones to be added to the system without reconfiguring the blackhole servers.
Direct delegation
DNS zones are directly delegated to the blackhole servers in this approach.
RFC 7534 defines the static set of reverse lookup zones for which AS112 name servers should answer authoritatively. They are as follows:
10.in-addr-arpa
16.172.in-addr.arpa
17.172.in-addr.arpa
18.172.in-addr.arpa
19.172.in-addr.arpa
20.172.in-addr.arpa
21.172.in-addr.arpa
22.172.in-addr.arpa
23.172.in-addr.arpa
24.172.in-addr.arpa
25.172.in-addr.arpa
26.172.in-addr.arpa
27.172.in-addr.arpa
28.172.in-addr.arpa
29.172.in-addr.arpa
30.172.in-addr.arpa
31.172.in-addr.arpa
168.192.in-addr.arpa
254.169.in-addr.arpa (corresponding to the IPv4 link-local address block)
Zone files for these zones are quite simple because essentially they are empty apart from the required SOA and NS records. A template of the zone file is defined as:
; db.dd-empty
;
; Empty zone for direct delegation AS112 service.
;
$TTL 1W
@ IN SOA prisoner.iana.org. hostmaster.root-servers.org. (
1 ; serial number
1W ; refresh
1M ; retry
1W ; expire
1W ) ; negative caching TTL
;
NS blackhole-1.iana.org.
NS blackhole-2.iana.org.
IP addresses of the direct delegation name servers are covered by the single IPv4 prefix 192.175.48.0/24 and the IPv6 prefix 2620:4f:8000::/48.
Name server
IPv4 address
IPv6 address
blackhole-1.iana.org
192.175.48.6
2620:4f:8000::6
blackhole-2.iana.org
192.175.48.42
2620:4f:8000::42
DNAME redirection
Firstly, what is DNAME? Introduced by RFC 6672, a DNAME record or Delegation Name Record creates an alias for an entire subtree of the domain name tree. In contrast, the CNAME record creates an alias for a single name and not its subdomains. For a received DNS query, the DNAME record instructs the name server to substitute all those appearing in the left hand (owner name) with the right hand (alias name). The substituted query name, like the CNAME, may live within the zone or may live outside the zone.
Like the CNAME record, the DNS lookup will continue by retrying the lookup with the substituted name. For example, if there are two DNS zone as follows:
# zone: example.com
www.example.com. A 203.0.113.1
foo.example.com. DNAME example.net.
# zone: example.net
example.net. A 203.0.113.2
bar.example.net. A 203.0.113.3
The query resolution scenarios would look like this:
Query (Type + Name)
Substitution
Final result
A www.example.com
(no DNAME, don’t apply)
203.0.113.1
DNAME foo.example.com
(don’t apply to the owner name itself)
example.net
A foo.example.com
(don’t apply to the owner name itself)
<NXDOMAIN>
A bar.foo.example.com
bar.example.net
203.0.113.2
RFC 7535 specifies adding another special zone, empty.as112.arpa, to support DNAME redirection for AS112 nodes. When there are new zones to be added, there is no need for AS112 node operators to update their configuration: instead, the zones’ parents will set up DNAME records for the new domains with the target domain empty.as112.arpa. The redirection (which can be cached and reused) causes clients to send future queries to the blackhole server that is authoritative for the target zone.
Note that blackhole servers do not have to support DNAME records themselves, but they do need to configure the new zone to which root servers will redirect queries at. Considering there may be existing node operators that do not update their name server configuration for some reasons and in order to not cause interruption to the service, the zone was delegated to a new blackhole server instead – blackhole.as112.arpa.
This name server uses a new pair of IPv4 and IPv6 addresses, 192.31.196.1 and 2001:4:112::1, so queries involving DNAME redirection will only land on those nodes operated by entities that also set up the new name server. Since it is not necessary for all AS112 participants to reconfigure their servers to serve empty.as112.arpa from this new server for this system to work, it is compatible with the loose coordination of the system as a whole.
The zone file for empty.as112.arpa is defined as:
; db.dr-empty
;
; Empty zone for DNAME redirection AS112 service.
;
$TTL 1W
@ IN SOA blackhole.as112.arpa. noc.dns.icann.org. (
1 ; serial number
1W ; refresh
1M ; retry
1W ; expire
1W ) ; negative caching TTL
;
NS blackhole.as112.arpa.
The addresses of the new DNAME redirection name server are covered by the single IPv4 prefix 192.31.196.0/24 and the IPv6 prefix 2001:4:112::/48.
Name server
IPv4 address
IPv6 address
blackhole.as112.arpa
192.31.196.1
2001:4:112::1
Node identification
RFC 7534 recommends every AS112 node also to host the following metadata zones as well: hostname.as112.net and hostname.as112.arpa.
These zones only host TXT records and serve as identifiers for querying metadata information about an AS112 node. At Cloudflare nodes, the zone files look like this:
$ORIGIN hostname.as112.net.
;
$TTL 604800
;
@ IN SOA ns3.cloudflare.com. dns.cloudflare.com. (
1 ; serial number
604800 ; refresh
60 ; retry
604800 ; expire
604800 ) ; negative caching TTL
;
NS blackhole-1.iana.org.
NS blackhole-2.iana.org.
;
TXT "Cloudflare DNS, <DATA_CENTER_AIRPORT_CODE>"
TXT "See http://www.as112.net/ for more information."
;
$ORIGIN hostname.as112.arpa.
;
$TTL 604800
;
@ IN SOA ns3.cloudflare.com. dns.cloudflare.com. (
1 ; serial number
604800 ; refresh
60 ; retry
604800 ; expire
604800 ) ; negative caching TTL
;
NS blackhole.as112.arpa.
;
TXT "Cloudflare DNS, <DATA_CENTER_AIRPORT_CODE>"
TXT "See http://www.as112.net/ for more information."
;
Helping AS112 helps the Internet
As the AS112 project helps reduce the load on public DNS infrastructure, it plays a vital role in maintaining the stability and efficiency of the Internet. Being a part of this project aligns with Cloudflare’s mission to help build a better Internet.
Cloudflare is one of the fastest global anycast networks on the planet, and operates one of the largest, highly performant and reliable DNS services. We run authoritative DNS for millions of Internet properties globally. We also operate the privacy- and performance-focused public DNS resolver 1.1.1.1 service. Given our network presence and scale of operations, we believe we can make a meaningful contribution to the AS112 project.
How we built it
We’ve publicly talked about the Cloudflare in-house built authoritative DNS server software, rrDNS, several times in the past, but haven’t talked much about the software we built to power the Cloudflare public resolver – 1.1.1.1. This is an opportunity to shed some light on the technology we used to build 1.1.1.1, because this AS112 service is built on top of the same platform.
A platform for DNS workloads
We’ve created a platform to run DNS workloads. Today, it powers 1.1.1.1, 1.1.1.1 for Families, Oblivious DNS over HTTPS (ODoH), Cloudflare WARP and Cloudflare Gateway.
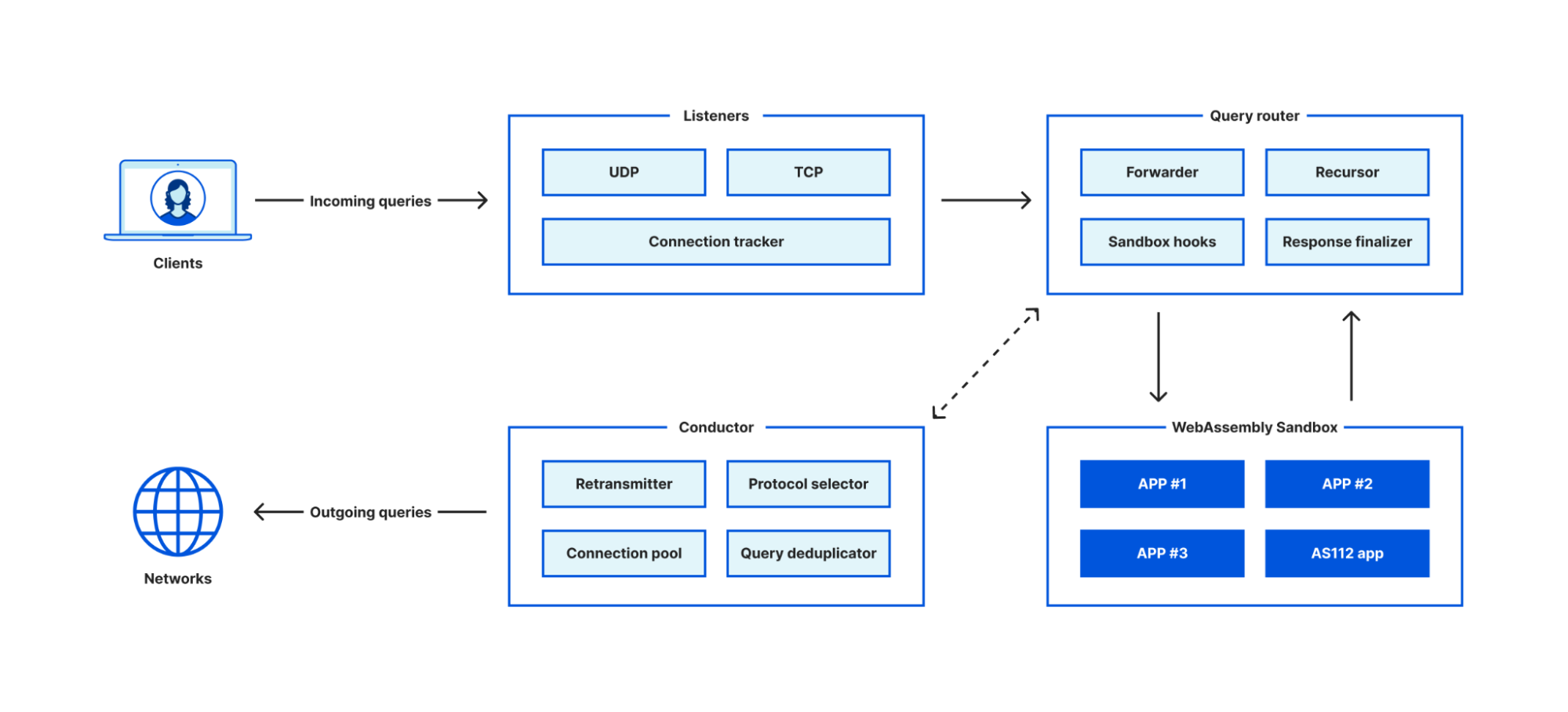
The core part of the platform is a non-traditional DNS server, which has a built-in DNS recursive resolver and a forwarder to forward queries to other servers. It consists of four key modules:
A highly efficient listener module that accepts connections for incoming requests.
A query router module that decides how a query should be resolved.
A conductor module that figures out the best way of exchanging DNS messages with upstream servers.
A sandbox environment to host guest applications.
The DNS server itself doesn’t include any business logic, instead the guest applications run in the sandbox environment can implement concrete business logic such as request filtering, query processing, logging, attack mitigation, cache purging, etc.
The server is written in Rust and the sandbox environment is built on top of a WebAssembly runtime. The combination of Rust and WebAssembly allow us to implement high efficient connection handling, request filtering and query dispatching modules, while having the flexibility of implementing custom business logic in a safe and efficient manner.
The host exposes a set of APIs, called hostcalls, for the guest applications to accomplish a variety of tasks. You can think of them like syscalls on Linux. Here are few examples functions provided by the hostcalls:
Obtain the current UNIX timestamp
Lookup geolocation data of IP addresses
Spawn async tasks
Create local sockets
Forward DNS queries to designated servers
Register callback functions of the sandbox hooks
Read current request information, and write responses
Emit application logs, metric data points and tracing spans/events
The DNS request lifecycle is broken down into phases. A request phase is a point in processing at which sandboxed apps can be called to change the course of request resolution. And each guest application can register callbacks for each phase.
AS112 guest application
The AS112 service is built as a guest application written in Rust and compiled to WebAssembly. The zones listed in RFC 7534 and RFC 7535 are loaded as static zones in memory and indexed as a tree data structure. Incoming queries are answered locally by looking up entries in the zone tree.
A router setting in the app manifest is added to tell the host what kind of DNS queries should be processed by the guest application, and a fallback_action setting is added to declare the expected fallback behavior.
# Declare what kind of queries the app handles.
router = [
# The app is responsible for all the AS112 IP prefixes.
"dst in { 192.31.196.0/24 192.175.48.0/24 2001:4:112::/48 2620:4f:8000::/48 }",
]
# If the app fails to handle the query, servfail should be returned.
fallback_action = "fail"
The guest application, along with its manifest, is then compiled and deployed through a deployment pipeline that leverages Quicksilver to store and replicate the assets worldwide.
The guest application is now up and running, but how does the DNS query traffic destined to the new IP prefixes reach the DNS server? Do we have to restart the DNS server every time we add a new guest application? Of course there is no need. We use software we developed and deployed earlier, called Tubular. It allows us to change the addresses of a service on the fly. With the help of Tubular, incoming packets destined to the AS112 service IP prefixes are dispatched to the right DNS server process without the need to make any change or release of the DNS server itself.
Meanwhile, in order to make the misdirected DNS queries land on the Cloudflare network in the first place, we use BYOIP (Bringing Your Own IPs to Cloudflare), a Cloudflare product that can announce customer’s own IP prefixes in all our locations. The four AS112 IP prefixes are boarded onto the BYOIP system, and will be announced by it globally.
Testing
How can we ensure the service we set up does the right thing before we announce it to the public Internet? 1.1.1.1 processes more than 13 billion of these misdirected queries every day, and it has logic in place to directly return NXDOMAIN for them locally, which is a recommended practice per RFC 7534.
However, we are able to use a dynamic rule to change how the misdirected queries are handled in Cloudflare testing locations. For example, a rule like following:
phase = post-cache and qtype in { PTR } and colo in { test1 test2 } and qname-suffix in { 10.in-addr.arpa 16.172.in-addr.arpa 17.172.in-addr.arpa 18.172.in-addr.arpa 19.172.in-addr.arpa 20.172.in-addr.arpa 21.172.in-addr.arpa 22.172.in-addr.arpa 23.172.in-addr.arpa 24.172.in-addr.arpa 25.172.in-addr.arpa 26.172.in-addr.arpa 27.172.in-addr.arpa 28.172.in-addr.arpa 29.172.in-addr.arpa 30.172.in-addr.arpa 31.172.in-addr.arpa 168.192.in-addr.arpa 254.169.in-addr.arpa } forward 192.175.48.6:53
The rule instructs that in data center test1 and test2, when the DNS query type is PTR, and the query name ends with those in the list, forward the query to server 192.175.48.6 (one of the AS112 service IPs) on port 53.
Because we’ve provisioned the AS112 IP prefixes in the same node, the new AS112 service will receive the queries and respond to the resolver.
It’s worth mentioning that the above-mentioned dynamic rule that intercepts a query at the post-cache phase, and changes how the query gets processed, is executed by a guest application too, which is named override. This app loads all dynamic rules, parses the DSL texts and registers callback functions at phases declared by each rule. And when an incoming query matches the expressions, it executes the designated actions.
Public reports
We collect the following metrics to generate the public statistics that an AS112 operator is expected to share to the operator community:
Number of queries by query type
Number of queries by response code
Number of queries by protocol
Number of queries by IP versions
Number of queries with EDNS support
Number of queries with DNSSEC support
Number of queries by ASN/Data center
We’ll serve the public statistics page on the Cloudflare Radar website. We are still working on implementing the required backend API and frontend of the page – we’ll share the link to this page once it is available.
What’s next?
We are going to announce the AS112 prefixes starting December 15, 2022.
After the service is launched, you can run a dig command to check if you are hitting an AS112 node operated by Cloudflare, like:
$ dig @blackhole-1.iana.org TXT hostname.as112.arpa +short
"Cloudflare DNS, SFO"
"See http://www.as112.net/ for more information."
Eufy cameras claim to be local only, but uploaddata to the cloud. The company is basically lying to reporters, despite being shown evidence to the contrary. The company’s behavior is so egregious that ReviewGeek is no longer recommending them.
This will be interesting to watch. If Eufy can ignore security researchers and the press without there being any repercussions in the market, others will follow suit. And we will lose public shaming as an incentive to improve security.
After further testing, we’re not seeing the VLC streams begin based solely on the camera detecting motion. We’re not sure if that’s a change since yesterday or something I got wrong in our initial report. It does appear that Eufy is making changes—it appears to have removed access to the method we were using to get the address of our streams, although an address we already obtained is still working.
This is a really interesting paper that discusses what the authors call the Decoupling Principle:
The idea is simple, yet previously not clearly articulated: to ensure privacy, information should be divided architecturally and institutionally such that each entity has only the information they need to perform their relevant function. Architectural decoupling entails splitting functionality for different fundamental actions in a system, such as decoupling authentication (proving who is allowed to use the network) from connectivity (establishing session state for communicating). Institutional decoupling entails splitting what information remains between non-colluding entities, such as distinct companies or network operators, or between a user and network peers. This decoupling makes service providers individually breach-proof, as they each have little or no sensitive data that can be lost to hackers. Put simply, the Decoupling Principle suggests always separating who you are from what you do.
Researchers at University of Guelph in Ontario, Canada, recovered logs from laptops after receiving overnight repairs from 12 commercial shops. The logs showed that technicians from six of the locations had accessed personal data and that two of those shops also copied data onto a personal device. Devices belonging to females were more likely to be snooped on, and that snooping tended to seek more sensitive data, including both sexually revealing and non-sexual pictures, documents, and financial information.
[…]
In three cases, Windows Quick Access or Recently Accessed Files had been deleted in what the researchers suspect was an attempt by the snooping technician to cover their tracks. As noted earlier, two of the visits resulted in the logs the researchers relied on being unrecoverable. In one, the researcher explained they had installed antivirus software and performed a disk cleanup to “remove multiple viruses on the device.” The researchers received no explanation in the other case.
[…]
The laptops were freshly imaged Windows 10 laptops. All were free of malware and other defects and in perfect working condition with one exception: the audio driver was disabled. The researchers chose that glitch because it required only a simple and inexpensive repair, was easy to create, and didn’t require access to users’ personal files.
Half of the laptops were configured to appear as if they belonged to a male and the other half to a female. All of the laptops were set up with email and gaming accounts and populated with browser history across several weeks. The researchers added documents, both sexually revealing and non-sexual pictures, and a cryptocurrency wallet with credentials.
A few notes. One: this is a very small study—only twelve laptop repairs. Two, some of the results were inconclusive, which indicated—but did not prove—log tampering by the technicians. Three, this study was done in Canada. There would probably be more snooping by American repair technicians.
The moral isn’t a good one: if you bring your laptop in to be repaired, you should expect the technician to snoop through your hard drive, taking what they want.
Researchers claim that supposedly anonymous device analytics information can identify users:
On Twitter, security researchers Tommy Mysk and Talal Haj Bakry have found that Apple’s device analytics data includes an iCloud account and can be linked directly to a specific user, including their name, date of birth, email, and associated information stored on iCloud.
Apple has long claimed otherwise:
On Apple’s device analytics and privacy legal page, the company says no information collected from a device for analytics purposes is traceable back to a specific user. “iPhone Analytics may include details about hardware and operating system specifications, performance statistics, and data about how you use your devices and applications. None of the collected information identifies you personally,” the company claims.
Apple was just sued for tracking iOS users without their consent, even when they explicitly opt out of tracking.
Here in 2022, we have a newly declassified 2016 Inspector General report—”Misuse of Sigint Systems”—about a 2013 NSA program that resulted in the unauthorized (that is, illegal) targeting of Americans.
Given all we learned from Edward Snowden, this feels like a minor coda. There’s nothing really interesting in the IG document, which is heavily redacted.
This technique measures device response time to determine distance:
The scientists tested the exploit by modifying an off-the-shelf drone to create a flying scanning device, the Wi-Peep. The robotic aircraft sends several messages to each device as it flies around, establishing the positions of devices in each room. A thief using the drone could find vulnerable areas in a home or office by checking for the absence of security cameras and other signs that a room is monitored or occupied. It could also be used to follow a security guard, or even to help rival hotels spy on each other by gauging the number of rooms in use.
There have been attempts to exploit similar WiFi problems before, but the team says these typically require bulky and costly devices that would give away attempts. Wi-Peep only requires a small drone and about $15 US in equipment that includes two WiFi modules and a voltage regulator. An intruder could quickly scan a building without revealing their presence.
According to these internal documents, SIAM is a computer system that works behind the scenes of Iranian cellular networks, providing its operators a broad menu of remote commands to alter, disrupt, and monitor how customers use their phones. The tools can slow their data connections to a crawl, break the encryption of phone calls, track the movements of individuals or large groups, and produce detailed metadata summaries of who spoke to whom, when, and where. Such a system could help the government invisibly quash the ongoing protests —or those of tomorrow —an expert who reviewed the SIAM documents told The Intercept.
[…]
SIAM gives the government’s Communications Regulatory Authority —Iran’s telecommunications regulator —turnkey access to the activities and capabilities of the country’s mobile users. “Based on CRA rules and regulations all telecom operators must provide CRA direct access to their system for query customers information and change their services via web service,” reads an English-language document obtained by The Intercept. (Neither the CRA nor Iran’s mission to the United Nations responded to a requests for comment.)
Lots of details, and links to the leaked documents, at the Intercept webpage.
If you’re running a privacy-oriented application or service on the Internet, your options to provably protect users’ privacy are limited. You can minimize logs and data collection but even then, at a network level, every HTTP request needs to come from somewhere. Information generated by HTTP requests, like users’ IP addressesand TLS fingerprints, can be sensitive especially when combined with application data.
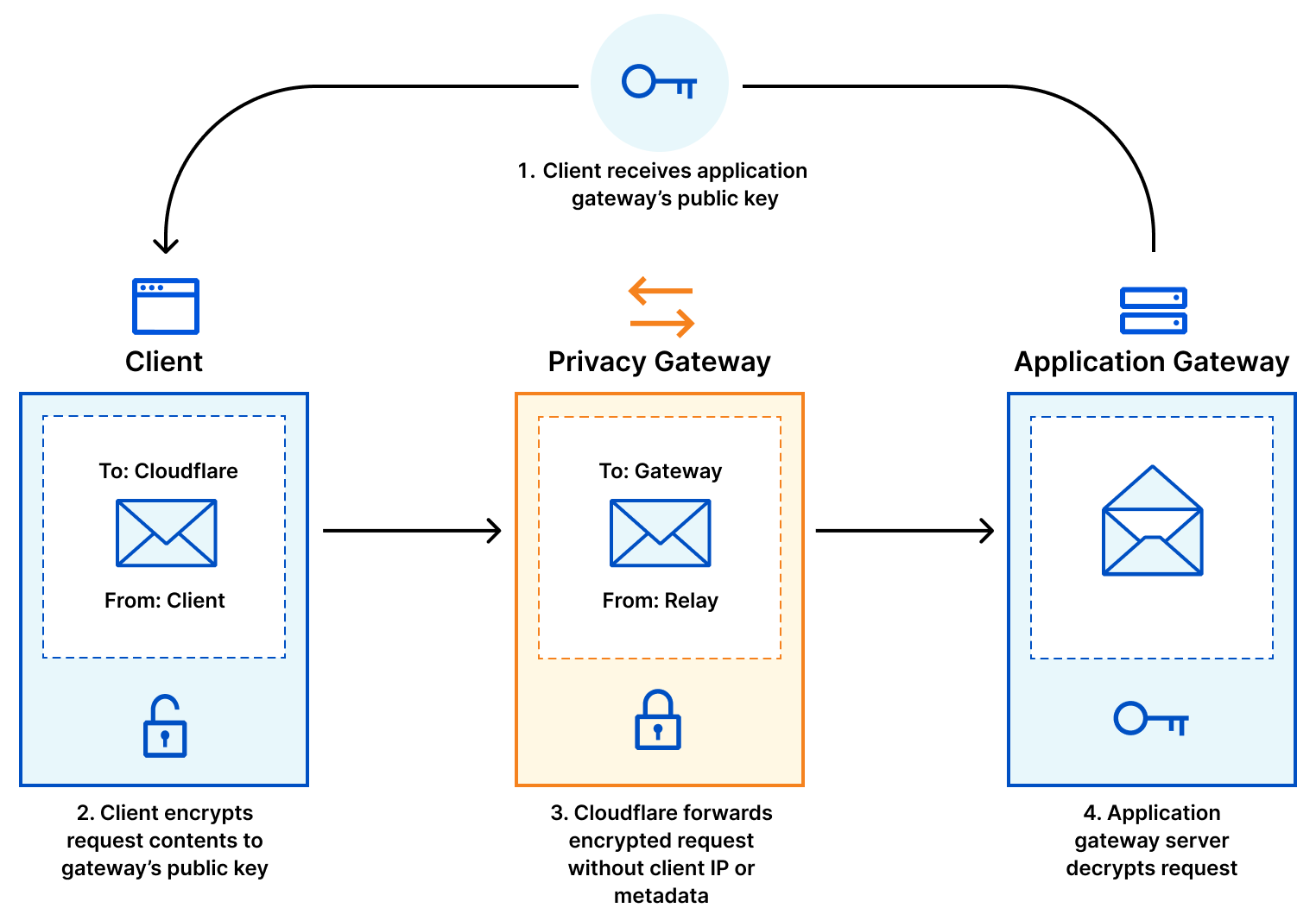
Meaningful improvements to your users’ privacy require a change in how HTTP requests are sent from client devices to the server that runs your application logic. This was the motivation for Privacy Gateway: a service that relays encrypted HTTP requests and responses between a client and application server. With Privacy Gateway, Cloudflare knows where the request is coming from, but not what it contains, and applications can see what the request contains, but not where it comes from. Neither Cloudflare nor the application server has the full picture, improving end-user privacy.
We recently deployed Privacy Gateway for Flo Health, a period tracking app, for the launch of their Anonymous Mode. With Privacy Gateway in place, all request data for Anonymous Mode users is encrypted between the app user and Flo, which prevents Flo from seeing the IP addresses of those users and Cloudflare from seeing the contents of that request data.
With Privacy Gateway in place, several other privacy-critical applications are possible:
Browser developers can collect user telemetry in a privacy-respecting manner– what extensions are installed, what defaults a user might have changed — while removing what is still a potentially personal identifier (the IP address) from that data.
Users can visit a healthcare site to report a Covid-19 exposure without worrying that the site is tracking their IP address and/or location.
The main innovation in the Oblivious HTTP standard – beyond a basic proxy service – is that these messages are encrypted to the application’s server, such that Privacy Gateway learns nothing of the application data beyond the source and destination of each message.
Privacy Gateway enables application developers and platforms, especially those with strong privacy requirements, to build something that closely resembles a “Mixnet”: an approach to obfuscating the source and destination of a message across a network. To that end, Privacy Gateway consists of three main components:
Client: the user’s device, or any client that’s configured to forward requests to Privacy Gateway.
Privacy Gateway: a service operated by Cloudflare and designed to relay requests between the Client and the Gateway, without being able to observe the contents within.
Application server: the origin or application web server responsible for decrypting requests from clients, and encrypting responses back.
If you were to imagine request data as the contents of the envelope (a letter) and the IP address and request metadata as the address on the outside, with Privacy Gateway, Cloudflare is able to see the envelope’s address and safely forward it to its destination without being able to see what’s inside.
An Oblivious HTTP transaction using Privacy Gateway
In slightly more detail, the data flow is as follows:
Client encapsulates an HTTP request using the public key of the application server, and sends it to Privacy Gateway over an HTTPS connection.
Privacy Gateway forwards the request to the server over its own, separate HTTPS connection with the application server.
The application server decapsulates the request, forwarding it to the target server which can produce the response.
The application server returns an encapsulated response to Privacy Gateway, which then forwards the result to the client. As specified in the protocol, requests from the client to the server are encrypted using HPKE, a state-of-the-art standard for public key encryption – which you can read more about here. We’ve taken additional measures to ensure that OHTTP’s use of HPKE is secure by conducting a formal analysis of the protocol, and we expect to publish a deeper analysis in the coming weeks.
How Privacy Gateway improves end-user privacy
This interaction offers two types of privacy, which we informally refer to as request privacy and client privacy.
Request privacy means that the application server does not learn information that would otherwise be revealed by an HTTP request, such as IP address, geolocation, TLS and HTTPS fingerprints, and so on. Because Privacy Gateway uses a separate HTTPS connection between itself and the application server, all of this per-request information revealed to the application server represents that of Privacy Gateway, not of the client. However, developers need to take care to not send personally identifying information in the contents of requests. If the request, once decapsulated, includes information like users’ email, phone number, or credit card info, for example, Privacy Gateway will not meaningfully improve privacy.
Client privacy is a stronger notion. Because Cloudflare and the application server are not colluding to share individual user’s data, from the server’s perspective, each individual transaction came from some unknown client behind Privacy Gateway. In other words, a properly configured Privacy Gateway deployment means that applications cannot link any two requests to the same client. In particular, with Privacy Gateway, privacy loves company. If there is only one end-user making use of Privacy Gateway, then it only provides request privacy (since the client IP address remains hidden from the Gateway). It would not provide client privacy, since the server would know that each request corresponds to the same, single client. Client privacy requires that there be many users of the system, so the application server cannot make this determination.
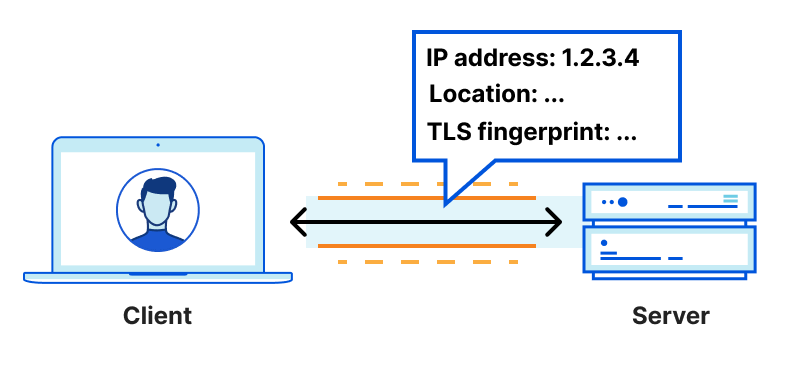
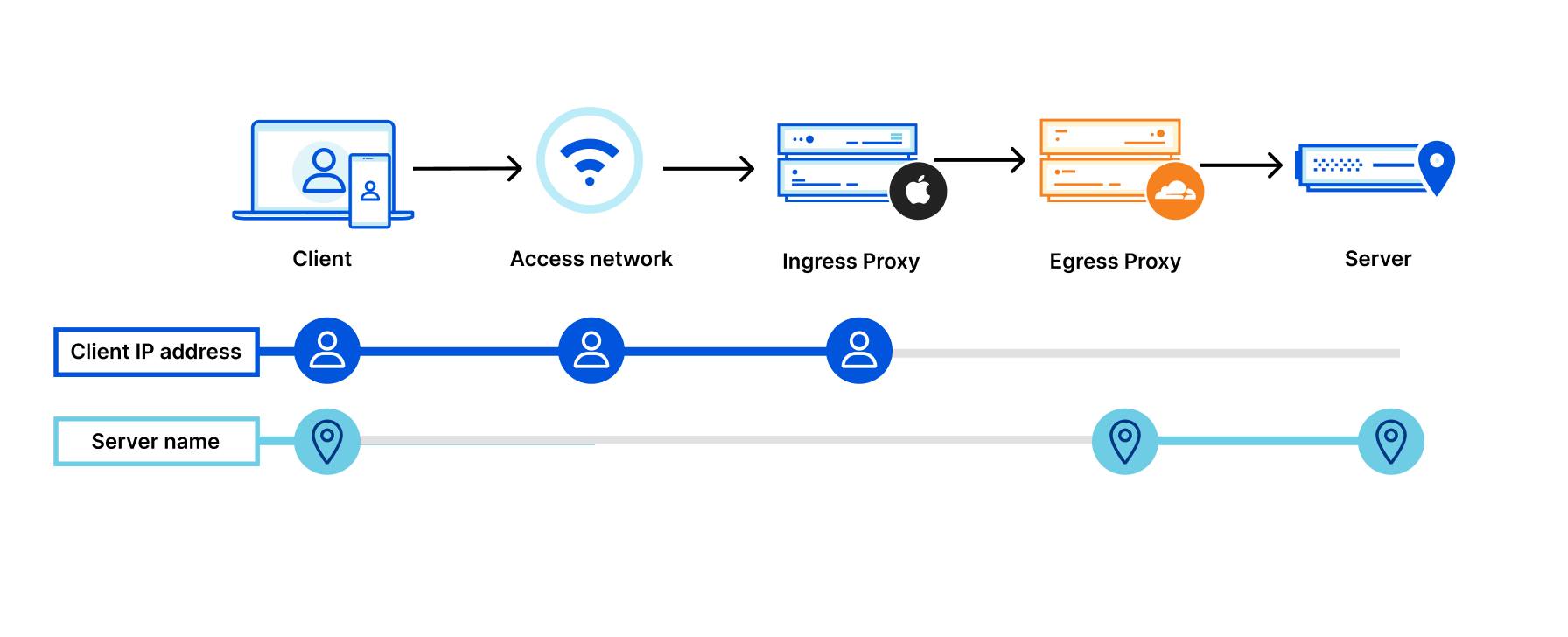
To better understand request and client privacy, consider the following HTTP request between a client and server:
Normal HTTP configuration with a client anonymity set of size 1
If a client connects directly to the server (or “Gateway” in OHTTP terms), the server is likely to see information about the client, including the IP address, TLS cipher used, and a degree of location data based on that IP address:
- ipAddress: 192.0.2.33 # the client’s real IP address
- ASN: 7922
- AS Organization: Comcast Cable
- tlsCipher: AEAD-CHACHA20-POLY1305-SHA256 # potentially unique
- tlsVersion: TLSv1.3
- Country: US
- Region: California
- City: Campbell
There’s plenty of sensitive information here that might be unique to the end-user. In other words, the connection offers neither request nor client privacy.
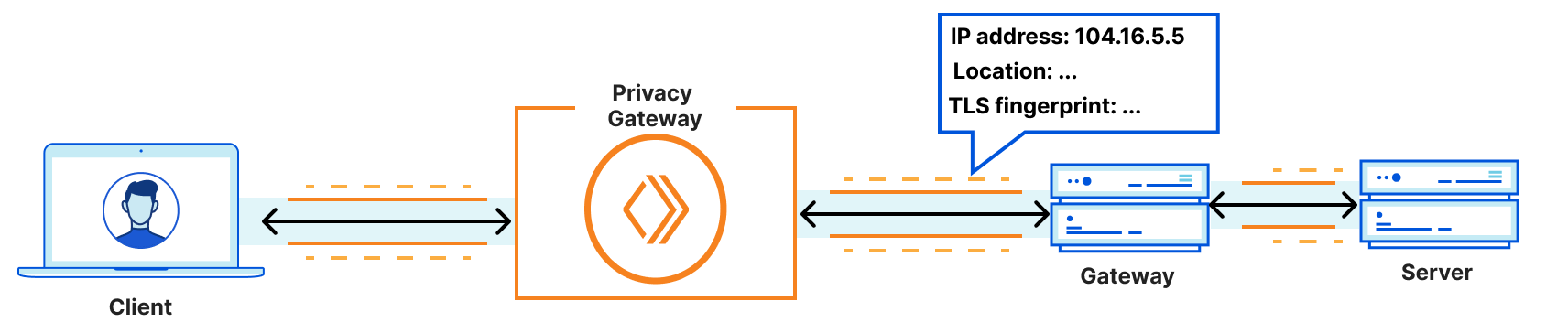
With Privacy Gateway, clients do not connect directly to the application server itself. Instead, they connect to Privacy Gateway, which in turn connects to the server. This means that the server only observes connections from Privacy Gateway, not individual connections from clients, yielding a different view:
- ipAddress: 104.16.5.5 # a Cloudflare IP
- ASN: 13335
- AS Organization: Cloudflare
- tlsCipher: ECDHE-ECDSA-AES128-GCM-SHA256 # shared across several clients
- tlsVersion: TLSv1.3
- Country: US
- Region: California
- City: Los Angeles
Privacy Gateway configuration with a client anonymity set of size k
This is request privacy. All information about the client’s location and identity are hidden from the application server. And all details about the application data are hidden from Privacy Gateway. For sensitive applications and protocols like DNS, keeping this metadata separate from the application data is an important step towards improving end-user privacy.
Moreover, applications should take care to not reveal sensitive, per-client information in their individual requests. Privacy Gateway cannot guarantee that applications do not send identifying info – such as email addresses, full names, etc – in request bodies, since it cannot observe plaintext application data. Applications which reveal user identifying information in requests may violate client privacy, but not request privacy. This is why – unlike our full application-level Privacy Proxy product – Privacy Gateway is not meant to be used as a generic proxy-based protocol for arbitrary applications and traffic. It is meant to be a special purpose protocol for sensitive applications, including DNS (as is evidenced by Oblivious DNS-over-HTTPS), telemetry data, or generic API requests as discussed above.
Integrating Privacy Gateway into your application
Integrating with Privacy Gateway requires applications to implement the client and server side of the OHTTP protocol. Let’s walk through what this entails.
Server Integration
The server-side part of the protocol is responsible for two basic tasks:
Publishing a public key for request encapsulation; and
Decrypting encapsulated client requests, processing the resulting request, and encrypting the corresponding response.
A public encapsulation key, called a key configuration, consists of a key identifier (so the server can support multiple keys at once for rotation purposes), cryptographic algorithm identifiers for encryption and decryption, and a public key:
HPKE Symmetric Algorithms {
HPKE KDF ID (16),
HPKE AEAD ID (16),
}
OHTTP Key Config {
Key Identifier (8),
HPKE KEM ID (16),
HPKE Public Key (Npk * 8),
HPKE Symmetric Algorithms Length (16),
HPKE Symmetric Algorithms (32..262140),
}
Clients need this public key to create their request, and there are lots of ways to do this. Servers could fix a public key and then bake it into their application, but this would require a software update to rotate the key. Alternatively, clients could discover the public key some other way. Many discovery mechanisms exist and vary based on your threat model – see this document for more details. To start, a simple approach is to have clients fetch the public key directly from the server over some API. Below is a snippet of the API that our open source OHTTP server provides:
func (s *GatewayResource) configHandler(w http.ResponseWriter, r *http.Request) {
config, err := s.Gateway.Config(s.keyID)
if err != nil {
http.Error(w, http.StatusText(http.StatusInternalServerError), http.StatusInternalServerError)
return
}
w.Write(config.Marshal())
}
Once public key generation and distribution is solved, the server then needs to handle encapsulated requests from clients. For each request, the server needs to decrypt the request, translate the plaintext to a corresponding HTTP request that can be resolved, and then encrypt the resulting response back to the client.
Open source OHTTP libraries typically offer functions for request decryption and response encryption, whereas plaintext translation from binary HTTP to an HTTP request is handled separately. For example, our open source server delegates this translation to a different library that is specific to how Go HTTP requests are represented in memory. In particular, the function to translate from a plaintext request to a Go HTTP request is done with a function that has the following signature:
While there exist several open source libraries that one can use to implement OHTTP server support, we’ve packaged all of it up in our open source server implementation available here. It includes instructions for building, testing, and deploying to make it easy to get started.
Client integration
Naturally, the client-side behavior of OHTTP mirrors that of the server. In particular, the client must:
Discover or obtain the server public key; and
Encode and encrypt HTTP requests, send them to Privacy Gateway, and decrypt and decode the HTTP responses.
Discovery of the server public key depends on the server’s chosen deployment model. For example, if the public key is available over an API, clients can simply fetch it directly:
Encoding, encrypting, decrypting, and decoding are again best handled by OHTTP libraries when available. With these functions available, building client support is rather straightforward. A trivial example Go client using the library functions linked above is as follows:
A standalone client like this isn’t likely very useful to you if you have an existing application. To help integration into your existing application, we created a sample OHTTP client library that’s compatible with iOS and macOS applications. Additionally, if there’s language or platform support you would like to see to help ease integration on either or the client or server side, please let us know!
Interested?
Privacy Gateway is currently in early access – available to select privacy-oriented companies and partners. If you’re interested, please get in touch.
Long and interesting interview with Signal’s new president, Meredith Whittaker:
WhatsApp uses the Signal encryption protocol to provide encryption for its messages. That was absolutely a visionary choice that Brian and his team led back in the day - and big props to them for doing that. But you can’t just look at that and then stop at message protection. WhatsApp does not protect metadata the way that Signal does. Signal knows nothing about who you are. It doesn’t have your profile information and it has introduced group encryption protections. We don’t know who you are talking to or who is in the membership of a group. It has gone above and beyond to minimize the collection of metadata.
WhatsApp, on the other hand, collects the information about your profile, your profile photo, who is talking to whom, who is a group member. That is powerful metadata. It is particularly powerful—and this is where we have to back out into a structural argument for a company to collect the data that is also owned by Meta/Facebook. Facebook has a huge amount, just unspeakable volumes, of intimate information about billions of people across the globe.
It is not trivial to point out that WhatsApp metadata could easily be joined with Facebook data, and that it could easily reveal extremely intimate information about people. The choice to remove or enhance the encryption protocols is still in the hands of Facebook. We have to look structurally at what that organization is, who actually has control over these decisions, and at some of these details that often do not get discussed when we talk about message encryption overall.
I am a fan of Signal and I use it every day. The one feature I want, which WhatsApp has and Signal does not, is the ability to easily export a chat to a text file.
California just legalized digital license plates, which seems like a solution without a problem.
The Rplate can reportedly function in extreme temperatures, has some customization features, and is managed via Bluetooth using a smartphone app. Rplates are also equipped with an LTE antenna, which can be used to push updates, change the plate if the vehicle is reported stolen or lost, and notify vehicle owners if their car may have been stolen.
Perhaps most importantly to the average car owner, Reviver said Rplate owners can renew their registration online through the Reviver mobile app.
That’s it?
Right now, an Rplate for a personal vehicle (the battery version) runs to $19.95 a month for 48 months, which will total $975.60 if kept for the full term. If opting to pay a year at a time, the price is $215.40 a year for the same four-year period, totaling $861.60. Wired plates for commercial vehicles run $24.95 for 48 months, and $275.40 if paid yearly.
That’s a lot to pay for the luxury of not having to find an envelope and stamp.
Plus, the privacy risks:
Privacy risks are an obvious concern when thinking about strapping an always-connected digital device to a car, but the California law has taken steps that may address some of those concerns.
“The bill would generally prohibit an alternative device [i.e. digital plate] from being equipped with GPS or other vehicle location tracking capability,” California’s legislative digest said of the new law. Commercial fleets are exempt from the rule, unsurprisingly.
More important are the security risks. Do we think for a minute that your digital license plate is secure from denial-of-service attacks, or number swapping attacks, or whatever new attacks will be dreamt up? Seems like a piece of stamped metal is the most secure option.
The Greek journalist Thanasis Koukakis was spied on by his own government, with a commercial spyware product called “Predator.” That product is sold by a company in North Macedonia called Cytrox, which is in turn owned by an Israeli company called Intellexa.
The lawsuit filed by Koukakis takes aim at Intellexa and its executive, alleging a criminal breach of privacy and communication laws, reports Haaretz. The founder of Intellexa, a former Israeli intelligence commander named Taj Dilian, is listed as one of the defendants in the suit, as is another shareholder, Sara Hemo, and the firm itself. The objective of the suit, Koukakis says, is to spur an investigation to determine whether a criminal indictment should be brought against the defendants.
Why does it always seem to be Israel? The world would be a much safer place if that government stopped this cyberweapons arms trade from inside its borders.
Depending on where you are when you download your Android apps, it might collect more or less data about you.
The apps we downloaded from Google Play also showed differences based on country in their security and privacy capabilities. One hundred twenty-seven apps varied in what the apps were allowed to access on users’ mobile phones, 49 of which had additional permissions deemed “dangerous” by Google. Apps in Bahrain, Tunisia and Canada requested the most additional dangerous permissions.
Three VPN apps enable clear text communication in some countries, which allows unauthorized access to users’ communications. One hundred and eighteen apps varied in the number of ad trackers included in an app in some countries, with the categories Games, Entertainment and Social, with Iran and Ukraine having the most increases in the number of ad trackers compared to the baseline number common to all countries.
One hundred and three apps have differences based on country in their privacy policies. Users in countries not covered by data protection regulations, such as GDPR in the EU and the California Consumer Privacy Act in the U.S., are at higher privacy risk. For instance, 71 apps available from Google Play have clauses to comply with GDPR only in the EU and CCPA only in the U.S. Twenty-eight apps that use dangerous permissions make no mention of it, despite Google’s policy requiring them to do so.
Abstract: Recent studies on the web ecosystem have been raising alarms on the increasing geodifferences in access to Internet content and services due to Internet censorship and geoblocking. However, geodifferences in the mobile app ecosystem have received limited attention, even though apps are central to how mobile users communicate and consume Internet content. We present the first large-scale measurement study of geodifferences in the mobile app ecosystem. We design a semi-automatic, parallel measurement testbed that we use to collect 5,684 popular apps from Google Play in 26 countries. In all, we collected 117,233 apk files and 112,607 privacy policies for those apps. Our results show high amounts of geoblocking with 3,672 apps geoblocked in at least one of our countries. While our data corroborates anecdotal evidence of takedowns due to government requests, unlike common perception, we find that blocking by developers is significantly higher than takedowns in all our countries, and has the most influence on geoblocking in the mobile app ecosystem. We also find instances of developers releasing different app versions to different countries, some with weaker security settings or privacy disclosures that expose users to higher security and privacy risks. We provide recommendations for app market proprietors to address the issues discovered.
When Cloudflare was founded, our value proposition had three pillars: more secure, more reliable, and more performant. Over time, we’ve realized that a better Internet is also a more private Internet, and we want to play a role in building it.
User awareness and expectations of and for privacy are higher than ever, but we believe that application developers and platforms shouldn’t have to start from scratch. We’re excited to introduce Privacy Edge – Code Auditability, Privacy Gateway, Privacy Proxy, and Cooperative Analytics – a suite of products that make it easy for site owners and developers to build privacy into their products, by default.
Building network-level privacy into the foundations of app infrastructure
As you’re browsing the web every day, information from the networks and apps you use can expose more information than you intend. When accumulated over time, identifiers like your IP address, cookies, browser and device characteristics create a unique profile that can be used to track your browsing activity. We don’t think this status quo is right for the Internet, or that consumers should have to understand the complex ecosystem of third-party trackers to maintain privacy. Instead, we’ve been working on technologies that encourage and enable website operators and app developers to build privacy into their products at the protocol level.
Getting privacy right is hard. We figured we’d start in the area we know best: building privacy into our network infrastructure. Like other work we’ve done in this space – offering free SSL certificates to make encrypted HTTP requests the norm, and launching 1.1.1.1, a privacy-respecting DNS resolver, for example – the products we’re announcing today are built upon the foundations of open Internet standards, many of which are co-authored by members of our Research Team.
Privacy Edge – the collection of products we’re announcing today, includes:
Privacy Gateway: A lightweight proxy that encrypts request data and forwards it through an IP-blinding relay
Code Auditability: A solution to verifying that code delivered in your browser hasn’t been tampered with
Private Proxy: A proxy that offers the protection of a VPN, built natively into application architecture
Cooperative Analytics: A multi-party computation approach to measurement and analytics based on an emerging distributed aggregation protocol.
Today’s announcement of Privacy Edge isn’t exhaustive. We’re continuing to explore, research and develop new privacy-enabling technologies, and we’re excited about all of them.
Privacy Gateway: IP address privacy for your users
There are situations in which applications only need to receive certain HTTP requests for app functionality, but linking that data with who or where it came from creates a privacy concern.
We recently partnered with Flo Health, a period tracking app, to solve exactly that privacy concern: for users that have turned on “Anonymous mode,” Flo encrypts and forwards traffic through Privacy Gateway so that the network-level request information (most importantly, users’ IP addresses) are replaced by the Cloudflare network.
How data is encapsulated, forwarded, and decapsulated in the Privacy Gateway system.
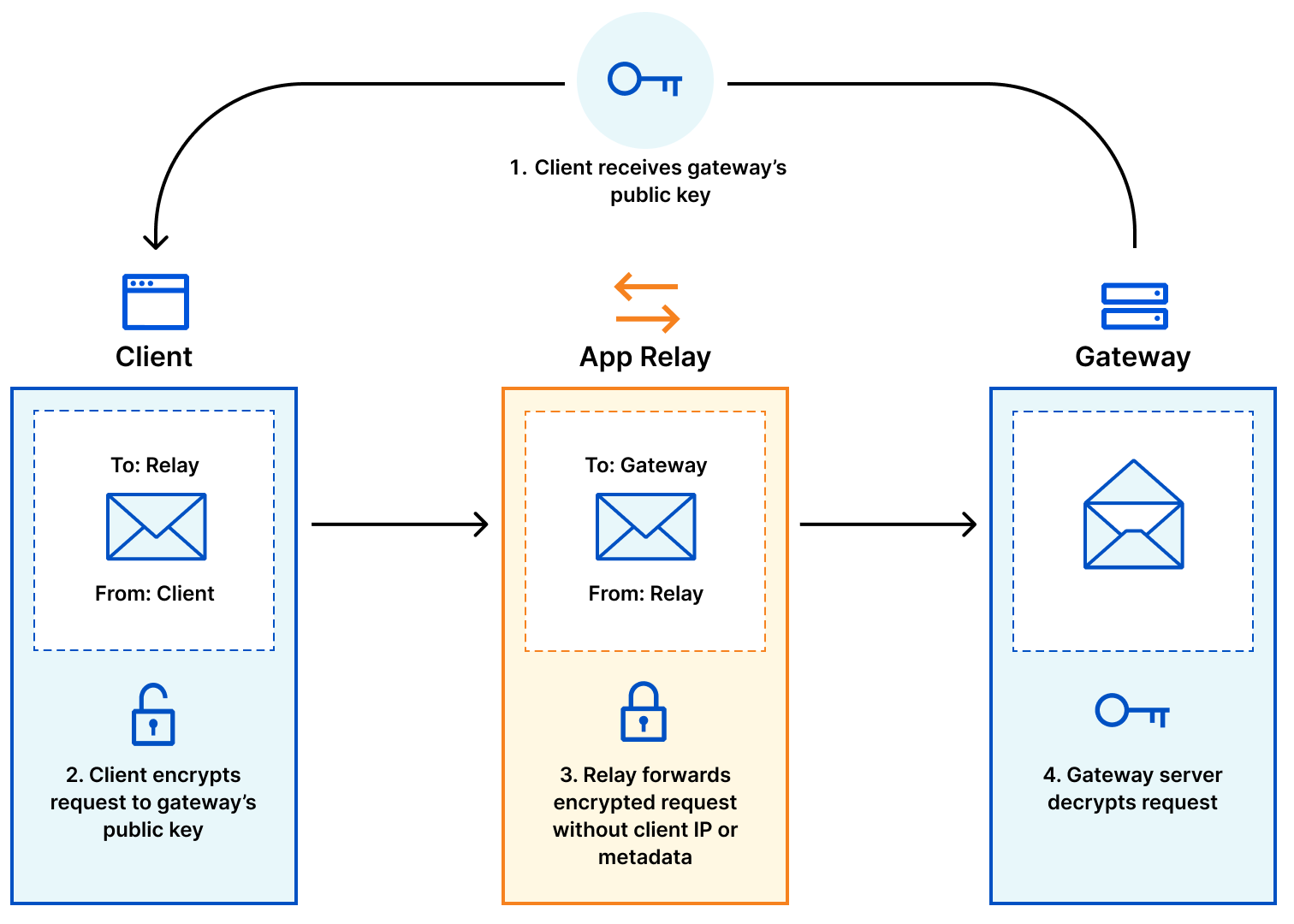
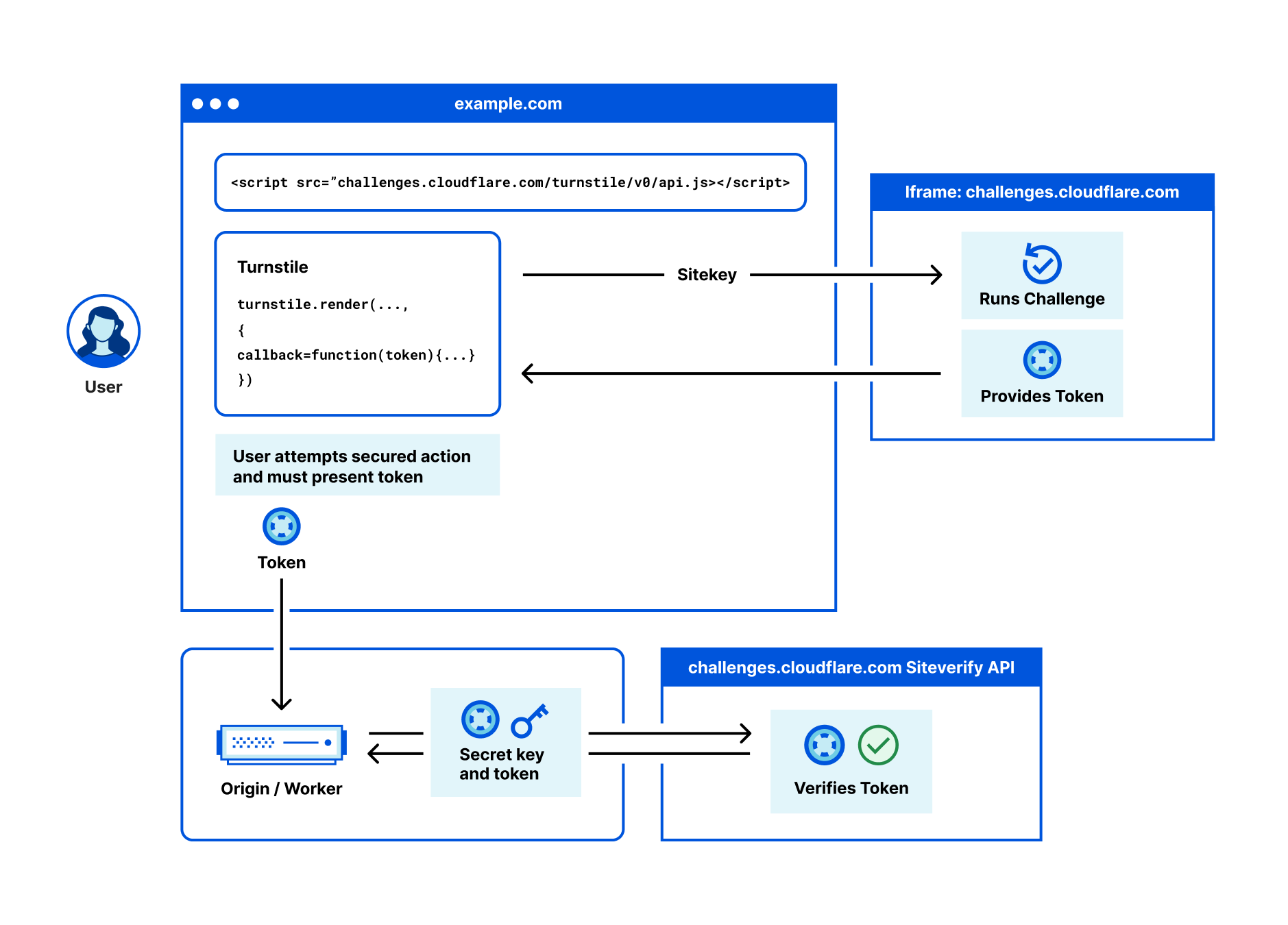
So how does it work? Privacy Gateway is based on Oblivious HTTP, an emerging IETF standard, and at a high level describes the following data flow:
The client encapsulates an HTTP request using the public key of the customer’s gateway server, and sends it to the relay over a client<>relay HTTPS connection.
The relay forwards the request to the server over its own relay<>gateway HTTPS connection.
The gateway server decapsulates the request, forwarding it to the application server.
The gateway server returns an encapsulated response to the relay, which then forwards the result to the client.
The novel feature Privacy Gateway implements from the OHTTP specification is that messages sent through the relay are encrypted (via HPKE) to the application server, so that the relay learns nothing of the application data beyond the source and destination of each message.
The end result is that the relay will know where the data request is coming from (i.e. users’ IP addresses) but not what it contains (i.e. contents of the request), and the application can see what the data contains but won’t know where it comes from. A win for end-user privacy.
Delivering verifiable and authentic code for privacy-critical applications
How can you ensure that the code — the JavaScript, CSS or even HTML —delivered to a browser hasn’t been tampered with?
One way is to generate a hash (a consistent, unique, and shorter representation) of the code, and have two independent parties compare those hashes when delivered to the user’s browser.
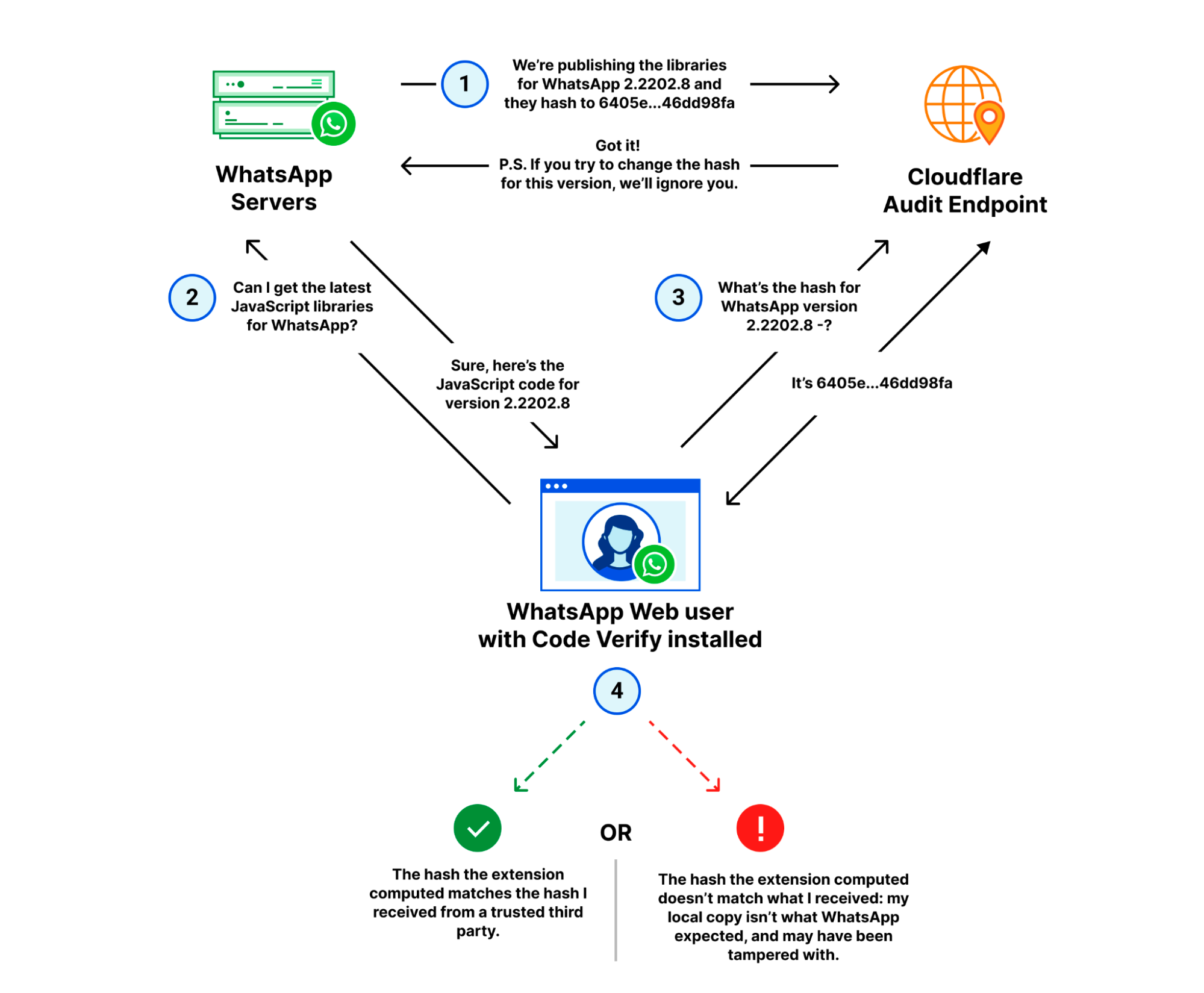
Our Code Auditability service does exactly that, and our recent partnership with Meta deployed it at scale to WhatsApp Web. Installing their Code Verify browser extension ensures users can be sure that they are delivered the code they’re intended to run – free of tampering or corrupted files.
With WhatsApp Web:
WhatsApp publishes the latest version of their JavaScript libraries to their servers, and the corresponding hash for that version to Cloudflare’s audit endpoint.
A WhatsApp web client fetches the latest libraries from WhatsApp.
The Code Verify browser extension subsequently fetches the hash for that version from Cloudflare over a separate, secure connection.
Code Verify compares the “known good” hash from Cloudflare with the hash of the libraries it locally computed.
If the hashes match, as they should under almost any circumstance, the code is “verified” from the perspective of the extension. If the hashes don’t match, it indicates that the code running on the user’s browser is different from the code WhatsApp intended to run on all its user’s browsers.
How Cloudflare and WhatsApp Web verify code shipped to users isn’t tampered with.
Right now, we call this “Code Auditability” and we see a ton of other potential use cases including password managers, email applications, certificate issuance – all technologies that are potentially targets of tampering or security threats because of the sensitive data they handle.
In the near term, we’re working with other app developers to co-design solutions that meet their needs for privacy-critical products. In the long term, we’re working on standardizing the approach, including building on existing Content Security Policy standards, or the Isolated Web Apps proposal, and even an approach towards building Code Auditability natively into the browser so that a browser extension (existing or new) isn’t required.
Privacy-preserving proxying – built into applications
What if applications could build the protection of a VPN into their products, by default?
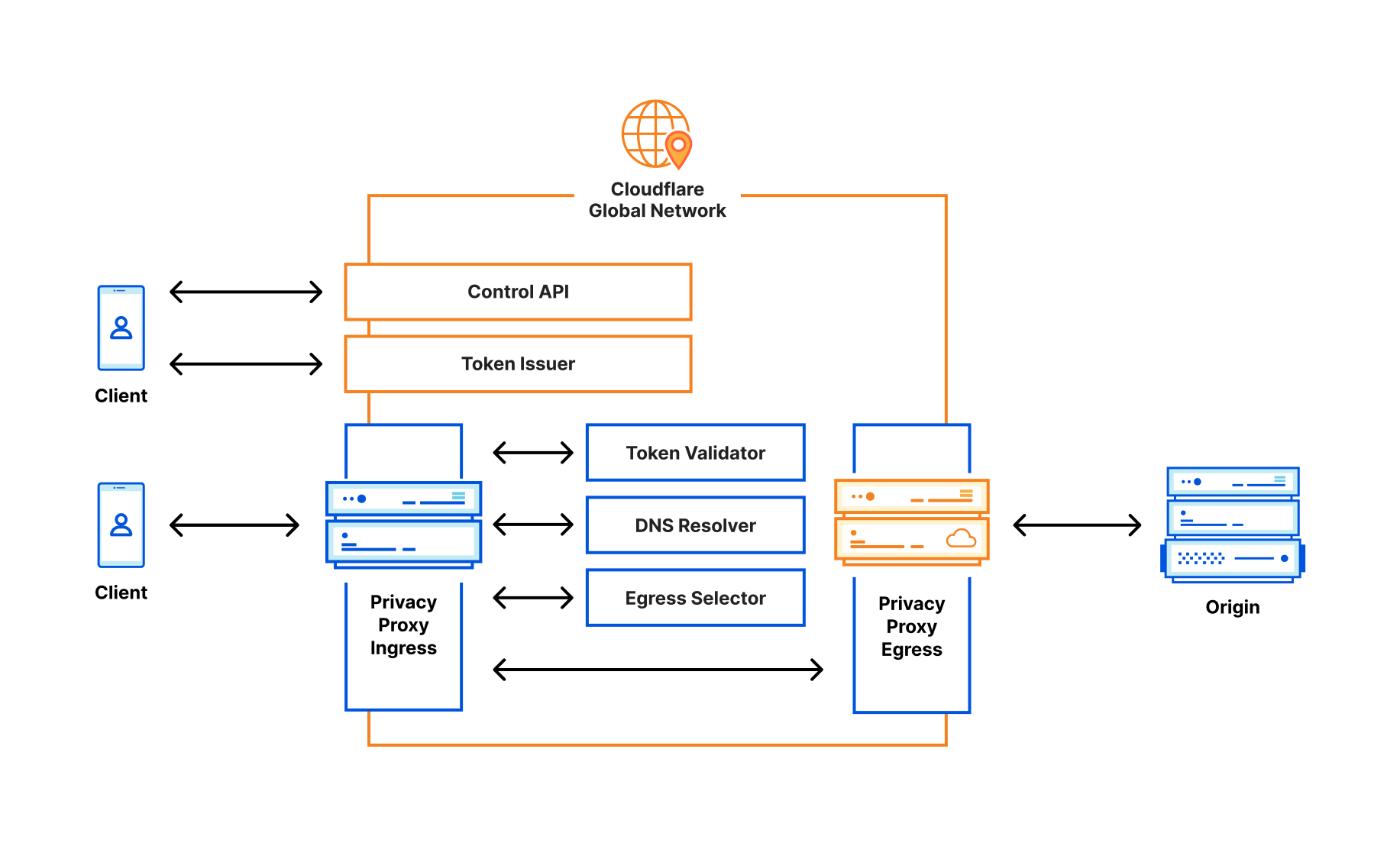
Privacy Proxy is our platform to proxy traffic through Cloudflare using a combination of privacy protocols that make it much more difficult to track users’ web browsing activity over time. At a high level, the Privacy Proxy Platform encrypts browsing traffic, replaces a device’s IP address with one from the Cloudflare network, and then forwards it onto its destination.
System architecture for Privacy Proxy.
The Privacy Proxy platform consists of several pieces and protocols to make it work:
Privacy API: a service that issues unique cryptographic tokens, later redeemed against the proxy service to ensure that only valid clients are able to connect to the service.
Geolocated IP assignment: a service that assigns each connection a new Cloudflare IP address based on the client’s approximate location.
Privacy Proxy: the HTTP CONNECT-based service running on Cloudflare’s network that handles the proxying of traffic. This service validates the privacy token passed by the client, enforces any double spend prevention necessary for the token.
We’re working on several partnerships to provide network-level protection for user’s browsing traffic, most recently with Apple for Private Relay. Private Relay’s design adds privacy to the traditional proxy design by adding an additional hop – an ingress proxy, operated by Apple – that separates handling users’ identities (i.e., whether they’re a valid iCloud+ user) from the proxying of traffic – the egress proxy, operated by Cloudflare.
Measurements and analytics without seeing individual inputs
What if you could calculate the results of a poll, without seeing individuals’ votes, or update inputs to a machine learning model that predicted COVID-19 exposure without seeing who was exposed?
It might seem like magic, but it’s actually just cryptography. Cooperative Analytics is a multi-party computation system for aggregating privacy-sensitive user measurements that doesn’t reveal individual inputs, based on the Distributed Aggregation Protocol (DAP).
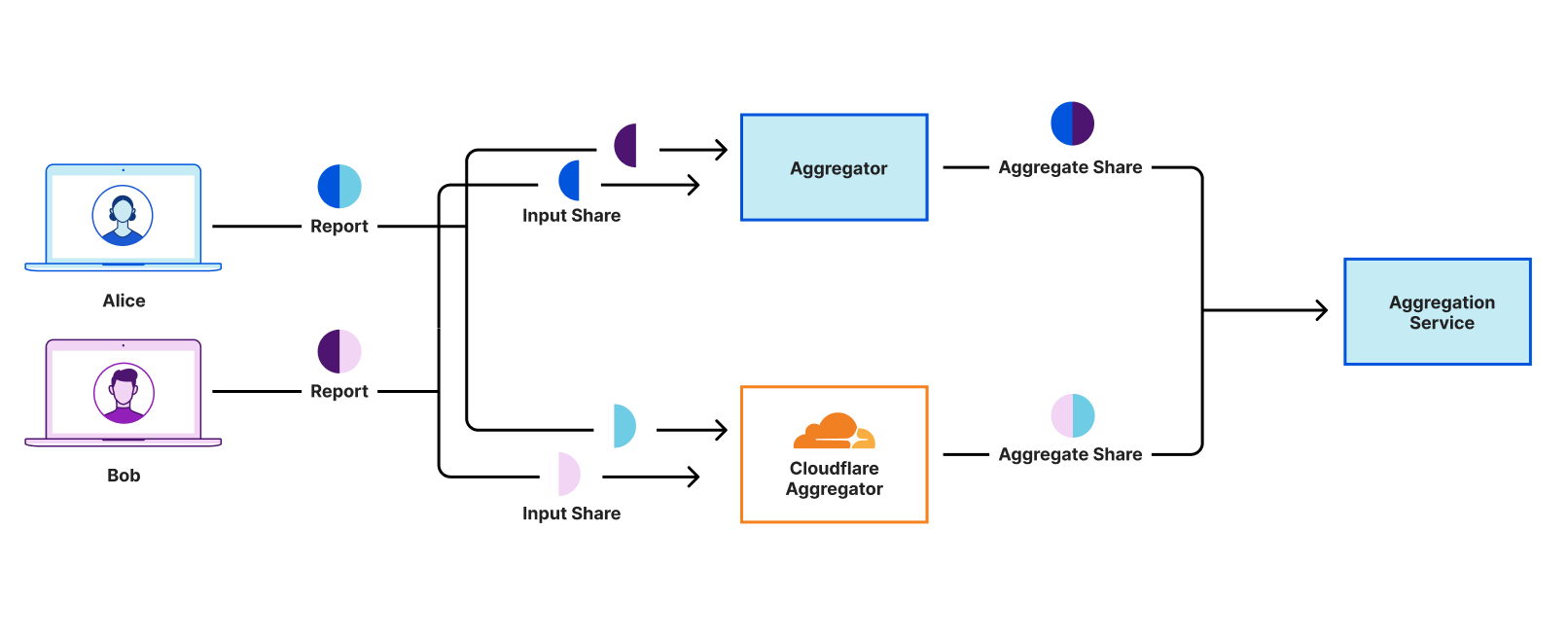
How data flows through the Cooperative Analytics system.
At a high-level, DAP takes the core concept behind MapReduce — what became a fundamental way to aggregate large amounts of data — and rethinks how it would work with privacy-built in, so that each individual input cannot be (provably) mapped back to the original user.
Specifically:
Measurements are first “secret shared,” or split into multiple pieces. For example, if a user’s input is the number 5, her input could be split into two shares of [10,-5].
The input share pieces are then distributed between different, non-colluding servers for aggregation (in this example, simply summed up). Similar to Privacy Gateway or Private Proxy, no one party has all the information needed to reconstruct any user’s input.
Depending on the use case, the servers will then communicate with one another in order to verify that the input is “valid” – so that no one can insert an input that throws off the entire results. The magic of multi-party computation is that the servers can perform this computation without learning anything about the input beyond its validity.
Once enough input shares have been aggregated to ensure strong anonymity and a statistically significant sample size – each server sends its sum of the input shares to the overall consumer of this service to then compute the final result.
For simplicity, the above example talks about measurements as summed up numbers, but DAP describes algorithms for multiple different types of inputs: the most common string input, or a linear regression, for example.
Early iterations of this system have been implemented by Apple and Google for COVID-19 exposure notifications, but there are many other potential use cases for a system like this: think sensitive browser telemetry, geolocation data – any situation where one has a question about a population of users, but doesn’t want to have to measure them directly.
Because this system requires different parties to operate separate aggregation servers, Cloudflare is working with several partners to act as one of the aggregation servers for DAP. We’re calling our implementation Daphne, and it’s built on top of Cloudflare Workers.
Privacy still requires trust
Part of what’s cool about these systems is that they distribute information — whether user data, network traffic, or both — amongst multiple parties.
While we think that products included in Privacy Edge are moving the Internet in the right direction, we understand that trust only goes so far. To that end, we’re trying to be as transparent as possible.
We’ve open sourced the code for Privacy Gateway’s server and DAP’s aggregation server, and all the standards work we’re doing is in public with the IETF.
We’re also working on detailed and accessible privacy notices for each product that describe exactly what kind of network data Cloudflare sees, doesn’t see, and how long we retain it for.
And, most importantly, we’re continuing to develop new protocols (like Oblivious HTTP) and technologies that don’t just require trust, but that can provably minimize the data observed or logged.
We’d love to see more folks get involved in the standards space, and we welcome feedback from privacy experts and potential customers on how we can improve the integrity of these systems.
We’re looking for collaborators
Privacy Edge products are currently in early access.
We’re looking for application developers who want to build more private user-facing apps with Privacy Gateway; browser and existing VPN vendors looking to improve network-level security for their users via Privacy Proxy; and anyone shipping sensitive software on the Internet that is looking to iterate with us on code auditability and web app signing.
If you’re interested in working with us on furthering privacy on the Internet, then please reach out, and we’ll be in touch!
Today, we’re announcing the open beta of Turnstile, an invisible alternative to CAPTCHA. Anyone, anywhere on the Internet, who wants to replace CAPTCHA on their site will be able to call a simple API, without having to be a Cloudflare customer or sending traffic through the Cloudflare global network. Sign up here for free.
There is no point in rehashing the fact that CAPTCHA provides a terrible user experience. It’s been discussed in detail before on this blog, and countless times elsewhere. The creator of the CAPTCHA has even publicly lamented that he “unwittingly created a system that was frittering away, in ten-second increments, millions of hours of a most precious resource: human brain cycles.” We hate it, you hate it, everyone hates it. Today we’re giving everyone a better option.
Turnstile is our smart CAPTCHA alternative. It automatically chooses from a rotating suite of non-intrusive browser challenges based on telemetry and client behavior exhibited during a session. We talked in an earlier post about how we’ve used our Managed Challenge system to reduce our use of CAPTCHA by 91%. Now anyone can take advantage of this same technology to stop using CAPTCHA on their own site.
UX isn’t the only big problem with CAPTCHA — so is privacy
While having to solve a CAPTCHA is a frustrating user experience, there is also a potential hidden tradeoff a website must make when using CAPTCHA. If you are a small site using CAPTCHA today, you essentially have one option: an 800 pound gorilla with 98% of the CAPTCHA market share. This tool is free to use, but in fact it has a privacy cost: you have to give your data to an ad sales company.
According to security researchers, one of the signals that Google uses to decide if you are malicious is whether you have a Google cookie in your browser, and if you have this cookie, Google will give you a higher score. Google says they don’t use this information for ad targeting, but at the end of the day, Google is an ad sales company. Meanwhile, at Cloudflare, we make money when customers choose us to protect their websites and make their services run better. It’s a simple, direct relationship that perfectly aligns our incentives.
Less data collection, more privacy, same security
In June, we announced an effort with Apple to use Private Access Tokens. Visitors using operating systems that support these tokens, including the upcoming versions of macOS or iOS, can now prove they’re human without completing a CAPTCHA or giving up personal data.
By collaborating with third parties like device manufacturers, who already have the data that would help us validate a device, we are able to abstract portions of the validation process, and confirm data without actually collecting, touching, or storing that data ourselves. Rather than interrogating a device directly, we ask the device vendor to do it for us.
Private Access Tokens are built directly into Turnstile. While Turnstile has to look at some session data (like headers, user agent, and browser characteristics) to validate users without challenging them, Private Access Tokens allow us to minimize data collection by asking Apple to validate the device for us. In addition, Turnstile never looks for cookies (like a login cookie), or uses cookies to collect or store information of any kind. Cloudflare has a long track record of investing in user privacy, which we will continue with Turnstile.
We are opening our CAPTCHA replacement to everyone
To improve the Internet for everyone, we decided to open up the technology that powers our Managed Challenge to everyone in beta as a standalone product called Turnstile.
Rather than try to unilaterally deprecate and replace CAPTCHA with a single alternative, we built a platform to test many alternatives and rotate new challenges in and out as they become more or less effective. With Turnstile, we adapt the actual challenge outcome to the individual visitor/browser. First we run a series of small non-interactive JavaScript challenges gathering more signals about the visitor/browser environment. Those challenges include proof-of-work, proof-of-space, probing for web APIs, and various other challenges for detecting browser-quirks and human behavior. As a result, we can fine-tune the difficulty of the challenge to the specific request.
Turnstile also includes machine learning models that detect common features of end visitors who were able to pass a challenge before. The computational hardness of those initial challenges may vary by visitor, but is targeted to run fast.
Swap out your existing CAPTCHA in a few minutes
You can take advantage of Turnstile and stop bothering your visitors with a CAPTCHA even without being on the Cloudflare network. While we make it as easy as possible to use our network, we don’t want this to be a barrier to improving privacy and user experience.
To switch from a CAPTCHA service, all you need to do is:
Create a Cloudflare account, navigate to the `Turnstile` tab on the navigation bar, and get a sitekey and secret key.
Copy our JavaScript from the dashboard and paste over your old CAPTCHA JavaScript.
Update the server-side integration by replacing the old siteverify URL with ours.
There is more detail on the process below, including options you can configure, but that’s really it. We’re excited about the simplicity of making a change.
Deployment options and analytics
To use Turnstile, first create an account and get your site and secret keys.
Once a challenge has been solved, a token is injected in your form, with the name cf-turnstile-response. This token can be used with our siteverify endpoint to validate a challenge response. A token can only be validated once, and a token cannot be redeemed twice. The validation can be done on the server side or even in the cloud, for example using a simple Workers fetch (see a demo here):
async function handleRequest() {
// ... Receive token
let formData = new FormData();
formData.append('secret', turnstileISecretKey);
formData.append('response', receivedToken);
await fetch('https://challenges.cloudflare.com/turnstile/v0/siteverify',
{
body: formData,
method: 'POST'
});
// ...
}
For more complex use cases, the challenge can be invoked explicitly via JavaScript:
You can also create what we call ‘Actions’. Custom labels that allow you to distinguish between different pages where you’re using Turnstile, like a login, checkout, or account creation page.
Once you’ve deployed Turnstile, you can go back to the dashboard and see analytics on where you have widgets deployed, how users are solving them, and view any defined actions.
Why are we giving this away for free?
While this is sometimes hard for people outside to believe, helping build a better Internet truly is our mission. This isn’t the first time we’ve built free tools that we think will make the Internet better, and it won’t be the last. It’s really important to us.
So whether or not you’re a Cloudflare customer today, if you’re using a CAPTCHA, try Turnstile for free, instead. You’ll make your users happier, and minimize the data you send to third parties.
Visit this page to sign up for the best invisible, privacy-first, CAPTCHA replacement and to retrieve your Turnstile beta sitekey.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.