Post Syndicated from Светла Енчева original https://www.toest.bg/smiana-na-pola-na-detsa/

Не им е лесно на опитните мишки. Подлагат ги на всевъзможни експерименти, при които животинките не само страдат, а и оцеляването им не е гарантирано. От това лято в подобно положение са и децата в България, които принадлежат към групата на ЛГБТИ хората (лесбийки, гей мъже, бисексуални, транс и интерсекс хора). Както е тръгнало, експериментите с тях ще продължат в най-добрия случай до края на 50-тото Народно събрание. Но с немалка вероятност – и в следващия парламент.
Законът на „Възраждане“ и проектозаконът на ИТН
На 7 август 2024 г. парламентът прие – по предложение на „Възраждане“ – промени в Закона за предучилищното и училищното образование, с които се забранява т.нар. пропаганда на „нетрадиционна“ сексуална ориентация или полова идентичност. Формулировката е толкова широка, че практически включва всякакъв тип изразяване. Защото освен самата пропаганда се забраняват и „популяризирането“ и „подстрекаването“. А всяко нещо, налично в публична среда, каквато е училището, може да се интерпретира като „популяризиране“.
„Нетрадиционната“ сексуална ориентация пък беше дефинирана като „различно от общоприетите и заложените в българската правна традиция схващания за емоционално, романтично, сексуално или чувствено привличане между лица от противоположни полове“.
Междувременно на 2 август от „Има такъв народ“ внесоха законопроект за промяна в Закона за закрила на детето (ЗЗД). С него се предлага забраната на „излагането, представянето, предлагането или по какъвто и да е друг начин разпространяването“ на „съдържание, което не съответства на разбирането на пол на физическите лица като биологична категория“ на всякакви обществени места, които могат да бъдат посетени от деца. Също и на беседи с подобно съдържание и „реклама на половата идентичност, алтернатива на биологичния пол“ и подобни теми, както и всякакви медицински дейности за промяна на пола на деца. За нарушителите се предвиждат глоби между 300 и 50 000 лв.
В законопроекта на ИТН се предвижда и промяна на Закона за здравето, с която отново се забранява „прякото представяне, рекламата и извършването на медицински дейности с методи или технологии за промяна на биологичния пол на лица, ненавършили 18 години“. От партията на Слави Трифонов предлагат и санкции за нарушителите в Наказателния кодекс – затвор между една и шест години и обществено порицание, както и лишаване от право на упражняване на професията.
ПП–ДБ – едно неизпълнено обещание и два проектозакона
Промените в образователния закон станаха обект на остри критики, след като от варненския клон на „Възраждане“ инициираха репресии срещу местните учители и други педагогически служители, включили се в подписка против измененията.
На 22 август „Продължаваме промяната“ (ПП) даде на избирателите си обещание, че депутатите от партията още следващата седмица ще внесат предложение „за отмяна на „нетрадиционната“ дефиниция [на сексуалната ориентация – б.а.], която реално започна този опасен процес към фашизма в България“. От партията заявиха:
С действия в парламента, не само с постове, ще противодействаме на черните списъци към българските учители.
Обещаните „действия в парламента“ не последваха – нито през следващата седмица, нито по-късно. На 11 септември обаче депутати от ПП и „Демократична България“ (ДБ) внесоха законопроект за изменение на ЗЗД. Те искат в закона да се включат текстове, че всяко дете „има право на закрила от прилагане на медицински дейности, които целят промяна на фенотипните [тоест видимите – б.а.] и други полови белези на генотипния му пол“, както и на „медицинска, психологическа, социална и експертна помощ по въпроси, свързани с пола му, които да укрепят психологическото му развитие и да осигурят лечение при необходимост“.
Същевременно от ПП–ДБ предлагат и промяна в Закона за здравето:
Забранява се извършването на медицински дейности за промяна на фенотипните и други полови белези на генотипния пол на непълнолетни лица, освен в случаите, когато съществува сериозна опасност за живота или здравето им.
За неспазване на горното се предвиждат глоби от 30 000 до 50 000 лв., а при повторно нарушение – лишаване от правото да се упражнява медицинска професия за срок от 6 месеца до две години. Финансовите санкции, предложени от коалицията, са далеч по-строги от тези на ИТН, които все пак слагат долна граница от 300 лв. Но ПП–ДБ не плашат със затвор.
Смяна на пола на деца в България не се извършва – нещо, което споменават и от ПП–ДБ в мотивите към предложението си. Тоест поне на пръв поглед идеята е да се забрани нещо, което така или иначе го няма.
Същия ден група от петима народни представители, предвождани от Елисавета Белобрадова, внесоха друг законопроект за промяна на ЗЗД. Те искат в него да влезе и следната алинея:
Всяко дете има право на защита от политическа пропаганда, неистини и предизборни политически и партийни действия, които предизвикват страх, изолация и самота у детето и се отразяват на семейната среда.
За спазването на това трябва да следят предвидените в закона органи.
Белобрадова огласи инициативата в социалните мрежи с аргумента, че нито в българските училища има пропаганда, нито в България се сменя полът на деца под 18 години. Не става ясно обаче на какъв принцип ще се преценява кои политически действия предизвикват у децата „страх, изолация и самота“. В мотивите не се споменават нито анти-ЛГБТИ поправката в образователния закон, нито предложенията на ИТН и ПП–ДБ. А те със сигурност са предизвикали „страх, изолация и самота“ у много деца. Така че предложението е по-скоро показен жест, отколкото има някаква практическа стойност.
В ПП–ДБ имат ли общо мнение какво се опитват да забранят?
След предложението на ПП–ДБ за забраната на медицинските дейности за промяна на половите белези, сред ЛГБТИ активистите настъпи разнобой. Докато според едни то е по-страшно и от законопроекта на „Възраждане“ за чуждестранните агенти, други се опитват да убедят критикуващите, че малко трансфобия (омраза към транс хората) е за предпочитане пред много трансфобия, каквато има в предложението на ИТН. Макар нищо да не гарантира, че парламентът няма да приеме някаква комбинация от предложенията на ИТН и ПП–ДБ. А според трети идеята на законопроекта всъщност е „да се защитават интерсекс децата от принудително генитално осакатяване“.
Интерсекс са хората, чийто пол по рождение не е еднозначен – не като идентичност, а биологично. Разпространена практика до неотдавна (в България – и до днес) е на интерсекс деца и тийнейджъри да се правят – без тяхното съгласие – „нормализиращи“ операции, за да заприличат на момчета или момичета. Това обаче не означава, че те ще се чувстват като представители на пола, в който са насилени да се впишат.
Съветът на Европа и редица държави признават правата на интерсекс хората. В тях се включва и правото да не бъдат принудително подлагани на медицински процедури. Противното се възприема като „генитално осакатяване“.
Ако човек обаче внимателно прочете мотивите на законопроекта, в тях трудно може да се открие нещо, свързано със защитата от генитално осакатяване на интерсекс деца. В мотивите се изтъква верният факт, че смяна на пола на деца в България не се извършва. Но се споменават „абсурдни, квази-нормативни текстове [вероятно се намеква за предложението на ИТН – б.а.] , с които […] се застрашават правата на децата с редки генетични заболявания и на българските лекари“. Затова, твърди се, предложените промени „запазват правото на здравна и психологическа подкрепа и лечение, в случай на доказана необходимост“.
Кои са децата „с редки генетични заболявания“ и каква е тази „доказана необходимост“? Най-вероятно се имат предвид интерсекс децата, чиито „нормализиращи“ операции се възприемат като „доказана необходимост“.
Това предположение е в синхрон и с публикация във Facebook на депутатката от ДБ Кристина Петкова:
Вчера внесохме наши поправки в Закона за закрила на детето, провокирани от безумния проект на ИТН, които да гарантират правата на децата при лечение, в случай на доказана медицинска необходимост и да осигурят защита на българските лекари.
Според нея „предложението на ИТН на практика щеше да попречи на хирургичните интервенции при деца с вродени малформации на половите органи“.
Любопитен детайл е, че самата Петкова не е сред вносителите на законопроекта, за разлика от Вяра Тодева, Ивайло Митковски и Даниел Лорер. Тодева и Митковски са единствените депутати от ПП–ДБ, които на първо четене подкрепиха закона на „Възраждане“ против ЛГБТИ пропагандата в училище. Лорер пък заяви по bTV емпирично неверния факт, че „всички в България имат подсъзнателен страх, че говоренето в училище за сексуалната ориентация може да повлияе на децата“. Според него родителите – също като него – се страхували „с какво ще се върне детето му от училище и дали няма да се върне по друг начин, защото са му говорили неща за неговите сексуални наклонности“.
Малко вероятно е основният проблем на тези трима депутати да са интерсекс децата. В мотивите на законопроекта обаче се казва още:
Много млади хора са изложени на различни социални и културни влияния, които водят със себе си дебата за […] осигуряване на защита на децата и младежите, [за] гарантиране на правото им на физическо и психическо здраве.
Подчертава се и че предложенията „отчитат индивидуалните права, медицинската етика и обществения интерес. Те осигуряват нужната защита на децата срещу влияния и тенденции“.
С тези текстове се правят внушения, че транс хората са станали такива, защото са „изложени“ на „социални и културни влияния“, и затова трябва да бъдат защитени от вредни „влияния и тенденции“. Тоест транс децата са станали такива поради някаква мода – твърдение, което съвременната наука отхвърля.
В този контекст обаче може да се интерпретира и предложението, че детето има право на „психологическа, социална и експертна помощ по въпроси, свързани с пола му, които да укрепят психологическото му развитие“. Ако да си транс е въпрос на „влияние“, тогава укрепването на психологическото развитие ще рече „излекуване“ от въпросното влияние.
Опитите за „лечение“ на сексуалната ориентация или джендър идентичността на хомосексуални или транс лица се наричат конверсионна терапия. Няма доказателства за тяхната успешност, затова пък конверсионната терапия е допринесла за самоомраза, депресия и опити за самоубийство (включително успешни) сред много ЛГБТИ хора. И докато все повече държави я забраняват, Русия я прави задължителна.
Интерсекс активистът, когото законотворците не питат и не чуват
Темата за интерсекс хората е сложна и специфична, а в България тя е и като цяло непозната. Много лекари продължават да смятат, че „нормализиращите“ операции са необходими, а не са принудително генитално осакатяване.
Затова е обяснимо и политици, които не са се задълбочавали в тази проблематика, от най-добро сърце да повярват, че ако интерсекс децата не бъдат подлагани на операция, това ще е опасно за здравето и живота им. И не допускат, че в зряла възраст те сами биха могли преценят дали искат тялото им да притежава външните белези на някой (и на кой) пол. Че могат да изберат да си останат, каквито са – като главния герой в романа на Джефри Юдженидис „Мидълсекс“, или да отложат решението си за неопределено бъдеще – като героинята от тийнейджърския филм Fitting In („Да се впишеш“).
Първият (и почти единственият) интерсекс активист в България се казва Пол Найденов. Той е също така първият интерсекс човек в страната, спечелил дело за промяна на гражданския си пол. „Тоест“ се обърна към него с въпроса дали смята, че предложеният от ПП–ДБ законопроект защитава интерсекс децата, или легитимира принудителното генитално осакатяване.
Според Найденов законопроектът не защитава интерсекс децата, а напротив. За „нормализиращите“ операции той казва, че са „руска рулетка, само че срещу дулото е главата на интерсекс дете“. Защото някой друг решава каква ще е половата му идентичност, и формира тялото му съобразно представите си за „най-доброто“ за детето.
Найденов напомня, че дори според Конституционния съд интерсекс хората имат право сами да определят пола си, което противоречи на принудителните операции на деца. И иронично предлага пластичните операции на тийнейджъри – например на бюст или устни – също да се забранят, защото са вид промяна на видимите полови белези.
Пол Найденов обръща внимание и на друг проблем във формулировката на проектозакона: „А ако имаме смесен кариотип, кой е генотипният пол?“ „Смесен кариотип“ ще рече, че съществуват хора, чиито хромозоми не са ХХ (жена) или ХУ (мъж), а са в други комбинации, при част от които полът не може да бъде еднозначно определен.
Разпространеното схващане, че „нормализиращите“ операции спасяват живота на интерсекс децата, Найденов коментира с думите, че „в някакъв извратен смисъл в нашата държава реално е така“. Но има предвид не здравословното състояние на тези деца, а социалната стигма и отхвърлянето, на които са подложени и които съдебните решения, вменяващи „бинарно съществуване на човешкия вид“, и анти-ЛГБТИ законодателството допълнително подсилват.
Мижав, но пък вреден резултат
С предложението си за забрана на несъществуващите операции за смяна на пола на транс деца и легитимиране на съществуващите операции за „нормализиране“ на пола на интерсекс деца от ПП–ДБ се опитват угодят на всички. И на хомофобите и трансфобите, и на ЛГБТИ активистите, и на консервативните, и на либералните избиратели. В тези перманентно предизборни времена те хем се опитват да покажат някаква позиция, хем да не си създават врагове.
Законопроектът обаче прави внушения, че да си транс не е добра идея и че това е въпрос на някакви вредни влияния. Ако той се приеме, интерсекс децата няма да бъдат защитени. За сметка на това транс младежи може да бъдат подлагани на безплодни, но мъчителни „терапии“ за „вкарване в правия път“.
В електорален план ПП–ДБ едва ли печелят нещо с предложението си. След толкова дълга поредица от избори последното, от което имат нужда избирателите, е още хлъзгави, безгръбначни и противоречиви позиции. Политиката е свързана с отстояването на принципи и ценности. Ако се опитваш да се харесаш на всички, накрая може вече никой да не те харесва.



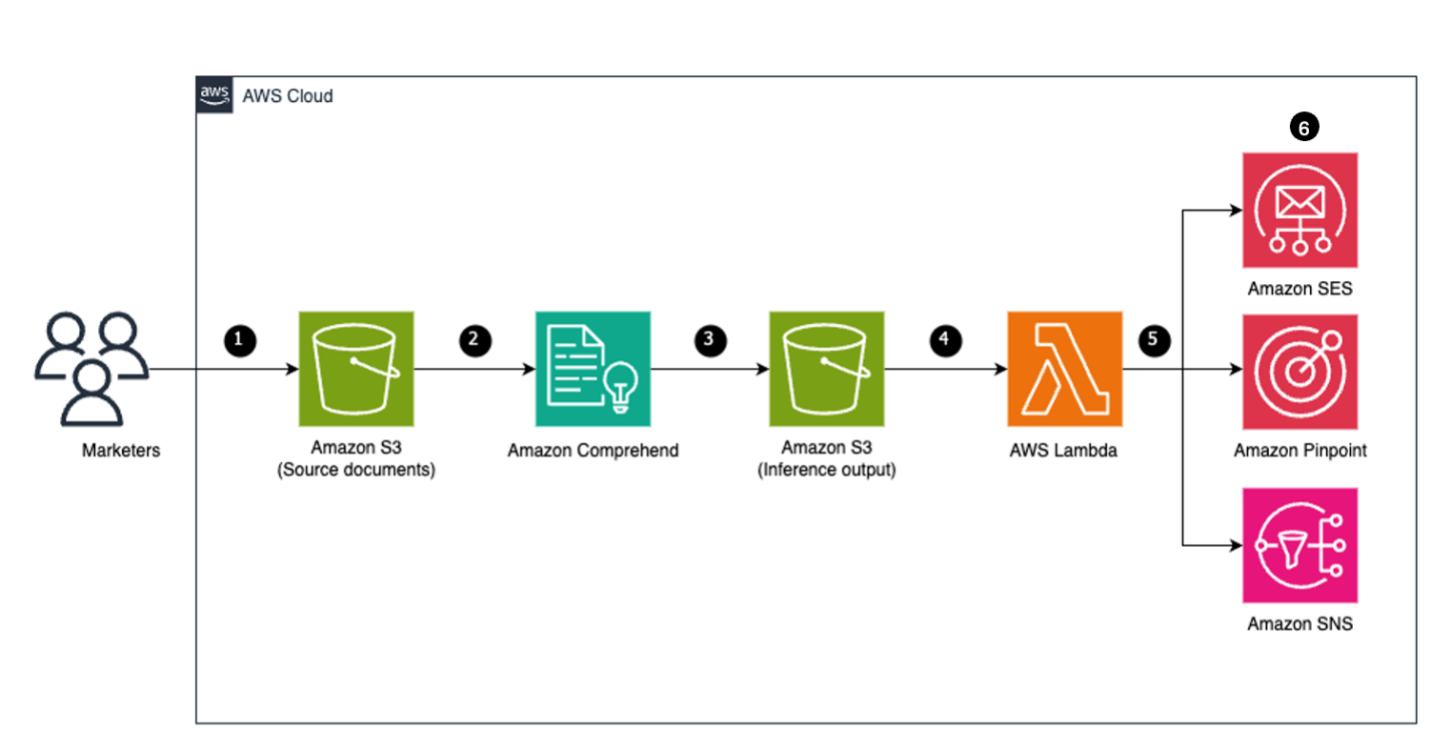





 Figure 8: Amazon Comprehend – Endpoint settings
Figure 8: Amazon Comprehend – Endpoint settings