Post Syndicated from daroc original https://lwn.net/Articles/969442/
The LWN.net Weekly Edition for April 18, 2024 is available.
Post Syndicated from daroc original https://lwn.net/Articles/969442/
The LWN.net Weekly Edition for April 18, 2024 is available.
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=PdIviJ5Ezn4
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=eppIlSjnCHc
Post Syndicated from Chris Betz original https://aws.amazon.com/blogs/security/how-the-unique-culture-of-security-at-aws-makes-a-difference/
Our customers depend on Amazon Web Services (AWS) for their mission-critical applications and most sensitive data. Every day, the world’s fastest-growing startups, largest enterprises, and most trusted governmental organizations are choosing AWS as the place to run their technology infrastructure. They choose us because security has been our top priority from day one. We designed AWS from its foundation to be the most secure way for our customers to run their workloads, and we’ve built our internal culture around security as a business imperative.
While technical security measures are important, organizations are made up of people. A recent report from the Cyber Safety Review Board (CSRB) makes it clear that a deficient security culture can be a root cause for avoidable errors that allow intrusions to succeed and remain undetected.
Our security culture starts at the top, and it extends through every part of our organization. Over eight years ago, we made the decision for our security team to report directly to our CEO. This structural design redefined how we build security into the culture of AWS and informs everyone at the company that security is our top priority by providing direct visibility to senior leadership. We empower our service teams to fully own the security of their services and scale security best practices and programs so our customers have the confidence to innovate on AWS.
We believe that there are four key principles to building a strong culture of security:
At AWS, we view security as a core function of our business, deeply connected to our mission objectives. This goes beyond good intentions—it’s embedded directly into our organizational structure. At Amazon, we make an intentional choice for all our security teams to report directly to the CEO while also being deeply embedded in our respective business units. The goal is to build security into the structural fabric of how we make decisions. Every week, the AWS leadership team, led by our CEO, meets with my team to discuss security and ensure we’re making the right choices on tactical and strategic security issues and course-correcting when needed. We report internally on operational metrics that tie our security culture to the impact that it has on our customers, connecting data to business outcomes and providing an opportunity for leadership to engage and ask questions. This support for security from the top levels of executive leadership helps us reinforce the idea that security is accelerating our business outcomes and improving our customers’ experiences rather than acting as a roadblock.
AWS operates with a strong ownership model built around our culture of security. Ownership is one of our key Leadership Principles at Amazon. Employees in every role receive regular training and reinforcement of the message that security is everyone’s job. Every service and product team is fully responsible for the security of the service or capability that they deliver. Security is built into every product roadmap, engineering plan, and weekly stand-up meeting, just as much as capabilities, performance, cost, and other core responsibilities of the builder team. The best security is not something that can be “bolted on” at the end of a process or on the outside of a system; rather, security is integral and foundational.
AWS business leaders prioritize building products and services that are designed to be secure. At the same time, they strive to create an environment that encourages employees to identify and escalate potential security concerns even when uncertain about whether there is an actual issue. Escalation is a normal part of how we work in AWS, and our practice of escalation provides a “security reporting safe space” to everyone. Our teams and individuals are encouraged to report and escalate any possible security issues or concerns with a high-priority ticket to the security team. We would much rather hear about a possible security concern and investigate it, regardless of whether it is unlikely or not. Our employees know that we welcome reports even for things that turn out to be nonissues.
Our central AWS Security team provides a number of critical capabilities and services that support and enable our engineering and service teams to fulfill their security responsibilities effectively. Our central team provides training, consultation, threat-modeling tools, automated code-scanning frameworks and tools, design reviews, penetration testing, automated API test frameworks, and—in the end—a final security review of each new service or new feature. The security reviewer is empowered to make a go or no-go decision with respect to each and every release. If a service or feature does not pass the security review process in the first review, we dive deep to understand why so we can improve processes and catch issues earlier in development. But, releasing something that’s not ready would be an even bigger failure, so we err on the side of maintaining our high security bar and always trying to deliver to the high standards that our customers expect and rely on.
One important mechanism to distribute security ownership that we’ve developed over the years is the Security Guardians program. The Security Guardians program trains, develops, and empowers service team developers in each two-pizza team to be security ambassadors, or Guardians, within the product teams. At a high level, Guardians are the “security conscience” of each team. They make sure that security considerations for a product are made earlier and more often, helping their peers build and ship their product faster, while working closely with the central security team to help ensure the security bar remains high at AWS. Security Guardians feel empowered by being part of a cross-organizational community while also playing a critical role for the team and for AWS as a whole.
Another way we scale security across our culture at AWS is through innovation. We innovate to build tools and processes to help all of our people be as effective as possible and maintain focus. We use artificial intelligence (AI) to accelerate our secure software development process, as well as new generative AI–powered features in Amazon Inspector, Amazon Detective, AWS Config, and Amazon CodeWhisperer that complement the human skillset by helping people make better security decisions, using a broader collection of knowledge. This pattern of combining sophisticated tooling with skilled engineers is highly effective because it positions people to make the nuanced decisions required for effective security.
For large organizations, it can take years to assess every scenario and prove systems are secure. Even then, their systems are constantly changing. Our automated reasoning tools use mathematical logic to answer critical questions about infrastructure to detect misconfigurations that could potentially expose data. This provable security provides higher assurance in the security of the cloud and in the cloud. We apply automated reasoning in key service areas such as storage, networking, virtualization, identity, and cryptography. Amazon scientists and engineers also use automated reasoning to prove the correctness of critical internal systems. We process over a billion mathematical queries per day that power AWS Identity and Access Management Access Analyzer, Amazon Simple Storage Service (Amazon S3) Block Public Access, and other security offerings. AWS is the first and only cloud provider to use automated reasoning at this scale.
At AWS, we care deeply about our culture of security. We’re consistently working backwards from our customers and investing in raising the bar on our security tools and capabilities. For example, AWS enables encryption of everything. AWS Key Management Service (AWS KMS) is the first and only highly scalable, cloud-native key management system that is also FIPS 140-2 Level 3 certified. No one can retrieve customer plaintext keys, not even the most privileged admins within AWS. With the AWS Nitro System, which is the foundation of the AWS compute service Amazon Elastic Compute Cloud (Amazon EC2), we designed and delivered first-of-a-kind and still unique in the industry innovation to maximize the security of customers’ workloads. The Nitro System provides industry-leading privacy and isolation for all their compute needs, including GPU-based computing for the latest generative AI systems. No one, not even the most privileged admins within AWS, can access a customer’s workloads or data in Nitro-based EC2 instances.
We continue to innovate on behalf of our customers so they can move quickly, securely, and with confidence to enable their businesses, and our track record in the area of cloud security is second to none. That said, cybersecurity challenges continue to evolve, and while we’re proud of our achievements to date, we’re committed to constant improvement as we innovate and advance our technologies and our culture of security.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=3loBHMmrRgQ
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=5ywS7rGh10k
Post Syndicated from Tyler Holmes original https://aws.amazon.com/blogs/messaging-and-targeting/how-to-implement-self-managed-opt-outs-for-sms-with-amazon-pinpoint/
Amazon Pinpoint offers marketers and developers the ability to send SMS to over 240 countries and/or regions around the world; giving users the global reach, scalability, cost effective pricing, and high deliverability that is required to build a successful SMS program. SMS is a flexible communication channel that facilitates different business requirements, including One-Time Password (OTP), reminders, and bulk marketing to name a few. Regardless of the content that you are sending via SMS there is a requirement to manage your recipients’ opt-in/out status. Read on to learn your two options for managing opt-outs and how you can configure them. Amazon Pinpoint offers a fully managed opt-out capability and the ability to self-manage the process with your own tools.
NOTE: If you are sending to US numbers with a toll-free (TFN) number the carriers will automatically manage those numbers and are not eligible for either of these processes.
Managed Opt-Out Process
If you prefer to have Pinpoint manage your opt-out processes you can refer to our blog “How to Manage SMS Opt-Outs with Amazon Pinpoint” to learn how to configure keywords and opt-out lists.
Self-Managed Opt-Out Process
Many customers use Pinpoint’s Managed Opt-Out process to deliver their communications, but some scenarios require the ability to self-manage this process. Self-managing the opt-out process provides more granular control over customer communication preferences and allows customers to centralize those preferences within their own applications.
Common reasons for organizations to implement self-managed opt-out include but aren’t limited to:
How to implement Self-Managed Opt-Outs with Pinpoint
Choosing to self-manage your opt-outs requires some configuration within Pinpoint and the use of other AWS services. The solution outlined in this blog will use Amazon Pinpoint in addition to the following services:
NOTE: If you have existing services/applications that allow you to implement similar functionality as explained in this blog, you don’t have to use these services listed above.
What’s in scope?
This blog covers the following scenario:
While the following scenarios can be self-managed this blog does not cover the following cases:
Keywords in scope
NOTE: The code examples in this blog can be modified to add any additional custom keywords for your use case.
Assumptions/Prerequisites
Solution Overview
The solution proposed in this blog is fully serverless arhitecture and uses AWS managed services to eliminate a need for you to maintain and manage any of the infrastructure components.

NOTE: Amazon DynamoDB table can also be configured to receive the Opt-out or Opt-in information through various other channels (app, website, customer care etc.) if you have multiple interfaces for customer to do so but that is not in the scope for this blog.
Refer to the section, ‘InvokeSendTextMessage function code’ to understand the sample AWS Lambda function code. The code uses Python 3.12 language.
NOTE: Refer the section ‘AddOptOutInDynamoDB function code’ to understand the sample code. The code uses Python3.12 language.
Amazon Pinpoint setup
2-way SMS setting:

Self Managed Opt-Out feature setting:

Amazon SNS setup


Amazon DynamoDB Setup
Table Name: ‘SMSOptOut‘
The Customer phone number is used as the primary key(PK). The sort key(SK) contains multiple values that include OID, timestamp, and the customer response separated by #. By having generic attribute names as PK and SK, you can expand the usage of this table for accommodating any custom business needs. For example: Customer can use any of the individual phone numbers like short code, long code, or 10DLC to send the SMS and any of these values can be accomodated as a part of the sort key (SK). The sort key can be used for granular retrieval to see the latest customer status (For example: ‘STOP‘). It can then additionally have attributes like OID, Timestamp, Response and others as per your requirements. The table uses On-demand Read/Write capacity mode. Refer to this document to understand On-demand capacity mode in detail.

Sample item in DynamoDB table is below

InvokeSendTextMessage function code
This AWS Lambda function calls Amazon Pinpoint SMS and Voice V2 API – SendTextMessage. It uses Query API for DynamoDB to scan the items for SourcePhoneNumber (customer phone number) and OID (Part of SK) in descending order of the timestamp. If an item exists with customer response value is a valid keyword for Opt-out (Refer section Keywords in scope), it means the customer has opted-out and the SMS can’t be sent. If no item is found or the customer response value is a valid keyword for Opt-in (Refer section Keywords in scope), the customer can be contacted and the funtion calls SendTextMessage API with the same OID and customer phone number.
import boto3
import os
from boto3.dynamodb.conditions import Key, Attr
import json
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('SMSOptOut')
pinpoint = boto3.client('pinpoint-sms-voice-v2')
OptOutKeyword = ['ARRET','CANCEL','END','OPT-OUT','OPTOUT','QUIT','REMOVE','STOP','TD','UNSUBSCRIBE']
OptInKeyword = ['JOIN']
#adds item in the DynamoDB table
def query_table(OID, SourcePhoneNumber):
try:
response = table.query(
KeyConditionExpression=Key('PK').eq(SourcePhoneNumber) & Key('SK').begins_with(OID),
ScanIndexForward=False,
Limit=1
)
except Exception as e:
print("Error when writing an item in DynamoDB table: ",e)
raise e
return response
#send opt-in/opt-out confirmation text using send_text_message.
def send_confirmation_text(SourcePhoneNumber,OID,messageBody,messageType):
try:
response = pinpoint.send_text_message(DestinationPhoneNumber=SourcePhoneNumber,
OriginationIdentity=OID,
MessageBody=messageBody,
MessageType=messageType
)
except Exception as e:
print("Error in sending text message using Pinpoint send_text_message api:", e)
raise e
#gets the message from SNS topic
def lambda_handler(event, context):
OID = event['OID']
SourcePhoneNumber = event['SourcePhoneNumber']
response=query_table(OID, SourcePhoneNumber)
items = response['Items']
#Count number of items. The value will be either 1 or 0.
count = len(items)
# If the latest customer response is any OptOutKeyword
if count == 1 and items[0]['Response'] in OptOutKeyword:
print("Exit : Customer has opted out, do not send SMS")
# If the latest customer response is any OptOutKeyword
elif count == 0 or (count == 1 and items[0]['Response'] in OptInKeyword):
send_confirmation_text(SourcePhoneNumber,OID,'This is a test message from Amazon Pinpoint','TRANSACTIONAL')
# Only allowed values for customer response are valid OptOutKeyword or OptInKeyword
else:
print("The customer response is not one of the allowed keyword")
AddOptOutInDynamoDB Lambda function code
For example: When customer responds with ‘STOP’, the response is captured in the SNS topic that you configured with Amazon Pinpoint. The response json looks as shown below –
{
"originationNumber": "+1224xxxxxxx",
"destinationNumber": "+1844xxxxxxx",
"messageKeyword": "KEYWORD_xxxxxxxxxxxx",
"messageBody": "STOP",
"previousPublishedMessageId": "xxxxxxxxxxxxxx",
"inboundMessageId": "xxxxxxxxxxxxxx"
}This Lambda function extracts the OID (destinationNumber), Customer phone number (originationNumber), and the customer response (messageBody) from the json payload above and adds an entry in the DynamoDB table (SMSOptOut). Once the item is put successfully in DynamoDB table, the function also sends out a confirmation SMS (either Opt-in or Opt-out) to the customer phone number using SendTextMessage.
For example:
import json
import boto3
import datetime
dynamodb = boto3.resource('dynamodb')
dynamodb_table = dynamodb.Table('SMSOptOut')
pinpoint = boto3.client('pinpoint-sms-voice-v2')
OptOutKeyword = ['ARRET','CANCEL','END','OPT-OUT','OPTOUT','QUIT','REMOVE','STOP','TD','UNSUBSCRIBE']
OptInKeyword = ['JOIN']
#adds item in the DynamoDB table
def put_item(data,current_timestamp):
print(dynamodb_table)
try:
response = dynamodb_table.put_item(
Item = {
'PK': data['originationNumber'],
'SK': data['destinationNumber']+'#'+current_timestamp+'#'+data['messageBody'],
'OID': data['destinationNumber'],
'Timestamp': current_timestamp,
'Response': data['messageBody']
}
)
except Exception as e:
print("Error when writing an item in DynamoDB table: ",e)
raise e
#send opt-in/opt-out confirmation text using send_text_message.
def send_confirmation_text(data,messageBody,messageType):
try:
response = pinpoint.send_text_message(
DestinationPhoneNumber=data['originationNumber'],
OriginationIdentity=data['destinationNumber'],
MessageBody=messageBody,
MessageType=messageType
)
except Exception as e:
print("Error in sending text message using Pinpoint send_text_message api:", e)
raise e
#gets the message from SNS topic
def lambda_handler(event, context):
message = event['Records'][0]['Sns']['Message']
data = json.loads(message)
current_timestamp = datetime.datetime.now().isoformat()
if data['messageBody'] in OptOutKeyword:
put_item(data,current_timestamp)
send_confirmation_text(data, 'YOU HAVE BEEN UNSUBSCRIBED. IF THIS WAS A MISTAKE PLEASE TEXT "JOIN" TO THIS NUMBER TO BE RESUBSCRIBED', 'TRANSACTIONAL')
elif data['messageBody'] in OptInKeyword:
put_item(data,current_timestamp)
send_confirmation_text(data, 'YOU HAVE BEEN SUBSCRIBED. IF THIS WAS A MISTAKE PLEASE TEXT "STOP" OR "UNSUBSCRIBE" TO THIS NUMBER TO BE UNSUBSCRIBED', 'TRANSACTIONAL')
else:
print("The customer response is not one of the allowed keyword")Clean Up
DynamoDB storage and any Lambda invocation will incur a cost so it is important to delete these resources if you do not plan on using them as shown below.
DynamoDB:

Lambda:

Amazon Pinpoint

Conclusion
In this post, you learned how to implement a self-managed opt-out workflow when using Pinpoint SMS. Keep in mind that when you implement the self-managed Opt-out flow, Pinpoint will not track or maintain any opt-out status for the OID that it was enabled for.
Take the time to plan out your approach, follow the steps outlined in this blog, and take advantage of any resources available to you within your support tier.
Decide what origination IDs you will need here
Review the documentation for the V2 SMS and Voice API here
Check out the support tiers comparison here
Resources:
https://docs.aws.amazon.com/sms-voice/latest/userguide/phone-numbers-sms-by-country.html
https://aws.amazon.com/blogs/messaging-and-targeting/how-to-utilise-amazon-pinpoint-to-retry-unsuccessful-sms-delivery/
https://docs.aws.amazon.com/pinpoint/latest/userguide/channels-sms-limitations-opt-out.html
https://docs.aws.amazon.com/pinpoint/latest/userguide/channels-sms-simulator.html
https://docs.aws.amazon.com/dynamodb/
https://docs.aws.amazon.com/sns/
https://docs.aws.amazon.com/lambda/
Post Syndicated from jake original https://lwn.net/Articles/969904/
Managing to-do lists is something of a universal necessity. While some
people handle them mentally or on paper, others resort to a web-based tool or
a mobile
application. For those preferring the command line, the MIT-licensed Taskwarrior offers a flexible solution
with a healthy community and lots of extensions.
Post Syndicated from Bukhtawar Khan original https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-under-the-hood-opensearch-optimized-instancesor1/
Amazon OpenSearch Service recently introduced the OpenSearch Optimized Instance family (OR1), which delivers up to 30% price-performance improvement over existing memory optimized instances in internal benchmarks, and uses Amazon Simple Storage Service (Amazon S3) to provide 11 9s of durability. With this new instance family, OpenSearch Service uses OpenSearch innovation and AWS technologies to reimagine how data is indexed and stored in the cloud.
Today, customers widely use OpenSearch Service for operational analytics because of its ability to ingest high volumes of data while also providing rich and interactive analytics. In order to provide these benefits, OpenSearch is designed as a high-scale distributed system with multiple independent instances indexing data and processing requests. As your operational analytics data velocity and volume of data grows, bottlenecks may emerge. To sustainably support high indexing volume and provide durability, we built the OR1 instance family.
In this post, we discuss how the reimagined data flow works with OR1 instances and how it can provide high indexing throughput and durability using a new physical replication protocol. We also dive deep into some of the challenges we solved to maintain correctness and data integrity.
OpenSearch Service manages tens of thousands of OpenSearch clusters. We’ve gained insights into typical cluster configurations that customers use to meet high throughput and durability goals. To achieve higher throughput, customers often choose to drop replica copies to save on the replication latency; however, this configuration results in sacrificing availability and durability. Other customers require high durability and as a result need to maintain multiple replica copies, resulting in higher operating costs for them.
The OpenSearch Optimized Instance family provides additional durability while also keeping costs lower by storing a copy of the data on Amazon S3. With OR1 instances, you can configure multiple replica copies for high read availability while maintaining indexing throughput.
The following diagram illustrates an indexing flow involving a metadata update in OR1

During indexing operations, individual documents are indexed into Lucene and also appended to a write-ahead log also known as a translog. Before sending back an acknowledgement to the client, all translog operations are persisted to the remote data store backed by Amazon S3. If any replica copies are configured, the primary copy performs checks to detect the possibility of multiple writers (control flow) on all replica copies for correctness reasons.
The following diagram illustrates the segment generation and replication flow in OR1 instances

Periodically, as new segment files are created, the OR1 copy those segments to Amazon S3. When the transfer is complete, the primary publishes new checkpoints to all replica copies, notifying them of a new segment being available for download. The replica copies subsequently download newer segments and make them searchable. This model decouples the data flow that happens using Amazon S3 and the control flow (checkpoint publication and term validation) that happens over inter-node transport communication.
The following diagram illustrates the recovery flow in OR1 instances

OR1 instances persist not only the data, but the cluster metadata like index mappings, templates, and settings in Amazon S3. This makes sure that in the event of a cluster-manager quorum loss, which is a common failure mode in non-dedicated cluster-manager setups, OpenSearch can reliably recover the last acknowledged metadata.
In the event of an infrastructure failure, an OpenSearch domain can end up losing one or more nodes. In such an event, the new instance family guarantees recovery of both the cluster metadata and the index data up to the latest acknowledged operation. As new replacement nodes join the cluster, the internal cluster recovery mechanism bootstraps the new set of nodes and then recovers the latest cluster metadata from the remote cluster metadata store. After the cluster metadata is recovered, the recovery mechanism starts to hydrate the missing segment data and translog from Amazon S3. Then all uncommitted translog operations, up to the last acknowledged operation, are replayed to reinstate the lost copy.
The new design doesn’t modify the way searches work. Queries are processed normally by either the primary or replica shard for each shard in the index. You may see longer delays (in the 10-second range) before all copies are consistent to a particular point in time because the data replication is using Amazon S3.
A key advantage of this architecture is that it serves as a foundational building block for future innovations, like separation of readers and writers, and helps segregate compute and storage layers.
OpenSearch supports two replication strategies: logical (document) and physical (segment) replication. In the case of logical replication, the data is indexed on all the copies independently, leading to redundant computation on the cluster. The OR1 instances use the new physical replication model, where data is indexed only on the primary copy and additional copies are created by copying data from the primary. With a high number of replica copies, the node hosting the primary copy requires significant network bandwidth, replicating the segment to all the copies. The new OR1 instances solve this problem by durably persisting the segment to Amazon S3, which is configured as a remote storage option. They also help with scaling replicas without bottlenecking on primary.
After the segments are uploaded to Amazon S3, the primary sends out a checkpoint request, notifying all replicas to download the new segments. The replica copies then need to download the incremental segments. Because this process frees up compute resources on replicas, which is otherwise required to redundantly index data and network overhead incurred on primaries to replicate data, the cluster is able to churn more throughput. In the event the replicas aren’t able to process the newly created segments, due to overload or slow network paths, the replicas beyond a point are marked as failed to prevent them from returning stale results.
Although all committed segments are durably persisted to Amazon S3 whenever they get created, one of key challenges in achieving high durability is synchronously writing all uncommitted operations to a write-ahead log on Amazon S3, before acknowledging back the request to the client, without sacrificing throughput. The new semantics introduce additional network latency for individual requests, but the way we’ve made sure there is no impact to throughput is by batching and draining requests on a single thread for up to a specified interval, while making sure other threads continue to index requests. As a result, you can drive higher throughput with more concurrent client connections by optimally batching your bulk payloads.
Other challenges in designing a highly durable system include enforcing data integrity and correctness at all times. Although some events like network partitions are rare, they can break the correctness of the system and therefore the system needs to be prepared to deal with these failure modes. Therefore, while switching to the new segment replication protocol, we also introduced a few other protocol changes, like detecting multiple writers on each replica. The protocol makes sure that an isolated writer can’t acknowledge a write request, while another newly promoted primary, based on the cluster-manager quorum, is concurrently accepting newer writes.
The new instance family automatically detects the loss of a primary shard while recovering data, and performs extensive checks on network reachability before the data can be re-hydrated from Amazon S3 and the cluster is brought back to a healthy state.
For data integrity, all files are extensively checksummed to make sure we are able to detect and prevent network or file system corruption that may result in data being unreadable. Furthermore, all files including metadata are designed to be immutable, providing additional safety against corruptions and versioned to prevent accidental mutating changes.
The OR1 instances hydrate copies directly from Amazon S3 in order to perform recovery of lost shards during an infrastructure failure. By using Amazon S3, we are able to free up the primary node’s network bandwidth, disk throughput, and compute, and therefore provide a more seamless in-place scaling and blue/green deployment experience by orchestrating the entire process with minimal primary node coordination.
OpenSearch Service provides automatic data backups called snapshots at hourly intervals, which means in case of accidental modifications to data, you have the option to go back to a previous point in time state. However, with the new OpenSearch instance family, we’ve discussed that the data is already durably persisted on Amazon S3. So how do snapshots work when we already have the data present on Amazon S3?
With the new instance family, snapshots serve as checkpoints, referencing the already present segment data as it exists at a point in time. This makes snapshots more lightweight and faster because they don’t need to re-upload any additional data. Instead, they upload metadata files that capture the view of the segments at that point in time, which we call shallow snapshots. The benefit of shallow snapshots extends to all operations, namely creation, deletion, and cloning of snapshots. You still have the option to snapshot an independent copy with manual snapshots for other administrative operations.
OpenSearch is an open source, community-driven software. Most of the foundational changes including the replication model, remote-backed storage, and remote cluster metadata have been contributed to open source; in fact, we follow an open source first development model.
Efforts to improve throughput and reliability is a never-ending cycle as we continue to learn and improve. The new OpenSearch optimized instances serve as a foundational building block, paving the way for future innovations. We are excited to continue our efforts in improving reliability and performance and to see what new and existing solutions builders can create using OpenSearch Service. We hope this leads to a deeper understanding of the new OpenSearch instance family, how this offering achieves high durability and better throughput, and how it can help you configure clusters based on the needs of your business.
If you’re excited to contribute to OpenSearch, open up a GitHub issue and let us know your thoughts. We would also love to hear about your success stories achieving high throughput and durability on OpenSearch Service. If you have other questions, please leave a comment.
 Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in building distributed and autonomous systems. He is a maintainer and an active contributor to OpenSearch.
Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in building distributed and autonomous systems. He is a maintainer and an active contributor to OpenSearch.
 Gaurav Bafna is a Senior Software Engineer working on OpenSearch at Amazon Web Services. He is fascinated about solving problems in distributed systems. He is a maintainer and an active contributor to OpenSearch.
Gaurav Bafna is a Senior Software Engineer working on OpenSearch at Amazon Web Services. He is fascinated about solving problems in distributed systems. He is a maintainer and an active contributor to OpenSearch.
 Sachin Kale is a senior software development engineer at AWS working on OpenSearch.
Sachin Kale is a senior software development engineer at AWS working on OpenSearch.
 Rohin Bhargava is a Sr. Product Manager with the Amazon OpenSearch Service team. His passion at AWS is to help customers find the correct mix of AWS services to achieve success for their business goals.
Rohin Bhargava is a Sr. Product Manager with the Amazon OpenSearch Service team. His passion at AWS is to help customers find the correct mix of AWS services to achieve success for their business goals.
 Ranjith Ramachandra is a Senior Engineering Manager working on Amazon OpenSearch Service. He is passionate about highly scalable distributed systems, high performance and resilient systems.
Ranjith Ramachandra is a Senior Engineering Manager working on Amazon OpenSearch Service. He is passionate about highly scalable distributed systems, high performance and resilient systems.
Post Syndicated from Sandipan Bhaumik original https://aws.amazon.com/blogs/big-data/power-analytics-as-a-service-capabilities-using-amazon-redshift/
Analytics as a service (AaaS) is a business model that uses the cloud to deliver analytic capabilities on a subscription basis. This model provides organizations with a cost-effective, scalable, and flexible solution for building analytics. The AaaS model accelerates data-driven decision-making through advanced analytics, enabling organizations to swiftly adapt to changing market trends and make informed strategic choices.
Amazon Redshift is a cloud data warehouse service that offers real-time insights and predictive analytics capabilities for analyzing data from terabytes to petabytes. It offers features like data sharing, Amazon Redshift ML, Amazon Redshift Spectrum, and Amazon Redshift Serverless, which simplify application building and make it effortless for AaaS companies to embed rich data analytics capabilities. Amazon Redshift delivers up to 4.9 times lower cost per user and up to 7.9 times better price-performance than other cloud data warehouses.
The Powered by Amazon Redshift program helps AWS Partners operating an AaaS model quickly build analytics applications using Amazon Redshift and successfully scale their business. For example, you can build visualizations on top of Amazon Redshift and embed them within applications to provide outstanding analytics experiences for end-users. In this post, we explore how AaaS providers scale their processes with Amazon Redshift to deliver insights to their customers.
While serving analytics at scale, AaaS providers and customers can choose where to store the data and where to process the data.
AaaS providers could choose to ingest and process all the customer data into their own account and deliver insights to the customer account. Alternatively, they could choose to directly process data in-place within the customer’s account.
The choice of these delivery models depends on many factors, and each has their own benefits. Because AaaS providers service multiple customers, they could mix these models in a hybrid fashion, meeting each customer’s preference. The following diagram illustrates the two delivery models.

We explore the technical details of each model in the next sections.
Amazon Redshift has features that allow AaaS providers the flexibility to deploy three unique delivery models:
These delivery models give AaaS providers the flexibility to deliver insights to their customers no matter where the data warehouse is located.
Let’s look at how each of these delivery models work in practice.
In this model, the AaaS provider ingests customer data in their own account, and engages their own Redshift data warehouse for processing. Then they use one or more methods to deliver the generated insights to their customers. Amazon Redshift enables companies to securely build multi-tenant applications, ensuring data isolation, integrity, and confidentiality. It provides features like row-level security (RLS), column-level security (CLS) for fine-grained access control, role-based access control (RBAC), and assigning permissions at the database and schema level.
The following diagram illustrates the managed delivery model and the various methods AaaS providers can use to deliver insights to their customers.

The workflow includes the following steps:
In this model, the customer shifts the responsibility of data management and governance to the AaaS providers, with light services to consume insights. This leads to improved decision-making as customers focus on core activities and save time from tedious data management tasks. Because AaaS providers move data from the customer accounts, there could be associated data transfer costs depending on how they move the data. However, because they deliver this service at scale to multiple customers, they can offer cost-efficient services using economies of scale.
In cases where the customer hosts a Redshift data warehouse and wants to run analytics in their own data platform without moving data out, you use the BYOR model.
The following diagram illustrates the BYOR model, where AaaS providers process data to add insights directly in their customer’s data warehouse so the data never leaves the customer account.

The solution includes the following steps:
This delivery model allows customers to manage their own data, reducing dependency on AaaS providers and cutting data transfer costs. By keeping data in their own environment, customers can reduce the risk of data breach while benefiting from insights for better decision-making.
Customers have diverse needs influenced by factors like data security, compliance, and technical expertise. To cover a broader range of customers, AaaS providers can choose a hybrid approach that delivers both the managed model and the BYOR model depending on the customer, offering flexibility and the ability to serve multiple customers.
The following diagram illustrates the AaaS provider delivering insights through the BYOR model for Customer 1 and 4, the managed model for Customer 2 and 3, and so on.

In this post, we talked about the rising demand of analytics as a service and how providers can use the capabilities of Amazon Redshift to deliver insights to their customers. We examined two primary delivery models: the managed model, where AaaS providers process data on their own accounts, and the BYOR model, where AaaS providers process and enrich data directly in their customer’s account. Each method offers unique benefits, such as cost-efficiency, enhanced control, and personalized insights. The flexibility of the AWS Cloud facilitates a hybrid model, accommodating diverse customer needs and allowing AaaS providers to scale. We also introduced the Powered by Amazon Redshift program, which supports AaaS businesses in building effective analytics applications, fostering improved user engagement and business growth.
We take this opportunity to invite our ISV partners to reach out to us and learn more about the Powered by Amazon Redshift program.
 Sandipan Bhaumik is a Senior Analytics Specialist Solutions Architect based in London, UK. He helps customers modernize their traditional data platforms using the modern data architecture in the cloud to perform analytics at scale.
Sandipan Bhaumik is a Senior Analytics Specialist Solutions Architect based in London, UK. He helps customers modernize their traditional data platforms using the modern data architecture in the cloud to perform analytics at scale.
 Sain Das is a Senior Product Manager on the Amazon Redshift team and leads Amazon Redshift GTM for partner programs, including the Powered by Amazon Redshift and Redshift Ready programs.
Sain Das is a Senior Product Manager on the Amazon Redshift team and leads Amazon Redshift GTM for partner programs, including the Powered by Amazon Redshift and Redshift Ready programs.
Post Syndicated from Cliff Robinson original https://www.servethehome.com/amd-ryzen-pro-8000-and-ryzen-pro-8040-series-launched/
New AMD Ryzen Pro 8000 and Ryzen Pro 8040 series chips are out, many with NPUs for AI, and a clear emphasis on the commercial mobile market
The post AMD Ryzen Pro 8000 and Ryzen Pro 8040 Series Launched appeared first on ServeTheHome.
Post Syndicated from Pete Pang original https://blog.cloudflare.com/how-cloudflare-cloud-email-security-protects-against-the-evolving-threat-of-qr-phishing
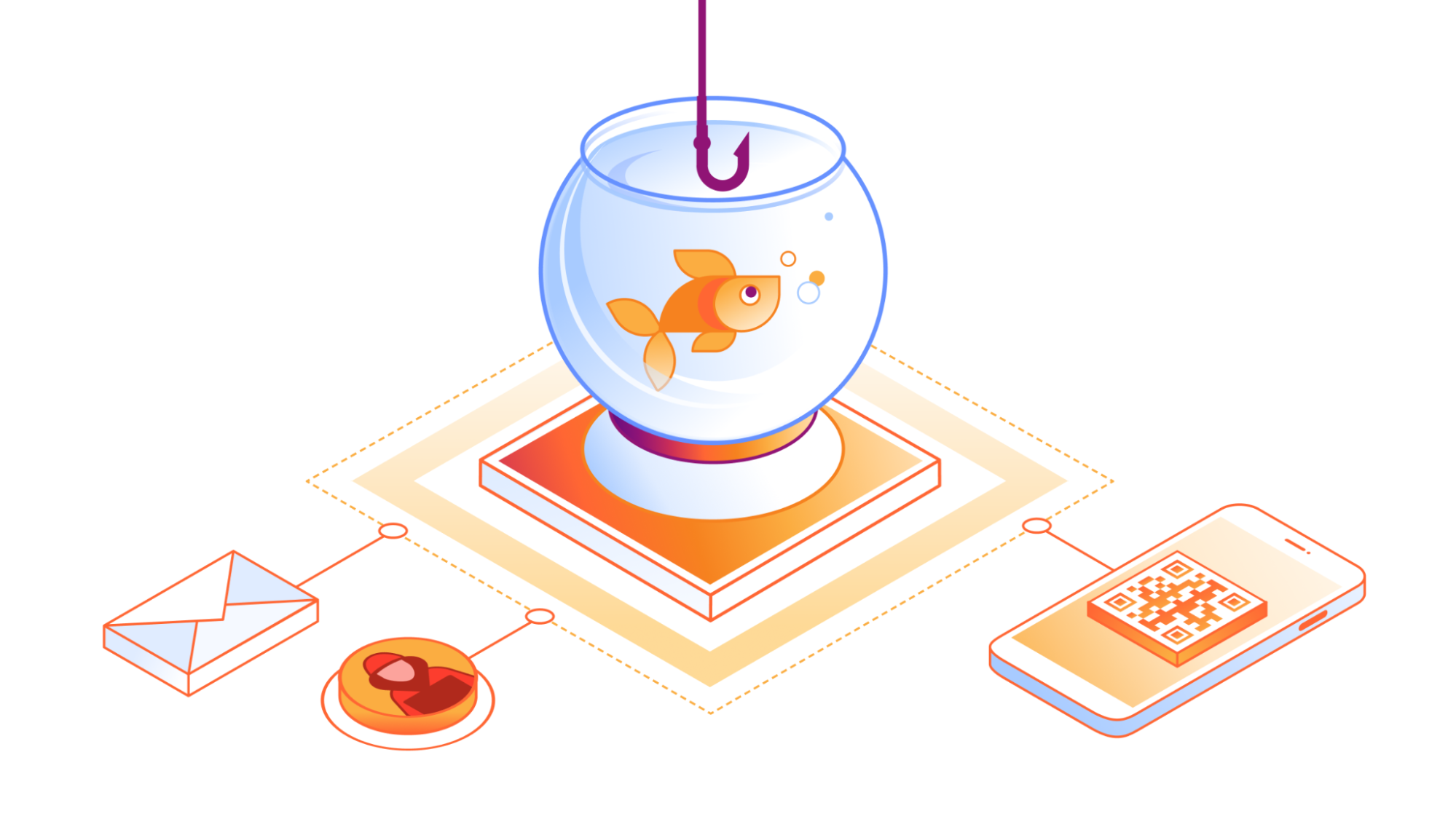
In the ever-evolving landscape of cyber threats, a subtle yet potent form of phishing has emerged — quishing, short for QR phishing. It has been 30 years since the invention of QR codes, yet quishing still poses a significant risk, especially after the era of COVID, when QR codes became the norm to check statuses, register for events, and even order food.
Since 2020, Cloudflare’s cloud email security solution (previously known as Area 1) has been at the forefront of fighting against quishing attacks, taking a proactive stance in dissecting them to better protect our customers. Let’s delve into the mechanisms behind QR phishing, explore why QR codes are a preferred tool for attackers, and review how Cloudflare contributes to the fight against this evolving threat.
The impact of phishing and quishing are quite similar, as both can result in users having their credentials compromised, devices compromised, or even financial loss. They also leverage malicious attachments or websites to provide bad actors the ability to access something they normally wouldn’t be able to. Where they differ is that quishing is typically highly targeted and uses a QR code to further obfuscate itself from detection.
Since phish detection engines require inputs like URLs or attachments inside an email in order to detect, quish succeeds by hampering the detection of these inputs. In Example A below, the phish’s URL was crawled and after two redirects landed on a malicious website that automatically tries to run key logging malware that copies login names and passwords. For Example A, this clearly sets off the detectors, but Example B has no link to crawl and therefore the same detections that worked on Example A are rendered inert.
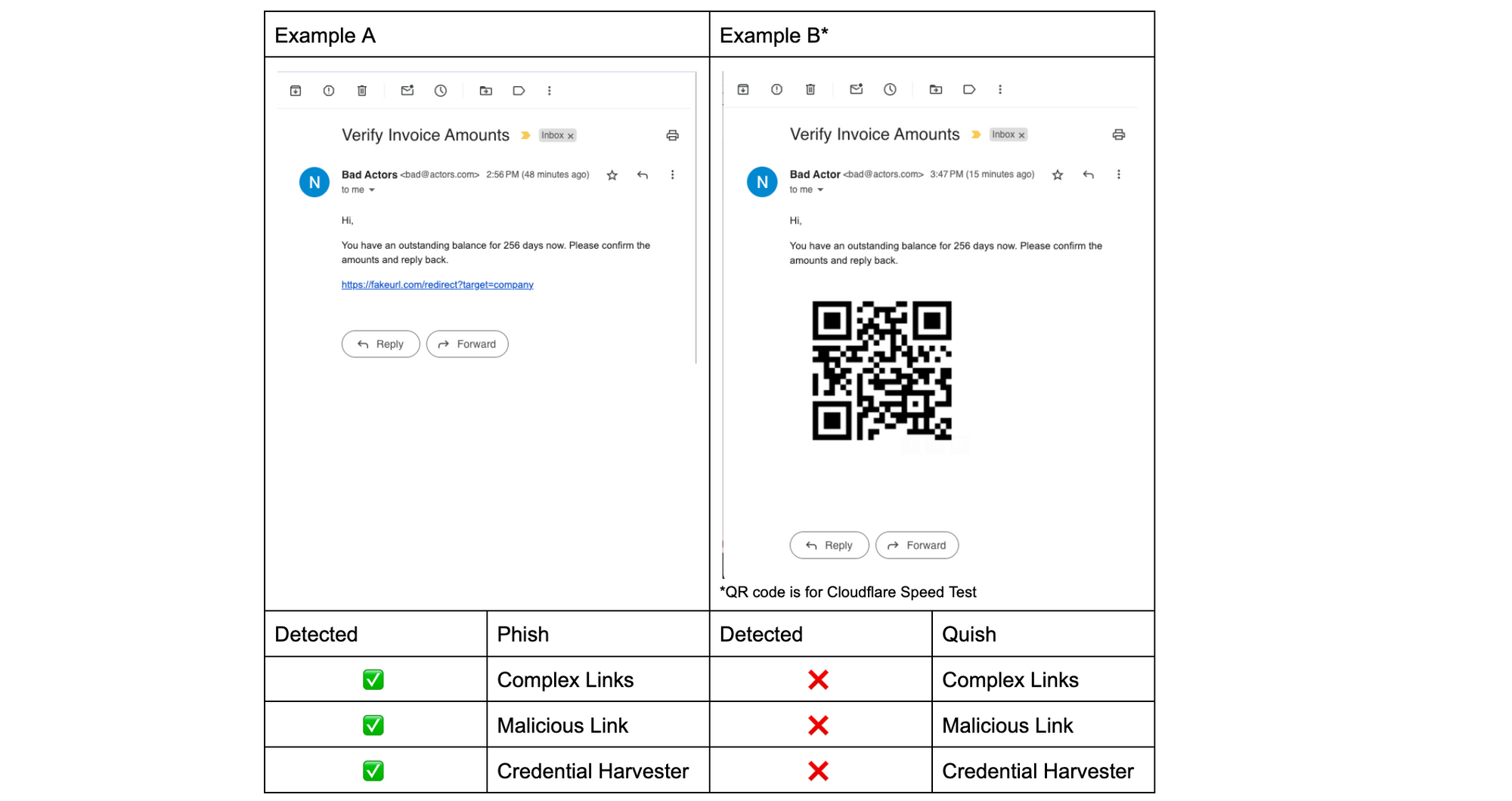
Strange you say, if my phone can scan that QR code then can’t a detection engine recognize the QR code as well? Simply put, no, because phish detection engines are optimized for catching phish, but to identify and scan QR codes requires a completely different engine – a computer vision engine. This brings us to why QR codes are a preferred tool for attackers.
There are three main reasons QR codes are popular in phishing attacks. First, QR codes boast strong error correction capabilities, allowing them to withstand resizing, pixel shifting, variations in lighting, partial cropping, and other distortions. Indeed, computer vision models can scan QR codes, but identifying which section of an email, image, or webpage linked in an email has a QR code is quite difficult for a machine, and even more so if the QR codes have been obfuscated to hide themselves from some computer vision models. For example, by inverting them, blending them with other colors or images, or making them extremely small, computer vision models will have trouble even identifying the presence of QR codes, much less even being able to scan them. Though filters and additional processing can be applied to any image, not knowing what or where to apply makes the deobfuscation of a QR code an extremely expensive computational problem. This not only makes catching all quish hard, but is likely to cause frustration for an end user who won’t get their emails quickly because an image or blob of text looks similar to a QR code, resulting in delivery delays.
Even though computer vision models may have difficulty deobfuscating QR codes, we have discovered from experience that when a human encounters these obfuscated QR codes, with enough time and effort, they are usually able to scan the QR code. By doing everything from increasing the brightness of their screen, to printing out the email, to resizing the codes themselves, they can make a QR code that has been hidden from machines scan successfully.
Don’t believe us? Try it for yourself with the QR codes that have been obfuscated for machines. They all link to https://blog.cloudflare.com/

If you scanned any of the example QR codes above, you have just proven the next reason bad actors favor quish. The devices used for accessing QR codes are typically personal devices with a limited security posture, making them susceptible to exploitation. While secured corporate devices typically have measures to warn, stop, or sandbox users when they access malicious links, these protections are not available natively on personal devices. This can be especially worrisome, as we have seen a trend towards custom QR codes targeting executives in organizations.
QR codes can also be seamlessly layered in with other obfuscation techniques, such as encrypted attachments, mirrors that mimic well-known websites, validations to prove you are human before malicious content is revealed, and more. This versatility makes them an attractive choice for cybercriminals seeking innovative ways to deceive unsuspecting users by adding QR codes to previously successful phishing vectors that have now been blocked by security products.
Cloudflare has been at the forefront of defending against quishing attacks. We employ a multi-faceted approach, and instead of focusing on archaic, layered email configuration rules, we have trained our machine learning (ML) detection models on almost a decade’s worth of detection data and have a swath of proactive computer vision models to ensure all of our customers start with a turnkey solution.
For quish detections, we break it into two parts: 1) identification and scanning of QR codes 2) analysis of decoded QR codes.
The first part is solved by our own QR code detection heuristics that inform how, when, and where for our computer vision models to execute. We then leverage the newest libraries and tools to help identify, process, and most importantly decode QR codes. While it is relatively easy for a human to identify a QR code, there is almost no limit to how many ways they can be obfuscated to machines. The examples we provided above are just a small sample of what we’ve seen in the wild, and bad actors are constantly discovering new methods to make QR codes hard to quickly find and identify, making it a constant cat and mouse game that requires us to regularly update our tools for the trending obfuscation technique.
The second part, analysis of decoded QR codes, goes through all the same treatment we apply to phish and then some. We have engines that deconstruct complex URLs and drill down to the final URL, from redirect to redirect, whether they are automatic or not. Along the way, we scan for malicious attachments and malicious websites and log findings for future detections to cross-reference. If we encounter any files or content that are encrypted or password protected, we leverage another group of engines that attempt to decrypt and unprotect them, so we can identify if there was any obfuscated malicious content. Most importantly, with all of this information, we continuously update our databases with this new data, including the obfuscation of the QR code, to make better assessments of similar attacks that leverage the methods we have documented.
However, even with a well-trained suite of phish detection tools, quite often the malicious content is at the end of a long chain of redirects that prevent automated web crawlers from identifying anything at all, much less malicious content. In between redirects, there might be a hard block that requires human validation, such as a CAPTCHA, which makes it virtually impossible for an automated process to crawl past, and therefore unable to classify any content at all. Or there might be a conditional block with campaign identification requirements, so if anyone is outside the original target’s region or has a web browser and operating system version that doesn’t meet the campaign requirements, they would simply view a benign website, while the target would be exposed to the malicious content. Over the years, we have built tools to identify and pass these validations, so we can determine malicious content that may be there.
However, even with all the technologies we’ve built over the years, there are cases where we aren’t able to easily get to the final content. In those cases, our link reputation machine learning models, which have been trained on multiple years of scanned links and their metadata, have proven to be quite valuable and are easily applied after QR codes are decoded as well. By correlating things like domain metadata, URL structure, URL query strings, and our own historical data sets, we are able to make inferences to protect our customers. We also take a proactive approach and leverage our ML models to tell us where to hunt for QR codes, even if they aren’t immediately obvious, and by scrutinizing domains, sentiment, context, IP addresses, historical use, and social patterns between senders and recipients, Cloudflare identifies and neutralizes potential threats before they can inflict harm.
With the thousands of QR codes we process daily, we see some interesting trends. Notable companies, including Microsoft and DocuSign, have frequently been the subjects of impersonation for quishing attacks. What makes this more confusing for users, and even more likely to scan them, is that these companies actually use QR codes in their legitimate workflows. This further underscores the urgency for organizations to fortify their defenses against this evolving threat.
Below are three examples of the most interesting quish we have found and compared against the real use cases by the respective companies. The QR codes used in these emails have been masked.
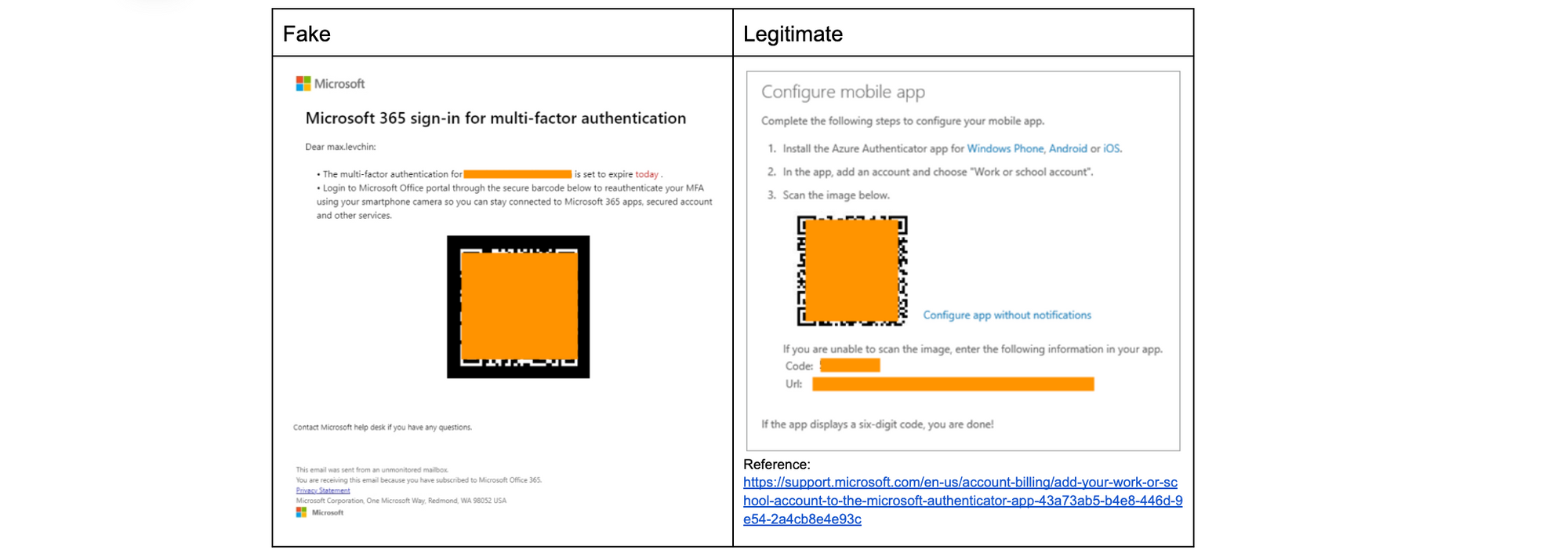
Microsoft uses QR codes as a faster way to complete MFA instead of sending six digit SMS codes to users’ phones that can be delayed and are also considered safer, as SMS MFA can be intercepted through SIM swap attacks. Users would have independently registered their devices and would have previously seen the registration screen on the right, so receiving an email that says they need to re-authenticate doesn’t seem especially odd.
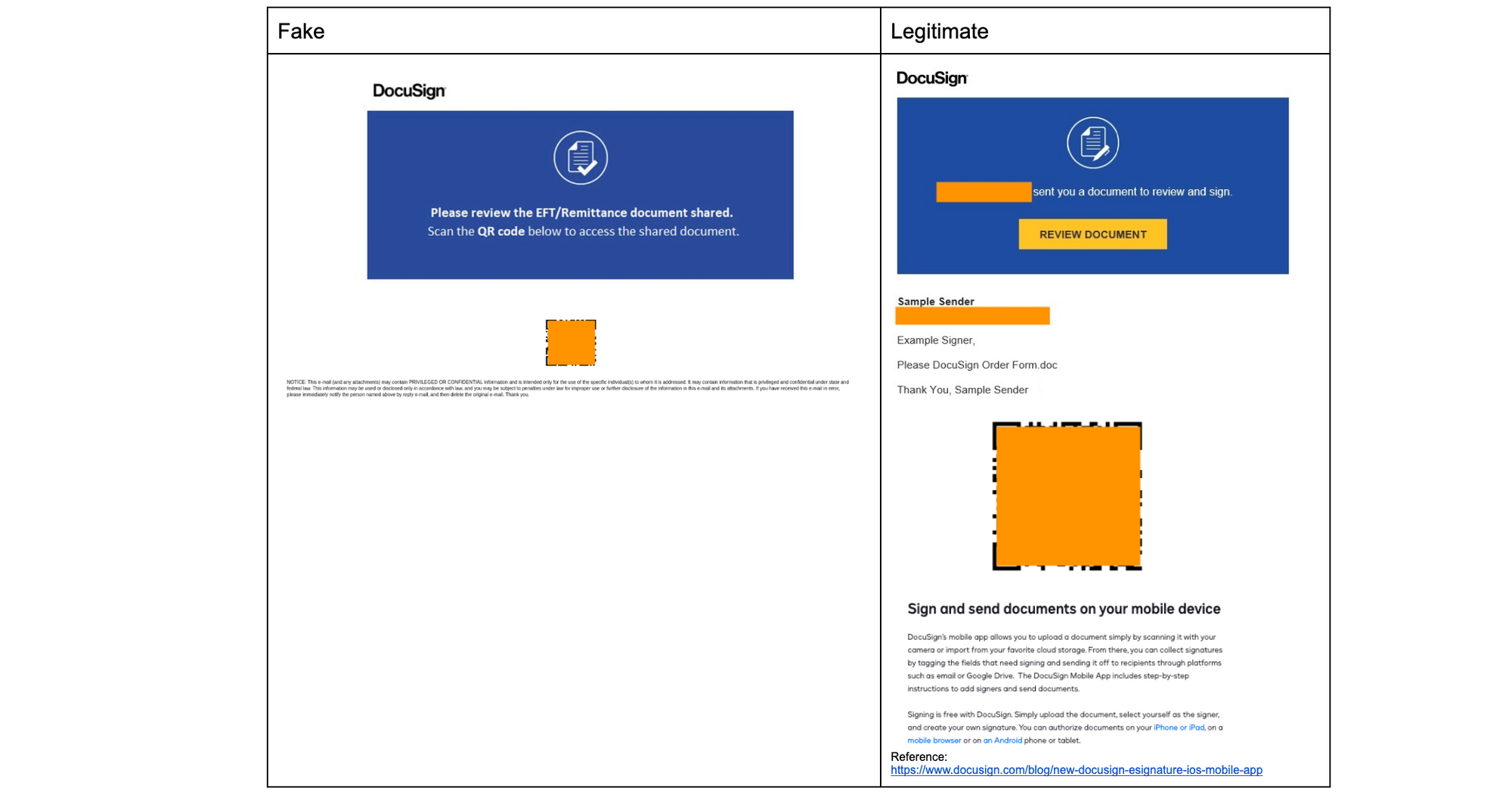
DocuSign uses QR codes to make it easier for users to download their mobile app tosign documents, identity verification via a mobile device to take photos, and supports embedding DocuSign features in third party apps which have their own QR code scanning functionality. The use of QR codes in native DocuSign apps and non-native apps makes it confusing for frequent DocuSign users and not at all peculiar for users that rarely use DocuSign. While the QR code for downloading the DocuSign app is not used in signature requests, to a frequent user, it might just seem like a fast method to open the request in the app they already have downloaded on their mobile device.
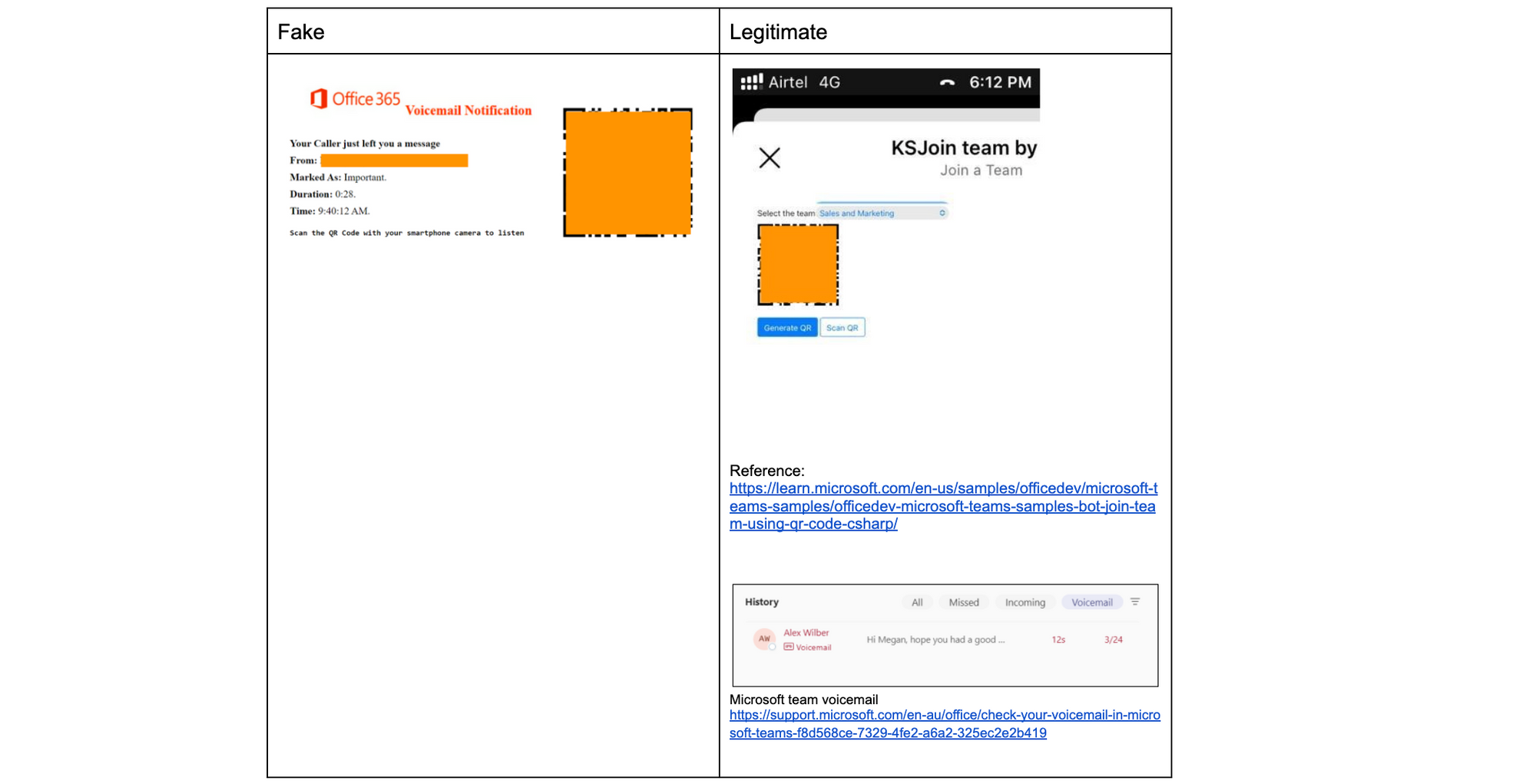
Microsoft uses QR codes for Teams to allow users to quickly join a team via a mobile device, and while Teams doesn’t use QR codes for voicemails, it does have a voicemail feature. The email on the left seems like a reminder to check voicemail in Teams and combines the two real use cases on the right.
As we confront the persistent threat of quishing, it’s crucial for individuals and organizations to be vigilant. While no solution can guarantee 100% protection, collective diligence can significantly reduce the risk, and we encourage collaboration in the fight against quishing.
If you are already a Cloud Email Security customer, we remind you to submit instances of quish from within our portal to help stop current threats and enhance the capabilities of future machine learning models, leading to more proactive defense strategies. If you aren’t a customer, you can still submit original quish samples as an attachment in EML format to [email protected], and remember to leverage your email security provider’s submission process to inform them of these quishing vectors as well.
The battle against quishing is ongoing, requiring continuous innovation and collaboration. To support submissions of quish, we are developing new methods for customers to provide targeted feedback to our models and also adding additional transparency to our metrics to facilitate tracking a variety of vectors, including quish.
Post Syndicated from Lara Sunday original https://blog.rapid7.com/2024/04/17/enforce-and-report-on-pci-dss-v4-compliance-with-rapid7/

The PCI Security Standards Council (PCI SSC) is a global forum that connects stakeholders from the payments and payment processing industries to craft and facilitate adoption of data security standards and relevant resources that enable safe payments worldwide.
According to the PCI SSC website, “PCI Security Standards are developed specifically to protect payment account data throughout the payment lifecycle and to enable technology solutions that devalue this data and remove the incentive for criminals to steal it. They include standards for merchants, service providers, and financial institutions on security practices, technologies and processes, and standards for developers and vendors for creating secure payment products and solutions.”
Perhaps the most recognizable standard from PCI, their Data Security Standard (PCI DSS), is a global standard that provides a baseline of technical and operational requirements designed to protect account data. In March 2022, PCI SSC published version v4.0 of the standard, which replaces version v3.2.1. The updated version addresses emerging threats and technologies and enables innovative methods to combat new threats. This post will cover the changes to the standard that came with version 4.0 along with a high-level overview of how Rapid7 helps teams ensure their cloud-based applications can effectively implement and enforce compliance.
So, why are we talking about the new standard nearly two years after it was published? That’s because when the standard was published there was a two year transition period for organizations to adopt the new version and implement required changes that came with v4.0. During this transition period, organizations were given the option to assess against either PCI DSS v4.0 or PCI DSS v3.2.1.
For those that haven’t yet made the jump, the time is now This is because the transition period concluded on March 31, 2024, at which time version 3.2.1 was retired and organizations seeking PCI DSS certification will need to adhere to the new requirements and best practices. Important to note, there are some requirements that have been “future-dated.” For those requirements, organizations have been granted another full year, with those updates being required by March 31, 2025.
The changes were driven by direct feedback from organizations across the global payments industry. According to PCI, more than 200 organizations provided feedback to ensure the standard continues to meet the complex, ever-changing landscape of payment security.
A primary goal for PCI DSS v4.0 was to provide greater flexibility for organizations in how they can achieve their security objectives. PCI DSS v4.0 introduces a new method – known as the Customized Approach – by which organizations can implement and validate PCI DSS controls Previously, organizations had the option of implementing Compensating controls, however these are only applicable when a situation arises whereby there is a constraint – such as legacy systems or processes – impacting the ability to meet a requirement.
PCI DSS v4.0 now provides organizations the means to choose to meet a requirement leveraging other means than the stated requirement. Requirement 12.3.2 and Appendices D and E outline the customized approach and how to apply it. To support customers, Rapid7’s new PCI DSS v4.0 compliance pack provides a greater number of insights than in previous iterations. This should lead to increased visibility and refinement in the process of choosing to mitigate and manage requirements.
Alongside the customized approach concept, one of the most significant updates is the introduction of targeted risk analysis (TRA). TRAallows organizations to assess and respond to risks in the context of an organization’s specific operational environment. The PCI council has published guidance “PCI DSS v4 x: Targeted Risk Analysis Guidance” that outlines the two types of TRAs that an entity can employ regarding frequency of performing a given control and the second addressing any PCI DSS requirement for when an entity utilizes a customized approach.
To assist in understanding and having a consolidated view of security risks in their cloud environments, Rapid7 customers can leverage InsightCloudSec Layered Context and the recently introduced Risk Score feature. This feature combines a variety of risk signals, assigning a higher risk score to resources that suffer from toxic combinations or multiple risk vectors.Risk score holistically analyzes the risks that compound and increase the likelihood or impact of compromise.
PCI DSS v4.0 has provided improvements to the self-assessment (SAQ) document and to the Report on Compliance (RoC) template, increasing alignment between them and the information summarized in an Attestation of Compliance to support organizations in their efforts when self-attesting or working with assessors to increase transparency and granularity.
PCI DSS v4.0 has brought with it a range of new requirements to address emerging threats. With modernization of network security controls, explicit guidance on cardholder data protections, and process maturity, the standard focuses on establishing sustainable controls and governance. While there are quite a few updates – which you can find detailed here on the summary of changes – let’s highlight a few of particular importance:
These controls place role-based access control, configuration management, risk analysis and continuous monitoring as foundations, assisting organizations to mature and achieve their security objectives. Rapid7 can help with implementing and enforcing these new controls, with a host of solutions that offer PCI-related support – all of which have been updated to align with these new requirements.
InsightCloudSec allows security teams to establish, continuously measure, and illustrate compliance against organizational policies. This is accomplished via compliance packs, which are sets of checks that can be used to continuously assess your entire cloud environment – whether single or multi-cloud. The platform comes out of the box with dozens of compliance packs, including a dedicated pack for the PCI DSS v4.0.
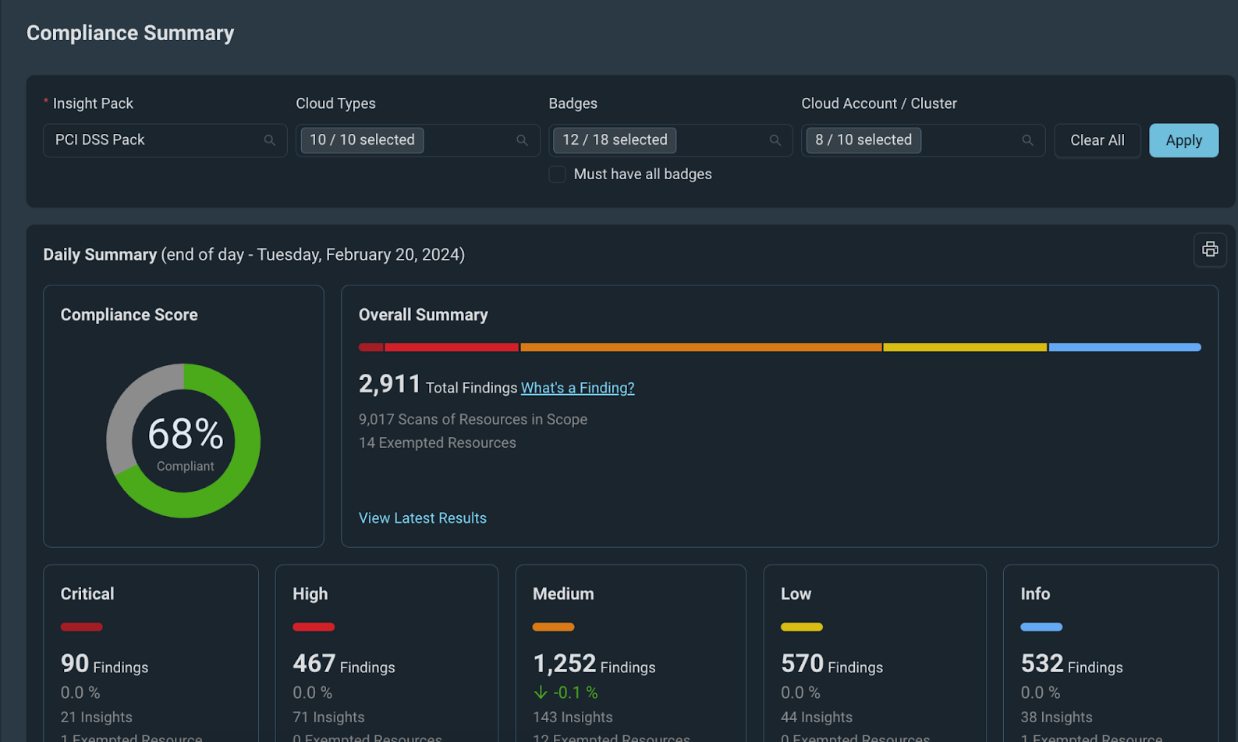
InsightCloudSec assesses your cloud environments in real-time for compliance with the requirements and best practices outlined by PCI It also enables teams to identify, assess, and act on noncompliant resources when misconfigurations are detected. If you so choose, you can make use of the platform’s native, no-code automation to remediate the issue the moment it’s detected, whether that means alerting relevant resource owners, adjusting the configuration or permissions directly or even deleting the non-compliant resource altogether without any human intervention. Check out the demo to learn more about how InsightCloudSec helps continuously and automatically enforce cloud security standards.
InsightAppSec also enables measurement against PCI v4.0 requirements to help you obtain PCI compliance. It allows users to create a PCI v4.0 report to help prepare for an audit, assessment or a questionnaire around PCI compliance. The PCI report gives you the ability to uncover potential issues that will affect the outcome or any of these exercises. Crucially, the report allows you to take action and secure critical vulnerabilities on any assets that deal with payment card data. PCI compliance auditing comes out of the box and is simple to generate once you have completed a scan against which to run the report.
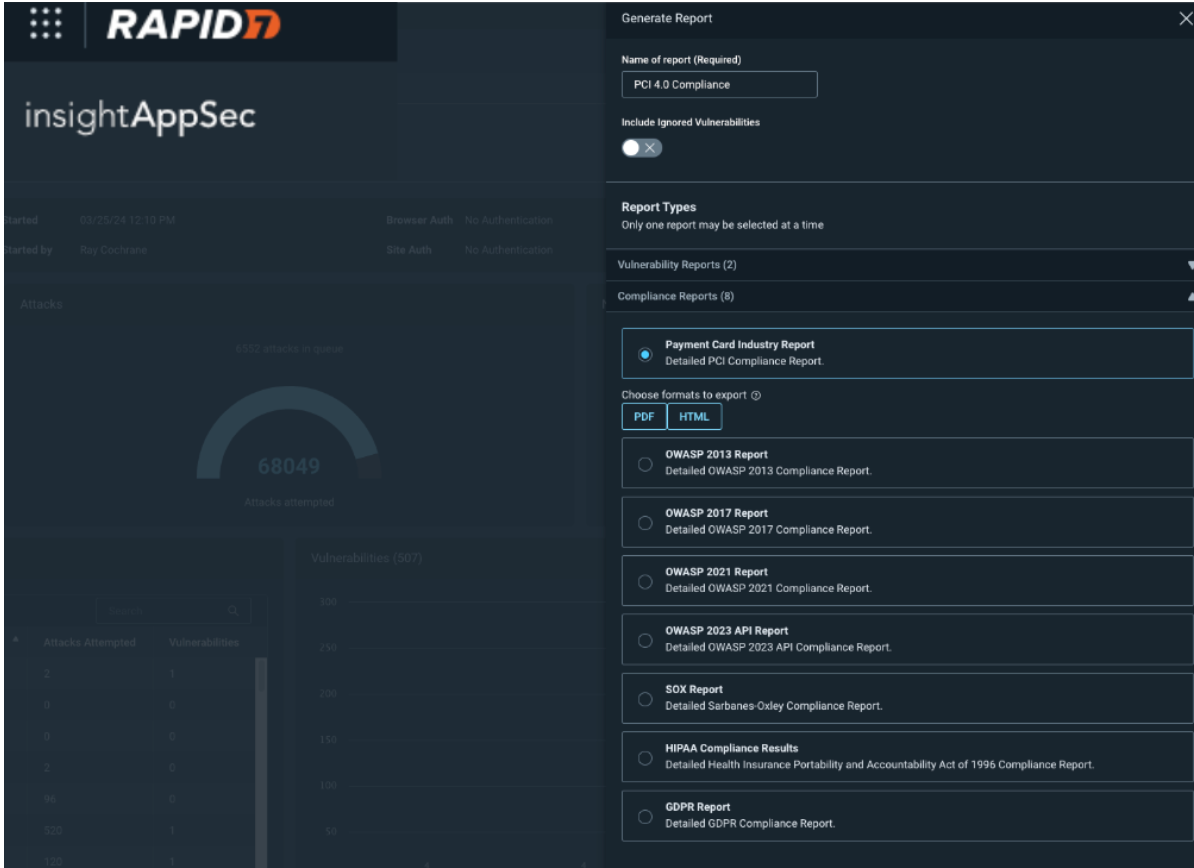
InsightAppSec achieves this coverage by cross referencing and then mapping our suite of 100+ attack modules against PCI requirements, identifying which attacks are relevant to particular requirements and then attempting to exploit your application with those attacks to obtain areas where your application may be vulnerable. Those vulnerabilities are then packaged up in the PCI 4.0 report where you can see vulnerabilities listed by PCI requirements This provides you with crucial insights into any vulnerabilities you may have as well as enabling management of those vulnerabilities in a simplistic format.
For InsightVM customers, an important change in the revision is the need to perform authenticated internal vulnerability scans for requirement 11.3.1.2. Previous versions of the standard allowed for internal scanning without the use of credentials, which is no longer sufficient. For more details see this blog post.
Rapid7 provides a wide array of solutions to assist you in your compliance and governance efforts. Contact a member of our team to learn more about any of these capabilities or sign up for a free trial.
Post Syndicated from daroc original https://lwn.net/Articles/970169/
Security updates have been issued by Debian (apache2 and cockpit), Fedora (firefox, kernel, mbedtls, python-cbor2, wireshark, and yyjson), Mageia (nghttp2), Red Hat (kernel, kernel-rt, opencryptoki, pcs, shim, squid, and squid:4), Slackware (firefox), SUSE (emacs, firefox, and kernel), and Ubuntu (linux-aws, linux-aws-5.15, linux-aws-6.5, linux-raspi, and linux-iot).
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=NuUtQ2AcQ0g
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/04/using-ai-generated-legislative-amendments-as-a-delaying-technique.html
Canadian legislators proposed 19,600 amendments—almost certainly AI-generated—to a bill in an attempt to delay its adoption.
I wrote about many different legislative delaying tactics in A Hacker’s Mind, but this is a new one.
Post Syndicated from VassilKendov original https://kendov.com/%D0%BA%D0%B0%D0%BA-%D0%B4%D0%B0-%D1%81%D0%B5-%D1%80%D0%B5%D1%88%D0%B8-%D0%BF%D1%80%D0%BE%D0%B1%D0%BB%D0%B5%D0%BC%D1%8A%D1%82-%D1%81-%D0%B2%D0%BE%D0%B4%D0%B0%D1%82%D0%B0-%D0%B2-%D1%81-%D0%B1%D1%80/
 Как да се реши проблемът с водата в Брестовица
Как да се реши проблемът с водата в Брестовица
След 4 одини проблеми с водата, най-накрая местните жители на Брестовица напипаха правилния начин за решаването на този пробем и той е ПРОТЕСТИ.
Ако обаче не знаем какъв е зародиша на проблема, да се скъсаме от протести, решение няма да има. Затова ще опиша основните точки, които имат отношение към решаването на проблема с водата на Брестовица.
Става въпрос за пари
Тук всички ще отбележат, че е много ясно, но да Ви кажа за какви конкретно пари става въпрос.
Без да съм хидроинженер, мога доста точно да предположа, че на село като Бретовица, подмяната на тръбите би струвало около 30 милиона лева. Поне на подобни села в други общини на които съм съдействал за финансиане беше толкова. Брестовица е доста по-голямо и затова съм завишил, но предполагам неоходимата сума е близка до тази.

Откъде може да дойдат тези пари?
Имайте предвид, че бюджета на Община Родопи е 52 млн лева. Тук влизат всички раходи, включтелно новата служебна кола на кмета на общината, новите фотоапарати за отразяване на ПР акциите, но също така и заплатите на учителите и закуските на деата в училище. Това е цялата сума.
Отделно предизборно беше теглен кредит от 7 млн лева.
Акцентирам на кредита, тъйкато той се прибавя към съществуващия вече такъв, което отрязва най-естествената възможност за финансиране на подмяната на тръбите на Брестовица, а именно финансиране чрез кредит.
Искам да припомня, че голяма част от кредита от 7 млн беше похарчен за други села или за разходи, покривани безплатно по Програмата за възстановяване и устойчивост. Нали помните каква еуфория и гордост настана след смяната на осветлението на селата? Беше отразено доста добре във ФБ и на страницата на всяко село от Община Родопи. Е тозно този разход нямаше смисъл да се прави, тъйкато се покриваха безплатно от въпросната Програма за възстановяване и устойчивост. И тук идва следващия проблем.
Общината няма капацитет да усвоява средства по програми и европейски проекти.
Като казвам няма капацитет, разбирайте интелектуален. Демонстрирах го достатъчно добре с горния пример с осветлението. Вместо администрацията да седне и да напише проект за финансиране, те теглят кредит. Както се казва – Те толкова си могат!
Ако поглднете отчета за бюджета ще видите, че миналата година има заложени 500 000 лева приходи от европейски проекти и 0 лева изпълнени. Това значи, че няма нито един проект.
Друг е въпросът, че 500 000 приходи от проекти е нищо за една община. Примерно осветлението на омразния гр. Пловдив в който всички от администрацията на Община Родопи се надпреварват да купуват апартаменти, има улично осветление изградено по Норвежката програма. Не знам дали в нашата община са чували за тази програма, но поне в отчетите и плановете за бюджета не се виждат такива планове.
Да обобщя до тук
След изтегления и рададен на други села предизборно кредит, Община Родопи не може да изтегли нов за водоснабдителната мрежа на Брестовица.
От досегашната работа и финансовите отчети е видно, че по програма средства също няма как да бъдат отпуснати. И това вече 4 години.
Моля използвайте приложената форма за записване на час за среща
[contact-form-7]
Средства от държавния бюджет
Предвид това, че предходните 2 най естествени начини за финансиране са недостъпни за Община Родопи, помощ от централния бюджет явно остава единствения начин на финансиране. Това, което забелязвам обаче в принципа на работа на общинската администрация е кастовия принцип. „Ти не си от нашите и затова за теб няма“ или обратното – „Ти си гласувал за нас, ще видим какво можем да направим“.
На същия принцип стоят нещата и в държавата. Избраме си Бате Бойко и едни фирми печелят. Идват ППДБ и правят чистка в администрацията и назначават свои.
За съжаление този принцип съществува от „време оно“, а в повечето случаи дори работи. Поне докато се се изчерпат парите.
В нашия случай парите са изчерпани. Борим се да влизаме в монетарния съюз и бюджетния дефецит е много важен, а пари за други разходи НЯМА.
Ще падат ли цените на имотите през 2024?
Защо ви ги пиша тези работи?
Защото населението на Община Родопи си избра кмет от БСП. Няма лошо, но когато стане въпрос за пари, а принципа в държавното управление е същия като в нашата община, то тогав ана кой кмет да дадеш 30 милиона? На кмета на БСП или на твоя си кмет, който е избран от твоята партия?
Пак казвам – не се сърдете на управляващите. Те работят по същия начин както нашата администрация. За едни села има, за други няма. Брестовица е селото за което вече 4 години няма. Сега кметицата е „на г-н Михайлов“, но пари пак няма, ЗАЩОТО ВЕЧЕ ВСИЧКИ КМЕТОВЕ СА НА Г-Н МИХАЙЛОВ.
А баницата е малка. Не става да се разпредели, пък и на кредит сме яли досега.
Въпреки всичко решение има
И хората от Брестовица го намират. От моя опит с администрацията на Родопи съм разбрал едно – приесняват се единствено от обединени групи хора и лош ПР. Ако има начин нещо да се случи, то тов аще бъде само следствие на протести. Като не Ви чува кмета Михайлов, прескочете го. Протестирайте пред Областната управа. Там не са от БСП и ще имат изгода да се намесят. Пишете на Областния, идват избори това ще му е дивидент. Викайте повече телевизии, пишете във ФБ, идвайте на заседания на общинския съвет и поставяйте исканията си.
Говорете със съседите си, обединете се и изисквайте. Пари в бюджета както казах няма, няма и скоро да има. Този път с „мазнене“ във Фейсбук няма да стане. Ясно е, че много хора свикнаха на подаяния от кмета, но идва момента в който трябва да изискваш полагащото ти се.
Обединете се с други хора със същите проблеми в Община Родопи. Примерно комитета в Белащица. Хората и до референдум стигнаха. Тогава много други им се смяха, а общината се опита да го осуети, но сега става въпрос за вашите деца.
Какво да очакват хората с ипотеки след въвеждането на еврото
Нма да стане от един път, но няма друг начин. Пасивността не води до нищо добро. Положението е такова, че с ръкопляскане на ПР постовете на г-н Михайлов във ФБ няма да се случи. “Пари си трябват”, а парите следват проектите или интересите. След последното гласуване, интересът към вас явно е спаднал. Щом от 4 години е този проблем и пак гласуваме за още от същото, значи проблем няма.
Идват избори, използвайте ги. Ако ли не, заредете се с още 4 години търпение. За който трябва вода има достатъчно.
Васил Кендов – финансист
Моля използвайте приложената форма за записване на час за среща
[contact-form-7]
The post Как да се реши проблемът с водата в с. Брестовица appeared first on Kendov.com.
Post Syndicated from Светла Енчева original https://www.toest.bg/sluchayat-na-sudiya-vladislava-tsarigradska-ili-kakvo-oznachava-da-nyama-pravosudie/

Широко разпространено в България (а и в други страни) е убеждението, че увеличаването на наказанията е превенция срещу престъпността. Затова след всяко тежко престъпление, станало водеща тема в новинарските емисии, се чуват гласове за промяна на Наказателния кодекс (НК) и по-тежки присъди. Някои изразяват носталгия по законите от времето на хан Крум, когато за кражба са се рязали крайници, а националпопулисти като председателя на „Възраждане“ Костадин Костадинов дори искат връщане на смъртното наказание.
Проблемите с това популярно убеждение са два. Първо, то не почива на реални факти. В изследването на историка Стефан Иванов „От кражби до убийства. Криминалните престъпления в България (1944–1989 г.)“ например се доказва, че въпреки ефективното изпълнение на смъртни присъди, умишлените убийства по времето на социализма са дори повече, отколкото в посттоталитарния период.
Второ, въпреки това въпросното убеждение стои в основата на не една и две законови промени. Не поради некадърност на законотворците, а от чист популизъм, достигащ шизофренни висини. Например през 2020 г. отзвукът от катастрофата, при която загина журналистът Милен Цветков, стана повод ГЕРБ да предложи увеличаване на наказанията в НК за шофьори, употребили алкохол или наркотици. Две седмици по-късно партията представи концепция за наказателната политика за пет години напред, в която се казва: „Статистиката ясно сочи, че повишаването на размерите на наказанията не води до намаляване на престъпността.“
Към тези проблеми се прибавя и трети, местен – правосъдната система в България не изпълнява основната си функция да гарантира справедливо правосъдие в съответствие със законите. В такъв случай какво значение има колко строги са те? След като някои извършители на престъпления няма да бъдат осъдени, каквото и да са направили, а някои жертви на престъпления няма да получат не само справедливост, а дори и защита.
Ако правосъдната система не е в състояние да защити един съдия, който просто се опитва да работи както трябва, тя не може да защити никого. Пример за такъв съдия e Владислава Цариградска. Одисеята си тя обобщава в писмо, което на 12 април изпраща до членовете на Висшия съдебен съвет и председателката на Върховния касационен съд, както и до медии. Татяна Ваксберг го обобщава:
Съдийката твърди, че я заплашват със смърт, а хората, които трябва да я защитят, все едно не я чуват. И така пет години.
В този период от пет години, в който се сменят трима главни прокурори, Цариградска работи в Районния съд в Луковит, а след това – в Окръжния съд в Плевен. Първоначално я заплашват Мартин Божанов, известен като Нотариуса, и хора около него, защото тя отказва да решава дела така, както той иска, и да си направи отвод по тях. Божанов дори отправя заплахи към нея в съдебната зала.
Следва компроматна кампания срещу Цариградска първоначално в ПИК, но тъй като съдийката продължава да не се подчинява, компроматите се множат и из други от „пеевските“ медии. Същевременно тя получава и заплахи. През 2020 г. е под охрана за 6 месеца, но охраната си тръгва, а заплахите постоянстват. Цариградска търси правата си в съда, не я държат в течение по хода на делата ѝ, но пък сайтът „Афера“ публикува части от нейни показания – значи се е сдобил с тях от вътрешен на съда човек.
След убийството на Мартин Божанов заплахите не престават, а стават все повече (над 70) и все по-страшни – че ако не „млъкне“, ще ѝ изкормят гениталиите, че съпругът и трите ѝ деца „ще са с бетонирани крака на дъното на язовира“ и т.н. Полицията задържа клошар, който беше обвинен, че е изпращал анонимни заплахи и до различни институции. Тази версия не изглежда реалистична – най-малкото заради упоритата слепота на правосъдната система за случая на Цариградска. А и например защото предупреждение „да се кротне“ идва също от човек на име Веселин Иванов – бивш служител в Дирекция „Публична комуникация“ при главния прокурор.
От средата на февруари 2024 г. Цариградска отново е с охрана, но след смяната на правителството отговорна за охраната в Министерството на правосъдието става представителка на прокуратурата. А прокуратурата години наред упорито отказва да разследва заплахите срещу съдийката. В писмото си Цариградска иска мерки, които да осигурят защита и правото на честно правосъдие както за нея, така и за всеки съдия, който е в подобна ситуация.
Съчетанието от компроматна война и излагане на риск на „непослушни“ съдии не е прецедент, независимо на колко висока позиция се намират те. Лозан Панов, който беше председател на Върховния касационен съд между 2015 и 2020 г., беше редовен обект на компромати в „пеевските“ медии. В писмото си Владислава Цариградска припомня протеста срещу него през 2017 г., който се запомни с одраните агнешки главички. След години Любена Павлова – тогава бъдеща, а днес бивша съпруга на Петьо Петров, известен като Еврото – призна, че е организирала протеста по поръчка на Еврото, чието име нашумя покрай аферата „Осемте джуджета“.
Цариградска припомня и част от перипетиите на съдия Мирослава Тодорова. През 2021 г. Европейският съд по правата на човека (ЕСПЧ) осъди България заради дисциплинарни производства срещу съдийката в периода 2011–2012 г. Тя е уволнена през 2012 г., а през 2013 г. е възстановена на работа, но на по-ниска длъжност за една година.
Обвиненията срещу Тодорова са скалъпени, а истинската причина е, че по онова време тя е председателка на Съюза на съдиите в България – неправителствена организация, позволяваща си критични позиции по отношение на правосъдната система. През 2012 г. организацията излиза с остра реакция срещу назначаването на Владимира Янева за председател на Софийския градски съд. На следващия ден Мирослава Тодорова е уволнена.
Затова ЕСПЧ отсъжда, че по отношение на нея е нарушена Европейската конвенция за правата на човека, по силата на която, казано накратко, човек не може да бъде наказван по причини, различни от описаните в закона, по който е наказан. Обвиненията срещу Тодорова са, че бави делата си, но по същество „наложените ѝ санкции са представлявали намеса в упражняването на правото ѝ на свобода на изразяване“.
Янева впрочем също е уволнена през 2015 г. , а после – осъдена условно. Причината е, че е разрешавала незаконно подслушване. Името ѝ беше замесено в редица скандали, свързани с отношенията между политическата власт и прокуратурата – достатъчно е да си спомним за „опраскването“ и „двете каки“.
С това обаче репресиите срещу Мирослава Тодорова от страна на върховете на правосъдната система не престават. През 2019 г. Инспекторатът на Висшия съдебен съвет (ИВСС) публикува онлайн, както всяка година, имотните декларации на съдиите. От всички над 4400 декларации само тази на Тодорова е с незаличени лични данни. Така ЕГН-то, адресът и номерът на личната ѝ карта стават общодостъпни (включително за хората, които е осъдила), както и ЕГН-тата на нейния партньор и непълнолетния ѝ син – в противоречие със Закона за защита на личните данни.
Според ИВСС става въпрос за „пропуск“. Файлът с декларацията на Тодорова е озаглавен NE SE CHISTIIIIIIIIIIIIIIIIII, което навежда на мисълта, че съответната информация умишлено не е изчистена и ИВСС нарочно е изложил съдийката на риск.
Освен че правосъдната система ги репресира, защото имат дързостта да работят съвестно и да имат високи професионални стандарти, между Владислава Цариградска и Мирослава Тодорова има още нещо общо – и двете застават зад принципите на възстановителното правосъдие. Това означава не просто извършителите на престъпление да бъдат наказани, а да имат възможност да компенсират поне отчасти стореното и да помогнат на жертвите.
„Това не значи някой да бъде освободен от отговорност, означава да се намесиш и да подпомогнеш след това съвместното живеене на хората“, разяснява Владислава Цариградска пред „Свободна Европа“. В статия за „Тоест“ съдиите Мирослава Тодорова и Калин Калпакчиев дефинират възстановителното правосъдие като „способ да видиш другия като пълноценно човешко същество“.
Да си представим правосъдна система, в която хората носят отговорност за престъпленията си, но тя не се свежда до изолиране от обществото и издевателства в затвора, а включва сериозни усилия за превъзпитание и възможност за компенсиране на щетите впоследствие.
В тази система Мартин Божанов не е оръжие за кални поръчки, докато стане неудобен и съответно бъде убит, а просто далавераджия и имотен измамник. След като е осъден и излежава намален срок на присъдата си, защото се съгласява да премине през рехабилитационна програма, той се свързва, с посредничеството на медиатор, със свои жертви и им помага. На единия прави ремонт в дома, който преди се е опитал незаконно да отнеме. На друг помага да си отвори кафене, понеже има опит в това. И той е жив и доволен от живота си, и потърпевшите са компенсирани, и правосъдната система си е свършила работата.
Ще си кажете: проблемът не е, че нямаме възстановително правосъдие, а че и това правосъдие, което имаме, не работи справедливо и не успява да гарантира справедливост дори за онези, които го практикуват. Прави сте, знам. От друга страна обаче, ако една система не функционира, може би трябва да бъде конструирана по друг начин. И след като по-строгите наказания така и така не дават желания ефект, защо да не пробваме с добро?
Post Syndicated from Cliff Robinson original https://www.servethehome.com/nvidia-rtx-a400-and-rtx-a1000-lower-cost-single-slot-gpus/
NVIDIA launched two new 50W low profile single-slot GPUs, the NVIDIA RTX A400 and RTX A1000 are lower-end professional GPUs for tight spaces
The post NVIDIA RTX A400 and RTX A1000 Lower-Cost Single Slot GPUs appeared first on ServeTheHome.