Post Syndicated from digiblurDIY original https://www.youtube.com/watch?v=110Ib-bnU9c
Good Morning, Captain
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=hDUEEqJer9k
Кой всъщност спечели изборите
Post Syndicated from Светла Енчева original https://toest.bg/koy-vsushtnost-specheli-izborite/
Резултатите от четвъртите за година и половина избори за народно събрание не бяха неочаквани. Въпреки това следизборното настроение няма как да е приповдигнато. Чака ни поредният период на политическа нестабилност, а само след няколко месеца – по всяка вероятност и нови избори. Всичко това в контекста на война на няколкостотин метра от границите, все по-отчаяни и ескалиращи действия на един диктатор, загубил връзка с реалността, несигурност на доставките на газ, инфлация, поредни бежански вълни, неясни перспективи за влизането на България в еврозоната и шенгенското пространство. В тази ситуация, изглежда, няма кой да поеме политическата отговорност.
Макар на изборите формално да имаше победител, всички участници по един или друг начин загубиха.
Загуби ГЕРБ, защото, макар и да получи почти толкова проценти, колкото „Продължаваме промяната“ на изборите през ноември 2021 г., няма начин да състави правителство, без допълнително да дискредитира и без това спорния си морален интегритет. Или без да се раздели с Бойко Борисов, което би било началото на края на тази по същество лидерска партия. Предложението на Борисов всички партийни лидери „да се дръпнат назад“ би го поставило в ролята на сив кардинал от типа на Ахмед Доган. Ясно е, че дори партиите да приемат призива му, нищо в ГЕРБ не би се променило.
Нищожна е вероятността „Продължаваме промяната“ и „Демократична България“ да се отзоват на поканата на ГЕРБ за „евро-атлантически кабинет“, защото това би ги обезсмислило политически. Те знаят, че зад мантрата за евро-атлантизма се крие желанието на Борисов да остане на власт и да се съхрани клиентелистката структура на партията по места.
Същият Борисов, който:
– е взел активно участие в т.нар. Възродителен процес;
– е бил бодигард на социалистическия диктатор Тодор Живков;
– през 1991 г. предпочел да напусне работата си, за да остане в БКП;
– подари на Путин кученце;
– остави паравоенни пропутински групировки да се вихрят необезспокоявано в България;
– направи всичко по силите си да бетонира енергийната зависимост на България от Русия;
– вложи милиарди държавни пари за тръба, която заобикаля Украйна, знаейки, че от нея България няма полза…
Та същият Борисов днес се вживява в една от многото си роли – на евро-атлантик.
Понеже ПП и ДБ „не ядат доматите с колците“, комай единственият вариант за управление на ГЕРБ би бил в коалиция с ДПС, „Български възход“ и няколко „разсеяни“ депутати от „Възраждане“, които пропуснат да присъстват при гласуването на кабинета. Подобна конфигурация би била „самоубийствена“ за всички участници, смята социологът Живко Георгиев. Според него ГЕРБ „е токсична за всички без ДПС, но пък ДПС е токсично за всички, в това число и за ГЕРБ“.
Вариантът „експертно правителство“ също е спорен. Строго погледнато, експертни правителства няма – зад всяко правителство стоят определени политики, за които следва да се поеме политическа отговорност. А зад българските експертни правителства стои все ДПС. „Експертни“ бяха правителствата на Любен Беров и Пламен Орешарски. Днес никой не ги споменава с добро.
Безспорно загуби „Продължаваме промяната“, която не удържа заявката си за изборна победа, въпреки че получи повече, отколкото проучванията ѝ отреждаха. И която няма полезен ход, ако получи втория мандат за съставянето на правителство, защото не може да сформира коалиционно мнозинство. Именно в този контекст следва да се интерпретира и отказът за обща парламентарна група с ДБ.
За загубата на партията допринесоха не толкова недостатъчните успехи на коалиционното правителство на Кирил Петков в контекста на всеобщата кризисна ситуация, колкото последователното очерняне на ПП от страна на медии, ГЕРБ и президента, както и грешки на самата партия по време на кампанията. Ето някои от предварителните заключения на Международната мисия за наблюдение на изборите за медийното отразяване на предизборната кампания:
В уебсайтовете на няколко ненадеждни медии, свързани със страници във Facebook и канали в Telegram, се разпространяваше заблуждаваща информация, имаща за цел главно да дискредитира ПП и ДБ и да накърни информационната среда. […] Информационните бюлетини в най-гледаното време на ефирните медии бяха съсредоточени върху решенията на правителството и президента, като от време на време се споменаваха ГЕРБ, БСП, ДПС и ПП във връзка с работата им в предходните кабинети. Отразяването на БСП и ПП беше главно с негативен тон.
Що се отнася до грешките на ПП, те са както в поведението на лидерите ѝ, така и в таргетирането на кампанията. Пример за първия тип грешка е начинът, по който Кирил Петков аргументира участието си в предизборен дебат на bTV. Думите му прозвучаха като изсмукано от пръстите оправдание. Това, заедно с драматичната реакция на представителите на ГЕРБ и неумерено агресивното поведение на водещата на дебата Мария Цънцарова, затвърди впечатлението, че не е в реда на нещата партиен лидер да участва в дебат.
Що се отнася до таргетирането, кампанията на ПП се целеше в три основни групи – антикорупционно настроени, пенсионери и млади хора, предимно негласуващи. Първите се опитваше да привлече с изтъкване на усилията си за спиране на корупционни канали, вторите – с напомняне как са увеличили пенсиите, третите – със симпатично, леко „хулиганско“ поведение, с концерт и особено с изявите на „депутата Христо“ (Христо Петров, известен с рапърския си прякор Ицо Хазарта). Проблемът е, че първите две групи са и типичен електорат на ДБ и БСП и привличайки част от него, ПП „обезкървява“ потенциалните си коалиционни партньори. В същото време партията на Кирил Петков и Асен Василев не зае категорична позиция за войната в Украйна, с което може би отблъсна повече избиратели, отколкото привлече.
ДПС се класира като трета политическа сила от общо седем, преминали 4-процентовата бариера, което е безспорно добро постижение. Проблемът е обаче в споменатата от Живко Георгиев „токсичност“ на партията. ДПС отдавна не се асоциира с турския етнос на огромната част от избирателите си, а с корупция, клиентелизъм и скрити лостове за влияние в институциите и медиите. За партията с почетен председател Ахмед Доган остават следните алтернативи – да бъде групата на „прокажените“, които никой не иска; да влезе в управлението, с което да повлече доверието към другите партии в него надолу; или да продължава да „дърпа конците зад кулисите“, както прави и сега.
На пръв поглед „Възраждане“ определено печели. Продължава тенденцията на увеличаваща се електорална подкрепа за партията, за потенциала на която „Тоест“ обръща внимание от години (например тук, тук и тук). Само че партията на Костадин Костадинов трудно може да капитализира политически възхода си. Може да го капитализира най-вече финансово, примерно с още някоя луксозна къща за председателя си. Радикалният вот в България обаче си има граница и „Възраждане“ е на път да я достигне.
Още повече че войната в Украйна ескалира по такъв начин, че вече е трудно да си путинофил – дори доскорошни верни съюзници на Путин вече се дистанцират от него. А и темата за ваксините се поизтърка. Костадинов е изобретателен и все ще намери нещо ново, чрез което да канализира омраза за политическа употреба. Но това ще е до време.
Не е изключено и „Възраждане“ да влезе в ролята на „златния пръст“ (ала Волен Сидеров), осигурявайки мнозинство за някое управление. В такъв случай я чака съдбата на „Атака“, която на последните избори получи 0,3%, или 7605 гласа. За сравнение: през 2013 г. за партията гласуваха 258 481 души, а на изборите само година по-късно подкрепата за нея се стопи почти наполовина. Докато се стопи толкова подкрепата за партията на Костадинов обаче, ще минат още няколко години от живота ни, стига да сме живи и здрави.
За разлика от „Възраждане“, БСП еднозначно губи. Най-старата действаща партия у нас е сведена до пета политическа сила. Тенденцията на намаляваща електорална подкрепа за „Столетницата“ се запазва, откакто Корнелия Нинова я оглавява. БСП отказва да се превърне в „модерна лява партия“ от европейски тип, към каквато се стремеше, поне на декларативно равнище, бившият ѝ председател Сергей Станишев.
Електоратът на БСП, значителна част от който е на преклонна възраст, оредява все повече по демографски причини. Някои от социално настроените избиратели мигрират към ПП. „Фобският“ електорат, когото Нинова плаши с Истанбулската конвенция, се чувства по-комфортно при „Възраждане“. А путинофилите могат да избират – освен БСП, над чиято председателка тегне „клеймото“, че е подписвала разрешения за износ на оръжие, което в последна сметка е отишло в Украйна – между партията на Костадинов и „Български възход“.
На последните избори „Демократична България“ получи близо 20 000 гласа повече, отколкото през ноември 2021 г. И все пак коалицията се класира на шесто място и сред парламентарно представените партии не е изпреварена само от „Български възход“. А това трудно може да се нарече успех, особено за политическа формация, имала свои министри в предишното редовно правителство.
Всъщност ДБ така и не може да определи кой е нейният електорат, освен тесен слой високообразовани хора в големите градове, преобладаващо в София. Сред тях най-адекватни са посланията на коалицията за програмистите, защото тъкмо те най биха се радвали да могат да общуват с администрацията „само с един клик“ и имат интерес максималният осигурителен праг да е по-нисък.
Опитите на ДБ да „слезе до народа“ са понякога нелепи до конфузност – колкото нелепи са родители, които искат да „стопят леда“ с децата си тийнейджъри, като отиват на купона им и имитират стила и поведението им. Една политическа сила може да разшири електоралната си база, ако отправи адекватни послания за по-широки групи от населението, а не ако нейни кандидати вземат рецепти за туршия от баби от провинцията.
Що се отнася до предизборния слоган „Довери се на разума“, той стана обект на остри критики дори от избиратели на партията и вероятно се харесва само на тези, които са го измислили, и на тесния кръг около тях. Както каза един избирател на ДБ в частен разговор: „Какво искат да ми кажат с това послание, че съм тъп ли?“
„Български възход“ прескочи бариерата за влизане в парламента, което на пръв поглед си е успех. Вероятно това стана, защото някои гласоподаватели асоциират председателя на партията Стефан Янев с президента Румен Радев. Въпреки че последният се разграничи от назначения от него бивш служебен премиер, след като той беше отстранен като военен министър от правителството на Кирил Петков заради пропутинските си позиции.
На Янев много му се участва в управлението – по собственото си признание е готов на всякаква коалиция. Може да се окаже обаче, че няма с кого. Междувременно с публичните си изяви Янев създава впечатлението, че е много объркан човек, пък макар и генерал. След още някой бисер като „защо тръбата е цяла“ току-виж парламентарното битие на „Български възход“ се окаже по-кратко и от това на ИТН.
„Има такъв народ“ загуби, защото не успя да стигне заветните 4%. Или може би не загуби, защото всъщност постигна целта си да дискредитира парламентарната система. Отломките от разрушенията, които нанесе, още не позволяват да има работещо управление.
Може би не загуби и „Изправи се, България“ на Мая Манолова, защото с 1,01% от гласовете си осигури субсидия. И ще получава пари, без да се налага да прави политика.
ВМРО обаче безусловно загуби, защото с 0,81% си остана и без субсидията.
Ако някой все пак спечели от изборите, това е президентът Румен Радев.
По време на предизборната кампания Радев не демонстрира подкрепа към никоя партия или коалиция, но пък не спестяваше критиките си към ПП и БСП, а за кусурите на неотдавнашния си главен враг – ГЕРБ – оставаше сляп.
Тъй като вероятността за работещ редовен кабинет не е голяма, изглежда, Радев за пети път ще има възможността да направи служебно правителство – след кабинета на Огнян Герджиков, двата на Стефан Янев и последния на Гълъб Донев. Така Радев ще продължи да провежда политика според собствените си разбирания, което означава, че в контекста на войната на Русия срещу Украйна България все така няма да заема ясна позиция и ще възпроизвежда пропутински послания, макар декларативно да се обявява за ЕС и НАТО.
Поредното служебно правителство, на свой ред, допълнително ще подкопае доверието в парламентарната демокрация и ще засили настроенията за „силна ръка“ и „президентска република“. Ако подкрепата към Радев, която заради войната е намаляла, не се срине напълно, все повече хора ще си зададат логичния въпрос – след като страната така и така се управлява, аз защо да гласувам? А пътят от този въпрос до отказа от демокрацията, която за българското общество все още е важна, е кратък.
Ала както гласи горчивият хумор по повод на „частичната мобилизация“ в Русия – когато не се интересуваш от политика, рано или късно получаваш повиквателно.
Заглавна снимка: Giorgio Trovato / Unsplash
State of the Open Home 2022
Post Syndicated from Home Assistant original https://www.youtube.com/watch?v=D936T1Ze8-4
Archimedes Principle
Post Syndicated from original https://xkcd.com/2681/

THG’s Tank Duel
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=6V6P7FpUcN4
[$] A discussion on printk()
Post Syndicated from original https://lwn.net/Articles/909980/
The kernel’s print function, printk(), has been the target of
numerous improvement efforts over the years for a
variety of reasons. One persistent problem with printk() has been
that its latency is unacceptably high for the realtime Linux kernel; at
this point, printk() represents the last piece needing changes
before the
RT_PREEMPT patches can be fully merged. So there have been efforts
to rework printk() for latency and lots of other reasons, but
those have not made it into the mainline; a recent discussion at
the 2022 Linux Plumbers Conference (LPC)
seems to have paved the way for new solution to land in the mainline before
too long.
Tiago Forte | The 4 Areas You Need to Know to Organize Your Life #shorts
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=fUe8NdGYYR0
Manage your Amazon QuickSight datasets more efficiently with the new user interface
Post Syndicated from Arturo Duarte original https://aws.amazon.com/blogs/big-data/manage-your-amazon-quicksight-datasets-more-efficiently-with-the-new-user-interface/
Amazon QuickSight has launched a new user interface for dataset management. Previously, the dataset management experience was a popup dialog modal with limited space, and all functionality was displayed in this one small modal. The new dataset management experience replaces the existing popup dialog with a full-page experience, providing a clearer breakdown of a dataset’s properties.
In this post, we walk through the end-to-end dataset management user experience.
Access the new UI
To get started, choose Datasets in the navigation pane on the QuickSight console, and choose any dataset that you want to manage.
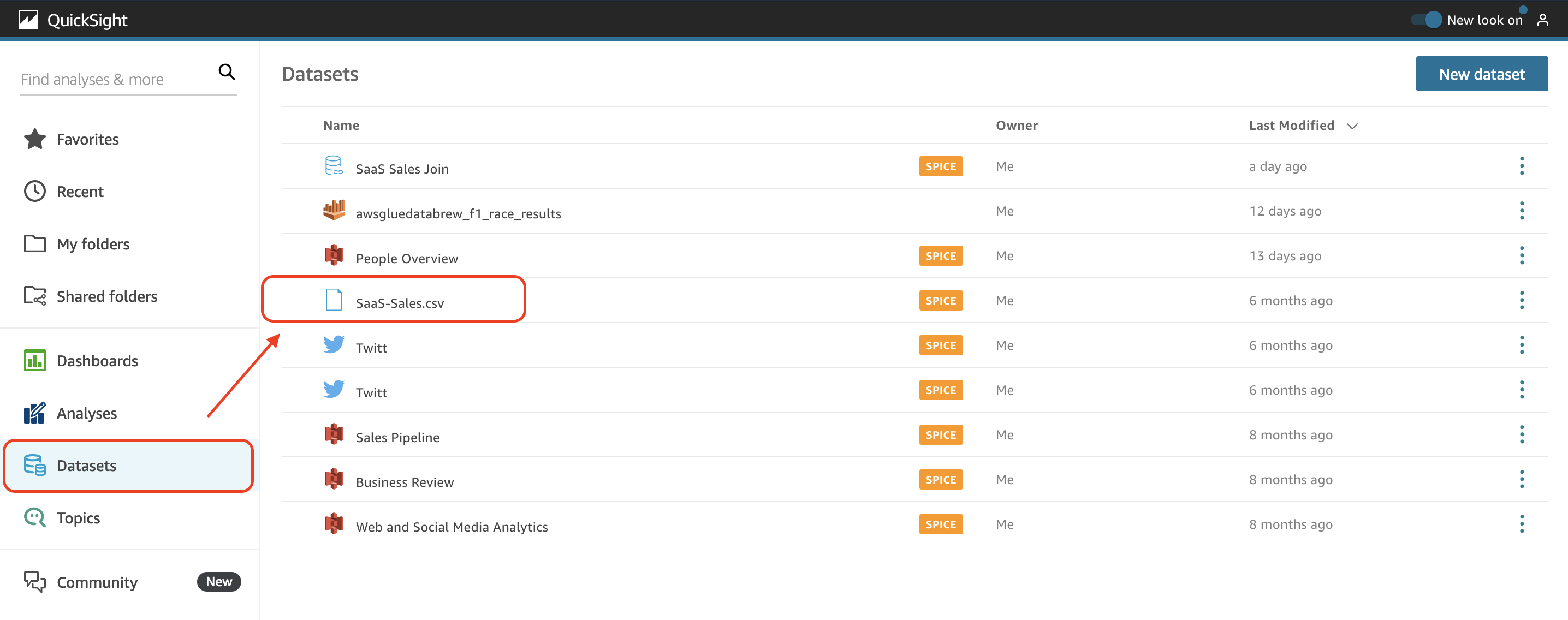
When you choose a dataset, you see the full-page dataset management UI. This new UI is divided into four main tabs: Summary, Refresh, Permissions, and Usage.
Use case overview
Let’s consider a fictional company, AnyCompany. They have used QuickSight for a long time and now have a large number of datasets that have to be managed. Among the datasets they use, they have a combination of Direct Query and SPICE modes. They need a unified view of each dataset, with details related to permissions, refreshes, and usage. Additionally, they need to be able to schedule when they want to refresh the data and have a history of all the successful and failed attempts of these updates.
The Summary tab
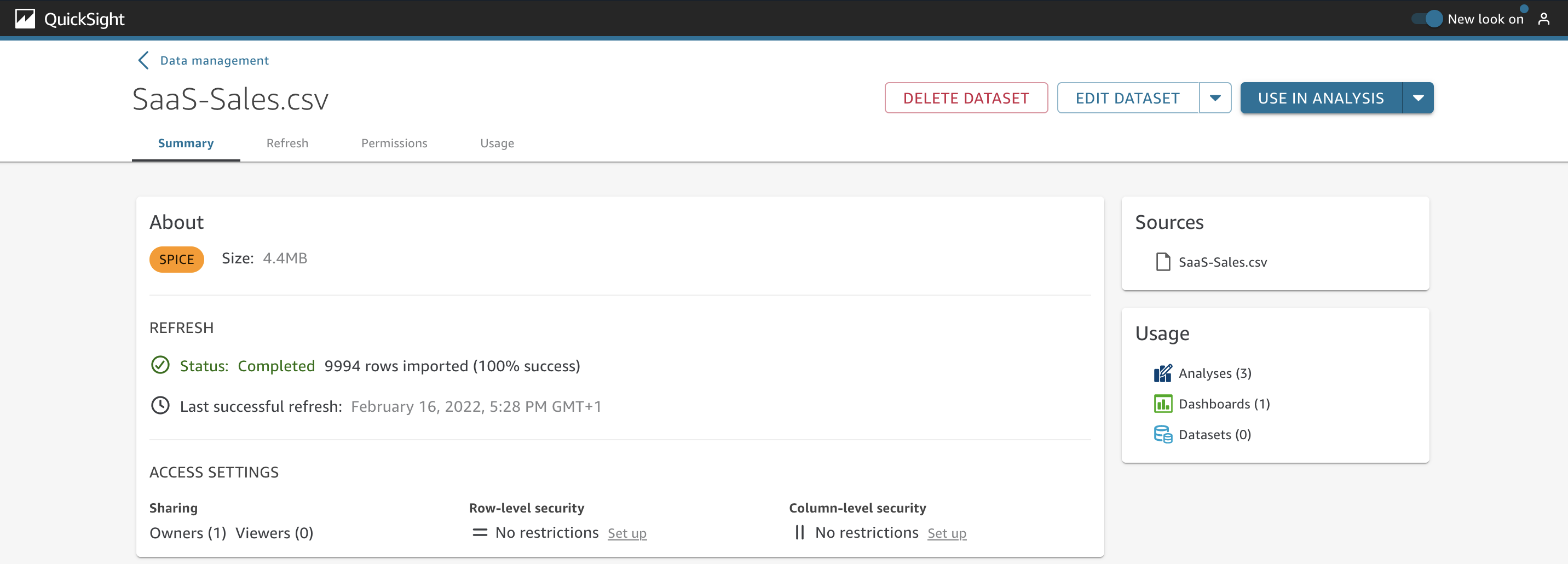
As a data analyst at AnyCompany, you need to review details about your datasets. You can find several options by navigating to the Summary tab.
The About section shows if the dataset is stored in SPICE or if it’s using Direct Query. If the dataset is stored in SPICE, you can also get the size of the dataset. If the dataset is using Direct Query, you can choose Set alert schedule to setup a schedule for when alerts on dashboards should be evaluated.
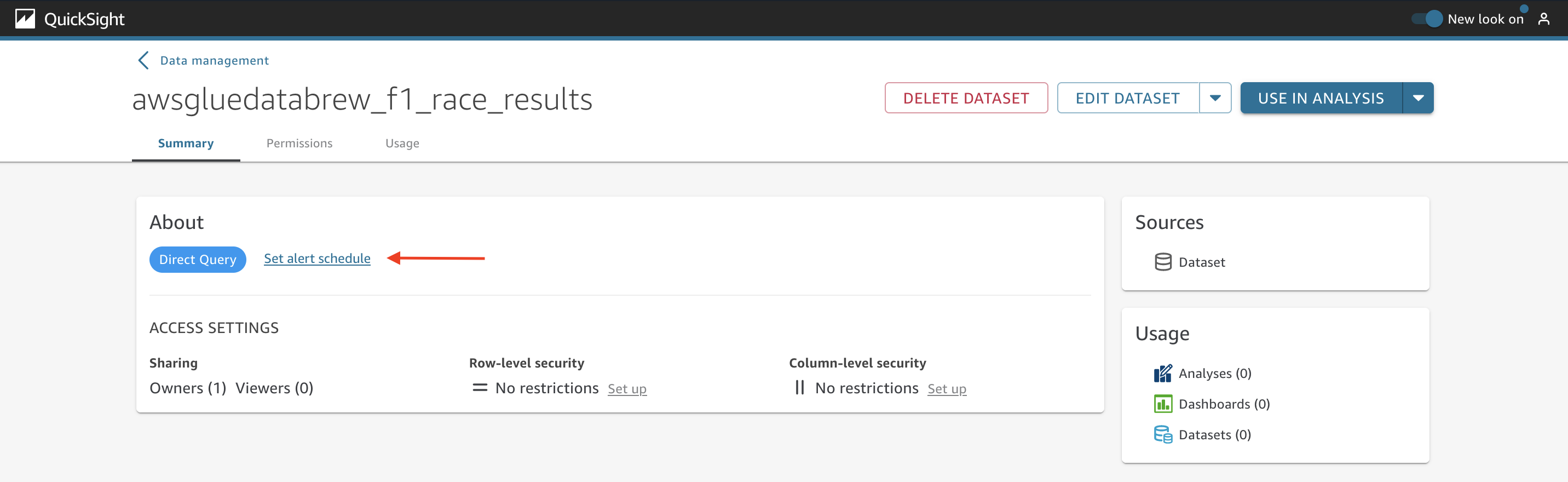
Specify the time zone, if you want to repeat it daily or hourly, and the start time.

To continue exploring the dataset, choose a new dataset that is stored in SPICE. In the Refresh section, you can verify the status of the SPICE dataset and the last successful refresh date.

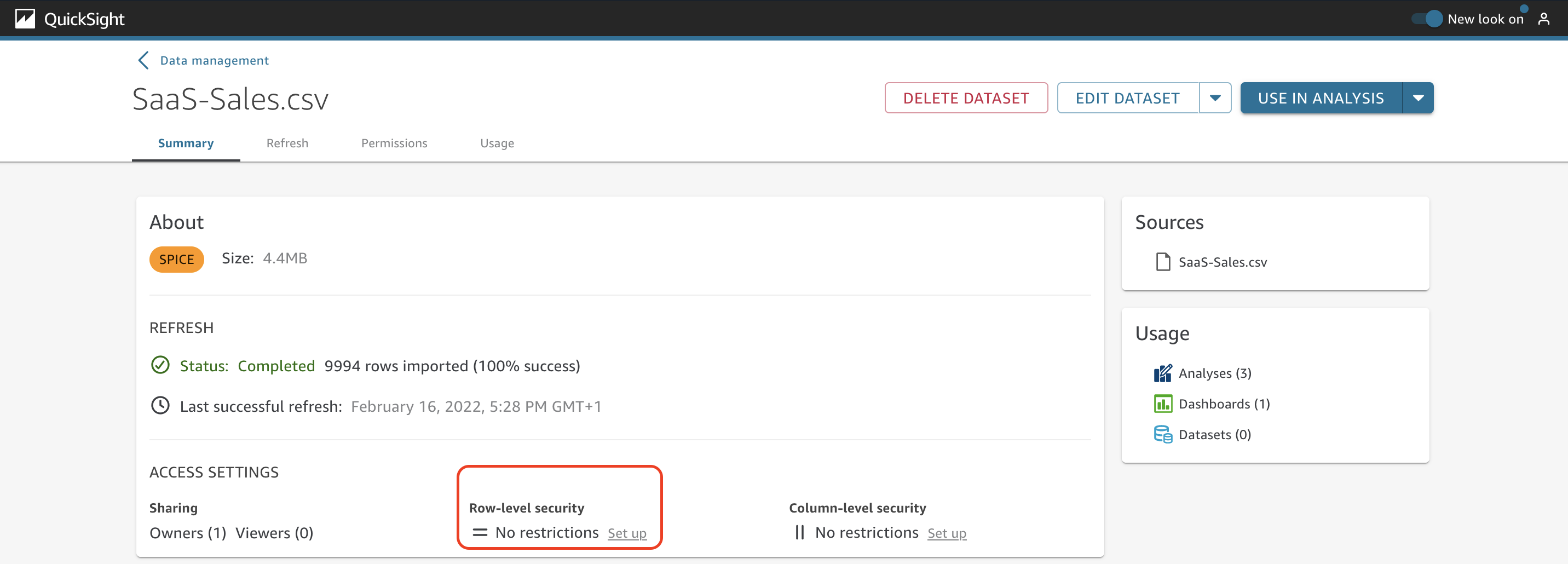
Under Access Settings, you can see details about how many owners and viewers this dataset has and also the options to enable row-level and column-level security.
To add row-level security to this dataset, choose Set up under Row-level security.
Under User-based rules, select the permissions dataset with rules to restrict access for each user or group.
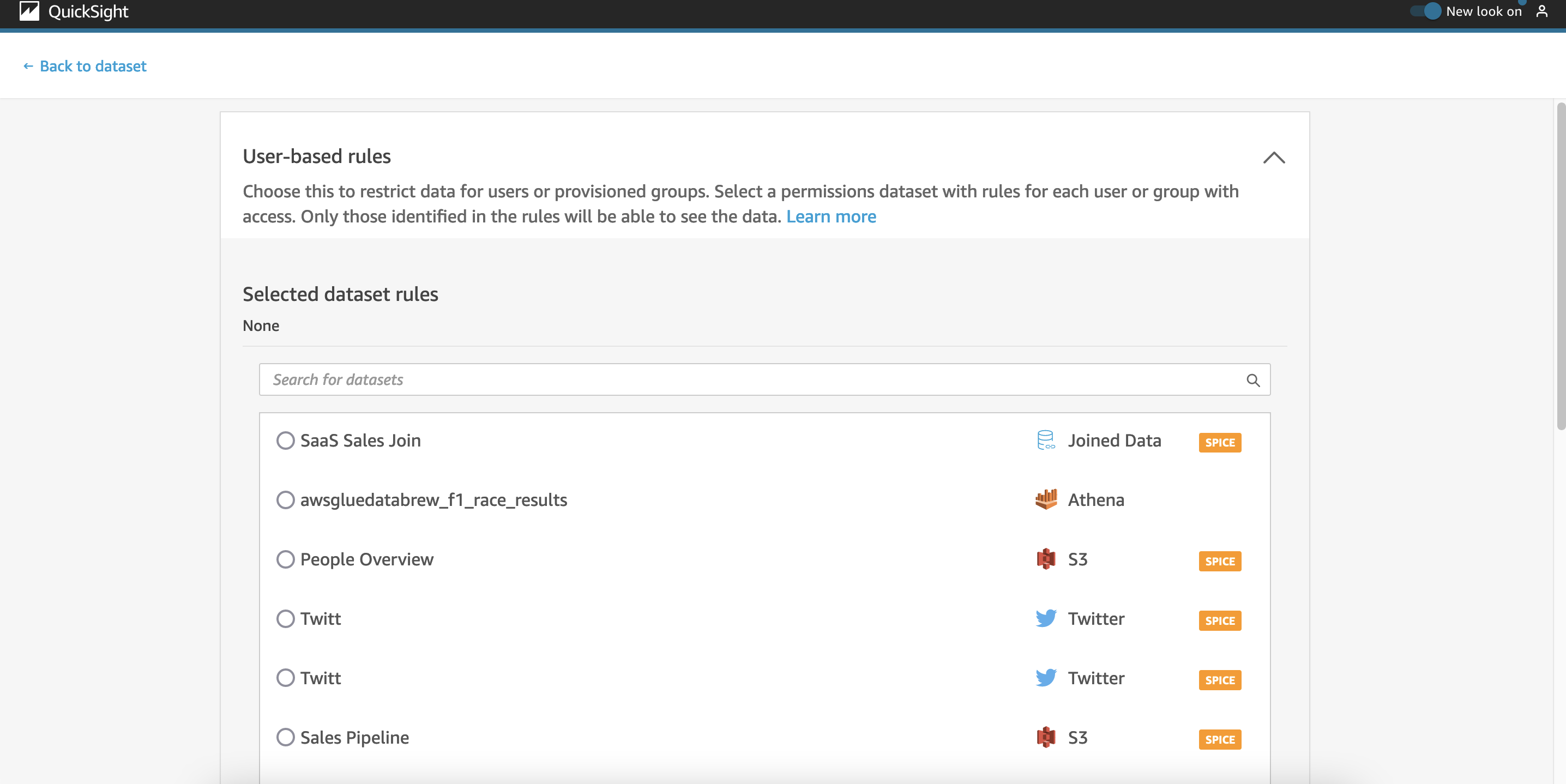
To apply column-level security, choose Set up under Column-level security.
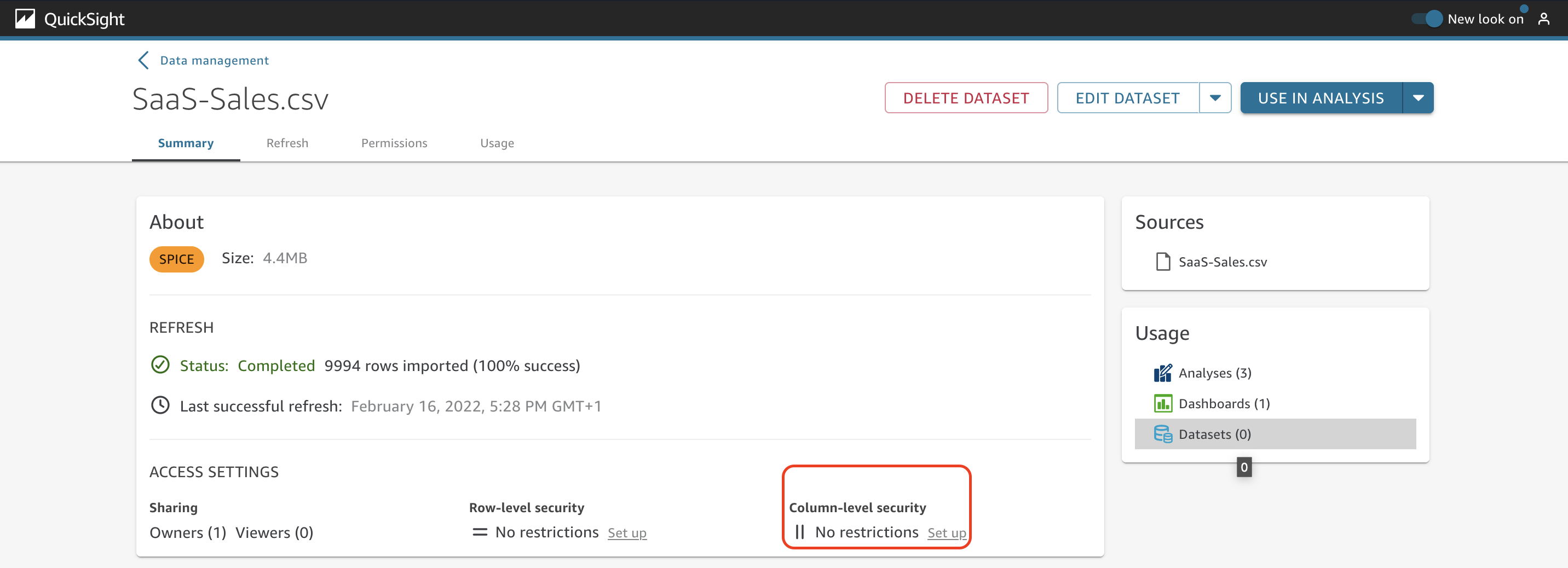
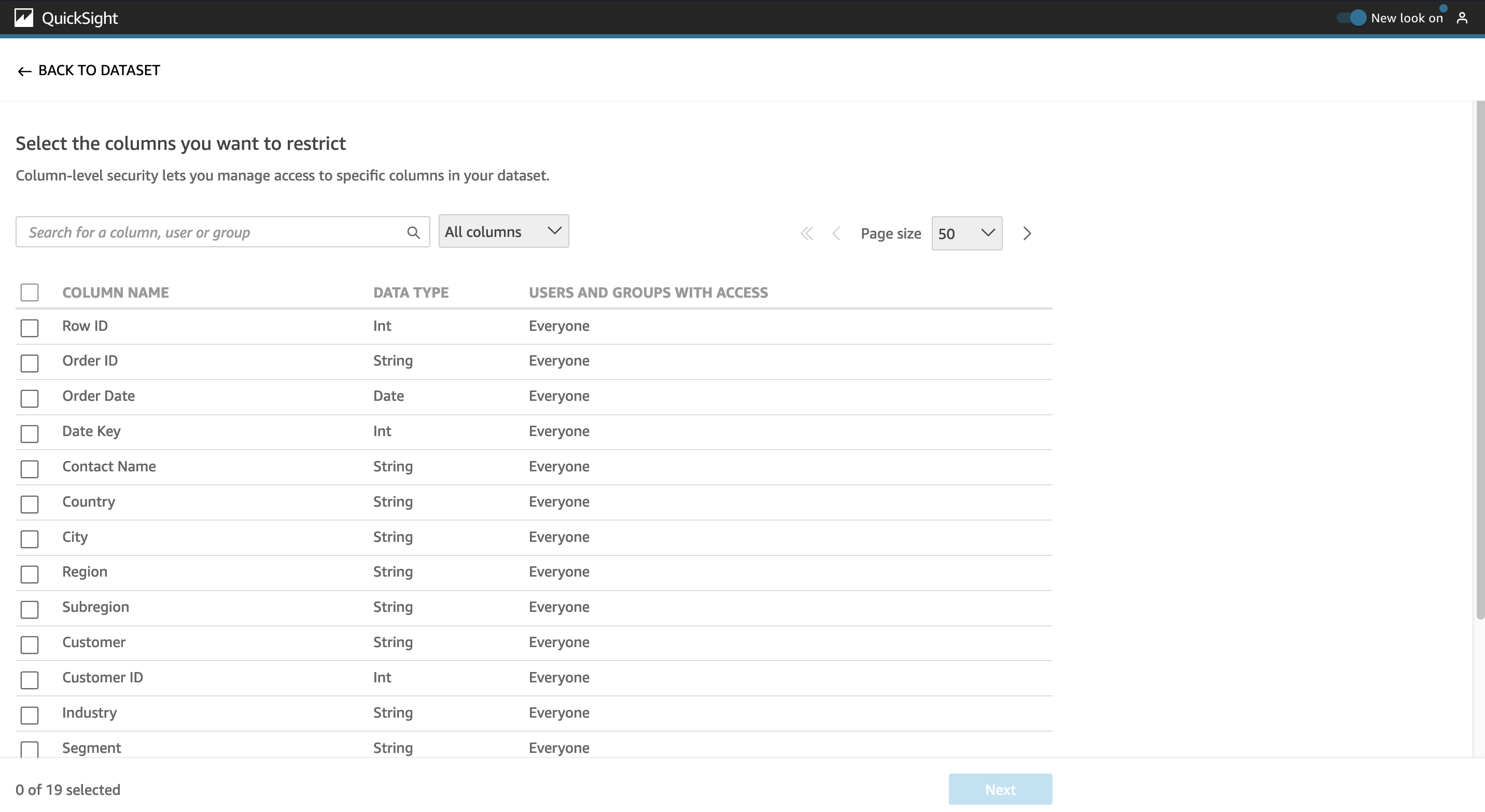
Select the columns to be restricted and choose Next.
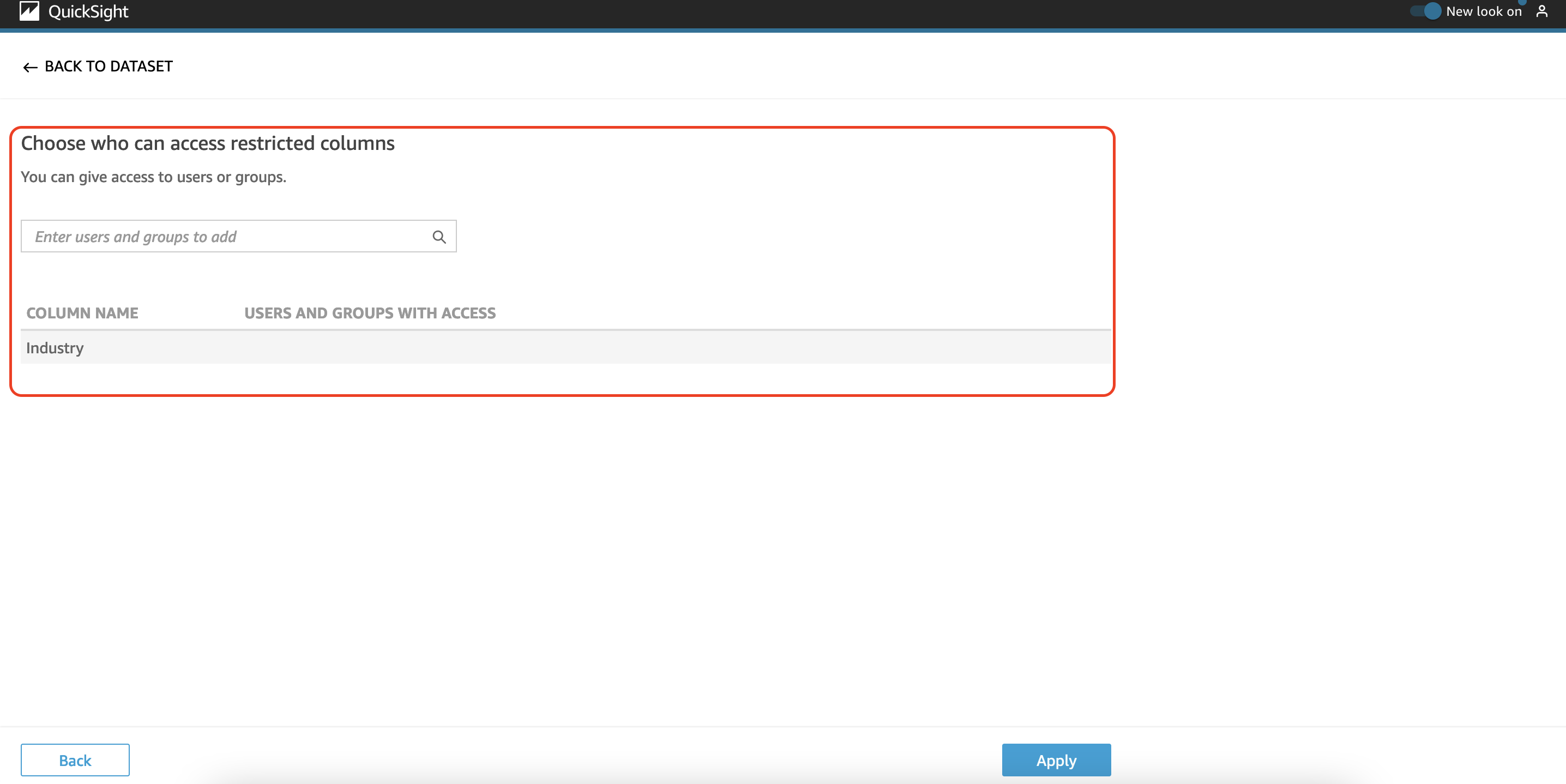
Choose who can access the restricted columns and choose Apply.
In the Sources section on the Summary tab, a list of data sources is displayed to show the ones used in this dataset. In the following example, we can see the sources SaaS Sales 2022.csv and SaaS-Sales-MonthlySummary.
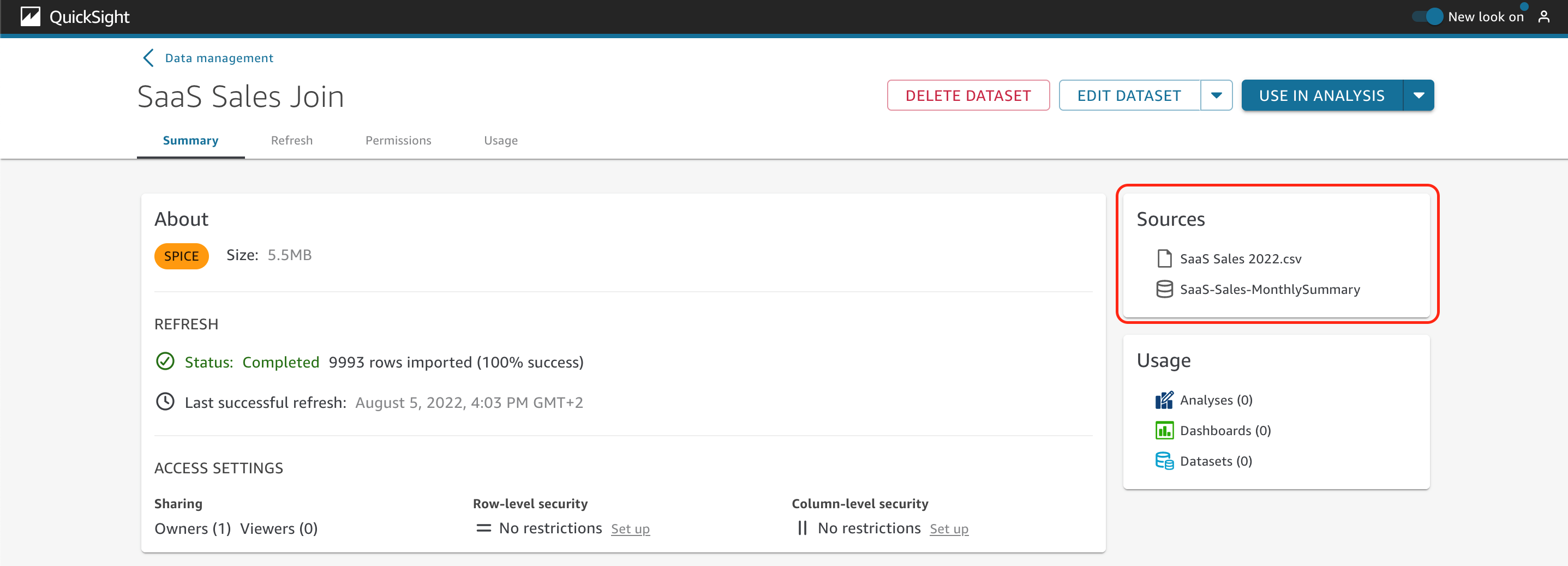
You also need to identify where (analysis, dashboards, or other datasets) the different datasets are being used, to determine if you can eliminate some unused ones.
To verify this, you just have to look at the Usage section (more details are on the Usage tab).
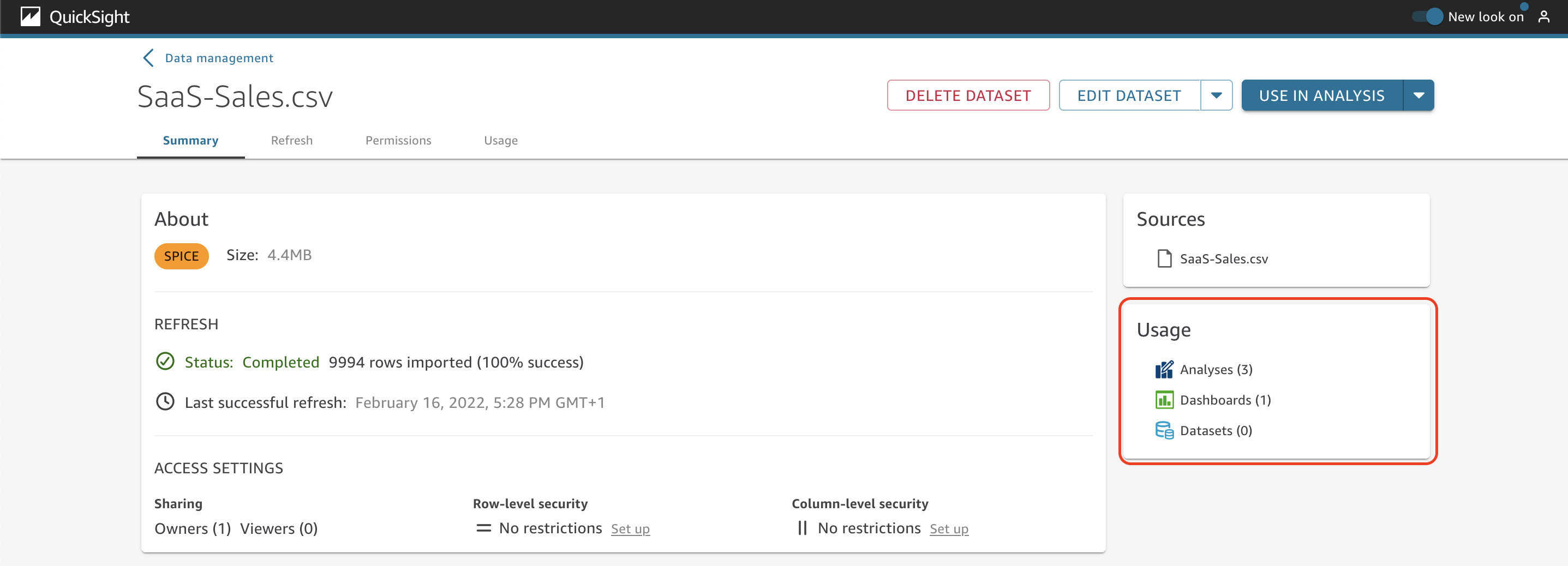
It’s also possible to go to the data prep interface by choosing Edit dataset or duplicate it by opening the drop-down menu.
You can also directly create a new analysis with this dataset or choose Use in dataset to take advantage of dataset as a source capability. When you use this option, any data preparation that the parent dataset contains, such as any joins or calculated fields, is kept. You can add additional preparation to the data in the new, child datasets, such as joining new data and filtering data. You can also set up your own data refresh schedule for the child dataset and track the dashboards and analyses that use it. Some of the advantages are: Central management of datasets, reduction of dataset management, predefined key metrics and flexibility to customize data.

The Refresh tab
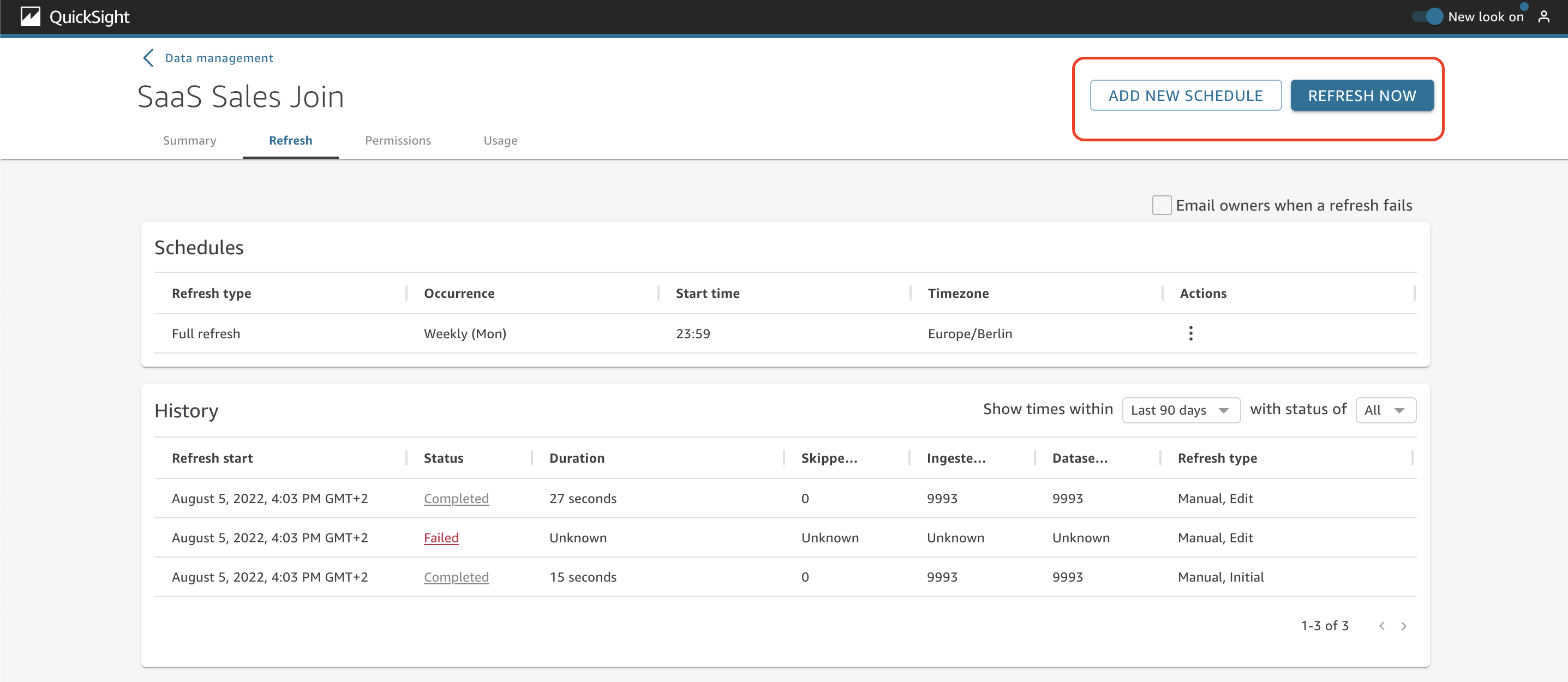
At AnyCompany, you also need to refresh the latest data for your datasets. To achieve this, you have two different options.
You can choose Refresh now to manually get the latest records in the dataset.
You can also choose Add new schedule to create a refresh schedule and not worry about running it manually in the future. You can set the time zone, start time, and frequency.
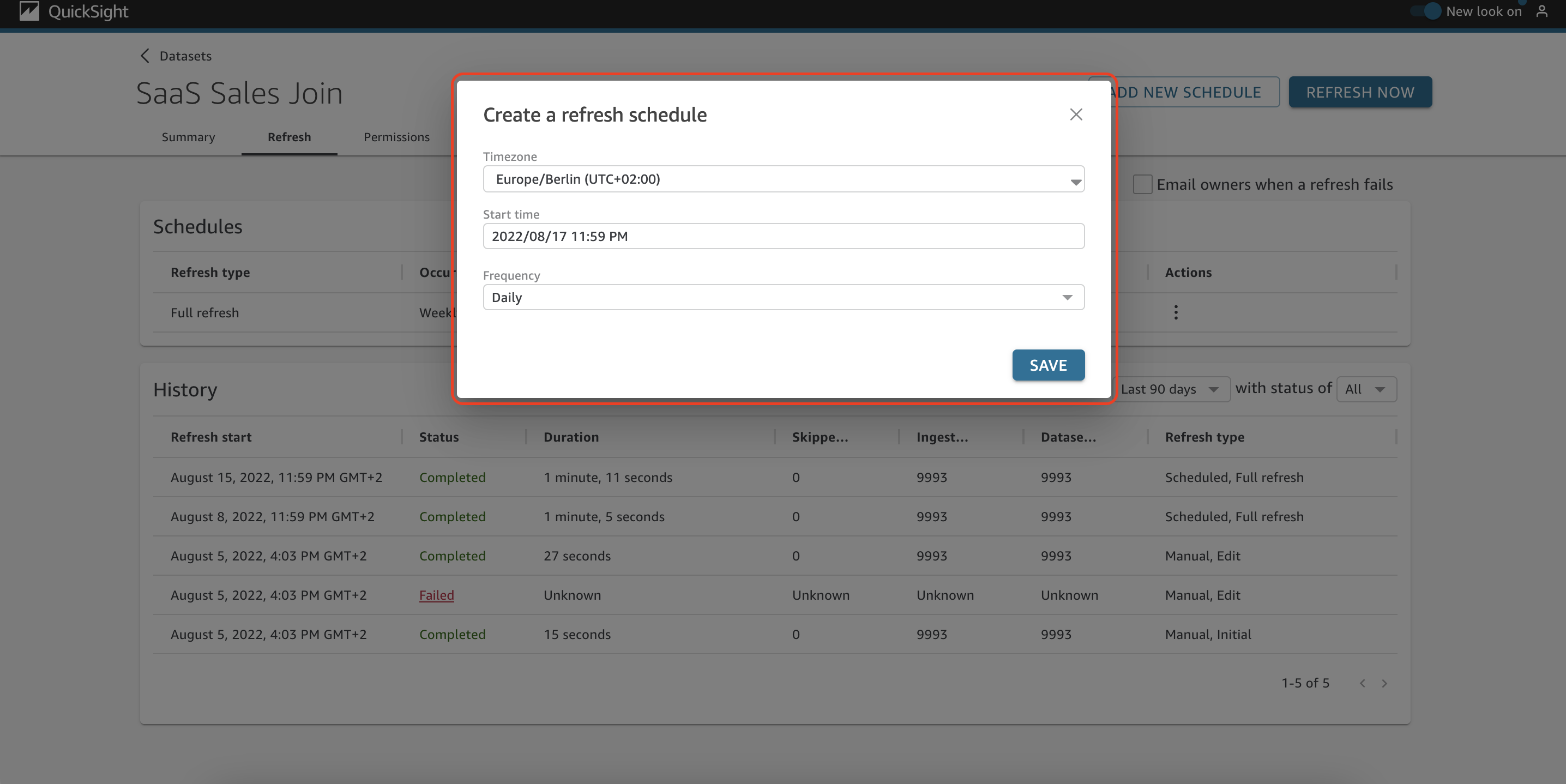
There are two types of scheduled refresh: full refresh and incremental refresh. Full refresh will completely reload the whole dataset, while incremental refresh only updates a specified small portion of your dataset. Using incremental refresh enables you to access the most recent insights much sooner.
In order to setup the incremental refresh, you need to perform the following actions:
- Choose Refresh Now.
- For Refresh type, choose Incremental refresh.
- If this is your first incremental refresh on the dataset, choose Configure.
- On the Configure incremental refresh page, do the following:
- For Date column, choose a date column that you want to base the look-back window on.
- For Window size, enter a number for size, and then choose an amount of time that you want to look back for changes.You can choose to refresh changes to the data that occurred within a specified number of hours, days, or weeks from now. For example, you can choose to refresh changes to the data that occurred within two weeks of the current date.
- Choose Submit.

There are two main sections on the Refresh tab: Schedules and History. Under Schedules, you can see details about the scheduled refreshes of the dataset. There is also the option to edit and delete the schedule.
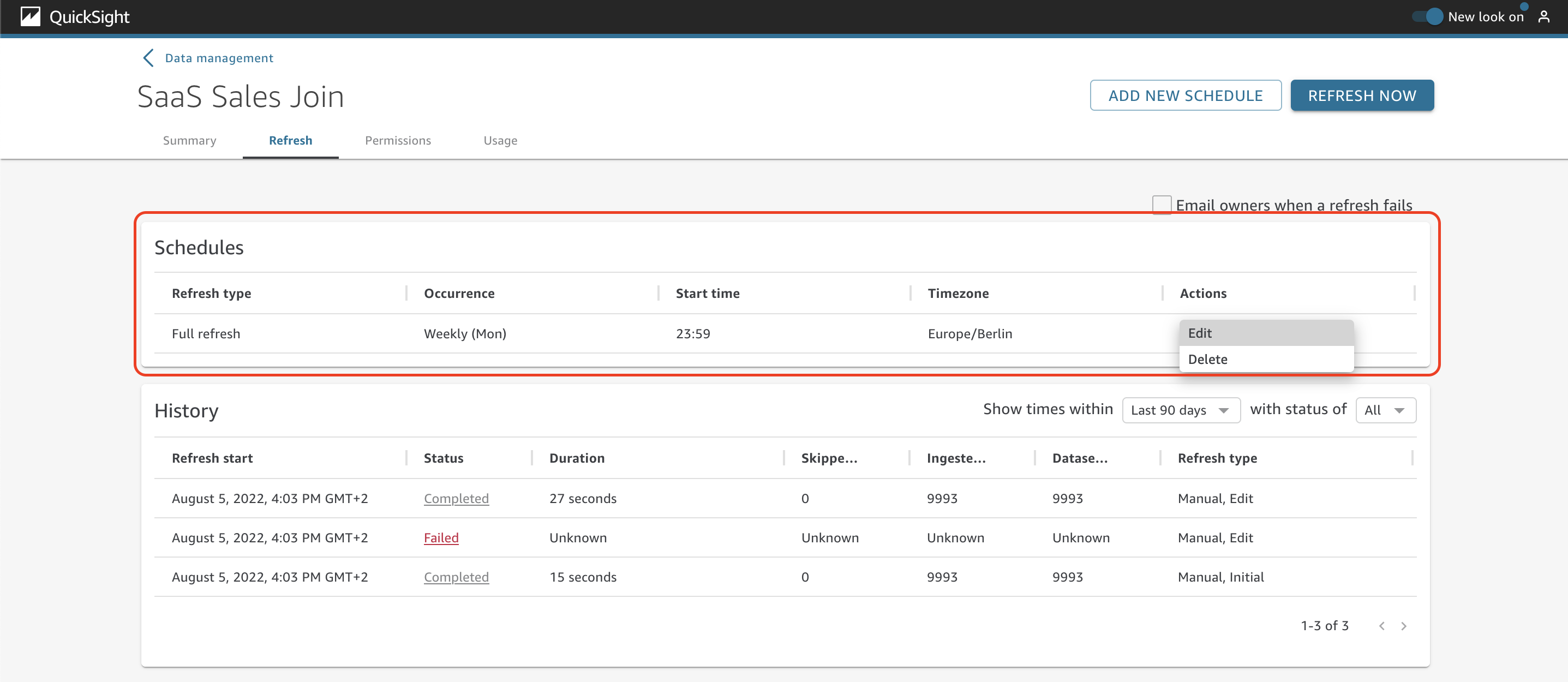
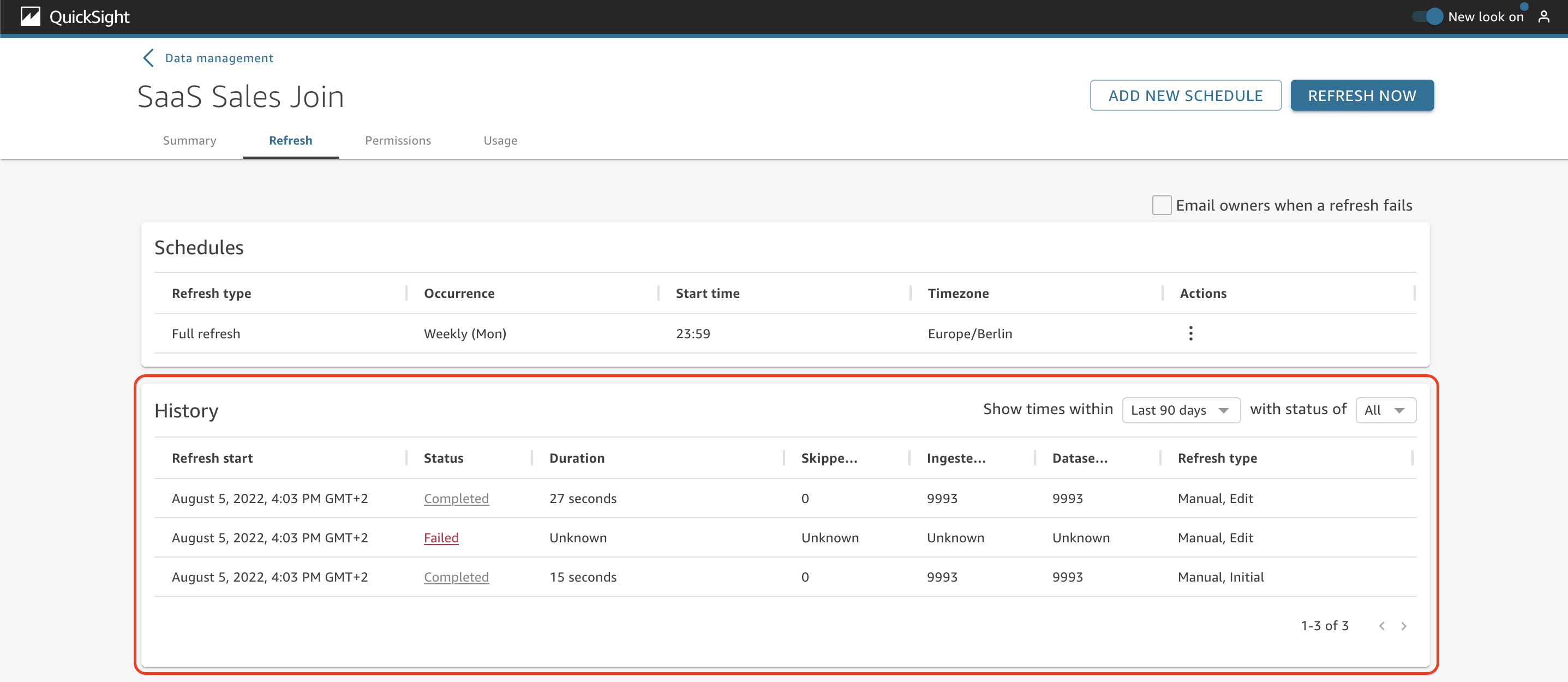
In the History section, you can see details about the past refreshes, such as status, duration, skipped rows, ingested rows, dataset rows, and refresh type.
The Permissions tab
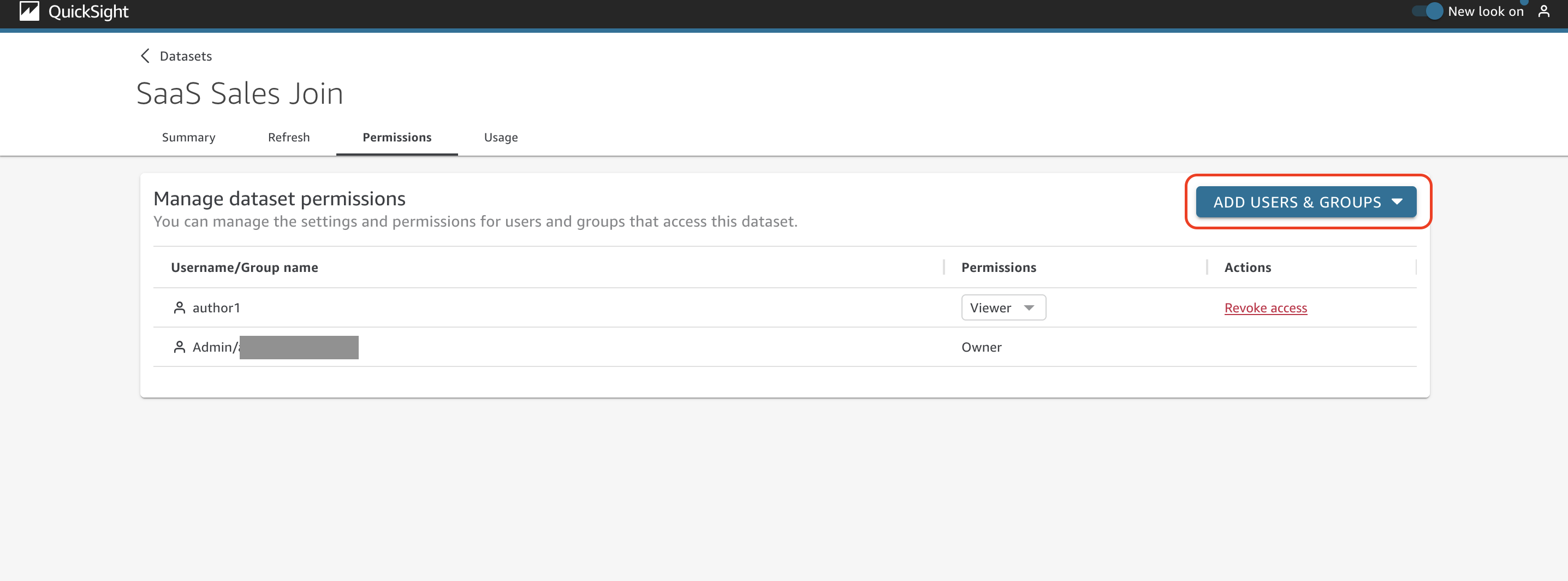
On the Permissions tab, you can manage the settings and permissions for users and groups that access the dataset.
As the dataset owner at AnyCompany, you need to manage access to the datasets and add users and groups. To do so, simply choose Add users & groups.
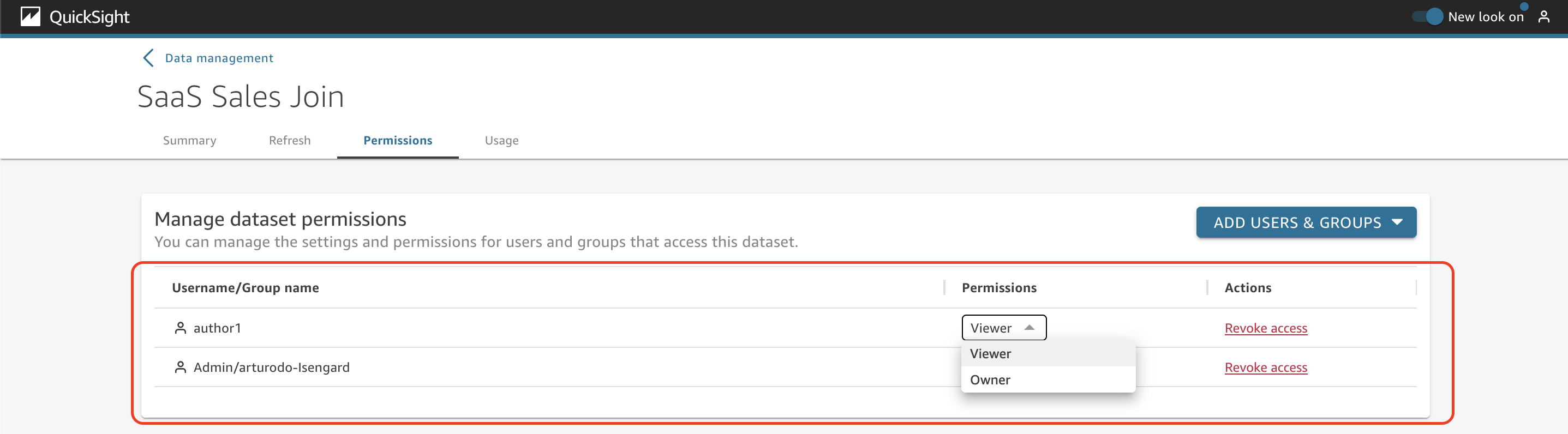
Choose the specific user or group to provide access to this dataset.

Review the list of users and groups that have access to the dataset as well as the level of permission (viewer or owner). You can also revoke access to the users or groups.
The Usage tab
It’s not always easy for AnyCompany to determine whether or not a dataset is being used by users or in other assets such as analyses or dashboards.
To answer this kind of question, you can easily review the information on the Usage tab. Here you can review the list of analyses and dashboards where the dataset is being used (choose the name of an analysis or dashboard to view the actual asset).
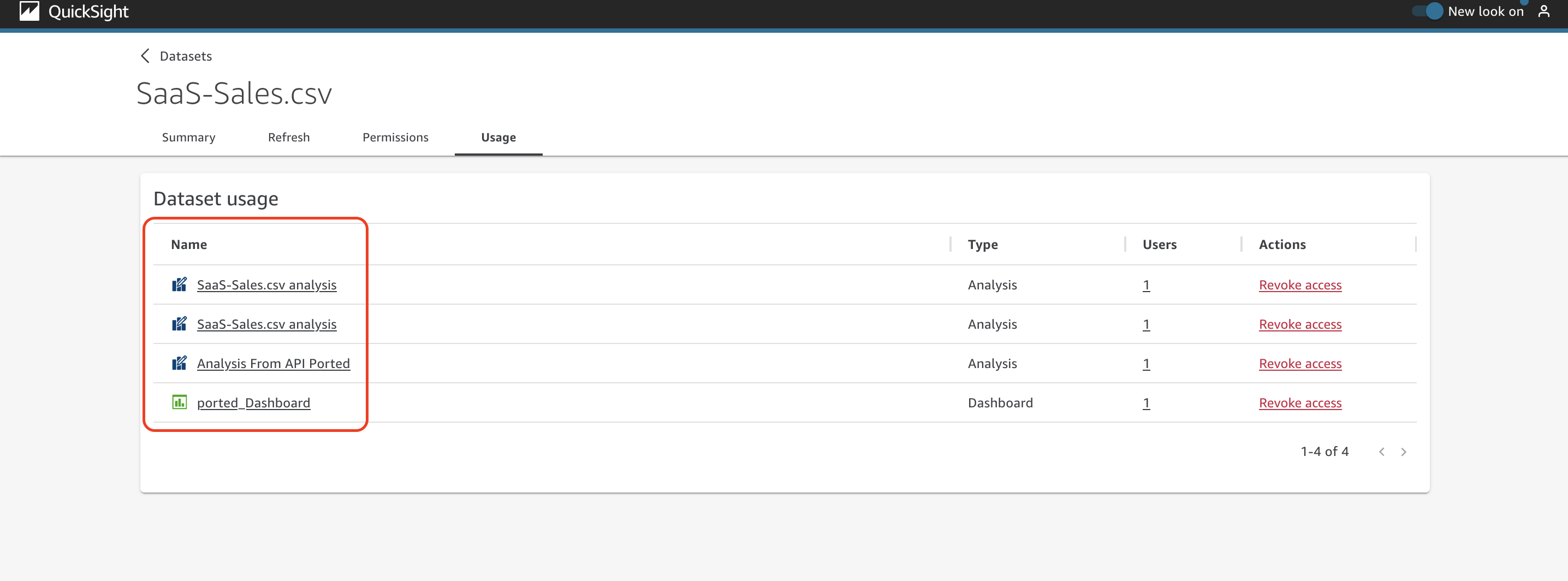
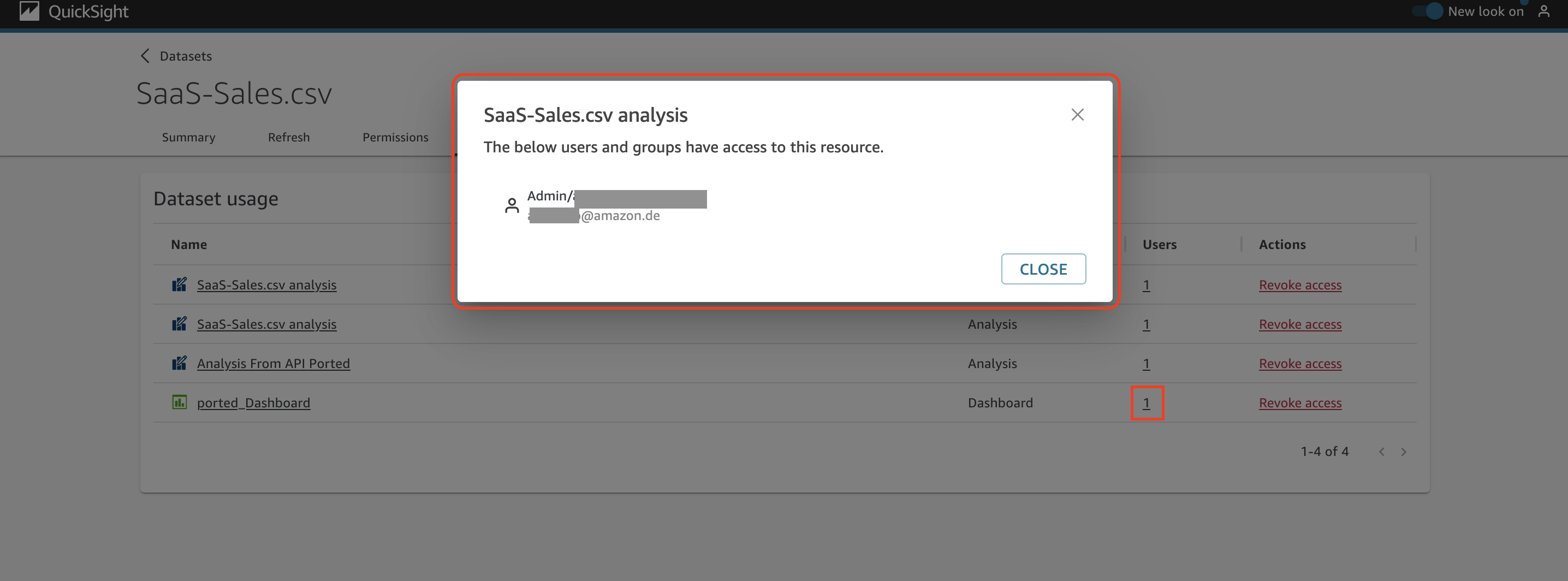
Under the Users column, you can get the details about who is using this analysis or dashboard.
Conclusion
In this post, we introduced the new user interface of the dataset management page on the QuickSight console. This new user interface simplifies the administration and use of datasets by having everything organized and centralized. This will primarily help authors and administrators quickly manage their datasets, while also contributing to a better QuickSight navigation experience. The new user interface is now generally available in all supported QuickSight Regions.
We look forward to your feedback and stories on how you use the new dataset management interface for your business needs.
About the Authors
 Arturo Duarte is a Partner Solutions Architect focused on Amazon QuickSight at Amazon Web Services. He works with EMEA APN Partners to help develop their data and analytics practices with enterprise and mission-critical solutions for their end customers.
Arturo Duarte is a Partner Solutions Architect focused on Amazon QuickSight at Amazon Web Services. He works with EMEA APN Partners to help develop their data and analytics practices with enterprise and mission-critical solutions for their end customers.
 Emily Zhu is a Senior Product Manager at Amazon QuickSight, AWS’s cloud-native, fully managed SaaS BI service. She leads the development of the QuickSight analytics and query capability. Before joining AWS, she worked in the Amazon Prime Air drone delivery program and the Boeing company as senior strategist for several years. Emily is passionate about the potential of cloud-based BI solutions and looks forward to helping customers advance in their data-driven strategy making.
Emily Zhu is a Senior Product Manager at Amazon QuickSight, AWS’s cloud-native, fully managed SaaS BI service. She leads the development of the QuickSight analytics and query capability. Before joining AWS, she worked in the Amazon Prime Air drone delivery program and the Boeing company as senior strategist for several years. Emily is passionate about the potential of cloud-based BI solutions and looks forward to helping customers advance in their data-driven strategy making.
Automate data archival for Amazon Redshift time series tables
Post Syndicated from Nita Shah original https://aws.amazon.com/blogs/big-data/automate-data-archival-for-amazon-redshift-time-series-tables/
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all of your data using standard SQL. Tens of thousands of customers today rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the most widely used cloud data warehouse. You can run and scale analytics in seconds on all your data without having to manage your data warehouse infrastructure.
A data retention policy is part of an organization’s overall data management. In a big data world, the size of data is consistently increasing, which directly affects the cost of storing the data in data stores. It’s necessary to keep optimizing your data in data warehouses for consistent performance, reliability, and cost control. It’s crucial to define how long an organization needs to hold on to specific data, and if data that is no longer needed should be archived or deleted. The frequency of data archival depends on the relevance of the data with respect to your business or legal needs.
Data archiving is the process of moving data that is no longer actively used in a data warehouse to a separate storage device for long-term retention. Archive data consists of older data that is still important to the organization and may be needed for future reference, as well as data that must be retained for regulatory compliance.
Data purging is the process of freeing up space in the database or deleting obsolete data that isn’t required by the business. The purging process can be based on the data retention policy, which is defined by the data owner or business need.
This post walks you through the process of how to automate data archival and purging of Amazon Redshift time series tables. Time series tables retain data for a certain period of time (days, months, quarters, or years) and need data to be purged regularly to maintain the rolling data to be analyzed by end-users.
Solution overview
The following diagram illustrates our solution architecture.
We use two database tables as part of this solution.
The arch_table_metadata database table stores the metadata for all the tables that need to be archived and purged. You need to add rows into this table that you want to archive and purge. The arch_table_metadata table contains the following columns.
| ColumnName | Description |
id |
Database-generated, automatically assigns a unique value to each record. |
schema_name |
Name of the database schema of the table. |
table_name |
Name of the table to be archived and purged. |
column_name |
Name of the date column that is used to identify records to be archived and purged. |
s3_uri |
Amazon S3 location where the data will be archived. |
retention_days |
Number of days the data will be retained for the table. Default is 90 days. |
The arch_job_log database table stores the run history of stored procedures. Records are added to this table by the stored procedure. It contains the following columns.
| ColumnName | Description |
job_run_id |
Assigns unique numeric value per stored procedure run. |
arch_table_metadata_id |
Id column value from table arch_table_metadata. |
no_of_rows_bfr_delete |
Number of rows in the table before purging. |
no_of_rows_deleted |
Number of rows deleted by the purge operation. |
job_start_time |
Time in UTC when the stored procedure started. |
job_end_time |
Time in UTC when the stored procedure ended. |
job_status |
Status of the stored procedure run: IN-PROGRESS, COMPLETED, or FAILED. |
Prerequisites
For this solution, complete the following prerequisites:
- Create an Amazon Redshift provisioned cluster or Amazon Redshift serverless workgroup.
- In Amazon Redshift query editor v2 or a compatible SQL editor of your choice, create the tables
arch_table_metadataandarch_job_log. Use the following code for the table DDLs: - Create the stored procedure
sp_archive_datawith the following code snippet. The stored procedure takes the AWS Identity and Access Management (IAM) role ARN as an input argument if you’re not using the default IAM role. If you’re using the default IAM role for your Amazon Redshift cluster, you can pass the input parameter as default. For more information, refer to Creating an IAM role as default in Amazon Redshift.
Archival and purging
For this use case, we use a table called orders, for which we want to archive and purge any records older than the last 30 days.
Use the following DDL to create the table in the Amazon Redshift cluster:
The O_ORDERDATE column makes it a time series table, which you can use to retain the rolling data for a certain period.
In order to load the data into the orders table using the below COPY command , you would need to have default IAM role attached to your Redshift cluster or replace the default keyword in the COPY command with the arn of the IAM role attached to the Redshift cluster
When you query the table, you can see that this data is for 1998. To test this solution, you need to manually update some of the data to the current date by running the following SQL statement:
The table looks like the following screenshot after running the update statement.
Now let’s run the following SQL to get the count of number of records to be archived and purged:

Before running the stored procedure, we need to insert a row into the arch_file_metadata table for the stored procedure to archive and purge records in the orders table. In the following code, provide the Amazon Simple Storage Service (Amazon S3) bucket name where you want to store the archived data:
The stored procedure performs the following high-level steps:
- Open a cursor to read and loop through the rows in the
arch_table_metadatatable. - Retrieve the total number of records in the table before purging.
- Export and archive the records to be deleted into the Amazon S3 location as specified in the
s3_uricolumn value. Data is partitioned in Amazon S3 based on thecolumn_namefield inarch_table_metadata. The stored procedure uses the IAM role passed as input for the UNLOAD operation. - Run the DELETE command to purge the identified records based on the
retention_dayscolumn value. - Add a record in
arch_job_logwith the run details.
Now, let’s run the stored procedure via the call statement passing a role ARN as input parameter to verify the data was archived and purged correctly:
As shown in the following screenshot, the stored procedure ran successfully.

Now let’s validate the table was purged successfully by running the following SQL:

We can navigate to the Amazon S3 location to validate the archival process. The following screenshot shows the data has been archived into the Amazon S3 location specified in the arch_table_metadata table.

Now let’s run the following SQL statement to look at the stored procedure run log entry:
The following screenshot shows the query results.

In this example, we demonstrated how you can set up and validate your Amazon Redshift table archival and purging process.
Schedule the stored procedure
Now that you have learned how to set up and validate your Amazon Redshift tables for archival and purging, you can schedule this process. For instructions on how to schedule a SQL statement using either the AWS Management Console or the AWS Command Line Interface (AWS CLI), refer to Scheduling SQL queries on your Amazon Redshift data warehouse.
Archive data in Amazon S3
As part of this solution, data is archived in an S3 bucket before it’s deleted from the Amazon Redshift table. This helps reduce the storage on the Amazon Redshift cluster and enables you to analyze the data for any ad hoc requests without needing to load back into the cluster. In the stored procedure, the UNLOAD command exports the data to be purged to Amazon S3, partitioned by the date column, which is used to identify the records to purge. To save costs on Amazon S3 storage, you can manage the storage lifecycle with Amazon S3 lifecycle configuration.
Analyze the archived data in Amazon S3 using Amazon Redshift Spectrum
With Amazon Redshift Spectrum, you can efficiently query and retrieve structured and semistructured data from files in Amazon S3, and easily analyze the archived data in Amazon S3 without having to load it back in Amazon Redshift tables. For further analysis of your archived data (cold data) and frequently accessed data (hot data) in the cluster’s local disk, you can run queries joining Amazon S3 archived data with tables that reside on the Amazon Redshift cluster’s local disk. The following diagram illustrates this process.
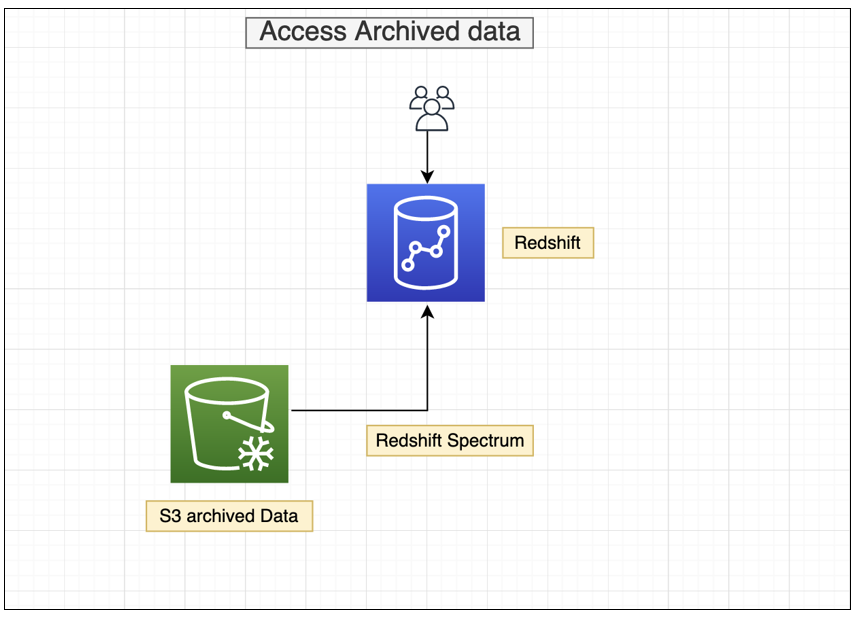
Let’s take an example where you want to view the number of orders for the last 2 weeks of December 1998, which is archived in Amazon S3. You need to complete the following steps using Redshift Spectrum:
- Create an external schema in Amazon Redshift.
- Create a late-binding view to refer to the underlying Amazon S3 files with the following query:
- To see a unified view of the orders historical data archived in Amazon S3 and the current data stored in the Amazon Redshift local table, you can use a UNION ALL clause to join the Amazon Redshift orders table and the Redshift Spectrum orders table:
To learn more about the best practices for Redshift Spectrum, refer to Best Practices for Amazon Redshift Spectrum.
Best practices
The following are some best practices to reduce your storage footprint and optimize performance of your workloads:
- Working with column compression
- Choose the best distribution style
- Use the smallest possible column size
- Use date/time data types for date columns
Conclusion
In this post, we demonstrated the automatic archival and purging of data in Amazon Redshift tables to meet your compliance and business requirements, thereby optimizing your application performance and reducing storage costs. As an administrator, you can start working with application data owners to identify retention policies for Amazon Redshift tables to achieve optimal performance, prevent any storage issues specifically for DS2 and DC2 nodes, and reduce overall storage costs.
About the authors
 Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
 Ranjan Burman is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 15 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with the use of cloud solutions.
Ranjan Burman is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 15 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with the use of cloud solutions.
 Prathap Thoguru is an Enterprise Solutions Architect at Amazon Web Services. He has over 15 years of experience in the IT industry and is a 9x AWS certified professional. He helps customers migrate their on-premises workloads to the AWS Cloud.
Prathap Thoguru is an Enterprise Solutions Architect at Amazon Web Services. He has over 15 years of experience in the IT industry and is a 9x AWS certified professional. He helps customers migrate their on-premises workloads to the AWS Cloud.
Ekstrand: Introducing NVK
Post Syndicated from original https://lwn.net/Articles/910319/
Jason Ekstrand announces
a new Vulkan driver for NVIDIA hardware on the Collabora blog. It
seems to be off to a good start, but there is some work yet to do:
Normally, I would have submitted the merge request long ago. There
are far more alpha-quality drivers already in Mesa. The problem is
that we really need a new kernel uAPI to support Vulkan properly
and I don’t want to be stuck supporting the current nouveau uAPI
for the next five years.
“An Ideal Solution”: Daltix’s Automated Data Lake Archive Saves $100K
Post Syndicated from Amrit Singh original https://www.backblaze.com/blog/an-ideal-solution-daltixs-automated-data-lake-archive-saves-100k/

In the fast-moving consumer goods space, Daltix is a pioneer in providing complete, transparent, and high-quality retail data. With global industry leaders like GFK and Unilever depending on their pricing, product, promotion, and location data to build go-to market strategies and make critical decisions, maintaining a reliable data ecosystem is an imperative for Daltix.
As the company has grown since its founding in 2016, the amount of data Daltix is processing has increased exponentially. They’re currently managing around 250TB, but that amount is spread across billions of files, which soon created a massive drag on time and resources. With an infrastructure built almost entirely around AWS and billions of miniscule files to manage, Daltix started to outgrow AWS’ storage options in both scalability and cost efficiency.

We got to chat with Charlie Orford, Principal Software Engineer for Daltix, about how Datix switched to Backblaze B2 Cloud Storage and their takeaways from that process. Here are some highlights:
- They used a custom engine to migrate billions of files from AWS S3 to Backblaze B2.
- Monthly costs reduced by $2,500 while increasing data portability and reliability.
- Daltix established the infrastructure to automatically back up 8.4 million data objects every day.
Read on to learn how they did it.
A Complex Data Pipeline Built Around AWS
Most of the S3-based infrastructure Daltix built in the company’s early days is still intact. Historically, the data pipeline started with web-scraped resources written directly to Amazon S3, which were then standardized by Lamba-based extractors before being sent back to S3. Then AWS Batch picked up the resources to be augmented and enriched using other data sources.
All those steps took place before the data was ready for Daltix’s team of analysts. In order to optimize the pipeline and increase efficiency, Orford started absorbing pieces of that process into Kubernetes. But there was still a data storage problem; Daltix generates about 300GB of compressed data per day, and that figure was growing rapidly. “As we’d scaled up our data collection, we’d had to sharpen our focus on cost control, data portability, and reliability,” said Orford. “They’re obvious, but at scale, they’re extremely important.”
Cost Concerns Inspire The Search For Warm Archival Storage
By 2020, Daltix had started to realize the limitations of building so much of their infrastructure in AWS. For example, heavy customization around S3 metadata made the ability to move objects entirely dependent on the target system’s compatibility with S3. Orford was also concerned about the costs of permanently storing such a huge data lake in S3. As he puts it, “It was clear that there was no need to have everything in S3 forever. If we didn’t do anything about it, our S3 costs were going to continue to rise and eventually dwarf virtually all of our other AWS costs.”
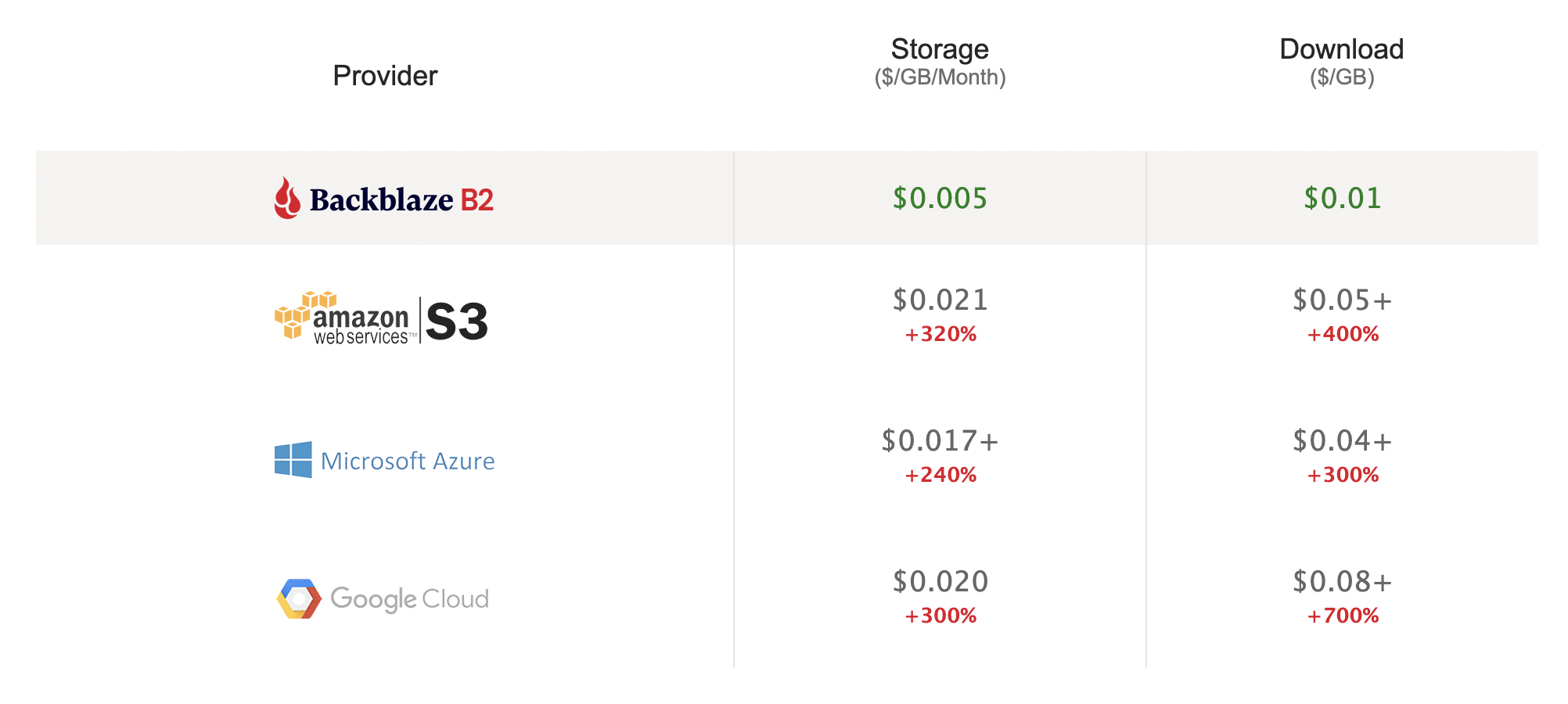
Because Daltix works with billions of tiny files, using Glacier was out of the question as its pricing model is based around retrieval fees. Even using Glacier Instant Retrieval, the sheer number of files Daltix works with would have forced them to rack up an additional $200,000 in fees per year. So Daltix’s data collection team—which produces more than 85% of the company’s overall data—pushed for an alternative solution that could address a number of competing concerns:
- The sheer size of the data lake.
- The need to store raw resources as discrete files (which means that batching is not an option).
- Limitations on the team’s ability to invest time and effort.
- A desire for simplicity to guarantee the solution’s reliability.
Daltix settled on using Amazon S3 for hot storage and moving warm storage into a new archival solution, which would reduce costs while keeping priority data accessible—even if the intention is to keep files stored away. “It was important to find something that would be very easy to integrate, have a low development risk, and start meaningfully eating into our costs,” said Orford. “For us, Backblaze really ticked all the boxes.”
Initial Migration Unlocks Immediate Savings of $2,000 Per Month
Before launching into a full migration, Orford and his team tested a proof of concept (POC) to make sure the solution addressed his key priorities:
- Making sure the huge volume of data was migrated successfully.
- Avoiding data corruption and checking for errors with audit logs.
- Preserving custom metadata on each individual object.
“Early on, Backblaze worked with us hand-in-hand to come up with a custom migration tool that fit all our requirements,” said Orford. “That’s what gave us the confidence to proceed.” In partnership with Flexify, Backblaze delivered a tailor-made engine to ensure that the migration process would transfer the entire data lake reliably and with object-level metadata intact. After the initial POC bucket was migrated successfully, Daltix had everything they needed to start modeling and forecasting future costs. “As soon as we started interacting with Backblaze, we stopped looking at other options,” Orford said.
In August 2021, Daltix moved a 120TB bucket of 2.2 billion objects from standard storage in S3 to Backblaze B2 cloud storage. That initial migration alone unlocked an immediate cost savings of $2,000 per month, or $24,000 per year.

Quadruple the Data, Direct S3 Compatibility, and $100,000 Cumulative Savings
Today, Daltix is migrating about 3.2 million data objects (approximately 70GB of data) from Amazon S3 into Backblaze B2 every day. They keep 18 months of hot data in S3, and as soon as an object reaches 18 months and one day, it becomes eligible for archiving in B2. On the rare occasions that Daltix receives requests for data outside that 18-month window, they can pull data directly from Backblaze B2 into Amazon S3 thanks to Backblaze’s S3-compatible API and ever-available data.
Daily audit logs summarize how much data has been transferred, and the entire migration process happens automatically every day. “It runs in the background, there’s nothing to manage, we have full visibility, and it’s cost effective,” Orford said. “Backblaze B2 is an ideal solution for us.”
As daily data collection increases and more data ages out of the hot storage window, Orford expects more cost reductions. Orford expects it will take about a year and a half for daily migrations to nearly triple their current levels: that means Daltix will be backing up 9 million objects (about 450GB of data) to Backblaze B2 every day. Taking that long-term view, we see incredible cost savings for Daltix by switching from Amazon S3 to Backblaze B2. “By 2023, we forecast we will have realized a cumulative saving in the region of $75,000-$100,000 on our storage spend thanks to leveraging Backblaze B2, with expected ongoing savings of at least $30,000 per year,” said Orford.
“It runs in the background, there’s nothing to manage, we have full visibility, and it’s cost effective. B2 is an ideal solution for us.” —Charlie Orford, Principal Software Engineer, Daltix
Crunch the Numbers and See for Yourself
Want to find out what your business could do with an extra $30,000 a year? Check out our Cloud Storage Pricing Calculator to see what you could save switching to Backblaze B2.
The post “An Ideal Solution”: Daltix’s Automated Data Lake Archive Saves $100K appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
It’s Smaller, but Is It Faster? Testing the tp-link EAP610 v2.
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=RLOcNbURFPI
Stable kernel update 5.19.13 released
Post Syndicated from original https://lwn.net/Articles/910313/
The 5.19.13 stable kernel update is out.
“This release is to resolve a regression on some Intel graphics
”
systems that had problems with 5.19.12. If you do not have this
problem with 5.19.12, there is no need to upgrade.
Velociraptor Version 0.6.6: Multi-Tenant Mode and More Let You Dig Deeper at Scale Like Never Before
Post Syndicated from Carlos Canto original https://blog.rapid7.com/2022/10/04/velociraptor-version-0-6-6-multi-tenant-mode-and-more-let-you-dig-deeper-at-scale-like-never-before/

Rapid7 is excited to announce the release of version 0.6.6 of Velociraptor – an advanced, open-source digital forensics and incident response (DFIR) tool that enhances visibility into your organization’s endpoints. After several months of development and testing, we are excited to share its powerful new features and improvements.
Multi-tenant mode
The largest improvement in the 0.6.6 release by far is the introduction of organizational division within Velociraptor. Velociraptor is now a fully multi-tenanted application. Each organization is like a completely different Velociraptor installation, with unique hunts, notebooks, and clients. That means:
- Organizations can be created and deleted easily with no overheads.
- Users can seamlessly switch between organizations using the graphic user interface (GUI).
- Operations like hunting and post processing can occur across organizations.
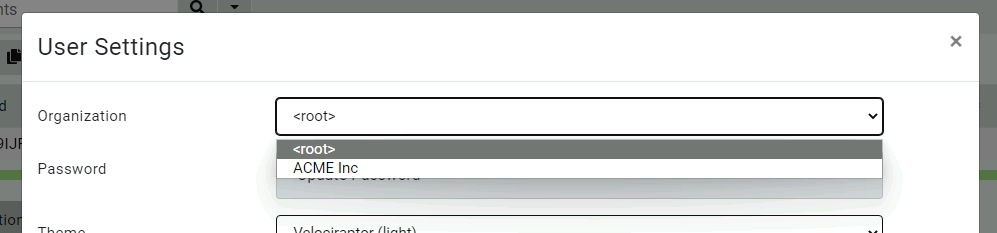
When looking at the latest Velociraptor GUI you might notice the organizations selector in the User Setting page.
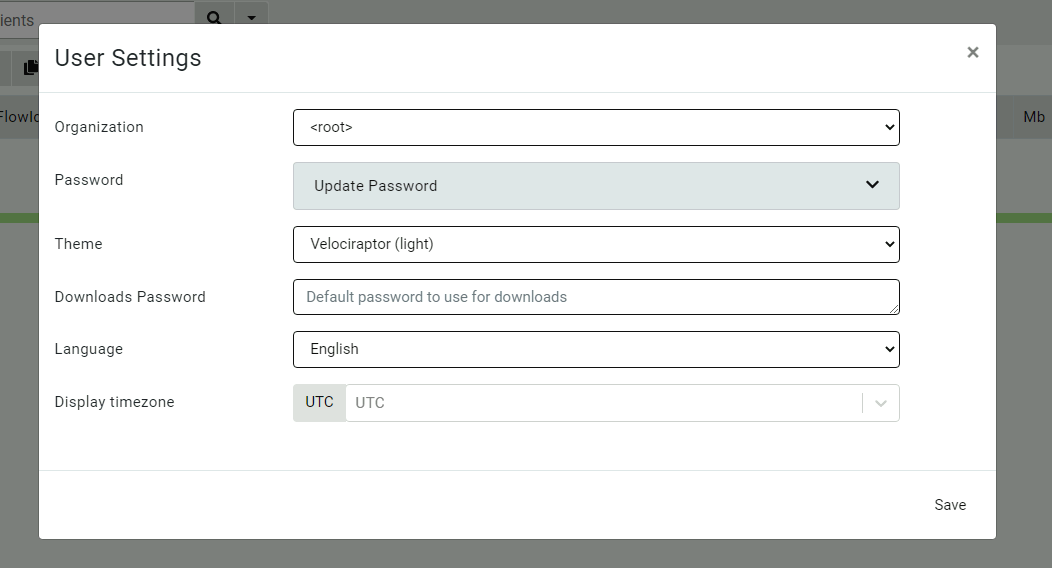
This allows the user to switch between the different organizations they belong in.
Multi-tenanted example
Let’s go through a quick example of how to create a new organization and use this feature in practice.
Multi-tenancy is simply a layer of abstraction in the GUI separating Velociraptor objects (such as clients, hunts, notebooks, etc.) into different organizational units.
You do not need to do anything specific to prepare for a multi-tenant deployment. Every Velociraptor deployment can create a new organization at any time without affecting the current install base at all.
By default all Velociraptor installs (including upgraded ones) have a root organization which contains their current clients, hunts, notebooks, etc. (You can see this in the screenshot above.) If you choose to not use the multi-tenant feature, your Velociraptor install will continue working with the root organization without change.
Suppose a new customer is onboarded, but they do not have a large enough install base to warrant a new cloud deployment (with the associated infrastructure costs). We want to create a new organization for this customer in the current Velociraptor deployment.
Creating a new organization
To create a new organization, we simply run the Server.Orgs.NewOrg server artifact from the Server Artifacts screen.
All we need to do is give the organization a name.
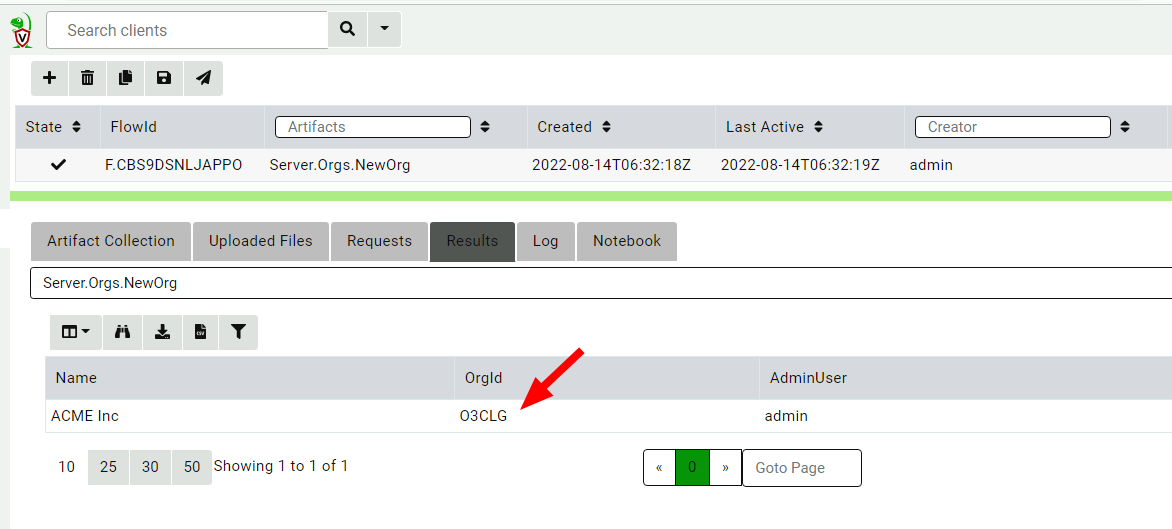
Velociraptor uses the OrgId internally to refer to the organization, but the organization name is used in the GUI to select the different organizations. The new organization is created with the current user being the new administrator of this org.
Deploying clients to the new organization
Since all Velociraptor agents connect to the same server, there has to be a way for the server to identify which organization each client belongs in. This is determined by the unique nonce inside the client’s configuration file. Therefore, each organization has a unique client configuration that should be deployed to that organization.
We will list all the organizations on the server using the Server.Orgs.ListOrgs artifact. Note that we are checking the AlsoDownloadConfigFiles parameter to receive the relevant configuration files.
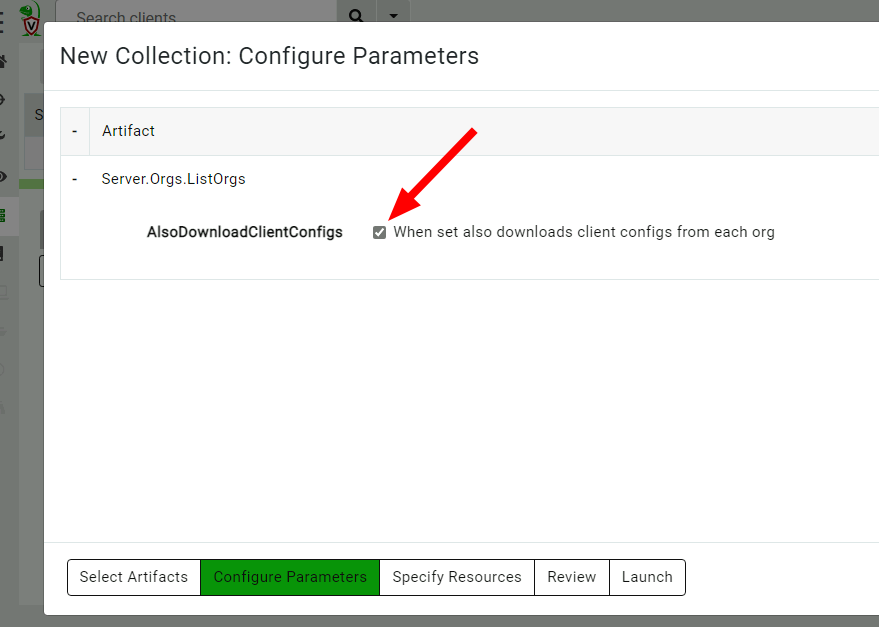
The artifact also uploads the configuration files.
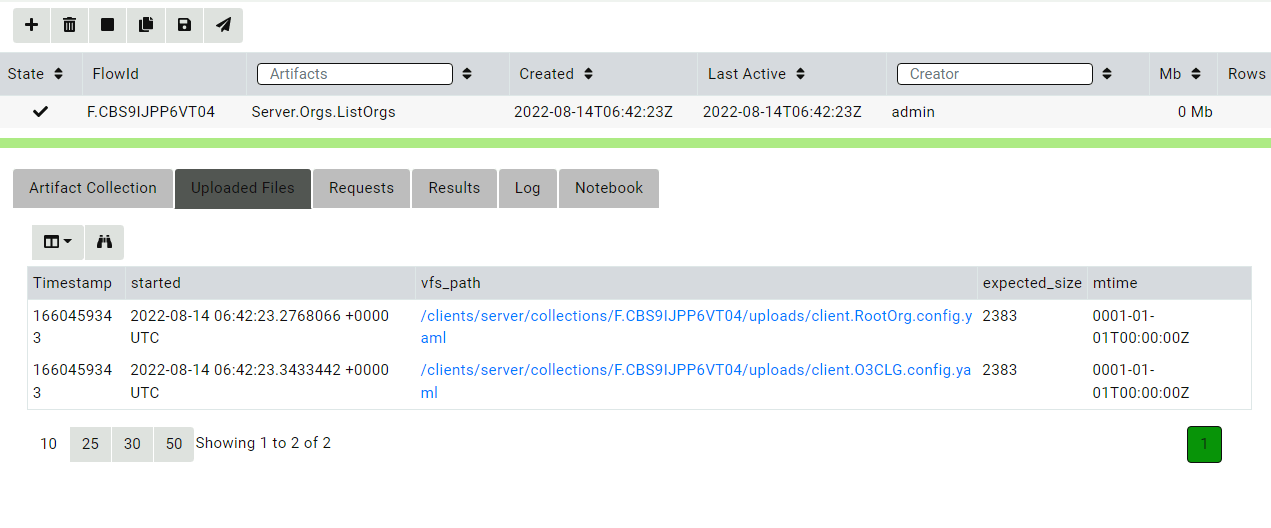
Now, we go through the usual deployment process with these configuration files and prepare MSI, RPM, or Deb packages as normal.
Switching between organizations
We can now switch between organizations using the organization selector.
Now the interface is inside the new organization.
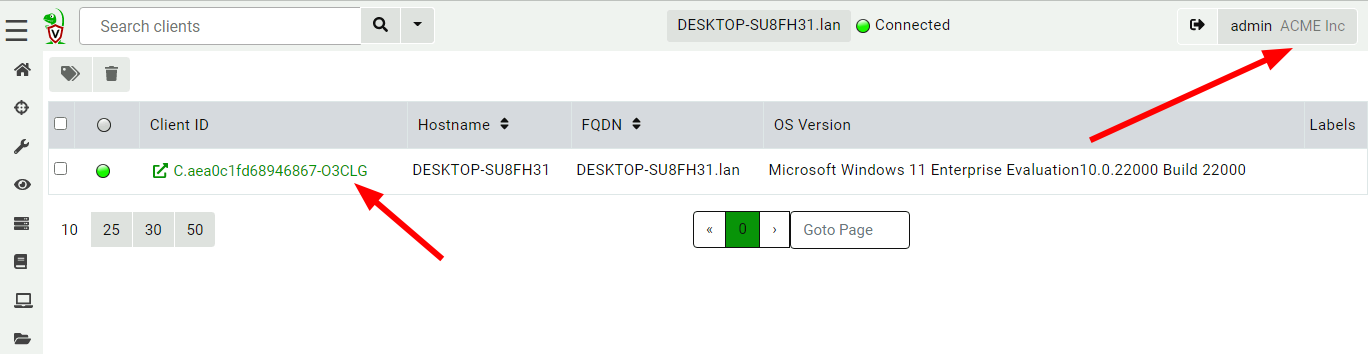
Note the organization name is shown in the user tile, and client IDs have the org ID appended to them to remind us that the client exists within the org.
The new organization is functionally equivalent to a brand-new deployed server! It has a clean data store with new hunts, clients, notebooks, etc. Any server artifacts will run on this organization only, and server monitoring queries will also only apply to this organization.
Adding other users to the new organization
By default, the user which created the organization is given the administrator role within that organization. Users can be assigned arbitrary roles within the organization – so, for example, a user may be an administrator in one organization but a reader in another organization.
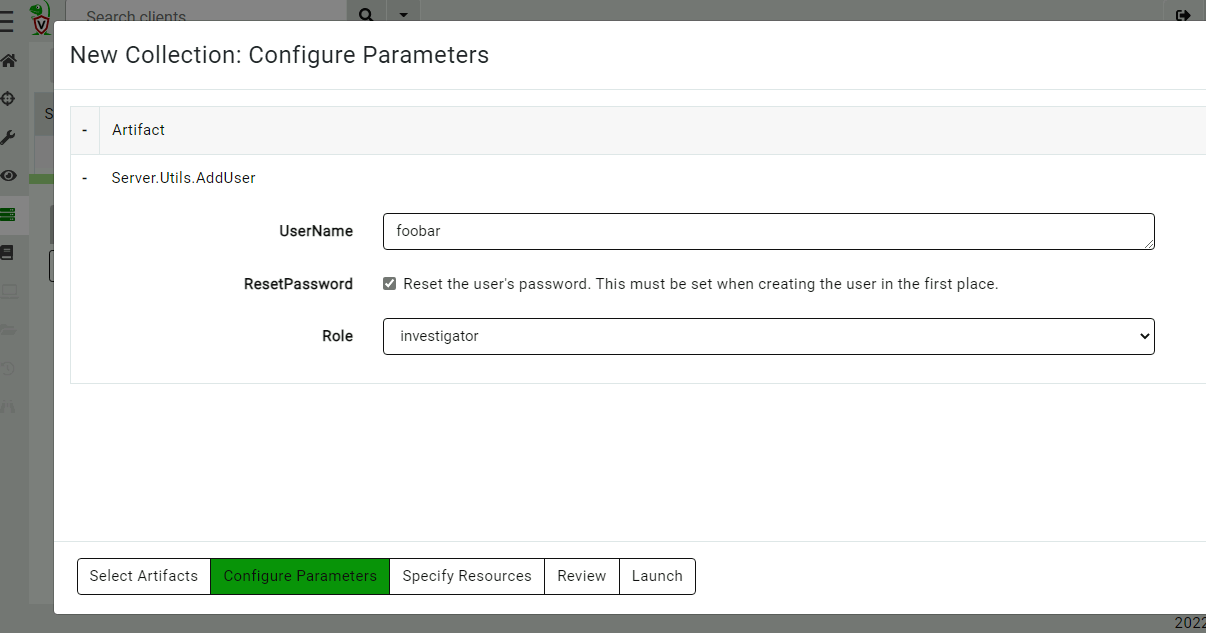
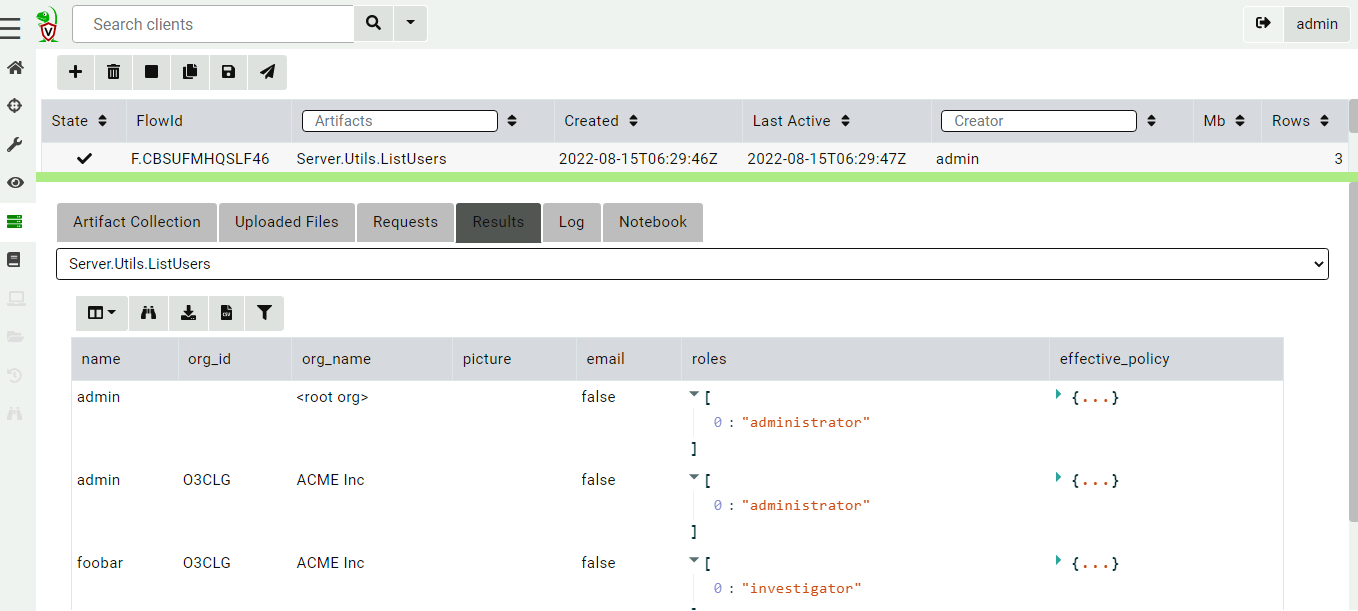
You can add new users or change the user’s roles using the Server.Utils.AddUser artifact. When using basic authentication, this artifact will create a user with a random password. The password will then be stored in the server’s metadata, where it can be shared with the user. We normally recommend Velociraptor to be used with single sign-on (SSO), such as OAuth2 or SAML, and not to use passwords to manage access.
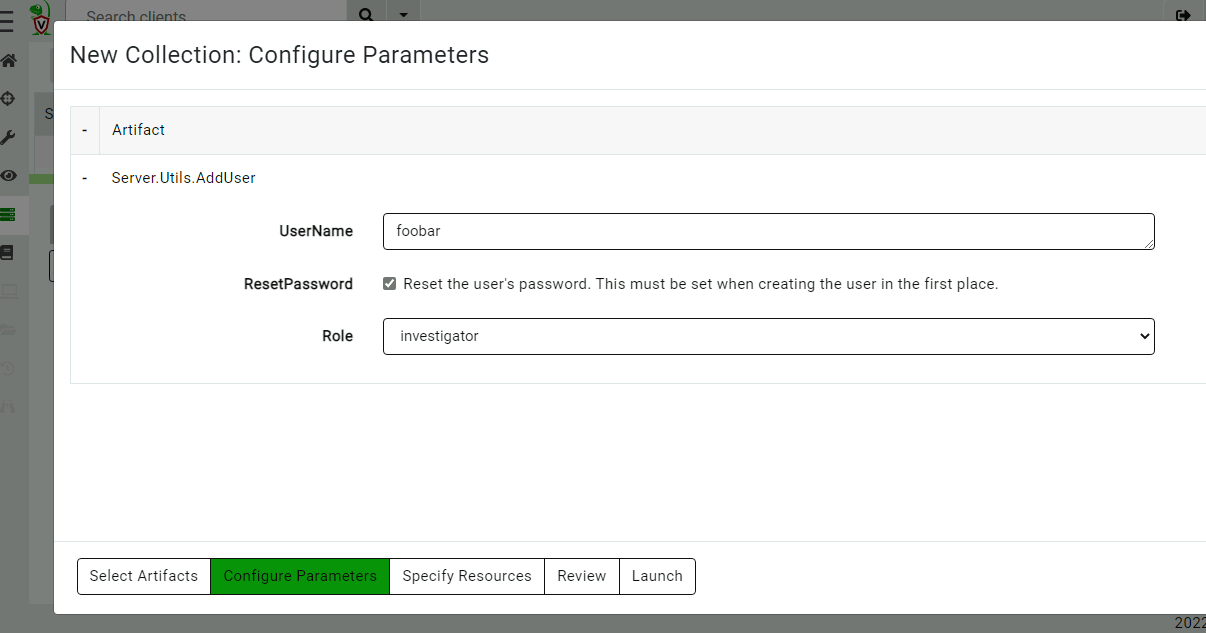
View the user’s password in the server metadata screen. (You can remove this entry when done with it or ask the user to change their password.)
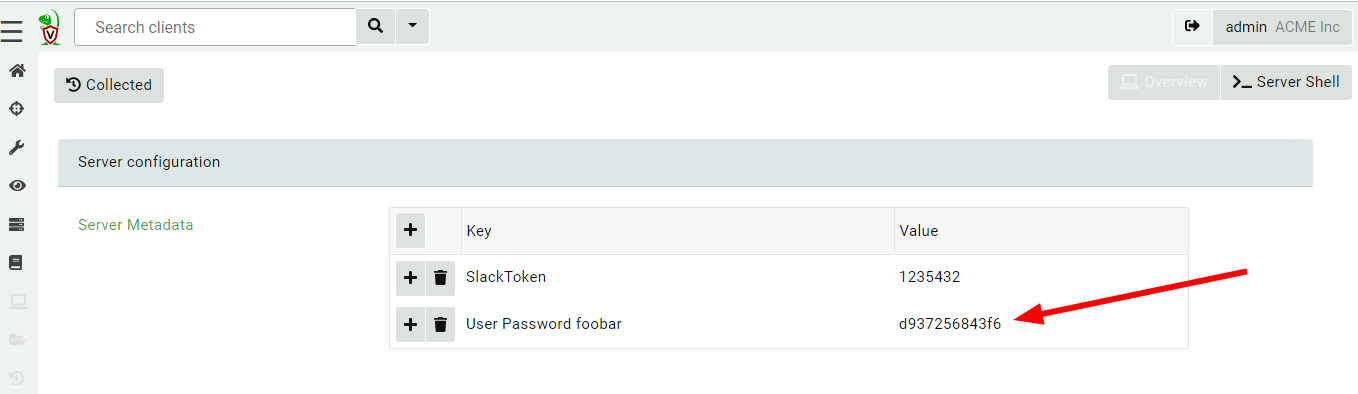
You can view all users in all orgs by collecting the Server.Utils.ListUsers artifact within the root org context.
Although Velociraptor respects the assigned roles of users within an organization, at this stage this should not be considered an adequate security control. This is because there are obvious escalation paths between roles on the same server. For example, currently an administrator role by design has the ability to write arbitrary files on the server and run arbitrary commands (primarily this functionality allows for post processing flows with external tools).
This is currently also the case in different organizations, so an organization administrator can easily add themselves to another organization (or indeed to the root organization) or change their own role.
Velociraptor is not designed to contain untrusted users to their own organization unit at this stage – instead, it gives administrators flexibility and power.
GUI improvements
The 0.6.6 release introduces a number of other GUI improvements.
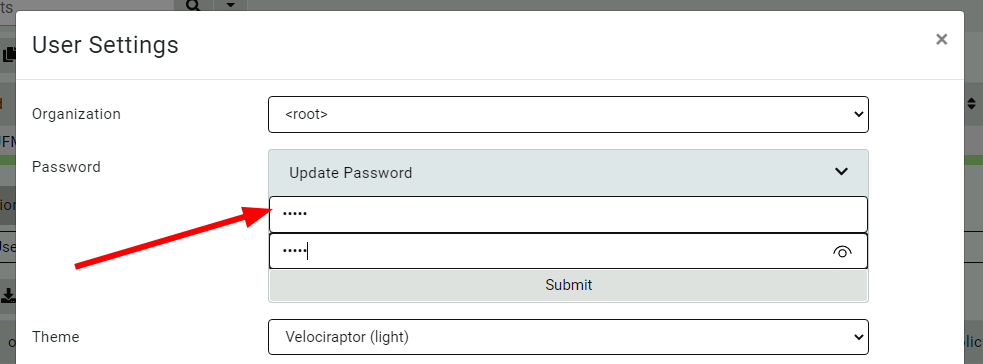
Updating user’s passwords
Usually Velociraptor is deployed in production using SSO such as Google’s OAuth2, and in this case, users manage their passwords using the provider’s own infrastructure.
However, it is sometimes convenient to deploy Velociraptor in Basic authentication mode (for example, for on-premises or air-gapped deployment). Velociraptor now lets users change their own passwords within the GUI.
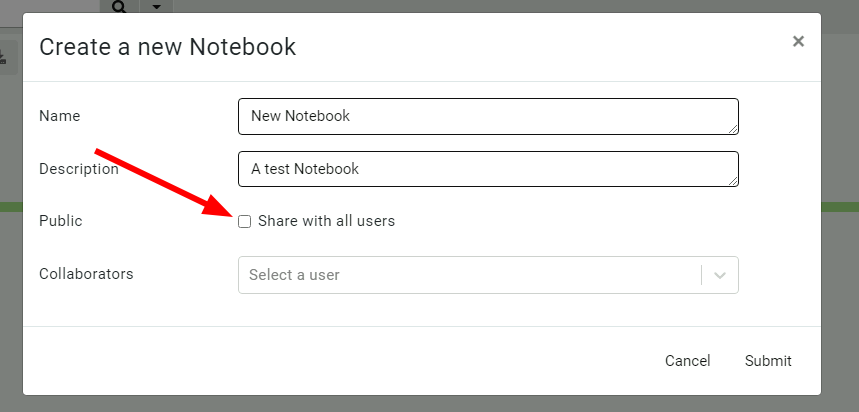
Allow notebook GUI to set notebooks to public
Previously, notebooks could be shared with specific other users, but this proved unwieldy for larger installs with many users. In this release, Velociraptor offers a notebook to be public – this means the notebook will be shared with all users within the org.
More improvements to the process tracker
The experimental process tracker is described in more details here, but you can already begin using it by enabling the Windows.Events.TrackProcessesBasic client event artifact and using artifacts just as Generic.System.Pstree, Windows.System.Pslist, and many others.
Context menu
A new context menu is now available to allow sending any table cell data to an external service.
This allows for quick lookups using VirusTotal or a quick CyberChef analysis. You can also add your own send to items in the configuration files.
Conclusion
If you’re interested in the new features, take Velociraptor for a spin by downloading it from our release page. It’s available for free on GitHub under an open-source license.
As always, please file bugs on the GitHub issue tracker or submit questions to our mailing list by emailing [email protected]. You can also chat with us directly on our Discord server.
Learn more about Velociraptor by visiting any of our web and social media channels below:
Additional reading:
OpenSSH 9.1 released
Post Syndicated from original https://lwn.net/Articles/910301/
OpenSSH 9.1 has been released. It is advertised as a bug-fix release (and
it addresses a few low-priority memory-safety bugs), but
there’s also a new option to set the minimum RSA key size for
authentication, a few sftp extensions, and more.
Security updates for Tuesday
Post Syndicated from original https://lwn.net/Articles/910300/
Security updates have been issued by Debian (barbican), Fedora (libdxfrw, librecad, and python-oauthlib), Oracle (bind), Red Hat (bind and rh-python38-python), SUSE (bind, chromium, colord, libcroco, libgit2, lighttpd, nodejs12, python, python3, slurm, slurm_20_02, and webkit2gtk3), and Ubuntu (linux-azure, python-django, strongswan, and wayland).
NSA Employee Charged with Espionage
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/10/nsa-employee-charged-with-espionage.html
An ex-NSA employee has been charged with trying to sell classified data to the Russians (but instead actually talking to an undercover FBI agent).
It’s a weird story, and the FBI affidavit raises more questions than it answers. The employee only worked for the NSA for three weeks—which is weird in itself. I can’t figure out how he linked up with the undercover FBI agent. It’s not clear how much of this was the employee’s idea, and whether he was goaded by the FBI agent. Still, hooray for not leaking NSA secrets to the Russians. (And, almost ten years after Snowden, do we still have this much trouble vetting people before giving them security clearances?)
Mr. Dalke, who had already left the N.S.A. but told the agent that he still worked there on a temporary assignment, then revealed that had taken “highly sensitive information” related to foreign targeting of U.S. systems and information on cyber operations, the prosecutors said. He offered the information in exchange for cryptocurrency and said he was in “financial need.” Court records show he had nearly $84,000 in debt between student loans and credit cards.
EDITED TO ADD (10/5): Marcy Wheeler notes that the FBI seems to be sitting on some common recruitment point, and collecting potential Russian spies.
Защо нямаме „Закон за Фалит на Физическите лица” и как би ни помогнал?
Post Syndicated from VassilKendov original http://kendov.com/personal_bankruptcy/
 Защо нямаме „Закон за Фалита на Физическите лица” и как би ни помогнал?
Защо нямаме „Закон за Фалита на Физическите лица” и как би ни помогнал?
Ще започна с това, че години наред аз и други икономисти, и юристи сме се опитвали многократно да „убедим” политическите партии в нуждата от Закон за Фалита на Физическите лица.
Личният ми опит от последното народно събрание също претърпя неуспех, след доста арогантно отношение и изказване от трибуната на Асен Василев, но няма да ви занимавам с това. Важното е да знаете, че сегашните пратии в парламента освен, че нямат желание, нямат и капацитет да го направят. Естествено по някое време някоя партия ще бъде „мотивирана” да въвеже такъв закон, само и само да не го въведе някой друг „по-мотивиран”, по начин по който „мотивиращия” не харесва.

КАКАВО ТРЯБВА ДА РЕГУЛИРА ЕДИН ТАКЪВ ЗАКОН
В медицинската статистика се приема, че ако едно заболяване причинява 1% смътност, то всеки от нас ще има познат, който е починал от него. Така е и с лошите гредити. Сигурен съм, че всчки от вас познава човек, който има лош кредит. Тези хора рядко споделят този факт, защото ситуацията е нова и надали очакват „помощ от приятел”, което ги оставя на милостта на банките и банковото законодателство. А то не е съвсем равноправно. На практика човек става нещо като „роб” за следващите 10 години от живота си. А ако има неблагоразумието да почине в този период, децата му ще наследят задълженията му. Nice, a?
В моята практика „упътвам” доста клиенти какво да правят в този случай. Много от тях избират ЧУЖБИНА, за да не бъдат оставени на мислостта на банките и банковото законодателство в тази сфера. Друга част са принудени да излязат в сивата икономика, за да могат да живеят следващите 10 години, защото в противен случай дори да взимат 5000 лева на месец, банките ще им оставят минимална работна заплата. Как очакваме един човек да живее, да се развива и да гледа семейство с минимална работна заплата аз не знам, но законът е такъв към момента. ЕТО ТОВА ТРЯБВА ДА СЕ РЕГУЛИРА СЪС ЗАКОН ЗА ФАЛИТА НА ФИЗИЧЕСКИТЕ ЛИЦА. Трябва да се създадат условия за оставане в България на длъжниците и участието им в икономическия живот на България, а не на друга държава или сива икономика!
МАНТРАТА „ЗАЩО КРЕДИТОИСКАТЕЛЯ НЕ СИ Е НАПРАВИЛ СМЕТКАТА”
Много странен въпрос, макар и задаван от хора с претенции за добро образование.
Когато кандидатстваш за кредит, банката прави оценка на твоя личен риск и ти прави предложение. ЗАБЕЛЕЖЕТЕ – Не вие казвате на банката какъв кредит да отпусне, а банката решава какви параметри и за какъв период. И това е след оценка на риска.
Нали не си представяте как една шивачка или един компютърен специалист ще има повече икономическа информация от Отдел Риск на която и да е банка? Ако те не могат да оценят Вашия риск, след цялата предоставена информация и справки, как очаквате Вие да го оцените?
В никакъв случай не казвам, че проблемът с лошия кредит е само на банката, но определно не трябва да бъде и изцяло за сметка на получателя. Това също се регламентира със закон за фалита на физическите лица. Той ще определи докъде е отговорен кредитоискатели и докъде е отговорна банката.
За срещи и консултации по банкови кредити и неволи, моля използвайте посочената форма.
[contact-form-7]
КАК Е РЕШЕН ТОЗИ ПРОБЛЕМ В ЦИВИЛИЗОВАНИЯ СВЯТ
Има два подхода и модела на един такъв закон. Първият е АНГЛОСАКСОНСКИЯ. При него процедурите са максимално бързи и опростени с цел кредитоискателя да влезе максимално бързо отново в икономическия живот на общството и съответно да плаща данъци. Няма да влизам в подробности как функционира там един такъв закон, но 2 месеца са приемлив срок за приклюване на една такава процедура по фалит. Разбира се има и последствия свързани с невъзможност на взимане на нови кредити за определен период или купуване на стоки на изплащане, но ако работиш няма да ти взимат всички заработени пари.
Вторият е ЕВРОПЕЙСКИЯ (КОНТИНЕНТАЛНИЯ). Аз му казвам Германския. Той се характеризира с 10 годишен период, в който кредиторите си търсят парите, но за сметка на това кредитоискателят се ползва от всички придобивки на социалната система – карта за градски траспорт, помощи за безработица, здравни, социално жилище…
У НАС няма модел, защото няма такъв закон. Ние сме взели най-непрактичното от двата модела. От една страна дължиш за срок от 10 години, от друга не можеш да разчиташ на социални придобивки. Едиствените избори са свързани със сиват аикономика или чужбина.
МОЕТО ВИЖДАНЕ ПО ВЪПРОСА КАКЪВ ДА БЪДЕ МОДЕЛА У НАС
Най-важно е да създадем модел, в който хората не напускат България и не влизат в сивата икономика. Повярвайте ми веднъж влезли там, няма излизане. От една страна забравяш за държавата (и тя за теб), от друга се услажда. Губим обаче всички останали.
Предвид слабата социална политика, които имаме, не виждам начин един работещ човек да издържи на социални помощи 10 години и да се развие в някаква насока. ЗАТОВА АНГЛОСАКСОНСКИЯ МОДЕЛ Е ЗА ПРЕДПОЧИТАНЕ! Ние просто нямаме финансовата възможност да приложим германския.
Относно загубите на банките. Ако се заровите в отчетите на БНБ, ще видите, че печалбата на банковата ни система върви само нагоре. Без значение дали е криза или подем, банковата печалба расте. И какво се прави с тази печалба? Дали се харчи за „подобряване на финансовите услуги”? Кога последно си казахте – „Ей тая моята банка е страшна работа. Много съм доволен”? Аз ще Ви кажа – печалбите се изнасят!
От друга страна все още нямаме Финансов Омбудсман или бюро за кредитен рейтинг, но това е тема на друг анализ. Въпросът си остава – ПРАВИЛНО ЛИ ПРЕРАЗПРЕДЕЛЯМЕ ПЕЧАЛБАТА ОТ БАНКОВИЯ СЕКТОР? Дали няма да е по-разумно да жертваме част от нея в полза на кредитоискателите с лоши кредити, за да не отиват те в чужбина и да не излизат в сивата икономика?
Оставям всеки да реши за себе си. Аз аз продължавам да напомням за този закон и да помагам кредитоискатели с лоши кредити.
Нямам голяма надежда и за този праламент, но нищо не пречи отново да пробвам.
Ако текста Ви е харесал, моля абонирайте се за каналите в Youtube, Telegram или споделете във ФБ
https://www.youtube.com/channel/Kendov
https://t.me/KendovCom
Васил Кендов
www.Draftis.com – Кредитни Консултанти
За срещи и консултации по банкови неволи, моля използвайте посочената форма.
[contact-form-7]
The post Защо нямаме „Закон за Фалит на Физическите лица” и как би ни помогнал? appeared first on Kendov.com.
What’s Up, Home? – Staring at the Video Stream
Post Syndicated from Janne Pikkarainen original https://blog.zabbix.com/whats-up-home-staring-at-the-video-stream/23882/
Can you make sure your video streams are up with Zabbix? Of course, you can! By day, I am a monitoring technical lead in a global cyber security company. By night, I monitor my home with Zabbix & Grafana Labs and do some weird experiments with them. Welcome to my weekly blog about the project.
You might have a surveillance camera at home to record suspicious activities in your yard while you are away or so. Most of the time the cameras do work just fine but might require a hard reboot from time to time, for example, due to harsh weather, or not coming back after a network outage. A networked camera responding to ping does not 100% mean the camera is actually functional. I have seen our camera going black and refusing to connect to its stream even though it thinks it’s working just fine.
Zabbix to the rescue!
Connecting to your camera
My post for this week is mostly to maybe give you a new approach for monitoring your cameras, not so much a functional solution as I’m still figuring out how to do this properly.
For example, I can connect to our camera via RTSP protocol and pass some credentials with it, so rtsp://myusername:[email protected]:443/myAddress
To figure out a connection address for your camera model, iSpyConnect has a nice camera database.
Playing the stream
To test if the video stream works, VLC and mplayer are good options; for visually verifying the stream works, try something like
mplayer ‘rtsp://myusername:[email protected]:443/myAddress’
or for those who like to use a GUI, in VLC, File –> Open Network –> enter your camera address.
For obvious reasons, I am not posting here an image from our camera. Anyway, trust me, this method should work if you have a compatible camera.
Let’s go next for the neat tricks part, which I’m still figuring out myself, too.
Making sure the stream works
To make sure the video stream is up and running, make your Zabbix server, Zabbix proxy, or a dedicated media server to continuously stream your video feed. For example:
mplayer -vo null ‘rtsp://myusername:[email protected]:443/myAddress’
The combination above would make mplayer play the stream with a null video driver; thus, the stream will be continuously played, but just with no visual video output generated. In other words, under perfect conditions, the mplayer process should be running on the server all the time. If anything goes wrong with the stream, mplayer quits itself, and the process goes away from the process list, too.
Using Zabbix to check the player status
Now that you have some server continuously playing the stream, it’s time to check the status with Zabbix.
From here, checking the stream status with Zabbix is simple, just
- create a new item to check if for example mplayer process is around with Zabbix Agent item type and proc.num[,mplayer] key and
- make your Zabbix alert about it if the number of mplayer processes is <1
Camera screenshots to your Zabbix user interface
Both mplayer and VLC can be controlled remotely, so here’s an idea I have not yet implemented but testing out.
If a motion sensor, either an external unit or a built-in, detects movement, make Zabbix send a command to the camera to record a screenshot of the camera stream, or possibly a short video. Then just make the script to save the photo or video in a directory that Zabbix can access and then show with its URL widget type.
mplayer has a slave mode for receiving commands from external programs, which might work together with a FIFO pipe.
Real-time video stream in your Zabbix user interface
At least VLC can transcode RTSP to HTTP stream in real-time, so in theory, then embedding the resulting stream to your Zabbix user interface should very much be doable with a short HTML file and Zabbix URL widget type. This one I did not yet even start to try out, though.
So, that’s all for this week’s blog post. I’m still building this thing out, but if you have successfully done something similar, please let me know!
I have been working at Forcepoint since 2014 and am a true fan of functional testing. — Janne Pikkarainen
This post was originally published on the author’s LinkedIn account.
The post What’s Up, Home? – Staring at the Video Stream appeared first on Zabbix Blog.