Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=oTBLOvcXZBU
The “Incriminating Video” Scam
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/08/the-incriminating-video-scam.html
A few years ago, scammers invented a new phishing email. They would claim to have hacked your computer, turned your webcam on, and videoed you watching porn or having sex. BuzzFeed has an article talking about a “shockingly realistic” variant, which includes photos of you and your house—more specific information.
The article contains “steps you can take to figure out if it’s a scam,” but omits the first and most fundamental piece of advice: If the hacker had incriminating video about you, they would show you a clip. Just a taste, not the worst bits so you had to worry about how bad it could be, but something. If the hacker doesn’t show you any video, they don’t have any video. Everything else is window dressing.
I remember when this scam was first invented. I calmed several people who were legitimately worried with that one fact.
Celebrating impact: Code Clubs are thriving in Kenya and South Africa
Post Syndicated from Vicky Fisher original https://www.raspberrypi.org/blog/celebrating-impact-code-clubs-are-thriving-in-kenya-and-south-africa/
Across Kenya and South Africa, Code Clubs are going from strength to strength. We’re excited to share their incredible progress and positive impact with you and shine a spotlight on our fantastic partner organisations, whose support makes it all possible!

Partnering up to increase our reach
Code Club is a thriving global community of clubs where young people can develop the confidence to create with digital technologies in a fun and supportive space. In Kenya we’ve been working closely with Oasis Mathare, Young Scientists Kenya, Kenya Connect, Tech Kidz Africa, STEAM Labs Africa, and Futures Infinite, while in South Africa we’ve teamed up with Keep a Child Alive and Coder:Level Up.
We used a train-the-trainer model to help our partners in Kenya and South Africa train Code Club mentors. We began by training community trainers from each partner, who then went on to deliver training to club mentors. This has allowed us to reach 1,498 mentors across both countries. Club mentors told us how grateful they have been to these partners for their ongoing support, including providing training and visiting the clubs.
As part of our ongoing evaluation of the Code Club programme in Kenya and South Africa, we’ve collected feedback from our partners, club mentors, and creators via feedback surveys, club visits, and focus groups to help us understand the impact of our work.

Reaching areas of disadvantage
There are 397 Code Clubs running in Kenya and 622 in South Africa — we estimate we’re reaching over 42,000 young people through Code Clubs and nearly 20,000 through related one-off events such as summer programmes.
This broad reach means that young people who might otherwise have had limited or no access to computing are now engaging with coding, and doing so in truly exciting ways.
One Kenyan Code Club leader, working in a particularly disadvantaged and marginalised area, said Code Club was so important to young people as it means “you don’t have to be left behind”. They shared that such a large number are attending the club — and that many more are wanting to join — because young people are eager to be “part of the digital future”.
Impact on young people
89% of surveyed mentors reported an increase in their young people’s skills in coding and confidence to engage with emerging technology.
According to one South African Code Club mentor, taking part in Code Club “changes your perception and thinking…. it’s possible to do things… it becomes a reality because it’s not a really difficult thing. It’s something that you can do step by step and it really changes the mindset. It really redefines how someone thinks.”

Mentors consistently told us that young people are collaborating more, and supporting each other in their learning journeys. One South African young person perfectly captured this spirit: “if they don’t know something, we can teach it to them.”
Mentors also shared that young people are inspired to continue developing their coding and computing skills beyond club sessions. They’re actively seeking opportunities to deepen their knowledge and are already thinking about how they could use their newfound skills in their future careers.
Empowering Code Club mentors
Overall, club mentors felt well prepared to run clubs and found the training high quality and useful. This is reflected in the high percentage of mentors who agreed that the training increased their skills, confidence, and knowledge, with some partners showing an agreement rate as high as 91%.
Partners have also worked hard delivering extra training on requested topics such as additional computer skills and mentorship to help mentors feel more confident running Code Clubs.

Continuing to improve
We recognise the unique challenges that can arise when running clubs in areas of Kenya and South Africa where access to technology and the internet isn’t always consistent. We’re continuing to develop resources and support for these clubs, as well as working with partners to better understand what their clubs need.
We’re also continually reflecting on and refining our train-the-trainer model to understand how best to equip community trainers with the confidence and skills they need to train others.
Next steps
The dedication and hard work of our partners have been instrumental in allowing us to significantly expand our reach and impact in Kenya and South Africa. Alongside this incredible growth, we’ve strengthened our commitment by increasing the size of our teams operating directly from both countries. This means we can continue to grow our support for our thriving Code Club communities.
We’re excited to have a number of new partners setting up Code Clubs over the next year. We look forward to sharing the invaluable insights and feedback we’ve received from our existing partners to ensure our new partners are fully supported and feel empowered to deliver transformative Code Clubs in their areas.
Watch this space!
The post Celebrating impact: Code Clubs are thriving in Kenya and South Africa appeared first on Raspberry Pi Foundation.
Running Zabbix with PostgreSQL and PG Auto Failover
Post Syndicated from Patrik Uytterhoeven original https://blog.zabbix.com/running-zabbix-with-postgresql-and-pg-auto-failover/31026/
Running a monitoring platform like Zabbix in a production environment requires bulletproof availability at the database layer. Any downtime in PostgreSQL, even for seconds, can disrupt monitoring visibility, triggering blind spots in alerts and data collection.
This post introduces a streamlined High-Availability (HA) architecture for Zabbix using PostgreSQL, pg_auto_failover, HAProxy, and PgBackRest. Built on RHEL 9 or derivatives, this architecture removes single points of failure and automates failover using minimal external dependencies, making it a strong candidate for modern observability backends.
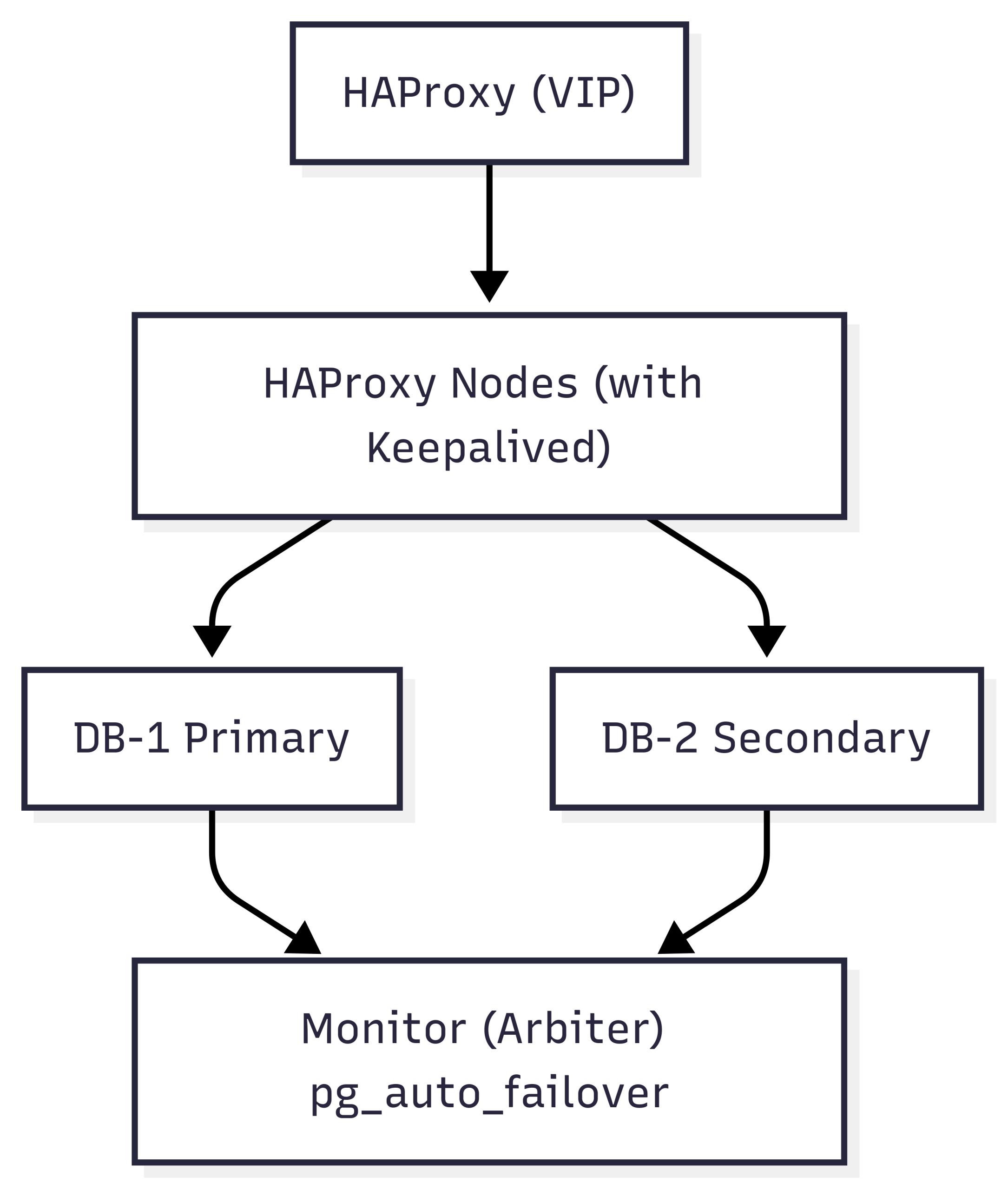
Architecture overview
This HA design simplifies deployment by using a dedicated monitor node to orchestrate automatic failover between two PostgreSQL database nodes. With pg_auto_failover, we avoid the need for complex consensus layers like etcd or Consul while still achieving fast, reliable failover and recovery.
Database layer
Two PostgreSQL nodes are deployed in a primary/secondary configuration. These nodes are registered with a dedicated pg_auto_failover monitor, which continuously checks node health and replication status. In the event of a failure, the monitor promotes the secondary to primary with no manual intervention.
Each node is securely configured using scram-sha-256 authentication and self-signed / or owned SSL certificates to ensure encrypted communication within the cluster.
Monitor node (Arbiter)
The monitor node is a lightweight PostgreSQL instance that runs the pgautofailover extension. It holds state information about all participating nodes and acts as the arbiter during failover events. It requires only one node, reducing complexity compared to consensus-based DCS (Distributed Configuration Store) systems like etcd or ZooKeeper.
Load balancing layer
Two HAProxy nodes route all client (Zabbix) connections to the current PostgreSQL primary. A lightweight HTTP service on each DB node reports its current role (primary or not) and allows HAProxy to determine which node is writable. These proxies are kept highly available using Keepalived, which manages a shared Virtual IP (VIP) across both proxy servers.
This way, applications like Zabbix always connect to a stable endpoint, even during failover events.
Backup layer
Backups are handled using PgBackRest, deployed on a dedicated backup server. This server connects to both PostgreSQL nodes over SSH and performs the following:
- Full and incremental backups
- WAL archiving
- Point-In-Time Recovery (PITR)
Passwordless SSH and proper pgbackrest.conf mappings are set up to support seamless interaction regardless of which node is currently primary.
Component overview
| Component | Role |
| PostgreSQL | Relational backend storing all Zabbix metrics, alerts, events |
| pg_auto_failover | Ensures continuous availability by promoting replicas automatically |
| Monitor Node | Decides failover based on health checks and cluster state |
| HAProxy | Routes client traffic to the current primary |
| Keepalived | Provides VIP failover between HAProxy nodes |
| PgBackRest | Performs PITR-capable backups from any node |
| Zabbix Server | Connects to PostgreSQL via VIP to ensure continuity |
Topology at a glance
Design
Unlike Patroni, which requires a distributed configuration store like etcd, pg_auto_failover uses a dedicated monitor node that simplifies orchestration. This setup reduces the operational burden while still delivering robust failover, automatic reconfiguration, and synchronization safeguards, including:
- Synchronous_standby_names to enforce replication integrity
- Service integration with systemd for reliable restarts
- Failover detection with minimal latency
This design also ensures SSL-enabled encrypted communication, self-healing role changes, and full observability using Zabbix itself, which can be configured to monitor the PostgreSQL cluster through exposed health endpoints.
Real-world considerations
- Upgrade Planning: The pg_auto_failover version in RPM repos may lag behind the latest upstream features like set_monitor_setting. Pin the package version if consistency is required.
- Network Security: Only HAProxy nodes are allowed to query the internal role-check API on the DB nodes using custom firewall rules.
- Cluster Hygiene: Always clean up config folders (~postgres/.config/pg_autoctl/…) if a node is misconfigured or needs to rejoin.
- SELinux: Configure SELinux, use semanage and audit2allow to fix custom ports (e.g., 9877 for health checks).
- Hybrid Logging: Setup PostgreSQL to log to both journald and traditional log files via stderr + logging_collector.
Conclusion
This architecture strikes a balance between simplicity and resilience. While Patroni is great for large-scale, multi-region setups requiring distributed consensus, pg_auto_failover offers a lighter-weight solution that covers most enterprise needs without complex dependencies.
By layering the following…
- PostgreSQL 17
- Pg_auto_failover with a single monitor
- HAProxy + Keepalived for VIP failover
- PgBackRest for backups
…you can then confidently run Zabbix in a highly available and secure fashion with minimal operational overhead.
If you’re considering implementing this setup or migrating from a single-node database backend, reach out to Opensource ICT Solutions, a Zabbix Premium Partner with global presence in the USA, the UK, the Netherlands, and Belgium. We can help you architect, deploy, and monitor Zabbix environments that scale with your needs.
The post Running Zabbix with PostgreSQL and PG Auto Failover appeared first on Zabbix Blog.
USS Wyoming in WWII
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/shorts/wr87wGOiWM0
Comic for 2025.08.12 – Wine
Post Syndicated from Explosm.net original https://explosm.net/comics/wine
New Cyanide and Happiness Comic
Aligning our prices and packaging with the problems we help customers solve
Post Syndicated from Liam Reese original https://blog.cloudflare.com/aligning-our-prices-and-packaging-with-the-problems-we-help-customers-solve/
At Cloudflare, we have a simple but audacious goal: to help build a better Internet. That mission has driven us to build one of the world’s largest networks, to stand up for content providers, and to innovate relentlessly to make the Internet safer, faster, and more reliable for everyone, everywhere.
Building world-class products is only part of the battle, however. Fulfilling our mission means making these products accessible, including a pricing model that is fair, predictable, and aligned with the value we provide. If our packaging is confusing, or if our pricing penalizes you for using the service, then we’re not living up to our mission. And the best way to ensure that alignment?
Listen to our customers.
Over the years, your feedback has shaped our product roadmap, helping us evolve to offer nearly 100 products across four solution areas — Application Services, Network Services, Zero Trust Services, and our Developer Platform — on a single, unified platform and network infrastructure. Recently, we’ve heard a new theme emerge: the need for simplicity. You’ve asked us, “A hundred products is a lot. Can you please be more prescriptive?” and “Can you make your pricing more straightforward?”
We heard that feedback loud and clear. That’s why we are incredibly excited to introduce Externa and Interna, two new families of use-case bundles designed to simplify your journey with Cloudflare.

When we speak with CIOs, CTOs, and CISOs, their challenges almost always boil down to connecting and protecting two fundamental domains: (1) their external, public-facing infrastructure and (2) their internal, private systems.
Historically, the industry has sold dozens of point products to solve these problems with a series of band-aids. A WAF from one vendor, a DDoS scrubber from another, a VPN from a third. The result is a mess of complexity, vendor lock-in, and a security posture riddled with gaps. It’s expensive, inefficient, and insecure.

We think that’s backwards. There’s a simpler, more integrated approach with our new solution packages:
-
Externa to connect and protect the part of your business facing the public Internet — the websites, APIs, applications, and networks that are the front doors and face of your business
-
Interna to connect and protect your internal private systems and resources — the employees, devices, data, and networks that are at the heart of your organization
These packages represent our prescriptive view on what a modern connectivity and security architecture should look like. And, they’re best when used together.

With Externa, we’re solving for the complexity of connecting and protecting your public-facing infrastructure. A key principle here is fairness. We’ve seen competitors send customers astronomical bills after a DDoS attack because they charge for all traffic — clean or malicious. It’s like a fire department charging you for the water they use to save your house. We don’t do that and never have, which is why with Externa, you only pay for legitimate traffic.

We believe a simple, integrated model will reduce total cost of ownership and lead to a stronger security posture. A patchwork of band-aids is a lot of overhead to manage. Externa bundles our WAF, DDoS, API security, networking, application performance services, and more, into a simple package with units of measure that scale with value.
What does this mean for you?
-
No attack traffic tax: your costs remain predictable, even during a massive DDoS attack.
-
Simple, value-driven price units: no origin fetch fees, duplicate charges per request, or paying per rule.
-
Simplified connectivity costs: free private interconnects to on-ramp easily, wherever you’re hosted.
And because security shouldn’t stop at your perimeter, every Externa package includes 50 seats of Interna, our SASE solution package.
With Interna, we’re fixing the broken economics of networking and security. The old models were built for a world where everyone came into an office. The world has changed: in today’s hybrid work environment, your internal network isn’t just confined to your offices and data centers anymore. It’s wherever your employees and data are. But many vendors still effectively charge you twice for the same user — once for the seat and again when they’re using the office network.

We believe you should never pay for user bandwidth. Our model recognizes that a user is a user, wherever they are; we don’t double-charge for bandwidth; we actually subtract the traffic that’s generated from user device clients from your WAN meter. We’ve gone a step further: every Interna user license contributes to a shared bandwidth pool that you can use to build a modern, secure, and fast corporate WAN. With Interna, the budget you already have for security now builds your corporate network, too.
What does this mean for you?
-
Never pay for user bandwidth: a single per-seat price covers your users wherever they work, reducing your WAN bill and eliminating the hybrid work penalty.
-
Each license expands your WAN: pooled bandwidth from user licenses helps you replace expensive, dedicated WAN contracts.
-
All-inclusive security: premium features like Digital Experience Monitoring (DEM) and both in-line and API-based Cloud Access Security Broker (CASB) are included, not expensive add-ons.

Our unique advantage has always been our network. Serving millions of customers — from individual developers on our Free plan to the world’s largest enterprises — on one platform and one global network gives us incredible leverage. It’s what allows us to offer robust free services and protect journalists and nonprofits. It’s also what makes our platform structurally better: our AI models are trained on data from 20% of the web, providing more effective threat detection than siloed platforms ever could.
We believe that the same structural advantage should help businesses of all sizes scale without compromise. As companies grow, they often face a difficult choice: does the patchwork of point products they started with become too complex to manage, or does the integrated platform they chose become too limited? You asked for a more prescriptive path, one that solves this false choice.
With our new Externa and Interna bundles, that trade-off is over. The Essentials, Advantage, and Premier tiers in each family are designed to provide a clear path for businesses of all sizes, allowing you to adopt stage-appropriate networking and security solutions that scale seamlessly. As your business grows, you move up the tiers from Essentials to Advantage to Premier, gaining access to more advanced features along the way. It’s growth, simplified.

We’ve aimed to deliver pricing and packaging that is fair, accessible, predictable, and scales with value. This is what it means to align our pricing and packaging with our principles. It’s another step toward a better Internet.
Learn more about these packages or contact our sales team today to learn how to transform your business.
Are you Confused by UniFi OS Server? Let’s Clear it Up!
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=-xXiJ1i5nc0
Accelerating Video Quality Control at Netflix with Pixel Error Detection
Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/accelerating-video-quality-control-at-netflix-with-pixel-error-detection-47ef7af7ca2e
By Leo Isikdogan, Jesse Korosi, Zile Liao, Nagendra Kamath, Ananya Poddar
At Netflix, we support the filmmaking process that merges creativity with technology. This includes reducing manual workloads wherever possible. Automating tedious tasks that take a lot of time while requiring very little creativity allows our creative partners to devote their time and energy to what matters most: creative storytelling.
With that in mind, we developed a new method for quality control (QC) that automatically detects pixel-level artifacts in videos, reducing the need for manual visual reviews in the early stages of QC.

Why This Matters
Netflix is deeply invested in ensuring our content creators’ stories are accurately carried from production to screen. As such, we invest manual time and energy in reviewing for technical errors that could distract from our members’ immersion in and enjoyment of these stories.
Teams spend a lot of time manually reviewing every shot to identify any issues that could cause problems down the line. One of the problems they look for is tiny bright spots caused by malfunctioning camera sensors (often called hot or lit pixels). Flagging those issues is a painstaking and error-prone process. They can be hard to catch even when every single frame in a shot is manually inspected. And if left undetected, they can surface unexpectedly later in production, leading to labor-intensive and costly fixes.
By automating these QC checks, we help production teams spot and address issues sooner, reduce tedious manual searches, and address issues before they accumulate.

Precision at the Pixel Level: Pixel Error Detection
Pixel errors come in two main types:
- Hot (lit) pixels: single frame bright pixels
- Dead (stuck) pixels: pixels that don’t respond to light
Earlier work at Netflix addressed detecting dead pixels using techniques based on pixel intensity gradients and statistical comparisons [1, 2]. In this work, we focus on hot pixels, which are a lot harder to flag manually.
Hot pixels in a frame can occupy only a few pixels and appear for just a single frame. Imagine reviewing thousands of high-resolution video frames looking for hot pixels. To reduce manual effort, we built a highly efficient neural network to pinpoint pixel-level artifacts in real time. While detection of hot pixels is not entirely new in video production workflows, we do it at scale and with near-perfect recall rates.
Detecting artifacts at the pixel level requires the ability to identify small-scale, fine features in large images. It also requires leveraging temporal information to distinguish between actual pixel artifacts and naturally bright pixels with artifact-like features, such as small lights, catch lights, and other specular reflections.
Given those requirements, we designed a bespoke model for this task. Many mainstream computer vision models downsample inputs to reduce dimensionality, but pixel errors are sensitive to this. For example, if we downsample a 4K frame to 480p resolution, pixel-level errors almost entirely disappear. For that reason, our model processes large-scale inputs at full resolution rather than explicitly downsampling them in pre-processing.

The network analyzes a window of five consecutive frames at a time, giving it the temporal context it needs to tell the difference between a one-off sensor glitch and a naturally bright object that persists across frames.
For every frame, the model outputs a continuous-valued map of pixel error occurrences at the input resolution. During training, we directly optimize those error maps by minimizing dense, pixel-wise loss functions.
During inference, our algorithm binarizes the model’s outputs using a confidence threshold, then performs connected component labeling to find clusters of pixel errors. Finally, it calculates the centroids of those clusters to report (x, y) locations of the found pixel errors.
All of this processing happens in real-time on a single GPU.
Building a Synthetic Pixel Error Generator
Pixel errors are rare and make up a very small portion of videos, both temporally and spatially, in the context of the total volume of footage captured and the full resolution of a given frame. Therefore, they are hard to annotate manually. Initially, we had virtually no data to train our model. To overcome this, we developed a synthetic pixel error generator that closely mimicked real-world artifacts. We simulated two main types of pixel errors: symmetrical and curvilinear.
Symmetrical: Most pixel errors are symmetrical along at least one axis.

Curvilinear: Some pixel errors follow curvilinear structures.

To create realistic training samples, we superimposed these synthetic errors onto frames from the Netflix catalog. We added those artificial hot pixels to where they would be most visible: dark, still areas in the scenes. Instead of sampling (x, y) coordinates for the synthetic errors uniformly, we sampled them from a heatmap, with selection probabilities determined by the amount of motion and image intensity.
Synthetic data was essential for training our initial model. However, to close the domain gap and improve precision, we needed to run multiple tuning cycles on fresh, real-world footage.
After training an initial model solely on this synthetic data, we refined it iteratively with real-world data as follows:
- Inference: Run the model on previously unseen footage without any added synthetic hot pixels.
- False Positive Elimination: Manually review detections and zero out labels for false positives, which is easier than labeling hot pixels from scratch.
- Fine-tuning and Iteration: Fine-tune on the refined dataset and repeat until convergence.

While false positives represent a small percentage of total input volume, they can still constitute a meaningful number of alerts in absolute terms given the scale of content processing. We continue to refine our model and reduce false positives through ongoing application on real-world datasets. This synthetic-to-real refinement loop steadily reduces false alarms while preserving high sensitivity.
Looking Ahead
What once required hours of painstaking manual review can now potentially be completed in minutes, freeing creative teams to focus on what matters most: the art of storytelling. As we continue refining these capabilities through ongoing real-world deployment, we’re inspired by the many ways production teams can gain more time to build amazing stories for audiences around the world. We are also working with our partners to better understand how pixel errors affect the viewing experience, which will help us further optimize our models.
![]()
Accelerating Video Quality Control at Netflix with Pixel Error Detection was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Comic for 2025.08.11 – Directly In Front
Post Syndicated from Explosm.net original https://explosm.net/comics/directly-in-front
New Cyanide and Happiness Comic
NVIDIA RTX Pro 4000 SFF Blackwell Edition and RTX Pro 2000 Blackwell Announced
Post Syndicated from Cliff Robinson original https://www.servethehome.com/nvidia-rtx-pro-4000-sff-blackwell-edition-and-rtx-pro-2000-blackwell-announced/
The new NVIDIA RTX Pro 4000 SFF Blackwell Edition adds newer compute and more memory to the already successful low-profile GPU formula
The post NVIDIA RTX Pro 4000 SFF Blackwell Edition and RTX Pro 2000 Blackwell Announced appeared first on ServeTheHome.
Malware analysis on AWS: Setting up a secure environment
Post Syndicated from Gilad Sharabi original https://aws.amazon.com/blogs/security/malware-analysis-on-aws-setting-up-a-secure-environment/
Security teams often need to analyze potentially malicious files, binaries, or behaviors in a tightly controlled environment. While this has traditionally been done in on-premises sandboxes, the flexibility and scalability of AWS make it an attractive alternative for running such workloads.
However, conducting malware analysis in the cloud brings a unique set of challenges—not only technical, but also policy-driven. Amazon Web Services (AWS) enforces a range of policies that govern acceptable use, prohibited activities, and testing permissions. For more information see AWS Acceptable Use Policy and AWS Service Terms.
Security teams must architect their malware analysis environments in a way that adheres to these policies, enforces strong isolation, and helps prevent misuse or escalation of privileges.
Setting up secure malware analysis environments that meet compliance requirements can be challenging, especially in cloud environments. Security teams need isolated sandbox environments, robust security controls, and proper monitoring policies to safely analyze malware. In this post, we discuss the basic steps to build these capabilities in AWS, showing you how to implement best practices for both new deployments and migrations of existing malware analysis workloads. You’ll learn how to create secure, compliance-aligned analysis environments that align with AWS policy requirements.
Problem statement
Performing malware analysis in AWS introduces unique security and operational challenges. Unlike typical workloads, malware analysis environments must be treated with heightened caution because of the risk of malicious behavior and the need to strictly adhere to the AWS Acceptable Use Policy and AWS Service Terms.
Figure 1 is a high-level illustration of the malware analysis architecture.
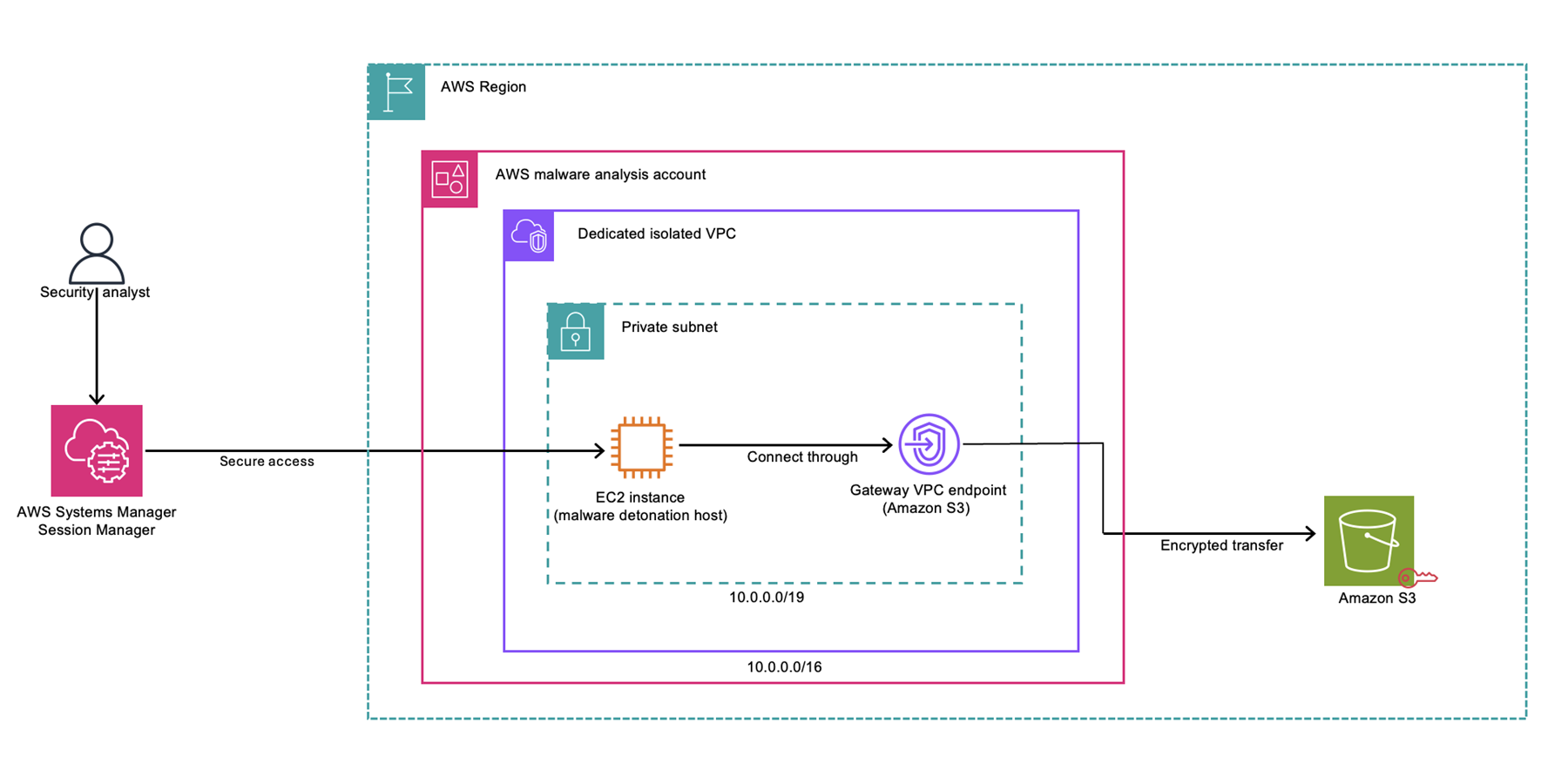
Figure 1: Malware analysis architecture
At a high level, the malware analysis architecture includes:
- A security analyst gains access to the environment through AWS Systems Manager Session Manager.
- The analyst connects to an EC2 instance (malware detonation host) in a private subnet.
- The subnet resides in a dedicated isolated VPC within the AWS malware analysis account and has no outbound connectivity.
- The EC2 instance connects to the malware samples and artifacts bucket through a VPC gateway endpoint for Amazon S3.
- Data is transferred securely using encrypted transfer.
Key considerations
Conducting malware analysis in AWS requires a thoughtful balance between flexibility, security, and compliance to help make sure that teams operate within AWS policies while minimizing risk and cost.
- Adhering to AWS policies and service terms: Activities such as simulating malware behavior or generating exploit traffic might fall under restricted use cases defined in the AWS Acceptable Use Policy and Service Terms. In addition, teams must submit a formal request for approval through the penetration testing and simulated events form for malware testing.
- Need for isolation: Malware analysis requires isolated environments that can safely contain malicious code without exposing internal resources, AWS services, or other accounts. In addition, no malicious traffic is allowed to leave the Amazon Virtual Private Cloud (Amazon VPC).
- Guardrails and lifecycle management: Without clear boundaries, sandbox accounts can become long-lived, misused, or even treated as production environments—potentially increasing your exposure to security risks or incurring ongoing costs unnecessarily. Guardrails such as budget alerts, lifecycle automation, and AWS Identity and Access Management (IAM) permission boundaries are essential.
- Lack of unified patterns: Existing AWS guidance covers sandboxing and security best practices but doesn’t provide a focused blueprint for malware analysis that aligns with policy constraints, isolation needs, and security operations.
Architecture building blocks
Designing a secure malware analysis environment in AWS begins with containment. The architecture must assume that the code under investigation is malicious and capable of attempting escape, exfiltration, or lateral movement. That’s why isolation, tight access controls, and strict egress management are a core requirement of the architecture described below.
Network isolation with Amazon VPC
The foundation of a secure sandbox is a dedicated VPC in a dedicated account that is fully isolated from other workloads. Key considerations include:
- No public IPs: Amazon Elastic Compute Cloud (Amazon EC2) instances used for analysis must launch without public IP addresses. Access should only be possible through tightly controlled bastion or jump hosts, restricted to specific corporate CIDR blocks through security groups and network access control lists (network ACLs). In addition you can use AWS Management Console tools such as Amazon Elastic Compute Cloud (Amazon EC2) Instance Connect or AWS Systems Manager Session Manager.
Note: Outbound traffic can be allowed out from AWS in a bring your own IP (BYOIP) scenario for approved use cases.
- No internet access: Egress should be completely blocked. NAT gateways, internet gateways, and VPC endpoints should be avoided unless explicitly needed and secured. This helps make sure that malware samples cannot beacon out or download additional payloads.
- DNS disabled: To help prevent malware from resolving command-and-control (C2) infrastructure, disable DNS resolution in the VPC settings unless simulation tools (such as INetSim) require it, in which case they must operate strictly inside the same VPC.
IAM and permission boundaries
IAM plays a critical role in helping to make sure that the sandbox doesn’t gain unexpected permissions over time.
- Enforce the principle of least privilege (PoLP), which means granting only the minimum permissions necessary for users, roles, and services to perform their required tasks.
- Use permission boundaries to scope what roles within the sandbox can do, even if they’re granted broader policies later.
- Help prevent sandbox IAM roles or users from creating or modifying IAM resources or attaching policies.
- Use service control policies (SCPs) to block privilege escalation or cross-account access from the start.
Instance hardening
Even though malware analysis sandbox accounts are designed to be isolated, every instance should be hardened:
- Use hardened Amazon Machine Images (AMIs) (such as CIS benchmark), and keep systems fully patched before use. See Building CIS hardened Golden Images as an example.
- Make sure that host-level monitoring is enabled using agents such as AWS Systems Manager, Amazon CloudWatch Agent, Amazon GuardDuty Runtime Monitoring, or external endpoint detection and response (EDR) tooling (without enabling internet connectivity).
Note: The Systems Manager Agent requires access to Systems Manager endpoints to maintain updates and will regularly report node status. Consider this connectivity requirement when designing your isolation strategy.
GuardDuty Runtime Monitoring requires a VPC endpoint and will transmit telemetry data to the GuardDuty service. GuardDuty findings can be generated based on activities observed on the host, which could be expected behavior in a malware analysis environment.
- Detonation hosts should be built to be ephemeral—treated as single-use, with instance refreshes after each session to avoid persistence.
Storage and containment
Proper storage configuration is critical when handling malware samples and related artifacts. Storage solutions, particularly Amazon Simple Storage Service (Amazon S3) buckets, must implement multiple layers of security controls, as described in the following lists.
Encryption requirements:
- Enable default encryption on all S3 buckets
- Use either AWS Key Management Service (AWS KMS) customer managed keys (CMK) or AWS managed keys for encryption based on your security requirements
- Enforce encryption in transit by requiring HTTPS (TLS) using bucket policies
- Deny any unencrypted object uploads using bucket policies
Network access:
- Configure VPC endpoints (gateway endpoints) for Amazon S3 to help facilitate private communication within the VPC
- Implement endpoint policies to restrict access to specific buckets and actions
- Avoid cross-account sharing of buckets used in malware analysis unless absolutely necessary and reviewed on an ongoing basis.
Access control:
- Enable Amazon S3 Block Public Access settings at both account and bucket levels
- Implement least-privilege bucket policies that explicitly deny access except to approved sandbox roles or accounts
- Use resource-based policies to help prevent cross-account access unless specifically required
- Enable Versioning in Amazon S3 to help prevent accidental or malicious overwrites
- Enable Amazon S3 Object Lock (if needed) to help prevent deletion of critical log files or samples
Monitoring, guardrails, and operational controls
A secure malware analysis environment in AWS must balance controlled flexibility with enforced boundaries. Even in an isolated VPC, human error is possible, tools might not operate as intended, and malicious code can attempt to escape or persist. That’s why you need layers: visibility, guardrails, and operational discipline.
This section covers how to monitor activity, detect threats, and enforce sandbox boundaries—whether you’re operating in an organization within AWS Organizations or a standalone account.
Monitoring activity using AWS CloudTrail
AWS CloudTrail is an AWS service that helps you enable operational and risk auditing, governance, and compliance of your AWS account. Actions taken by a user, role, or an AWS service are recorded as events in CloudTrail.
GuardDuty: Native threat detection
GuardDuty is a threat detection service that continuously monitors your AWS environment for malicious activity through the analysis of VPC Flow Logs, CloudTrail logs, and DNS logs. When implemented in a malware analysis environment, GuardDuty generates findings that detail potential security threats that it detects through machine learning models and threat intelligence feeds. Security teams should note that in a malware analysis sandbox, GuardDuty will generate findings for activities that might be intentional parts of the analysis process. It’s crucial to establish proper procedures for reviewing and categorizing these findings, distinguishing between expected sandbox behavior and actual security concerns.
Organizations should configure appropriate notification workflows and create baseline expectations for normal sandbox operations. This enables security teams to focus on findings that might indicate sandbox escape attempts or unexpected malicious activities while properly managing expected alerts from normal analysis operations. Each finding provides detailed information about the detected activity, including the affected resources, severity level, and specific details about the potential security issue, enabling teams to make informed decisions about necessary response actions.
Service control policies: Policy guardrails in AWS Organizations
For malware analysis environments, we recommend operating the sandbox account within AWS Organizations rather than as a standalone account. This strategy uses SCPs to establish critical security boundaries while maintaining necessary operational flexibility. Operating within Organizations enables centralized security policy enforcement, clear isolation from production workloads, and enhanced audit capabilities—all essential for secure malware analysis operations. While this approach might require additional governance overhead and careful organizational unit (OU) structure design, the security benefits outweigh these considerations.
By placing the malware analysis account in a dedicated OU with specific SCPs, you can enforce strict security controls while enabling necessary analysis capabilities. This organizational structure maintains clear separation from production workloads while providing the robust security controls needed for malware analysis activities. The ability to implement granular permission boundaries through SCPs, combined with centralized logging and monitoring, creates a more secure and manageable environment for conducting malware analysis while helping to prevent potential security risks from affecting other organizational resources.
For malware analysis we recommend implementing SCPs to enforce the following:
- Deny accounts from leaving the organization: When an account leaves an organization, it’s no longer bounded by the controls established within that organization. This SCP can be used to help prevent someone from moving an account to a different organization that has a set of different controls that aren’t as restrictive and there is risk of someone making undesired changes.
- Deny access to specific AWS Regions (reduce surface area): AWS has 37 Regions, yet customers scope down to one Region when it comes to malware analysis. This SCP gives you the ability to limit the Regions where AWS resources can be deployed, thus reducing the scope of impact.
- Help prevent escalation of privileges: Privilege escalation refers to the ability of a threat actor to use stealthy permissions to elevate permission levels and compromise security. To help prevent privilege escalation, use SCPs to help prevent users in your accounts from using administrative IAM actions, except from approved roles. With this policy, administrative IAM actions can be restricted to delegated IAM admins. You can use permissions boundaries to safely delegate permissions management to trusted employees or a continuous integration and delivery CI/CD pipeline.
For additional information, see Best Practices for AWS Organizations Service Control Policies in a Multi-Account Environment.
What if your account isn’t a part of an organization?
If your environment doesn’t use AWS Organizations and SCPs aren’t available, you can enforce similar boundaries using IAM permissions boundaries and identity-based policies:
- Use permissions boundaries for roles used in the sandbox to prevent them from escalating or accessing other AWS services
- Explicitly deny sensitive IAM actions (such as
iam:*Policy, iam:PassRole) at the identity policy level - Implement resource tagging policies through AWS Organizations or custom enforcement logic to provide resource ownership and control
Operational best practices
The following best practices help make sure your sandbox remains ephemeral, controlled, and cost-aware.
- Immutable by design: Treat analysis virtual machines (VMs) as disposable. Never reuse a detonation instance across sessions
- Automated teardown: Use lifecycle policies or automation scripts to destroy resources after each use
- Cost and drift control: Tag relevant resources (
Environment=sandbox, Owner=security), enable AWS Budgets, and monitor with AWS Config to help maintain sandbox hygiene
Setup checklist
This checklist provides a step-by-step guide for creating a secure malware analysis environment in AWS, focusing on isolation, access control, monitoring, and cost.
- Policy compliance
- Review the AWS Acceptable Use Policy and Service terms.
- Submit a formal request for approval through the penetration testing and simulated events form for malware testing. This needs to be done for every simulated event you plan on running.
- Account setup
- Use a dedicated AWS account for malware analysis (if the account is part of an organization, also use a dedicated OU).
- Apply SCPs to restrict Region access, deny IAM changes, and enforce tagging and encryption.
- VPC design
- Create a dedicated sandbox VPC with no internet gateway or NAT gateway.
- Disable DNS resolution at the VPC level (unless simulating Amazon EC2 behavior internally).
- Verify that no public IPs are assigned to any resource.
- Use security groups and network access control lists (network ACLs) to restrict ingress to known internal IP ranges.
- Instance configuration
- Only launch instances that are allowed AMIs.
- Disable SSH; use Systems Manager Session Manager for access.
- Use EC2 Auto Recovery or instance refresh patterns for teardown between analyses.
- Storage and logging
- Use encrypted S3 buckets for sample storage and log archival.
- Make sure that audit logs (CloudTrail) are retained and protected.
- Store logs centrally in a secure logging account.
- Monitoring and detection
- Enable GuardDuty for behavioral detection (VPC, API, and DNS analysis).
- Enable AWS Config rules to detect drift (for example, internet gateways and public IPs).
- Set up a dedicated CloudTrail log for the relevant account with multi-Region logging for full traceability.
- Enabling VPC Flow Logs and Amazon Route 53 query logs might provide additional visibility into how the malware is operating.
- IAM and permissions
- Generate policies using AWS IAM Access Analyzer policy generation. You can use this to generate an IAM policy that is based on access activity for an entity. You can then refine the policy to exactly what is needed to operate in the account and adhere to the principle of least privilege.
- Apply permission boundaries to sandbox roles to restrict privilege scope.
- IAM permissions should forbid/minimize cross account access where applicable
- Restrict use of services outside the malware analysis scope. See the following documentation on how to only allow the use of a subset of services in your environment
- Lifecycle and cost controls
- Use automation (for example, AWS Lambda or Amazon EventBridge) to shut down or delete resources on a schedule.
- Enable AWS Budgets and billing alerts to monitor spend. For more information, see Best practices for AWS Budgets.
- Tag to assist with financial allocation, ownership and support use cases (for example,
Environment=sandbox, Purpose=malware-analysis). For more information, see Best Practices for Tagging AWS Resources.
Conclusion
Malware analysis can be an effective addition to modern security operations—but when conducted in cloud environments, it demands strict architectural discipline and adherence to system-level policies. AWS offers the tools and services needed to build secure, isolated, and policy-aligned environments.
This guide has outlined a defense-in-depth approach that you can use to create a malware analysis sandbox in AWS that prioritizes isolation, visibility, and control. From VPC configuration and IAM boundaries to monitoring and organizational guardrails, each layer contributes to a controlled and repeatable environment while reducing risk to your broader AWS environment.
By following these patterns, you can empower your security teams to investigate threats without compromising the integrity, security, or governance of your broader AWS environment.
If you have questions or feedback about this post, contact AWS Support.
Immigration Enforcement #lastweektonight
Post Syndicated from LastWeekTonight original https://www.youtube.com/shorts/ZSTM7-rq4eE
Amazon EC2 defenses against L1TF Reloaded
Post Syndicated from Ali Saidi original https://aws.amazon.com/blogs/security/ec2-defenses-against-l1tf-reloaded/
The guest data of AWS customers running on the AWS Nitro System and Nitro Hypervisor is not at risk from a new attack dubbed “L1TF Reloaded.” No additional action is required by AWS customers; however, AWS continues to recommend that customers isolate their workloads using instance, enclave, or function boundaries as described in AWS public documentation. The AWS Nitro System and Nitro Hypervisor are designed to help protect against this class of attacks.
A research paper titled Rain: Transiently Leaking Data from Public Clouds Using Old Vulnerabilities, and its presentation titled Spectre in the real world: Leaking your private data from the cloud with CPU vulnerabilities, demonstrate the attack L1TF Reloaded, which combines half-Spectre gadgets with L1 Terminal Fault (L1TF) to leak guest data. While this attack can successfully leak guest data from upstream Linux/Kernel-based Virtual Machine (KVM) and other cloud providers, it does not impact the guest data of AWS customers running on the AWS Nitro System and Nitro Hypervisor.
The Nitro Hypervisor’s protection against L1TF Reloaded is not the result of a specific patch or reactive mitigation, but rather due to the proactive approach to security at AWS. The fundamental security design principles of the Nitro Hypervisor—particularly the implementation of secret hiding through an extensive use of the eXclusive Page Frame Ownership (XFPO) concept (in some contexts referred to as process-local memory)—provides robust protection against this class of attacks. L1TF Reloaded represents an innovative approach to transient execution attacks, showing how threat actors can combine seemingly mitigated vulnerabilities to create new attacks that are more than the sum of their parts. The research is impressive and constructs a multilayer end-to-end exploit with real-world applicability. AWS sponsored a portion of this work and would like to thank the researchers for their collaboration and coordinated disclosure. The remainder of this post is a deeper dive into the published research.
The Nitro Hypervisor: Purpose-built for security
The Nitro Hypervisor is a foundational component of the AWS Nitro System, designed from the ground up with security as a primary consideration. Unlike traditional hypervisors that evolved from general-purpose operating systems, the Nitro Hypervisor, which is based on Linux/Kernel-based Virtual Machine (KVM), has been intentionally minimized and purpose-built with only the capabilities needed to perform its assigned functions.
The Nitro Hypervisor’s responsibilities are deliberately constrained: it receives virtual machine (VM) management requests from the Nitro Controller, partitions memory and CPU resources using hardware virtualization features, and assigns PCIe devices, including both Physical (PF) and Single Root I/O Virtualization (SR-IOV) Virtual Functions (VF) provided by Nitro hardware (such as NVMe for EBS and instance storage, and Elastic Network Adapter for networking) and third party devices (GPUs), to VMs. Critically, the Nitro Hypervisor excludes entire categories of functionality that exist in conventional hypervisors. There is no networking stack, no general-purpose file system implementations, no peripheral device-driver support, no shell, and no interactive access mode. This meticulous exclusion of non-essential features helps avoid entire classes of issues and attack vectors that can impact other hypervisors, such as remote networking attacks or driver-based privilege escalations.
Understanding transient execution vulnerabilities
To understand why the Nitro Hypervisor’s defenses are effective against L1TF Reloaded, it is important to first understand the fundamentals of transient execution vulnerabilities that emerged in 2018. Modern CPUs implement out-of-order and prediction-based speculative execution to optimize performance by executing operations before they are needed or before the CPU knows whether it should perform them at all. When predictions are wrong, or the CPU encounters execution faults, the CPU will eventually detect these errors and roll back all speculatively computed changes to the architectural state. However, traces of these “transient executions” remain detectable in the microarchitectural state, such as data that was speculatively loaded into CPU caches, creating opportunities for data leakage through side-channel attacks.
Half-Spectre gadgets: Incomplete but dangerous code patterns
While traditional Spectre attacks require complete “gadgets” that both access secret data and transmit it through side channels, researchers have identified a weaker class of gadgets called “half-Spectre gadgets.” These are incomplete Spectre-like code patterns that perform speculative out-of-bounds memory accesses, but lack the transmission component that would make them immediately exploitable.
A classic Spectre v1 gadget contains two key elements: first, a speculative access that loads secret data (such as x = A[index] where index is out of bounds), and second, a transmission mechanism that leaks the data through a side channel (such as y = B[64 * x] that creates cache patterns based on the secret value). Half-Spectre gadgets contain only the first element—the speculative access—without the transmission component.
Because half-Spectre gadgets appear harmless in isolation, they are commonly found throughout software, including hypervisors. These gadgets typically arise from array-indexing operations where bounds checking occurs, but the transient execution window allows out-of-bounds access before the bounds check resolves. The gadgets can be either absolute (directly providing the address to access) or relative (controlling an offset from a base address), with relative gadgets being more common due to typical array indexing patterns. The key insight of L1TF Reloaded is that half-Spectre gadgets, while harmless alone, become dangerous when combined with other vulnerabilities like L1TF. A threat actor can trigger a half-Spectre gadget in the hypervisor to speculatively load arbitrary data into the L1 data cache and then use L1TF to extract that cached data—effectively turning the “harmless” half-Spectre gadget into a complete gadget.
Intel L1TF: Leveraging speculative address translation
L1 Terminal Fault (L1TF), discovered in January 2018 and disclosed in August 2018, represents a significant type of transient execution vulnerability that affects Intel processors up to Coffee Lake. These processors are used in some 5th generation EC2 instance families and all older instance types. L1TF leverages faulty address translations during transient execution when accessing invalid page table entries. Under normal operation, when a CPU encounters a Page Table Entry (PTE) with the present bit cleared or reserved bits set, address translation should halt immediately. However, during transient execution, Intel processors affected by L1TF ignore these invalid page table states and utilize a partially translated address. If the target data exists in the L1 data cache, the CPU will speculatively load it and make it available to subsequent instructions, even though the access should be blocked. This behavior is particularly problematic in virtualized environments. A malicious guest operating system can deliberately clear present bits in its own page tables to trigger terminal faults. When this happens, the CPU skips the normal host address translation process and passes the guest physical address directly to the L1 data cache. This allows the threat actor to potentially read any cached physical memory on the system, regardless of ownership or privilege boundaries. For affected processors, comprehensive software mitigation requires expensive measures, like disabling Simultaneous Multi-Threading (SMT), flushing the L1 data cache on every context switch, or disabling Extended Page Tables (EPT) entirely—performance costs so significant that many systems implement only partial mitigations.
The L1TF Reloaded attack: Exploiting mitigation gaps using Spectre
The research paper demonstrates how threat actors can combine half-Spectre gadgets with L1TF to create a powerful attack vector against hypervisors that lack complete implementation of the previously outlined mitigations. The attack shows that vulnerabilities considered individually mitigated can still be leveraged if combined in novel ways. L1TF Reloaded works by leveraging the fact that while L1TF mitigations like L1 data cache flushing and core scheduling help prevent guest-to-guest attacks, they do not fully mitigate guest-to-host attacks. The attack operates across logical cores that share the L1 data cache in an SMT core. On one logical core, the threat actor triggers a half-Spectre gadget. By mistraining the branch predictor, the threat actor causes the hypervisor to speculatively access out-of-bounds memory, loading sensitive data into the shared L1 data cache. Simultaneously, on the other logical core, the threat actor uses L1TF to extract the cached data. While other research papers have demonstrated L1TF exploitation, this research paper has successfully demonstrated a multilayer end-to-end attack on upstream Linux/KVM and other cloud providers. The authors were able to use an existing half-Spectre gadget, break host Kernel Address Space Layout Randomization (KASLR), gain host address translation capability, find all the processes running on the host, identify the victim VM, break guest KASLR, gain guest address translation capability, identify the init process in the victim VM, enumerate the child processes of the init process, identify the nginx webserver process, locate the private TLS certificate in the guest process heap, and finally leak the private TLS certificate. However, when they attempted the same attack on AWS instances, they encountered a critical limitation: while they could leak some non-sensitive host data, they were unable to access guest data due to what they described as “an undocumented defense in the hypervisor that unmaps victim data from it. This “undocumented defense” is the Nitro Hypervisor’s implementation of secret hiding—a fundamental architectural decision that prevented this type of attack.
Secret hiding: Rethinking hypervisor memory architecture
Traditional hypervisor designs follow a hierarchical privilege model where each higher level of privilege is granted access to all lower level memory. In conventional systems, the hypervisor running at the highest privilege level can access all VM memory, ostensibly for legitimate management purposes. However, this design creates a vulnerability: if a threat actor can trick the hypervisor into speculatively accessing guest data, that data becomes available for extraction through side-channel attacks. The Nitro Hypervisor takes a fundamentally different approach through a technique called secret hiding. Instead of following the traditional model where the hypervisor has access to all VM memory (Figure 1), the Nitro Hypervisor makes sure that guest data is not present in the hypervisor’s virtual address space. By removing VM memory pages from the hypervisor’s virtual address space (Figure 2), we avoid the possibility of transient execution attacks accessing guest data, even if a threat actor successfully triggers gadgets within the hypervisor.
Figure 1: Memory view of the hypervisor without mitigations in the context of VM1
Figure 2: Memory view of the Nitro Hypervisor in the context of VM1. While no guest memory is mapped, only the state of the active guest can be accessed with other guest states remaining inaccessible.
This architectural decision means that when transient execution occurs in the Nitro Hypervisor—whether through L1TF, half-Spectre gadgets, or other transient execution vulnerabilities—there is simply no guest data available to be leaked, creating a barrier against this class of vulnerabilities. The Nitro Hypervisor retains access only to its own data, but guest data remain isolated and inaccessible. While we could not anticipate L1TF Reloaded exactly, we knew transient execution vulnerabilities would continue to be discovered and built defense-in-depth mechanisms which blocked extraction of guest data on AWS instances. This design decision was made proactively during the Nitro Hypervisor development, based on our threat model that explicitly includes guest-to-host attacks that exploit the hypervisor. By assuming that threat actors might find ways to trigger transient execution vulnerabilities within the Nitro Hypervisor—whether through known vulnerabilities like L1TF or future unknown attack vectors—we designed the system to limit the scope of such attacks from the outset.
Beyond memory: Protecting guest CPU context
When VMs are scheduled and context-switched, guest CPU context information such as general-purpose and floating-point register content must be saved and restored. Guest CPU context can contain highly sensitive information. Registers might contain cryptographic keys, memory addresses that could defeat Address Space Layout Randomization (ASLR), or other secrets that applications rely on for security. In traditional hypervisors, guest CPU context is often stored in memory accessible to the hypervisor, creating another potential target for transient execution attacks. The original XPFO (eXclusive Page Frame Ownership) implementation makes sure that either user space or the kernel—but not both—can access a memory page and does not protect guest CPU context since it is exclusively owned by the kernel. The Nitro Hypervisor extends the XPFO concept to guest CPU context by saving it in memory—also known as process-local memory—that is solely mapped by process-specific kernel Page Table Entries (PTEs), as is shown in Figure 2 above. This memory is specifically designed to be only accessible from the Nitro Hypervisor in the context of the process it belongs to. This makes sure that even if a threat actor successfully triggers transient execution vulnerabilities within the Nitro Hypervisor, they cannot access the guest CPU context from other guests. The researchers confirmed this protection, noting that the AWS threat model accounts for guest-to-host attacks and that secret hiding, combined with existing L1 data cache flushing and core scheduling, prevented them from leaking guest data. This comprehensive approach to secret hiding demonstrates the defense-in-depth philosophy of the Nitro System: rather than protecting only known attack vectors, AWS systematically identifies and protects potential sources of guest data leakage, including both VM memory and guest CPU context.
Applying secret hiding principles to Xen
Most AWS Xen instances are now running on the AWS Nitro System and hence enjoy the benefits of the Nitro Hypervisor thanks to Xen-on-Nitro. For our portfolio of instance families running on the AWS Xen Hypervisor, we have implemented similar secret hiding principles to provide protection against transient execution attacks.
Defense in depth: The Nitro Hypervisor’s proven security model
L1TF Reloaded represents an important advancement in our understanding of how seemingly mitigated vulnerabilities can be combined to create new attack vectors. The researchers of the Rain paper demonstrated how L1TF and half-Spectre gadgets can work together to leak guest data from hypervisors. We are pleased to support their work and collaborate with them. The Nitro Hypervisor’s protection against L1TF Reloaded is not the result of a specific patch or reactive mitigation, but rather due to AWS deeply investing in securing multi-tenant cloud environments against sophisticated adversaries. This research reinforces our confidence in the Nitro System’s security model against both known and unknown attack vectors. The proactive security approach of AWS includes designing systems with defense-in-depth principles from the ground up. The threat landscape will continue to evolve, and at the same time, the defense-in-depth mechanisms built into the Nitro Hypervisor and our other products and services will continue to help protect AWS customers from sophisticated attacks, while maintaining the performance and functionality they depend on.
If you have questions or feedback about this post, contact AWS Support.
Hughes: LVFS Sustainability Plan
Post Syndicated from jake original https://lwn.net/Articles/1033335/
Richard Hughes, creator and maintainer of the Linux Vendor Firmware Service (LVFS), has
written a blog
post about the sustainability
plan he has put together for the service. He is calling for the
vendors that use the service to help fund its development and maintenance
going forward.
The Linux Foundation is kindly paying for all the hosting costs of the LVFS, and Red Hat pays for all my time — but as LVFS grows and grows that’s going to be less and less sustainable longer term. We’re trying to find funding to hire additional resources as a “me replacement” so that there is backup and additional attention to LVFS (and so that I can go on holiday for two weeks without needing to take a laptop with me).
This year there will be a fair-use quota introduced, with different sponsorship levels having a different quota allowance. Nothing currently happens if the quota is exceeded, although there will be additional warnings asking the vendor to contribute. The “associate” (free) quota is also generous, with 50,000 monthly downloads and 50 monthly uploads. This means that almost all the 140 vendors on the LVFS should expect no changes.
(Thanks to Paul Wise.)
[$] StarDict sends X11 clipboard to remote servers
Post Syndicated from daroc original https://lwn.net/Articles/1032732/
StarDict is a
GPLv3-licensed cross-platform dictionary application. It includes dictionaries
for a number of languages, and has a rich plugin ecosystem. It also has a
glaring security problem: while running on X11, using Debian’s default configuration,
it will send a user’s text selections over unencrypted HTTP to two remote servers.
AWS Weekly Roundup: OpenAI models, Automated Reasoning checks, Amazon EVS, and more (August 11, 2025)
Post Syndicated from Veliswa Boya original https://aws.amazon.com/blogs/aws/aws-weekly-roundup-openai-models-automated-reasoning-checks-amazon-evs-and-more-august-11-2025/
AWS Summits in the northern hemisphere have mostly concluded but the fun and learning hasn’t yet stopped for those of us in other parts of the globe. The community, customers, partners, and colleagues enjoyed a day of learning and networking last week at the AWS Summit Mexico City and the AWS Summit Jakarta.


Last week’s launches
These are the launches from last week that caught my attention:
- OpenAI open weight models on AWS — OpenAI open weight models (gpt-oss-120b and gpt-oss-20b) are now available on AWS. These open weight models excel at coding, scientific analysis, and mathematical reasoning, with performance comparable to leading alternatives.
- Amazon Elastic VMware Service — Amazon Elastic VMware Service (Amazon EVS), a new AWS service that lets you run VMware Cloud Foundation (VCF) environments directly within your Amazon Virtual Private Cloud (Amazon VPC), is now generally available.
- Automated Reasoning checks — Automated Reasoning checks, a new Amazon Bedrock Guardrails policy that was previewed during AWS re:Invent, is now generally available. Automated Reasoning checks helps you validate the accuracy of content generated by foundation models (FMs) against a domain knowledge. Read more in Danilo’s post on how this can help prevent factual errors that can be caused by AI hallucinations.
- Multi-Region application recovery service — In this post, Sébastien writes about the announcement of Amazon Application Recovery Controller (ARC) Region switch, a fully managed, highly available capability that enables organizations to plan, practice, and orchestrate Region switches with confidence, eliminating the uncertainty around cross-Region recovery operations.
Additional updates
I thought these projects, blog posts, and news items were also interesting:
- Amazon Simple Queue Service (Amazon SQS) — Amazon SQS has increased the maximum message payload size from 256 KiB to 1 MiB, enabling customers to send and receive larger messages through their Amazon SQS standard and FIFO queues.
- AWS Lambda now supports GitHub Actions — AWS Lambda now enables you to use GitHub Actions to automatically deploy Lambda functions when you push code or configuration changes to your GitHub repository, streamlining your continuous integration and continuous deployment (CI/CD) pipeline for serverless applications.
- Console-to-Code on Amazon DynamoDB — Amazon DynamoDB announced the support of Console-to-Code, powered by Amazon Q Developer. Console-to-Code to make it simple, fast, and cost-effective to create DynamoDB resources at scale by getting you started with your automation code.
- You can dive deep into conversational AI with Amazon Lex by following this course built by AWS Hero Faye Ellis, available free as part of a free trial.
- AWS Community Builder Raphael Manke has published this year’s Unofficial AWS re:Invent Session Planner 2025. This planner is becoming highly awaited every year since it first launched a few years ago.
- AWS Hero Rosius Ndimofor built Educloud Academy and it’s heartwarming to see stories from community members who’re benefiting from this platform, such as this builder who’s participating in the latest Cloud and AI Challenge.
Upcoming AWS events
Keep a look out and be sure to sign up for these upcoming events:
AWS re:Invent 2025 (December 1-5, 2025, Las Vegas) — AWS’s flagship annual conference offering collaborative innovation through peer-to-peer learning, expert-led discussions, and invaluable networking opportunities.
AWS Summits — Join free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. Coming up soon are the summits at São Paulo (August 13) and Johannesburg (August 20).
AWS Community Days — Join community-led conferences that feature technical discussions, workshops, and hands-on labs led by expert AWS users and industry leaders from around the world: Australia (August 15), Adria (September 5), Baltic (September 10), Aotearoa (September 18), and South Africa (September 20).
Join the AWS Builder Center to learn, build, and connect with builders in the AWS community. Browse here for upcoming in-person and virtual developer-focused events.
That’s all for this week. Check back next Monday for another Weekly Roundup!
– Veliswa.
[$] The rest of the 6.17 merge window
Post Syndicated from corbet original https://lwn.net/Articles/1032095/
The 6.17-rc1 prepatch was released by
Linus Torvalds on August 10; the 6.17 merge window is now closed.
There were 11,404 non-merge changesets pulled into the mainline this time
around, a little over 7,000 of which came in after the first-half merge-window summary was
written. As one would expect, quite a few changes and new features were
included in that work.
Security updates for Monday
Post Syndicated from jake original https://lwn.net/Articles/1033328/
Security updates have been issued by AlmaLinux (jackson-annotations, jackson-core, jackson-databind, jackson-jaxrs-providers, and jackson-modules-base and libxml2), Debian (distro-info-data, gnutls28, modsecurity-crs, and node-tmp), Fedora (chromium, incus, perl, perl-Devel-Cover, perl-PAR-Packer, polymake, varnish, and xen), Red Hat (kernel, kernel-rt, and rhc), and SUSE (chromedriver, ffmpeg-4, go1.23, go1.24, go1.25, govulncheck-vulndb, himmelblau, iperf, keylime-ima-policy, net-tools, sqlite3, texmaker, tomcat, and zabbix).
Distress: The History of S.O.S
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=6sAm9Uscp2U