Post Syndicated from LGR original https://www.youtube.com/watch?v=qx45r-BRHxY
Даниела Везиева отклонява искания отговор от Биволъ по ЗДОИ Служебният кабинет бави информация за е-мобилите в Ловеч
Post Syndicated from Екип на Биволъ original https://bivol.bg/%D1%81%D0%BB%D1%83%D0%B6%D0%B5%D0%B1%D0%BD%D0%B8%D1%8F%D1%82-%D0%BA%D0%B0%D0%B1%D0%B8%D0%BD%D0%B5%D1%82-%D0%B1%D0%B0%D0%B2%D0%B8-%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D1%8F-%D0%B7.html
петък 3 декември 2021

Служебното правителство на Стефан Янев и конкретно министърката на икономиката Даниела Везиева не предоставиха в 14 дневен срок исканата от “Биволъ” информацията по Закона за достъп до обществена информация (ЗДОИ)…
[$] A filesystem for namespaces
Post Syndicated from original https://lwn.net/Articles/877308/rss
It is natural, when looking at the kernel development process, to focus on
patches that find their way to acceptance and become a part of future
kernels. But there can be value in looking at work that doesn’t clear the
bar; in failing, these patches often reveal things about the kernel and the
community that creates it. Such is the case with the proof-of-concept
namespacefs
patch series recently posted by Yordan Karadzhov. One should not
expect to see namespacefs in a future kernel but, in failing, this work
showed a real use case and why it is hard to satisfy that use case in the
kernel.
Security updates for Friday
Post Syndicated from original https://lwn.net/Articles/877582/rss
Security updates have been issued by CentOS (krb5 and mailman), Debian (gmp and librecad), Fedora (php-symfony4 and wireshark), Mageia (bluez, busybox, docker-containerd, gfbgraph, hivex, nss, perl/perl-Encode, and udisks2/libblockdev), openSUSE (permissions), Oracle (mailman and mailman:2.1), Red Hat (mailman, mailman:2.1, and nss), Scientific Linux (mailman and nss), and SUSE (nodejs14).
Nikon Z – Guide to Manual Focus
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=ZmuBmANib_U
Get notified when your site is under attack
Post Syndicated from Michael Tremante original https://blog.cloudflare.com/get-notified-when-your-site-is-under-attack/
Our core application security features such as the WAF, firewall rules and rate limiting help keep millions of Internet properties safe. They all do so quietly without generating any notifications when attack traffic is blocked, as our focus has always been to stop malicious requests first and foremost.
Today, we are happy to announce a big step in that direction. Business and Enterprise customers can now set up proactive alerts whenever we observe a spike in firewall related events indicating a likely ongoing attack.
Alerts can be configured via email, PagerDuty or webhooks, allowing for flexible integrations across many systems.
You can find and set up the new alert types under the notifications tab in your Cloudflare account.
What Notifications are available?
Two new notification types have been added to the platform.
Security Events Alert
This notification can be set up on Business and Enterprise zones, and will alert on any spike of firewall related events across all products and services. You will receive the alert within two hours of the attack being mitigated.
Advanced Security Events Alert
This notification can be set up on Enterprise zones only. It allows you to filter on the exact security service you are interested in monitoring and different notifications can be set up for different services as necessary. The alert will fire within five minutes of the attack being mitigated.
Alerting on Application Security Anomalies
We’ve previously blogged about how accurately calculating anomalies in time series data sets is hard. Simple threshold alerting — “notify me if there are more than X events” — doesn’t work well. It takes a lot of work to tune the specific thresholds to be accurate, and even then you’re still likely to end up with false positives or missed events.
For Origin Error Rate notifications, we leaned on the methodology outlined in the Google SRE Handbook for alerting based on Service Level Objectives (SLOs). However, SLO alerting assumes that there is an established baseline. We know exactly what percentage of responses from your origin are “allowed” to be errors before something is definitely wrong. We don’t know what that percentage is for Firewall events. For example, Internet properties with many Firewall rules are more likely to have more Firewall events than Internet properties with few Firewall rules.
Instead of using SLO based alerting for Security Event notifications, we’re using Z-score calculations. The z-score methodology calculates how many standard deviations away from the mean a certain data point is. For Security Event notifications we can take the mean number of Firewall events for each distinct Internet property as the effective “baseline”, and compare the current number of Firewall events to see if there is a significant spike.
In this first iteration, a z-score threshold of 3.5 has been configured in the system and will be adjusted based on customer feedback. You can read more about the system in our WAF developer docs.
Getting started with Application Security Event notifications
To configure these notifications, navigate to the Notifications tab of the dashboard and click “Add”. Select Security Events Alert or Advanced Security Events Alert.
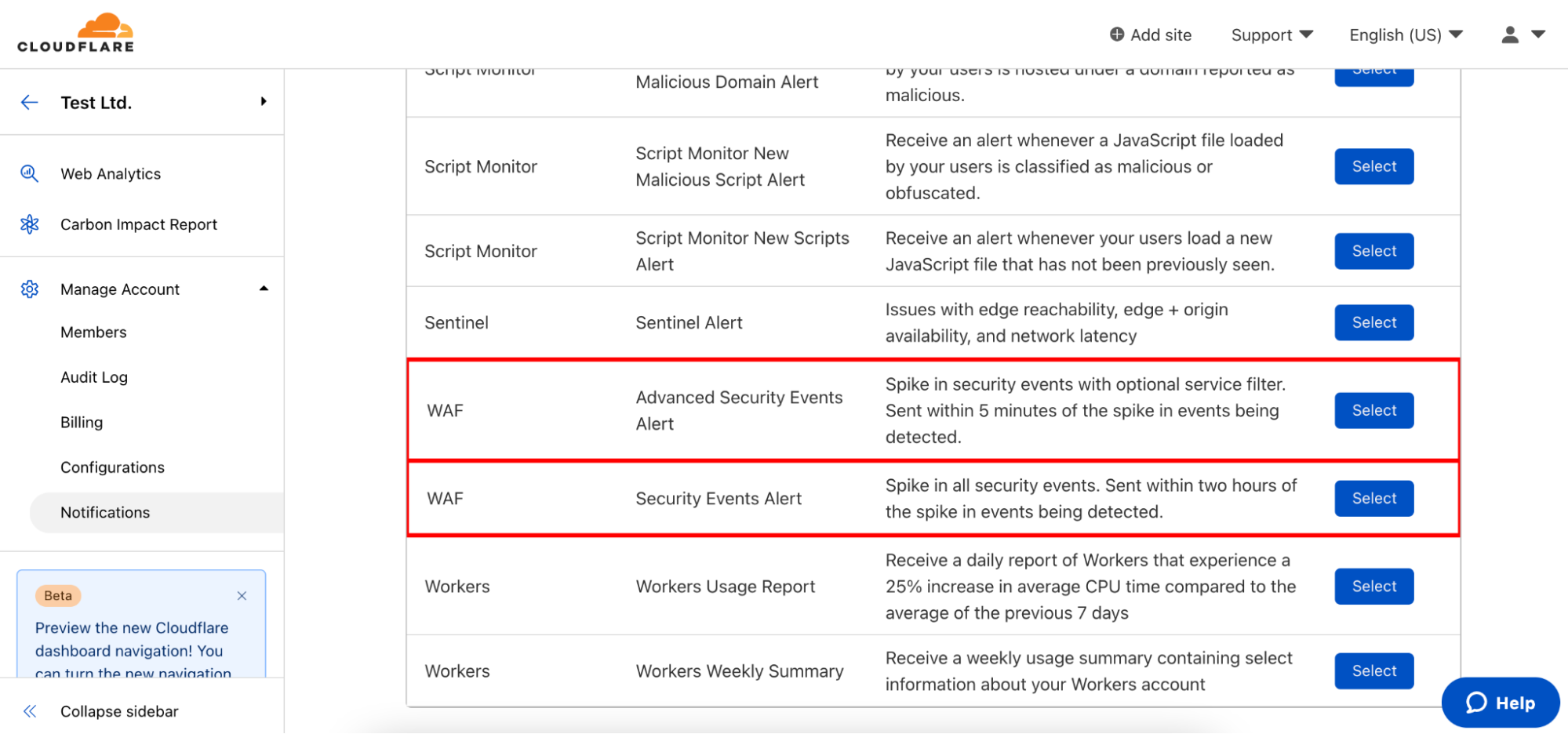
As with all Cloudflare notifications, you’re able to name and describe your notification, and choose how you want to be notified. From there, you can select which domains you want to monitor.
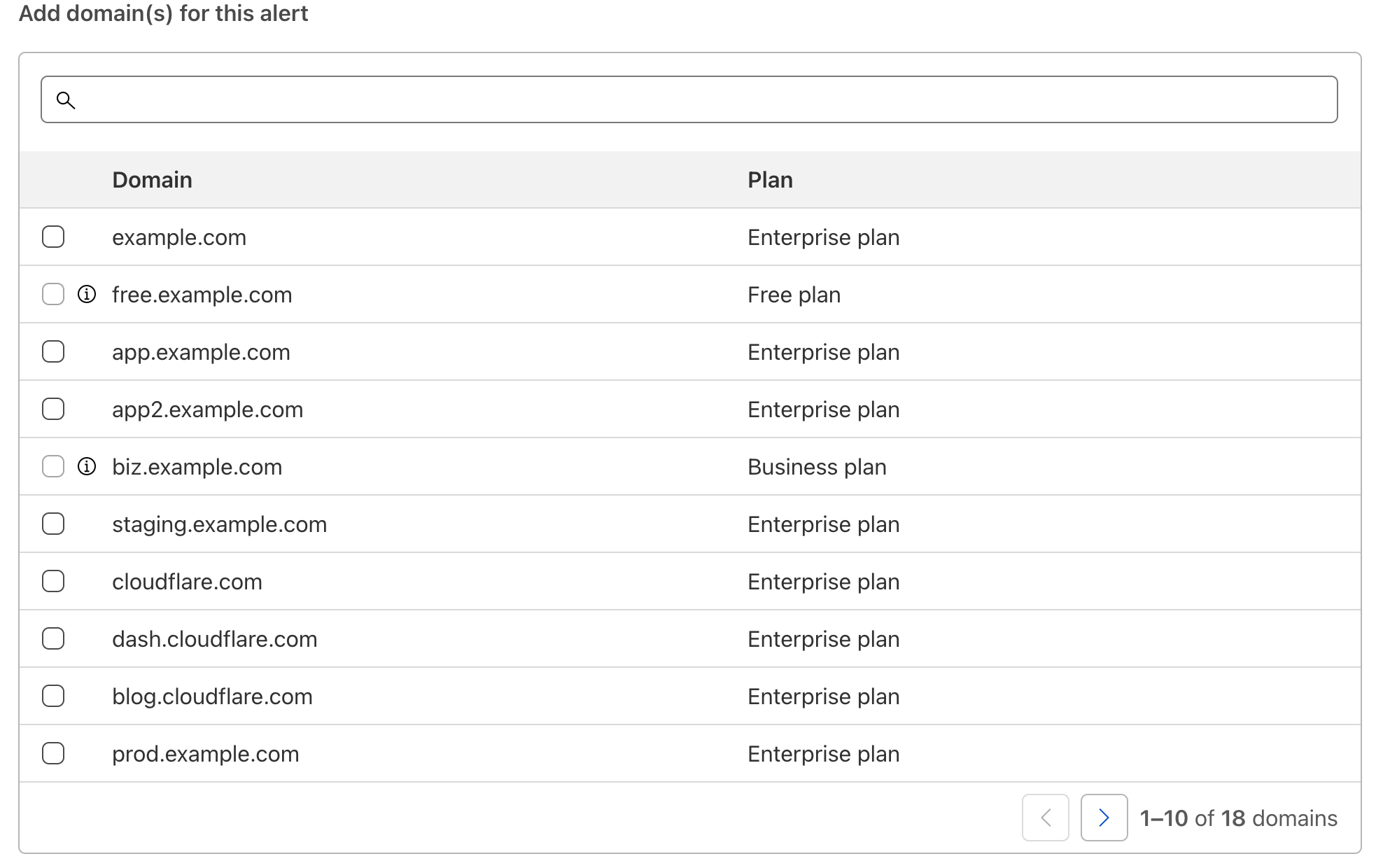
For Advanced Security Event notifications, you can also select which services the notification should monitor. The log value in Firewall Event logs for each relevant service is also displayed in the event you are integrating directly with Cloudflare logs and wish to filter relevant events in your existing SIEMs.
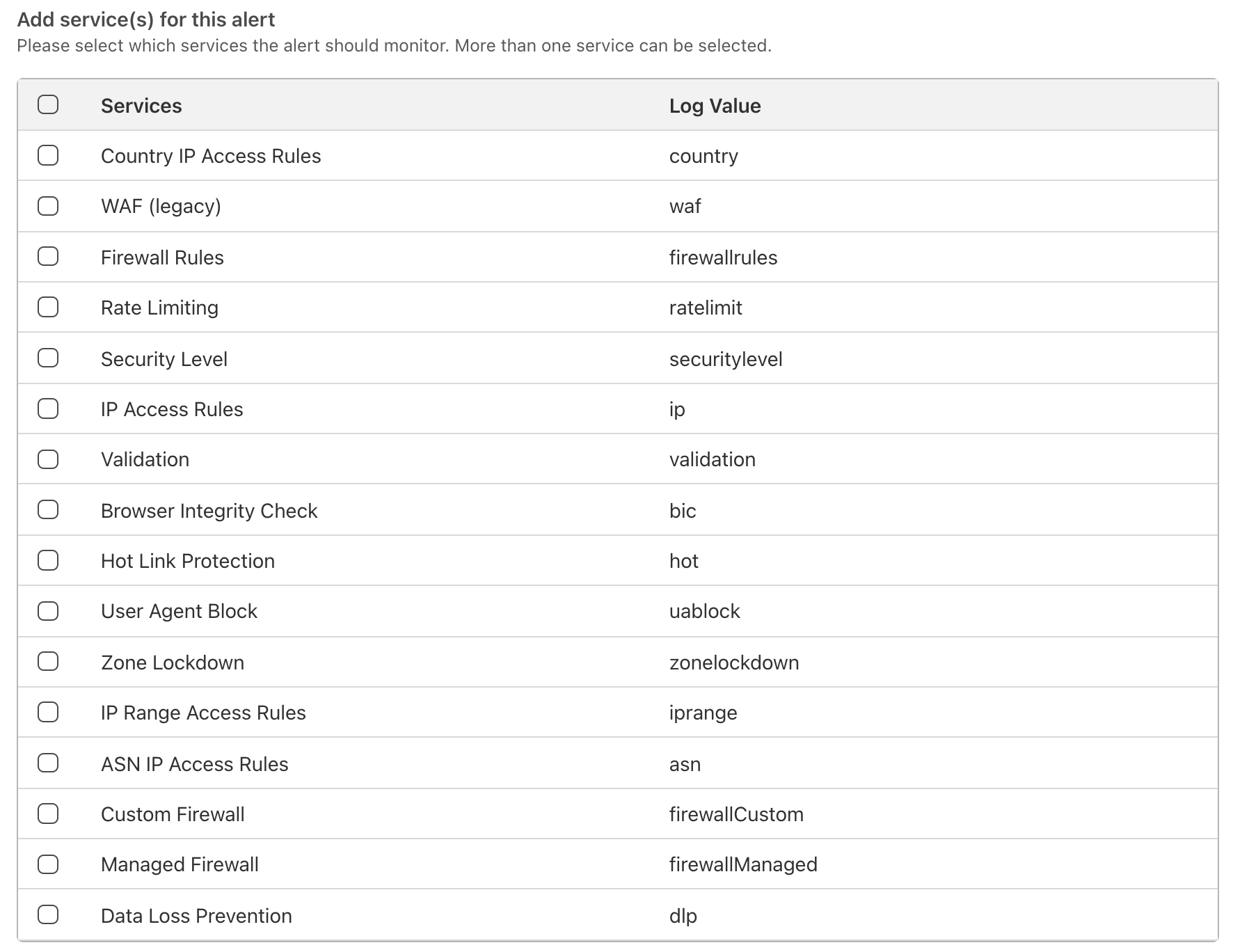
Once the notifications have been set up, you can rely on Cloudflare to warn you whenever an anomaly is detected. An example email notification is shown below:
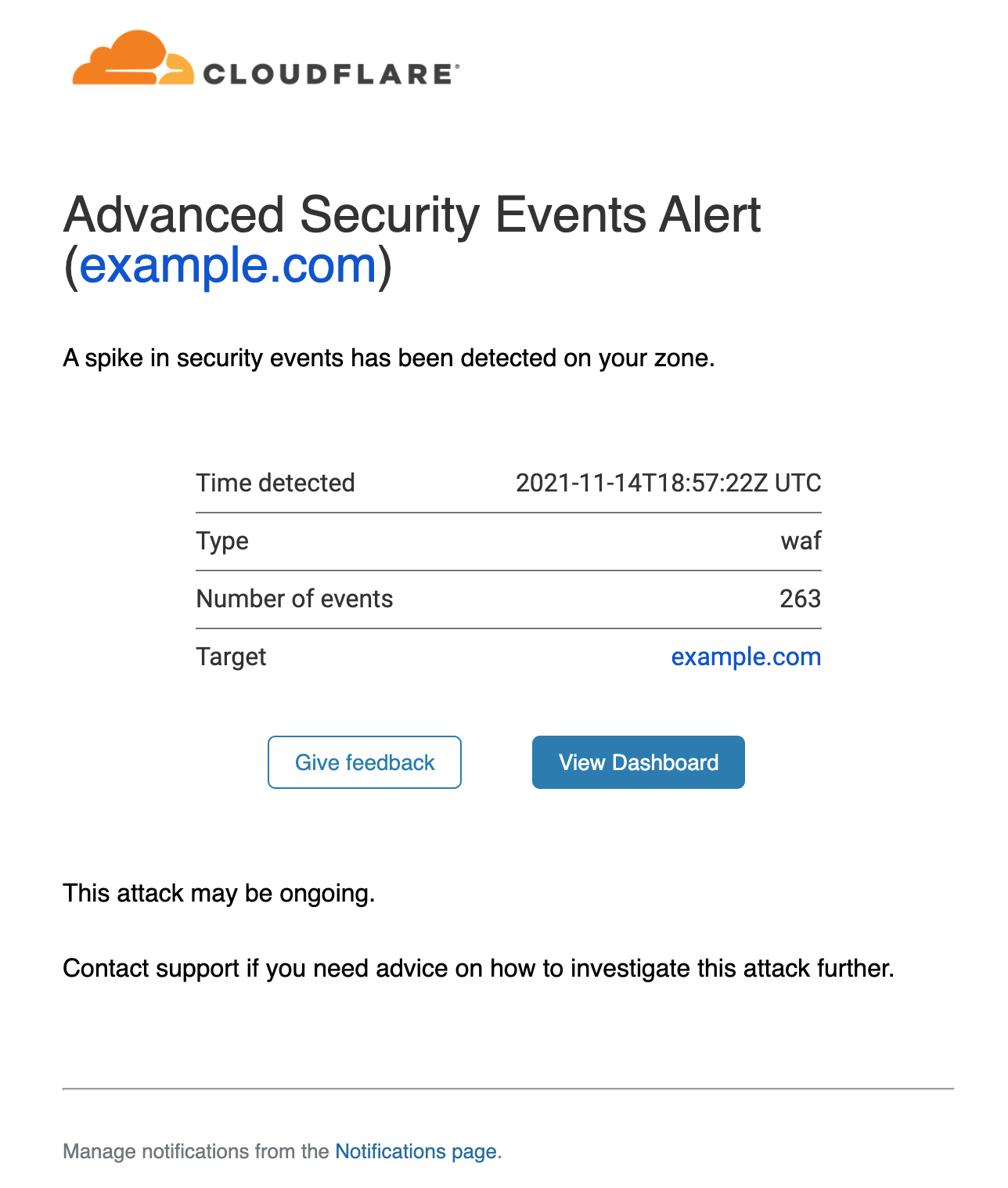
The alert provides details on the service detecting the events (in this case the WAF), the timestamp and the affected zone. A link is provided that will direct you to the Firewall Events dashboard filtered on the correct service and time range.
The first of many alerts!
We are looking forward to customers setting up their notifications, so they can stay on top of any malicious activity affecting their applications.
This is just the first step of many towards building a much more comprehensive suite of notifications and incident management systems directly embedded in the Cloudflare dashboard. We look forward to posting feature improvements to our application security alert system in the near future.
Andy Granatelli: Motorsport Legend
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=Ek3tVk-Z6eU
Testing Faraday Cages
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2021/12/testing-faraday-cages.html
Matt Blaze tested a variety of Faraday cages for phones, both commercial and homemade.
The bottom line:
A quick and likely reliable “go/no go test” can be done with an Apple AirTag and an iPhone: drop the AirTag in the bag under test, and see if the phone can locate it and activate its alarm (beware of caching in the FindMy app when doing this).
This test won’t tell you the exact attenuation level, of course, but it will tell you if the attenuation is sufficient for most practical purposes. It can also detect whether an otherwise good bag has been damaged and compromised.
At least in the frequency ranges I tested, two commercial Faraday pouches (the EDEC OffGrid and Mission Darkness Window pouches) yielded excellent performance sufficient to provide assurance of signal isolation under most real-world circumstances. None of the makeshift solutions consistently did nearly as well, although aluminum foil can, under ideal circumstances (that are difficult to replicate) sometimes provide comparable levels of attenuation.
Comic for 2021.12.03
Post Syndicated from Explosm.net original http://explosm.net/comics/6044/
New Cyanide and Happiness Comic
Mark Pollock | Unbroken | Talks at Google
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=1u8e9a0EI0A
Webb
Post Syndicated from original https://xkcd.com/2550/

Is There Justice in Felony Murder?—The Experiment Podcast
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=rSGMSnOeKW4
Field Notes: Building an Industrial Data Platform to Gather Insights from Operational Data
Post Syndicated from Shailaja Suresh original https://aws.amazon.com/blogs/architecture/field-notes-building-an-industrial-data-platform-to-gather-insights-from-operational-data/
Co-authored with Russell de Pina, former Sr. Partner Solutions Architect at AWS
Manufacturers looking to achieve greater operational efficiency need actionable insights from their operational data. Traditionally, operational technology (OT) and enterprise information technology (IT) existed in silos with various manual processes to clean and process data. Leveraging insights at a process level requires converging data across silos and abstracting the right data for the right use case in a scalable fashion.
The AWS Industrial Data Platform (IDP) facilitates the convergence of enterprise and operational data for gathering insights that lead to overall operational efficiency of the plant. In this blog, we demonstrate a sample AWS IDP architecture along with the steps to gather data across multiple data sources on the shop floor.
Overview of solution
With the IDP Reference Architecture as the backdrop, let us walk through the steps to implement this solution. Let us say we have gas compressors being used in our factory. The Operations Team has identified an anomaly in the wear of the bearings used in some of these compressors. Currently the bearings are supplied by two manufacturers, ABC and XYZ.
The graphs in Figures 1 and 2 show the expected and actual performance data of the bearings with respect to the vibration (actual and expected) against time. The points represent a cluster of plots which are represented as single dots here. The Mean Time Between Maintenance (MTBM) per the manufacturer for these bearings is five years. The factory has detected that for ABC bearings, the actual vibrations detected during its half-life is much more than the normal (expected) as shown. This clearly requires further analysis to identify the root cause for this discrepancy to prevent compressor breakdowns, unplanned downtime and cost.

Figure 1 – ABC Bearings Anomaly

Figure 2 – XYZ Bearings Vibration
Although the deviation observed from expected is much less in XYZ bearings, there is still a deviation which needs to be understood. This blog provides an overview of how the various AWS services of the IDP architecture help with this analysis. Figure 3, shows the AWS architecture used for this specific use case.

Figure 3 – IDP AWS Architecture to solve for the Bearings Anomaly
Tracking Anomaly Data
The sensors on the compressor bearings send the vibration/chatter data to AWS through AWS IoT core. Amazon Lookout for Equipment is configured as detailed out in the user guide with the necessary data formatting guidelines.
The raw sensor data from IoT Core which is in a JSON format is converted into a CSV format with the necessary headers to match the schema (one schema for each sensor) in Figure 7 using AWS Lambda. This CSV conversion is needed for the data to be processed by Amazon Lookout for Equipment. A sample sensor data from the ABC sensor, the AWS Lambda code snippet to convert this JSON to CSV and the output CSV which is to be ingested into Lookout for Equipment are shown in Figure 4,5 and 6 respectively. For detailed steps on how a dataset is created to be ingested into Lookout For Equipment, please refer the user guide.

Figure 4: Sample Sensor Data from ABC Bearings’ Sensor
import boto3
import botocore
import csv
import json
def lambda_handler(event, context):
BUCKET_NAME = 'L4EData'
OUTPUT_KEY = 'csv/ABCSensor.csv' # OUTPUT FILE
INPUT_KEY = 'ABCSensor.json'# INPUT FILE
s3client = boto3.client('s3')
s3 = boto3.resource('s3')
obj = s3.Object(BUCKET_NAME, INPUT_KEY)
data = obj.get()['Body'].read().decode('utf-8')
json_data = json.loads(data)
print(json_data)
output_file_path = "/tmp/data.csv"
with open(output_file_path, "w") as file:
csv_file = csv.writer(file)
csv_file.writerow(['TIMESTAMP', 'Sensor'])
for item in json_data:
csv_file.writerow([item.get('TIMESTAMP'),item.get('Sensor')])
csv_binary = open(output_file_path, 'rb').read()
try:
obj = s3.Object(BUCKET_NAME, OUTPUT_KEY)
obj.put(Body=csv_binary)
except botocore.exceptions.ClientError as e:
if e.response['Error']['Code'] == "404":
print("The object does not exist.")
else:
raise
try:
download_url = s3client.generate_presigned_url(
'get_object',
Params={
'Bucket': BUCKET_NAME,
'Key': OUTPUT_KEY
},
ExpiresIn=3600
)
return json.dumps(download_url)
except Exception as e:
raise utils_exception.ErrorResponse(400, e, Log)
Figure 5 – AWS Lambda Python Code snippet to Convert CSV to JSON

Figure 6 – Output CSV from AWS Lambda with Timestamp and Vibration values from Sensor

Figure 7 – Data Schema used for Dataset Ingestion in Amazon Lookout for Equipment for ABC Vibration Sensor
Once the model is trained the anomaly is detected on bearing ABC as already stated.
Analyze Factory Environment Data
For our analysis, it is important to factor in the factory environment conditions. There are variables like factory humidity, machine temperature, bearing lubrication levels that could attribute to increased vibration. We have all the environment data gathered from factory sensors made available through AWS IoT Core as shown in Figure 3. Since the number of parameters measured through the factory sensors can change over time, the architecture uses a no-SQL database, Amazon DynamoDB, to persist this data for downstream analysis.
Since we only need sensor events that exceed a particular threshold, we set rules under AWS IoT Core to capture those events that could potentially cause increased vibration on the bearings. For example, we just want only those events that exceed a temperature threshold, say anything above 75-degree Fahrenheit along with the timestamp in Amazon DynamoDB. This is beyond the normal operating temperature for the bearings and certainly demands our interest.
So, we set a rule trigger as shown in Figure 8 in the Rule query statement while defining an action under IoT Core. The flow of events from an IoT sensor to Amazon DynamoDB is illustrated in Figure 9.

Figure 8 – Define a Rule in IoT Core
The events are received on a minute basis. So, if there are 3 records inserted in Amazon DynamoDB on a day, it means that there has been a temperature threshold breach for a maximum of 3 minutes.
We set up similar rules and actions to DynamoDB for humidity and compressor lubrication levels.

Figure 9: Event from IoT factory sensor to Amazon DynamoDB
1) Factory Data Storage
It is required to factor in both the factory data like machine id, shift number, shop floor and the operator data like the operator name, machine-operator relationships, operator’s shift, etc., for this analysis since we are drilling down to the granular details of which operators where working on the machines which have ABC bearings. Since this data is relational, it is stored in Amazon Aurora. We opt for the serverless option of the Aurora database since the operations team requires a database that is fully managed.
The data of the vendors who supply ABC and XYZ bearings and their contracts are stored in Amazon S3. We also have the operators’ performance scores pre-calculated and stored in Amazon S3.
2) Querying the Data Lake
Now that we have data ingested and stored in various channels – Amazon S3, AWS IoT Core, Amazon DynamoDB and Amazon Aurora, it is required that we collate this data for further analysis and querying. We use Athena Federated Query under Amazon Athena for querying across these multiple data sources and store the results in Amazon S3 as shown in Figure 10. It is required that we create a workgroup and configure connectors to set up Amazon S3, Amazon DynamoDB and Amazon Aurora as the data sources under Amazon Athena. The detailed steps to create and connect the data sources are provided in the user guide.

Figure 10: Athena Federated Query across Data Sources
We are now interested to gather some insights across the three different data sources. Let us find all those machines and their corresponding operators with performance scores in factory shop floor 1 which have the lubrication levels as demonstrated in Figure 11.

Figure 11: Query to Determine Operators and their Performance
From the output in Table 1, we see that operators on these machines which have the machine temperature levels of above the threshold to be having good scores (above 5, which is the average) based on past performance. Hence, we could conclude for now that they have been operating these machines under the normal expected conditions with the right controls and settings.

Table 1: Operators and their Scores
We would then want to find all those machines which have ABC Bearings and the vendors who supplied them as demonstrated in Figure 12.

Figure 12: Vendors Supplying ABC Bearings

Table 2: Names of Vendors Who Supply ABC Bearings
As a next step, we would want to reach out to the vendors, Jane Doe Enterprises and Scott Inc.(see Table 2) to report the issue with ABC Bearings. The next step is to potentially modify the supply contracts and purchase only from XYZ manufacturer and/or to look for other bearing manufacturers in the vendor supply chain.
Conclusion
In this blog, we covered a sample use case to demonstrate how the AWS Industrial Data Platform can help gather actionable insights from factory floor data to gain operation efficiencies. We also did a walkthrough of a sample use case to demonstrate how the various AWS services can be used to build a scalable data platform for seamless querying and processing of data coming in with various formats.
[$] Detecting missing memory barriers with KCSAN
Post Syndicated from original https://lwn.net/Articles/877200/rss
Writing (correct) concurrent code that uses locking to avoid race
conditions is difficult enough. When the objective is to use lockless algorithms, relying on memory
barriers instead of locks to eliminate locking overhead, the problem
becomes harder
still. Bugs are easy to create and hard to find in this type of code.
There may be some help on the way, though, in the form of this
patch set from Marco Elver that enhances the Kernel
Concurrency
Sanitizer (KCSAN) with the ability to detect some types of missing
memory barriers.
New – FreeRTOS Extended Maintenance Plan for Up to 10 Years
Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/new-freertos-extended-maintenance-plan-for-up-to-10-years/
![]() Last AWS re:Invent 2020, we announced FreeRTOS Long Term Support (LTS) that offers a more stable foundation than standard releases, as manufacturers deploy and later update devices in the field. FreeRTOS is an open source, real-time operating system for microcontrollers that makes small, low-power edge devices easy to program, deploy, secure, connect, and manage.
Last AWS re:Invent 2020, we announced FreeRTOS Long Term Support (LTS) that offers a more stable foundation than standard releases, as manufacturers deploy and later update devices in the field. FreeRTOS is an open source, real-time operating system for microcontrollers that makes small, low-power edge devices easy to program, deploy, secure, connect, and manage.
In 2021, FreeRTOS LTS released 202012.01 to include AWS IoT Over-the-Air (OTA) update, AWS IoT Device Defender, and AWS IoT Jobs libraries that provides feature stability, security patches, and critical bug fixes for the next two years.
Today, I am happy to announce FreeRTOS Extended Maintenance Plan (EMP), which allows embedded developers to receive critical bug fixes and security patches on their chosen FreeRTOS LTS version for up to 10 years beyond the expiry of the initial LTS period. FreeRTOS EMP lets developers improve device security (or helps keep devices secure) for years, save on operating system upgrade costs, and reduce the risks associated with patching their devices.
FreeRTOS EMP applies to libraries covered by FreeRTOS LTS. Therefore, developers have device lifecycles longer than the LTS period of 2 years and can continue using a version that provides feature stability, security patches, and critical bug fixes, all without having to plan a costly version upgrade.
Here are main features of FreeRTOS EMP:
| Features | Description | Why is it important? |
| Feature stability | Get FreeRTOS libraries that maintain the same set of features for years | Save upgrade costs by using a stable FreeRTOS codebase for their product lifecycle |
| API stability | Get FreeRTOS libraries that have stable APIs for years | |
| Critical fixes | Receive security patches and critical bug* fixes on your chosen FreeRTOS libraries | Security patches help keep their IoT devices secure for the product lifecycle |
| Notification of patches | Receive timely notification upcoming patches | Timely awareness of security patches helps proactively plan the deployment of patches |
| Flexible subscription plan | Extend maintenance by a year or longer | Continue to renew their annual subscription for a longer period to keep the same version for the entire device lifecycle, or for a shorter period to buy time before upgrading to the latest FreeRTOS version. |
* A critical bug is a defect determined by AWS to impact the functionality of the affected library and has no reasonable workaround.
Getting Started with FreeRTOS EMP
To get started, subscribe to the plan using your AWS account, and renew the subscription annually or for a longer period to either cover their product lifecycle or until you are ready to transition to a new FreeRTOS LTS release.
 Before the end of the current LTS period, you will be able to use your AWS account to complete the FreeRTOS EMP registration on the FreeRTOS console, review and agree to the associated terms and conditions, select the LTS version, and buy an annual subscription. You will then gain access to the private repository where you’ll receive .zip files containing a git repo with chosen libraries, patches, and related notifications.
Before the end of the current LTS period, you will be able to use your AWS account to complete the FreeRTOS EMP registration on the FreeRTOS console, review and agree to the associated terms and conditions, select the LTS version, and buy an annual subscription. You will then gain access to the private repository where you’ll receive .zip files containing a git repo with chosen libraries, patches, and related notifications.
Under NDA, AWS will notify you via official AWS Security channels of an upcoming patch and its timelines (if AWS is reasonably able to do so and deems it appropriate). Patches will be sent to your private repository within three business days of successfully implementing and getting AWS Security approval for our mitigation.
AWS will provide technical support for FreeRTOS EMP customers via separate subscriptions to AWS Support. AWS Support is not included in FreeRTOS EMP subscriptions. You can track issues such as AWS accounts, billing, and bugs, or get access to technical experts such as patch integration issues based on your AWS Support plan.
Available Now
FreeRTOS EMP will be available for the current and all previous FreeRTOS LTS releases. Subscriptions can be renewed annually for up to 10 years from the end of the chosen LTS version’s support period. For example, a subscription for FreeRTOS 202012.01 LTS, whose LTS period ends March 2023, may be renewed annually for up to 10 years (i.e., March 2033).
You can find more information on the FreeRTOS feature page. Please send us feedback on the forum of FreeRTOS or AWS Support.
Sign up to get periodic updates on when and how you can subscribe to FreeRTOS EMP.
— Channy
AWS re:Post – A Reimagined Q&A Experience for the AWS Community
Post Syndicated from Steve Roberts original https://aws.amazon.com/blogs/aws/aws-repost-a-reimagined-qa-experience-for-the-aws-community/
The internet is an excellent resource for well-intentioned guidance and answers. However, it can sometimes be hard to tell if what you’re reading is, in fact, advice you should follow. Also, some users have a preference toward using a single, trusted online community rather than the open internet to provide them with reliable, vetted, and up-to-date answers to their questions.
Today, I’m happy to announce AWS re:Post, a new, question and answer (Q&A) service, part of the AWS Free Tier, that is driven by the community of AWS customers, partners, and employees. AWS re:Post is an AWS-managed Q&A service offering crowd-sourced, expert-reviewed answers to your technical questions about AWS that replaces the original AWS Forums. Community members can earn reputation points to build up their community expert status by providing accepted answers and reviewing answers from other users, helping to continually expand the availability of public knowledge across all AWS services.

You’ll find AWS re:Post to be an ideal resource when:
- You are building an application using AWS, and you have a technical question about an AWS service or best practices.
- You are learning about AWS or preparing for an AWS certification, and you have a question on an AWS service.
- Your team is debating issues related to design, development, deployment, or operations on AWS.
- You’d like to share your AWS expertise with the community and build a reputation as a community expert.
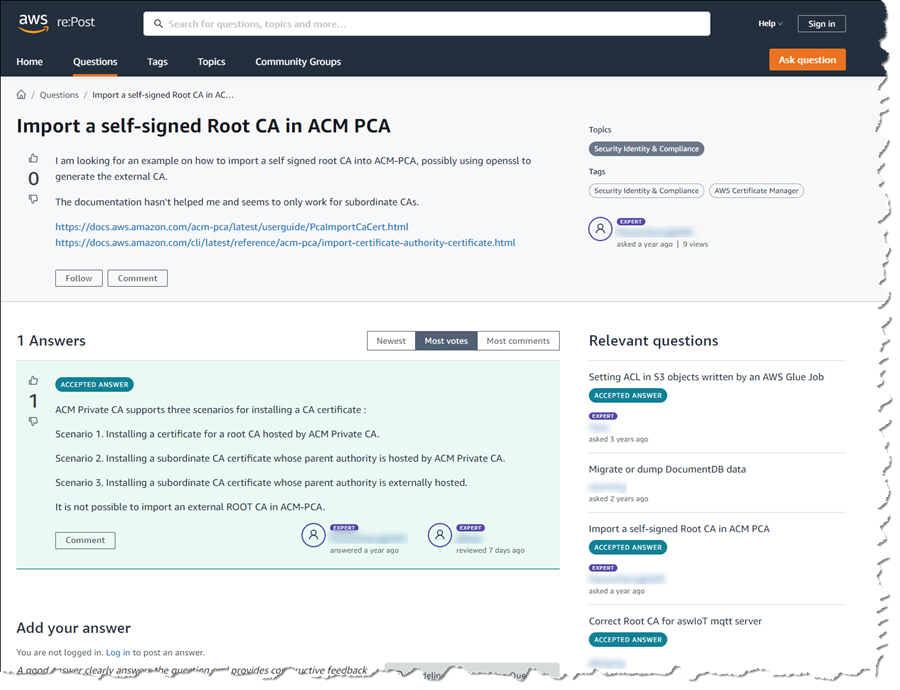
There is no requirement to sign in to AWS re:Post to browse the content. For users who do choose to sign in, using their AWS account, there is the opportunity to create a profile, post questions and answers, and interact with the community. Profiles enable users to link their AWS certifications through Credly and to indicate interests in specific AWS technology domains, services, and experts. AWS re:Post automatically shares new questions with these community experts based on their areas of expertise, improving the accuracy of responses as well as encouraging responses for unanswered questions. An opt-in email is also available to receive email notifications to help users stay informed.
Over the last four years, AWS re:Post has been used internally by AWS employees helping customers with their cloud journeys. Today, that same trusted technical guidance becomes available to the entire AWS community. Additionally, all active users from the previous AWS Forums have been migrated onto AWS re:Post, as well as the most-viewed content.
Questions from AWS Premium Support customers that do not receive a response from the community are passed on to AWS Support engineers. If the question is related to a customer-specific workload, AWS support will open a support case to take the conversation into a private setting. Note, however, that AWS re:Post is not intended to be used for questions that are time-sensitive or involve any proprietary information, such as customer account details, personally identifiable information, or AWS account resource data.
Have Questions? Need Answers? Try AWS re:Post Today
If you have a technical question about an AWS service or product or are eager to get started on your journey to becoming a recognized community expert, I invite you to get started with AWS re:Post today!
New – Sustainability Pillar for AWS Well-Architected Framework
Post Syndicated from Alex Casalboni original https://aws.amazon.com/blogs/aws/sustainability-pillar-well-architected-framework/
The AWS Well-Architected Framework has been helping AWS customers improve their cloud architectures since 2015. The framework consists of design principles, questions, and best practices across multiple pillars: Operational Excellence, Security, Reliability, Performance Efficiency, and Cost Optimization.
Today we are introducing a new Sustainability Pillar to help organizations learn, measure, and improve their workloads using environmental best practices for cloud computing.
Similar to the other pillars, the Sustainability Pillar contains questions aimed at evaluating the design, architecture, and implementation of your workloads to reduce their energy consumption and improve their efficiency. The pillar is designed as a tool to track your progress toward policies and best practices that support a more sustainable future, not just a simple checklist.
The Shared Responsibility Model of Cloud Sustainability
The shared responsibility model also applies to sustainability. AWS is responsible for the sustainability of the cloud, while AWS customers are responsible for sustainability in the cloud.
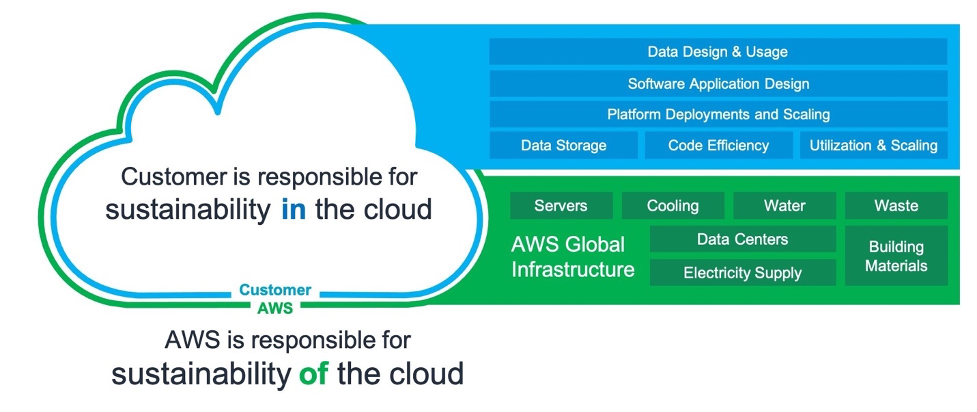
The sustainability of the cloud allows AWS customers to reduce associated energy usage by nearly 80% with respect to a typical on-premises deployment. This is possible because of the much higher server utilization, power and cooling efficiency, custom data center design, and continued progress on the path to powering AWS operations with 100% renewable energy by 2025. But we can achieve much more by collectively designing sustainable architectures.
We are introducing the new Sustainability Pillar to help organizations improve their sustainability in the cloud. This is a continuous effort focused on energy reduction and efficiency of all types of workloads. In practice, the pillar helps developers and cloud architects surface the trade-offs, highlight patterns and best practices, and avoid anti-patterns. For example, selecting an efficient programming language, adopting modern algorithms, using efficient data storage techniques, and deploying correctly sized and efficient infrastructure.
Specifically, the pillar is designed to support organizations in developing a better understanding of the state of their workloads, as well as the impact related to defined sustainability targets, how to measure against these targets, and how to model where they cannot directly measure.
In addition to building sustainable workloads in the cloud, you can use AWS technology to solve broader sustainability challenges. For example, reducing the environmental incidents caused by industrial equipment failure using Amazon Monitron to detect abnormal behavior and conduct preventative maintenance. We call this sustainability through the cloud.
Well-Architected Design Principles for Sustainability in the Cloud
The Sustainability Pillar includes design principles and operational guidance, as well as architectural and software patterns.
The design principles will facilitate good design for sustainability:
- Understand your impact – Measure business outcomes and the related sustainability impact to establish performance indicators, evaluate improvements, and estimate the impact of proposed changes over time.
- Establish sustainability goals – Set long-term goals for each workload, model return on investment (ROI) and give owners the resources to invest in sustainability goals. Plan for growth and design your architecture to reduce the impact per unit of work such as per user or per operation.
- Maximize utilization – Right size each workload to maximize the energy efficiency of the underlying hardware, and minimize idle resources.
- Anticipate and adopt new, more efficient hardware and software offerings – Support upstream improvements by your partners, continually evaluate hardware and software choices for efficiencies, and design for flexibility to adopt new technologies over time.
- Use managed services – Shared services reduce the amount of infrastructure needed to support a broad range of workloads. Leverage managed services to help minimize your impact and automate sustainability best practices such as moving infrequent accessed data to cold storage and adjusting compute capacity.
- Reduce the downstream impact of your cloud workloads – Reduce the amount of energy or resources required to use your services and reduce the need for your customers to upgrade their devices; test using device farms to measure impact and test directly with customers to understand the actual impact on them.
Well-Architected Best Practices for Sustainability
The design principles summarized above correspond to concrete architectural best practices that development teams can apply every day.
Some examples of architectural best practices for sustainability:
- Optimize geographic placement of workloads for user locations
- Optimize areas of code that consume the most time or resources
- Optimize impact on customer devices and equipment
- Implement a data classification policy
- Use lifecycle policies to delete unnecessary data
- Minimize data movement across networks
- Optimize your use of GPUs
- Adopt development and testing methods that allow rapid introduction of potential sustainability improvements
- Increase the utilization of your build environments
Many of these best practices are generic and apply to all workloads, while others are specific to some use cases, verticals, and compute platforms. I’d highly encourage you to dive into these practices and identify the areas where you can achieve the most impact immediately.
Transforming sustainability into a non-functional requirement can result in cost effective solutions and directly translate to cost savings on AWS, as you only pay for what you use. In some cases, meeting these non-functional targets might involve tradeoffs in terms of uptime, availability, or response time. Where minor tradeoffs are required, the sustainability improvements are likely to outweigh the change in quality of service. It’s important to encourage teams to continuously experiment with sustainability improvements and embed proxy metrics in their team goals.
Available Now
The AWS Well-Architected Sustainability Pillar is a new addition to the existing framework. By using the design principles and best practices defined in the Sustainability Pillar Whitepaper, you can make informed decisions balancing security, cost, performance, reliability, and operational excellence with sustainability outcomes for your workloads on AWS.
Learn more about the new Sustainability Pillar.
— Alex
Announcing General Availability of Construct Hub and AWS Cloud Development Kit Version 2
Post Syndicated from Steve Roberts original https://aws.amazon.com/blogs/aws/announcing-general-availability-of-construct-hub-and-aws-cloud-development-kit-version-2/
Today, I’m happy to announce that both the Construct Hub and AWS Cloud Development Kit (AWS CDK) version 2 are now generally available (GA).
The AWS CDK is an open-source framework that simplifies working with cloud resources using familiar programming languages: C#, TypeScript, Java, Python, and Go (in developer preview). Within their applications, developers create and configure cloud resources using reusable types called constructs, which they use just as they would any other types in their chosen language. It’s also possible to write custom constructs, which can then be shared across your teams and organization.
With the new releases generally available today, defining your cloud resources using the CDK is now even more simple and convenient, and the Construct Hub enables sharing of open-source construct libraries within the wider cloud development community.

AWS Cloud Development Kit (AWS CDK) Version 2
Version 2 of the AWS CDK focuses on productivity improvements for developers working with CDK projects. The individual packages (libraries) used in version 1 to distribute and consume the constructs available for each AWS service have been consolidated into a single monolithic package. This simplifies dependency management in your CDK applications and when publishing construct libraries. It also makes working with CDK projects that reference constructs from multiple services more convenient, especially when those services have peer dependencies (for example, an Amazon Simple Storage Service (Amazon S3) bucket that needs to be configured with an AWS Key Management Service (KMS) key).
Version 1 of the CDK contained some APIs that were experimental. Over time, some of these were marked as deprecated in favor of other preferred approaches based on community experience and feedback. The deprecated APIs have been removed in version 2 to aid clarity for developers working with construct properties and methods. Additionally, the CDK team has adopted a new release process for creating and releasing experimental constructs without needing to include them in the monolithic GA package. From version 2 onwards, the monolithic CDK package will contain only stable APIs that customers can always rely on. Experimental APIs will be shipped in separate packages, making it easier for the team and community to revise them and ensure customers don’t incur the accidental breaking changes that caused some issues in version 1.
You can read about all the changes in version 2 of the AWS CDK, and how you can update your CDK applications to use it, in the Developer Guide.
Construct Hub
The Construct Hub is a single home where the open-source community, AWS, and cloud technology providers can discover and share construct libraries for all CDKs. The most popular CDKs today are AWS CDK, which generates AWS CloudFormation templates; cdk8s, which generates Kubernetes manifests; and cdktf, which generates Terraform JSON files. Anyone can create a CDK, and we are open to adding other construct-based tools as they evolve!
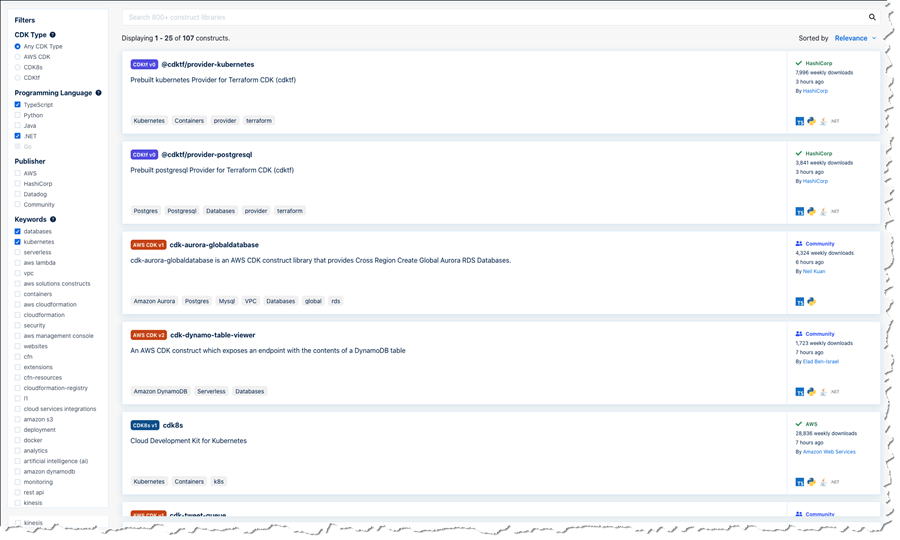
As of this post’s publication, the Construct Hub contains over 700 CDK libraries, including core AWS CDK modules, to help customers build their cloud applications using their preferred programming languages, for their preferred use case, and with their preferred provisioning engine (CloudFormation, Terraform, or Kubernetes). For example, there are 99 libraries for working with containers, 210 libraries for serverless development, 53 libraries for websites, 65 libraries for integrations with cloud services providers like Datadog, Logz.io, Cloudflare, Snyk, and more, and dozens of additional libraries which integrate with Slack, Twitter, GitLab, Grafana, Prometheus, WordPress, Next.js, and more. Many of these were created by the open-source community.
Anyone can contribute construct libraries to the Construct Hub. New libraries that you wish to share need to be published to the npm public registry and tagged. The Construct Hub will automatically detect the published libraries and make them visible and discoverable to consumers on the hub. Consumers can search and filter for construct libraries for familiar technologies, third-party integrations, AWS services, and use cases such as compliance, monitoring, websites, containers, serverless, and more. Filters are available for publisher, language, CDK type, and keywords. In the screenshot below, I’m searching the hub for .NET and TypeScript libraries related to databases and Kubernetes across all CDKs. I could also filter to a specific CDK or a CDK version.
Publishers determine which programming languages should be supported by their packages. Construct Hub then automatically generates API references for all the supported languages and transliterates all code samples the authors provide to those supported languages. The screenshots below show an example of language-specific API documentation for the cdk-spa-deploy construct library, which you can use to deploy a single-page web application (SPA). First, the documentation for .NET developers working with the library:
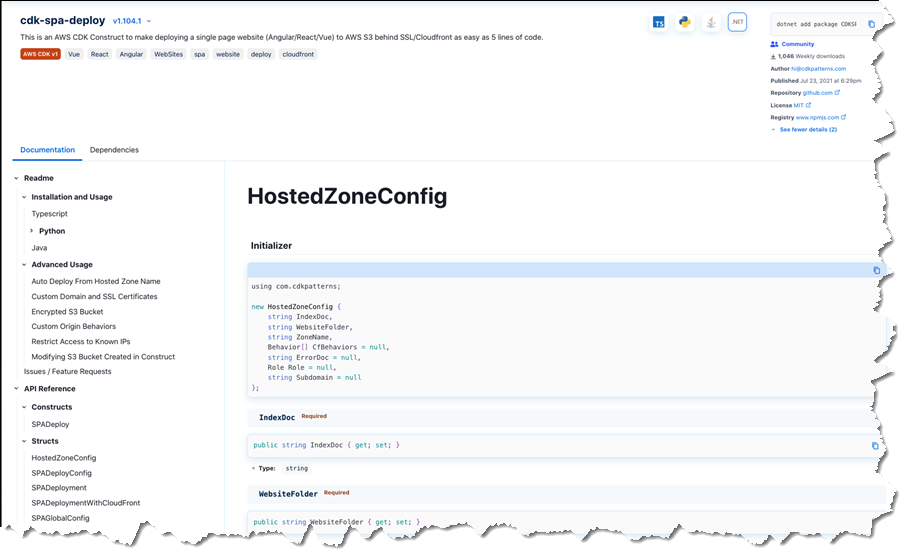
The second image below shows the generated documentation for the same construct library, but this time for TypeScript developers:
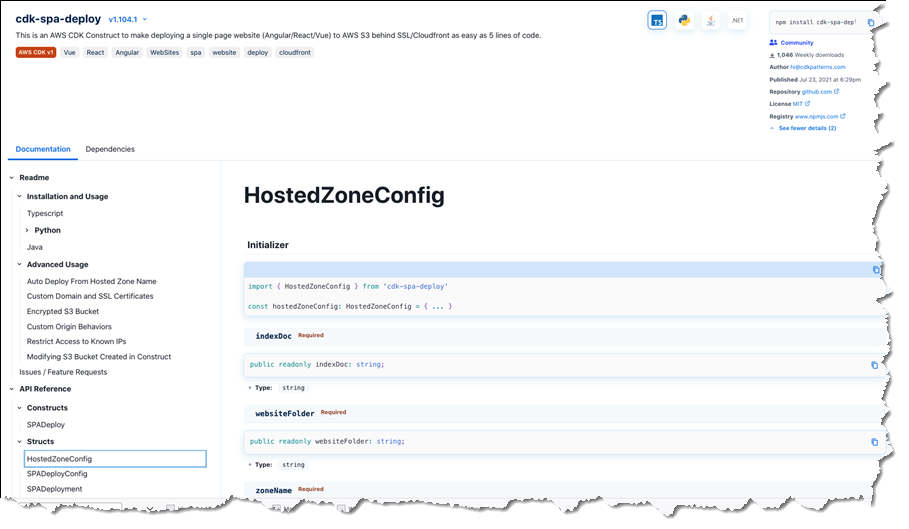
All construct libraries published to the Construct Hub must be open-source. This enables users to exercise their good judgment and perform due diligence to verify that the libraries meet their security and compliance needs, just as they would with any other third-party package source consumed in their applications. Issues with a published construct library can be raised on the library’s GitHub repository using convenient links accessible from the hub entry for the library.
The Construct Hub employs a trust-through-transparency model. Users can report libraries for abuse by clicking the ‘Report abuse’ link in the hub, which will engage AWS Support teams to investigate the issue and remove the offending packages from Construct Hub listings if problems are found. Users can also send us feedback by clicking a ‘Provide feedback to Construct Hub’ link, which allows them to open an issue on our GitHub repository. And last but not least, they can click ‘Provide feedback to publisher’, which redirects to the repository the publisher provided with the package.
Just like the AWS CDK, the Construct Hub is open-source, built as a construct, and is, in fact, itself available on the Construct Hub! If you’re interested, you can see how the CDK team uses the CDK to develop the hub in their GitHub repository.
Get Started with the AWS CDK Version 2 and the Construct Hub, Today
If you’ve built CDK applications to define your cloud infrastructure using version 1 of the AWS Cloud Development Kit (AWS CDK), then I encourage you to take a look at the documented changes for version 2 and see how the new version can help simplify your project setup going forward. And, if you’re interested in sharing new constructs with the wider community, please get involved with the Construct Hub.
What Are Microservices?
Post Syndicated from Molly Clancy original https://www.backblaze.com/blog/what-are-microservices/

Back in 2008, Netflix was facing scaling challenges: service outages, database corruption, a three-day lapse in DVD shipments. (Remember when Netflix still shipped DVDs?) Netflix solved these problems by refactoring their monolithic application to avoid the single points of failure that caused these issues. They implemented a microservices architecture before the term “microservices” even existed, making them pioneers in the field.
Today, almost all of the most popular applications—Uber, Amazon, Etsy—run in a microservices environment. If you’ve ever wondered what that means, you’re not alone. In this post, we’re digging into this popular method for developing web applications: the benefits, drawbacks, and considerations for choosing a cloud provider to support your microservices approach.
First, Some History: Monolithic Software Development
How would you develop a large, complex software system before the age of microservices? For developers who learned their craft in the dot com boom, it meant a large and complex development process, with tightly interlocking subsystems, a waterfall development model, and an extensive QA phase. Most of the code was built from scratch. There was a lot of focus on developing extremely reliable code, since it was very difficult and expensive to update products in the field. This is how software was developed for many years. The approach works, but it has some major issues. It’s slower, and it tends to produce complex software monoliths that are tough to maintain and upgrade.
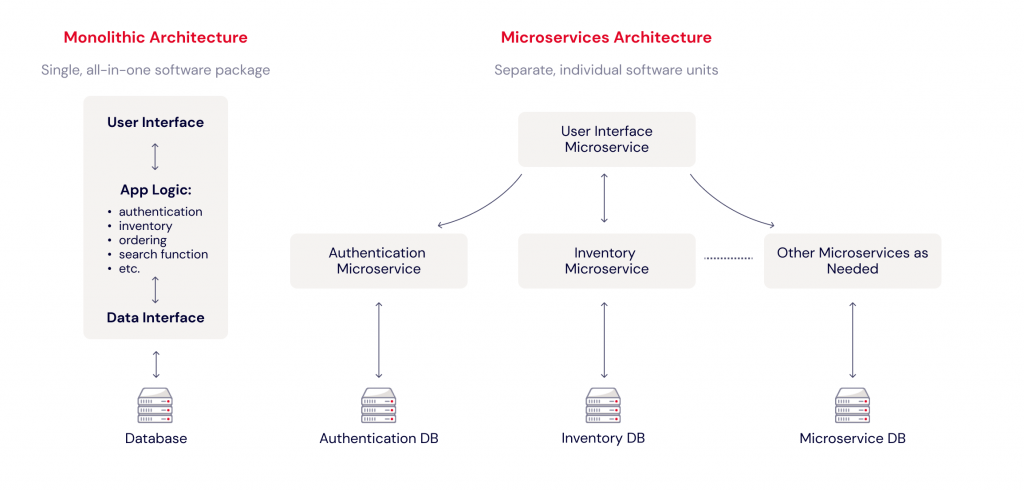
What Are Microservices?
Current software engineering practices encourage a DevOps model using small, reusable units of functionality, or microservices. Microservices run essentially as a standalone process, carrying whatever information or intelligence they need to do their job. Their interfaces are limited and standardized to encourage reuse. This restricted access to internal logic very effectively implements the information-hiding practices that prevent other code from “peeking inside” your modules and making internal tweaks that destabilize your code. The result is (hopefully) an assortment of tools (databases, web servers, etc.) that can be snapped together like Legos to greatly reduce the development effort.
to greatly reduce the development effort.
Microservices: Pros and Cons
This newer approach has many advantages:
- It encourages and supports code reuse. Developers usually have access to an extensive library of microservices that can easily be plugged into their application.
- It enforces logical module isolation to simplify the architecture and improve reliability. This makes initial design, implementation, product updates, enhancements, and bug fixes much easier and less error-prone.
- It enables much more nimble development and delivery techniques, like DevOps and Agile. It’s much easier to add new functionality when you can just tweak a small piece of code (not worrying about potential invisible linkages to other modules), and then instantly push out an update to your users. You can improve your time to market by getting a “good enough” solution out there, and improve it to “ultimate” through ongoing updates.
- It’s inherently scalable. By implementing microservices with containers, you can use an orchestration tool like Kubernetes or Cycle.io to handle scaling, failover, and load balancing. Each microservice component is independently scalable—if one part of your application experiences high load, it can respond to that demand without impacting other components.
However, like anything else, there are drawbacks. For one, moving from a monolithic architecture to a microservices architecture requires not just a change to the way your software is built but also the way your software team functions. And while a microservices architecture is more nimble, it also introduces complexity where none may have existed before in a monolithic deployment.
Microservices Use Cases
Microservices, and especially the containers and orchestration used to structure them, enable a number of different use cases that could benefit your organization, including:
- Making a legacy application cloud-ready. If you want to modernize a legacy application and move it to the cloud, taking a microservices approach to your architecture is helpful. Refactoring a monolithic application and moving it to the cloud allows you to achieve the cost savings associated with the cloud’s pay-as-you-go model.
- Cloud-native development. Similarly, if you want to take a cloud-first approach, it can help to start with a microservices architecture as it will serve you well later as your application scales.
- Moving to DevOps. Microservices as an architectural model lend themselves to, and in many cases require, a change to a DevOps or Agile operational model. If you’re interested in moving from Waterfall to Agile development, microservices go hand in hand.
- Running big data applications. Applications that ingest and process large amounts of data benefit from being broken down into microservices where each step in the data processing pipeline is handled independently.
When NOT to Use Microservices
The microservices model can introduce unnecessary complexity into an otherwise simple solution. If you have a simple or monolithic implementation and it’s meeting your needs just fine, then there is no need to throw it away and microservice-ize it. But if (when) it becomes difficult to update or maintain it, or when you’re planning new development, consider a more modular architecture for the new implementation.
Microservices + Cloud Storage: Considerations for Choosing a Cloud Provider
One impact of moving to a containerized, microservices model is the need for persistent storage. The state of a container can be lost at any time due to situations like hardware/software crashes or spinning down excess containers when load drops. The application running in the container should store its state in external (usually cloud) storage, and read the current state when it starts up.
Thus, administrators should carefully consider different providers before selecting one to trust with their data. Consider the following factors in an evaluation of any cloud provider:
- Integrations/partner network: One of the risks of moving to the cloud is vendor lock-in. Avoid getting stuck in one cloud ecosystem by researching the providers’ partner network and integrations. Does the provider already work with software you have in place? Will it be easy to change vendors should you need to? Consider the provider’s egress fees both in general and between partners, especially if you have a high-bandwidth use case.
- Interoperability and API compatibility: Similarly, make sure the cloud provider you’re considering favors an open ecosystem and offers APIs that are compatible with your architecture.
- Security: What protections does the provider have against ransomware and other data corruption? Does the provider include features like Object Lock to make data immutable? Protection like this is recommended considering the rising threat of ransomware attacks.
- Infrastructure as Code capability: Does the provider enable you to use infrastructure as code (IaC) to provision storage automatically? Using IaC to provision storage enables you to scale your storage without manually managing the process.
- Pricing transparency: With varying data retention requirements, transparent pricing tiers will help you budget more easily. Understand how the provider prices their service including fees for things like egress, retention minimums, and other fine print. Look for backup providers that offer pricing compatible with your organization’s needs.
Are You Using Microservices?
Are you using microservices to build your applications? According to a TechRepublic survey, 73% of organizations have integrated microservices into their application architectures. If you’re one of them, we’d love to know how it’s going. Let us know in the comments.
The post What Are Microservices? appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
Use New Amazon EC2 M1 Mac Instances to Build & Test Apps for iPhone, iPad, Mac, Apple Watch, and Apple TV
Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/use-amazon-ec2-m1-mac-instances-to-build-test-macos-ios-ipados-tvos-and-watchos-apps/
Last year at AWS re:Invent, Jeff Barr wrote about the exciting availability of Amazon Elastic Compute Cloud (Amazon EC2) Mac instances. Today, we’re announcing the preview of a new EC2 M1 Mac instance.
The introduction of EC2 Mac instances brought the flexibility, scalability, and cost benefits of AWS to all Apple developers. EC2 Mac instances are dedicated Mac mini computers attached through Thunderbolt to the AWS Nitro System, which lets the Mac mini appear and behave like another EC2 instance. It connects to your Amazon Virtual Private Cloud (VPC), boot from Amazon Elastic Block Store (EBS) volumes, and leverage EBS snapshots, security groups and other AWS services. EC2 Mac instances let you scale your build and test fleets of Macs, paying as you go. There is no hypervisor involved, and you get full bare metal performance of the underlying Mac mini. An EC2 dedicated host reserves a Mac mini for your usage.
The availability (in preview) of EC2 M1 Mac instances lets you access machines built around the Apple-designed M1 System on Chip (SoC). If you are a Mac developer and re-architecting your apps to natively support Macs with Apple silicon, you may now build and test your apps and take advantage of all the benefits of AWS. Developers building for iPhone, iPad, Apple Watch, and Apple TV will also benefit from faster builds. EC2 M1 Mac instances deliver up to 60% better price performance over the x86-based EC2 Mac instances for iPhone and Mac app build workloads.
EC2 M1 Mac instances are powered by a combination of two hardware components:
- The Mac mini, featuring M1 SoC with 8 CPU cores, 8 GPU cores, 16 GiB of memory, and a 16 core Apple Neural Engine.
- The AWS Nitro System, providing up to 10 Gbps of VPC network bandwidth and 8 Gbps of EBS storage bandwidth through a high-speed Thunderbolt connection.
How to Get Started
As I explained previously, when using EC2 Mac instances, there is no virtual machine involved. These are running on bare metal servers, each hosting a Mac mini. The first step, therefore, involves grabbing a dedicated server. I open the AWS Management Console, navigate to the Amazon EC2 section, then I select Dedicated Hosts. I select Allocate Dedicated Host to allocate a server to my AWS account.
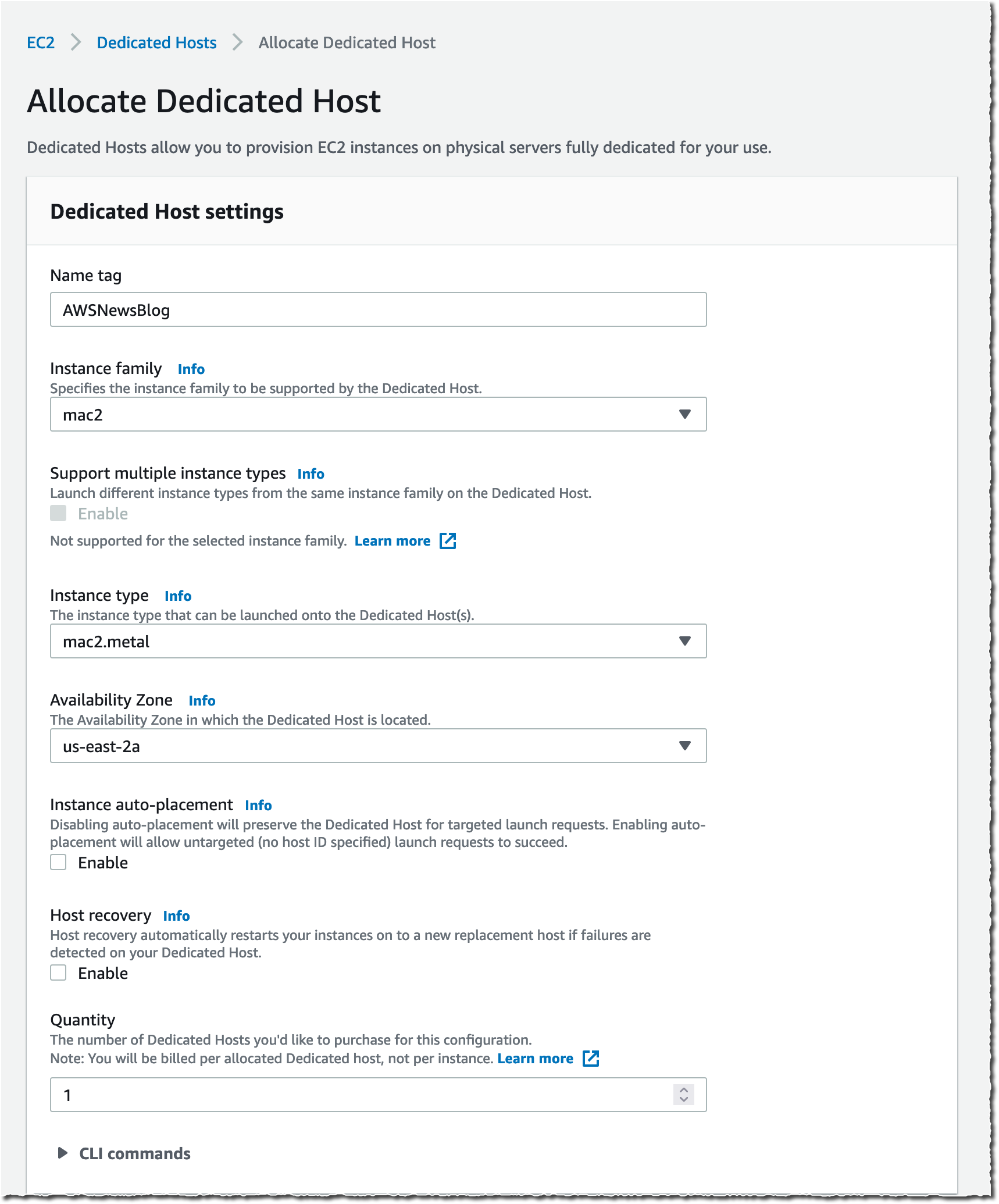
Alternatively, I may use the AWS Command Line Interface (CLI).
➜ ~ aws ec2 allocate-hosts \
--instance-type mac2.metal \
--availability-zone us-east-2b \
--quantity 1
{
"HostIds": [
"h-0fxxxxxxx90"
]
}
Once the host is allocated, I start an EC2 instance on it. The procedure is no different from starting any EC2 instance type. I just have to ensure I select a macOS AMI version that suits my requirements. I select the mac2.metal instance type and select host Tenancy and the dedicated Host I just created.
 Alternatively, I may use the CLI.
Alternatively, I may use the CLI.
➜ ~ aws ec2 run-instances \
--instance-type mac2.metal \
--key-name my_key \
--placement HostId=h-0fxxxxxxx90 \
--security-group-ids sg-01000000000000032 \
--image-id AWS_OR_YOUR_AMI_ID
{
"Groups": [],
"Instances": [
{
"AmiLaunchIndex": 0,
"ImageId": "ami-01xxxxbd",
"InstanceId": "i-08xxxxx5c",
"InstanceType": "mac2.metal",
"KeyName": "my_key",
"LaunchTime": "2021-11-08T16:47:39+00:00",
"Monitoring": {
"State": "disabled"
},
... redacted for brevity ....
When you use EC2 Mac instances for the first time, you’re likely to ask questions such as, “How do I connect through Apple Remote Desktop?” or “How do I increase the size of the APFS file system on the EBS volume?” The EC2 Mac documentation covers the answers for you and provides examples of commands to run on macOS to perform these common tasks.
I use SSH to connect to the newly launched instance as usual.

I may enable Apple Remote Desktop and start a VNC session to the EC2 instance. The EC2 Mac instance documentation page has the details.

Availability and Pricing
EC2 M1 Mac instances are now available in preview in US East (N. Virginia) and US West (Oregon), with other AWS Regions coming at launch.
Pricing metrics are similar to the previous generation of EC2 Mac instances. You are charged per hour of reservation of the dedicated host, not for the time the instance is running, and there is a minimum charge of 24 hours for reserving a dedicated host.
In the two preview Regions, the on-demand price is $0.6498 per hour. You can save up to 42 percent over the on-demand price with Savings Plans. Check our Dedicated Host on-demand pricing page, as well as the Savings Plans page to learn the details.
You can sign up for the preview of EC2 Mac M1 instances today!