Post Syndicated from LastWeekTonight original https://www.youtube.com/shorts/e_Sv2Jva5D0
Python steering council accepts lazy imports
Post Syndicated from jake original https://lwn.net/Articles/1044844/
Barry Warsaw, writing for the Python steering council, has announced
that PEP 810 (“Explicit lazy
imports”) has been approved, unanimously, by the four who could vote. Since
Pablo Galindo Salgado was one of the PEP authors, he did not vote. The PEP provides a way to defer importing modules until the names
defined in a module are
needed by other parts of the program. We covered the PEP and the discussion around it
a few weeks back. The council also had “recommendations about some of
“, including:
the PEP’s details, a few suggestions for filling a couple of small
gaps
Use lazy as the keyword. We debated many of the given alternatives
(and some we came up with ourselves), and ultimately agreed with the PEP’s
choice of the lazy keyword. The closest challenger was
defer, but once we tried to use that in all the places where the
term is visible, we ultimately didn’t think it was as good an overall
fit. The same was true with all the other alternative keywords we could
come up with, so… lazy it is!What about from foo lazy import bar? Nope! We like that in both module imports and from-imports that the lazy keyword is the first thing on the line. It helps to visually recognize lazy imports of both varieties.
AWS Weekly Roundup: Project Rainier online, Amazon Nova, Amazon Bedrock, and more (November 3, 2025)
Post Syndicated from Betty Zheng (郑予彬) original https://aws.amazon.com/blogs/aws/aws-weekly-roundup-project-rainier-online-amazon-nova-amazon-bedrock-and-more-november-3-2025/
 Last week I met Jeff Barr at the AWS Shenzhen Community Day. Jeff shared stories about how builders around the world are experimenting with generative AI and encouraged local developers to keep pushing ideas into real prototypes. Many attendees stayed after the sessions to discuss model grounding, evaluation, and how to bring generative AI into real applications.
Last week I met Jeff Barr at the AWS Shenzhen Community Day. Jeff shared stories about how builders around the world are experimenting with generative AI and encouraged local developers to keep pushing ideas into real prototypes. Many attendees stayed after the sessions to discuss model grounding, evaluation, and how to bring generative AI into real applications.
Community builders showcased creative Kiro-themed demos, AI-powered IoT projects, and student-led experiments. It was inspiring to see new developers, students, and long-time Amazon Web Services (AWS) community leaders connecting over shared curiosity and excitement for generative AI innovation.
Project Rainier, one of the world’s most powerful operational AI supercomputers is now online. Built by AWS in close collaboration with Anthropic, Project Rainier brings nearly 500,000 AWS custom-designed Trainium2 chips into service using a new Amazon Elastic Compute (Amazon EC2) UltraServer and EC2 UltraCluster architecture designed for high-bandwidth, low-latency model training at hyperscale.
Anthropic is already training and running inference for Claude on Project Rainier, and is expected to scale to more than one million Trainium2 chips across direct usage and Amazon Bedrock by the end of 2025. For architecture details, deployment insights, and behind-the-scenes video of an UltraServer coming online, refer to AWS activates Project Rainier for the full announcement.
Last week’s launches
Here are the launches that got my attention this week:
- Amazon Nova – Adds Web Grounding as a new built-in tool for real-time, citation-based web retrieval, and introduces Multimodal Embeddings, a state-of-the-art model that produces unified cross-modal vectors, improving accuracy for Retrieval Augmented Generation (RAG) and semantic search. Both capabilities are available in Amazon Bedrock.
- Amazon Bedrock – TwelveLabs’ Marengo Embed 3.0 is now available for long-form, video-native multimodal embeddings across video, images, audio, and text with improved domain accuracy. Stability AI Image Services added four new tools: Outpaint, Fast Upscale, Conservative Upscale, and Creative Upscale for high-resolution upscaling, outpainting, and controlled variations.
- Model Context Protocol (MCP) Proxy for AWS – Now generally available as a client-side proxy that connects MCP clients to remote AWS hosted MCP servers using SigV4 authentication. It works with tools like Amazon Q Developer CLI, Kiro, Cursor, and Strands Agents, and provides safety controls such as read-only mode, retry logic, and logging. The Proxy is open-source. You can visit the AWS GitHub repository to view the installation and configuration options and start connecting with remote AWS MCP servers.
- Amazon Elastic Container Service (Amazon ECS) – Now supports built-in linear and canary deployment strategies, providing gradual traffic shifting, canary testing with small production slices, deployment bake times for safe rollback, and Amazon CloudWatch alarm-based automated rollbacks.
- Amazon DocumentDB – Adds a new query planner in Amazon DocumentDB 5.0 that delivers up to 10 times faster query performance with more optimal index plans and support for
$neq,$nin, and nested$elementMatch, and can be enabled through cluster parameter groups without downtime. - Amazon Elastic Block Store (Amazon EBS) – You can now use new per-volume CloudWatch metrics, VolumeAvgIOPS and VolumeAvgThroughput, to get minute-level visibility into average IOPS and throughput for EBS volumes on AWS Nitro based instances. These metrics help monitor performance trends, troubleshoot bottlenecks, and optimize provisioned capacity.
- Amazon Kinesis Data Streams – You can now send individual records up to 10 MiB, a tenfold increase from the previous limit, helping support larger Internet of Things (IoT), change data capture (CDC), and AI-generated payloads.
Amazon SageMaker – Unified Studio search results now provide additional search context, showing matched metadata fields and ranking rationale to improve transparency and relevance in data discovery.
Additional updates
Here are some additional projects, blog posts, and news items that I found interesting:
- Building production-ready 3D pipelines with AWS VAMS and 4D Pipeline – A reference architecture for creating scalable, cloud-based 3D asset pipelines using AWS Visual Asset Management System (VAMS) and 4D Pipeline, supporting ingest, validation, collaborative review, and distribution across games, visual effects (VFX), and digital twins.
- Amazon Location Service introduces new API key restrictions – You can now create granular security policies with bundle IDs to restrict API access to specific mobile applications, improving access control and strengthening application-level security across location-based workloads.
- AWS Clean Rooms launches advanced SQL configurations – A performance enhancement for Spark SQL workloads that supports runtime customization of Spark properties and compute sizes, plus table caching for faster and more cost-efficient processing of large analytical queries.
- AWS Serverless MCP Server adds event source mappings (ESM) tools – A capability for event-driven serverless applications that supports configuration, performance tuning, and troubleshooting of AWS Lambda event source mappings, including AWS Serverless Application Model (AWS SAM) template generation and diagnostic insights.
- AWS IoT Greengrass releases an AI agent context pack – A development accelerator for cloud-connected edge applications that provides ready-to-use instructions, examples, and templates, helping teams integrate generative AI tools such as Amazon Q for faster software creation, testing, and fleet-wide deployment. It’s available as open source on the GitHub repository.
- AWS Step Functions introduces a new metrics dashboard – You can now view usage, billing, and performance metrics at the state-machine level for standard and express workflows in a single console view, improving visibility and troubleshooting for distributed applications.
Upcoming AWS events
Check your calendars so that you can sign up for these upcoming events:
- AWS Builder Loft – A community tech space in San Francisco where you can learn from expert sessions, join hands-on workshops, explore AI and emerging technologies, and collaborate with other builders to accelerate their ideas. Browse the upcoming sessions and join the events that interest you.
- AWS Community Days – Join community-led conferences that feature technical discussions, workshops, and hands-on labs led by experienced AWS users and industry leaders from around the world: Hong Kong (November 2), Abuja (November 8), Cameroon (November 8), and Spain (November 15).
- AWS Skills Center Seattle 4th Anniversary Celebration – A free, public event on November 20 with a keynote, learned panels, recruiter insights, raffles, and virtual participation options.
Join the AWS Builder Center to learn, build, and connect with builders in the AWS community. Browse here for upcoming in-person events, developer-focused events, and events for startups.
That’s all for this week. Check back next Monday for another Weekly Roundup!
– Betty
[$] An explicit thread-safety proposal for Python
Post Syndicated from daroc original https://lwn.net/Articles/1043568/
Python already has several ways to run programs concurrently —
including asynchronous functions, threads, subinterpreters, and multiprocessing
— but all of those options have drawbacks of one kind or another.
PEP 703 (“Making the Global Interpreter Lock Optional in CPython”)
removed a major barrier to running Python
threads in parallel, but also exposed Python programmers to the same tricky
synchronization problems found in other languages supporting multithreaded
programs. A new draft proposal
by Mark Shannon,
PEP 805 (“Safe Parallel Python”), suggests a way for the CPython runtime
to cut down on concurrency bugs, making it more practical for Python programmers
to use versions of the language without the global interpreter lock (GIL).
Rapid7 Extends AWS Hosting Capability with India Region Launch
Post Syndicated from Ed Montgomery original https://www.rapid7.com/blog/post/pt-rapid7-extends-aws-hosting-capability-with-india-region-launch
We are delighted to announce Rapid7 launched a new Amazon Web Service (AWS) cloud region in India with the API name ap-south-2.
This follows an announcement in March 2025, when Rapid7 announced plans for expansion in India, including the opening of a new Global Capability Center (GCC) in Pune to serve as an innovation hub and Security Operations Center (SOC).
The GCC opened in April 2025, quickly followed by dedicated events in the country, to demonstrate our commitment to our partners and customers in the region. Three Security Day events took place in May, in Mumbai, Delhi, and Bangalore. These events brought together key stakeholders from the world of commerce, academia, and government to explore our advancements in Continuous Threat Exposure Management (CTEM) and Managed Extended Detection and Response (MXDR).
“Expanding into India is a critical step in accelerating Rapid7’s investments in security operations leadership and customer-centric innovation,” said Corey Thomas, chairman and CEO of Rapid7. “Innovation thrives when multi-dimensional teams come together to solve complex challenges, and this new hub strengthens our ability to deliver the most adaptive, predictive, and responsive cybersecurity solutions to customers worldwide. Establishing a security operations center in Pune also enhances our ability to scale threat detection and response globally while connecting the exceptional technical talent in the region to impactful career opportunities. We are excited to grow a world-class team in India that will play a pivotal role in shaping the future of cybersecurity.”
Rapid7 expands to 8 AWS platform regions
Today, Rapid7 operates in eight platform regions (us-east-1, us-east-2, us-west-1, ap-northeast-1, ap-southeast-2, ca-central-1, eu-central-1, govcloud).
These regions allow our customers to meet their data sovereignty requirements by choosing where their sensitive security data is hosted. We have extended this capability to ap-south-2 and me-central-1 to process additional data and serve more customers with region requirements we have not previously been able to meet.
What this means for Rapid7 customers in India
This gives our customers in India the ability to access and store data in the India region for our Exposure Management product family.
⠀
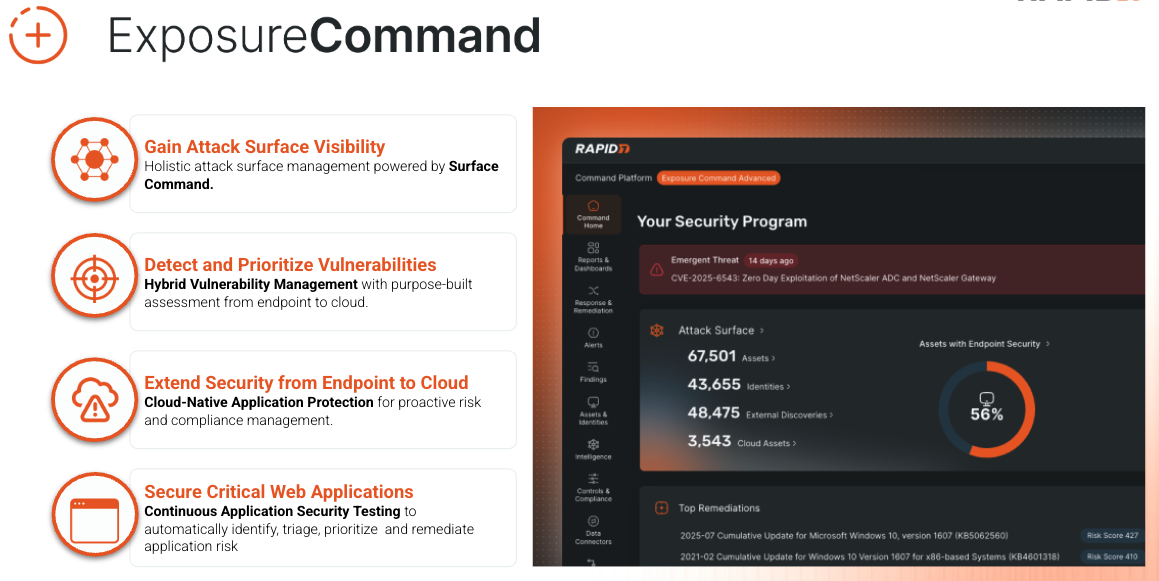
⠀
Exposure Command combines complete attack surface visibility with high-fidelity risk context and insight into your organization’s security posture, aggregating findings from both Rapid7’s native exposure detection capabilities – as well as third-party exposure and enrichment sources you’ve already got in place – allowing you to:
-
Extend risk coverage to cloud environments with real-time agentless assessment
-
Zero-in on exposures and vulnerabilities with threat-aware risk context
-
Continuously assess your attack surface, validate exposures, and receive actionable remediation guidance
-
Efficiently operationalize your exposure management program and automate enforcement of security and compliance policies with native, no-code automation
Learn more about Exposure Command.
⠀
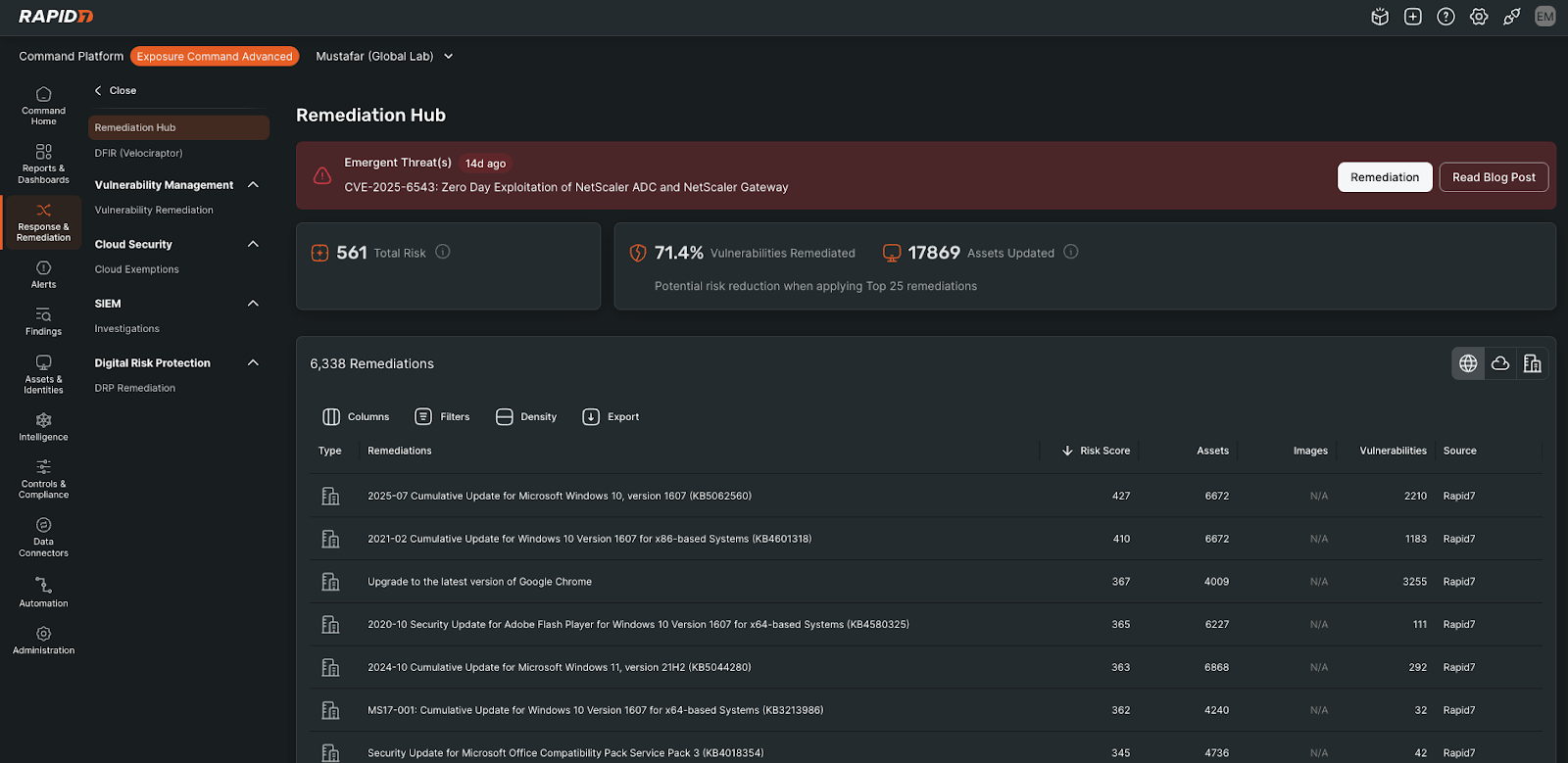
Figure 1: Exposure Command Remediation Hub
Devuan 6.0 released
Post Syndicated from corbet original https://lwn.net/Articles/1044823/
Version
6.0 (“Excalibur”) of the systemd-averse Devuan distribution has been
released. It is based on Debian 13 (“trixie”), and includes some of
the significant changes from that release, including the merged
/usr hierarchy. See the
release notes for details.
[$] Namespace reference counting and listns()
Post Syndicated from corbet original https://lwn.net/Articles/1043824/
The kernel’s namespaces feature is, among
other things, a key part of the implementation of containers. Like much in
the kernel, though, the namespace API evolved over time; there was no
design at the outset. As a result, this API has some rough edges and
missing features. Christian Brauner is working to straighten out the
namespace situation somewhat with this
daunting 72-part patch series that, among other things, adds a new
system call to allow user space to query the namespaces present on the
system.
A new kernel port — to WebAssembly
Post Syndicated from corbet original https://lwn.net/Articles/1044786/
Joel Severin has announced
the availability of his port of the Linux kernel to WebAssembly; one can go
to this page and
watch it boot in a browser.
Wasm is similar to every other arch in Linux, but also
different. One important difference is that there is no way to
suspend execution of a task. There is a way around this though:
Linux supports up to 8k CPUs (or possibly more…). We can just
spin up a new CPU dedicated to each user task (process/thread) and
never preempt it
Streamlining Multi-Account Infrastructure with AWS CloudFormation StackSets and AWS CDK
Post Syndicated from Franco Abregu original https://aws.amazon.com/blogs/devops/streamlining-multi-account-infrastructure-with-aws-cloudformation-stacksets-and-aws-cdk/
Introduction
Organizations operating at scale on AWS often need to manage resources across multiple accounts and regions. Whether it’s deploying security controls, compliance configurations, or shared services, maintaining consistency can be challenging.
AWS CloudFormation StackSets (StackSets) has been helping organizations deploy resources across multiple accounts and regions since its launch. While the service is powerful on its own, combining it with Infrastructure as Code (IaC) tools and implementing automated deployments can significantly enhance its capabilities.
In this post, we’ll show you how to leverage AWS CloudFormation StackSets at scale using AWS CDK and implement a robust CI/CD pipeline for automated deployments with AWS CodePipeline.
StackSets key concepts
AWS CloudFormation StackSets allows you to create, update, or delete CloudFormation stacks across multiple AWS accounts and regions with a single operation. It’s essentially a way to manage infrastructure at scale across your AWS organization. Using an administrator account, you define and manage a CloudFormation template, and use the template as the basis for provisioning stacks into selected target accounts across specified AWS Regions:
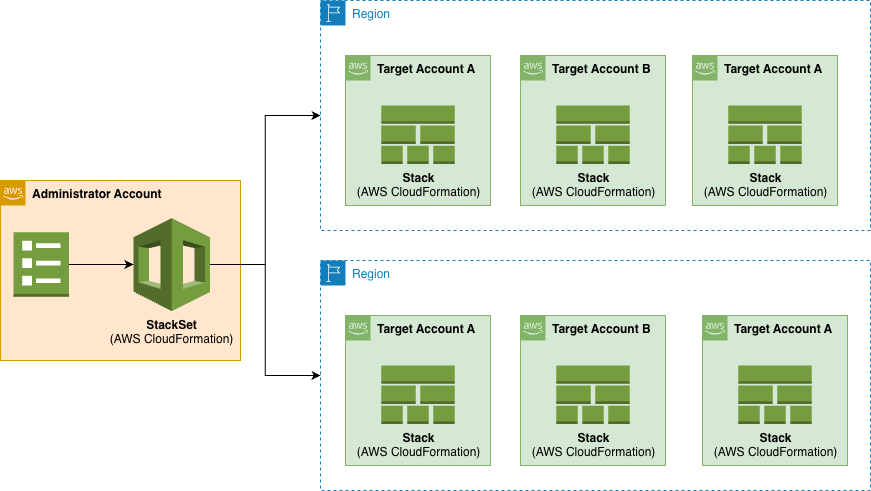
Figure 1. StackSets overview.
The Administrator Account is the AWS account where you create and manage StackSets and the Target Accounts are the AWS accounts where the stack instances are deployed.
The Stack Instances are individual stacks created from the StackSet template deployed to specific account-region combinations.
You can make the following operations using StackSets: Create, update, and delete actions performed on stack instances. These operations can be applied in concurrent or sequential way.
Sequential Deployment:
- Account-by-account deployment
- Region-by-region within accounts
- Configurable failure thresholds
Parallel Deployment:
- Concurrent account deployments
- Maximum concurrent account setting
- Region priority configuration
Hybrid Deployment:
- Combine sequential and parallel
- Account group-based deployment
- Regional deployment strategies
The power of StackSets
The use of StackSets allows us to extend AWS CloudFormation’s capabilities in several important ways:
Governance
It provides you with Centralized Management as a single point of control while including consistent deployment patterns and automated stack instance management across AWS accounts and regions.
With Drift Detection feature, you can identify if any of the stack instances of your StackSet have configuration differences according to its expected configuration. You detect changes made outside CloudFormation and changes made to an instance stack through CloudFormation directly without using the StackSet.
Flexible Deployment
You also have flexible deployment options with controlled rollout. For example, with Concurrent Deployments you can deploy to multiple accounts within each region simultaneously while controlling deployment order. It also includes failure tolerance with automated retry failed operations.
Operational Efficiency
It reduces manual effort in managing multi-account and multi-region environments while minimizes human error in deployments.
Cost Management
It delivers comprehensive resource organization and streamlined tracking of resources across accounts and regions containing instance stacks. Using centralized management, simplifies the resource tracking and organization enabling you you to have:
- unified visibility: view all related stacks from a single StackSet console (with their deployment status)
- consistent tagging: apply standardized tags across all stack instances for cost allocation and resource grouping
- drift detection: run drift detection across all stack instances simultaneously
- operations tracking: track all operations (create, update and delete) across account/regions from one place
Built-in Safety
You can establish maximum concurrent operation limits, failure tolerance thresholds and automatic retry mechanisms. You also have recovery capabilities through update operations. All these features make a built-in safety mechanisms that prevent widespread failures.
Let’s say you have 100 target accounts, with the maximum concurrent limits, you can for example deploy a change to only 10 accounts. Also, with a failure threshold you can set how many failures do you allow before automatically stopping the process (e.g., stop if more than 5 accounts fail). This way you can gradually deploy and test your templates with a little group, establishing failure thresholds, instead of affecting the stacks preventing mass failures.
When an operation fails, AWS CloudFormation performs a rollback in the stack instances deploying the previous working template. You will still need to correct the template and apply it again in all the stack instances. With StackSets, you can fix the issues in the template and run again an update across all the stacks including the concurrent limit and failure threshold mentioned before to safety test the fix.
Security and Compliance management
This security-focused approach with StackSets helps organizations maintain a strong security posture across their AWS environment while reducing the operational overhead of managing security at scale.
You can use StackSets to deploy standardized security policies across accounts, enforce security baselines automatically and implement security guardrails organization-wide. For example, you can deploy detective control resource and its configuration in all your accounts like Amazon GuardDuty or Amazon Macie. You can also deploy preventive controls like SCPs, AWS Firewall Manager or AWS Shield Advanced. For example you can deploy through StackSets the following CloudFormation template en each target account to block certain actions in a region:
Other capabilities include compliance-related resources consistently, maintain audit trails of security configurations and ensure regulatory requirements are met across all accounts. For example, you can enable CouldTrail and deploy AWS Config rules across all the instance stacks managed by the StackSet.
For both Security and Compliance incidents you can use StackSets to deploy automated response workflows, configure event notifications and implement remediation actions across your accounts and regions.
Import existing stacks into StackSets
A stack import operation can import existing stacks into new or existing StackSets, so that you can migrate existing stacks to a StackSet in one operation.
Solution Overview
This solution includes an AWS CodePipeline stack that creates a CI/CD pipeline to deploy our StackSet. This pipeline deploys an application stack containing the AWS CloudFormation StackSet with a monitoring dashboard in AWS CloudWatch.
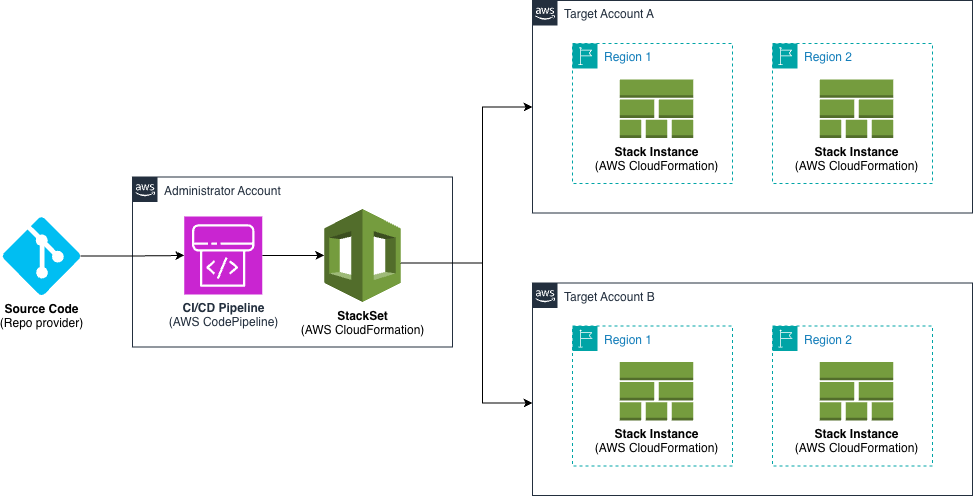
Figure 2. Solution overview
The following Amazon CloudWatch dashboard is an example of what you will in the target accounts after the StackSet is deployed:
Figure 3. Dashboard example
In the CI/CD pipeline, before running the deployment commands, it applies python security and quality code checks to ensure code quality and security and cdk-nag to ensure AWS Well Architected best practices. You can find more details about these checks in the solution repository in README.md file.
The solution includes 2 AWS CloudFormation stacks defined by in the AWS CDK application and a template for the StackSet that will be deployed in the target accounts and regions. This stack contains the monitoring dashboard that will be deployed en the target regions of each target account as a single unit.
The idea of using AWS CodePipeline with IaC is that development teams can define and share “pipelines-as-code” patterns for deploying their applications making it easy to add stages. This way, security and quality code testing can run any time you change the source code.
Figure 4. Pipeline overview
The best practice is to ensure shift-left: adding this checks to the earlier stages of the SDLC. You can accomplish this complementing your CI/CD pipeline with githooks or IDE Plugins. For example with Amazon Q Developer IDE extension you can use the review function to analyze the security of your code locally.
Walkthrough
If you’d like to try this solution out yourself, visit the walkthrough in the corresponding GitHub repo: https://github.com/aws-cloudformation/aws-cloudformation-templates/tree/main/CloudFormation/StackSets-CDK
To use the CI/CD pipeline just create a repository using any of the AWS CodeConnection git supported providers and add the contents of the folder. All details are included in the README.md so you can always get the latest version of the code and how it works.
Conclusion
In this post, we showed how to use AWS CDK to deploy AWS CloudFormation StackSets to reduce operational overhead and ensure consistency, compliance and security across multiple regions and accounts. We also learned how to create a CI/CD pipeline to guarantee a robust DevSecOps cycle for our Infrastructure as Code.
Now that we’ve explored the main concepts together, you can clone the example repository from the walkthrough section, follow the setup instructions, and customize the implementation to enhance AWS resources management across accounts and regions. Whether you’re managing a single account or multiple organizations, these practices can be adapted to your specific needs. Now that you learned the main concepts, go ahead and clone the example repository from walkthrough section, follow the setup instructions and customize the implementation to improve the AWS resources management across your accounts and regions.
Security updates for Monday
Post Syndicated from jzb original https://lwn.net/Articles/1044763/
Security updates have been issued by AlmaLinux (.NET 8.0, .NET 9.0, and webkit2gtk3), Debian (ruby-rack, strongswan, ublock-origin, and wordpress), Fedora (firefox, kea, openapi-python-client, openbao, python-uv-build, qt5-qtbase, ruby, ruff, rust-astral-tokio-tar, rust-attribute-derive, rust-attribute-derive-macro, rust-backon, rust-collection_literals, rust-get-size-derive2, rust-get-size2, rust-interpolator, rust-manyhow, rust-manyhow-macros, rust-proc-macro-utils, rust-quote-use, rust-quote-use-macros, rust-reqsign, rust-reqsign-aws-v4, rust-reqsign-command-execute-tokio, rust-reqsign-core, rust-reqsign-file-read-tokio, rust-reqsign-http-send-reqwest, rust-tikv-jemalloc-sys, rust-tikv-jemallocator, samba, skopeo, sssd, Thunar, unbound, uv, vgrep, and xorg-x11-server-Xwayland), Mageia (bind, libtiff, sope, and transfig), Oracle (compat-libtiff3, kernel, libtiff, redis, redis:6, and redis:7), Red Hat (kernel, kernel-rt, libssh, xorg-x11-server, and xorg-x11-server-Xwayland), Slackware (seamonkey), SUSE (bind, chromedriver, chromium, colord, coreboot-utils, git-bug, ImageMagick, java-11-openj9, java-17-openj9, java-21-openj9, java-25-openj9, kea, libmozjs-115-0, libmozjs-140-0, libssh, libtiff-devel-32bit, nodejs18, ongres-scram, poppler, python311-starlette, rav1e, squid, strongswan, webkit2gtk3, xorg-x11-server, and xwayland), and Ubuntu (linux-gcp-6.14 and linux-hwe-6.8).
Tinclads: Unsung Heroes of the Civil War
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=EE3HqgNSjAs
Fresh insights from old data: corroborating reports of Turkmenistan IP unblocking and firewall testing
Post Syndicated from Luke Valenta original https://blog.cloudflare.com/fresh-insights-from-old-data-corroborating-reports-of-turkmenistan-ip/
Here at Cloudflare, we frequently use and write about data in the present. But sometimes understanding the present begins with digging into the past.
We recently learned of a 2024 turkmen.news article (available in Russian) that reports Turkmenistan experienced “an unprecedented easing in blocking,” causing over 3 billion previously-blocked IP addresses to become reachable. The same article reports that one of the reasons for unblocking IP addresses was that Turkmenistan may have been testing a new firewall. (The Turkmen government’s tight control over the country’s Internet access is well-documented.)
Indeed, Cloudflare Radar shows a surge of requests coming from Turkmenistan around the same time, as we’ll show below. But we had an additional question: Does the firewall activity show up on Radar, as well? Two years ago, we launched the dashboard on Radar to give a window into the TCP connections to Cloudflare that close due to resets and timeouts. These stand out because they are considered ungraceful mechanisms to close TCP connections, according to the TCP specification.
In this blog post, we go back in time to share what Cloudflare saw in connection resets and timeouts. We must remind our readers that, as passive observers, there are limitations on what we can glean from the data. For example, our data can’t reveal attribution. Even so, the ability to observe our environment can be insightful. In a recent example, our visibility into resets and timeouts helped corroborate reports of large-scale blocking and traffic tampering by Russia.
Let’s look first at the number of requests, since those should increase if IP addresses are unblocked. In mid-June 2024 Cloudflare started receiving a noticeable increase in HTTP requests, consistent with reports of Turkmenistan unblocking IPs.

Source: Cloudflare Radar
The Transmission Control Protocol (TCP) is a lower-layer mechanism used to create a connection between clients and servers, and also carries 70% of HTTP traffic to Cloudflare. A TCP connection works much like a telephone call between humans, who follow graceful conventions to end a call—and who are acutely aware when conventions are broken if a call ends abruptly.
TCP also defines conventions to end the connection gracefully, and we developed mechanisms to detect when they don’t. An ungraceful end is triggered by a reset instruction or a timeout. Some are due to benign artifacts of software design or human user behaviours. However, sometimes they are exploited by third parties to close connections in everything from school and enterprise firewalls or software, to zero-rating on mobile plans, to nation-state filtering.
When we look at connections from Turkmenistan, we see that on June 13, 2024, the combined proportion of the four coloured regions increases; each coloured region represents ungraceful ends at a distinct stage of the connection lifetime. In addition to the combined increase, the relative proportions between stages (or colours) changes as well.

Source: Cloudflare Radar
Further changes appeared in the weeks that followed. Among them are an increase in Post-PSH (orange) anomalies starting around July 4; a reduction in Post-ACK (light blue) anomalies around July 13; and an increase in anomalies later in connections (green) starting July 22.

Source: Cloudflare Radar
The shifts above could be explained by a large firewall system. It’s important to keep in mind that data in each of the connection stages (captured by the four coloured regions in the graphs) can be explained by browser implementations or user actions. However, the scale of the data would need a great number of browsers or users doing the same thing to show up. Similarly, individual changes in behaviour would be lost unless they occur in large numbers at the same time.
We’ve learned that it can be helpful to look at the data for individual networks to reveal common patterns between different networks in different regions operated by single entities.
Looking at individual networks within Turkmenistan, trends and timelines appear more pronounced. July 22 in particular sees greater proportions of anomalies associated with the Server Name Indication, or domain name, rather than the IP address (dark blue), although the connection stage where the anomalies appear varies by individual network.
The general Turkmenistan trends are largely mirrored in connections from AS20661 (TurkmenTelecom), indicating that this autonomous system (AS) accounts for a large proportion of Turkmenistan’s traffic to Cloudflare’s network. There is a notable reduction in Post-ACK (light blue) anomalies starting around July 26.

Source: Cloudflare Radar
A different picture emerges from AS51495 (Ashgabat City Telephone Network). Post-ACK anomalies almost completely disappear on July 12, corresponding with an increase in anomalies during the Post-PSH stage. An increase of anomalies in the Later (green) connection stage on July 22 is apparent for this AS as well.

Source: Cloudflare Radar
Finally, for AS59974 (Altyn Asyr), you can see below that there is a clear spike in Post-ACK anomalies starting July 22. This is the stage of the connection where a firewall could have seen the SNI, and chooses to drop the packets immediately, so they never reach Cloudflare’s servers.

Source: Cloudflare Radar
We’ve previously discussed how to use the resets and timeouts data because, while useful, it can also be misinterpreted. Radar’s data on resets and timeouts is unique among operators, but in isolation it’s incomplete and subject to human bias.
Take the figure above for AS59974 where Post-ACK (light blue) anomalies markedly increased on July 22. The Radar view is proportional, meaning that the increase in proportion could be explained by greater numbers of anomalies – but could also be explained, for example, by a smaller number of valid requests. Indeed, looking at the HTTP request levels for the same AS, there was a similarly pronounced drop starting on the same day, as shown below.

Source: Cloudflare Radar
If we look at the same two graphs before July 22, however, rates of reset and timeout anomalies do not appear to mirror the very large shifts up and down in HTTP requests.
These charts from Radar above offer a way to analyze news events from a different angle, by looking at requests and TCP connection resets and timeouts. Does this data tell us definitively that new firewalls were being tested in Turkmenistan? No. But the trends in the data are consistent with what we could expect to see if that were the case.
If thinking about ways to use the resets and timeouts data going forward, we’d encourage also looking at the data in retrospect—or even further past to improve context.
A natural question might be, for example, “If Turkmenistan stopped blocking IPs in mid-2024, what did the data say beforehand?” The figure below captures October and November 2023. (The red-shaded region contains missing data due to the Nov. 2 Cloudflare control plane and metrics outage.) Signals about the Internet in Turkmenistan were evolving well before the news article that prompted us to look.

Source: Cloudflare Radar
To learn more, see our guide about how to use the resets and timeouts data available on Radar, as well as the technical details about our third-party tampering measurement and some perspectives by a former intern who helped drive the study.
We’re proud to offer a unique view of TCP connection anomalies on Radar. It’s a testament to the long-lived benefits that emerge when approaching Internet measurement as a science. In keeping with the open spirit of science, we’ve also shared how we detect and log resets and timeouts so that others can reproduce the observability on their servers, whether by hobbyists or other large operators.
AI Summarization Optimization
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/11/ai-summarization-optimization.html
These days, the most important meeting attendee isn’t a person: It’s the AI notetaker.
This system assigns action items and determines the importance of what is said. If it becomes necessary to revisit the facts of the meeting, its summary is treated as impartial evidence.
But clever meeting attendees can manipulate this system’s record by speaking more to what the underlying AI weights for summarization and importance than to their colleagues. As a result, you can expect some meeting attendees to use language more likely to be captured in summaries, timing their interventions strategically, repeating key points, and employing formulaic phrasing that AI models are more likely to pick up on. Welcome to the world of AI summarization optimization (AISO).
Optimizing for algorithmic manipulation
AI summarization optimization has a well-known precursor: SEO.
Search-engine optimization is as old as the World Wide Web. The idea is straightforward: Search engines scour the internet digesting every possible page, with the goal of serving the best results to every possible query. The objective for a content creator, company, or cause is to optimize for the algorithm search engines have developed to determine their webpage rankings for those queries. That requires writing for two audiences at once: human readers and the search-engine crawlers indexing content. Techniques to do this effectively are passed around like trade secrets, and a $75 billion industry offers SEO services to organizations of all sizes.
More recently, researchers have documented techniques for influencing AI responses, including large-language model optimization (LLMO) and generative engine optimization (GEO). Tricks include content optimization—adding citations and statistics—and adversarial approaches: using specially crafted text sequences. These techniques often target sources that LLMs heavily reference, such as Reddit, which is claimed to be cited in 40% of AI-generated responses. The effectiveness and real-world applicability of these methods remains limited and largely experimental, although there is substantial evidence that countries such as Russia are actively pursuing this.
AI summarization optimization follows the same logic on a smaller scale. Human participants in a meeting may want a certain fact highlighted in the record, or their perspective to be reflected as the authoritative one. Rather than persuading colleagues directly, they adapt their speech for the notetaker that will later define the “official” summary. For example:
- “The main factor in last quarter’s delay was supply chain disruption.”
- “The key outcome was overwhelmingly positive client feedback.”
- “Our takeaway here is in alignment moving forward.”
- “What matters here is the efficiency gains, not the temporary cost overrun.”
The techniques are subtle. They employ high-signal phrases such as “key takeaway” and “action item,” keep statements short and clear, and repeat them when possible. They also use contrastive framing (“this, not that”), and speak early in the meeting or at transition points.
Once spoken words are transcribed, they enter the model’s input. Cue phrases—and even transcription errors—can steer what makes it into the summary. In many tools, the output format itself is also a signal: Summarizers often offer sections such as “Key Takeaways” or “Action Items,” so language that mirrors those headings is more likely to be included. In effect, well-chosen phrases function as implicit markers that guide the AI toward inclusion.
Research confirms this. Early AI summarization research showed that models trained to reconstruct summary-style sentences systematically overweigh such content. Models over-rely on early-position content in news. And models often overweigh statements at the start or end of a transcript, underweighting the middle. Recent work further confirms vulnerability to phrasing-based manipulation: models cannot reliably distinguish embedded instructions from ordinary content, especially when phrasing mimics salient cues.
How to combat AISO
If AISO becomes common, three forms of defense will emerge. First, meeting participants will exert social pressure on one another. When researchers secretly deployed AI bots in Reddit’s r/changemyview community, users and moderators responded with strong backlash calling it “psychological manipulation.” Anyone using obvious AI-gaming phrases may face similar disapproval.
Second, organizations will start governing meeting behavior using AI: risk assessments and access restrictions before the meetings even start, detection of AISO techniques in meetings, and validation and auditing after the meetings.
Third, AI summarizers will have their own technical countermeasures. For example, the AI security company CloudSEK recommends content sanitization to strip suspicious inputs, prompt filtering to detect meta-instructions and excessive repetition, context window balancing to weight repeated content less heavily, and user warnings showing content provenance.
Broader defenses could draw from security and AI safety research: preprocessing content to detect dangerous patterns, consensus approaches requiring consistency thresholds, self-reflection techniques to detect manipulative content, and human oversight protocols for critical decisions. Meeting-specific systems could implement additional defenses: tagging inputs by provenance, weighting content by speaker role or centrality with sentence-level importance scoring, and discounting high-signal phrases while favoring consensus over fervor.
Reshaping human behavior
AI summarization optimization is a small, subtle shift, but it illustrates how the adoption of AI is reshaping human behavior in unexpected ways. The potential implications are quietly profound.
Meetings—humanity’s most fundamental collaborative ritual—are being silently reengineered by those who understand the algorithm’s preferences. The articulate are gaining an invisible advantage over the wise. Adversarial thinking is becoming routine, embedded in the most ordinary workplace rituals, and, as AI becomes embedded in organizational life, strategic interactions with AI notetakers and summarizers may soon be a necessary executive skill for navigating corporate culture.
AI summarization optimization illustrates how quickly humans adapt communication strategies to new technologies. As AI becomes more embedded in workplace communication, recognizing these emerging patterns may prove increasingly important.
This essay was written with Gadi Evron, and originally appeared in CSO.
Comic for 2025.11.03 – No Nut
Post Syndicated from Explosm.net original https://explosm.net/comics/no-nut-2
New Cyanide and Happiness Comic
Police Chases: Last Week Tonight with John Oliver (HBO)
Post Syndicated from LastWeekTonight original https://www.youtube.com/watch?v=wVFXUkFx5Y8
S12 E28: U.S. Government Shutdown & Police Chases: 11/2/25: Last Week Tonight with John Oliver
Post Syndicated from LastWeekTonight original https://www.youtube.com/watch?v=0qmNAOCgbgY
A Meta Vision for GPU Scale Compute with 1PB E2 SSDs
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/a-meta-vision-for-gpu-scale-compute-with-1pb-e2-ssds/
Meta shared its vision for GPU scale compute with 1PB SSDs and a new E2 form factor to maximize QLC NAND SSD capacities
The post A Meta Vision for GPU Scale Compute with 1PB E2 SSDs appeared first on ServeTheHome.
Why Are There Two Dakotas?
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/shorts/fzSbdYnZdVk
Repair Video
Post Syndicated from xkcd.com original https://xkcd.com/3163/

Kernel prepatch 6.18-rc4
Post Syndicated from corbet original https://lwn.net/Articles/1044582/
Linus has released 6.18-rc4 for testing.
“Last week in fact felt *so* calm that I was surprised to notice that
“
rc4 isn’t really smaller than usual: all the stats look very normal, both
in number of changes and where the changes are.