Post Syndicated from Vineedh George original https://aws.amazon.com/blogs/compute/simulating-amazon-ec2-ebs-burst-credits-before-downsizing-an-instance/
When downsizing an Amazon Elastic Compute Cloud (Amazon EC2) instance, teams often evaluate CPU and memory utilization but overlook the instance’s Amazon Elastic Block Store (Amazon EBS) performance limits for throughput and IOPS. Smaller Amazon EBS-optimized instance types have lower baselines and rely on burst credits to handle peaks. If your workload’s I/O pattern drains those credits faster than the instance can refill them, the instance will throttle your workload to baseline. This post applies to burstable EBS-optimized instances with baselines below their maximum.
This post shows how to pull your instance’s Amazon EBS metrics from Amazon CloudWatch, simulate the burst credit balance against a target instance type’s limits, and help evaluate whether the downsize might be appropriate before making the change.
Solution overview
The analysis compares your workload’s actual I/O pattern against the target instance type’s Amazon EBS limits.
- Measure your current Amazon EBS usage. Pull instance-level throughput and IOPS from Amazon CloudWatch at 5-minute granularity. You need at least two weeks of data to capture weekly patterns. Four weeks is better if your workload has monthly cycles. While you pull data, check whether your current instance already hits its Amazon EBS-optimized performance limits.
- Compare against the target instance’s limits. Look up the baseline and burst ceiling for your target instance type. Simulate the burst credit balance across your observation window: for each 5-minute interval, calculate whether credits are draining or refilling, and track whether the balance ever hits zero. If it does, you will experience throttling on the smaller instance.
- Monitor after the move. Watch InstanceEBSThroughputExceededCheck and InstanceEBSIOPSExceededCheck for immediate throttle detection. Track EBSByteBalance% and EBSIOBalance% to gauge how much headroom remains for workload growth.
Note: These balance metrics are only available on burstable instance sizes where the baseline is lower than the maximum.
Prerequisites
An AWS account with permissions for cloudwatch:GetMetricData and ec2:DescribeInstanceTypes. The instance must be Amazon EBS-optimized (AWS enables EBS-optimization by default on most current-generation instance types).
Note: AWS doesn’t provide these instance-level Amazon CloudWatch metrics in AWS Outposts, AWS Local Zones, or AWS Wavelength Zones.
Pulling instance-level Amazon EBS metrics from Amazon CloudWatch
Amazon CloudWatch provides Amazon EBS metrics at the instance level in the AWS/EC2 namespace, using the InstanceId dimension. Here are the metrics that you need:
| Metric |
What it measures |
| EBSReadBytes |
Total read bytes in the period |
| EBSWriteBytes |
Total write bytes in the period |
| EBSReadOps |
Total read operations in the period |
| EBSWriteOps |
Total write operations in the period |
| EBSIOBalance% |
IOPS burst credit balance (0-100%) |
| EBSByteBalance% |
Throughput burst credit balance (0-100%) |
| InstanceEBSIOPSExceededCheck |
1 if instance hit IOPS limit, 0 otherwise |
| InstanceEBSThroughputExceededCheck |
1 if instance hit throughput limit, 0 otherwise |
The first four metrics are the inputs for the simulation. The rest are useful context:
- EBSIOBalance% and EBSByteBalance% show how much of the burst credit pool remains, as a percentage. On the current (larger) instance, these should sit at or near 100 percent. If they’re dipping, the workload is already consuming burst credits at the current size, and a downsize will make it worse.
Note: These metrics only appear on instances where the baseline is lower than the maximum.
- InstanceEBSIOPSExceededCheck and InstanceEBSThroughputExceededCheck are binary: 1 means the instance hit its EBS-optimized performance limit within the last minute. If either is firing on the current instance, the workload is already throttling and should be addressed before considering a downsize.
Pull these at 5-minute granularity for at least two weeks (four if your workload has monthly cycles). Amazon CloudWatch retains 5-minute data points for 63 days, so that’s your upper bound. You can retrieve the data through the AWS Command Line Interface (AWS CLI) (GetMetricData API), the Amazon CloudWatch console, or any AWS SDK. The metrics live in the AWS/EC2 namespace with your InstanceId as the dimension.
Use the Maximum statistic for the four I/O metrics and Minimum for the balance percentages. Maximum captures the highest 1-minute data point within each 5-minute window, which is the conservative choice for the simulation inputs. The Sum statistic gives a more precise total for each interval, but Maximum is the intentionally conservative choice. It assumes the peak 1-minute rate held for the full 5-minute window, which overstates actual consumption. Minimum on the balance metrics captures the lowest point the balance hit within each window, so you see the actual dips rather than averaging them away. For the ExceededCheck metrics, use Maximum (you want to know if the limit was hit at any point in the window).
Combine read and write values to get totals per interval. To convert to per-second rates:
total_throughput_MBps = (EBSReadBytes + EBSWriteBytes) / (60 * 1024 * 1024)
total_iops = (EBSReadOps + EBSWriteOps) / 60
The division by 60 (not by the period length) is intentional. The Maximum statistic for a 5-minute period returns the highest 1-minute aggregate within that window, not a 5-minute total. Dividing by 60 converts that 1-minute peak to a per-second rate. The additional divisions by 1,024 convert bytes to mebibytes to match the units in describe-instance-types.
Comparing actual usage against target limits
From the Amazon EBS-optimized instances documentation, find the baseline and maximum (burst ceiling) for both IOPS and throughput on your target instance type. You can also pull these programmatically:
aws ec2 describe-instance-types \
--instance-types r8i.large \
--query 'InstanceTypes[0].EbsInfo.EbsOptimizedInfo' \
--output table
This returns the baseline and maximum bandwidth (MB/s) and IOPS for the instance type. Note that BandwidthInMbps is megabits per second (network-style units), while ThroughputInMBps is megabytes per second. The throughput values are what you compare against your Amazon CloudWatch data.
-------------------------------------------
| EbsOptimizedInfo |
+----------------------------+------------+
| BaselineBandwidthInMbps | 650 |
| BaselineThroughputInMBps | 81.25 |
| BaselineIops | 3600 |
| MaximumBandwidthInMbps | 10000 |
| MaximumThroughputInMBps | 1250.0 |
| MaximumIops | 40000 |
+----------------------------+------------+
BaselineThroughputInMBps is the sustained rate the instance can deliver indefinitely. MaximumThroughputInMBps is the burst ceiling, the absolute maximum the instance can deliver while it has burst credits. Same relationship for IOPS. IOPS and throughput have separate burst budgets, tracked by EBSIOBalance% and EBSByteBalance% respectively.
How burst credits work
The instance maintains a credit pool for each budget (IOPS and throughput). The pool capacity is:
credit_pool = (burst_ceiling - baseline) * 1800
The 1800 comes from 30 minutes (1800 seconds) of burst at the maximum rate, which AWS provisions as the pool size for burstable Amazon EBS-optimized instances. Credits drain when usage exceeds baseline and refill when usage is below baseline, at a rate of baseline – effective_usage per second, where effective_usage is min(actual_usage, burst_ceiling). The instance cannot deliver more than the ceiling regardless of credit balance, so credits drain at the ceiling rate, not the requested rate. The pool is capped at its maximum and floored at zero. When credits hit zero, your workload is throttled to baseline performance. AWS resets the pool to full every 24 hours, giving you at least 30 minutes of burst capacity per day.
See Improving application performance and reducing costs with Amazon EBS-optimized instance burst capability for a detailed walkthrough of how burst credits work.
Simulating the credit balance
With the time series data and the target limits, you can simulate what the credit balance would look like on the smaller instance. For each 5-minute interval in your observation window:
effective_usage = min(actual_usage, burst_ceiling)
net_credit_change = (baseline - effective_usage) * interval_seconds
new_balance = previous_balance + net_credit_change
new_balance = clamp(new_balance, 0, credit_pool)
Where interval_seconds is 300 for 5-minute data or 60 for 1-minute data.
When actual usage is below baseline, credits accumulate. When above, they drain. Run this across the full observation window, resetting the pool to full at the start of each 24-hour period to model the AWS top-off guarantee. Start each day with a full pool, then drain and refill through the day’s intervals. If the balance hits zero on any day, the workload will throttle on the smaller instance.
Run the simulation twice: once for IOPS, once for throughput. Throttling happens if either pool hits zero.
A Python script that pulls Amazon CloudWatch data for a given instance ID, looks up the target instance type’s Amazon EBS limits, and runs this simulation end-to-end is available at sample-ec2-ebs-burst-analyzer repository.
This simulation is an approximation
It models credit behavior at 5-minute (or 1-minute) granularity using Amazon CloudWatch aggregates, not the actual per-second I/O stream. Two factors make the simulation more conservative than reality, and two can make reality worse than the simulation.
The Maximum statistic returns the highest 1-minute total within each 5-minute window. The simulation applies that peak rate across the full 300-second interval. This overestimates credit drain by up to 5x for any given interval, because the other 4 minutes likely had lower usage. The tradeoff is intentional. If the simulation says the workload fits, the result is reliable. If it says the workload doesn’t fit, the actual situation might be better than predicted. In that case, re-run with the Average statistic for a less conservative check, or pull 1-minute data (available for the most recent 15 days in Amazon CloudWatch) for higher fidelity.
Working in the other direction, two things can make the real situation worse than the simulation predicts. If the downsize also reduces memory, database workloads (SQL Server buffer pool, PostgreSQL shared_buffers, Oracle SGA) will generate more disk I/O than what you measured because the smaller cache forces more page reads from Amazon EBS. Account for this by including additional headroom in the burst credit budget. And I/O spikes that last milliseconds don’t show up in 5-minute Amazon CloudWatch data. If EBSByteBalance% or EBSIOBalance% are trending down on the current instance but your throughput metrics look fine, the workload is microbursting.
What to look for in the results
The simulation produces two outputs per budget (IOPS and throughput): the low-water mark (lowest credit balance across the observation window) and the number of intervals where the balance hit zero.
- IOPS credit balance (EBSIOBalance%) – If the simulated low-water mark stays well above zero, the workload’s IOPS pattern fits within the target’s burst budget. A low-water mark of 90 percent means the workload barely touches the IOPS burst pool. A low-water mark of 40 percent means it fits today but has limited room for IOPS growth.
- Throughput credit balance (EBSByteBalance%) – Same logic for throughput. Check this independently because a workload can be comfortable on IOPS but tight on throughput, or the reverse.
- Intervals at zero – If either balance hits zero on any day, the workload will throttle to baseline on this instance type.
- Peak usage vs. burst ceiling – The ceiling is the absolute maximum regardless of credit balance. If your peak throughput exceeds
MaximumThroughputInMBps or peak IOPS exceeds MaximumIops, the instance will cap I/O at the ceiling rate during those intervals. This doesn’t mean the workload doesn’t fit overall (credits might still be fine), but the application will experience reduced I/O during those peaks. A handful of brief spikes may be acceptable. Sustained ceiling breaches are a stronger signal to size up.
- Throttled intervals – The most direct measure of impact. A throttled interval is one where the credit balance is at zero and usage exceeds baseline. During these intervals, the instance cannot deliver what the workload is asking for. A few throttled intervals during a nightly batch may be tolerable. Dozens per day during business hours is a problem.
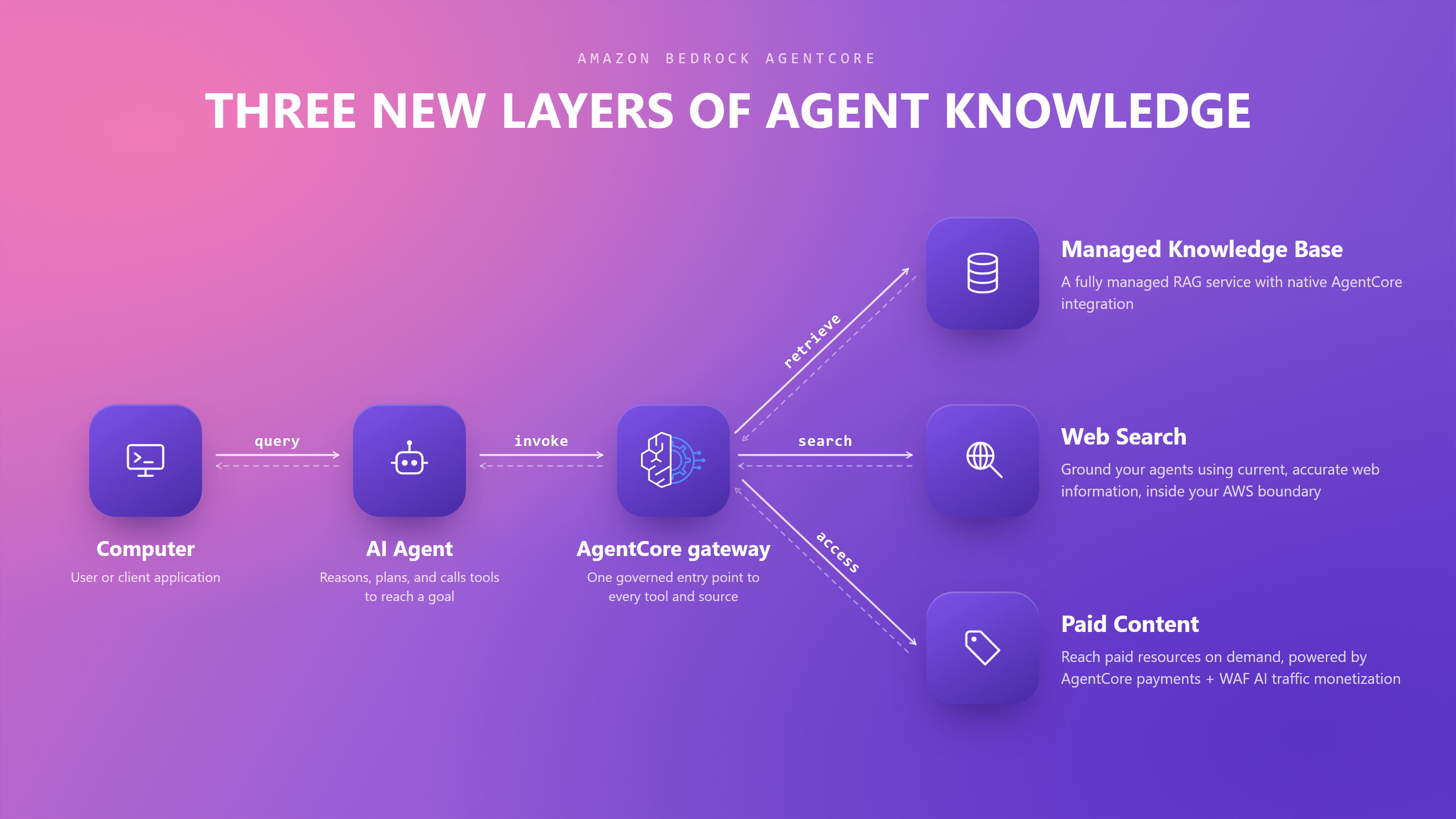
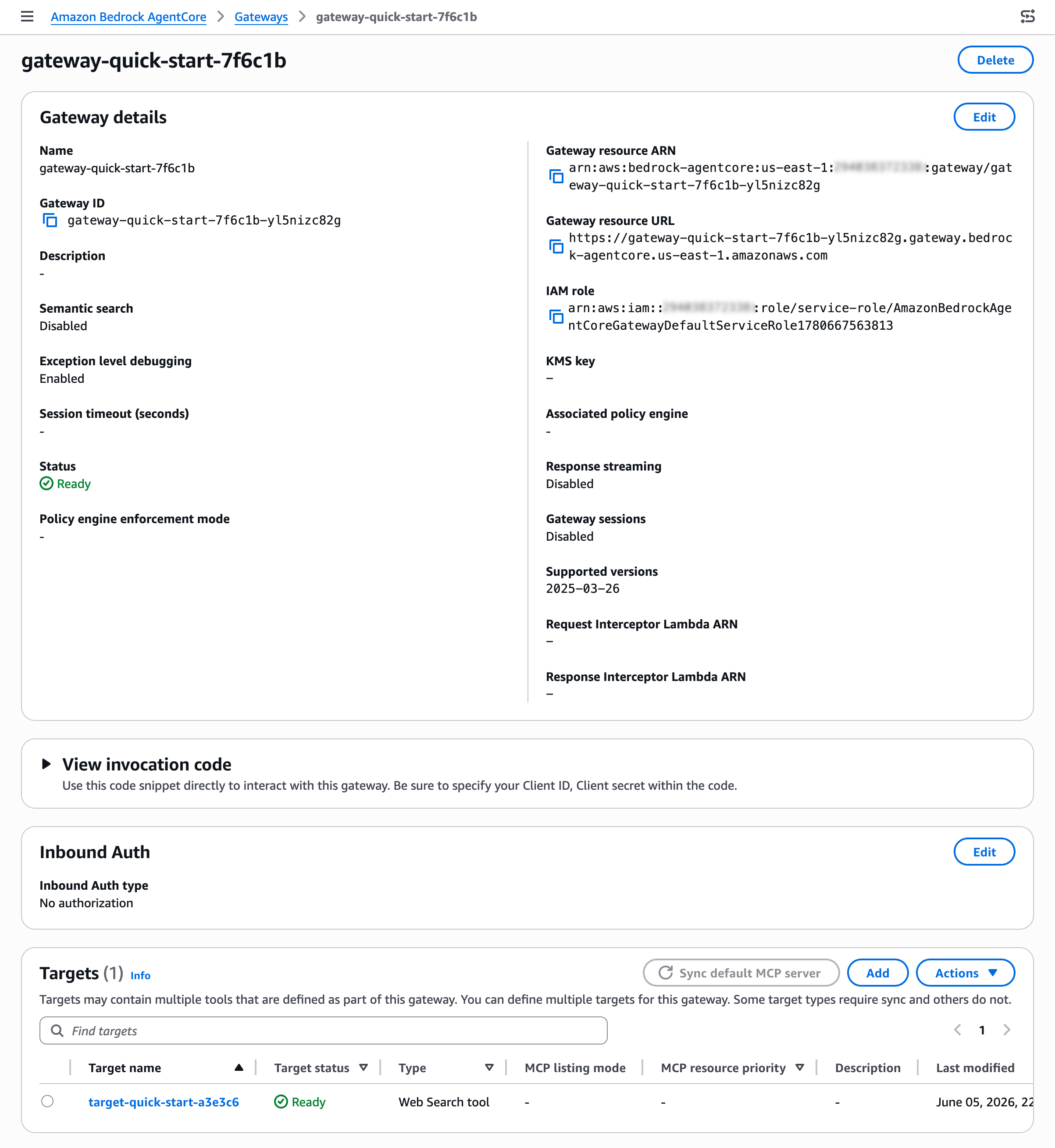
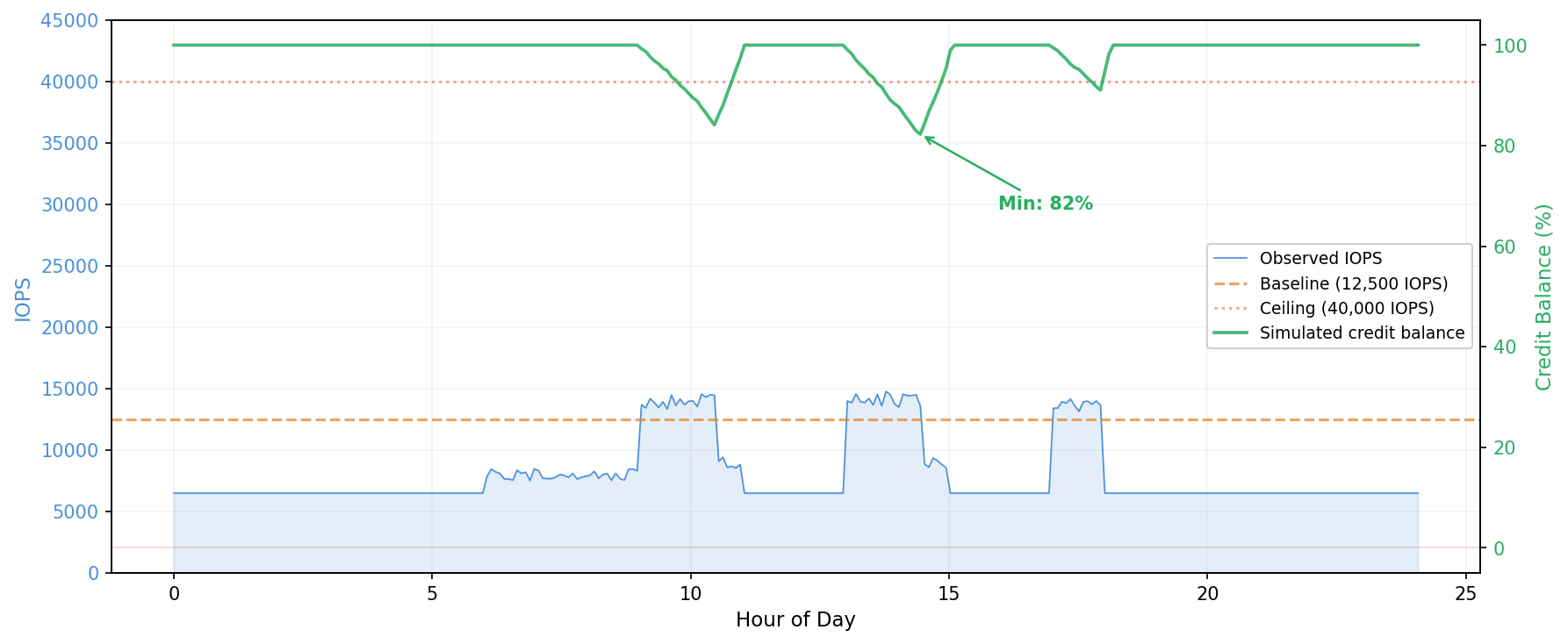
The following two figures show what these outcomes look like. In the first, the workload bursts above baseline during business hours but credits never fully deplete. The minimum balance stays at 82 percent, well above zero. This workload is safe to downsize.

Figure 1: Amazon EC2 EBS-optimized instance burst credit simulation: credits sustained
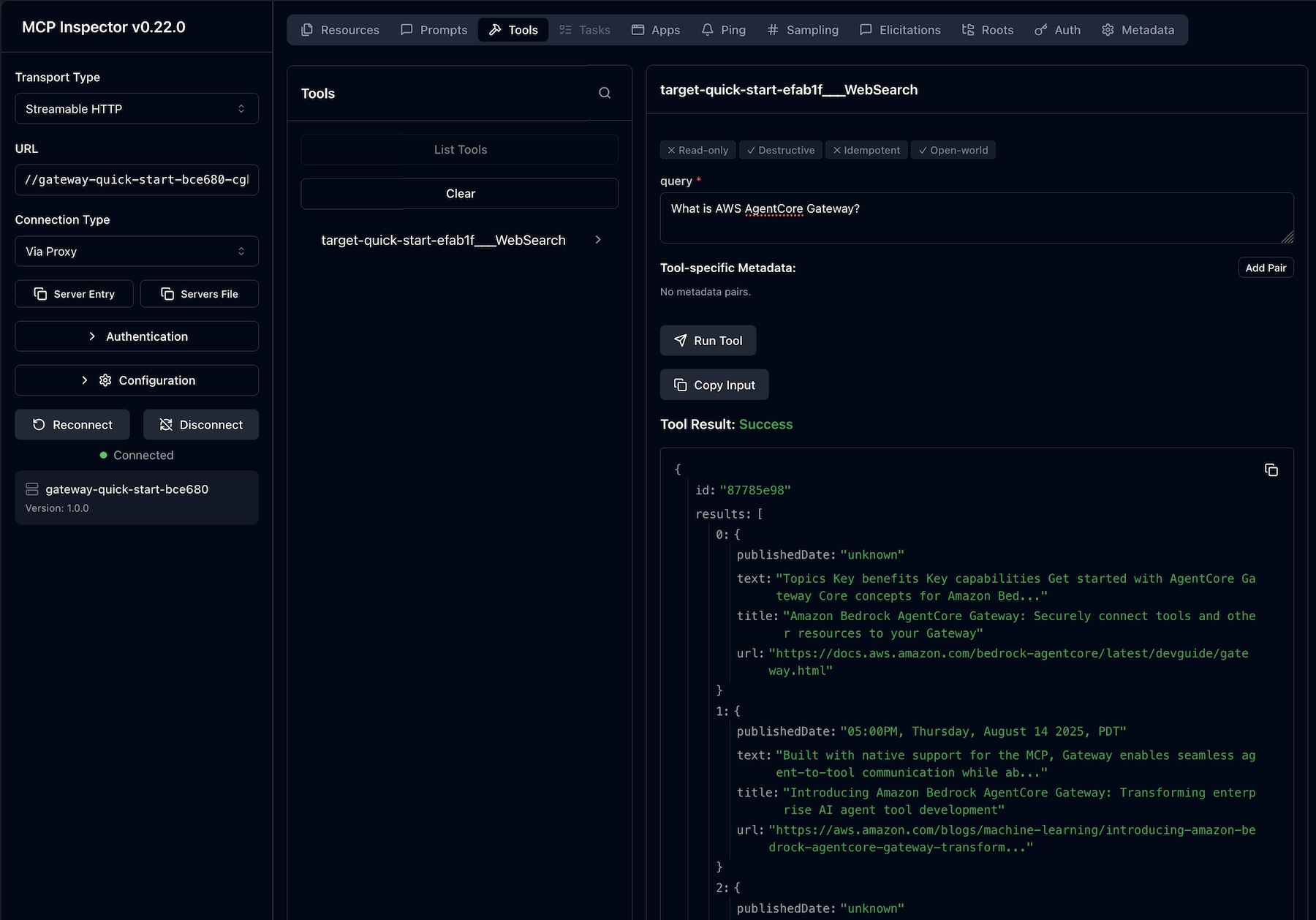
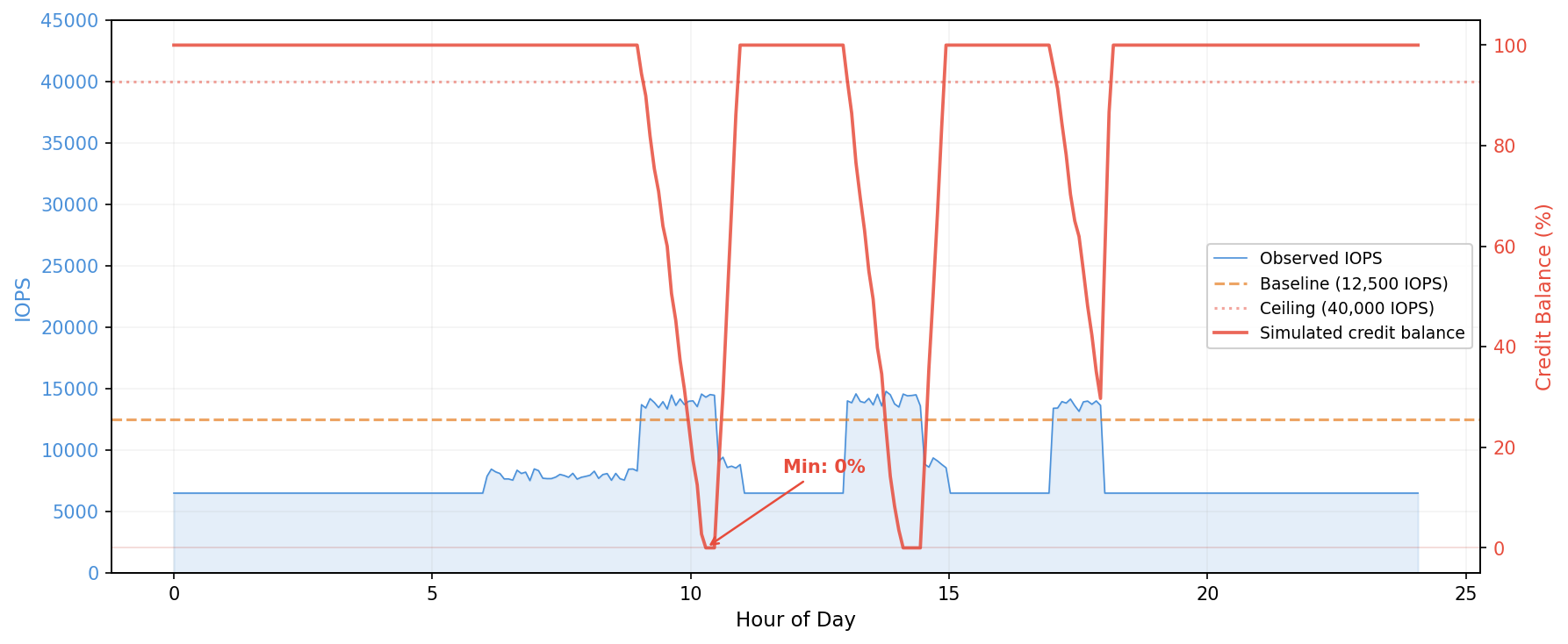
In the second figure, the same workload runs on a smaller instance type with a lower burst pool. Credits deplete within the first burst window and stay near zero for most of the business day. This workload would throttle on the smaller instance.
Figure 2: Amazon EC2 EBS-optimized instance burst credit simulation: credits depleted
Worked examples
The following servers are from a customer running SQL Server on EC2. We simulated the burst credit balance for each against the proposed target instance type, using 28 days of Amazon CloudWatch data at 5-minute granularity with the Maximum statistic.
Server A: fits comfortably (current: c6in.4xlarge; proposed: r6i.large)
Target limits: baseline 3,600 IOPS / 81.25 MB/s, burst ceiling 40,000 IOPS / 1,250 MB/s.
Simulating the credit balance across 28 days with a daily pool reset:
|
IOPS |
Throughput |
| Credit pool |
65,520,000 |
2,103,750 MB |
| Low-water mark |
52,084,325 (79.5%) |
1,656,415 MB (78.7%) |
| Intervals at zero |
0 |
0 |
On the worst day for throughput, here’s what the simulation looks like during the evening burst window, showing how credits drain and recover interval by interval:
| Time |
Throughput (MB/s) |
Net credit change |
Balance |
Balance % |
| 22:00 |
154.25 |
-21,900 |
1,854,076 |
88.1% |
| 22:05 |
22.57 |
+17,603 |
1,871,679 |
89.0% |
| 22:10 |
452.16 |
-111,273 |
1,760,406 |
83.7% |
| 22:15 |
427.89 |
-103,991 |
1,656,415 |
78.7% |
| 22:20 |
30.99 |
+15,077 |
1,671,492 |
79.5% |
At 22:10 and 22:15, throughput spiked above 400 MB/s, well above the 81.25 MB/s baseline but still under the 1,250 MB/s burst ceiling. Each interval drained roughly 100,000 credits. The pool hit its low-water mark of 78.7 percent at 22:15, then immediately began recovering as throughput dropped. By 23:55, the pool was back to 100 percent.
Assessment: fits, with roughly 20 percent headroom on the worst day.
Server B: fits but tight (same workload as Server A; proposed: r5.large)
Target limits: baseline 3,600 IOPS / 81.25 MB/s, burst ceiling 18,750 IOPS / 593.75 MB/s.
|
IOPS |
Throughput |
| Credit pool |
27,270,000 |
922,500 MB |
| Low-water mark |
13,834,325 (50.7%) |
475,165 MB (51.5%) |
| Intervals at zero |
0 |
0 |
Same workload, same burst pattern, but the r5.large has a smaller credit pool, so the same spikes drain a larger percentage. The throughput low-water mark drops from 78.7 percent to 51.5 percent. The same evening burst window that used 20 percent of the r6i.large pool now consumes nearly half the r5.large pool:
| Time |
Throughput (MB/s) |
Net credit change |
Balance |
Balance % |
| 22:00 |
154.25 |
-21,900 |
672,826 |
72.9% |
| 22:05 |
22.57 |
+17,603 |
690,429 |
74.8% |
| 22:10 |
452.16 |
-111,273 |
579,156 |
62.8% |
| 22:15 |
427.89 |
-103,991 |
475,165 |
51.5% |
| 22:20 |
30.99 |
+15,077 |
490,242 |
53.1% |
This still fits, but with limited margin. Any workload growth (more users, larger databases, additional backup jobs) could push the balance toward zero. Separately, a single IOPS interval reached 20,226, exceeding the r5.large burst ceiling of 18,750. The instance can only deliver up to the ceiling while credits remain, so the application received 18,750 IOPS during that interval. That single spike would not cause sustained throttling, but combined with the tight throughput margins, it confirms this workload is at the boundary of what r5.large can handle.
Assessment: fits today, but not a safe long-term choice.
Server C: ceiling breach (current: c6in.4xlarge; proposed: r6i.xlarge)
Target limits: baseline 6,000 IOPS / 156.25 MB/s, burst ceiling 40,000 IOPS / 1,250 MB/s.
Peak throughput: 1,502.94 MB/s. This exceeds the 1,250 MB/s burst ceiling. During those peak intervals, the instance would cap throughput at 1,250 MB/s while credits remain. If credits are exhausted, throughput drops to the 156.25 MB/s baseline. The credit simulation might still show the workload fits (credits never hit zero), but the application would experience reduced I/O during those peaks. For this customer, the peaks coincided with production SQL Server activity, so even brief throttling wasn’t acceptable, and a larger instance type was needed.
Assessment: workload will be throttled during peak intervals. Whether that’s acceptable depends on the application’s sensitivity to I/O latency.
Monitoring after the resize
The pre-migration analysis uses historical data from the larger instance. After you resize, real metrics replace the simulation. Monitor the following three layers:
- InstanceEBSThroughputExceededCheck and InstanceEBSIOPSExceededCheck = 1 means the instance is actively throttling. This is the definitive signal. Alarm on
Sum > 0 over 3 consecutive 1-minute periods to filter out single-second spikes that resolve on their own.
- EBSByteBalance% and EBSIOBalance% trending downward over days or weeks means the workload is growing into the instance’s limits. You’re not throttling yet, but you’re on a trajectory. An instance that dips to 90 percent nightly and recovers is in a different position than one that dips to 40 percent and barely recovers before the next burst. Neither instance is throttling, but the first has headroom while the second doesn’t.
- EBSByteBalance% and EBSIOBalance% stay at 100 percent means the workload never exceeds baseline. The instance has unused capacity, and you might even be able to go smaller.
If the workload has weekly patterns, allow at least one full week of data before drawing conclusions.
Conclusion
In this post, we showed how to simulate the EBS-optimized instance burst credit balance against a target instance type’s limits before downsizing an Amazon EC2 instance. The approach pulls Amazon CloudWatch metrics at 5-minute granularity, compares actual throughput and IOPS against the target’s baseline and burst ceiling, and tracks whether the credit balance would hit zero during the observation window.
This covers the Amazon EBS dimension of a right-sizing decision. A complete evaluation also considers CPU utilization, memory usage, and network throughput against the target instance’s limits. For workloads where Amazon EBS utilization is well below baseline, the burst credit simulation might not be necessary.
To run this analysis on your own instances, see the companion script in the sample-ec2-ebs-burst-analyzer repository. For more on how instance-level burst credits work, see Improving application performance and reducing costs with Amazon EBS-optimized instance burst capability. For instance-level EBS baseline and burst limits by instance type, see Amazon EBS-optimized instances.