Post Syndicated from Carmen Manzulli original https://aws.amazon.com/blogs/big-data/get-started-with-the-new-amazon-datazone-enhancements-for-amazon-redshift/
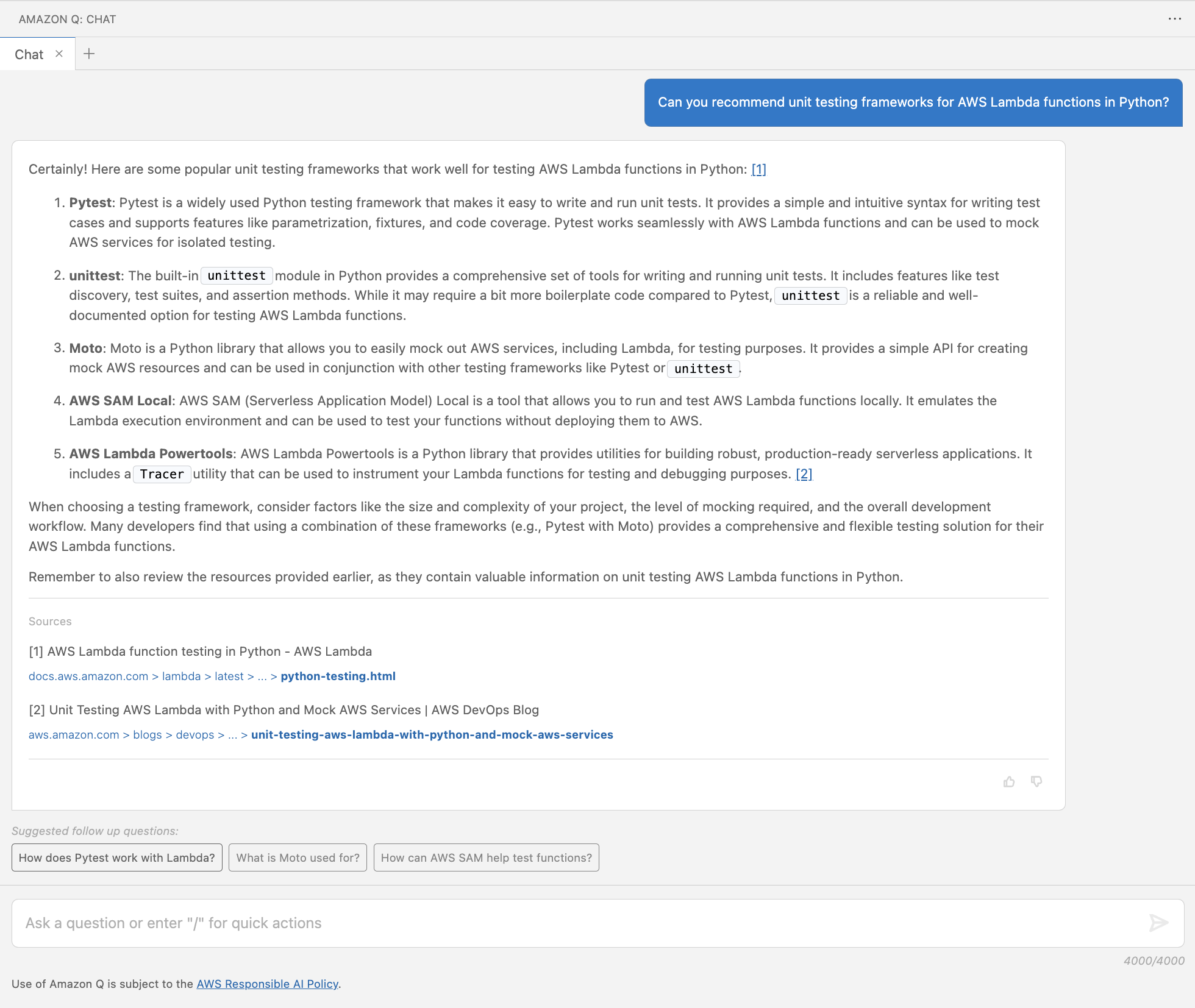
In today’s data-driven landscape, organizations are seeking ways to streamline their data management processes and unlock the full potential of their data assets, while controlling access and enforcing governance. That’s why we introduced Amazon DataZone.
Amazon DataZone is a powerful data management service that empowers data engineers, data scientists, product managers, analysts, and business users to seamlessly catalog, discover, analyze, and govern data across organizational boundaries, AWS accounts, data lakes, and data warehouses.
On March 21, 2024, Amazon DataZone introduced several exciting enhancements to its Amazon Redshift integration that simplify the process of publishing and subscribing to data warehouse assets like tables and views, while enabling Amazon Redshift customers to take advantage of the data management and governance capabilities or Amazon DataZone.
These updates empower the experience for both data users and administrators.
Data producers and consumers can now quickly create data warehouse environments using preconfigured credentials and connection parameters provided by their Amazon DataZone administrators.
Additionally, these enhancements grant administrators greater control over who can access and use the resources within their AWS accounts and Redshift clusters, and for what purpose.
As an administrator, you can now create parameter sets on top of DefaultDataWarehouseBlueprint by providing parameters such as cluster, database, and an AWS secret. You can use these parameter sets to create environment profiles and authorize Amazon DataZone projects to use these environment profiles for creating environments.
In turn, data producers and data consumers can now select an environment profile to create environments without having to provide the parameters themselves, saving time and reducing the risk of issues.
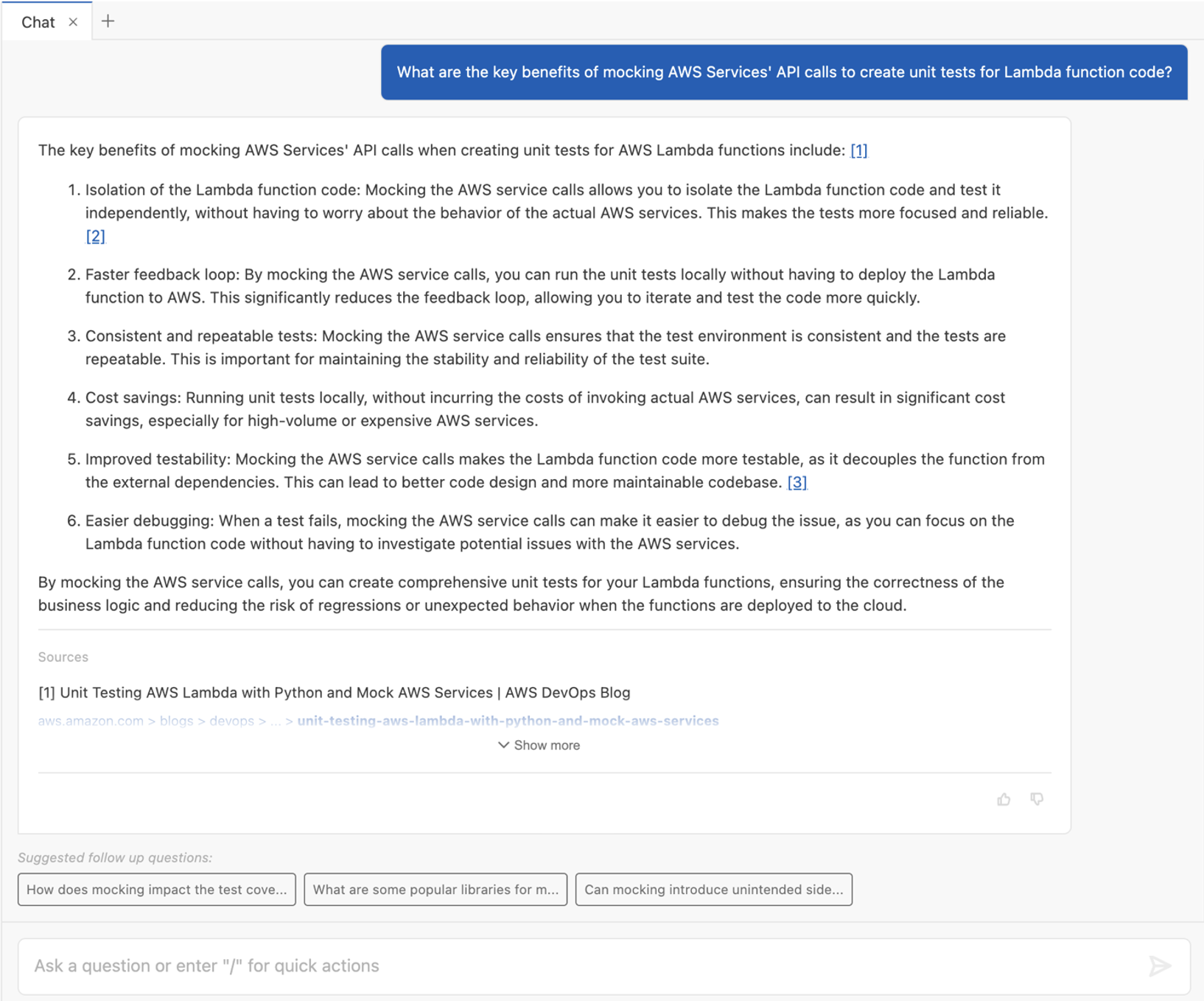
In this post, we explain how you can use these enhancements to the Amazon Redshift integration to publish your Redshift tables to the Amazon DataZone data catalog, and enable users across the organization to discover and access them in a self-service fashion. We present a sample end-to-end customer workflow that covers the core functionalities of Amazon DataZone, and include a step-by-step guide of how you can implement this workflow.
The same workflow is available as video demonstration on the Amazon DataZone official YouTube channel.
Solution overview
To get started with the new Amazon Redshift integration enhancements, consider the following scenario:
- A sales team acts as the data producer, owning and publishing product sales data (a single table in a Redshift cluster called
catalog_sales)
- A marketing team acts as the data consumer, needing access to the sales data in order to analyze it and build product adoption campaigns
At a high level, the steps we walk you through in the following sections include tasks for the Amazon DataZone administrator, Sales team, and Marketing team.
Prerequisites
For the workflow described in this post, we assume a single AWS account, a single AWS Region, and a single AWS Identity and Access Management (IAM) user, who will act as Amazon DataZone administrator, Sales team (producer), and Marketing team (consumer).
To follow along, you need an AWS account. If you don’t have an account, you can create one.
In addition, you must have the following resources configured in your account:
- An Amazon DataZone domain with admin, sales, and marketing projects
- A Redshift namespace and workgroup
If you don’t have these resources already configured, you can create them by deploying an AWS CloudFormation stack:
- Choose Launch Stack to deploy the provided CloudFormation template.
- For
AdminUserPassword, enter a password, and take note of this password to use in later steps.
- Leave the remaining settings as default.
- Select I acknowledge that AWS CloudFormation might create IAM resources, then choose Submit.
- When the stack deployment is complete, on the Amazon DataZone console, choose View domains in the navigation pane to see the new created Amazon DataZone domain.
- On the Amazon Redshift Serverless console, in the navigation pane, choose Workgroup configuration and see the new created resource.
You should be logged in using the same role that you used to deploy the CloudFormation stack and verify that you’re in the same Region.
As a final prerequisite, you need to create a catalog_sales table in the default Redshift database (dev).
- On the Amazon Redshift Serverless console, selected your workgroup and choose Query data to open the Amazon Redshift query editor.
- In the query editor, choose your workgroup and select Database user name and password as the type of connection, then provide your admin database user name and password.
- Use the following query to create the
catalog_sales table, which the Sales team will publish in the workflow:
CREATE TABLE catalog_sales AS
SELECT 146776932 AS order_number, 23 AS quantity, 23.4 AS wholesale_cost, 45.0 as list_price, 43.0 as sales_price, 2.0 as discount, 12 as ship_mode_sk,13 as warehouse_sk, 23 as item_sk, 34 as catalog_page_sk, 232 as ship_customer_sk, 4556 as bill_customer_sk
UNION ALL SELECT 46776931, 24, 24.4, 46, 44, 1, 14, 15, 24, 35, 222, 4551
UNION ALL SELECT 46777394, 42, 43.4, 60, 50, 10, 30, 20, 27, 43, 241, 4565
UNION ALL SELECT 46777831, 33, 40.4, 51, 46, 15, 16, 26, 33, 40, 234, 4563
UNION ALL SELECT 46779160, 29, 26.4, 50, 61, 8, 31, 15, 36, 40, 242, 4562
UNION ALL SELECT 46778595, 43, 28.4, 49, 47, 7, 28, 22, 27, 43, 224, 4555
UNION ALL SELECT 46779482, 34, 33.4, 64, 44, 10, 17, 27, 43, 52, 222, 4556
UNION ALL SELECT 46779650, 39, 37.4, 51, 62, 13, 31, 25, 31, 52, 224, 4551
UNION ALL SELECT 46780524, 33, 40.4, 60, 53, 18, 32, 31, 31, 39, 232, 4563
UNION ALL SELECT 46780634, 39, 35.4, 46, 44, 16, 33, 19, 31, 52, 242, 4557
UNION ALL SELECT 46781887, 24, 30.4, 54, 62, 13, 18, 29, 24, 52, 223, 4561
Now you’re ready to get started with the new Amazon Redshift integration enhancements.
Amazon DataZone administrator tasks
As the Amazon DataZone administrator, you perform the following tasks:
- Configure the
DefaultDataWarehouseBlueprint.
- Authorize the Amazon DataZone admin project to use the blueprint to create environment profiles.
- Create a parameter set on top of
DefaultDataWarehouseBlueprint by providing parameters such as cluster, database, and AWS secret.
- Set up environment profiles for the Sales and Marketing teams.
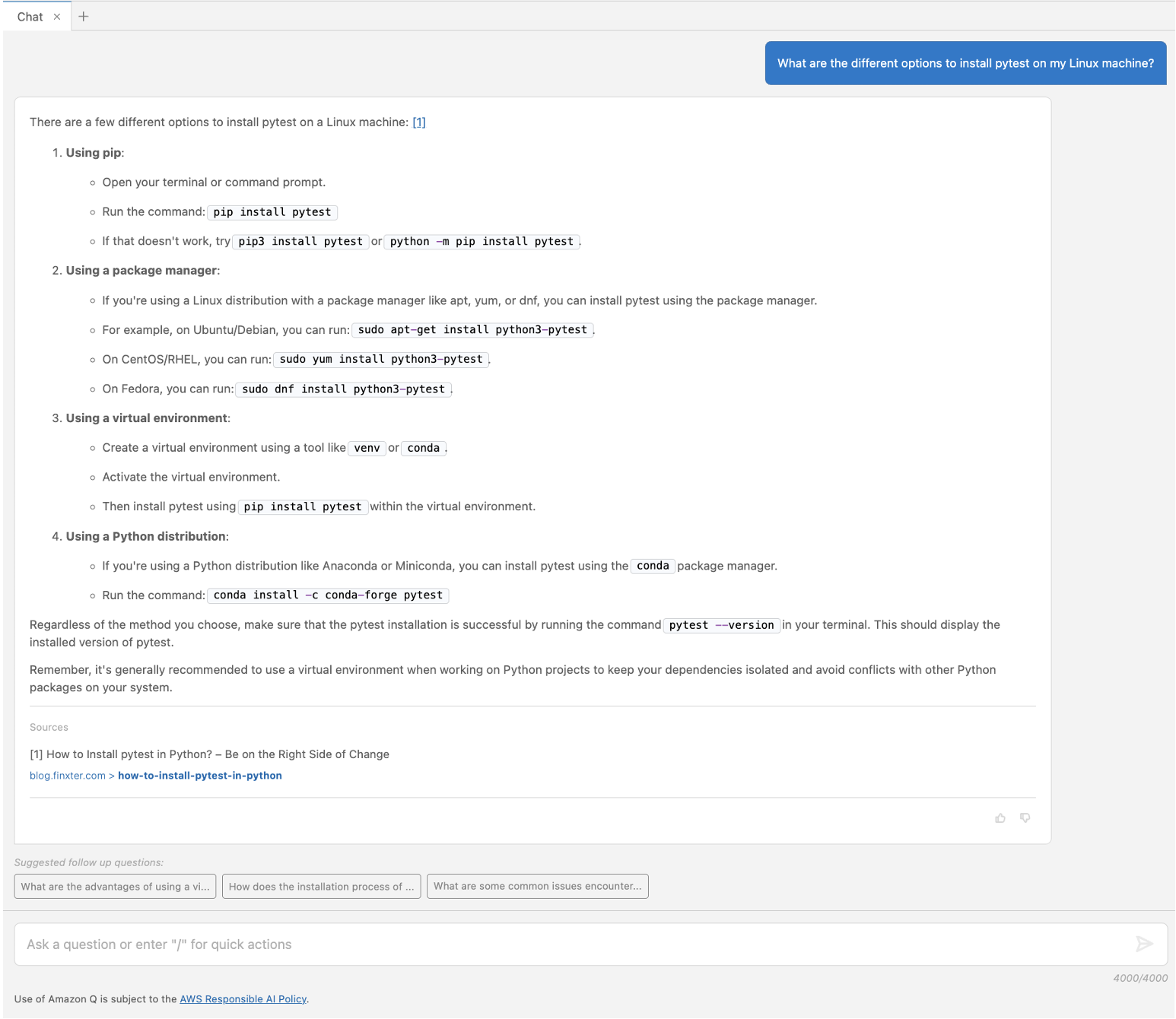
Configure the DefaultDataWarehouseBlueprint
Amazon DataZone blueprints define what AWS tools and services are provisioned to be used within an Amazon DataZone environment. Enabling the data warehouse blueprint will allow data consumers and data producers to use Amazon Redshift and the Query Editor for data sharing, accessing, and consuming.
- On the Amazon DataZone console, choose View domains in the navigation pane.
- Choose your Amazon DataZone domain.
- Choose Default Data Warehouse.
If you used the CloudFormation template, the blueprint is already enabled.

Part of the new Amazon Redshift experience involves the Managing projects and Parameter sets tabs. The Managing projects tab lists the projects that are allowed to create environment profiles using the data warehouse blueprint. By default, this is set to all projects. For our purpose, let’s grant only the admin project.
- On the Managing projects tab, choose Edit.

- Select Restrict to only managing projects and choose the
AdminPRJ project.
- Choose Save changes.
With this enhancement, the administrator can control which projects can use default blueprints in their account to create environment profile

The Parameter sets tab lists parameters that you can create on top of DefaultDataWarehouseBlueprint by providing parameters such as Redshift cluster or Redshift Serverless workgroup name, database name, and the credentials that allow Amazon DataZone to connect to your cluster or workgroup. You can also create AWS secrets on the Amazon DataZone console. Before these enhancements, AWS secrets had to be managed separately using AWS Secrets Manager, making sure to include the proper tags (key-value) for Amazon Redshift Serverless.
For our scenario, we need to create a parameter set to connect a Redshift Serverless workgroup containing sales data.
- On the Parameter sets tab, choose Create parameter set.

- Enter a name and optional description for the parameter set.
- Choose the Region containing the resource you want to connect to (for example, our workgroup is in
us-east-1).
- In the Environment parameters section, select Amazon Redshift Serverless.
If you already have an AWS secret with credentials to your Redshift Serverless workgroup, you can provide the existing AWS secret ARN. In this case, the secret must be tagged with the following (key-value): AmazonDataZoneDomain: <Amazon DataZone domain ID>.
- Because we don’t have an existing AWS secret, we create a new one by choosing Create new AWS Secret.

- In the pop-up, enter a secret name and your Amazon Redshift credentials, then choose Create new AWS Secret.
Amazon DataZone creates a new secret using Secrets Manager and makes sure the secret is tagged with the domain in which you’re creating the parameter set. 
- Enter the Redshift Serverless workgroup name and database name to complete the parameters list. If you used the provided CloudFormation template, use
sales-workgroup for the workgroup name and dev for the database name.
- Choose Create parameter set.
You can see the parameter set created for your Redshift environment and the blueprint enabled with a single managing project configured.
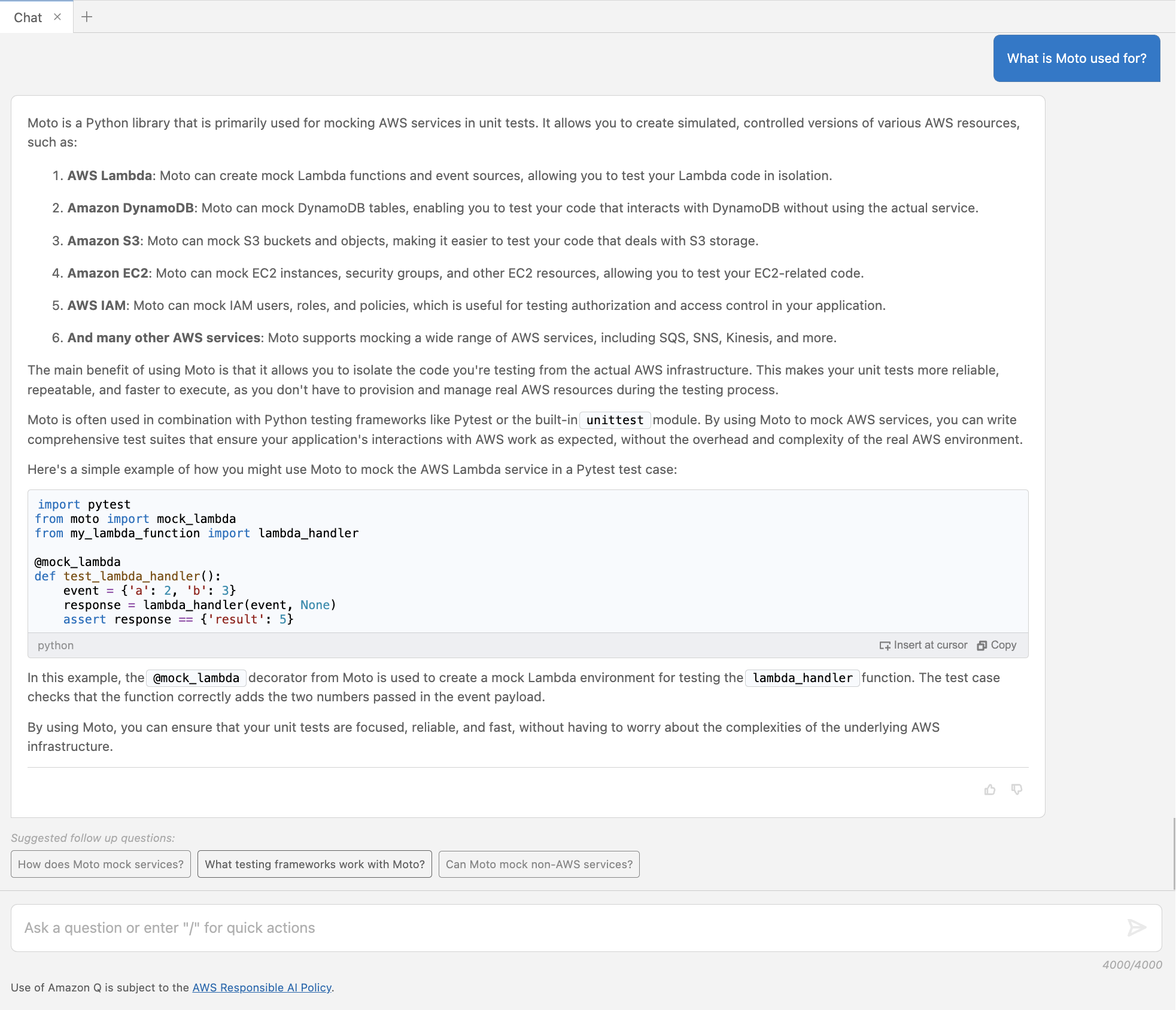
Set up environment profiles for the Sales and Marketing teams
Environment profiles are predefined templates that encapsulate technical details required to create an environment, such as the AWS account, Region, and resources and tools to be added to projects. The next Amazon DataZone administrator task consists of setting up environment profiles, based on the default enabled blueprint, for the Sales and Marketing teams.
This task will be performed from the admin project in the Amazon DataZone data portal, so let’s follow the data portal URL and start creating an environment profile for the Sales team to publish their data.
- On the details page of your Amazon DataZone domain, in the Summary section, choose the link for your data portal URL.

When you open the data portal for the first time, you’re prompted to create a project. If you used the provided CloudFormation template, the projects are already created.
- Choose the
AdminPRJ project. 
- On the Environments page, choose Create environment profile.

- Enter a name (for example,
SalesEnvProfile) and optional description (for example, Sales DWH Environment Profile) for the new environment profile.
- For Owner, choose
AdminPRJ.
- For Blueprint, select the
DefaultDataWarehouse blueprint (you’ll only see blueprints where the admin project is listed as a managing project). 
- Choose the current enabled account and the parameter set you previously created.
Then you will see each pre-compiled value for Redshift Serverless.  Under Authorized projects, you can pick the authorized projects allowed to use this environment profile to create an environment. By default, this is set to All projects.
Under Authorized projects, you can pick the authorized projects allowed to use this environment profile to create an environment. By default, this is set to All projects.
- Select Authorized projects only.
- Choose Add projects and choose the
SalesPRJ project.
- Configure the publishing permissions for this environment profile. Because the Sales team is our data producer, we select Publish from any schema.
- Choose Create environment profile.

Next, you create a second environment profile for the Marketing team to consume data. To do this, you repeat similar steps made for the Sales team.
- Choose the
AdminPRJ project.
- On the Environments page, choose Create environment profile.
- Enter a name (for example,
MarketingEnvProfile) and optional description (for example, Marketing DWH Environment Profile).
- For Owner, choose
AdminPRJ.
- For Blueprint, select the
DefaultDataWarehouse blueprint.
- Select the parameter set you created earlier.
- This time, keep All projects as the default (alternatively, you could select Authorized projects only and add
MarketingPRJ).
- Configure the publishing permissions for this environment profile. Because the Marketing team is our data consumer, we select Don’t allow publishing.
- Choose Create environment profile.
With these two environment profiles in place, the Sales and Marketing teams can start working on their projects on their own to create their proper environments (resources and tools) with fewer configurations and less risk to incur errors, and publish and consume data securely and efficiently within these environments.
To recap, the new enhancements offer the following features:
- When creating an environment profile, you can choose to provide your own Amazon Redshift parameters or use one of the parameter sets from the blueprint configuration. If you choose to use the parameter set created in the blueprint configuration, the AWS secret only requires the
AmazonDataZoneDomain tag (the AmazonDataZoneProject tag is only required if you choose to provide your own parameter sets in the environment profile).
- In the environment profile, you can specify a list of authorized projects, so that only authorized projects can use this environment profile to create data warehouse environments.
- You can also specify what data authorized projects are allowed to be published. You can choose one of the following options: Publish from any schema, Publish from the default environment schema, and Don’t allow publishing.
These enhancements grant administrators more control over Amazon DataZone resources and projects and facilitate the common activities of all roles involved.
Sales team tasks
As a data producer, the Sales team performs the following tasks:
- Create a sales environment.
- Create a data source.
- Publish sales data to the Amazon DataZone data catalog.
Create a sales environment
Now that you have an environment profile, you need to create an environment in order to work with data and analytics tools in this project.
- Choose the
SalesPRJ project.
- On the Environments page, choose Create environment.
- Enter a name (for example,
SalesDwhEnv) and optional description (for example, Environment DWH for Sales) for the new environment.
- For Environment profile, choose
SalesEnvProfile.
Data producers can now select an environment profile to create environments, without the need to provide their own Amazon Redshift parameters. The AWS secret, Region, workgroup, and database are ported over to the environment from the environment profile, streamlining and simplifying the experience for Amazon DataZone users.
- Review your data warehouse parameters to confirm everything is correct.
- Choose Create environment.
The environment will be automatically provisioned by Amazon DataZone with the preconfigured credentials and connection parameters, allowing the Sales team to publish Amazon Redshift tables seamlessly.
Create a data source
Now, let’s create a new data source for our sales data.
- Choose the
SalesPRJ project.
- On the Data page, choose Create data source.
- Enter a name (for example,
SalesDataSource) and optional description.
- For Data source type, select Amazon Redshift.
- For Environment¸ choose
SalesDevEnv.
- For Redshift credentials, you can use the same credentials you provided during environment creation, because you’re still using the same Redshift Serverless workgroup.
- Under Data Selection, enter the schema name where your data is located (for example,
public) and then specify a table selection criterion (for example, *).
Here, the * indicates that this data source will bring into Amazon DataZone all the technical metadata from the database tables of your schema (in this case, a single table called catalog_sales).
- Choose Next.
On the next page, automated metadata generation is enabled. This means that Amazon DataZone will automatically generate the business names of the table and columns for that asset.
- Leave the settings as default and choose Next.
- For Run preference, select when to run the data source. Amazon DataZone can automatically publish these assets to the data catalog, but let’s select Run on demand so we can curate the metadata before publishing.
- Choose Next.
- Review all settings and choose Create data source.
- After the data source has been created, you can manually pull technical metadata from the Redshift Serverless workgroup by choosing Run.
When the data source has finished running, you can see the catalog_sales asset correctly added to the inventory.
Publish sales data to the Amazon DataZone data catalog
Open the catalog_sales asset to see details of the new asset (business metadata, technical metadata, and so on).
In a real-world scenario, this pre-publishing phase is when you can enrich the asset providing more business context and information, such as a readme, glossaries, or metadata forms. For example, you can start accepting some metadata automatically generated recommendations and rename the asset or its columns in order to make them more readable, descriptive, and easy to search and understand from a business user.
For this post, simply choose Publish asset to complete the Sales team tasks. 
Marketing team tasks
Let’s switch to the Marketing team and subscribe to the catalog_sales asset published by the Sales team. As a consumer team, the Marketing team will complete the following tasks:
- Create a marketing environment.
- Discover and subscribe to sales data.
- Query the data in Amazon Redshift.
Create a marketing environment
To subscribe and access Amazon DataZone assets, the Marketing team needs to create an environment.
- Choose the
MarketingPRJ project.
- On the Environments page, choose Create environment.
- Enter a name (for example,
MarketingDwhEnv) and optional description (for example, Environment DWH for Marketing).
- For Environment profile, choose
MarketingEnvProfile.
As with data producers, data consumers can also benefit from a pre-configured profile (created and managed by the administrator) in order to speed up the environment creation process, avoiding mistakes and reducing risks of errors.
- Review your data warehouse parameters to confirm everything is correct.
- Choose Create environment.
Discover and subscribe to sales data
Now that we have a consumer environment, let’s search the catalog_sales table in the Amazon DataZone data catalog.
- Enter
sales in the search bar.
- Choose the
catalog_sales table.
- Choose Subscribe.

- In the pop-up window, choose your marketing consumer project, provide a reason for the subscription request, and choose Subscribe.

When you get a subscription request as a data producer, Amazon DataZone will notify you through a task in the sales producer project. Because you’re acting as both subscriber and publisher here, you will see a notification.
- Choose the notification, which will open the subscription request.
You can see details including which project has requested access, who is the requestor, and why access is needed.
- To approve, enter a message for approval and choose Approve.

Now that subscription has been approved, let’s go back to the MarketingPRJ. On the Subscribed data page, catalog_sales is listed as an approved asset, but access hasn’t been granted yet. If we choose the asset, you can see that Amazon DataZone is working on the backend to automatically grant the access. When it’s complete, you’ll see the subscription as granted and the message “Asset added to 1 environment.” 
Query data in Amazon Redshift
Now that the marketing project has access to the sales data, we can use the Amazon Redshift Query Editor V2 to analyze the sales data.
- Under
MarketingPRJ, go to the Environments page and select the marketing environment.
- Under the analytics tools, choose Query data with Amazon Redshift, which redirects you to the query editor within the environment of the project.
- To connect to Amazon Redshift, choose your workgroup and select Federated user as the connection type.
When you’re connected, you will see the catalog_sales table under the public schema.
- To make sure that you have access to this table, run the following query:
SELECT * FROM catalog_sales LIMIT 10
 As a consumer, you’re now able to explore data and create reports, or you can aggregate data and create new assets to publish in Amazon DataZone, becoming a producer of a new data product to share with other users and departments.
As a consumer, you’re now able to explore data and create reports, or you can aggregate data and create new assets to publish in Amazon DataZone, becoming a producer of a new data product to share with other users and departments.
Clean up
To clean up your resources, complete the following steps:
- On the Amazon DataZone console, delete the projects used in this post. This will delete most project-related objects like data assets and environments.
- Clean up all Amazon Redshift resources (workgroup and namespace) to avoid incurring additional charges.
Conclusion
In this post, we demonstrated how you can get started with the new Amazon Redshift integration in Amazon DataZone. We showed how to streamline the experience for data producers and consumers and how to grant administrators control over data resources.
Embrace these enhancements and unlock the full potential of Amazon DataZone and Amazon Redshift for your data management needs.
Resources
For more information, refer to the following resources:
About the author
 Carmen is a Solutions Architect at AWS, based in Milan (Italy). She is a Data Lover that enjoys helping companies in the adoption of Cloud technologies, especially with Data Analytics and Data Governance. Outside of work, she is a creative people who loves being in contact with nature and sometimes practicing adrenaline activities.
Carmen is a Solutions Architect at AWS, based in Milan (Italy). She is a Data Lover that enjoys helping companies in the adoption of Cloud technologies, especially with Data Analytics and Data Governance. Outside of work, she is a creative people who loves being in contact with nature and sometimes practicing adrenaline activities.



 Proven Practices for Developing a Multicloud Strategy
Proven Practices for Developing a Multicloud Strategy
 Randy Brumfield
Randy Brumfield Anne Grahn
Anne Grahn


















 Under Authorized projects, you can pick the authorized projects allowed to use this environment profile to create an environment. By default, this is set to All projects.
Under Authorized projects, you can pick the authorized projects allowed to use this environment profile to create an environment. By default, this is set to All projects.










 As a consumer, you’re now able to explore data and create reports, or you can aggregate data and create new assets to publish in Amazon DataZone, becoming a producer of a new data product to share with other users and departments.
As a consumer, you’re now able to explore data and create reports, or you can aggregate data and create new assets to publish in Amazon DataZone, becoming a producer of a new data product to share with other users and departments. Carmen is a Solutions Architect at AWS, based in Milan (Italy). She is a Data Lover that enjoys helping companies in the adoption of Cloud technologies, especially with Data Analytics and Data Governance. Outside of work, she is a creative people who loves being in contact with nature and sometimes practicing adrenaline activities.
Carmen is a Solutions Architect at AWS, based in Milan (Italy). She is a Data Lover that enjoys helping companies in the adoption of Cloud technologies, especially with Data Analytics and Data Governance. Outside of work, she is a creative people who loves being in contact with nature and sometimes practicing adrenaline activities.